
A Full-Scale Shadow Detection Network Based on Multiple Attention Mechanisms for Remote-Sensing Images

 , , , , , and
, , , , , and
Abstract
1. Introduction
- (1)
- Decreased accuracy in shadow detection across different scales: As shown in Figure 1a, the varying scales and morphological features of different objects in the image result in diverse scale differences in shadows, thereby affecting the current network’s accuracy in shadow detection across different scales.
- (2)
- False detection in non-shadow regions: As shown in Figure 1b, the image contains some dark objects, such as cars and roads, whose spectral information and texture structures closely resemble shadows, thus easily leading to false detection as shadows.
- (1)
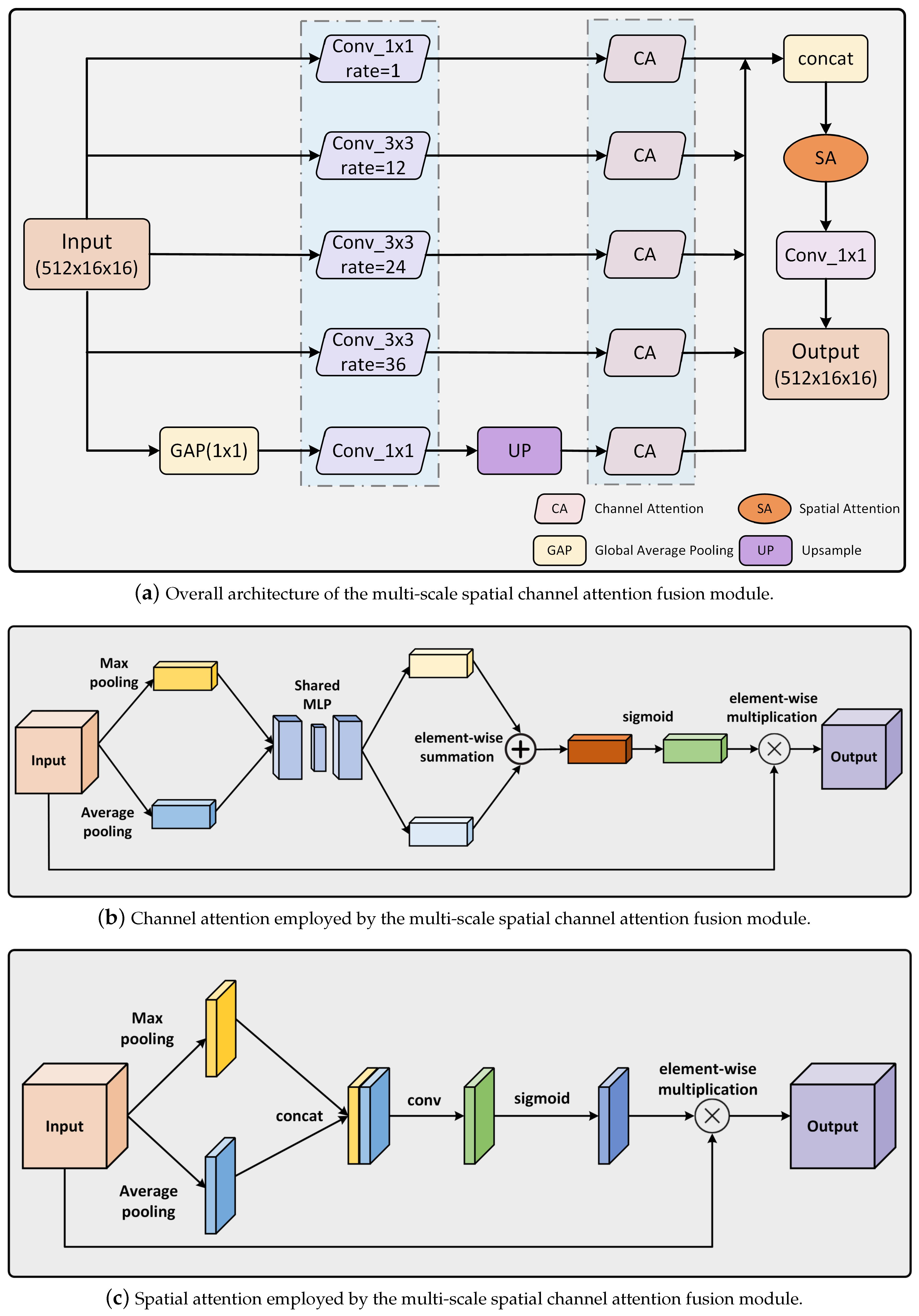
- We proposed a multi-scale spatial channel attention fusion module that fully exploited the deep features extracted by the encoder, accurately capturing the shadow positions, shapes, and channel information across different scales in shadow images, enabling the model to handle shadows of various scales with greater flexibility and effectively reducing the impact of scale differences.
