



MTCDNet: Multimodal Feature Fusion-Based Tree Crown Detection Network Using UAV-Acquired Optical Imagery and LiDAR Data

Abstract
1. Introduction
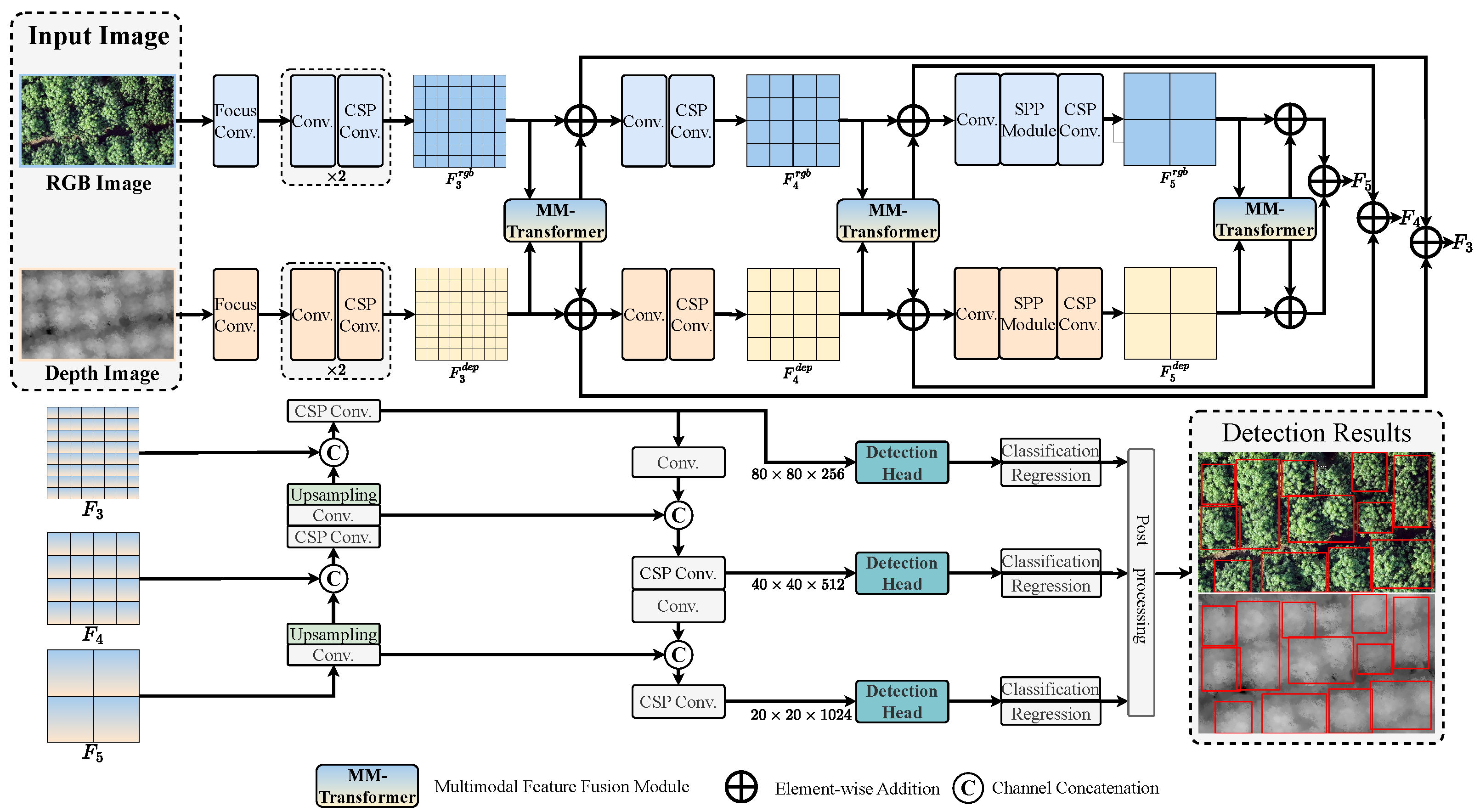
- This paper proposes an end-to-end crown detection network, MTCDNet, based on multimodal feature fusion. By integrating RGB images and CHM data, the model enhances detection performance in dense forest environments.
