1. Introduction
Throughout history, natural disasters have persistently challenged the resilience of our societies, often leading to tragic losses of life and widespread destruction. From 1998 to 2017, over 35,000 such events have resulted in more than one million deaths and 4.4 billion injuries [
1]. For instance, the 2011 Fukushima tsunami resulted in significant human and structural losses [
2], shown in
Figure 1. In recent years, technological advancements in forecasting natural hazards have contributed to reducing fatalities from disasters. However, forecasting systems show varied reliability across different disaster types and are insufficient as standalone solutions for comprehensive emergency management. Critically, the majority of disaster-related casualties occur within the initial hours following a disaster event, often due to delayed rescue operations. This reality positions effective disaster response as a crucial complement to forecasting efforts. Therefore, the ability to rapidly and accurately assess building damage is important to effective disaster response, guiding the deployment of rescue and aid efforts where they are needed the most. Meanwhile, beyond binary evaluation of damage, e.g., no damage or damaged building, a nuanced determination of damage severity from minor to complete destruction is needed and instrumental in optimizing rescue team deployment and enhancing the overall response efficacy.
As the need for accurate damage evaluation becomes increasingly recognized, experts across diverse fields such as geology, meteorology, and oceanography are enlisted to provide real-time data analysis and expert guidance during rescue missions. However, the sheer scale of devastation a single disaster can inflict, impacting an entire city or country, renders manual assessment methods impractical and unsustainable. While expert input is invaluable, the extensive scope of major disasters can compromise the effectiveness of such evaluations, introducing a high likelihood of error due to fatigue and the overwhelming volume of assessments required. Additionally, these assessments are subject to biases and subjectivity inherent to individual evaluators, which could skew the critical objectivity needed in these urgent situations. Therefore, there is a pressing need for a reliable and objective system capable of assessing damage across extensive areas, enhancing the efficiency and effectiveness of emergency response efforts by accurately determining the need and urgency of the situation.
As technology advances in remote sensing, satellites are capable of capturing high-resolution imagery for an area before and after a disaster event. As referenced in
Figure 1 and
Figure 2, the discrepancy between pre- and post-disaster images illustrates the transformative impact caused by natural disasters on the built environment. Those completely destroyed buildings are evident and easily recognizable from images. High-quality satellite images provide emergency management teams with a complementary approach to rapidly evaluate the extent of building damage in a disaster-affected area. However, accurately assessing the extent of damage with fine granularity, such as damage level 2 (minor damage) or 3 (major damage), of the buildings is hard but much needed. Such detailed and precise damage assessment can be crucial for directing emergency response efforts and allocating resources effectively to the areas in the greatest need.
Machine learning techniques have drastically transformed the analysis of satellite imagery, automating processes and enhancing prediction accuracy. However, a critical limitation of these state-of-the-art models is their specialized design, which is often tailored for a specific type of disaster or distinct geographical region. This specialization significantly restricts their generalizability and applicability across varying scenarios. When confronted with disasters beyond their training scope, these models often exhibit diminished performance, underscoring their limited versatility across different disaster types and regions. Furthermore, these approaches typically necessitate training the entire model from scratch, which demands significant computational resources, extensive datasets, and substantial training time. This requirement not only increases the training burden but also limits the models’ ability to be promptly applied to new or unforeseen disaster scenarios. This specialization and inefficiency highlight a critical research gap: the absence of a unified model that can seamlessly handle various disaster types and geo-locations while circumventing the computational and data-intensive demand of traditional deep learning’s full-model training process.
