
HyperTransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Hyperspectral Image Classification


Abstract
1. Introduction
- Current fusion methodologies exhibit insufficient spectral-spatial synergy; they tend to integrate local and global features in a rigid manner, thereby failing to adaptively balance their respective contributions.
- Computational inefficiencies persist, as redundant attention calculations and suboptimal parameterizations impede real-time deployment.
- Conventional architectures demonstrate a pronounced sensitivity to spectral noise, struggling to suppress redundant bands and enhance discriminative features, particularly under conditions of significant noise or limited sample sizes.
- We introduce HyperTransXNet, a novel hybrid framework that integrates CNN-driven local feature extraction, Transformer-based global dependency modeling, and Mamba-inspired efficiency through dynamic spectral-spatial fusion, thereby addressing the limitations of isolated architectural paradigms.
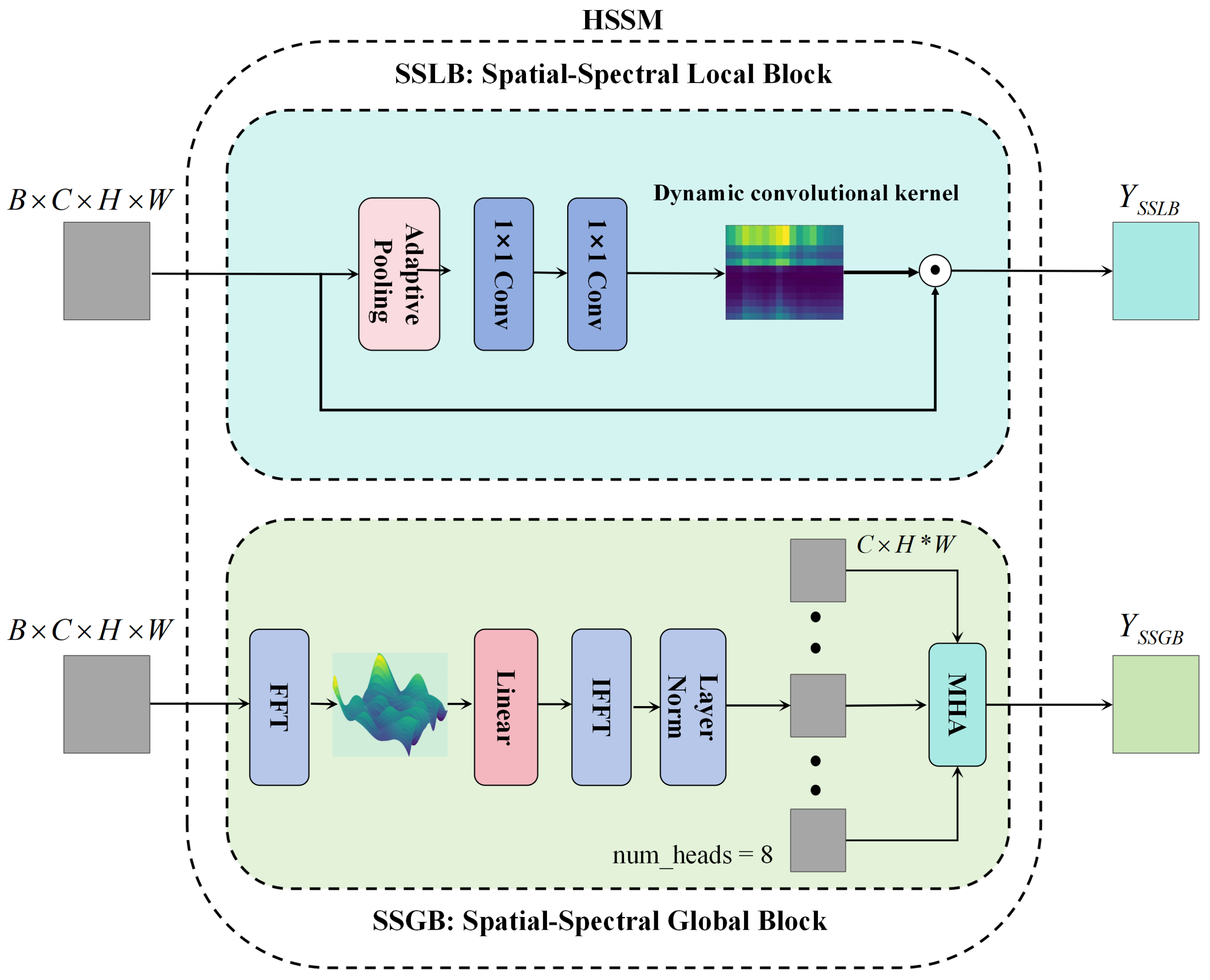
- We propose a Hybrid Spatial-Spectral Module (HSSM) that integrates depth-wise dynamic convolutions with frequency-domain attention. This design facilitates the simultaneous enhancement of local textures and global spectral correlations without incurring additional computational overhead.
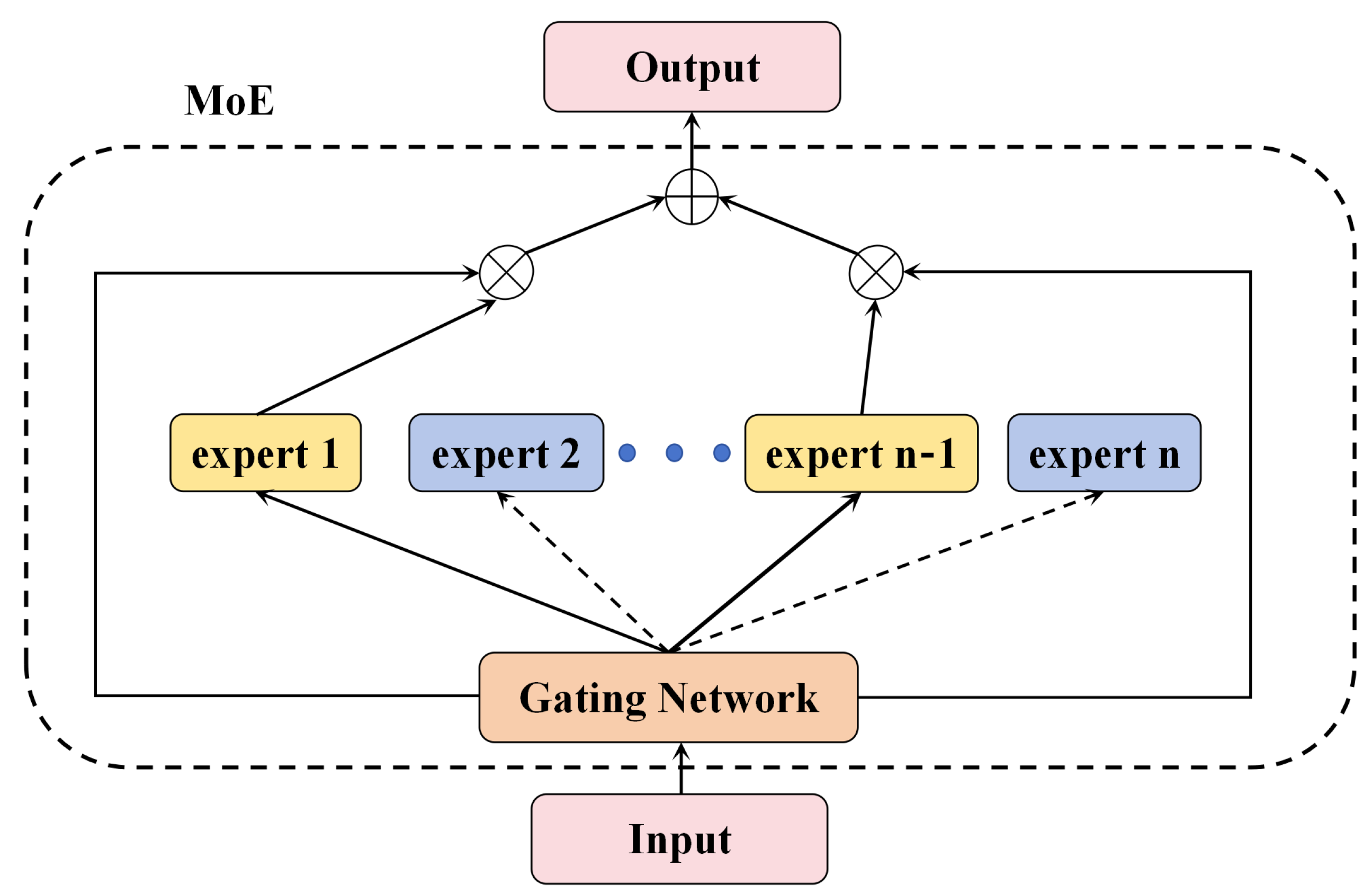
- We employ the Top-K sparse Mixture-of-Experts routing mechanism, marking its inaugural application in hyperspectral classification, which achieves parameter-efficient multi-scale feature aggregation via context-aware expert selection.
