
From Clusters to Communities: Enhancing Wetland Vegetation Mapping Using Unsupervised and Supervised Synergy



Abstract

1. Introduction
2. Materials and Methods
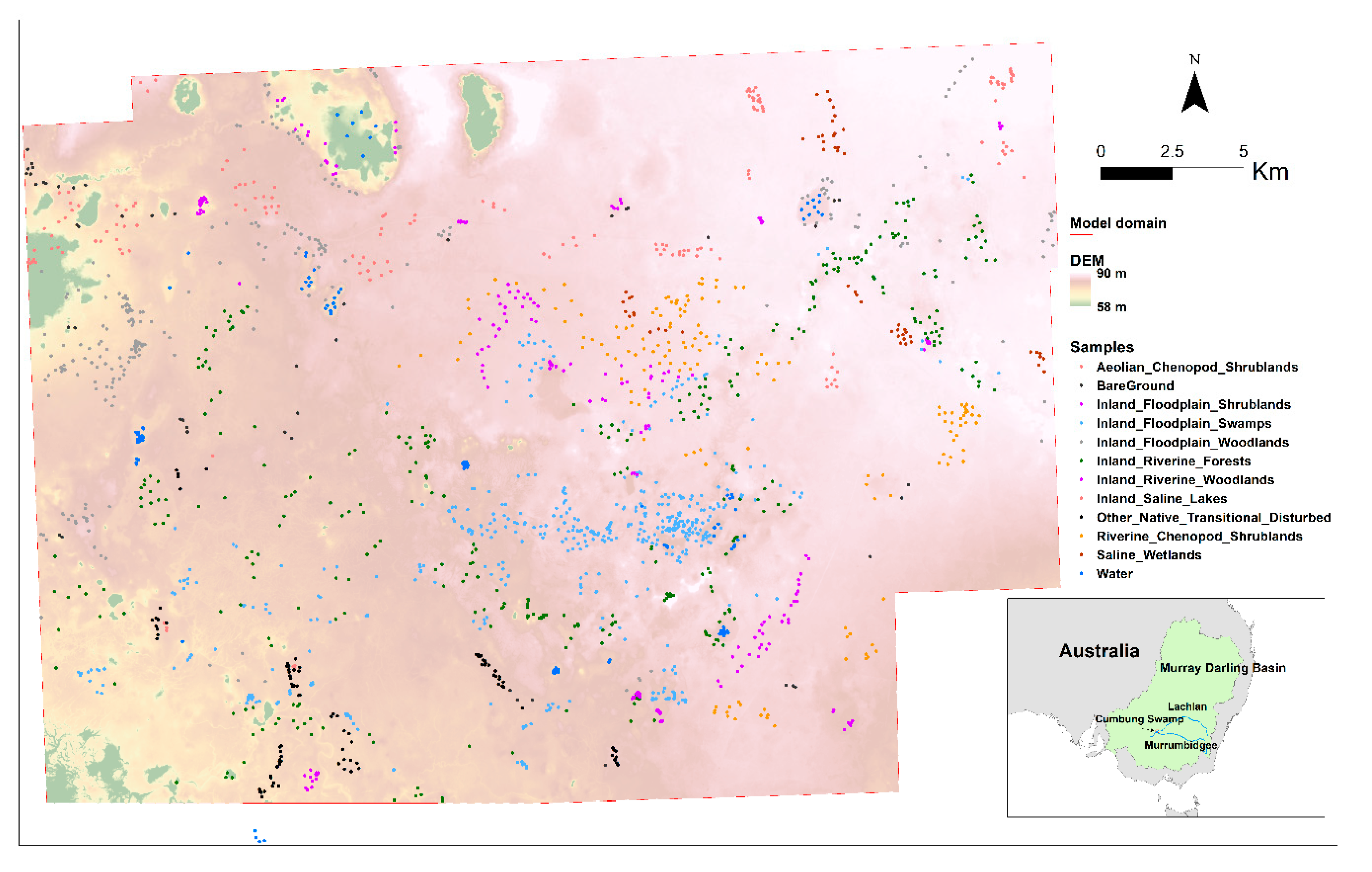
2.1. Study Site
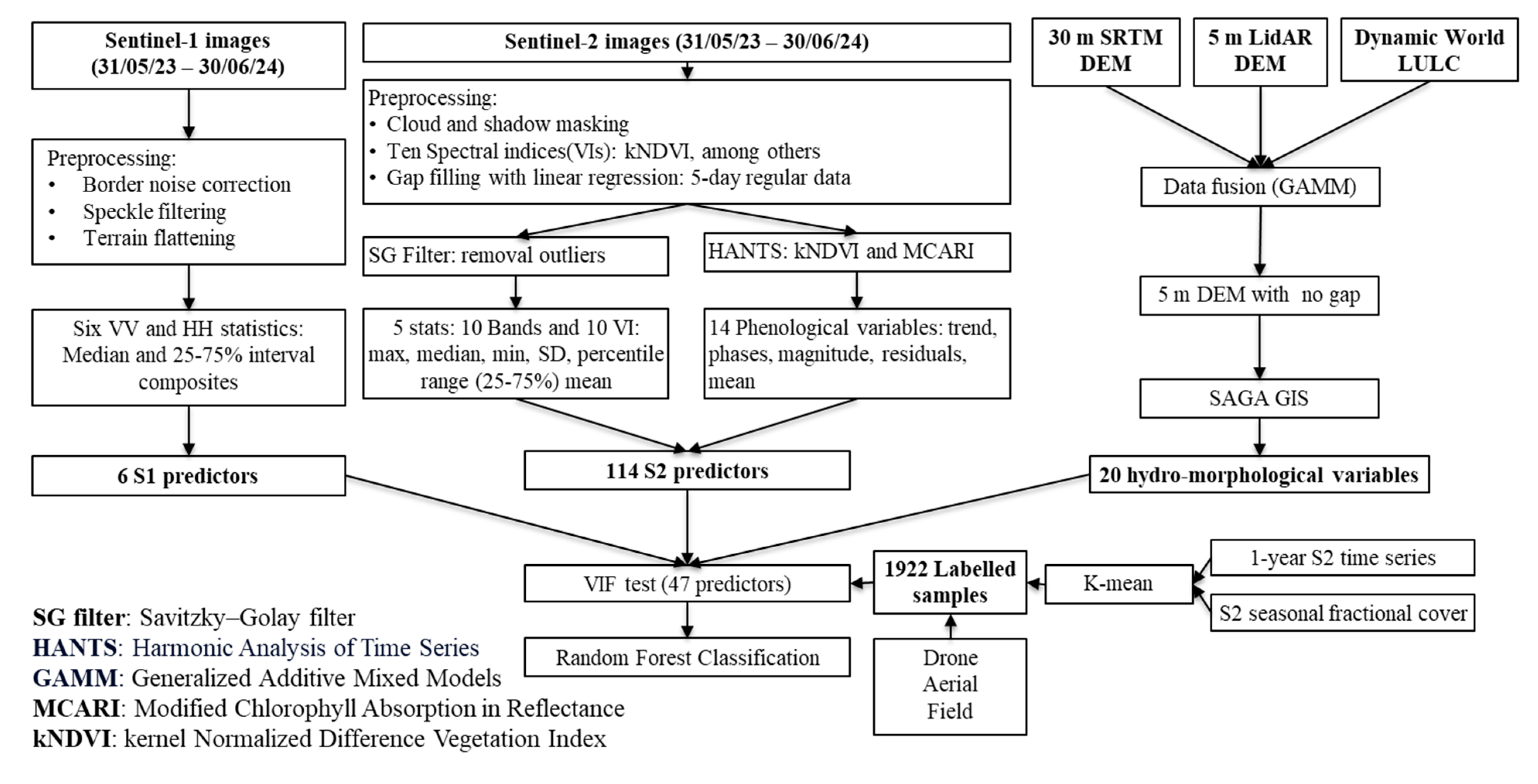
2.2. Data Source and Processing
2.2.1. Satellite Image Preparation
2.2.2. Hydro-Morphological Data
2.2.3. Unsupervised Clustering and Training Data Generation
- 1.
- Visually dominant and identifiable canopy or ground cover species,
- 2.
- Structural characteristics matching known vegetation types,
- 3.
- A landscape position consistent with the ecological descriptions of those types.
2.3. Model Development
2.4. Model Evaluation
2.4.1. Overall Accuracy (OA)
2.4.2. Cohen’s Kappa (κ)
2.4.3. Weighted F1 Score
2.4.4. Matthews Correlation Coefficient (MCC)
3. Results
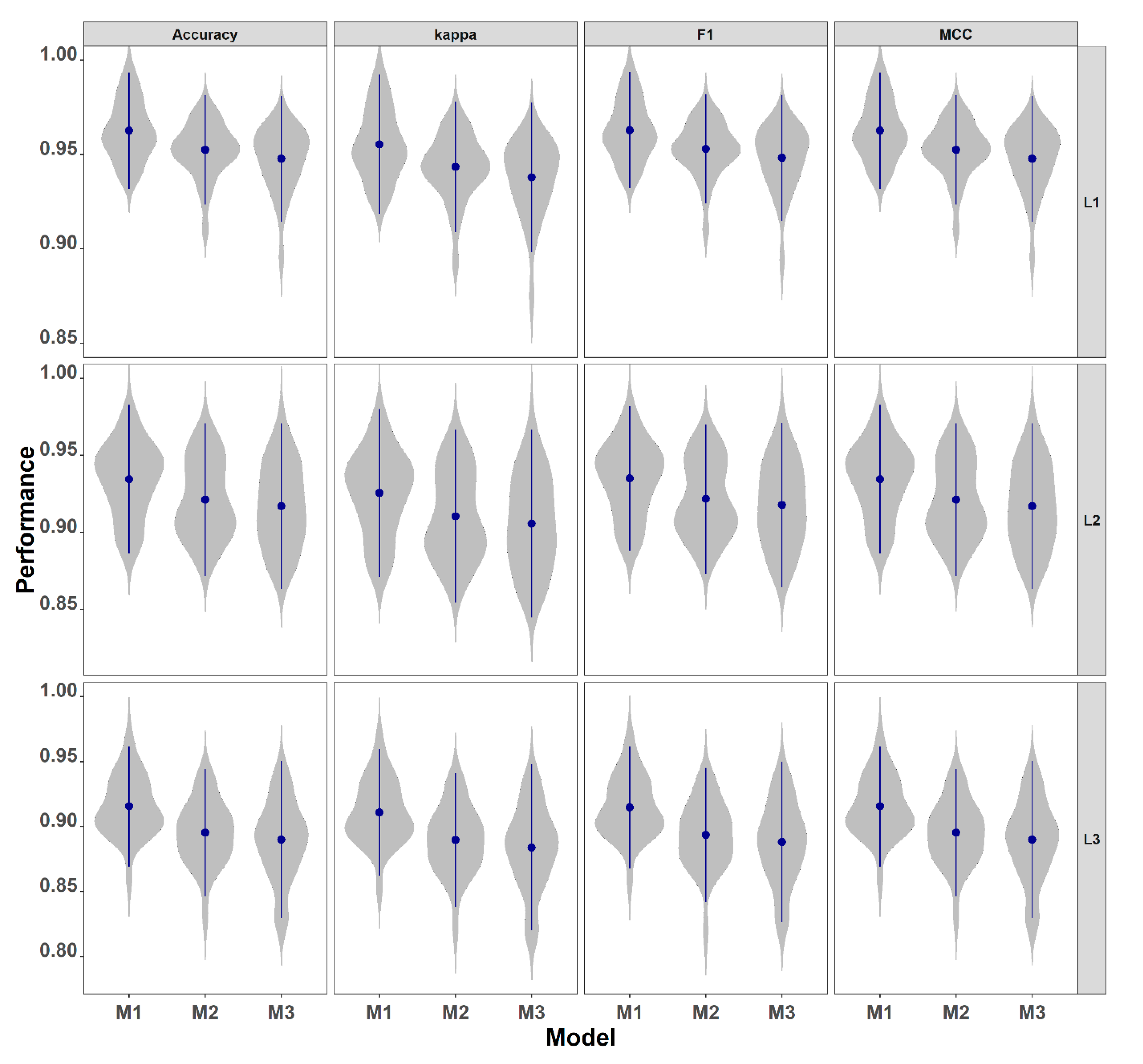
3.1. Classification Accuracy
3.1.1. Performance Across Predictor Sets
3.1.2. Effect of Classification Complexity
3.1.3. Statistical Comparison of Model Variants
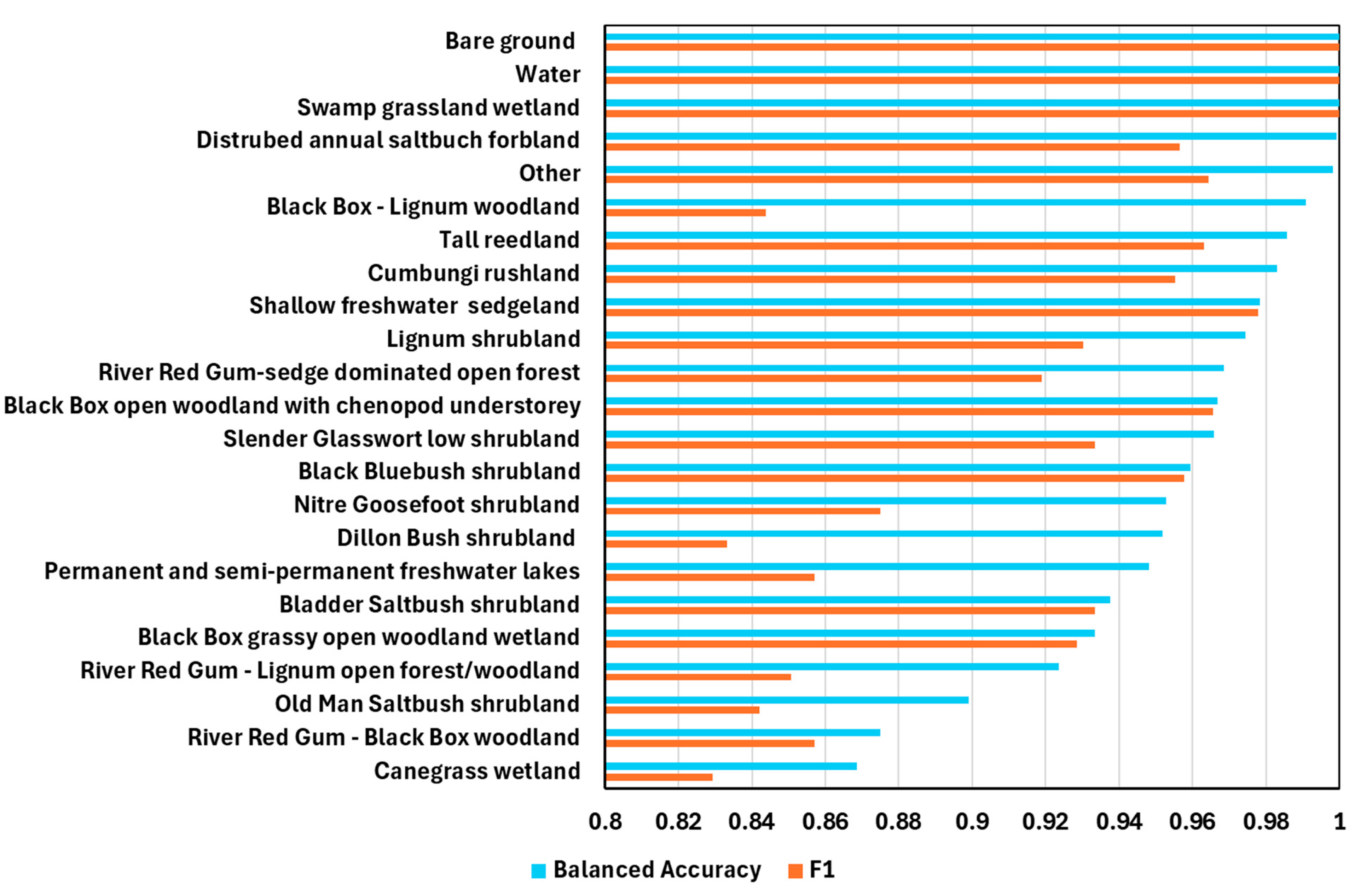
3.1.4. Model Assessment for Plant Community Types (PCTs)
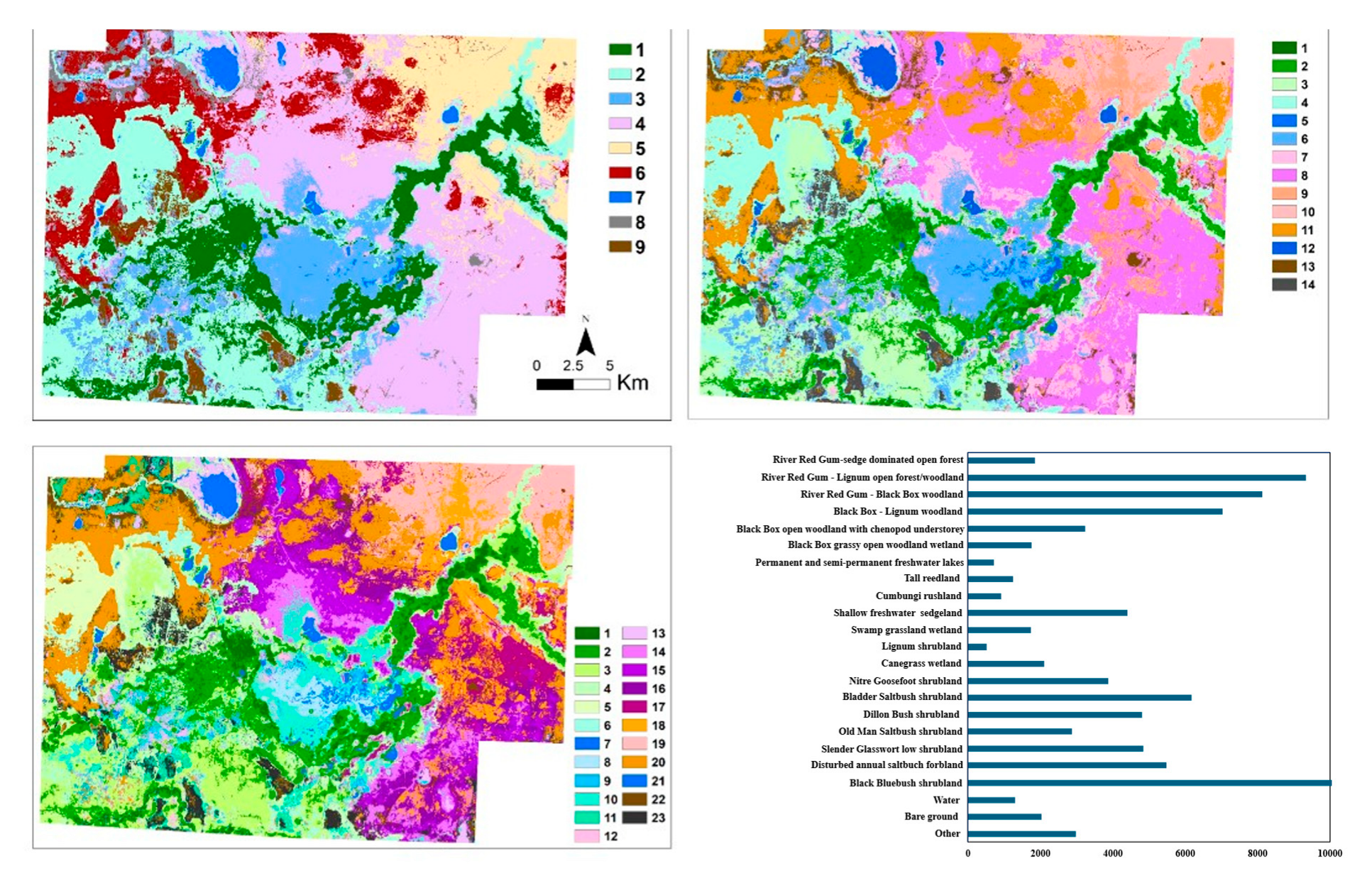
3.2. Vegetation Maps
4. Discussion
4.1. Performance in the Context of Recent Studies
4.2. Advantages of the Sequential Clustering–Labeling–Classification Approach
4.2.1. Refining Training Data Quality
4.2.2. Reducing Intra-Class Variability and Spectral Noise
4.2.3. Improving Delineation of Vegetation Boundaries
4.3. Implications and Transferability
4.4. Future Directions in Wetland Vegetation Classification