As the field of damage evaluation evolves, it has produced a range of sophisticated models and algorithms capable of assessing damage severity from satellite imagery. However, despite these technological advances, the field still faces significant challenges that hinder further progress: (1) Image Classification and Damage Detection: Earlier approaches utilized image classification models to distinguish between damaged and undamaged buildings within satellite imagery of disaster-affected areas. The authors of [
3] propose such a model specifically for hurricane damage detection, although its application was confined to hurricanes, highlighting a gap in generalizability across different disaster types. Similarly, the authors from [
4] develop three image classification models for damage prediction that lack building localization capabilities, suggesting the necessity of integrating these models with localization techniques for practical use. (2) Utilization of Pre- and Post-Disaster Imagery: The difference between pre- and post-disaster imagery has been leveraged for assessing building damage. The authors of [
5] utilize this contrast but face challenges with varying building types. In contrast, ref. [
6] employs a method that identifies building locations in pre-disaster images, using those same locations to extract features from the corresponding post-disaster images. However, this approach is limited by its reliance on spatial consistency across the image pairs. Any misalignment between pre- and post-disaster images can compromise their reliability. Similar to the adaptation method proposed in [
7], our unified model addresses this limitation by processing the pre- and post-disaster image pair simultaneously, allowing the model to learn to manage misalignments within the data. With sufficient training data, the deep learning model can automatically adapt to spatial inconsistencies, enhancing robustness in damage detection. (3) Ensemble Methods: The adoption of two-stage methods for damage detection, as proposed in [
8,
9,
10], increases computational cost because it utilizes separate models for building detection and damage level classification. The common challenges faced by all of these approaches are the specificity of models to particular disasters, the binary approach to damage assessment, the reliance on two-stage processing pipelines, the underutilization of valuable pre-disaster imagery, and the dependency on hard-coded distance calculations for feature comparison. These gaps highlight the need for a more adaptable, universally applicable model that can handle various disaster types and geographical locations efficiently. (4) 3D Data-driven Methods: Several recent studies have demonstrated the potential of 3D data, such as LiDAR point clouds and UAV-based photogrammetry, for building damage assessment (e.g., [
10,
11,
12]). These methods can capture structural deformations with high spatial precision; however, they face significant limitations in practice. The collection and processing of 3D data are often resource-intensive, require specialized equipment and/or flight path planning (and approval), and are not always feasible in post-disaster scenarios due to logistical and operational constraints. Additionally, airborne LiDAR data often lack sufficient spatial resolution and temporal availability to detect subtle structural damage, particularly for smaller residential buildings or roof-level changes. In contrast, 2D satellite imagery is more readily available and easier to deploy at scale. Therefore, our work focuses on developing a scalable and generalizable 2D image-based framework that leverages contrastive learning and prompt-based adaptation for damage assessment across diverse disaster types.
The advent of foundation models such as Chat-GPT [
13] and GPT-4 [
14] has markedly advanced AI, showcasing their broad applicability, particularly in natural language processing (NLP). This success has spurred adaptations in computer vision with models such as BEiT [
15], ViT [
16], and the Segment Anything Model (SAM) [
17], which apply transformer-based processing to visual tasks. However, these models are not inherently suited for tasks requiring contrastive image analysis, such as damage assessment in remote sensing. The evolution from “pre-training and fine-tuning” to “pre-training and prompting” represents a significant trend in the deployment of foundation models [
18,
19]. Innovations such as VPT [
19], which appends a set of learnable parameters to transformer encoders, significantly outperform full fine-tuning across multiple downstream recognition tasks. AdaptFormer [
20] incorporates lightweight modules into ViT, achieving superior performance over fully fine-tuned models on action recognition benchmarks.
Overall, addressing this gap, our work introduces a unified model capable of handling diverse disasters and locations with greater efficiency. By leveraging a pre-trained vision foundation model with frozen backbone parameters, we significantly reduce computational costs and expedite the training process. Central to our approach is the innovative use of a learnable visual prompt generator that requires training on only a minimal number of parameters. This methodology not only enhances training efficiency but also extends the model’s applicability, offering a scalable and comprehensive solution to disaster damage assessment across various environments.
