1. Introduction
Earth observation satellites (EOSs) provide large-scale observation coverage and are equipped with optical instruments to take photographs of specific areas at the request of users [
1,
2,
3]. EOSs have been extensively employed in scientific research and application, mainly in environmental and disaster surveillance, ocean monitoring, agricultural harvesting, etc. [
4]. Recently, agile EOSs (AEOSs) have drawn significant attention as a new generation of these platforms [
5]. Unlike conventional EOSs, AEOSs possess three-axis (roll, pitch, and yaw) maneuverability, which amplifies flexibility and expands the solution space of their task scheduling. Cooperatively multiple AEOSs can serve various demands, such as multi-angular observation and wide area observation [
6]. Consequently, multi-AEOS (MAEOS) scheduling has become a primary focus of satellite platforms.
However, although the number of AEOSs in orbit is increasing, they are still limited because of the vast number of applications they can be used for [
7,
8]. Therefore, an effective scheduling algorithm must be developed to improve the efficiency of observation systems. The MAEOS scheduling problem (MAEOSSP) is a large-scale combinatorial optimization problem and has been proven to be NP-hard [
9]. Algorithms applied to MAEOSSP are usually classified as exact methods, heuristic methods, metaheuristic methods and machine learning methods [
10].
Exact methods, such as mixed-integer linear programming [
9], dynamic programming [
11], and branch and price [
12], provide optimal solutions and are limited to the scale and complexity of corresponding problems. Simple heuristic rules are extensively used in most optimization problems because they are efficient and intuitive [
13,
14,
15]. Owing to their low computational complexity, heuristic methods have been widely applied in practical satellite scheduling, such as Pleiades in France [
16], FireBIRD in Germany [
17], and EO-1 in the USA [
18]. Heuristic methods can speed up the process by finding a satisfactory solution, but studies and engineering projects have also indicated that heuristic results can be improved further. Metaheuristic methods typically provide satisfactory observation plans with a longer run time. Various metaheuristic algorithms have been proposed, including genetic algorithms and their variants [
19,
20,
21,
22], tabu search [
23,
24,
25], simulated annealing [
26], ant colonies and their variants [
27], differential evolution algorithms [
28], and large neighborhood search [
29,
30]. However, the search difficulty and solution times of these algorithms increase dramatically as the scale of the problem increases. Traditional exact and metaheuristic algorithms cannot meet the requirements of high efficiency and fast response in practical applications [
31].
A major breakthrough in deep reinforcement learning (DRL) was achieved by Mnih et al. [
32], where their proposed Deep Q-Network (DQN) demonstrated for the first time that DRL could attain human-level performance in complex decision-making tasks. In recent years, DRL has made remarkable achievements in games and has been applied to combinatorial optimization problems [
33,
34,
35,
36,
37]. Combinatorial optimization allows one to optimally select variables in a discrete decision space, which is similar to the action selection of DRL. Moreover, with its “offline training and online decision making” characteristics, DRL demonstrates the potential for quick responses to requirements and shows a high solving speed compared with metaheuristics [
38].
Therefore, DRL has become a promising method for solving satellite scheduling problems. Research efforts on DRL have been dedicated to single-AEOS scheduling [
39,
40,
41,
42], but there is little research on DRL for MAEOS scheduling.
Research efforts have been dedicated to addressing single-satellite Earth observation scheduling problems through DRL. Wang et al. [
39] integrated case-based learning and a genetic algorithm to schedule EOS. Shi et al. [
40] proposed an efficient and fair proximal policy optimization-based integrated scheduling method for multiple tasks using the Satech-01 satellite. Wang et al. [
41] formulated a dynamic and stochastic knapsack model to describe the online EOS scheduling problem and proposed a DRL-based insertion process. He et al. [
42] investigated a general Markov decision process (MDP) model and a Deep Q-Network for AEOS scheduling, and this solution method has also been employed for satellite range scheduling [
43]. Chen et al. [
44] regarded neural networks as feasible rule-based heuristics in their proposed end-to-end DRL framework. Zhao et al. [
45] proposed a two-phase neural combinatorial optimization approach to address the EOS scheduling problem. Lam et al. [
46] proposed a DRL-based approach that could provide solutions in nearly real time. Huang et al. [
10] addressed the AEOS task scheduling problem within one orbit using the deep deterministic policy gradient (DDPG) method. Huang et al. [
47] focused on decision-making in the task sequence and proposed a dynamic destroy deep-reinforcement learning (D3RL) model with two application modes. Liu et al. [
48] proposed an attention decision network to optimize the task sequence in the AEOS scheduling problem. Liu et al. [
49] presented a DRL algorithm with a local attention mechanism to investigate the single agile optical satellite scheduling problem. Wei et al. [
50] introduced a DRL and parameter transfer based approach to solve a multi-objective agile earth observation satellite scheduling problem. Chun et al. [
31] investigated a graph attention network-based decision neural network for the agile Earth observation satellite scheduling problem.
