1. Introduction
Over the past few years, Unmanned Aerial Vehicle (UAV) technology has undergone rapid and significant development. Due to their exceptional flexibility, stealth, and high efficiency, UAVs have become indispensable reconnaissance and detection tools in both civilian and military domains, with a broad spectrum of applications. UAV-based object detection technologies have been widely applied across diverse sectors, including agriculture, surveying and mapping, disaster management, healthcare, firefighting, and national defense. As illustrated in
Figure 1, researchers have extensively studied UAV object detection applications in these fields. For example, in agriculture, F. Ahmad et al. [
1] performed field studies to investigate how UAV sprayer configurations influence spray deposition patterns in both target and non-target zones for weed control purposes. Their findings demonstrated how UAVs enabled the optimization of spraying efficacy and the reduction of pesticide drift. In surveying and mapping, M. Gašparović et al. [
2] utilized UAVs equipped with low-cost RGB cameras to acquire high-resolution imagery and combined photogrammetric processing with machine-learning classification techniques to develop an automated method for generating high-precision weed distribution maps in farmland, providing crucial spatial information support for precision agriculture. In disaster management, N. D. Nath et al. [
3] employed UAV video for spatial mapping. By integrating SIFT feature matching, progressive homography estimation, multi-object tracking, and iterative closest point registration, they achieved GPS-independent, high-precision localization and mapping of features in disaster-stricken areas. In firefighting, Kinaneva et al. [
4] proposed an early forest fire detection method combining UAV platforms with artificial-intelligence techniques. Their approach utilized thermal imaging and real-time image analysis to enhance the identification of initial fire indicators, thereby improving the timeliness and accuracy of fire response in forest fire prevention, emergency response, and disaster management. In national defense, He et al. [
5] introduced the YOLOv5s-pp algorithm, which integrates channel attention (CA) modules to optimize small-object detection from UAV perspectives, thereby boosting the robustness and safety of UAV platforms during essential operations, including military reconnaissance, security monitoring, and route patrolling.
Currently, Convolutional Neural Networks (CNNs) stand as the predominant framework in the domain of object detection. CNN-based object detection methods can generally be categorized into two-stage and single-stage approaches. Two-stage algorithms, such as R-CNN [
6], SPPNet [
7], Fast R-CNN [
8], and Faster R-CNN [
9], depend on region proposal generation and generally achieve higher localization accuracy, despite being hindered by relatively slow inference speeds. Single-stage algorithms, such as SSD [
10], YOLO [
11] and RetinaNet [
12], directly regress object locations and categories, achieving faster detection speeds. Their detection performance, especially for small objects, has been continuously improved through techniques like multi-scale feature fusion. Owing to their excellent trade-off between being lightweight and highly accurate, YOLO series algorithms have found widespread application in UAV object detection, spurring further research in this domain (e.g., YBUT [
13]).
However, object detection from a UAV perspective typically faces several challenges: (1) complex and cluttered backgrounds; (2) highly variable object scales; (3) large fields of view (FOV) that yield sparse or uneven object distributions; (4) frequent changes in object location, orientation, and angle; and (5) stringent limits on onboard computational resources. These factors significantly impede the performance of UAV-based detectors. To address these challenges, researchers have introduced numerous methodologies adapted for distinct UAV operational environments. To mitigate background complexity in UAV imagery, Bo et al. [
14] employed an enhanced YOLOv7-tiny network architecture. By redesigning the anchor box mechanism and incorporating key modules such as SPPFCSPC-SR, InceptionNeXt, and Get-and-Send, they improved feature representation for small targets and cross-level information fusion. This method significantly boosted detection precision and system resilience in complex dynamic environments, though its feature extraction capability remains limited in highly challenging scenarios. Similarly targeting background complexity, Wang et al. [
15] proposed OATF-YOLO, which introduces an Orthogonal Channel Attention mechanism (OCAC2f), integrates a triple feature encoder and a scale-sequence feature fusion module (TESSF), and incorporates an internal factor (I-MPDIoU) into the loss function to enhance feature extraction and background discrimination. However, its robustness remains insufficient for aerial images with variable viewpoints, arbitrary orientations, complex illumination, and diverse weather conditions.
To cope with small, low-resolution targets, Zhao et al. [
16] presented Subtle-YOLOv8. Building on YOLOv8, it integrates an Efficient Multi-Scale Attention module (EMA), Dynamic Serpentine Convolution (DSConv), a dedicated small-object detection head, and a Wise-IoU loss function. Although it markedly improves small-object detection, its performance degrades for slightly larger targets (e.g., trucks), and the overall model complexity increases. Similarly, Chen et al. [
17] developed a Residual Progressive Feature Pyramid Network (R-AFPN). It fuses features via a Residual Progressive Feature Fusion (RAFF) module for adaptive spatial and cross-scale connections, employs a Shallow Information Extraction (SIE) module to capture fine low-level details, and uses a Hierarchical Feature Fusion (HFF) module to enrich deep features through bottom-up incremental fusion. While R-AFPN excels at single-class, small-object detection with low parameter counts, its robustness on multi-class, large-scale-variation datasets (e.g., VisDrone2019) remains inferior to some state-of-the-art networks. To correct severe radial distortion in wide-angle and fisheye images, Kakani et al. [
18] devised an outlier-optimized automatic distortion-correction method. By extracting and aggregating straight-line segments into line-member sets, introducing an iterative outlier-optimization mechanism, and applying an accumulated vertical-line-angle loss, they jointly optimize distortion parameters and purify line members. Although this significantly improves corrected image quality and downstream vision tasks, the method’s robustness degrades in scenes lacking abundant linear features. To fulfill timeliness stipulations amidst constrained resources, Ma et al. [
19] proposed LW-YOLOv8, a lightweight detector based on an improved YOLOv8s. They designed a CSP-CTFN module combining CNNs with multi-head self-attention and a parameter-sharing PSC-Head detection head, and adopted SIoU loss to boost localization precision. While this approach drastically reduces model size and accelerates inference, its adaptability on extremely resource-limited devices and in complex environments still needs enhancement. Within the YOLOv5 framework, Chen et al. [
20] replaced the backbone’s C3 modules with Efficient Layer Shuffle Aggregation Networks (ELSANs) to improve speed and efficiency, and integrated Partial Convolution (PCConv) with an SE attention mechanism in the neck to further reduce computation and increase accuracy. This method significantly improves detection in heavily overlapping and occluded agricultural scenes, but its performance declines under extreme overlap, and false positives persist in complex backgrounds. Finally, the issue of object rotation in UAV imagery has also been addressed. Pan et al. [
21] extended YOLOv8 by adding a rotation-angle (
) output dimension in the detection head to remedy object deformation and rotation, as seen from UAV viewpoints. Li et al. [
22] improved the S2A-Net by embedding PSA/CIM modules for richer feature representation and combining D4 dehazing with an image-weighted sampling strategy for optimized training. Although this enhances rotated-object detection, its generalization ability and runtime efficiency remain areas in need of further optimization.
Despite substantial advancements in the domain of UAV object detection, investigations that effectively integrate multi-scale feature fusion strategies with compact network designs to synergistically enhance both detection accuracy and operational efficiency remain relatively limited. To tackle these challenges and achieve a better balance between high-precision detection and model lightweighting, this work introduces a specialized lightweight UAV object detection approach. The main contributions of this paper are as follows:
In response to the resource constraints and real-time requirements of UAV platforms, this paper constructs a systematic lightweight detection architecture. Firstly, an efficient ShuffleNetV2 is adopted as the backbone network to significantly reduce the base parameter count and computational costs. To compensate for the potential decline in feature representation capability caused by deep lightweight design, particularly in capturing contextual information of small targets against complex backgrounds, a Multi-Scale Dilated Attention (MSDA) mechanism is further integrated into the backbone network. This mechanism effectively enhances the feature extraction efficiency of the backbone network through its dynamic multi-scale receptive field capability. The synergistic optimization of this backbone and the lightweight design of the neck network result in a remarkable 65.3% reduction in the model’s computational load (GFLOPs) compared to the baseline model.
To address the challenge of high false detection rates caused by the low resolution and limited feature information of small targets, this paper abandons the conventional approach of stacking or replacing modules. Instead, it proposes a novel neck network design paradigm centered on the concept of “heterogeneous feature decoupling and dynamic aggregation”. This paradigm aims to maximize the model’s ability to extract and fuse diverse features at minimal computational cost, achieved through our original two core components:
Original bottleneck modules for heterogeneous decoupling (C2f_ConvX & C2f_MConv): This paper introduces a novel “split-differentiate-merge” strategy within the C2f architecture. Unlike standard group convolution’s homogeneous processing, the proposed C2f_ConvX and C2f_MConv modules asymmetrically split the information flow and apply convolutional transformations with divergent scales and complexities. This asymmetric design decouples and extracts richer gradient combinations and feature spectra from raw features, significantly enhancing the discernibility of small targets in complex backgrounds without a substantial parameter increase.
Original lightweight convolution for dynamic aggregation (DRFAConvP): To efficiently fuse the aforementioned decoupled heterogeneous features, this paper proposes DRFAConvP—a fundamental advancement over existing lightweight convolutions (e.g., GhostConv). While GhostConv relies on static linear transformations for feature generation, DRFAConvP innovatively integrates an input-dependent dynamic attention mechanism into this process. This enables adaptive aggregation of multi-receptive-field information, where the network dynamically focuses on the most discriminative spatial details for the current target, effectively resolving the severe scale variation challenges in UAV-based detection.
To enhance the model’s small-target localization precision in complex scenarios, the Wise-IoU (WIoU) loss function is introduced, incorporating a dynamic non-monotonic focusing mechanism. This mechanism intelligently modulates gradient weights according to anchor boxes’ outlier degrees, prioritizing the optimization of medium-quality anchors while suppressing harmful gradients from low-quality samples, thereby achieving more accurate small-target localization in cluttered backgrounds and effectively reducing both missed detection and false alarm rates.
