
Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events




Abstract
1. Introduction
2. Data Sources and Methods
2.1. Study Area
2.2. Data Sources
2.2.1. Satellite Data
2.2.2. Meteorological Data
2.2.3. Crop Data
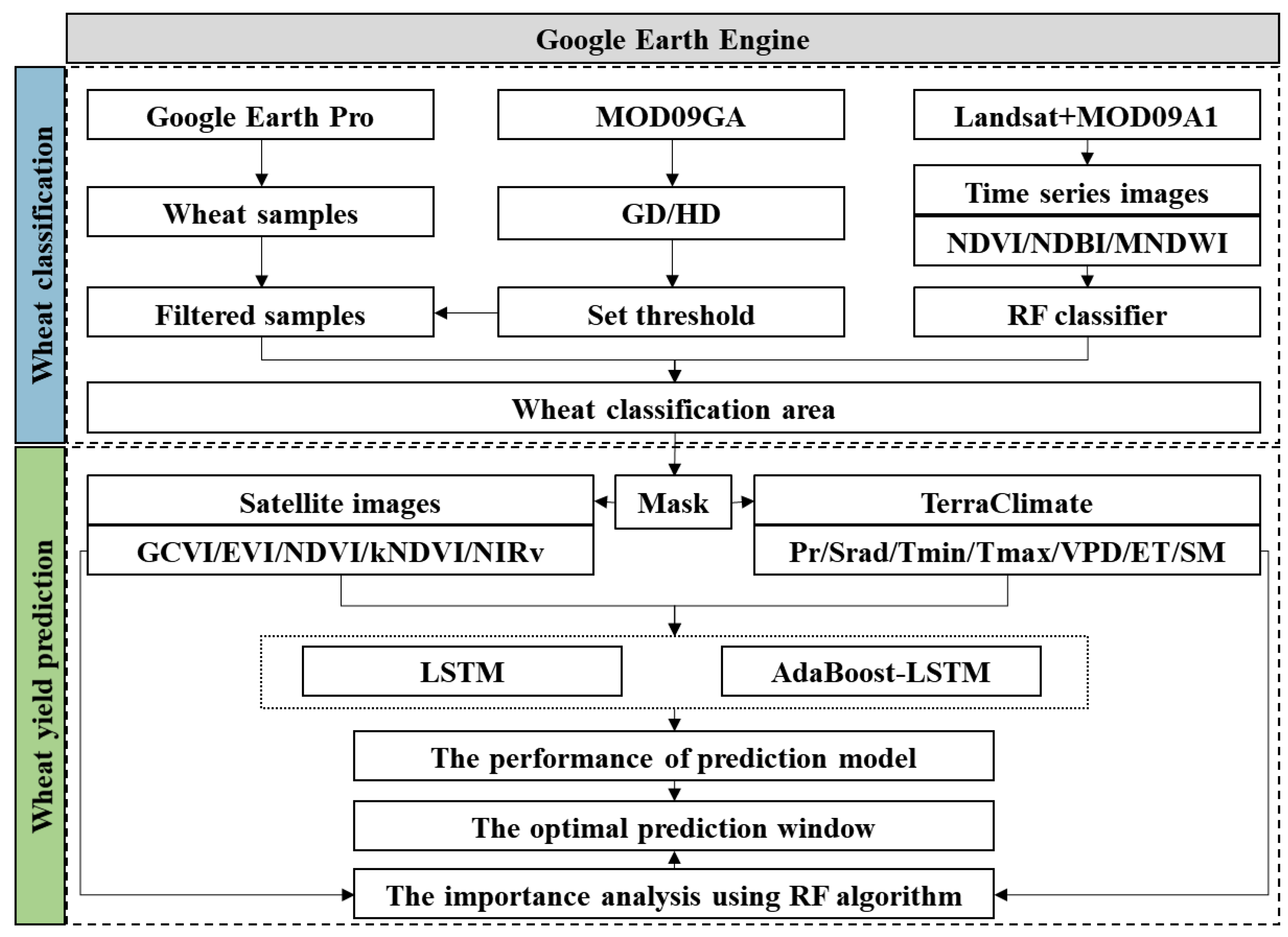
2.3. Methods
2.3.1. Extraction of Planting Area
2.3.2. Development of Wheat Yield Prediction Model
2.4. Assessment of Model Performance
3. Results
3.1. Wheat Planting Map at 30 m Spatial Resolution
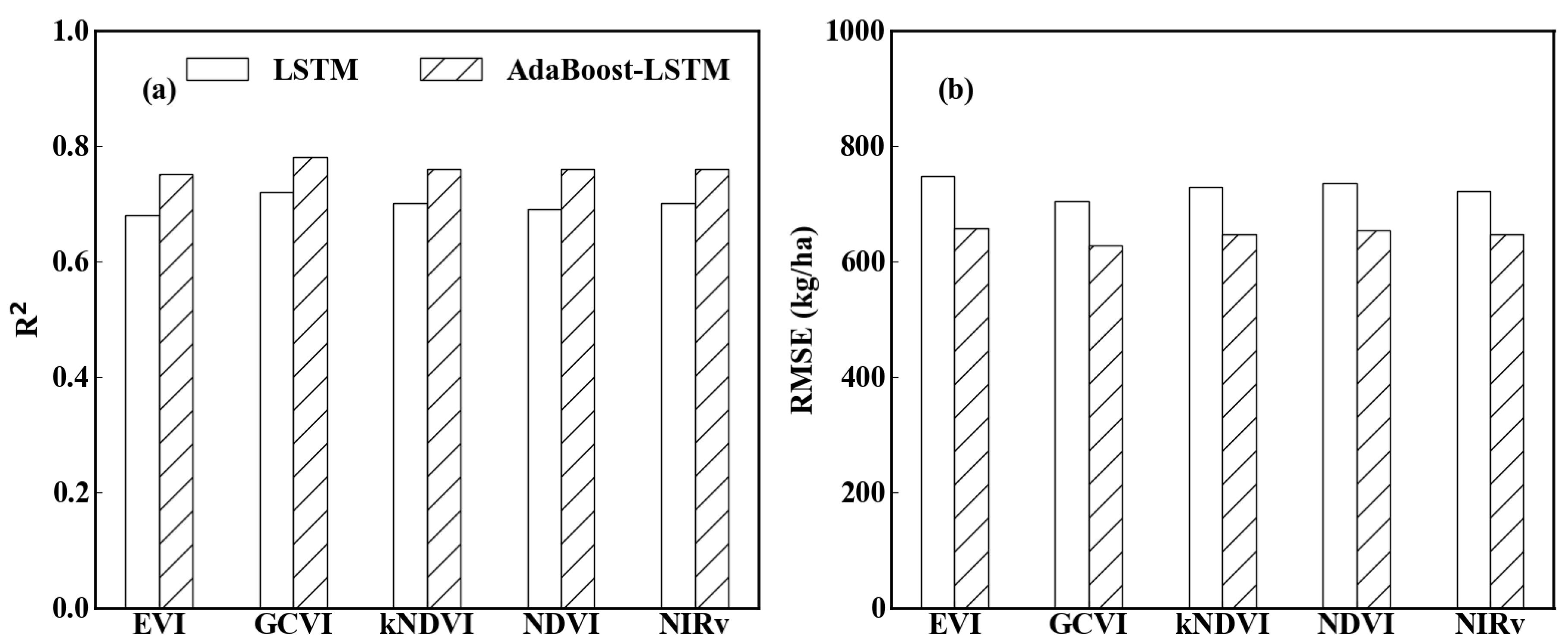
3.2. Performances of Different Yield Prediction Models
3.3. Performance of the Optimal Model under Different Irrigation and Extreme Weather Events
3.4. The Optimal Prediction Window for Wheat Yield Prediction in the HHHP
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kong, X.; Lal, R.; Li, B.; Liu, H.; Li, K.; Feng, G.; Zhang, Q.; Zhang, B. Fertilizer Intensification and Its Impacts in China’s HHH Plains. In Advances in Agronomy; Sparks, D.L., Ed.; Academic Press: Cambridge, MA, USA, 2014; Volume 125, pp. 135–169. [Google Scholar]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- Tao, F.; Zhang, L.; Zhang, Z.; Chen, Y. Designing wheat cultivar adaptation to future climate change across China by coupling biophysical modelling and machine learning. Eur. J. Agron. 2022, 136, 126500. [Google Scholar] [CrossRef]
- Vintrou, E.; Desbrosse, A.; Bégué, A.; Traoré, S.; Baron, C.; Lo Seen, D. Crop area mapping in West Africa using landscape stratification of MODIS time series and comparison with existing global land products. Int. J. Appl. Earth. Obs. 2012, 14, 83–93. [Google Scholar] [CrossRef]
- Benami, E.; Jin, Z.; Carter, M.R.; Ghosh, A.; Hijmans, R.J.; Hobbs, A.; Kenduiywo, B.; Lobell, D.B. Uniting remote sensing, crop modelling and economics for agricultural risk management. Nat. Rev. Earth Environ. 2021, 2, 140–159. [Google Scholar] [CrossRef]
- Zhou, K.; Cao, L.; Shen, X.; Wang, G. Novel spectral indices for enhanced estimations of 3-dimentional flavonoid contents for Ginkgo plantations using UAV-borne LiDAR and hyperspectral data. Remote Sens. Environ. 2023, 299, 113882. [Google Scholar] [CrossRef]
- Satir, O.; Berberoglu, S. Crop yield prediction under soil salinity using satellite derived vegetation indices. Field Crops Res. 2016, 192, 134–143. [Google Scholar] [CrossRef]
- Jeffries, G.R.; Griffin, T.S.; Fleisher, D.H.; Naumova, E.N.; Koch, M.; Wardlow, B.D. Mapping sub-field maize yields in Nebraska, USA by combining remote sensing imagery, crop simulation models, and machine learning. Precis. Agric. 2019, 21, 678–694. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Yu, Q. Incorporating machine learning with biophysical model can improve the evaluation of climate extremes impacts on wheat yield in south-eastern Australia. Agric. For. Meteorol. 2019, 275, 100–113. [Google Scholar] [CrossRef]
