
An Up-View Visual-Based Indoor Positioning Method via Deep Learning

 ,
,  ,
, 
 , ,
, ,  and
and 
Abstract
1. Introduction
- (1)
- We innovatively propose an up-view visual-based indoor positioning algorithm, avoiding the shortcomings of the side-view visual-based positioning.
- (2)
- We propose a deep-learning-based up-view landmark detection and extraction method. This method combines the YOLO V7 model with the edge detection operators, realizing the high-accuracy up-view landmark detection and precision landmark extraction.
- (3)
- We propose an INS-based landmark matching method. This method uses IMU data to estimate the smartphone’s position and find the closest point from the pre-labeled light sequence, realizing the matching between up-view images and the light sequence.
- (4)
- To verify the feasibility of the up-view-based positioning concept, we conducted static experiments in a shopping mall near Aalto University and the laboratory at Finish Geospatial Research Institute (FGI). We also conduct kinematic experiments in FGI’s laboratory to further verify the performance of the proposed positioning algorithm.
2. Up-View Visual-Based Indoor Positioning Algorithm
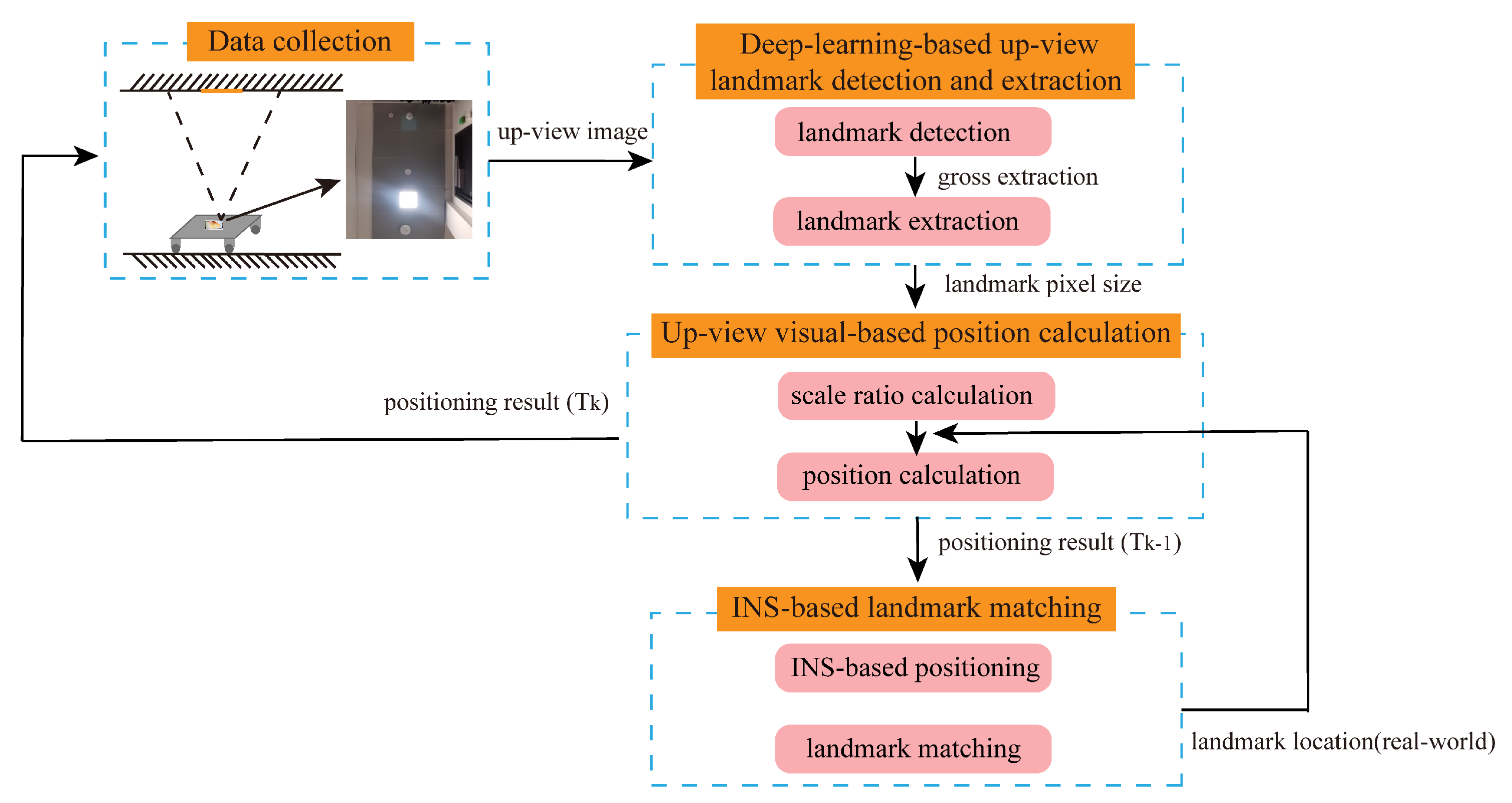
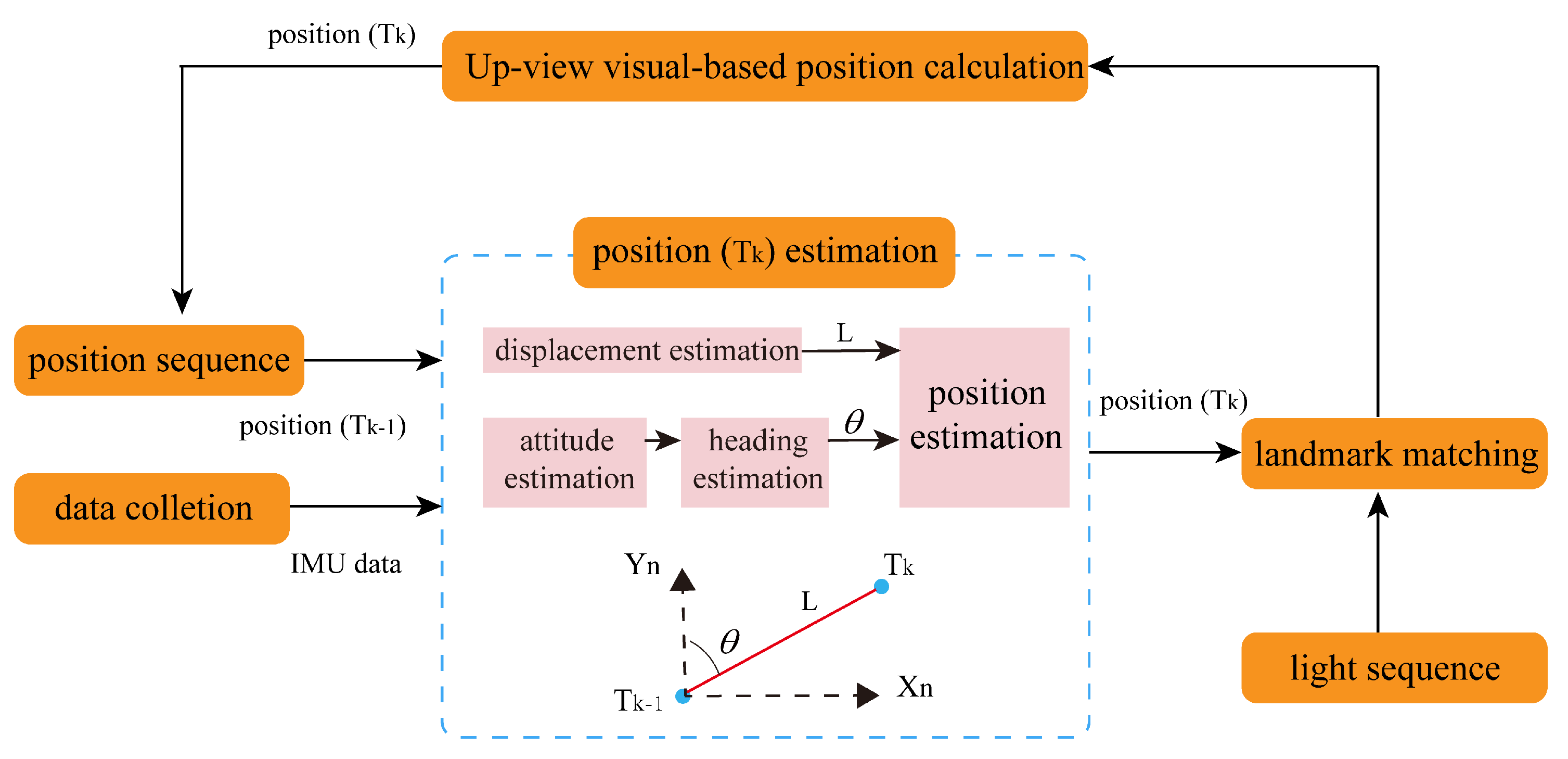
2.1. Up-View Visual-Based Indoor Positioning Mechanism
- (1)
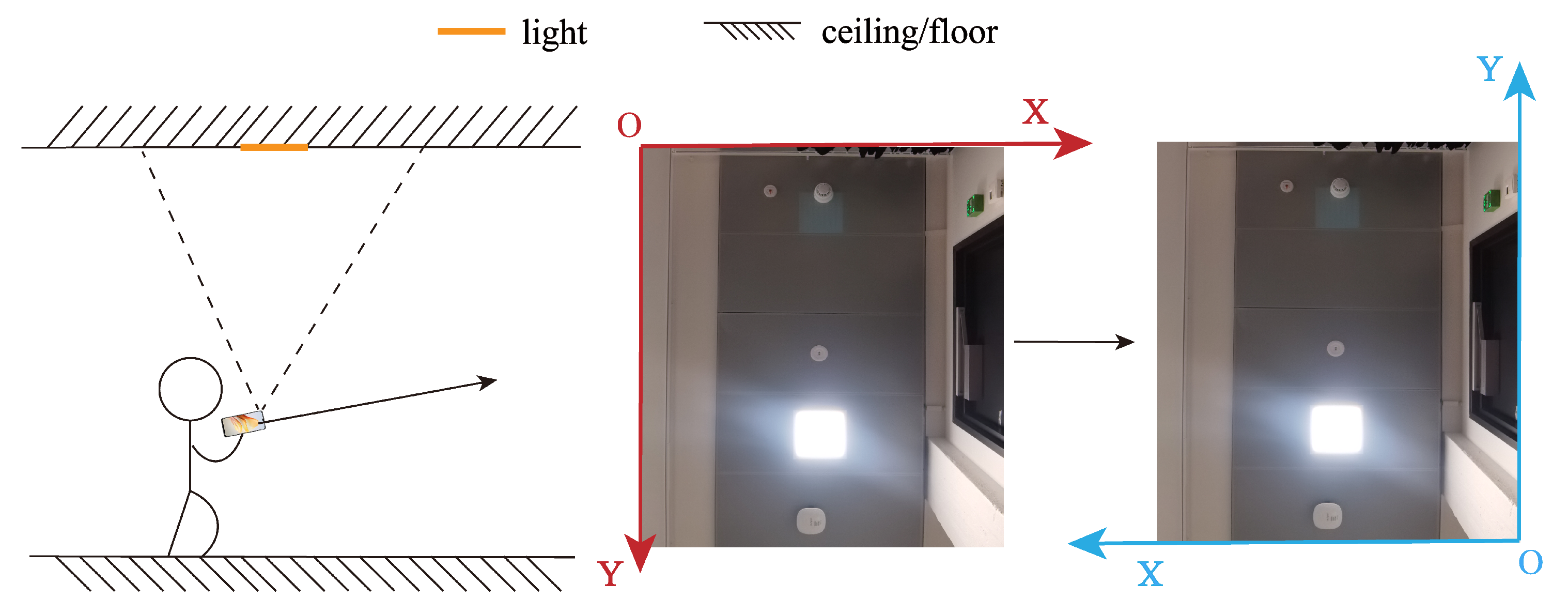
- Data collection: This module uses the camera to capture the up-view images via self-developed software. Additionally, the smartphone’s self-contained sensor data is also collected.