- (2)
- By introducing the criss-cross attention module, non-shadow pixels were compared with other shadow and non-shadow pixels in the same row and column, learning similar characteristics of pixels in the same category, which improved the classification accuracy of non-shadow pixels and avoided false detections in non-shadow areas.
- (3)
- To address the issue of important information from the other two modules being lost due to continuous upsampling during the decoding phase, we proposed an auxiliary branch module to assist the main branch in decision-making, which ensured that the final output retained key information from all stages.
- (4)
- Experimental validation was conducted on the AISD dataset, showcasing the superior performance of MAMNet compared to existing state-of-the-art methods. Additionally, visualization results indicated that our model could effectively detect shadows of various scales while avoiding false detection in non-shadow areas.
2. Materials and Methods
2.1. Data Preprocessing
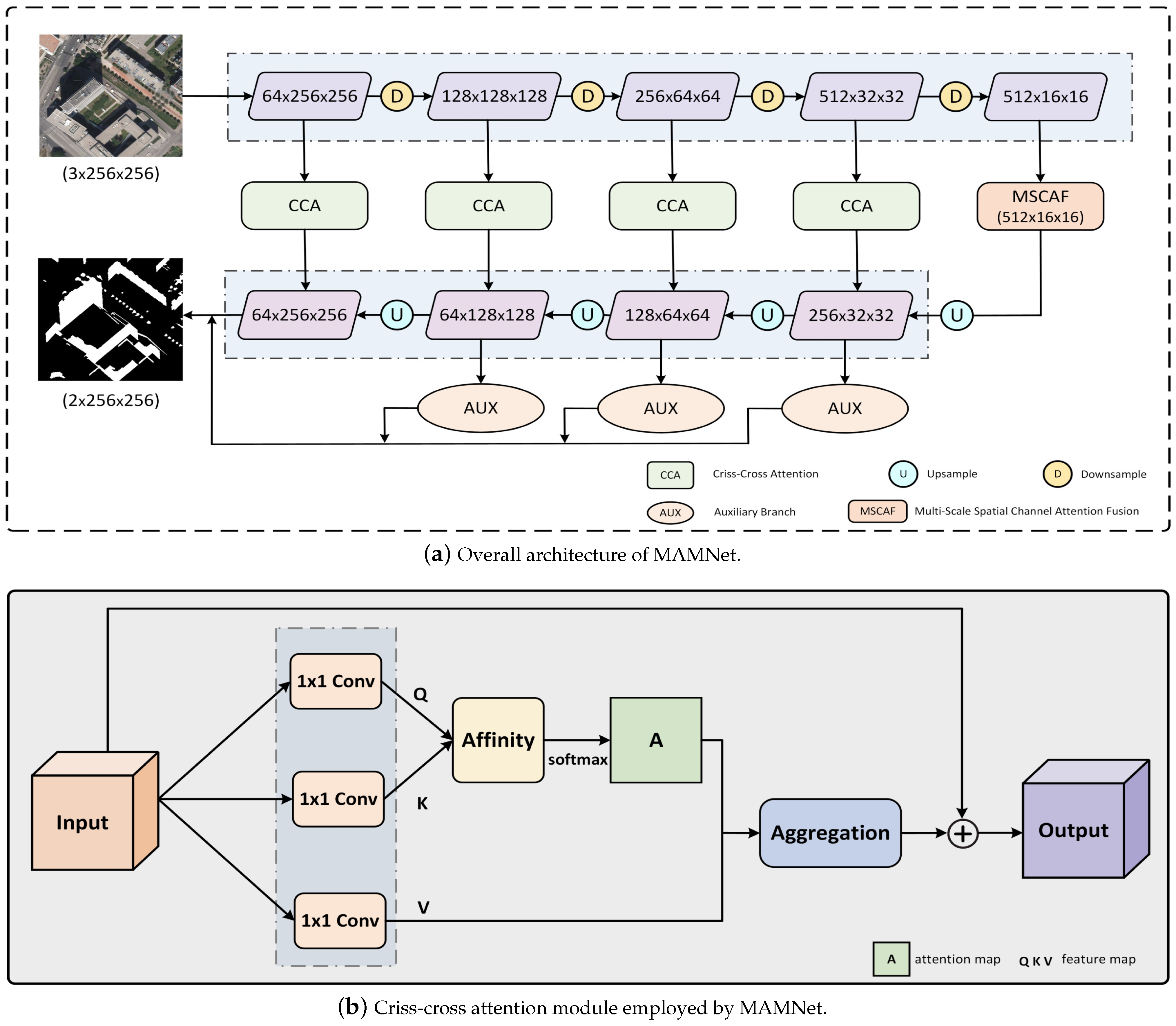
2.2. Method Overview
2.3. Multi-Scale Spatial Channel Attention Fusion Module
2.4. Criss-Cross Attention Module
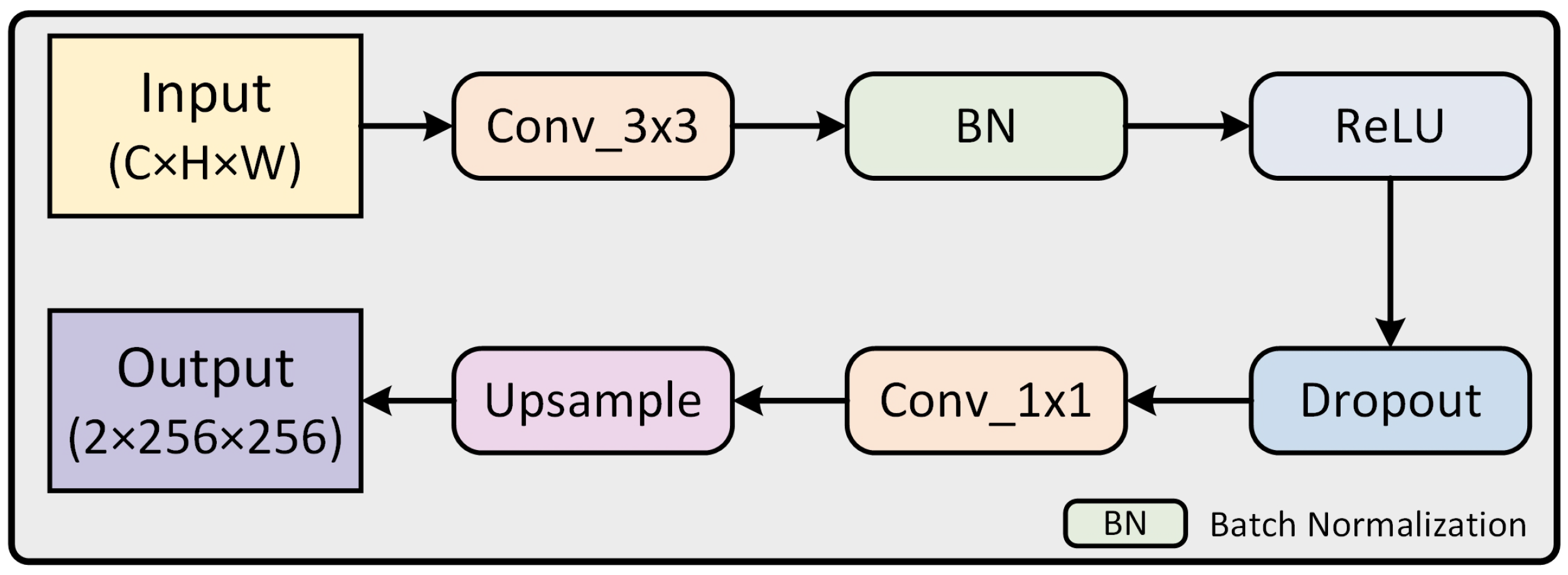
2.5. Auxiliary Branch Module
3. Experiments and Analysis
3.1. Dataset and Implementation Details
3.2. Ablation Study
3.3. Quantitative Analysis
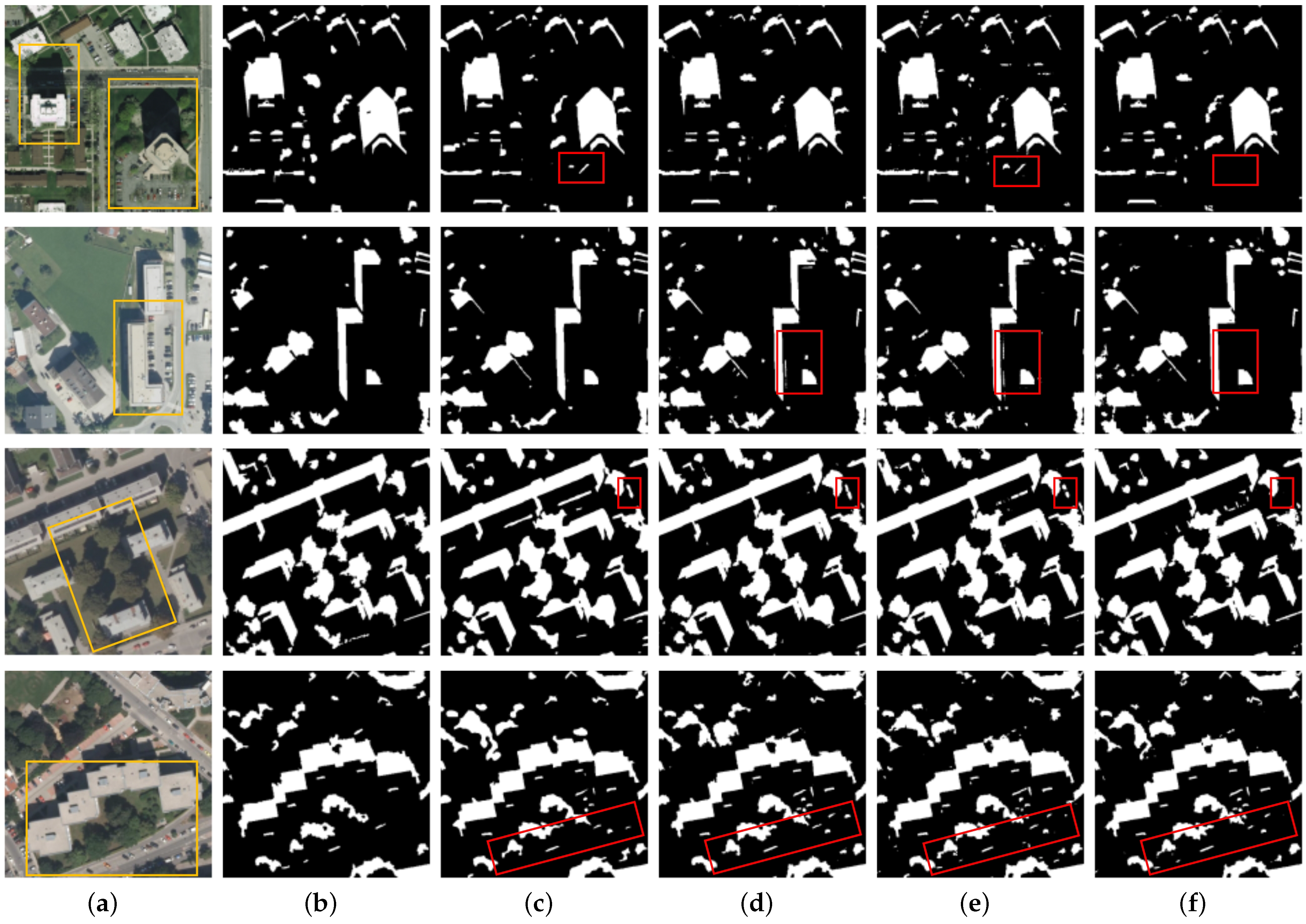
3.4. Qualitative Analysis
4. Discussion
4.1. Advantages of the Proposed Method
4.2. Limitations and Further Improvements
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shimoni, M.; Tolt, G.; Perneel, C.; Ahlberg, J. Detection of Vehicles in Shadow Areas. In Proceedings of the 2011 3rd Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Lisbon, Portugal, 6–9 June 2011; pp. 1–4. [Google Scholar]
- Chen, M.; Pang, S.K.; Cham, T.J.; Goh, A. Visual Tracking with Generative Template Model Based on Riemannian Manifold of Covariances. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- Li, H.; Zhang, L.; Shen, H. An Adaptive Nonlocal Regularized Shadow Removal Method for Aerial Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 106–120. [Google Scholar] [CrossRef]
