Abstract
Traditional Multiple Object Tracking (MOT) methods in satellite videos mostly follow the Detection-Based Tracking (DBT) framework. However, the DBT framework assumes that all objects are correctly recognized and localized by the detector. In practice, the low resolution of satellite videos, small objects, and complex backgrounds inevitably leads to a decline in detector performance. To alleviate the impact of detector degradation on track, we propose Coarse-Fine Tracker, a framework that integrates the MOT framework with the Tracking Any Point (TAP) method CoTracker for the first time, leveraging TAP’s persistent point correspondence modeling to compensate for detector failures. In our Coarse-Fine Tracker, we divide the satellite video into sub-videos. For one sub-video, we first use ByteTrack to track the outputs of the detector, referred to as coarse tracking, which involves the Kalman filter and box-level motion features. Given the small size of objects in satellite videos, we treat each object as a point to be tracked. We then use CoTracker to track the center point of each object, referred to as fine tracking, by calculating the appearance feature similarity between each point and its neighboring points. Finally, the Consensus Fusion Strategy eliminates mismatched detections in coarse tracking results by checking their geometric consistency against fine tracking results and recovers missed objects via linear interpolation or linear fitting. This method is validated on the VISO and SAT-MTB datasets. Experimental results in VISO show that the tracker achieves a multi-object tracking accuracy (MOTA) of 66.9, a multi-object tracking precision (MOTP) of 64.1, and an IDF1 score of 77.8, surpassing the detector-only baseline by 11.1% in MOTA while reducing ID switches by 139. Comparative experiments with ByteTrack demonstrate the robustness of our tracking method when the performance of the detector deteriorates.
1. Introduction
With the rapid advancement of satellite remote-sensing technology, object tracking in satellites is playing an increasingly important role in fields such as urban management, ocean monitoring, and disaster response. This progress is significantly driven by the development of deep learning and the emergence of video satellite tracking datasets like VISO [1,2] and AIR-MOT [3].
Based on the number of tracked objects, object tracking tasks include Single Object Tracking (SOT) and Multiple Object Tracking (MOT). SOT requires the location of a specific object to be provided in a frame and requires a tracker to locate the object in subsequent frames continuously. Unlike SOT, MOT inherently requires simultaneous detection of all targets and continuous maintenance of their identity associations across video frames, a dual-task paradigm that amplifies its computational complexity. Satellite videos, the most commonly used MOT methods rely on Detection-Based Tracking (DBT) [4,5,6,7,8,9,10,11,12], where detection and tracking are handled independently using a detector and a tracker. The detector is used to locate objects in each individual frame, and then the tracker associates these positions across frames to generate trajectories. This approach allows for leveraging the strengths of specialized detectors and trackers but may suffer from the compounded errors of the two separate stages. Other popular methods based on Joint Detection and Tracking (JDT) [13,14,15] use one model for end-to-end tracking, simultaneously performing detection and tracking tasks. While JDT methods benefit from unified optimization, they require highly sophisticated models capable of handling both tasks simultaneously.
While MOT methods achieve robust performance in natural scenes through reliable detection, their effectiveness in satellite videos is substantially constrained by the dependence on detection accuracy. The inherent limitations of satellite videos, namely low-resolution tiny objects and complex backgrounds, compromise detection reliability, thereby propagating errors through tracking modules.
- Low-resolution tiny objects: As shown in Figure 1, satellite videos are captured from significant heights, resulting in lower-resolution imagery where objects appear much smaller, often losing detailed information. The blurring of appearance features makes it more difficult for detectors to recognize and distinguish tiny objects, potentially leading to misidentification or missed detection.
 Figure 1. Some challenges in satellite videos. A remote-sensing image is shown in the middle. On the left, two randomly selected white objects are marked in green. On the right, an image along a road is shown, where white and dark objects are marked in green. Trees on both sides of the road cause slight occlusions.
Figure 1. Some challenges in satellite videos. A remote-sensing image is shown in the middle. On the left, two randomly selected white objects are marked in green. On the right, an image along a road is shown, where white and dark objects are marked in green. Trees on both sides of the road cause slight occlusions. - Complex background: In satellite videos, such as those involving urban roads and natural terrains, pose significant challenges for object detection. As shown in Figure 1, objects can become indistinct due to their surroundings—such as the dark object blending with the road surface and the occlusion caused by trees along the roadside. These environmental factors make it difficult to accurately detect and track objects, especially when they are small and low resolution.
To mitigate the tracking accuracy decline stemming from suboptimal detector outputs, some methods directly update the detector. For example, GMFTracker [16] uses the tiny object task correction module to employ feature correction, compensating for the offset between the classification task and the localization task to improve the detection accuracy of tiny objects. Using the latest object detection algorithms like the YOLO series [17,18,19,20,21] as detectors is also a common method in DBT. Meanwhile, some methods enhance detection results with spatio-temporal information. SMTNet [22] regresses a new virtual position for tracked objects with historical information for the missed or occluded object. CFTracker [23] uses a cross-frame feature update module to enhance object recognition and reduce the response to background noises using rich temporal semantic information. MTT-STPTR [24] utilizes a spatial-temporal relationship sparse attention module to enhance small target features and a joint feature matching module to reduce association errors. Some methods have achieved notable results by using SOT trackers to partially replace the function of detectors. In BMTC [25], the SOT tracker locates objects in the satellite video, while the detector is used only for detecting and distinguishing new objects. Consequently, the framework demonstrates reduced reliance on detector efficacy while being restricted to offline applications and necessitating specialized strategies for multi-object scenarios. LocaLock [26] further advances this idea by embedding SOT-style local matching into an online MOT network: its Local Cost Volume supplies appearance-based priors to an anchor-free detector, while a Motion-Flow module aggregates short-term dynamics, together yielding detector-agnostic yet real-time tracking without the offline fusion required in BMTC.