- Extensive experiments conducted on three public HSI datasets demonstrate that the proposed HyperTransXNet outperforms state-of-the-art methods based on CNNs and Transformers.
2. Related Works
2.1. CNN-Based Hyperspectral Image Classification
2.2. Transformers-Based Hyperspectral Image Classification
2.3. Mamba-Based Hyperspectral Image Classification
- Ineffective joint spectral-spatial representation learning: CNN-based methods are constrained by fixed receptive fields that fail to adapt to the varying complexities of spectral curves. In contrast, Mamba architectures suffer from fragmented local context modeling due to their unidirectional scanning. Although Transformer-based approaches effectively model global dependencies, they incur quadratic computational costs, thereby limiting their applicability to large-scale HSIs.
- Suboptimal feature fusion strategies: Contemporary methods predominantly rely on static fusion techniques to integrate spectral and spatial features. These heuristic approaches lack the adaptability needed to suppress noisy bands or to emphasize discriminative spectral regions, resulting in performance degradation in complex scenes, such as those encountered in urban-rural transitions.
2.4. Different from TransXNet
3. MoE
4. Proposed Methodology
4.1. Overview
4.2. Stem
4.3. HyperTransXNet Block
Hybrid Spatial-Spectral Module (HSSM)
| Algorithm 1 Generate dynamic convolution kernels |
|
4.4. Spatial-Spectral Tokens Enhancer (SSTE)
| Algorithm 2 Top-K Gating Mechanism for Mixture-of-Experts |
|
5. Experiment
5.1. Datasets and Setting
5.1.1. Datasets
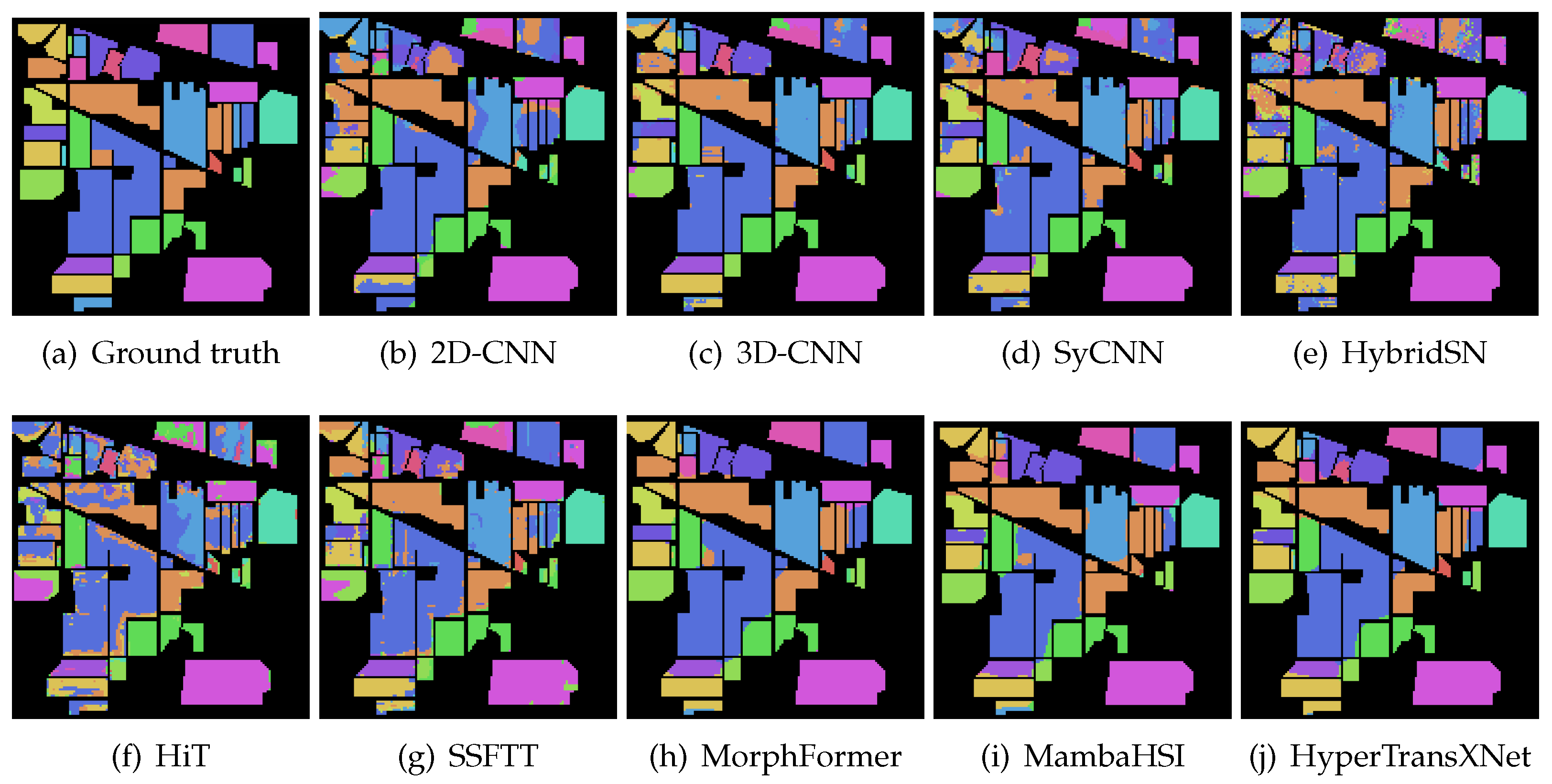
- The Indian Pines Scene dataset was collected by the AVIRIS sensor in 1992 in the northwestern part of Indiana, USA. It contains hyperspectral image data with a spatial resolution of and 220 spectral bands. During preprocessing, 20 noisy bands were removed, leaving 200 valid bands for analysis. The dataset includes 16 land-cover classes, such as Alfalfa, Corn, and Woods, and is widely used in hyperspectral image classification tasks. In the experiment, 10% of the samples were randomly selected for training, and the remaining 90% were used for testing to evaluate the model’s performance.