2. Model Design
2.1. YOLOv8 Architecture Analysis
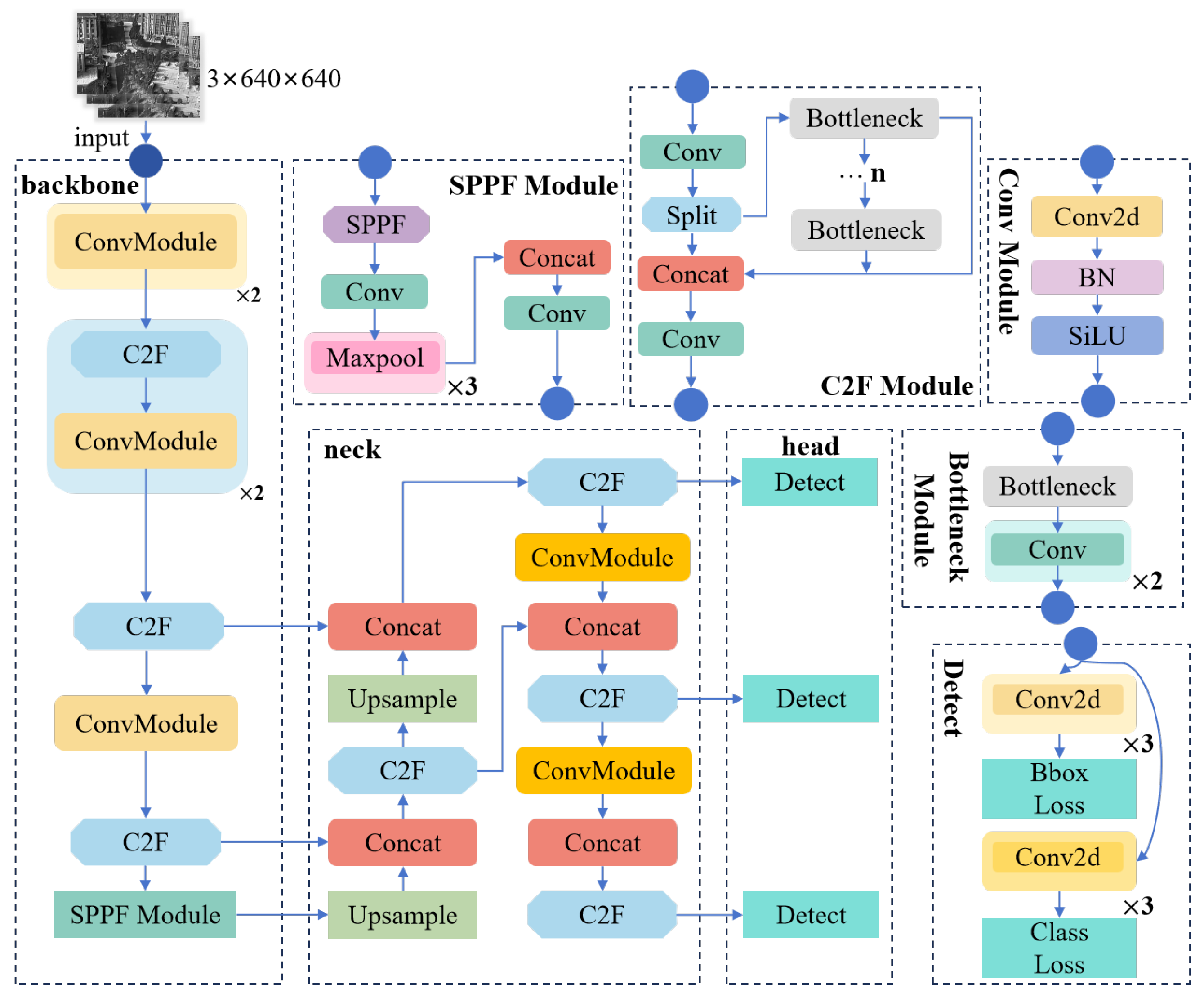
YOLOv8 is a family of YOLO models released by Ultralytics in 2023. It can be applied to multiple computer vision tasks, including image classification, object detection, instance segmentation, and keypoint detection. The model is available in five different sizes, ranging from the compact YOLOv8n to the large YOLOv8x, with detection accuracy increasing alongside model size. The YOLOv8 architecture consists of four primary components: Input, Backbone, Neck, and Head. The Input module preprocesses images for efficient network processing, employing adaptive scaling to improve both image quality and inference speed [
23]. The Backbone consists of Conv, C2f, and SPPF modules that collaboratively extract features from the input. Notably, the C2f module integrates two convolutional layers and multiple Bottleneck blocks to capture richer gradient information [
24], while the SPPF module applies three successive max-pooling operations to harvest multi-scale object features, thereby enhancing detection accuracy across various object sizes [
25]. The overall YOLOv8 architecture is illustrated in
Figure 2.
2.2. Improved YOLOv8s Model Network Structure
Object detection tasks performed from a UAV perspective face multiple inherent challenges. Firstly, high-altitude, long-distance imaging and a wide field of view (FoV) often result in targets appearing small, with low resolution. Their faint features can easily be confounded with complex backgrounds containing diverse terrains (such as buildings, vegetation, and textures), severely hindering accurate identification and localization. Secondly, the inherent limitations in computational power, storage space, and energy consumption of UAV platforms impose stringent demands on the lightweight design and computational efficiency of detection models. Therefore, while pursuing high detection accuracy, it is crucial to consider the resource efficiency for model deployment; achieving an effective balance between these two aspects is key in this research field.
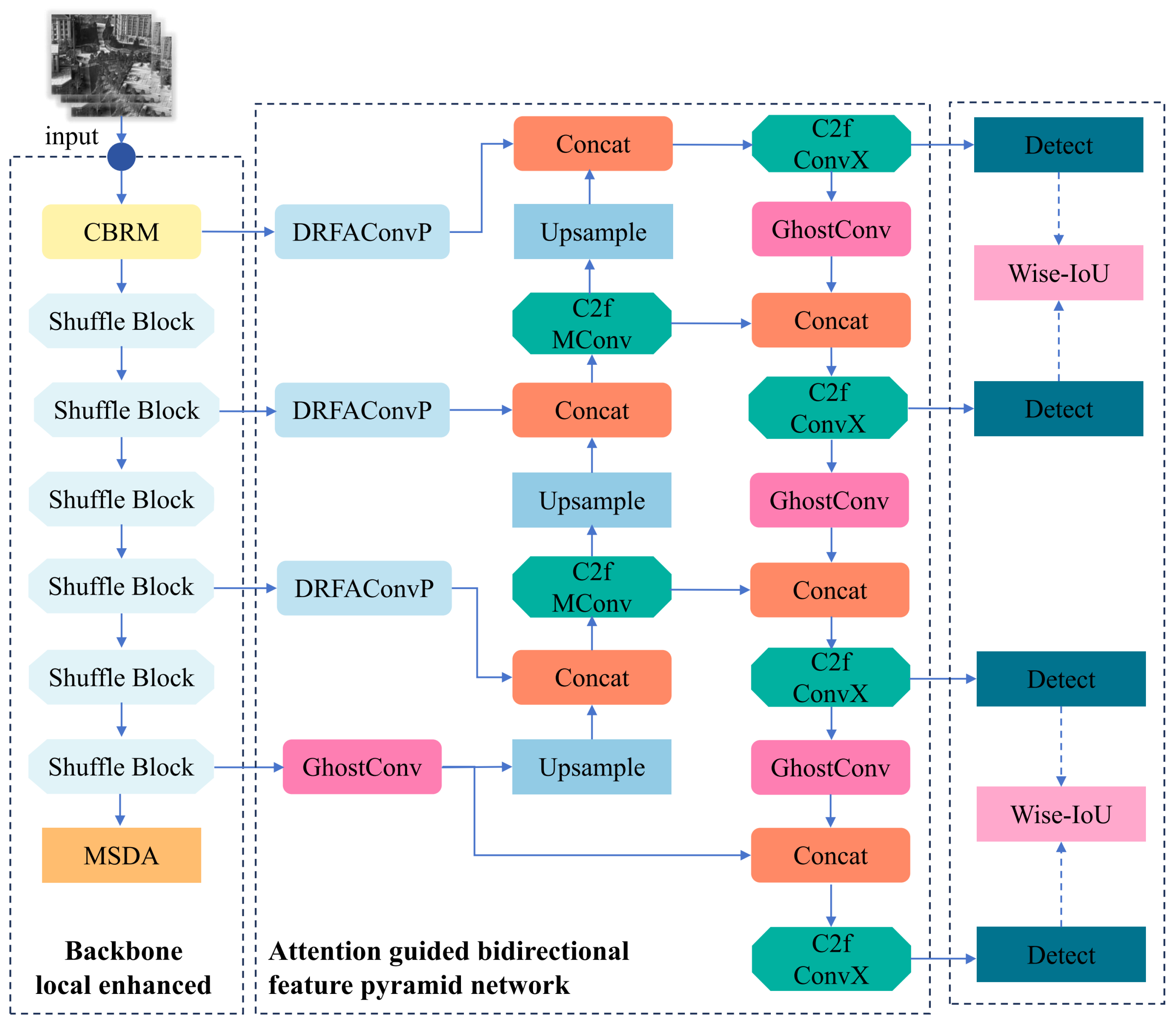
To surmount these difficulties, we present YOLO-SRMX, an efficient detection architecture customized for infrared targets, built upon YOLOv8s.
Figure 3 delineates the refined YOLOv8 structure, which comprises the following augmentations:
In the Backbone network, an efficient ShuffleNetV2 architecture is employed and integrated with the MSDA mechanism. This design significantly reduces computational overhead while leveraging MSDA’s dynamic focusing and contextual awareness capabilities to strengthen the extraction efficacy of critical features.
In the Neck network, several optimizations are implemented to enhance feature fusion and reduce computational load. Novel composite convolutions, ConvX and MConv, along with their corresponding C2f_ConvX and C2f_MConv modules, are designed based on a “split–differentiate–process–concatenate” strategy. Additionally, the lightweight GhostConv is introduced, and by combining the multi-branch processing principles of composite convolutions with the lightweight characteristics of GhostConv, a novel Dynamic Receptive Field Attention Convolution, DRFAConvP, is proposed. These collective improvements optimize the neck network’s computational efficiency and feature processing capabilities.
