

Mapping Forest Carbon Stock Distribution in a Subtropical Region with the Integration of Airborne Lidar and Sentinel-2 Data

 ,
, 
Abstract

1. Introduction
2. Study Area
3. Materials and Methods
3.1. Datasets
3.1.1. Field Measurements
3.1.2. Airborne Lidar Data
3.1.3. Sentinel-2 Multispectral Images
3.1.4. Ancillary Data
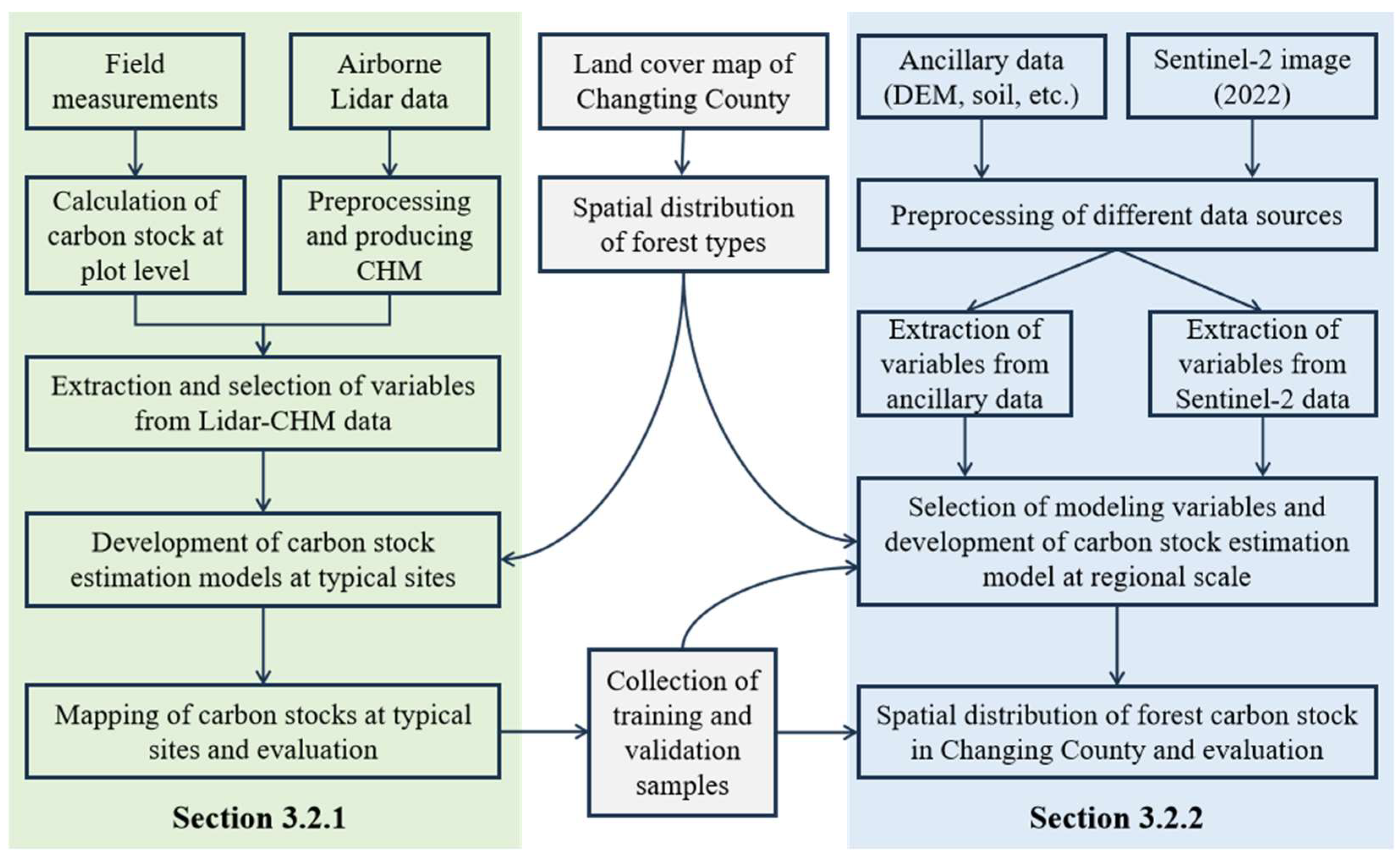
3.2. Methods
3.2.1. Forest Carbon Stock Mapping in Typical Sites Based on Lidar-Derived Variables
- (1)
- Extraction and selection of predictive variables from Lidar data
- (2)
- Construction of carbon stock estimation models based on the selected variables
3.2.2. Forest Carbon Stock Mapping at Regional Scale Using Sentinel-2 and Ancillary Data
4. Results
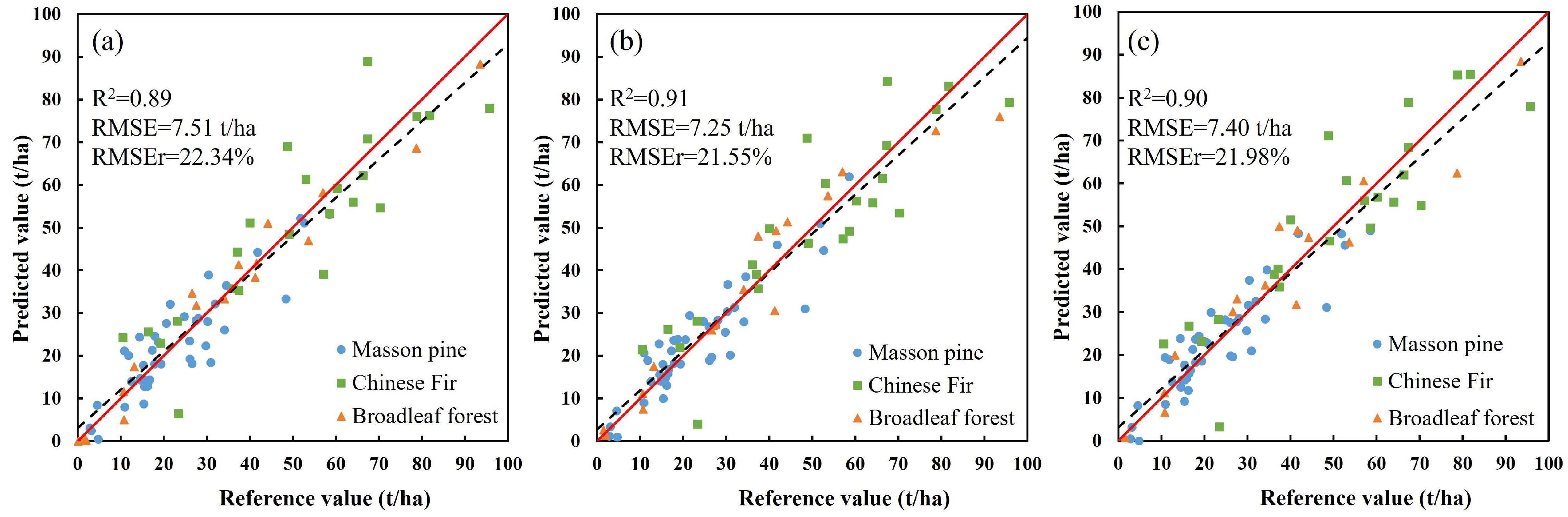
4.1. Analysis of Forest Carbon Stock Estimation Results in Typical Sites
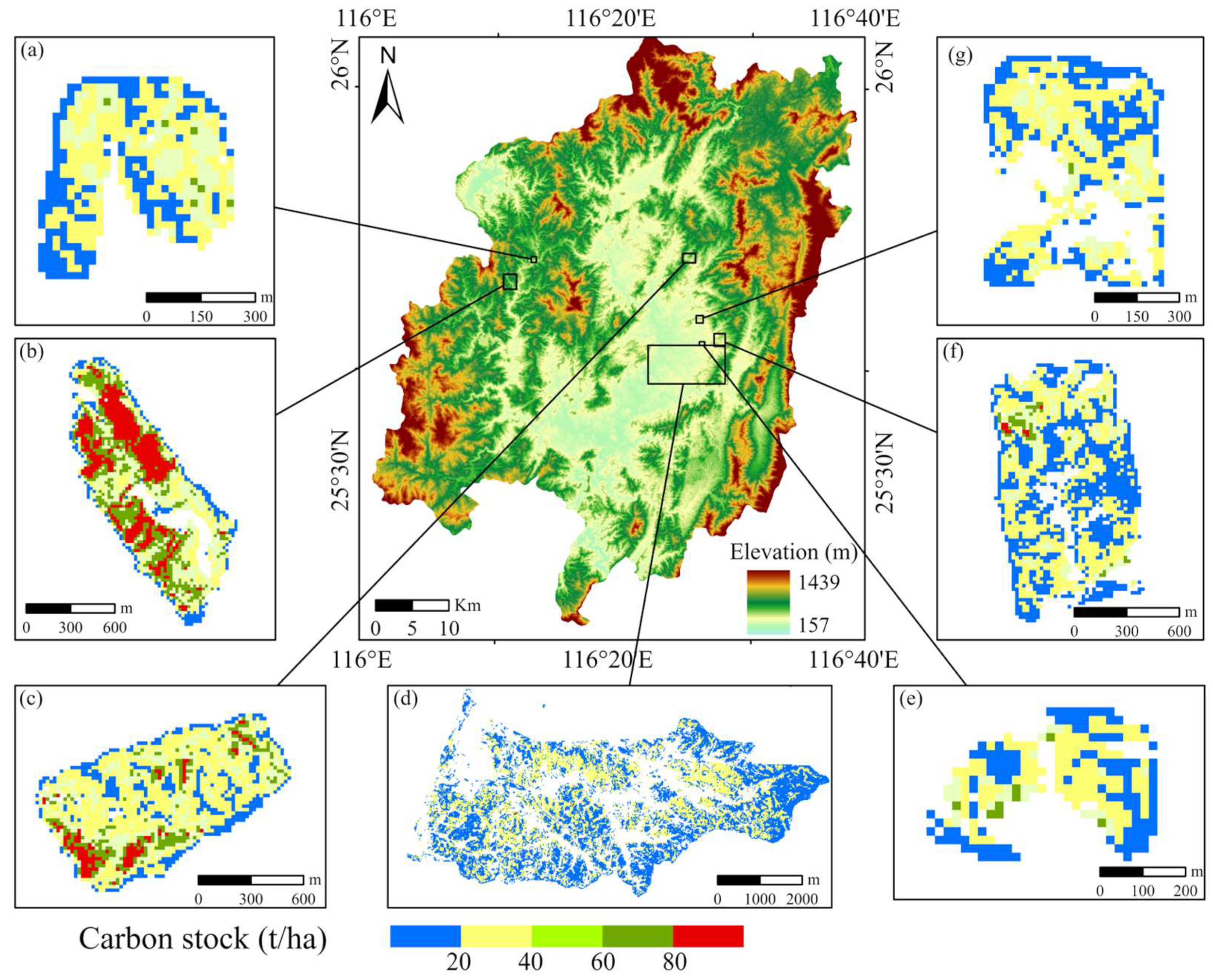
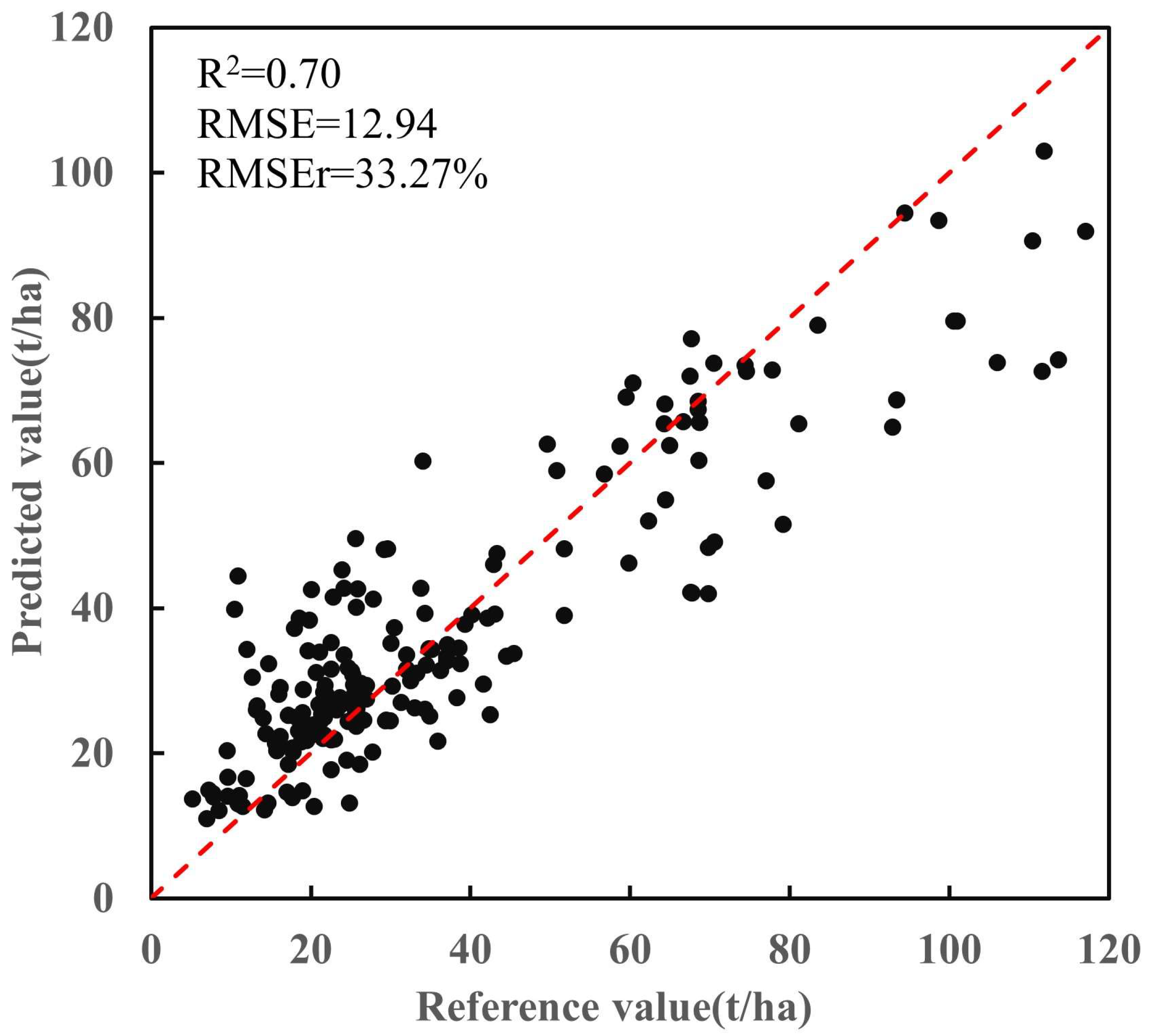
4.2. Analysis of Forest Carbon Stock Estimation Results at Regional Scale
4.3. Comparison of Carbon Stock between Conservation and Non-Conservation Regions
5. Discussion
5.1. The Role of Airborne Lidar Data in Regional Carbon Stock Estimation
5.2. The Need to Develop Proper Modeling Methods for Different Sites
5.3. The Need to Use Multi-Source Data for Developing Forest Carbon Stock Estimation Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cook-Patton, S.C.; Leavitt, S.M.; Gibbs, D.; Harris, N.L.; Lister, K.; Anderson-Teixeira, K.J.; Briggs, R.D.; Chazdon, R.L.; Crowther, T.W.; Ellis, P.W.; et al. Mapping Carbon Accumulation Potential from Global Natural Forest Regrowth. Nature 2020, 585, 545–550. [Google Scholar] [CrossRef]
- Soto-Navarro, C.; Ravilious, C.; Arnell, A.; de Lamo, X.; Harfoot, M.; Hill, S.; Wearn, O.; Santoro, M.; Bouvet, A.; Mermoz, S.; et al. Mapping Co-Benefits for Carbon Storage and Biodiversity to Inform Conservation Policy and Action. Philos. Trans. R. Soc. B Biol. Sci. 2020, 375, 20190128. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Liu, L.; Li, G.; Moran, E. A Survey of Remote Sensing-Based Aboveground Biomass Estimation Methods in Forest Ecosystems. Int. J. Digit. Earth 2016, 9, 63–105. [Google Scholar] [CrossRef]
- Sun, W.; Liu, X. Review on Carbon Storage Estimation of Forest Ecosystem and Applications in China. For. Ecosyst. 2019, 7, 4. [Google Scholar] [CrossRef]
- Qin, S.; Nie, S.; Guan, Y.; Zhang, D.; Wang, C.; Zhang, X. Forest Emissions Reduction Assessment Using Airborne LiDAR for Biomass Estimation. Resour. Conserv. Recycl. 2022, 181, 106224. [Google Scholar] [CrossRef]
- Cook-Patton, S.C.; Shoch, D.; Ellis, P.W. Dynamic Global Monitoring Needed to Use Restoration of Forest Cover as a Climate Solution. Nat. Clim. Change 2021, 11, 366–368. [Google Scholar] [CrossRef]
