

A Coarse-to-Fine Transformer-Based Network for 3D Reconstruction from Non-Overlapping Multi-View Images

Abstract

1. Introduction
- We innovatively design a novel deep neural network named PCR-T to reconstruct high-quality 3D shapes from non-overlapping multi-view images. Equipped with a well-designed generator and refiner, PCR-T demonstrates enhanced capabilities in handling this challenging task.
- We innovatively propose a Transformer-based architecture to refine the shape of point clouds, facilitating adaptive information exchange among unordered points and leading to more accurate predictions of 3D structures.
- Experimental results on the ShapeNet [8] dataset showcase that the proposed approach outperforms state-of-the-art methods.
2. Related Work
2.1. Single-View Reconstruction Methods
2.2. Multi-View Reconstruction Methods
2.3. Transformer-Based Methods
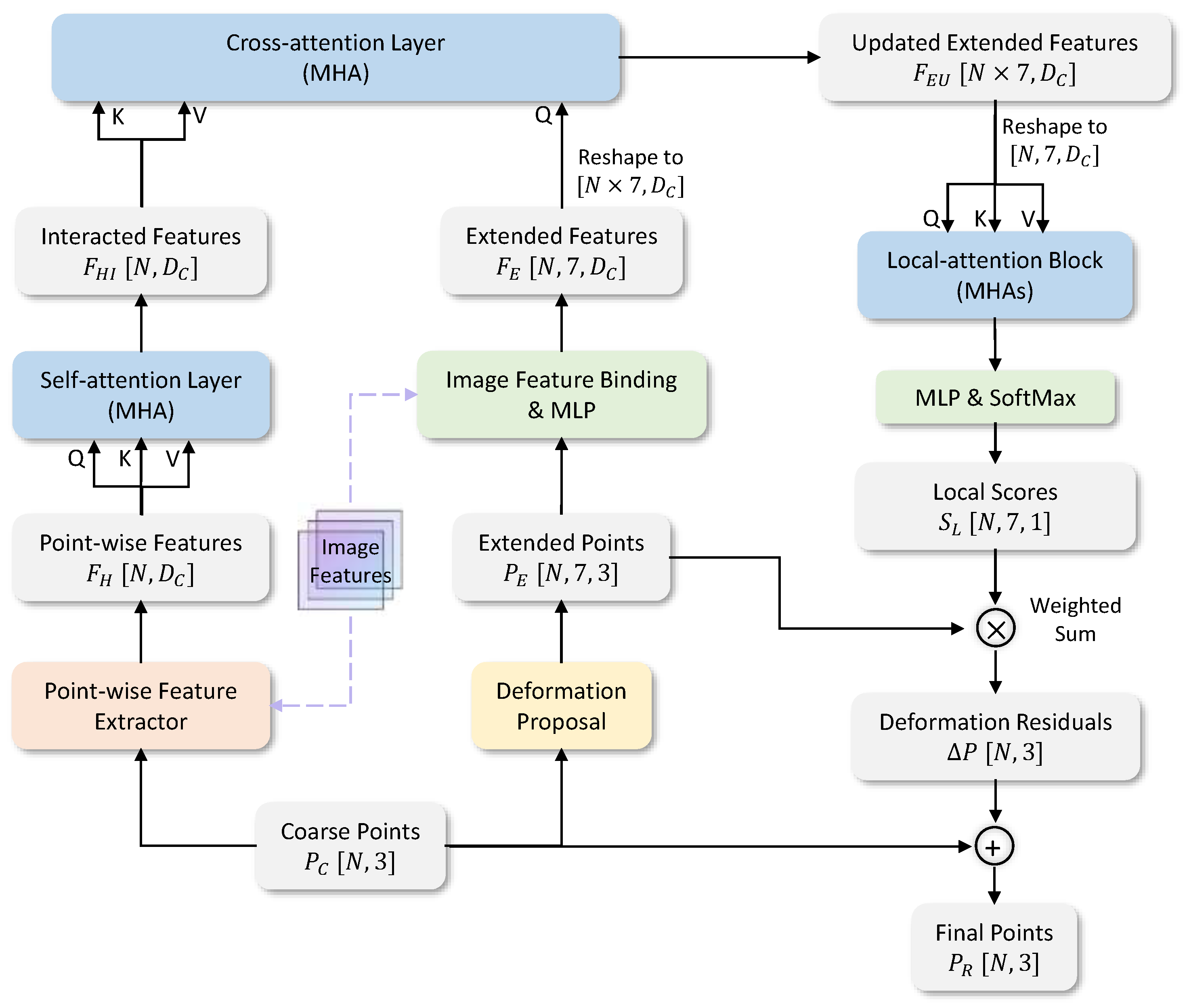
3. Method
3.1. Preliminaries
3.2. Point Cloud Generator
3.3. Transformer-Based Refiner
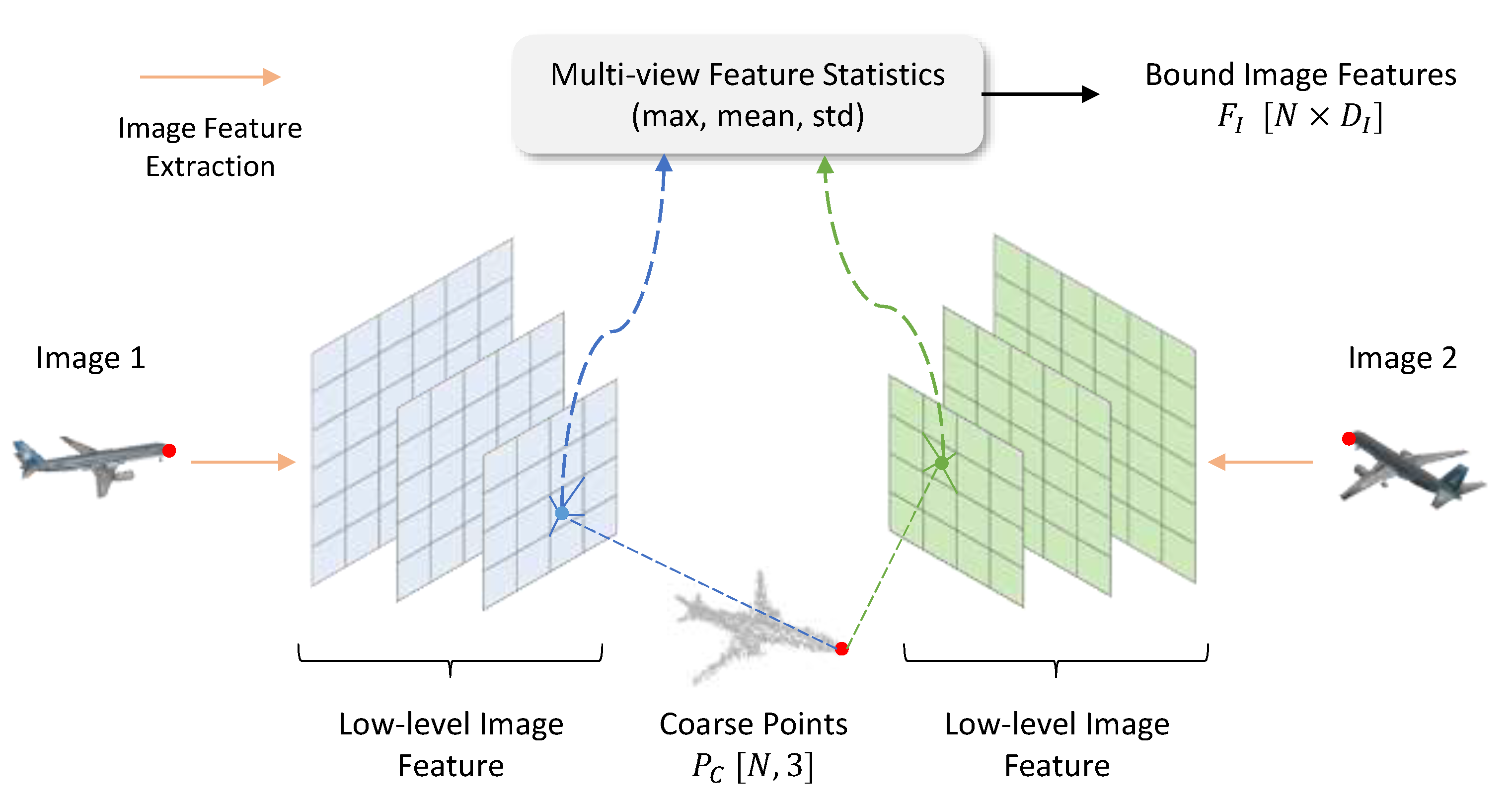
3.3.1. Point-Wise Feature Extractor
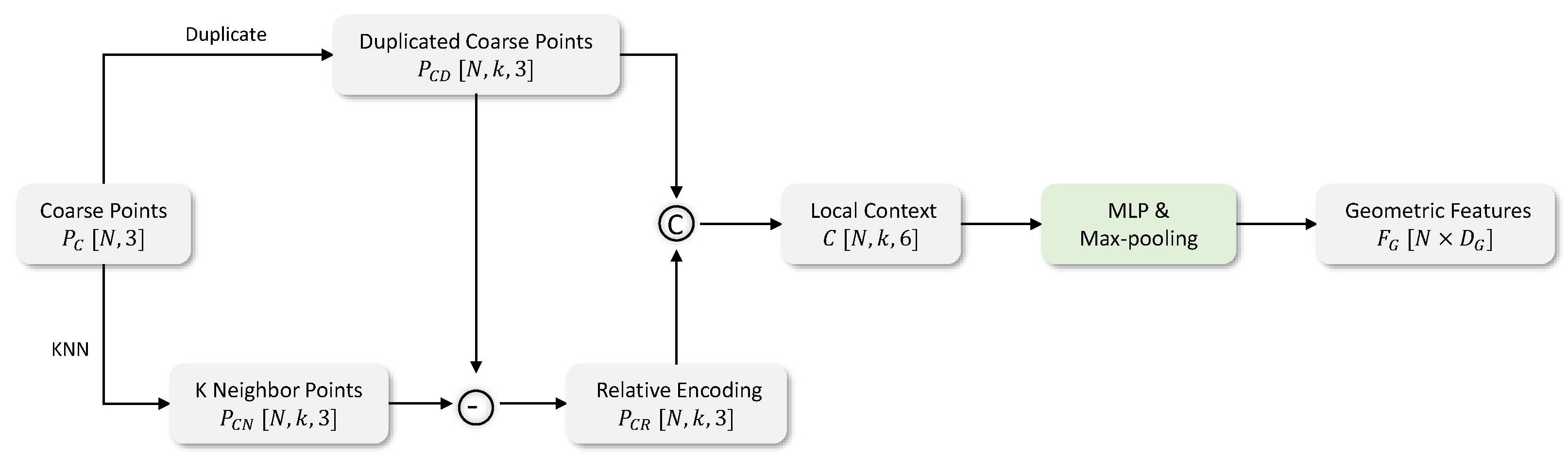
3.3.2. Self-Attention Feature Encoder
3.3.3. Deformation Decoder
4. Experiment
4.1. Experimental Setup
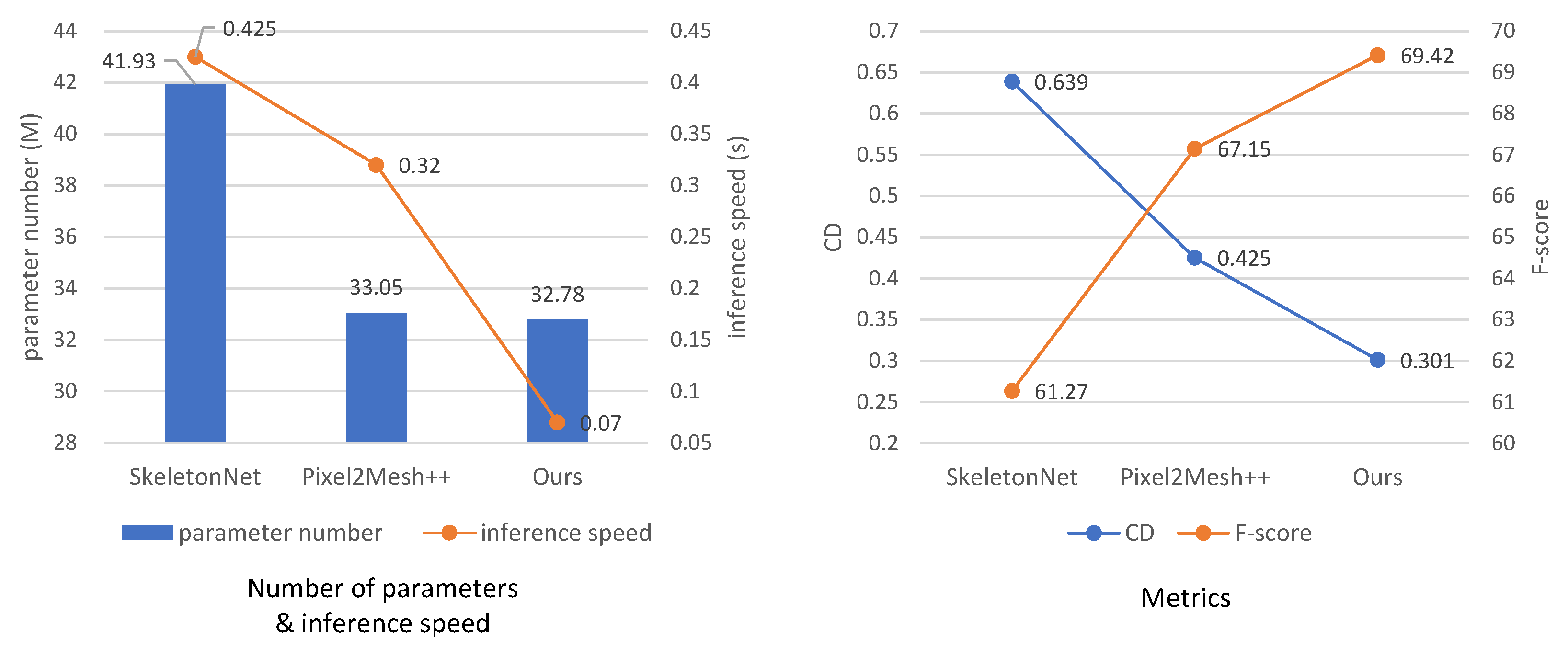
4.2. Comparison to Sparse-View Reconstruction
4.3. Reconstruction from Real-World Images
4.4. Ablation Study
4.5. Failure Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 767–783. [Google Scholar]
- Chen, R.; Han, S.; Xu, J.; Su, H. Point-based multi-view stereo network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1538–1547. [Google Scholar]
- Li, J.; Lu, Z.; Wang, Y.; Wang, Y.; Xiao, J. DS-MVSNet: Unsupervised Multi-view Stereo via Depth Synthesis. In Proceedings of the ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 5593–5601. [Google Scholar]