In the Loss function component, the original loss function is replaced with Wise-IoU (WIoU). It incorporates a dynamic non-monotonic focusing approach. Through this approach, gradient weights are judiciously apportioned based on the respective outlier degree of each anchor box. The optimization of anchor boxes with intermediate quality is emphasized, whereas the gradient influence from samples of poor quality is mitigated. This allows the model to achieve more exact localization of multi-scale targets and bolsters its overall stability.
2.3. Lightweight Feature Extraction Network Fusing Attention Mechanism
In practical application deployment, especially on mobile platforms with limited computational power and memory resources, such as unmanned aerial vehicles (UAVs), model deployment faces significant challenges. Large-scale neural network algorithms are often difficult to run effectively in these environments due to their high resource demands. Therefore, optimizing model parameter count and computational complexity is a key prerequisite for ensuring deployment feasibility and operational efficiency in resource-constrained scenarios.
Although the original YOLOv8 model exhibits good detection performance, it has inherent defects in losing key target information during the feature extraction stage. Coupled with its large model size and high computational requirements, its effective deployment on resource-constrained devices (such as UAVs) is limited. To overcome these limitations, this paper makes critical improvements to the backbone network of YOLOv8s: it adopts the lightweight and computationally efficient ShuffleNetV2 as the basic architecture, leveraging its unique Channel Shuffle and Group Convolution mechanisms to significantly reduce model complexity and parameter count. Concurrently, the MSDA mechanism is integrated to enhance the network’s dynamic capture and perception capabilities for multi-scale key features. This alternative backbone solution, combining ShuffleNetV2 and MSDA, aims to achieve a significant reduction in parameter count and computational load and improve the effectiveness of feature extraction, thereby constructing a lightweight and efficient detection model more suitable for resource-constrained application scenarios.
2.3.1. ShuffleNetV2 Module
Ma et al. [
26] proposed a set of design guidelines for optimizing efficiency metrics, addressing the issue of existing networks being overly reliant on indirect indicators like FLOPs while neglecting actual operational speed. Based on these guidelines, They introduced the ShuffleNetV2 network module, evolving from their prior work on the ShuffleNetV1 model.
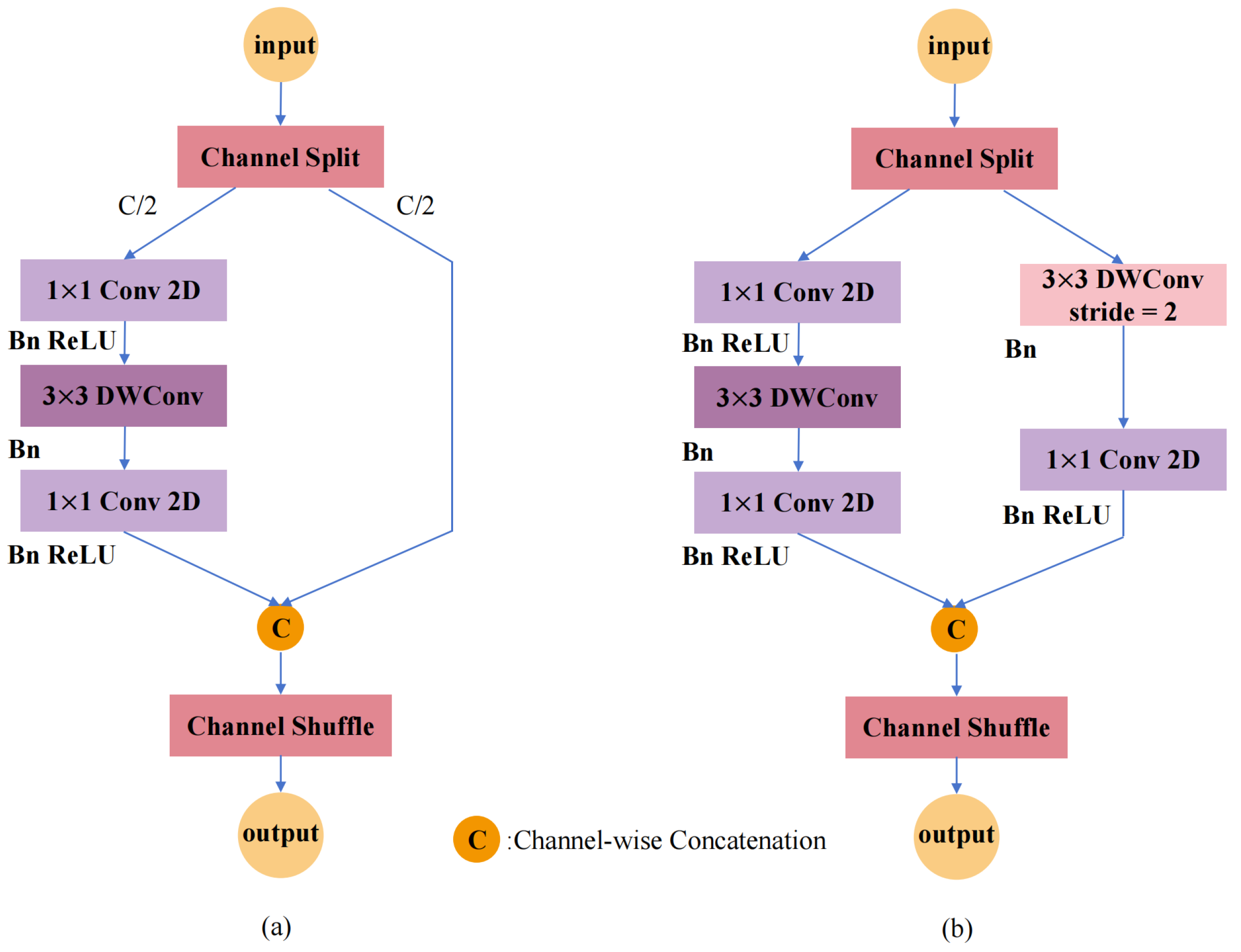
Figure 4 shows that this module fundamentally comprises two main sections: a basic unit and a downsampling unit.
For the basic unit, as shown in
Figure 4a, input channels
C are separated into dual pathways (typically
and
). One path serves as an identity mapping, which is directly passed through, effectively achieving feature reuse. The other path processes features using a combination of a standard convolution (kernel size 1 × 1), a depthwise separable convolution (kernel size 3 × 3), and activation layers. This design enables efficient cross-channel feature fusion while minimizing computational overhead. To prevent network fragmentation and improve operational efficiency, feature channels are not evenly divided. Furthermore, a serial structure is used to ensure consistent channel widths across all convolutional layers, thereby minimizing memory access costs. Channel shuffle is also employed to facilitate effective communication between different channel groups.
The downsampling unit, shown in
Figure 4b, differs from the basic unit by omitting the channel split operation, meaning all input
c channels participate in computation. Concurrently, the branch that performs identity mapping in the basic unit introduces a depthwise separable convolution (kernel size 3 × 3), a standard convolution (kernel size 1 × 1), and activation layers. The downsampling unit reduces the spatial dimensions of the feature map by half, concurrently doubling the number of channels. Subsequent to combining the two branches, a channel rearrangement technique is employed to facilitate an exchange of data across channels. By directly increasing the network’s width and the number of feature channels, the downsampling unit enhances feature extraction capabilities without significantly increasing computational costs.
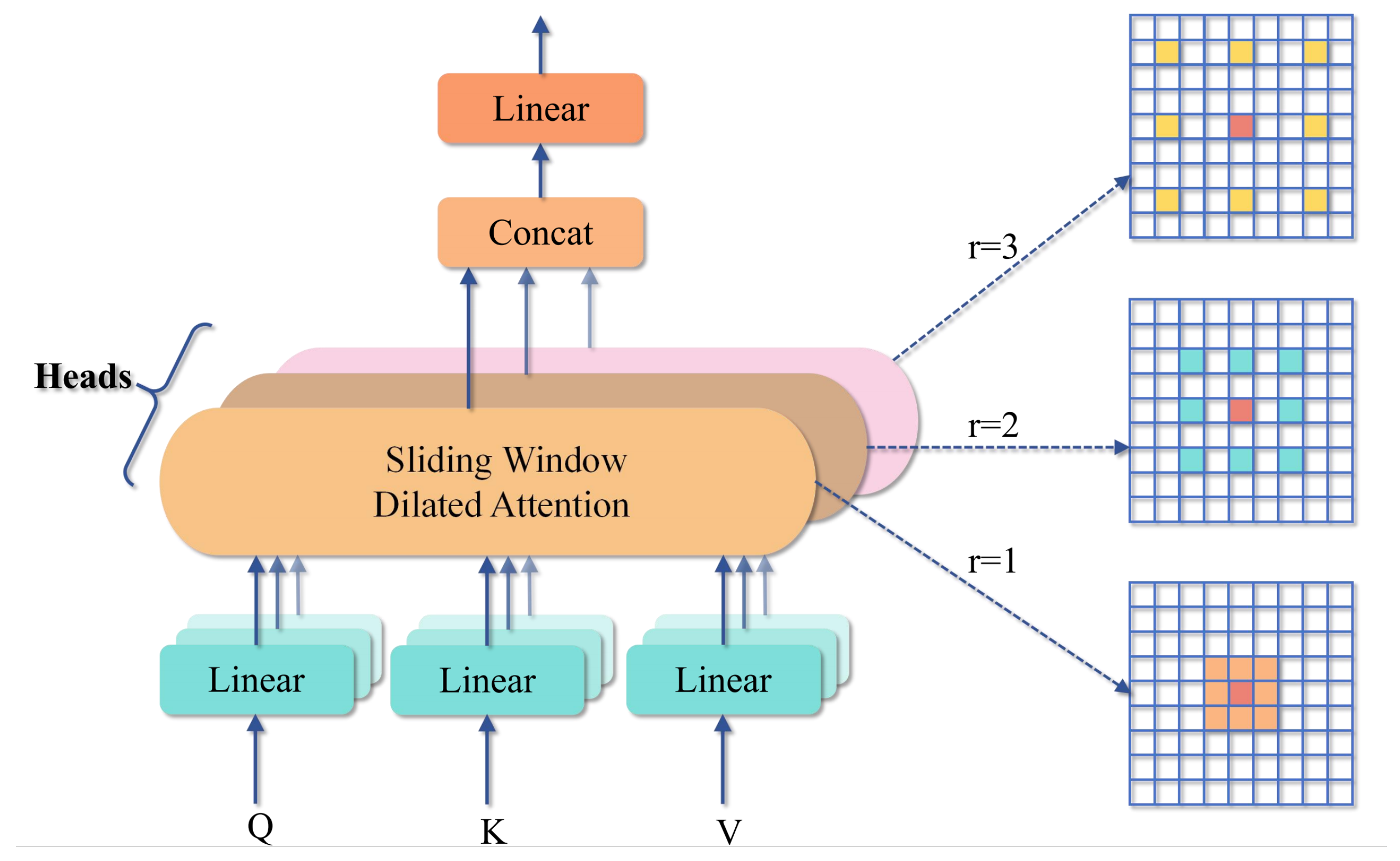
2.3.2. MSDA Attention Mechanism
Object detection tasks in remote sensing images face two inherent challenges: first, complex and variable backgrounds can easily interfere with targets; second, target scales vary greatly, ranging from small vehicles to large areas. Traditional convolutional operations, owing to their fixed receptive field sizes, struggle to efficiently acquire both the fine-grained attributes of diminutive objects alongside the holistic structural data of macroscopic objects in parallel. Although the aforementioned ShuffleNetV2 backbone network significantly improves the model’s computational efficiency, laying a foundation for lightweight deployment, its standard structure still has limitations in adequately addressing the feature representation challenges posed by extreme scale variations and strong background interference in remote sensing images. To precisely address these obstacles and subsequently bolster the robustness and distinctiveness of feature extraction, this study judiciously incorporates the MSDA module subsequent to the introduction of ShuffleNetV2.