- Araza, A.; de Bruin, S.; Herold, M.; Quegan, S.; Labriere, N.; Rodriguez-Veiga, P.; Avitabile, V.; Santoro, M.; Mitchard, E.T.A.; Ryan, C.M.; et al. A Comprehensive Framework for Assessing the Accuracy and Uncertainty of Global above-Ground Biomass Maps. Remote Sens. Environ. 2022, 272, 112917. [Google Scholar] [CrossRef]
- Xiao, J.; Chevallier, F.; Gomez, C.; Guanter, L.; Hicke, J.A.; Huete, A.R.; Ichii, K.; Ni, W.; Pang, Y.; Rahman, A.F.; et al. Remote Sensing of the Terrestrial Carbon Cycle: A Review of Advances over 50 Years. Remote Sens. Environ. 2019, 233, 111383. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, D.; Cao, Y.; Zhang, L.; Peng, H.; Wang, K.; Xie, H.; Wang, C. An Integrated Remote Sensing and Model Approach for Assessing Forest Carbon Fluxes in China. Sci. Total Environ. 2022, 811, 152480. [Google Scholar] [CrossRef]
- Grant, R.F.; Oechel, W.C.; Ping, C.L. Modelling Carbon Balances of Coastal Arctic Tundra under Changing Climate. Glob. Change Biol. 2003, 9, 16–36. [Google Scholar] [CrossRef]
- Zhou, W.; Guan, K.; Peng, B.; Tang, J.; Jin, Z.; Jiang, C.; Robert, G.; Mezbahuddin, S. Quantifying carbon budget, crop yields and their responses to environmental variability using the ecosys model for US Midwestern agroecosystems. Agric. For. Meteorol. 2021, 307, 108521. [Google Scholar] [CrossRef]
- Nguyen, T.; Jones, S.; Soto-Berelov, M.; Haywood, A.; Hislop, S. Landsat Time-Series for Estimating Forest Aboveground Biomass and Its Dynamics across Space and Time: A Review. Remote Sens. 2019, 12, 98. [Google Scholar] [CrossRef]
- Emick, E.; Babcock, C.; White, G.W.; Hudak, A.T.; Domke, G.M.; Finley, A.O. An Approach to Estimating Forest Biomass While Quantifying Estimate Uncertainty and Correcting Bias in Machine Learning Maps. Remote Sens. Environ. 2023, 295, 113678. [Google Scholar] [CrossRef]
- Ma, T.; Zhang, C.; Ji, L.; Zuo, Z.; Beckline, M.; Hu, Y.; Li, X.; Xiao, X. Development of Forest Aboveground Biomass Estimation, Its Problems and Future Solutions: A Review. Ecol. Indic. 2024, 159, 111653. [Google Scholar] [CrossRef]
- Lu, D.; Jiang, X. A Brief Overview and Perspective of Using Airborne Lidar Data for Forest Biomass Estimation. Int. J. Image Data Fusion 2024, 15, 1–24. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Moran, E.; Batistella, M.; Zhang, M.; Vaglio Laurin, G.; Saah, D. Aboveground Forest Biomass Estimation with Landsat and LiDAR Data and Uncertainty Analysis of the Estimates. Int. J. For. Res. 2012, 2012, 436537. [Google Scholar] [CrossRef]
- Hu, Y.; Sun, Z. Assessing the Capacities of Different Remote Sensors in Estimating Forest Stock Volume Based on High Precision Sample Plot Positioning and Random Forest Method. Nat. Environ. Pollut. Technol. 2022, 21, 1113–1123. [Google Scholar] [CrossRef]
