
Multi-Level Feature-Refinement Anchor-Free Framework with Consistent Label-Assignment Mechanism for Ship Detection in SAR Imagery

Abstract
1. Introduction
- A one-stage anchor-free detector named multi-level feature-refinement anchor-free framework with a consistent label-assignment mechanism is proposed to boost the detection performance of SAR ships in complex scenes. A series of qualitative and quantitative experiments on three public datasets, SSDD, HRSID, and SAR-Ship-Dataset, demonstrate that the proposed method outperforms many state-of-the-art detection methods.
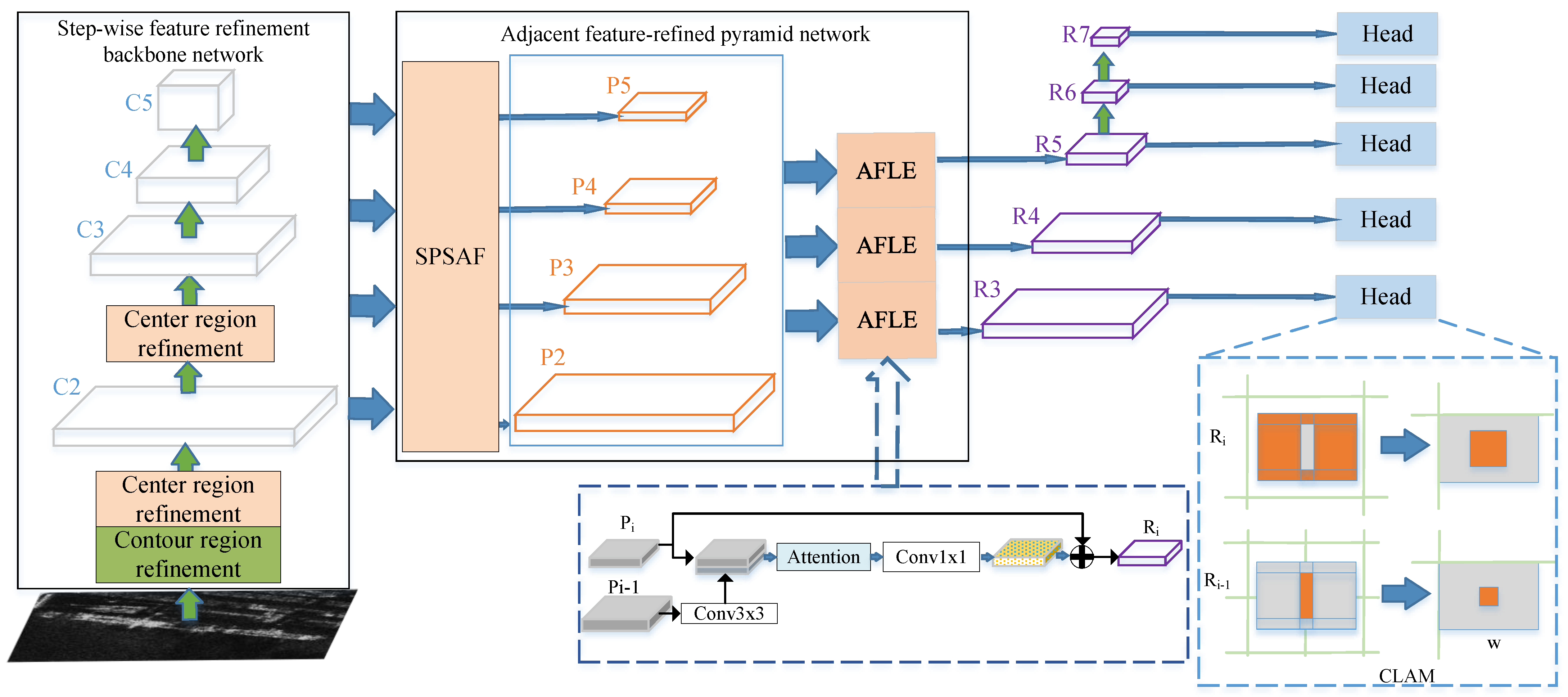
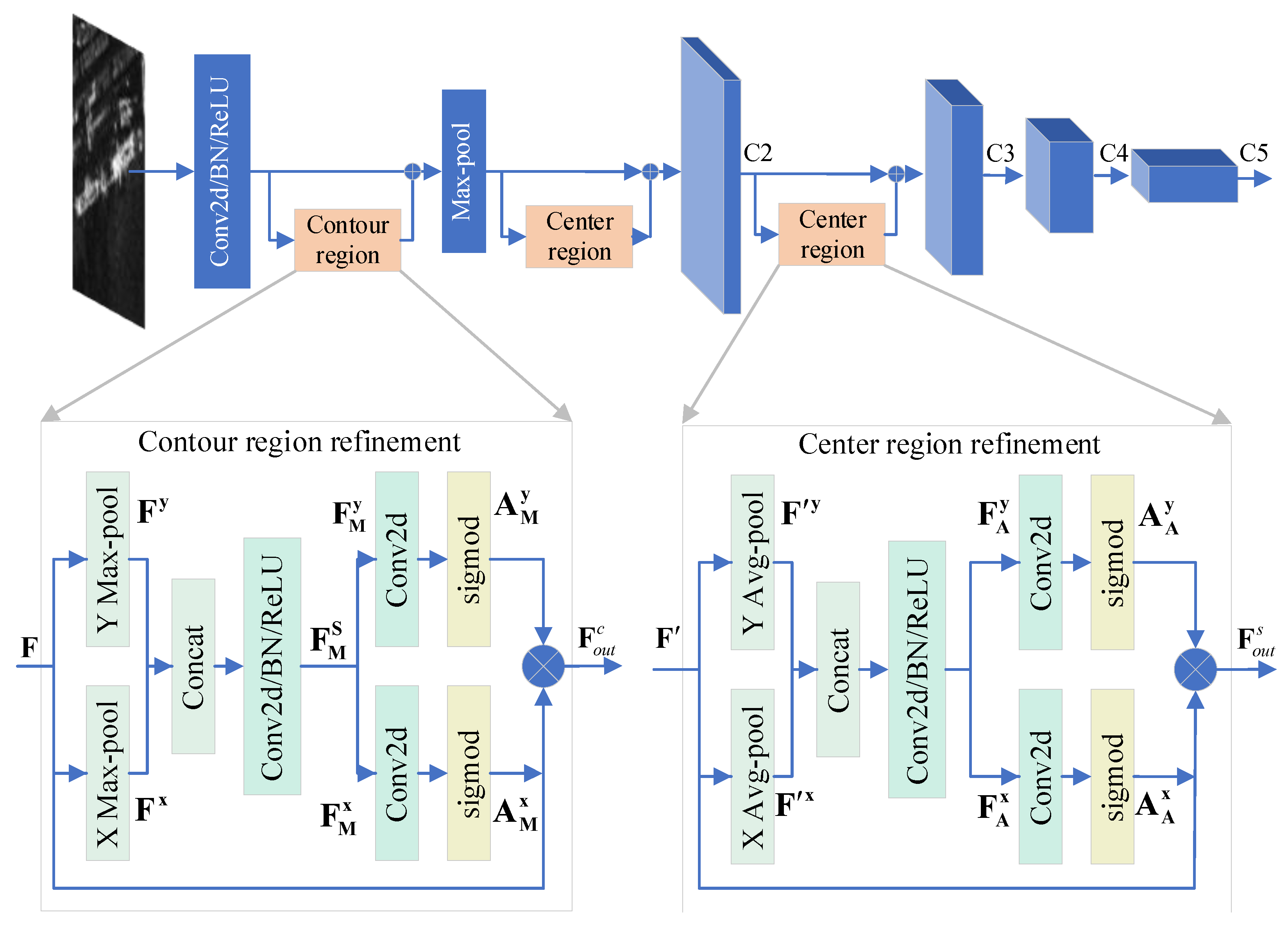
