
Modeling the Land Cover Change in Chesapeake Bay Area for Precision Conservation and Green Infrastructure Planning



Abstract
1. Introduction
2. Materials and Methods
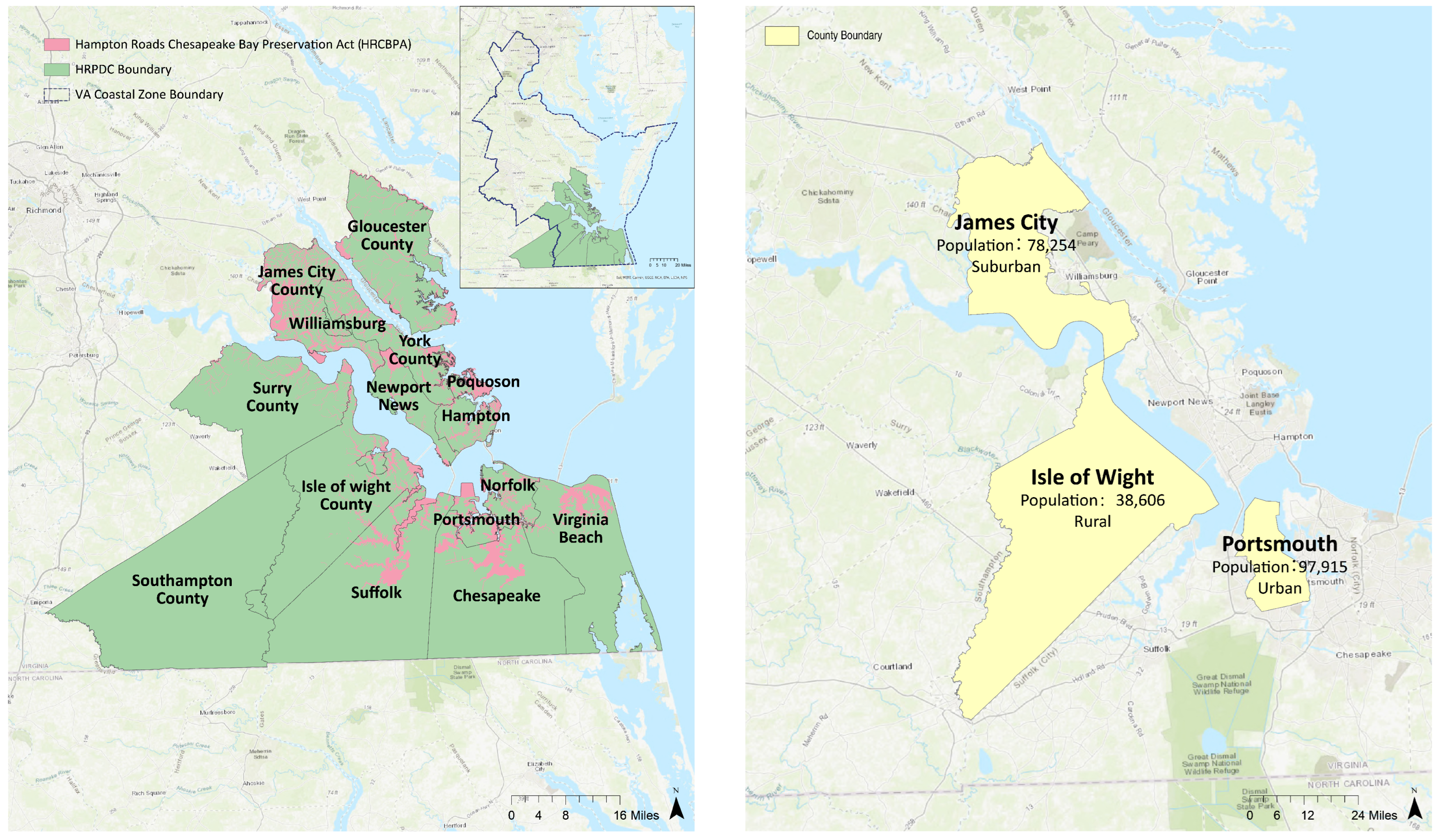
2.1. Study Area
2.2. Data Source
2.3. Data Processing
2.3.1. Unit of Analysis
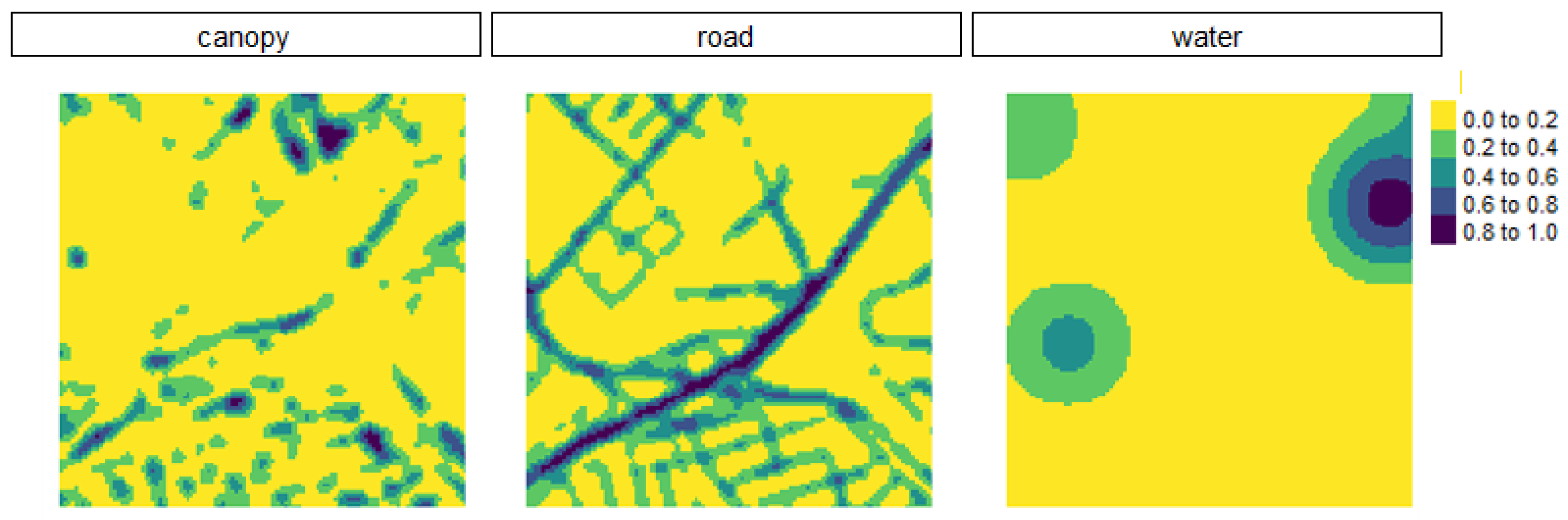
2.3.2. Equation for Feature Engineering
2.3.3. Spatial Pattern Analysis
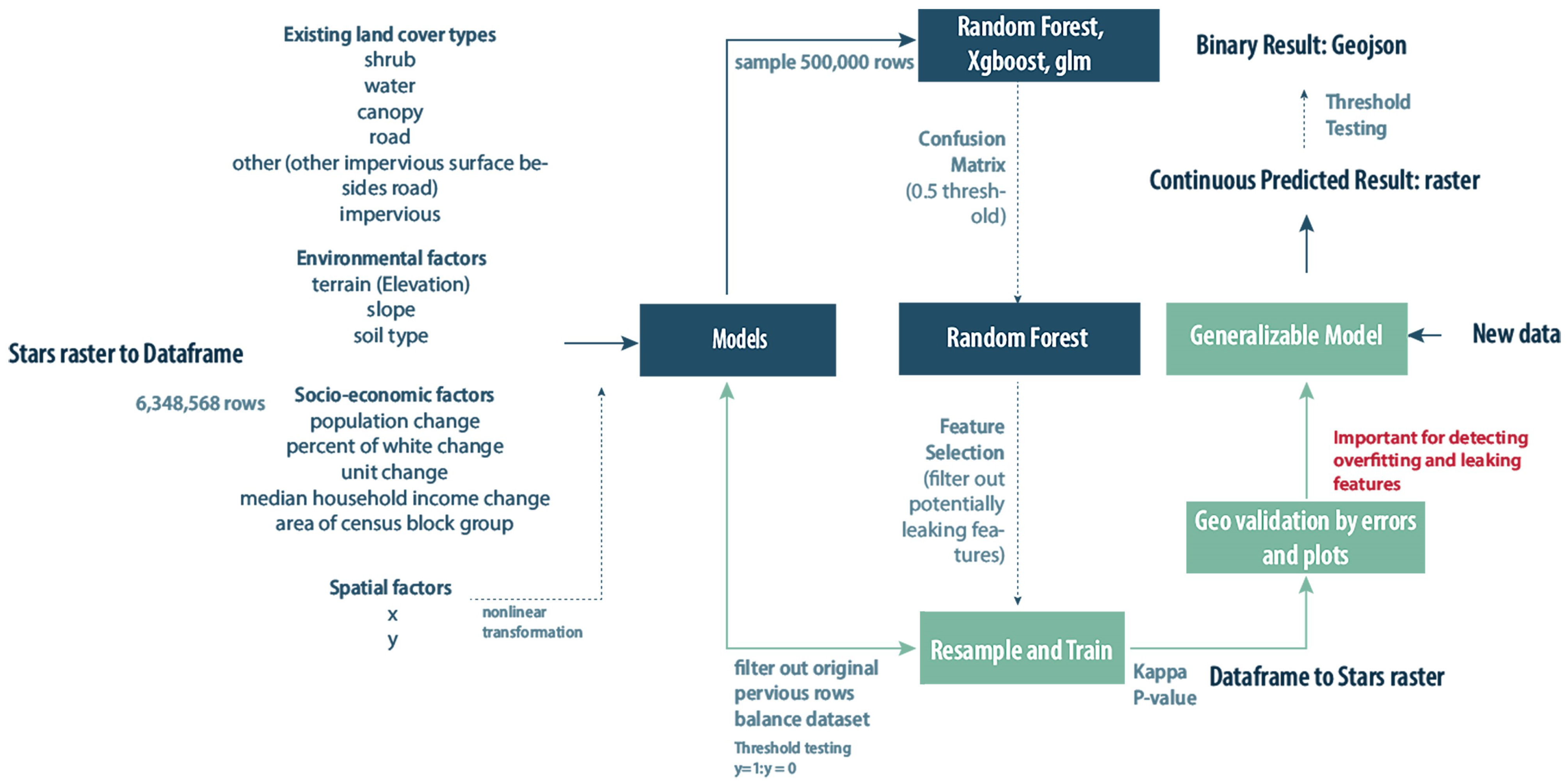
2.4. Modeling
2.4.1. Model Selection
2.4.2. Model Re-Sampling
2.4.3. Geo Cross-Validation
3. Results
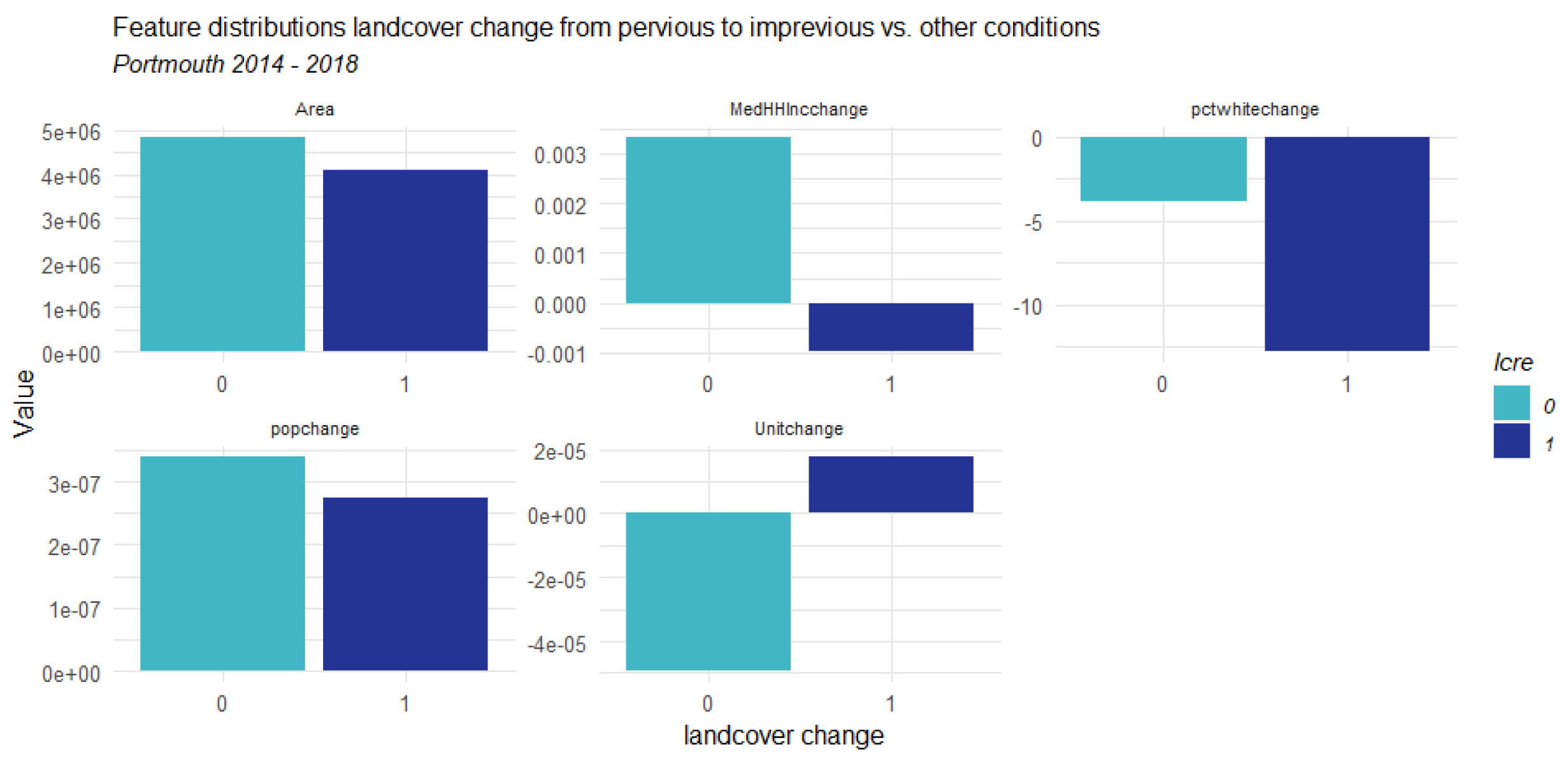
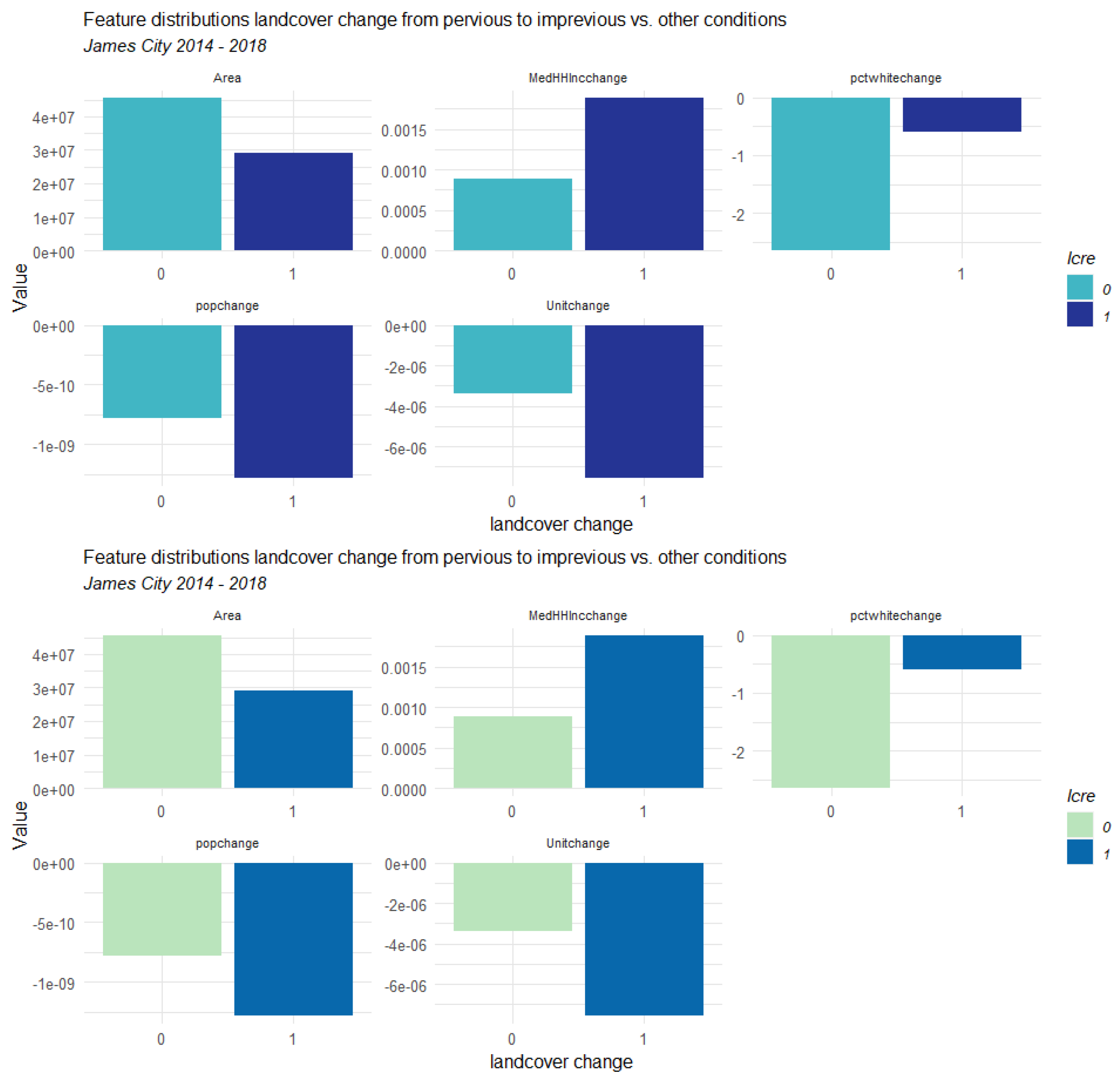