- We designed a Transformer-based cross-modal feature fusion module, which improves the interaction between heterogeneous features and enhances the representation of canopy structures.
- A learnable positional encoding scheme was introduced in the Transformer-based feature fusion framework, explicitly embedding spatial context to precisely locate densely distributed canopies.
- Extensive experiments conducted on two forest datasets show that the proposed method outperforms existing single-modal detection frameworks in evaluation metrics, validating the effectiveness of the multimodal feature fusion strategy.
2. Materials and Methods
2.1. Study Area and Dataset
2.2. Methods
2.2.1. MM-Transformer
2.2.2. Learnable Positional Encoding
2.2.3. Loss Function
3. Results and Discussion
3.1. Experiment Setting
3.1.1. Metrics
3.1.2. Comparative Experiments
3.2. Ablation Studies
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Zhen, Z.; Quackenbush, L.J.; Zhang, L. Trends in automatic individual tree crown detection and delineation—Evolution of LiDAR data. Remote Sens. 2016, 8, 333. [Google Scholar] [CrossRef]
- Hirschmugl, M.; Ofner, M.; Raggam, J.; Schardt, M. Single tree detection in very high resolution remote sensing data. Remote Sens. Environ. 2007, 110, 533–544. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Torresan, C.; Berton, A.; Carotenuto, F.; Di Gennaro, S.F.; Gioli, B.; Matese, A.; Miglietta, F.; Vagnoli, C.; Zaldei, A.; Wallace, L. Forestry applications of UAVs in Europe: A review. Int. J. Remote Sens. 2017, 38, 2427–2447. [Google Scholar] [CrossRef]
- Gan, Y.; Wang, Q.; Iio, A. Tree crown detection and delineation in a temperate deciduous forest from UAV RGB imagery using deep learning approaches: Effects of spatial resolution and species characteristics. Remote Sens. 2023, 15, 778. [Google Scholar] [CrossRef]
- Panagiotidis, D.; Abdollahnejad, A.; Surovỳ, P.; Chiteculo, V. Determining tree height and crown diameter from high-resolution UAV imagery. Int. J. Remote Sens. 2017, 38, 2392–2410. [Google Scholar] [CrossRef]
- Safonova, A.; Hamad, Y.; Dmitriev, E.; Georgiev, G.; Trenkin, V.; Georgieva, M.; Dimitrov, S.; Iliev, M. Individual tree crown delineation for the species classification and assessment of vital status of forest stands from UAV images. Drones 2021, 5, 77. [Google Scholar] [CrossRef]
- Osco, L.P.; Junior, J.M.; Ramos, A.P.M.; de Castro Jorge, L.A.; Fatholahi, S.N.; de Andrade Silva, J.; Matsubara, E.T.; Pistori, H.; Gonçalves, W.N.; Li, J. A review on deep learning in UAV remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102456. [Google Scholar] [CrossRef]
- Guimarães, N.; Pádua, L.; Marques, P.; Silva, N.; Peres, E.; Sousa, J.J. Forestry remote sensing from unmanned aerial vehicles: A review focusing on the data, processing and potentialities. Remote Sens. 2020, 12, 1046. [Google Scholar] [CrossRef]
- Dash, J.P.; Watt, M.S.; Pearse, G.D.; Heaphy, M.; Dungey, H.S. Assessing very high resolution UAV imagery for monitoring forest health during a simulated disease outbreak. ISPRS J. Photogramm. Remote Sens. 2017, 131, 1–14. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual tree segmentation and tree species classification in subtropical broadleaf forests using UAV-based LiDAR, hyperspectral, and ultrahigh-resolution RGB data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep learning in forestry using uav-acquired rgb data: A practical review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Gu, J.; Grybas, H.; Congalton, R.G. Individual tree crown delineation from UAS imagery based on region growing and growth space considerations. Remote Sens. 2020, 12, 2363. [Google Scholar] [CrossRef]
