
Nighttime Thermal Infrared Image Translation Integrating Visible Images


Abstract
1. Introduction
2. Related Works
2.1. Enhancement of Low-light Nighttime Visible Images
2.2. Thermal InfraRed and Visible Image Fusion
2.3. GAN-based Thermal InfraRed Image to Visible Image Translation
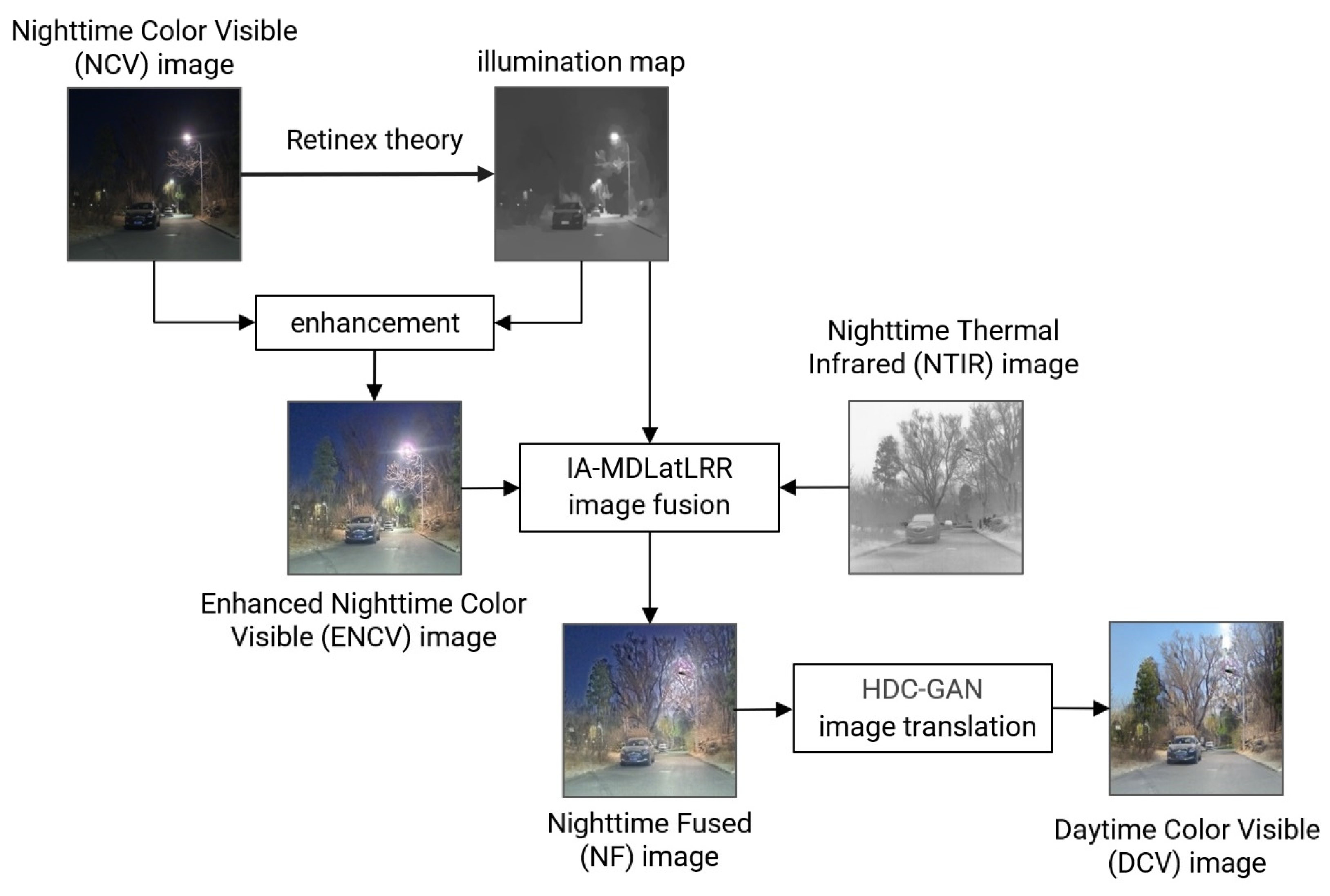
3. Research Methods
3.1. Illumination Map Calculation and NCV Image Enhancement
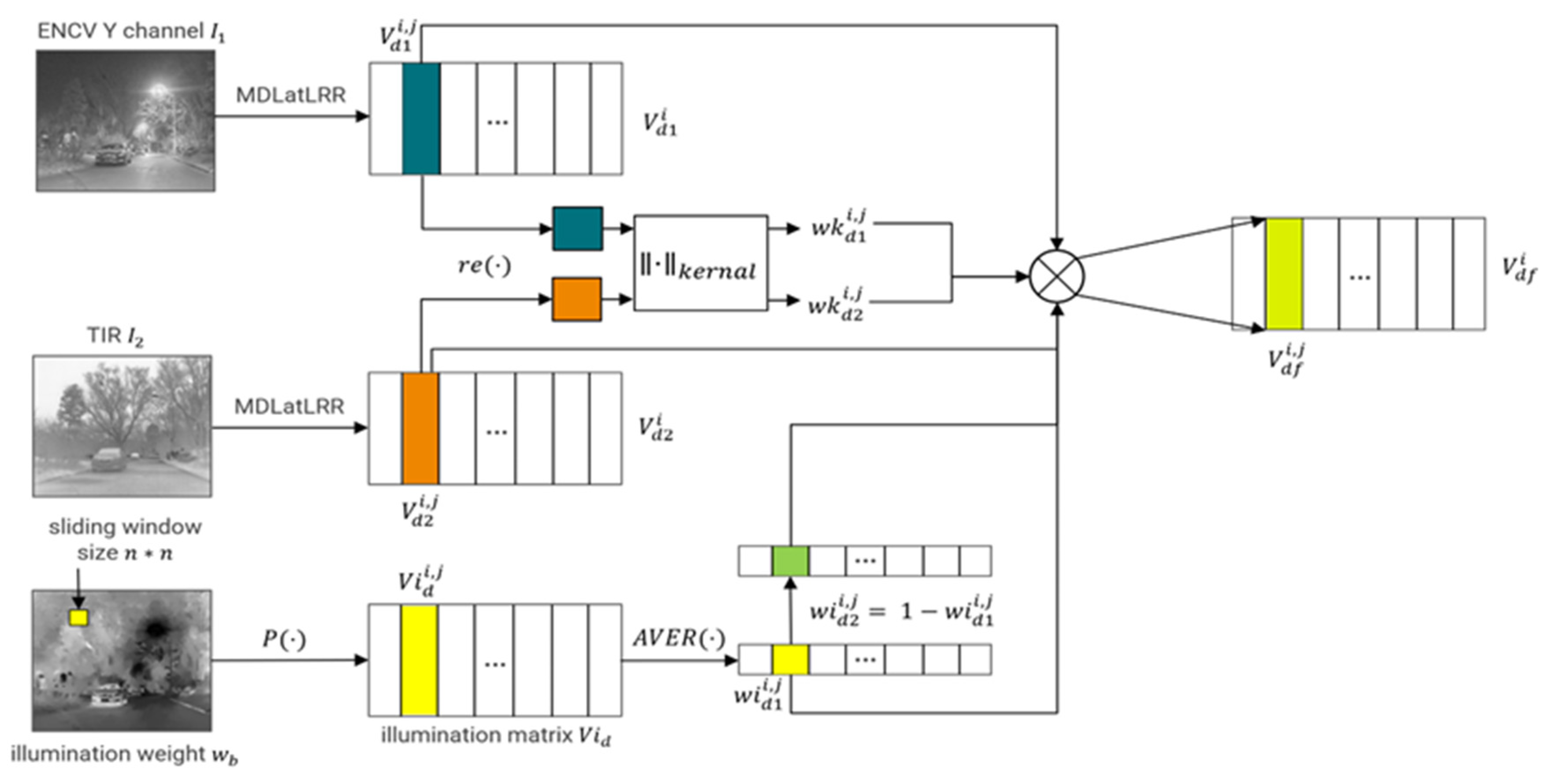
3.2. NTIR and NCV Image Fusion Based on IA-MDLatLRR
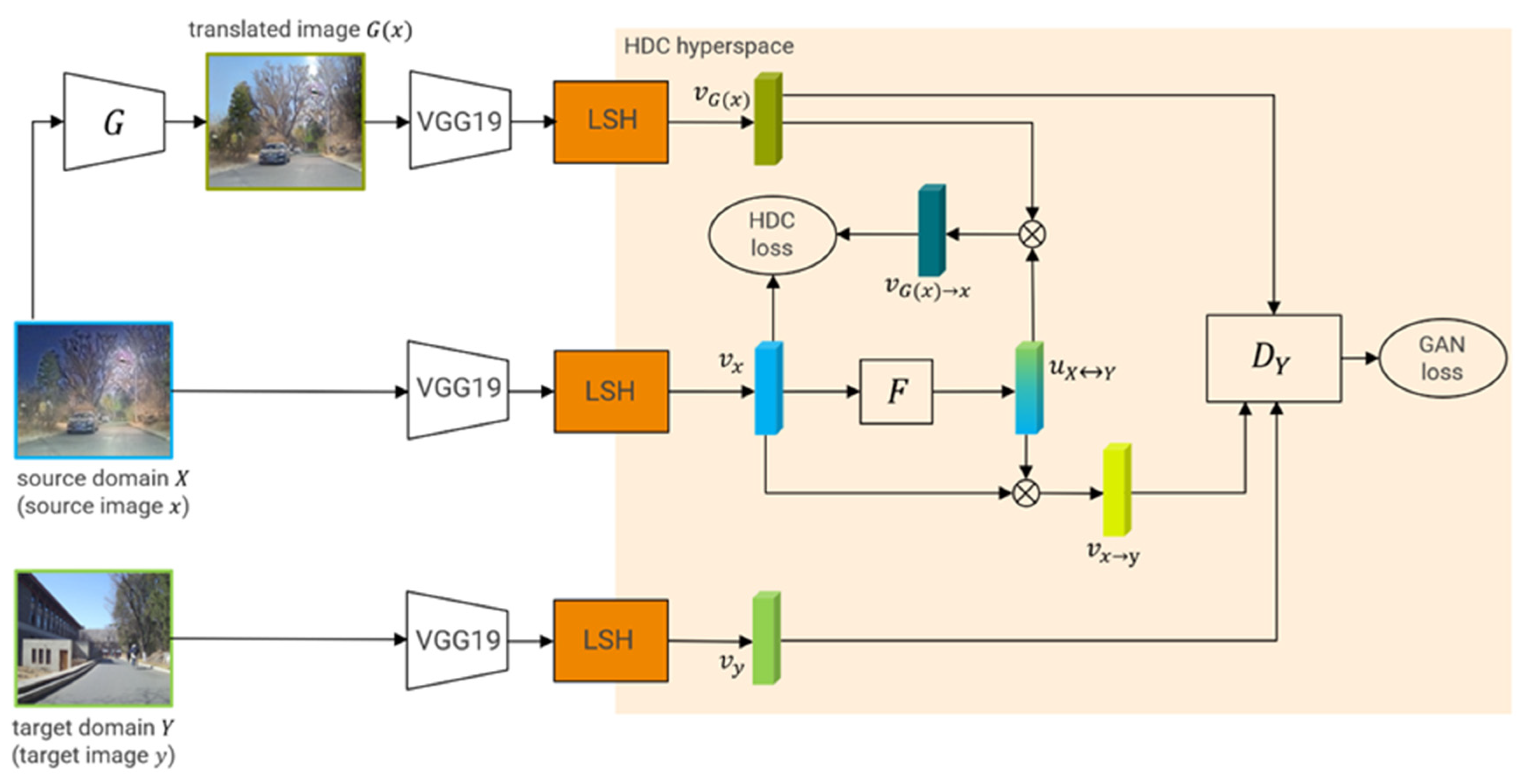
3.3. Nighttime to Daytime Image Translation Based on HDC-GAN
4. Experimental Methods and Evaluation Metrics
4.1. Datasets
4.2. Experimental Methods
4.3. Evaluation Metrics
5. Experimental Results
5.1. Image Fusion Experiment
5.2. Image Translation Experiments
- (a)
- NCV to DCV
- (b)
- NTIR to DCV
- (c)
- NF to DCV
6. Discussion
6.1. Eliminating the Influence of Lights in Nighttime Images
6.2. Integrating NCV to NTIR Translation
6.3. HDC-GAN Algorithm Used to Process Remote Sensing Images
6.4. Problems with HDC-GAN
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Guan, D.; Huang, W.; Yang, J.; Cao, Y.; Qiao, Y. Pedestrian Detection with Unsupervised Multispectral Feature Learning Using Deep Neural Networks. Inf. Fusion 2019, 46, 206–217. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-Modal Ranking with Soft Consistency and Noisy Labels for Robust RGB-T Tracking. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11217, pp. 831–847. ISBN 978-3-030-01260-1. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-Modality Person Re-Identification with Shared-Specific Feature Transfer. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13376–13386. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards Real-Time Semantic Segmentation for Autonomous Vehicles with Multi-Spectral Scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2014, 63, 139–144. [Google Scholar] [CrossRef]