- (2)
- Deep-learning-based landmark detection and extraction module: This module uses YOLO V7 to realize landmark detection and gross extraction. Then, we compensate for the exposure of the extracted region. Finally, an edge detection operator is employed to realize landmark precise extraction, obtaining the landmark pixel size.
- (3)
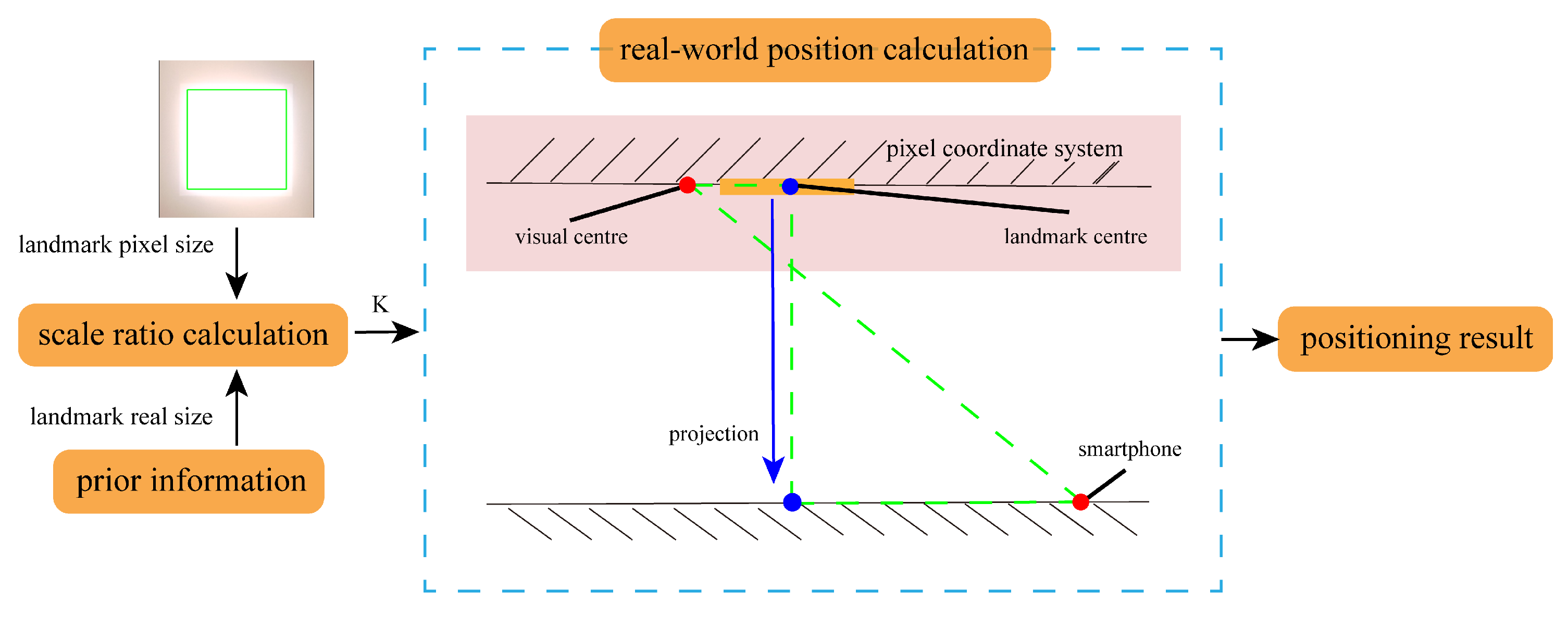
- Up-view visual-based position calculation module: This module uses light’s pixel size and real size to figure the scale ratio between the pixel world and the real world. Then, it uses the Similar Triangle Principle to calculate the smartphone’s position based on the light’s pixel coordinates and real-world coordinates.