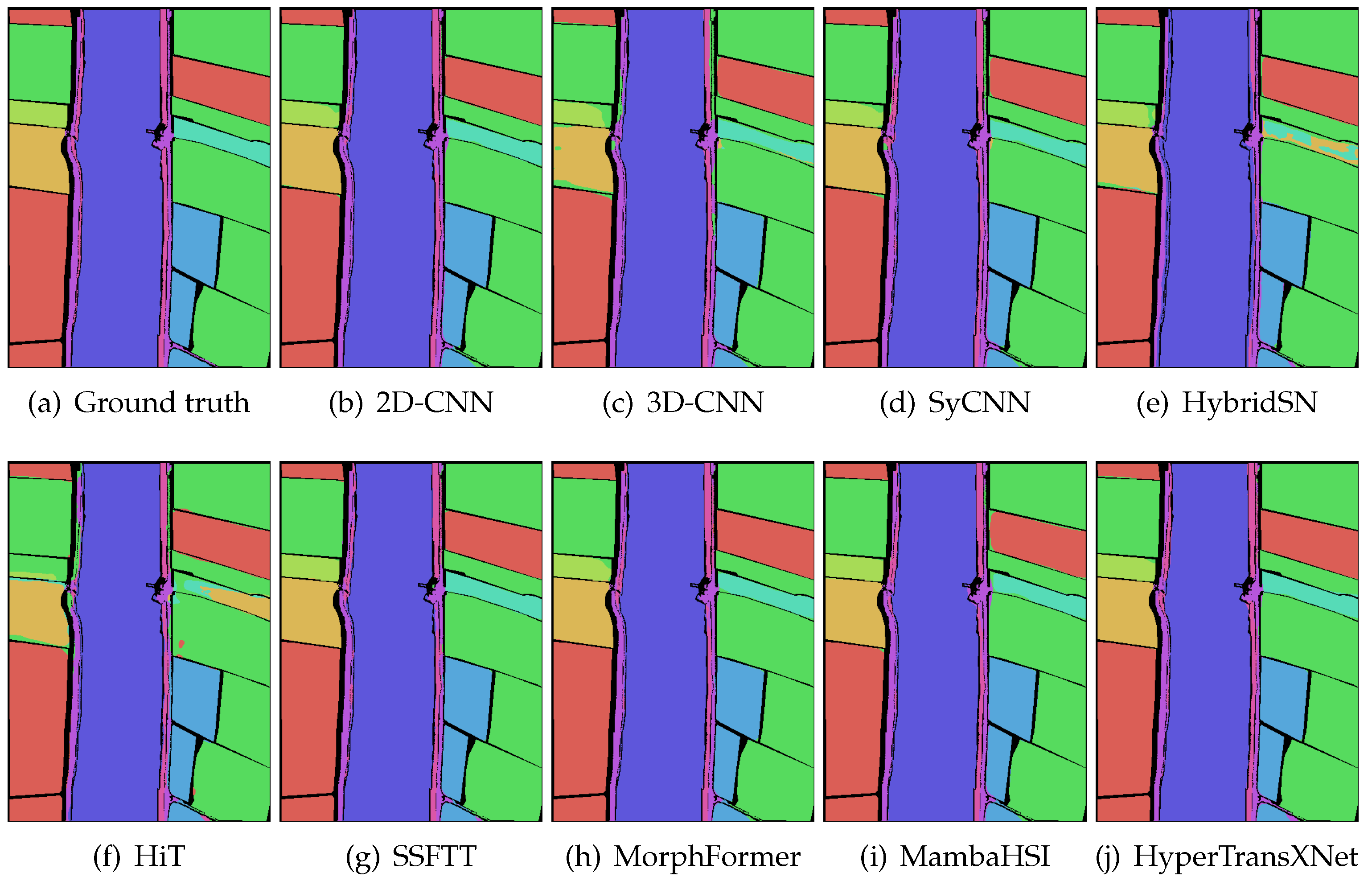
- Houston 2013 dataset: This dataset encompasses the geographical information of Houston, Texas, USA, and its surrounding areas, acquired using the ITRES CASI-1500 imaging spectrometer. It features a spatial resolution of pixels and covers 144 spectral bands. The dataset is based on a high-quality, cloud-free image provided by the Geo-Science and Remote Sensing Society (GRRSS). It contains 15 distinct land-use categories, such as highways, roads, and vegetation. In our experimental setup, we randomly selected 10% of the dataset for model training, with the remaining 90% reserved for validation and testing.
- The WHU-HI-Longkou (WHL) dataset was collected on 17 July 2018, in Longkou Town, Hubei Province, China, using a DJI M600 Pro drone equipped with a Headwall Nano Hyperspectral Imaging Sensor. The sensor has an 8 mm focal length, and the drone flew at an altitude of 500 m, capturing images with a resolution of pixels and covering 270 spectral bands, with wavelengths ranging from 400 to 1000 nm. The dataset includes nine land cover types with a total of 204,542 labeled samples, providing rich hyperspectral information for classification method evaluation. In this study, 1% of the labeled samples were used for training, and the remaining 99% for testing, simulating classification tasks with limited labeled data to assess the model’s generalization ability in small sample learning.