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kingsford, R.T.; Basset, A.; Jackson, L. Wetlands: Conservation’s poor cousins. Aquat. Conserv. Mar. Freshw. Ecosyst. 2016, 26, 892–916. [Google Scholar] [CrossRef]
- Junk, W.J.; An, S.; Finlayson, C.M.; Gopal, B.; Květ, J.; Mitchell, S.A.; Mitsch, W.J.; Robarts, R.D. Current state of knowledge regarding the world’s wetlands and their future under global climate change: A synthesis. Aquat. Sci. 2013, 75, 151–167. [Google Scholar] [CrossRef]
- Bhowmik, S. Ecological and economic importance of wetlands and their vulnerability: A review. In Research Anthology on Ecosystem Conservation and Preserving Biodiversity; IGI Publication: Hershey, PA, USA, 2022; pp. 11–27. [Google Scholar]
- Dar, S.A.; Bhat, S.U.; Rashid, I.; Dar, S.A. Current status of wetlands in Srinagar City: Threats, management strategies, and future perspectives. Front. Environ. Sci. 2020, 7, 199. [Google Scholar] [CrossRef]
- Newton, A.; Icely, J.; Cristina, S.; Perillo, G.M.; Turner, R.E.; Ashan, D.; Cragg, S.; Luo, Y.; Tu, C.; Li, Y.; et al. Anthropogenic, direct pressures on coastal wetlands. Front. Ecol. Evol. 2020, 8, 144. [Google Scholar] [CrossRef]
- Doody, T.M.; McInerney, P.J.; Thoms, M.C.; Gao, S. Resilience and adaptive cycles in water-dependent ecosystems: Can panarchy explain trajectories of change among floodplain trees? In Resilience and Riverine Landscapes; Elsevier: Amsterdam, The Netherlands, 2024; pp. 97–115. [Google Scholar]
- Keddy, P.A.; Fraser, L.H.; Solomeshch, A.I.; Junk, W.J.; Campbell, D.R.; Arroyo, M.T.; Alho, C.J. Wet and wonderful: The world’s largest wetlands are conservation priorities. BioScience 2009, 59, 39–51. [Google Scholar] [CrossRef]