- Huang, H.; Li, X.; Chen, C. Individual tree crown detection and delineation from very-high-resolution UAV images based on bias field and marker-controlled watershed segmentation algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2253–2262. [Google Scholar] [CrossRef]
- Zhao, H.; Morgenroth, J.; Pearse, G.; Schindler, J. A systematic review of individual tree crown detection and delineation with convolutional neural networks (CNN). Curr. For. Rep. 2023, 9, 149–170. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Marconi, S.; Aubry-Kientz, M.; Vincent, G.; Senyondo, H.; White, E.P. DeepForest: A Python package for RGB deep learning tree crown delineation. Methods Ecol. Evol. 2020, 11, 1743–1751. [Google Scholar] [CrossRef]
- Wu, W.; Fan, X.; Qu, H.; Yang, X.; Tjahjadi, T. TCDNet: Tree crown detection from UAV optical images using uncertainty-aware one-stage network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6517405. [Google Scholar] [CrossRef]
- Zhang, J.; Lei, F.; Fan, X. Parameter-Efficient Fine-Tuning for Individual Tree Crown Detection and Species Classification Using UAV-Acquired Imagery. Remote Sens. 2025, 17, 1272. [Google Scholar] [CrossRef]
- Santos, A.A.d.; Marcato Junior, J.; Araújo, M.S.; Di Martini, D.R.; Tetila, E.C.; Siqueira, H.L.; Aoki, C.; Eltner, A.; Matsubara, E.T.; Pistori, H.; et al. Assessment of CNN-based methods for individual tree detection on images captured by RGB cameras attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Weinstein, B.G.; Marconi, S.; Bohlman, S.; Zare, A.; White, E. Individual tree-crown detection in RGB imagery using semi-supervised deep learning neural networks. Remote Sens. 2019, 11, 1309. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Barnes, C.; Balzter, H.; Barrett, K.; Eddy, J.; Milner, S.; Suárez, J.C. Individual tree crown delineation from airborne laser scanning for diseased larch forest stands. Remote Sens. 2017, 9, 231. [Google Scholar] [CrossRef]
- Li, Y.; Xie, D.; Wang, Y.; Jin, S.; Zhou, K.; Zhang, Z.; Li, W.; Zhang, W.; Mu, X.; Yan, G. Individual tree segmentation of airborne and UAV LiDAR point clouds based on the watershed and optimized connection center evolution clustering. Ecol. Evol. 2023, 13, e10297. [Google Scholar] [CrossRef]
- Luo, T.; Rao, S.; Ma, W.; Song, Q.; Cao, Z.; Zhang, H.; Xie, J.; Wen, X.; Gao, W.; Chen, Q.; et al. YOLOTree-Individual Tree Spatial Positioning and Crown Volume Calculation Using UAV-RGB Imagery and LiDAR Data. Forests 2024, 15, 1375. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhao, C.; Sun, Y.; Wang, W.; Chen, Q.; Ding, E.; Yang, Y.; Wang, J. Ms-detr: Efficient detr training with mixed supervision. In Proceedings of the IEEE/Cvf Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 17027–17036. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Changyu, L.; Hogan, A.; Diaconu, L.; Ingham, F.; Poznanski, J.; Fang, J.; Yu, L.; et al. ultralytics/yolov5, Version v3.1. Bug Fixes and Performance Improvements. Zenodo: Genève, Switzerland, 2020.
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO, Version 8.0.0; Zenodo: Genève, Switzerland, 2023.