The emergence of Tracking Any Point (TAP) techniques [27,28,29,30,31] represents a significant breakthrough in the field of multi-object tracking (MOT) due to their unprecedented capability for spatiotemporal tracking of arbitrary points in dynamic environments. TAP techniques take an RGB video and a pixel coordinate on the first frame as input, producing per-timestep coordinates for tracking a target across time, along with visibility or occlusion estimates for each timestep. This unique approach is especially valuable in contexts where traditional detection-based tracking methods face challenges, such as in satellite videos, where detection performance is often degraded due to various environmental factors, such as low resolution, occlusions, and dynamic background changes. TAP effectively mitigates these issues by relying on first-frame detections to initialize object tracking and then using spatiotemporal modeling to track the objects without the need for continuous detections, thus circumventing detection degradation in satellite videos. This key feature ensures that tracking precision is maintained even in the absence of reliable detections during certain timeframes, a common limitation in satellite video analysis.
As demonstrated by recent works, such as CoTracker [31], TAP excels in its ability to simultaneously track points initialized across asynchronous frames, making it ideally suited for handling dynamically occurring objects in complex video scenes. Inspired by this, we have seamlessly integrated the powerful TAP method (CoTracker) into the established DBT method (ByteTrack [9]), resulting in a new and robust multi-object tracking framework termed the Coarse-Fine Tracker. In our framework, satellite videos are partitioned into multiple sub-videos to facilitate the timely handling of newly appearing objects, while ByteTrack is used for coarse tracking of the outputs from a moderately performing detector. ByteTrack employs a Kalman filter and the Hungarian algorithm, yielding motion-based coarse tracking results and priors for the subsequent fine-tracking process. Given the challenges posed by small objects in satellite videos, we treat each object as a point to be tracked. CoTracker performs fine tracking based on the priors provided by the coarse tracking step, calculating the appearance-based similarity between each point and its surrounding region to produce fine-grained tracking results. Finally, our Consensus Fusion Strategy synergistically combines the coarse and fine-tracking results by using geometric consistency checks to eliminate erroneous detections in the coarse-tracking phase while recovering missed objects through linear interpolation or fitting techniques. This motion-appearance consensus fusion greatly enhances the robustness of the tracking process, ensuring precise spatio-temporal consistency even in challenging satellite video scenarios.
Our method stands out by addressing the inherent shortcomings of detection-based tracking in satellite videos, particularly the degradation of detector performance due to environmental complexities. By incorporating the TAP method, we effectively decouple tracking accuracy from the reliance on continuous detections, offering a more reliable and accurate tracking solution. The core contributions of our approach are as follows:
- We introduce Coarse-Fine Tracker, an innovative online MOT framework designed for scenarios with tiny objects. This framework is the first to integrate the TAP method into a traditional DBT framework, combining motion-based coarse tracking and appearance-based fine tracking to achieve robust tracking performance beyond the capabilities of the detector alone.
- We propose a novel Consensus Fusion Strategy that uses both coarse and fine-tracking results: geometric consistency checks eliminate erroneous coarse detections, while missed objects are recovered via linear interpolation or fitting. This fusion of motion and appearance information significantly enhances the robustness and spatio-temporal accuracy of the tracker, making it particularly suitable for challenging satellite video environments.
2. Materials and Methods
2.1. Notation
Generally, DBT paradigm first processes each frame with a detector to obtain the detection results from a video , which is a sequence of T RBG frames . The detections are denoted as containing N detections in the frame t. A detection represented as , where means the center of the bounding box, and w and h indicate its width and height, respectively. The set of M tracklets is denoted by . Each represents a tracklet with identity j and is defined as , where is the bounding box represented as if the object is present, or otherwise, and denotes the initialization moment.
As shown in Figure 2, our Coarse-Fine Tracker follows the DBT paradigm, with coarse tracking using ByteTrack and fine tracking using CoTracker. In a satellite video, there are multiple objects, each appearing at random times. To promptly utilize the CoTracker for simultaneous tracking after detecting these objects, we divide the video into K sub-videos with an interval of S frames, denoted as , where is defined as and is the initialized time in the sub-video. Correspondingly, we obtain the sub-detections , where is defined as . Our Coarse-Fine Tracker mainly executes two steps for each sub-video:
- Coarse-to-FineThis step aims to provide necessary information to fine tracking through coarse tracking. For a sub-video and the corresponding sub-detections , we first use ByteTrack for coarse tracking and obtain the predicted state vectors x and the observed state vectors z for each object in every frame. The observed state vectors z are used to generate coarse sub-tracklets , which provide initial matching trajectories and the time and location of each object’s initial appearance. The predicted state vectors x and z can be used to generate the prior to reduce errors in fine tracking.
- Fine-to-CoarseThis step aims to improve tracking accuracy by supplementing coarse sub-tracklets with fine sub-tracklets. CoTracker, a transformer-based model, can determine the subsequent positions of an object through feature similarity calculations, including some positions that the detector missed. So, CoTracker is given as input the sub-video and the prior , and outputs the fine estimate of the track locations and visibility flags . Finally, and are used in the Consensus Fusion Strategy to form the final sub-tracklets .
All the sub-tracklets are combined to form the overall tracking results . Our goal is to get tracklets throughout the duration of a video.
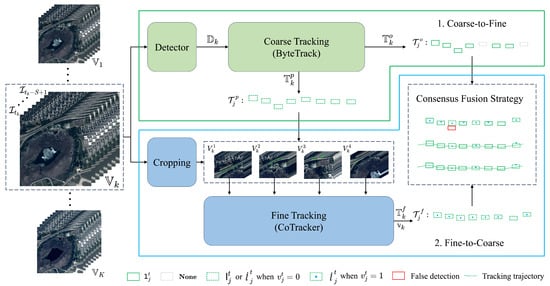
Figure 2.
The overview of our Coarse-Fine Tracker. The framework takes a sub-video as input and produces tracking results through two main steps: Coarse-to-Fine and Fine-to-Coarse. In the Coarse-to-Fine process, Coarse Tracking first generates coarse tracking trajectories and provides positional priors for Fine Tracking. In the Fine-to-Coarse process, Fine Tracking produces finer tracking results, which are then further integrated with the coarse-grained trajectories through the Consensus Fusion Strategy to yield the final tracking results.
Figure 2.
The overview of our Coarse-Fine Tracker. The framework takes a sub-video as input and produces tracking results through two main steps: Coarse-to-Fine and Fine-to-Coarse. In the Coarse-to-Fine process, Coarse Tracking first generates coarse tracking trajectories and provides positional priors for Fine Tracking. In the Fine-to-Coarse process, Fine Tracking produces finer tracking results, which are then further integrated with the coarse-grained trajectories through the Consensus Fusion Strategy to yield the final tracking results.
