


Multi-View Scene Classification Based on Feature Integration and Evidence Decision Fusion

Abstract

1. Introduction
- The proposed MVEDFN method can process multi-view remote sensing images at the same time, enhance the reliability and anti-interference level of scene classification, realize multi-view scene classification end to end, and further improve the accuracy of multi-view remote sensing scene classification.
- In order to reduce information loss from multi-view images and generate more discriminative and robust classification features, an Asymptotic Adaptive Feature Fusion Module (AAFFM) is proposed. The AAFFM can quickly fuse multi-scale features from multi-view images, which is beneficial for the subsequent classification of multi-view scenes.
- An Evidence Decision Fusion Module (EDFM) is proposed based on evidence theory. The module can combine Dirichlet distributions to dynamically evaluate and integrate multi-view feature information, effectively mitigating conflicts between aerial and ground imagery information and rendering the evidentiary data more consistent, with intuition and conclusions to accomplish a reliable classification task performance.
2. Methods
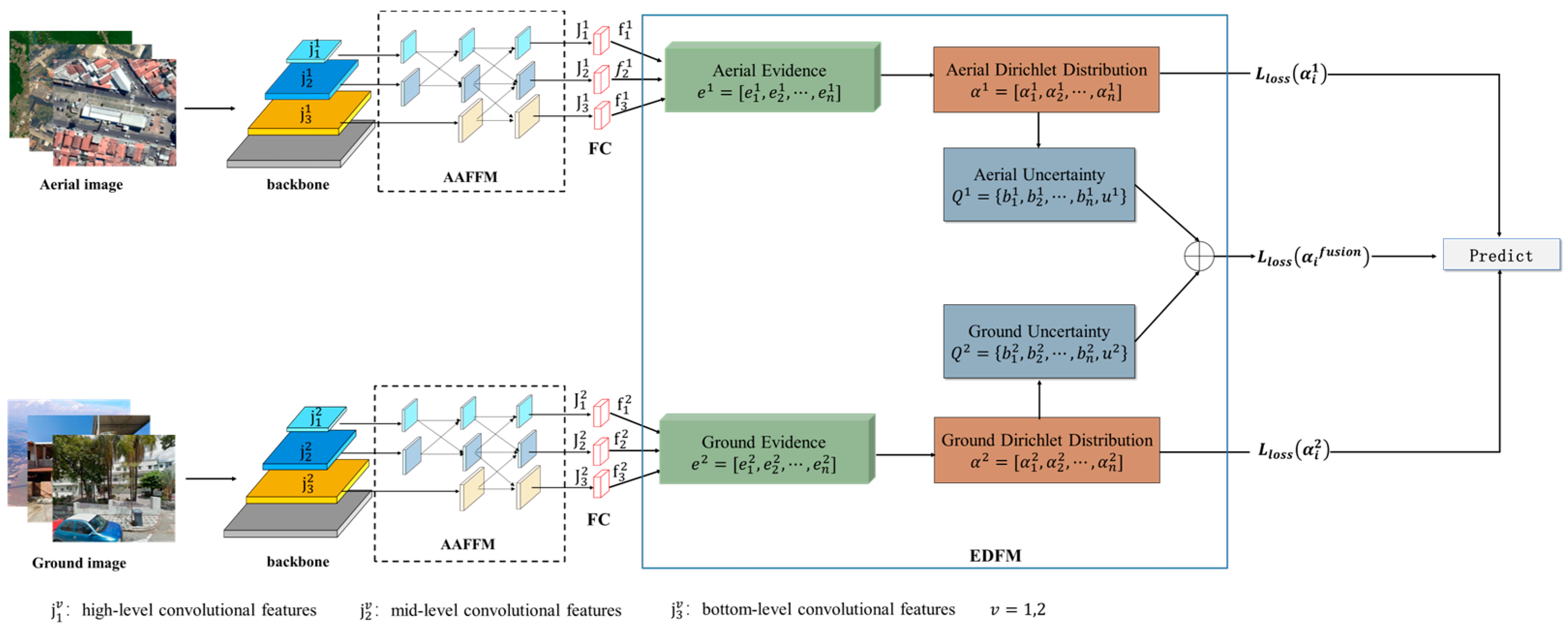
2.1. Methodology Overview
2.1.1. Asymptotic Adaptive Feature Fusion Module (AAFFM)
2.1.2. Evidence Decision Fusion Module (EDFM)
2.2. Loss Function
3. Experiment and Result Analysis
3.1. Dataset Descriptions
3.2. Experimental Parameters
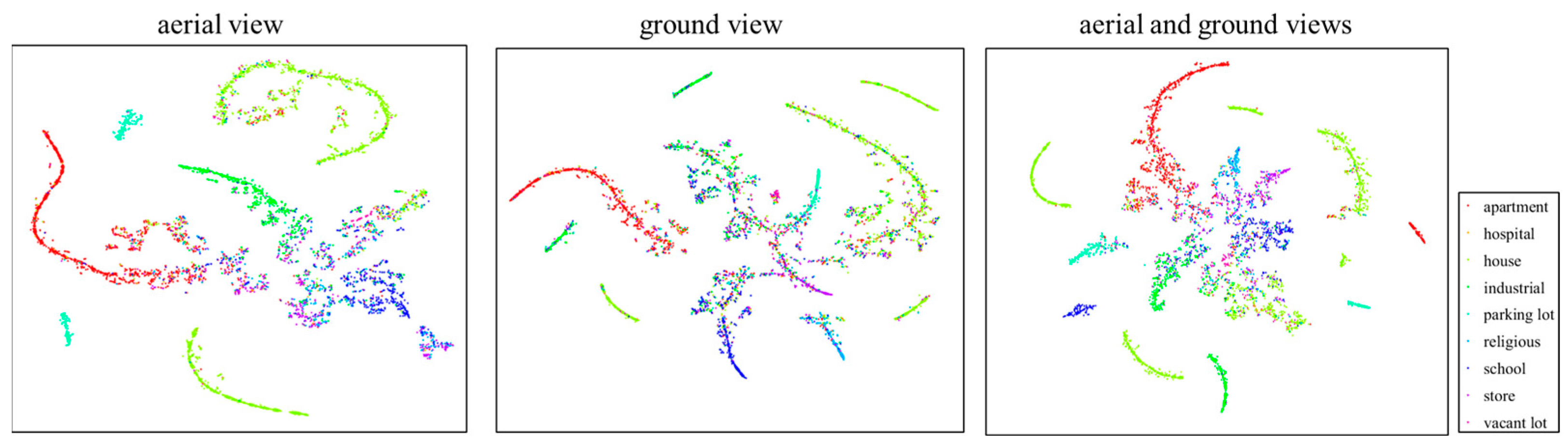
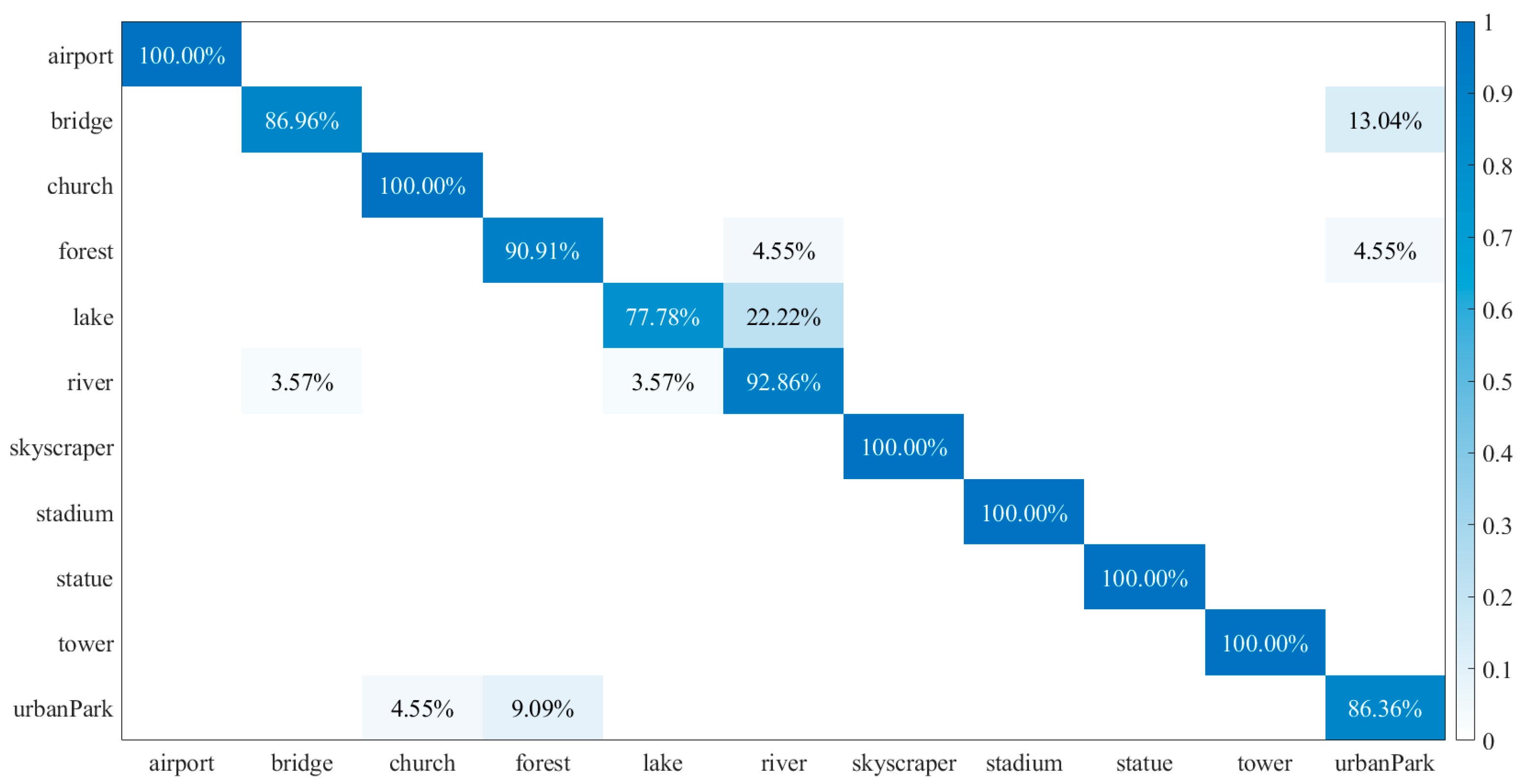