- To extract abundant ship features while suppressing complex background clutter, a stepwise feature-refinement backbone network is proposed, which refines the position and contour of the ship in turn via stepwise spatial information decoupling function, therefore improving ship-detection performance.
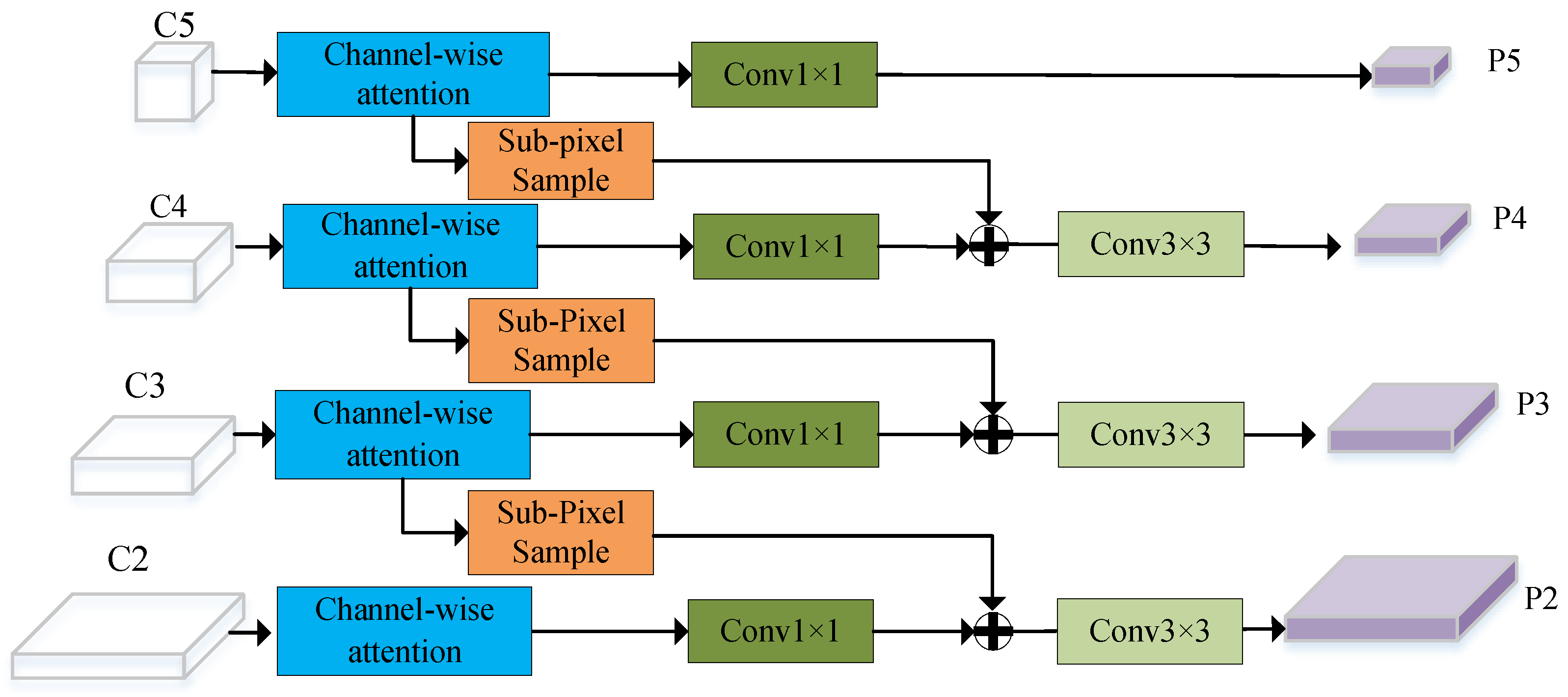
- To effectively fuse the multi-scale features of the ships and avoid the semantic aliasing effect in cross-scale layers, an adjacent feature-refined pyramid network consisting of sub-pixel sampling-based adjacent feature-fusion sub-module and adjacent feature-localization enhancement sub-module is proposed, which is beneficial for multi-scale ship detection by alleviating multi-scale high-level semantic loss and enhancing low-level localization features at the adjacent feature layers.
