


Estimating Forest Aboveground Biomass Using a Combination of Geographical Random Forest and Empirical Bayesian Kriging Models



Abstract
1. Introduction
2. Study Area and Data
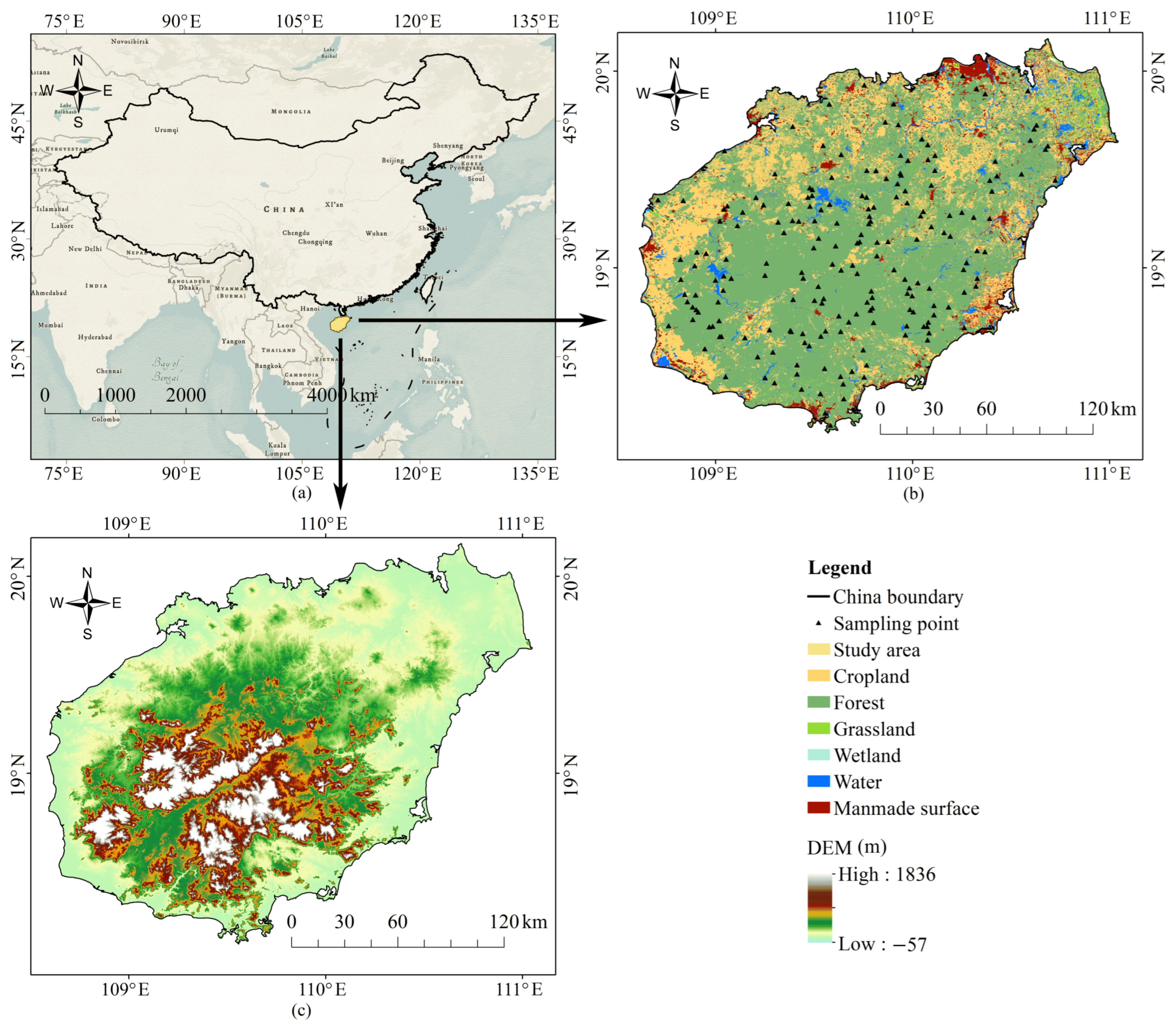
2.1. Study Area
2.2. Data Acquisition and Preprocessing
2.2.1. Landsat-8-Based Data
2.2.2. ALOS-2-Based Data
2.2.3. Forest Canopy Height Data
2.2.4. Topographic Data
2.2.5. Land Cover/Use Data
2.2.6. Field Measurement Data
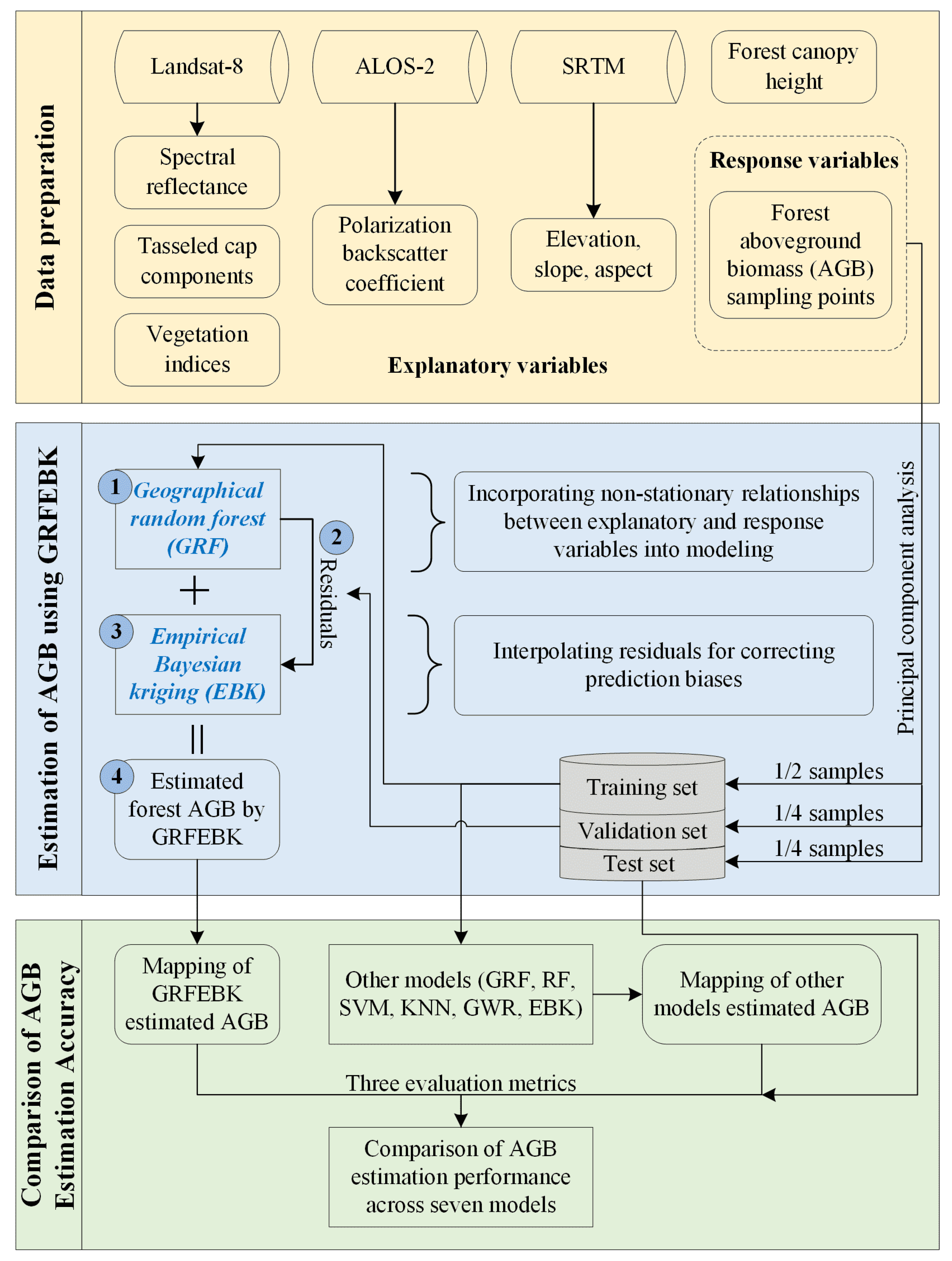
3. Methods
