1. Introduction
Using hyperspectral imaging sensors, hyperspectral images (HSIs) can simultaneously capture spectral and spatial information from objects in the visible, near-infrared, and shortwave infrared wavelength ranges. Owing to the varying physical and chemical properties of reflective substances, the spectral curves of HSI exhibit different manifestations. The hyperspectral images captured by satellites are usually composed of pixels in a certain area on the Earth’s surface. Based on these, the HSI has been widely used in various fields [
1,
2,
3], including agriculture, land-cover classification, forestry, urban planning, national defense, and medical diagnostic imaging. Currently, the HSI classification has drawn broad attention in the field of remote sensing [
4].
In early research, most classification methods focused on exploring correlations between pixels of HSIs. Some traditional models have been introduced for classifying HSIs, including neural networks [
5], support vector machines (SVM) [
6], multiple logistic regression [
7] and random forest [
8]. In addition, considering the high dimensionality of HSIs, some theoretical techniques were introduced for extracting the discriminative information and reducing the dimensions of HSIs, including principal component analysis (PCA) [
9], independent component analysis (ICA) [
10], and linear discriminant analysis (LDA) [
11].
Owing to the geographical characteristics, the same type of land-cover object is often gathered in the same area and has the spatial consistence. Some classifiers were proposed for HSI classification [
12,
13,
14,
15,
16] by combing spatial consistency and spectral correlations. The traditional methods mentioned above have obtained good classification results on specific tasks or data. However, these methods often rely on artificially defined shallow representations, which results in weak generalization and limits their applicability in practical scenarios.
The key to addressing the above problems is considered as extracting sufficiently discriminative features. By exploiting deeper features with the rich discriminative information, deep learning (DL) has been widely applied for HSI classification [
4]. The representative models include the stacked autoencoder (SAE) [
17], recurrent neural network (RNN) [
18,
19], convolutional neural network (CNN) [
20], deep belief network (DBN) [
21], generative adversarial networks (GAN) [
22], and long short-term memory (LSTM) [
23].
Nowadays, convolutional neural networks are more extensive classification tools than others based on DL. Deng et al. proposed the S-DMM network, employing one-dimensional convolution to extract spectral features [
24]. Yu et al. adopted 1 × 1 convolutional layers and pooling layers to analyze the HSI, achieving significant advancements in the DL-based HSI classification [
20]. Li et al. utilized 3D convolution to extract spatial information on neighborhood pixel blocks of hyperspectral images [
25], which has been cited as the comparing method and performed on large datasets with good performance. Roy et al. [
26] proposed a hybrid spectral CNN (HybridSN), which explored using a spectral–spatial 3D CNN followed by a spatial 2D CNN to further learn more abstract-level spatial representation. To effectively integrate the spatial–spectral information, various variants based on CNNs have been developed for HSI classification. Zhong et al. (SSRN) used spectral–spatial residual networks to solve the gradient vanishing problem and facilitate network backpropagation [
27]. Zhou et al. [
28] proposed the spatial–spectral joint feature extraction with local and global information at different scales to classify the HSI. Firat et al. [
29] proposed a hybrid 3D residual spatial–spectral convolution network to extract deep spatial–spectral features utilizing 3D CNN and ResNet18. Additionally, the classification methods combined with the transformer architecture and attention mechanism have been applied to classify the HSI [
30,
31,
32,
33]. These methods have effectively enhanced the classification efficiency. Due to irregularities of the spatial features in HSIs, solely employing regular convolutional kernels may not adequately capture the irregular structures inherent in HSI features. This is because CNNs are specifically designed for processing Euclidean data and regular spatial structures. Furthermore, CNNs often fail to efficiently depict long-range dependencies when processing spectral sequential data [
33] and become too time consuming as the number of layers and input data increase.
GCNs are increasingly being employed for HSI classification, as they can perform convolutions on arbitrarily structured graphs. Specifically, GCNs can model the relationships between adjacent samples and the spatial contextual structure in HSIs. So, they can be used to capture the long-range spatial relations, which CNN cannot do. Mou et al. [
34] proposed a nonlocal GCN in which the entire HSI is input to the network. Yu et al. [
35] proposed a novel two-branch deeper GCN by simultaneously exploiting superpixel- and pixel-level features in HSI. Ding et al. [
36] proposed a novel multi-feature fusion network for HSI classification by combing a GCN and CNN. In reality, it is better if the GCN can overcome the inapplicability of the fixed structure and gradually refine the graph with different inputs. Therefore, the dynamic GCN was developed to enhance the generality. Ding et al. [
37] developed a novel dynamic adaptive sampling GCN model, which can capture neighbor information by adaptive sampling and allow the receptive field to be dynamically obtained. Yang et al. [
38] proposed a novel deep network with adaptive graph structure integration, which can learn the graph structure of the HSI dynamically and enhance the discriminative ability by devising a much deeper network architecture. Wan et al. [
39] proposed a dual interactive GCN to leverage contextual relationships among pixels and effectively capture multiscale spatial information. To harness the strengths of both CNNs and GCNs, Liu et al. [
40] introduced a CNN-enhanced GCN method by generating complementary spectral–spatial features at both pixel and superpixel levels. Dong et al. [
41] fused the superpixel-based graph attention network and pixel-based CNN, which proved to be complementary. These models based on GCN have shown a promising classification performance, but they face the challenge of high spatial complexity while calculating large-scale graphs.
