1. Introduction
Automatic road extraction from remote sensing images plays an important role in road network planning, traffic control and management, etc. Compared to the traditional algorithms that focus on hand-crafted features to extract roads [
1,
2,
3], deep-learning-based models [
4,
5,
6] have achieved a satisfactory accuracy in the task of automatic road extraction from remote sensing imagery [
7,
8] in an economic and effective way. There are two main deep learning strategies for this task: (1) graph-based approaches [
9,
10,
11,
12,
13,
14,
15,
16,
17], and (2) segmentation-based approaches [
18,
19,
20,
21,
22].
Graph-based methods have gained popularity recently, which could enhance the topological correctness of roads and consequently improve the completeness of predicted road results. In comparison to methods that use intermediate representations like mask images, they directly predict graph nodes and edges in a vectorized form. An autoregressive approach is utilized in graph-based methods to construct road graphs incrementally, which, however, makes it difficult to parallelize as this approach relies on the outcomes of previous steps. Although keypoint-based graph representations have exhibited an outstanding performance, many methods of this type face a considerable drawback in terms of the substantial training cost. This high training cost can be traced back to the oversampling strategy which is utilized in defining the so-called “key points” in the graph annotations.
The segmentation-based methods are characterized by the classification of each pixel in the images by drawing different colors to different categories. These methods can be categorized into two primary types: those based on Transformers and those based on convolutional neural networks (CNNs).
Since the emergence of Vision Transformers (ViTs) [
23,
24], they have demonstrated remarkable proficiency in a diverse array of vision tasks and have contributed pioneering concepts for the design of vision networks, so the application of ViTs in road extraction tasks has become pervasive. Due to the self-attention mechanism, ViTs differ from traditional convolutional networks in their capacity for long-range context modeling. However, in contrast to natural image segmentation tasks, road extraction tasks require the model to pay more attention to local or relatively large receptive fields rather than the global context information. As shown in
Figure 1, in the context of natural images, a large receptive field is a requisite for recognizing the horse and the girl. Conversely, in the domain of remote sensing images, road detection merely necessitates the utilization of a local window. Some works combine CNNs and Transformers to simultaneously capture local and global interactions. C
2net [
25] adopted the pre-trained ResNet34 as the encoder, and Swin-Transformer blocks were used in the sub-module in order to merge the convolution and the Transformer network to utilize the advantages of both networks. However, it is essential to acknowledge that the implementation of shifted window self-attention in Swin-Transformer demands sophisticated engineering, which includes the rewriting of CUDA codes.
Most recently, it has been demonstrated in several studies [
26,
27,
28] that a pure CNN can attain satisfactory results as well as ViTs and graph-based methods [
25]. Firstly, CNNs inherently excel at capturing local spatial patterns and hierarchical features through the convolutional layers, which is crucial for delineating intricate road networks from high-resolution imagery. This localized feature extraction capability allows CNNs to effectively discern fine-grained details such as road edges, textures and connectivity, which are often challenging for graph-based methods that rely on the predefined graph structures and may struggle with capturing subtle spatial variations. Secondly, CNNs are more computationally efficient during inference compared to ViTs, since ViTs require substantial computational resources due to their self-attention mechanisms, making them less practical for large-scale, high-resolution datasets. Additionally, CNNs benefit from extensive architectural optimizations, enabling them to achieve robust performance with relatively fewer data requirements compared to ViTs and graph-based approaches. Overall, CNNs offer a balanced combination of precision, efficiency and scalability, making them particularly well suited for high-resolution road extraction tasks.
Drawing inspiration from the SOTA CNN models [
25,
26,
28], a range of progressively intricate approaches based on increasingly sophisticated CNN architectures have been steadily enhancing their performance on well-established benchmark road extraction datasets. However, these methods that rely on dense connectivity cannot realize the effective interaction of full-scale features. In addition, these models require high-performance devices for training, which limit their practical applications.
In this paper, we adopt a reflective stance and delve into the actual requirements underlying the complexity of current models. To the best of our knowledge, current road detection datasets [
29,
30] contain thousands of image pairs, which are far from sufficient compared to natural image datasets [
31,
32]. For datasets like ImageNet [
32], the scale of the images is often limited to an individual or a small number of objects, where global context is more important for feature representation. In contrast, in remote sensing imagery, the scale of each object is generally smaller, making the acquisition of global features less meaningful. Instead, local features become more critical, which is why CNN models offer a significant advantage over Transformer-based models on remote sensing imagery processing tasks. Due to the translation equivariance and locality characteristics, CNNs can generalize better when trained on insufficient amounts of data like that in road detection datasets.
In light of the fact that current models are confronted with challenges pertaining to hefty computational demands, it is imperative to design lightweight networks without compromising high accuracy. Considering the special features of the task, the model should have a relatively large receptive field while preserving the detailed spatial information. To this end, we propose a simplified approach that employs a single convolutional layer in lieu of the traditional convolutional blocks in classic CNN architectures. To ensure the preservation of fine-grained road details and mitigate information loss during downsampling operations, we only perform downsampling twice, while four downsampling layers are adopted in conventional models. However, a pivotal challenge arises: the reduced downsampling operation results in a smaller receptive field and a higher number of FLOPs of the model, making it difficult to capture the elongated distribution characteristics of roads. To address this limitation, we incorporate dilated convolution that can enlarge the receptive field without sacrificing the spatial resolution. Despite its advantages, it could introduce gridding artifacts, leading to a detrimental effect on the performance of CNNs. To address these issues, we draw inspiration from the concept of smoothed dilated convolution [
33], stacking this block six times and effectively resolving the aforementioned problems. In addition, to fuse the different levels of features, we further propose an attention-guided feature fusion module to determine the importance of features of different levels and aggregate them based on their corresponding importance maps. Only a single convolutional layer is used to learn the attention maps of different levels and feature fusion is processed via element-wise multiplication. In this way, a simple encoder–decoder architecture is constructed, dubbed as Effi-RoadNet. Since the encoder of the network contains only 17 convolutional layers, which is lightweight but might suggest a limited representational ability of the model, we cascade this encoder–decoder architecture twice to enhance its feature representation ability with an acceptable increase in complexity. The encouraging results obtained by the model on two benchmark datasets demonstrate its efficacy, concurrently ensuring that the complexity remains at a minimal level. The contributions can be summarized as follows:
- (1)
We introduce a simple yet effective Effi-RoadNet, which utilizes smoothed dilated convolution to mitigate gridding artifacts and incorporates an attention-guided feature fusion subnetwork to aggregate features from different levels.
- (2)
We propose a straightforward extension, dubbed as CE-RoadNet, which further improves the feature representation ability for effective road network detection, and achieves superior performance on established benchmark datasets.
- (3)
We evaluate our CE-RoadNet against baseline methods on two large-scale public datasets, demonstrating its superior performance.
The rest of the contents of this article are structured as follows:
Section 2 introduces the related works about road extraction tasks.