- Zhao, P.; Lu, D.; Wang, G.; Wu, C.; Huang, Y.; Yu, S. Examining Spectral Reflectance Saturation in Landsat Imagery and Corresponding Solutions to Improve Forest Aboveground Biomass Estimation. Remote Sens. 2016, 8, 469. [Google Scholar] [CrossRef]
- Coops, N.C.; Tompalski, P.; Goodbody, T.R.H.; Queinnec, M.; Luther, J.E.; Bolton, D.K.; White, J.C.; Wulder, M.A.; van Lier, O.R.; Hermosilla, T. Modelling Lidar-Derived Estimates of Forest Attributes over Space and Time: A Review of Approaches and Future Trends. Remote Sens. Environ. 2021, 260, 112477. [Google Scholar] [CrossRef]
- Puliti, S.; Breidenbach, J.; Schumacher, J.; Hauglin, M.; Klingenberg, T.F.; Astrup, R. Above-Ground Biomass Change Estimation Using National Forest Inventory Data with Sentinel-2 and Landsat. Remote Sens. Environ. 2021, 265, 112644. [Google Scholar] [CrossRef]
- Silveira, E.M.O.; Radeloff, V.C.; Martinuzzi, S.; Martinez Pastur, G.J.; Bono, J.; Politi, N.; Lizarraga, L.; Rivera, L.O.; Ciuffoli, L.; Rosas, Y.M.; et al. Nationwide Native Forest Structure Maps for Argentina Based on Forest Inventory Data, SAR Sentinel-1 and Vegetation Metrics from Sentinel-2 Imagery. Remote Sens. Environ. 2023, 285, 113391. [Google Scholar] [CrossRef]
- Ni, W.; Yu, T.; Pang, Y.; Zhang, Z.; He, Y.; Li, Z.; Sun, G. Seasonal Effects on Aboveground Biomass Estimation in Mountainous Deciduous Forests Using ZY-3 Stereoscopic Imagery. Remote Sens. Environ. 2023, 289, 113520. [Google Scholar] [CrossRef]
- Shen, W.; Li, M.; Huang, C.; Tao, X.; Wei, A. Annual Forest Aboveground Biomass Changes Mapped Using ICESat/GLAS Measurements, Historical Inventory Data, and Time-Series Optical and Radar Imagery for Guangdong Province, China. Agric. For. Meteorol. 2018, 259, 23–38. [Google Scholar] [CrossRef]
- Dalponte, M.; Jucker, T.; Liu, S.; Frizzera, L.; Gianelle, D. Characterizing Forest Carbon Dynamics Using Multi-Temporal Lidar Data. Remote Sens. Environ. 2019, 224, 412–420. [Google Scholar] [CrossRef]
- Jiang, X.; Li, D.; Li, G.; Lu, D. Eucalyptus Carbon Stock Estimation in Subtropical Regions with the Modeling Strategy of Sample Plots–Airborne LiDAR–Landsat Time Series Data. For. Ecosyst. 2023, 10, 100149. [Google Scholar] [CrossRef]
- Dong, P.; Chen, Q. LiDAR Remote Sensing and Applications; CRC Press, Taylor & Francis Group: New York, NY, USA, 2017. [Google Scholar]
- Poorazimy, M.; Shataee, S.; McRoberts, R.E.; Mohammadi, J. Integrating Airborne Laser Scanning Data, Space-Borne Radar Data and Digital Aerial Imagery to Estimate Aboveground Carbon Stock in Hyrcanian Forests, Iran. Remote Sens. Environ. 2020, 240, 111669. [Google Scholar] [CrossRef]
- Oehmcke, S.; Li, L.; Trepekli, K.; Revenga, J.C.; Nord-Larsen, T.; Gieseke, F.; Igel, C. Deep Point Cloud Regression for above-Ground Forest Biomass Estimation from Airborne LiDAR. Remote Sens. Environ. 2024, 302, 113968. [Google Scholar] [CrossRef]