- Li, Y.; Guan, K.; Yu, A.; Peng, B.; Zhao, L.; Li, B.; Peng, J. Toward building a transparent statistical model for improving crop yield prediction: Modeling rainfed corn in the U.S. Field Crops Res. 2019, 234, 55–65. [Google Scholar] [CrossRef]
- Kamir, E.; Waldner, F.; Hochman, Z. Estimating wheat yields in Australia using climate records, satellite image time series and machine learning methods. ISPRS. J. Photogramm. 2020, 160, 124–135. [Google Scholar] [CrossRef]
- Oliveira, R.A.; Näsi, R.; Niemeläinen, O.; Nyholm, L.; Honkavaara, E. Machine learning estimators for the quantity and quality of grass swards used for silage production using drone-based imaging spectrometry and photogrammetry. Remote Sens. Environ. 2020, 246, 111830. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Liu, D.L.; Waters, C.; Xiao, D.; Shi, L.; Yu, Q. Dynamic wheat yield forecasts are improved by a hybrid approach using a biophysical model and machine learning technique. Agric. For. Meteorol. 2020, 285–286, 107922. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Khaki, S.; Pham, H.; Wang, L. Simultaneous corn and soybean yield prediction from remote sensing data using deep transfer learning. Sci. Rep. 2021, 11, 11132. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Zhang, Z.; Kang, Y.; Özdoğan, M. Corn yield prediction and uncertainty analysis based on remotely sensed variables using a Bayesian neural network approach. Remote Sens. Environ. 2021, 259, 112408. [Google Scholar] [CrossRef]
- Tian, H.; Wang, P.; Tansey, K.; Zhang, J.; Zhang, S.; Li, H. An LSTM neural network for improving wheat yield estimates by integrating remote sensing data and meteorological data in the Guanzhong Plain, PR China. Agric. For. Meteorol. 2021, 310, 108629. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Luo, Y.; Cao, J.; Xie, R.; Li, S. Integrating satellite-derived climatic and vegetation indices to predict smallholder maize yield using deep learning. Agric. For. Meteorol. 2021, 311, 108666. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, Z.; Ma, Y.; Du, Q.; Williams, P.; Drewry, J.; Luck, B. Alfalfa Yield Prediction Using UAV-Based Hyperspectral Imagery and Ensemble Learning. Remote Sens. 2020, 12, 2028. [Google Scholar] [CrossRef]
- Fu, B.; He, X.; Yao, H.; Liang, Y.; Deng, T.; He, H.; Fan, D.; Lan, G.; He, W. Comparison of RFE-DL and stacking ensemble learning algorithms for classifying mangrove species on UAV multispectral images. Int. J. Appl. Earth Obs. 2022, 112, 102890. [Google Scholar] [CrossRef]
- Long, X.; Li, X.; Lin, H.; Zhang, M. Mapping the vegetation distribution and dynamics of a wetland using adaptive-stacking and Google Earth Engine based on multi-source remote sensing data. Int. J. Appl. Earth. Obs. 2021, 102, 102453. [Google Scholar] [CrossRef]
- Ma, J.-W.; Nguyen, C.-H.; Lee, K.; Heo, J. Regional-scale rice-yield estimation using stacked auto-encoder with climatic and MODIS data: A case study of South Korea. Int. J. Remote Sens. 2019, 40, 51–71. [Google Scholar] [CrossRef]
