

Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface



Abstract
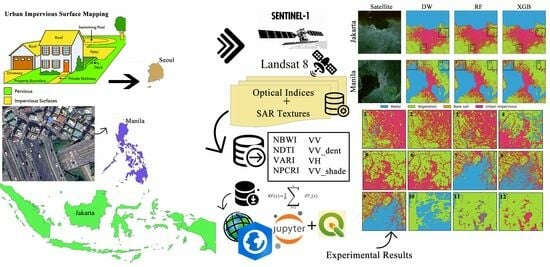
1. Introduction
2. Materials and Methods
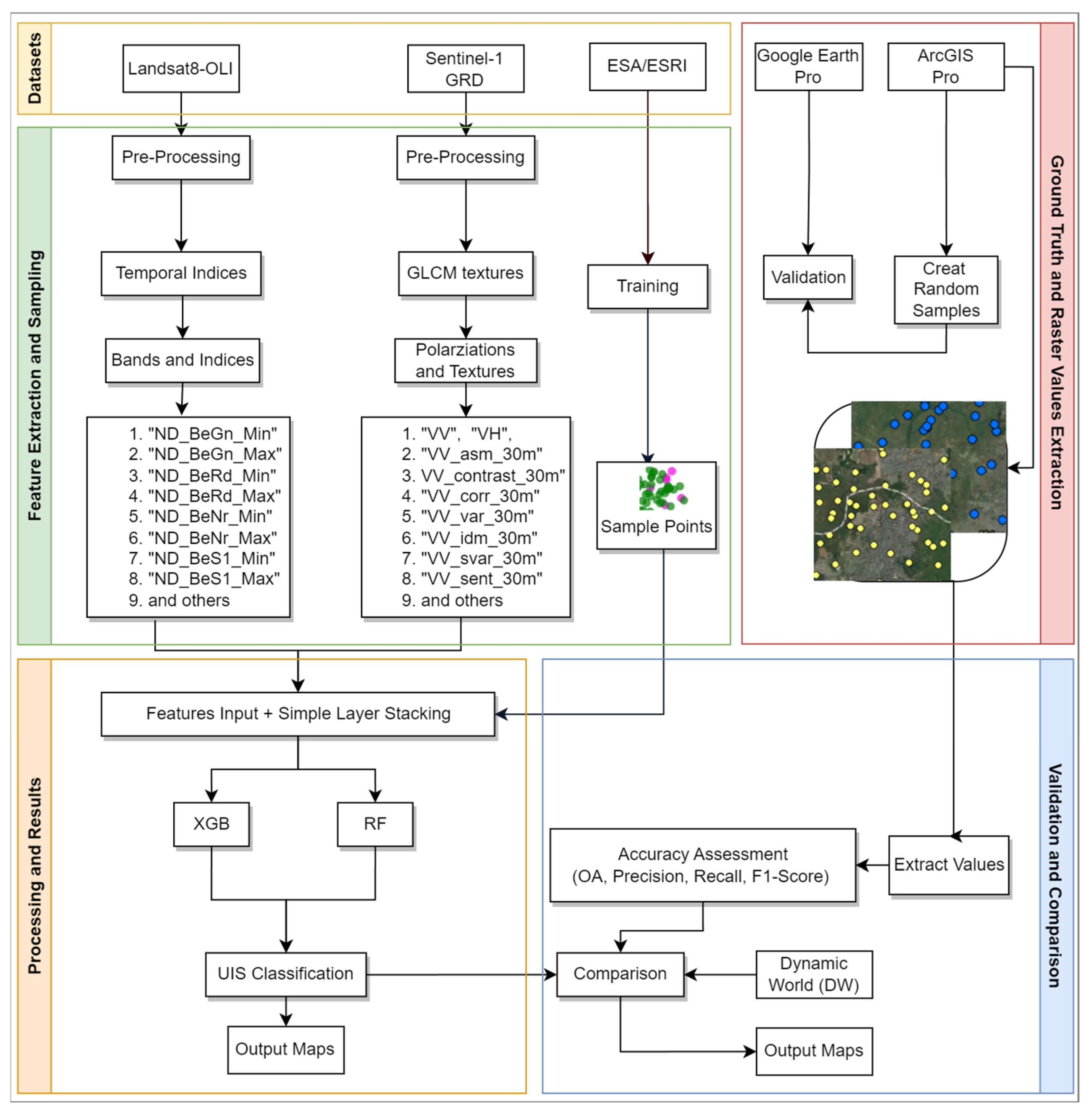
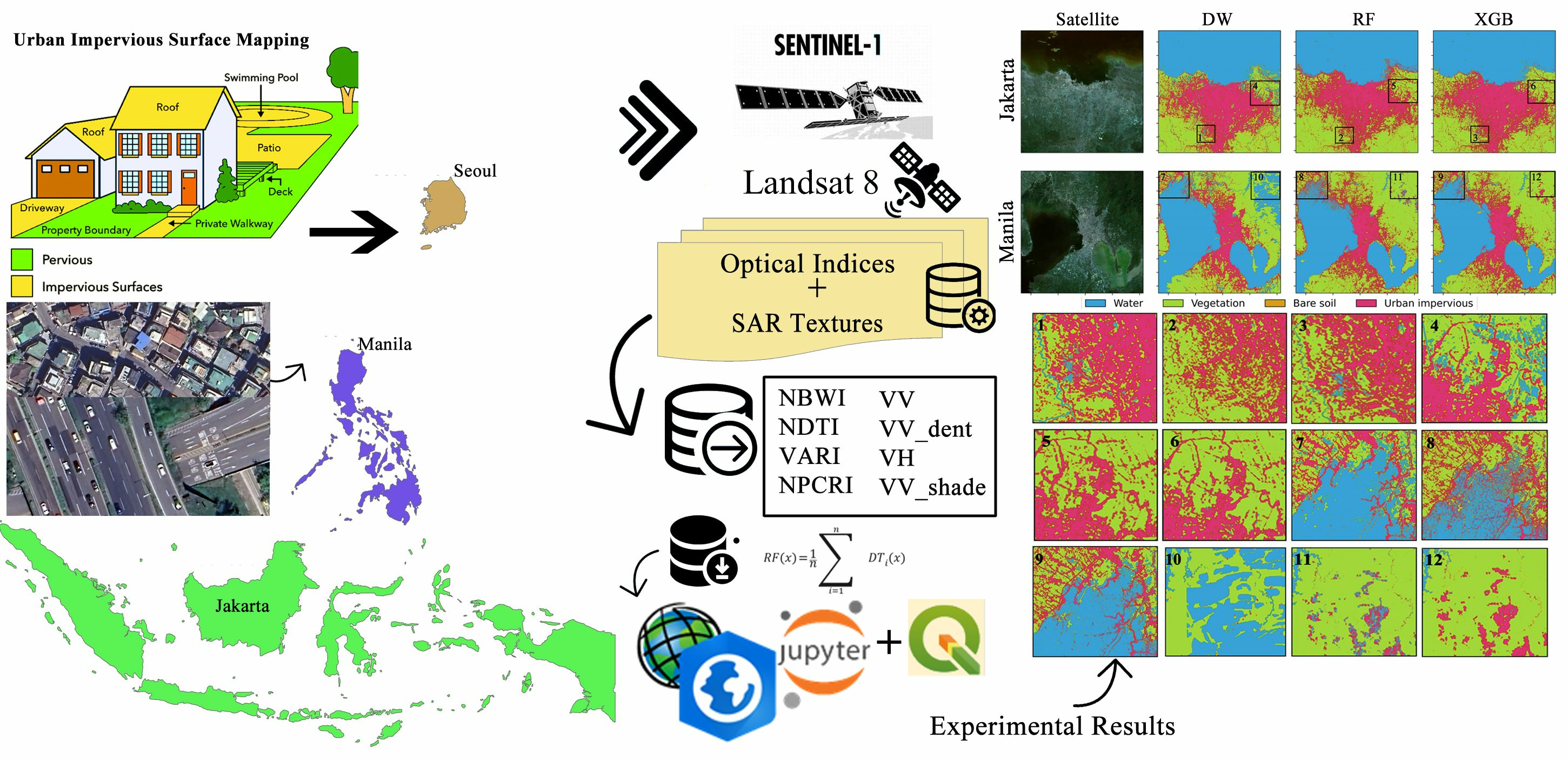
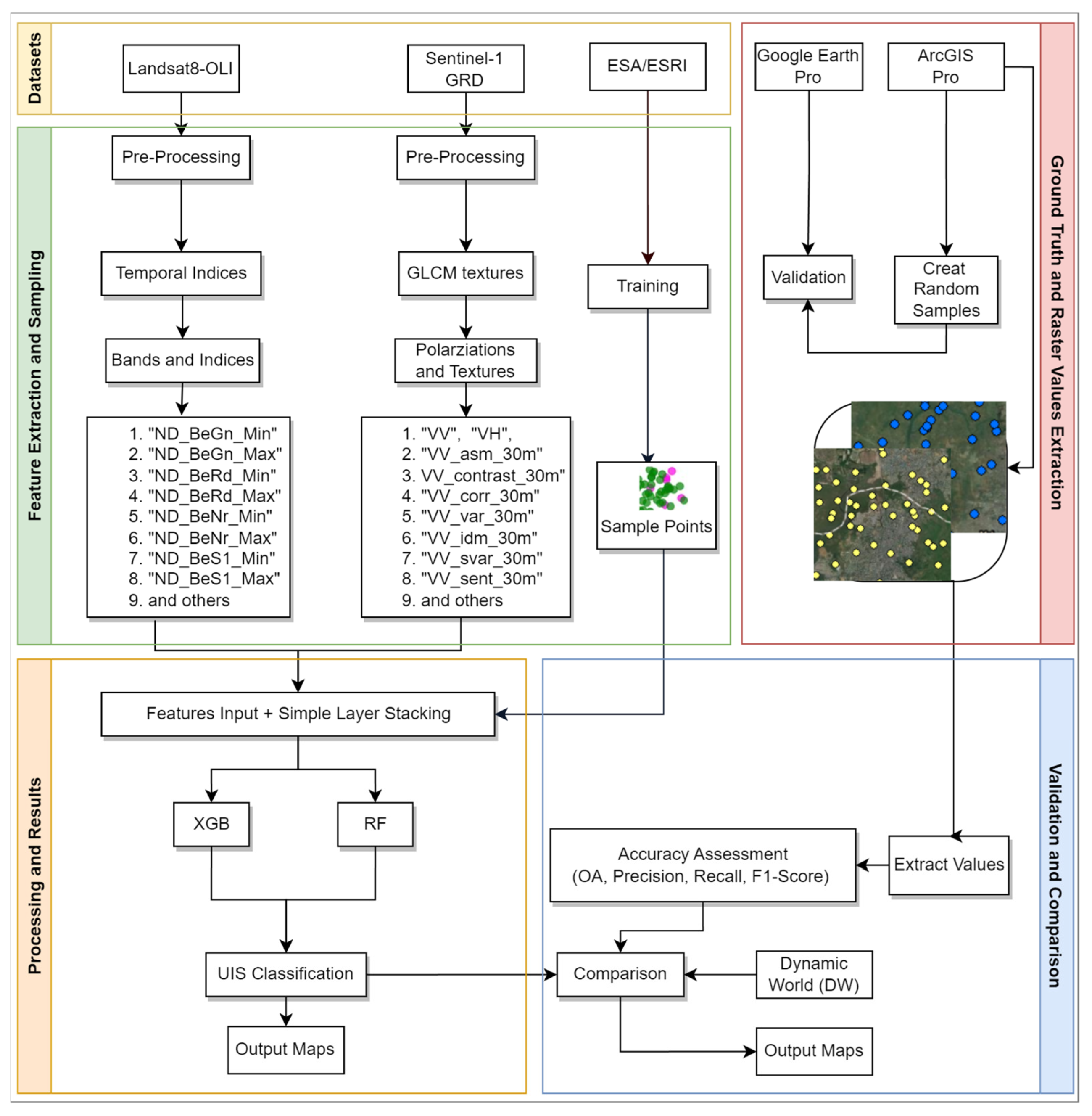
2.1. Proposed Framework