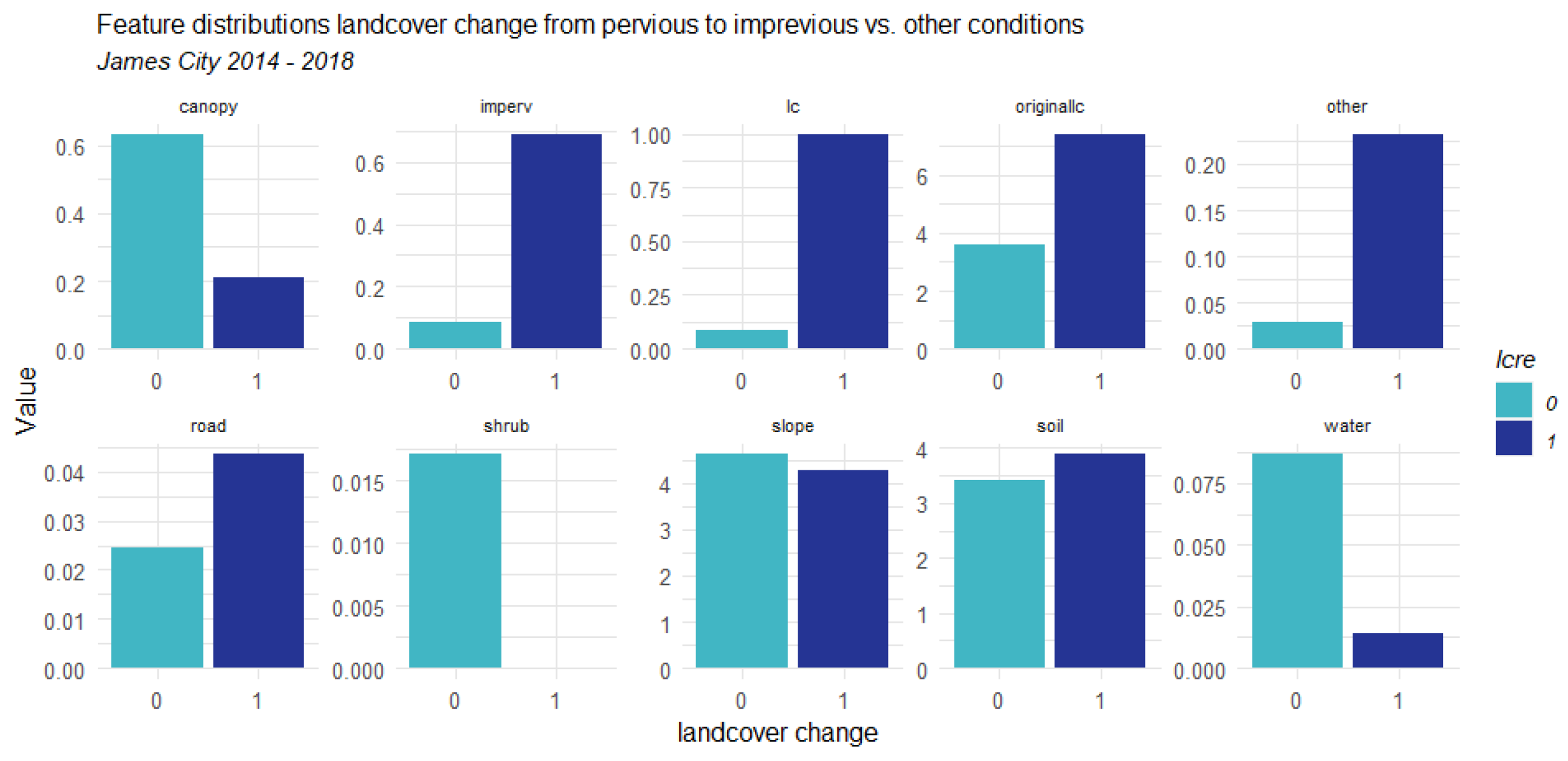
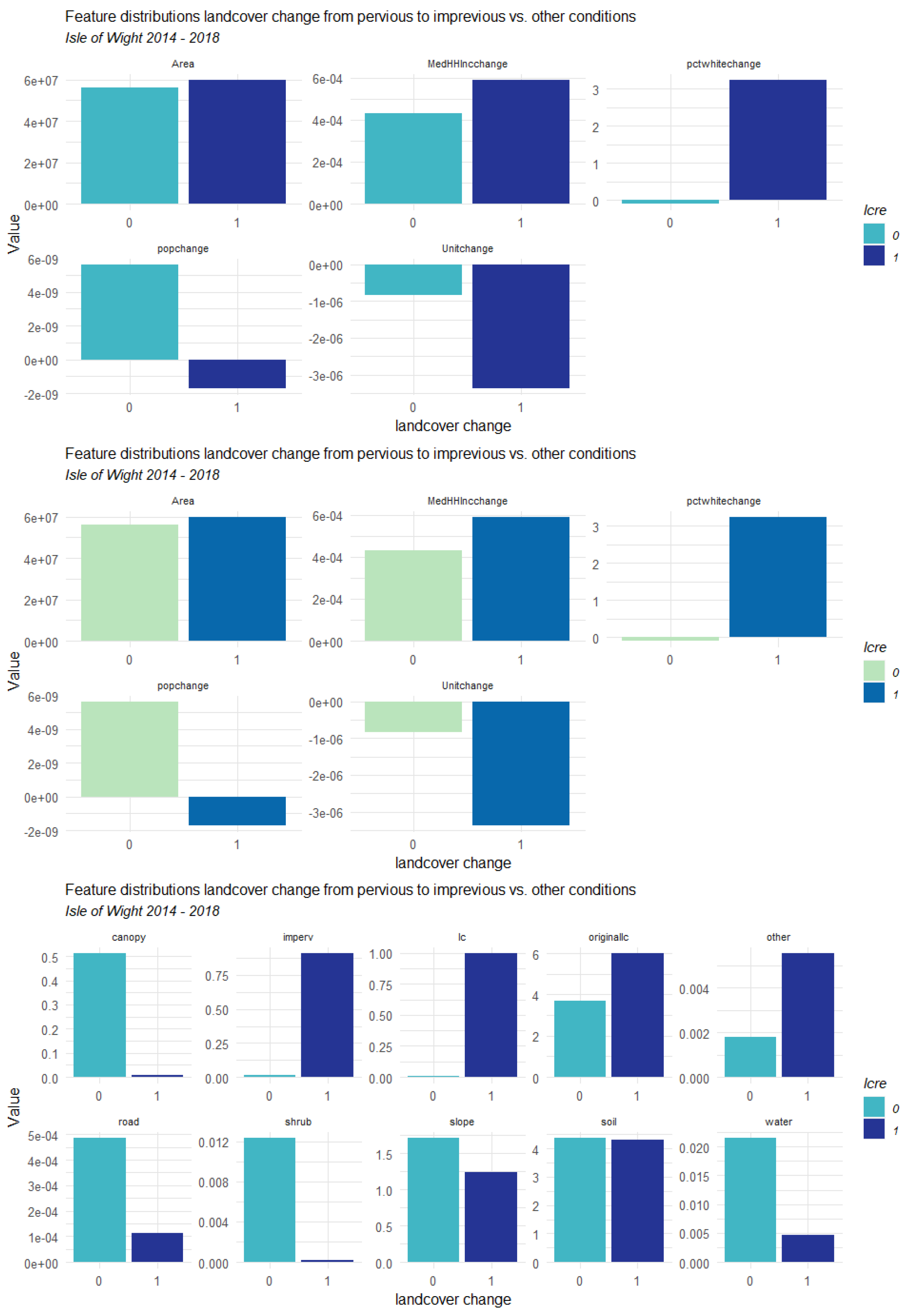
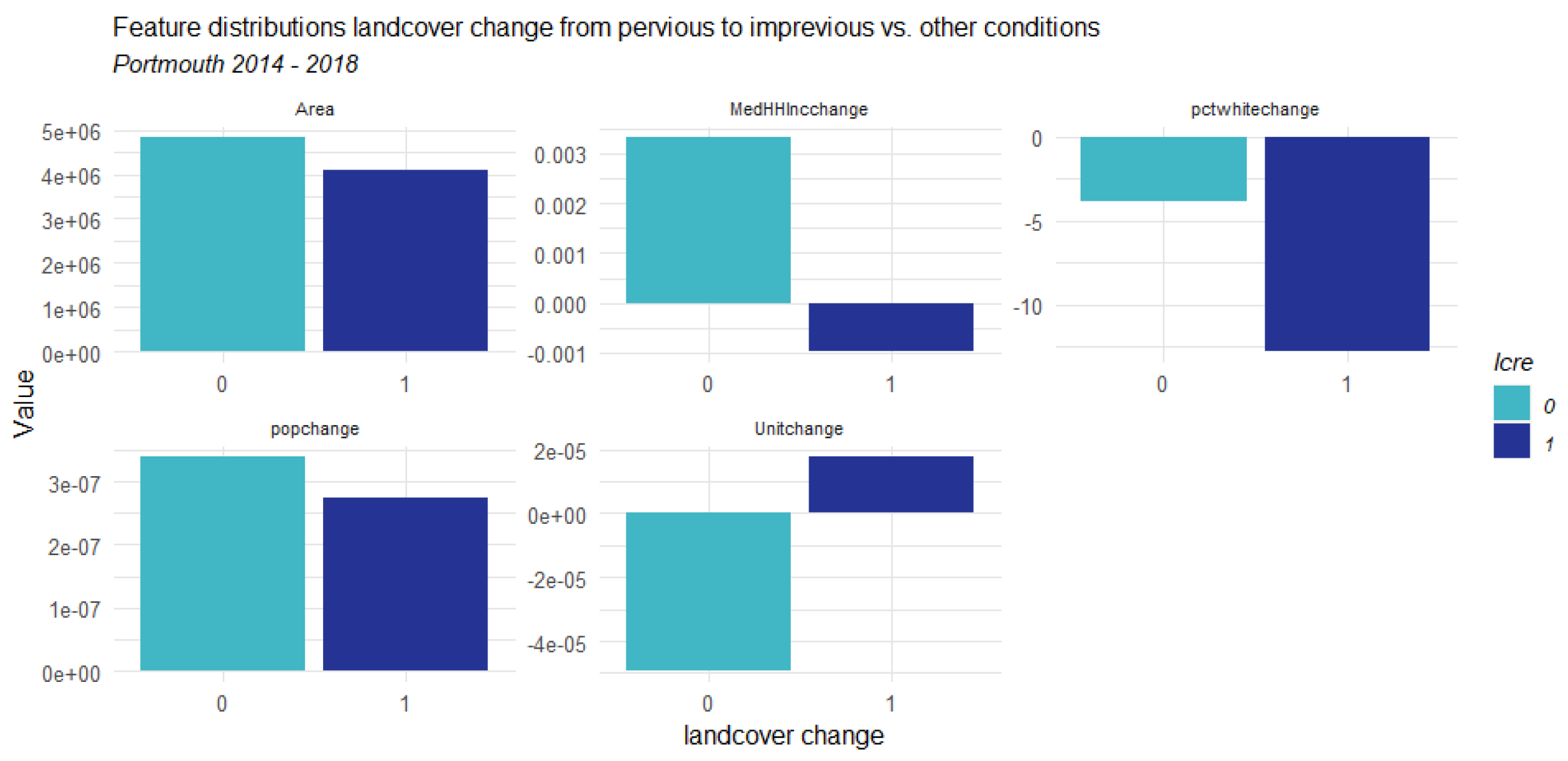
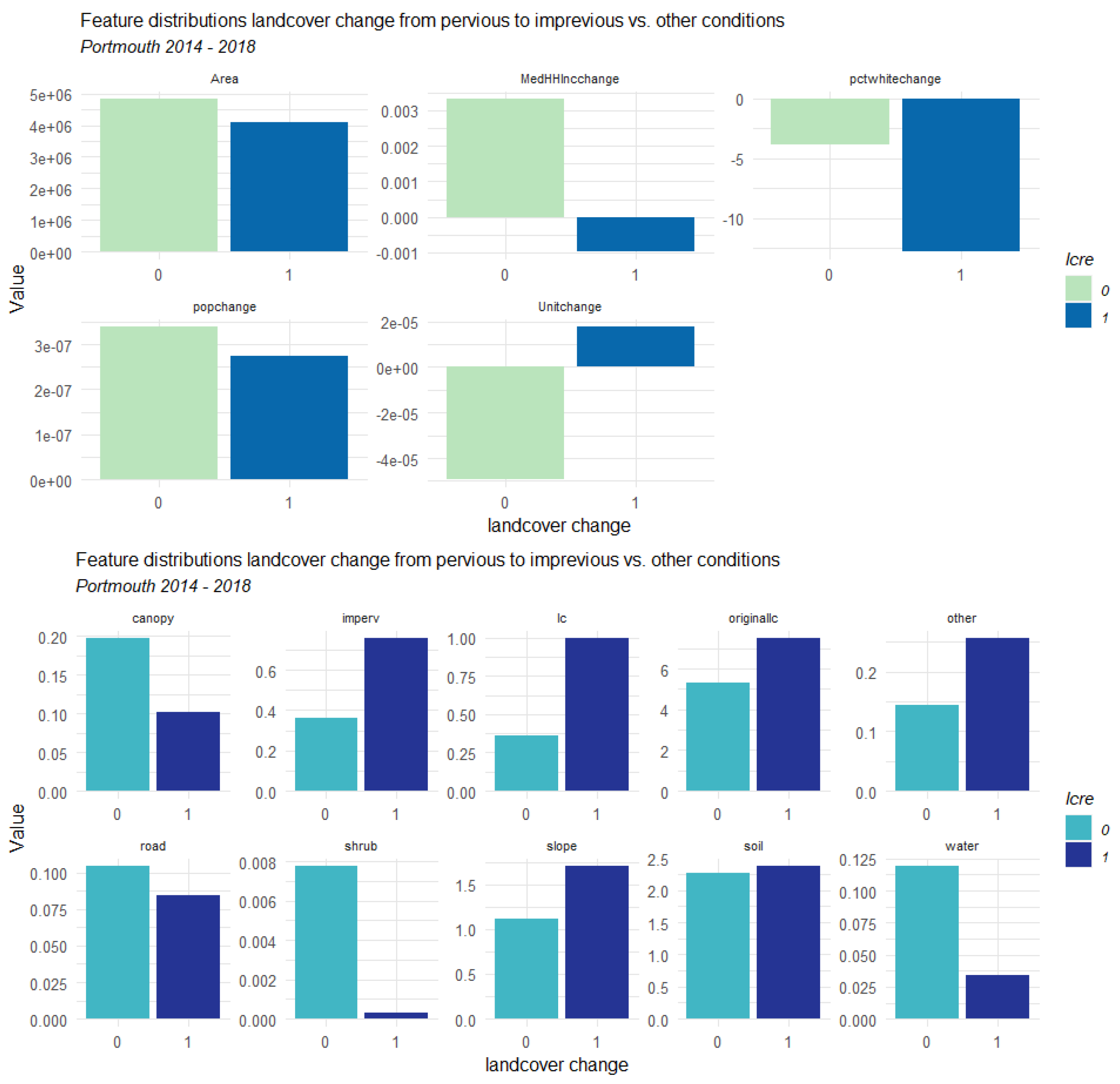
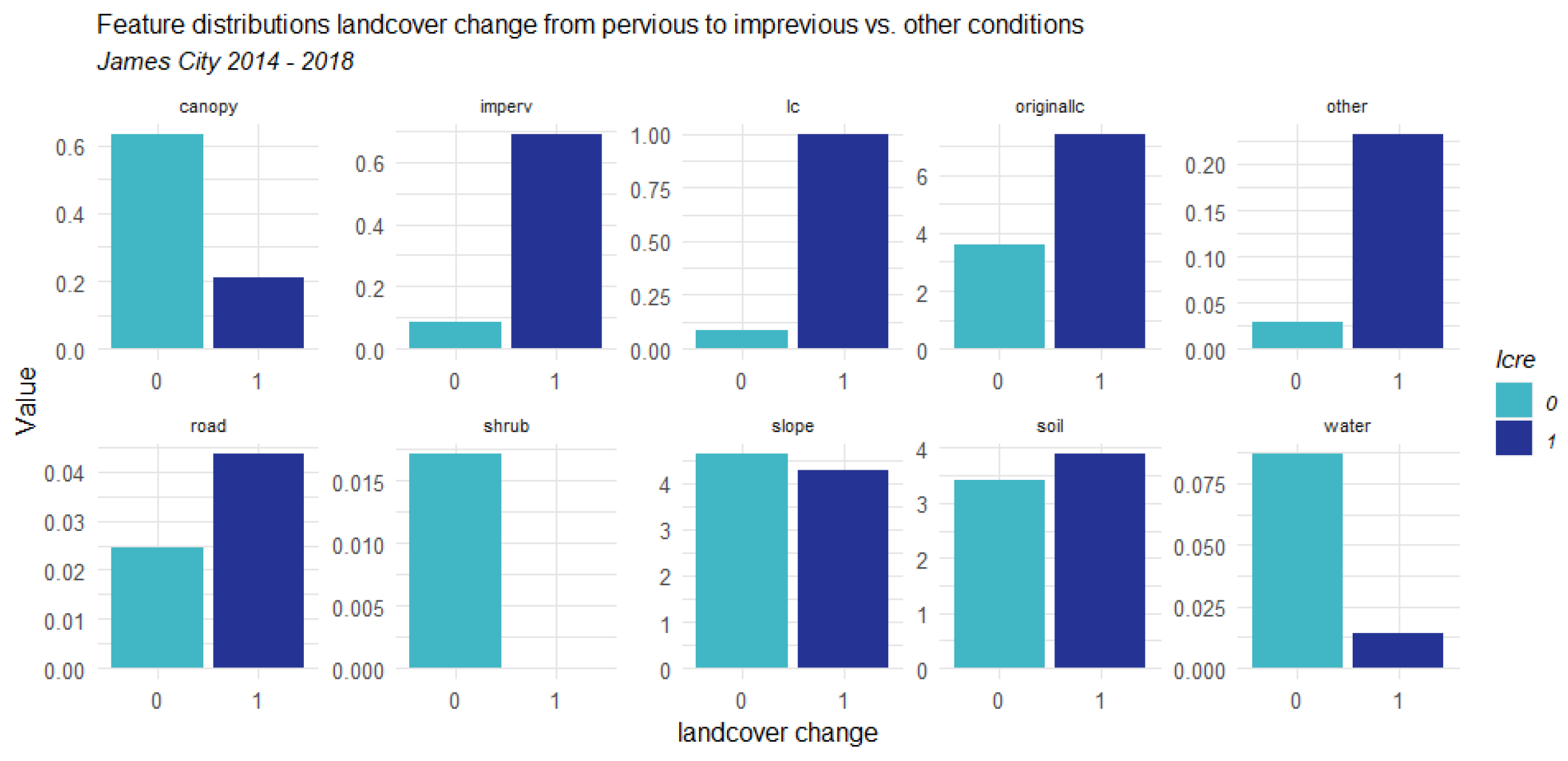
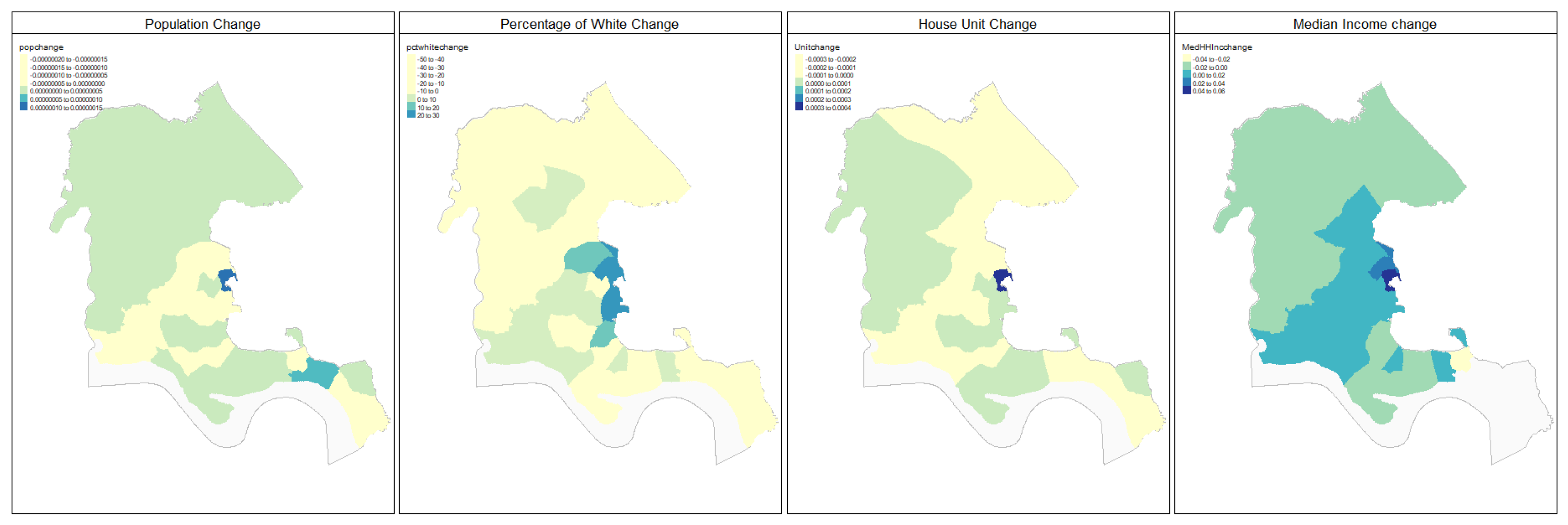
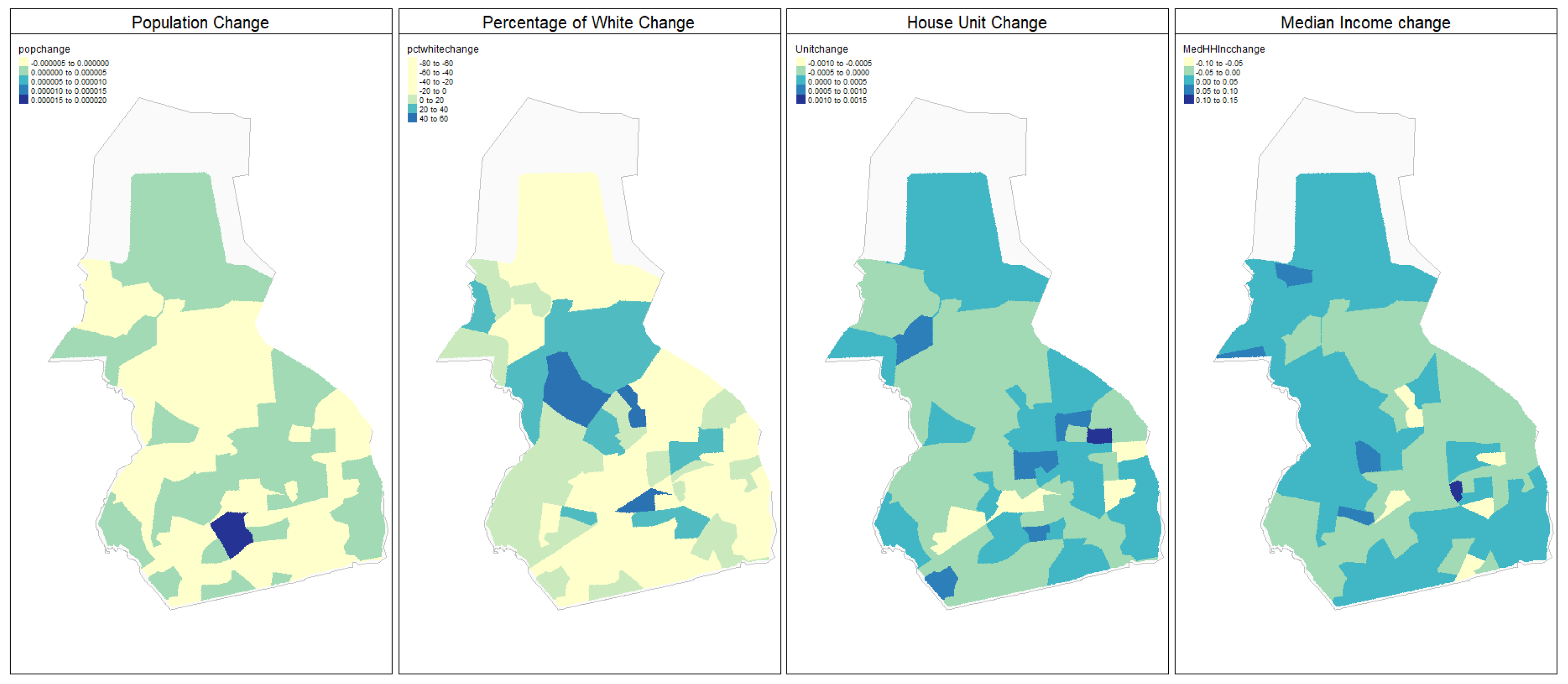
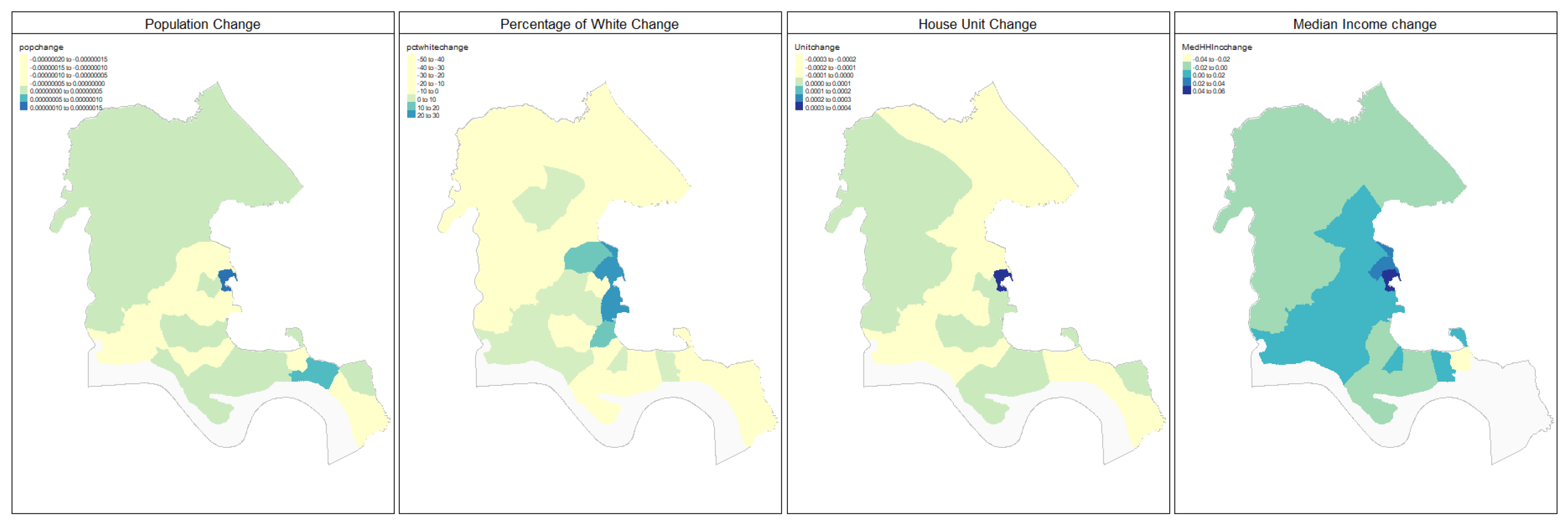
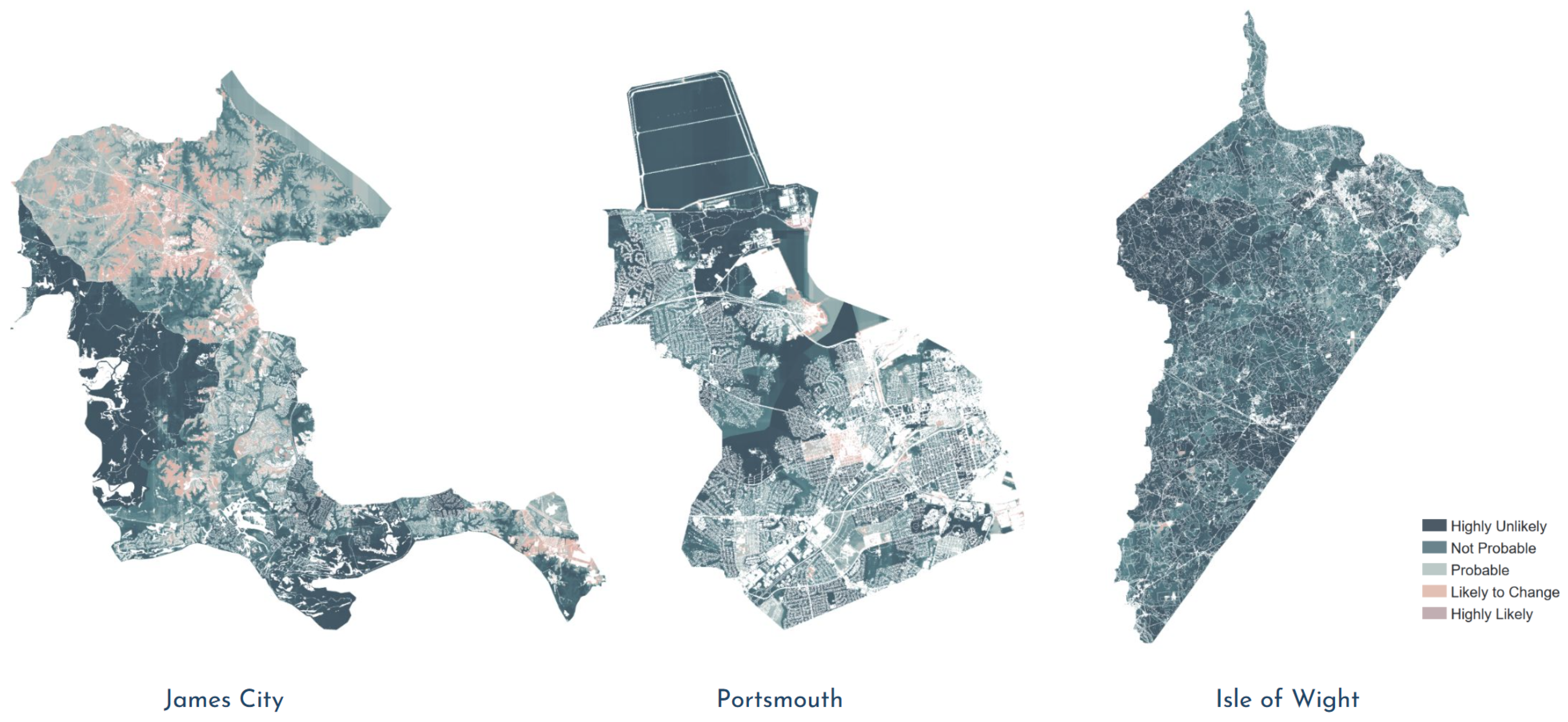
3.1. Counties Context Comparison and Influence Analysis
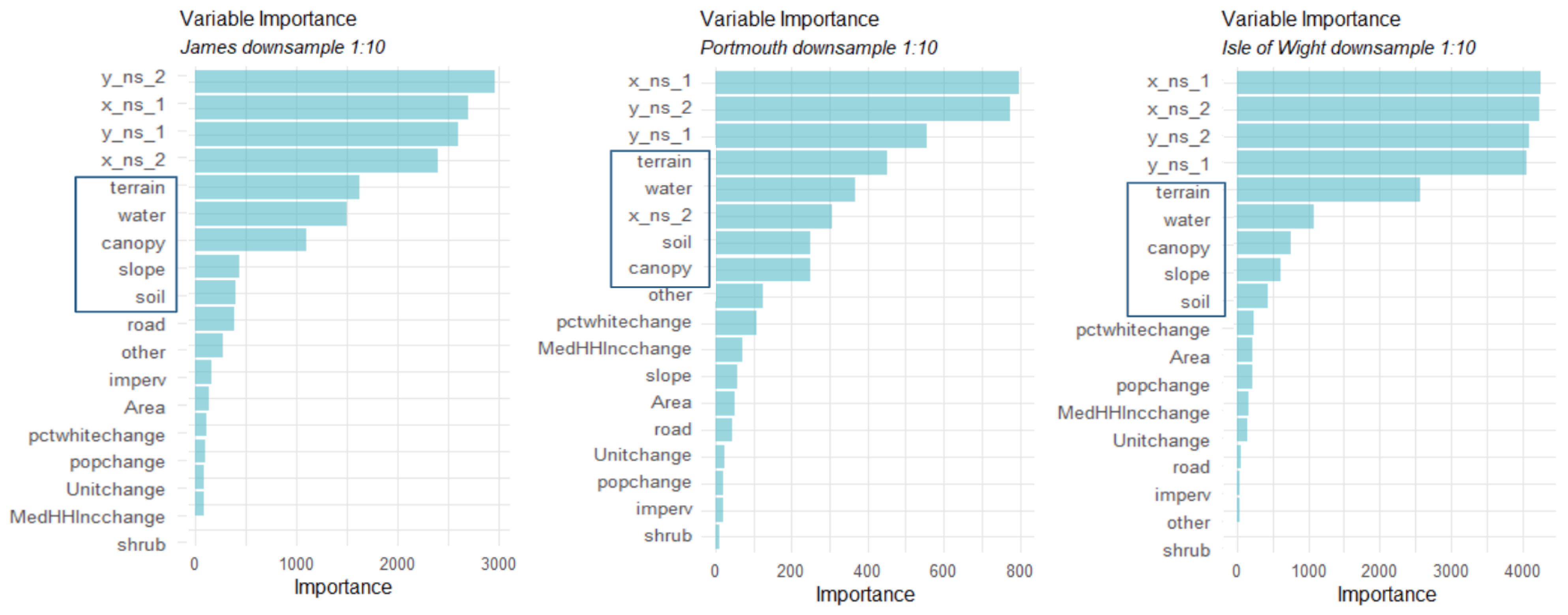
3.1.1. Factors Analysis
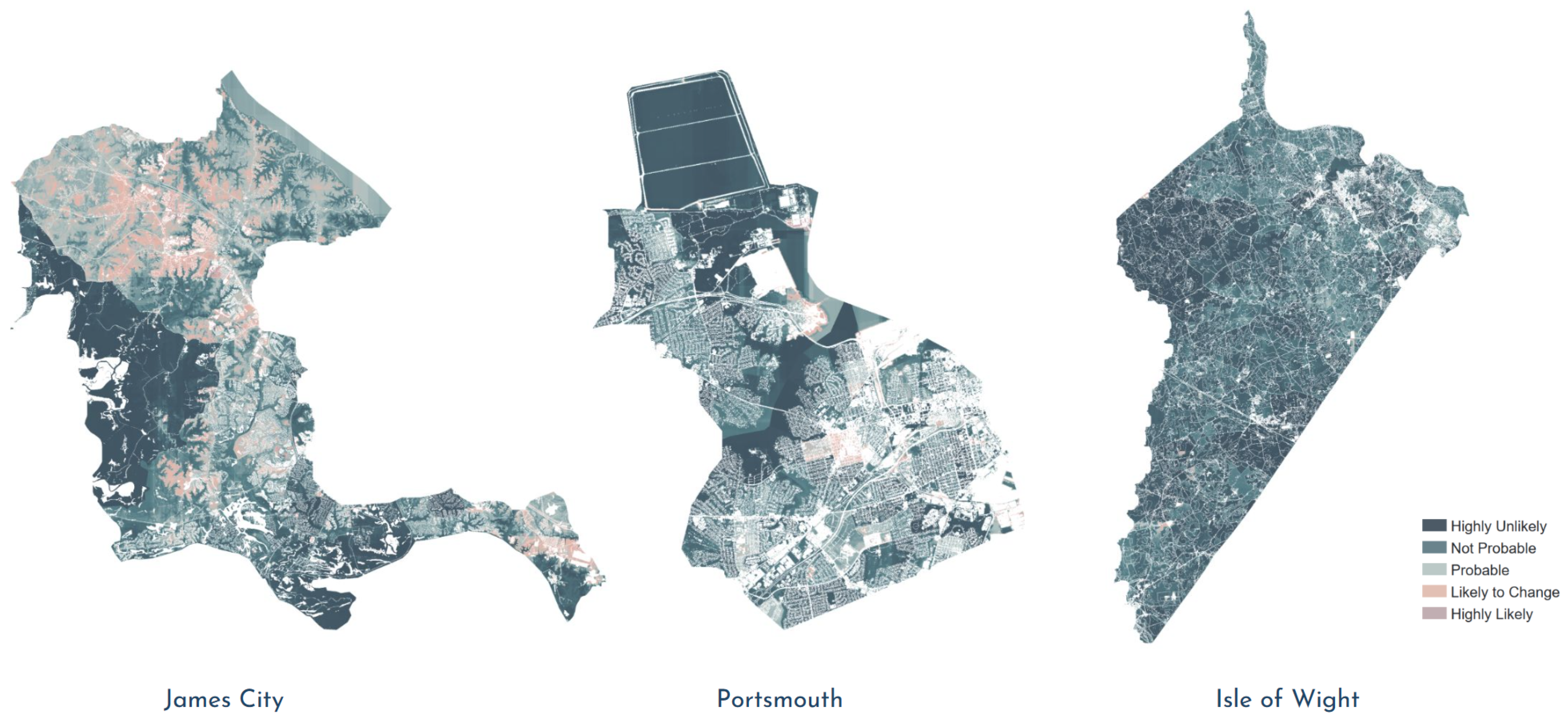
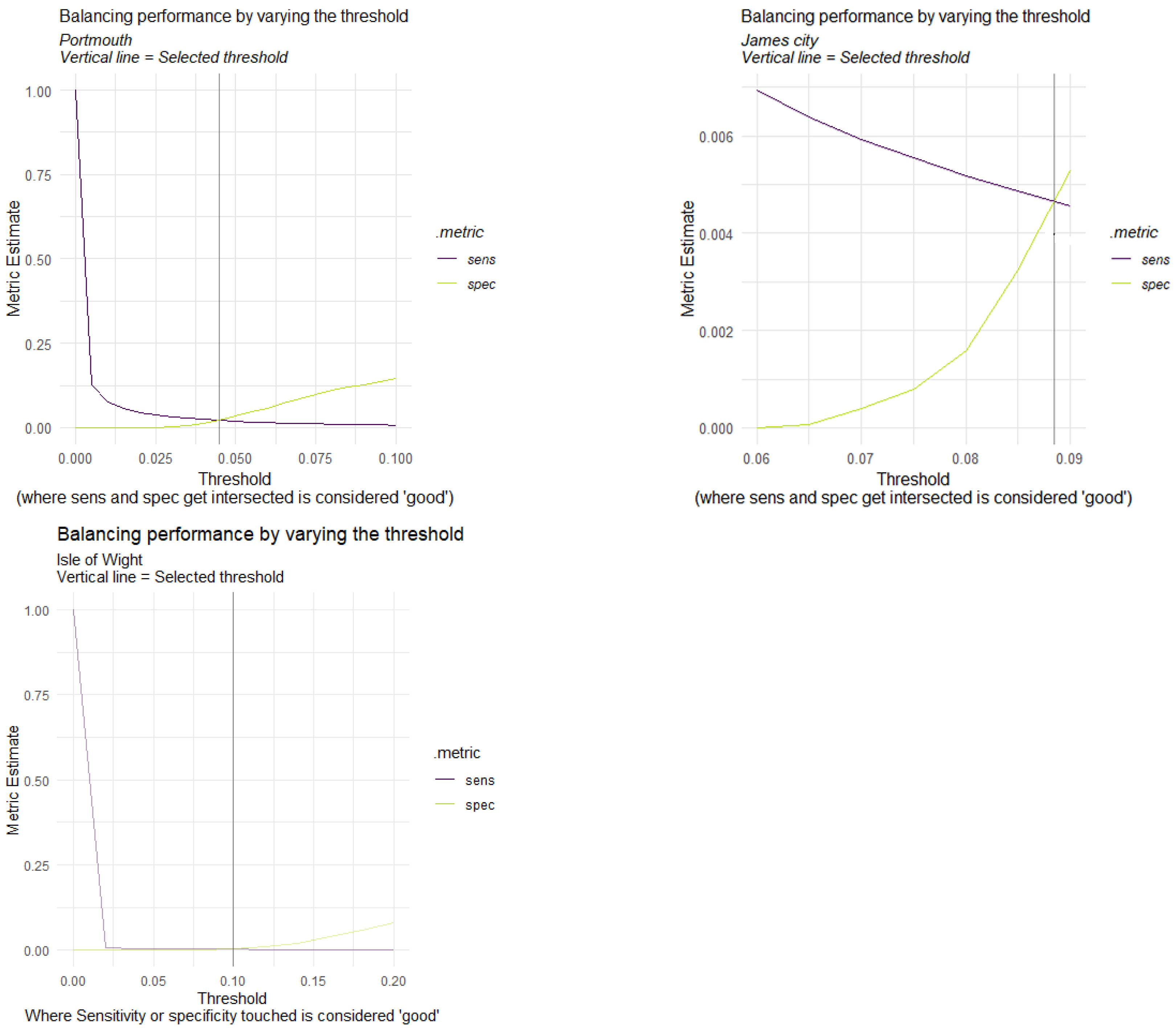
3.1.2. Prediction and Error Analysis
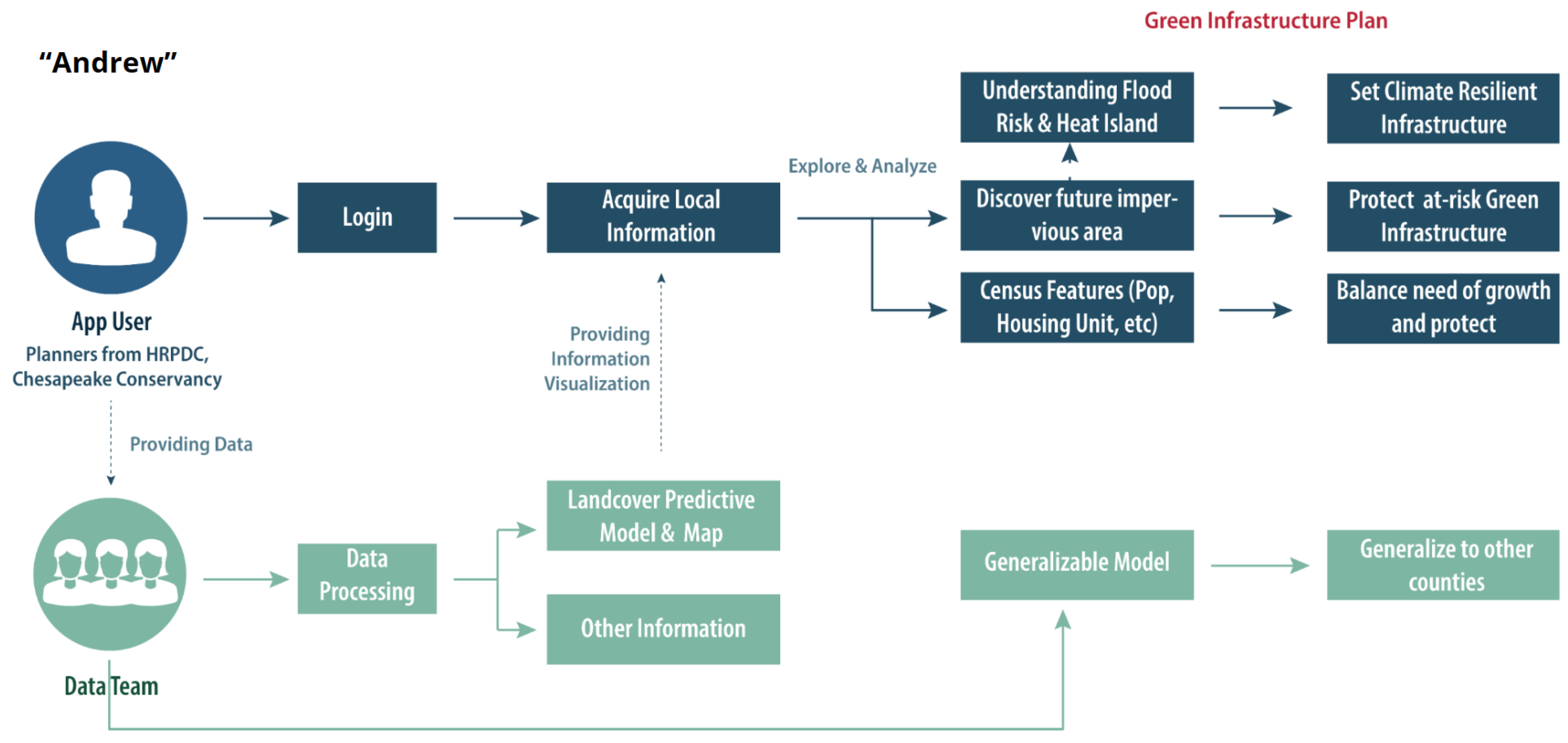
3.2. App Application