Therefore, our research proposes the Visual Prompt Damage Evaluation (ViPDE) framework, a novel contrastive learning-based approach that leverages the embedded knowledge within foundation models and the discrepancy within pairs of remote sensing images to enhance building damage assessment. Our contribution can be summarized as follows:
Visual Prompt Damage Evaluation Framework (ViPDE): We propose a contrastive learning-based dual-branch architecture that enables the Segment Anything Model (SAM) to dynamically utilize high-level features from paired pre- and post-disaster satellite images to enhance building damage evaluation. ViPDE integrates cascaded lightweight learnable Visual Prompt Generators while keeping the foundation model’s pre-trained weights frozen. This approach effectively utilizes the contrasts between the image pair to enhance accuracy and efficiently fine-tunes the model’s performance for damage evaluation while avoiding the extensive retraining that traditional methods typically require.
Visual Prompt Generator (VPG): We introduce a learnable, lightweight, cascaded Visual Prompt Generator that provides tailored visual prompts, enriched with semantic information from pre- and post-disaster images. These prompts act as navigational cues, focusing the pre-trained vision foundation models on essential damage indicators. The generator’s design, with its minimal trainable parameters, strategically amplifies the model’s pre-trained knowledge, enabling a more precise and expedient evaluation of disaster damage.
Prompt-Driven Contrastive Learning: Our framework introduces a novel visual prompting mechanism that enables a frozen vision foundation model (SAM) to perform contrastive analysis between pre- and post-disaster image pairs without modifying its internal representations. By leveraging contrastive learning at the prompt level, the model is guided to attend to semantic discrepancies indicative of damage, enhancing its ability to segment buildings into detailed categories: “no damage”, “minor damage”, “major damage”, and “destroyed”. This disaster-agnostic design allows for direct deployment across a wide range of natural disasters and geographic regions without the need for retraining or full-model fine-tuning. The resulting fine-grained assessments are crucial for the timely and targeted deployment of emergency resources, improving the overall effectiveness of disaster response efforts.
The remainder of this paper is structured as follows:
Section 1 provides a review of the relevant literature.
Section 2 elaborates on our methodology, detailing the innovative techniques utilized in our approach.
Section 3 describes the dataset used in this study.