- Gao, Y.; Lu, D.; Li, G.; Wang, G.; Chen, Q.; Liu, L.; Li, D. Comparative Analysis of Modeling Algorithms for Forest Aboveground Biomass Estimation in a Subtropical Region. Remote Sens. 2018, 10, 627. [Google Scholar] [CrossRef]
- Xie, D.; Huang, H.; Feng, L.; Sharma, R.P.; Chen, Q.; Liu, Q.; Fu, L. Aboveground Biomass Prediction of Arid Shrub-Dominated Community Based on Airborne LiDAR through Parametric and Nonparametric Methods. Remote Sens. 2023, 15, 3344. [Google Scholar] [CrossRef]
- Jiang, X.; Li, G.; Lu, D.; Erxue, C.; Wei, X. Stratification-Based Forest Aboveground Biomass Estimation in a Subtropical Region Using Airborne Lidar Data. Remote Sens. 2020, 12, 1101. [Google Scholar] [CrossRef]
- Lin, W.; Lu, Y.; Li, G.; Jiang, X.; Lu, D. A Comparative Analysis of Modeling Approaches and Canopy Height-Based Data Sources for Mapping Forest Growing Stock Volume in a Northern Subtropical Ecosystem of China. GISci. Remote Sens. 2022, 59, 568–589. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Saint-Geours, N.; Guyon, D.; Grau, E.; de Boissieu, F. Influence of Sampling Design Parameters on Biomass Predictions Derived from Airborne LiDAR Data. Can. J. Remote Sens. 2019, 45, 650–672. [Google Scholar] [CrossRef]
- Nuthammachot, N.; Askar, A.; Stratoulias, D.; Wicaksono, P. Combined Use of Sentinel-1 and Sentinel-2 Data for Improving above-Ground Biomass Estimation. Geocarto Int. 2022, 37, 366–376. [Google Scholar] [CrossRef]
- Chen, Z. Desertification Induced by Water Erosion and Its Combat of Hetian Town in Changding County, Fujian Province. Prog. Geogr. 1998, 17, 67–72. [Google Scholar]
- Zeng, J.; Zhong, B. Historical Changes in Strategies to Control Soil and Water Erosion in Changting County. Subtrop. Soil Water Conserv. 2002, 14, 37–39. [Google Scholar]
- Wang, C.; Yang, Y.; Zhang, Y. Rural Household Livelihood Change, Fuelwood Substitution, and Hilly Ecosystem Restoration: Evidence from China. Renew. Sustain. Energy Rev. 2012, 16, 2475–2482. [Google Scholar] [CrossRef]
- Gao, J.; Shi, C.; Yang, J.; Yue, H.; Liu, Y.; Chen, B. Analysis of Spatiotemporal Heterogeneity and Influencing Factors of Soil Erosion in a Typical Erosion Zone of the Southern Red Soil Region, China. Ecol. Indic. 2023, 154, 110590. [Google Scholar] [CrossRef]
- Sun, X.; Li, G.; Wu, Q.; Li, D.; Lu, D. Examining the Effects of Soil and Water Conservation Measures on Patterns and Magnitudes of Vegetation Cover Change in a Subtropical Region Using Time Series Landsat Imagery. Remote Sens. 2024, 16, 714. [Google Scholar] [CrossRef]
- LY/T 2263-2014; Tree Biomass Models and Related Parameters to Carbon Accounting for Pinus massoniana. Standards Press of China: Beijing, China, 2014.