In practice, the high cost of manual annotation often results in the scarcity of training samples for HSI classification [
42]. DCFSL [
42] is a deep cross-domain few-shot learning (FSL) method, which can execute FSL in source and target classes at the same time. It has been cited as the comparing method and performed on larger datasets in the literature. When used with limited labeled samples, classifiers based on a CNN and GCN easily lead to issues of overfitting and weak generalization due to the insufficient extraction of representative and discriminative features.
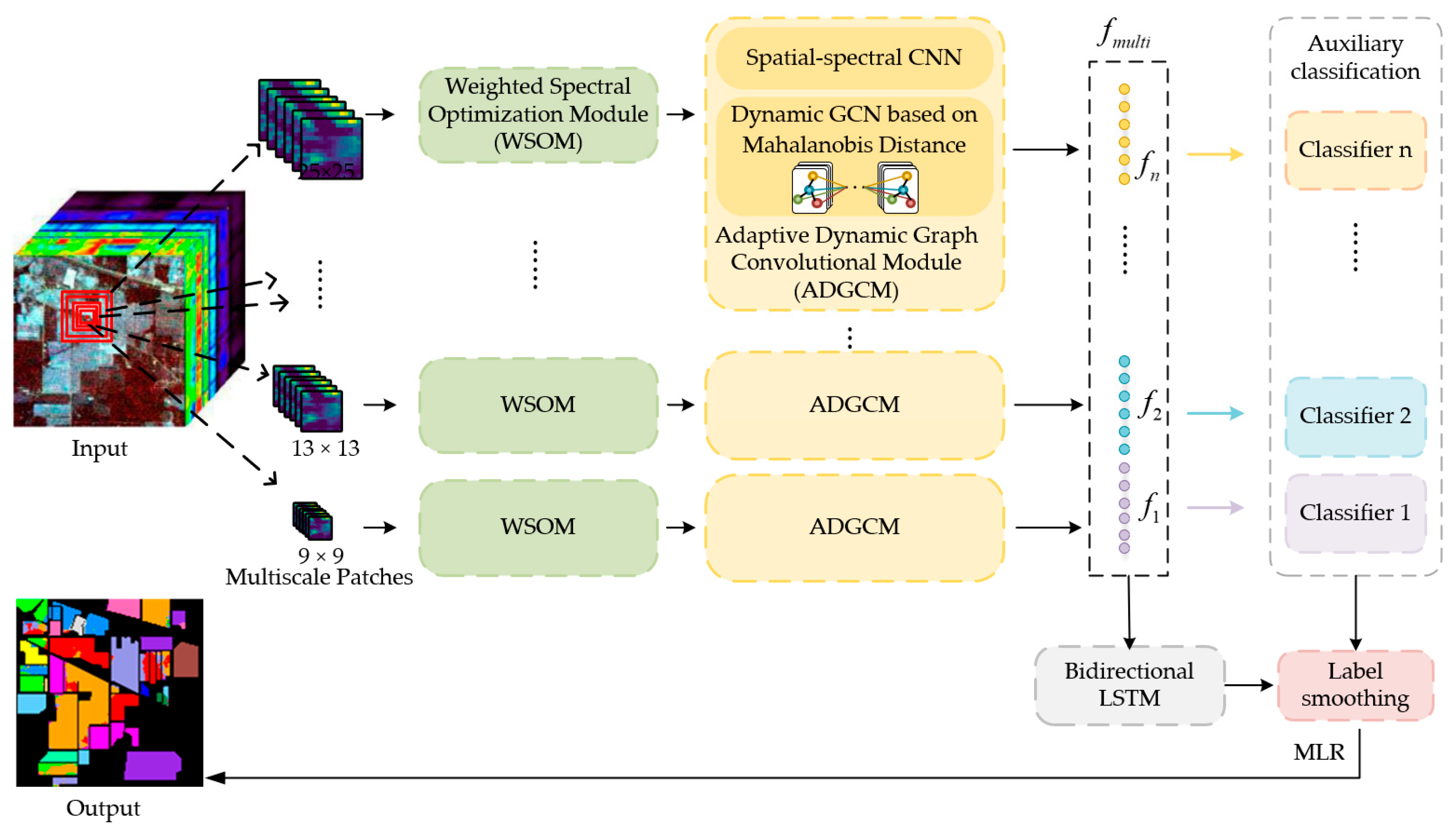
By integrating the advantages of the CNN and GCN, and reducing their disadvantages, the spectral–spatial graph convolutional network with dynamic-synchronized multiscale features is proposed for few-shot HSI classification. Its overall architecture is shown in