5.1.2. Evaluation Metrics
5.1.3. Comparison Methods
5.1.4. Setting
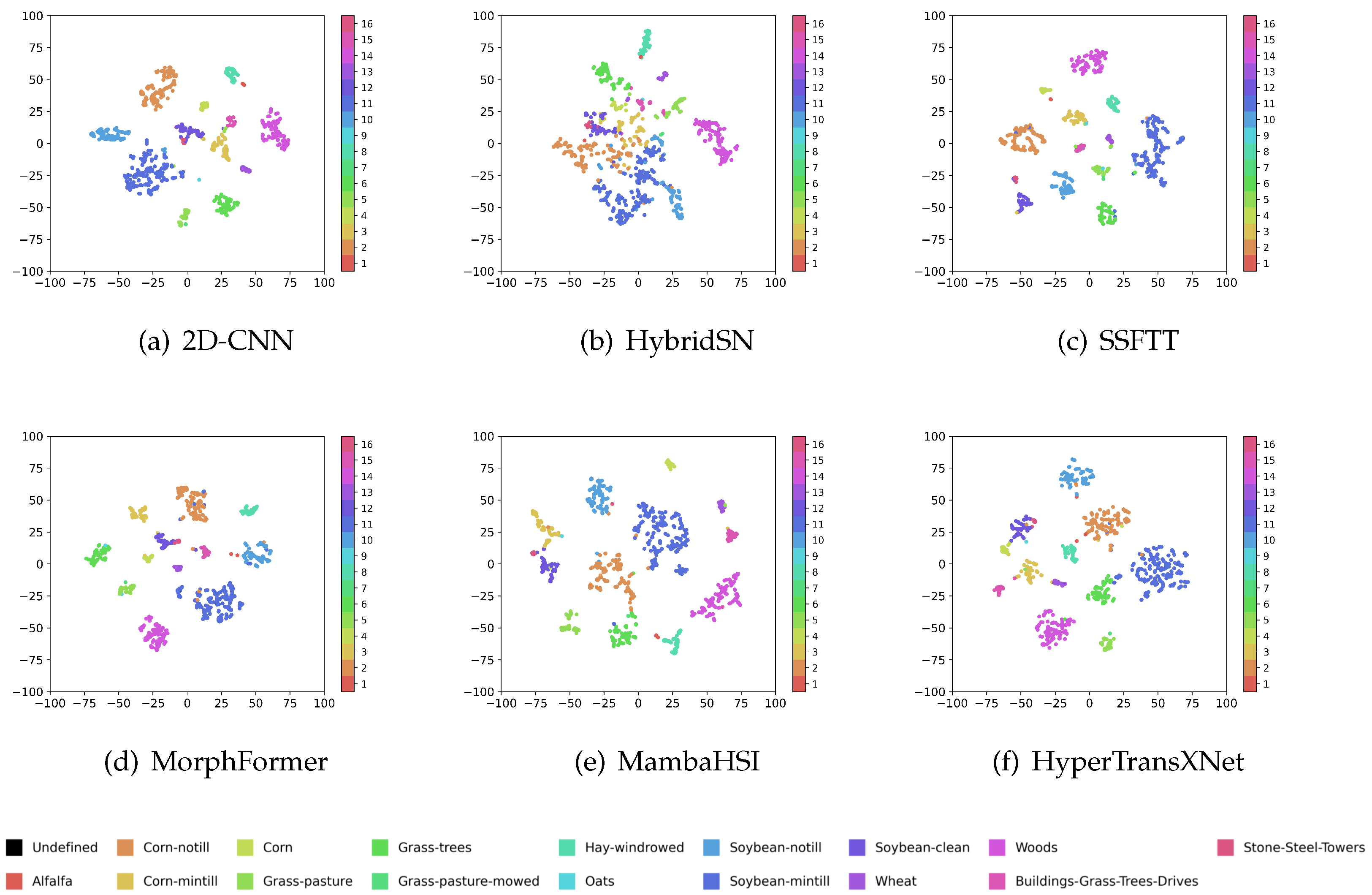
5.2. Results and Analysis
5.3. Comparison of Computational Complexity
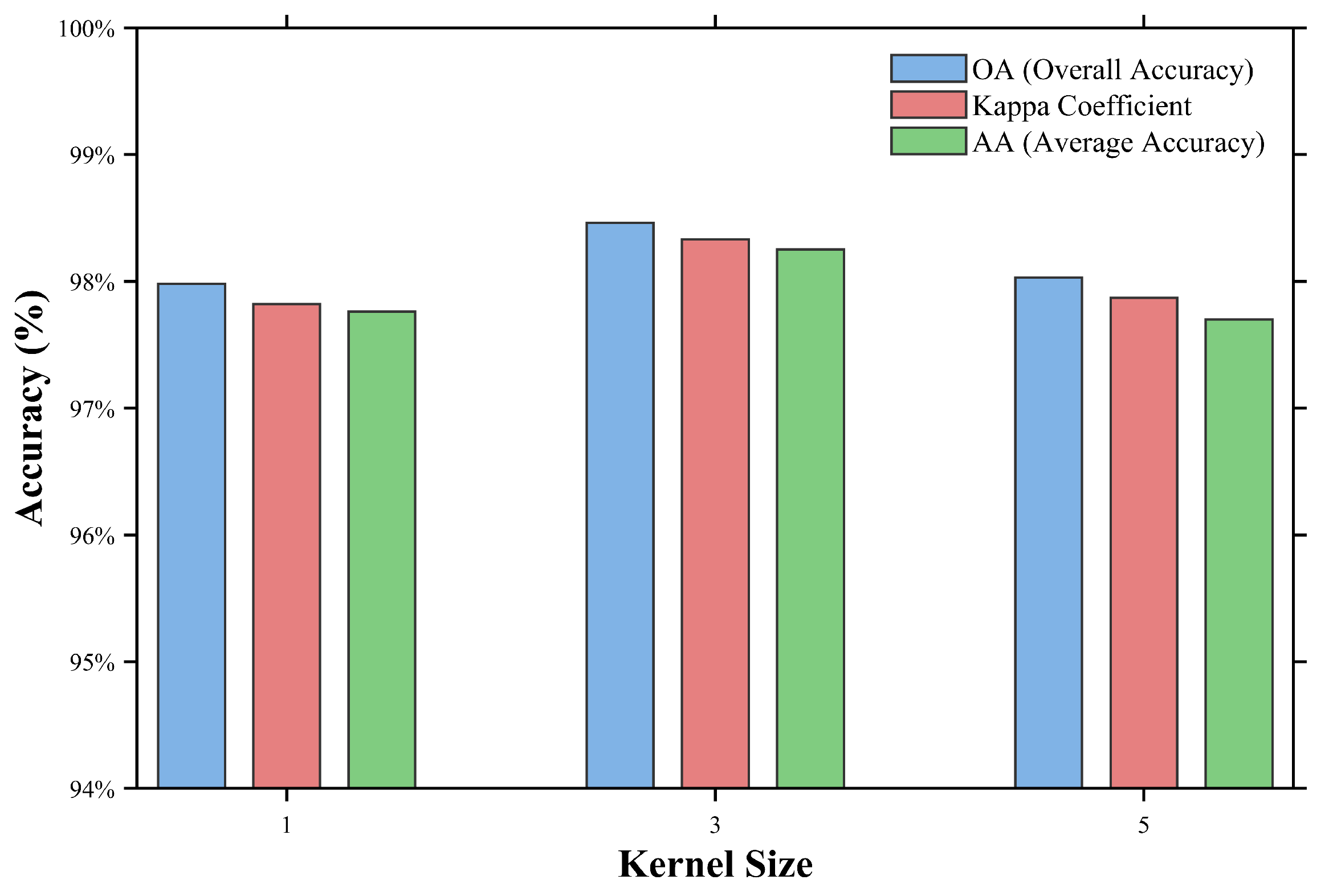
5.4. Ablation Studies
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kang, X.; Wang, Z.; Duan, P.; Wei, X. The potential of hyperspectral image classification for oil spill mapping. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar]
- Chen, F.; Wang, K.; Van de Voorde, T.; Tang, T.F. Mapping urban land cover from high spatial resolution hyperspectral data: An approach based on simultaneously unmixing similar pixels with jointly sparse spectral mixture analysis. Remote Sens. Environ. 2017, 196, 324–342. [Google Scholar]
- Yang, X.; Zhang, X.; Ye, Y.; Lau, R.Y.; Lu, S.; Li, X.; Huang, X. Synergistic 2D/3D convolutional neural network for hyperspectral image classification. Remote Sens. 2020, 12, 2033. [Google Scholar]
- Shen, J.; Zhang, D.; Dong, G.; Sun, D.; Liang, X.; Su, M. Classification of hyperspectral images based on fused 3D inception and 3D-2D hybrid convolution. Signal Image Video Process. 2024, 18, 3031–3041. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep dense convolutional neural network for hyperspectral image classification. Remote Sens. 2018, 10, 1454. [Google Scholar]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar]
- Sun, L.; Zhao, G.; Zheng, Y.; Wu, Z. Spectral–spatial feature tokenization transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5522214. [Google Scholar]
- Yao, J.; Hong, D.; Li, C.; Chanussot, J. Spectralmamba: Efficient mamba for hyperspectral image classification. arXiv 2024, arXiv:2404.08489. [Google Scholar]
- Sheng, J.; Zhou, J.; Wang, J.; Ye, P.; Fan, J. Dualmamba: A lightweight spectral-spatial mamba-convolution network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 63, 5501415. [Google Scholar]
- Li, Y.; Zhang, H.; Shen, Q. Spectral-spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar]
- Xu, H.; Yao, W.; Cheng, L.; Li, B. Multiple spectral resolution 3D convolutional neural network for hyperspectral image classification. Remote Sens. 2021, 13, 1248. [Google Scholar]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral image classification using a hybrid 3D-2D convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network. Remote Sens. Lett. 2017, 8, 438–447. [Google Scholar]
- Haque, M.R.; Mishu, S.Z.; Palash Uddin, M.; Al Mamun, M. A lightweight 3D-2D convolutional neural network for spectral-spatial classification of hyperspectral images. J. Intell. Fuzzy Syst. 2022, 43, 1241–1258. [Google Scholar]
- Luo, Y.; Zou, J.; Yao, C.; Zhao, X.; Li, T.; Bai, G. HSI-CNN: A novel convolution neural network for hyperspectral image. In Proceedings of the 2018 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–17 July 2018; pp. 464–469. [Google Scholar]
- Liang, L.; Zhang, S.; Li, J.; Plaza, A.; Cui, Z. Multi-scale spectral-spatial attention network for hyperspectral image classification combining 2D octave and 3D convolutional neural networks. Remote Sens. 2023, 15, 1758. [Google Scholar]
- Diakite, A.; Jiangsheng, G.; Xiaping, F. Hyperspectral image classification using 3D 2D CNN. IET Image Process. 2021, 15, 1083–1092. [Google Scholar]
- Cao, J.; Li, X. A 3D 2D convolutional neural network model for hyperspectral image classification. arXiv 2021, arXiv:2111.10293. [Google Scholar]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Gao, C.Z.; Tao, R. Central Attention Network for Hyperspectral Imagery Classification. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8989–9003. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Tao, R. Multiarea Target Attention for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5524916. [Google Scholar] [CrossRef]