- LY/T 2264-2014; Tree Biomass Models and Related Parameters to Carbon Accounting for Cunninghamia lanceolata. Standards Press of China: Beijing, China, 2014.
- Poortinga, A.; Tenneson, K.; Shapiro, A.; Nguyen, Q.; San Aung, K.; Chishtie, F.; Saah, D. Mapping Plantations in Myanmar by Fusing Landsat-8, Sentinel-2 and Sentinel-1 Data along with Systematic Error Quantification. Remote Sens. 2019, 11, 831. [Google Scholar] [CrossRef]
- Buckley, S.M.; Agram, P.S.; Belz, J.E.; Crippen, R.E.; Gurrola, E.M.; Hensley, S.; Kobrick, M.; Lavalle, M.; Martin, J.M.; Neumann, M.; et al. NASADEM: User Guide (Technical Report January). 2020. Available online: https://lpdaac.usgs.gov/documents/592/NASADEM_User_Guide_V1.pdf (accessed on 8 June 2021).
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1998. [Google Scholar]
- Tan, L.; Liu, H.; Tan, L. Algorithm Comparative Analysis with Stepwise Linear Regression and Neural Network. J. North China Univ. Sci. Technol. 2014, 11, 6. [Google Scholar]
- Arhonditsis, G.B.; Stow, C.A.; Steinberg, L.J.; Kenney, M.A.; Lathrop, R.C.; McBride, S.J.; Reckhow, K.H. Exploring Ecological Patterns with Structural Equation Modeling and Bayesian Analysis. Ecol. Model. 2006, 192, 385–409. [Google Scholar] [CrossRef]
- Bürkner, P.C. Brms: An R Package for Bayesian Multilevel Models Using Stan. J. Stat. Softw. 2017, 80, 1–28. [Google Scholar] [CrossRef]
- Huang, J.; Lu, D.; Li, J.; Wu, J.; Chen, S.; Zhao, W.; Ge, H.; Huang, X.; Yan, X.-D. Integration of Remote Sensing and GIS for Evaluating Soil Erosion Risk in Northwestern Zhejiang, China. Photogramm. Eng. Remote Sens. 2012, 78, 935–946. [Google Scholar] [CrossRef]
- Cheng, Z.; Lu, D.; Li, G.; Huang, J.; Sinha, N.; Zhi, J.; Li, S. A Random Forest-Based Approach to Map Soil Erosion Risk Distribution in Hickory Plantations in Western Zhejiang Province, China. Remote Sens. 2018, 10, 1899. [Google Scholar] [CrossRef]
- Marchesan, J.; Alba, E.; Schuh, M.S.; Favarin, J.A.S.; Fantinel, R.A.; Marchesan, L.; Pereira, R.S. Aboveground Biomass Stock and Change Estimation in Amazon Rainforest Using Airborne Light Detection and Ranging, Multispectral Data, and Machine Learning Algorithms. J. Appl. Remote Sens. 2023, 17, 24509. [Google Scholar] [CrossRef]
- Gao, L.; Chai, G.; Zhang, X. Above-Ground Biomass Estimation of Plantation with Different Tree Species Using Airborne LiDAR and Hyperspectral Data. Remote Sens. 2022, 14, 2568. [Google Scholar] [CrossRef]
- Belgiu, M.; Drǎguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Yu, X.; Lu, D.; Jiang, X.; Li, G.; Chen, Y.; Li, D.; Chen, E. Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region. Remote Sens. 2020, 12, 2907. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; Moran, E. Satellite Estimation of Aboveground Biomass and Impacts of Forest Stand Structure. Photogramm. Eng. Remote Sens. 2005, 71, 967–974. [Google Scholar] [CrossRef]