- (4)
- INS-based landmark matching module: This module utilizes the inertial sensors’ data to estimate the target’s position at the current epoch based on the target’s position at the previous epoch. Then, we match the up-view image and the real-world light based on the comparison between the estimated target’s position and the pre-labeled light sequence.
2.2. Deep-Learning-Based Landmark Detection and Extraction Method
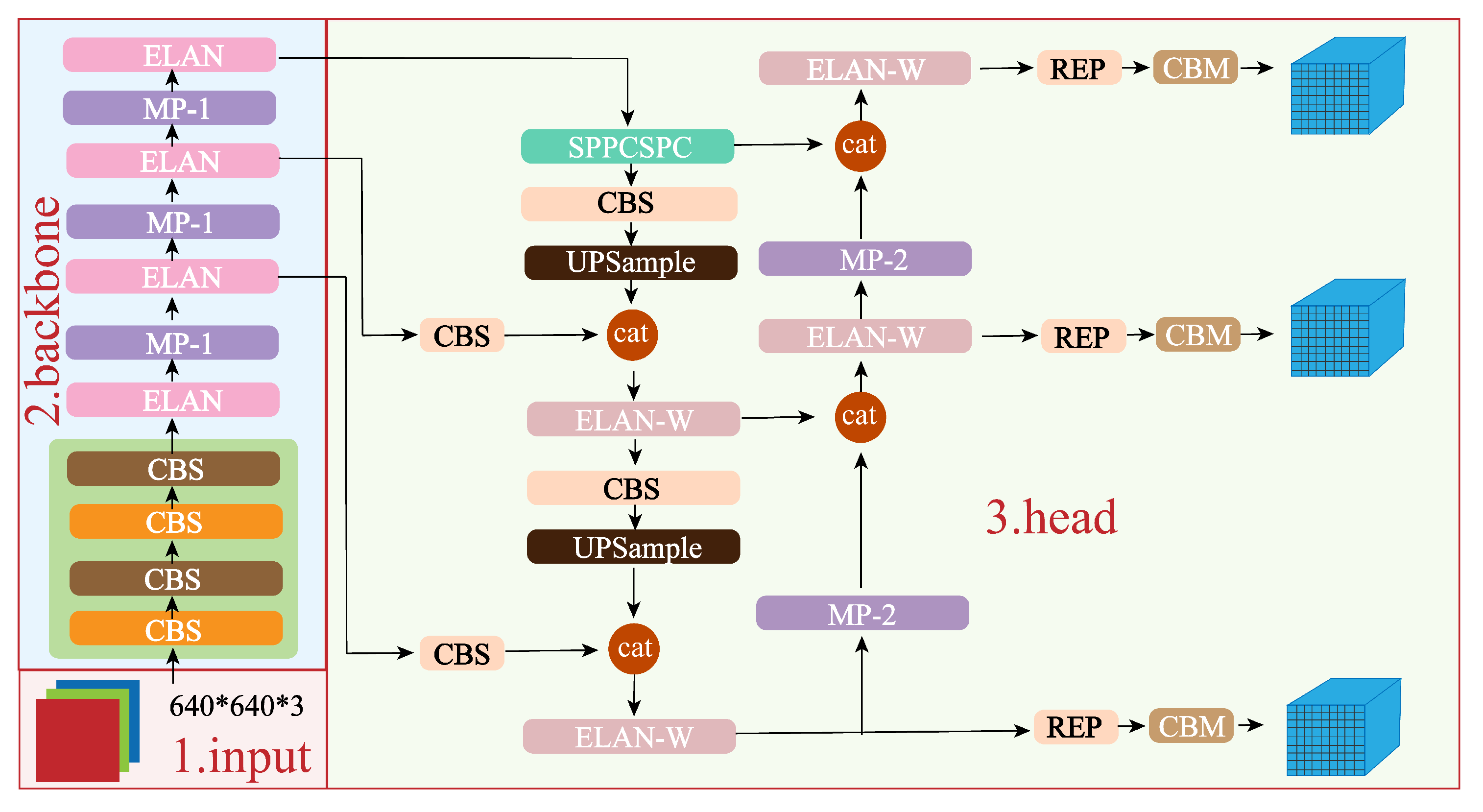
2.2.1. YOLO V7 Module
2.2.2. Edge Detection Algorithm
2.2.3. Deep-Learning-Based Up-View Landmark Detection and Extraction Mechanism
2.3. Up-View Visual-Based Position Calculation Method
2.4. INS-Based Landmark Matching Method
3. Experiments and Results
3.1. Landmark Detection and Extraction
3.1.1. Training of YOLO V7 Model
3.1.2. Indicators of YOLO V7 Model
- (1)
- TP (True Positive): Means the number of the detected instances that are real positive samples, which indicates the correct prediction.