2.2. Coarse-Fine Tracker
2.2.1. Coarse-to-Fine
- Coarse Tracking
In our framework, ByteTrack performs coarse tracking across sub-videos using imperfect detection results. This achieves dual capability: preserving spatial-temporal information critical for fine tracking and maintaining cross-subvideo identity consistency via the Linear Kalman filter. The ByteTrack uses the Linear Kalman filter to predict the tracklets of the objects and then employs the Hungarian algorithm to associate the tracklets sequentially with high-confidence detection boxes and low-confidence detection boxes. Through iterative prediction-update cycles, the Kalman filter generates the predicted state vectors x as motion priors while dynamically calibrating them against the observed state vectors z derived from detection bounding boxes.
As shown in Algorithm 1, the ByteTrack is given as input the , and outputs motion-based coarse sub-tracklets , where is defined as . Despite potential matching errors in due to inaccuracies in , they at least include the position and time of each object’s initial appearance used in fine tracking. In practice, besides the initial appearance time and position, providing approximate prior information for subsequent positions can slightly help reduce errors in CoTracker. So for each sub-tracklet, we save the observed state vectors and the predicted state vectors .
| Algorithm 1 Pseudo-code for Coarse Tracking | |
| Input: Sub-detections , previous coarse sub-tracklets | |
| Output: Coarse sub-tracklets , Prediction states , Observed states | |
| 1: Initialize: , , | |
| 2: for to do | |
| 3: | |
| 4: | |
| 5: for do | |
| 6: | ▹ The prediction process of Kalmen filter |
| 7: | ▹ Save the predicted state vectors |
| 8: | ▹ Save the observed state vectors |
| 9: end for | |
| 10: | |
| 11: | |
| 12: for do | ▹ Update the tracked tracks |
| 13: if is matched in then | |
| 14: | |
| 15: | ▹ The update process of Kalmen filter |
| 16: | ▹ Save the observed state vectors |
| 17: | |
| 18: else | |
| 19: | |
| 20: end if | |
| 21: end for | |
| 22: Initialize new tracks from | |
| 23: for in new tracks do | |
| 24: | ▹ Add the new tracks |
| 25: end for | |
| 26: Remove lost tracks from | ▹ Remove the lost tracks |
| 27: end for | |
| 28: return | |
- Provide Prior for Better Fine Tracking
Due to the nature of satellite video scenes, where the objects to be tracked are tiny and move in approximately linear trajectories, the object bounding boxes do not undergo significant deformation. Therefore, we can treat each tiny object as a point by using the bounding box center and leverage state-of-the-art TAP techniques to handle them. CoTracker is a transformer-based point tracker that tracks several points jointly, making it particularly well-suited for this task.
CoTracker initializes the subsequent coordinates with the initial coordinates for a trajectory, then updates them iteratively. This approach, however, may extract spatial correlation features from wrong coordinates, which can propagate localization errors and gradually degrade tracking robustness due to error accumulation. In our method, we enhance CoTracker using motion-aware positional priors, where the trajectory initialization is governed by the posterior predicted state vector instead of copying initial coordinates. This replacement is critical because the observation vector from the detector fails to reliably locate tiny objects in consecutive frames, whereas encodes motion continuity to suppress error accumulation. Therefore, we can obtain , where is defined as . Here, denotes the initial timestamp of object j in the sub-video, where its starting position is directly derived from the observation state vector . For subsequent frames, the positional prior is inferred from the predicted state vector .
2.2.2. Fine-to-Coarse
- Cropping Sub-videos
When using CoTracker for fine tracking, the satellite video frames are too large, making tracking difficult. Training a model with an input size of 1024 × 1024 is impractical, and the model’s processing time also needs to be considered. Therefore, we crop the video frames to avoid this problem.
We first calculate the maximum movement area for each object in all sub-videos (the area covered by the movement of its center point plus its width and height) and find that it does not exceed 50 × 50 with . Therefore, as long as the overlapping area between adjacent cropped sub-videos exceeds two 50 × 50 regions, we can ensure that every object will appear completely in at least one of the cropped sub-videos.
As shown in Figure 3, we crop the sub-video into 12 cropped sub-videos , with the overlapping area between adjacent videos being much larger than 50 × 50. Then, each trajectory in is assigned to one of the 12 cropped sub-videos based on the location of the midpoint of the line connecting its start and end center points. At this point, some of the cropped sub-videos may not contain any trajectory and can be discarded. Finally, fine tracking is performed in parallel using CoTracker model based on the number of cropped sub-videos.
- Fine Tracking
Fine tracking begins from the center position of each object’s first detection and returns the estimated position of the bounding box center in subsequent sub-videos. Using the prior information , Cotracker is thus given as input the n-th cropped sub-video , starting and subsequent coordinates , where are included in . It then outputs the estimate of the center positions and visibility flags , where is defined as . Center positions and in can combine to form . By merging 12 cropped sub-videos, we can obtain the fine sub-tracklets and , where is defined as .
Compared with motion-based coarse tracking that associates based on the bounding boxes, fine tracking is at point-level by calculating similarity after extracting appearance features from objects and sub-videos. Therefore, in situations where the detector does not work well, fine tracking can still detect the object and return the approximate position of the bounding box center. It is important to note that if an object is missed during the initialization phase, particularly in the frames prior to detection, our method is currently unable to recover such objects, as it relies on the detection initialized within the stride. And next, we can use fine sub-tracklets to identify and correct erroneous trajectories in coarse sub-tracklets , which is detailed in Section 2.3.

Figure 3.
(a) Cropping regions of a 1024 × 1024 image with overlapping areas between adjacent regions, where green bounding boxes indicate objects to be tracked. (b) The 12 cropped sub-videos obtained after croppping (a). (c) Cropped sub-videos numbered 1, 2, 3, and 4 are selected for fine tracking from (b).
Figure 3.
(a) Cropping regions of a 1024 × 1024 image with overlapping areas between adjacent regions, where green bounding boxes indicate objects to be tracked. (b) The 12 cropped sub-videos obtained after croppping (a). (c) Cropped sub-videos numbered 1, 2, 3, and 4 are selected for fine tracking from (b).