- Jia, R.; Chen, X.; Cui, J.; Hu, Z. MVS-T: A coarse-to-fine multi-view stereo network with transformer for low-resolution images 3D reconstruction. Sensors 2022, 22, 7659. [Google Scholar] [CrossRef] [PubMed]
- Wen, C.; Zhang, Y.; Li, Z.; Fu, Y. Pixel2mesh++: Multi-view 3d mesh generation via deformation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1042–1051. [Google Scholar]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2vox: Context-aware 3d reconstruction from single and multi-view images. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2690–2698. [Google Scholar]
- Tang, J.; Han, X.; Tan, M.; Tong, X.; Jia, K. Skeletonnet: A topology-preserving solution for learning mesh reconstruction of object surfaces from rgb images. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6454–6471. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Durou, J.D.; Falcone, M.; Sagona, M. Numerical methods for shape-from-shading: A new survey with benchmarks. Comput. Vis. Image Underst. 2008, 109, 22–43. [Google Scholar] [CrossRef]
- Richter, S.R.; Roth, S. Discriminative shape from shading in uncalibrated illumination. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1128–1136. [Google Scholar]
- Witkin, A.P. Recovering surface shape and orientation from texture. Artif. Intell. 1981, 17, 17–45. [Google Scholar] [CrossRef]
- Zhang, R.; Tsai, P.S.; Cryer, J.E.; Shah, M. Shape-from-shading: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 690–706. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, W.T.; Tenenbaum, J.B. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In Proceedings of the International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Mandikal, P.; Navaneet, K.; Agarwal, M.; Babu, R.V. 3D-LMNet: Latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image. arXiv 2018, arXiv:1807.07796. [Google Scholar]