- Feng, L.; Li, Y.; Wang, Y.; Du, Q. Estimating hourly and continuous ground-level PM2.5 concentrations using an ensemble learning algorithm: The ST-stacking model. Atmos. Environ. 2020, 223, 117242. [Google Scholar] [CrossRef]
- Jiang, Z.; Yang, S.; Smith, P.; Pang, Q. Ensemble machine learning for modeling greenhouse gas emissions at different time scales from irrigated paddy fields. Field Crops Res. 2023, 292, 108821. [Google Scholar] [CrossRef]
- Su, B.; Huang, J.; Mondal, S.K.; Zhai, J.; Wang, Y.; Wen, S.; Gao, M.; Lv, Y.; Jiang, S.; Jiang, T.; et al. Insight from CMIP6 SSP-RCP scenarios for future drought characteristics in China. Atmos. Res. 2021, 250, 105375. [Google Scholar] [CrossRef]
- Yu, W.; Yang, G.; Li, D.; Zheng, H.; Yao, X.; Zhu, Y.; Cao, W.; Qiu, L.; Cheng, T. Improved prediction of rice yield at field and county levels by synergistic use of SAR, optical and meteorological data. Agric. For. Meteorol. 2023, 342, 109729. [Google Scholar] [CrossRef]
- Li, M.; Zhao, J.; Yang, X. Building a new machine learning-based model to estimate county-level climatic yield variation for maize in Northeast China. Comput. Electron. Agric. 2021, 191, 106557. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Hu, D.; Zhang, C.; Cao, W.; Lv, X.; Xie, S. Grain Yield Predict Based on GRA-AdaBoost-SVR Model. J. Big Data 2021, 3, 65–76. [Google Scholar] [CrossRef]
- Sun, S.; Wei, Y.; Wang, S. AdaBoost-LSTM Ensemble Learning for Financial Time Series Forecasting. In Computational Science–ICCS 2018; Shi, Y., Fu, H., Tian, Y., Krzhizhanovskaya, V.V., Lees, M.H., Dongarra, J., Sloot, P.M.A., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 590–597. [Google Scholar]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Minh, V.Q.; Trung, N.H. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Zhang, J.; Han, J.; Xie, J. Integrating multi-source data for rice yield prediction across China using machine learning and deep learning approaches. Agric. For. Meteorol. 2021, 297, 108275. [Google Scholar] [CrossRef]
- Li, Z.; Ding, L.; Xu, D. Exploring the potential role of environmental and multi-source satellite data in crop yield prediction across Northeast China. Sci. Total Environ. 2022, 815, 152880. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, Y.; Ata-Ul-Karim, S.T.; Ge, Q.; Li, X.; Xiao, J. Integrating climate and satellite remote sensing data for predicting county-level wheat yield in China using machine learning methods. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102861. [Google Scholar] [CrossRef]
- Guan, K.; Berry, J.A.; Zhang, Y.; Joiner, J.; Guanter, L.; Badgley, G.; Lobell, D.B. Improving the monitoring of crop productivity using spaceborne solar-induced fluorescence. Glob. Change Biol. 2016, 22, 716–726. [Google Scholar] [CrossRef]