Section 4 outlines the experimental setup and metrics.
Section 5 analyzes the results, discussing the implications and significance of our findings. Finally,
Section 6 summarizes the key outcomes of our research and proposes directions for future work, highlighting potential advancements of our work.
2. Methodology
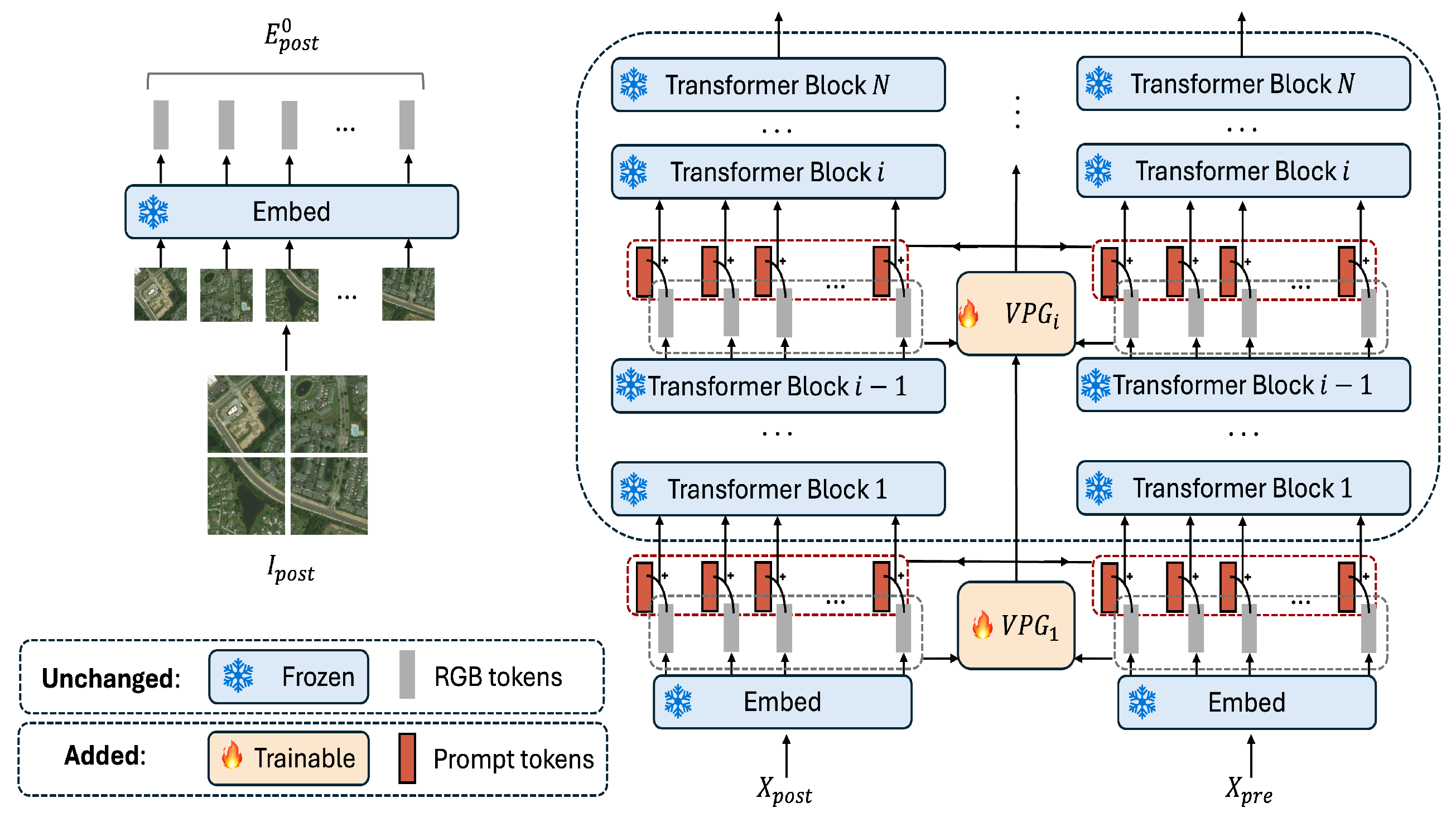
In this section, we introduce the Visual Prompt Damage Evaluation (ViPDE), a novel contrastive learning-based approach that utilizes a pre-trained vision foundation model, specifically SAM, for the semantic damage segmentation of satellite imagery. The cornerstone of ViPDE is the learnable Visual Prompt Generator (VPG) module, which can provide visual prompts guiding SAM to effectively analyze pre- and post-disaster image pairs and form a nuanced representation of the affected. As illustrated in
Figure 3, VPG is meticulously designed to generate multi-stage visual prompts enriched with semantic information extracted from both pre- and post-disaster imagery. These prompts serve as navigational semantic cues, steering the foundation model’s focus toward critical features indicative of damage. The VPG automates contrastive learning, enabling the model to effectively differentiate between damaged and undamaged areas, thereby significantly boosting accuracy in damage assessment.
2.1. The Overall Architecture of ViPDE
Our proposed approach treats the building damage evaluation task as a semantic segmentation task. It utilizes a pair of pre-disaster (
) and post-disaster (
) RGB images as the input to enhance building damage evaluation accuracy. The frozen SAM’s image encoder, structured in a sequence of Transformer blocks, is adopted to extract nuanced features from those images. For each image pair,
and
, the process begins by projecting them into initial token embeddings
and
, respectively. These embeddings are then combined with the visual prompt
(
Figure 3) to create new merged embeddings,
and
. Subsequently, these refined embeddings are processed through
N encoder Transformer blocks
, where
:
Here,
and
are outputs from the
i-th encoder block for pre- and post-disaster images, respectively. Our Visual Prompt Generator (VPG) module augments the original RGB data flow with context-specific semantic visual prompts tailored to damage assessment:
and denote the input token sequences for pre- and post-disaster images, respectively, at the i-th stage, each enhanced by the addition of prompt provided by the VPG module. This inclusion of disaster-specific prompts at multiple stages effectively enriches SAM’s semantic analysis across different levels of feature abstraction.