- Mandikal, P.; Radhakrishnan, V.B. Dense 3d point cloud reconstruction using a deep pyramid network. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1052–1060. [Google Scholar]
- Wang, P.; Liu, L.; Zhang, H.; Wang, T. CGNet: A Cascaded Generative Network for dense point cloud reconstruction from a single image. Knowl.-Based Syst. 2021, 223, 107057. [Google Scholar] [CrossRef]
- Li, B.; Zhu, S.; Lu, Y. A single stage and single view 3D point cloud reconstruction network based on DetNet. Sensors 2022, 22, 8235. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Nguyen, A.D.; Kim, J.; Ahn, S.; Lee, S. Point cloud deformation for single image 3d reconstruction. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 2379–2383. [Google Scholar]
- Ping, G.; Esfahani, M.A.; Wang, H. Visual enhanced 3D point cloud reconstruction from a single image. arXiv 2021, arXiv:2108.07685. [Google Scholar]
- Wen, X.; Zhou, J.; Liu, Y.S.; Su, H.; Dong, Z.; Han, Z. 3D shape reconstruction from 2D images with disentangled attribute flow. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3803–3813. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A unified approach for single and multi-view 3d object reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 628–644. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2088–2096. [Google Scholar]
- Shen, W.; Jia, Y.; Wu, Y. 3D shape reconstruction from images in the frequency domain. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4471–4479. [Google Scholar]