The core idea of MSDA is to divide the channel dimension of the input feature map into
n groups (or “heads”) and apply a Scaled Dilated Attention (SWDA) operation with different dilation rates within each group, as shown in
Figure 5. This multi-head, multi-dilation rate design enables the model to
Parallelly capture multi-scale contextual information: heads with a dilation rate of 1 focus on local, nearby details, while heads with larger dilation rates (e.g., r = 3, 5) can capture longer-range sparse dependencies, effectively expanding the receptive field.
Dynamically adjust attention regions: through a self-attention mechanism, the importance weights of features within each head are calculated, assigning greater weights to more relevant features (such as target regions) while suppressing interference from irrelevant background information.
The SWDA operation applied to each attention head
i can be represented by the following equation:
where
denote the query, key, and value in order. The dilation rate specific to each head is designated by
(e.g.,
). The output generated by each attention head is identified as
.
For a position
in the original feature map, before the feature map is split, the output component
from the SWDA operation is
where the feature map’s height and width are denoted by
H and
w, respectively.
and
comprise the key and value aggregates derived from feature maps
K and
V, governed by the dilation rate
r. When considering a query
at coordinates
, the key-value pairs involved in its attention calculation originate from the coordinate set
, detailed as follows:
where
w denotes the size of the local window (or kernel) employed for key and value selection, while
r specifies the dilation rate of this attention head.
After extracting multi-scale features through SWDA operations with different dilation rates, the MSDA module concatenates all head outputs and performs effective feature fusion through a linear layer. This procedure enables the model to synthesize data from varied receptive fields, thereby encompassing both fine-grained local specifics and comprehensive global architectures.
Through the parallel deployment of attention heads with diverse dilation rates, the MSDA mechanism empowers the network to concurrently acquire contextual data spanning various extents. This significantly bolsters the discernment of fine points in diminutive targets and the comprehension of broad structures in large targets. This adaptable receptive field significantly enhances the network’s capacity to accommodate substantial variations in target dimensions within remote sensing imagery [
27]. Furthermore, the built-in attention mechanism of MSDA further optimizes the features extracted by ShuffleNetV2. By adaptively assigning higher weights to key features and suppressing background noise, it significantly improves the network’s ability to distinguish targets in cluttered backgrounds.
To objectively assess the practical effectiveness of the MSDA mechanism within our framework and to clarify its performance differences relative to current mainstream attention techniques, we conducted a systematic comparison—under a unified experimental benchmark—between MSDA and representative modules such as Global Attention Mechanism (GAM) [
28], inverted Residual Mobile Block (iRMB) [
29], Coordinate Attention Moudule (CA) [
30], Efficient Channel Attention (ECA) [
31], and Convolutional Block Attention Moudule (CBAM) [
32]. The specific results of this comparison are presented and analyzed in the Model Training and Evaluation section.
The synergy between ShuffleNetV2’s efficiency and MSDA’s multi-scale perceptual and attention-focusing strengths collectively forms the novel lightweight and highly expressive backbone architecture proposed in this paper, thereby substantially boosting the model’s object detection accuracy and robustness in intricate conditions.
2.4. Improved Feature Fusion Network Design
To refine the YOLOv8 neck component (Neck) to meet the demands of high efficiency and robust feature fusion in UAV applications, this study presents two principal enhancements: firstly, the integration of lightweight convolutions, which curtail the complexity of fundamental computational units by utilizing more streamlined feature extraction and rearrangement mechanisms; secondly, the development of innovative multi-scale feature fusion modules intended to supersede the conventional C2f structure, thereby bolstering the acquisition and integration capacities for multi-scale data through the optimization of feature extraction and aggregation strategies within parallel branches.
2.4.1. Lightweight Convolution: GhostConv Module
In the YOLOv8 network architecture, the feature fusion module employs a Cross-Stage Partial (CSP) network. Although CSP modules can reduce the parameter count to some extent, for efficient deployment of object detection tasks on UAV platforms with limited computational resources, the overall scale of the YOLOv8 network remains excessively large.
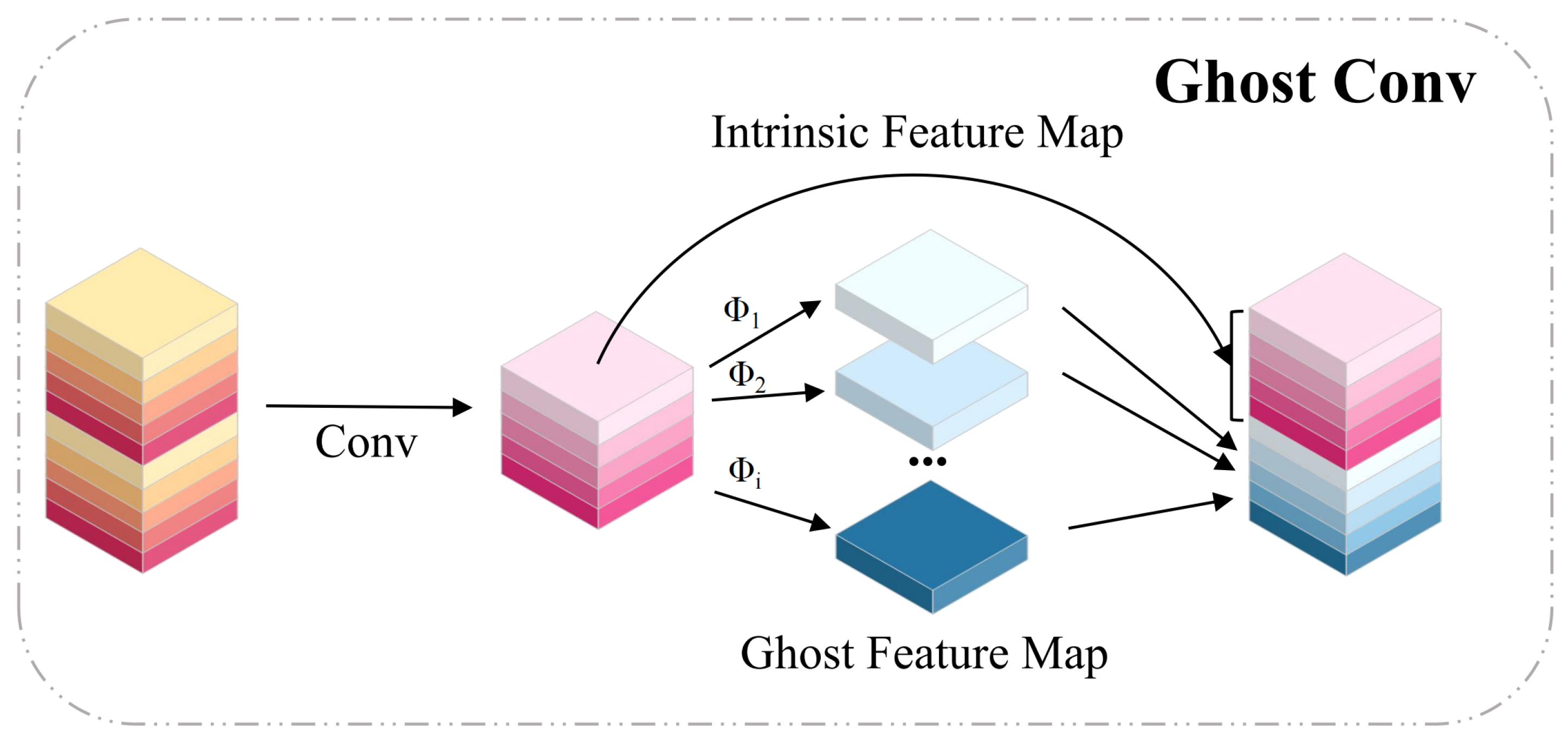
In the current research context of neural network model compression and pruning, extensive research has shown that feature maps generated by many mainstream convolutional neural network architectures often contain rich redundant information, manifesting as highly similar content in some features. Addressing this common phenomenon, GhostNet [
33] proposes a viewpoint: these seemingly redundant features are crucial for ensuring certain neural networks achieve high-performance detection, and these features can be generated more efficiently. To achieve this goal, GhostNet [
33] introduces the GhostConv module, as shown in
Figure 6.