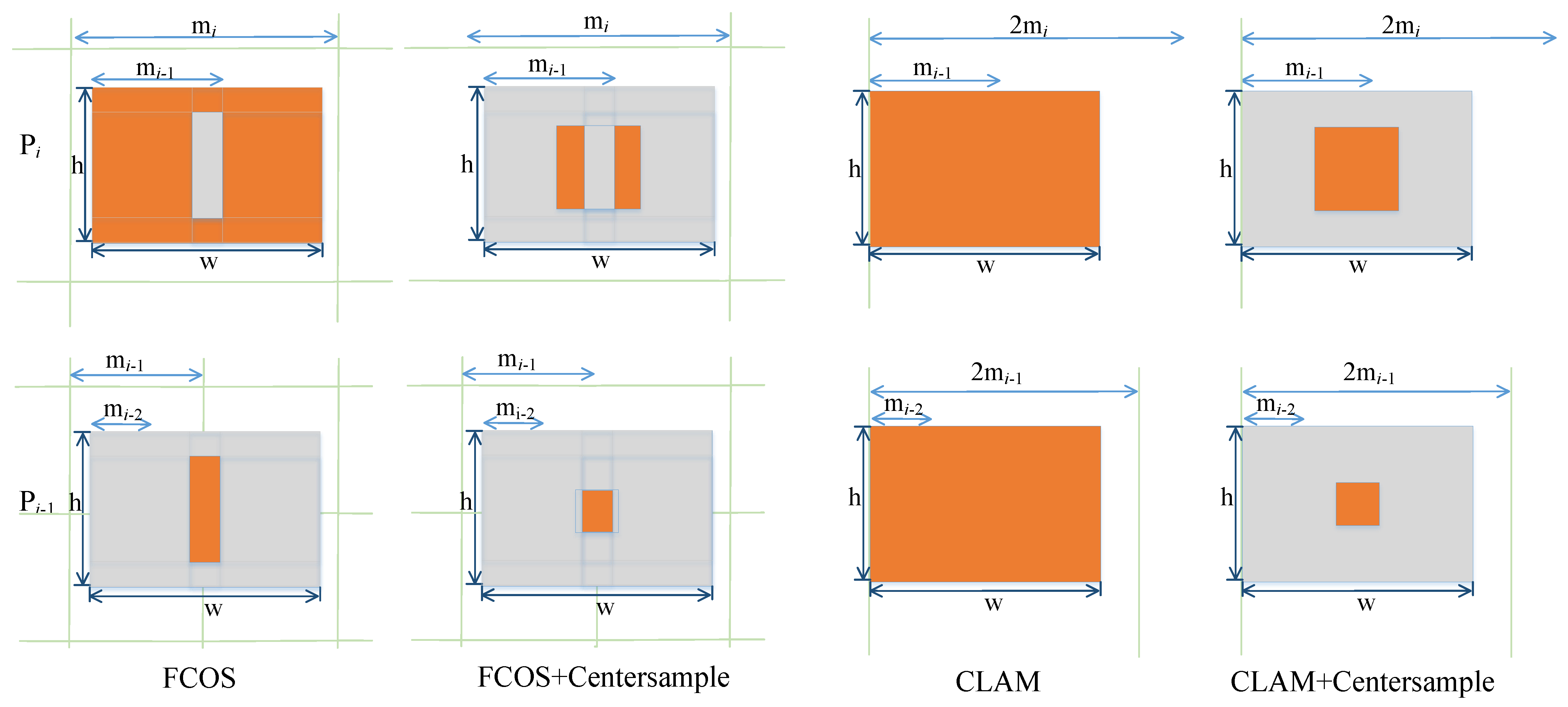
- In light of the problem of unbalanced label assignment of samples in one-stage anchor-free detection, a consistent label-assignment mechanism based on consistent feature scale constraints is presented, which is also beneficial in meeting the challenges of dense prediction, especially densely arranged ships inshore.
2. Methodology
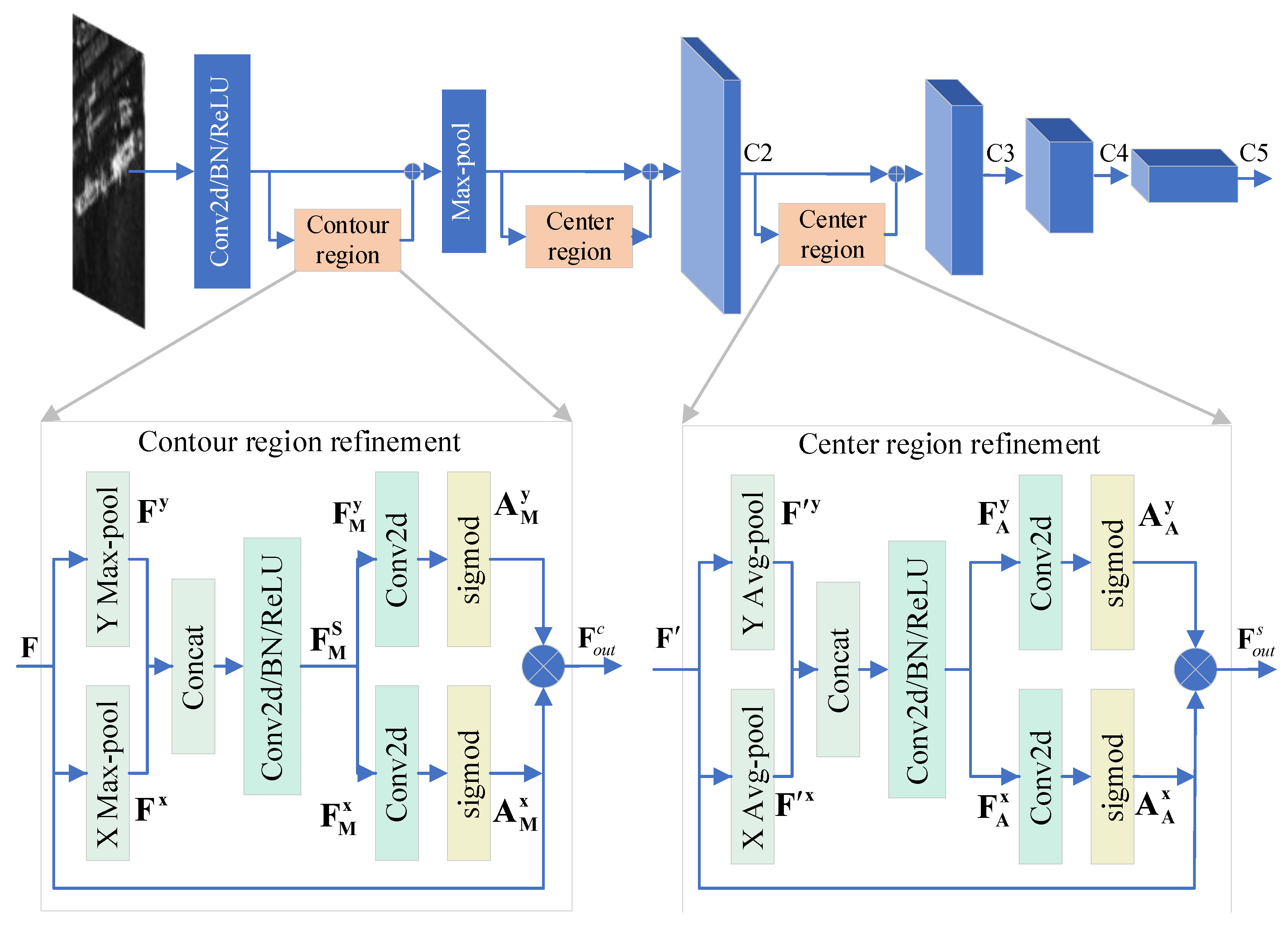
2.1. Stepwise Feature-Refinement Backbone Network
2.2. Adjacent Feature-Refined Pyramid Network
2.3. Consistent Label-Assignment Mechanism
2.4. Loss Function
3. Experimental Results
3.1. Datasets Description
3.2. Experimental Settings
3.3. Evaluation Metric
3.4. Ablation Experiment
3.5. Contrastive Experiments
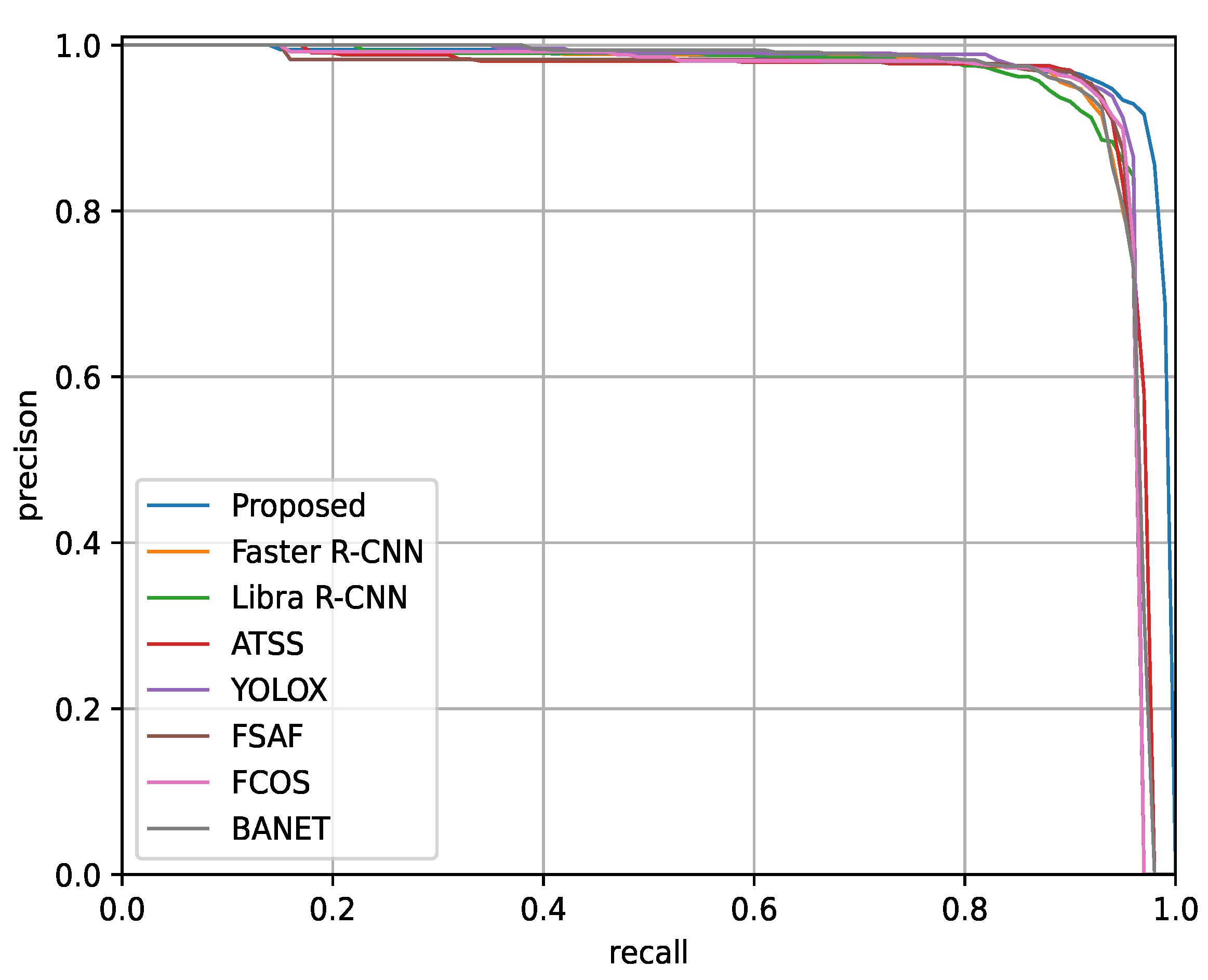
3.5.1. Experimental Results on SSDD
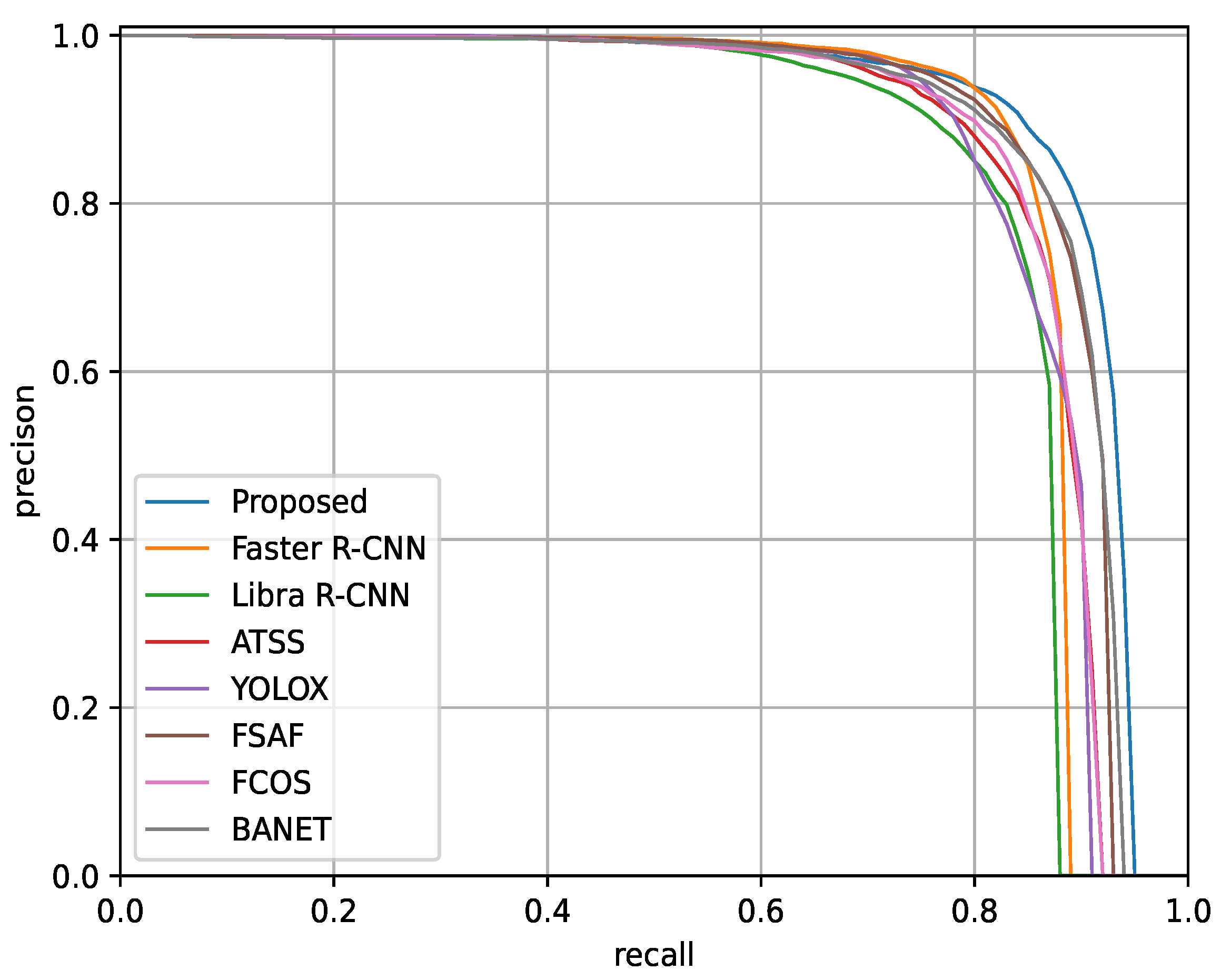
3.5.2. Experimental Results on HRSID
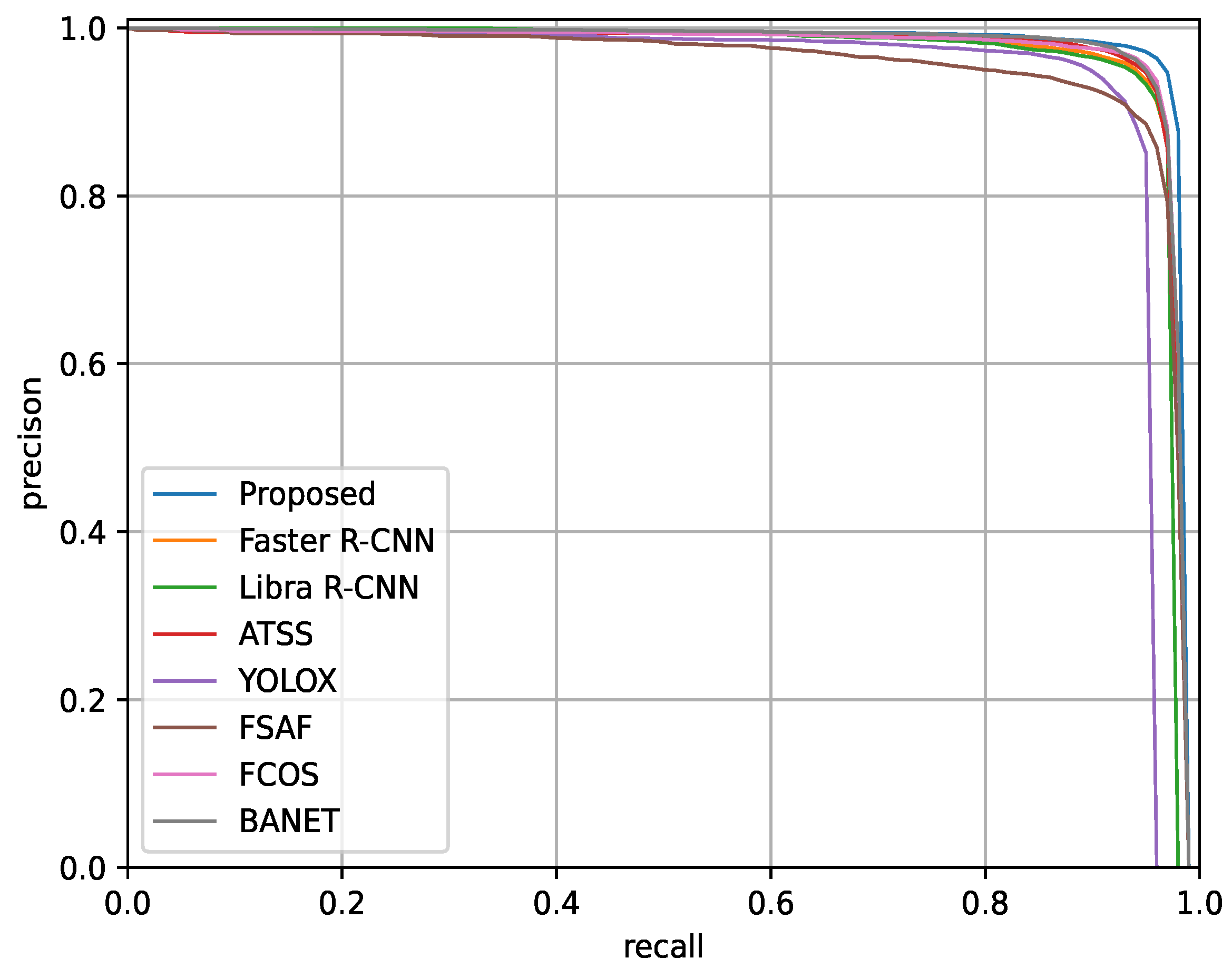
3.5.3. Experimental Results on the SAR-Ship-Dataset
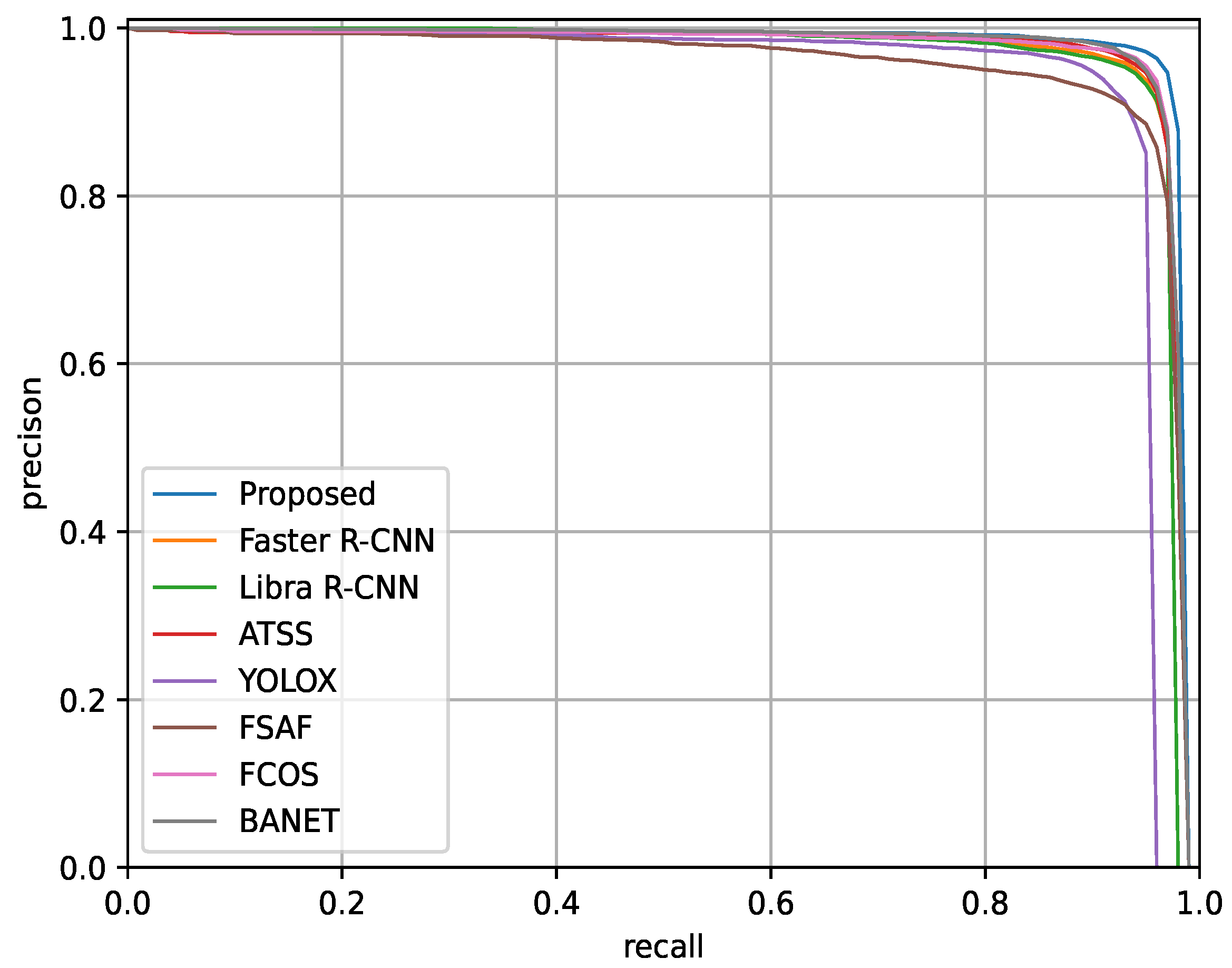
3.6. Visual Results and Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Robey, F.C.; Fuhrmann, D.R.; Kelly, E.J.; Nitzberg, R. A CFAR adaptive matched filter detector. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 208–216. [Google Scholar] [CrossRef]
- Conte, E.; De Maio, A.; Ricci, G. Recursive estimation of the covariance matrix of a compound-Gaussian process and its application to adaptive CFAR detection. IEEE Trans. Signal Process. 2002, 50, 1908–1915. [Google Scholar] [CrossRef]
- Lei, S.; Zhao, Z.; Nie, Z.; Liu, Q.H. A CFAR adaptive subspace detector based on a single observation in system-dependent clutter background. IEEE Trans. Signal Process. 2014, 62, 5260–5269. [Google Scholar] [CrossRef]
- Dai, H.; Du, L.; Wang, Y.; Wang, Z. A modified CFAR algorithm based on object proposals for ship target detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1925–1929. [Google Scholar] [CrossRef]
