
Advances and Challenges in Deep Learning-Based Change Detection for Remote Sensing Images: A Review through Various Learning Paradigms



Abstract
1. Introduction
2. Basic Network Architectures of DL
2.1. Convolutional Neural Network
2.2. Recurrent Neural Network
2.3. AutoEncoder
2.4. Transformer
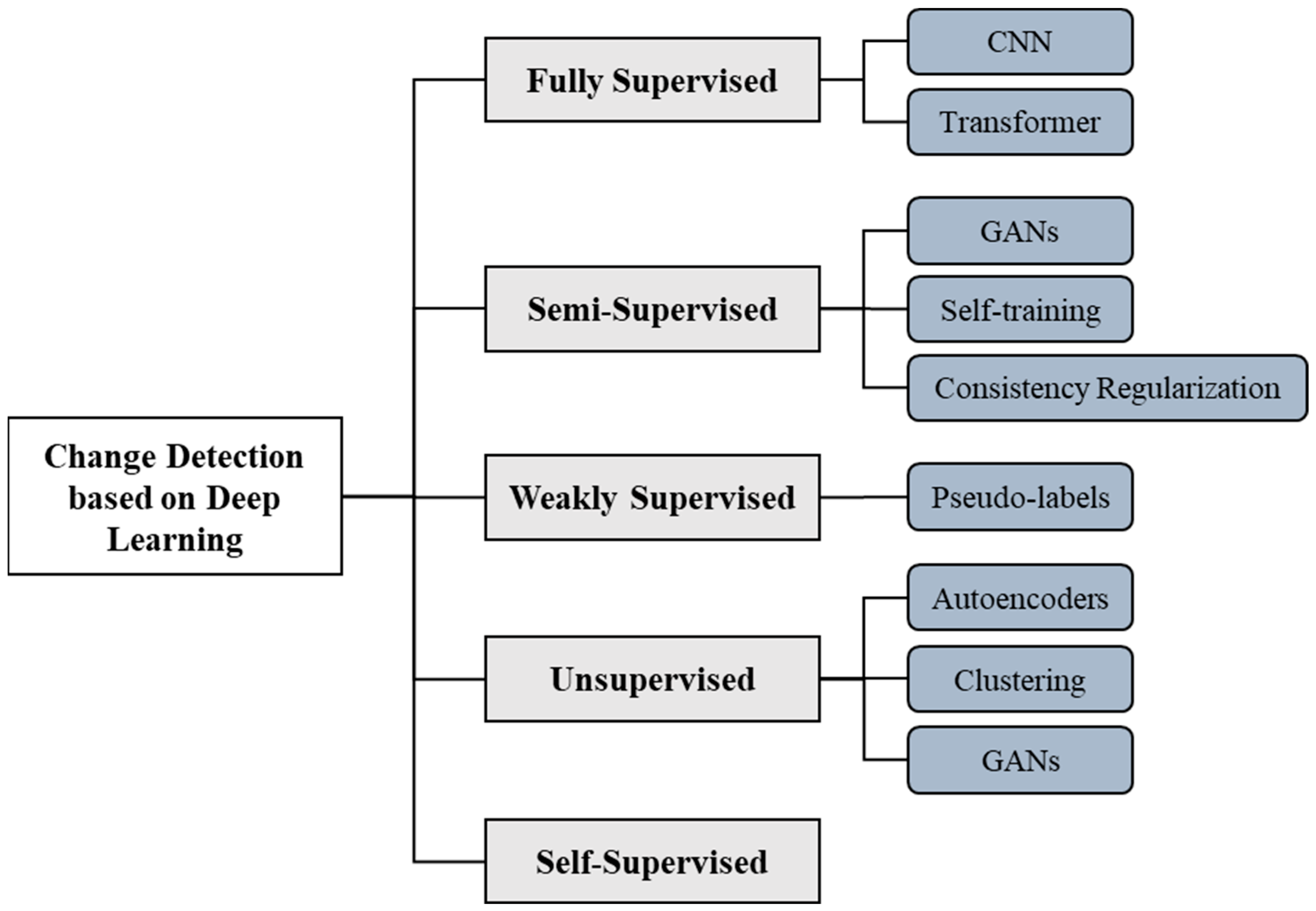
3. DL-Based CD Methods across Various Learning Paradigms
3.1. Fully Supervised Learning
3.1.1. Fully Supervised CD Methods Based on CNN
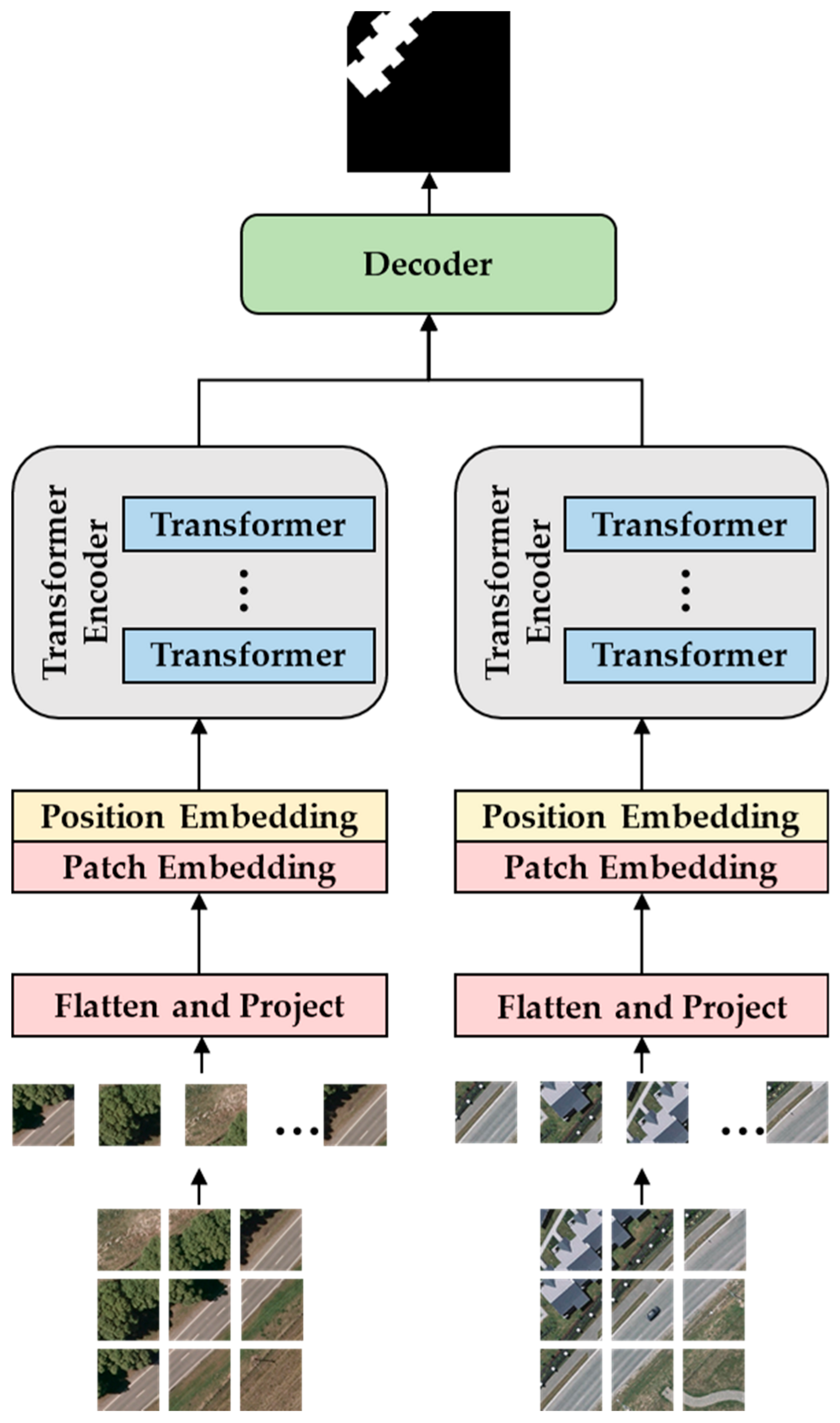
3.1.2. Fully Supervised CD Methods Based on Transformer
- Transformer Encoder + Transformer Decoder [61,62,63,96,97,98,99,100]. This design fully exploits the Transformer’s self-attention mechanism in both encoding and decoding phases, effectively integrating global information during up-sampling in the decoding process. Additionally, this all-attention architecture maintains efficiency in handling long-distance dependencies and large-scale contextual information, especially in parsing complex remote sensing data structures. For example, Cui et al. [61] proposed SwinSUNet, a pure Transformer network with a Siamese U-shaped structure, comprising encoders, fusers, and decoders, all based on Swin Transformer blocks. The encoder uses hierarchical Swin Transformers to extract multi-scale features, while the fuser primarily merges bi-temporal features generated by the encoders. Similar to the encoder, the decoder, also based on hierarchical Swin Transformers, uses up-sampling to restore the feature map to the original input image size and employs linear projection for dimensionality reduction to generate the CD map. Chen et al. [98] introduced an RS image CD framework based on bi-temporal image Transformers. This uses Siamese CNN to extract high-level semantic features and spatial attention to convert each temporal feature map into a compact processing unit (token) sequence. The Transformer encoder then models the context of these two token sequences, generating context-rich tokens. An improved Transformer decoder reprojects these back into pixel space, enhancing the original pixel-level features. Finally, a feature difference map is computed from the two refined feature maps and input into a shallow CNN to produce the CD map.
