


Performance Comparison of Deep Learning (DL)-Based Tabular Models for Building Mapping Using High-Resolution Red, Green, and Blue Imagery and the Geographic Object-Based Image Analysis Framework


Abstract
1. Introduction
2. Methodological Framework
2.1. Image Segmentation
2.2. Object-Based Feature Extraction
2.3. SL Classifiers
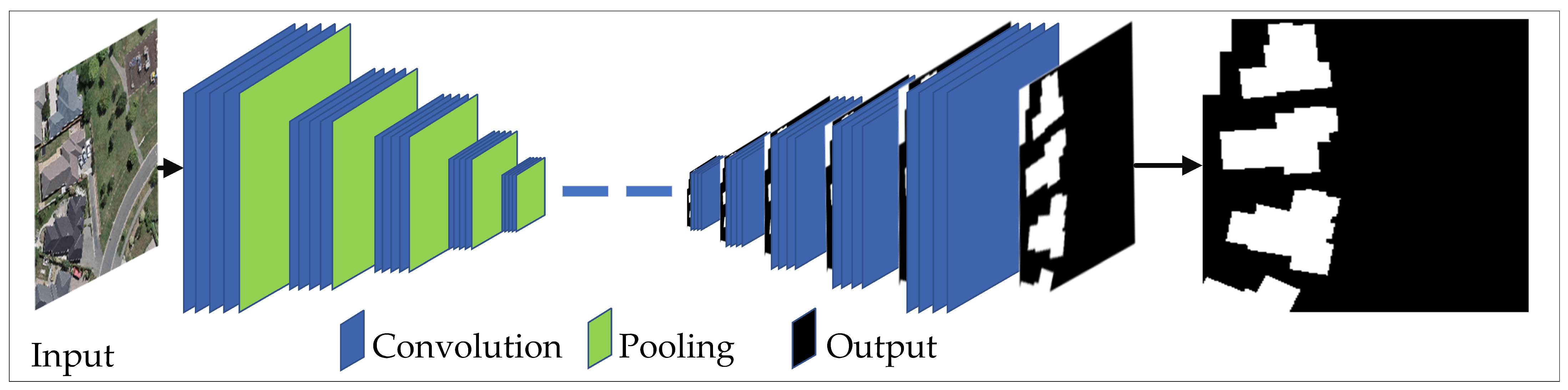
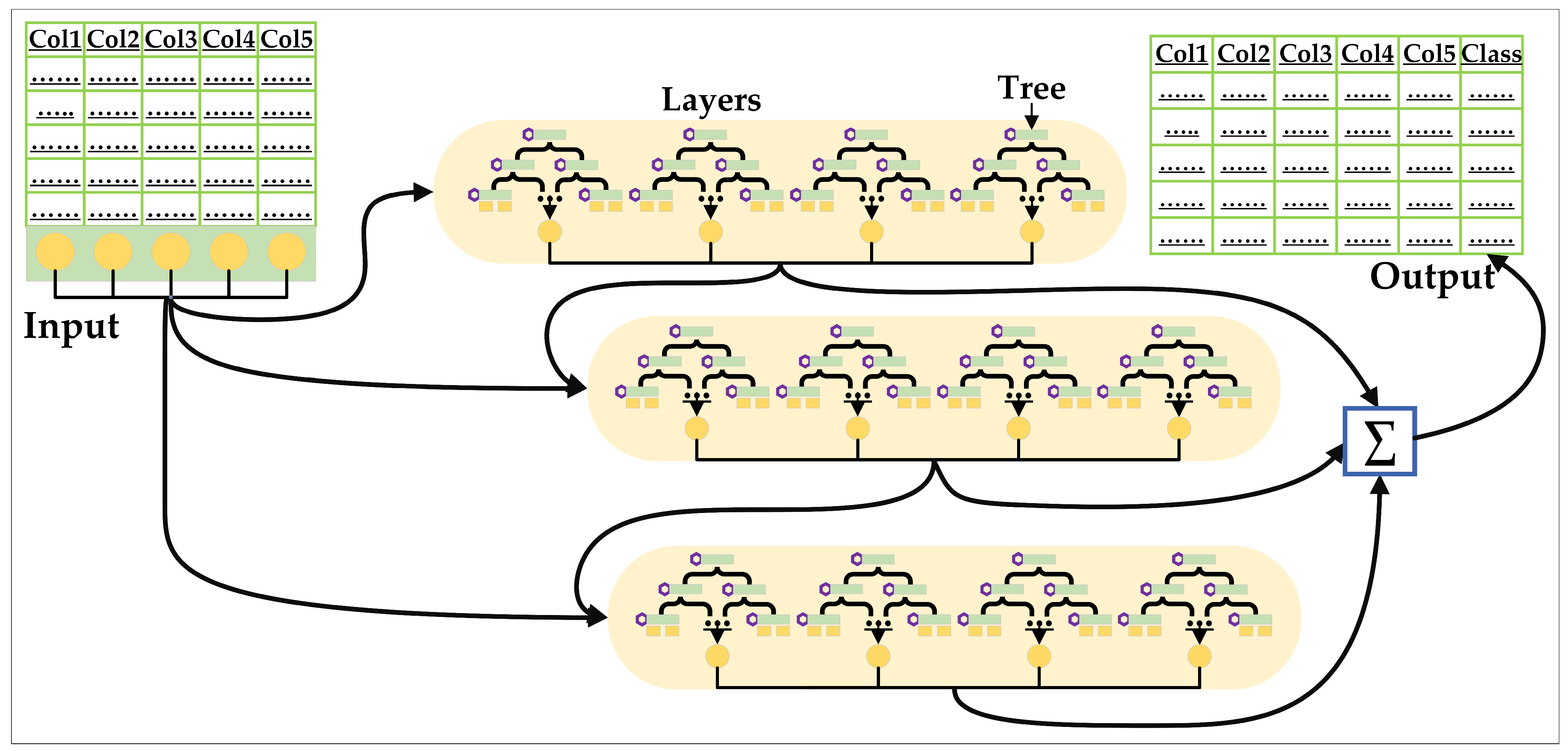
2.4. DL Classifiers
2.5. Object Classification
2.6. Accuracy Assessment
3. Study Area and Data
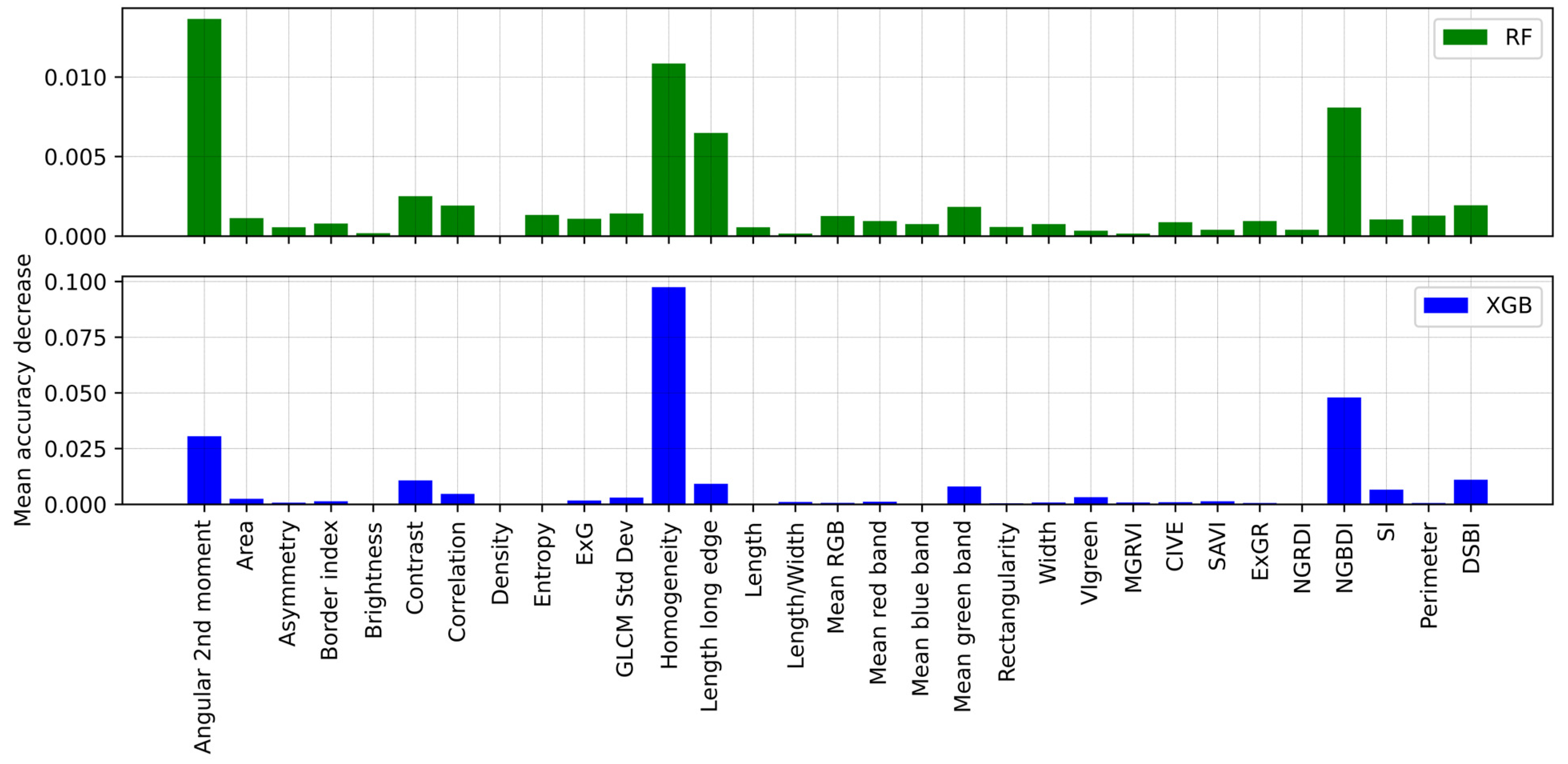
4. Results
4.1. Buildings versus Shadows
4.2. Buildings Versus Vegetation
4.3. Buildings versus Soil
4.4. Buildings versus Other Impervious Surfaces
4.5. Heterogeneity within a Building
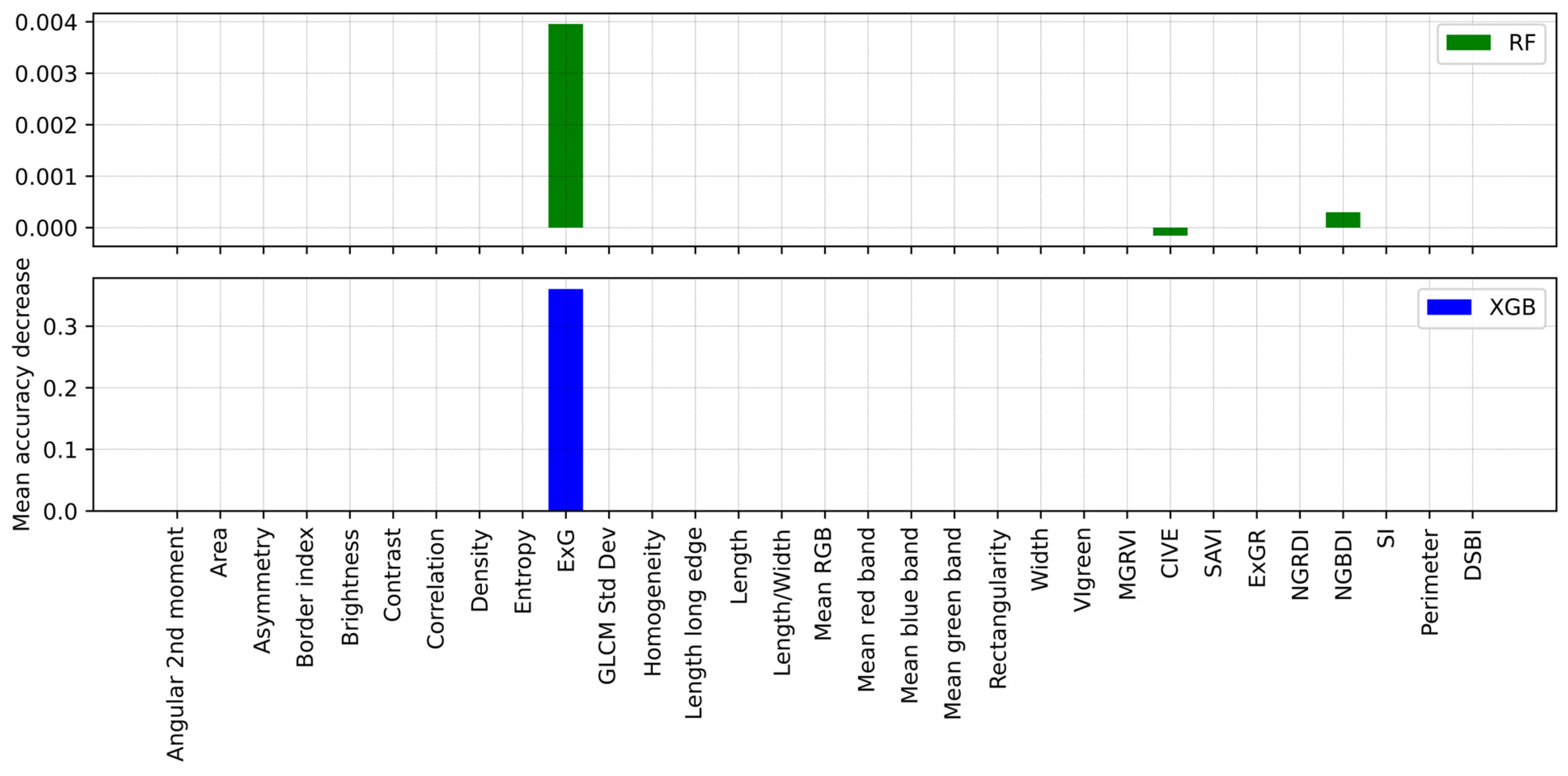
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Welch, R. Spatial Resolution Requirements for Urban Studies. Int. J. Remote Sens. 1982, 3, 139–146. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building Extraction from High-Resolution Satellite Images in Urban Areas: Recent Methods and Strategies against Significant Challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Ahmadi, S.; Zoej, M.J.V.; Ebadi, H.; Moghaddam, H.A.; Mohammadzadeh, A. Automatic Urban Building Boundary Extraction from High Resolution Aerial Images Using an Innovative Model of Active Contours. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, 150–157. [Google Scholar] [CrossRef]
- Hermosilla, T.; Ruiz, L.A.; Recio, J.A.; Estornell, J. Evaluation of Automatic Building Detection Approaches Combining High Resolution Images and LiDAR Data. Remote Sens. 2011, 3, 1188–1210. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef]
- San, D.K.; Turker, M. Building Extraction from High Resolution Satellite Images Using Hough Transform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2010, 38, 1063–1068. [Google Scholar] [CrossRef]
- Lu, T.; Ming, D.; Lin, X.; Hong, Z.; Bai, X.; Fang, J. Detecting Building Edges from High Spatial Resolution Remote Sensing Imagery Using Richer Convolution Features Network. Remote Sens. 2018, 10, 1496. [Google Scholar] [CrossRef]
- Yari, D.; Mokhtarzade, M.; Ebadi, H.; Ahmadi, S. Automatic Reconstruction of Regular Buildings Using a Shape-Based Balloon Snake Model. Photogramm. Rec. 2014, 29, 187–205. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L. Morphological Building/Shadow Index for Building Extraction from High-Resolution Imagery over Urban Areas. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 161–172. [Google Scholar] [CrossRef]
