
Long-Term Spatiotemporal Information Extraction of Cultivated Land in the Nomadic Area: A Case Study of the Selenge River Basin

Abstract
1. Introduction
2. Study Area and Datasets
2.1. Study Area
2.2. Datasets
3. Methods
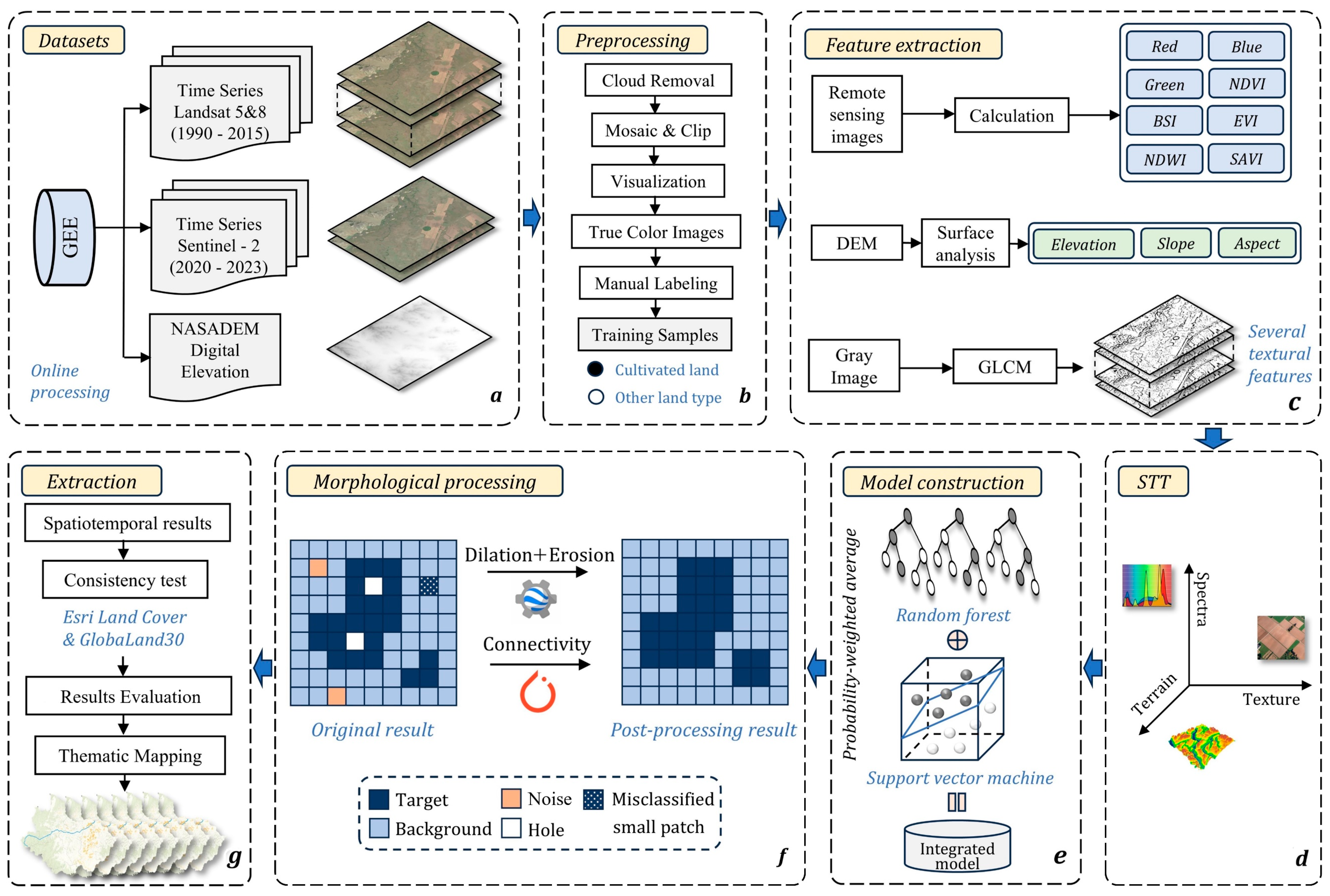
3.1. Overall Framework
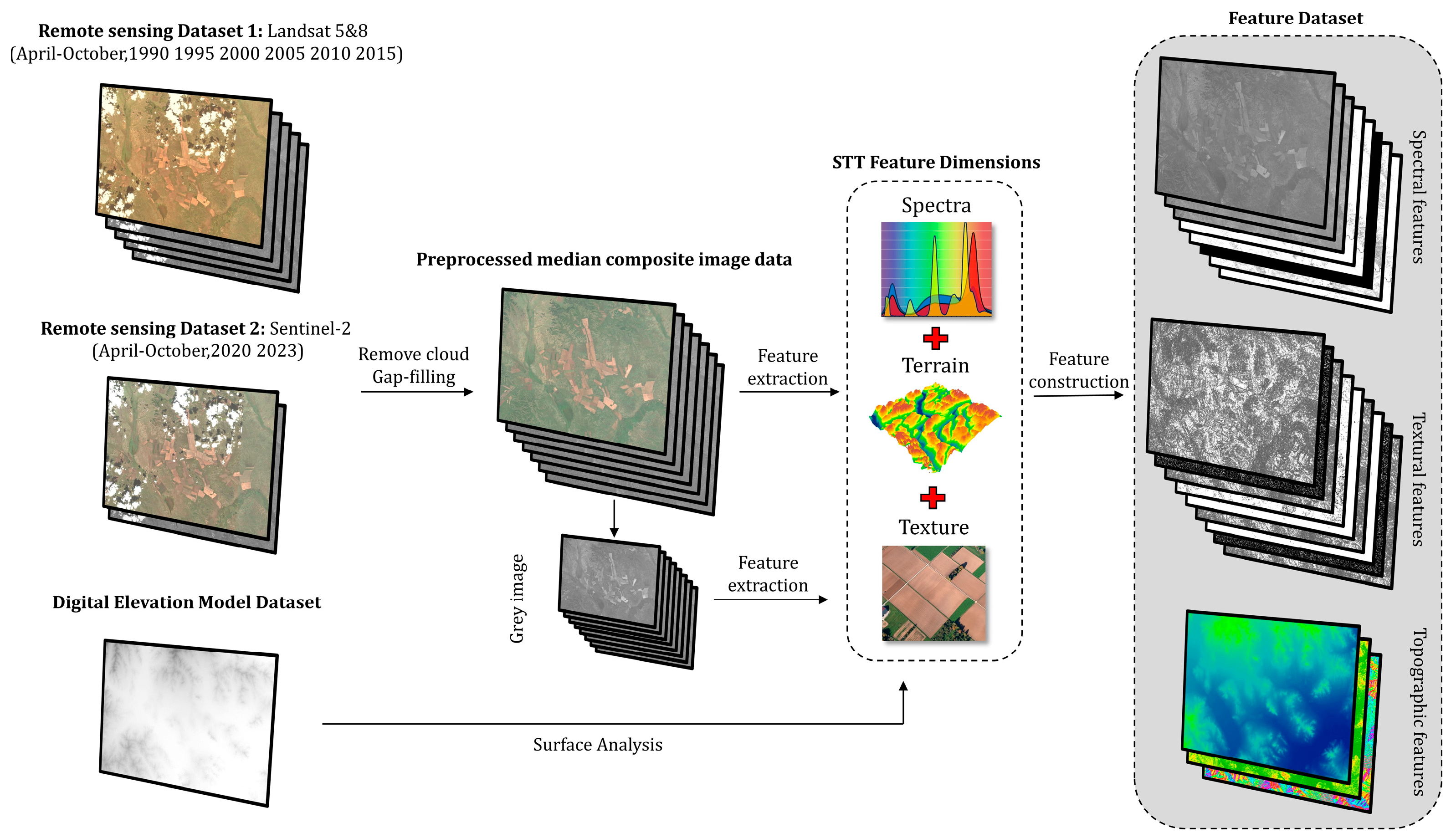
3.2. Feature Space Construction
3.3. Sample Generation and Selection
3.4. Machine Learning Model Construction
3.5. Morphological Post-Processing
4. Results
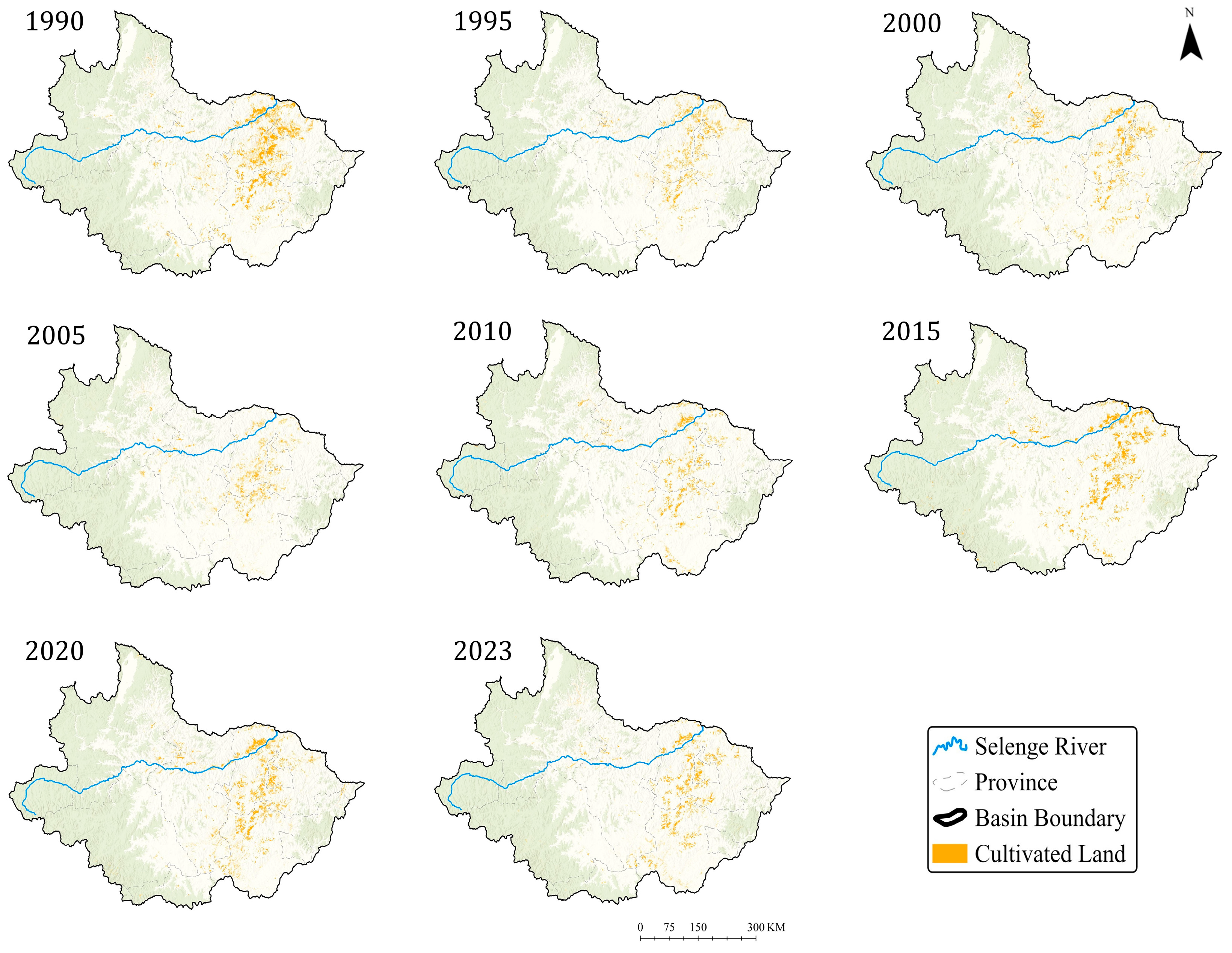
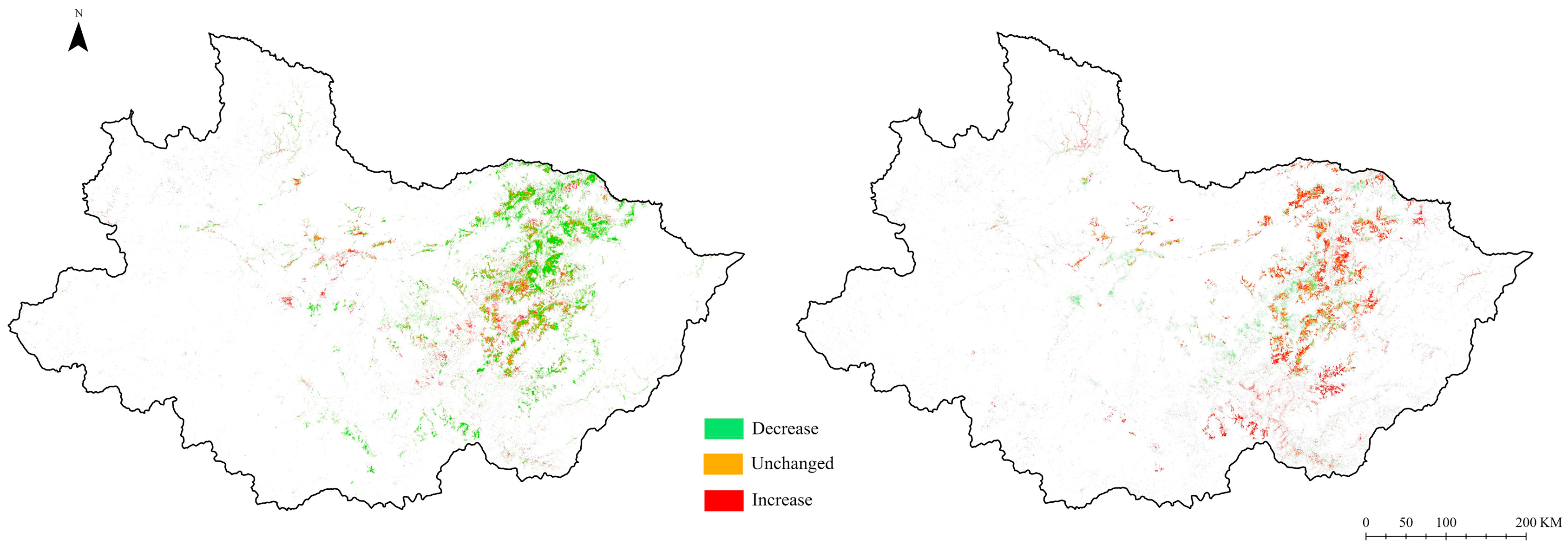
4.1. Analysis of Temporal and Spatial Distribution Patterns
4.2. Quantitative Statistics on Area Changes
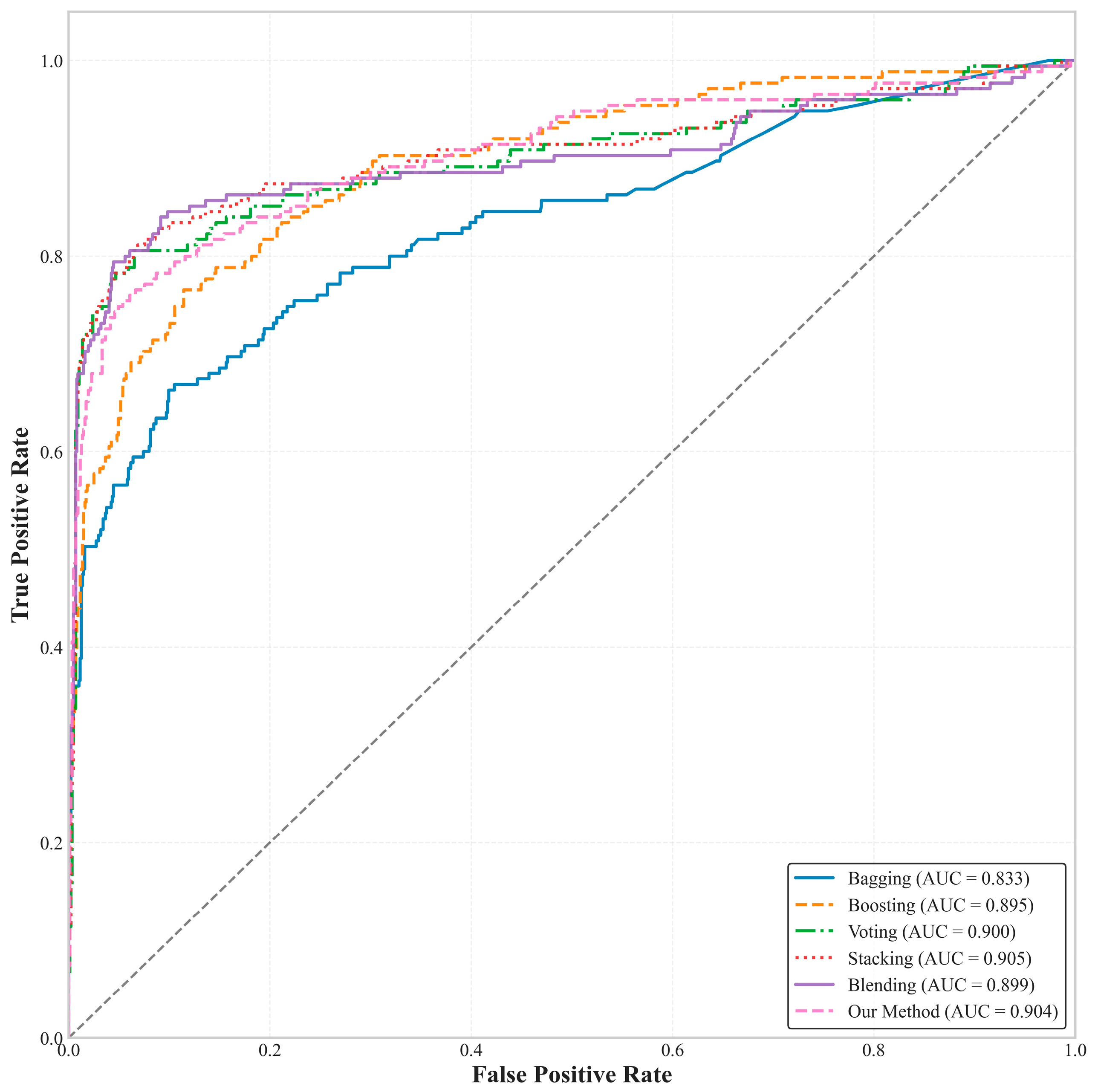
4.3. Accuracy Assessment
5. Discussion
5.1. Evaluation and Validation of Results
5.2. Comparative Analysis of Methodological Advantages
5.3. Analysis of Drivers of Spatial and Temporal Change
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bren d’Amour, C.; Reitsma, F.; Baiocchi, G.; Barthel, S.; Guneralp, B.; Erb, K.H.; Haberl, H.; Creutzig, F.; Seto, K.C. Future urban land expansion and implications for global croplands. Proc. Natl. Acad. Sci. USA 2017, 114, 8939–8944. [Google Scholar] [CrossRef] [PubMed]
- Rudel, T.K.; Schneider, L.; Uriarte, M.; Turner, B.L.; DeFries, R.; Lawrence, D.; Geoghegan, J.; Hecht, S.; Ickowitz, A.; Lambin, E.F.; et al. Agricultural intensification and changes in cultivated areas, 1970–2005. Proc. Natl. Acad. Sci. USA 2009, 106, 20675–20680. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, H.; Gu, X.; Liu, J.; Yin, Z.; Sun, Q.; Wei, Z.; Pan, Y. Monitoring the spatio-temporal changes of non-cultivated land via long-time series remote sensing images in xinghua. IEEE Access 2022, 10, 84518–84534. [Google Scholar] [CrossRef]