4. Discussion
4.1. Novelty of the Study
4.2. Uncertainties and Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Landuse Type 1 | Ksize | Times 2 |
|---|---|---|
| other | 3 | 2 |
| canopy | 3 | 2 |
| road | 3 | 2 |
| shrub | 3 | 2 |
| water | 25 | 2 |
| Model | Portmouth | Isle of Wight | James City |
|---|---|---|---|
| Random Forest | 0.9896 | 0.9988 | 0.9576 |
| Xgboost | 0.9599 | 0.9928 | 0.9268 |
| Glm | 0.8905 |
| Model | True Result as 0 | True Result as 1 | p-Value [Acc > NIR] | Kappa |
|---|---|---|---|---|
| Model1 result | 535,388 | 48 | 1 | 0.5464 |
| 2777 | 1716 | |||
| Model2 result | 535,359 | 77 | <2.2 × 10−16 | 0.726 |
| 1879 | 2614 |
References
- Pesaresi, M.; Corbane, C.; Julea, A.; Florczyk, A.J.; Syrris, V.; Soille, P. Assessment of the Added-Value of Sentinel-2 for Detecting Built-up Areas. Remote Sens. 2016, 8, 305. [Google Scholar] [CrossRef]
- Sharma, R.C.; Tateishi, R.; Hara, K.; Gharechelou, S.; Iizuka, K. Global mapping of urban built-up areas of year 2014 by combining MODIS multispectral data with VIIRS nighttime light data. Int. J. Digit. Earth 2016, 9, 1004–1020. [Google Scholar] [CrossRef]
- Godefroid, S.; Koedam, N. Urban plant species patterns are highly driven by density and function of built-up areas. Landsc. Ecol. 2007, 22, 1227–1239. [Google Scholar] [CrossRef]