- Benarchid, O.; Raissouni, N.; El Adib, S.; Abbous, A.; Azyat, A.; Achhab, N.B.; Lahraoua, M.; Chahboun, A. Building Extraction Using Object-Based Classification and Shadow Information in Very High Resolution Multispectral Images, a Case Study: Tetuan, Morocco. Can. J. Image Process. Comput. Vis. 2013, 4, 1–8. [Google Scholar]
- Deng, X.; Li, W.; Liu, X.; Guo, Q.; Newsam, S. One-Class Remote Sensing Classification: One-Class vs. Binary Classifiers. Int. J. Remote Sens. 2018, 39, 1890–1910. [Google Scholar] [CrossRef]
- Partovi, T.; Bahmanyar, R.; Kraus, T.; Reinartz, P. Building Outline Extraction Using a Heuristic Approach Based on Generalization of Line Segments. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 933–947. [Google Scholar] [CrossRef]
- Chai, D. A Probabilistic Framework for Building Extraction from Airborne Color Image and DSM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 948–959. [Google Scholar] [CrossRef]
- You, Y.; Wang, S.; Ma, Y.; Chen, G.; Wang, B.; Shen, M.; Liu, W. Building Detection from VHR Remote Sensing Imagery Based on the Morphological Building Index. Remote Sens. 2018, 10, 1287. [Google Scholar] [CrossRef]
- Gavankar, N.L.; Ghosh, S.K. Automatic Building Footprint Extraction from High-Resolution Satellite Image Using Mathematical Morphology. Eur. J. Remote Sens. 2018, 51, 182–193. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. A Hybrid Image Segmentation Method for Building Extraction from High-Resolution RGB Images. ISPRS J. Photogramm. Remote Sens. 2022, 192, 299–314. [Google Scholar] [CrossRef]
- Kotaridis, I.; Lazaridou, M. Remote Sensing Image Segmentation Advances: A Meta-Analysis. ISPRS J. Photogramm. Remote Sens. 2021, 173, 309–322. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.Q.; Van Der Meer, F.; Van Der Werff, H.; Van Coillie, F.; et al. Geographic Object-Based Image Analysis—Towards a New Paradigm. ISPRS J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef]
- Ninsawat, S.; Hossain, M.D. Identifying Potential Area and Financial Prospects of Rooftop Solar Photovoltaics (PV). Sustainability 2016, 8, 1068. [Google Scholar] [CrossRef]
- Som-ard, J.; Hossain, M.D.; Ninsawat, S.; Veerachitt, V. Pre-Harvest Sugarcane Yield Estimation Using UAV-Based RGB Images and Ground Observation. Sugar Tech. 2018, 20, 645–657. [Google Scholar] [CrossRef]
