
UCrack-DA: A Multi-Scale Unsupervised Domain Adaptation Method for Surface Crack Segmentation


Abstract

1. Introduction
- Design a hierarchical adversarial mechanism to extract domain-invariant features of different scales, combined with a prediction entropy minimization mechanism to sharpen decision boundaries, which improves the model’s domain adaptation capability for crack segmentation tasks in various scenes.
- To enhance the model’s ability to capture features of cracks at different scales and morphologies, we design a U-shaped crack semantic segmentation network. It extracts multi-scale receptive field features through stacking dilated convolutions with multiple dilation rates and optimizes the reconstruction of multi-morphological crack structures in the upsampling stage by combining mixed convolutional kernels.
- Construct a UAV ground surface crack dataset, containing a variety of complex factors in real-world scenes, which verifies the applicability of the proposed method on UAV images and provides important data support for the research on ground surface crack segmentation.
2. Related Work
2.1. Crack Semantic Segmentation
2.2. Unsupervised Domain Adaptation
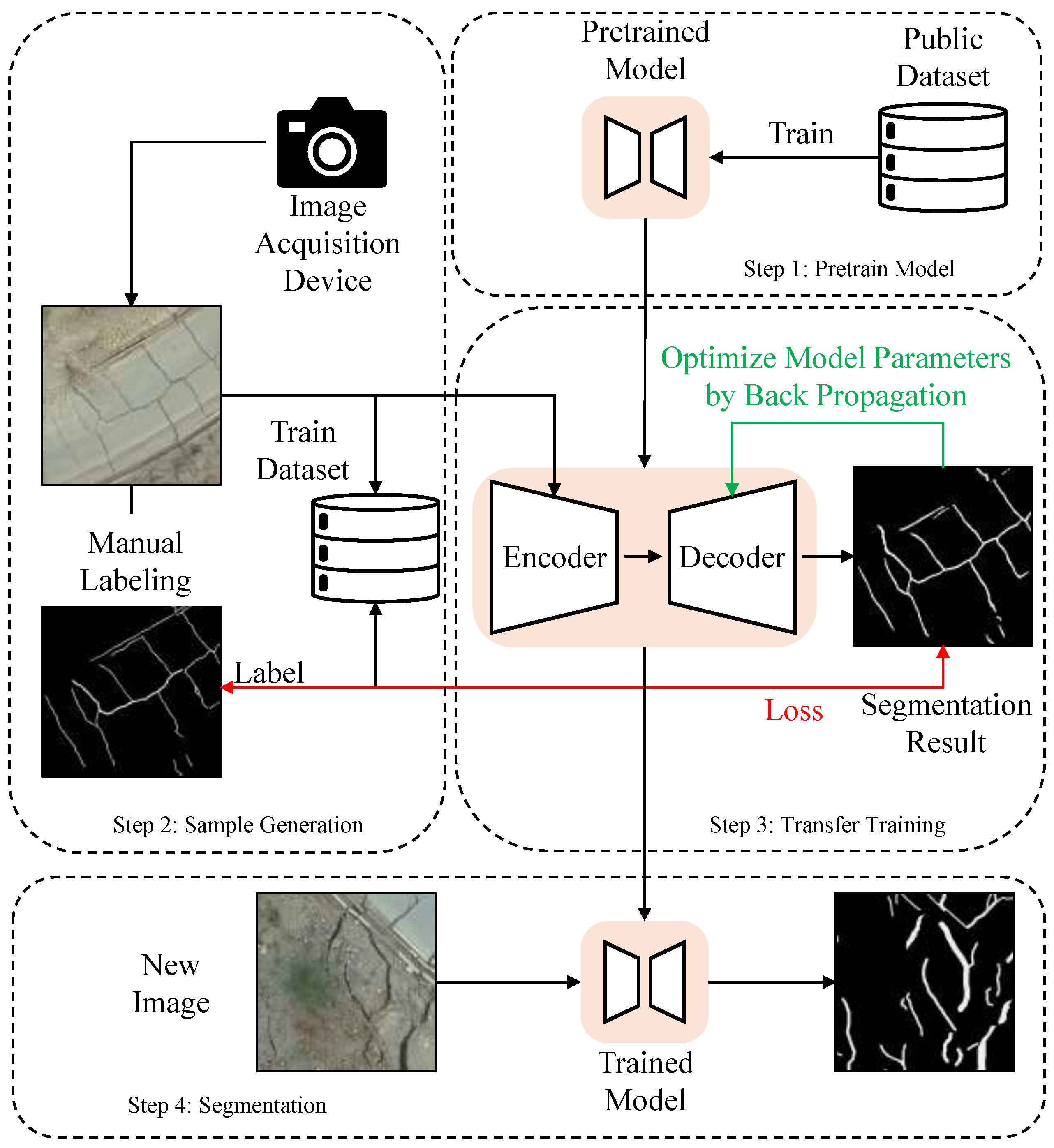
3. Method
3.1. Overview
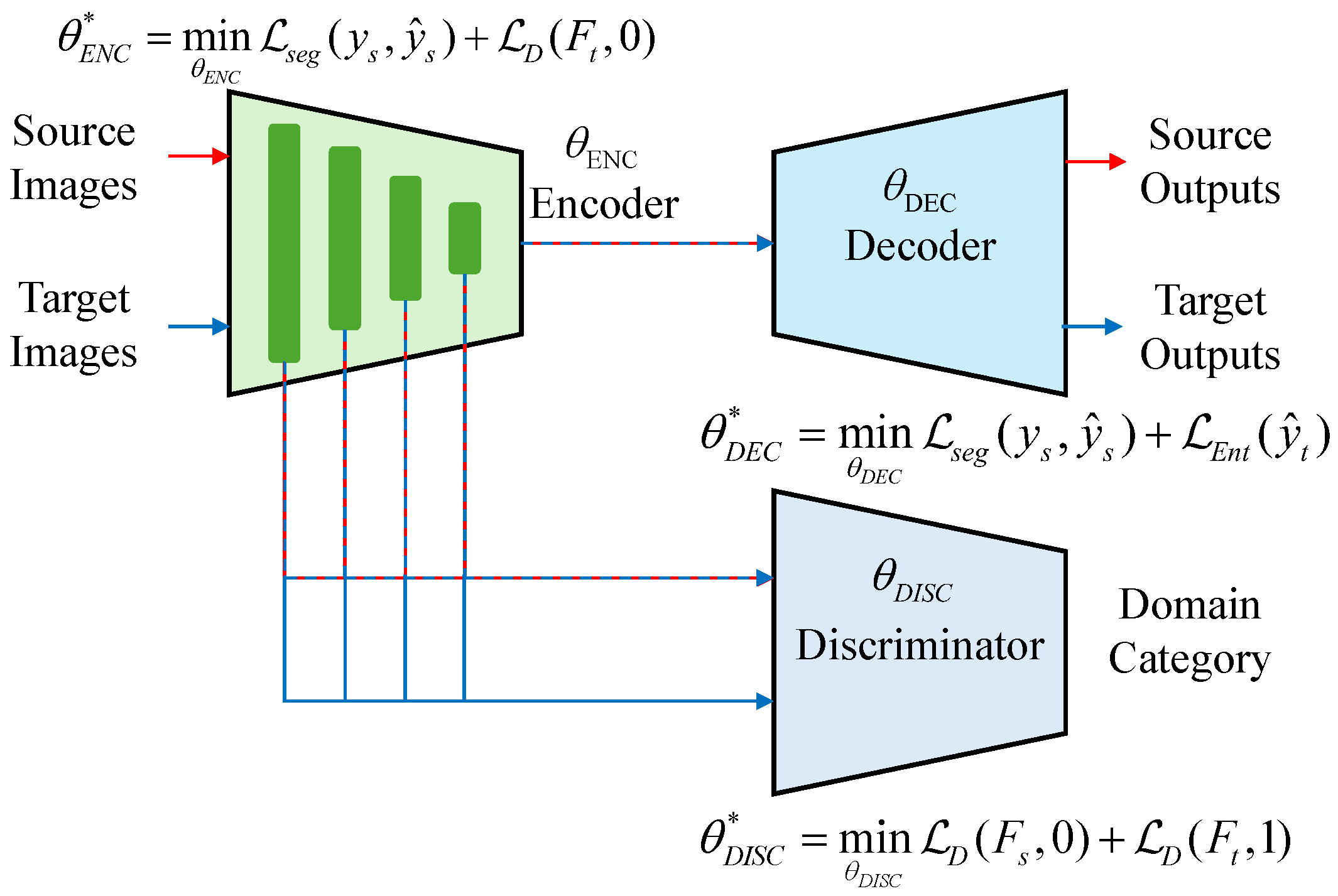