Compared with single-EOS scheduling, there is little research on DRL for MAEOS scheduling. Dalin et al. [
51] proposed a DRL-based multi-satellite mission planning algorithm for high and low-orbit AEOSs, which kept the revenue rate difference compared with A-ALNS [
30] below 5%. Wang et al. [
52] focused on the autonomous mission planning problem for AEOSs, in which the visible time window (VTW) was set as a time interval. Li et al. [
53] tackled the issue of multi-satellite rapid mission re-planning using a deep reinforcement learning method that incorporated mission sequence modeling. Chen et al. [
54] addressed a multi-objective learning evolutionary algorithm for solving the multi-objective multi-satellite imaging mission planning problem. Wang et al. [
55] developed an improved DRL method to address the MAEOSSP with variable imaging durations. Song et al. [
56] introduced a genetic algorithm (GA) framework incorporating DRL for generating both initial solutions and neighborhood search solutions to address the multitype satellite observation scheduling problem. These studies focus on scenarios in which each task has only one VTW in each satellite.
In this study, we propose a DRL-based two-phase hybrid optimization (TPHO) method to generate an observation plan for the MAEOSSP. For each AEOS, tasks may have different numbers of VTWs. We propose an encoder–decoder network to optimize the task sequence and a heuristic method to allocate satellites for tasks. We model the MAEOS scheduling process using with a finite MDP with a continuous state space. The major contributions of this study are summarized as follows:
An MDP for the MAEOSSP is constructed, in which the action space is decomposed into task action and resource action subspaces corresponding to the task sequence and resource allocation subproblems, and a new reward function is proposed.
A DRL-based TPHO framework is proposed for the MAEOSSP. An encoder–decoder network in TPHO is designed to determine the task sequence, and a heuristic method is proposed to optimize the resource allocation problem.
A comprehensive experiment is conducted to examine the performance of our method. Based on the computational results, the proposed method has proven to be effective and has high time efficiency. The experimental results also show that this study provides an intuitive and effective resource allocation rule in capacity limited application scenarios.
The remainder of this study is organized as follows:
Section 2 presents the MAEOSSP in detail.
Section 3 describes the proposed methods.
Section 4 presents the experimental results, followed by discussions in
Section 5.
Section 6 presents the conclusions.
2. Problem Description
This study generates observation schemes for static tasks over an execution period. The tasks observe point targets according to user demands that include the latitude and longitude of the point target, observation duration, required observation time, etc. All user demands in the past period are collected and sent to the operation center. Then, considering the objectives and constraints, the operation center exports an observation scheme based on optimization algorithms. Subsequently, the scheme codes are sent to satellites, which execute tasks according to the uploaded scheme codes. After the current execution period ends, the observation system proceeds to the next execution period.
In practical management, generating a schedule can be considerably complicated because many details must be considered, such as regulations and user requirements. Following previous research [
6,
30,
56,
57], we simplified the problem by considering several assumptions.
- (1)
A solar panel can provide sufficient energy for each satellite.
- (2)
The download management of the acquired images is not considered because this issue falls outside the scope of this study.
- (3)
There is, at most, one observation sensor running on a satellite at any time.
- (4)
The maneuver time for pitch and roll maneuvers is considered when calculating the attitude transition time between two continuous tasks.
- (5)
Observation tasks are point targets and targets preprocessed to be covered in a single observation.
- (6)
Each task can be conducted once at most and does not need to be repeated.
- (7)
If a task is successfully scheduled, it can be executed successfully without being affected by other factors.
- (8)
The task and its execution demands are defined before scheduling starts; no new tasks or variations in demands occur.
Given the above assumptions, the MAEOSSP in this study can be described as follows. The task set containing a total of M tasks is defined as . For task , the observation time required by the user is , the observation duration is , the observation profit is , and the storage occupied by is . The satellite set is . Each satellite, , has a memory capacity of . The number of VTWs for task in satellite is . The set of VTWs for task in satellite is , where . represents the observation time for task , where .
The symbols and notations are shown in
Table 1.
The objective function of the MAEOSSP in this study is to maximize the total observation profit of all scheduled tasks. The objective function is defined as follows:
where
if task
is observed by satellite
, and
otherwise.
- 2.
Uniqueness constraint:
All tasks are one-time tasks. That is, each task can be observed no more than once over the entire time horizon.
where
if task
is observed by satellite
and the start time of task
is
, and
otherwise.
- 3.
Memory capacity constraint:
The total storage consumed by observed tasks for each satellite cannot exceed the memory capacity of the satellite.
- 4.
Observation time request constraint:
Task
can be observed by any satellite, but the observation should start and be completed within the required observation time by users.
- 5.
VTW constraint:
If task
is observed by satellite
, the observation should start and be completed within VTW
, where
.
- 6.
Attitude transition time constraint:
When two adjacent tasks,
and
, are observed by satellite
, the time gap between the two tasks should not exceed the satellite attitude transition time,
:
where the transition time,
, is the ratio of angles for observing the two tasks on satellite
at the start time of the observation and the satellite maneuvering velocity.
The attitude transition time,
, is calculated as follows:
where
θpij is the pitch attitude angle to task
i observed by satellite
j,
θrij is the roll attitude angle to task
i observed by satellite
j, and
vp and
vr are the angular velocities of the pitch and roll maneuvers, respectively.
Based on the assumptions, objective function, and constraints of the problem, we present a detailed solving method in
Section 3.
3. Solving Method
The MAEOSSP investigated in this study involves determining the execution resources and time windows for each task under temporal and capacity constraints to optimize the objective function. Given the finite nature of satellite resources, tasks exhibit competitive relationships where scheduling sequences critically influence objective values. To mitigate complexity, the problem is decomposed into three interdependent decisions: task sequence determination, resource allocation, and execution time window determination. Once the task sequence is established, the subsequent focus narrows to identifying appropriate resources and temporal windows for individual tasks. As a promising approach, deep reinforcement learning (DRL) demonstrates balanced capabilities in decision quality and efficiency and has shown good sequential decision-making abilities, motivating our proposed DRL-based algorithm for task sequence determination.