- Liu, J.; Fang, T.; Li, D. Shadow Detection in Remotely Sensed Images Based on Self-Adaptive Feature Selection. IEEE Trans. Geosci. Remote Sens. 2011, 49, 5092–5103. [Google Scholar]
- Elbakary, M.I.; Iftekharuddin, K.M. Shadow Detection of Man-Made Buildings in High-Resolution Panchromatic Satellite Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5374–5386. [Google Scholar] [CrossRef]
- Silva, G.F.; Carneiro, G.B.; Doth, R.; Amaral, L.A.; Azevedo, D.F.G.D. Near Real-Time Shadow Detection and Removal in Aerial Motion Imagery Application. ISPRS J. Photogramm. Remote Sens. 2018, 140, 104–121. [Google Scholar] [CrossRef]
- Li, D.; Wang, M.; Jiang, J. China’s High-Resolution Optical Remote Sensing Satellites and Their Mapping Applications. Geo-Spat. Inf. Sci. 2020, 24, 85–94. [Google Scholar] [CrossRef]
- Li, D.; Wang, S.; Xiang, S.; Li, J.; Yang, Y.; Tang, X.-S. Dual-Stream Shadow Detection Network: Biologically Inspired Shadow Detection for Remote Sensing Images. Neural Comput. Appl. 2022, 34, 10039–10049. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q.; Zhang, Y.; Du, X.; Wang, H. Two-Step Urban Water Index (TSUWI): A New Technique for High-Resolution Mapping of Urban Surface Water. Remote Sens. 2018, 10, 1704. [Google Scholar] [CrossRef]
- Xie, C.; Huang, X.; Zeng, W.; Fang, X. A Novel Water Index for Urban High-Resolution Eight-Band WorldView-2 Imagery. Int. J. Digit. Earth 2016, 10, 925–941. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. CPNet: A Context Preserver Convolutional Neural Network for Detecting Shadows in Single RGB Images. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar]
- Luo, S.; Shen, H.; Li, H.; Chen, Y. Shadow Removal Based on Separated Illumination Correction for Urban Aerial Remote Sensing Images. Signal Process. 2019, 165, 197–208. [Google Scholar] [CrossRef]