- Bizikova, L.; Jungcurt, S.; McDougal, K.; Tyler, S. How can agricultural interventions enhance contribution to food security and sdg 2.1? Glob. Food Secur. 2020, 26, 100450. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.S.; Gumma, M.K.; Teluguntla, P.; Poehnelt, J.; Congalton, R.G.; Yadav, K.; Thau, D. Automated cropland mapping of continental africa using google earth engine cloud computing. ISPRS J. Photogramm. Remote Sens. 2017, 126, 225–244. [Google Scholar] [CrossRef]
- Waldner, F.; Canto, G.S.; Defourny, P. Automated annual cropland mapping using knowledge-based temporal features. ISPRS J. Photogramm. Remote Sens. 2015, 110, 1–13. [Google Scholar] [CrossRef]
- Liu, W.; Wu, Z.; Luo, J.; Sun, Y.; Wu, T.; Zhou, N.; Hu, X.; Wang, L.; Zhou, Z. A divided and stratified extraction method of high-resolution remote sensing information for cropland in hilly and mountainous areas based on deep learning. Acta Geod. Cartogr. Sin. 2021, 50, 105–116. [Google Scholar]
- Potapov, P.; Turubanova, S.; Hansen, M.C.; Tyukavina, A.; Zalles, V.; Khan, A.; Song, X.P.; Pickens, A.; Shen, Q.; Cortez, J. Global maps of cropland extent and change show accelerated cropland expansion in the twenty-first century. Nat. Food 2022, 3, 19–28. [Google Scholar] [CrossRef]
- Pittman, K.; Hansen, M.C.; Becker-Reshef, I.; Potapov, P.V.; Justice, C.O. Estimating global cropland extent with multi-year modis data. Remote Sens. 2010, 2, 1844–1863. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.S.; Maunahan, A.; Islam, S.; Nelson, A. Mapping seasonal rice cropland extent and area in the high cropping intensity environment of bangladesh using modis 500 m data for the year 2010. ISPRS J. Photogramm. Remote Sens. 2014, 91, 98–113. [Google Scholar] [CrossRef]