These processed features are combined to generate the final segmentation output
through a specialized decoder
that accounts for the nuances of disaster impact:
ViPDE maintains all SAM parameters in a frozen state, including those for patch embedding and feature extraction, except for the learnable VPG module. The VPG only introduces a minimal number of trainable parameters for generating and integrating visual prompts into the pre-disaster and post-disaster input sequences. By doing so, ViPDE ensures the pre-trained model’s architecture is preserved while enabling efficient, task-specific adaptations through prompt insertion. This approach allows for precise post-disaster damage assessment without necessitating extensive retraining or requiring an explicit distance function for alignment between pre- and post-disaster features.
2.2. Visual Prompt Generator (VPG)
As depicted in
Figure 3, our learnable VPG module is innovatively integrated at multiple stages within the foundational network to inject task-specific enhancements. The architecture of VPG is visualized in
Figure 4.
As shown in Equation (
6), visual prompt
is generated by
module based on the prompt
and embedding sequences
and
generated in the previous stage. The VPG module is designed to learn and apply visual prompts that effectively capture the difference between the pre- and post-disaster states. The process proceeds as follows:
where
denotes the input visual prompts at the
i-th stage of the Transformer blocks, seeded by three flows:
,
, and
. This strategy enables stage-wise refinement, enhancing the model’s sensitivity to visual changes induced by disasters. The VPG module undergoes three key phases: (i) projecting each flow to a lower-dimensional space for streamlined processing, (ii) enriching feature representations to highlight areas of change or damage, and (iii) merging these enhanced embeddings to form comprehensive visual prompts:
The channel size is reduced to a lower-dimensional space (from 768 to 192 channels) using 1 × 1 convolutional networks, denoted as , , and , for the pre-disaster, post-disaster, and previously generated prompt flows, respectively.
Following this, Channel Attention [
21] is applied to both
and
, focusing the model’s attention on areas of interest within the images. This module dynamically recalibrates channel-wise features using global spatial information from two pipelines: average and max pooling. Specifically, each pipeline’s importance is computed by processing the pooled features through a shared Multi-Layer Perceptron (MLP), followed by a sigmoid activation to obtain attention weights:
where
denotes the sigmoid function, ensuring the resulting attention weights range between 0 and 1; AvgPool and MaxPool represent the global average and max pooling operations; and MLP is the shared Multi-Layer Perceptron that models channel-wise dependencies. This attention mechanism significantly enhances the model’s ability to focus on regions undergoing changes between the pre- and post-disaster states, effectively highlighting areas of damage while suppressing irrelevant background noise. The feature maps,
and
, are thus refined representations that emphasize critical damage indicators for subsequent processing steps.
The subsequent phase merges the processed embeddings:
,
, and
to construct the final prompt for the next stage:
Here, is 1 × 1 ConvNet to project the features back to the original dimension.
Our decoder, as outlined in Equation (
5), processes only the final features,
and
, derived from the last set of Transformer blocks. Those features are merged and subsequently upsampled through two 2 × 2 transpose convolution layers (
) to match the resolution of the input image. Following the upsampling, a multi-scale convolutional strategy (
), as proposed in [
22], effectively integrates these features across different scales. The resulting segmentation map is generated by a linear layer (
), which classifies the level of damage for each pixel, ranging from “no damage” to “destroyed”.
Through the integration of multi-scale convolution and resolution reconstruction, the ViPDE decoder effectively synthesizes the processed features into a precise segmentation of building damage levels. This approach ensures that ViPDE not only leverages the power of pre-trained foundation models through the VPG but also applies advanced decoding techniques to achieve unparalleled accuracy in post-disaster image analysis.
3. Dataset and Loss Functions
In this study, we utilize the xBD satellite image dataset [
9], consisting of 22,068 high-resolution images (1024 × 1024 × 3) that cover a comprehensive range of pre- and post-disaster scenarios. Several samples are displayed in
Figure 2, with the top row showing pre-disaster images and the bottom row presenting the corresponding post-disaster images. These three pairs of images are sampled from three different types of disasters, i.e., tornado, flooding, and tsunami. In (a), most buildings are destroyed by the hurricane except the buildings at the bottom right corner. In (b), the building suffered major damage because it is completely surrounded by water. In (c), the two commercial buildings within the red rectangle are destroyed by the tsunami. Even though the xBD dataset has lots of merits mentioned above, there are two main issues with this dataset, which are an imbalanced class issue and a misalignment issue between pre- and post-disaster images.