2.3. Consensus Fusion Strategy
Our framework produces two outputs: (1) motion-based coarse sub-tracklets , generated by associating detection outputs through ByteTrack’s Kalman filter; and (2) appearance-based fine sub-tracklets , constructed by correlating cross-frame features via CoTracker. While provides temporally coherent object proposals by associating detections across frames, it inevitably inherits detection errors from the moderately performing detector. recovers detector-missed objects through appearance similarity, but convolutional operations in CoTracker (e.g., downsampling) cause its predicted centers to deviate from actual box centers. Our Consensus Fusion Strategy synergistically integrates motion-based trajectories and appearance-based predictions through dual mechanisms: geometric consistency validation purges mismatched trajectories in , while appearance-guided interpolation recovers undetected objects from , thus achieving temporally stable and spatially precise tracking.
2.3.1. Filter Erroneous Detections
This stage eliminates detection errors by spatio-temporal cross-validation between and . Temporal validation first locates missed detections where ByteTrack fails (e.g., ), while signals appearance-based visibility, as in frames 5 and 8 of Figure 4. Spatial coherence then flags false positive detections through geometric consistency, where ’s centers should not exceed ’s bounding box:
Violations of this spatial consensus trigger false positive invalidation, as in frame 3 of Figure 4. These geometrically inconsistent detections are reclassified as missed detections. Based on the outcome of this process, sub-tracklets are categorized into three classes: valid detections with confirmed localization (e.g., satisfying geometric consistency), non-detection frames indicating object absence (e.g., and ), and missed detections (e.g., and , or failing to satisfy geometric consistency).
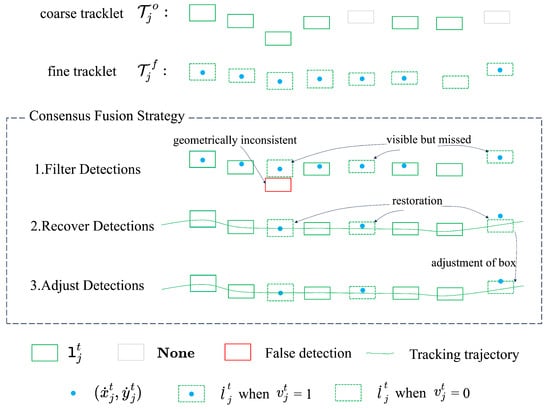
Figure 4.
Consensus Fusion Strategy workflow for an object tracked from frame 1 to 8. Given coarse tracklet and fine tracklet : (1) Filter Erroneous Detections: Spatio-temporal cross-validation discards if ’s center violates bounding box constraints (Equation (1)). (2) Recover Missed Detections: Linear interpolation or fitting estimates missed detection center based on valid detections (≥4 or <4 per segment), inheriting / from . (3) Adjust Recovered Detections: Enforce geometric consistency (Equation (1)) by aligning recovered boxes with ’s centers.
Figure 4.
Consensus Fusion Strategy workflow for an object tracked from frame 1 to 8. Given coarse tracklet and fine tracklet : (1) Filter Erroneous Detections: Spatio-temporal cross-validation discards if ’s center violates bounding box constraints (Equation (1)). (2) Recover Missed Detections: Linear interpolation or fitting estimates missed detection center based on valid detections (≥4 or <4 per segment), inheriting / from . (3) Adjust Recovered Detections: Enforce geometric consistency (Equation (1)) by aligning recovered boxes with ’s centers.
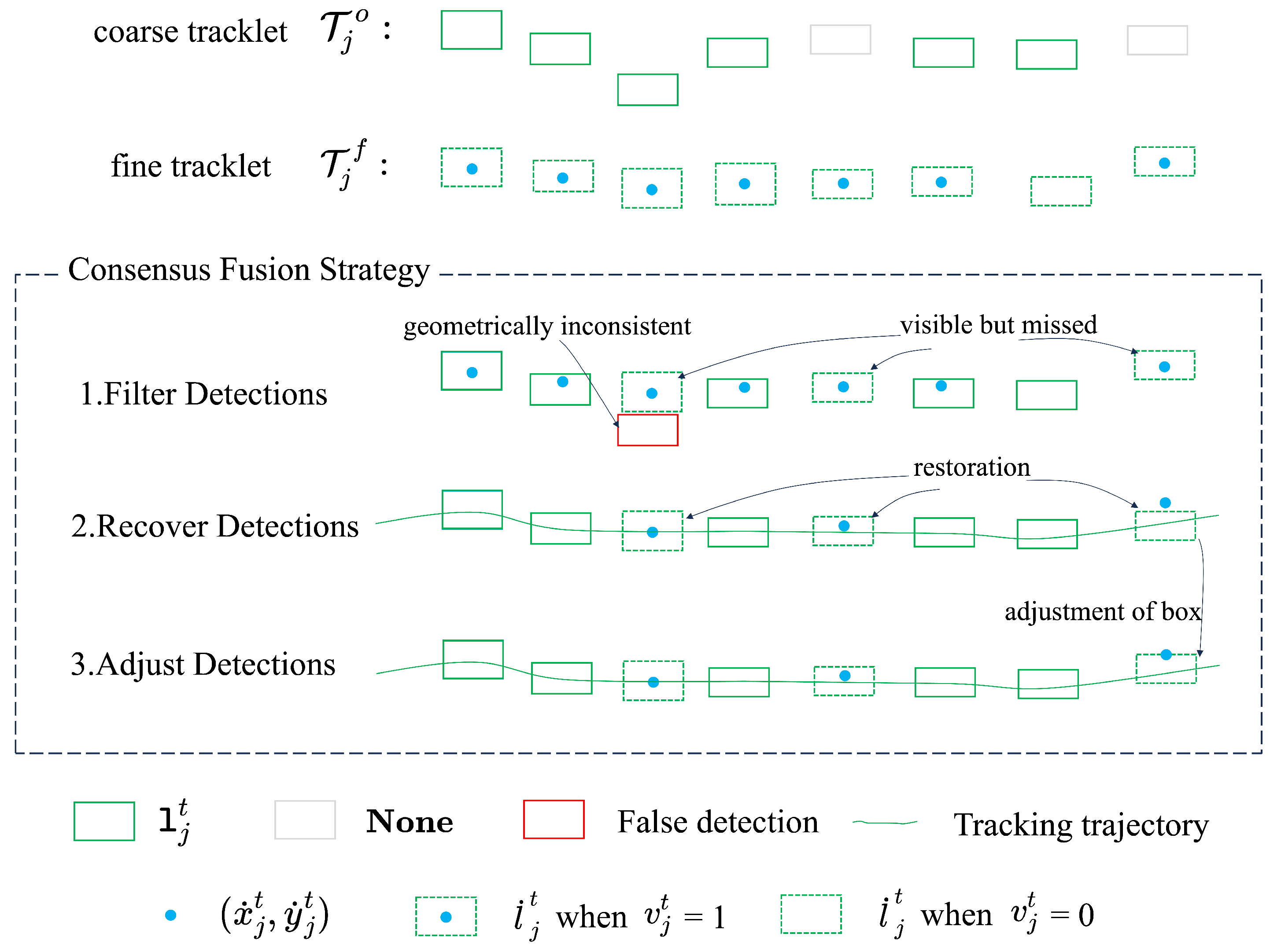
2.3.2. Recover Missed Detections
Our restoration strategy processes missed frames based on the quantity of valid detections within each sub-video segment, utilizing the center coordinates of and the width and height from of the valid detections.