The fundamental concept behind the Ghost module involves breaking down the standard convolution operation into a two-stage process: First, it processes the input feature map
using a standard (or backbone) convolutional layer to generate a few basic, representative intrinsic feature maps
. Next, the Ghost module applies a series of inexpensive linear transformations (such as depthwise separable convolutions or simple pointwise operations). Each intrinsic feature map undergoes
linear transformations and one identity mapping, thereby deriving additional ghost feature maps.The formation of the ghost feature map
is articulated by Equation (
4):
As per Equation (
4),
n indicates the number of channels in
, with
representing the
a-th channel, and
b referring to the
b-th linear transformation applied to
. For each feature map
,
linear transformations are executed, followed by a single identity transformation, thereby yielding an output
Y with
channels. Hence, the total number of linear transformations performed on the feature maps is
. Assuming a kernel dimension of
, Equations (
5) and (
6) detail the Ghost module’s theoretical computational speedup ratio
and its parameter compression ratio
:
From the above equations, it can be seen that Ghost convolution reduces the number of parameters by approximately l times without significantly impairing the network’s ability to effectively extract features.
2.4.2. Efficient Multi-Scale Feature Extraction Modules: C2f_ConvX and C2f_MConv
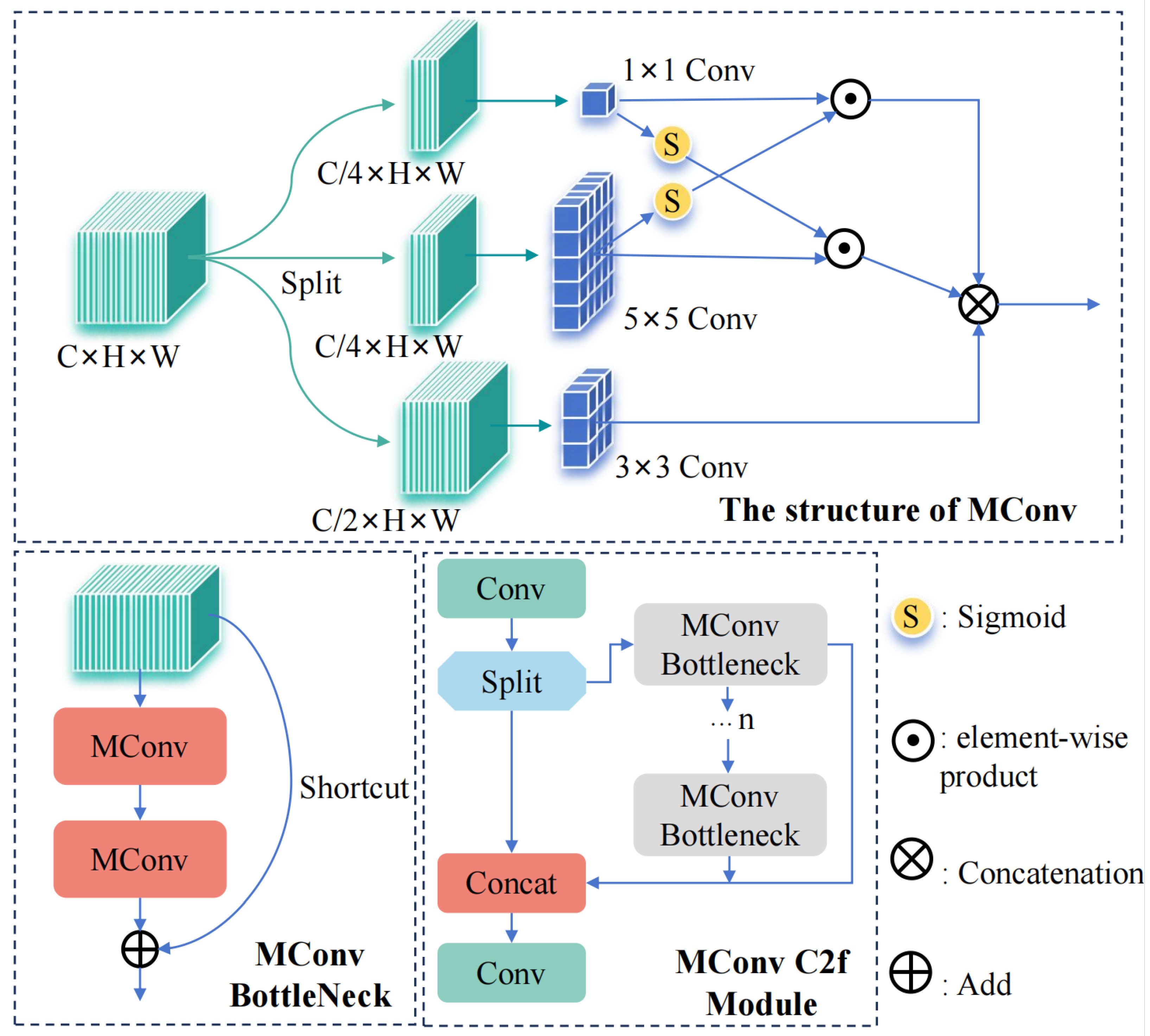
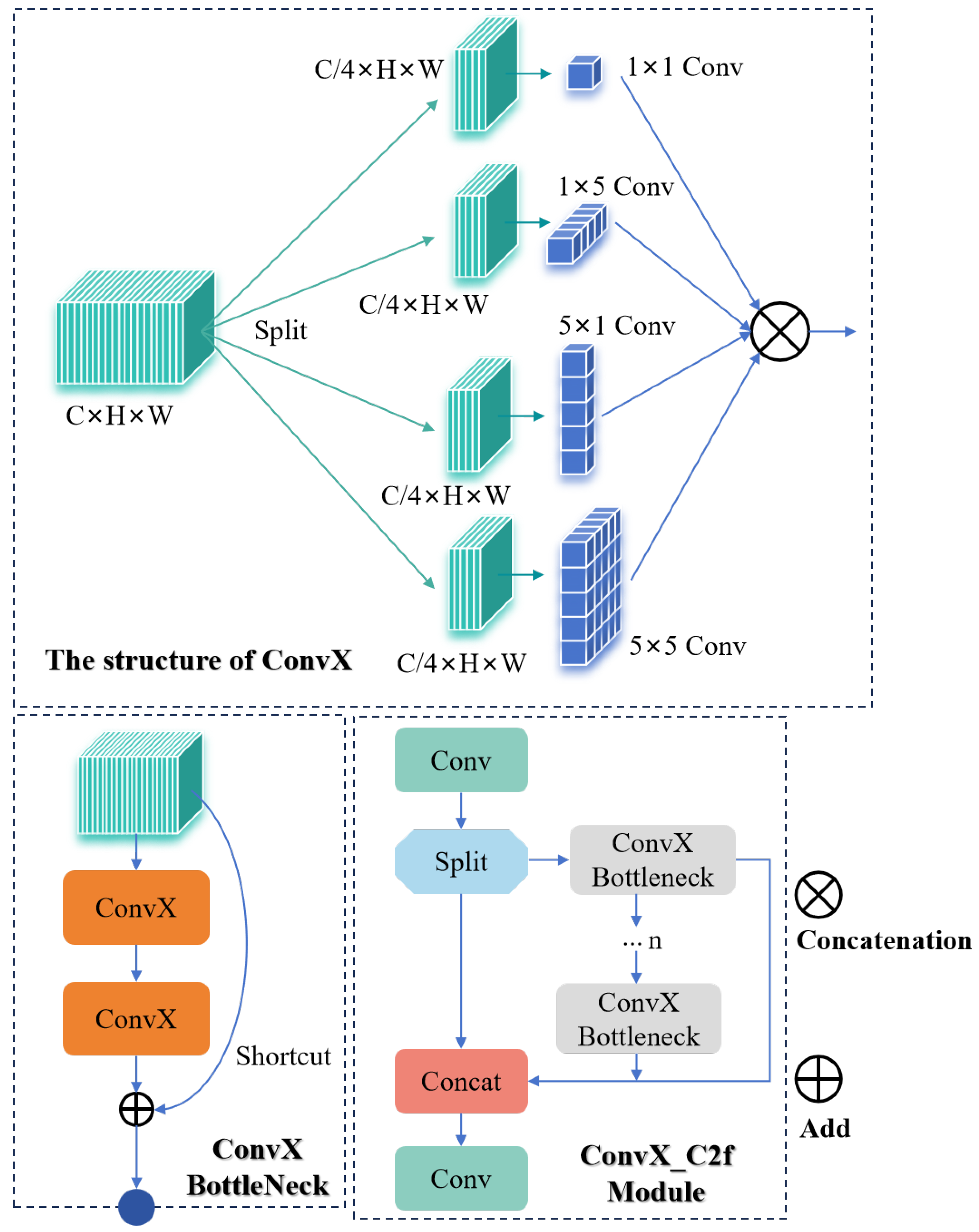
Standard convolutions face inherent limitations due to their fixed receptive fields, while existing multi-branch architectures, though capable of providing multi-scale information, often incur substantial computational redundancy. To resolve this “efficiency versus feature diversity” dilemma, we propose an original design philosophy of “asymmetric heterogeneous convolution”. Building upon this foundation, we pioneer two novel composite convolution operators (MConv (
Figure 7) and ConvX (
Figure 8)) and introduce two groundbreaking bottleneck modules (C2f_ConvX and C2f_MConv).
The core design of MConv and ConvX follows the “Split–Process–Concatenate” strategy, a mechanism aimed at efficiently capturing and fusing the inherently multi-scale features in UAV imagery. The key lies in “differentiated processing”: unlike standard group convolution, which primarily aims to homogeneously reduce computational load, this strategy intentionally assigns different convolutional operations—varying in kernel scale, shape, or type—to different parallel branches. This design enables each branch to specialize in extracting specific types or scales of feature information—small kernels for fine texture details, large kernels for contours and macroscopic structures, and asymmetric convolutions potentially more sensitive to edges in specific orientations. Since the features extracted by each branch are designed to be highly complementary, they collectively cover a broader feature spectrum. Consequently, in the final “concatenate” stage, a simple channel concatenation operation itself constitutes an efficient and information-rich feature fusion method, directly pooling diverse information from different receptive fields and semantic levels. The advantage of this mechanism is that it avoids the extra overhead often required by traditional parallel structures (like standard group convolution) to facilitate information interaction, such as the channel shuffle operation needed in ShuffleNet [
26], or the additional 1 × 1 Pointwise Convolution used for channel information fusion in the depthwise separable convolutions of MobileNet [
34]. Ultimately, this strategy improves the model’s capacity to represent multi-scale, multi-morphology features, concurrently realizing optimized computational efficiency.