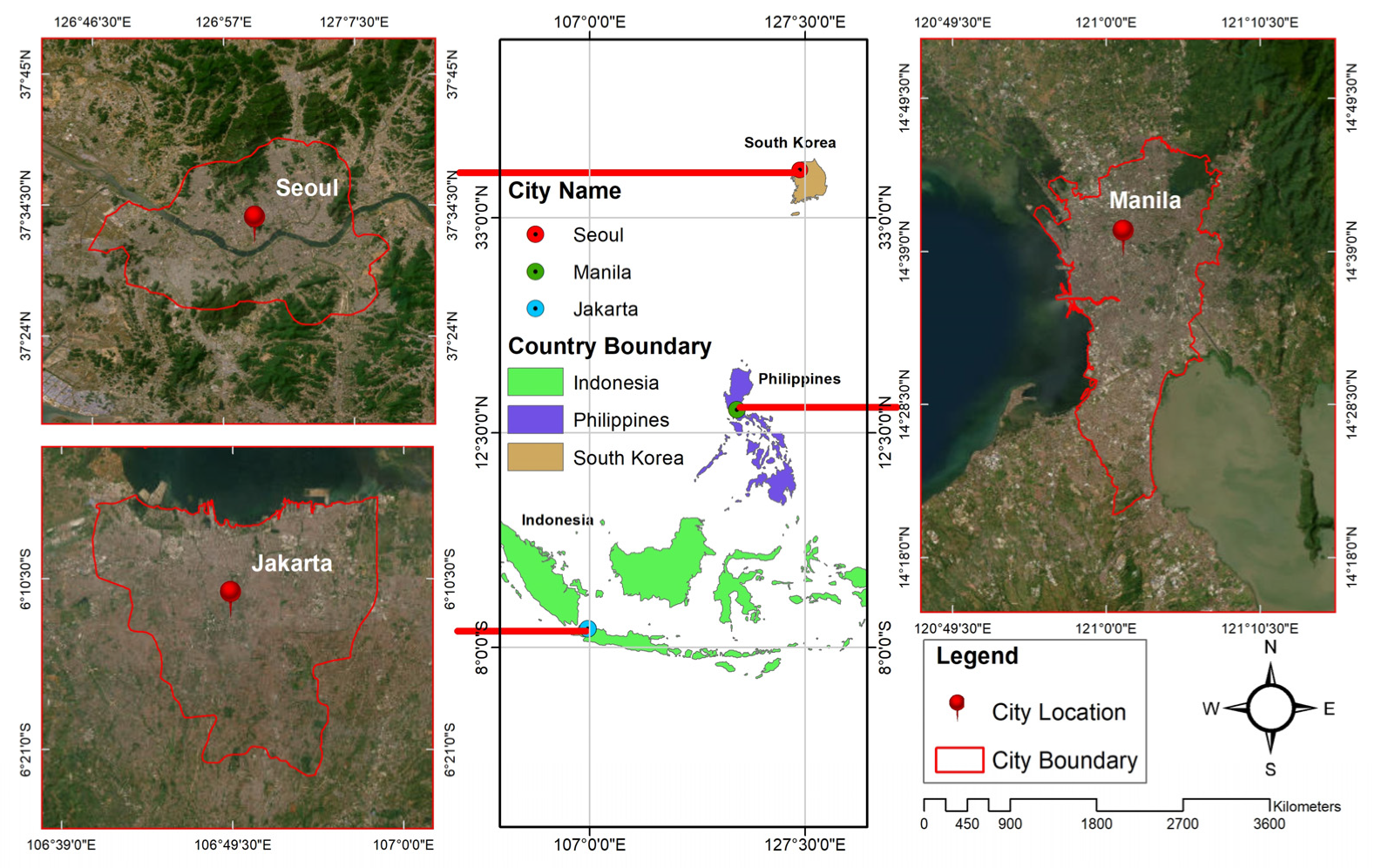
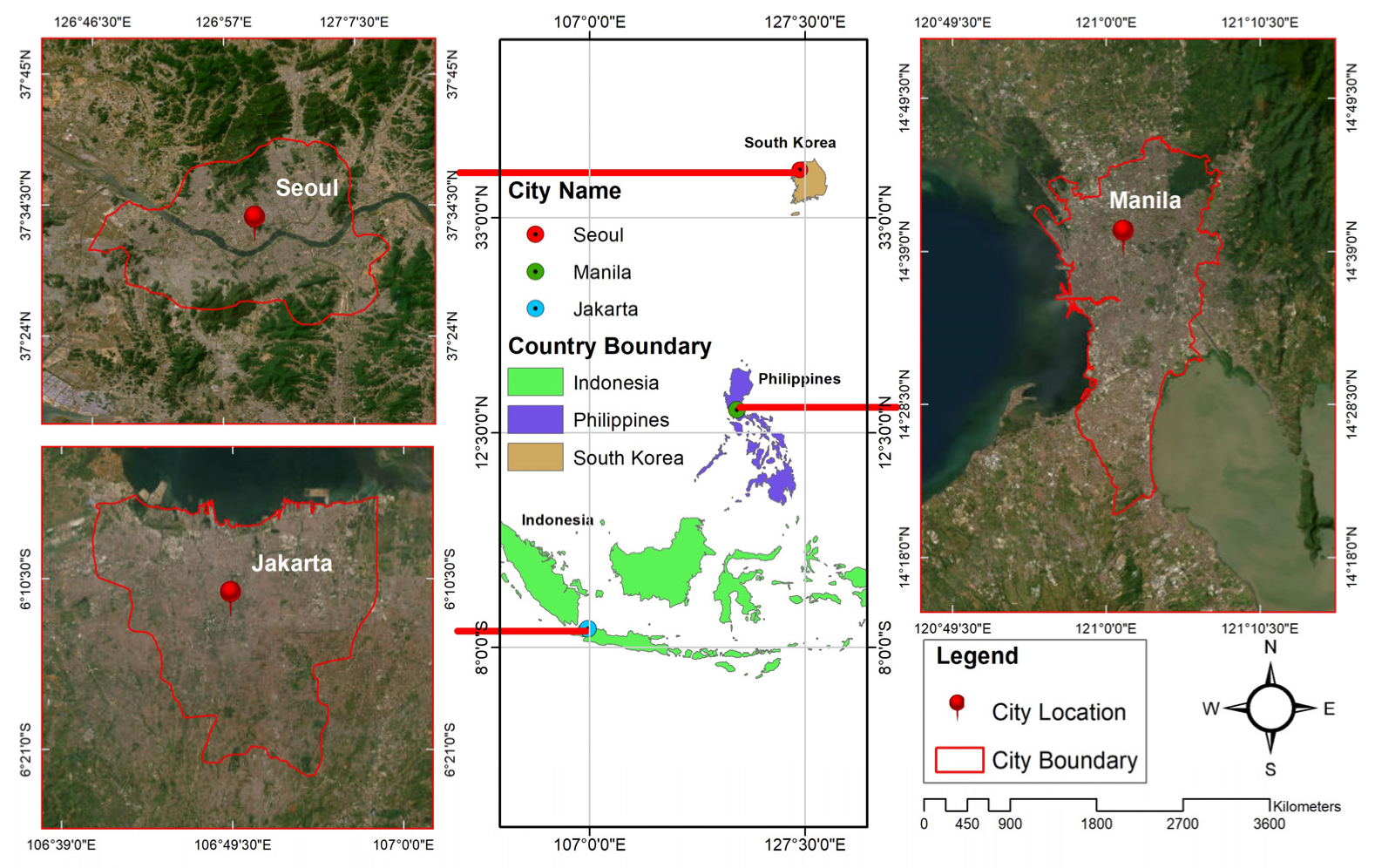
2.2. Study Area
2.3. Datasets
2.4. Processing
2.4.1. Preprocessing, Sampling, and Ground Truth Labels
2.4.2. Random Forest Classifier
2.4.3. XGBoost Classifier
2.4.4. Optical Temporal Indices
2.4.5. Textural Features
2.5. Accuracy Assessment Method
- True positives (TP): number of samples correctly predicted as “positive”.
- False positives (FP): number of samples wrongly predicted as “positive”.
- True negatives (TN): number of samples correctly predicted as “negative”.
- False negatives (FN): number of samples wrongly predicted as “negative”.