When the number of valid detections exceeds or equals 4, linear interpolation reconstructs object trajectories between adjacent positions of valid detections. When the number of valid detections is less than 4, we perform linear fitting on the centers of the sub-tracklet in the last sub-video and the centers of the valid detections in the current sub-video. Then, we sample this fitted model at the timestamps of the missed detections to estimate and recover their center points. The recovered boxes inherit width () and height () from to maintain scale consistency. As demonstrated in Figure 4, the 3 missed detections in frames 3, 5, and 8 are recovered through interpolation between 5 valid detections.
2.3.3. Adjust Recovered Detections
We enforce the geometric consistency from Equation (1) on recovered detections to maintain spatial coherence. For each recovered box, we verify containment of ’s center within its boundaries. As shown in Figure 4, frame 8, the recovered box is adjusted to ensure full compliance with the geometric consistency.
3. Results
3.1. Experiment Setting
3.1.1. Datasets
We validate our Coarse-Fine Tracker using the VISO [2] and SAT-MTB [32] datasets, which are captured by the Jilin-1 satellite.
The VISO and SAT-MTB datasets present a variety of traffic scenes, including traffic jams, urban roads, and highways. Therefore, it covers common challenges in MOT tasks in satellite videos, such as tiny objects and complex backgrounds. We follow the official split provided by the VISO dataset authors: the seven 1024 × 1024 test videos are used for evaluation, while the remaining seventy videos at 512 × 512 resolution constitute the official training split and are used to train the detector. Likewise, we adopt the SAT-MTB test split, which contains two 1024 × 1024 sequences and twenty-eight 512 × 512 sequences. The remaining sixty-two 512 × 512 sequences in the training split are employed for detector training.
3.1.2. Evaluation Metrics
In our experiments, we employ the CLEAR metrics [33] from MOTChallenge [34] and KITTI Tracking [35] to quantitatively assess the accuracy of our method, including multi-object tracking accuracy (MOTA), multi-object tracking precision (MOTP), IDF1 score (IDF1), ID precision (IDP), ID recall (IDR), the percentage of mostly tracked trajectories (MT), and most lost (ML), the number of false positives (FP), false negatives (FN), and ID switches (IDS).
In particular, IDF1 focuses more on association performance, MOTA quantifies the accumulated tracking errors with values ranging from , and IDS represents the total number of ID switches. Note that a negative MOTA indicates that the tracker has made more errors than the total number of objects in the video. Higher values of IDF1 and MOTA, or lower IDS, indicate a better tracking performance of the model. Their calculation formulas are as follows:
where t is the frame index and is the number of ground truth objects. The official evaluation code is available at TrackEval [36].
3.1.3. Implementation Details
For our implementation, we first segment the video into portions with frames and process each segment sequentially. Initially, we perform Coarse Tracking on these video segments with a track threshold of 0.4. After this, we crop the video and proceed with Fine Tracking using the CoTracker model.
The CoTracker model used in Fine Tracking is retrained on the VISO dataset. Since the open-source weights of CoTracker accept an input size of 512 × 384, we preprocess the VISO dataset accordingly, using the VISO training set to construct the CoTracker training set and the VISO test set to construct the CoTracker test set. The training set of VISO, originally in 512 × 512 resolution, is split into multiple 512 × 384 video clips of 24 frames each. These clips are used to generate npy files in the same format as TAP-Vid-Kubric [29], according to the annotations. For the test set of VISO, which is in 1024 × 1024 resolution, it is similarly split into 512 × 384 video clips of 24 frames. These clips are used to generate a pkl file in the same format as TAP-Vid-DAVIS [29], according to the annotations and videos.
During the training of the CoTracker model, we set the batch size to 1, the model stride to 2, and the number of virtual trajectories to 4, while keeping all other parameters at their default values. We train the model for 50,000 iterations with a learning rate of using the AdamW [37] optimizer. All experiments, including tracking experiments, are conducted on a single NVIDIA RTX 4090 GPU.
3.2. Quantitative Results
We test our Coarse-Fine Tracker on the VISO test dataset [2] using DSFNet [2] as the detector and compare it with other multi-object tracking methods, including methods designed for ground-based videos such as FairMOT [14] and ByteTrack [9], as well as methods specifically designed for satellite videos, namely, including DBT methods such as TGraM [3], CFTracker [23], and LocaLock [26]. We adopt the settings of LocaLock [26] in VISO: predicted detection is considered TP if the predicted bounding box overlaps with the ground truth (GT) bounding box. Therefore, we set the IoU threshold to . The experimental results are shown in Table 1, with the best results highlighted in bold.

Table 1.
Quantitative results on the VISO test set. IoU threshold is . ↑ indicates that higher is better, ↓ indicates that lower is better. The best results are shown in bold.
Our proposed Coarse-Fine Tracker outperforms other methods and achieves the highest MOTA and IDF1 scores, indicating that our method surpasses all current leading MOT models in overall performance. For ByteTrack, which also uses DSFNet as the detector, our method has lower FN and the sum of FN and FP, indicating CoTracker and Consensus Fusion Strategy provide more accurate detections beyond the capabilities of the detector alone. This results in improvements in MOTA, MOTP, IDF1, IDS, and other metrics at the track threshold of 0.4.