- Mei, S.; Li, X.; Liu, X.; Cai, H.; Du, Q. Hyperspectral image classification using attention-based bidirectional long short-term memory network. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5509612. [Google Scholar]
- Ayas, S.; Tunc-Gormus, E. SpectralSWIN: A spectral-swin transformer network for hyperspectral image classification. Int. J. Remote Sens. 2022, 43, 4025–4044. [Google Scholar]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. QTN: Quaternion transformer network for hyperspectral image classification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7370–7384. [Google Scholar]
- Qiao, X.; Huang, W. A dual frequency transformer network for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 10344–10358. [Google Scholar]
- Li, Y.; Yang, X.; Tang, D.; Zhou, Z. RDTN: Residual Densely Transformer Network for hyperspectral image classification. Expert Syst. Appl. 2024, 250, 123939. [Google Scholar]
- Yang, X.; Cao, W.; Tang, D.; Zhou, Y.; Lu, Y. ACTN: Adaptive Coupling Transformer Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5503115. [Google Scholar]
- Gong, Z.; Zhou, X.; Yao, W. MultiScale spectral–spatial convolutional transformer for hyperspectral image classification. IET Image Process. 2024, 18, 4328–4340. [Google Scholar]
- Luo, Y.; Tang, D.; Yang, X.; Li, Y. Spectral-spatial attention transformer network for hyperspectral image classification. In Proceedings of the The International Conference Optoelectronic Information and Optical Engineering (OIOE2024), Wuhan, China; 2024; Volume 13513, pp. 833–838. [Google Scholar]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Guo, Z.; Song, L. SegHSI: Semantic Segmentation of Hyperspectral Images with Limited Labeled Pixels. IEEE Trans. Image Process. 2024, 33, 6469–6482. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Roy, S.K.; Deria, A.; Shah, C.; Haut, J.M.; Du, Q.; Plaza, A. Spectral–spatial morphological attention transformer for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5503615. [Google Scholar]
- Yang, X.; Cao, W.; Lu, Y.; Zhou, Y. Hyperspectral image transformer classification networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5528715. [Google Scholar]
- Liu, B.; Liu, Y.; Zhang, W.; Tian, Y.; Kong, W. Spectral Swin Transformer Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 3721. [Google Scholar] [CrossRef]
- Wang, C.; Huang, J.; Lv, M.; Du, H.; Wu, Y.; Qin, R. A local enhanced mamba network for hyperspectral image classification. Int. J. Appl. Earth Obs. Geoinf. 2024, 133, 104092. [Google Scholar]
- He, Y.; Tu, B.; Liu, B.; Li, J.; Plaza, A. 3DSS-Mamba: 3D-spectral-spatial mamba for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5534216. [Google Scholar]
- Liu, Q.; Yue, J.; Fang, Y.; Xia, S.; Fang, L. HyperMamba: A Spectral-Spatial Adaptive Mamba for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5536514. [Google Scholar]
- Lou, M.; Zhang, S.; Zhou, H.Y.; Yang, S.; Wu, C.; Yu, Y. TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 11534–11547. [Google Scholar] [CrossRef]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 1–39. [Google Scholar]
- Li, J.; Su, Q.; Yang, Y.; Jiang, Y.; Wang, C.; Xu, H. Adaptive gating in mixture-of-experts based language models. arXiv 2023, arXiv:2310.07188. [Google Scholar]
- Wu, J.; Hou, M. Enhancing diversity for logical table-to-text generation with mixture of experts. Expert Syst. 2024, 41, e13533. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Lin, B.; Tang, Z.; Ye, Y.; Cui, J.; Zhu, B.; Jin, P.; Huang, J.; Zhang, J.; Pang, Y.; Ning, M.; et al. Moe-llava: Mixture of experts for large vision-language models. arXiv 2024, arXiv:2401.15947. [Google Scholar]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar]