Figure 1. Firstly, multiscale patches of different sizes are generated by utilizing the selected pixel and the neighbors centered at it. For each scale, the patches are sequentially input into the weighted spectral optimization module (WSOM) and adaptive dynamic graph convolutional module (ADGCM). Then, a bidirectional LSTM is adopted to synchronize multiscale features extracted from all scales. Finally, the auxiliary classifier is introduced into the calculation of the loss to obtain the final results. Our contributions are summarized as follows:
(1) To ease the burden of limited labeled samples, multiscale patches of different sizes are generated to enrich training samples in the feature space. Meanwhile, the proposed model learns sufficiently the spectral–spatial information in the HSI to conduct the classification. WSOM is designed to set weights for each band according to its amount of discriminant information. ADGCM is designed to depict the local spatial–spectral and long-range spatial–spectral features of patches. The scheduled DropBlock in ADGCM is used to learn more generalizable features and avoid the overfitting due to limited labeled samples. Additionally, the auxiliary classifier is introduced to integrate classification results of patches with the rich information of each scale. Label smoothing is utilized to mitigate the interference caused by the insufficient samples and imbalance of classes, and obtain a more general label representation.
(2) To reduce the time complexity of the CNN and spatial complexity of the GCN in HSI classification, ADGCM is constructed by performing the CNN and adaptive dynamic GCN in parallel. The Mahalanobis distance metric avoids the issue that the fixed distance metric is not suited to the real data. Using the Mahalanobis