DRL updates model parameters through agent–environment interactions, with the MDP framework serving as its foundational model, comprising states, actions, state transitions, and reward mechanisms. Establishing an MDP enables the precise specification of agent–environment interactions, which we systematically formalize in this section.
The state vector, representing environmental characteristics, is the input to the deep neural network. To enhance feature representation, state elements are categorized into static and dynamic elements based on their value variability during iterations.
Actions, the network’s output, constitute the agent’s decision space. While environmental state transitions must jointly determine task sequences, resource allocations, and temporal windows, the deep network primarily generates sequence decisions. This necessitates complementary mechanisms for resource and execution time determination. Considering computational efficiency, heuristic methods are employed. Given that tasks with visible time windows form satellite-specific sets, different satellites correspond to sets with different tasks due to distinct orbital parameters. To preserve resource diversity during the whole scheduling process, a maximum residual capacity (MRC) rule is proposed. An MRC rule indicates that a feasible satellite with maximum residual capacity is allocated to the determined task. This mechanism ensures that the observation system maintains resource diversity without premature depletion due to storage capacity constraints. Following previous studies [
26,
30,
42,
48], the beginning execution time of the determined task is set to the earliest of its feasible time windows in the determined satellite, i.e., the Earliest Start Time (EST) rule.
State transitions occur through the interplay of current states, DRL-generated task sequences, and heuristic-based resource allocations, with the agent receiving immediate reward feedback. The agent optimizes its policy by maximizing cumulative rewards representing long-term returns. Upon completing the scheduling process, the total return of the whole scheduling process is obtained. However, determining the contributions of individual step decisions to final returns remains challenging. As each decision schedules one task, task profit has naturally served as the immediate reward feedback in previous studies [
42,
47,
48].
Nevertheless, task execution simultaneously consumes finite resources, significantly impacting long-term returns. In this study, resources are categorized into temporal resources and storage capacity resources. Temporal resources involve complex factors such as durations, visible time windows, and transition time, making them difficult to simply characterize. Furthermore, since task execution timing is determined by the EST (Earliest Start Time) heuristic, temporal attributes are partially accounted for in the scheduling process. Consequently, a reward function combining task profit and storage consumption ratios is proposed. This formulation incorporates the impacts of both resource consumption and task profit on cumulative returns. Given that the reward values undergo standardization prior to neural network training, the introduction of weighting coefficients to either task profit or storage consumption becomes unmeaningful.
Section 3.1 describes the description of the Markov decision process model in detail.
Based on the above description, we propose a DRL-based TPHO framework. A deep neural network determines a task action, then based on the task action, a heuristic algorithm determines the resource action and the execution time. The decisions of the deep neural network and heuristic algorithms jointly drive the state transition of the environment. The sample (state, task action, reward, and next state) is generated in this process and trains the deep neural network model.
Figure 1 shows the interaction between the environment, MDP model, and TPHO framework. The deep neural network in TPHO determines the task sequence. It receives task information sequences that describe the environment and outputs probability sequences for task selection. Since encoder–decoder architecture is a universal framework for sequence-to-sequence learning, an encoder–decoder is designed to determine the task action.
The state vector comprises both static and dynamic elements, where static components maintain invariant values across decision steps while dynamic counterparts vary temporally. Given their distinct characteristics, these elements undergo separate feature encoding through individual fully connected layers. This architectural design serves dual purposes: (1) the fully connected structure prevents information loss through linear transformation preservation, and (2) parallel encoding significantly reduces computational overhead compared with concatenation before encoding.
To provide scheduling sequences for the neural network, gated recurrent unit (GRU) networks receive historical static elements from previously scheduled tasks, effectively capturing sequential dependencies. GRU selection over long short-term memory (LSTM) networks is strategically motivated by two factors [
58]: (1) the moderate sequence lengths in this decision-making context and (2) the limited dataset scale characteristic of satellite scheduling problems. The GRU’s streamlined architecture with fewer gating mechanisms enables accelerated training convergence while maintaining essential memory retention capabilities.
Section 3.2 details the encoder–decoder network and
Section 3.2 details the training process. To train the encoder–decoder network, the soft actor–critic (SAC) algorithm is employed. According to Liu et al. [
59], proximal policy optimization (PPO) faces stability challenges, and deep deterministic policy gradient (DDPG) and SAC demonstrate robust performance, notably in moderate-elasticity scenarios. The real-world application of the SAC model further affirmed its practical viability, marking a significant performance improvement [
59].
3.1. Markov Decision Process Model
The Markov decision process presents the state space of the environment, the action space of the agent, the state transition function, and the reward function. the state describes the features of the environment, based on which the proposed encoder–decoder network selects a task action. According to the state transition function, the next state is reached based on the current state, task action, and resource action decision made by the heuristic algorithm. Then, a reward from the environment is received.
The state,
, is described by the following equations:
where
is the state element of task
, including static elements,
, and dynamic elements,
. The value of static elements is unchanged in the entire decision process, and the value of dynamic elements may vary in each new state. If task
has been scheduled before,
, and
, otherwise.