Section 3 provides a comprehensive description of CE-RoadNet, including the design of the attention-guided feature fusion module and Effi-RoadNet.
Section 4 showcases the experiments validating the effectiveness and generalization capability of the proposed approach across various datasets.
Section 5 presents our conclusions.
2. Related Works
2.1. Road Extraction Using ViTs
Roads are widely distributed and slender in remote sensing images. This characteristic often renders traditional methods deficient in terms of global context perception and localization accuracy. The Transformer architecture has demonstrated remarkable proficiency in capturing global information and making use of contextual cues from the input imagery. In recent years, a plethora of methods based on Vision Transformers have been put forward for road extraction tasks. Nevertheless, only a handful of them rely solely on ViTs, since they lack the spatial inductive bias and demand excessive data and computational resources.
By integrating ViTs into a CNN architecture, most methods enable the Transformer to interact with other components, thereby collaboratively accomplishing the task of road extraction [
13,
34,
35,
36,
37]. Ge et al. [
34] integrated the Swin-Transformer, which is known for its efficient multi-head and shifted window self-attention, into a U-shaped architecture to boost global learning. The Swin-Transformer was utilized in TransRoadNet [
35] to downsample the feature maps. A Transformer-based approach, presented by Zhang et al. [
36], comes with modules dedicated to the extraction of detailed road features as well as the fusion of global/local contexts. Yang et al. [
37] proposed SSEANet, in which the CNN and Swin-Transformer are jointly trained with consistency loss to enhance their cross-supervised capabilities. ResUNetFormer [
38] proposed a deep semantic segmentation neural network that utilizes the abilities of residual learning, HetConvs, UNet and vision transformers. Hetang et al. [
9] made use of the intrinsic strengths of the Segment Anything Model, which adopts Transformers as a special form of graph convolutional network. A Vit-B SAM model is used as the backbone, and two decoders are adopted to predict the road map, vertex and road topology. RNGDet++ [
13] employed a DETR-like Transformer network to fully utilize its multi-scale features. Training this model on a moderately sized dataset consisting of thousands of images demands approximately 192 GPU hours. In general, the combination of self-attention and Conv-blocks can strike a balance between efficiency and effectiveness, but these approaches still need a substantial training cost.
Transformer-based models exhibit several disadvantages in road extraction. Firstly, they possess high computational complexity, entailing long training/inference times and stringent hardware requirements. Secondly, they rely heavily on large-scale, high-quality datasets, since insufficient or poor data can trigger overfitting and limit generalization. Thirdly, while being good at capturing long-distance dependencies, these models are weak in delineating local road features precisely. Finally, their intricate structures result in poor interpretability, complicating debugging and result evaluation.
2.2. Graph-Based Neural Architectures
To better preserve the connectivity of roads, some methods perform preprocessing on ground truth road maps. They convert these images into graph-structured data consisting of nodes and edges, which can better showcase the linear connectivity characteristics of roads [
10,
11,
12,
13,
14,
15,
16,
17]. Batra et al. [
14] propose a muti-branch CNN model to jointly learn orientation and per-pixel segmentation, thereby improving road connectivity. They also design a connectivity refinement mechanism that closes the gaps in the prediction. Vecroad [
16] employ a point-based iterative graph exploration scheme. The core of this method lies in maintaining the precise alignment between the graph and the actual roads through segmentation-cue guidance and flexible step sizes. Zao et al. [
17] predict vectorized representations by employing decoupled lightweight network branches. This method circumvents the need for a computationally intensive tracking framework or the use of heavy graph tensors, thereby enhancing efficiency and performance. Xu et al. [
39] present a novel approach to computing vector road maps from satellite remotely sensed images, building upon a well-defined Patched Line Segment (PaLiS) representation for road graphs that holds geometric significance. To improve the accuracy and integrity of road network structures, various methods have been developed to refine road topology. They form multi-task branches by integrating CNNs with graph-based approaches. This integration ensures the preservation of contextual semantic information while maintaining the connectivity of roads. For instance, within an encoder–decoder framework, Li et al. [
40] design a multi-task architecture that can concurrently predict the connectivity and segmentation of road maps. Zhang et al. [
41] propose to extract road nodes and infer the connectivity between them. By learning the confidence map and the connectivity map for the nodes, the model predicts road nodes through a multi-task framework. With a GCN-based dual-view perceptor at its core, RDPGNet [
42] integrates a CNN and a GCN to promote the exchange of multi-scale information.
Graph-based models, despite their potential, present notable drawbacks in road extraction. Firstly, graph construction is intricate. The precise definition of nodes, edges and their associated attributes demands profound domain knowledge, and inaccuracies in this stage can cascade, degrading the overall extraction quality. Secondly, graph-based models possess high computational complexity as well. Operations like graph traversal and message passing algorithms involve substantial computations, which not only slow down the extraction process but also call for powerful computational resources, restricting their application in real-time and large-scale scenarios.
2.3. ConvNets Based Architectures
With the advancement of convolutional networks (ConvNets) in deep learning, architectures such as U-Net [
6,
43], LinkNet [
19,
44], ResNet [
25,
45] and DeepLab [
46,
47] have been effectively applied in road extraction. There are several highly regarded encoder–decoder structures based on ConvNets for learning thin curvilinear road structures [
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56]. D-LinkNet [
19] incorporates an encoder–decoder structure, dilated convolution and a pre-trained encoder to predict the road segmentation maps. The network is built upon the LinkNet [
44] architecture, with the addition of dilated convolution layers in its central part. To achieve more precise segmentation results, Richer Unet [
48] proposed a road detection approach by employing an enhanced detail recovery structure that can retain more abundant features. A Cascaded Attention DenseUNet (CADUNet) [
49] used the core attention module to extract road areas, including the occluded parts, and used the global attention module to enhance global contextual information about the road network. To solve the dense road occlusion problem, OARENet [
50] is proposed to explicitly model the texture feature for road regions with dense occlusions. Ai et al. [
51] applied variance and the coefficient of variation to the squeeze-and-excitation (SE) mechanism, designing a multi-parameter-guided SE module named MPGSE, which was then integrated into the D-LinkNet architecture. Hu et al. [
52] developed the location-guided network (LGNet), inspired by strategies used in lane detection. The primary goal of LGNet was to address the common issue of disjointed extraction results that are prevalent in segmentation techniques. Qiu et al. [
53] proposed a multimodal framework that synthesized GPS trajectory data with remote sensing features, significantly amplifying the model’s discriminative power for road representation. Zhu et al. [
43] introduced GCBNet, incorporating a global context-aware (GCA) block into the network to capture the global contextual information of roads. RADANet [
54] incorporated a road augmentation module (RAM) and a deformable attention module (DAM) to effectively capture multi-scale semantic information. The RAM is designed to capture the semantic shape information of roads through four strip convolutions, while the DAM combines the sparse sampling capability of deformable convolution with a spatial self-attention mechanism.