- Melchiorri, M.; Kemper, T. Establishing an operational and continuous monitoring of global built-up surfaces with the Copernicus Global Human Settlement Layer. In Proceedings of the 2023 Joint Urban Remote Sensing Event (JURSE), Heraklion, Greece, 17–19 May 2023; pp. 1–4. [Google Scholar]
- Liu, F.; Wang, S.; Xu, Y.; Ying, Q.; Yang, F.; Qin, Y. Accuracy assessment of Global Human Settlement Layer (GHSL) built-up products over China. PLoS ONE 2020, 15, e0233164. [Google Scholar] [CrossRef]
- Ban, Y.; Gong, P.; Giri, C. Global land cover mapping using Earth observation satellite data: Recent progresses and challenges. ISPRS J. Photogramm. Remote Sens. 2015, 103, 1–6. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land cover classification and feature extraction from National Agricultural Imagery Program (NAIP) orthoimagery: A review. J. Environ. Manag. 2017, 83, 737–747. [Google Scholar]
- Dicks, L.; Haddaway, N.; Hernández-Morcillo, M.; Mattsson, B. Knowledge synthesis for environmental decisions: An evaluation of existing methods, and guidance for their selection, use and development: A report from the EKLIPSE Project. Available online: https://api.semanticscholar.org/CorpusID:186674101 (accessed on 30 January 2024).