- Feng, Y.; Lu, D.; Chen, Q.; Keller, M.; Moran, E.; dos-Santos, M.N.; Bolfe, E.L.; Batistella, M. Examining Effective Use of Data Sources and Modeling Algorithms for Improving Biomass Estimation in a Moist Tropical Forest of the Brazilian Amazon. Int. J. Digit. Earth 2017, 10, 996–1016. [Google Scholar] [CrossRef]
- Ploton, P.; Mortier, F.; Réjou-Méchain, M.; Barbier, N.; Picard, N.; Rossi, V.; Dormann, C.; Cornu, G.; Viennois, G.; Bayol, N.; et al. Spatial Validation Reveals Poor Predictive Performance of Large-Scale Ecological Mapping Models. Nat. Commun. 2020, 11, 4540. [Google Scholar] [CrossRef] [PubMed]
- Nie, S.; Wang, C.; Zeng, H.; Xi, X.; Li, G. Above-Ground Biomass Estimation Using Airborne Discrete-Return and Full-Waveform LiDAR Data in a Coniferous Forest. Ecol. Indic. 2017, 78, 221–228. [Google Scholar] [CrossRef]
- van Ewijk, K.; Tompalski, P.; Treitz, P.; Coops, N.C.; Woods, M.; Pitt, D. Transferability of ALS-Derived Forest Resource Inventory Attributes Between an Eastern and Western Canadian Boreal Forest Mixedwood Site. Can. J. Remote Sens. 2020, 46, 214–236. [Google Scholar] [CrossRef]
- Fekety, P.A.; Falkowski, M.J.; Hudak, A.T.; Jain, T.B.; Evans, J.S. Transferability of Lidar-Derived Basal Area and Stem Density Models within a Northern Idaho Ecoregion. Can. J. Remote Sens. 2018, 44, 131–143. [Google Scholar] [CrossRef]
- Schwieder, M.; Leitão, P.J.; Pinto, J.R.R.; Teixeira, A.M.C.; Pedroni, F.; Sanchez, M.; Bustamante, M.M.; Hostert, P. Landsat Phenological Metrics and Their Relation to Aboveground Carbon in the Brazilian Savanna. Carbon Balance Manag. 2018, 13, 7. [Google Scholar] [CrossRef]
- Hislop, S.; Jones, S.; Soto-Berelov, M.; Skidmore, A.; Haywood, A.; Nguyen, T. Using Landsat Spectral Indices in Time-Series to Assess Wildfire Disturbance and Recovery. Remote Sens. 2018, 10, 460. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Descriptions |
|---|---|
| Field measurements | Eighty-four forest sample plots in Changting County and Baisha State Forest Farm in Shanghang County were inventoried in 2022, where every single tree within the plots was measured. |
| Airborne Lidar data | Airborne Lidar data were acquired in 7 typical sites in Changting County in January 2022, in Luodihe watershed of Changting County and Baisha State Forest Farm of Shanghang County in August 2022. The point density was over 40 points/m2. |
| Sentinel-2 data | Sentinel-2 L2A images with a 10 m spatial resolution that were acquired on 23 October 2022 were obtained from Google Earth Engine (https://earthengine.google.com, accessed on 7 September 2023). |