These encoder–decoder-based methods also bring some drawbacks: on the one hand, these methods fuse multi-scale features by inserting well-designed but sophisticated modules into the networks, which introduce large parameters and limit their application in real world scenes. On the other hand, the downsampling operations of these networks on shallow feature maps inevitably lead to the loss of the crucial, detailed information of the thin, curvilinear roads, while upsampling operations on deep feature maps may cause the introduction of inaccurate semantic information. Hence, these methods fail to realize the effective aggregation of multi-scale features, and the generated fused feature cannot provide accurate road structural features for the decoder.
3. Proposed Method
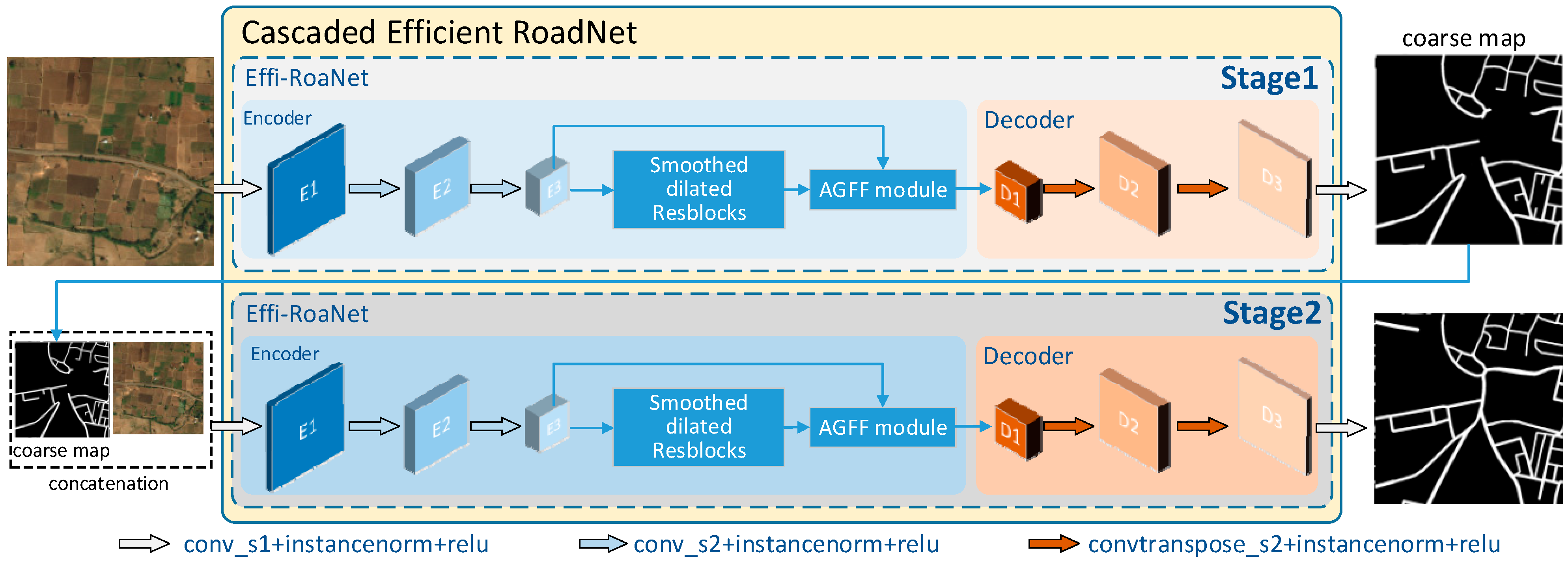
In this section, we present the details of our Cascaded Efficient Road Network and introduce how we enhance the feature representation ability of our proposed model.
3.1. Overview
In this paper, we adopt the encoder–decoder structure as the overall framework. The main idea is to design a simple network architecture that can learn the importance maps of features at multiple levels and accurately aggregate them from a spatial perspective. Conventional hierarchical encoder–decoder architectures directly utilize the convolutional layer to reduce the resolution through downsampling operations and increase the channel number by a factor of two at each stage [
26,
45]. Since the downsampling operation enlarges the receptive field by sacrificing the detailed information of roads, we propose to downsample the satellite image by a factor of 2 only twice, instead of four times. Apart from this, to address the issue of the shrinking receptive field caused by the reduced downsample operations, we replace the Convblocks with smoothed dilated convolution residual blocks. An attention-guided feature fusion sub-module is inserted as the bottleneck to fuse the multi-scale features to further strengthen the feature representation of roads. Finally, a simple decoder, which is made up of three convolutional layers, together with the aforementioned elements, form our encoder–decoder architecture, which we call Effi-RoadNet. Effi-RoadNet is cascaded twice to refine the extracted coarse road map and enhance the feature representation ability, as shown in
Figure 2. In general, the proposed method can parallel patch-wise inference for large areas due to its low complexity. We demonstrate that the sequential application of a cascade of the proposed Effi-RoadNet is able to predict road locations efficiently and effectively.
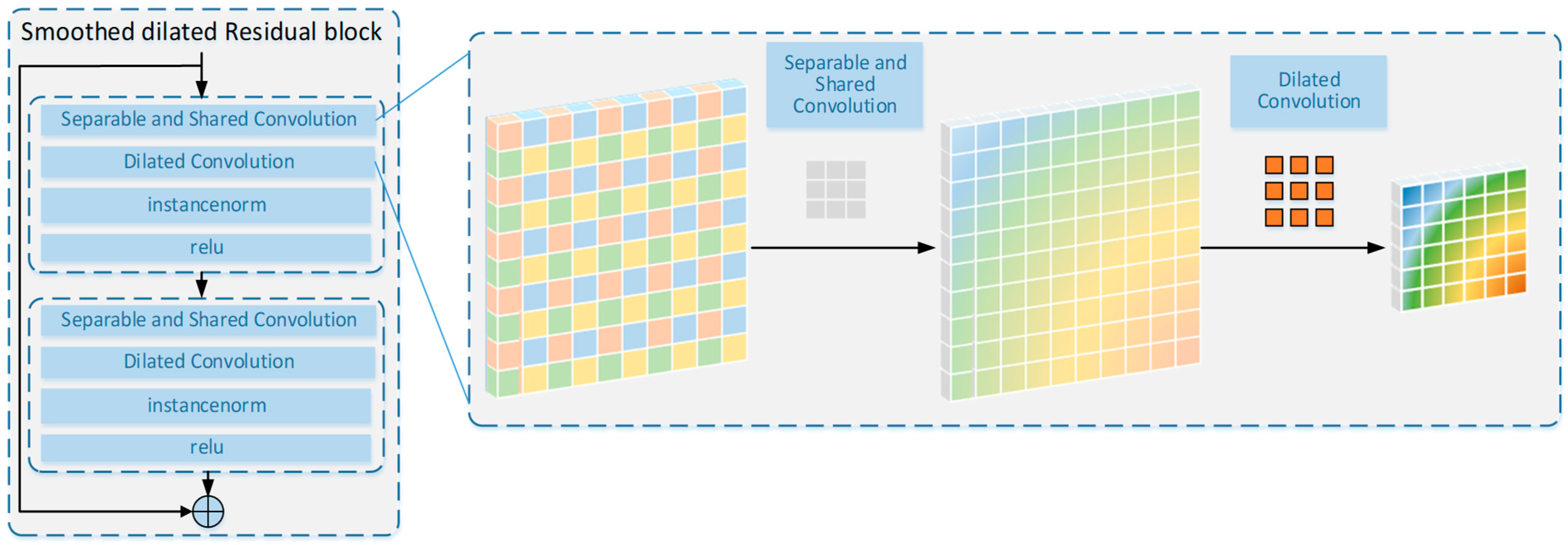
3.2. Smoothed Dilated Residual Block
Given the narrowness, connectivity, complexity and extensive length of roads in remote sensing images, it is crucial to enhance the receptive field of the feature points in the central part of the network while preserving detailed information. Dilated convolution is a valuable technique to expand the receptive fields of feature points without reducing the resolution of feature maps. Furthermore, smoothed dilated convolution [
33] addresses the gridding artifacts inherent in standard atrous convolutions by decomposing and smoothing the dilated convolution operations, thereby enhancing local consistency and reducing discontinuous receptive fields. Unlike conventional methods that rely on cascaded layers or hybrid dilation rates to mitigate gridding issues, this approach directly modifies the dilated convolution itself, achieving significant performance improvements with negligible additional parameters. As for road extraction tasks, smoothed dilated convolution is able to capture long-range dependencies in the image data while maintaining spatial resolution, enabling it to accurately delineate the road boundaries even in complex scenarios with various background textures and occlusions. The smoothing mechanism also helps in handling noise and irregularities in the remote sensing data, resulting in more reliable and detailed road extraction results compared to those of the standard atrous convolution. It should be noted that a separable and shared convolution is employed as the additional convolutional layer to integrate the neighboring information for each unit in the input feature maps. As shown in
Figure 3, we stack the smoothed dilated convolution layer twice and add a shortcut connection to build a smoothed dilated residual block.