- Zhang, C.; Dong, J.; Ge, Q. Mapping 20 years of irrigated croplands in china using modis and statistics and existing irrigation products. Sci. Data 2022, 9, 407. [Google Scholar] [CrossRef] [PubMed]
- Dong, J. State of the art and perspective of agricultural land use remote sensing information extraction. J. Geo-Inf. Sci. 2020, 22, 772–783. [Google Scholar]
- Azzari, G.; Lobell, D.B. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sens. Environ. 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of australia and china using random forest machine learning algorithm on google earth engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Tu, Y.; Wu, S.; Chen, B.; Weng, Q.; Bai, Y.; Yang, J.; Yu, L.; Xu, B. A 30 m annual cropland dataset of china from 1986 to 2021. Earth Syst. Sci. Data 2024, 16, 2297–2316. [Google Scholar] [CrossRef]
- Xiong, J.; Thenkabail, P.; Tilton, J.; Gumma, M.; Teluguntla, P.; Oliphant, A.; Congalton, R.; Yadav, K.; Gorelick, N. Nominal 30-m cropland extent map of continental africa by integrating pixel-based and object-based algorithms using sentinel-2 and landsat-8 data on google earth engine. Remote Sens. 2017, 9, 1065. [Google Scholar] [CrossRef]
- Oliphant, A.J.; Thenkabail, P.S.; Teluguntla, P.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K. Mapping cropland extent of southeast and northeast asia using multi-year time-series landsat 30-m data using a random forest classifier on the google earth engine cloud. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 110–124. [Google Scholar] [CrossRef]