- Liasis, G.; Stavrou, S. Satellite Images Analysis for Shadow Detection and Building Height Estimation. ISPRS J. Photogramm. Remote Sens. 2016, 119, 437–450. [Google Scholar] [CrossRef]
- Xie, Y.; Feng, D.; Xiong, S.; Zhu, J.; Liu, Y. Multi-Scene Building Height Estimation Method Based on Shadow in High Resolution Imagery. Remote Sens. 2021, 165, 2862. [Google Scholar] [CrossRef]
- Xue, L.; Yang, S.; Li, Y.; Ma, J. An Automatic Shadow Detection Method for High-Resolution Remote Sensing Imagery Based on Polynomial Fitting. Int. J. Remote Sens. 2018, 40, 2986–3007. [Google Scholar] [CrossRef]
- Kang, X.; Huang, Y.; Li, S.; Lin, H.; Benediktsson, J.A. Extended Random Walker for Shadow Detection in Very High Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 867–876. [Google Scholar] [CrossRef]
- Xie, Y.; Feng, D.; Chen, H.; Liao, Z.; Zhu, J.; Li, C.; Baik, S.W. An Omni-Scale Global-Local Aware Network for Shadow Extraction in Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2022, 193, 29–44. [Google Scholar] [CrossRef]
- Li, Y.; Gong, P.; Sasagawa, T. Integrated Shadow Removal Based on Photogrammetry and Image Analysis. Int. J. Remote Sens. 2007, 26, 3911–3929. [Google Scholar] [CrossRef]
- Tolt, G.; Shimoni, M.; Ahlberg, J. A Shadow Detection Method for Remote Sensing Images Using VHR Hyperspectral and LIDAR Data. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium, Vancouver, BC, Canada, 24–29 July 2011; pp. 4423–4426. [Google Scholar]
- Wang, Q.; Yan, L.; Yuan, Q.; Ma, Z. An Automatic Shadow Detection Method for VHR Remote Sensing Orthoimagery. Remote Sens. 2017, 9, 469. [Google Scholar] [CrossRef]
- Mostafa, Y. A Review on Various Shadow Detection and Compensation Techniques in Remote Sensing Images. Can. J. Remote Sens. 2017, 43, 545–562. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-Feature Combined Cloud and Cloud Shadow Detection in GaoFen-1 Wide Field of View Imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Ma, H.; Qin, Q.; Shen, X. Shadow Segmentation and Compensation in High Resolution Satellite Images. In Proceedings of the 2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 7–11 July 2008; pp. 1036–1039. [Google Scholar]