distance, the adaptive dynamic GCN can be established to extend GCNs to large graphs by adaptively capturing the topological structure resemblance between nodes, which can be more suitable for the real HSI. The parameters of the auxiliary classifier can be simultaneously calculated with parameters of both ADGCM and bidirectional LSTM, enabling fast information extraction.
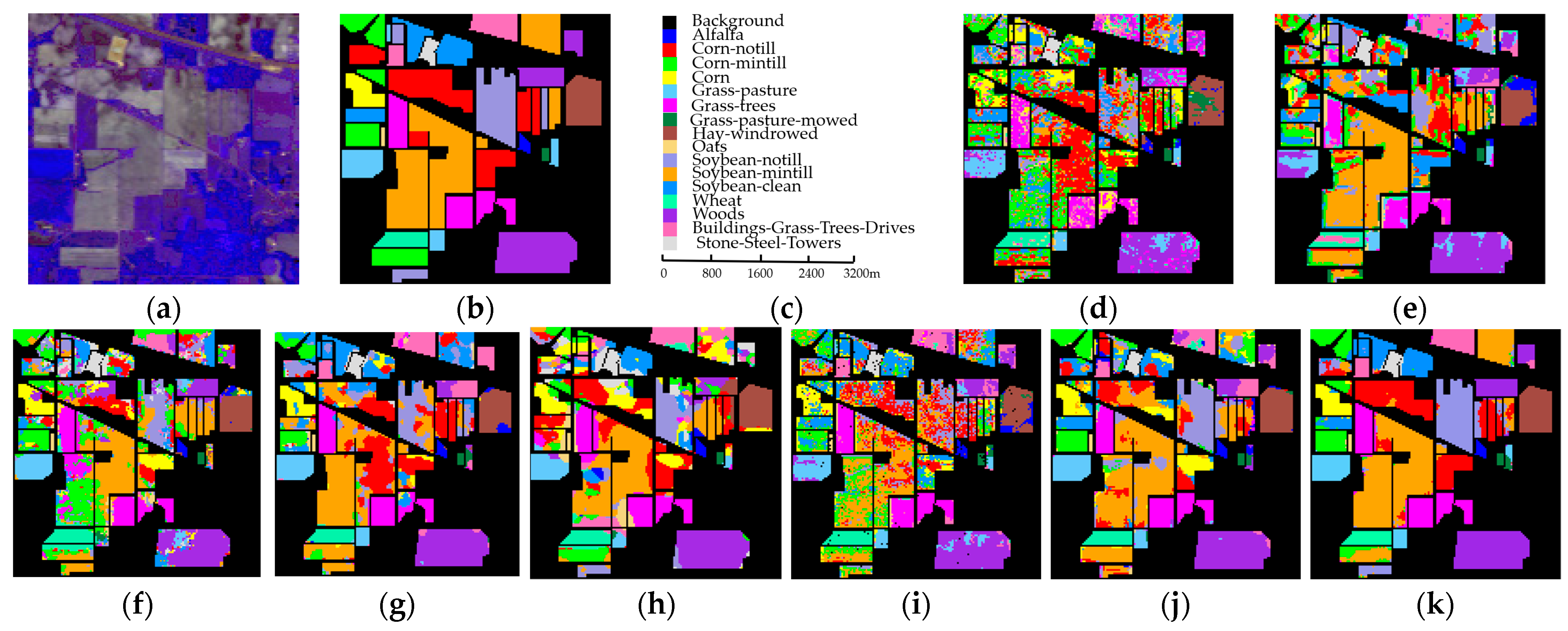
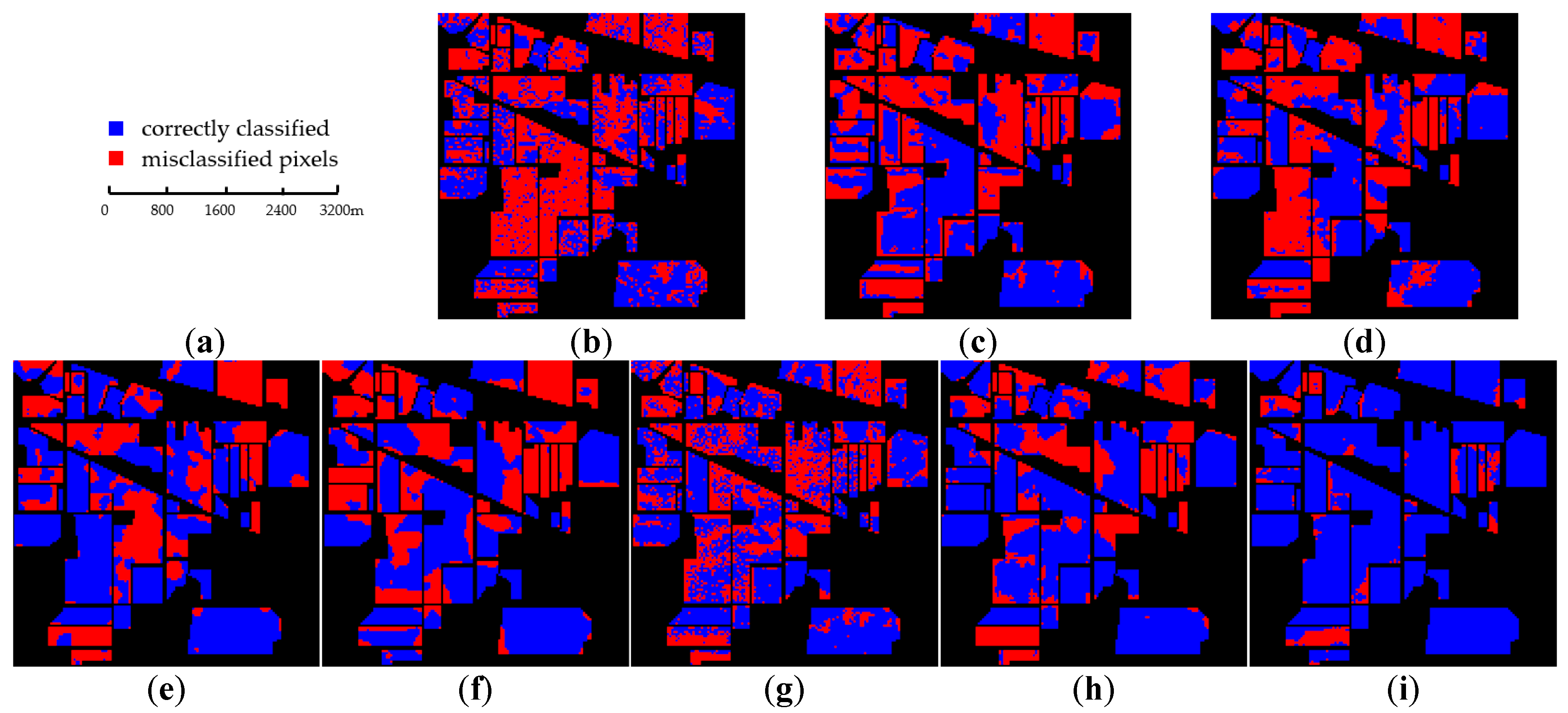
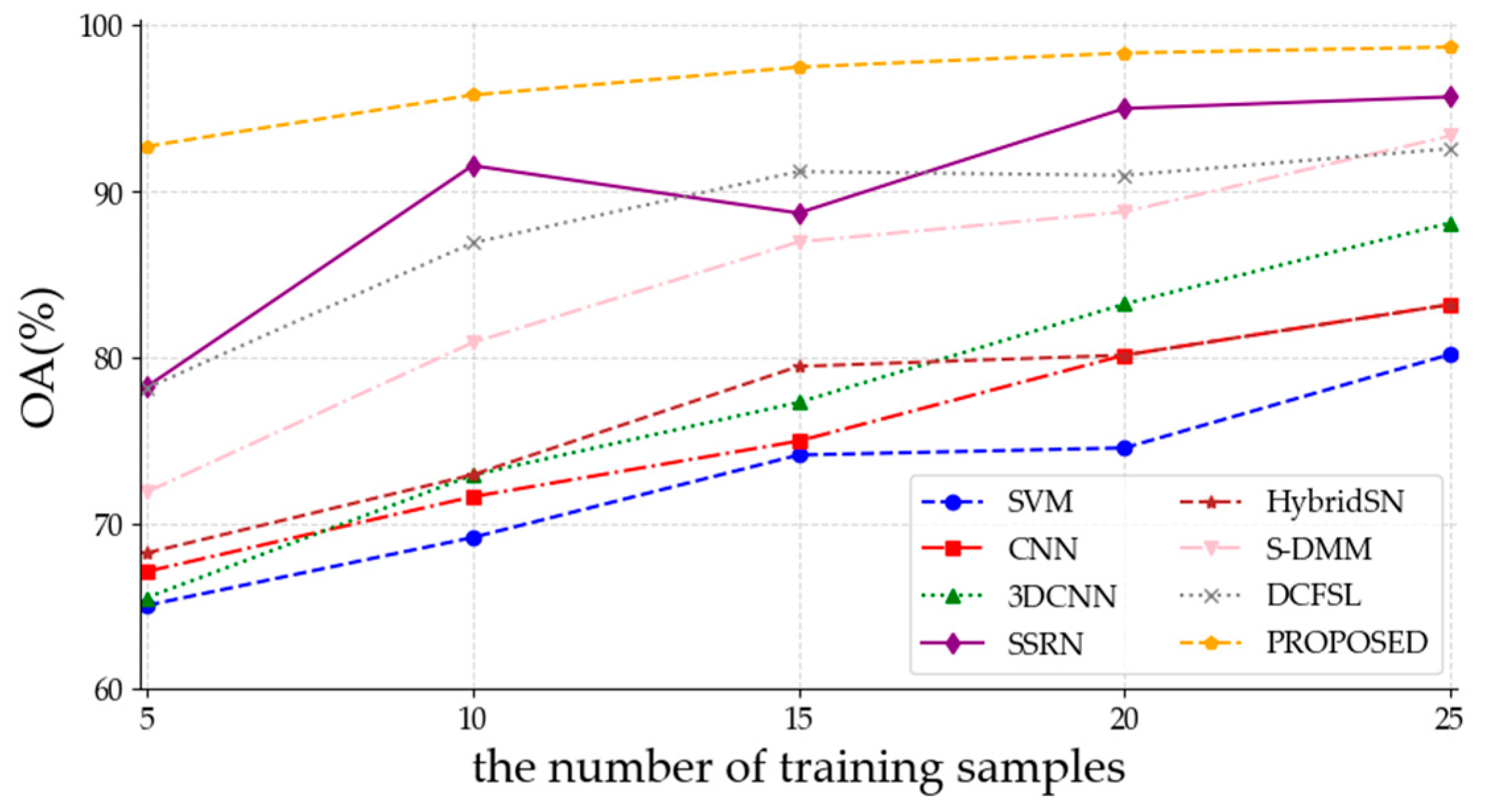
(3) Experiments on three benchmark datasets show that the proposed framework can obtain competitive results compared with seven state-of-the-art methods.
The remainder of this paper is organized as follows. The proposed method is presented in
Section 2. The experimental results on three benchmark datasets are systematically shown in
Section 3. Finally, the conclusion is given in
Section 4.