- Thamaga, K.H.; Dube, T.; Shoko, C. Advances in satellite remote sensing of the wetland ecosystems in Sub-Saharan Africa. Geocarto Int. 2022, 37, 5891–5913. [Google Scholar] [CrossRef]
- Sun, W.; Chen, D.; Li, Z.; Li, S.; Cheng, S.; Niu, X.; Cai, Y.; Shi, Z.; Wu, C.; Yang, G.; et al. Monitoring wetland plant diversity from space: Progress and perspective. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103943. [Google Scholar] [CrossRef]
- Jones, H.G.; Vaughan, R.A. Remote Sensing of Vegetation: Principles, Techniques, and Applications; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Wang, Y.; Gong, Z.; Zhou, H. Long-term monitoring and phenological analysis of submerged aquatic vegetation in a shallow lake using time-series imagery. Ecol. Indic. 2023, 154, 110646. [Google Scholar] [CrossRef]
- McCarthy, M.J.; Radabaugh, K.R.; Moyer, R.P.; Muller-Karger, F.E. Enabling efficient, large-scale high-spatial resolution wetland mapping using satellites. Remote Sens. Environ. 2018, 208, 189–201. [Google Scholar] [CrossRef]
- Mansaray, A.S.; Dzialowski, A.R.; Martin, M.E.; Wagner, K.L.; Gholizadeh, H.; Stoodley, S.H. Comparing PlanetScope to Landsat-8 and Sentinel-2 for sensing water quality in reservoirs in agricultural watersheds. Remote Sens. 2021, 13, 1847. [Google Scholar] [CrossRef]
- Pan, B.; Xiao, X.; Luo, S.; Pan, L.; Yao, Y.; Zhang, C.; Meng, C.; Qin, Y. Identify and track white flower and leaf phenology of deciduous broadleaf trees in spring with time series PlanetScope images. ISPRS J. Photogramm. Remote Sens. 2025, 226, 127–145. [Google Scholar] [CrossRef]