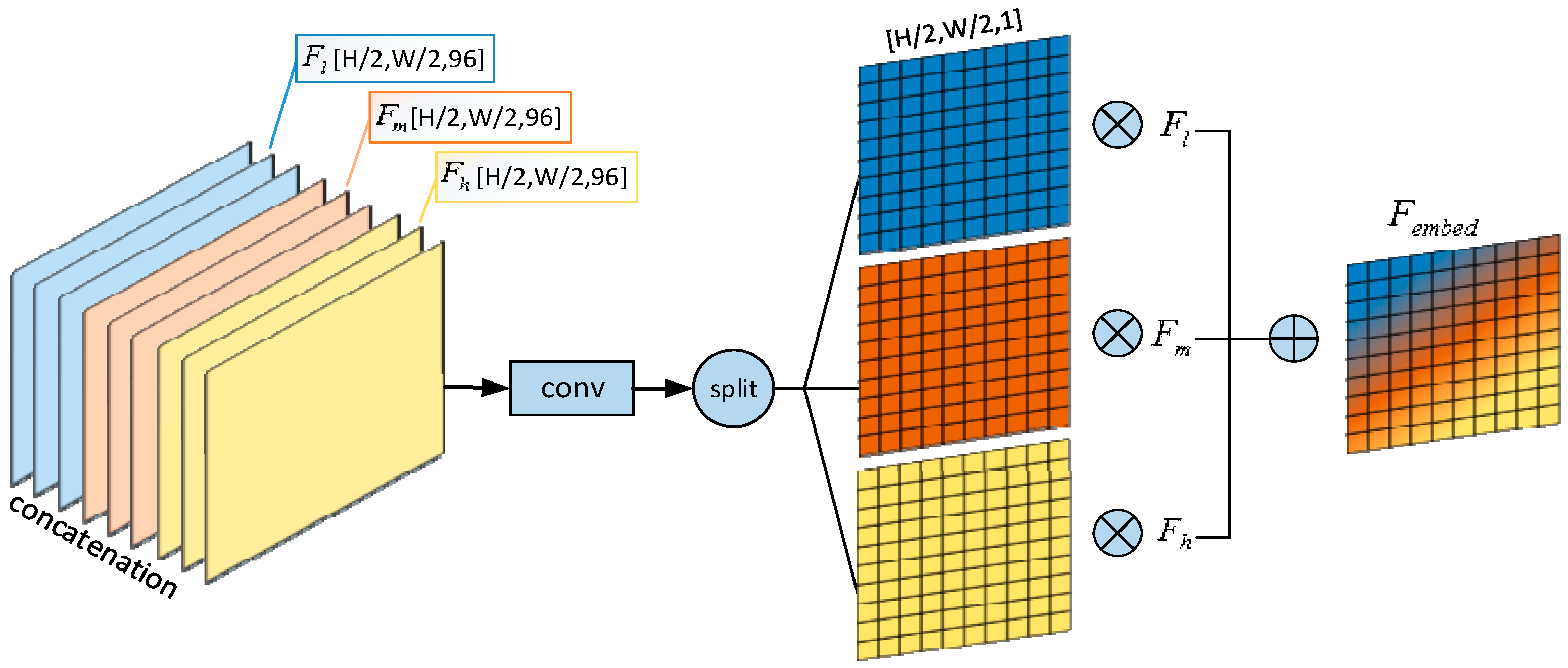
3.3. Attention-Guided Feature Fusion Sub-Module
The attention mechanism has been extensively utilized across a range of computer vision tasks. In this paper, we introduce a novel approach to fuse features from different levels by incorporating an additional attention-guided feature fusion (AGFF) module. Although local evidence is crucial for the identification of long-span, curvilinear, road-like features, a final estimate of the road necessitates a consistent comprehension of the scenes around roads. The orientation of the road, the layout of the surrounding buildings and tree shadows as well as the relationships of the adjacent joints are some of the numerous cues that are most effectively recognized at multiple scales within the image. The attention mechanism of AGFF has the capacity to aggregate contextual information from diverse levels. Consequently, it enhances the model’s ability to learn contextual features.
By analyzing the positional correlation between feature maps at different levels, AGFF directly computes a 3D attention map to accurately aggregate features from channel and spatial perspectives. A single convolution operation is employed to compress the channel–spatial information of different features. First, we extract multi-layer features from the encoder, which are denoted as
Fl,
Fm and
Fh. Then, we feed them into the AGFF sub-module. More precisely,
Fl represents the feature map that is fed into the first smoothed dilated convolution layer,
Fm is the output generated by the third smoothed dilated convolution layer and
Fh is the final output of the smoothed dilated convolution layers. After that,
Fl,
Fm and
Fh are concatenated and fed into the feature fusion module. The output of the AGFF module consists of spatial attention maps (
Wl,
Wm,
Wh), which correspond to each feature level, respectively. These maps are generated to selectively emphasize the importance maps of features at different scales. In the end, these three feature maps from different levels, namely
Fl,
Fm and
Fh, are linearly combined with the regressed spatial attention maps. We describe the detailed operation below.