2. Proposed Method
In this section, we explain the spectral–spatial graph convolutional network with dynamic-synchronized multiscale features in detail. As illustrated in
Figure 1, the proposed model firstly generates the multiscale patches of different sizes. Then the patches within the same scale are sequentially input into WSOM and ADGCM. To explore the rich contents of all scales, the bidirectional LSTM is utilized by synchronously learning the multiscale features. Finally, the auxiliary classifier is introduced into the calculation of the classification loss to obtain the final results.
We denote the original HSI as and , where represents whether the pixel belongs to class or not, taking values of 1 or 0, respectively, and represents the spatial size, and and denote the total number of spectral bands and categories separately.
2.1. Construction of Multiscale Patches
For each labeled pixel in , its corresponding set of patches with scales is defined as , which are generated by collecting the pixels within the window size centered at the given labeled pixel. In this paper, is set to 5, indicating 5 different scales. The spatial size of the multiscale patches is set to , , , , and . Note that a higher-scale patch consistently encompasses a lower-scale patch for the same pixel, indicating the spatial dependency among them. For example, has a size of , and encompasses but with an increased size of . Generated from the same central pixel, the multiscale patches not only share the same central spectrum but also have identical class labels, which means the multiscale patches can exhibit spatial correlations. These multiscale spatial correlations can be considered to extract more abundant and discriminative features, and enlarge the amount of training samples to alleviate the overfitting in few-shot scenarios.
2.2. Weighted Spectral Optimization Module
In an HSI, different spectral bands provide the differential amount of discriminate information for classification. Using this, WSOM is proposed to calculate the weights representing the discriminative information among all spectral bands.
Figure 2 presents the diagram of the weighted spectral optimization module.
For the input patch , global average pooling (GAP) is utilized to compress the two-dimensional spatial information along each spectral dimension, forming an original spectral vector which aggregates the global information of . Then two consecutive one-dimensional convolutions are performed to capture cross-band dependencies. To be specific, the first is designed to capture the shallow correlation among local spectral bands, while the second is exploited to extract deep correlations among broader spectral bands. They can effectively convert the spectral information into weights, empowering the network to prioritize significant spectral features while disregarding irrelevant information. Additionally, the residual connection is adopted to reduce the information loss and achieve the fusing of spectral features. Then the weighted patch is obtained by the band-wise multiplication of the weighted vector and the input patch . Finally, two consecutive two-dimensional convolution blocks are applied to the weighted patches to reduce the spectral dimension. Each convolution block consists of a 3 × 3 convolution layer, LeakyReLU activation function layer, and batch normalization layer. The output feature map is denoted as , which is input to the next adaptive dynamic graph convolutional module.