- Li, Y.; Luo, Y.; Zhang, L.; Wang, Z.; Du, B. MambaHSI: Spatial-spectral mamba for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5524216. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | 2D-CNN | 3D-CNN | Hybridsn | HiT | SSFTT | Morphformer | MambaHSI | HyperTransXNet |
|---|---|---|---|---|---|---|---|---|
| Alfalfa | 92.82 ± 4.80 | 69.95 ± 17.92 | 18.85 ± 29.79 | 16.34 ± 15.70 | 89.65 ± 6.91 | 82.13 ± 22.40 | 76.83 ± 22.15 | 89.51 ± 14.39 |
| Corn-notill | 93.81 ± 1.97 | 88.61 ± 1.17 | 84.84 ± 11.22 | 90.48 ± 1.22 | 94.11 ± 1.08 | 93.38 ± 2.14 | 90.97 ± 3.50 | 94.23 ± 1.72 |
| Corn-mintill | 92.19 ± 1.77 | 86.74 ± 1.90 | 75.93 ± 18.40 | 93.13 ± 3.63 | 90.13 ± 2.66 | 91.28 ± 3.66 | 90.46 ± 5.05 | 96.22 ± 2.30 |
| Corn | 97.94 ± 1.50 | 93.92 ± 2.44 | 80.93 ± 17.01 | 91.17 ± 5.12 | 94.90 ± 3.46 | 95.26 ± 4.04 | 90.38 ± 6.24 | 93.90 ± 5.63 |
| Grass-pasture | 93.09 ± 3.32 | 93.44 ± 0.70 | 73.56 ± 16.43 | 81.89 ± 10.59 | 93.08 ± 2.52 | 94.72 ± 1.55 | 95.26 ± 2.14 | 95.61 ± 2.37 |
| Grass-trees | 95.65 ± 2.97 | 94.82 ± 0.67 | 75.90 ± 15.75 | 95.11 ± 0.98 | 95.98 ± 1.29 | 95.47 ± 1.38 | 94.70 ± 2.37 | 97.26 ± 1.22 |
| Grass-pasture-mowed | 7.94 ± 18.29 | 0.00 ± 0.00 | 0.00 ± 0.00 | 0.00 ± 0.00 | 54.69 ± 35.84 | 71.56 ± 18.01 | 44.40 ± 32.52 | 28.40 ± 30.54 |
| Hay-windrowed | 99.69 ± 0.55 | 98.87 ± 1.10 | 87.72 ± 13.09 | 99.86 ± 0.21 | 98.77 ± 1.35 | 99.81 ± 0.39 | 99.72 ± 0.46 | 100.00 ± 0.00 |
| Oats | 73.30 ± 29.09 | 0.00 ± 0.00 | 2.45 ± 5.09 | 0.00 ± 0.00 | 54.34 ± 32.04 | 21.28 ± 30.14 | 57.22 ± 25.95 | 50.56 ± 36.47 |
| Soybean-notill | 87.78 ± 1.60 | 83.25 ± 1.22 | 78.05 ± 9.87 | 77.61 ± 2.07 | 87.11 ± 1.77 | 88.80 ± 3.58 | 84.25 ± 5.74 | 83.09 ± 2.03 |
| Soybean-mintill | 96.26 ± 1.24 | 94.38 ± 0.51 | 91.41 ± 4.16 | 96.09 ± 1.74 | 96.78 ± 0.82 | 96.27 ± 0.59 | 96.12 ± 3.54 | 98.40 ± 0.54 |
| Soybean-clean | 91.80 ± 2.21 | 89.11 ± 1.71 | 78.53 ± 12.76 | 91.18 ± 3.46 | 89.52 ± 3.35 | 87.66 ± 5.08 | 92.96 ± 5.99 | 93.16 ± 4.09 |
| Wheat | 98.12 ± 1.32 | 86.71 ± 7.81 | 54.68 ± 33.43 | 91.89 ± 2.96 | 95.00 ± 3.62 | 94.35 ± 4.88 | 95.14 ± 2.90 | 90.76 ± 5.41 |
| Woods | 98.28 ± 2.42 | 97.81 ± 0.58 | 94.10 ± 5.22 | 99.45 ± 0.38 | 98.67 ± 0.66 | 98.87 ± 0.31 | 99.16 ± 0.43 | 99.49 ± 0.39 |
| Buildings-Grass-Trees-Drives | 97.82 ± 1.46 | 93.48 ± 2.25 | 73.19 ± 17.09 | 87.90 ± 11.83 | 96.08 ± 2.76 | 96.06 ± 1.48 | 90.86 ± 4.12 | 96.31 ± 3.60 |
| Stone-Steel-Towers | 52.74 ± 21.39 | 46.87 ± 17.62 | 41.04 ± 32.91 | 16.79 ± 20.55 | 39.20 ± 32.30 | 25.11 ± 33.4 | 22.98 ± 18.69 | 45.36 ± 17.65 |
| OA (%) | 94.48 ± 1.41 | 91.48 ± 0.52 | 83.10 ± 10.19 | 90.85 ± 1.13 | 94.09 ± 0.97 | 94.03 ± 0.90 | 92.72 ± 1.15 | 94.74 ± 0.39 |
| AA (%) | 83.81 ± 3.38 | 73.92 ± 2.12 | 62.87 ± 12.02 | 70.56 ± 2.84 | 84.54 ± 3.91 | 82.75 ± 2.85 | 82.59 ± 3.35 | 84.52 ± 2.76 |
| (%) | 93.69 ± 1.61 | 90.25 ± 0.59 | 80.70 ± 11.52 | 89.53 ± 1.31 | 93.25 ± 1.10 | 93.18 ± 1.03 | 91.69 ± 1.30 | 93.99 ± 0.44 |
| Class | 2D-CNN | 3D-CNN | HybridSN | HiT | SSFTT | Morphformer | MambaHSI | HyperTransXNet |
|---|---|---|---|---|---|---|---|---|
| Healthy Grass | 95.21 ± 1.66 | 91.06 ± 3.44 | 90.76 ± 1.88 | 90.02 ± 3.40 | 96.42 ± 1.16 | 85.97 ± 8.75 | 96.94 ± 1.80 | 98.41 ± 1.19 |
| Stressed grass | 95.51 ± 1.72 | 88.85 ± 6.46 | 86.26 ± 8.27 | 95.63 ± 0.83 | 97.16 ± 1.42 | 88.97 ± 5.58 | 94.21 ± 2.69 | 97.25 ± 2.50 |
| Synthetic GrassTrees | 99.24 ± 0.45 | 97.36 ± 3.06 | 95.85 ± 3.67 | 97.48 ± 0.66 | 99.30 ± 0.58 | 91.37 ± 13.84 | 97.26 ± 1.06 | 97.62 ± 0.73 |