- Lamb, B.T.; Tzortziou, M.A.; McDonald, K.C. Evaluation of approaches for mapping tidal wetlands of the Chesapeake and Delaware Bays. Remote Sens. 2019, 11, 2366. [Google Scholar] [CrossRef]
- Niculescu, S.; Boissonnat, J.B.; Lardeux, C.; Roberts, D.; Hanganu, J.; Billey, A.; Constantinescu, A.; Doroftei, M. Synergy of high-resolution radar and optical images satellite for identification and mapping of wetland macrophytes on the Danube Delta. Remote Sens. 2020, 12, 2188. [Google Scholar] [CrossRef]
- Hubert-Moy, L.; Fabre, E.; Rapinel, S. Contribution of SPOT-7 multi-temporal imagery for mapping wetland vegetation. Eur. J. Remote Sens. 2020, 53, 201–210. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Gill, L.; Regan, S.; Naughton, O.; Johnston, P.; Waldren, S.; Ghosh, B. Mapping vegetation communities inside wetlands using sentinel-2 imagery in Ireland. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102083. [Google Scholar] [CrossRef]
- Wen, L.; Hughes, M. Coastal wetland mapping using ensemble learning algorithms: A comparative study of bagging, boosting and stacking techniques. Remote Sens. 2020, 12, 1683. [Google Scholar] [CrossRef]
- Mutanga, O.; Adam, E.; Cho, M.A. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Lane, C.; Liu, H.; Autrey, B.; Anenkhonov, O.; Chepinoga, V.; Wu, Q. Improved Wetland Classification Using Eight-Band High Resolution Satellite Imagery and a Hybrid Approach. Remote Sens. 2014, 6, 12187–12216. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Zhu, X. Semi-Supervised Learning Literature Survey. In Computer Sciences Technical Report 1530; University of Wisconsin-Madison: Madison, WI, USA, 2005. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-Supervised Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Dronova, I.; Gong, P.; Wang, L. Object-based analysis and change detection of major wetland cover types and their classification uncertainty during the low water period at Poyang Lake, China. Remote Sens. Environ. 2011, 115, 3220–3236. [Google Scholar] [CrossRef]
- Viana, C.M.; Girão, I.; Rocha, J. Long-term satellite image time-series for land use/land cover change detection using refined open source data in a rural region. Remote Sens. 2019, 11, 1104. [Google Scholar] [CrossRef]
- Higgisson, W.; Cobb, A.; Tschierschke, A.; Dyer, F. The role of environmental water and reedbed condition on the response of Phragmites australis reedbeds to flooding. Remote Sens. 2022, 14, 1868. [Google Scholar] [CrossRef]
- Dyer, F.; Broadhurst, B.; Tschierschke, A.; Higgisson, W.; Allan, H.; Thiem, J.; Wright, D.; Thompson, R. Commonwealth Environmental Water Office Long Term Intervention Monitoring Project: Lachlan River System Selected Area 2018-19 Monitoring and Evaluation Summary Report; Commonwealth Environmental Water Holder: Canberra, Australia, 2019. [Google Scholar]
- DEECCW. Plan to Protect the Great Cumbung Swamp. 2023. Available online: https://www.dcceew.gov.au/cewh/resources-media/news/plan-to-protect-the-great-cumbung-swamp (accessed on 12 February 2025).