Following a previous study [
48], we use two dynamic elements,
and
, to include the VTW information for each task. This state representation for the MDP can be applied to cases where tasks may have various numbers of VTWs.
is the total length of the feasible time windows of all satellites for task
at time step
. The feasible time windows for task
at time step
, denoted as
, are the intersection of the required observation time by users and the VTWs for task
.
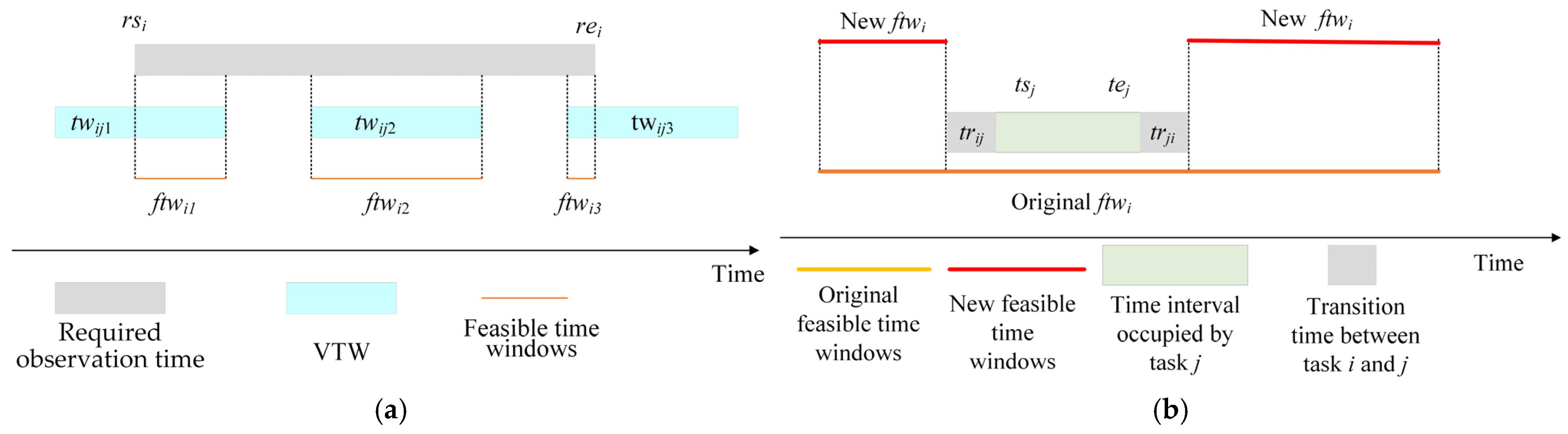
Figure 2 describes the feasible time windows for task
i.
is the earliest end time of task in all satellites at time step . and are updated at each time step, since a newly scheduled task may occupy the VTWs of task . The value of each element is normalized by the maximum value.
is the value of storage occupied by task . is the value of the remaining capacity in all satellites for task . is calculated by Equation (12). if task is observed by satellite at time step , and otherwise. was originally a static element; here, and are normalized together by the maximum value of the two types of elements. Thus, the value of may change over time steps.
The action space is decomposed into the task action and resource action subspaces:
and are the collections of task number and satellite number, respectively. The action is selecting a task and a satellite, and the selected task is executed at the earliest of its feasible time windows by the selected satellite.
If task and satellite are determined at time step , the state, , is then updated to . In , the static elements of all tasks remain unchanged. is set to 0. The and values of the other tasks are updated according to the time interval occupied by task in satellite . The for other tasks is updated according to the storage occupied by task in satellite . The for all tasks is normalized by the updated maximum value.
In previous studies [
42,
47,
48], the reward function is usually described as the increment in total profit. Here, we propose a novel reward function considering the storage occupied by the tasks, as defined in the following equation:
where
,
if task
has been scheduled at time step
, and
, otherwise. Normalizing of the reward function can avoid the impact of excessive or insufficient rewards on learning effectiveness and improve the comparability of reward values. Normalization of the reward function can avoid the impact of excessive or insufficient rewards on learning effectiveness and improve the comparability of reward values. Therefore, reward normalization is implemented to stabilize the learning dynamics during policy optimization. The value of
is normalized by the maximum value of all tasks.
3.2. Two-Phase Hybrid Optimization
According to the MDP in this study, the decision process of the MAEOSSP is decomposed into a task sequence decision and a resource allocation decision. We propose a two-phase hybrid optimization that includes an encoder–decoder network for task sequence decision and a heuristic algorithm for resource allocation decision.
Since DRL has demonstrated a strong ability in sequential decision-making, we propose an encoder–decoder network to make decision in the task sequence.