- Wang, W.; Xu, Q.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep implicit surface network for high-quality single-view 3D reconstruction. In Proceedings of the International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 492–502. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. ACM SIGGRAPH Comput. Graph. 1987, 21, 163–169. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 52–67. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Lin, C.H.; Kong, C.; Lucey, S. Learning efficient point cloud generation for dense 3d object reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7114–7121. [Google Scholar]
- Insafutdinov, E.; Dosovitskiy, A. Unsupervised learning of shape and pose with differentiable point clouds. In Proceedings of the International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 2807–2817. [Google Scholar]
- Wang, J.; Sun, B.; Lu, Y. Mvpnet: Multi-view point regression networks for 3d object reconstruction from a single image. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8949–8956. [Google Scholar]
- Jia, X.; Yang, S.; Peng, Y.; Zhang, J.; Chen, S. DV-Net: Dual-view network for 3D reconstruction by fusing multiple sets of gated control point clouds. Pattern Recognit. Lett. 2020, 131, 376–382. [Google Scholar]
- Xie, H.; Yao, H.; Zhang, S.; Zhou, S.; Sun, W. Pix2Vox++: Multi-scale context-aware 3D object reconstruction from single and multiple images. Int. J. Comput. Vis. 2020, 128, 2919–2935. [Google Scholar] [CrossRef]
- Spezialetti, R.; Tan, D.J.; Tonioni, A.; Tateno, K.; Tombari, F. A divide et Impera approach for 3D shape reconstruction from multiple views. In Proceedings of the International Conference on 3D Vision, Fukuoka, Japan, 25–28 November 2020; pp. 160–170. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Lu, D.; Xie, Q.; Wei, M.; Gao, K.; Xu, L.; Li, J. Transformers in 3d point clouds: A survey. arXiv 2022, arXiv:2205.07417. [Google Scholar]