| DEM data | NASADEM data with a 30 m spatial resolution were downloaded from USGS (https://lpdaac.usgs.gov/tools/earthdata-search/, accessed on 25 September 2023). |
| Soil data | Eight soil indices with six depth levels at 250 m spatial resolution were collected from OPENLANDMAP (https://openlandmap.org, accessed on 25 September 2023). |
| Land use/cover map | The land use/cover map was developed in our previous study based on Sentinel-2 data on 31 January 2021 and DEM data using random forest method [39]. |
| Conservation measures | Different measures for water and soil erosion control with implementation dates were collected from the Soil Protection Station of Changting County. |
| Species | Carbon Coefficient | Equation of Aboveground Biomass Calculation | Sources |
|---|---|---|---|
| Masson pine (Pinus massoniana) | 0.4596 | W = 0.099488D2.40859 | PRC LY/T 2263-2014 [40], Tree biomass models and related parameters to carbon accounting for Pinus massoniana |
| Chinese fir (Cunninghamia lanceolate) | 0.499 | W = 0.043629D2.54589 | PRC LY/T 2264-2014 [41], Tree biomass models and related parameters to carbon accounting for Cunninghamia lanceolata |
| Broadleaf forest | 0.4901 | Wstem = −80.049 + 50.0544lnD | China’s normalized tree biomass equation dataset. |
| Wbranch = −30.5257 + 18.6683lnD | |||
| Wleaf = −11.905 + 7.247lnD |
| Forest Type | Number of Plots | Range of Carbon Stocks (t/ha) | Mean (t/ha) | Standard Deviation (t/ha) | Coefficient of Variation |
|---|---|---|---|---|---|
| Masson pine | 43 | 2.89–58.58 | 22.91 | 13.03 | 0.57 |
| Chinese fir | 24 | 10.56–103.99 | 55.07 | 24.59 | 0.45 |
| Broadleaf forest | 17 | 0.14–93.60 | 36.73 | 25.49 | 0.69 |
| Data | Variables | Description |
|---|---|---|
| Spectral bands | Blue; green; red; red edge 1, 2, and 3; near-infrared; narrow near-infrared; and shortwave infrared bands 1 and 2 | Ten spectral bands with 10 m spatial resolution from Sentinel-2 data were used |
| Vegetation indices | Normalized Difference Vegetation Index (NDVI) | (NIR − R)/(NIR + R) |
| Green Normalized Difference Vegetation Index (GNDVI) | (NIR − G)/(NIR + R) | |
| Nitrogen reflectance index (NRI) | NIR/G | |
| Ratio Vegetation Index (RVI) | NIR/R | |
| Atmospherically Resistant Vegetation Index (ARVI) | (NIR − 2R + B)/(NIR + 2R-B) | |
| Soil Adjusted Vegetation Index (SAVI) | 1.5(NIR − R)/(NIR + R + 0.5) | |
| Green Leaf Index (GLI) | (2G − R − B)/(G + R + B) | |
| Enhanced Vegetation Index (EVI) | 2.5(NIR − R)/(NIR + 6R − 7.5B + 1) | |
| Textural images | Mean, variance, homogeneity, contrast, heterogeneity, entropy, second moment, and correlation coefficient | The GLCM were used to extract textural images with window size of 9 × 9 pixels based on the 10 Sentinel-2 spectral bands |