3. Results
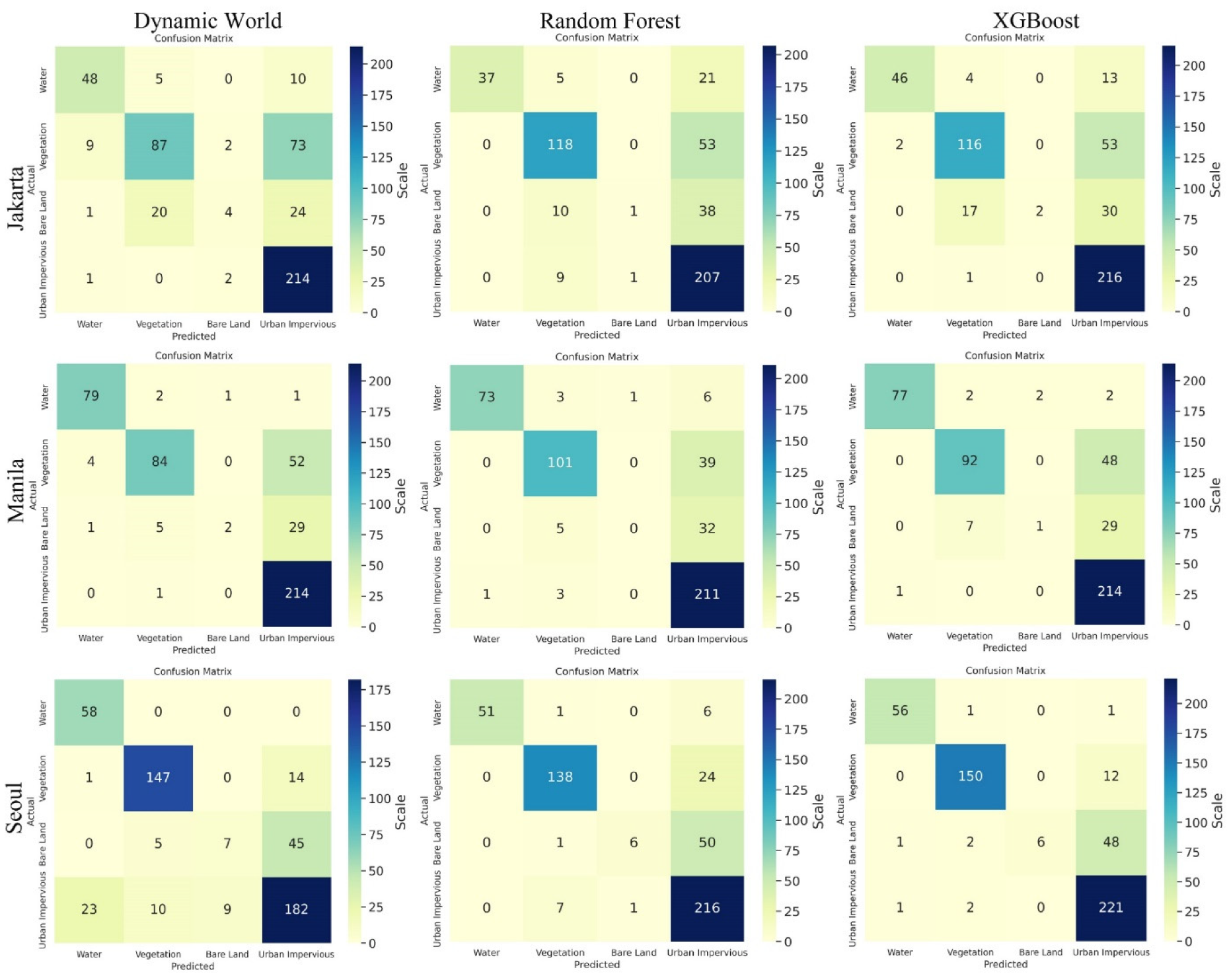
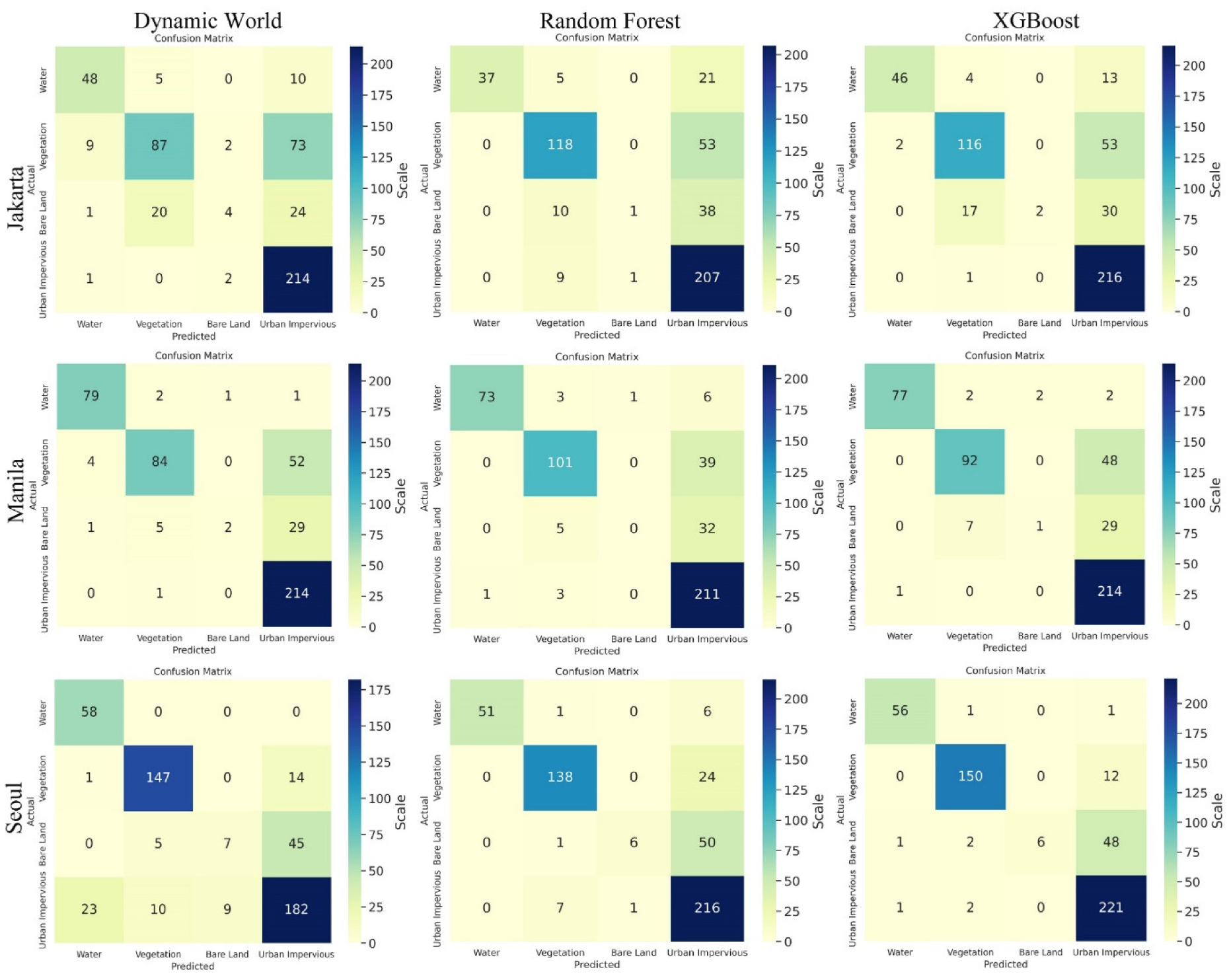
3.1. Confusion Matrix
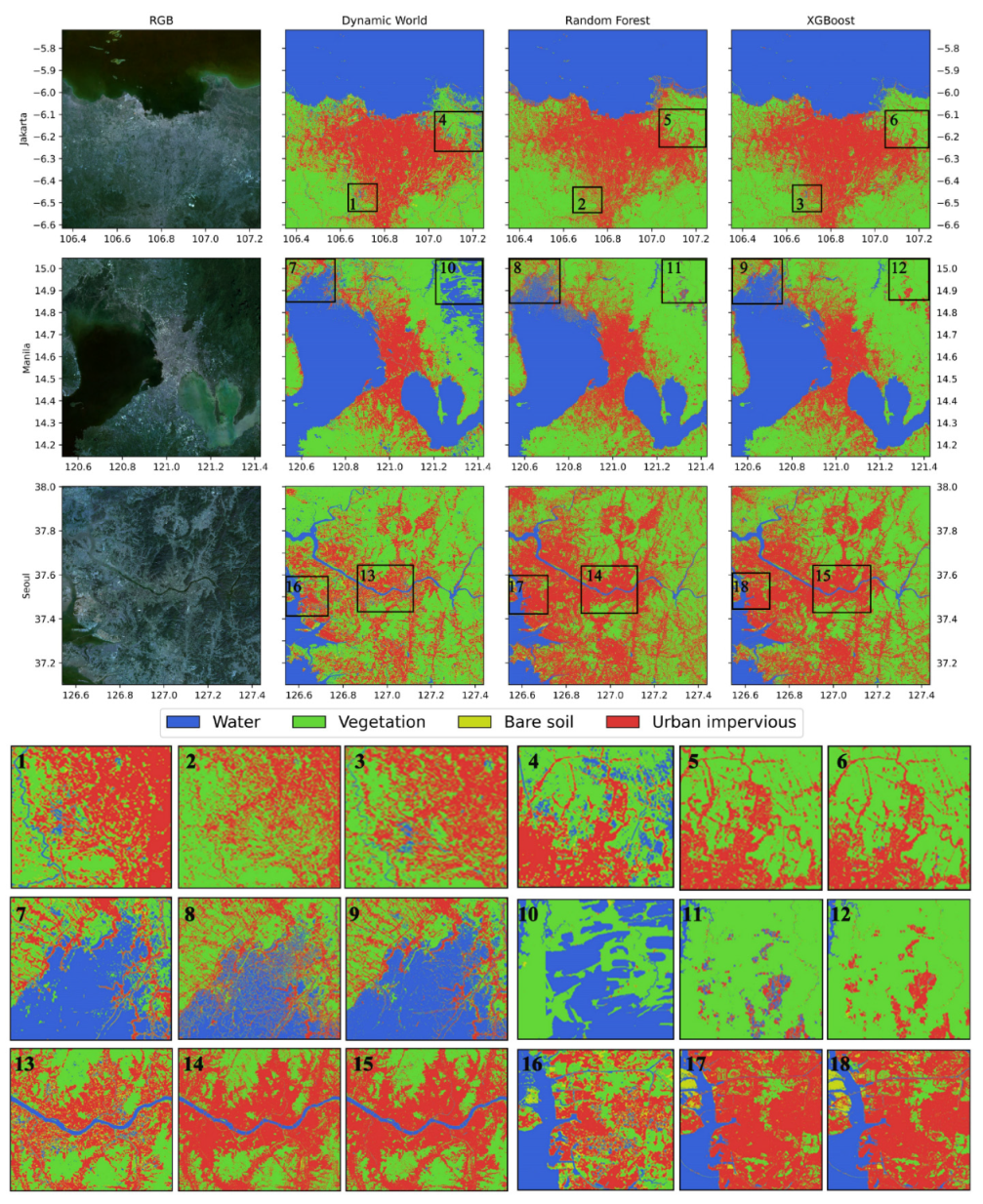
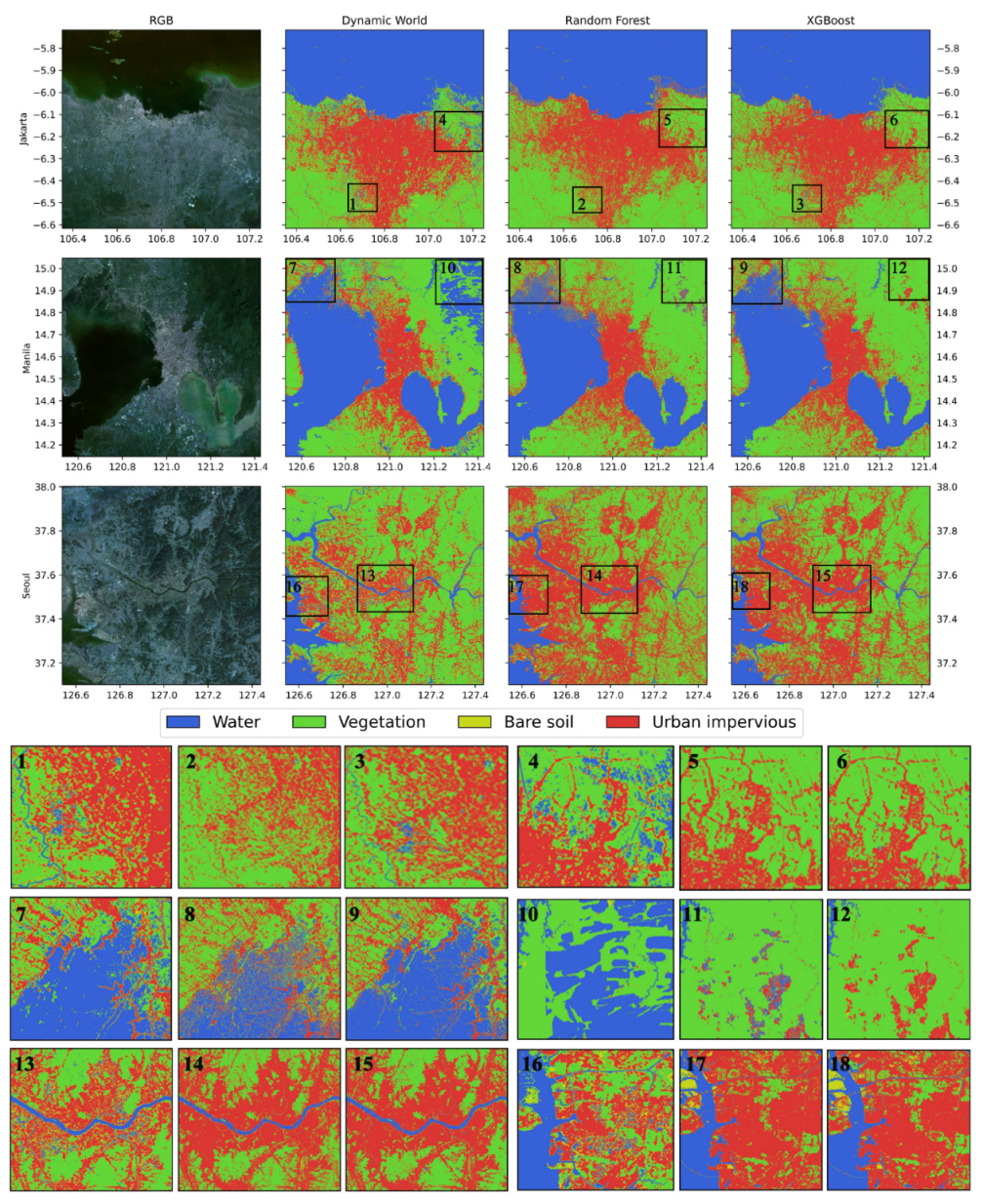
3.2. Extraction of Urban Impervious Surface (UIS)
3.3. Comparison with Dynamic World Google Data Product
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Features Collection for Forward Stepwise Selection
| Category | Features Names |
| Landsat dual-band normalized and temporal indices from six primary bands | “ND_BeGn_Min”, “ND_BeGn_Median”, “ND_BeGn_Max”, “ND_BeGn_SD”, “ND_BeRd_Min”, “ND_BeRd_Median”, “ND_BeRd_Max”, “ND_BeRd_SD”, “ND_BeNr_Min”, “ND_BeNr_Median”, “ND_BeNr_Max”, “ND_BeNr_SD”, “ND_BeS1_Min”, “ND_BeS1_Median”, “ND_BeS1_Max”, “ND_BeS1_SD”, “ND_BeS2_Min”, “ND_BeS2_Median”, “ND_BeS2_Max”, “ND_BeS2_SD”, “ND_GnRd_Min”, “ND_GnRd_Median”, “ND_GnRd_Max”, “ND_GnRd_SD”, “ND_GnNr_Min”, “ND_GnNr_Median”, “ND_GnNr_Max”, “ND_GnNr_SD”, “ND_GnS1_Min”, “ND_GnS1_Median”, “ND_GnS1_Max”, “ND_GnS1_SD”, “ND_GnS2_Min”, “ND_GnS2_Median”, “ND_GnS2_Max”, “ND_GnS2_SD”, “ND_RdNr_Min”, “ND_RdNr_Median”, “ND_RdNr_Max”, “ND_RdNr_SD”, “ND_RdS1_Min”, “ND_RdS1_Median”, “ND_RdS1_Max”, “ND_RdS1_SD”, “ND_RdS2_Min”, “ND_RdS2_Median”, “ND_RdS2_Max”, “ND_RdS2_SD”, “ND_NrS1_Min”, “ND_NrS1_Median”, “ND_NrS1_Max”, “ND_NrS1_SD”, “ND_NrS2_Min”, “ND_NrS2_Median”, “ND_NrS2_Max”, “ND_NrS2_SD”, “ND_S1S2_Min”, “ND_S1S2_Median”, “ND_S1S2_Max”, and “ND_S1S2_SD” |
| Sentinel-1 VV and VH polarization after GLCM textures with Neighborhood Square Size | “VV”, “VH”, “VV_asm_30m”, “VV_contrast_30m”, “VV_corr_30m”, “VV_var_30m”, “VV_idm_30m”, “VV_svar_30m”, “VV_sent_30m”, “VV_ent_30m”, “VV_diss_30m”, “VV_dvar_30m”, “VV_dent_30m”, “VV_imcorr1_30m”, “VV_imcorr2_30m”, “VV_inertia_30m”, “VV_shade_30m”, “VH_asm_30m”, “VH_contrast_30m”, “VH_corr_30m”, “VH_var_30m”, “VH_idm_30m”, “VH_svar_30m”, “VH_sent_30m”, “VH_ent_30m”, “VH_diss_30m”, “VH_dvar_30m”, “VH_dent_30m”, “VH_imcorr1_30m”, “VH_imcorr2_30m”, “VH_inertia_30m”, “VH_shade_30m”, “VV_asm_50m”, “VV_contrast_50m”, “VV_corr_50m”, “VV_var_50m”, “VV_idm_50m”, “VV_svar_50m”, “VV_sent_50m”, “VV_ent_50m”, “VV_diss_50m”, “VV_dvar_50m”, “VV_dent_50m”, “VV_imcorr1_50m”, “VV_imcorr2_50m”, “VV_inertia_50m”, “VV_shade_50m”, “VH_asm_50m”, “VH_contrast_50m”, “VH_corr_50m”, “VH_var_50m”, “VH_idm_50m”, “VH_svar_50m”, “VH_sent_50m”, “VH_ent_50m”, “VH_diss_50m”, “VH_dvar_50m”, “VH_dent_50m”, “VH_imcorr1_50m”, “VH_imcorr2_50m”, “VH_inertia_50m”, “VH_shade_50m”, “VV_asm_70m”, “VV_contrast_70m”, “VV_corr_70m”, “VV_var_70m”, “VV_idm_70m”, “VV_svar_70m”, “VV_sent_70m”, “VV_ent_70m”, “VV_diss_70m”, “VV_dvar_70m”, “VV_dent_70m”, “VV_imcorr1_70m”, “VV_imcorr2_70m”, “VV_inertia_70m”, “VV_shade_70m”, “VH_asm_70m”, “