2.3. Adaptive Dynamic Graph Convolutional Module
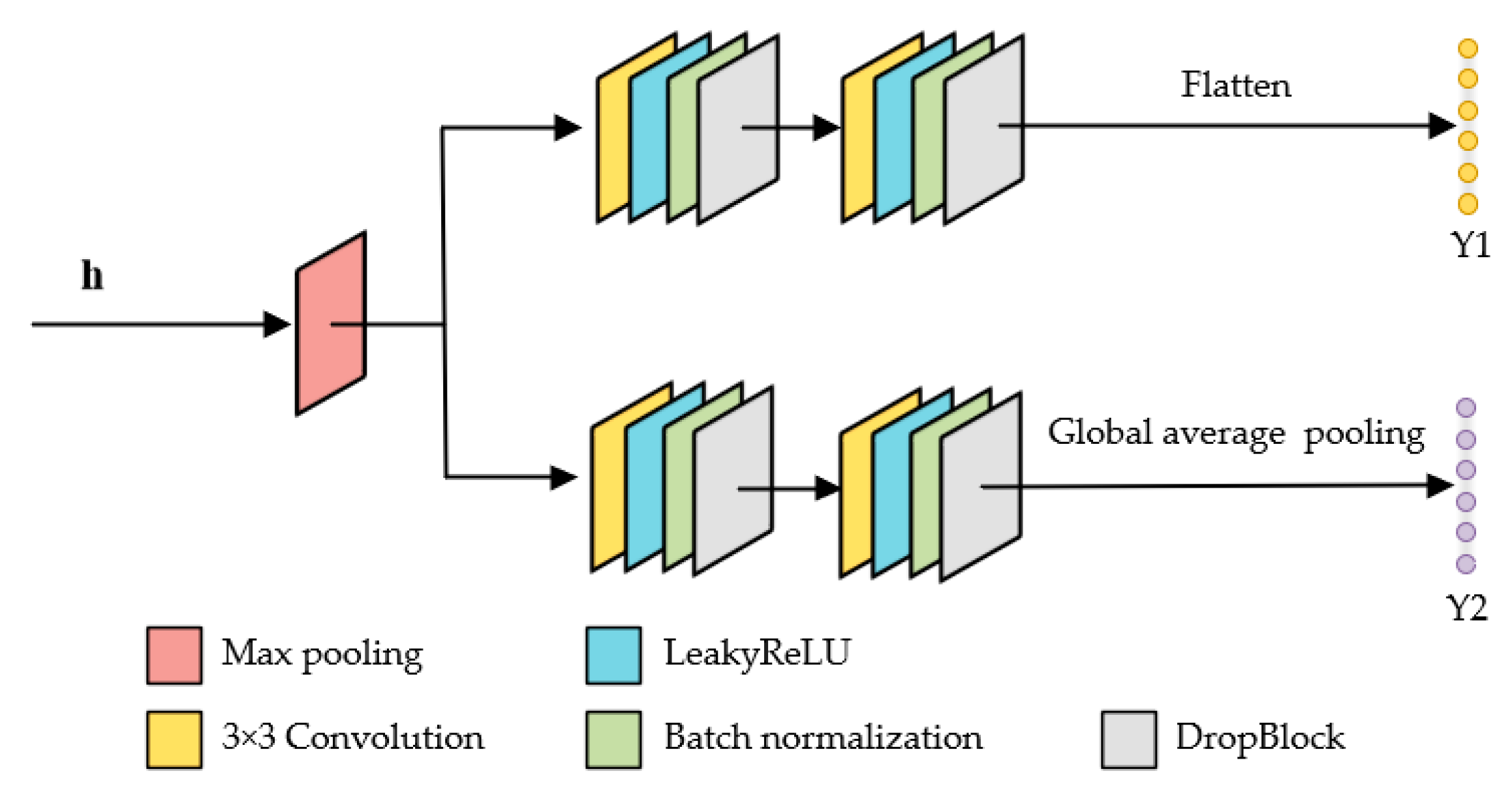
2.3.1. Spatial–Spectral CNN
The CNN-based model has the unique advantage of feature representation between different bands and is good at extracting local features [
43]. Based on this, a spatial–spectral convolutional network with two branches is designed to extract local spatial–spectral features from the HSI. Its diagram is illustrated in
Figure 3. Max pooling is firstly performed to reduce the number of parameters in the network, speeding up the learning process and reducing the risk of overfitting. Both branches contain two convolutional blocks separately, and each convolutional block consists of a 3 × 3 convolutional layer, a LeakyReLU activation layer, a batch normalization layer, and a DropBlock layer.
The convolutional process can be formulated as in Equation (1).
where
denotes the convolution operation; the matrices
and
represent the feature maps of the
th layer and the
th layer, respectively;
and
is the weight vector and bias vector of the
th convolutional layer, respectively;
denotes the LeakyReLU activation function; and
represents the number of filters. In few-shot scenarios, the CNN tends to remember all features of samples, leading to overfitting. In addition, there is a strong dependency between adjacent pixels on HSIs. The proposed model employs DropBlock [
44] to randomly drop neurons and learn more generalized features. Discarding a proper portion of neighboring regions through DropBlock, the proposed network can learn similar features from the neighboring neurons of dropped ones, exhibiting better generalization and mitigating overfitting in few-shot scenarios. DropBlock has two predefined parameters, including drop block size
and drop probability
. The impact of
and
on the classification results will be investigated in
Section 3.
Let Y1 and Y2 represent distinct features extracted by the spatial–spectral CNN. As shown in
Figure 3, Y1 and Y2 are obtained by flattening and global average pooling the output feature maps of two convolutional branches, respectively.
2.3.2. Dynamic GCN Based on Mahalanobis Distance
The classical GCN can efficiently extract the structural information and has shown satisfactory performance for HSI classification. However, it demands a considerable number of computational resources while calculating large-scale graphs, which limits the classification performance on high-dimensional HSIs. To address this issue, we design an adaptive dynamic GCN as shown in
Figure 4, which consists of the category representation, the static graph convolutional layer, the dynamic graph convolutional layer, and the calculation of the correlation matrix.