- Transformer Encoder + CNN Decoder [101,102,103,104,105,106,107]: In this configuration, the Transformer encoder acts as the feature extractor, capturing the global contextual information of the input data. The extracted features are then passed to a CNN decoder for more refined image segmentation and reconstruction. For instance, Li et al. [102] proposed TransUNetCD, an end-to-end CD model combining Transformer and UNet. The Transformer encoder, based on the UNet architecture, encodes feature maps obtained from Siamese CNN, models the context, and extracts rich global contextual information. The CNN-based decoder up-samples the encoded features and integrates them with high-resolution, multi-scale features through skip connections. This process learns local–global semantic features, restoring the feature map to the original input image size to generate the CD map.
3.2. Semi-Supervised Learning
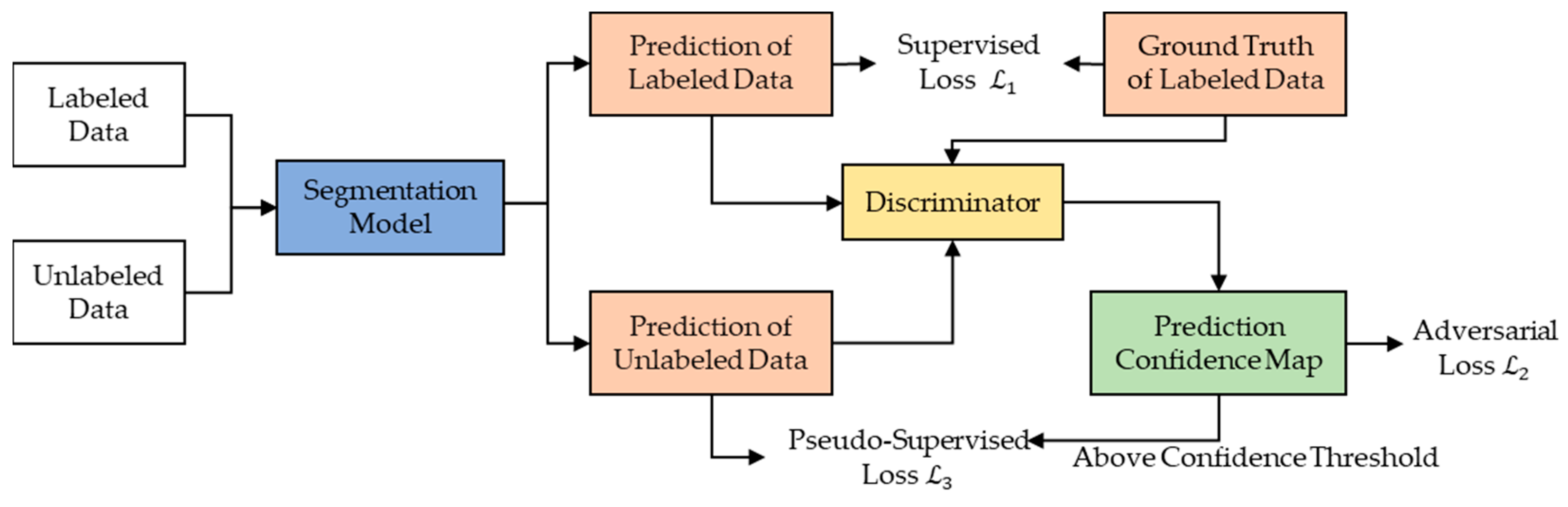
3.2.1. Semi-Supervised CD Methods Based on Adversarial Learning
3.2.2. Semi-Supervised CD Methods Based on Self-Training
- Initialization: Train the initial model using the available labeled dataset.
- Pseudo-Label Generation: Predict unlabeled samples using the initial model, select those with high prediction confidence, and assign the prediction results as their pseudo-labels.
- Model Re-Training: Merge unlabeled samples with pseudo-labels into the labeled dataset to form an expanded training set and retrain the model using this dataset.
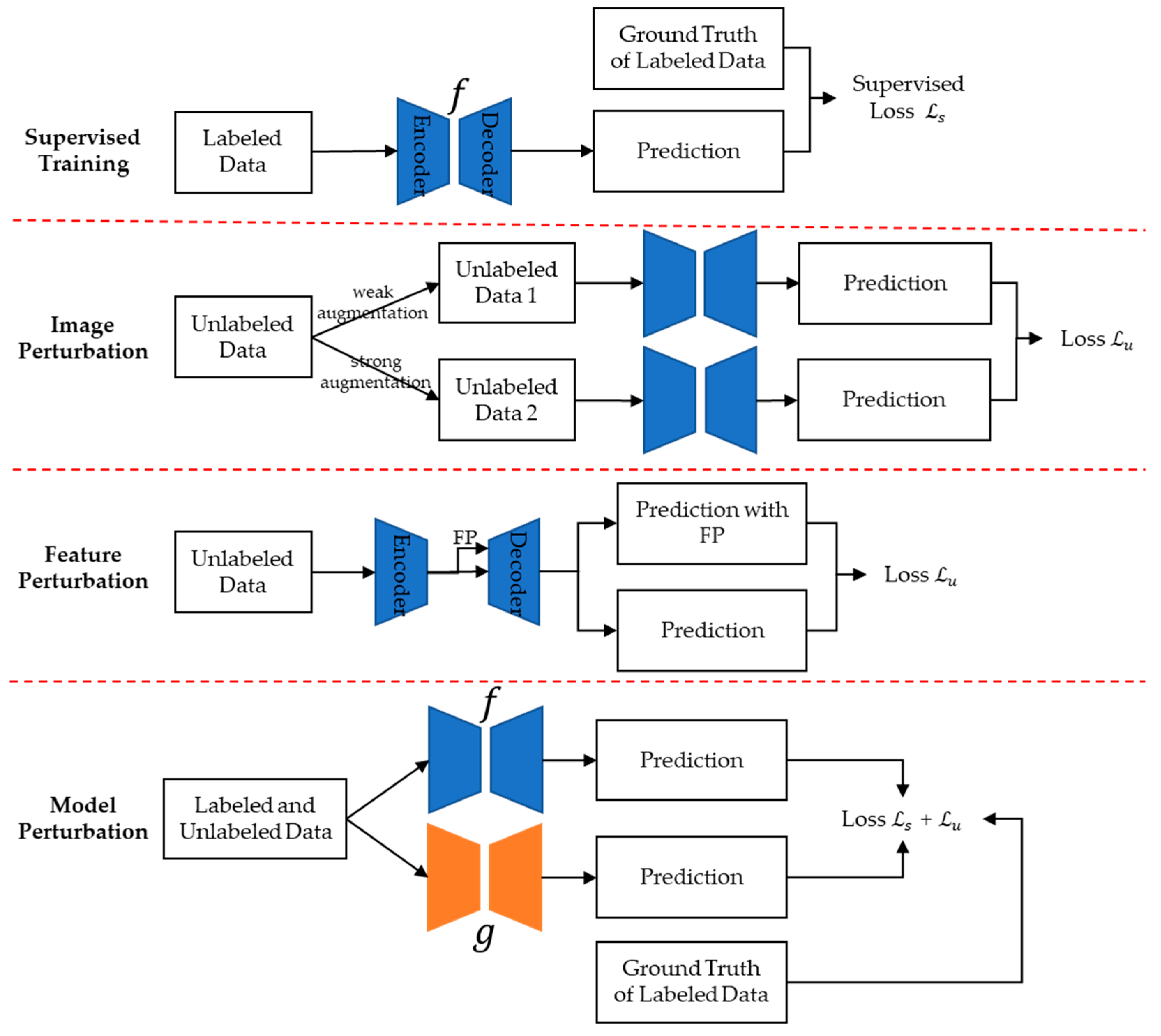
3.2.3. Semi-Supervised CD Methods Based on Consistency Regularization
- Image Perturbation Space [116,119,124,125]. This approach involves applying operations, like rotation, scaling, and color transformations, to images, generating a series of perturbed images. For example, Sun et al. [124] proposed a semi-supervised CD method using data augmentation strategies to access image perturbation space and generate pseudo bi-temporal images to further expand this space. The method then minimizes the differences between the change maps obtained from the image perturbation space and the original images.