- Liu, J.; Hossain, M.D.; Chen, D. A Procedure for Identifying Invasive Wild Parsnip Plants Based on Visible Bands from UAV Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, XLIII, 173–181. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A Review of Algorithms and Challenges from Remote Sensing Perspective. ISPRS J. Photogramm. Remote Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, L.; Li, M.; Liu, Y.; Ma, X. Training Set Size, Scale, and Features in Geographic Object-Based Image Analysis of Very High Resolution Unmanned Aerial Vehicle Imagery. ISPRS J. Photogramm. Remote Sens. 2015, 102, 14–27. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An Object-Based Convolutional Neural Network (OCNN) for Urban Land Use Classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef]
- Hossain, M.D. An Improved Segmentation and Classification Method for Building Extraction from RGB Images Using GEOBIA Framework; Queen’s University: Kingston, ON, Canada, 2023. [Google Scholar]
- Kucharczyk, M.; Hay, G.J.; Ghaffarian, S.; Hugenholtz, C.H. Geographic Object-Based Image Analysis: A Primer and Future Directions. Remote Sens. 2020, 12, 2012. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A Review of Supervised Object-Based Land-Cover Image Classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Strager, M.P.; Warner, T.A.; Ramezan, C.A.; Morgan, A.N.; Pauley, C.E. Large-Area, High Spatial Resolution Land Cover Mapping Using Random Forests, GEOBIA, and NAIP Orthophotography: Findings and Recommendations. Remote Sens. 2019, 11, 1409. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Fonseca, J.; Khudinyan, M. Imbalanced Learning in Land Cover Classification: Improving Minority Classes’ Prediction Accuracy Using the Geometric SMOTE Algorithm. Remote Sens. 2019, 11, 3040. [Google Scholar] [CrossRef]
- Waldner, F.; Jacques, D.C.; Löw, F. The Impact of Training Class Proportions on Binary Cropland Classification. Remote Sens. Lett. 2017, 8, 1122–1131. [Google Scholar] [CrossRef]
- Jozdani, S.E.; Johnson, B.A.; Chen, D. Comparing Deep Neural Networks, Ensemble Classifiers, and Support Vector Machine Algorithms for Object-Based Urban Land Use/Land Cover Classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef]
- Liu, B.; Du, S.; Du, S.; Zhang, X. Incorporating Deep Features into GEOBIA Paradigm for Remote Sensing Imagery Classification: A Patch-Based Approach. Remote Sens. 2020, 12, 3007. [Google Scholar] [CrossRef]
- Joseph, M. PyTorch Tabular: A Framework for Deep Learning with Tabular Data. arXiv 2021, arXiv:2104.13638. [Google Scholar]