- Sohl, T.L.; Claggett, P.R. Clarity versus complexity: Land-use modeling as a practical tool for decision-makers. J. Environ. Manag. 2013, 129, 235–243. [Google Scholar] [CrossRef]
- Wellmann, T.; Lausch, A.; Andersson, E.; Knapp, S.; Cortinovis, C.; Jache, J.; Haase, D. Remote sensing in urban planning: Contributions towards ecologically sound policies? Landsc. Urban Plan. 2020, 204, 103921. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhou, Y.; Seto, K.C.; Stokes, E.C.; Deng, C.; Pickett, S.T.A.; Taubenböck, H. Understanding an urbanizing planet: Strategic directions for remote sensing. Remote Sens. Environ. 2019, 228, 164–182. [Google Scholar] [CrossRef]
- Geneletti, D. Reasons and options for integrating ecosystem services in strategic environmental assessment of spatial planning. Int. J. Biodivers. Sci. Ecosyst. Serv. Manag. 2011, 7, 143–149. [Google Scholar] [CrossRef]
- Paul, B.K.; Rashid, H. Land Use Change and Coastal Management. In Climatic Hazards in Coastal Bangladesh; Elsevier: Amsterdam, The Netherlands, 2017; pp. 183–207. [Google Scholar]
- Barnaud, C.; Jantz, T.P.; Goetz, S.J.; Donato, D.; Claggett, P. Designing and implementing a regional urban modeling system using the SLEUTH cellular urban model. Comput. Environ. Urban Syst. 2010, 34, 1–16. [Google Scholar]
- MacFaden, S.W.; O’Neil-Dunne, J.P.M.; Royar, A.R.; Lu, J.W.T.; Rundle, A.G. High-resolution tree canopy mapping for New York City using LiDAR and object-based image analysis. J. Appl. Remote Sens. 2012, 6, 063567. [Google Scholar] [CrossRef]
- MacFaden, S.W.; Raney, P.A.; O’Neil-Dunne, J. LiDAR-aided hydrogeologic modeling and object-based wetland mapping approach for Pennsylvania. J. Appl. Remote Sens. 2021, 15, 026503. [Google Scholar] [CrossRef]
- Luan, C.; Liu, R. A Comparative Study of Various Land Use and Land Cover Change Models to Predict Ecosystem Service Value. Int. J. Environ. Res. Public Health 2022, 19, 16484. [Google Scholar] [CrossRef]
- Hartfield, K.A.; Landau, K.I.; van Leeuwen, W.J.D. Fusion of High-Resolution Aerial Multispectral and LiDAR Data: Land Cover in the Context of Urban Mosquito Habitat. Remote Sens. 2011, 3, 2364–2383. [Google Scholar] [CrossRef]
- Fan, C.; Wang, Z. Spatiotemporal Characterization of Land Cover Impacts on Urban Warming: A Spatial Autocorrelation Approach. Remote Sens. 2020, 12, 1631. [Google Scholar] [CrossRef]
- Khan, M.S.; Ullah, S.; Sun, T.; Rehman, A.; Chen, L. Land-Use/Land-Cover Changes and Its Contribution to Urban Heat Island: A Case Study of Islamabad, Pakistan. Sustainability 2020, 12, 3861. [Google Scholar] [CrossRef]
- Grove, J.M.; Locke, D.H.; O’Neil-Dunne, J.P.M. An Ecology of Prestige in New York City: Examining the Relationships Among Population Density, Socio-Economic Status, Group Identity, and Residential Canopy Cover. Environ. Manag. 2014, 54, 402–419. [Google Scholar] [CrossRef]
- Bockstael, N.E. Modeling Economics and Ecology: The Importance of a Spatial Perspective. Am. J. Agric. Econ. 1996, 78, 1168–1180. [Google Scholar] [CrossRef]
- Jantz, C.A.; Goetz, S.J. Can smart growth save the Chesapeake Bay? J. Green Build. 2007, 2, 41–51. [Google Scholar] [CrossRef]
- U.S. Global Change Research Program. 2018. Impacts, Risks, and Adaptation in the United States: Fourth National Climate Assessment, Volume II. Available online: https://www.epa.gov/climate-indicators/climate-change-indicators-great-lakes-ice-cover (accessed on 8 January 2024).
- Arnold, C.L.; Gibbons, C.J. Impervious Surface Coverage: The Emergence of a Key Environmental Indicator. J. Am. Plan. Assoc. 1996, 62, 243–258. [Google Scholar] [CrossRef]
- Winkler, K.; Fuchs, R.; Rounsevell, M.; Herold, M. Global land use changes are four times greater than previously estimated. Nat. Commun. 2021, 12, 2501. [Google Scholar] [CrossRef]
- Abunnasr, Y.; Mhawej, M. Pervious Area Change as Surrogate to Diverse Climatic Variables Trends in the CONUS: A County-Scale Assessment. Urban Clim. 2021, 35, 100733. [Google Scholar] [CrossRef]
- Lechner, A.M.; Foody, G.M.; Boyd, D.S. Applications in Remote Sensing to Forest Ecology and Management. One Earth 2020, 2, 405–412. [Google Scholar] [CrossRef]
- Li, X.; Li, W.; Middel, A.; Harlan, S.L.; Brazel, A.J.; Turner, B.L. Remote sensing of the surface urban heat island and land architecture in Phoenix, Arizona: Combined effects of land composition and configuration and cadastral–demographic–economic factors. Remote Sens. Environ. 2016, 174, 233–243. [Google Scholar] [CrossRef]
- Corzo Perez, G.A.; Muñoz-Arriola, F.; Yadava, R.N. (Eds.) Application of Remote Sensing and GIS in Natural Resources and Built Infrastructure Management; Water Science and Technology Library; Springer International Publishing: Cham, Switzerland, 2022; Volume 105. [Google Scholar]
- Woodward, H.; Schroeder, A.; de Nazelle, A.; Pain, C.C.; Stettler, M.E.J.; ApSimon, H.; Robins, A.; Linden, P.F. Do We Need High Temporal Resolution Modelling of Exposure in Urban Areas? A Test Case. Sci. Total Environ. 2023, 885, 163711. [Google Scholar] [CrossRef] [PubMed]
- Qu, L.; Chen, Z.; Li, M.; Zhi, J.; Wang, H. Accuracy Improvements to Pixel-Based and Object-Based LULC Classification with Auxiliary Datasets from Google Earth Engine. Remote Sens. 2021, 13, 453. [Google Scholar] [CrossRef]
- Bihamta, N.; Soffianian, A.; Fakheran, S.; Gholamalifard, M. Using the SLEUTH Urban Growth Model to Simulate Future Urban Expansion of the Isfahan Metropolitan Area, Iran. J. Indian Soc. Remote Sens. 2015, 43, 407–414. [Google Scholar] [CrossRef]
- Bununu, Y.A. Integration of Markov Chain Analysis and Similarity-Weighted Instance-Based Machine Learning Algorithm (SimWeight) to Simulate Urban Expansion. Int. J. Urban Sci. 2017, 21, 217–237. [Google Scholar] [CrossRef]
- Ziter, C.D.; Pedersen, E.J.; Kucharik, C.J.; Turner, M.G. Scale-Dependent Interactions between Tree Canopy Cover and Impervious Surfaces Reduce Daytime Urban Heat during Summer. Proc. Natl. Acad. Sci. USA 2019, 116, 7575–7580. [Google Scholar] [CrossRef]
- Smalling, K.L.; Lorah, M.; Allen, G.; Blaney, L.; Cantwell, M.; Fowler, L.; Ihde, T.F.; Mank, M.; Majcher, E.H.; Onyullo, G.; et al. Improving understanding and coordination of science activities for PFAS in the Chesapeake watershed. In STAC Workshop Report; Chesapeake Bay Science and Technical Advisory Committee (STAC): Lawrenceville, GA, USA, 2023. [Google Scholar]
- Gunawardena, K.R.; Wells, M.J.; Kershaw, T. Utilizing green and bluespace to mitigate urban heat island intensity. Sci. Total Environ. 2017, 584–585, 1040–1055. [Google Scholar] [CrossRef]
- Vujovic, S.; Haddad, B.; Karaky, H.; Sebaibi, N.; Boutouil, M. Urban Heat Island: Causes, Consequences, and Mitigation Measures with Emphasis on Reflective and Permeable Pavements. CivilEng 2021, 2, 459–484. [Google Scholar] [CrossRef]
- Newburn, D.; Semeraro, T.; Scarano, A.; Buccolieri, R.; Santino, A.; Aarrevaara, E. Planning of Urban Green Spaces: An Ecological Perspective on Human Benefits. Land 2021, 10, 105. [Google Scholar]
- Mutinova, P.T.; Kahlert, M.; Kupilas, B.; McKie, B.G.; Friberg, N.; Burdon, F.J. Benthic Diatom Communities in Urban Streams and the Role of Riparian Buffers. Water 2020, 12, 2799. [Google Scholar] [CrossRef]
- Hampton Roads Planning Region. Available online: https://www.deq.virginia.gov/coasts/coastal-planning-districts/hampton-roads (accessed on 10 February 2023).
- Tomer, M.D.; Porter, S.A.; James, D.E.; Boomer, K.M.B.; Kostel, J.A.; McLellan, E. Combining Precision Conservation Technologies into a Flexible Framework to Facilitate Agricultural Watershed Planning. J. Soil Water Conserv. 2013, 68, 113A–120A. [Google Scholar] [CrossRef]
- Chesapeake Bay Program Office (CBPO). One-meter Resolution Land Cover Change Dataset for the Chesapeake Bay Watershed, 2013/14 – 2017/18. Developed by the University of Vermont Spatial Analysis Lab, Chesapeake Conservancy, and U.S. Geological Survey. 2 October 2023. Available online: https://www.chesapeakeconservancy.org/conservation-innovation-center/high-resolution-data/lulc-data-project-2022/ (accessed on 17 January 2023).