- Feature Perturbation (FP) Space [126,127]. This involves perturbing the internal feature space of the image within the model, rather than directly manipulating the image itself. This can be achieved through operations like dropout on features. For instance, Bandara et al. [126] introduced a semi-supervised CD method based on feature consistency regularization. The method perturbs the deep feature space of bi-temporal difference features of unlabeled image pairs, minimizing the differences between change maps derived from various feature perturbation spaces and the original space as a consistency loss.
- Model Perturbation Space [128,129]. This approach involves altering the model itself to create pseudo-labels for unlabeled samples using different models and then supervising them mutually. For example, Chen et al. [129] used two networks with the same structure but different initializations during model training. They added a loss function to ensure that both networks produce similar outputs for the same sample.
- Combined Perturbation Space [130]. This approach synergizes elements from Image Perturbation Space, Feature Perturbation Space, and Model Perturbation Space. Yang et al. [130] effectively merged image perturbation techniques with feature perturbation strategies, an integration that led to the exploration of a broader perturbation space and yielded models with superior performance and enhanced generalization capabilities. Notably, their method demonstrated commendable results in CD datasets, underscoring the benefits of this integrated perturbation approach.
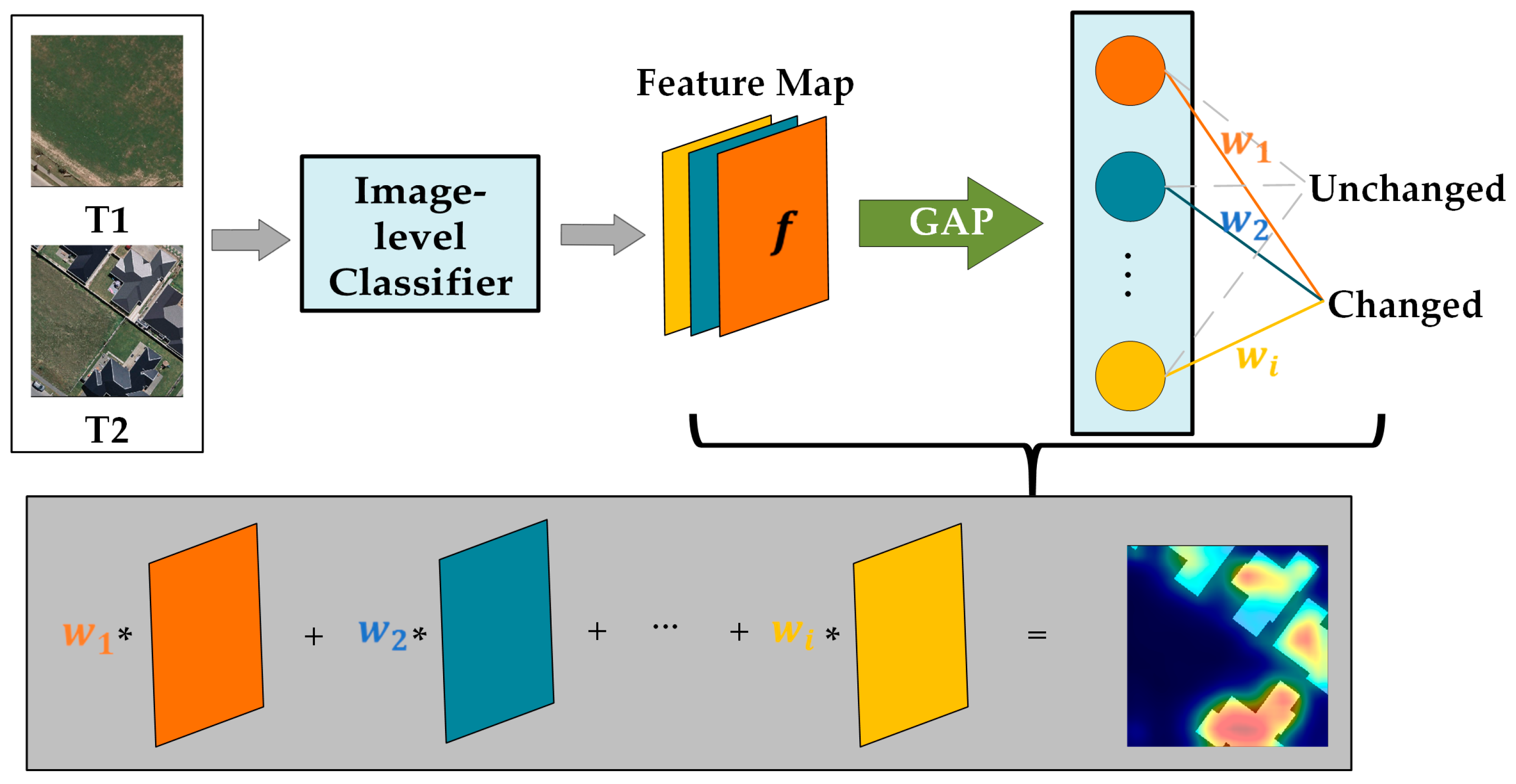
3.3. Weakly Supervised Learning
- Step 1: Extract information from incomplete or imprecise labels to generate pixel-level pseudo-labels.
- Step 2: Utilize these pseudo-labels to train a pixel-level CD model.
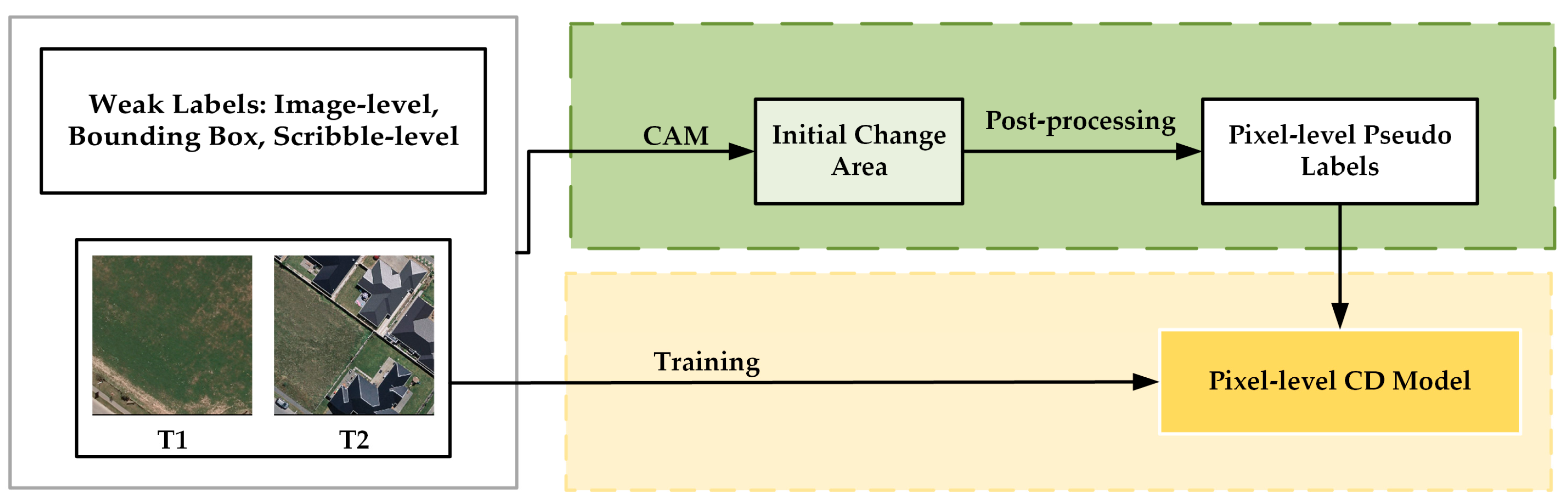
- Firstly, creating initial change areas from the image-level labels for each image pair.
- Then, propagating semantic information from these initial areas across the entire image pair to generate pixel-level pseudo-labels.
3.4. Unsupervised Learning
4. Discussion of Different Learning Paradigms for CD
4.1. Adaptation of Datasets for Various Learning Paradigms
- In the case of semi-supervised learning, a subset of the data (typically around 5% to 10%) is used as labeled data, with the remainder serving as unlabeled data.
- In the case of weakly supervised learning, weak labels are generated from these precise labels. The transition from dense to weak labels is made by transforming the detailed annotations into more generalized or less informative labels.