- Badgley, G.; Field, C.B.; Berry, J.A. Canopy near-infrared reflectance and terrestrial photosynthesis. Sci. Adv. 2017, 3, e1602244. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, Y.; Ju, W.; Qiu, B.; Zhang, Z. Tracking the seasonal and inter-annual variations of global gross primary production during last four decades using satellite near-infrared reflectance data. Sci. Total Environ. 2021, 755, 142569. [Google Scholar] [CrossRef]
- Li, L.; Wang, B.; Feng, P.; Li Liu, D.; He, Q.; Zhang, Y.; Wang, Y.; Li, S.; Lu, X.; Yue, C.; et al. Developing machine learning models with multi-source environmental data to predict wheat yield in China. Comput. Electron. Agric. 2022, 194, 106790. [Google Scholar] [CrossRef]
- Zhang, J.; Xiao, J.; Tong, X.; Zhang, J.; Meng, P.; Li, J.; Liu, P.; Yu, P. NIRv and SIF better estimate phenology than NDVI and EVI: Effects of spring and autumn phenology on ecosystem production of planted forests. Agric. For. Meteorol. 2022, 315, 108819. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Campos-Taberner, M.; Moreno-Martínez, Á.; Walther, S.; Duveiller, G.; Cescatti, A.; Mahecha, M.D.; Muñoz-Marí, J.; García-Haro, F.J.; Guanter, L.; et al. A unified vegetation index for quantifying the terrestrial biosphere. Sci. Adv. 2021, 7, eabc7447. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Viña, A.; Arkebauer, T.J.; Rundquist, D.C.; Keydan, G.; Leavitt, B. Remote estimation of leaf area index and green leaf biomass in maize canopies. Geophys. Res. Lett. 2003, 30, 1248. [Google Scholar] [CrossRef]
- Nguy-Robertson, A.; Gitelson, A.; Peng, Y.; Viña, A.; Arkebauer, T.; Rundquist, D. Green leaf area index estimation in maize and soybean: Combining vegetation indices to achieve maximal sensitivity. Agron. J. 2012, 104, 1336–1347. [Google Scholar] [CrossRef]
- Pan, Y.; Li, L.; Zhang, J.; Liang, S.; Zhu, X.; Sulla-Menashe, D. Winter wheat area estimation from MODIS-EVI time series data using the Crop Proportion Phenology Index. Remote Sens. Environ. 2012, 119, 232–242. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Z.; Li, Z.; Chen, Y.; Zhang, L.; Cao, J.; Tao, F. Identifying the spatiotemporal changes of annual harvesting areas for three staple crops in China by integrating multi-data sources. Environ. Res. Lett. 2020, 15, 074003. [Google Scholar] [CrossRef]
- Yang, G.; Yu, W.; Yao, X.; Zheng, H.; Cao, Q.; Zhu, Y.; Cao, W.; Cheng, T. AGTOC: A novel approach to winter wheat mapping by automatic generation of training samples and one-class classification on Google Earth Engine. Int. J. Appl. Earth. Obs. 2021, 102, 102446. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, H.; Zhong, R.; Xu, J.; Xu, J.; Huang, J.; Wang, S.; Ying, Y.; Lin, T. A deep learning approach to conflating heterogeneous geospatial data for corn yield estimation: A case study of the US Corn Belt at the county level. Glob. Change Biol. 2020, 26, 1754–1766. [Google Scholar] [CrossRef] [PubMed]