- Hao, J.; Lin, Q.; Wu, T.; Chen, J.; Li, W.; Wu, X.; Hu, G.; La, Y. Spatial–temporal and driving factors of land use/cover change in mongolia from 1990 to 2021. Remote Sens. 2023, 15, 1813. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, J. Ecological security assessment of selenge river basin in mongolia based on psr model. J. Agric. Big Data 2023, 5, 87–94. [Google Scholar]
- Ren, Y.; Li, Z.; Li, J.; Ding, Y.; Miao, X. Analysis of land use/cover change and driving forces in the selenga river basin. Sensors 2022, 22, 1041. [Google Scholar] [CrossRef] [PubMed]
- Taskin, G.; Kaya, H.; Bruzzone, L. Feature selection based on high dimensional model representation for hyperspectral images. IEEE Trans. Image Process. 2017, 26, 2918–2928. [Google Scholar] [CrossRef] [PubMed]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Bhargava, A.; Sachdeva, A.; Sharma, K.; Alsharif, M.H.; Uthansakul, P.; Uthansakul, M. Hyperspectral imaging and its applications: A review. Heliyon 2024, 10, e33208. [Google Scholar] [CrossRef]
- Sankey, T.T.; Massey, R.; Yadav, K.; Congalton, R.G.; Tilton, J.C. Post-socialist cropland changes and abandonment in mongolia. Land Degrad. Dev. 2018, 29, 2808–2821. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Jun, C.; Ban, Y.; Li, S. Open access to earth land-cover map. Nature 2014, 514, 434. [Google Scholar] [CrossRef] [PubMed]
- Qiu, B.; Liu, B.; Tang, Z.; Dong, J.; Xu, W.; Liang, J.; Chen, N.; Chen, J.; Wang, L.; Zhang, C.; et al. National-scale 10-m maps of cropland use intensity in china during 2018–2023. Sci. Data 2024, 11, 691. [Google Scholar] [CrossRef]