- For unsupervised learning, the original labels of the dataset are completely disregarded.
- Furthermore, in self-supervised learning, the focus is on exploiting the unlabeled dataset for primary model training. This is followed by a fine-tuning phase, wherein a minimal subset of the data (approximately 1%) with labels is employed to refine the model’s performance.
4.2. Analysis of SOTA Methods for Different Learning Paradigms
4.3. Pros and Cons of Different Learning Paradigms in CD
4.4. Application Scenarios for Different Learning Paradigms
- Fully Supervised Learning: This approach is most apt for the detailed monitoring of urban expansion and land use changes, such as tracking the growth of urban buildings or the development of roadways. These scenarios often demand highly accurate CD, as they directly impact urban planning and management. Moreover, in these contexts, there are usually sufficient resources available to acquire a large amount of precise ground truth data.
- Semi-Supervised Learning: This is suitable for the monitoring of natural resources, such as assessing deforestation or degradation. Given the vast coverage of forest areas, often only a portion of these regions may have detailed annotated data, with the majority remaining unlabeled. In such cases, the limited annotated data, in conjunction with extensive unlabeled data, can be utilized to monitor the health of forests over large areas, thus efficiently evaluating environmental impacts.
- Weakly Supervised Learning: This paradigm is ideal for rapid disaster response, such as quick assessment of changes following floods or fire disasters. In these instances, rapidly acquiring a general understanding of the disaster-affected areas through limited and coarse annotated data is of paramount importance.
- Unsupervised Learning: This method is suitable for monitoring global environmental changes, such as glacier retreat or desertification. The long-term nature of these changes often makes it challenging to obtain a large quantity of precise annotated data.
5. Opportunities and Challenges for DL-based CD
5.1. Incomplete Supervised CD
- Model Performance: In CD tasks, the performance of models is crucial, directly impacting their practical efficacy. Weakly supervised methods, which rely on vague or incomplete labels (image-level, bounding box, scribble-level), may struggle with recognition in complex scenarios. Additionally, sensitivity to subtle changes poses a challenge, particularly in applications sensitive to fine-grained variations.
- Uncertainty Management: Incompleteness, imprecision, or vagueness in annotations can lead to uncertainty in weakly supervised learning predictions, affecting reliability and trust in practical applications. Managing this uncertainty—accurately representing and quantifying it in predictions—is key to enhancing the effectiveness of weakly supervised models. Current strategies include integrating Bayesian methods and confidence assessments into the training process to explicitly account for uncertainties and achieve more reliable model outcomes.
- Severe Sample Imbalance: Existing semi-supervised CD studies typically select 5% to 40% of samples from supervised datasets to simulate a semi-supervised scenario. In real-world contexts, this ratio is often more skewed, with labeled samples possibly comprising less than 1% of a much larger total sample size. Thus, developing robust semi-supervised learning algorithms that utilize a minimal amount of labeled data and learn from a large pool of unlabeled data is a significant challenge.
- Existing incomplete supervision methods in CD primarily utilize CNN as the backbone. The swift evolution of DL has introduced more powerful and flexible network architectures capable of handling complex and high-dimensional data more effectively, thereby enhancing the accuracy and efficiency of CD. For instance, the ViT has become a popular model in image processing, recently applied to supervised CD with satisfying results. Exploring its application in incomplete supervision CD is one of the most promising future research directions.
- Emerging learning paradigms, like self-supervised learning, not only provide effective solutions for handling severely imbalanced datasets but also offer new approaches for rapid model adaptation and generalization. Self-supervised learning will be further discussed in Section 5.2.
- Additionally, the emergence of Visual Foundation Models opens new possibilities. Their exceptional transferability offers novel tools and innovative potential for incomplete supervision in CD, which will be further discussed in Section 5.3.
5.2. Self-Supervised Learning
5.3. Visual Foundation Models
- In incomplete supervision CD scenarios, Visual Foundation Models can serve as a powerful auxiliary tool. Researchers can generate high-quality pseudo-labels using Visual Foundation Models combined with appropriate prompts, reducing reliance on extensive accuracy annotations. However, the potential of Visual Foundation Models extends beyond this; developing effective learning algorithms to leverage Foundation Models’ advantages in incomplete supervision and integrating them more directly into the main process of CD are crucial areas for further exploration.
- Existing research shows that pre-training datasets for Visual Foundation Models often lack images specific to certain domains, like RS imagery. Further exploration into developing specialized Foundation Models using large-scale RS datasets could enable models to capture the unique features of remote sensing imagery more accurately, facilitating zero-shot transfer to related tasks. However, processing and analyzing large-scale RS datasets require immense computational resources.
- In scenarios with limited computational resources, fine-tuning Visual Foundation Models through open interfaces is a practical solution. Employing a partial weight-locking strategy allows researchers to update the model for specific RS image-related tasks selectively. This method not only conserves computational resources but also ensures the model’s ability to adapt quickly to new tasks. Developing more effective fine-tuning strategies to maintain the model’s generalizability and ensuring its continuous update and maintenance remain significant challenges.
5.4. Multimodal CD
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A. Review Article Digital Change Detection Techniques Using Remotely-Sensed Data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous Change Detection and Classification of Land Cover Using All Available Landsat Data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, M.; Shen, X.; Shi, W. Landslide Mapping Using Multilevel-Feature-Enhancement Change Detection Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3599–3610. [Google Scholar] [CrossRef]
- Luo, H.; Liu, C.; Wu, C.; Guo, X. Urban Change Detection Based on Dempster–Shafer Theory for Multitemporal Very High-Resolution Imagery. Remote Sens. 2018, 10, 980. [Google Scholar] [CrossRef]
- Shi, W.; Zhang, M.; Zhang, R.; Chen, S.; Zhan, Z. Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges. Remote Sens. 2020, 12, 1688. [Google Scholar] [CrossRef]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep Learning-Based Change Detection in Remote Sensing Images: A Review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Deng, J.S.; Wang, K.; Deng, Y.H.; Qi, G.J. PCA-Based Land-Use Change Detection and Analysis Using Multitemporal and Multisensor Satellite Data. Int. J. Remote Sens. 2008, 29, 4823–4838. [Google Scholar] [CrossRef]
- Chen, J.; Gong, P.; He, C.; Pu, R.; Shi, P. Land-Use/Land-Cover Change Detection Using Improved Change-Vector Analysis. Photogramm. Eng. Remote Sens. 2003, 69, 369–379. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Automatic Analysis of the Difference Image for Unsupervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2000, 38, 1171–1182. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and k-Means Clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- National Academies of Sciences, Engineering, and Medicine. Thriving on Our Changing Planet: A Decadal Strategy for Earth Observation from Space; National Academies Press: Washington, DC, USA, 2019. [Google Scholar]
- Zhao, Q.; Yu, L.; Du, Z.; Peng, D.; Hao, P.; Zhang, Y.; Gong, P. An Overview of the Applications of Earth Observation Satellite Data: Impacts and Future Trends. Remote Sens. 2022, 14, 1863. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote Sensing Big Data Computing: Challenges and Opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big Data for Remote Sensing: Challenges and Opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Asokan, A.; Anitha, J. Change Detection Techniques for Remote Sensing Applications: A Survey. Earth Sci. Inform. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Girshick, R. Fast R-Cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 3085870. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 3056416. [Google Scholar] [CrossRef]