- Lobell, D.B.; Deines, J.M.; Tommaso, S.D. Changes in the drought sensitivity of US maize yields. Nat. Food. 2020, 1, 729–735. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Tao, H.; He, P.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Annual 30 m winter wheat yield mapping in the Huang-Huai-Hai plain using crop growth model and long-term satellite images. Comput. Electron. Agric. 2023, 214, 108335. [Google Scholar] [CrossRef]
- Huang, H.; Chen, Y.; Clinton, N.; Wang, J.; Wang, X.; Liu, C.; Gong, P.; Yang, J.; Bai, Y.; Zheng, Y.; et al. Mapping major land cover dynamics in Beijing using all Landsat images in Google Earth Engine. Remote Sens. Environ. 2017, 202, 166–176. [Google Scholar] [CrossRef]
- Liu, X.; Hu, G.; Chen, Y.; Li, X.; Xu, X.; Li, S.; Pei, F.; Wang, S. High-resolution multi-temporal mapping of global urban land using Landsat images based on the Google Earth Engine Platform. Remote Sens. Environ. 2018, 209, 227–239. [Google Scholar] [CrossRef]
- Tucker, C.J. Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 1979, 8, 127–150. [Google Scholar] [CrossRef]
- Teluguntla, P.; Thenkabail, P.S.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS. J. Photogramm. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Zhang, Y.; Qi, Y.; Shen, Y.; Wang, H.; Pan, X. Mapping the agricultural land use of the North China plain in 2002 and 2012. J. Geogr. Sci. 2019, 29, 909–921. [Google Scholar] [CrossRef]
- Zha, Y.; Ni, S.; Yang, S. An effective approach to automatically extract urban land-use from TM imagery. J. Remote Sens. 2003, 7, 37–41. [Google Scholar]
- Xu, H. A study on information extraction of water body with the modified normalized difference water index (MNDWI). J. Remote Sens. 2005, 9, 589–595. [Google Scholar]
- Li, K.; Chen, Y. A genetic algorithm-based urban cluster automatic threshold method by combining VIIRS DNB, NDVI, and NDBI to monitor urbanization. Remote Sens. 2018, 10, 277. [Google Scholar] [CrossRef]
- Titolo, A. Use of Time-Series NDWI to Monitor Emerging Archaeological Sites: Case Studies from Iraqi Artificial Reservoirs. Remote Sens. 2021, 13, 786. [Google Scholar] [CrossRef]
- Abatzoglou, J.T.; Dobrowski, S.Z.; Parks, S.A.; Hegewisch, K.C. TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Sci. Data 2018, 5, 170191. [Google Scholar] [CrossRef]
- Bushong, J.T.; Mullock, J.L.; Miller, E.C.; Raun, W.R.; Klatt, A.R.; Arnall, D.B. Development of an in-season estimate of yield potential utilizing optical crop sensors and soil moisture data for winter wheat. Precis. Agric. 2016, 17, 451–469. [Google Scholar] [CrossRef]
- Babaeian, E.; Paheding, S.; Siddique, N.; Devabhaktuni, V.K.; Tuller, M. Estimation of root zone soil moisture from ground and remotely sensed soil information with multisensor data fusion and automated machine learning. Remote Sens. Environ. 2021, 260, 112434. [Google Scholar] [CrossRef]
- Fang, Q.; Wang, Y.; Uwimpaye, F.; Yan, Z.; Li, L.; Liu, X.; Shao, L. Pre-sowing soil water conditions and water conservation measures affecting the yield and water productivity of summer maize. Agric. Water Manag. 2021, 245, 106628. [Google Scholar] [CrossRef]