- Qin, X.; Zhou, S.; Zou, H.; Gao, G. A CFAR detection algorithm for generalized gamma distributed background in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2012, 10, 806–810. [Google Scholar]
- Pappas, O.; Achim, A.; Bull, D. Superpixel-level CFAR detectors for ship detection in SAR imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1397–1401. [Google Scholar] [CrossRef]
- Gao, G.; Shi, G. CFAR ship detection in nonhomogeneous sea clutter using polarimetric SAR data based on the notch filter. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4811–4824. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lee, H.; Eum, S.; Kwon, H. Me r-cnn: Multi-expert r-cnn for object detection. IEEE Trans. Image Process. 2019, 29, 1030–1044. [Google Scholar] [CrossRef]
- Yang, L.; Song, Q.; Wang, Z.; Hu, M.; Liu, C. Hier R-CNN: Instance-level human parts detection and a new benchmark. IEEE Trans. Image Process. 2020, 30, 39–54. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Yu, N.; Ren, H.; Deng, T.; Fan, X. A Lightweight Radar Ship Detection Framework with Hybrid Attentions. Remote Sens. 2023, 15, 2743. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zhang, H.; Tian, Y.; Wang, K.; Zhang, W.; Wang, F.Y. Mask SSD: An effective single-stage approach to object instance segmentation. IEEE Trans. Image Process. 2019, 29, 2078–2093. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Shi, H.; Fang, Z.; Wang, Y.; Chen, L. An adaptive sample assignment strategy based on feature enhancement for ship detection in SAR images. Remote Sens. 2022, 14, 2238. [Google Scholar] [CrossRef]
- Yao, C.; Xie, P.; Zhang, L.; Fang, Y. ATSD: Anchor-Free Two-Stage Ship Detection Based on Feature Enhancement in SAR Images. Remote Sens. 2022, 14, 6058. [Google Scholar] [CrossRef]