VH_contrast_70m”, “VH_corr_70m”, “VH_var_70m”, “VH_idm_70m”, “VH_svar_70m”, “VH_sent_70m”, “VH_ent_70m”, “VH_diss_70m”, “VH_dvar_70m”, “VH_dent_70m”, “VH_imcorr1_70m”, “VH_imcorr2_70m”, “VH_inertia_70m”, “VH_shade_70m”, “VV_asm_90m”, “VV_contrast_90m”, “VV_corr_90m”, “VV_var_90m”, “VV_idm_90m”, “VV_svar_90m”, “VV_sent_90m”, “VV_ent_90m”, “VV_diss_90m”, “VV_dvar_90m”, “VV_dent_90m”, “VV_imcorr1_90m”, “VV_imcorr2_90m”, “VV_inertia_90m”, “VV_shade_90m”, “VH_asm_90m”, “VH_contrast_90m”, “VH_corr_90m”, “VH_var_90m”, “VH_idm_90m”, “VH_svar_90m”, “VH_sent_90m”, “VH_ent_90m”, “VH_diss_90m”, “VH_dvar_90m”, “VH_dent_90m”, “VH_imcorr1_90m”, “VH_imcorr2_90m”, “VH_inertia_90m”, and “VH_shade_90m” |
| Soil-related indices (10) | “NSAI1_min”, “NSAI1_median”, “NSAI1_max”, “NSAI2_min”, “NSAI2_median”, “NSAI2_max”, “swirSoil_min”, “swirSoil_median”, “swirSoil_max”, and “SISAI” |
Appendix B. Features Collection for Forward Stepwise Selection
| Dataset LULC Class | Value | Samples | Recoded LULC Class | Value | Samples | Training Class | Value | Samples |
| Water | 0 | 88,834 | Water | 0 | 88,834 | Water | 0 | 33,000 |
| Trees | 1 | 81,179 | Vegetation | 1 | 162,795 | Vegetation | 1 | 33,000 |
| Bare | 2 | 19,445 | Bare | 2 | 19,445 | Bare | 2 | 33,000 |
| Grassland | 3 | 28,176 | Built-up | 3 | 66,930 | Built-up | 3 | 33,000 |
| Crops | 4 | 53,440 | Snow/ice | 4 | 4341 | |||
| Built-up | 5 | 66,930 | ||||||
| Snow/ice | 6 | 4341 |
References
- Ban, Y.; Jacob, A. Fusion of multitemporal spaceborne SAR and optical data for urban mapping and urbanization monitoring. In Multitemporal Remote Sensing: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2016; pp. 107–123. [Google Scholar]
- Li, J.; Zhang, J.; Yang, C.; Liu, H.; Zhao, Y.; Ye, Y. Comparative Analysis of Pixel-Level Fusion Algorithms and a New High-Resolution Dataset for SAR and Optical Image Fusion. Remote Sens. 2023, 15, 5514. [Google Scholar] [CrossRef]
- Adrian, J.; Sagan, V.; Maimaitijiang, M. Sentinel SAR-optical fusion for crop type mapping using deep learning and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 175, 215–235. [Google Scholar] [CrossRef]
- Zhang, Z.; Zeng, Y.; Huang, Z.; Liu, J.; Yang, L. Multi-source data fusion and hydrodynamics for urban waterlogging risk identification. Int. J. Environ. Res. Public Health 2023, 20, 2528. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Wang, J.; Gong, P. ROBOT: A spatiotemporal fusion model toward seamless data cube for global remote sensing applications. Remote Sens. Environ. 2023, 294, 113616. [Google Scholar] [CrossRef]
- Moreno-Martínez, Á.; Izquierdo-Verdiguier, E.; Maneta, M.P.; Camps-Valls, G.; Robinson, N.; Muñoz-Marí, J.; Sedano, F.; Clinton, N.; Running, S.W. Multispectral high resolution sensor fusion for smoothing and gap-filling in the cloud. Remote Sens. Environ. 2020, 247, 111901. [Google Scholar] [CrossRef]