- Jonsson, P.; Eklundh, L. Seasonality extraction by function fitting to time-series of satellite sensor data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 1824–1832. [Google Scholar] [CrossRef]
- Wu, W.; Yang, P.; Tang, H.; Shibasaki, R.; Zhou, Q.; Zhang, L. Monitoring spatial patterns of cropland phenology in North China based on NOAA NDVI data. Sci. Agric. Sin. 2009, 42, 552–560. [Google Scholar]
- Luo, Y.; Zhang, Z.; Chen, Y.; Li, Z.; Tao, F. ChinaCropPhen1km: A high-resolution crop phenological dataset for three staple crops in China during 2000–2015 based on leaf area index (LAI) products. Earth Syst. Sci. Data 2020, 12, 197–214. [Google Scholar] [CrossRef]
- Sakamoto, T.; Wardlow, B.D.; Gitelson, A.A.; Verma, S.B.; Suyker, A.E.; Arkebauer, T.J. A Two-Step Filtering approach for detecting maize and soybean phenology with time-series MODIS data. Remote Sens. Environ. 2010, 114, 2146–2159. [Google Scholar] [CrossRef]
- Carrasco, L.; Fujita, G.; Kito, K.; Miyashita, T. Historical mapping of rice fields in Japan using phenology and temporally aggregated Landsat images in Google Earth Engine. ISPRS. J. Photogramm. 2022, 191, 277–289. [Google Scholar] [CrossRef]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Hunt, M.L.; Blackburn, G.A.; Carrasco, L.; Redhead, J.W.; Rowland, C.S. High resolution wheat yield mapping using Sentinel-2. Remote Sens. Environ. 2019, 233, 111410. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Song, X.-P.; Li, H.; Potapov, P.; Hansen, M.C. Annual 30 m soybean yield mapping in Brazil using long-term satellite observations, climate data and machine learning. Agric. For. Meteorol. 2022, 326, 109186. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, Z.; Luo, Y.; Zhang, L.; Zhang, J.; Li, Z.; Tao, F. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine. Eur. J. Agron. 2021, 123, 126204. [Google Scholar] [CrossRef]
- Johnson, D.M. An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Luo, Y.; Cao, J.; Tao, F. Combining optical, fluorescence, thermal satellite, and environmental data to predict county-level maize yield in China using machine learning approaches. Remote Sens. 2020, 12, 21. [Google Scholar] [CrossRef]
- Guan, K.; Li, Z.; Rao, L.N.; Gao, F.; Xie, D.; Hien, N.T.; Zeng, Z. Mapping paddy rice area and yields over Thai Binh province in Viet Nam from MODIS, Landsat, and ALOS-2/PALSAR-2. IEEE J.-Stars 2018, 11, 2238–2252. [Google Scholar] [CrossRef]
- Wang, Q.; Moreno-Martínez, Á.; Muñoz-Marí, J.; Campos-Taberner, M.; Camps-Valls, G. Estimation of vegetation traits with kernel NDVI. ISPRS. J. Photogramm. 2023, 195, 408–417. [Google Scholar] [CrossRef]
- Lobell, D.B.; Thau, D.; Seifert, C.; Engle, E.; Little, B. A scalable satellite-based crop yield mapper. Remote Sens. Environ. 2015, 164, 324–333. [Google Scholar] [CrossRef]