- Gorishniy, Y.; Rubachev, I.; Khrulkov, V.; Babenko, A. Revisiting Deep Learning Models for Tabular Data. Adv. Neural Inf. Process. Syst. 2021, 23, 18932–18943. [Google Scholar]
- Popov, S.; Babenko, A. Neural Oblivious Decision Ensembles for Deep Learning on Tabular Data. arXiv 2019, arXiv:1909.06312b. [Google Scholar]
- Hazimeh, H.; Ponomareva, N.; Mol, P.; Tan, Z.; Mazumder, R. The Tree Ensemble Layer: Differentiability Meets Conditional Computation. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 4138–4148. [Google Scholar]
- Arık, S.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; Association for the Advancement of Artificial Intelligence: Washington, DC, USA, 2021; Volume 35-8A, pp. 6679–6687. [Google Scholar]
- Huang, X.; Khetan, A.; Cvitkovic, M.; Karnin, Z. TabTransformer: Tabular Data Modeling Using Contextual Embeddings. arXiv 2020, arXiv:2012.06678. [Google Scholar]
- Somepalli, G.; Goldblum, M.; Goldstein, T. SAINT: Improved Neural Networks for Tabular Data via Row Attention and Contrastive Pre-Training. arXiv 2021, arXiv:2106.01342. [Google Scholar]
- Joseph, M.; Raj, H. GATE: Gated Additive Tree Ensemble for Tabular Classification and Regression. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2022. [Google Scholar]
- Pan, X.; Zhang, C.; Xu, J.; Zhao, J. Simplified Object-Based Deep Neural Network for Very High Resolution Remote Sensing Image Classification. ISPRS J. Photogramm. Remote Sens. 2021, 181, 218–237. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Mohammadzade Alajujeh, K.; Lakes, T.; Blaschke, T.; Omarzadeh, D. A Comparison of the Integrated Fuzzy Object-Based Deep Learning Approach and Three Machine Learning Techniques for Land Use/Cover Change Monitoring and Environmental Impacts Assessment. GIScience Remote Sens. 2021, 58, 1543–1570. [Google Scholar] [CrossRef]
- Beniaich, A.; Silva, M.L.N.; Avalos, F.A.P.; De Menezes, M.D.; Cândido, B.M. Determination of Vegetation Cover Index under Different Soil Management Systems of Cover Plants by Using an Unmanned Aerial Vehicle with an Onboard Digital Photographic Camera. Semin. Agrar. 2019, 40, 49–66. [Google Scholar] [CrossRef]
- Yuan, Y.; Wang, X.; Shi, M.; Wang, P. Performance Comparison of RGB and Multispectral Vegetation Indices Based on Machine Learning for Estimating Hopea Hainanensis SPAD Values under Different Shade Conditions. Front. Plant Sci. 2022, 13, 928953. [Google Scholar] [CrossRef] [PubMed]