σ represents a straightforward convolutional layer with a kernel size of 3 × 3. The input fed into σ is the concatenation of the feature maps
Fl,
Fm and
Fh.
implies element-wise multiplication. Element-wise multiplication and addition are computationally efficient for fusing features from different levels. The combined feature map
Fembed will then be fed into the decoder to produce the road map, as shown in
Figure 4.
3.4. Effi-RoadNet
With the development of AI chips, the bottleneck of the neural network’s inference speed will no longer be the FLOPs or the number of parameters, as modern GPUs can easily perform parallel calculations with powerful computing capabilities. In contrast, the complex designs and extensive depths of these networks impede their inference speed. To address this issue, we introduce Effi-RoadNet, the architecture of which is depicted in
Figure 2. We adopt the conventional autoencoder architecture, which consists of an encoder, a bottleneck and a decoder. Unlike conventional deep networks, our approach utilizes only one single layer at each stage, resulting in an extremely streamlined network architecture with a minimal number of layers. Apart from this, Effi-RoadNet eschews excessive depth, skip connections and complex operations such as self-attention. This results in a series of simplified network architectures that effectively mitigate inherent computation complexity.
To be more specific, we start by using three convolutional layers to encode the input image into feature maps. Notably, only the last two of these layers perform downsampling with stride 2. Symmetrically, in the decoder part, two deconvolutional layers with a stride of 2 are employed to upsample the feature map to its original resolution. This operation not only extracts the spatial context but also projects the fused feature map back into the image space. Once the network reaches the output resolution, two consecutive convolutional layers with 3 × 3 and 1 × 1 kernel sizes are utilized to generate the final target road map. Since only two downsample layers are incorporated in the encoding phase, the detailed information of the roads is well preserved. As a result, no more high-resolution information needs to be supplemented. We remove the skip connections between the encoder and the decoder because such operations would consume significant off-chip memory when they merge multi-level features.
We use six smoothed dilated residual blocks as the bottleneck, and each is made up of two smoothed dilated convolutional layers with a skip connection. The dilation rates are set as (2, 2, 2, 4, 4, 4, 1), respectively. The dilation rate of the last smoothed dilated residual block is 1, so that it is degraded to a normal residual block. The AGFF sub-module is inserted after the bottleneck to accurately aggregate context features from different levels. To balance performance and runtime efficiency, we configure the channel numbers of the intermediate convolutional layers to be 48, 64 and 96, respectively. With a simple yet minimal design, the proposed encoder–decoder architecture has the ability to aggregate different levels of context, enabling the fusion of features and the generation of pixel-wise predictions. It can fuse features and combine them to output pixel-wise predictions.
3.5. Cascaded Effi-RoadNet
We introduce a modification of the proposed Effi-RoadNet architecture, which we refer to as CE-RoadNet based on the idea behind Went [
57]. Our overall architecture is constructed by stacking two Effi-RoadNets in an end-to-end configuration, where the output of the first Effi-RoadNet serves as a partial input to the second. This configuration enables the network to perform repeated encoder–decoder inference, allowing for the refinement and re-evaluation of initial estimates. The key point of this approach lies in the prediction of a coarse road map, upon which a loss function can be applied. The first road map is generated after passing through the first Effi-RoadNet, which converts images into coarse road maps. The second Effi-RoadNet enables the reprocessing of these high-level features (coarse maps) to further evaluate and reassess the higher order spatial relationships between the road and its surrounding scenes. Specifically, the pre-calculated coarse road map and the input remote sensing image are concatenated along the channel dimension to form the input for the second Effi-RoadNet. The first Effi-RoadNet is designed for coarse road detection tasks, leveraging its strong representational capabilities to effectively handle complex backgrounds and occlusions caused by trees and cars. To refine the road topology and fix wrong predictions, the other Effi-RoadNet is cascaded to the former, fully utilizing the previously produced feature maps.
As demonstrated in Equation (3), for an input image
x, the output obtained from passing it through the first Effi-RoadNet
is concatenated with x, and this combined input is then passed through the second Effi-RoadNet
. This process can be mathematically represented as:
In practice,
produces a rough prediction of the road’s location. This prediction can then be employed by
as a form of attention map, enabling it to concentrate more intently on the areas of interest in the image, as illustrated in
Figure 2. The cascade design incorporates twice the number of learnable parameters compared to the raw Effi-RoadNet. However, since the Effi-RoadNet involved in its definition contains only 1.39 M parameters each, the CE-RoadNet considered in this paper will have around 2.78 M parameters in total. This number is still less than that of the simplest architecture proposed to date for road segmentation, and is one order of magnitude lighter than the current state-of-the-art models.
4. Experimental Results
4.1. Datasets
The DeepGlobe dataset [
29] is a comprehensive and widely used dataset in the field of geospatial image analysis and deep learning. It encompasses a diverse range of geographical regions around the world, providing a rich variety of landscapes, including urban areas, rural landscapes, forests and water bodies. There are 6226 images in it, each with a resolution of 1024 × 1024. It is observed that certain portions of the images within the dataset are partially occluded. These images may have a severe detrimental impact on the performance of the models. Consequently, these occluded images are removed. We crop the rest of the images into 256 × 256 patches and obtain 56,192 images for training and 1172 images for testing.
The Massachusetts Road dataset [
58] is another benchmark dataset used for road segmentation tasks. It is known for its high-quality annotations and is often used to evaluate the robustness of road extraction models across different geographical and environmental conditions. Following the same approach, we generate 25,619, 439 and 1380 images for the training, testing and validation sets, respectively.
4.2. Training Strategy
In this paper, we adopt the sum of binary cross entropy (BCE) and dice coefficient loss as the loss function. It is important to note that in the cascade case, the loss computed for the output of the second network is linearly combined with an auxiliary loss that is calculated for the output of the first network:
The loss is back propagated and minimized using the AdamW optimization technique.
4.3. Experimental Settings
All the experiments are performed on two NVIDIA Tesla V100-PCIE GPUs (with 32 GB GPU memory) (NVIDIA, Santa Clara, CA, USA), with a fixed batch size of 16 samples. We set the initial learning rate to 6 × 10−3, and when the loss does not decrease for five consecutive epochs, we reduce it to one-fifth of its current value. The early stop strategy is used to avoid overfitting.
An augmentation strategy that includes horizontal/vertical flipping and shift scale rotation is used during the training phase. During the prediction phase, no test time augmentation (TTA) is employed. A threshold value of 0.5 is applied to generate the final output. In road segmentation tasks, 0.5 is often used as the threshold because it is intuitive for probability interpretation, offers symmetry in binary classification, is an empirical default and simplifies calculations.