- Li, Z.; Tang, C.; Liu, X.; Zhang, W.; Dou, J.; Wang, L.; Zomaya, A.Y. Lightweight Remote Sensing Change Detection with Progressive Feature Aggregation and Supervised Attention. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3241436. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Representations by Back-Propagating Errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Černocký, J.; Khudanpur, S. Extensions of Recurrent Neural Network Language Model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Rangapuram, S.S.; Seeger, M.; Gasthaus, J.; Stella, L.; Wang, Y.; Januschowski, T. Deep State Space Models for Time Series Forecasting. In Proceedings of the 32nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 7796–7805. [Google Scholar]
- Lyu, H.; Lu, H.; Mou, L.; Li, W.; Wright, J.; Li, X.; Li, X.; Zhu, X.X.; Wang, J.; Yu, L.; et al. Long-Term Annual Mapping of Four Cities on Different Continents by Applying a Deep Information Learning Method to Landsat Data. Remote Sens. 2018, 10, 471. [Google Scholar] [CrossRef]
- Lyu, H.; Lu, H.; Mou, L. Learning a Transferable Change Rule from a Recurrent Neural Network for Land Cover Change Detection. Remote Sens. 2016, 8, 506. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Kramer, M.A. Nonlinear Principal Component Analysis Using Autoassociative Neural Networks. AIChE J. 1991, 37, 233–243. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ng, A. Sparse Autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5884–5888. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-Augmented Transformer for Speech Recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-Xl: Attentive Language Models beyond a Fixed-Length Context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable Detr: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.-C. Max-Deeplab: End-to-End Panoptic Segmentation with Mask Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 5463–5474. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3160007. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. Remote Sensing Image Change Detection Transformer Network Based on Dual-Feature Mixed Attention. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3209972. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Chai, Z.; Li, J. PA-Former: Learning Prior-Aware Transformer for Remote Sensing Building Change Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3200396. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A Nested u-Net Architecture for Medical Image Segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: DLMIA 2018, Granada, Spain, 20 September 2018; pp. 3–11. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef]
- Zhang, X.; Yue, Y.; Gao, W.; Yun, S.; Su, Q.; Yin, H.; Zhang, Y. DifUnet++: A Satellite Images Change Detection Network Based on UNet++ and Differential Pyramid. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Lei, T.; Zhang, Q.; Xue, D.; Chen, T.; Meng, H.; Nandi, A.K. End-to-End Change Detection Using a Symmetric Fully Convolutional Network for Landslide Mapping. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3027–3031. [Google Scholar]
- Liu, J.; Gong, M.; Qin, K.; Zhang, P. A Deep Convolutional Coupling Network for Change Detection Based on Heterogeneous Optical and Radar Images. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 545–559. [Google Scholar] [CrossRef] [PubMed]
- Zhan, T.; Gong, M.; Liu, J.; Zhang, P. Iterative Feature Mapping Network for Detecting Multiple Changes in Multi-Source Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2018, 146, 38–51. [Google Scholar] [CrossRef]
- Johnson, R.D.; Kasischke, E.S. Change Vector Analysis: A Technique for the Multispectral Monitoring of Land Cover and Condition. Int. J. Remote Sens. 1998, 19, 411–426. [Google Scholar] [CrossRef]
- Vorovencii, I.; Nir, R. A Change Vector Analysis Technique for Monitoring Land Cover Changes in Copsa Mica, Romania, in the Period 1985–2011; Transilvania University of Brasov, Faculty of Silviculture: Brasov, Romania, 2011. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Wang, L.; Li, Y.; Zhang, M.; Shen, X.; Peng, W.; Shi, W. MSFF-CDNet: A Multiscale Feature Fusion Change Detection Network for Bi-Temporal High-Resolution Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3305623. [Google Scholar] [CrossRef]
- Chen, T.; Lu, Z.; Yang, Y.; Zhang, Y.; Du, B.; Plaza, A. A Siamese Network Based U-Net for Change Detection in High Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 2357–2369. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Zhu, Q.; Guo, X.; Deng, W.; Shi, S.; Guan, Q.; Zhong, Y.; Zhang, L.; Li, D. Land-Use/Land-Cover Change Detection Based on a Siamese Global Learning Framework for High Spatial Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 63–78. [Google Scholar] [CrossRef]
- Ding, L.; Guo, H.; Liu, S.; Mou, L.; Zhang, J.; Bruzzone, L. Bi-Temporal Semantic Reasoning for the Semantic Change Detection in HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3154390. [Google Scholar] [CrossRef]
- Feng, Y.; Jiang, J.; Xu, H.; Zheng, J. Change Detection on Remote Sensing Images Using Dual-Branch Multilevel Intertemporal Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3241257. [Google Scholar] [CrossRef]
- Lei, T.; Geng, X.; Ning, H.; Lv, Z.; Gong, M.; Jin, Y.; Nandi, A.K. Ultralightweight Spatial–Spectral Feature Cooperation Network for Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3261273. [Google Scholar] [CrossRef]
- Xing, Y.; Jiang, J.; Xiang, J.; Yan, E.; Song, Y.; Mo, D. LightCDNet: Lightweight Change Detection Network Based on VHR Images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3304309. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Almahairi, A.; Ballas, N.; Cooijmans, T.; Zheng, Y.; Larochelle, H.; Courville, A. Dynamic Capacity Networks. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2549–2558. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Others Spatial Transformer Networks. Adv. Neural Inf. Process Syst. 2015, 28, 2017–2025. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. Bam: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lee, C.-Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; pp. 562–570. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Adv. Neural Inf. Process Syst. 2021, 34, 9355–9366. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going Deeper with Image Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 32–42. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Process Syst. 2021, 34, 15908–15919. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Tian, S.; Ma, A.; Zhang, L. ChangeMask: Deep Multi-Task Encoder-Transformer-Decoder Architecture for Semantic Change Detection. ISPRS J. Photogramm. Remote Sens. 2022, 183, 228–239. [Google Scholar] [CrossRef]
- Zhang, X.; Cheng, S.; Wang, L.; Li, H. Asymmetric Cross-Attention Hierarchical Network Based on CNN and Transformer for Bitemporal Remote Sensing Images Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3245674. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 3095166. [Google Scholar] [CrossRef]
- Liu, M.; Shi, Q.; Li, J.; Chai, Z. Learning Token-Aligned Representations with Multimodel Transformers for Different-Resolution Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3200684. [Google Scholar] [CrossRef]
- Song, X.; Hua, Z.; Li, J. PSTNet: Progressive Sampling Transformer Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8442–8455. [Google Scholar] [CrossRef]
- Yan, T.; Wan, Z.; Zhang, P. Fully Transformer Network for Change Detection of Remote Sensing Images. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 1691–1708. [Google Scholar]
- Li, Q.; Zhong, R.; Du, X.; Du, Y. TransUNetCD: A Hybrid Transformer Network for Change Detection in Optical Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–19. [Google Scholar] [CrossRef]
- Jiang, B.; Wang, Z.; Wang, X.; Zhang, Z.; Chen, L.; Wang, X.; Luo, B. VcT: Visual Change Transformer for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3327139. [Google Scholar] [CrossRef]
- Yan, T.; Wan, Z.; Zhang, P.; Cheng, G.; Lu, H. TransY-Net: Learning Fully Transformer Networks for Change Detection of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3327253. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, D.; Sha, J.; Gao, L.; Liu, L.; Zhang, Y.; Rong, X. Spectral–Spatial–Temporal Transformers for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3203075. [Google Scholar] [CrossRef]
- Li, W.; Xue, L.; Wang, X.; Li, G. ConvTransNet: A CNN–Transformer Network for Change Detection with Multiscale Global–Local Representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3272694. [Google Scholar] [CrossRef]
- Xue, D.; Lei, T.; Yang, S.; Lv, Z.; Liu, T.; Jin, Y.; Nandi, A.K. Triple Change Detection Network via Joint Multi-Frequency and Full-Scale Swin-Transformer for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4408415. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar]
- Song, F.; Zhang, S.; Lei, T.; Song, Y.; Peng, Z. MSTDSNet-CD: Multiscale Swin Transformer and Deeply Supervised Network for Change Detection of the Fast-Growing Urban Regions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3165885. [Google Scholar] [CrossRef]