- Gu, L.; Cao, Q.; Ren, R. Building Extraction Method Based on the Spectral Index for High-Resolution Remote Sensing Images over Urban Areas. J. Appl. Remote Sens. 2018, 12, 045501. [Google Scholar] [CrossRef]
- Kurbatova, E. Road Detection Based on Color and Geometry Characteristics. In Proceedings of the 6th IEEE International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 26–29 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Pal, M.; Mather, P.M. An Assessment of the Effectiveness of Decision Tree Methods for Land Cover Classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Belgiu, M.; Drǎguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Lawrence, R.L.; Wood, S.D.; Sheley, R.L. Mapping Invasive Plants Using Hyperspectral Imagery and Breiman Cutler Classifications (RandomForest). Remote Sens. Environ. 2006, 100, 356–362. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Paelinckx, D. Evaluation of Random Forest and Adaboost Tree-Based Ensemble Classification and Spectral Band Selection for Ecotope Mapping Using Airborne Hyperspectral Imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Mohajane, M.; Costache, R.; Karimi, F.; Bao Pham, Q.; Essahlaoui, A.; Nguyen, H.; Laneve, G.; Oudija, F. Application of Remote Sensing and Machine Learning Algorithms for Forest Fire Mapping in a Mediterranean Area. Ecol. Indic. 2021, 129, 107869. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Wolff, E. Very High Resolution Object-Based Land Use-Land Cover Urban Classification Using Extreme Gradient Boosting. IEEE Geosci. Remote Sens. Lett. 2018, 15, 607–611. [Google Scholar] [CrossRef]
- Bui, Q.T.; Chou, T.Y.; Van Hoang, T.; Fang, Y.M.; Mu, C.Y.; Huang, P.H.; Pham, V.D.; Nguyen, Q.H.; Anh, D.T.N.; Pham, V.M.; et al. Gradient Boosting Machine and Object-Based CNN for Land Cover Classification. Remote Sens. 2021, 13, 2709. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Shah, C.; Du, Q.; Xu, Y.; Shah, C.; Du, Q.; Xu, Y. Enhanced TabNet: Attentive Interpretable Tabular Learning for Hyperspectral Image Classification. Remote Sens. 2022, 14, 716. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Y.; Shao, Y.; Li, L.; Hao, H. A Comparative Study on the Most Effective Machine Learning Model for Blast Loading Prediction: From GBDT to Transformer. Eng. Struct. 2023, 276, 115310. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Armon, A. Tabular Data: Deep Learning Is Not All You Need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Silva, J.; Bacao, F.; Dieng, M.; Foody, G.M.; Caetano, M. Improving Specific Class Mapping from Remotely Sensed Data by Cost-Sensitive Learning. Int. J. Remote Sens. 2017, 38, 3294–3316. [Google Scholar] [CrossRef]