3.2. Proposed Unsupervised Domain Adaptation Method
3.2.1. Hierarchical Adversarial Training
3.2.2. Prediction Entropy Minimization
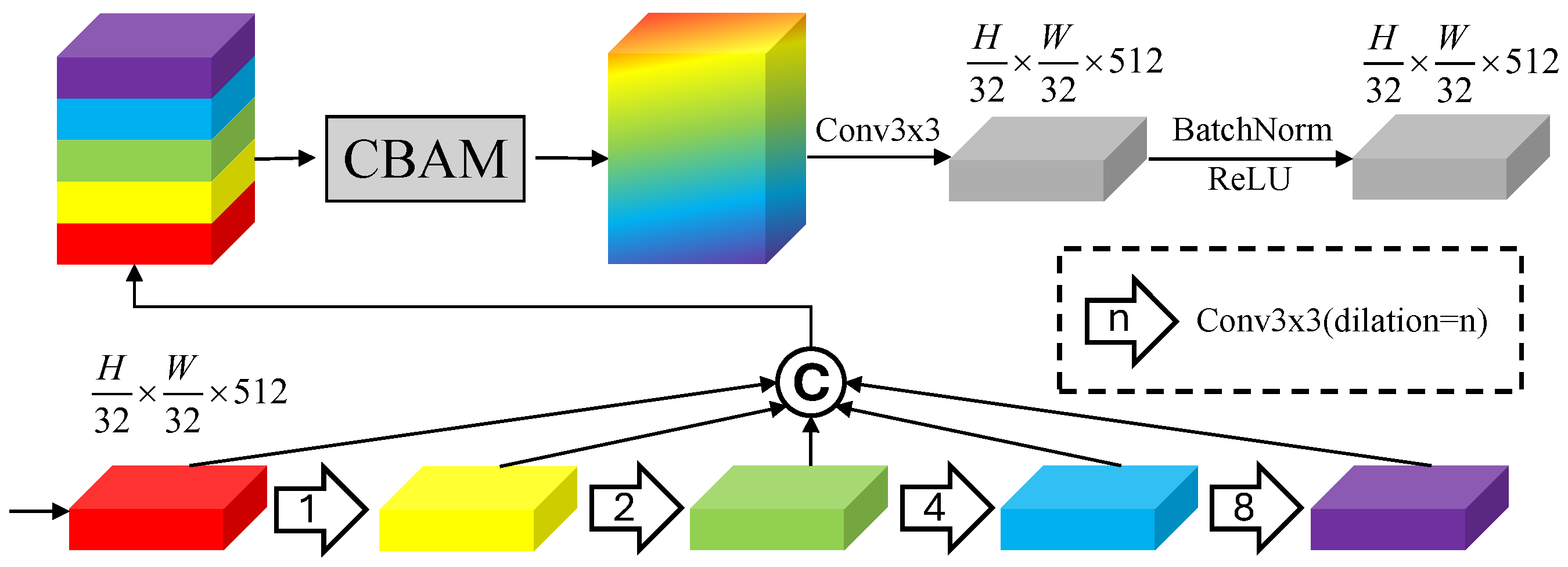
3.3. Multi-Scale Dilated Attention Module
3.4. Mixed Convolutional Attention Module
4. Experimental Results and Analysis
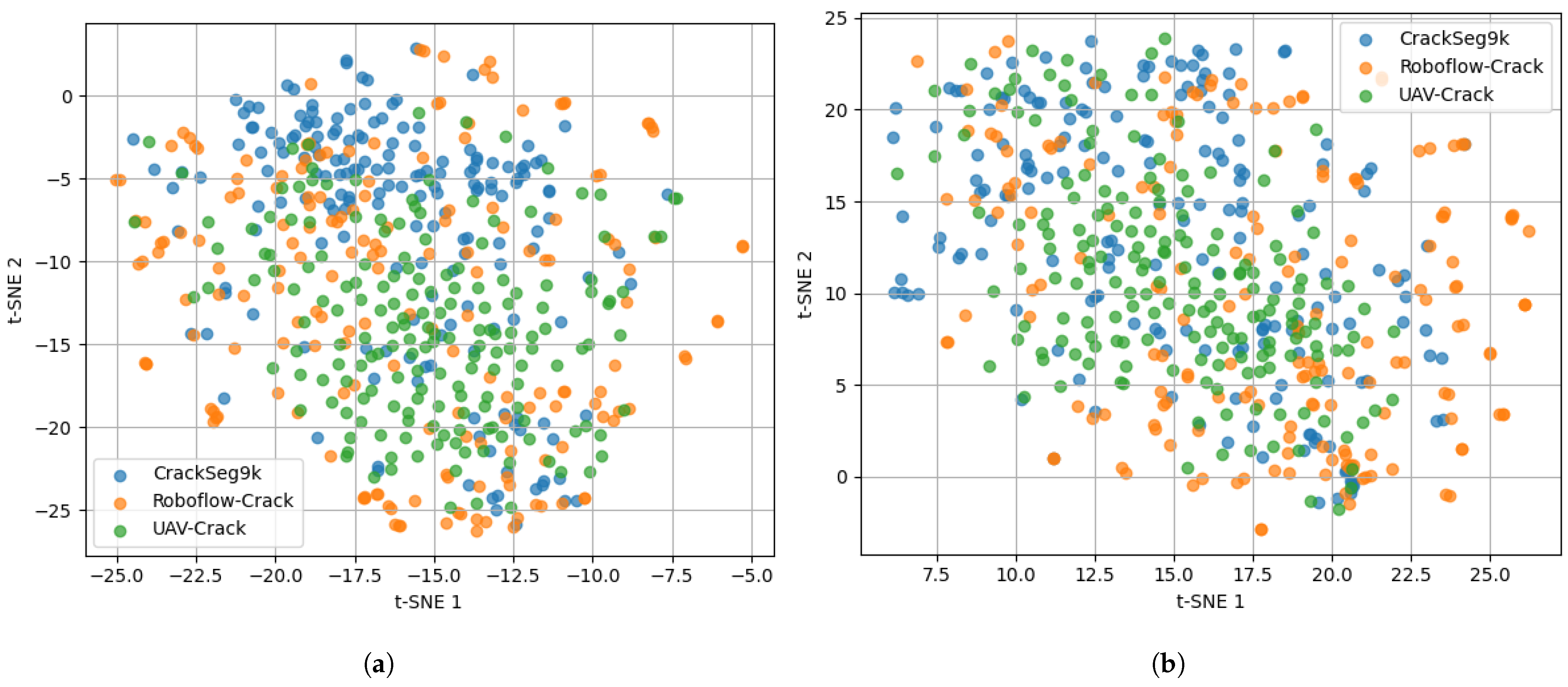
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Ablation Study
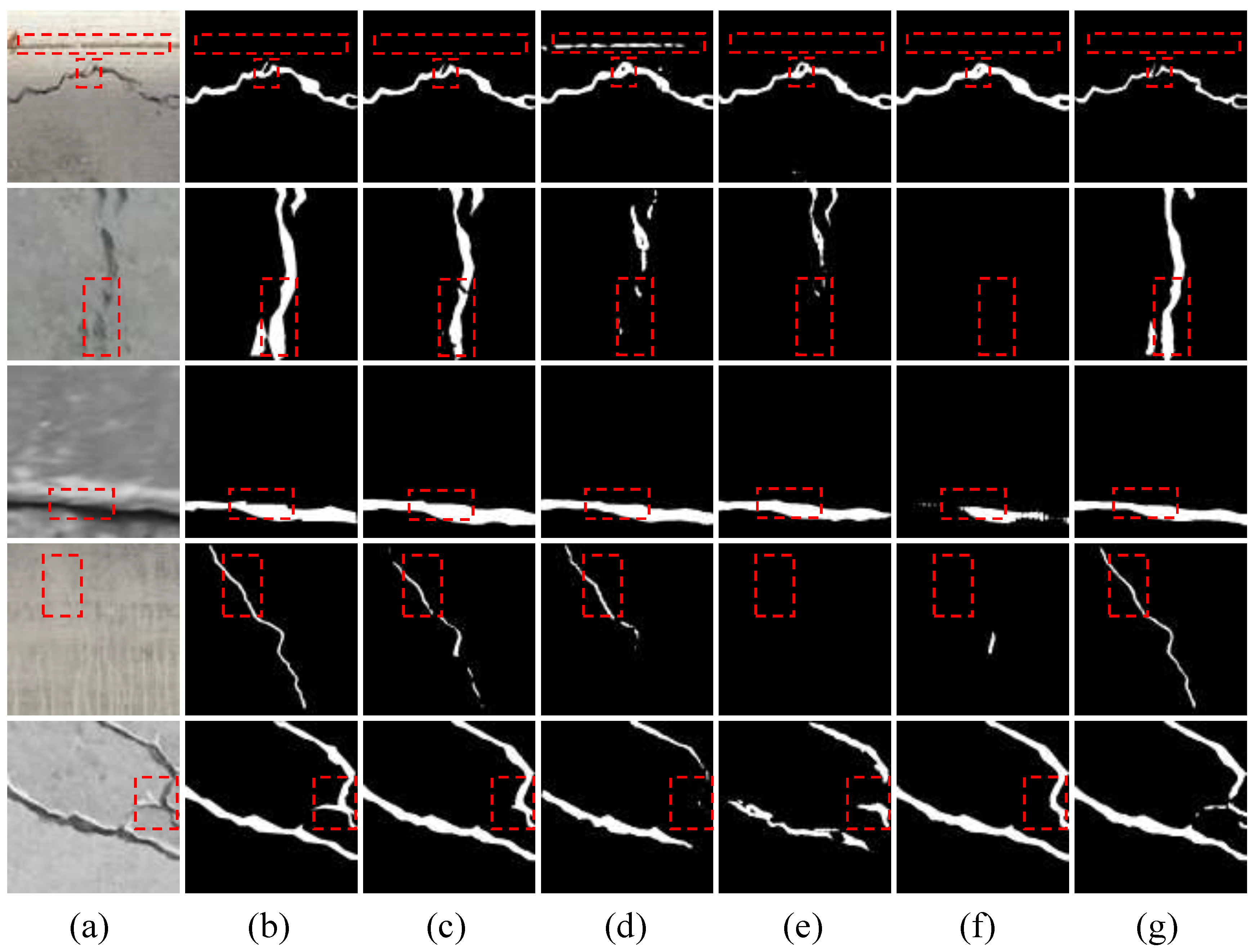
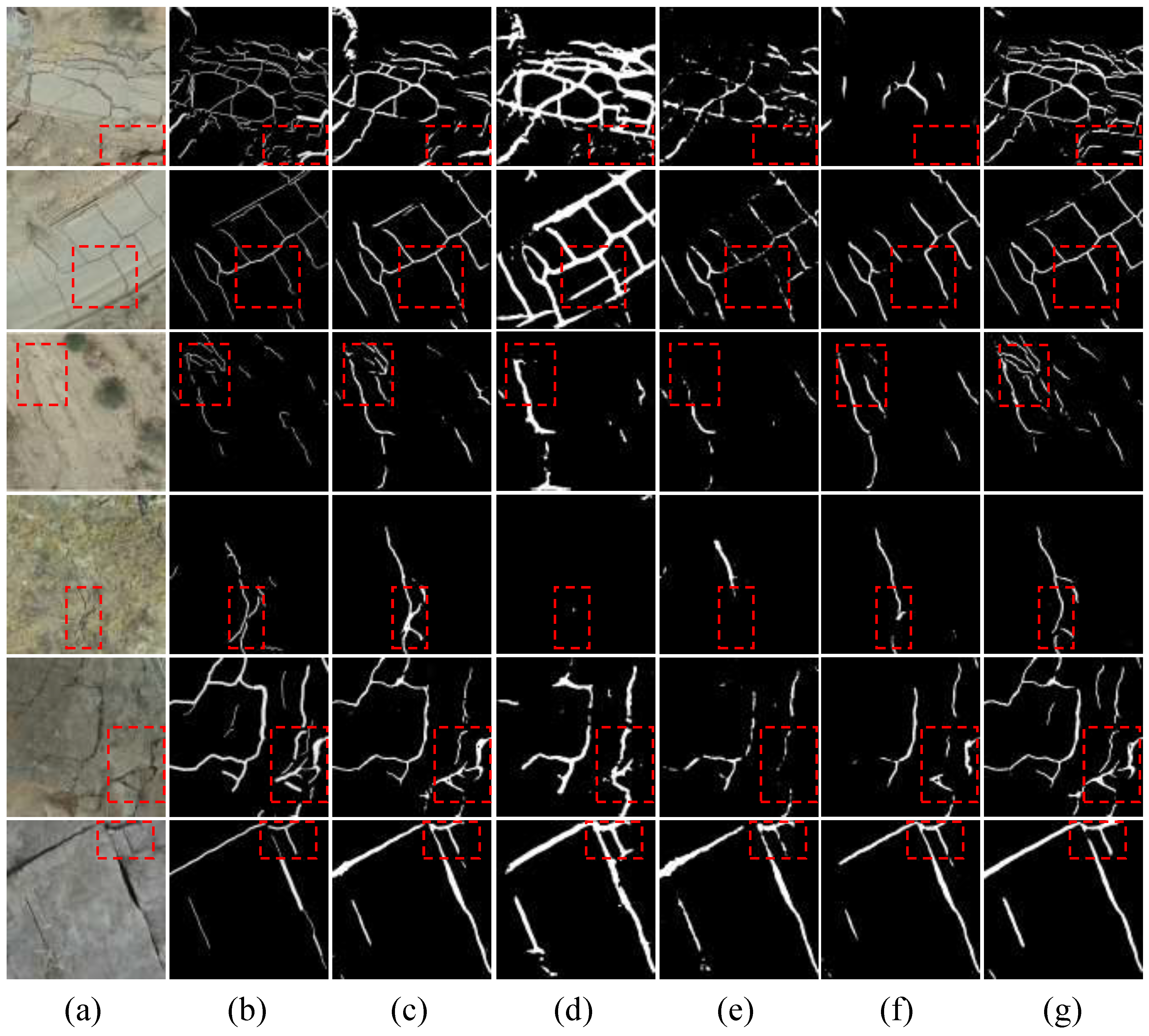
4.5. Comparison with Other Methods
4.5.1. Crackseg9K→Roboflow-Crack
4.5.2. Crackseg9K→UAV-Crack
4.5.3. Comprehensive Analysis
4.6. Efficiency Analysis
5. Discussion
5.1. Limitations
5.2. Future Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| UAV | unmanned aerial vehicle |
| CNN | Convolutional Neural Network |
| DA | domain adaptation |
| UDA | unsupervised domain adaptation |
| ENC | encoder |
| DEC | decoder |
| DISC | discriminator |
| MSDAM | Multi-Scale Dilated Attention Module |
| MCAM | Mixed Convolutional Attention Module |
| MLP | Multi-layer Perceptron |
| WBCE | Weighted Binary Cross-Entropy |
| CBAM | Convolutional Block Attention Module |
| t-SNE | t-distributed Stochastic Neighbor Embedding |
| LR | learning rate |
| mIoU | mean Intersection over Union |
| mPA | mean Pixel Accuracy |