- Mao, Z.; Tong, X.; Luo, Z.; Zhang, H. MFATNet: Multi-Scale Feature Aggregation via Transformer for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 5379. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Jiang, F.; Gong, M.; Zhan, T.; Fan, X. A Semisupervised GAN-Based Multiple Change Detection Framework in Multi-Spectral Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1223–1227. [Google Scholar] [CrossRef]
- Yang, S.; Hou, S.; Zhang, Y.; Wang, H.; Ma, X. Change Detection of High-Resolution Remote Sensing Image Based on Semi-Supervised Segmentation and Adversarial Learning. In Proceedings of the IGARSS 2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 1055–1058. [Google Scholar]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; DIng, H.; Huang, X. SemiCDNet: A Semisupervised Convolutional Neural Network for Change Detection in High Resolution Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 5891–5906. [Google Scholar] [CrossRef]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.-L. Fixmatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process Syst. 2020, 33, 596–608. [Google Scholar]
- Wang, L.; Zhang, M.; Shi, W. STCRNet A Semi-Supervised Network Based on Self-Training and Consistency Regularization for Change Detection in VHR Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 2272–2282. [Google Scholar] [CrossRef]
- Yang, L.; Zhuo, W.; Qi, L.; Shi, Y.; Gao, Y. St++: Make Self-Training Work Better for Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4268–4277. [Google Scholar]
- Wang, J.X.; Li, T.; Chen, S.B.; Tang, J.; Luo, B.; Wilson, R.C. Reliable Contrastive Learning for Semi-Supervised Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3228016. [Google Scholar] [CrossRef]
- Sun, C.; Wu, J.; Chen, H.; Du, C. SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention. Remote Sens. 2022, 14, 2801. [Google Scholar] [CrossRef]
- Chen, Z.; Zhang, R.; Zhang, G.; Ma, Z.; Lei, T. Digging into Pseudo Label: A Low-Budget Approach for Semi-Supervised Semantic Segmentation. IEEE Access 2020, 8, 41830–41837. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, Z.; Wu, C.; Zhang, Z.; He, T.; Zhang, H.; Manmatha, R.; Li, M.; Smola, A.J. Improving Semantic Segmentation via Efficient Self-Training. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 46, 1589–1602. [Google Scholar] [CrossRef] [PubMed]
- He, R.; Yang, J.; Qi, X. Re-Distributing Biased Pseudo Labels for Semi-Supervised Semantic Segmentation: A Baseline Investigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6930–6940. [Google Scholar]
- Yuan, J.; Liu, Y.; Shen, C.; Wang, Z.; Li, H. A Simple Baseline for Semi-Supervised Semantic Segmentation with Strong Data Augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8229–8238. [Google Scholar]
- Sun, C.; Chen, H.; Du, C.; Jing, N. SemiBuildingChange: A Semi-Supervised High-Resolution Remote Sensing Image Building Change Detection Method with a Pseudo Bi-Temporal Data Generator. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5622319. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, X.; Li, J. Joint Self-Training and Rebalanced Consistency Learning for Semi-Supervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3314452. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. Revisiting Consistency Regularization for Semi-Supervised Change Detection in Remote Sensing Images. arXiv 2022, arXiv:2204.08454. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation with Cross-Consistency Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12674–12684. [Google Scholar]
- Shu, Q.; Pan, J.; Zhang, Z.; Wang, M. MTCNet: Multitask Consistency Network with Single Temporal Supervision for Semi-Supervised Building Change Detection. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103110. [Google Scholar] [CrossRef]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 2613–2622. [Google Scholar]
- Yang, L.; Qi, L.; Feng, L.; Zhang, W.; Shi, Y. Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7236–7246. [Google Scholar]
- Shen, W.; Peng, Z.; Wang, X.; Wang, H.; Cen, J.; Jiang, D.; Xie, L.; Yang, X.; Tian, Q. A Survey on Label-Efficient Deep Image Segmentation: Bridging the Gap Between Weak Supervision and Dense Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9284–9305. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-Cam++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P.; Hu, X. Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 24–25. [Google Scholar]
- Jiang, P.-T.; Zhang, C.-B.; Hou, Q.; Cheng, M.-M.; Wei, Y. Layercam: Exploring Hierarchical Class Activation Maps for Localization. IEEE Trans. Image Process. 2021, 30, 5875–5888. [Google Scholar] [CrossRef]
- Muhammad, M.B.; Yeasin, M. Eigen-Cam: Class Activation Map Using Principal Components. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal Component Analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Kalita, I.; Karatsiolis, S.; Kamilaris, A. Land Use Change Detection Using Deep Siamese Neural Networks and Weakly Supervised Learning. In Proceedings of the Computer Analysis of Images and Patterns: 19th International Conference, CAIP 2021, Virtual Event, 28–30 September 2021; pp. 24–35. [Google Scholar]
- Jiang, X.; Tang, H. Dense High-Resolution Siamese Network for Weakly-Supervised Change Detection. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 547–552. [Google Scholar]
- Andermatt, P.; Timofte, R. A Weakly Supervised Convolutional Network for Change Segmentation and Classification. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting Dilated Convolution: A Simple Approach for Weakly-and Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7268–7277. [Google Scholar]
- Zhang, F.; Gu, C.; Zhang, C.; Dai, Y. Complementary Patch for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7242–7251. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation with Inter-Pixel Relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2204–2213. [Google Scholar] [CrossRef]
- Lee, J.; Kim, E.; Mok, J.; Yoon, S. Anti-Adversarially Manipulated Attributions for Weakly Supervised Semantic Segmentation and Object Localization. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 1618–1634. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, Z.; Zhu, P.; Zhang, T.; Li, C.; Zhou, H.; Jiao, L. Adaptive Affinity Loss and Erroneous Pseudo-Label Refinement for Weakly Supervised Semantic Segmentation; Association for Computing Machinery: New York, NY, USA, 2021; Volume 1, ISBN 978-1-45038-651-7. [Google Scholar]
- Ahn, J.; Kwak, S. Learning Pixel-Level Semantic Affinity with Image-Level Supervision for Weakly Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar] [CrossRef]
- Ru, L.; Zhan, Y.; Yu, B.; Du, B. Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16846–16855. [Google Scholar]
- Huang, R.; Wang, R.; Guo, Q.; Wei, J.; Zhang, Y.; Fan, W.; Liu, Y. Background-Mixed Augmentation for Weakly Supervised Change Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 7919–7927. [Google Scholar]
- Zhao, W.; Shang, C.; Lu, H. Self-Generated Defocus Blur Detection via Dual Adversarial Discriminators. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 6933–6942. [Google Scholar]
- Wu, C.; Du, B.; Zhang, L. Fully Convolutional Change Detection Framework with Generative Adversarial Network for Unsupervised, Weakly Supervised and Regional Supervised Change Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9774–9788. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Shi, W.; Chen, S.; Zhan, Z.; Shi, Z. Deep Multiple Instance Learning for Landslide Mapping. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1711–1715. [Google Scholar] [CrossRef]
- Lv, N.; Chen, C.; Qiu, T.; Sangaiah, A.K. Deep Learning and Superpixel Feature Extraction Based on Contractive Autoencoder for Change Detection in SAR Images. IEEE Trans. Ind. Inform. 2018, 14, 5530–5538. [Google Scholar] [CrossRef]
- Kosiorek, A.; Sabour, S.; Teh, Y.W.; Hinton, G.E. Stacked Capsule Autoencoders. Adv. Neural Inf. Process Syst. 2019, 32, 15486–15496. [Google Scholar]
- Luppino, L.T.; Hansen, M.A.; Kampffmeyer, M.; Bianchi, F.M.; Moser, G.; Jenssen, R.; Anfinsen, S.N. Code-Aligned Autoencoders for Unsupervised Change Detection in Multimodal Remote Sensing Images. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Bergamasco, L.; Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised Change-Detection Based on Convolutional-Autoencoder Feature Extraction. In Proceedings of the Image and Signal Processing for Remote Sensing XXV, Strasbourg, France, 9–11 September 2019; Volume 11155, pp. 325–332. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2011: 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Saha, S.; Bovolo, F.; Bruzzone, L. Unsupervised Deep Change Vector Analysis for Multiple-Change Detection in VHR Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3677–3693. [Google Scholar] [CrossRef]