- Liu, L.; Kang, S.; Xiong, X.; Qin, Y.; Wang, J.; Liu, Z.; Xiao, X. Cropping intensity map of china with 10 m spatial resolution from analyses of time-series landsat-7/8 and sentinel-2 images. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103504. [Google Scholar] [CrossRef]
- Shi, K.; Yang, Q.; Li, Y.; Sun, X. Mapping and evaluating cultivated land fallow in southwest china using multisource data. Sci. Total Environ. 2019, 654, 987–999. [Google Scholar] [CrossRef]
- Svoboda, J.; Štych, P.; Laštovička, J.; Paluba, D.; Kobliuk, N. Random forest classification of land use, land-use change and forestry (lulucf) using sentinel-2 data—A case study of czechia. Remote Sens. 2022, 14, 1189. [Google Scholar] [CrossRef]
- Shao, Z.; Ahmad, M.N.; Javed, A. Comparison of random forest and xgboost classifiers using integrated optical and sar features for mapping urban impervious surface. Remote Sens. 2024, 16, 665. [Google Scholar] [CrossRef]
- Xu, S.; Xiao, W.; Ruan, L.; Chen, W.; Du, J. Assessment of ensemble learning for object-based land cover mapping using multi-temporal sentinel-1/2 images. Geocarto Int. 2023, 38, 2195832. [Google Scholar] [CrossRef]
- Subedi, M.R.; Portillo-Quintero, C.; McIntyre, N.E.; Kahl, S.S.; Cox, R.D.; Perry, G.; Song, X. Ensemble machine learning on the fusion of sentinel time series imagery with high-resolution orthoimagery for improved land use/land cover mapping. Remote Sens. 2024, 16, 2778. [Google Scholar] [CrossRef]
- Mohanty, V.; Behera, D.K.; Panda, A.R.; Swetanisha, S. Comparative analysis of machine learning and deep learning models for lulc classification using remote sensing data. Indian J. Sci. Technol. 2025, 18, 1397–1409. [Google Scholar] [CrossRef]
- Konagaya, Y. The impact of agricultural development on nomadic pastoralism in mongolia. In The Mongolian Ecosystem Network; Springer: Tokyo, Japan, 2013; pp. 255–267. [Google Scholar]