The xBD dataset offers a unique advantage by providing paired pre- and post-disaster satellite images for each affected location, making it well-suited for building damage assessment tasks. As visualized in
Figure 5, the xBD dataset includes fine-grained ground truth annotations, where each building is labeled with one of four damage levels: “no damage”, “minor damage”, “major damage”, or “destroyed”. These labels are determined through expert visual analysis of image pairs, supported by metadata. The dataset covers 11 types of natural disasters—including floods, hurricanes, and earthquakes—across 19 countries and cities, with a diverse mix of residential and commercial building structures. Its scale, diversity, and detailed labeling make xBD a comprehensive benchmark for training models to generalize across varied disaster scenarios and architectural contexts.
3.1. Imbalanced Classes
In the xBD dataset, there are five classes, including “no damage”, “minor damage”, “major damage”, “destroyed”, and “unclassified”. A building labeled with “no damage” class means that there is no sign of water, structural or shingle damage, or burn marks. Buildings with “minor damage” means that these buildings are partially burnt or in water surrounding structures, etc. A building annotated as “major damage” means that there exists partial wall or roof collapse, or the building is surrounded by water or mud, etc. The “destroyed” class is for the building that is completely collapsed, covered by water or mud, etc. The “unclassified” class is the data without ground truth, which are removed from our study. Several samples are shown in
Figure 6.
The xBD dataset exhibits a significant class imbalance, where the “no damage” category dominates the label distribution. In particular, the number of “no damage” instances exceeds that of “minor damage”, “major damage”, and “destroyed” by at least an order of magnitude. As a result, models trained on this dataset tend to show low predictive accuracy for the minority classes, especially “minor” and “major” damage, which are not only underrepresented but also more difficult to distinguish due to similar visual characteristics.
Additionally, each image pair in the dataset presents a pixel-level imbalance between the background and building classes. The vast majority of pixels belong to the background, while only a small fraction corresponds to damaged or undamaged buildings. This imbalance can lead to biased training dynamics, where the model quickly minimizes loss for the dominant background class while under-optimizing for the more critical yet sparse damage-related categories. To address both types of imbalance, we integrate class-balancing strategies through a composite loss function, as discussed in
Section 3.4.
3.2. Misalignment Issues
In addition to class imbalance, another challenge in the xBD dataset is the spatial misalignment between pre- and post-disaster images. This misalignment is often caused by shifts or tilting in satellite imaging, which occur when images are captured at different times under varying conditions. For example, in some cases, the post-disaster image shows a building that is no longer aligned with the corresponding pre-disaster building footprint, sometimes appearing entirely outside the expected region. In other cases, slight angular differences introduce geometric distortions. These inconsistencies make hard-coded pixel-wise distance calculations, such as L1 or L2 distances, unreliable for assessing damage, since they assume perfect alignment between corresponding image pairs. Our method addresses this issue by leveraging a contrastive learning framework that is robust to such spatial variations.
3.3. Data Cleaning and Augmentation
In order to deal with the imbalanced data mentioned above, we applied data cleaning and augmentation to the original xBD dataset in three steps: in the first step, we eliminated the samples containing the “unclassified” class and the samples that did not contain any foreground classes. In the second step, we split the dataset obtained by step one into a 9:1 ratio to form the basic training dataset and the validation dataset. In the last step, from the basic training dataset, we find the set of images containing at least one minor or major damaged building (minor–major group) and the set in which each image is dominated by major damaged or destroyed buildings (major-destroyed group). We then add one copy of each image in the minor–major group and the major-destroyed group into the training dataset. For example, if an image contains minor, major, and destroyed buildings and is “destroyed” dominated, there will be three copies of this image, including the original one, in the training dataset. However, if it is minor-damage dominated, then only two copies, including the original image, will be in the training set. The testing set remains unaugmented, consisting of 1866 images provided by the xBD team [
9]. The size of the refined dataset is shown in
Table 1.