- Wang, H.; Miao, F. Building Extraction from Remote Sensing Images Using Deep Residual U-Net. Eur. J. Remote Sens. 2022, 55, 71–85. [Google Scholar] [CrossRef]
- Novelli, A.; Aguilar, M.A.; Aguilar, F.J.; Nemmaoui, A.; Tarantino, E. AssesSeg—A Command Line Tool to Quantify Image Segmentation Quality: A Test Carried Out in Southern Spain from Satellite Imagery. Remote Sens. 2017, 9, 40. [Google Scholar] [CrossRef]
- Sohn, G.; Dowman, I. Data Fusion of High-Resolution Satellite Imagery and LiDAR Data for Automatic Building Extraction. ISPRS J. Photogramm. Remote Sens. 2007, 62, 43–63. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Attribute | Mathematical Formulation |
|---|---|---|
| Spectral | Brightness [44] | where B is an object’s average brightness, is its average brightness in the visible bands, and is its band count |
| Mean band [44] | ||
| Standard deviation [44] | where represents the standard deviation of the intensity values for image layer k of all pixels that form an image object v; the set of pixels that belong to the image object v is denoted by ; the total number of pixels in is represented by ; the pixel coordinates are presented by and the image layer intensity value at each pixel is represented by ; and is the data range of image layer k, with = | |
| ExG [45] | where is the ExG value of a segment v, is the mean green band’s value for the segment v, is the mean red band’s value for the segment v, and is the mean blue band’s value for the segment v | |
| VIgreen [45] | where is the vegetation index of a segment v, is the mean green band’s value for the segment v, and is the mean blue band’s value for the segment v. a is a constant with a reference value of 0.667 | |
| MGRVI [46] | where is the modified green–red vegetation indices of a segment v, is the mean green band’s value for the segment v, and is the mean red band’s value for the segment v. | |
| CIVE [45] | where is the color index of vegetation of a segment v, is the mean red band’s value for the segment v, is the mean green band’s value for the segment v, and is the mean blue band’s value for the segment v. | |
| SAVI [45] | where is the soil adjusted vegetation index of a segment v, is the mean red band’s value for the segment v, and is the mean green band’s value for the segment v. | |