There are some papers that consider a prediction to be a TP if the IoU between the predicted bounding box and the ground-truth bounding box exceeds 0.4. Therefore, we also report Coarse-Fine Tracker’s quantitative results for the VISO test dataset in Table 2 when the IoU threshold is 0.4. Our Coarse-Fine Tracker achieves state-of-the-art performance in MOTA, IDF1, FP, FN, and IDS. Compared with OC-SORT and Bot-YOLOv7 in natural scenes, our method reduces IDS by 50.3% and 90%, respectively, confirming its excellent stability. Compared with CFTracker and GMFTracker, specialized trackers for remote sensing videos, our method surpasses them in MOTA, IDF1, IDS, and other metrics, demonstrating the competitiveness and robustness of our method.
Table 2.
Quantitative results on the VISO test set. IoU threshold is 0.4. ↑ indicates that higher is better, ↓ indicates that lower is better. The best are results are shown in bold.
Additionally, we conduct tests on the SAT-MTB vehicle dataset [32] using YOLOX [19] as the detector and compare it with some methods designed for ground-based and satellite videos. As shown in Table 3, the proposed Coarse-Fine Tracker achieves the best performance on the metrics. It achieves the highest MOTA score of 28.4 and the IDF1 score of 53.1 among the evaluated methods, surpassing ByteTrack by 1.7 and 1.2, respectively. Our framework maintains competitive efficiency while reducing IDS relative to CFTracker, proving robust handling of complex tracking scenarios.
Table 3.
Quantitative results on the SAT-MTB test set. IoU threshold is . ↑ indicates that higher is better, ↓ indicates that lower is better. The best results are shown in bold.
3.3. Visualization Results
To visually demonstrate the performance of our framework, we provide visualization results from the VISO test videos in Figure 5.

Figure 5.
The leftmost column shows the zoom-out tracking results of Coarse-Fine Tracker. The right side displays the zoomed-in areas corresponding to the red boxes in the first column, with trajectories shown from left to right for (a) GT, (b) our Coarse-Fine Tracker, (c) CFTracker, and (d) ByteTrack, respectively.
Overall, compared with CFTracer and ByteTrack, our Coarse-Fine Tracker has more complete trajectories, indicating better tracking ability. At the same time, the colors in Figure 5 show lower complexity, indicating fewer IDS. In addition, the trajectory is more continuous, which is particularly evident in videos 003, 006, and 008. This indicates that our method successfully recovered some previously undiscovered objects through Fine Tracking and Consensus Fusion Strategy, resulting in an increase in MT and a decrease in FN.
4. Discussion
4.1. Effect of the Detector
To rigorously evaluate the generalization capability of our framework across varying detector architectures, we conduct ablation studies on the VISO test dataset using three different detectors: YOLOX (a widely adopted natural-scene detector), DSFNet (a detector designed for satellite videos), and CFTracker (a JDT tracker in remote sensing). This selection spans the conventional detection paradigm, the specialized remote sensing detection model, and the JDT framework, thereby systematically validating method robustness. As evidenced in Table 4, although detector selection significantly impacts tracking performance, our approach consistently improves MOTA, IDF1, and continuity metrics under all detector configurations, demonstrating reduced sensitivity to detection quality fluctuations compared with baseline ByteTrack. Under the YOLOX detector, our framework increases MT by 10.2% while maintaining higher MOTA. With CFTracker’s tracking results, our method elevates IDF1 from 73.0 to 75.9 and decreases IDS by 28.3%, despite comparable MOTP scores. Based on DSFNet detections, our approach achieves a MOTA of 66.9, surpassing ByteTrack by 6.7 while simultaneously improving MOTP from 60.5 to 64.1 and reducing FN by 12.3%. These improvements highlight our method’s robustness in decoupling detection dependency.
Table 4.
Comparison of the performance of Coarse-Fine Tracker using different detectors on VISO test dataset. ↑ indicates that higher is better, ↓ indicates that lower is better.
Considering that CFTracker uses a cross-frame feature update module, its tracking results mainly from segmented trajectories, allowing simple associations to achieve good scores in MOTP and other metrics. Given the challenges in satellite videos, where targets are small and backgrounds are complex, conventional detectors often struggle to achieve such results, either failing to detect objects or producing low-confidence detections. To evaluate the performance of Coarse-Fine Tracker when the detector’s performance is insufficient, we systematically removed the CFTracker detection results at deletion probabilities of 2%, 4%, 6%, 8%, and 10%. Concurrently, we adjusted the tracking threshold to 0.3, 0.4, 0.5, and 0.6 across the experiments. The results of these studies are detailed in Table 5.
Table 5.
Comparison of the performance of Coarse-Fine Tracker and ByteTrack in detector performance degradation on VISO test dataset.
The results, as shown in Table 5, indicate that our method consistently outperforms ByteTrack across all conditions. Specifically, our method achieves a higher MOTA and IDF1 scores, indicating better tracking accuracy and identity preservation. In addition, it results in fewer IDS, demonstrating more stable tracking.
As the deletion probability increases, both ours and ByteTrack exhibit a marked decline in performance, particularly at higher tracking thresholds of 0.5 and 0.6, underscoring the dependency of DBT methods on the underlying detector’s performance, especially in scenarios where high-confidence detections are scarce.
Focusing on the tracking thresholds of 0.3, 0.4, and 0.5, our method consistently outperforms ByteTrack in terms of MOTA degradation. Specifically, at a tracking threshold of 0.3, ours experiences a MOTA degradation of 0.7 compared with ByteTrack’s 5.7. Similarly, at thresholds of 0.4 and 0.5, our MOTA degradation remains significantly lower than that of ByteTrack, demonstrating enhanced robustness. When examining fixed deletion ratios, ours maintains smaller MOTA degradations across all tested probabilities, with degradations ranging from 6.4% to 8.9%, whereas ByteTrack experiences much larger degradations between 21.6% and 23.4%. These comparisons clearly demonstrate our superior robustness, particularly under conditions of increased detection result degradation. Our ability to maintain higher tracking accuracy despite reduced detection inputs highlights its effectiveness and reliability in satellite video scenarios where detector performance may fluctuate.