- National Statistical Office of Mongolia. Mongolia Statistical Yearbook 2005; National Statistical Office of Mongolia: Ulaanbaatar, Mongolia, 2006. [Google Scholar]
- FAO. World Food and Agriculture—Statistical Yearbook 2024; FAO: Rome, Italy, 2024. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Satellite | Sensor | Bands | Resolution | Year | Scenes |
|---|---|---|---|---|---|
| Landsat 5 | Thematic Mapper | B1 Blue | 30 m | 1990 1995 2000 2005 2010 | 236 285 305 322 291 |
| B2 Green | 30 m | ||||
| B3 Red | 30 m | ||||
| B4 Nir | 30 m | ||||
| B5 Swir1 | 30 m | ||||
| B6 Thermal | 120 m | ||||
| B7 Swir2 | 30 m | ||||
| Landsat 8 | Operational Land Imager | B1 Coastal | 30 m | 2015 | 272 |
| B2 Blue | 30 m | ||||
| B3 Green | 30 m | ||||
| B4 Red | 30 m | ||||
| B5 Nir | 30 m | ||||
| B6 Swir1 | 30 m | ||||
| B7 Swir2 | 30 m | ||||
| B8 Pan | 15 m | ||||
| B9 Cirrus | 30 m | ||||
| Sentinel-2 | Multi-Spectral Instrument | B1 Coastal | 60 m | 2020 2023 | 1133 683 |
| B2 Blue | 10 m | ||||
| B3 Green | 10 m | ||||
| B4 Red | 10 m | ||||
| B5 RE1 | 20 m | ||||
| B6 RE2 | 20 m | ||||
| B7 Nir1 | 20 m | ||||
| B8 Nir2 | 10 m | ||||
| B8a Nir3 | 20 m | ||||
| B9 Water vapor | 60 m | ||||
| B10 Cirrus | 60 m | ||||
| B11 Swir1 | 20 m | ||||
| B12 Swir2 | 20 m |
| Spectral Index | Formulation |
|---|---|
| NDVI | |
| BSI | |
| EVI | |
| SAVI | |
| NDWI |
| Texture Feature | Formulation |
|---|---|
| Asm(Angular Second Moment) | |
| Ent(Entropy) | |
| Con(Contrast) | |
| Idm(Inverse Difference Moment) | |
| Corr(Correlation) | |
| Var(Variance) | |
| Savg(Sum Average) | |
| Svag(Sum Variance) | |
| Sent(Sum Entropy) |