- Wang, J.; Cui, Z.; Jiang, T.; Cao, C.; Cao, Z. Lightweight Deep Neural Networks for Ship Target Detection in SAR Imagery. IEEE Trans. Image Process. 2022, 32, 565–579. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, R.; Ai, J.; Zou, H.; Li, J. Global and Local Context-Aware Ship Detector for High-Resolution SAR Images. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4159–4167. [Google Scholar] [CrossRef]
- Zhang, T.; Zeng, T.; Zhang, X. Synthetic aperture radar (SAR) meets deep learning. Remote Sens. 2023, 15, 303. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6569–6578. [Google Scholar]
- Guo, H.; Yang, X.; Wang, N.; Gao, X. A CenterNet++ model for ship detection in SAR images. Pattern Recognit. 2021, 112, 107787. [Google Scholar] [CrossRef]
- Sun, Z.; Dai, M.; Leng, X.; Lei, Y.; Xiong, B.; Ji, K.; Kuang, G. An anchor-free detection method for ship targets in high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7799–7816. [Google Scholar] [CrossRef]
- Wan, H.; Chen, J.; Huang, Z.; Xia, R.; Wu, B.; Sun, L.; Yao, B.; Liu, X.; Xing, M. AFSar: An anchor-free SAR target detection algorithm based on multiscale enhancement representation learning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5219514. [Google Scholar] [CrossRef]
- Hu, Q.; Hu, S.; Liu, S. BANet: A balance attention network for anchor-free ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5222212. [Google Scholar] [CrossRef]
- Li, J.; Xu, C.; Su, H.; Gao, L.; Wang, T. Deep learning for SAR ship detection: Past, present and future. Remote Sens. 2022, 14, 2712. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Cheng, P.; Yu, Z.; Yu, L.; Chi, C. A Survey on Deep-Learning-Based Real-Time SAR Ship Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3218–3247. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, X.; Wang, N.; Gao, X. A robust one-stage detector for multiscale ship detection with complex background in massive SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5217712. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 7–30 June 2016; pp. 1874–1883. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–22 June 2018; pp. 7132–7141. [Google Scholar]