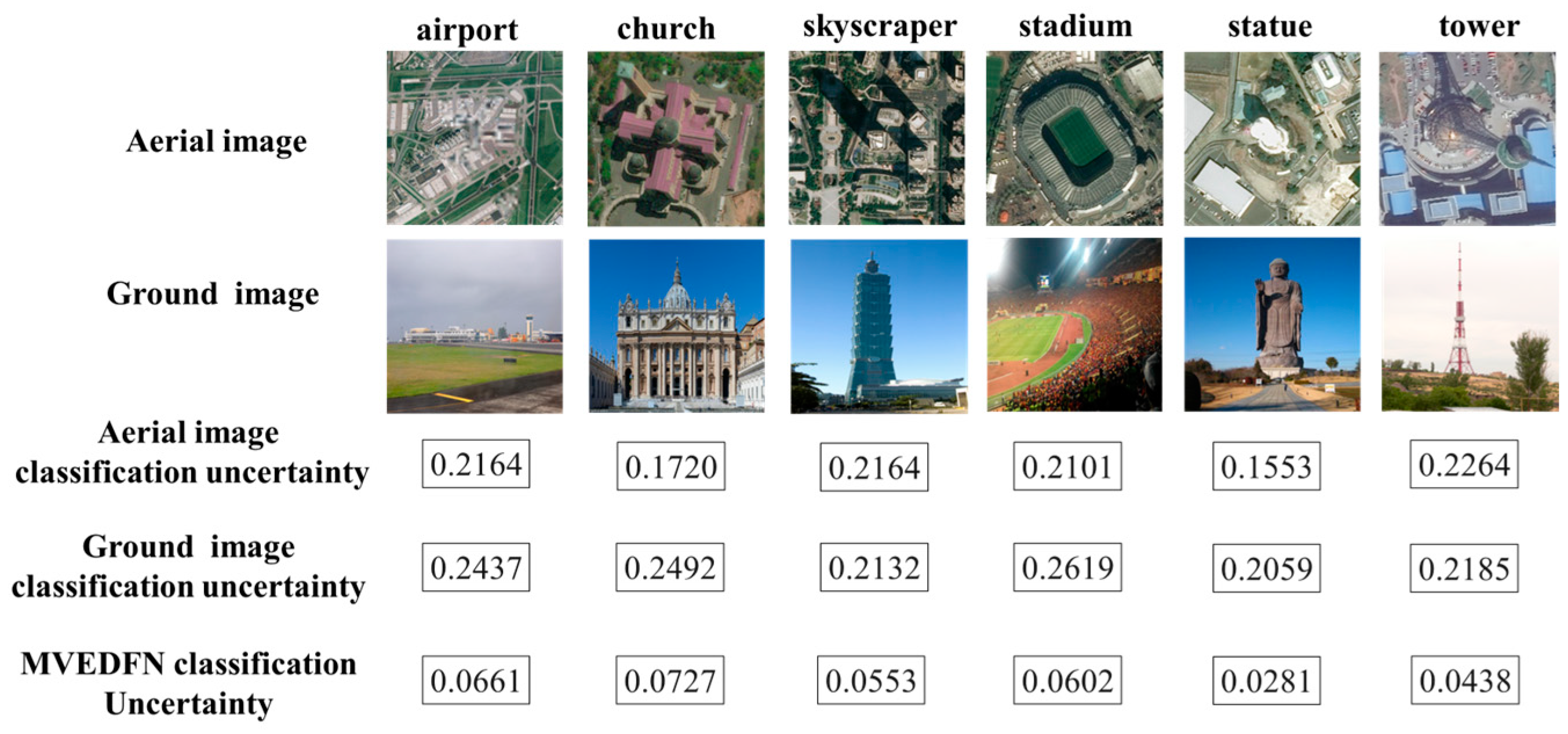
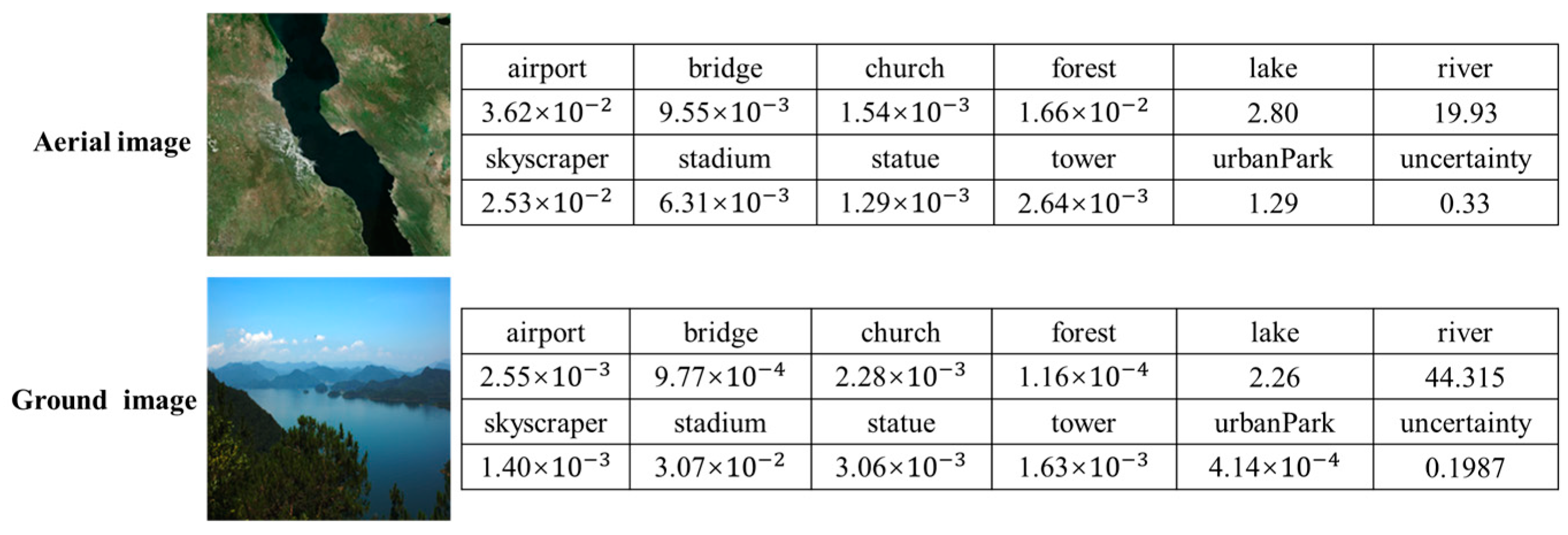
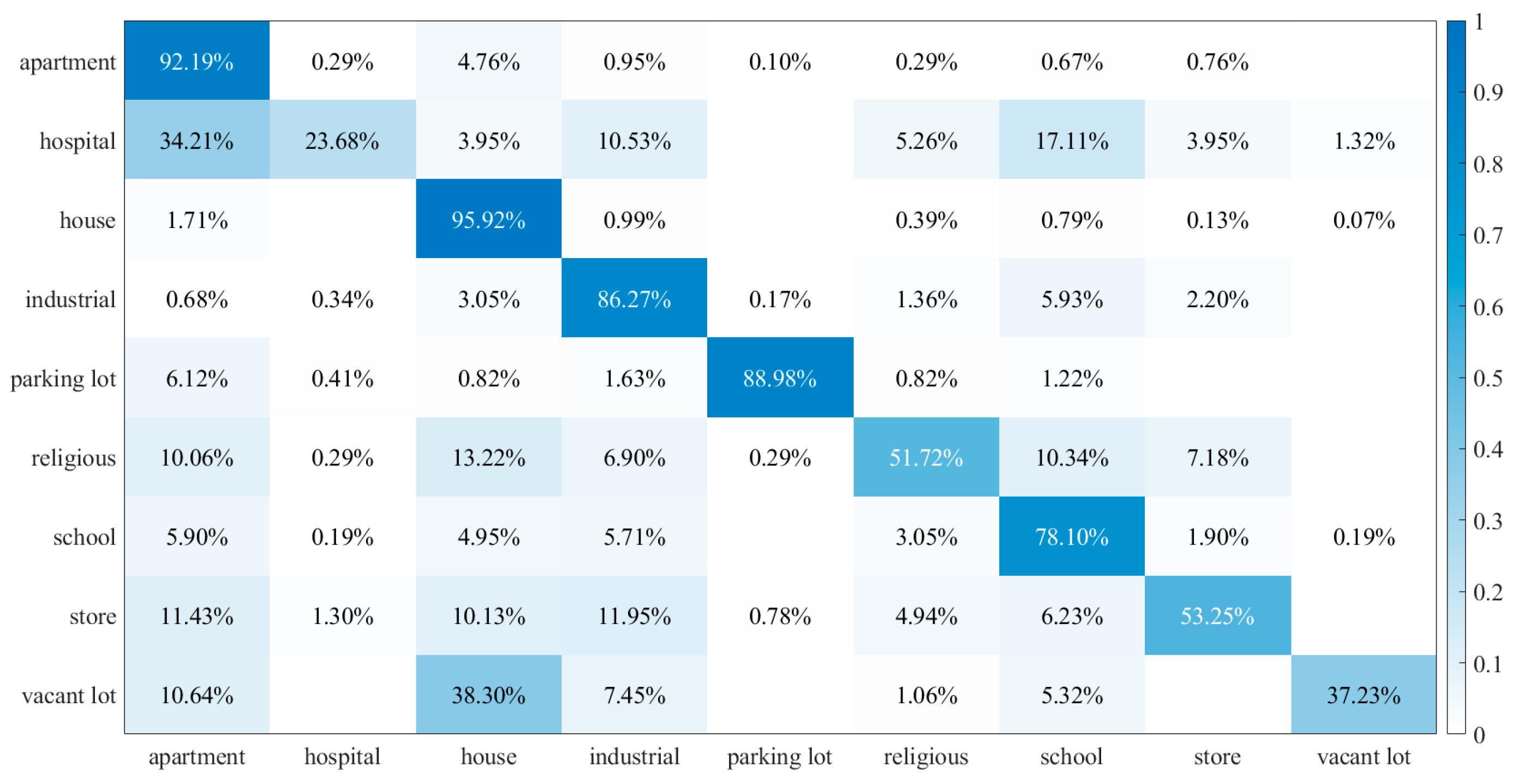
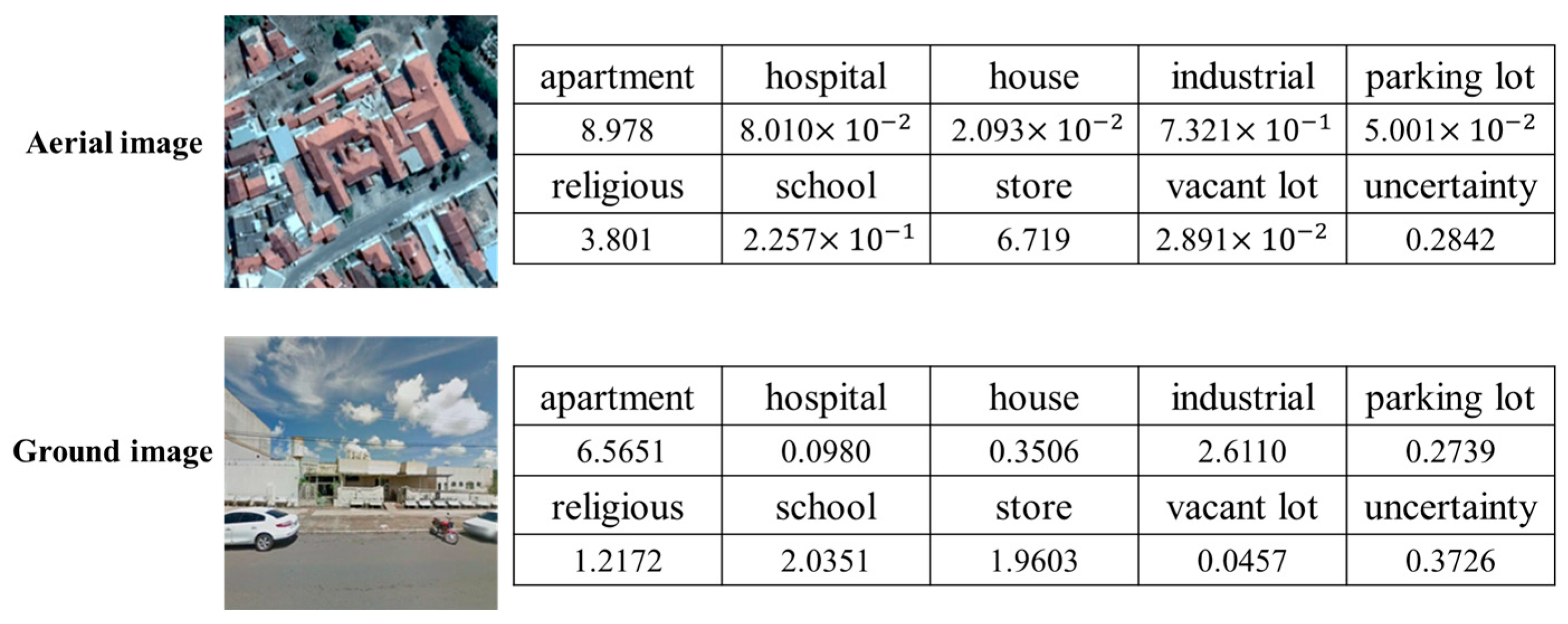
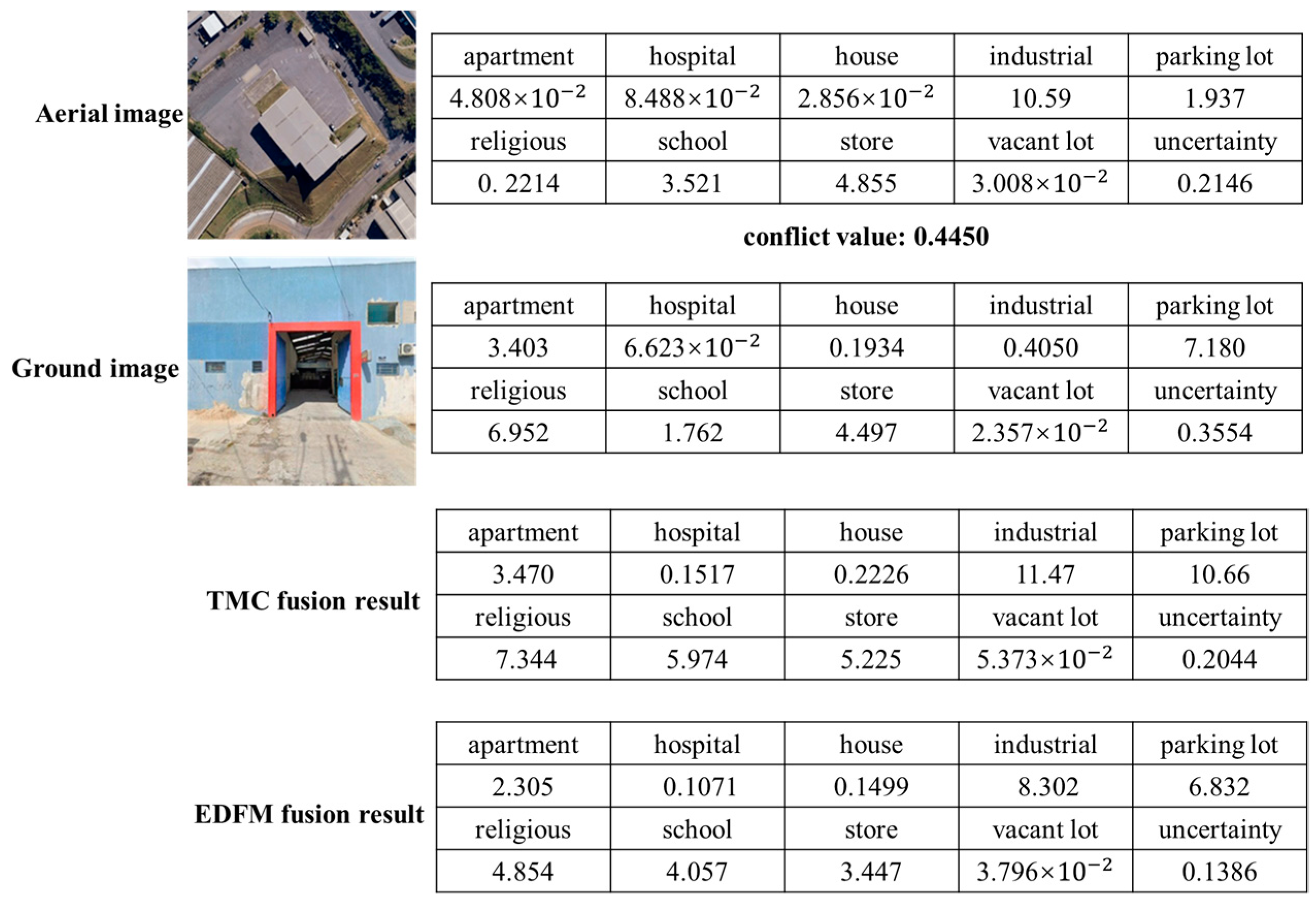
3.3. MVEDFN Classification Results and Analysis
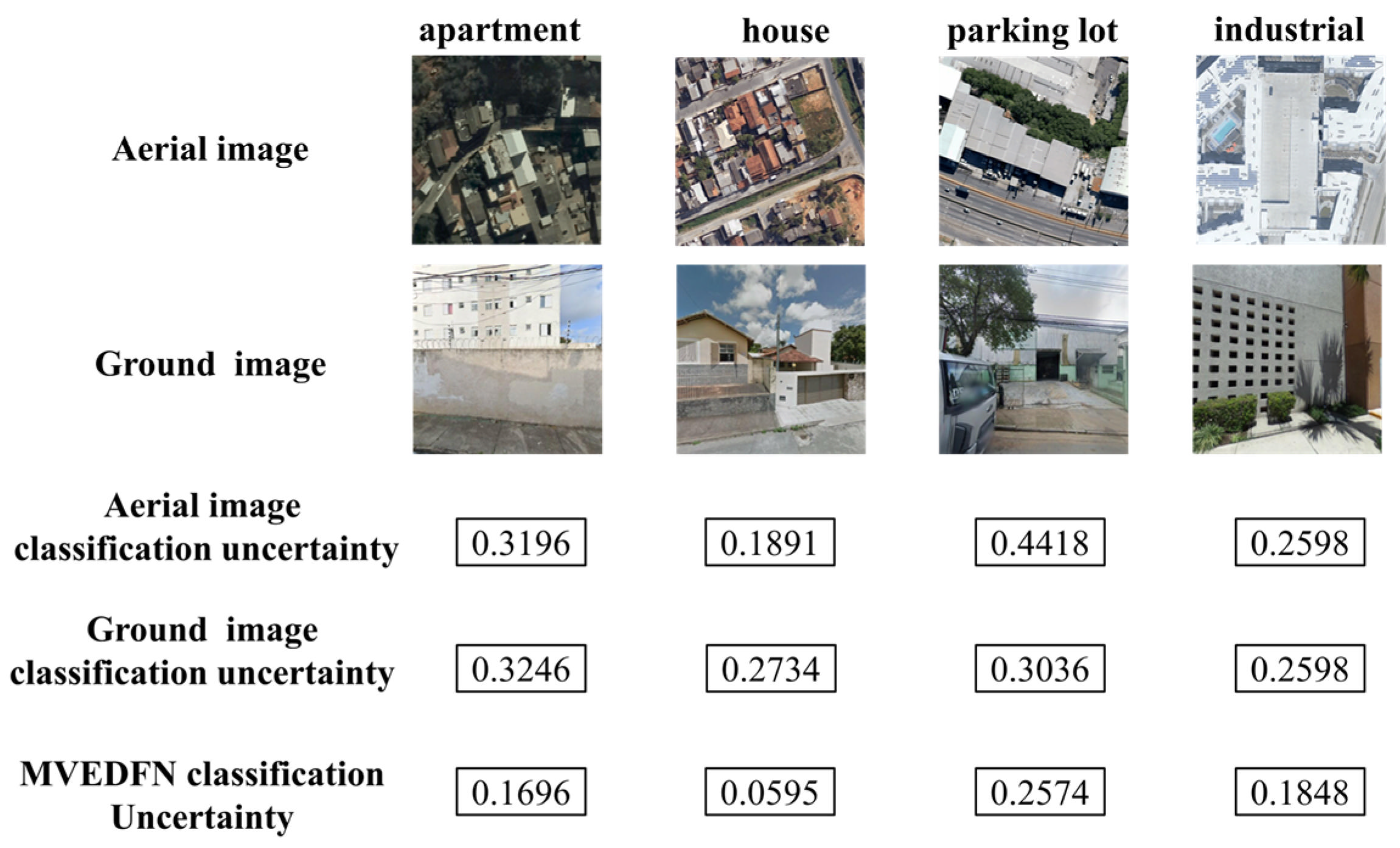
3.4. Ablation Study
3.5. Comparison Experiment
- Six-channel: The method involves fusing pairs of aerial and ground images into six channels and then performing a multi-view remote sensing scene classification task.
- CILM: The proposed method integrates the cross-entropy loss function and contrast loss function, presenting a novel information-based learning model for extracting and fusing two viewpoint image features without weight sharing in a CNN.