MConv (
Figure 7): The input (C channels) is split into three branches of C/4, C/4, and C/2 channels. These are processed by 1 × 1, 5 × 5, and 3 × 3 convolutions, respectively. The output of the 1 × 1 branch, after a Sigmoid activation, is element-wise multiplied with the output of the 5 × 5 branch. Finally, the attention-enhanced features, the 3 × 3 branch’s output, and the original output of the 1 × 1 branch undergo concatenation to restore C channels.
ConvX (
Figure 8): The input (C channels) is uniformly split into four branches (each C/4). These are processed by 1 × 1 Conv, 5 × 1 Conv, 1 × 5 Conv, and 5 × 5 Conv, respectively. Finally, the four branch outputs undergo concatenation to restore C channels.
Based on MConv and ConvX, we constructed corresponding MConv Bottleneck and ConvX Bottleneck modules and used them to replace the bottleneck blocks in the original C2f module, forming the C2f_MConv and C2f_ConvX modules.
This design offers two prominent advantages: a significant reduction in computational complexity and an effective enhancement of feature representation capability.
1. Significant reduction in computational load: Specifically, taking a feature map of size as an example, the comparison of computational costs (FLOPs) between standard convolution and MConv/ConvX is as follows:
Standard convolution:
where
represents the height of the output feature map,
represents the width of the output feature map,
represents the number of channels in the output feature map,
K represents the size of the convolution kernel, and
represents the number of input channels.
MConv:
where
represents the computational cost of the
i-th branch,
represents the computational cost of element-wise multiplication between branch 1 and branch 2, and
represents the computational cost of the MConv composite convolution.
ConvX:
where
represents the computational cost of the
i-th branch, and
represents the computational cost of the ConvX composite convolution.
As demonstrated in Equations (
12) and (
17), the computational costs of MConv and ConvX are 3.875HWC
2 and 2.25HWC
2, respectively. Compared to a standard 5 × 5 convolution (25HWC
2 FLOPs) providing equivalent receptive fields, their computational costs represent merely 15% and 9% of the latter. This substantial theoretical efficiency advantage proves that our heterogeneous design achieves significant computation reduction while maintaining rich feature representation, thereby effectively meeting real-time requirements for UAV platforms.
2. Enhanced feature richness: Thanks to the diverse and complementary features extracted and fused by the “differentiated processing” strategy, the final output feature map possesses stronger representation capabilities. This helps improve the model’s detection accuracy when dealing with targets of varying sizes and blurred details in UAV images.
Finally, to cater to the feature requirements at different positions in the network, we strategically deployed the following two modules:
C2f_MConv module is deployed at the connection point linking the backbone network and the neck network. This position requires effective integration of high-level semantic information from the deep backbone network with shallow-level detail information. The multi-scale parallel processing capability of C2f_MConv can better bridge and fuse semantic and spatial features from different levels, providing a solid foundation for subsequent cross-level feature fusion.
C2f_ConvX is deployed near the detection head. The detection head is directly responsible for predicting target class and location, requiring more detailed and discriminative features. C2f_ConvX, with its diverse convolutional branches, can extract richer and more comprehensive fine-grained features, providing higher-quality information support for the final detection task, thereby improving the accuracy of target localization and classification.
2.4.3. Composite Receptive Field Lightweight Convolution: DRFAConvP Module
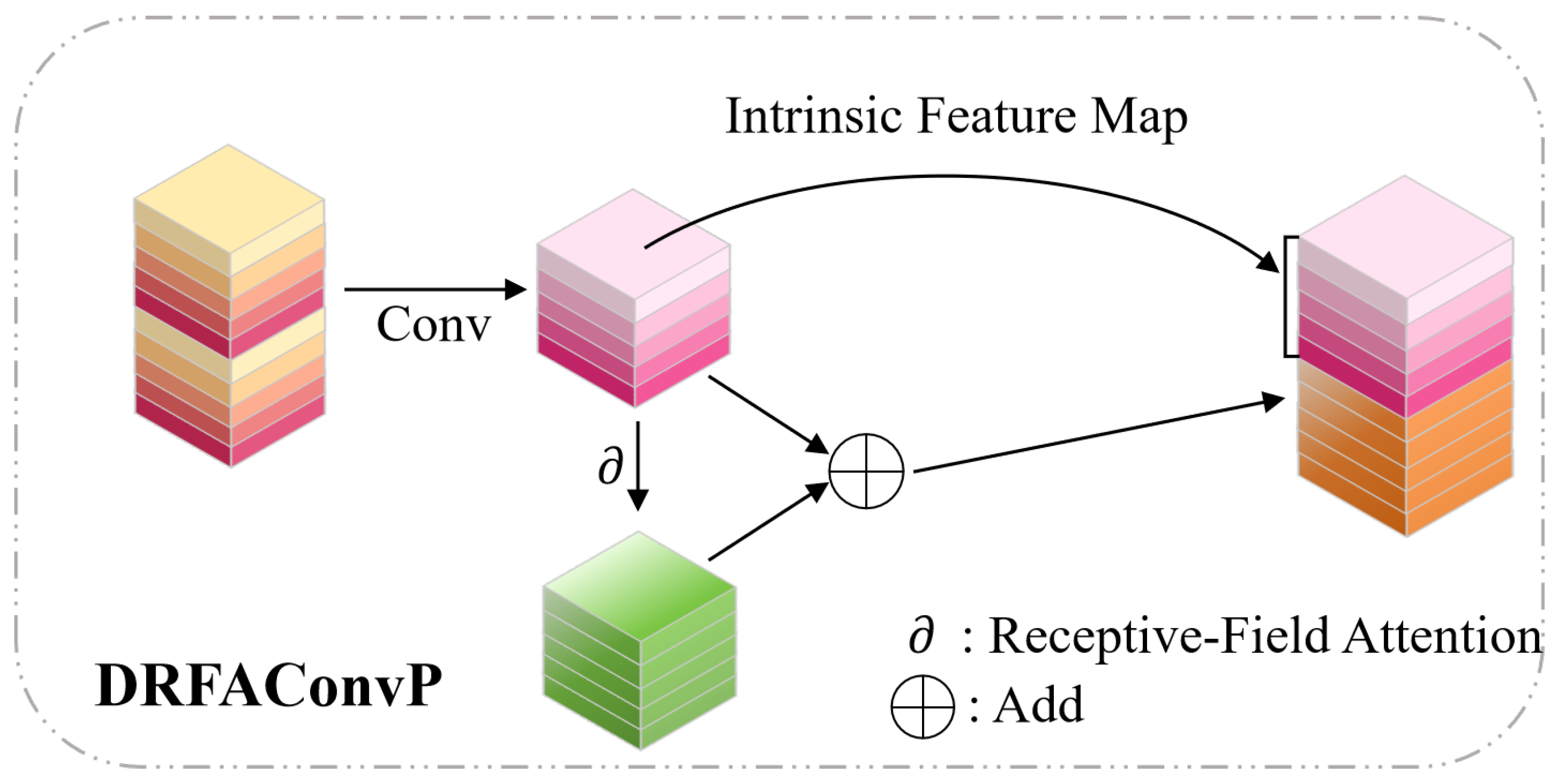
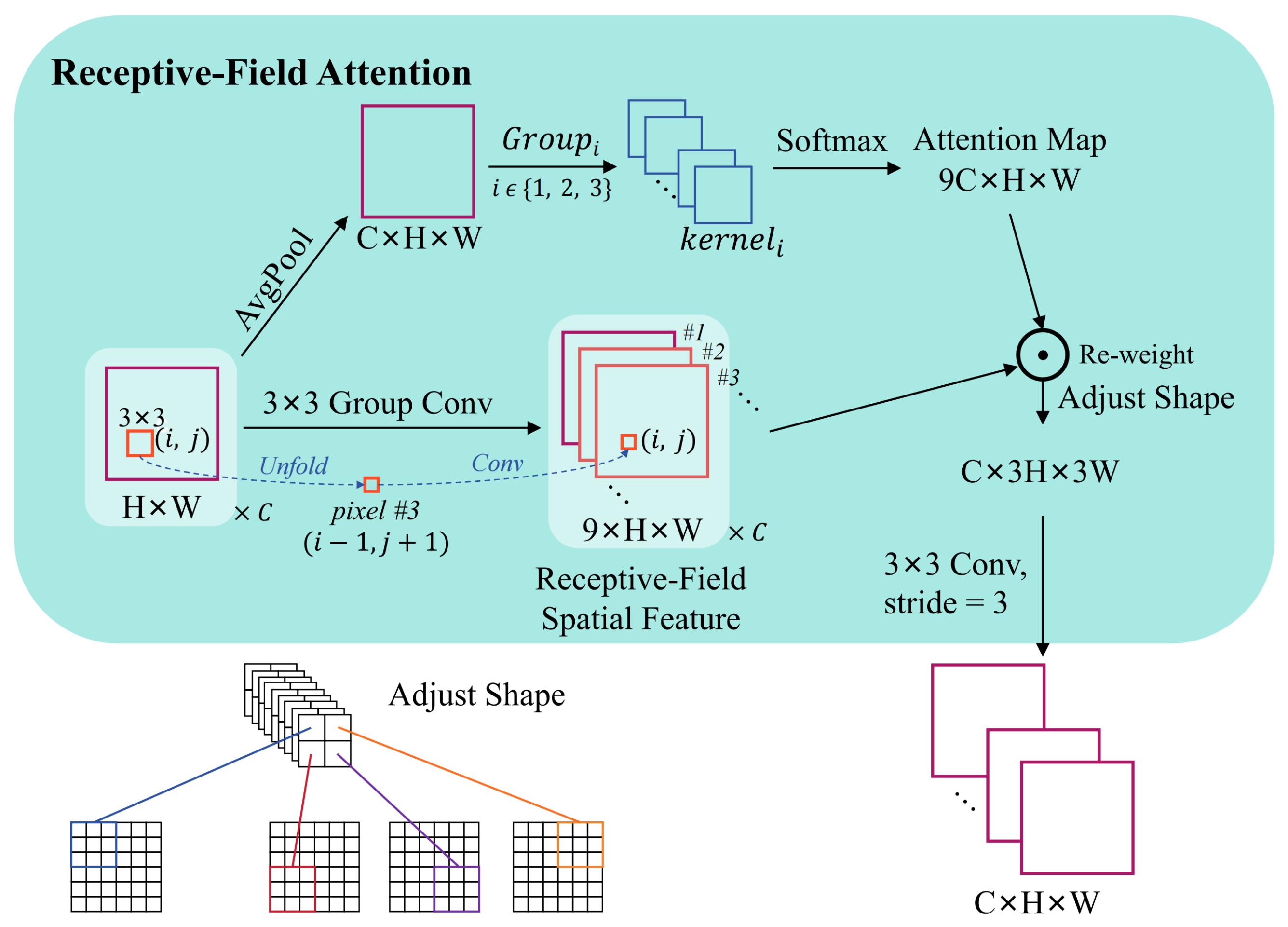
While GhostConv provides an effective theoretical framework for model lightweighting, its reliance on static and homogeneous linear transformations to generate “ghost” features inevitably sacrifices feature richness—a critical drawback for detail-sensitive UAV remote sensing tasks. To break this “efficiency–performance” trade-off, we propose DRFAConvP, a novel method that transforms GhostConv’s simple linear operations for feature generation into an intelligent feature enhancement process. This innovation integrates two advanced concepts: (1) the multi-branch heterogeneous processing from our composite convolutions, and (2) a dynamic input-dependent spatial attention mechanism inspired by RFAConv [
35]. As illustrated in
Figure 9, DRFAConvP’s core advancement lies in its dynamic attention mechanism and sophisticated heterogeneous transformations, enabling stronger feature representation at low computational cost; the structure of the receptive-field attention mechanism is detailed in
Figure 10.