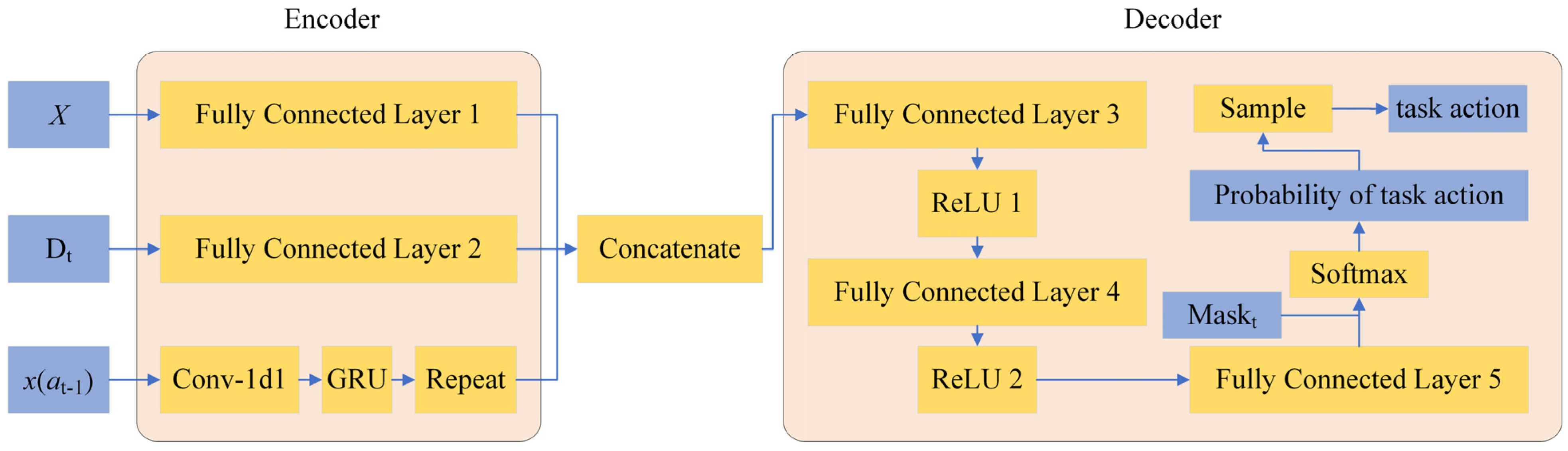
Figure 3 shows the architecture of the proposed encoder–decoder network. The encoder architecture comprises three parallel neural network layers, each specialized for encoding static elements, dynamic elements, and scheduling sequences. The decoder is structured as a stacked series of fully connected layers integrated with activation functions and incorporates the softmax-based normalization to probabilistically constrain the output space. Given their distinct characteristics, static and dynamic elements undergo separate feature encoding through individual fully connected layers. To provide scheduling sequences to the encoder–decoder network, the GRU receives historical static elements from previously scheduled tasks.
is the matrix of the static elements, is the matrix of the dynamic elements, is the task action selected in the last time step, , and is the -th element in . According to Equations (10) and (11), the dimension of is , the dimension of is , and the dimension of is . , , and are transposed before encoding, and after encoding, their dimensions are , , and , respectively. hd is the hidden dimensions of the fully connected layers and the GRU. We use a repeat operation to expand the dimension of encoded from to . Then, the encoded vectors are concatenated column-wise. In order not to lose information, and are encoded by fully connected networks. To save sequence information, is encoded by a one-dimensional convolutional network and GRU.
The encoded inputs are concatenated as illustrated in
Figure 3, after three linear layers and two activation layers, the value of each task action is obtained. The values are mapped to
by applying the Softmax function, and then the probability of each task action is obtained, based on which the task action selection is determined via sampling.
All neural network components, including fully connected layers, convolutional layers, GRUs, activation functions, and the Softmax layer are implemented using PyTorch 2.5.1. The specific implementation commands and corresponding parameters for each network layer are detailed in
Table A1 in the
Appendix A.
is a mask matrix used to mask unfeasible task actions. , if task i is feasible at time step t and has not been scheduled, and otherwise. The probability of an unfeasible task is modified to zero by the mask matrix. Task i is feasible if least one satellite has feasible time windows for task i and the remaining capacity of the satellite is no less than the storage consumed by task i.
The task action is determined by the proposed encoder–decoder network, and then the resource action and beginning time decisions for task execution are needed to update the state. When allocating a satellite to observe the determined task, we consider decreasing the impact of resource occupation by the determined task on the feasibility of other unscheduled tasks. We propose a heuristic rule denoted as MRC that indicates a feasible satellite with maximum residual capacity is allocated to the determined task. The MRC rule is illustrated in Algorithm 1.
| Algorithm 1 Heuristic rule MRC |
| Input: Determined task , feasible time windows in satellite , remaining capacity of satellite , initialize = 0 |
| Output: Number of the determined satellite |
| 1: for number of satellites = 1, 2, …, N do |
| 2: if do |
| 3: continue |
| 4: else if and do |
| 5:
|
| 6:
|
| 7:
end if |
| 8:
end for |
In accordance with previous studies [
26,
30,
42,
48], the beginning execution time of the determined task is set to the earliest of its feasible time windows in the determined satellite. We also employ a heuristic rule as a comparison, denoted as EFT, indicating that a feasible satellite with the earliest feasible time windows is determined. The heuristic rule EFT is illustrated in Algorithm 2, where Max_v represents a big enough number, and
represents the earliest feasible time windows in satellite.
| Algorithm 2 Heuristic rule EFT |
| Input: Determined task , feasible time windows in satellite , initialize = Max_v |
| Output: Number of the determined satellite |
| 1: for number of satellites = 1, 2, …, N do |
| 2: if do |
| 3:
continue |
| 4: else if and do |
| 5: et |
| 6:
|
| 7:
end if |
| 8:
end for |
The task action and resource action, as determined by the encoder–decoder network and the heuristic rule, interact with the environment resulting in experience samples for training. The trained encoder–decoder network and heuristic rule form the proposed TPHO framework.