- MSAN: The method is a convolutional neural network fusing multi-scale attention, based on feature fusion and an attention mechanism to achieve multi-scale feature extraction and fusion from aerial and ground images.
- SoftMax product: The method involves generating category probability vectors by inputting aerial and ground images separately into CNNs. Subsequently, the viewpoint probability vectors from both perspectives are fused using an element-wise multiplication operation. Finally, the prediction is determined based on the largest element in the fused vector.
- SoftMax sum: The method involves generating category probability vectors by inputting aerial and ground images separately into CNNs. Subsequently, the viewpoint probability vectors from both perspectives are fused using an element-wise sum operation. Finally, the prediction is determined based on the largest element in the fused vector.
- EFN: The method proposes a simpler and easier-to-train loss function for multi-view scene classification in conjunction with evidence theory.
- TMC: The method employs evidence fusion theory to generate plausible classification decisions for aerial and ground image data, with a specific focus on decision making through the integration of uncertainty from multiple-viewpoint images.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
References
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Wang, J.; Li, W.; Zhang, M.; Tao, R.; Chanussot, J. Remote sensing scene classification via multi-stage self-guided separation network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar]
- Miao, W.; Geng, J.; Jiang, W. Multigranularity Decoupling Network with Pseudolabel Selection for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Samat, A. Integrating multilayer features of convolutional neural networks for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, B.; Su, H.; Li, W.; Wang, L. Land-use scene classification using multi-scale completed local binary patterns. Signal Image Video Process. 2016, 10, 745–752. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1461–1474. [Google Scholar] [CrossRef]
- Chen, X.; Ma, M.; Li, Y.; Cheng, W. Fusing deep features by kernel collaborative representation for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12429–12439. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Cui, K.; Li, Y.; Polk, S.L.; Lin, Y.; Zhang, H.; Murphy, J.M.; Plemmons, R.J.; Chan, R.H. Superpixel-based and Spatially-regularized Diffusion Learning for Unsupervised Hyperspectral Image Clustering. arXiv 2023, arXiv:2312.15447. [Google Scholar]
- Wei, Y.; Luo, X.; Hu, L.; Peng, Y.; Feng, J. An improved unsupervised representation learning generative adversarial network for remote sensing image scene classification. Remote Sens. Lett. 2020, 11, 598–607. [Google Scholar] [CrossRef]
- Polk, S.L.; Cui, K.; Chan, A.H.; Coomes, D.A.; Plemmons, R.J.; Murphy, J.M. Unsupervised Diffusion and Volume Maximization-Based Clustering of Hyperspectral Images. Remote Sens. 2022, 15, 1053. [Google Scholar] [CrossRef]
- Yu, D.; Xu, Q.; Guo, H.; Lu, J.; Lin, Y.; Liu, X. Aggregating features from dual paths for remote sensing image scene classification. IEEE Access 2022, 10, 16740–16755. [Google Scholar] [CrossRef]
- Yasir, M.; Liu, S.; Xu, M.; Wan, J.; Pirasteh, S.; Dang, K.B. ShipGeoNet: SAR Image-Based Geometric Feature Extraction of Ships Using Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–13. [Google Scholar] [CrossRef]
- Yang, M.; Wang, H.; Hu, K.; Yin, G.; Wei, Z. IA-Net: An inception–attention-module-based network for classifying underwater images from others. IEEE J. Ocean. Eng. 2022, 47, 704–717. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Cao, L.; Zhang, L. Pre-trained alexnet architecture with pyramid pooling and supervision for high spatial resolution remote sensing image scene classification. Remote Sens. 2017, 9, 848. [Google Scholar] [CrossRef]
- Ma, A.; Wan, Y.; Zhong, Y.; Wang, J.; Zhang, L. SceneNet: Remote sensing scene classification deep learning network using multi-objective neural evolution architecture search. ISPRS J. Photogramm. Remote Sens. 2021, 172, 171–188. [Google Scholar] [CrossRef]
- Wang, G.; Fan, B.; Xiang, S.; Pan, C. Aggregating rich hierarchical features for scene classification in remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4104–4115. [Google Scholar] [CrossRef]
- Machado, G.; Ferreira, E.; Nogueira, K.; Oliveira, H.; Brito, M.; Gama, P.H.T.; Santos, J.A.d. AiRound and CV-BrCT: Novel multiview datasets for scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 488–503. [Google Scholar] [CrossRef]
- Geng, W.; Zhou, W.; Jin, S. Multi-view urban scene classification with a complementary-information learning model. Photogramm. Eng. Remote Sens. 2022, 88, 65–72. [Google Scholar] [CrossRef]