Through the above design, the DRFAConvP module, in the process of generating “ghost” features, no longer relies on fixed, simple linear transformations. Instead, it introduces a dynamic receptive field attention mechanism that depends on the input content. Consequently, the convolutional process can adaptively fine-tune the weighting coefficients across distinct spatial zones, guided by the input features. This results in a more efficient acquisition of critical details vital for subsequent tasks, considerably elevating the network’s feature descriptive power. Compared to the original GhostConv, DRFAConvP effectively mitigates the problem of accuracy degradation while maintaining model lightweightness and computational efficiency. The detailed procedure of the DRFAConvP module is outlined in Algorithm 1.
| Algorithm 1 DRFAConvP Module operations |
Input: Input feature map X
Output: Output feature map Z
procedure DRFAConvP (X)
▹ 1. Intrinsic Feature Extraction
▹ Channels of Y are typically half of Z’s target channels
▹ 2. Dynamic Weight Generation
▹ Kernel 1 × 1
▹ Spatial dynamic weights
▹ 3. Feature Transformation and Weighting
▹ Depth-wise separable convolution
▹ Element-wise multiplication
▹ 4. Information Fusion and Enhancement
▹ Residual connection
▹ 5. Feature Concatenation
return Z
end procedure |
2.5. Wise-IoU-Based Loss Function Design
The standard YOLOv8s network uses the CIoU loss to guide its box predictions, measuring differences based on the overlap area, the distance between box centers, and how similar their aspect ratios are. But when we work with UAV datasets—where targets vary greatly in size, backgrounds are cluttered, and infrared images often have low contrast—these less reliable samples can skew training. The CIoU loss may end up focusing too much on large errors from poor-quality labels, or it might give undue weight to anchors that happen to match noisy ground-truth boxes well. Either way, this imbalance can hurt the model’s ability to generalize and ultimately worsen its localization performance.
To overcome these challenges and boost localization accuracy on UAV platforms, we employ the Wise-IoU (WIoU) loss function [
36] for bounding-box regression. The main innovation of WIoU is its dynamic, non-monotonic focusing mechanism. Rather than using fixed criteria or relying solely on IoU to gauge anchor quality, WIoU introduces an outlier degree
, defined as the ratio between an anchor’s instantaneous IoU loss (detached from the gradient graph) and the moving average of IoU losses:
where
denotes the current loss value with gradients blocked, and
is its dynamic mean.
Building on the outlier degree , WIoU introduces an adaptive gradient modulation strategy. It reduces the gradient contribution from high-quality anchors (i.e., those with smaller ), which are already well-aligned with the ground truth, helping to avoid overfitting. At the same time, it also lowers the gradient for low-quality anchors with larger , often caused by noisy labels or inherently difficult examples. This dual suppression prevents extreme cases—either too easy or too poor—from dominating gradient updates, which could otherwise impair the model’s generalization. Consequently, WIoU encourages the model to prioritize moderate-quality samples, where improvements are most meaningful.
Crucially, this strategy is dynamic: the benchmark value is updated continuously during training, allowing gradient weights to adapt based on the model’s evolving state.
The formulation of the WIoU v3 loss is
Here,
represents the first version of the WIoU loss, enhanced with a distance-based attention mechanism that adjusts the standard IoU loss as follows:
We compute the attention term
as
This term penalizes predictions that are spatially far from the target center, using the size of the ground truth box to normalize the displacement.
In this context, represents the base IoU loss, while acts as a spatial attention coefficient. The terms and denote the center coordinates of the predicted and ground truth bounding boxes, respectively. The variables and refer to the width and height of the smallest enclosing box that covers both predicted and ground truth boxes. The asterisk (∗) marks that and are detached from gradient computation—treating them as constants to help keep the optimization stable.
The key focusing term
r is derived based on the outlier degree
, as defined by
Here, and are tunable parameters that shape the focusing curve.
In conclusion, WIoU adopts a novel dynamic focusing strategy that adaptively reweights gradient contributions based on anchor box quality, represented by . This mechanism suppresses the influence of both overly easy and noisy hard examples, redirecting training emphasis toward moderately challenging samples—those with higher potential for meaningful learning. Such a property is crucial when handling UAV imagery, which often contains cluttered scenes and imprecise annotations. By emphasizing more learnable samples, WIoU contributes to improvements in localization precision and generalization capability.
To evaluate the suitability of Wise-IoU (WIoU) for object detection tasks involving infrared UAV images, we compared it with several widely adopted IoU-based loss functions. These include DIoU [
37], EIoU [
38], SIoU [
39], Shape-IoU [
40], MPDIoU [
41], and Focal-GIoU [
42]. All comparisons were conducted on a unified model architecture incorporating the backbone and neck improvements proposed in this paper. The detailed results and performance analysis of this comparison are presented in the Model Training and Evaluation section.
4. Discussion
The experimental results confirm that the proposed YOLO-SRMX model significantly enhances the accuracy and efficiency of real-time object detection for UAVs, exhibiting outstanding performance, particularly in addressing the challenges of complex backgrounds and small targets commonly encountered from a UAV perspective. The ablation studies clearly demonstrate the contribution of each improved module: the lightweight ShuffleNetV2 backbone, combined with the MSDA attention mechanism, effectively reduces computational costs while enhancing multi-scale feature extraction capabilities, which is crucial for UAV scenarios with complex backgrounds and variable target scales. In the neck network, the combination of DRFAConvP and GhostConv, along with the innovative C2f_ConvX and C2f_MConv modules, successfully balances accuracy and efficiency through efficient multi-scale feature fusion and dynamic receptive field adjustment. Furthermore, the introduction of the Wise-IoU (WIoU) loss function optimizes bounding box regression accuracy and enhances the model’s robustness to low-quality samples by intelligently adjusting gradient weights.