3.4. The Loss
As we explained above, there exist two main issues in the dataset: first, an imbalance problem between classes “no damage”, “minor damage”, “major damage”, and “destroyed”. Second, there is an imbalance issue between the negative class, “background”, and the four non-background classes. To address these two issues, we apply two strategies in constructing the loss functions. In the first strategy, the classes in the model are assigned different weights based on our empirical observations. The “no damage” class is the majority among the four non-background classes. The size of the “no damage” class is at least one order of magnitude larger than any other four “foreground” classes. Moreover, the “background” class is the majority compared with the “foreground” classes. Therefore, we assign different weights to these classes, which intends to place more emphasis on these minority classes and the classes that are harder to distinguish, including the “minor damage” class and the “major damage” class. We reduce the weights for the majority classes, including the “background” class and the “no damage” class. This operation can alleviate the negative impact caused by these two imbalanced issues. The weights used in our paper are shown in
Table 2. In practice, there exist a lot of ensemble method-based applications that train the models with different weights and sample their outputs as one output. Because of the computational cost, that line of method is not discussed in our paper.
In addition to assigning a different weight to each class, we further choose a combined loss, which consists of Cross-Entropy Loss, Dice Loss, and Focal Loss. We expect the Dice Loss to alleviate the problem caused by the imbalance between a “background” class and the “foreground” classes. Moreover, because it is hard for models to distinguish between the “minor damage” class and the “major damage” class, we expect to use Focal Loss to better address this issue.
The Cross-Entropy Loss is commonly used in segmentation tasks, which can be formulated as Equation (
14), where
n,
m,
, and
represent the number of samples, the number of classes, the ground truth label, and the predicted probability for the sample
i being class
j, respectively.
The focal loss can be formulated as Equation (
15), where
, and
is a weight hyper-parameter. When an example is misclassified and the corresponding
is small, the loss is large. However, when an example is well classified and the corresponding
is close to 1, the loss for this well-classified example is down-weighted [
23]. This is helpful for models to distinguish the “minor damage” class from the “major damage” class.
Dice Loss is one of the losses that can be used to directly optimize the segmentation metric (F1 score). It aims to minimize the mismatched regions and maximize the overlap regions between the ground truth and predicted segmentation [
24]. It evolves from the Dice coefficient which is shown in
Figure 7. In this figure, the shaded area is the overlap of the ground truth and the prediction. The numerator consists of twice the overlap, and the denominator is the sum of the ground truth and the prediction. Dice Loss can be defined as Equation (
16), where
is a small positive infinitesimal quantity.
The definition of the total loss for the proposed Siamese-based model is shown in Equation (
17), where
,
, and
represents the weights for the Cross-Entropy Loss, the Focal Loss, and the Dice Loss, respectively. Based on empirical tuning and following a widely adopted strategy in segmentation tasks, we assign a larger weight to the Cross-Entropy Loss, as it provides stable convergence across all classes. The Focal Loss and Dice Loss are incorporated as auxiliary components to improve performance on imbalanced data and hard-to-classify samples. Specifically, Dice Loss addresses pixel-level foreground–background imbalance, while Focal Loss emphasizes learning on underrepresented and ambiguous damage categories, such as “minor” and “major” damage. Based on this rationale, the weights for the Cross-Entropy Loss, the Focal Loss, and the Dice Loss are set and tuned to be 0.8, 0.1, and 0.1, respectively.
6. Conclusions
This work introduces the Visual Prompt Damage Evaluation (ViPDE), a pioneering approach that integrates prompt learning and contrastive learning with building damage evaluation to enhance post-disaster analysis through satellite imagery. By employing the Segment Anything Model (SAM) and innovatively utilizing pre- and post-disaster imagery, our approach demonstrates a significant advancement in the field of disaster management technology.