| ExGR [45] | where is the excess green minus excess red index of a segment v, is the excessive green for the segment v, is the mean red band’s value for the segment v, and is the mean green band’s value for the segment v. | |
| NGRDI [45] | where is the normalized green–red difference index of a segment v, is the mean red band’s value for the segment v, and is the mean green band’s value for the segment v. | |
| NGBDI [46] | where is the normalized green–blue difference index of a segment v, is the mean blue band’s value for the segment v, and is the mean green band’s value for the segment v. | |
| DSBI [47] | where is the difference spectral building index of a segment v, is the mean blue band’s value for the segment v, and is the mean green band’s value for the segment v. | |
| Geometric | Length/width [44] | where denotes the length of the segment; represents the width of the segment |
| Asymmetry [44] | where is the minimal eigenvalue; is the maximum eigenvalue | |
| Rectangularity [44] | ||
| Shape index [44] | where is the segment’s border length; is the border of the square with the area of | |
| SI [48] | where is the shape index of a segment v, is the perimeter, and is the area of the segment v. | |
| Perimeter | Perimeter of a segment | |
| Textural | Contrast [44] | In the context of textural measures, the notation, represents the row number; represents the column number; is the total number of rows or columns; and denotes the probability value derived from the GLCM. It is important to note that these notations can also be applied to other textural measures described below. |
| Correlation [44] | where σ is the GLCM standard deviation; is the GLCM mean | |
| Entropy [44] | ||
| Homogeneity [44] | ||
| Angular second moment [44] | ||
| Mean [44] | ||
| Standard deviation [44] |
| Method | Precision/User Accuracy | Recall/Sensitivity/ Producer Accuracy | Overall | Specificity | Geometric Mean | F1 |
|---|---|---|---|---|---|---|
| SVM | 0.93 | 0.96 | 0.93 | 0.94 | 0.95 | 0.94 |
| RF | 0.96 | 0.98 | 0.97 | 0.97 | 0.97 | 0.97 |
| XGB | 0.97 | 0.99 | 0.98 | 0.98 | 0.98 | 0.98 |
| TabNet | 0.97 | 0.97 | 0.97 | 0.96 | 0.96 | 0.97 |
| FTT | 0.98 | 0.99 | 0.98 | 0.98 | 0.98 | 0.98 |
| GATE | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| NODE | 0.97 | 0.99 | 0.98 | 0.99 | 0.99 | 0.98 |
| Method | Precision/User Accuracy | Recall/Sensitivity/ Producer Accuracy | Overall | Specificity | Geometric Mean | F1 |
|---|---|---|---|---|---|---|
| SVM | 0.97 | 0.99 | 0.98 | 0.99 | 0.99 | 0.98 |
| RF | 0.97 | 0.98 | 0.97 | 0.98 | 0.98 | 0.97 |