3.3. Training Process
The SAC algorithm is employed to train the proposed encoder–decoder network [
60]. SAC is an off-policy algorithm based on the actor–critic framework with maximum entropy.
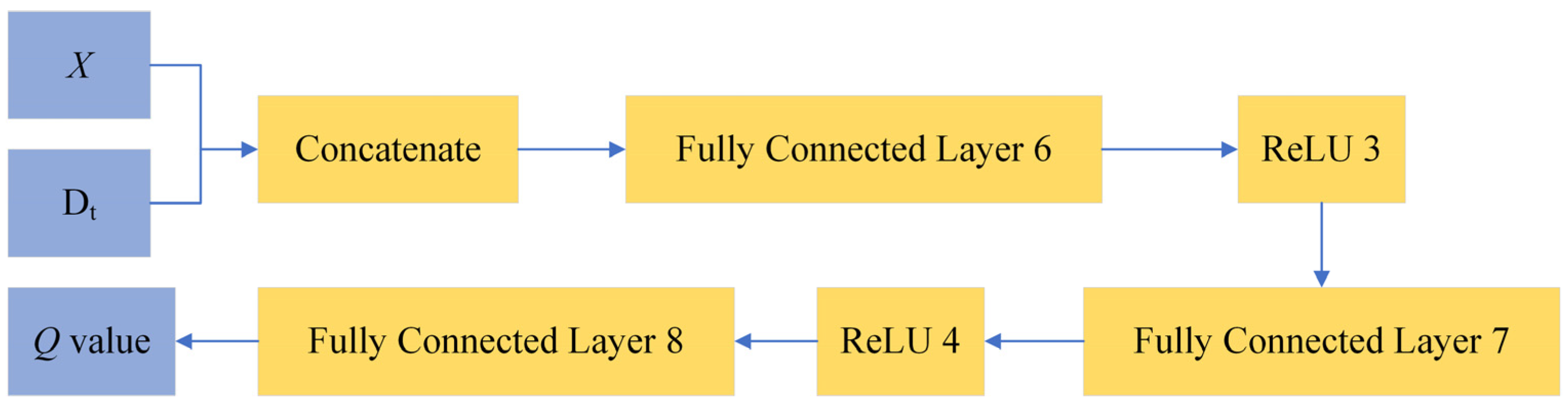
Figure 4 presents the architecture of the critic network in this study. The PyTorch 2.5.1 implementation specifications and corresponding parameters for each network layer are reported in
Table A1 of the
Appendix A.
The actor in the SAC algorithm maintains the diversity of exploration. A soft target update technique is used to smoothen the alterations during the training process. A dual Q-network is also adopted in SAC. The loss function of SAC is defined as follows [
60]:
where
represents the parameter of the
function,
is the
function,
is the action decision at time step
,
is the reward value,
is the parameter of the target network, and
is the target
value function.
is the network parameter of the policy network
.
represents the regularization parameter of entropy.
D is the experience replay pool used to store experience samples. The training process is illustrated in Algorithm 3, where Max
e is the maximum episode number.
done = false indicates
is not terminal. Learning begins when the number of samples in the experience pool reaches learning size.
| Algorithm 3 Training process based on SAC |
| Input: Initial SAC parameters , , , experience replay buffer D |
| Output: Trained encoder–decoder network |
| 1: for number of episode = 1, 2, …, Maxe do |
| 2: Initial state |
| 3: done = False |
| 4: while not done do |
| 5: Get a task action based on the network |
| 6: Get a resource action based on the heuristic rule MRC |
| 7: Execute and , observe next state |
| 8: Get reward r and update done |
| 9: Store experience sample () in D |
| 10:
|
| 11: if size(D) > learning size do |
| 12: Sample a batch of () from D randomly |
| 13: Compute the loss as in (18)~(19) |
| 14: Update , , using Adam |
| 15:
end if |
| 16:
end for |
3.4. Testing Process
The output of the encoder–decoder network is the probability distribution for the task action. During the training process, the task is selected according to the probability distribution. In the testing process, the action with the maximum probability is selected. Algorithm 4 describes the testing process.
| Algorithm 4 Testing process |
| Input: Task profit , trained encoder–decoder network, heuristic rule MRC, initialize , doneFalse, total profits0 |
| Output: Total profits, observation plan |
| 1: while not done do |
| 2: Input and sequence information into encoder–decoder network |
| 3: Select the task with the maximum probability |
| 4: Select a satellite based on MRC |
| 5: Execute at the earliest feasible time windows |
| 6: update done and state |
| 7: total profits = total profits + |
The performance of the proposed method is validated through numerical experiments in
Section 4.