Our learnable Visual Prompt Generator (VPG) module, a cornerstone of ViPDE, showcases the utility of semantic visual prompts in directing pre-trained vision foundation models for detailed damage evaluation. This method not only streamlines the adaptation process of these models to the task of disaster damage assessment but also circumvents the limitations posed by conventional, computationally intensive data fusion techniques.
Extensive experiments validate the effectiveness of ViPDE, with our model outperforming state-of-the-art methods. The ablation study further underscores the significance of incorporating pre-disaster imagery, affirming the dual-branch model’s superior performance.
ViPDE establishes a new standard in disaster management, providing a scalable, precise, and versatile tool for post-disaster damage assessment. Looking forward, we aim to expand this approach to encompass a broader range of disaster types, enhancing the model’s applicability and effectiveness. Future work will also focus on developing sophisticated alignment techniques to address the misalignment issues prevalent in the dataset and on testing the adaptability of our VPG within other contrastive learning-based tasks in diverse domains.











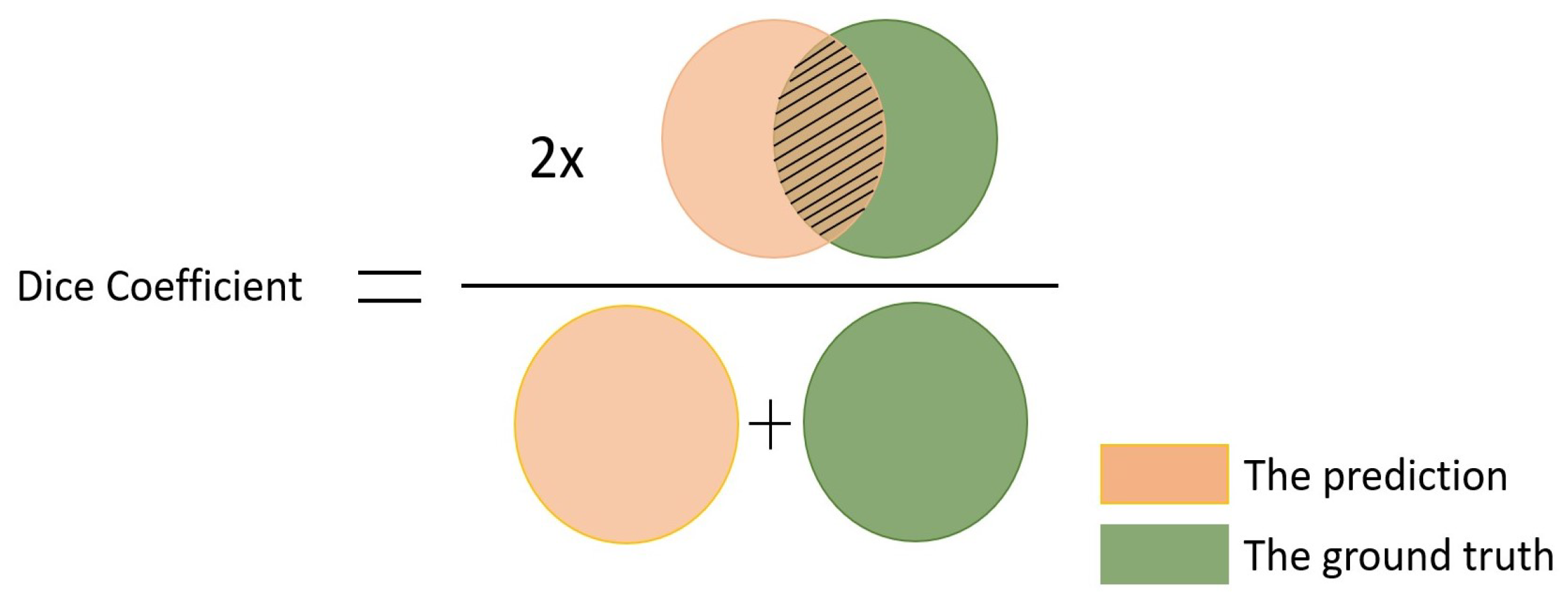

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}