| MMD | Maximum Mean Discrepancy |
| M | million |
| GFLOPs | Giga Floating Point Operations per Second |
References
- Lian, X.; Li, Z.; Yuan, H.; Liu, J.; Zhang, Y.; Liu, X.; Wu, Y. Rapid identification of landslide, collapse and crack based on low-altitude remote sensing image of UAV. J. Mt. Sci. 2020, 17, 2915–2928. [Google Scholar] [CrossRef]
- Colica, E.; D’Amico, S.; Iannucci, R.; Martino, S.; Gauci, A.; Galone, L.; Galea, P.; Paciello, A. Using unmanned aerial vehicle photogrammetry for digital geological surveys: Case study of Selmun promontory, northern of Malta. Environ. Earth Sci. 2021, 80, 551. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1525–1535. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-net: A novel deep convolutional neural network for pixelwise pavement crack detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. Multi-level feature fusion in densely connected deep-learning architecture and depth-first search for crack segmentation on images collected with smartphones. Struct. Health Monit. 2020, 19, 1726–1744. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar] [CrossRef]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. Crackformer: Transformer network for fine-grained crack detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3783–3792. [Google Scholar] [CrossRef]
- Taha, H.; El-Habrouk, H.; Bekheet, W.; El-Naghi, S.; Torki, M. Pixel-level pavement crack segmentation using UAV remote sensing images based on the ConvNeXt-UPerNet. Alex. Eng. J. 2025, 124, 147–169. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified perceptual parsing for scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar] [CrossRef]
- Liu, H.; Jia, C.; Shi, F.; Cheng, X.; Chen, S. SCSegamba: Lightweight structure-aware vision mamba for crack segmentation in structures. In Proceedings of the Computer Vision and Pattern Recognition Conference, Nashville, TN, USA, 11–15 June 2025; pp. 29406–29416. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 4–6 October 2023; pp. 4015–4026. [Google Scholar] [CrossRef]
- Huang, H.; Wu, Z.; Shen, H. A three-stage detection algorithm for automatic crack-width identification of fine concrete cracks. J. Civ. Struct. Health Monit. 2024, 14, 1373–1382. [Google Scholar] [CrossRef]
- Joshi, D.; Singh, T.P.; Sharma, G. Automatic surface crack detection using segmentation-based deep-learning approach. Eng. Fract. Mech. 2022, 268, 108467. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Dang, L.M.; Lee, S.; Moon, H. Pixel-level tunnel crack segmentation using a weakly supervised annotation approach. Comput. Ind. 2021, 133, 103545. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef]