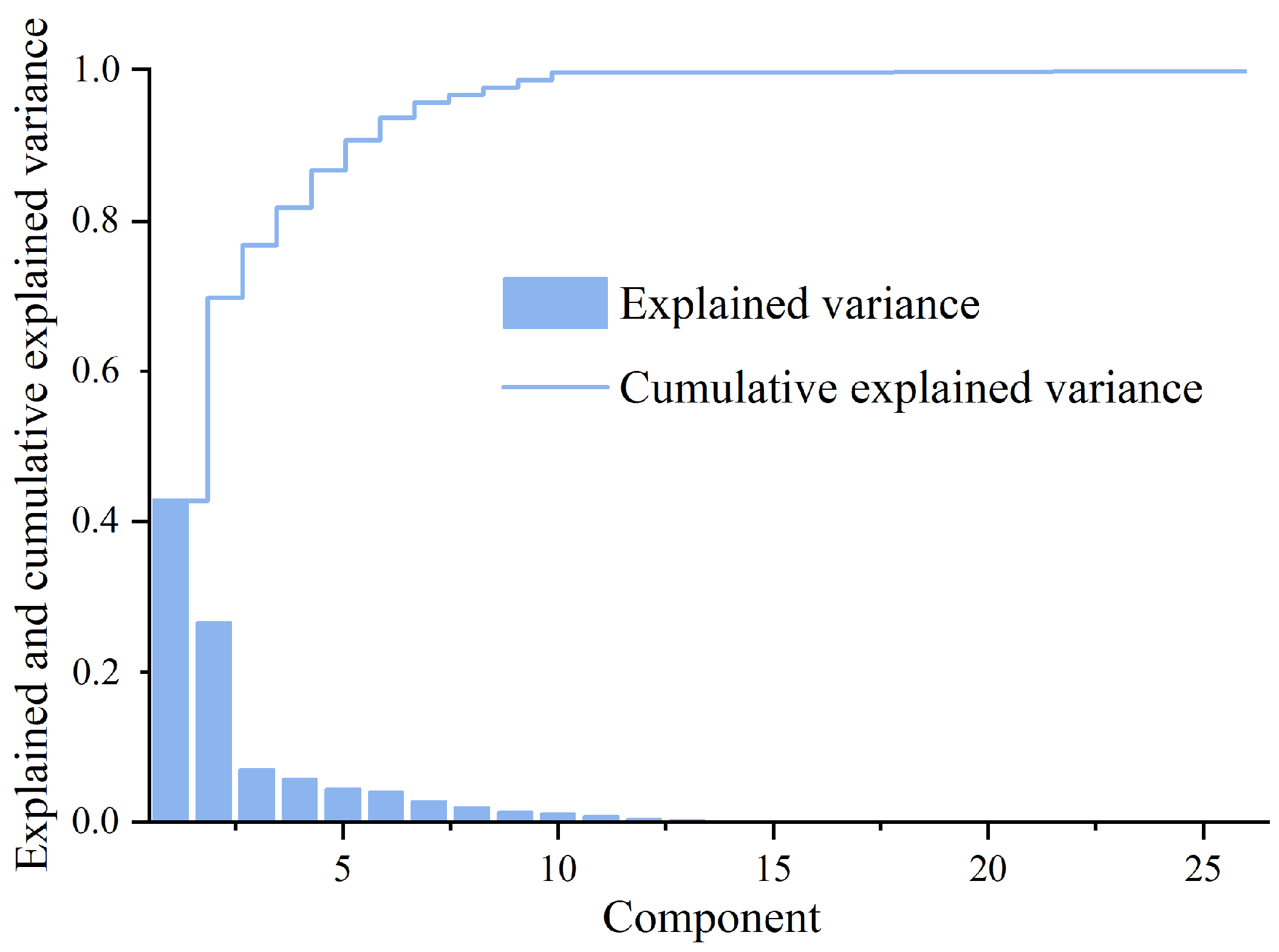
3.1. Feature Dimension Reduction and Hyperparameter Optimization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Variable | Description | Reference |
|---|---|---|---|
| Spectral reflectance | B, G, R, NIR, SWIR1, SWIR2 | L8 2-7 bands | [43] |
| VIs | NDVI | (Band 5 − Band 4)/(Band 5 + Band 4) | [44] |
| RVI | Band 5/Band 4 | [44] | |
| EVI | (2.5 × (Band 5 − Band 4))/(Band 5 + 6 × Band 4 − 7.5 × Band 2 + 1) | [44] | |
| DVI | 2.4 × Band 5 − Band 4 | [45] | |