| Trees | 94.72 ± 2.18 | 88.28 ± 4.52 | 79.71 ± 7.46 | 87.64 ± 4.96 | 97.68 ± 0.90 | 90.96 ± 4.95 | 94.49 ± 2.31 | 96.98 ± 1.97 |
| Soil | 99.81 ± 0.17 | 95.72 ± 3.71 | 96.41 ± 3.83 | 99.90 ± 0.14 | 99.43 ± 0.63 | 97.96 ± 2.17 | 99.63 ± 0.38 | 99.97 ± 0.04 |
| Water | 94.05 ± 0.97 | 86.16 ± 1.92 | 91.69 ± 3.12 | 74.69 ± 3.14 | 93.61 ± 3.07 | 90.85 ± 4.25 | 90.86 ± 6.69 | 92.57 ± 3.57 |
| Residential | 96.82 ± 1.02 | 83.00 ± 6.98 | 78.74 ± 17.12 | 73.54 ± 8.98 | 97.52 ± 0.80 | 85.78 ± 24.73 | 95.88 ± 1.52 | 98.89 ± 0.68 |
| Commercial | 97.62 ± 1.51 | 89.55 ± 1.61 | 93.01 ± 2.65 | 87.67 ± 4.75 | 97.88 ± 1.24 | 90.76 ± 9.56 | 96.46 ± 1.38 | 96.06 ± 1.43 |
| Road | 95.42 ± 1.51 | 85.03 ± 3.38 | 73.95 ± 14.36 | 81.45 ± 3.15 | 96.70 ± 1.56 | 87.54 ± 7.99 | 96.16 ± 1.59 | 99.00 ± 0.90 |
| Highway | 99.09 ± 1.57 | 91.67 ± 6.54 | 91.92 ± 7.92 | 96.51 ± 2.25 | 99.78 ± 0.38 | 93.89 ± 9.76 | 99.94 ± 0.19 | 100.00 ± 0.00 |
| Railway | 99.58 ± 0.46 | 81.57 ± 5.87 | 85.29 ± 7.92 | 93.82 ± 3.78 | 99.76 ± 0.44 | 91.69 ± 16.26 | 97.00 ± 1.92 | 99.62 ± 0.80 |
| Parking Lot 1 | 97.88 ± 1.83 | 94.30 ± 1.81 | 95.79 ± 2.71 | 93.77 ± 3.09 | 98.70 ± 1.24 | 88.63 ± 13.89 | 97.32 ± 1.71 | 99.22 ± 0.84 |
| Parking Lot 2 | 97.55 ± 2.44 | 81.89 ± 6.24 | 86.51 ± 8.08 | 90.28 ± 3.60 | 98.54 ± 1.23 | 92.25 ± 6.66 | 97.27 ± 1.79 | 98.13 ± 2.36 |
| Tennise Court | 99.98 ± 0.07 | 98.60 ± 0.97 | 92.98 ± 6.16 | 99.82 ± 0.55 | 99.67 ± 0.47 | 99.04 ± 1.46 | 99.77 ± 0.50 | 100.00 ± 0.00 |
| Running Track | 97.87 ± 1.71 | 94.77 ± 5.41 | 91.48 ± 5.60 | 99.21 ± 1.37 | 98.95 ± 0.71 | 93.32 ± 7.49 | 97.17 ± 4.63 | 100.00 ± 0.00 |
| OA (%) | 97.32 ± 0.48 | 89.54 ± 3.21 | 88.19 ± 4.75 | 90.67 ± 1.01 | 98.15 ± 0.53 | 90.98 ± 7.71 | 96.80 ± 0.55 | 98.46 ± 0.29 |
| AA (%) | 97.03 ± 0.37 | 89.74 ± 2.87 | 88.97 ± 4.09 | 90.76 ± 0.92 | 97.81 ± 0.59 | 90.99 ± 7.46 | 96.69 ± 0.69 | 98.25 ± 0.22 |
| 97.10 ± 0.51 | 88.70 ± 3.47 | 87.24 ± 5.13 | 89.91 ± 1.09 | 98.00 ± 0.58 | 90.24 ± 8.36 | 96.54 ± 0.59 | 98.33 ± 0.31 |
| Class | 2D-CNN | 3D-CNN | HybridSN | HiT | SSFTT | Morphformer | MambaHSI | HyperTransXNet |
|---|---|---|---|---|---|---|---|---|
| Corn | 99.87 ± 0.03 | 99.34 ± 0.40 | 99.34 ± 0.58 | 99.79 ± 0.08 | 99.88 ± 0.04 | 99.89 ± 0.06 | 99.73 ± 0.24 | 99.84 ± 0.11 |
| Cotton | 99.72 ± 0.09 | 96.30 ± 1.24 | 97.55 ± 3.18 | 97.26 ± 2.05 | 99.69 ± 0.11 | 99.78 ± 0.13 | 99.78 ± 0.25 | 99.19 ± 0.75 |
| Sesame | 94.97 ± 1.27 | 55.88 ± 29.79 | 81.52 ± 14.54 | 94.55 ± 3.24 | 98.93 ± 0.54 | 99.44 ± 0.42 | 95.44 ± 1.70 | 98.82 ± 0.77 |
| Broad-leaf soybean | 99.12 ± 0.08 | 96.24 ± 0.89 | 98.22 ± 0.64 | 99.77 ± 0.10 | 99.63 ± 0.05 | 99.65 ± 0.16 | 99.61 ± 0.22 | 99.83 ± 0.13 |
| Narrow-leaf soybean | 95.42 ± 0.71 | 87.80 ± 2.44 | 81.06 ± 10.19 | 88.16 ± 3.47 | 98.30 ± 0.48 | 97.60 ± 1.50 | 95.25 ± 3.24 | 96.38 ± 1.97 |
| Rice | 98.57 ± 0.19 | 98.11 ± 0.66 | 97.28 ± 0.91 | 99.36 ± 0.19 | 98.96 ± 0.44 | 99.05 ± 0.23 | 98.33 ± 0.72 | 98.54 ± 0.49 |
| Water | 99.74 ± 0.04 | 99.51 ± 0.22 | 97.11 ± 0.53 | 99.99 ± 0.01 | 99.56 ± 0.12 | 99.49 ± 0.15 | 99.86 ± 0.11 | 99.85 ± 0.10 |
| Roads and houses | 85.56 ± 0.78 | 82.84 ± 2.22 | 78.60 ± 7.09 | 84.38 ± 3.87 | 89.32 ± 2.82 | 91.03 ± 1.82 | 87.57 ± 3.60 | 87.32 ± 2.85 |
| Mixed weed | 78.58 ± 2.04 | 79.05 ± 2.99 | 37.10 ± 12.86 | 70.44 ± 3.65 | 84.48 ± 3.09 | 83.76 ± 1.79 | 86.64 ± 5.89 | 88.04 ± 4.99 |
| OA(%) | 98.35 ± 0.09 | 96.60 ± 0.63 | 95.77 ± 0.80 | 98.12 ± 0.14 | 98.86 ± 0.20 | 98.74 ± 0.16 | 98.74 ± 0.22 | 98.91 ± 0.16 |
| AA (%) | 93.24 ± 0.46 | 84.58 ± 3.95 | 82.29 ± 3.59 | 92.63 ± 0.80 | 95.72 ± 0.72 | 95.03 ± 0.67 | 95.80 ± 0.94 | 96.42 ± 0.69 |
| 97.82 ± 0.13 | 95.49 ± 0.85 | 94.38 ± 1.07 | 97.52 ± 0.19 | 98.50 ± 0.26 | 98.34 ± 0.21 | 98.35 ± 0.29 | 98.57 ± 0.21 |