- Sara, D.; Mandava, A.K.; Kumar, A.; Duela, S.; Jude, A. Hyperspectral and multispectral image fusion techniques for high resolution applications: A review. Earth Sci. Inform. 2021, 14, 1685–1705. [Google Scholar] [CrossRef]
- Meng, T.; Jing, X.; Yan, Z.; Pedrycz, W. A survey on machine learning for data fusion. Inf. Fusion 2020, 57, 115–129. [Google Scholar] [CrossRef]
- Meraner, A.; Ebel, P.; Zhu, X.X.; Schmitt, M. Cloud removal in Sentinel-2 imagery using a deep residual neural network and SAR-optical data fusion. ISPRS J. Photogramm. Remote Sens. 2020, 166, 333–346. [Google Scholar] [CrossRef]
- Ounoughi, C.; Yahia, S. Ben Data fusion for ITS: A systematic literature review. Inf. Fusion 2023, 89, 267–291. [Google Scholar] [CrossRef]
- Kalamkar, S. Multimodal image fusion: A systematic review. Decis. Anal. J. 2023, 9, 100327. [Google Scholar] [CrossRef]
- Liu, S.; Zhao, H.; Du, Q.; Bruzzone, L.; Samat, A.; Tong, X. Novel cross-resolution feature-level fusion for joint classification of multispectral and panchromatic remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5619314. [Google Scholar] [CrossRef]
- Pinar, A.J.; Rice, J.; Hu, L.; Anderson, D.T.; Havens, T.C. Efficient multiple kernel classification using feature and decision level fusion. IEEE Trans. Fuzzy Syst. 2016, 25, 1403–1416. [Google Scholar] [CrossRef]
- Karathanassi, V.; Kolokousis, P.; Ioannidou, S. A comparison study on fusion methods using evaluation indicators. Int. J. Remote Sens. 2007, 28, 2309–2341. [Google Scholar] [CrossRef]
- Xu, L.; Xie, G.; Zhou, S. Panchromatic and Multispectral Image Fusion Combining GIHS, NSST, and PCA. Appl. Sci. 2023, 13, 1412. [Google Scholar] [CrossRef]
- Yan, B.; Kong, Y. A fusion method of SAR image and optical image based on NSCT and gram-Schmidt transform. In Proceedings of the IGARSS 2020-2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2332–2335. [Google Scholar]
- Singh, S.; Singh, H.; Bueno, G.; Deniz, O.; Singh, S.; Monga, H.; Hrisheekesha, P.N.; Pedraza, A. A review of image fusion: Methods, applications and performance metrics. Digit. Signal Process. 2023, 137, 104020. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ghamisi, P.; Piles, M.; Werner, M.; Cuadra, L.; Moreno-Martínez, A.; Izquierdo-Verdiguier, E.; Muñoz-Marí, J.; Mosavi, A.; Camps-Valls, G. Machine learning information fusion in Earth observation: A comprehensive review of methods, applications and data sources. Inf. Fusion 2020, 63, 256–272. [Google Scholar] [CrossRef]