- Wu, C.; Chen, H.; Du, B.; Zhang, L. Unsupervised Change Detection in Multitemporal VHR Images Based on Deep Kernel PCA Convolutional Mapping Network. IEEE Trans. Cybern. 2021, 52, 12084–12098. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Smola, A.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised Deep Slow Feature Analysis for Change Detection in Multi-Temporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature Learning and Change Feature Classification Based on Deep Learning for Ternary Change Detection in SAR Images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Zhang, H.; Gong, M.; Zhang, P.; Su, L.; Shi, J. Feature-Level Change Detection Using Deep Representation and Feature Change Analysis for Multispectral Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1666–1670. [Google Scholar] [CrossRef]
- Gong, M.; Niu, X.; Zhang, P.; Li, Z. Generative Adversarial Networks for Change Detection in Multispectral Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2310–2314. [Google Scholar] [CrossRef]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi-and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [PubMed]
- Gong, M.; Yang, Y.; Zhan, T.; Niu, X.; Li, S. A Generative Discriminatory Classified Network for Change Detection in Multispectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 321–333. [Google Scholar] [CrossRef]
- Liu, Y.-H.; Van Nieuwenburg, E.P.L. Discriminative Cooperative Networks for Detecting Phase Transitions. Phys. Rev. Lett. 2018, 120, 176401. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Ju, J.; Seo, M.; Park, J.; Choi, D.-G. Unsupervised Change Detection Based on Image Reconstruction Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1352–1361. [Google Scholar]
- Zhang, J.; Shao, Z.; Ding, Q.; Huang, X.; Wang, Y.; Zhou, X.; Li, D. AERNet: An Attention-Guided Edge Refinement Network and a Dataset for Remote Sensing Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3300533. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, W.; Pun, M.-O.; Shi, W. Cross-Domain Landslide Mapping from Large-Scale Remote Sensing Images Using Prototype-Guided Domain-Aware Progressive Representation Learning. ISPRS J. Photogramm. Remote Sens. 2023, 197, 1–17. [Google Scholar] [CrossRef]
- Holail, S.; Saleh, T.; Xiao, X.; Li, D. AFDE-Net: Building Change Detection Using Attention-Based Feature Differential Enhancement for Satellite Imagery. IEEE Geosci. Remote Sens. Lett. 2023, 20, 3283505. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Yuan, X.; Li, H.; Liu, C.; Liu, C.; Fu, G.; Ding, Y.; Zhu, Q. BCE-Net: Reliable Building Footprints Change Extraction Based on Historical Map and up-to-Date Images Using Contrastive Learning. ISPRS J. Photogramm. Remote Sens. 2023, 201, 138–152. [Google Scholar] [CrossRef]
- Pang, C.; Wu, J.; Ding, J.; Song, C.; Xia, G.-S. Detecting Building Changes with Off-Nadir Aerial Images. Sci. China Inf. Sci. 2023, 66, 140306. [Google Scholar] [CrossRef]
- Toker, A.; Kondmann, L.; Weber, M.; Eisenberger, M.; Camero, A.; Hu, J.; Hoderlein, A.P.; Şenaras, Ç.; Davis, T.; Cremers, D. DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 21158–21167. [Google Scholar]
- Liu, M.; Chai, Z.; Deng, H.; Liu, R. A CNN-Transformer Network with Multiscale Context Aggregation for Fine-Grained Cropland Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4297–4306. [Google Scholar] [CrossRef]
- Shen, L.; Lu, Y.; Chen, H.; Wei, H.; Xie, D.; Yue, J.; Chen, R.; Lv, S.; Jiang, B. S2Looking: A Satellite Side-Looking Dataset for Building Change Detection. Remote Sens 2021, 13, 5094. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask Learning for Large-Scale Semantic Change Detection. Comput. Vision Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Lebedev, M.A.; Vizilter, Y.V.; Vygolov, O.V.; Knyaz, V.A.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef]
- Benedek, C.; Sziranyi, T. Change Detection in Optical Aerial Images by a Multilayer Conditional Mixed Markov Model. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3416–3430. [Google Scholar] [CrossRef]
- López-Fandiño, J.; Garea, A.S.; Heras, D.B.; Argüello, F. Stacked Autoencoders for Multiclass Change Detection in Hyperspectral Images. In Proceedings of the IGARSS 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1906–1909. [Google Scholar]
- Wang, Q.; Yuan, Z.; Du, Q.; Li, X. GETNET: A General End-to-End 2-D CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, L.; Du, B. Kernel Slow Feature Analysis for Scene Change Detection. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2367–2384. [Google Scholar] [CrossRef]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. Urban Change Detection for Multispectral Earth Observation Using Convolutional Neural Networks. In Proceedings of the IGARSS 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2115–2118. [Google Scholar]
- Fuentes Reyes, M.; Xie, Y.; Yuan, X.; d’Angelo, P.; Kurz, F.; Cerra, D.; Tian, J. A 2D/3D Multimodal Data Simulation Approach with Applications on Urban Semantic Segmentation, Building Extraction and Change Detection. ISPRS J. Photogramm. Remote Sens. 2023, 205, 74–97. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Chen, H.; Zou, Z.; Shi, Z. Remote Sensing Image Change Captioning with Dual-Branch Transformers: A New Method and a Large Scale Dataset. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3218921. [Google Scholar] [CrossRef]
- Li, H.; Zhu, F.; Zheng, X.; Liu, M.; Chen, G. MSCDUNet: A Deep Learning Framework for Built-Up Area Change Detection Integrating Multispectral, SAR, and VHR Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5163–5176. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, M.; Shi, W. CS-WSCDNet: Class Activation Mapping and Segment Anything Model-Based Framework for Weakly Supervised Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3330479. [Google Scholar] [CrossRef]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Grill, J.-B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap Your Own Latent—A New Approach to Self-Supervised Learning. Adv. Neural Inf. Process Syst. 2020, 33, 21271–21284. [Google Scholar]
- Caron, M.; Misra, I.; Mairal, J.; Goyal, P.; Bojanowski, P.; Joulin, A. Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Adv. Neural Inf. Process Syst. 2020, 33, 9912–9924. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with Improved Denoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Akiva, P.; Purri, M.; Leotta, M. Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8203–8215. [Google Scholar]
- Manas, O.; Lacoste, A.; Giró-i-Nieto, X.; Vazquez, D.; Rodriguez, P. Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9414–9423. [Google Scholar]
- Chen, Y.; Bruzzone, L. A Self-Supervised Approach to Pixel-Level Change Detection in Bi-Temporal RS Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3203897. [Google Scholar] [CrossRef]
- Leenstra, M.; Marcos, D.; Bovolo, F.; Tuia, D. Self-Supervised Pre-Training Enhances Change Detection in Sentinel-2 Imagery. In Proceedings of the Pattern Recognition ICPR International Workshops and Challenges, Virtual Event, 10–15 January 2021; pp. 578–590. [Google Scholar]
- Jiang, F.; Gong, M.; Zheng, H.; Liu, T.; Zhang, M.; Liu, J. Self-Supervised Global–Local Contrastive Learning for Fine-Grained Change Detection in VHR Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3238327. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Chen, S.; Shi, Z. Semantic-Aware Dense Representation Learning for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3203769. [Google Scholar] [CrossRef]
- Saha, S.; Ebel, P.; Zhu, X.X. Self-Supervised Multisensor Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3109957. [Google Scholar] [CrossRef]
- Chen, Y.; Bruzzone, L. Self-Supervised Change Detection in Multiview Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3089453. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Dong, Y.; Du, B. Self-Supervised Pretraining via Multimodality Images with Transformer for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3271024. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process Syst. 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling Language Modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. Ernie: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.-T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.-H.; Li, Z.; Duerig, T. Scaling up Visual and Vision-Language Representation Learning with Noisy Text Supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Yuan, L.; Chen, D.; Chen, Y.-L.; Codella, N.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A New Foundation Model for Computer Vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Zhong, Y.; Yang, J.; Zhang, P.; Li, C.; Codella, N.; Li, L.H.; Zhou, L.; Dai, X.; Yuan, L.; Li, Y.; et al. Regionclip: Region-Based Language-Image Pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16793–16803. [Google Scholar]
- Fang, H.; Xiong, P.; Xu, L.; Chen, Y. Clip2video: Mastering Video-Text Retrieval via Image Clip. arXiv 2021, arXiv:2106.11097. [Google Scholar]