| Year | Cultivated Land | Non-Cultivated Land | Total |
|---|---|---|---|
| 1990 | 248 | 372 | 620 |
| 1995 | 205 | 306 | 511 |
| 2000 | 200 | 272 | 472 |
| 2005 | 211 | 429 | 640 |
| 2010 | 272 | 490 | 762 |
| 2015 | 302 | 458 | 760 |
| 2020 | 265 | 466 | 731 |
| 2023 | 240 | 493 | 733 |
| Arkhangai | Bulgan | Darkhan | Zavkhan | Khentii | Khuvsgul | Orhon | Oevoerkhangai | Selenge | Tuv | Ulaanbaatar | Sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1990 | 337.01 | 1571.68 | 1241.69 | 15.70 | 28.22 | 569.19 | 97.60 | 162.78 | 7807.47 | 2830.40 | 137.48 | 14,799.22 |
| 1995 | 10.97 | 1051.86 | 687.96 | 2.20 | 4.61 | 237.86 | 42.19 | 2.53 | 6721.63 | 2570.58 | 11.75 | 11,344.14 |
| 2000 | 205.40 | 1666.88 | 709.70 | 9.28 | 9.12 | 864.42 | 43.81 | 17.37 | 4034.30 | 2183.65 | 66.45 | 9810.37 |
| 2005 | 156.96 | 973.53 | 284.97 | 28.85 | 0.01 | 505.56 | 34.75 | 12.82 | 2886.49 | 1438.40 | 10.42 | 6332.78 |
| 2010 | 69.35 | 1067.92 | 320.94 | 65.11 | 0.30 | 546.28 | 44.42 | 8.24 | 3432.81 | 2070.90 | 28.51 | 7654.78 |
| 2015 | 247.63 | 1181.77 | 482.68 | 21.66 | 1.66 | 409.24 | 39.89 | 47.53 | 3599.06 | 1976.48 | 11.30 | 8018.91 |
| 2020 | 120.98 | 988.42 | 407.89 | 3.01 | 0.00 | 385.12 | 82.10 | 149.73 | 4016.56 | 2222.68 | 33.21 | 8409.69 |
| 2023 | 181.96 | 754.33 | 642.79 | 11.44 | 2.74 | 480.72 | 54.98 | 63.25 | 4091.14 | 2701.43 | 23.27 | 9008.04 |
| Year | OA | Kappa |
|---|---|---|
| 1990 | 0.9121 | 0.8410 |
| 1995 | 0.9072 | 0.8325 |
| 2000 | 0.9058 | 0.8230 |
| 2005 | 0.9023 | 0.8121 |
| 2010 | 0.9376 | 0.8673 |
| 2015 | 0.9016 | 0.8152 |
| 2020 | 0.9272 | 0.8573 |
| 2023 | 0.9123 | 0.8531 |
| Integrated Strategy | Base Models | Advantages/Disadvantages | OA | Kappa |
|---|---|---|---|---|