- Luo, Y.; Cao, X.; Zhang, J.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing channel information for object detection. Multimed. Tools Appl. 2022, 81, 30685–30704. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Li, J.; Qu, C.; Shao, J. Ship detection in SAR images based on an improved faster R-CNN. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SAR images dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. A SAR dataset of ship detection for deep learning under complex backgrounds. Remote Sens. 2019, 11, 765. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Li, J.; Xu, X.; Wang, B.; Zhan, X.; Xu, Y.; Ke, X.; Zeng, T.; Su, H.; et al. SAR ship detection dataset (SSDD): Official release and comprehensive data analysis. Remote Sens. 2021, 13, 3690. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X. Quad-FPN: A novel quad feature pyramid network for SAR ship detection. Remote Sens. 2021, 13, 2771. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SwFR | AFRPN | CLAM | P | R | F1 | AP | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| baseline | × | × | × | 93.9 | 92.5 | 93.2 | 58.9 | 94.3 | 67.2 | 55.1 | 65.3 | 57.4 |
| model1 | ✔ | × | × | 94.2 | 94.0 | 94.1 | 59.8 | 95.2 | 69.8 | 55.5 | 67.0 | 58.6 |
| model2 | ✔ | ✔ | × | 95.0 | 93.2 | 94.1 | 61.3 | 96.0 | 69.7 | 55.9 | 69.5 | 62.1 |
| model3 | ✔ | ✔ | ✔ | 95.1 | 94.0 | 94.5 | 62.0 | 97.2 | 71.2 | 58.3 | 67.6 | 65.7 |
| Method | Backbone | P | R | F1 | AP | Params (M) | FLOPs (G) | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [11] | ResNet-101 | 94.9 | 90.8 | 92.8 | 59.6 | 94.4 | 69.9 | 55.8 | 65.7 | 60.4 | 60.1 | 141.6 | 47.2 |
| Libra R-CNN [12] | ResNet-101 | 91.9 | 91.6 | 91.7 | 60.3 | 94.2 | 69.7 | 56.2 | 67.0 | 61.6 | 60.4 | 142.1 | 45.5 |