- Pfitzner, K.; Bartolo, R.; Whiteside, T.; Loewensteiner, D.; Esparon, A. Multi-temporal spectral reflectance of tropical savanna understorey species and implications for hyperspectral remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102870. [Google Scholar] [CrossRef]
- Chen, Y.; Cao, R.; Chen, J.; Liu, L.; Matsushita, B. A practical approach to reconstruct high-quality Landsat NDVI time-series data by gap filling and the Savitzky–Golay filter. ISPRS J. Photogramm. Remote Sens. 2021, 180, 174–190. [Google Scholar] [CrossRef]
- Liu, X.; Zhai, H.; Shen, Y.; Lou, B.; Jiang, C.; Li, T.; Hussain, S.B.; Shen, G. Large-scale crop mapping from multisource remote sensing images in google earth engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 414–427. [Google Scholar] [CrossRef]
- Montero, D.; Aybar, C.; Mahecha, M.D.; Martinuzzi, F.; Söchting, M.; Wieneke, S. A standardized catalogue of spectral indices to advance the use of remote sensing in Earth system research. Sci. Data 2023, 10, 197. [Google Scholar] [CrossRef]
- Geoscience Australia. Digital Elevation Model (DEM) of Australia Derived from LiDAR 5 Metre Grid; Geoscience Australia: Canberra, Australia, 2015.
- Pedersen, E.J.; Miller, D.L.; Simpson, G.L.; Ross, N. Hierarchical generalized additive models in ecology: An introduction with mgcv. PeerJ 2019, 7, e6876. [Google Scholar] [CrossRef]
- Gallant, J.C.; Dowling, T.I.; Read, A.M.; Wilson, N.; Tickle, P.K.; Inskeep, C. 1 Second SRTM-Derived Digital Elevation Models User Guide. Geoscience Australia. 2011. Available online: www.ga.gov.au/topographic-mapping/digital-elevation-data.html (accessed on 2 June 2025).