- (2)
- FP (False Positive): Means the number of the detected instances that are real negative samples, which indicates the wrong prediction.
- (3)
- FN (False Negative): Means the number of targets that are real positive samples but not detected, which indicates the wrong prediction.
- (4)
- TN (True Negative): Means the number of targets that are real negative samples and not detected, which indicates the correct prediction.
3.1.3. Landmark Detection and Extraction Results
3.2. Static Experiments
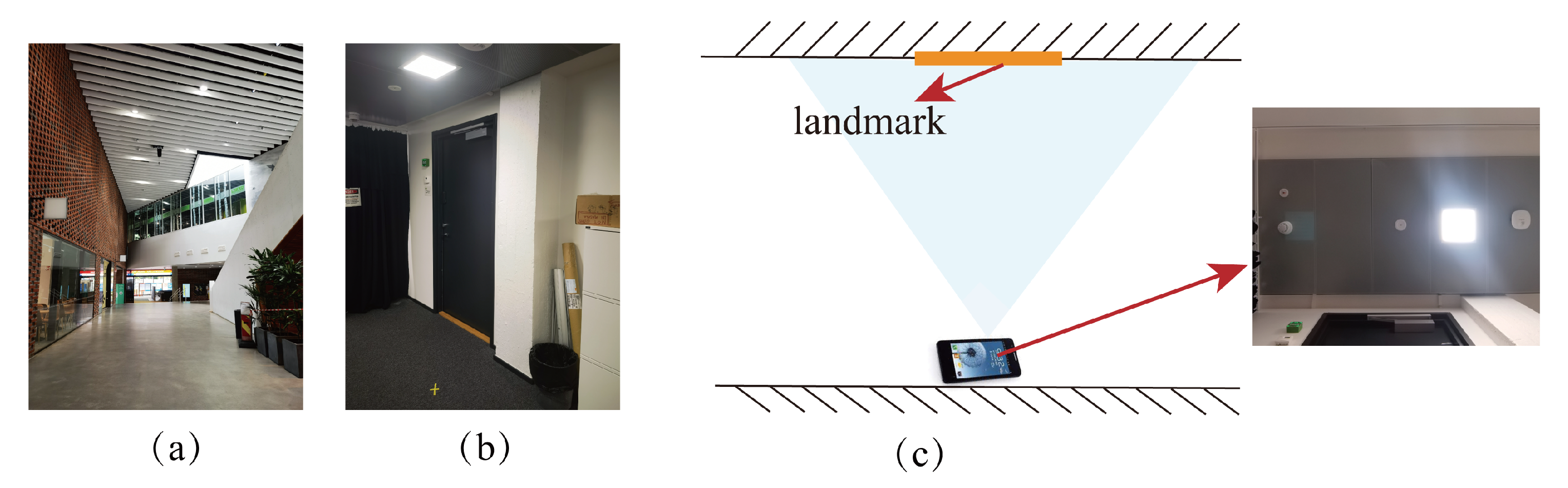
3.2.1. Static Experiment Design
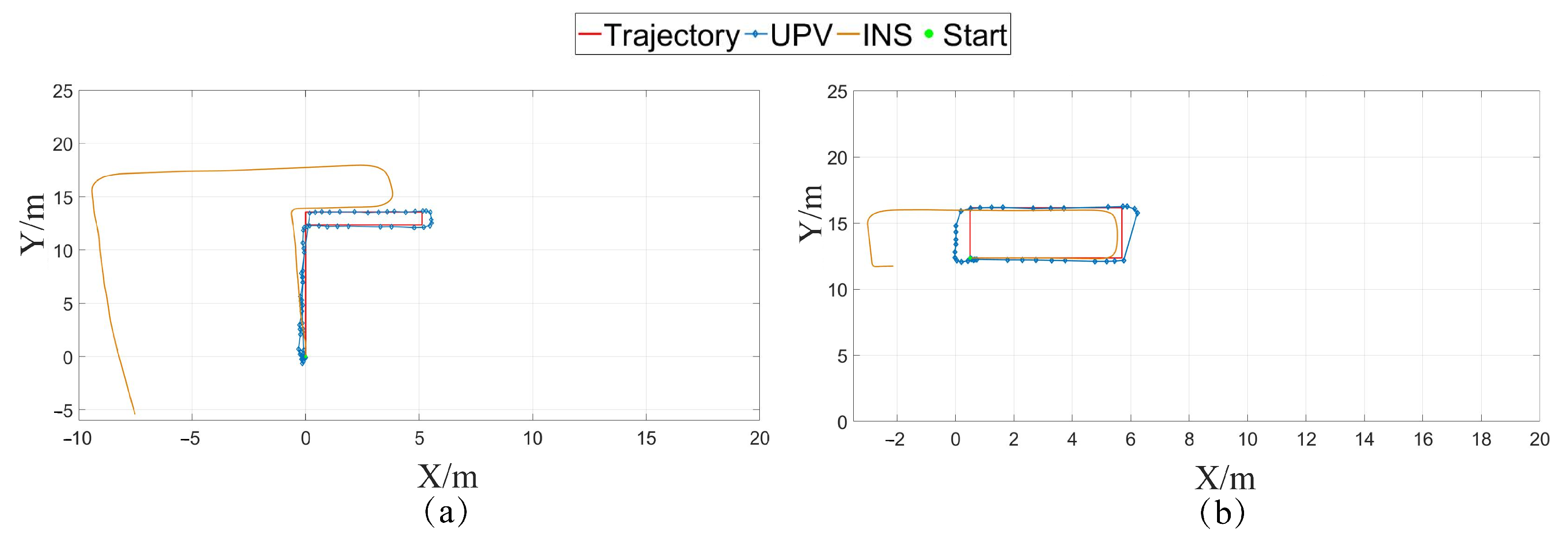
3.2.2. Static Single-Point Positioning Results
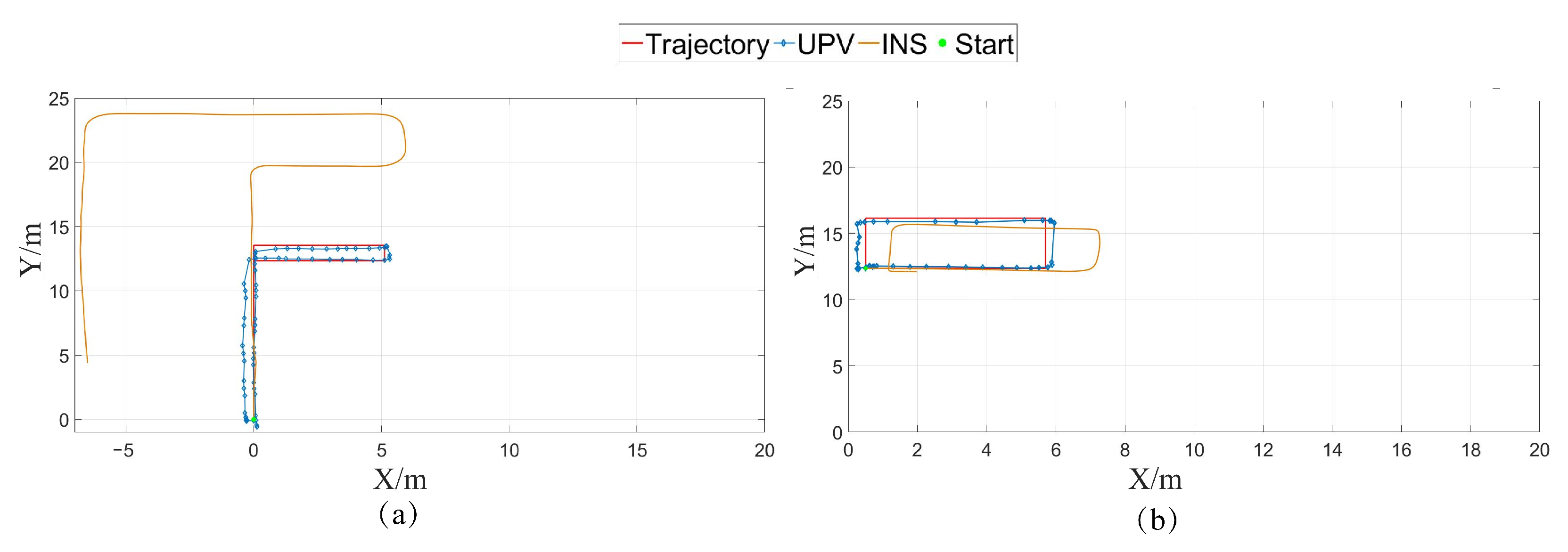
3.3. Kinematic Experiments
3.3.1. Kinematic Experiment Design
3.3.2. Kinematic Positioning Results
4. Conclusions
- (1)
- The up-view visual-based positioning method is proven to be a potential solution for indoor positioning. However, the matching module’s performance decays over time. Because the matching module is based on the IMU data. The IMU’s bias grows over time. Therefore, the matching module will probably miss the correct light in long-term cases, which significantly decreases the positioning accuracy.
- (2)
- The positioning accuracy of the proposed method is influenced by the image qualities and the landmark detection error. The robustness of this positioning method needed to be further improved.
- (3)
- The light distribution is often uneven in reality. The positioning performance of the proposed method is limited in areas where lights are sparsely distributed.