- Luo, F.; Cao, Y.; Li, Y. Nighttime Thermal Infrared Image Colorization with Dynamic Label Mining. In Image and Graphics; Peng, Y., Hu, S.-M., Gabbouj, M., Zhou, K., Elad, M., Xu, K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12890, pp. 388–399. ISBN 978-3-030-87360-8. [Google Scholar]
- Yang, S.; Sun, M.; Lou, X.; Yang, H.; Zhou, H. An Unpaired Thermal Infrared Image Translation Method Using GMA-CycleGAN. Remote Sens. 2023, 15, 663. [Google Scholar] [CrossRef]
- Luo, F.; Li, Y.; Zeng, G.; Peng, P.; Wang, G.; Li, Y. Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention. IEEE Trans. Intell. Transport. Syst. 2022, 23, 15808–15823. [Google Scholar] [CrossRef]
- Pizer, S.M.; Johnston, R.E.; Ericksen, J.P.; Yankaskas, B.C.; Muller, K.E. Contrast-Limited Adaptive Histogram Equalization: Speed and Effectiveness. In Proceedings of the First Conference on Visualization in Biomedical Computing, Atlanta, GA, USA, 22–25 May 1990; pp. 337–345. [Google Scholar]
- Abdullah-Al-Wadud, M.; Kabir, M.; Akber Dewan, M.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward Fast, Flexible, and Robust Low-Light Image Enhancement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 5627–5636. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-Revealing Low-Light Image Enhancement Via Robust Retinex Model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Luo, Z. Infrared and Visible Image Fusion: Methods, Datasets, Applications, and Prospects. Appl. Sci. 2023, 13, 10891. [Google Scholar] [CrossRef]
- Burt, P.; Adelson, E. The Laplacian Pyramid as a Compact Image Code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Niu, Y.; Xu, S.; Wu, L.; Hu, W. Airborne Infrared and Visible Image Fusion for Target Perception Based on Target Region Segmentation and Discrete Wavelet Transform. Math. Probl. Eng. 2012, 2012, 275138. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Y.; Li, F. Infrared and Visible Image Fusion with Edge Detail Implantation. Front. Phys. 2023, 11, 1180100. [Google Scholar] [CrossRef]