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Shrestha, N. Detecting multicollinearity in regression analysis. Am. J. Appl. Math. Stat. 2020, 8, 39–42. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; ISBN 3-900051-07-0. [Google Scholar]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 412–424. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Janssen, L.L.; Vanderwel, F.J. Accuracy assessment of satellite derived land-cover data: A review. Photogramm. Eng. Remote Sens. 1994, 60, 419–426. [Google Scholar]
- Liu, C.; Frazier, P.; Kumar, L. Comparative assessment of the measures of thematic classification accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Harbecke, D.; Chen, Y.; Hennig, L.; Alt, C. Why only micro-f1? class weighting of measures for relation classification. arXiv 2022, arXiv:2205.09460. [Google Scholar]
- Chicco, D.; Tötsch, N.; Jurman, G. The Matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min. 2021, 14, 13. [Google Scholar] [CrossRef]
- Yan, Y. MLmetrics: Machine Learning Evaluation Metrics; R Package Version 1.1.1; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Böge, M.; Bulatov, D.; Debroize, D.; Häufel, G.; Lucks, L. Efficient training data generation by clustering-based classification. ISPRS Annals of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2022, 3, 179–186. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 data for land cover/use mapping: A review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Dronova, I.; Gong, P.; Wang, L.; Zhong, L. Mapping dynamic cover types in a large seasonally flooded wetland using extended principal component analysis and object-based classification. Remote Sens. Environ. 2015, 158, 193–206. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Incorporating DeepLabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images. Int. J. Digit. Earth 2021, 14, 357–378. [Google Scholar] [CrossRef]
- Gonçalves, J.; Pôças, I.; Marcos, B.; Mücher, C.A.; Honrado, J.P. SegOptim—A new R package for optimizing object-based image analyses of high-spatial resolution remotely-sensed data. Int. J. Appl. Earth Obs. Geoinf. 2019, 76, 218–230. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Li, X.; Tian, J.; Li, X.; Yu, Y.; Ou, Y.; Zhu, L.; Zhu, X.; Zhou, B.; Gong, H. Annual mapping of Spartina alterniflora with deep learning and spectral-phenological features from 2017 to 2021 in the mainland of China. Int. J. Remote Sens. 2024, 45, 3172–3199. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Sakamoto, T.; Yokozawa, M.; Toritani, H.; Shibayama, M.; Ishitsuka, N.; Ohno, H. A crop phenology detection method using time-series MODIS data. Remote Sens. Environ. 2005, 96, 366–374. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.; Tong, K.; Chen, H.; Yuan, Y. Review of visual simultaneous localization and mapping based on deep learning. Remote Sens. 2023, 15, 2740. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, W.; Wang, H.; Zhang, X.; Yang, C.; Liu, H. Identification of soil texture classes under vegetation cover based on Sentinel-2 data with SVM and SHAP techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 3758–3770. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30, Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December2017; Curran Associates Inc.: Red Hook, NY, USA, 2018. [Google Scholar]
- Fu, B.; Deng, L.; Sun, W.; He, H.; Li, H.; Wang, Y.; Wang, Y. Quantifying vegetation species functional traits along hydrologic gradients in karst wetland based on 3D mapping with UAV hyperspectral point cloud. Remote Sens. Environ. 2024, 307, 114160. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Map ID | Formation | Map ID | Functional Group | Map ID | Plant Community Type | No of Samples |
|---|---|---|---|---|---|---|
| 1 | Riverine Forest | 1 | Riverine Forest | 1 | River Red Gum—sedge open forest | 120 |
| 2 | Riverine Forest/Woodland | 2 | River Red Gum—Lignum open forest/woodland | 80 | ||
| 2 | Riverine Woodland | 3 | Riverine Woodland | 3 | River Red Gum—Black Box woodland | 145 |
| 3 | Floodplain Woodland | 4 | Black Box—Lignum woodland | 90 | ||
| 5 | Black Box—chenopod open woodland | 103 | ||||
| 6 | Black Box grassy open woodland | 52 | ||||