- (1)
- We will integrate this method with other indoor positioning approaches (e.g., pedestrian dead reckoning), using data fusion algorithms such as the Kalman Filter and Factor Graph Optimization. So that, we can potentially solve the problem above and further improve the accuracy and robustness of the up-view visual-based indoor positioning system, extending this work to more complex scenarios.
- (2)
- We will further apply this method to pedestrian indoor positioning. In this case, we will take the human features such as the holding pose into account. Thus, we will consider more about the modification of the bias caused by human walking.
- (3)
- In this paper, we initially consider the positioning on the same floor. The change between different floors is also a topic worthy of research. We plan to extend this work to different floors utilizing the data of the smartphone’s self-contained pressure meter and IMU in our future work.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Werner, M.; Kessel, M.; Marouane, C. Indoor positioning using smartphone camera. In Proceedings of the 2011 International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21–23 September 2011; pp. 1–6. [Google Scholar]
- Rudić, B.; Klaffenböck, M.A.; Pichler-Scheder, M.; Efrosinin, D.; Kastl, C. Geometry-aided ble-based smartphone positioning for indoor location-based services. In Proceedings of the 2020 IEEE MTT-S International Conference on Microwaves for Intelligent Mobility (ICMIM), Linz, Austria, 23 November 2020; pp. 1–4. [Google Scholar]
- Davidson, P.; Piché, R. A survey of selected indoor positioning methods for smartphones. IEEE Commun. Surv. Tutor. 2016, 19, 1347–1370. [Google Scholar] [CrossRef]
- Quezada-Gaibor, D.; Torres-Sospedra, J.; Nurmi, J.; Koucheryavy, Y.; Huerta, J. Cloud platforms for context-adaptive positioning and localisation in GNSS-denied scenarios—A systematic review. Sensors 2021, 22, 110. [Google Scholar] [CrossRef] [PubMed]
- Jang, B.; Kim, H.; Wook Kim, J. Survey of landmark-based indoor positioning technologies. Inf. Fusion 2023, 89, 166–188. [Google Scholar] [CrossRef]
- El-Sheimy, N.; Li, Y. Indoor navigation: State of the art and future trends. Satell. Navig. 2021, 2, 7. [Google Scholar] [CrossRef]
- He, S.; Chan, S.H.G. Wi-Fi fingerprint-based indoor positioning: Recent advances and comparisons. IEEE Commun. Surv. Tutor. 2015, 18, 466–490. [Google Scholar] [CrossRef]
- Li, X.; Zhang, P.; Huang, G.; Zhang, Q.; Guo, J.; Zhao, Y.; Zhao, Q. Performance analysis of indoor pseudolite positioning based on the unscented Kalman filter. GPS Solut. 2019, 23, 79. [Google Scholar] [CrossRef]
- Maheepala, M.; Kouzani, A.Z.; Joordens, M.A. Light-based indoor positioning systems: A review. IEEE Sens. J. 2020, 20, 3971–3995. [Google Scholar] [CrossRef]
- Ren, J.; Wang, Y.; Niu, C.; Song, W.; Huang, S. A novel clustering algorithm for Wi-Fi indoor positioning. IEEE Access 2019, 7, 122428–122434. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhou, T. UWB indoor positioning algorithm based on TDOA technology. In Proceedings of the 2019 10th International Conference on Information Technology in Medicine and Education (ITME), Qingdao, China, 23–25 August 2019; pp. 777–782. [Google Scholar]
- Phutcharoen, K.; Chamchoy, M.; Supanakoon, P. Accuracy study of indoor positioning with bluetooth low energy beacons. In Proceedings of the 2020 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Pattaya, Thailand, 11–14 March 2020; pp. 24–27. [Google Scholar]
- Yao, L.; Wu, Y.W.A.; Yao, L.; Liao, Z.Z. An integrated IMU and UWB sensor based indoor positioning system. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sapporo, Japan, 18–21 September 2017; pp. 1–8. [Google Scholar]
- Cioffi, G.; Scaramuzza, D. Tightly-coupled fusion of global positional measurements in optimization-based visual-inertial odometry. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 5089–5095. [Google Scholar]
- Zou, Q.; Sun, Q.; Chen, L.; Nie, B.; Li, Q. A comparative analysis of LiDAR SLAM-based indoor navigation for autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6907–6921. [Google Scholar] [CrossRef]
- Li, M.; Chen, R.; Liao, X.; Guo, B.; Zhang, W.; Guo, G. A precise indoor visual positioning approach using a built image feature database and single user image from smartphone cameras. Remote Sens. 2020, 12, 869. [Google Scholar] [CrossRef]
- Naseer, T.; Burgard, W.; Stachniss, C. Robust visual localization across seasons. IEEE Trans. Robot. 2018, 34, 289–302. [Google Scholar] [CrossRef]