- Azzari, G.; Jain, M.; Lobell, D.B. Towards fine resolution global maps of crop yields: Testing multiple methods and satellites in three countries. Remote Sens. Environ. 2017, 202, 129–141. [Google Scholar] [CrossRef]
- Jin, Z.; Azzari, G.; Lobell, D.B. Improving the accuracy of satellite-based high-resolution yield estimation: A test of multiple scalable approaches. Agric. For. Meteorol. 2017, 247, 207–220. [Google Scholar] [CrossRef]
- Xiao, L.; Wang, G.; Zhou, H.; Jin, X.; Luo, Z. Coupling agricultural system models with machine learning to facilitate regional predictions of management practices and crop production. Environ. Res. Lett. 2022, 17, 114027. [Google Scholar] [CrossRef]
- Ren, C.; Zhou, X.; Wang, C.; Guo, Y.; Diao, Y.; Shen, S.; Reis, S.; Li, W.; Xu, J.; Gu, B. Ageing threatens sustainability of smallholder farming in China. Nature 2023, 616, 96–103. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Ren, H.; Zhang, L.; Zhao, Y.; Liu, Y.; He, Q.; Li, G.; Han, K.; Zhang, J.; Zhao, B.; et al. A sustainable approach to narrowing the summer maize yield gap experienced by smallholders in the North China Plain. Agric. Syst. 2023, 204, 103541. [Google Scholar] [CrossRef]
- Bailey-Serres, J.; Parker, J.E.; Ainsworth, E.A.; Oldroyd, G.E.D.; Schroeder, J.I. Genetic strategies for improving crop yields. Nature 2019, 575, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Zhang, Z.; Tao, F.; Zhang, L.; Luo, Y.; Han, J.; Li, Z. Identifying the contributions of multi-source data for winter wheat yield prediction in China. Remote Sens. 2020, 12, 750. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Variable | Source |
|---|---|---|
| Satellite data | NDBI, MNDWI, NDVI, EVI, GCVI, kNDVI, NIRv | Landsat5/7/8, MOD09A1, MOD09GA |
| Meteorological data | Pr Srad Tmin Tmax VPD ET SM | TerraClimate |
| Crop data | phenology | China’s Meteorological Administration |
| planting area | China Agricultural Statistical Yearbook | |
| yield |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; He, J.; Yao, X.; Cheng, T.; Zhu, Y.; Cao, W.; Tian, Y. Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events. Remote Sens. 2024, 16, 1259. https://doi.org/10.3390/rs16071259
Zhao Y, He J, Yao X, Cheng T, Zhu Y, Cao W, Tian Y. Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events. Remote Sensing. 2024; 16(7):1259. https://doi.org/10.3390/rs16071259
Chicago/Turabian StyleZhao, Yanxi, Jiaoyang He, Xia Yao, Tao Cheng, Yan Zhu, Weixing Cao, and Yongchao Tian. 2024. "Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events" Remote Sensing 16, no. 7: 1259. https://doi.org/10.3390/rs16071259
APA StyleZhao, Y., He, J., Yao, X., Cheng, T., Zhu, Y., Cao, W., & Tian, Y. (2024). Wheat Yield Robust Prediction in the Huang-Huai-Hai Plain by Coupling Multi-Source Data with Ensemble Model under Different Irrigation and Extreme Weather Events. Remote Sensing, 16(7), 1259. https://doi.org/10.3390/rs16071259