- Song, H.; Huang, B.; Zhang, K. Shadow Detection and Reconstruction in High-Resolution Satellite Images Via Morphological Filtering and Example-Based Learning. Remote Sens. Environ. 2014, 52, 2545–2554. [Google Scholar] [CrossRef]
- Lorenzi, L.; Melgani, F.; Mercier, G. A Complete Processing Chain for Shadow Detection and Reconstruction in VHR Images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3440–3452. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized Self-Attention: Towards High-Quality Pixel-Wise Mapping. Neurocomputing 2022, 506, 158–167. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; Springer International Publishing: Cham, Switzerland, 2018; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder–Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- He, Z.; Zhang, Z.; Guo, M.; Wu, L.; Huang, Y. Adaptive Unsupervised Shadow-Detection Approach for Remote-Sensing Image Based on Multi Channel Features. Remote Sens. 2022, 14, 2756. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, L.; Wan, L.; Wang, S.; Feng, W.; Heng, P. A Multi Task Mean Teacher for Semi-Supervised Shadow Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5610–5619. [Google Scholar]
- Luo, S.; Li, H.; Shen, H. Deeply Supervised Convolutional Neural Network for Shadow Detection Based on a Novel Aerial Shadow Imagery Dataset. ISPRS J. Photogramm. Remote Sens. 2020, 167, 443–457. [Google Scholar] [CrossRef]
- Jin, Y.; Xu, W.; Hu, Z.; Jia, H.; Luo, X.; Shao, D. GSCA-UNet: Towards Automatic Shadow Detection in Urban Aerial Imagery with Global-Spatial-Context Attention Module. Remote Sens. 2020, 12, 2864. [Google Scholar] [CrossRef]
- Luo, S.; Li, H.; Zhu, R.; Gong, Y.; Shen, H. ESPFNet: An Edge-Aware Spatial Pyramid Fusion Network for Salient Shadow Detection in Aerial Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4633–4646. [Google Scholar] [CrossRef]