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Tziafas, G.; Kasaei, H. Early or late fusion matters: Efficient RGB-D fusion in vision transformers for 3D object recognition. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 23–27 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 9558–9565. [Google Scholar]
- Eitel, A.; Springenberg, J.T.; Spinello, L.; Riedmiller, M.; Burgard, W. Multimodal deep learning for robust RGB-D object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 681–687. [Google Scholar]
- Lv, L.; Li, X.; Mao, F.; Zhou, L.; Xuan, J.; Zhao, Y.; Yu, J.; Song, M.; Huang, L.; Du, H. A deep learning network for individual tree segmentation in UAV images with a coupled CSPNet and attention mechanism. Remote Sens. 2023, 15, 4420. [Google Scholar] [CrossRef]
- Zheng, J.; Yuan, S.; Li, W.; Fu, H.; Yu, L.; Huang, J. A Review of Individual Tree Crown Detection and Delineation From Optical Remote Sensing Images: Current progress and future. IEEE Geosci. Remote Sens. Mag. 2025, 13, 209–236. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| DETR | 38.03 | 88.35 | 29.67 |
| MS-DETR | 39.46 | 89.92 | 30.92 |
| YOLOX | 40.25 | 90.37 | 31.29 |
| YOLOV5 | 38.98 | 89.21 | 33.87 |
| YOLOV8 | 42.83 | 91.29 | 33.21 |
| YOLOV10 | 43.03 | 91.29 | 33.21 |
| Early Fusion | 44.25 | 92.50 | 33.17 |
| MMFTNet (Ours) | 45.38 | 93.12 | 35.74 |
| Method | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| DETR | 37.61 | 89.50 | 19.12 |
| MS-DETR | 42.56 | 90.87 | 27.68 |
| YOLOX | 42.49 | 92.20 | 29.50 |
| YOLOV5 | 45.16 | 92.98 | 32.84 |
| YOLOV8 | 45.63 | 93.05 | 32.74 |
| YOLOV10 | 46.88 | 93.69 | 38.25 |
| Early Fusion | 45.31 | 93.22 | 31.79 |
| MTCDNet (Ours) | 48.41 | 94.58 | 40.65 |
| Method | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| Dataset_A-to-B | 43.50 | 92.65 | 28.87 |
| Dataset_B-to-A | 44.17 | 92.13 | 34.22 |
| MM-Transformer | Learnable PE | mAP (%) | AP50 (%) | AP75 (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| × | × | 41.27 | 91.25 | 32.56 | 43.10 | 41.84 |
| ✓ | × | 43.93 | 91.86 | 33.21 | 44.50 | 45.07 |
| ✓ | ✓ | 45.38 | 93.12 | 35.74 | 44.52 | 45.31 |
| Modality | mAP (%) | AP50 (%) | AP75 (%) |
|---|---|---|---|
| Only RGB | 42.96 | 91.31 | 33.20 |
| Only Depth Map | 37.20 | 86.01 | 26.54 |
| RGB + Depth Map (Ours) | 45.38 | 93.12 | 35.74 |
| Number of Heads | mAP (%) | mAP@.50 (%) | mAP@.75 (%) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| 1 | 43.46 | 93.91 | 33.09 | 44.51 | 22.32 |
| 2 | 43.96 | 91.48 | 31.74 | 44.51 | 29.76 |
| 4 | 44.93 | 94.76 | 32.90 | 44.52 | 37.14 |
| 8 | 45.38 | 93.12 | 35.74 | 44.52 | 45.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Yang, C.; Fan, X. MTCDNet: Multimodal Feature Fusion-Based Tree Crown Detection Network Using UAV-Acquired Optical Imagery and LiDAR Data. Remote Sens. 2025, 17, 1996. https://doi.org/10.3390/rs17121996
Zhang H, Yang C, Fan X. MTCDNet: Multimodal Feature Fusion-Based Tree Crown Detection Network Using UAV-Acquired Optical Imagery and LiDAR Data. Remote Sensing. 2025; 17(12):1996. https://doi.org/10.3390/rs17121996
Chicago/Turabian StyleZhang, Heng, Can Yang, and Xijian Fan. 2025. "MTCDNet: Multimodal Feature Fusion-Based Tree Crown Detection Network Using UAV-Acquired Optical Imagery and LiDAR Data" Remote Sensing 17, no. 12: 1996. https://doi.org/10.3390/rs17121996
APA StyleZhang, H., Yang, C., & Fan, X. (2025). MTCDNet: Multimodal Feature Fusion-Based Tree Crown Detection Network Using UAV-Acquired Optical Imagery and LiDAR Data. Remote Sensing, 17(12), 1996. https://doi.org/10.3390/rs17121996