| DEM | Elevation, slope, and slope aspect | The topographic factors were calculated from the NASADEM data with 30 m spatial resolution |
| Soil | Soil type, soil organic carbon, bulk density, pH level, soil texture class, soil available water content, soil clay content, and soil sand content at six standard depths (0, 10, 30, 60, 100, 200 cm) | The soil data were acquired from OpenLandMap (https://openlandmap.org/, accessed on 25 September 2023) through Google Earth Engine (GEE) |
| Hydrology | Flow direction, flow accumulation, and flow length | These variables were calculated using hydrology module in ArcGIS based on NASADEM data |
| Modeling Method | Stratification Scenario | Regression Models | Model R2 | Validation R2 | RMSE (t/ha) | RMSE% (%) |
|---|---|---|---|---|---|---|
| Linear regression | Non-stratification | −18.514 + 4.219H100 | 0.83 | 0.79 | 10.79 | 32.07 |
| Masson pine | −5.32 + 2.72Hmean + 2.20Hmin + 1.03Hvar | 0.88 | 0.81 | 5.64 | 24.64 | |
| Chinese fir | −15.30 + 3.93H25 + 1.99H100 | 0.89 | 0.78 | 11.24 | 21.29 | |
| Broadleaf | −5.46 + 5.36H70 − 2.80Hmin | 0.84 | 0.81 | 10.89 | 32.23 | |
| BHM | Forest type and soil subgroup | Fixed effect variables: H100 Random effect variables: H100, Hmean, Hmin, Hvar, H25, H70 | 0.94 | 0.89 | 7.51 | 22.34 |
| Forest type and conservation or not | 0.94 | 0.91 | 7.25 | 21.55 | ||
| Forest type and slope group | 0.94 | 0.90 | 7.40 | 21.98 |
| Forest Type | Average Carbon Stock (t/ha) | ||
|---|---|---|---|
| County | Conservation Regions | Non-Conservation Regions | |
| Masson pine | 43.44 | 29.18 | 45.29 |
| Chinese fir | 55.51 | 40.78 | 56.40 |
| Broadleaf forest | 57.04 | 42.28 | 57.46 |
| Overall | 48.55 | 31.28 | 50.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, X.; Li, G.; Wu, Q.; Ruan, J.; Li, D.; Lu, D. Mapping Forest Carbon Stock Distribution in a Subtropical Region with the Integration of Airborne Lidar and Sentinel-2 Data. Remote Sens. 2024, 16, 3847. https://doi.org/10.3390/rs16203847
Sun X, Li G, Wu Q, Ruan J, Li D, Lu D. Mapping Forest Carbon Stock Distribution in a Subtropical Region with the Integration of Airborne Lidar and Sentinel-2 Data. Remote Sensing. 2024; 16(20):3847. https://doi.org/10.3390/rs16203847
Chicago/Turabian StyleSun, Xiaoyu, Guiying Li, Qinquan Wu, Jingyi Ruan, Dengqiu Li, and Dengsheng Lu. 2024. "Mapping Forest Carbon Stock Distribution in a Subtropical Region with the Integration of Airborne Lidar and Sentinel-2 Data" Remote Sensing 16, no. 20: 3847. https://doi.org/10.3390/rs16203847
APA StyleSun, X., Li, G., Wu, Q., Ruan, J., Li, D., & Lu, D. (2024). Mapping Forest Carbon Stock Distribution in a Subtropical Region with the Integration of Airborne Lidar and Sentinel-2 Data. Remote Sensing, 16(20), 3847. https://doi.org/10.3390/rs16203847