- Zhu, Q.; Yang, Y.; Sun, X.; Guo, M. CDANet: Contextual Detail-Aware Network for High-Spatial-Resolution Remote-Sensing Imagery Shadow Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617415. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, J.; Wu, Y.; Zhang, Y. A Shadow Detection Algorithm Based on Multiscale Spatial Attention Mechanism for Aerial Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6003905. [Google Scholar] [CrossRef]
- Zhang, S.; Cao, Y.; Sui, B. DTHNet: Dual-Stream Network Based on Transformer and High-Resolution Representation for Shadow Extraction from Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8000905. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, X.; Zheng, C.; Wu, J.; Li, Y. MRPFA-Net for Shadow Detection in Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5514011. [Google Scholar] [CrossRef]
- Chen, H.; Feng, D.; Cao, S.; Xu, W.; Xie, Y.; Zhu, J.; Zhang, H. Slice-to-Slice Context Transfer and Uncertain Region Calibration Network for Shadow Detection in Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2023, 203, 166–182. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | OA (%) | Precision (%) | F1 Score (%) | BER (%) | IOU (%) |
|---|---|---|---|---|---|
| w/o MSCAF | 97.28 | 93.45 | 93.55 | 3.99 | 87.95 |
| w/o CCA | 97.37 | 94.76 | 93.74 | 4.25 | 88.28 |
| w/o AUX | 97.20 | 93.32 | 93.41 | 4.07 | 87.72 |
| MAMNet (Ours) | 97.50 | 95.06 | 94.07 | 4.05 | 88.87 |
| Methods | OA (%) | Precision (%) | F1 Score (%) | BER (%) | IOU (%) |
|---|---|---|---|---|---|
| w/o SA and CA | 97.33 | 94.19 | 93.64 | 4.12 | 88.12 |
| w/o MFE | 97.37 | 94.69 | 93.75 | 4.23 | 88.30 |
| MSCAF | 97.50 | 95.06 | 94.07 | 4.05 | 88.87 |
| Methods | OA (%) | Precision (%) | F1 Score (%) | BER (%) | IOU (%) |
|---|---|---|---|---|---|
| CA | 97.35 | 94.76 | 93.71 | 4.28 | 88.25 |
| SA | 97.38 | 94.36 | 93.74 | 4.09 | 88.30 |
| CCA | 97.50 | 95.06 | 94.07 | 4.05 | 88.87 |