- Sun, G.; Cheng, J.; Zhang, A.; Jia, X.; Yao, Y.; Jiao, Z. Hierarchical fusion of optical and dual-polarized SAR on impervious surface mapping at city scale. ISPRS J. Photogramm. Remote Sens. 2022, 184, 264–278. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, X.; Cheng, Q.; Fei, S.; Chen, Z. A Machine-Learning Model Based on the Fusion of Spectral and Textural Features from UAV Multi-Sensors to Analyse the Total Nitrogen Content in Winter Wheat. Remote Sens. 2023, 15, 2152. [Google Scholar] [CrossRef]
- Tavares, P.A.; Beltrão, N.E.S.; Guimarães, U.S.; Teodoro, A.C. Integration of sentinel-1 and sentinel-2 for classification and LULC mapping in the urban area of Belém, eastern Brazilian Amazon. Sensors 2019, 19, 1140. [Google Scholar] [CrossRef]
- Clerici, N.; Valbuena Calderón, C.A.; Posada, J.M. Fusion of Sentinel-1A and Sentinel-2A data for land cover mapping: A case study in the lower Magdalena region, Colombia. J. Maps 2017, 13, 718–726. [Google Scholar] [CrossRef]
- Haas, J.; Ban, Y. Sentinel-1A SAR and sentinel-2A MSI data fusion for urban ecosystem service mapping. Remote Sens. Appl. Soc. Environ. 2017, 8, 41–53. [Google Scholar] [CrossRef]
- Bui, D.H.; Mucsi, L. Comparison of layer-stacking and Dempster-Shafer theory-based methods using Sentinel-1 and Sentinel-2 data fusion in urban land cover mapping. Geo-Spatial Inf. Sci. 2022, 25, 425–438. [Google Scholar] [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Peel, M.C.; Finlayson, B.L.; McMahon, T.A. Updated world map of the Köppen-Geiger climate classification. Hydrol. Earth Syst. Sci. 2007, 11, 1633–1644. [Google Scholar] [CrossRef]
- Ahmad, M.N.; Shao, Z.; Javed, A. Mapping impervious surface area increase and urban pluvial flooding using Sentinel Application Platform (SNAP) and remote sensing data. Environ. Sci. Pollut. Res. 2023, 30, 125741–125758. [Google Scholar] [CrossRef]
- Wu, W.; Guo, S.; Shao, Z.; Li, D. Urban Impervious Surface Extraction Based on Deep Convolutional Networks Using Intensity, Polarimetric Scattering and Interferometric Coherence Information from Sentinel-1 SAR Images. Remote Sens. 2023, 15, 1431. [Google Scholar] [CrossRef]
- Shao, Z.; Ahmad, M.N.; Javed, A.; Islam, F.; Jahangir, Z.; Ahmad, I. Expansion of Urban Impervious Surfaces in Lahore (1993–2022) Based on GEE and Remote Sensing Data. Photogramm. Eng. Remote Sens. 2023, 89, 479–486. [Google Scholar] [CrossRef]
- Liu, S.; Wang, H.; Hu, Y.; Zhang, M.; Zhu, Y.; Wang, Z.; Li, D.; Yang, M.; Wang, F. Land Use and Land Cover Mapping in China Using Multi-modal Fine-grained Dual Network. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4405219. [Google Scholar]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S. ESA WorldCover 10 m 2021 v200. 2022. Available online: https://zenodo.org/records/7254221 (accessed on 2 February 2024).