4.4. Comparing Algorithms and Evaluation Metrics
To comprehensively verify the performance of the proposed method, a comparative analysis is conducted between the proposed method and five state-of-the-art road extraction algorithms, along with a retinal vessel segmentation method. The essential information of these methods is summarized as follows:
CasNet extracts consistent road areas and smooth road centerlines from very high resolution (VHR) remote sensing images simultaneously through a cascaded end-to-end convolutional neural network.
Dlink-net employs an encoder–decoder architecture, incorporating dilated convolutions and a pre-trained encoder to effectively perform the road extraction task.
SGCN integrates a split depth-wise separable graph convolutional network within an encoder–decoder architecture to capture better global contextual information.
CoANet proposes a connectivity attention network designed for road extraction from satellite imagery. It incorporates a strip convolution module to capture long-range context information from different directions, thereby aligning with the elongated and narrow shape of roads.
RCFS uses an improved encoder–decoder architecture, in which a multi-scale context extraction module is designed to boost the network’s inference ability by adding road context. In addition, multiple full-stage feature fusion modules are added to skip connections for accurate road structure information.
W-Net is a minimalistic model that achieves state-of-the-art performance in retinal vessel segmentation with significantly fewer parameters compared to other models.
It should be noted that the same learning rate scheduler and batch size are adopted for all the models.
All the approaches are evaluated with the TOPO [
59], clDice [
60] and average path length similarity (APLS) [
30]. TOPO randomly selects candidate vertices from the ground truth and identifies their corresponding elements in the prediction. It conducts a rigorous evaluation of the detailed topological correctness. This is achieved by comparing the similarity of the reachable subgraphs originating from the same vertex of the two graphs, with respect to precision, recall and F1 score. It is necessary to note that connectivity is an important factor that has to be considered for road extraction tasks, and APLS and clDice are also adopted as evaluation metrics. APLS evaluates the quality of the predicted graph by measuring the similarity of the shortest paths between corresponding locations in the predicted and ground truth graphs. The ClDice loss function is designed to improve the connectivity of the results in road segmentation tasks by leveraging topological information. It calculates the similarity between the segmentation mask and its morphological skeleton, ensuring that the topological structure of the segmented object is preserved. To evaluate the connectivity of the extracted road maps, we also use the clDice score, which is based on morphology. The following equations introduce the expression of the
clDice coefficient:
In this context, VP denotes the predicted segmentation mask, and VL stands for the ground truth mask. The skeletons SP and SL are extracted from VP and VL, respectively. Specifically, Tp(SP, VL) indicates the topology precision, and Ts(SL, VP) represents the relevant sensitivity.
APLS is defined as follows:
In this context, G represents the ground truth graph, while stands for the predicted graph. P refers to the quantity of unique paths in G. L(a, b) signifies the length of the path connecting the nodes a and b. Additionally, and are the nodes in that are closest in location to nodes a and b. It should be noted that the value of APLS ranges from 0 (poor) to 1 (perfect).
4.5. Results and Comparative Analysis
Figure 5 and
Figure 6 depict the output maps of the proposed and existing state-of-the-art models on the DeepGlobe and Massachusetts Road datasets. As visualized, compared with other techniques, CE-RoadNet stands out for its outstanding adaptability to diverse scenarios. It provides accurate edge information of the roads, proving its superiority for both datasets. Such an improvement demonstrates that our CE-RoadNet is capable of extracting road features with remarkable invariance across diverse scenes, such as roads obscured by shadows, narrow roads, complex intersections or roads with obstructions. The arrows highlight especially challenging areas.
In
Figure 5, for example, several roads are mislabeled in the ground truth road map where all methods predict part of the missing roads, among which CE-RoadNet achieves the best performance in preserving the continuity of the road topology (yellow arrows). Moreover, the predicted road masks by other methods suffer from varying degrees of fragmentation, while our CE-RoadNet exhibits better road connectivity (red arrows). CasNet encounters difficulties in accurately extracting roads in complex scenes with large areas of occlusion and interference; as shown in line 4, it cannot separate the road textures from those of the cluttered surroundings, leading to inaccurate segmentation results. In line 5, SGCN, CoANet and WNet face limitations in terms of recognizing the road-like features as roads. Among the seven models, the extraction results of WNet are the worst, since it is only a simple extension of UNet, which has a limited feature extraction ability. The degree of fragmentation of the extraction results and the number of extraction failures are the largest among all images, which is also consistent with the results of the quantitative analysis in
Table 1 and
Table 2.
In
Figure 6, some dual carriageways are labeled as being a single way (yellow arrows). All methods extract the parallel freeways correctly, while CE-RoadNet gives superior results in extracting detailed local information such as ring roads and roads obscured by the surrounding trees or the shadows. In line 2, D-LinkNet, CoANet and RCFS cannot detect the roads that are close in color to the background. D-LinkNet struggles with accurately delineating road boundaries in complex urban environments like the ring roads in line 2. In line 3, CasNet shows robustness against the occlusions of trees shadows to some extent, but the predicted road map still contains numerous fragments. For more complicated scenarios like that in line 4, the result predicted by CE-RoadNet more closely approximates ground truth, while all other methods tend to identify the roads as background and generate fragmented road maps. In general, CE-RoadNet is capable of predicting extremely precise road networks even under challenging circumstances, including multi-lane highways, intersections in heavily populated urban zones, winding roads with irregular geometries and complex overpasses.