5. Discussion
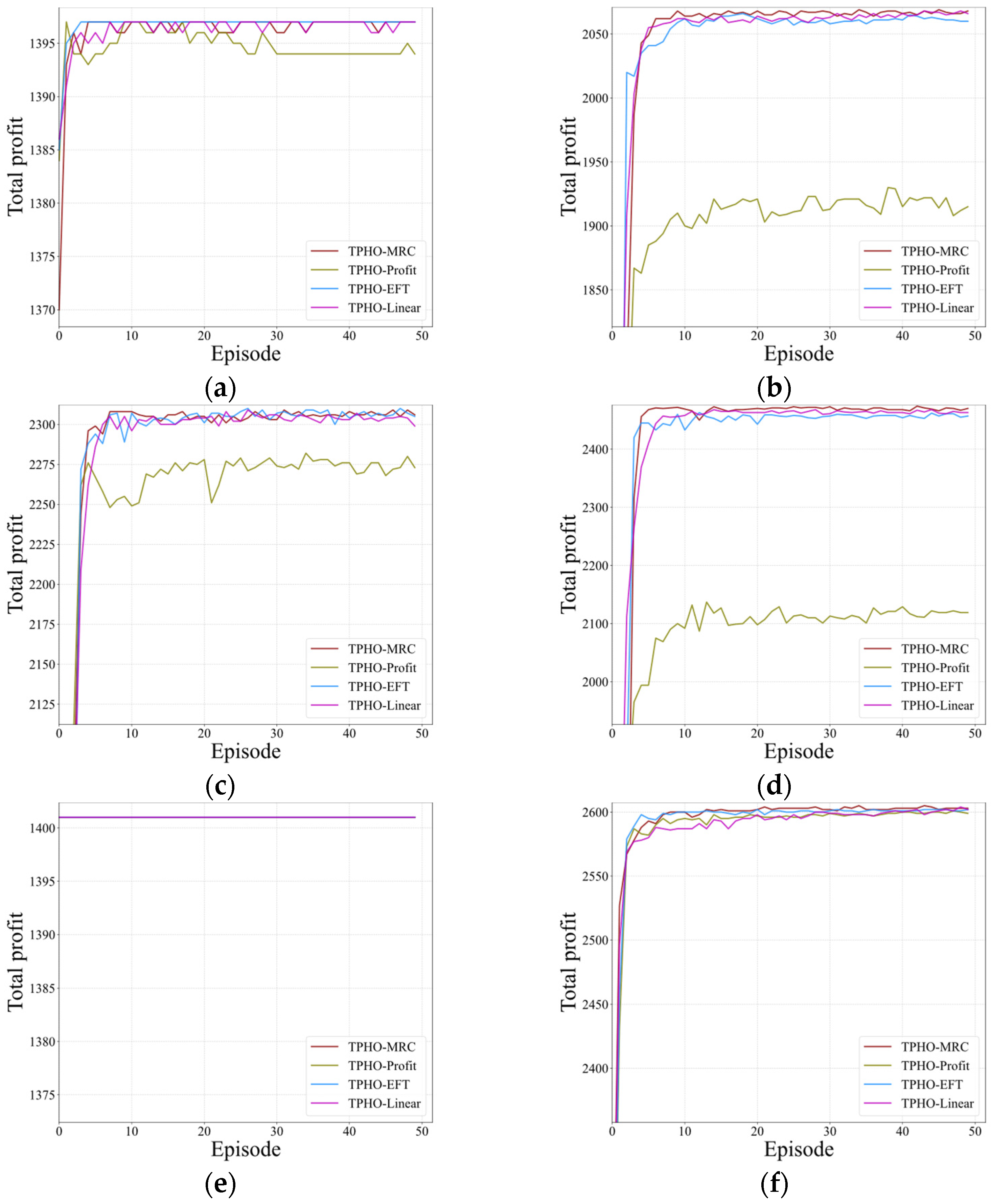
With the development of space science and technology, the collaborative operation of multiple AEOSs has shown advantages in enhanced remote sensing services, including speed. An effective scheduling algorithm is the key to improving the efficiency of AEOS applications. This study proposed a DRL-based TPHO framework with an effective heuristic rule, MRC, to rapidly generate an observation plan for the MAEOSSP. During the training process, the total profit increases at the beginning and then oscillates around a specific value, demonstrating that the network can converge on a stable policy. After training, the proposed method can be generalized to various application scenarios. According to the testing results, the proposed TPHO-MRC algorithm significantly outperforms other algorithms. Comparison results also indicate that the TPHO-based algorithms show good time efficiency and have the potential to apply to larger-scale MAEOSSPs.
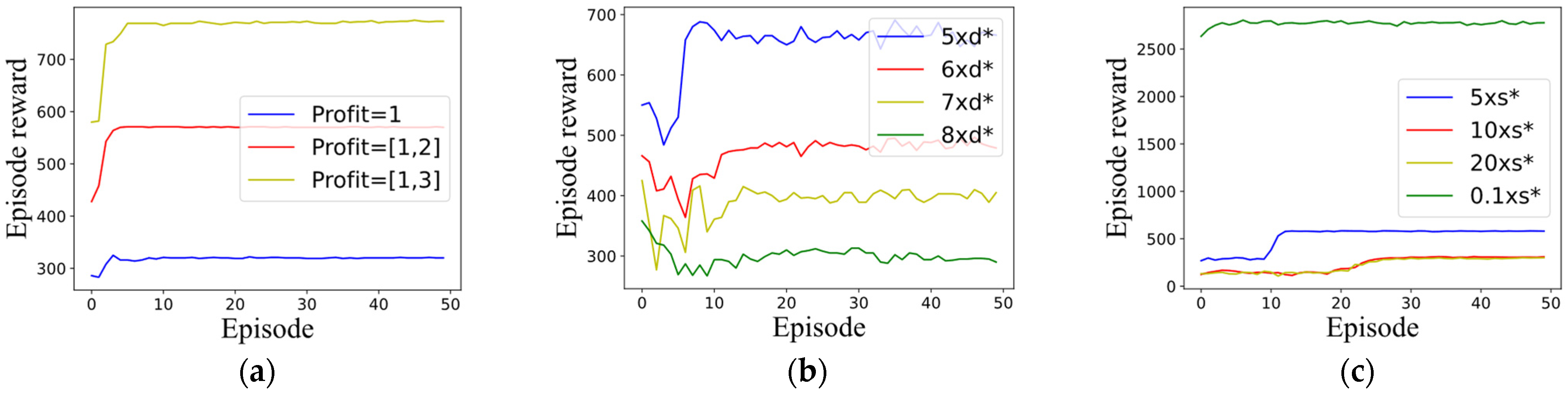
To further discuss the performance of the proposed TPHO-MRC, boundary value analysis of algorithm applicability was conducted. In the experimental section of this study, tasks were divided into nine priority levels based on importance, i.e., the task profit range was [1, 9]. Task reward serves as crucial information for the proposed algorithm’s task sequence decision-making. Here, we analyze the training convergence when differences in task importance decrease.