- Shi, Y.; Zhou, W.; Shao, Z. Multi-view remote sensing image scene classification by fusing multi-scale attention. Geomat. Inf. Sci. Wuhan Univ. 2024, 49, 366–375. [Google Scholar]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese convolutional neural networks for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Bai, L.; Liu, Q.; Li, C.; Ye, Z.; Hui, M.; Jia, X. Remote sensing image scene classification using multiscale feature fusion covariance network with octave convolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5620214. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A. Decision fusion for the classification of urban remote sensing images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2828–2838. [Google Scholar] [CrossRef]
- Liu, X.; He, J.; Yao, Y.; Zhang, J.; Liang, H.; Wang, H.; Hong, Y. Classifying urban land use by integrating remote sensing and social media data. Int. J. Geogr. Inf. Sci. 2017, 31, 1675–1696. [Google Scholar] [CrossRef]
- Tu, W.; Hu, Z.; Li, L.; Cao, J.; Li, Q.; Li, Q. Portraying urban functional zones by coupling remote sensing imagery and human sensing data. Remote Sens. 2018, 10, 141. [Google Scholar] [CrossRef]
- Zhao, K.; Gao, Q.; Hao, S.; Sun, J.; Zhou, L. Credible remote sensing scene classification using evidential fusion on aerial-ground dual-view images. Remote Sens. 2023, 15, 1546. [Google Scholar] [CrossRef]
- Sensoy, M.; Kaplan, L.; Kandemir, M. Evidential Deep Learning to Quantify Classification Uncertainty. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 3183–3193. [Google Scholar]
- Lu, X.; Sun, H.; Zheng, X. A feature aggregation convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Van Amersfoort, J.; Smith, L.; Teh, Y.W.; Gal, Y. Uncertainty Estimation Using a Single Deep Deterministic Neural Network. In Proceedings of the PMLR International Conference on Machine Learning (ICML), Online, 13–18 July 2020; Volume 119, pp. 9690–9700. [Google Scholar]
- Moon, J.; Kim, J.; Shin, Y.; Hwang, S. Confidence-Aware Learning for Deep Neural Networks. In Proceedings of the PMLR International Conference on Machine Learning (ICML), Online, 13–18 July 2020; Volume 119, pp. 7034–7044. [Google Scholar]
- Lin, J. On the Dirichlet Distribution. Master’ Thesis, Department of Mathematics and Statistics, Queens University, Kingston, ON, Canada, 2016; pp. 10–11. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jin, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Maaten, L.V.; Hinton, G.E. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Han, Z.; Zhang, C.; Fu, H.; Zhou, T. Trusted multi-view classification. arXiv 2021, arXiv:2102.02051. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and orienting street views using overhead imagery. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 494–509. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Batch Size | Learning Rate | Iterations |
|---|---|---|---|
| AiRound | 16 | 1 × 10−4 | first 100 |
| 1 × 10−5 | last 50 | ||
| CV-BrCT | 16 | 1 × 10−4 | first 100 |
| 1 × 10−5 | last 50 |
| Dataset | Algorithm | Accuracy (%) | Kappa (%) |
|---|---|---|---|
| AiRound | MVEDFN | 94.85% | 93.86% |
| CV-BrCT | MVEDFN | 82.79% | 78.47% |
| Single View | Dataset | |||
|---|---|---|---|---|
| AiRound | CV-BrCT | |||
| Accuracy (%) | Kappa (%) | Accuracy (%) | Kappa (%) | |
| Aerial image | 82.40% | 78.98 | 78.11% | 65.74% |
| Ground image | 83.69% | 80.03% | 73.62% | 56.76% |
| Algorithms | AiRound | CV-BrCT |
|---|---|---|
| Resnet101 + SoftMax product | 86.40% | 78.98% |
| Resnet101 + SoftMax sum | 90.13% | 79.98% |
| Resnet101 + TMC fusion | 91.84% | 80.87% |
| Resnet101 + EDFM | 92.70% | 81.28% |
| Resnet101 + AAFMM + SoftMax product | 87.27% | 79.79% |
| Resnet101 + AAFMM + SoftMax sum | 91.42% | 80.56% |
| Resnet101 + AAFMM + TMC fusion | 93.13% | 81.94% |
| Resnet101 + AAFMM + EDFM (MVEDFN) | 94.85% | 82.79% |
| Algorithms | AiRound | CV-BrCT | ||
|---|---|---|---|---|
| Aerial Image | Ground Image | Aerial Image | Ground Image | |
| ResNet101 + SoftMax | 82.22% | 83.31% | 77.65% | 64.77% |
| ResNet101 + AAFFM + SoftMax | 83.26% | 84.54% | 78.98% | 66.13% |
| ResNet101 + evidential | 81.12% | 81.40% | 77.13% | 63.57% |
| ResNet101 + AAFFM + evidential | 82.40% | 83.69% | 78.11% | 65.74% |
| Algorithms | Datasets | |
|---|---|---|
| AiRound | CV-BrCT | |
| Six-Ch. | 77.68% | 74.62% |
| MSAN | 93.56% | 81.69% |
| CILM | 92.27% | 81.28% |
| SoftMax product | 87.27% | 79.79% |
| SoftMax sum | 91.42% | 80.56% |
| EFN | 91.84% | 80.87% |
| TMC | 92.70% | 81.47% |
| MVEDFN | 94.85% | 82.79% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Shi, Y.; Huang, X. Multi-View Scene Classification Based on Feature Integration and Evidence Decision Fusion. Remote Sens. 2024, 16, 738. https://doi.org/10.3390/rs16050738
Zhou W, Shi Y, Huang X. Multi-View Scene Classification Based on Feature Integration and Evidence Decision Fusion. Remote Sensing. 2024; 16(5):738. https://doi.org/10.3390/rs16050738
Chicago/Turabian StyleZhou, Weixun, Yongxin Shi, and Xiao Huang. 2024. "Multi-View Scene Classification Based on Feature Integration and Evidence Decision Fusion" Remote Sensing 16, no. 5: 738. https://doi.org/10.3390/rs16050738
APA StyleZhou, W., Shi, Y., & Huang, X. (2024). Multi-View Scene Classification Based on Feature Integration and Evidence Decision Fusion. Remote Sensing, 16(5), 738. https://doi.org/10.3390/rs16050738