4.2. Component Analysis
To assess the contributions of individual components in Coarse-Fine Tracker, we systematically add the Fine Tracking, Providing Prior, and Consensus Fusion Strategy to evaluate their impact on performance. The experiments are carried out using the test dataset, and the results are detailed in Table 6 and Table 7. When evaluating Fine Tracking alone or the combined results of Fine Tracking and Providing Prior, if Fine Tracking identifies any missed detections, these are directly added to the coarse-grained tracking results as supplementary detections.
Table 6.
Ablation study for different structures using CFTracker’s tracking results on VISO test dataset. ↑ indicates that higher is better, ↓ indicates that lower is better. And ✔ indicates the use of the module.
Table 7.
Ablation study for different structures using DSFNet as the detector on VISO dataset. ↑ indicates that higher is better, ↓ indicates that lower is better. And ✔ indicates the use of the module.
As shown in Table 6, we test three components based on CFTracker’s tracking results. The inclusion of the Fine Tracking results in a slight decrease of 0.2 in MOTA but an improvement of 0.7 in IDF1, significantly reducing the IDS by 34. However, MOTP exhibits an unexpected decline. As MOTP specifically reflects the localization accuracy of tracking boxes, the original CFTracker has already generated continuous trajectory segments, resulting in a naturally higher MOTP baseline. While the Fine Tracking successfully detects previously missed objects, the convolutional operations in its design (as mentioned in Section 2.3) introduce localization inaccuracies, ultimately leading to degraded MOTP performance. Adding the Providing Prior to the Fine Tracking provides further performance gains, with MOTA increasing by 0.6 and IDF1 by 0.1, and MOPT improved. This combination also reduced IDS by 186 and 37, respectively. When all three parts are integrated, the model achieves the highest improvements, with MOTA increasing to 59.1, IDF1 to 75.9, and MOPT returning to 59.2. This configuration also yields significant reductions in IDS, demonstrating the effectiveness of each module.
As shown in Table 7, we also test three components based on the DSFNet detections. The cumulative integration of components progressively enhances MOTA, MOTP, and IDF1 while effectively suppressing IDS, thereby validating the effectiveness of each individual module. Overall, the combination of Fine Tracking, Providing Prior, and Consensus Fusion Strategy greatly enhances tracking performance, as evidenced by the improved MOTA and IDF1 scores and the reduction in IDS compared with the baseline ByteTrack.
4.3. Effect of Frame Interval Parameter S
To address the issue of large satellite video frames making tracking difficult with Fine Tracking, we crop the video frames. We found that when , the maximum area of movement for each object does not exceed 50 × 50, ensuring that objects appear completely in at least one cropped sub-video. Considering the practical limitations and the need to cover object movements, we experimented with different Frame Interval S of 4, 6, 8, 10, and 12. Given that the movement of objects in adjacent frames typically does not exceed 5 pixels in both x and y directions, and the overlap between adjacent sub-videos is at least 169 pixels, choosing and is feasible.
As shown in Table 8, the performance of our method varies with the different Frame Interval S values. When , the method achieves the highest MOTA of 66.9 and IDF1 of 77.8, reflecting the best balance between accuracy and tracking consistency. The MOTP reaches its lowest value of 64.1 at , suggesting a slight decrease in precision due to the larger range of object movement. However, this trade-off between MOTA and MOTP is offset by the fact that minimizes false negatives and false positives more effectively than smaller or larger stride values. As S increases further (to and ), the IDS decreases, with achieving the lowest IDS of 293, indicating fewer identity switches. However, the improvements in MOTA and IDF1 are less pronounced, and there is a noticeable increase in false positives with , suggesting that larger strides may introduce more fragmentation and less accurate matching.
Table 8.
Performance of S using DSFNet as the detector on VISO test dataset. ↑ indicates that higher is better, ↓ indicates that lower is better. The best results are shown in bold.
In conclusion, provides the best overall performance, with an optimal balance between tracking accuracy, consistency, and minimal false detections, making it the most suitable for tracking.
5. Conclusions
In this study, we present a novel Coarse-Fine Tracker for MOT in satellite videos, leveraging a two-step tracking approach that combines ByteTrack for coarse tracking and CoTracker for fine tracking. This framework integrates the complementary strengths of two tracking methods to deliver interpretable behavioral analytics, providing a robust, mission-critical-ready solution for high-stakes applications. Coarse tracking provides coarse tracking results and the prior for fine tracking through motion-based tracking based on a conventional detector. Fine tracking provides fine tracking results by focusing on appearance-based tracking. The final results are further enhanced by a Consensus Fusion Strategy, which eliminates erroneous matches in coarse tracking results while also incorporating objects that are detected by CoTracker but not by the detector. Our experiments show that this method achieves good performance and robustness against variations in detection quality, maintaining high tracking accuracy beyond the capabilities of the detector alone.
While the Coarse-Fine Tracker demonstrates notable performance when the detector’s performance is suboptimal, there is still room for further enhancement. Specifically, a TAP model designed for remote sensing video scenes could be developed to ensure accuracy while accelerating processing speed. In future work, we intend to combine advanced MOT methods to design a lightweight online TAP model that supports higher-resolution video input and faster processing speed.