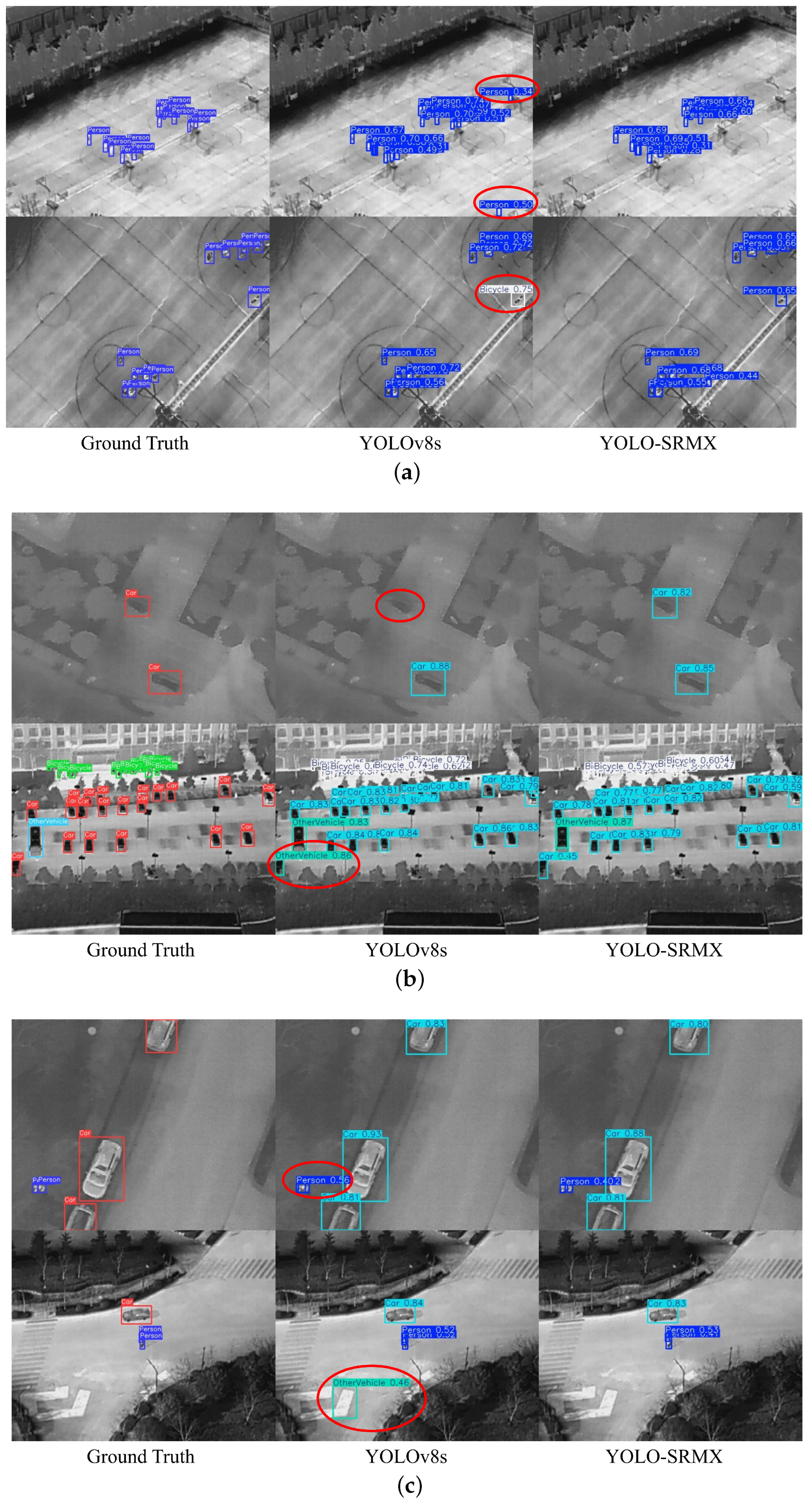
A comprehensive analysis reveals that YOLO-SRMX demonstrates robust object detection capabilities from a UAV perspective, especially in complex backgrounds and dense target distributions. Compared to the baseline YOLOv8s and other mainstream models, YOLO-SRMX achieves a superior balance between detection accuracy and computational efficiency (GFLOPs), delivering competitive or even superior detection performance with significantly reduced computational demands. The visualization results further validate the model’s robustness under different environmental conditions and intuitively show its superiority over the baseline model in terms of detection accuracy and the reduction of missed detections.
Another important aspect to discuss is the influence of input image resolution on model performance. This study employed a 640 × 512 resolution for training and optimization. Lowering the resolution would likely degrade accuracy by losing the fine-grained details crucial for identifying small targets, while increasing it would lead to a substantial rise in computational overhead, conflicting with the lightweight design objective of this research. Therefore, the 640 × 512 resolution represents a reasonable trade-off between detection performance and computational efficiency, aimed at meeting the specific demands of real-time UAV applications.
However, a primary limitation of the current study is that its validation is predominantly based on infrared (grayscale) datasets, which confines the model’s verified applications to thermal imaging-related scenarios. A key direction for future work is to extend and validate YOLO-SRMX on color (RGB) remote sensing images to assess its capability in processing richer visual information, thereby adapting it for broader UAV applications, such as standard visible-light monitoring tasks.
In summary, leveraging its significant advantages in accuracy and efficiency, YOLO-SRMX is poised to offer a more powerful and reliable real-time object detection solution for practical UAV applications such as search and rescue, environmental monitoring, and precision agriculture.
5. Conclusions
In this study, we addressed the challenges of accuracy, efficiency, and deployment for object detection in complex UAV environments by proposing a lightweight and highly efficient real-time detection model, YOLO-SRMX. To achieve this, we conducted a deep optimization of the model architecture. First, a novel backbone network was constructed based on the efficient ShuffleNetV2 and integrated with a Multi-Scale Dilated Attention (MSDA) mechanism. This design significantly reduces the model’s parameter count while enhancing its feature-capturing capabilities for targets of varying sizes by dynamically adjusting the receptive field, and it effectively suppresses interference from complex backgrounds. Second, we introduced two major architectural innovations in the neck network. On one hand, we pioneered novel bottleneck modules, C2f_ConvX and C2f_MConv, based on a “split–differentiate–concatenate” strategy. Fundamentally distinct from the homogeneous processing of traditional group convolution, this design decouples richer gradient information and a receptive field hierarchy from the original features at a minimal computational cost by processing asymmetric, multi-type convolutional branches in parallel. On the other hand, our original lightweight convolution, DRFAConvP, radically advances existing concepts by integrating a dynamic attention mechanism into the generation process of “phantom” features, thereby breaking through the performance bottleneck imposed by GhostConv’s reliance on static transformations. These original designs work in synergy, greatly enhancing the neck network’s adaptability to variable-scale targets from a UAV perspective without sacrificing efficiency. Finally, the Wise-IoU (WIoU) loss function was employed to optimize the bounding box regression process; its unique dynamic non-monotonic focusing mechanism intelligently assigns gradient gains to anchor boxes of varying quality, thereby significantly improving target localization accuracy and the model’s generalization ability.
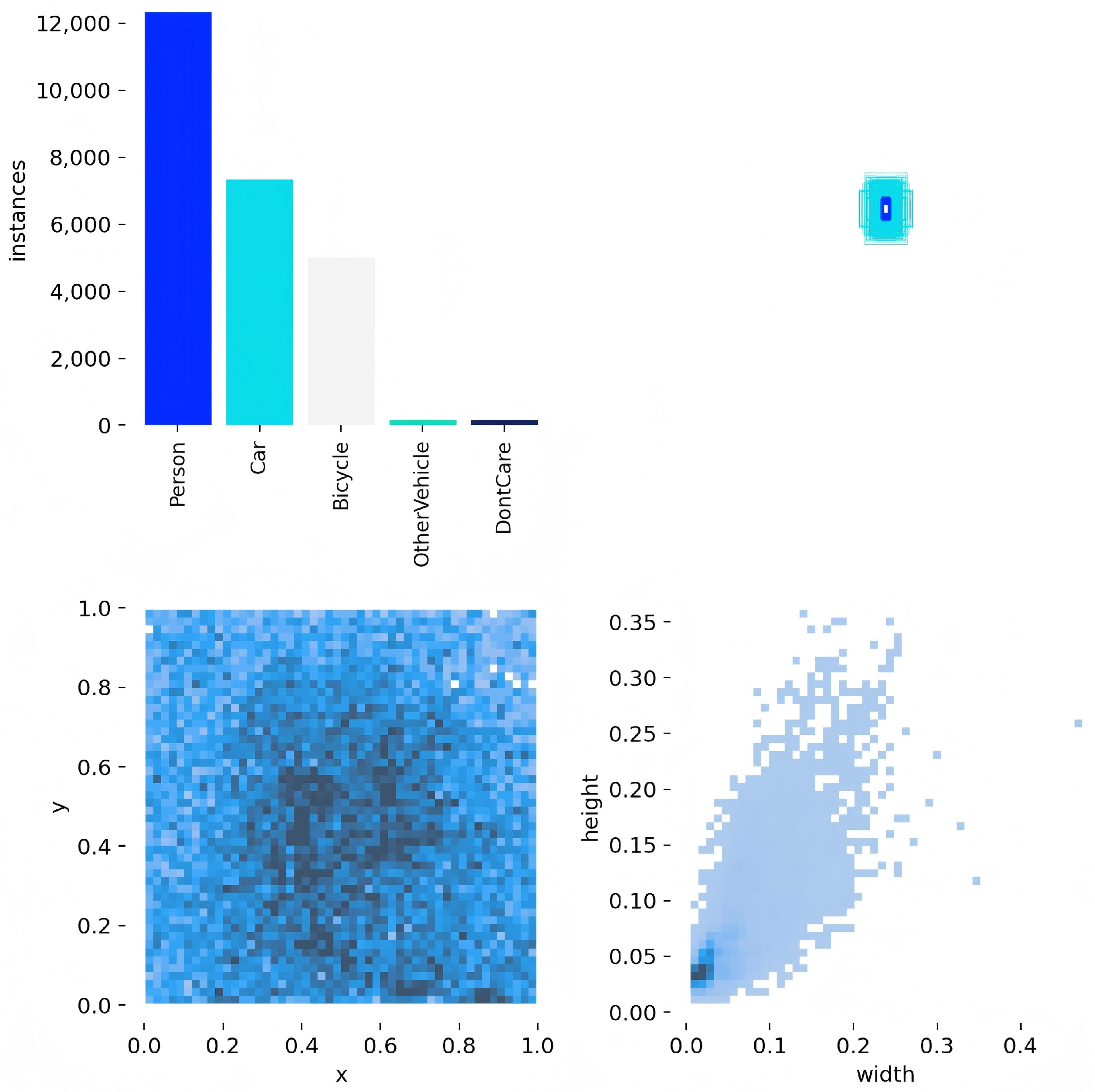
Extensive experimental evaluations of the challenging HIT-UAV and DroneVehicle infrared datasets demonstrate that YOLO-SRMX exhibits significant advantages in both detection accuracy and computational efficiency. Ablation studies clearly showcased the positive contributions of each improved component. On the primary HIT-UAV dataset, compared to the baseline model YOLOv8s, YOLO-SRMX achieved a remarkable performance boost: its metric increased by 7.81% to 82.8%; the F1 score rose by 3.9% to 80%; and the GFLOPs, a measure of computational complexity, were drastically reduced by 65.3%. Furthermore, comparative experiments against a series of models—encompassing traditional, specialized, and mainstream YOLO architectures—highlighted that YOLO-SRMX achieves a superior balance point between accuracy and efficiency on both datasets. Visualization analyses also confirmed the model’s robustness and superior detection performance in complex scenarios involving varied perspectives, flight altitudes, and target densities.
To further enhance the deployment speed and power efficiency of YOLO-SRMX in practical applications, a key future research direction lies in exploring hardware–software co-design. By performing model quantization, pruning, and operator fusion tailored for specific UAV hardware platforms, combined with custom designs that leverage the characteristics of hardware accelerators, it is possible to achieve further acceleration of the model inference process, thereby better satisfying the real-time and high-efficiency object detection demands of UAVs.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}