Figure 11a shows the training curves when task profits are in ranges [1, 3], [1, 2], and all equal to 1. When there are only two profit levels, the algorithm can still converge near the maximum value of the training curve. When all profits are equal, although the algorithm converges, it fails to approach the maximum value, indicating that the current algorithm is more suitable for scenarios with distinct task priorities.
In our experiments, task observation durations ranged from d* = [15 s, 30 s]. We analyze the training convergence when extending observation durations.
Figure 11b displays training curves for 5×, 6×, 7× and 8× original durations. The algorithm converges to maximum values at 5× and 6× duration, converges near initial values at 7×, and completely fails at 8× duration, demonstrating current applicability for observation durations within [90 s, 180 s].
For storage requirements, tasks occupied s* = [1.6 GB, 3.3 GB] with satellite capacity of 350 GB.
Figure 11c shows training curves when storage demands increase to 5×, 10×, 20× and capacity reduces to 1/10. The algorithm maintains convergence to maximum values in both scenarios, indicating broad adaptability to storage requirement variations.
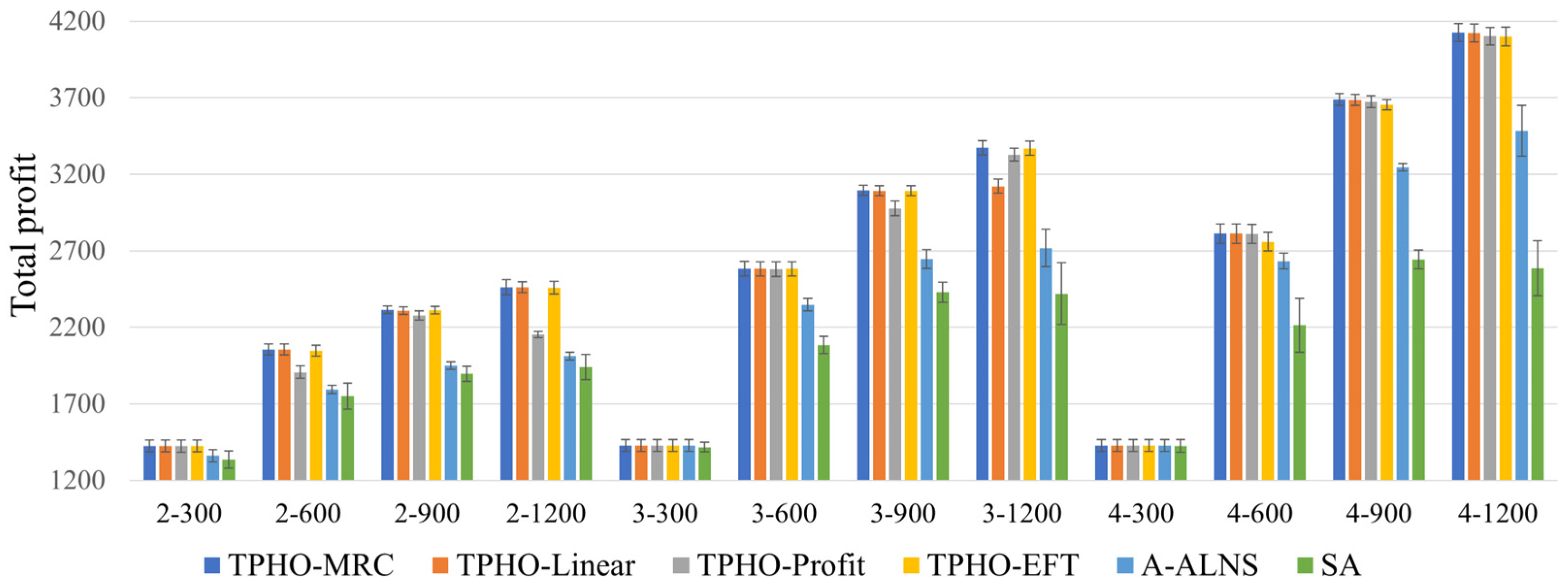
MAEOS scheduling usually serves as an oversubscription scenario in which the task load exceeds the resource ability. The proposed TPHO-MRC has shown the ability to make good selections from excess tasks. We also compared TPHO-MRC and TPHO-Profit with TPHO-EFT in two different memory capacity scenarios. The comparison results demonstrate that the proposed MRC rule is an intuitive and effective resource allocation rule in capacity-limited application scenarios.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}