| Bagging [31] | RF | Limited bias reduction; computationally intensive with many models | 0.8945 | 0.8274 |
| Boosting [32] | RF; XGBoost | Prone to overfitting noisy data; sensitive to outliers | 0.9056 | 0.8312 |
| Voting [33] | RF; SVM; KNN | Performance bounded by weakest base model | 0.8761 | 0.8012 |
| Stacking [34] | RF; XGBoost; GBM | Risk of meta-earner overfitting; complex training and data splitting | 0.9264 | 0.8671 |
| Blending [35] | XGBoost; SVM | Require careful validation-set tuning | 0.8614 | 0.7890 |
| Our method | RF, SVM | Simple and efficient; highly stable; avoid overfitting; offers interpretability and discriminative power | 0.9123 | 0.8531 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Y.; Wang, J.; Li, K.; Chonokhuu, S. Long-Term Spatiotemporal Information Extraction of Cultivated Land in the Nomadic Area: A Case Study of the Selenge River Basin. Remote Sens. 2025, 17, 1970. https://doi.org/10.3390/rs17121970
Sun Y, Wang J, Li K, Chonokhuu S. Long-Term Spatiotemporal Information Extraction of Cultivated Land in the Nomadic Area: A Case Study of the Selenge River Basin. Remote Sensing. 2025; 17(12):1970. https://doi.org/10.3390/rs17121970
Chicago/Turabian StyleSun, Yifei, Juanle Wang, Kai Li, and Sonomdagva Chonokhuu. 2025. "Long-Term Spatiotemporal Information Extraction of Cultivated Land in the Nomadic Area: A Case Study of the Selenge River Basin" Remote Sensing 17, no. 12: 1970. https://doi.org/10.3390/rs17121970
APA StyleSun, Y., Wang, J., Li, K., & Chonokhuu, S. (2025). Long-Term Spatiotemporal Information Extraction of Cultivated Land in the Nomadic Area: A Case Study of the Selenge River Basin. Remote Sensing, 17(12), 1970. https://doi.org/10.3390/rs17121970