| ATSS [21] | ResNet-101 | 95.0 | 91.9 | 93.4 | 58.4 | 94.6 | 65.0 | 52.9 | 67.0 | 60.4 | 50.9 | 131.9 | 47.4 |
| YOLOX [20] | CSPDarknet-53 | 94.2 | 93.8 | 94.0 | 61.2 | 95.0 | 69.6 | 57.3 | 66.8 | 67.2 | 54.2 | 92.2 | 67.1 |
| FSAF [22] | ResNet-101 | 95.1 | 92.0 | 93.5 | 56.6 | 94.0 | 65.0 | 52.6 | 63.4 | 58.4 | 55.0 | 132.3 | 47.7 |
| FCOS [19] | ResNet-101 | 93.9 | 92.5 | 93.2 | 58.9 | 94.3 | 67.2 | 55.1 | 65.3 | 57.4 | 50.8 | 129.6 | 48.8 |
| BANet [33] | ResNet-101 | 93.9 | 91.9 | 92.9 | 58.7 | 94.9 | 67.3 | 55.4 | 64.9 | 54.3 | 63.9 | 147.0 | 35.2 |
| Proposed | SwFR | 95.1 | 94.0 | 94.5 | 62.0 | 97.2 | 71.2 | 58.3 | 67.6 | 65.7 | 58.7 | 167.2 | 36.1 |
| Method | Backbone | P | R | F1 | AP | Params (M) | FLOPs (G) | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [11] | ResNet-101 | 91.7 | 82.0 | 86.5 | 62.2 | 86.1 | 71.4 | 63.3 | 63.8 | 14.2 | 60.1 | 289.2 | 26.2 |
| Libra R-CNN [12] | ResNet-101 | 87.4 | 78.4 | 82.7 | 60.3 | 83.7 | 68.2 | 61.3 | 63.2 | 10.5 | 60.4 | 290.3 | 26.1 |
| ATSS [21] | ResNet-101 | 89.9 | 78.7 | 84.0 | 61.5 | 86.3 | 68.8 | 62.6 | 65.0 | 16.9 | 50.9 | 284.1 | 26.2 |
| YOLOX [20] | CSPDarknet-53 | 90.8 | 77.8 | 83.8 | 62.8 | 85.8 | 71.9 | 66.2 | 51.8 | 1.7 | 54.2 | 198.8 | 35.9 |
| FSAF [22] | ResNet-101 | 89.0 | 82.9 | 85.8 | 61.5 | 88.6 | 69.4 | 62.2 | 63.8 | 13.5 | 55.0 | 285.0 | 26.7 |
| FCOS [19] | ResNet-101 | 89.5 | 80.3 | 84.7 | 60.7 | 86.4 | 67.6 | 62.0 | 61.6 | 14.7 | 50.8 | 279.2 | 26.5 |
| BANet [33] | ResNet-101 | 89.1 | 82.0 | 85.4 | 53.6 | 88.7 | 62.0 | 55.3 | 53.1 | 12.4 | 63.9 | 302.0 | 19.0 |
| Proposed | SwFR | 92.2 | 83.9 | 87.3 | 66.4 | 90.3 | 75.4 | 68.0 | 68.9 | 33.3 | 58.7 | 360.2 | 19.5 |
| Method | Backbone | P | R | F1 | AP | Params (M) | FLOPs (G) | FPS | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [11] | ResNet-101 | 94.9 | 93.7 | 94.3 | 61.4 | 96.0 | 71.1 | 56.4 | 67.8 | 51.6 | 60.1 | 82.7 | 68.4 |