- Lahoud, J.; Cao, J.; Khan, F.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Yang, M.H. 3D vision with transformers: A survey. arXiv 2022, arXiv:2208.04309. [Google Scholar]
- Lu, Q.; Xiao, M.; Lu, Y.; Yuan, X.; Yu, Y. Attention-based dense point cloud reconstruction from a single image. IEEE Access 2019, 7, 137420–137431. [Google Scholar] [CrossRef]
- Wang, D.; Cui, X.; Chen, X.; Zou, Z.; Shi, T.; Salcudean, S.; Wang, Z.J.; Ward, R. Multi-view 3d reconstruction with transformers. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5722–5731. [Google Scholar]
- Yuan, Y.; Tang, J.; Zou, Z. Vanet: A view attention guided network for 3d reconstruction from single and multi-view images. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Tiong, L.C.O.; Sigmund, D.; Teoh, A.B.J. 3D-C2FT: Coarse-to-fine Transformer for Multi-view 3D Reconstruction. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 1438–1454. [Google Scholar]
- Huang, Y.; Zhou, S.; Zhang, J.; Dong, J.; Zheng, N. VPFusion: Towards Robust Vertical Representation Learning for 3D Object Detection. arXiv 2023, arXiv:2304.02867. [Google Scholar]
- Yagubbayli, F.; Wang, Y.; Tonioni, A.; Tombari, F. Legoformer: Transformers for block-by-block multi-view 3d reconstruction. arXiv 2021, arXiv:2106.12102. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++ deep hierarchical feature learning on point sets in a metric space. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5105–5114. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3d: Dataset and methods for single-image 3d shape modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2974–2983. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | CD (×0.001) ↓ | ||||
|---|---|---|---|---|---|
| 3D-R2N2 | Pixel2Mesh++ | SkeletonNet | DV-Net | Ours | |
| Plane | 0.854 | 0.422 | 0.732 | 0.338 | 0.184 |