- Lawless, N.M.; Lucas, R.E. Predictors of Regional Well-Being: A County Level Analysis. Soc Indic Res 2011, 101, 341–357. [Google Scholar] [CrossRef]
- Landis, J.D. Chapter 8 Urban Growth Models: State-of-the-Art and Prospects. In Global Urbanization; University of Pennsylvania Press: Philadelphia, PA, USA, 2011. [Google Scholar]
- McLachlan, A.; Defeo, O. Chapter 17—Management and Conservation. In The Ecology of Sandy Shores, 3rd ed.; McLachlan, A., Defeo, O., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 451–495. ISBN 9780128094679. [Google Scholar]
- Reed, S.; Berck, P.; Merenlender, A. Economics and Land-Use Change in Prioritizing Private Land Conservation. Conserv. Biol. 2005, 19, 1411–1420. [Google Scholar]
- Tian, Y.; Yin, K.; Lu, D.; Hua, L.; Zhao, Q.; Wen, M. Examining Land Use and Land Cover Spatiotemporal Change and Driving Forces in Beijing from 1978 to 2010. Remote Sens. 2014, 6, 10593–10611. [Google Scholar] [CrossRef]
- Popp, A.; Humpenöder, F.; Weindl, I.; Bodirsky, B.L.; Bonsch, M.; Lotze-Campen, H.; Müller, C.; Biewald, A.; Rolinski, S.; Stevanovic, M.; et al. Land-use protection for climate change mitigation. Nat. Clim Change 2014, 4, 1095–1098. [Google Scholar] [CrossRef]
- Sims, K.R.E.; Thompson, J.R.; Meyer, S.R.; Nolte, C.; Plisinski, J.S. Assessing the local economic impacts of land protection. Conserv. Biol. 2019, 33, 1035–1044. [Google Scholar] [CrossRef]
- Rimal, B.; Zhang, L.; Keshtkar, H.; Haack, B.N.; Rijal, S.; Zhang, P. Land Use/Land Cover Dynamics and Modeling of Urban Land Expansion by the Integration of Cellular Automata and Markov Chain. ISPRS Int. J. Geo-Inf. 2018, 7, 154. [Google Scholar] [CrossRef]
- Hamad, R.; Balzter, H.; Kolo, K. Predicting Land Use/Land Cover Changes Using a CA-Markov Model under Two Different Scenarios. Sustainability 2018, 10, 3421. [Google Scholar] [CrossRef]
- Asif, M.; Kazmi, J.H.; Tariq, A.; Zhao, N.; Guluzade, R.; Soufan, W.; Almutairi, K.F.; Sabagh, A.E.; Aslam, M. Modelling of Land Use and Land Cover changes and prediction using CA-Markov and Random Forest. Geocarto Int. 2023, 38, 2210532. [Google Scholar] [CrossRef]
- Liping, C.; Yujun, S.; Saeed, S. Monitoring and predicting land use and land cover changes using remote sensing and GIS techniques—A case study of a hilly area, Jiangle, China. PLoS ONE 2018, 13, e0200493. [Google Scholar] [CrossRef]
- Mu, L.; Wang, L.; Wang, Y.; Chen, X.; Han, W. Urban Land Use and Land Cover Change Prediction via Self-Adaptive Cellular Based Deep Learning With Multisourced Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5233–5247. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Zhang, Y.; Zhou, P.; Wang, Y.; Shi, L.; Jiang, L.; Ling, F.; Du, Y. Spatiotemporal Continuous Impervious Surface Mapping by Fusion of Landsat Time Series Data and Google Earth Imagery. Remote Sens. 2021, 13, 2409. [Google Scholar] [CrossRef]
- Jantz, P.; Goetz, S.; Jantz, C. Urbanization and the Loss of Resource Lands in the Chesapeake Bay Watershed. Environ. Manag. 2005, 36, 808–825. [Google Scholar] [CrossRef] [PubMed]
- Ator, S.W.; Blomquist, J.D.; Webber, J.S.; Chanat, J.G. Factors driving nutrient trends in streams of the Chesapeake Bay watershed. J. Environ. Qual. 2020, 49, 508–524. [Google Scholar] [CrossRef]
- Goetz, S.J.; Jantz, C.A.; Prince, S.D.; Smith, A.J.; Varlyguin, D.; Wright, R.K. Integrated Analysis of Ecosystem Interactions with Land Use Change: The Chesapeake Bay Watershed. Ecosyst. Land Use Change 2004, 153, 263–275. [Google Scholar]
- Brent, D.A.; Gangadharan, L.; Lassiter, A.; Leroux, A.; Raschky, P.A. Valuing environmental services provided by local stormwater management. Water Resour. Res. 2017, 53, 4907–4921. [Google Scholar] [CrossRef]
- Jayasooriya, V.M.; Ng, A.W.M. Tools for Modeling of Stormwater Management and Economics of Green Infrastructure Practices: A Review. Water Air Soil Pollut. 2014, 225, 2055. [Google Scholar] [CrossRef]
- Turner, D.P.; Ollinger, S.V.; Kimball, J.S. Integrating Remote Sensing and Ecosystem Process Models for Landscape- to Regional-Scale Analysis of the Carbon Cycle. BioScience 2004, 54, 573–584. [Google Scholar] [CrossRef]
- Hesselbarth, M.H.K.; Nowosad, J.; Signer, J.; Graham, L.J. Open-Source Tools in R for Landscape Ecology. Curr. Landsc. Ecol. Rep. 2021, 6, 97–111. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, L.; Chiew, F.; Fu, B. Understanding the impacts of climate and land use change on water yield. Curr. Opin. Environ. Sustain. 2018, 33, 167–174. [Google Scholar] [CrossRef]
- Behr, J.G. Quality of Life in Hampton Roads, The Future of Hampton Roads Committee on Regional Priorities WHRO Studios; Social Science Research Center: Norfolk, VA, USA, 2004. [Google Scholar]
- Agboola, O.P.; Bashir, F.M.; Dodo, Y.A.; Mohamed, M.A.; Alsadun, I.S. The influence of information and communication technology (ICT) on stakeholders’ involvement and smart urban sustainability. Environ. Adv. 2023, 13, 100431. [Google Scholar] [CrossRef]
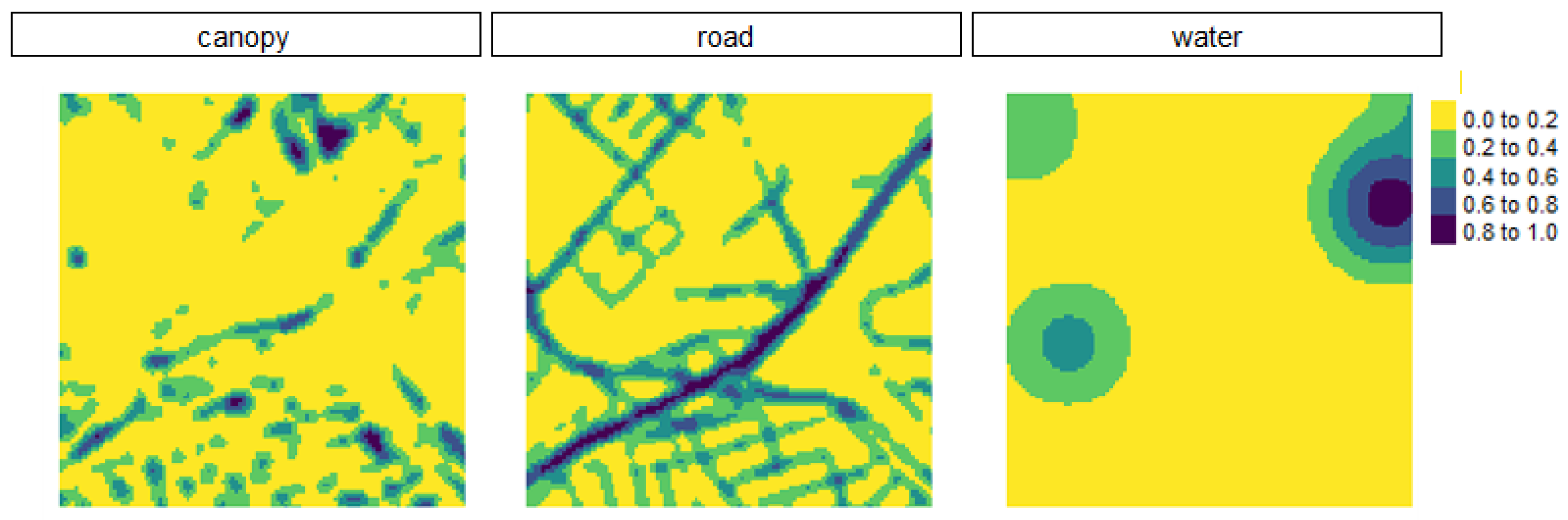



| Factors | Features |
|---|---|
| Socioeconomic factors 1 | Population change |
| Pct of white change | |
| Unitchange | |
| MedHHIncchange | |
| Environmental factors | Slope |
| Dem | |
| Soil Type | |
| Spatial Lag factors 2 | |
| Land cover factors | road |
| canopy | |
| water |
| County Names | Portsmouth | James City | Isle of Wight |
|---|---|---|---|
| Land Area (sq mi) | 46.75 | 178.72 | 362.86 |
| Impervious Area (2018) (sq mi) | 13.9 | 15 | 15.2 |
| Impervious Percentage | 29.80% | 8.40% | 4.20% |
| Population (2018) | 95,311 | 74,153 | 36,372 |
| Population Density (people/sq mi) | 2038.7 | 414.9 | 100.2 |
| Median Household Income (USD) | 48,577.89 | 88,701 | 74,591.75 |
| Percentage of White Population | 41.40% | 80% | 75.20% |
| Population Change Rate | −0.70% | 6.20% | 2.40% |
| Task | Data | Resolution | Model | Accuracy |
|---|---|---|---|---|
| LULC Classification | Landsat-8 OLI | 30 m | Random Forest | 96.01% |
| Urban Land Expansion | Landsat-8 OLI | 30 m | Cellular Automata and Markov Chain | 90.0 ± 1% |
| Land Use and Land Cover Change | Landsat (TM) 5, (ETM+) 7 and (OLI) 9 | 30 m | Neural Network | 93% |
| Impervious Surface Detection | Landsat Time Series Data and Google Earth Imagery | 5 m | Bayesian-STSRM and STCISM | 90–95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Li, K.; Dai, Y.; Yi, S. Modeling the Land Cover Change in Chesapeake Bay Area for Precision Conservation and Green Infrastructure Planning. Remote Sens. 2024, 16, 545. https://doi.org/10.3390/rs16030545
Zhang X, Li K, Dai Y, Yi S. Modeling the Land Cover Change in Chesapeake Bay Area for Precision Conservation and Green Infrastructure Planning. Remote Sensing. 2024; 16(3):545. https://doi.org/10.3390/rs16030545
Chicago/Turabian StyleZhang, Xinge, Kenan Li, Yuewen Dai, and Shujing Yi. 2024. "Modeling the Land Cover Change in Chesapeake Bay Area for Precision Conservation and Green Infrastructure Planning" Remote Sensing 16, no. 3: 545. https://doi.org/10.3390/rs16030545
APA StyleZhang, X., Li, K., Dai, Y., & Yi, S. (2024). Modeling the Land Cover Change in Chesapeake Bay Area for Precision Conservation and Green Infrastructure Planning. Remote Sensing, 16(3), 545. https://doi.org/10.3390/rs16030545