- Sun, X.; Hu, S.; Ma, X.; Hu, Q.; Xu, S. IMGAN: Infrared and Visible Image Fusion Using a Novel Intensity Masking Generative Adversarial Network. Infrared Phys. Technol. 2022, 125, 104221. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Jane Wang, Z. Image Fusion with Convolutional Sparse Representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. Infrared and Visible Image Fusion Using Latent Low-Rank Representation. arXiv 2022. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Tang, L.; Xiang, X.; Zhang, H.; Gong, M.; Ma, J. DIVFusion: Darkness-Free Infrared and Visible Image Fusion. Inf. Fusion 2023, 91, 477–493. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A Progressive Infrared and Visible Image Fusion Network Based on Illumination Aware. Inf. Fusion 2022, 83–84, 79–92. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Hu, X.; Zhou, X.; Huang, Q.; Shi, Z.; Sun, L.; Li, Q. QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18270–18279. [Google Scholar]
- Li, S.; Han, B.; Yu, Z.; Liu, C.H.; Chen, K.; Wang, S. I2V-GAN: Unpaired Infrared-to-Visible Video Translation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, China, 17 October 2021; pp. 3061–3069. [Google Scholar]
- Kleyko, D.; Rachkovskij, D.; Osipov, E.; Rahimi, A. A Survey on Hyperdimensional Computing Aka Vector Symbolic Architectures, Part II: Applications, Cognitive Models, and Challenges. ACM Comput. Surv. 2023, 55, 1–52. [Google Scholar] [CrossRef]
- Land, E.H. The Retinex Theory of Color Vision. Sci Am. 1977, 237, 108–128. [Google Scholar] [CrossRef]
- Xu, L.; Yan, Q.; Xia, Y.; Jia, J. Structure Extraction from Texture via Relative Total Variation. ACM Trans. Graph. 2012, 31, 1–10. [Google Scholar] [CrossRef]
- Neubert, P. An Introduction to Hyperdimensional Computing for Robotics. Künstliche Intell. 2019, 33, 319–330. [Google Scholar] [CrossRef]