- Yu, F.; Wang, D.; Chen, Y.; Karianakis, N.; Shen, T.; Yu, P.; Lymberopoulos, D.; Lu, S.; Shi, W.; Chen, X. Unsupervised domain adaptation for object detection via cross-domain semi-supervised learning. arXiv 2019, arXiv:1911.07158. [Google Scholar] [CrossRef]
- Mahapatra, D.; Korevaar, S.; Bozorgtabar, B.; Tennakoon, R. Unsupervised domain adaptation using feature disentanglement and GCNs for medical image classification. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 735–748. [Google Scholar] [CrossRef]
- Wang, B.; Deng, F.; Wang, S.; Luo, W.; Zhang, Z.; Jiang, P. SiamSeg: Self-Training with Contrastive Learning for Unsupervised Domain Adaptation Semantic Segmentation in Remote Sensing. arXiv 2024, arXiv:2410.13471. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, H.; Yang, C.; Shi, J.; Lin, D. Penalizing top performers: Conservative loss for semantic segmentation adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 568–583. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar] [CrossRef]
- Wang, Z.; Luo, Y.; Huang, D.; Ge, N.; Lu, J. Category-adaptive domain adaptation for semantic segmentation. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3773–3777. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, R.; Li, C.; Ye, G.; Sun, H.; Deng, H. Esam: Discriminative domain adaptation with non-displayed items to improve long-tail performance. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 579–588. [Google Scholar] [CrossRef]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar] [CrossRef]
- Srivastava, K.; Kancharla, D.D.; Tahereen, R.; Ramancharla, P.K.; Sarvadevabhatla, R.K.; Kandath, H. CrackUDA: Incremental Unsupervised Domain Adaptation for Improved Crack Segmentation in Civil Structures. In Proceedings of the International Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2025; pp. 74–89. [Google Scholar] [CrossRef]
- Kulkarni, S.; Singh, S.; Balakrishnan, D.; Sharma, S.; Devunuri, S.; Korlapati, S.C.R. CrackSeg9k: A collection and benchmark for crack segmentation datasets and frameworks. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 179–195. [Google Scholar] [CrossRef]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 1379–1389. [Google Scholar] [CrossRef]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9924–9935. [Google Scholar] [CrossRef]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7472–7481. [Google Scholar] [CrossRef]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Shen, Y.; Fei, J.; Li, W.; Jin, G.; Wu, L.; Zhao, R.; Le, X. Semi-supervised semantic segmentation using unreliable pseudo-labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4248–4257. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 205–218. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Jähne, B. Digital Image Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations; Rumelhart, D.E., McClelland, J.L., Eds.; MIT Press: Cambridge, MA, USA, 1986; pp. 318–362. ISBN 0-262-68053-X. [Google Scholar]
- King, G.; Zeng, L. Logistic regression in rare events data. Political Anal. 2001, 9, 137–163. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Zhu, Y.; Wan, L.; Xu, W.; Wang, S. ASPP-DF-PVNet: Atrous spatial pyramid pooling and distance-filtered PVNet for occlusion resistant 6D object pose estimation. Signal Process. Image Commun. 2021, 95, 116268. [Google Scholar] [CrossRef]
- Hu, L.; Zhou, X.; Ruan, J.; Li, S. ASPP+-LANet: A Multi-Scale Context Extraction Network for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1036. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar] [CrossRef]
- Thesis. Crack Segmentation Dataset. 2024. Available online: https://universe.roboflow.com/thesis-bvx2g/crack-segmentation-mtjxf (accessed on 29 April 2025).