Author Contributions
Conceptualization, H.S., X.L., X.Q., E.Z., J.J. and L.W.; methodology, H.S. and X.L.; software, H.S., X.Q. and E.Z.; validation, H.S., X.L. and E.Z.; formal analysis, H.S. and J.J.; investigation, H.S. and L.W.; data curation, H.S. and J.J.; writing—original draft preparation, H.S. and X.Q.; writing—review and editing, H.S., E.Z. and J.J.; visualization, X.Q. and E.Z.; project administration, L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by the Key Laboratory of Target Cognition and Application Technology under Grant 2023-CXPT-LC-005, the Science and Disruptive Technology Program under Grant AIRCAS2024-AIRCAS-SDTP-03, and the Key Program of the Chinese Academy of Sciences under Grants RCJJ-145-24-13 and KGFZD-145-25-38.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yin, Q.; Hu, Q.; Liu, H.; Zhang, F.; Wang, Y.; Lin, Z.; An, W.; Guo, Y. Detecting and Tracking Small and Dense Moving Objects in Satellite Videos: A Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Xiao, C.; Yin, Q.; Ying, X.; Li, R.; Wu, S.; Li, M.; Liu, L.; An, W.; Chen, Z. DSFNet: Dynamic and Static Fusion Network for Moving Object Detection in Satellite Videos. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- He, Q.; Sun, X.; Yan, Z.; Li, B.; Fu, K. Multi-Object Tracking in Satellite Videos with Graph-Based Multitask Modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar] [CrossRef]
- Du, Y.; Wan, J.; Zhao, Y.; Zhang, B.; Tong, Z.; Dong, J. GIAOTracker: A Comprehensive Framework for MCMOT with Global Information and Optimizing Strategies in VisDrone 2021. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; pp. 2809–2819. [Google Scholar]
- Cao, J.; Pang, J.; Weng, X.; Khirodkar, R.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]
- Shuai, B.; Berneshawi, A.; Li, X.; Modolo, D.; Tighe, J. SiamMOT: Siamese Multi-Object Tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12367–12377. [Google Scholar] [CrossRef]
- Qin, Z.; Zhou, S.; Wang, L.; Duan, J.; Hua, G.; Tang, W. MotionTrack: Learning Robust Short-Term and Long-Term Motions for Multi-Object Tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 17939–17948. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. ByteTrack: Multi-object Tracking by Associating Every Detection Box. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 1–21. [Google Scholar]
- Aharon, N.; Orfaig, R.; Bobrovsky, B.Z. BoT-SORT: Robust Associations Multi-Pedestrian Tracking. arXiv 2022, arXiv:2206.14651. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. StrongSORT: Make DeepSORT Great Again. IEEE Trans. Multimed. 2022, 25, 8725–8737. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Liu, Y.; Li, Y.; Wang, S. Towards Real-Time Multi-Object Tracking. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 107–122. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2020, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking Objects as Points. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 474–490. [Google Scholar]
- Chen, H.; Li, N.; Li, D.; Lv, J.; Zhao, W.; Zhang, R.; Xu, J. Multiple Object Tracking in Satellite Video with Graph-Based Multiclue Fusion Tracker. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–14. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Feng, J.; Zeng, D.; Jia, X.; Zhang, X.; Li, J.; Liang, Y.; Jiao, L. Cross-frame keypoint-based and spatial motion information-guided networks for moving vehicle detection and tracking in satellite videos. ISPRS J. Photogramm. Remote Sens. 2021, 177, 116–130. [Google Scholar] [CrossRef]
- Kong, L.; Yan, Z.; Zhang, Y.; Diao, W.; Zhu, Z.; Wang, L. CFTracker: Multi-Object Tracking with Cross-Frame Connections in Satellite Videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Hong, J.; Wang, T.; Han, Y.; Wei, T. Multi-Target Tracking for Satellite Videos Guided by Spatial-Temporal Proximity and Topological Relationships. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–20. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, X.; Huang, Z.; Cheng, X.; Feng, J.; Jiao, L. Bidirectional Multiple Object Tracking Based on Trajectory Criteria in Satellite Videos. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Kong, L.; Yan, Z.; Shi, H.; Zhang, T.; Wang, L. LocaLock: Enhancing Multi-Object Tracking in Satellite Videos via Local Feature Matching. Remote Sens. 2025, 17, 371. [Google Scholar] [CrossRef]
- Sand, P.; Teller, S. Particle Video: Long-Range Motion Estimation using Point Trajectories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2195–2202. [Google Scholar] [CrossRef]
- Harley, A.W.; Fang, Z.; Fragkiadaki, K. Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer: Cham, Switzerland, 2022; pp. 59–75. [Google Scholar]
- Doersch, C.; Gupta, A.; Markeeva, L.; Recasens, A.; Smaira, L.; Aytar, Y.; Carreira, J.; Zisserman, A.; Yang, Y. TAP-Vid: A Benchmark for Tracking Any Point in a Video. arXiv 2022, arXiv:2211.03726. [Google Scholar]
- Doersch, C.; Yang, Y.; Vecerík, M.; Gokay, D.; Gupta, A.; Aytar, Y.; Carreira, J.; Zisserman, A. TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–3 October 2023; pp. 10027–10038. [Google Scholar]
- Karaev, N.; Rocco, I.; Graham, B.; Neverova, N.; Vedaldi, A.; Rupprecht, C. CoTracker: It Is Better to Track Together. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer: Cham, Switzerland, 2025; pp. 18–35. [Google Scholar]
- Liao, X.; Li, Y.; He, J.; Jin, X.; Liu, Y.; Yuan, Q. Advancing Multiobject Tracking for Small Vehicles in Satellite Videos: A More Focused and Continuous Approach. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–19. [Google Scholar] [CrossRef]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. EURASIP J. Image Video Process. 2008, 2008, 1–10. [Google Scholar] [CrossRef]
- Milan, A.; Leal-Taixé, L.; Reid, I.D.; Roth, S.; Schindler, K. MOT16: A Benchmark for Multi-Object Tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Jonathon Luiten, A.H. TrackEval. 2020. Available online: https://github.com/JonathonLuiten/TrackEval (accessed on 17 June 2025).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yi, K.; Luo, K.; Luo, X.; Huang, J.; Wu, H.; Hu, R.; Hao, W. Ucmctrack: Multi-object tracking with uniform camera motion compensation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 6702–6710. [Google Scholar]
- Wang, Y.; Kitani, K.; Weng, X. Joint object detection and multi-object tracking with graph neural networks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–2 June 2021; pp. 13708–13715. [Google Scholar]
- Stanojevic, V.D.; Todorovic, B.T. BoostTrack: Boosting the similarity measure and detection confidence for improved multiple object tracking. Mach. Vis. Appl. 2024, 35, 53. [Google Scholar] [CrossRef]
- Morsali, M.M.; Sharifi, Z.; Fallah, F.; Hashembeiki, S.; Mohammadzade, H.; Shouraki, S.B. SFSORT: Scene features-based simple online real-time tracker. arXiv 2024, arXiv:2404.07553. [Google Scholar]
- Cetintas, O.; Brasó, G.; Leal-Taixé, L. Unifying short and long-term tracking with graph hierarchies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22877–22887. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).