- Kleyko, D.; Rachkovskij, D.A.; Osipov, E.; Rahimi, A. A Survey on Hyperdimensional Computing Aka Vector Symbolic Architectures, Part I: Models and Data Transformations. ACM Comput. Surv. 2023, 55, 1–40. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Kim, B.; Kwon, G.; Kim, K.; Ye, J.C. Unpaired Image-to-Image Translation via Neural Schrödinger Bridge. arXiv 2023. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-Domain Long-Range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.-Y. Contrastive Learning for Unpaired Image-to-Image Translation. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12354, pp. 319–345. ISBN 978-3-030-58544-0. [Google Scholar]
- Van Aardt, J. Assessment of Image Fusion Procedures Using Entropy, Image Quality, and Multispectral Classification. J. Appl. Remote Sens 2008, 2, 023522. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information Measure for Performance of Image Fusion. Electron. Lett. 2002, 38, 313. [Google Scholar] [CrossRef]
- Jagalingam, P.; Hegde, A.V. A Review of Quality Metrics for Fused Image. Aquat. Procedia 2015, 4, 133–142. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrović, V. Objective Image Fusion Performance Measure. Electron. Lett. 2000, 36, 308. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail Preserved Fusion of Visible and Infrared Images Using Regional Saliency Extraction and Multi-Scale Image Decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Rao, Y.-J. In-Fibre Bragg Grating Sensors. Meas. Sci. Technol. 1997, 8, 355–375. [Google Scholar] [CrossRef]
- Adu, J.; Gan, J.; Wang, Y.; Huang, J. Image Fusion Based on Nonsubsampled Contourlet Transform for Infrared and Visible Light Image. Infrared Phys. Technol. 2013, 61, 94–100. [Google Scholar] [CrossRef]
- Aslantas, V.; Bendes, E. A New Image Quality Metric for Image Fusion: The Sum of the Correlations of Differences. AEU Int. J. Electron. Commun. 2015, 69, 1890–1896. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A New Image Fusion Performance Metric Based on Visual Information Fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Bynagari, N.B. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Asian J. Appl. Sci. Eng. 2019, 8, 25–34. [Google Scholar] [CrossRef]