| Methods | FLOPs (G) | Param (MB) | Inference Speed (sample/s) | Peak Memory (MB) | Training Time (s) | Testing Time (s) | OA (%) | AA (%) | (%) |
|---|---|---|---|---|---|---|---|---|---|
| ViT | 2.71 | 52.22 | 565.30 | 715.06 | 727.89 | 3.43 | 90.27 ± 1.69 | 90.45 ± 1.42 | 89.48 ± 1.83 |
| DeepViT | 2.71 | 52.22 | 352.53 | 881.06 | 1497.97 | 6.82 | 91.58 ± 1.50 | 91.38 ± 1.43 | 90.89 ± 1.62 |
| CvT | 9.04 | 17.77 | 149.52 | 8494.94 | 2758.06 | 11.65 | 93.52 ± 1.88 | 93.75 ± 1.95 | 92.99 ± 2.04 |
| HiT | 1.81 | 16.94 | 103.91 | 8314.00 | 112.04 | 6.7 | 95.20 ± 0.33 | 94.80 ± 0.32 | 94.81 ± 0.35 |
| SSFTT | 0.97 | 87.04 | 148.29 | 8198.00 | 389.62 | 1.59 | 98.15 ± 0.53 | 97.82 ± 0.59 | 98.00 ± 0.58 |
| MorphFormer | 0.74 | 87.04 | 11.44 | 8200.00 | 874.99 | 4.16 | 90.98 ± 7.71 | 90.99 ± 7.46 | 90.24 ± 8.36 |
| MambaHSI | 0.006 | 0.10 | 440.88 | 8202.00 | 170.71 | 0.10 | 96.80 ± 0.55 | 96.69 ± 0.69 | 96.54 ± 0.59 |
| HyperTransXNet | 0.24 | 1.08 | 278.63 | 707.06 | 201.39 | 0.13 | 98.46 ± 0.29 | 98.25 ± 0.22 | 98.33 ± 0.31 |
| Sizes | IndianPines | WHU-HI-Longkou | Houston2013 | |||
|---|---|---|---|---|---|---|
| OA | Kapp | OA | Kapp | OA | Kapp | |
| 97.43 ± 0.34 | 97.07 ± 0.39 | 99.25 ± 0.08 | 99.01 ± 0.11 | 98.78 ± 0.27 | 98.69 ± 0.29 | |
| 95.82 ± 0.51 | 95.23 ± 0.58 | 99.14 ± 0.18 | 98.87 ± 0.23 | 98.50 ± 0.30 | 98.38 ± 0.33 | |
| 94.74 ± 0.39 | 93.99 ± 0.44 | 98.91 ± 0.16 | 98.57 ± 0.21 | 98.46 ± 0.29 | 98.33 ± 0.31 | |
| 92.88 ± 0.63 | 91.86 ± 0.71 | 98.49 ± 0.29 | 98.01 ± 0.38 | 98.14 ± 0.35 | 97.99 ± 0.38 | |
| 91.12 ± 1.53 | 89.85 ± 1.74 | 98.27 ± 0.13 | 97.72 ± 0.17 | 97.58 ± 0.23 | 97.38 ± 0.25 | |
| Methods | SSLB | SSGB | OA (%) | (%) |
|---|---|---|---|---|
| 2D-CNN | × | × | 97.32 ± 0.48 | 97.10 ± 0.51 |
| HyperTransXNet | √ | × | 98.05 ± 0.43 (↑0.73%) | 97.89 ± 0.46 (↑0.79%) |
| HyperTransXNet | × | √ | 98.18 ± 0.25 (↑0.86%) | 98.04 ± 0.27 (↑0.94%) |
| Methods | SSTE | OA (%) | (%) |
|---|---|---|---|
| HyperTransXNet_SSLB_SSGB | × | 98.16 ± 0.32 | 98.01 ± 0.34 |
| HyperTransXNet_SSLB_SSGB | √ | 98.46 ± 0.29 (↑0.30%) | 98.33 ± 0.31 (↑0.32%) |
| Methods | SSTE | MoE-R | OA (%) | (%) |
|---|---|---|---|---|
| HyperTransXNet_SSLB_SSGB | × | √ | 93.73 ± 1.53 | 93.22 ± 1.65 |
| HyperTransXNet_SSLB_SSGB | √ | × | 98.46 ± 0.29 (↑4.73%) | 98.33 ± 0.31 (↑5.11%) |
| Number of Experts (E) | FLOPs (G) | Param (MB) | Parameter Efficiency (Acc/Param) | Marginal Parameter Efficiency ( Acc/ Param) | OA (%) | AA (%) | (%) |
|---|---|---|---|---|---|---|---|
| 2 | 0.21 | 0.99 | 99.05 | - | 98.06 ± 0.44 | 97.63 ± 0.39 | 97.90 ± 0.48 |
| 4 | 0.24 | 1.08 | 91.17 | 4.44 | 98.46 ± 0.29 | 98.25 ± 0.22 | 98.33 ± 0.31 |
| 8 | 0.30 | 1.26 | 77.75 | −2.78 | 97.96 ± 0.49 | 97.51 ± 0.54 | 97.80 ± 0.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, X.; Li, Z.; Li, L.; Xue, S.; Huang, X.; Yang, X. HyperTransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Hyperspectral Image Classification. Remote Sens. 2025, 17, 2361. https://doi.org/10.3390/rs17142361
Dai X, Li Z, Li L, Xue S, Huang X, Yang X. HyperTransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Hyperspectral Image Classification. Remote Sensing. 2025; 17(14):2361. https://doi.org/10.3390/rs17142361
Chicago/Turabian StyleDai, Xin, Zexi Li, Lin Li, Shuihua Xue, Xiaohui Huang, and Xiaofei Yang. 2025. "HyperTransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Hyperspectral Image Classification" Remote Sensing 17, no. 14: 2361. https://doi.org/10.3390/rs17142361
APA StyleDai, X., Li, Z., Li, L., Xue, S., Huang, X., & Yang, X. (2025). HyperTransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Hyperspectral Image Classification. Remote Sensing, 17(14), 2361. https://doi.org/10.3390/rs17142361