| Libra R-CNN [12] | ResNet-101 | 94.6 | 94.1 | 94.3 | 63.7 | 95.9 | 75.0 | 58.4 | 70.1 | 53.3 | 60.4 | 83.0 | 66.7 |
| ATSS [21] | ResNet-101 | 95.2 | 94.7 | 94.9 | 63.8 | 96.5 | 74.5 | 58.5 | 71.1 | 64.8 | 50.9 | 71.0 | 70.9 |
| YOLOX [20] | CSPDarknet-53 | 94.6 | 90.5 | 92.5 | 56.8 | 93.4 | 62.1 | 51.3 | 64.3 | 43.2 | 54.2 | 49.7 | 102.8 |
| FSAF [22] | ResNet-101 | 91.1 | 92.9 | 91.9 | 59.5 | 94.8 | 66.9 | 54.7 | 65.7 | 62.2 | 55.0 | 71.3 | 71.4 |
| FCOS [19] | ResNet-101 | 95.5 | 95.0 | 95.2 | 63.2 | 96.6 | 74.6 | 57.9 | 70.5 | 64.1 | 50.8 | 69.8 | 73.4 |
| BANet [33] | ResNet-101 | 96.2 | 94.2 | 95.2 | 62.9 | 96.9 | 72.4 | 57.2 | 70.2 | 60.2 | 63.9 | 79.2 | 52.0 |
| Proposed | SwFR | 96.2 | 96.2 | 96.2 | 67.6 | 97.3 | 80.5 | 61.1 | 75.1 | 64.9 | 58.7 | 90.1 | 53.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Wang, S.; Ren, H.; Hu, J.; Zou, L.; Wang, X. Multi-Level Feature-Refinement Anchor-Free Framework with Consistent Label-Assignment Mechanism for Ship Detection in SAR Imagery. Remote Sens. 2024, 16, 975. https://doi.org/10.3390/rs16060975
Zhou Y, Wang S, Ren H, Hu J, Zou L, Wang X. Multi-Level Feature-Refinement Anchor-Free Framework with Consistent Label-Assignment Mechanism for Ship Detection in SAR Imagery. Remote Sensing. 2024; 16(6):975. https://doi.org/10.3390/rs16060975
Chicago/Turabian StyleZhou, Yun, Sensen Wang, Haohao Ren, Junyi Hu, Lin Zou, and Xuegang Wang. 2024. "Multi-Level Feature-Refinement Anchor-Free Framework with Consistent Label-Assignment Mechanism for Ship Detection in SAR Imagery" Remote Sensing 16, no. 6: 975. https://doi.org/10.3390/rs16060975
APA StyleZhou, Y., Wang, S., Ren, H., Hu, J., Zou, L., & Wang, X. (2024). Multi-Level Feature-Refinement Anchor-Free Framework with Consistent Label-Assignment Mechanism for Ship Detection in SAR Imagery. Remote Sensing, 16(6), 975. https://doi.org/10.3390/rs16060975