| XGB | 0.95 | 0.98 | 0.96 | 0.98 | 0.98 | 0.96 |
| TabNet | 0.91 | 0.98 | 0.93 | 0.97 | 0.97 | 0.94 |
| FTT | 0.98 | 0.99 | 0.98 | 0.99 | 0.99 | 0.98 |
| GATE | 0.97 | 0.99 | 0.98 | 0.98 | 0.98 | 0.98 |
| NODE | 0.99 | 0.99 | 0.99 | 0.98 | 0.98 | 0.99 |
| Method | Precision/User Accuracy | Recall/Sensitivity/ Producer Accuracy | Overall | Specificity | Geometric Mean | F1 |
|---|---|---|---|---|---|---|
| SVM | 0.99 | 0.97 | 0.99 | 0.97 | 0.97 | 0.98 |
| RF | 0.85 | 0.99 | 0.91 | 0.99 | 0.99 | 0.91 |
| XGB | 0.69 | 0.99 | 0.77 | 0.99 | 0.99 | 0.81 |
| TabNet | 0.57 | 0.99 | 0.63 | 0.96 | 0.97 | 0.72 |
| FTT | 0.92 | 0.99 | 0.95 | 0.99 | 0.99 | 0.95 |
| GATE | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| NODE | 0.78 | 0.99 | 0.86 | 0.99 | 0.99 | 0.87 |
| Method | Precision/User Accuracy | Recall/Sensitivity/ Producer Accuracy | Overall | Specificity | Geometric Mean | F1 |
|---|---|---|---|---|---|---|
| SVM | 0.63 | 0.91 | 0.66 | 0.76 | 0.83 | 0.74 |
| RF | 0.55 | 0.95 | 0.54 | 0.37 | 0.59 | 0.70 |
| XGB | 0.54 | 0.96 | 0.54 | 0.26 | 0.50 | 0.69 |
| TabNet | 0.54 | 0.97 | 0.54 | 0.23 | 0.47 | 0.69 |
| FTT | 0.99 | 0.44 | 0.69 | 0.59 | 0.51 | 0.61 |
| GATE | 0.99 | 0.70 | 0.84 | 0.73 | 0.71 | 0.82 |
| NODE | 0.93 | 0.88 | 0.89 | 0.86 | 0.87 | 0.90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossain, M.D.; Chen, D. Performance Comparison of Deep Learning (DL)-Based Tabular Models for Building Mapping Using High-Resolution Red, Green, and Blue Imagery and the Geographic Object-Based Image Analysis Framework. Remote Sens. 2024, 16, 878. https://doi.org/10.3390/rs16050878
Hossain MD, Chen D. Performance Comparison of Deep Learning (DL)-Based Tabular Models for Building Mapping Using High-Resolution Red, Green, and Blue Imagery and the Geographic Object-Based Image Analysis Framework. Remote Sensing. 2024; 16(5):878. https://doi.org/10.3390/rs16050878
Chicago/Turabian StyleHossain, Mohammad D., and Dongmei Chen. 2024. "Performance Comparison of Deep Learning (DL)-Based Tabular Models for Building Mapping Using High-Resolution Red, Green, and Blue Imagery and the Geographic Object-Based Image Analysis Framework" Remote Sensing 16, no. 5: 878. https://doi.org/10.3390/rs16050878
APA StyleHossain, M. D., & Chen, D. (2024). Performance Comparison of Deep Learning (DL)-Based Tabular Models for Building Mapping Using High-Resolution Red, Green, and Blue Imagery and the Geographic Object-Based Image Analysis Framework. Remote Sensing, 16(5), 878. https://doi.org/10.3390/rs16050878