- Couturier, A.; Akhloufi, M.A. A review on absolute visual localization for UAV. Robot. Auton. Syst. 2021, 135, 103666. [Google Scholar] [CrossRef]
- Khattar, F.; Luthon, F.; Larroque, B.; Dornaika, F. Visual localization and servoing for drone use in indoor remote laboratory environment. Mach. Vis. Appl. 2021, 32, 32. [Google Scholar] [CrossRef]
- Lei, X.; Zhang, F.; Zhou, J.; Shang, W. Visual Localization Strategy for Indoor Mobile Robots in the Complex Environment. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 1135–1140. [Google Scholar]
- Zhang, H.; Ye, C. A visual positioning system for indoor blind navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9079–9085. [Google Scholar]
- Himawan, R.W.; Baylon, P.B.A.; Sembiring, J.; Jenie, Y.I. Development of an Indoor Visual-Based Monocular Positioning System for Multirotor UAV. In Proceedings of the 2023 IEEE International Conference on Aerospace Electronics and Remote Sensing Technology (ICARES), Bali, Indonesia, 26–27 October 2023; pp. 1–7. [Google Scholar]
- Chi, P.; Wang, Z.; Liao, H.; Li, T.; Zhan, J.; Wu, X.; Tian, J.; Zhang, Q. Low-latency Visual-based High-Quality 3D Reconstruction using Point Cloud Optimization. IEEE Sens. J. 2023, 23, 20055–20065. [Google Scholar] [CrossRef]
- Bai, X.; Zhang, B.; Wen, W.; Hsu, L.T.; Li, H. Perception-aided visual-inertial integrated positioning in dynamic urban areas. In Proceedings of the 2020 IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; pp. 1563–1571. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Cao, L.; Zheng, X.; Fang, L. The Semantic Segmentation of Standing Tree Images Based on the Yolo V7 Deep Learning Algorithm. Electronics 2023, 12, 929. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operator | Introduction | Advantages/Disadvantages |
|---|---|---|
| Sobel | Detects edges by computing the horizontal and vertical gradients of each pixel in the image. | Robustness to noise; High computational efficiency; Bad performance for edges with large slopes. |
| Canny | A multi-stage edge detection method, including the steps of filtering, enhancement, non-maximum suppression, and dual thresholding. | High accuracy; High computational complexity; Complex implementation. |
| Laplace | Detect edges by computing the Laplacian transform of an image. | Can detect the position and direction of the edge; Sensitive to noise; High computational complexity. |
| Prewitt | Similar to the Sobel operator, it is also an edge detection method based on local gradients utilizing a different mask. | Low computational complexity; Easy implementation; Sensitive to noise. |
| Roberts | A diagonal gradient-based edge detection method. | Low computational complexity; Easy implementation; Sensitive to noise. |
| Indicator | Precision | Recall | F1-Score | ||
|---|---|---|---|---|---|
| Result | 0.994 | 0.985 | 0.989 | 0.988 | 0.833 |
| Scenario | Baseline (m) |
|---|---|
| A | 2.25 |
| B | 3.22 |
| C | 7.99 |
| Scenario | Mean Error (m) | STD (m) | Max Error (m) |
|---|---|---|---|
| A | 0.0441 | 0.0228 | 0.0783 |
| B | 0.0446 | 0.0261 | 0.0763 |
| C | 0.0698 | 0.0285 | 0.0979 |
| Trajectory 1 | Trajectory 2 | |
|---|---|---|
| Huawei mate40 pro | 91/91 | 50/50 |
| OnePlus Nord CE | 96/96 | 52/52 |
| Xiaomi Redmi note 11 | 101/101 | 54/54 |
| Trajectory 1 | Trajectory 2 | |
|---|---|---|
| Huawei mate40 pro | 0.5842 | 0.2227 |
| OnePlus Nord CE | 0.5436 | 0.1984 |
| Xiaomi Redmi note 11 | 0.5891 | 0.2665 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Chen, Y.; Zhu, J.; Jiang, C.; Jia, J.; Bo, Y.; Liu, X.; Dai, H.; Puttonen, E.; Hyyppä, J. An Up-View Visual-Based Indoor Positioning Method via Deep Learning. Remote Sens. 2024, 16, 1024. https://doi.org/10.3390/rs16061024
Chen C, Chen Y, Zhu J, Jiang C, Jia J, Bo Y, Liu X, Dai H, Puttonen E, Hyyppä J. An Up-View Visual-Based Indoor Positioning Method via Deep Learning. Remote Sensing. 2024; 16(6):1024. https://doi.org/10.3390/rs16061024
Chicago/Turabian StyleChen, Chen, Yuwei Chen, Jianliang Zhu, Changhui Jiang, Jianxin Jia, Yuming Bo, Xuanzhi Liu, Haojie Dai, Eetu Puttonen, and Juha Hyyppä. 2024. "An Up-View Visual-Based Indoor Positioning Method via Deep Learning" Remote Sensing 16, no. 6: 1024. https://doi.org/10.3390/rs16061024
APA StyleChen, C., Chen, Y., Zhu, J., Jiang, C., Jia, J., Bo, Y., Liu, X., Dai, H., Puttonen, E., & Hyyppä, J. (2024). An Up-View Visual-Based Indoor Positioning Method via Deep Learning. Remote Sensing, 16(6), 1024. https://doi.org/10.3390/rs16061024