- Shen, S.; Li, L.H.; Tan, H.; Bansal, M.; Rohrbach, A.; Chang, K.-W.; Yao, Z.; Keutzer, K. How Much Can Clip Benefit Vision-and-Language Tasks? arXiv 2021, arXiv:2107.06383. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical Text-Conditional Image Generation with Clip Latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Cha, K.; Seo, J.; Lee, T. A Billion-Scale Foundation Model for Remote Sensing Images. arXiv 2023, arXiv:2304.05215. [Google Scholar]
- Liu, F.; Chen, D.; Guan, Z.; Zhou, X.; Zhu, J.; Zhou, J. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing. arXiv 2023, arXiv:2306.11029. [Google Scholar]
- Zhang, J.; Zhou, Z.; Mai, G.; Mu, L.; Hu, M.; Li, S. Text2Seg: Remote Sensing Image Semantic Segmentation via Text-Guided Visual Foundation Models. arXiv 2023, arXiv:2304.10597. [Google Scholar]
- Wen, C.; Hu, Y.; Li, X.; Yuan, Z.; Zhu, X.X. Vision-Language Models in Remote Sensing: Current Progress and Future Trends. arXiv 2023, arXiv:2305.05726. [Google Scholar]
- Lüddecke, T.; Ecker, A. Image Segmentation Using Text and Image Prompts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7086–7096. [Google Scholar]
- Wang, X.; Zhang, X.; Cao, Y.; Wang, W.; Shen, C.; Huang, T. Seggpt: Segmenting Everything in Context. arXiv 2023, arXiv:2304.03284. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Gao, J.; Lee, Y.J. Segment Everything Everywhere All at Once. arXiv 2023, arXiv:2304.06718. [Google Scholar]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. Rsprompter: Learning to Prompt for Remote Sensing Instance Segmentation Based on Visual Foundation Model. arXiv 2023, arXiv:2306.16269. [Google Scholar] [CrossRef]
- Osco, L.P.; Wu, Q.; de Lemos, E.L.; Gonçalves, W.N.; Ramos, A.P.M.; Li, J.; Junior, J.M. The Segment Anything Model (Sam) for Remote Sensing Applications: From Zero to One Shot. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103540. [Google Scholar] [CrossRef]
- Ji, W.; Li, J.; Bi, Q.; Li, W.; Cheng, L. Segment Anything Is Not Always Perfect: An Investigation of Sam on Different Real-World Applications. arXiv 2023, arXiv:2304.05750. [Google Scholar]
- Wang, D.; Zhang, J.; Du, B.; Xu, M.; Liu, L.; Tao, D.; Zhang, L. SAMRS: Scaling-up Remote Sensing Segmentation Dataset with Segment Anything Model. In Proceedings of the Thirty-Seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Ding, L.; Zhu, K.; Peng, D.; Tang, H.; Guo, H. Adapting Segment Anything Model for Change Detection in HR Remote Sensing Images. arXiv 2023, arXiv:2309.01429. [Google Scholar]
- Zhao, X.; Ding, W.; An, Y.; Du, Y.; Yu, T.; Li, M.; Tang, M.; Wang, J. Fast Segment Anything. arXiv 2023, arXiv:2306.12156. [Google Scholar]
- Chen, H.; Yokoya, N.; Chini, M. Fourier Domain Structural Relationship Analysis for Unsupervised Multimodal Change Detection. ISPRS J. Photogramm. Remote Sens. 2023, 198, 99–114. [Google Scholar] [CrossRef]
- Hao, F.; Ma, Z.-F.; Tian, H.-P.; Wang, H.; Wu, D. Semi-Supervised Label Propagation for Multi-Source Remote Sensing Image Change Detection. Comput. Geosci. 2023, 170, 105249. [Google Scholar] [CrossRef]
- Chen, H.; Yokoya, N.; Wu, C.; Du, B. Unsupervised Multimodal Change Detection Based on Structural Relationship Graph Representation Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 3229027. [Google Scholar] [CrossRef]
- Jin, H.; Mountrakis, G. Fusion of Optical, Radar and Waveform LiDAR Observations for Land Cover Classification. ISPRS J. Photogramm. Remote Sens. 2022, 187, 171–190. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A Deep Translation (GAN) Based Change Detection Network for Optical and SAR Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Zhang, C.; Feng, Y.; Hu, L.; Tapete, D.; Pan, L.; Liang, Z.; Cigna, F.; Yue, P. A Domain Adaptation Neural Network for Change Detection with Heterogeneous Optical and SAR Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102769. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Image Type | Resolution | Number of Image Pair | Acquisition Year | Coverage Area | Image Source |
|---|---|---|---|---|---|---|
| HRCUS-CD [171] | RGB | 0.5 m | 11,388 pairs of 256 × 256 pixels | 2010 to 2022 | Zhuhai, China | - |
| GVLM [172] | RGB | 0.59 m | 17 pairs of varying sizes | 2010 to 2021 | Global | Google Earth |
| EGY-BCD [173] | RGB | 0.25 m | 6091 pairs of 256 × 256 pixels | 2015 to 2022 | Egypt | Google Earth |
| SI-BU [174] | RGB | 0.5–0.8 m | 4932 pairs of 512 × 512 pixels | 2019 to 2021 | Guiyang, China | Google Earth |
| BANDON [175] | RGB | 0.6 m | 2283 pairs of 2048 × 2048 pixels | - | Some cities in China | Google Earth, Microsoft Virtual Earth, ArcGIS |
| DynamicEarthNet [176] | RGB | 3 m | 730 pairs of 1024 × 1024 pixels | 2018 to 2019 | 75 regions worldwide | Planet Labs |
| CLCD [177] | RGB | 0.5–2 m | 600 pairs of 512 × 512 pixels | 2017 to 2019 | Guangdong Province, China | GF-2 |
| S2Looking [178] | RGB | 0.5–0.8 m | 5000 pairs of 1024 × 1024 pixels | Spanning 1–3 years | Global | - |
| SYSU-CD [31] | RGB | 0.5 m | 20,000 pairs of 256 × 256 pixels | 2007 to 2014 | Hong Kong, China | - |
| DSIFN [78] | RGB | - | 3940 pairs of 512 × 512 pixels | - | Six cities in China | Google Earth |
| SenseEarth2020 | RGB | 0.5–3 m | 4662 pairs of 512 × 512 pixels | - | - | - |
| Google Dataset [114] | RGB | 0.55 m | 1067 pairs of 256 × 256 pixels | 2006 to 2019 | Guangzhou, China | Google Earth |
| LEVIR-CD [30] | RGB | 0.5 m | 637 pairs of 1024 × 1024 pixels | Spanning 5–14 years | Texas, USA | Google Earth |
| HRSCD [179] | RGB | 0.5 m | 291 pairs of 10,000 × 10,000 pixels | 2005 to 2012 | France | IGN |
| WHU-CD [180] | RGB | 0.075 m | One pair of 15,354 × 32,507 pixels | 2012 to 2016 | New Zealand | Aerial |
| CDD [181] | RGB | 3–100 cm | 16,000 pairs of 256 × 256 pixels | - | - | Google Earth |
| SZTAKI [182] | RGB | 1.5 m | 13 pairs of 952 × 640 pixels | Spanning 5–23 years | - | - |
| Hyperspectral CDD [183] | Hyperspectral | - | Three pairs of varying sizes | 2004 to 2014 | USA | AVIRIS |
| River dataset [184] | Hyperspectral | 30 m | One pair of 463 × 241 pixels | 2013.5–2013.12 | Jiangsu Province, China | EO-1 Hyperion |
| MtS-WH [185] | Multispectral | 1 m | One pair of 7200 × 6000 pixels | 2002 to 2009 | Wuhan, China | IKONOS |
| OSCD [186] | Multispectral | 10–60 m | 24 pairs | 2015 to 2018 | Global | Sentinel-2 |
| SMARS [187] | RGB, DSM | 0.3 m/ 0.5 m | Two pairs of 5600 × 5600 pixels, one pair of 4500 × 3560 pixels | - | Paris and Venice | Synthetic |
| LEVIR-CC [188] | RGB, Natural Language | - | 10,077 pairs of 512 × 512 pixels, 50,385 natural language statements | Spanning 5–14 years | Texas, USA | Google Earth |
| MSBC [189] | RGB, Multispectral, SAR | 2 m | 3769 pairs of 256 × 256 pixels | 2018 to 2019 | Guigang, Guangxi, China | GF-2, Sentinel-1, Sentinel-2A |
| MSOSCD [189] | RGB, Multispectral, SAR | - | 5107 pairs of 256 × 256 pixels | 2015 to 2018 | Global | Sentinel-1, Sentinel-2 |
| Method | Paradigm | Pre. | Rec. | F1 | IoU |
|---|---|---|---|---|---|
| A2Net [33] | Fully Supervised | 0.9430 | 0.9644 | 0.9536 | 0.9113 |
| STCRNet (10% labeled) [116] | Semi-Supervised | - | - | 0.9006 | 0.8191 |
| CS-WSCDNet [190] | Weakly Supervised | 0.6457 | 0.8356 | 0.7284 | 0.5729 |
| CDRL [170] | Unsupervised | 0.5200 | 0.9300 | - | 0.5000 |
| Paradigm | Advantages | Disadvantages |
|---|---|---|
| Fully Supervised | High accuracy; Reliable performance with well-defined ground truth | Time-consuming and costly data annotation process; Less adaptable to new data scenarios |
| Semi-Supervised | Utilizes both labeled and unlabeled data; Balances performance with data availability | Performance depending on the quality and amount of label; Requires careful tuning; Less effective when label is not representative |
| Weakly Supervised | Reduces annotation burden with coarse labels; Suitable for rapid response | Limited performance; Struggles with complex scenarios; Dependent on the quality and relevance of weak labels |
| Unsupervised | No need for labeled data; Suitable for exploratory and large-scale monitoring | Lower performance; Challenging objective evaluation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zhang, M.; Gao, X.; Shi, W. Advances and Challenges in Deep Learning-Based Change Detection for Remote Sensing Images: A Review through Various Learning Paradigms. Remote Sens. 2024, 16, 804. https://doi.org/10.3390/rs16050804
Wang L, Zhang M, Gao X, Shi W. Advances and Challenges in Deep Learning-Based Change Detection for Remote Sensing Images: A Review through Various Learning Paradigms. Remote Sensing. 2024; 16(5):804. https://doi.org/10.3390/rs16050804
Chicago/Turabian StyleWang, Lukang, Min Zhang, Xu Gao, and Wenzhong Shi. 2024. "Advances and Challenges in Deep Learning-Based Change Detection for Remote Sensing Images: A Review through Various Learning Paradigms" Remote Sensing 16, no. 5: 804. https://doi.org/10.3390/rs16050804
APA StyleWang, L., Zhang, M., Gao, X., & Shi, W. (2024). Advances and Challenges in Deep Learning-Based Change Detection for Remote Sensing Images: A Review through Various Learning Paradigms. Remote Sensing, 16(5), 804. https://doi.org/10.3390/rs16050804