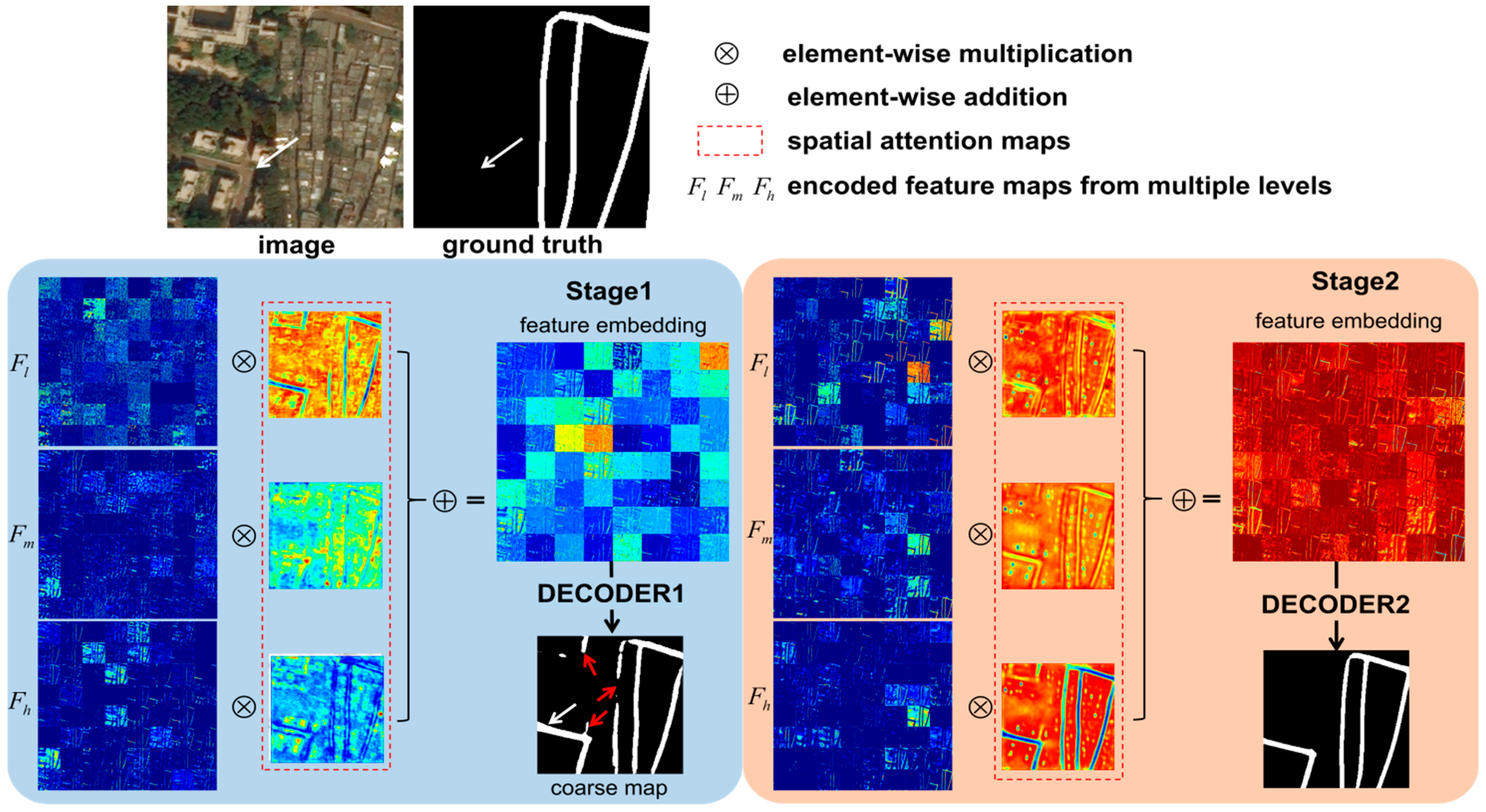
To dig deeper into the learning behavior and obtain more in-depth knowledge, we perform a qualitative analysis in the feature space. The normalized attention maps of both Effi-RoadNet stages are visualized in
Figure 7. Features from low/medium/high levels are, respectively, multiplied with the corresponding attention map to produce an attention-guided feature embedding, which is further fed into the decoder. As can be seen, the AGFF sub-module enhances competition across neurons by fusing features from multiple levels, among which the low/medium level features show more low-frequency information and redundancy across channels. The Effi-RoadNet of stage 1 outputs a coarse road map in which the missing road in the ground truth map (white arrow) is also correctly detected. The Effi-RoadNet of stage 2 refines the result of stage 1 and reduces some noise (red arrow), thus maintaining the road topology perfectly. Feature diversity is promoted through the second stage in which the road texture becomes more distinct.
Table 1 and
Table 2 provide a summary of the evaluation metrics achieved by the proposed CE-RoadNet tested on the Massachusetts and DeepGlobe Road datasets. The best values are presented in bold, while the second-best values are underlined. It is evident that the proposed CE-RoadNet has a significant advantage over the comparative methods across all metrics on both datasets. D-LinkNet proposes a bridge module composed of dilated convolutions between the encoder and decoder to expand the receptive field. While D-LinkNet performs well in capturing multi-scale features, it also struggles with accurately delineating road boundaries in complex urban environments, as its bottleneck only contains several dilated convolution layers that may not fully address the challenges of fine-grained spatial detail preservation, resulting in a low recall score. CasNet simultaneously copes with the road detection and centerline extraction tasks to obtain more consistent road detection result, resulting in the highest score on the Recall metric except for CE-RoadNet. Although it has two cascaded UNet, the final road centerlines are heavily dependent on the segmentation of the first network. Therefore, the feature extraction ability of this simple network architecture is very limited, making it difficult to maintain precise road connectivity in highly occluded or complex urban areas. SGCNNet presents a graph convolutional network in a CNN architecture to capture global contextual road information in channel and spatial features, but it has limitations in handling extremely complex road networks with dense occlusions or highly irregular road patterns, as its reliance on graph convolution and separable convolutions may struggle to fully capture fine-grained details in such scenarios. When dealing with roads with discontinuous segments in high-resolution imagery, CoANet shows degraded performance in road extraction tasks. The network’s architecture is not robust enough to adapt to these complex scenarios, thus affecting the recall and F1 score. Meanwhile, the RCFSNet achieves the second-best performance in terms of precision, F1 clDice and APLS, which reflects the importance of extracting the long-distance road context. Despite leveraging contextual and multi-stage features, RCFSNet struggles to precisely extract roads in scenarios with a high level of textural complexity in the background, as the full-stage feature fusion may introduce noise to the decoder, leading to a low score on the Recall metric. WNet fails to capture the road context since multi-level features are not incorporated in the decoding procedure, leading to the inferior accuracy of its generated road results on both the TOPO and APLS scores. The proposed CE-RoadNet outperforms the second-best-listed RCFSNet method by 4.6%, 4% and 4.3% on the Massachusetts dataset and 6.3%, 2.3% and 1.5% on the DeepGlobe dataset in terms of the TOPO metric. Moreover, the proposed CE-RoadNet achieves the best APLS and clDice by incorporating the AGFF module and the cascade architecture together to extract local details and different levels of contextual information and aggregates them adaptively. CE-RoadNet is superior for road extraction tasks because it effectively combines multi-scale feature learning, contextual understanding and precise spatial detail preservation. These characteristics are essential for accurately extracting road networks from complex and varied environments, making it a more suitable choice than simply increasing the depth of CNN or adding modules with complex designs. Furthermore, the architecture of CE-RoadNet allows for the efficient fusion of features from multiple levels, combining low-level details with high-level semantics. This fusion is beneficial for road extraction, where both detailed edges and semantic understanding of the road structure are included.