| Bench | 1.362 | 0.549 | 0.447 | 0.396 | 0.236 |
| Cabinet | 0.613 | 0.337 | 0.625 | 0.291 | 0.285 |
| Car | 0.358 | 0.253 | 0.278 | 0.246 | 0.203 |
| Chair | 1.534 | 0.461 | 0.589 | 0.466 | 0.324 |
| Monitor | 1.465 | 0.566 | 0.536 | 0.466 | 0.294 |
| Lamp | 6.780 | 1.135 | 1.268 | 0.857 | 0.760 |
| Speaker | 1.443 | 0.635 | 0.910 | 0.527 | 0.423 |
| Firearm | 0.432 | 0.305 | 0.365 | 0.354 | 0.197 |
| Coach | 0.806 | 0.439 | 0.491 | 0.396 | 0.308 |
| Table | 1.243 | 0.388 | 0.568 | 0.351 | 0.329 |
| Cellphone | 1.161 | 0.325 | 0.604 | 0.297 | 0.154 |
| Watercraft | 0.869 | 0.508 | 0.572 | 0.488 | 0.280 |
| Mean | 1.455 | 0.486 | 0.639 | 0.417 | 0.301 |
| Category | F-Score () ↑ | F-Score () ↑ | ||||||
|---|---|---|---|---|---|---|---|---|
| 3D-R2N2 | SkeletonNet | Pixel2Mesh++ | Ours | 3D-R2N2 | SkeletonNet | Pixel2Mesh++ | Ours | |
| Plane | 47.81 | 59.53 | 76.79 | 81.28 | 70.49 | 74.87 | 86.62 | 91.19 |
| Bench | 44.56 | 68.01 | 66.24 | 73.40 | 62.47 | 82.26 | 79.67 | 87.71 |
| Cabinet | 54.08 | 59.74 | 65.72 | 65.25 | 64.42 | 79.72 | 81.57 | 83.21 |
| Car | 59.86 | 68.39 | 68.45 | 71.19 | 78.31 | 84.50 | 85.19 | 88.82 |
| Chair | 37.62 | 59.59 | 62.05 | 63.88 | 54.26 | 75.82 | 77.68 | 81.30 |
| Monitor | 36.33 | 60.45 | 60.00 | 65.56 | 48.65 | 79.57 | 75.42 | 82.62 |
| Lamp | 32.25 | 49.52 | 62.56 | 58.78 | 49.38 | 56.81 | 74.00 | 73.08 |
| Speaker | 41.48 | 47.15 | 54.88 | 55.23 | 52.29 | 67.47 | 71.46 | 72.77 |
| Firearm | 55.72 | 67.95 | 74.85 | 82.38 | 76.79 | 83.15 | 89.29 | 91.39 |
| Coach | 45.47 | 57.23 | 57.56 | 58.91 | 59.97 | 74.56 | 75.33 | 79.91 |
| Table | 48.78 | 65.90 | 71.89 | 72.34 | 62.67 | 81.66 | 84.19 | 85.36 |
| Cellphone | 58.09 | 72.64 | 74.36 | 78.70 | 69.66 | 85.24 | 86.16 | 93.35 |
| Watercraft | 40.72 | 61.07 | 62.99 | 68.16 | 63.59 | 78.91 | 77.32 | 83.86 |