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; PMLR: New York, NY, USA, 2015; pp. 97–105. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Training Samples | Validation/Test Samples | Total |
|---|---|---|---|
| CrackSeg9K [35] | 7332 | 1827 | 9159 |
| Roboflow-Crack [56] | 748 | 138 | 886 |
| UAV-Crack | 150 | 45 | 195 |
| MSAdv | MinEnt | MSDAM | MCAM | Accuracy (%) | mPA (%) | mIoU (%) | |
|---|---|---|---|---|---|---|---|
| Remove | ✗ | ✓ | ✓ | ✓ | 96.55 | 68.28 | 63.27 |
| ✓ | ✗ | ✓ | ✓ | 96.39 | 70.31 | 64.80 | |
| ✓ | ✓ | ✗ | ✓ | 96.33 | 70.97 | 64.96 | |
| ✓ | ✓ | ✓ | ✗ | 96.58 | 69.66 | 64.16 | |
| ✗ | ✓ | ✗ | ✓ | 96.20 | 68.48 | 62.33 | |
| ✗ | ✓ | ✓ | ✗ | 95.68 | 68.14 | 60.74 | |
| ✓ | ✗ | ✗ | ✓ | 96.51 | 67.45 | 63.51 | |
| ✓ | ✗ | ✓ | ✗ | 96.43 | 68.75 | 64.05 | |
| UCrack-DA (Ours) | 96.31 | 71.76 | 65.33 | ||||
| Method | Accuracy (%) | mPA (%) | mIoU (%) |
|---|---|---|---|
| DACS [36] | 96.08 | 70.77 | 66.93 |
| DAFormer [37] | 96.61 | 75.04 | 71.19 |
| AdaptSegnet [38] | 97.07 | 77.06 | 71.69 |
| ADVENT [39] | 97.27 | 79.66 | 73.84 |
| CrackUDA [34] | 97.60 | 82.17 | 76.95 |
| UCrack-DA | 97.92 | 90.90 | 81.34 |
| Source Only | 96.81 | 76.79 | 69.54 |
| Oracle | 98.71 | 93.26 | 87.19 |
| Method | Accuracy (%) | mPA (%) | mIoU (%) |
|---|---|---|---|
| DACS [36] | 96.14 | 62.12 | 58.28 |
| DAFormer [37] | 95.58 | 68.11 | 60.49 |
| AdaptSegnet [38] | 95.82 | 66.77 | 61.13 |
| ADVENT [39] | 95.78 | 67.09 | 61.23 |
| CrackUDA [34] | 96.39 | 68.45 | 62.88 |
| UCrack-DA | 96.31 | 71.76 | 65.33 |
| Source Only | 96.21 | 63.18 | 59.15 |
| Oracle | 96.97 | 79.36 | 70.44 |
| Method | Params (M) | FLOPs (GFLOPs) | Inference Time (ms) |
|---|---|---|---|
| DACS [36] | 74.54 | 57.71 | 485.55 ± 9.68 |
| DAFormer [37] | 64.55 | 102.01 | 835.24 ± 10.8 |
| AdaptSegnet [38] | 74.54 | 57.71 | 489.88 ± 12.73 |
| ADVENT [39] | 74.54 | 57.71 | 486.35 ± 11.29 |
| CrackUDA [34] | 88.21 | 70.22 | 577.97 ± 9.35 |
| UCrack-DA (ours) | 97.64 | 73.36 | 652.13 ± 13.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, F.; Yang, S.; Wang, B.; Dong, X.; Tian, S. UCrack-DA: A Multi-Scale Unsupervised Domain Adaptation Method for Surface Crack Segmentation. Remote Sens. 2025, 17, 2101. https://doi.org/10.3390/rs17122101
Deng F, Yang S, Wang B, Dong X, Tian S. UCrack-DA: A Multi-Scale Unsupervised Domain Adaptation Method for Surface Crack Segmentation. Remote Sensing. 2025; 17(12):2101. https://doi.org/10.3390/rs17122101
Chicago/Turabian StyleDeng, Fei, Shaohui Yang, Bin Wang, Xiujun Dong, and Siyuan Tian. 2025. "UCrack-DA: A Multi-Scale Unsupervised Domain Adaptation Method for Surface Crack Segmentation" Remote Sensing 17, no. 12: 2101. https://doi.org/10.3390/rs17122101
APA StyleDeng, F., Yang, S., Wang, B., Dong, X., & Tian, S. (2025). UCrack-DA: A Multi-Scale Unsupervised Domain Adaptation Method for Surface Crack Segmentation. Remote Sensing, 17(12), 2101. https://doi.org/10.3390/rs17122101