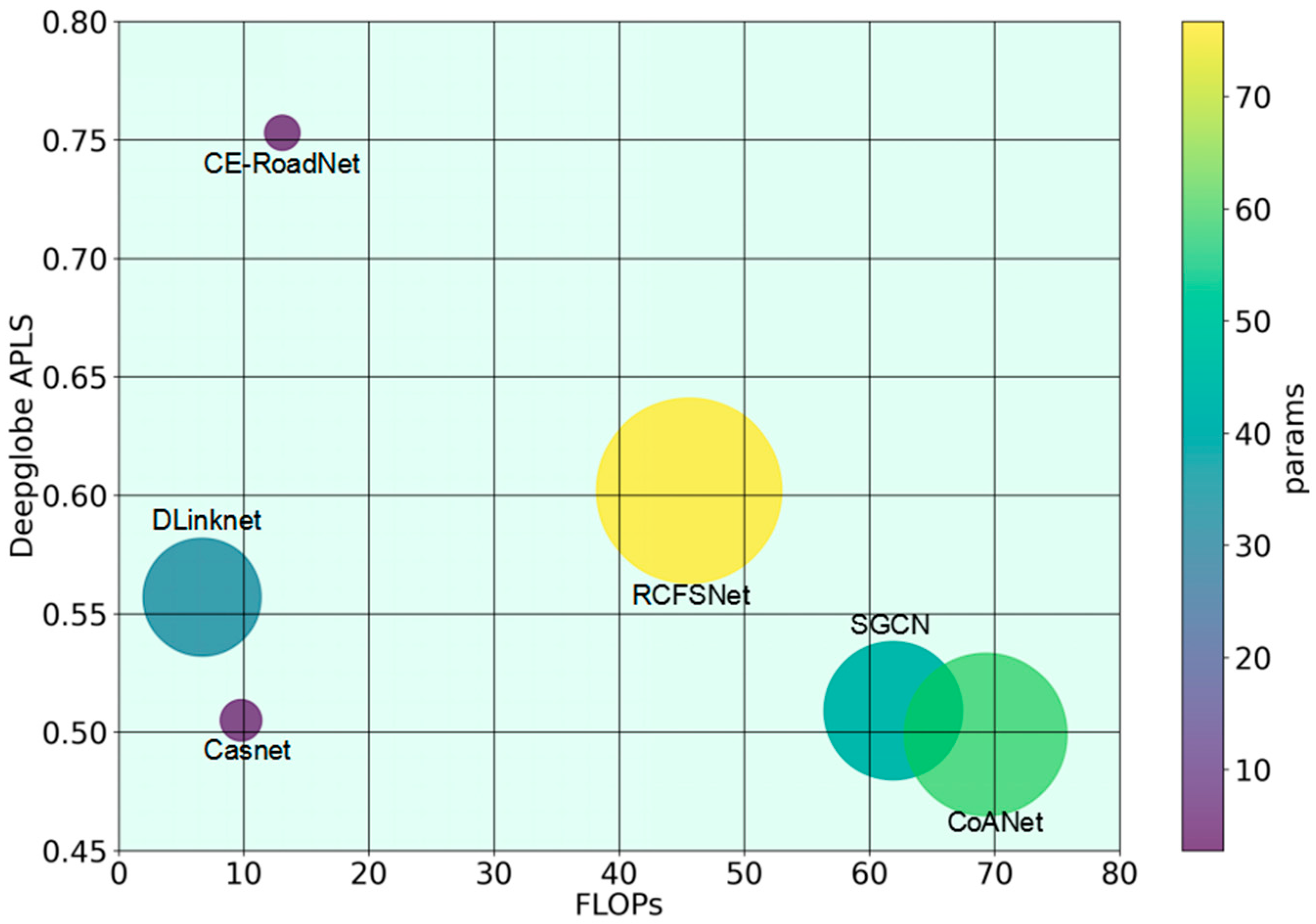
The FLOPs, params and the inference latency of the models are also compared in
Table 3 and
Figure 8. The latency is measured on one NVIDIA Tesla V100-PCIE GPU (with 32 GB GPU memory) and Intel(R) Core(TM) i7-7700CPU (Intel, Santa Clara, CA, USA), with a fixed batch size of four samples. As shown, the sophisticated design of SGCN, CoANet and RCFS leads to increased computational complexity and memory usage, particularly when processing high-resolution images. CE-RoadNet endeavors to achieve the optimal balance between computational complexity and performance. It has the least parameters and only spends one-third of the floating-point operations than the most complex model, indicating that it is a far less complex model than most approaches. The diminished complexity of the model presented in this paper enhances its suitability for wide-range remote sensing image road detection scenarios.
4.6. Ablation Experiments
In this section, we conduct further verification of the effectiveness of integrating the Effi-RoadNet, the cascade approach and skip connections in enhancing the performance of road extraction, as detailed in
Table 4.
Effect of Effi-RoadNet: With the aim of further validating the generalizability of the Effi-RoadNet framework we put forward, we replace Effi-RoadNet with Unet and compare the performance on both datasets. Compared to Wnet, which is extended based on Unet, CE-RoadNet significantly improves performance across all metrics. This validates that smoothed dilated convolution layers together with an AGFF sub-module can contribute to enhancing the capacity for aggregating information from a large receptive field.
Effect of cascade: CE-RoadNet is structured as a two-stage hierarchical encoder–decoder architecture. A single Effi-RoadNet spends only half the FLOPs and parameters than the baseline model. An acceptable decrease in the TOPO metrics occurs on the Massachusetts dataset when removing the cascade operation, since this refines the result of a single Effi-RoadNet and enhances the feature representation ability. With a significant increase of 2% in APLS, the cascade operation is thought to be more crucial in producing road maps with better connectivity. As a result, the cascade operation helps to predict difficult-to-recognize road areas by capturing accurate road contexts and yielding a significant improvement over a single Effi-RoadNet architecture. This result indicates that, except for the input image, pre-calculating the attention map of the road areas as the extra information is very beneficial for feature representation and network learning, leading to a predicted road map with better connectivity.
Effect of skip connection: To meet the requirement of efficiency, we remove the skip connection between the encoder and decoder. Here, we compare the performance under the two configurations. CE-RoadNet_cat indicates the model with skip connections to fuse the features of the same scale by concatenation and to alleviate the semantic gap of feature fusion. As is shown in
Table 4, skip connections bring an increase of 66% and 29.5% in terms of FLOPs and parameters, but only lead to a negligible increase in Precision and clDice on the Massachusetts dataset. Since feature maps are downsampled by half only twice from the original image, the crucial details of the road are maintained to a great extent, so that not much detailed information needs to be supplemented during the decoding procedure. As a consequence, the increasing complexity of skip connections cannot bring considerable improvements in performance.
Effect of cascade times: We have respectively compared the network performance by stacking Effi-RoadNet once, twice and three times (denoted as Effi-RoadNet, CE-RoadNet and CE-RoadNet3, respectively). Undoubtedly, CE-RoadNet is the most concise and efficient, with the lowest computational complexity and parameter count, but CE-RoadNet3 has the best metric performance, despite having the highest computational complexity and parameter count. On the other hand, CE-RoadNet achieves a balance between efficiency and effectiveness; its precision, recall and F1 score are nearly on par with CE-RoadNet3, yet its computational complexity is only 66% that of CE-RoadNet3.
Effect of AGFF: To test the effectiveness of the proposed AGFF module, we replace it with CBAM [
61], a simple yet effective attention module for feed-forward convolutional neural networks that can improve the representation power of CNN networks, and we denote it as CE-RoadNet_CBAM. The experimental results demonstrate that although AGFF experiences a slight decrease in Precision, it achieves improvements of 7% in recall and 6% in APLS, respectively. This indicates that AGFF has advantages in terms of comprehensive performance improvement compared with other attention mechanisms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}