As shown in
Figure 4, the input feature map
obtained from WSOM is first processed to derive a series of content-aware category representations. Each representation characterizes the content associated with a specific label from
. Specifically, we first use the classifier consisting of a global average pooling layer, a convolutional layer, and a Sigmoid activation function layer to classify
and obtain a category-specific activation map
. Then,
is used to convert
into the content-aware category representation
, which can be formulated as:
where
represents the weight of the
th activation map, and
is the feature vector of the feature map
at
.
can be treated as the graph node set.
selectively integrates features relevant to its specific category
, which can be considered as the graph node with D-dimensional features. Since each node
represents features relevant to its specific category
, the node acquisition process is named “category representation”, as shown in
Figure 4.
The static graph convolutional layer is utilized to obtain the coarse class dependencies. The node feature vector
is fed to the static graph convolutional layer to obtain the updated feature
. This process is represented as follows:
where the adjacency matrix
represents the adjacency relationship between nodes, that is, the information of edges in the graph.
represents the LeakyReLU activation function used to enhance the model’s non-linear expression. Here,
and
are randomly initialized and learned during training.
By simulating the long-term and short-term memory patterns in human brain memory, the dynamic graph convolutional layer is employed to overcome the inapplicability of the fixed-structure adjacency matrix and capture the class relation of each image. That is, the dynamic graph convolutional layer can gradually refine the graph with different input features, which is formulated as follows:
where
is the adjacency matrix and represents the adjacency relationship between nodes,
represents the learnable parameters, and
represents the LeakyReLU activation function.
The adjacency matrix
is used to update the node
and is dynamically updated with the change in input features.
is calculated by Equation (5).
where
is a learnable parameter that generates different
for each patch, enhancing the feature expression ability and reducing the risk of overfitting.
represents the Mahalanobis distance between
and
. It is calculated by:
where
U is a symmetric positive semidefinite matrix, and learned by the backpropagated gradient algorithm.
As illustrated in
Figure 3 and
Figure 4, the output of the spatial–spectral CNN is Y1 and Y2, and the output of the dynamic GCN based on Mahalanobis distance is Y3. By concatenating Y1, Y2, and Y3 along the spectral dimension, we can obtain the output feature Y of the adaptive dynamic graph convolutional module.
2.4. Bidirectional LSTM
In the literature, most approaches directly concatenate the multiscale features into a one-dimensional vector. They neglect the intrinsic correlations among multiscale features, which leads to the loss of scale-relevant information. Note that spectral features of multiscale patches have high correlations because they share the same central pixel with the identical class label. The extracted multiscale features can be treated as sequential data with spatial and spectral dependencies. Based on these, the bidirectional LSTM is explored to depict the forward and backward relationships of multiscale features [
45]. Its structure is shown in
Figure 5.
Let
represent the bidirectional LSTM operation, and
be the multiscale feature obtained by the adaptive dynamic graph convolutional module. Specifically,
is equal to 5 in this paper. The final feature
is formulated as follows:
2.5. Label Prediction and Label-Smoothing Regularization
As illustrated in
Figure 1, the final classification results are obtained by utilizing the feature
and the auxiliary classifier. Imposing constraints on the feature
, the auxiliary classifier exploits the feature
of each scale to conduct the classification by designing 5 sub-classification tasks separately. Based on these, the dominant role played by the parameters of the bidirectional LSTM is weakened during the training process, and the performance in the parameter learning is stabilized and enhanced.
Let
be the predicted probability of classes obtained from
.
is formulated as:
where
and
denote the weight matrix and bias in MLR, respectively.
is the MLR function and formulated as:
Let
denote the predicted probability of classes obtained from the
th scale feature
by utilizing the auxiliary classifier.
is calculated by Equation (10).
where
represents the
th feature scale of
,
and
are the weight matrix and bias of the
th feature scale, and
is the MLR function in Equation (9).
The predicted label
is formulated in Equation (11).
where the coefficient
is utilized to adjust the portion of the
th auxiliary classifier, and
represents the number of scales as illustrated in
Section 2.1.
The loss
is calculated by the cross-entropy loss function as shown in Equation (12), which can maintain stability and category balance. The loss
of the proposed model is defined as:
where
is the total number of samples,
denotes the number of categories, and
and
are the real and predicted probabilities of the
th of class
.
In practice, the pixels in an HSI are inevitably mislabeled due to manual errors, and face the problem of the imbalance of classes. In this case, the classifier may lead to overfitting if it becomes too confident about the predictions [
46]. These affect the values of the loss in Equations (12) and (13) and limit the generalization of the proposed model [
47]. Therefore, label-smoothing regularization is introduced to alleviate these problems and enhance the generalization [
46,
47].
After performing label smoothing, the updated truth probability
of the
th class of the
th sample is formulated as:
where
represents the label-smoothing coefficient and is set to 0.01 in this paper. Introducing Equation (13) into Equation (12), the updated loss
can be formulated as:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}