- Chen, R.; Huang, W.; Huang, B.; Sun, F.; Fang, B. Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8165–8174. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | EN | MI | PSNR | AG | SD | CC | SCD | VIF | |
|---|---|---|---|---|---|---|---|---|---|
| DenseFuse [38] | 6.5496 | 2.1373 | 65.3443 | 0.3964 | 2.9437 | 24.8076 | 0.6523 | 1.4365 | 0.6340 |
| SwinFusion [39] | 6.8680 | 2.4085 | 62.8285 | 0.5758 | 5.3090 | 34.4778 | 0.5883 | 1.4347 | 0.6933 |
| MDLatLRR [22] | 6.8430 | 1.8459 | 63.3278 | 0.4907 | 4.2988 | 30.1543 | 0.5215 | 1.1690 | 0.6363 |
| IA-MDLatLRR | 7.0048 | 2.7012 | 65.6855 | 0.6281 | 4.8661 | 34.3022 | 0.6769 | 1.5607 | 0.7619 |
| Method | NF- > DCV | NTIR- > DCV | NCV- > DCV | |||
|---|---|---|---|---|---|---|
| FID | FID | FID | KID ( | |||
| CycleGAN [27] | 109.6172 | 38.1537 | 121.8253 | 47.5827 | 130.7170 | 55.6975 |
| CUT [40] | 127.4195 | 58.4600 | 143.4373 | 78.3309 | 180.2604 | 101.1322 |
| QS-attn [28] | 123.4470 | 50.4946 | 132.0227 | 62.0031 | 133.2309 | 59.0322 |
| UNSB [36] | 108.6397 | 36.7278 | 120.5463 | 45.8972 | 125.1293 | 49.5961 |
| HDC-GAN | 94.5200 | 17.8051 | 108.9323 | 36.1451 | 111.5395 | 43.4754 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Sun, M.; Lou, X.; Yang, H.; Liu, D. Nighttime Thermal Infrared Image Translation Integrating Visible Images. Remote Sens. 2024, 16, 666. https://doi.org/10.3390/rs16040666
Yang S, Sun M, Lou X, Yang H, Liu D. Nighttime Thermal Infrared Image Translation Integrating Visible Images. Remote Sensing. 2024; 16(4):666. https://doi.org/10.3390/rs16040666
Chicago/Turabian StyleYang, Shihao, Min Sun, Xiayin Lou, Hanjun Yang, and Dong Liu. 2024. "Nighttime Thermal Infrared Image Translation Integrating Visible Images" Remote Sensing 16, no. 4: 666. https://doi.org/10.3390/rs16040666
APA StyleYang, S., Sun, M., Lou, X., Yang, H., & Liu, D. (2024). Nighttime Thermal Infrared Image Translation Integrating Visible Images. Remote Sensing, 16(4), 666. https://doi.org/10.3390/rs16040666