| Mean | 46.37 | 61.27 | 66.48 | 69.42 | 62.53 | 77.43 | 80.30 | 84.71 |
| Training Views | Metrics | Testing Views | |||
|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | ||
| 3 | CD ↓ | 0.348 | 0.301 | 0.297 | 0.291 |
| F-score () ↑ | 67.73 | 69.42 | 69.79 | 70.26 | |
| F-score () ↑ | 82.86 | 84.71 | 85.10 | 85.67 | |
| Resp. | CD ↓ | 0.356 | 0.301 | 0.293 | 0.288 |
| F-score () ↑ | 67.34 | 69.42 | 70.15 | 70.58 | |
| F-score () ↑ | 82.27 | 84.71 | 85.52 | 86.03 | |
| Variant Methods | CD ↓ | F-Score () ↑ | F-Score () ↑ |
|---|---|---|---|
| w/o centroid constraint | 0.315 | 68.53 | 83.79 |
| w/o position fusion | 0.312 | 68.72 | 84.28 |
| w/o local attention | 0.319 | 68.25 | 83.64 |
| w/o cross attention | 0.328 | 67.90 | 83.43 |
| full model | 0.301 | 69.42 | 84.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shan, Y.; Xiao, J.; Liu, L.; Wang, Y.; Yu, D.; Zhang, W. A Coarse-to-Fine Transformer-Based Network for 3D Reconstruction from Non-Overlapping Multi-View Images. Remote Sens. 2024, 16, 901. https://doi.org/10.3390/rs16050901
Shan Y, Xiao J, Liu L, Wang Y, Yu D, Zhang W. A Coarse-to-Fine Transformer-Based Network for 3D Reconstruction from Non-Overlapping Multi-View Images. Remote Sensing. 2024; 16(5):901. https://doi.org/10.3390/rs16050901
Chicago/Turabian StyleShan, Yue, Jun Xiao, Lupeng Liu, Yunbiao Wang, Dongbo Yu, and Wenniu Zhang. 2024. "A Coarse-to-Fine Transformer-Based Network for 3D Reconstruction from Non-Overlapping Multi-View Images" Remote Sensing 16, no. 5: 901. https://doi.org/10.3390/rs16050901
APA StyleShan, Y., Xiao, J., Liu, L., Wang, Y., Yu, D., & Zhang, W. (2024). A Coarse-to-Fine Transformer-Based Network for 3D Reconstruction from Non-Overlapping Multi-View Images. Remote Sensing, 16(5), 901. https://doi.org/10.3390/rs16050901