| 3 | Grassy Wetland | 5 | (Semi-)permanent Shallow Water | 7 | (Semi-) permanent freshwater lake | 71 |
| 6 | Grassy Wetland | 8 | Tall reedland | 53 | ||
| 9 | Cumbung rushland | 79 | ||||
| 10 | Shallow sedgeland | 50 | ||||
| 11 | Swamp grassland wetland | 155 | ||||
| 4 | Floodplain Shrubland | 7 | Floodplain Shrubland | 12 | Lignum shrubland | 124 |
| 13 | Canegrass wetland | 80 | ||||
| 14 | Nitre Goosefoot shrubland | 34 | ||||
| 8 | Riverine Chenopod Shrubland | 15 | Bladder Saltbush shrubland | 78 | ||
| 16 | Dillon Bush shrubland | 38 | ||||
| 17 | Old Man Saltbush shrubland | 37 | ||||
| 5 | Saline Wetland | 9 | Saline Wetland | 18 | Slender Glasswort low shrubland | 135 |
| 10 | Saline Lake | 19 | Disturbed annual saltbush forbland | 113 | ||
| 6 | Aeolian Shrubland | 11 | Aeolian Shrubland | 20 | Black Bluebush shrubland | 34 |
| 7 | Open Water | 12 | Open Water | 21 | Open water | 110 |
| 8 | Bare Ground | 13 | Bare Ground | 22 | Bare ground | 49 |
| 9 | Other * | 14 | Other | 23 | Other | 92 |
| Metric | Full_Model | S1S2_Model | S2_Model | Topo_Model | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L1 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L3 | |
| Overall Accuracy | 0.97 | 0.94 | 0.93 | 0.94 | 0.92 | 0.90 | 0.94 | 0.91 | 0.89 | 0.57 | 0.50 | 0.53 |
| Cohen’s Kappa | 0.96 | 0.93 | 0.92 | 0.93 | 0.91 | 0.89 | 0.93 | 0.89 | 0.88 | 0.50 | 0.44 | 0.51 |
| Macro F1 Score | 0.97 | 0.92 | 0.92 | 0.94 | 0.90 | 0.89 | 0.93 | 0.88 | 0.88 | 0.53 | 0.47 | 0.53 |
| Weighted F1 Score | 0.97 | 0.93 | 0.93 | 0.94 | 0.92 | 0.90 | 0.94 | 0.91 | 0.89 | 0.57 | 0.50 | 0.54 |
| Multiclass MCC | 0.96 | 0.93 | 0.92 | 0.93 | 0.91 | 0.89 | 0.93 | 0.90 | 0.88 | 0.50 | 0.44 | 0.51 |
| Levels | Pairs | Overall Accuracy | Kappa | Weigted F1 | MCC | ||||
|---|---|---|---|---|---|---|---|---|---|
| Difference | p_Value | Difference | p_Value | Difference | p_Value | Difference | p_Value | ||
| L1 | M1~M2 | 0.010 | 0.011 | 0.012 | 0.012 | 0.010 | 0.012 | 0.012 | 0.013 |
| M1~M3 | 0.015 | 0.001 | 0.018 | 0.001 | 0.015 | 0.001 | 0.017 | 0.001 | |
| M1~M4 | 0.400 | 0.000 | 0.468 | 0.000 | 0.399 | 0.000 | 0.465 | 0.000 | |
| M2~M3 | 0.005 | 0.240 | 0.006 | 0.244 | 0.005 | 0.235 | 0.005 | 0.258 | |
| M2~M4 | 0.389 | 0.000 | 0.456 | 0.000 | 0.389 | 0.000 | 0.453 | 0.000 | |
| M3~M4 | 0.385 | 0.000 | 0.450 | 0.000 | 0.384 | 0.000 | 0.448 | 0.000 | |
| L2 | M1~M2 | 0.013 | 0.039 | 0.015 | 0.037 | 0.013 | 0.034 | 0.015 | 0.038 |
| M1~M3 | 0.018 | 0.010 | 0.020 | 0.009 | 0.017 | 0.012 | 0.020 | 0.010 | |
| M1~M4 | 0.410 | 0.000 | 0.458 | 0.000 | 0.408 | 0.000 | 0.455 | 0.000 | |
| M2~M3 | 0.004 | 0.521 | 0.005 | 0.523 | 0.004 | 0.533 | 0.005 | 0.537 | |
| M2~M4 | 0.397 | 0.000 | 0.443 | 0.000 | 0.395 | 0.000 | 0.440 | 0.000 | |
| M3~M4 | 0.393 | 0.000 | 0.438 | 0.000 | 0.391 | 0.000 | 0.436 | 0.000 | |
| L3 | M1~M2 | 0.020 | 0.002 | 0.021 | 0.002 | 0.021 | 0.001 | 0.021 | 0.002 |
| M1~M3 | 0.026 | 0.001 | 0.027 | 0.001 | 0.027 | 0.001 | 0.027 | 0.001 | |
| M1~M4 | 0.381 | 0.000 | 0.399 | 0.000 | 0.396 | 0.000 | 0.397 | 0.000 | |
| M2~M3 | 0.005 | 0.429 | 0.006 | 0.436 | 0.005 | 0.453 | 0.006 | 0.437 | |
| M2~M4 | 0.361 | 0.000 | 0.378 | 0.000 | 0.374 | 0.000 | 0.375 | 0.000 | |
| M3~M4 | 0.356 | 0.000 | 0.372 | 0.000 | 0.369 | 0.000 | 0.370 | 0.000 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, L.; Ryan, S.; Powell, M.; Ling, J.E. From Clusters to Communities: Enhancing Wetland Vegetation Mapping Using Unsupervised and Supervised Synergy. Remote Sens. 2025, 17, 2279. https://doi.org/10.3390/rs17132279
Wen L, Ryan S, Powell M, Ling JE. From Clusters to Communities: Enhancing Wetland Vegetation Mapping Using Unsupervised and Supervised Synergy. Remote Sensing. 2025; 17(13):2279. https://doi.org/10.3390/rs17132279
Chicago/Turabian StyleWen, Li, Shawn Ryan, Megan Powell, and Joanne E. Ling. 2025. "From Clusters to Communities: Enhancing Wetland Vegetation Mapping Using Unsupervised and Supervised Synergy" Remote Sensing 17, no. 13: 2279. https://doi.org/10.3390/rs17132279
APA StyleWen, L., Ryan, S., Powell, M., & Ling, J. E. (2025). From Clusters to Communities: Enhancing Wetland Vegetation Mapping Using Unsupervised and Supervised Synergy. Remote Sensing, 17(13), 2279. https://doi.org/10.3390/rs17132279