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4704–4707. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-olmo, M.; Rigol-sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Sahin, E.K. Assessing the predictive capability of ensemble tree methods for landslide susceptibility mapping using XGBoost, gradient boosting machine, and random forest. SN Appl. Sci. 2020, 2, 1308. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, J.; Shen, W. A review of ensemble learning algorithms used in remote sensing applications. Appl. Sci. 2022, 12, 8654. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Teke, A. Predictive Performances of ensemble machine learning algorithms in landslide susceptibility mapping using random forest, extreme gradient boosting (XGBoost) and natural gradient boosting (NGBoost). Arab. J. Sci. Eng. 2022, 47, 7367–7385. [Google Scholar] [CrossRef]
- Saeys, Y.; Inza, I.; Larranaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Sosa, L.; Justel, A.; Molina, Í. Detection of crop hail damage with a machine learning algorithm using time series of remote sensing data. Agronomy 2021, 11, 2078. [Google Scholar] [CrossRef]
- Khadanga, G.; Jain, K. Tree census using circular hough transform and grvi. Procedia Comput. Sci. 2020, 171, 389–394. [Google Scholar] [CrossRef]
- Schneider, P.; Roberts, D.A.; Kyriakidis, P.C. A VARI-based relative greenness from MODIS data for computing the Fire Potential Index. Remote Sens. Environ. 2008, 112, 1151–1167. [Google Scholar] [CrossRef]
- Carlson, T.N.; Ripley, D.A. On the relation between NDVI, fractional vegetation cover, and leaf area index. Remote Sens. Environ. 1997, 62, 241–252. [Google Scholar] [CrossRef]
- Lacaux, J.P.; Tourre, Y.M.; Vignolles, C.; Ndione, J.A.; Lafaye, M. Classification of ponds from high-spatial resolution remote sensing: Application to Rift Valley Fever epidemics in Senegal. Remote Sens. Environ. 2007, 106, 66–74. [Google Scholar] [CrossRef]
- Javed, A.; Shao, Z.; Bai, B.; Yu, Z.; Wang, J.; Ara, I.; Huq, M.E.; Ali, M.Y.; Saleem, N.; Ahmad, M.N. Development of normalized soil area index for urban studies using remote sensing data. G Eofizika 2023, 40, 1–23. [Google Scholar] [CrossRef]
- Javed, A.; Shao, Z.; Ara, I.; Ahmad, M.N.; Huq, E.; Saleem, N.; Karim, F. Development of Soil-Suppressed Impervious Surface Area Index for Automatic Urban Mapping. Photogramm. Eng. Remote Sens. 2024, 90, 33–43. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man. Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Görtler, J.; Hohman, F.; Moritz, D.; Wongsuphasawat, K.; Ren, D.; Nair, R.; Kirchner, M.; Patel, K. Neo: Generalizing Confusion Matrix Visualization to Hierarchical and Multi-Output Labels. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 29 April–5 May 2022. [Google Scholar]
- Chen, Y.; Bruzzone, L. Self-supervised sar-optical data fusion of sentinel-1/-2 images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5406011. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | City Name | Climatic Zone | Population 2023 |
|---|---|---|---|
| 1 | Jakarta | Tropical | 11,248,839 |
| 2 | Manila | Humid subtropical | 14,667,089 |
| 3 | Seoul | Humid continental with dry winters | 9,988,049 |
| No. | Datasets | Bands/Polarization |
|---|---|---|
| 1 | Sentinel-1 (SAR) | VV (vertical vertical) and VH (vertical horizontal) |
| 2 | Landsat 8 OLI (optical) | Band 2 (blue), Band 3 (green), Band 4 (red), Band 5 (NIR), Band 6 (SWIR 1), Band 7 (SWIR 2) |
| Dataset | Model | Methods | Features Name | Training Data | Input Label | Training Dataset Used for Training | Platform Used for Training |
|---|---|---|---|---|---|---|---|
| Dynamic World | DL | Fully Convolutional Neural Network (FCNN) | Blue, green, red, redEdge1, redEdge2, redEdge3, NIR, swir1, swir2 | 24,000 image (510 × 510 pixels) tiles were labeled by expert and non-expert group | 9 classes (water, trees, grass, flooded vegetation, crops, scrub/shrub, built area, bare ground, snow/ice) | Sentinel-2 L2A surface reflectance, NASA MCD12Q1; | GEE, Cloud AI |
| ESRI Land Cover | DL | Large UNET | 6 primary bands (red, green, blue, nir, swir1, swir2) | 24 k 5 km × 5 km image chips, all hand-labeled | 9 classes (water, trees, grass, flooded vegetation, crops, scrub/shrub, built area, bare ground, snow/ice) | Sentinel-2 L2A surface reflectance G6M5H6:J6 | Data access from Microsoft Planetary Computer and trained in Microsoft Azure Batch, AI-based |
| ESA World Cover | ML | CATBoost | 64 features are extracted from Sentinel-2, 12 features from Sentinel-1, 2 features from the DEMs, 23 positional features, and 14 meteorological features, for a total of 115 features | 10% of the points are sampled, with a maximum of 30 points per class per location | 11 classes (open water, trees, grassland, herbaceous wetland, cropland, shrubland, built-up, bare ground/sparse vegetation, snow/ice, mangroves, moss and lichen) | Sentinel-1, Sentinel-2, TerraClimate | GEE Terrascope with Python |
| DW | DW Value | ESA | ESA Value | ESRI | ESRI Value | Recode Value |
|---|---|---|---|---|---|---|
| Water | 0 | Permanent water bodies | 80 | Water | 1 | 0 |
| Trees | 1 | Tree cover | 10 | Trees | 2 | 1 |
| Mangroves | 95 | 1 | ||||
| Bare | 7 | Bare/sparse vegetation | 60 | Bare ground | 8 | 2 |
| Grass | 2 | Shrubland | 20 | Rangeland | 11 | 3 |
| Shrub_and_Scrub | 5 | Grassland | 30 | 3 | ||
| Moss and lichen | 100 | 3 | ||||
| Crops | 4 | Cropland | 40 | Crops | 5 | 4 |
| Flooded_Vegetation | 3 | Herbaceous wetland | 90 | Flooded vegetation | 4 | 1 |
| Built | 6 | Built-up | 50 | Built area | 7 | 5 |
| Snow_and_Ice | 8 | 7 | Snow and ice | 70 | 7 | 6 |
| Selected Optical Features | Similar Index | Reference |
|---|---|---|
| ND_BeRd_SD | Normalized Pigment Chlorophyll Ratio Index (NPCRI) | [40] |
| ND_GnNr_Min, ND_GnNr_SD, ND_GnNr_Max | Green–Red Vegetation Index (GRVI) | [41] |
| ND_GnRd_Median | Visible Atmospheric Resistant Index (VARI) | [42] |
| ND_RdNr_Median | Normalized Difference Vegetation Index (NDVI) | [43] |
| ND_S1S2_Max, ND_S1S2_Median | Normalized Difference Tillage Index (NDTI) | [44] |
| NSAI1_median | Normalized Soil Area Index 1 (NSAI1) | [45] |
| swirSoil_median | swirSoil | [46] |
| ND_BeS2_Median | NBWI | A novel index was developed in this research |
| Classifiers | Selected Features |
|---|---|
| Random Forest | “ND_GnNr_Min”, “ND_GnRd_Median”, “VV_dent_90m”, “VV”, “ND_RdNr_Median”, “VH”, “ND_GnNr_SD”, and “ND_BeS2_Median” |
| XGBoost | “ND_GnNr_Min”, “ND_GnRd_Median”, “VH”, “VV_dent_90m”, “ND_S1S2_Max”, “NSAI1_median”, “ND_GnNr_Max”, “swirSoil_median”, “ND_S1S2_Median”, “ND_BeRd_SD”, and “VV_shade_90m” |
| Row Labels | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|
| DW | 0.763433333 | 0.733433 | 0.763167 | 0.763 |
| RF | 0.785633333 | 0.752867 | 0.784567 | 0.786 |
| XGB | 0.8109 | 0.7769 | 0.831033 | 0.811 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Z.; Ahmad, M.N.; Javed, A. Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface. Remote Sens. 2024, 16, 665. https://doi.org/10.3390/rs16040665
Shao Z, Ahmad MN, Javed A. Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface. Remote Sensing. 2024; 16(4):665. https://doi.org/10.3390/rs16040665
Chicago/Turabian StyleShao, Zhenfeng, Muhammad Nasar Ahmad, and Akib Javed. 2024. "Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface" Remote Sensing 16, no. 4: 665. https://doi.org/10.3390/rs16040665
APA StyleShao, Z., Ahmad, M. N., & Javed, A. (2024). Comparison of Random Forest and XGBoost Classifiers Using Integrated Optical and SAR Features for Mapping Urban Impervious Surface. Remote Sensing, 16(4), 665. https://doi.org/10.3390/rs16040665