| Methods | OA (%) | Precision (%) | F1 Score (%) | BER (%) | IOU (%) |
|---|---|---|---|---|---|
| One Branch | 97.34 | 93.52 | 93.62 | 3.93 | 88.10 |
| Two Branches | 97.36 | 93.45 | 93.70 | 3.81 | 88.23 |
| Three Branches | 97.50 | 95.06 | 94.07 | 4.05 | 88.87 |
| Methods | OA (%) | Precision (%) | F1 Score (%) | BER (%) | IOU (%) |
|---|---|---|---|---|---|
| PSPNet | 96.88 | 93.41 | 92.61 | 4.89 | 86.33 |
| MTMT | - | - | 90.68 | - | - |
| DSSDNet | 95.57 | - | 91.79 | 6.24 | - |
| GSCA-UNet | 96.29 | - | 91.69 | 5.51 | 84.88 |
| CADNet | - | - | 91.21 | - | - |
| ESPFNet | - | - | 92.04 | - | - |
| ECANet | 97.22 | 92.56 | 93.45 | 3.78 | 87.77 |
| CDANet | - | - | 92.41 | - | - |
| DLA-PSO | 94.90 | - | 88.73 | - | - |
| MSASD | 96.89 | 92.10 | 92.70 | 4.35 | 86.46 |
| MRPFA-Net | 96.11 | - | 92.60 | 5.42 | 86.24 |
| DTHNet | 96.15 | - | 91.71 | - | 84.70 |
| SCUCNet | - | - | 93.80 | - | 88.33 |
| MAMNet (Ours) | 97.50 | 95.06 | 94.07 | 4.05 | 88.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Zhang, Q.; Wu, Y.; Zhang, Y.; Xiang, S.; Xie, D.; Wang, Z. A Full-Scale Shadow Detection Network Based on Multiple Attention Mechanisms for Remote-Sensing Images. Remote Sens. 2024, 16, 4789. https://doi.org/10.3390/rs16244789
Zhang L, Zhang Q, Wu Y, Zhang Y, Xiang S, Xie D, Wang Z. A Full-Scale Shadow Detection Network Based on Multiple Attention Mechanisms for Remote-Sensing Images. Remote Sensing. 2024; 16(24):4789. https://doi.org/10.3390/rs16244789
Chicago/Turabian StyleZhang, Lei, Qing Zhang, Yu Wu, Yanfeng Zhang, Shan Xiang, Donghai Xie, and Zeyu Wang. 2024. "A Full-Scale Shadow Detection Network Based on Multiple Attention Mechanisms for Remote-Sensing Images" Remote Sensing 16, no. 24: 4789. https://doi.org/10.3390/rs16244789
APA StyleZhang, L., Zhang, Q., Wu, Y., Zhang, Y., Xiang, S., Xie, D., & Wang, Z. (2024). A Full-Scale Shadow Detection Network Based on Multiple Attention Mechanisms for Remote-Sensing Images. Remote Sensing, 16(24), 4789. https://doi.org/10.3390/rs16244789