| SAVI | ((1 + L) × (Band 5 − Band 4))/(Band 5 + Band 4 + L); L = 0.5 | [44] | |
| CIgreen | (Band 5/Band 3) − 1 | [46] | |
| GLI | (2 × Band 3 − Band 4 − Band 2)/(2 × Band 3 + Band 4 + Band 2) | [47] | |
| CVI | Band 5 × (Band 4/) | [47] | |
| MVI | Band 5/Band 6 | [48] | |
| NVI | ( − Band 4)/( + Band 4) | [49] | |
| SLAVI | Band 5/(Band 4 + Band 7) | [50] | |
| TCT components | Brightness, greenness, wetness | First three components of tassel cap transformation | [39] |
| Terrain features | Elevation, slope, aspect | Elevation, slope, and aspect of ground | [35] |
| Backscatter coefficients | HV, HH | Backscatter coefficient values of HV and HH polarization | [51] |
| Forest canopy height | FCH | Vertical distance from forest canopy top to ground | [38] |
3.2. Geographical Random Forest
3.3. Empirical Bayesian kriging
3.4. Other Comparative Models
3.5. Accuracy Assessment
4. Results
4.1. Feature Dimension Reduction and Hyperparameter Tuning
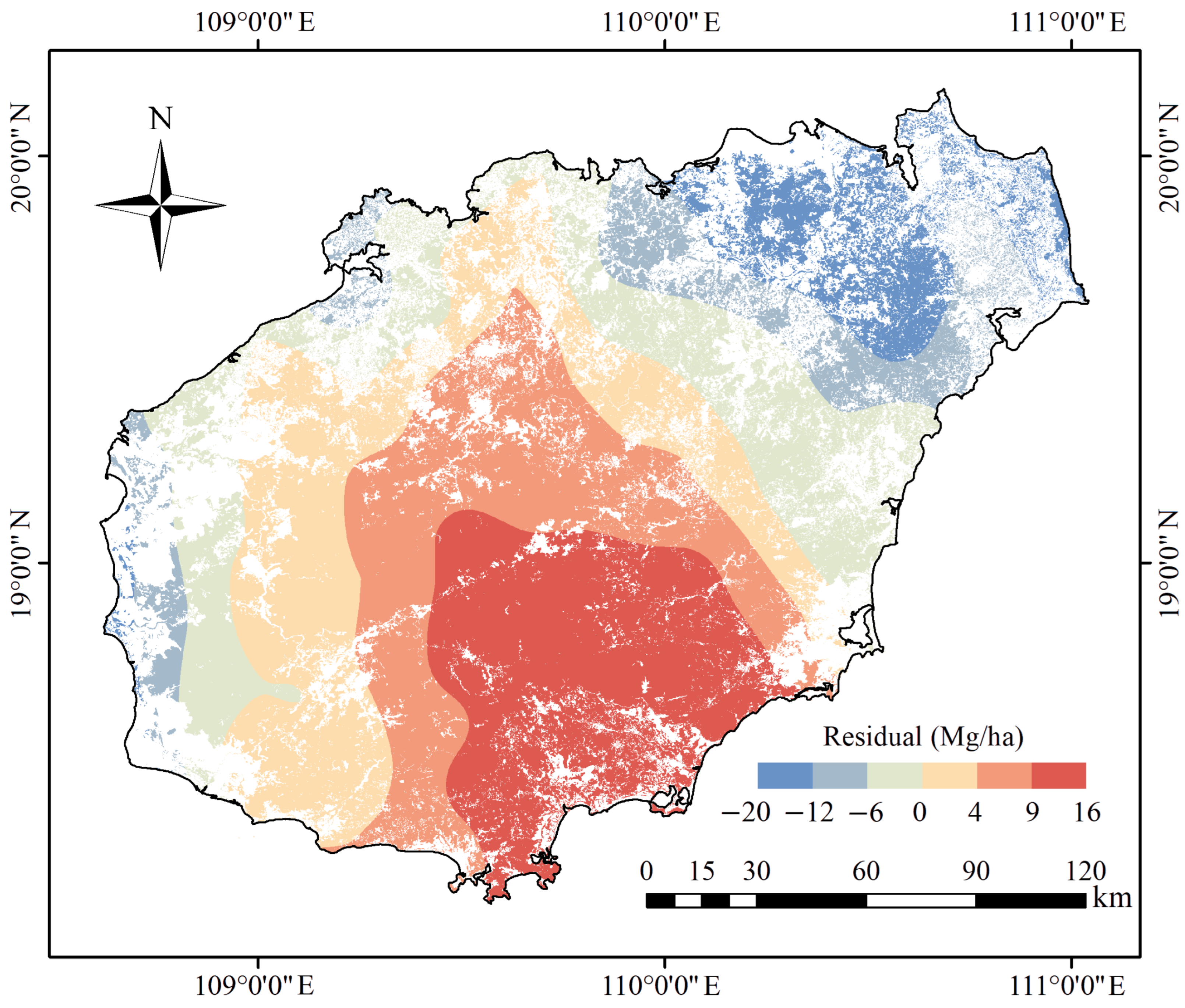
4.2. EBK Interpolation of Residuals from GRF AGB Estimation
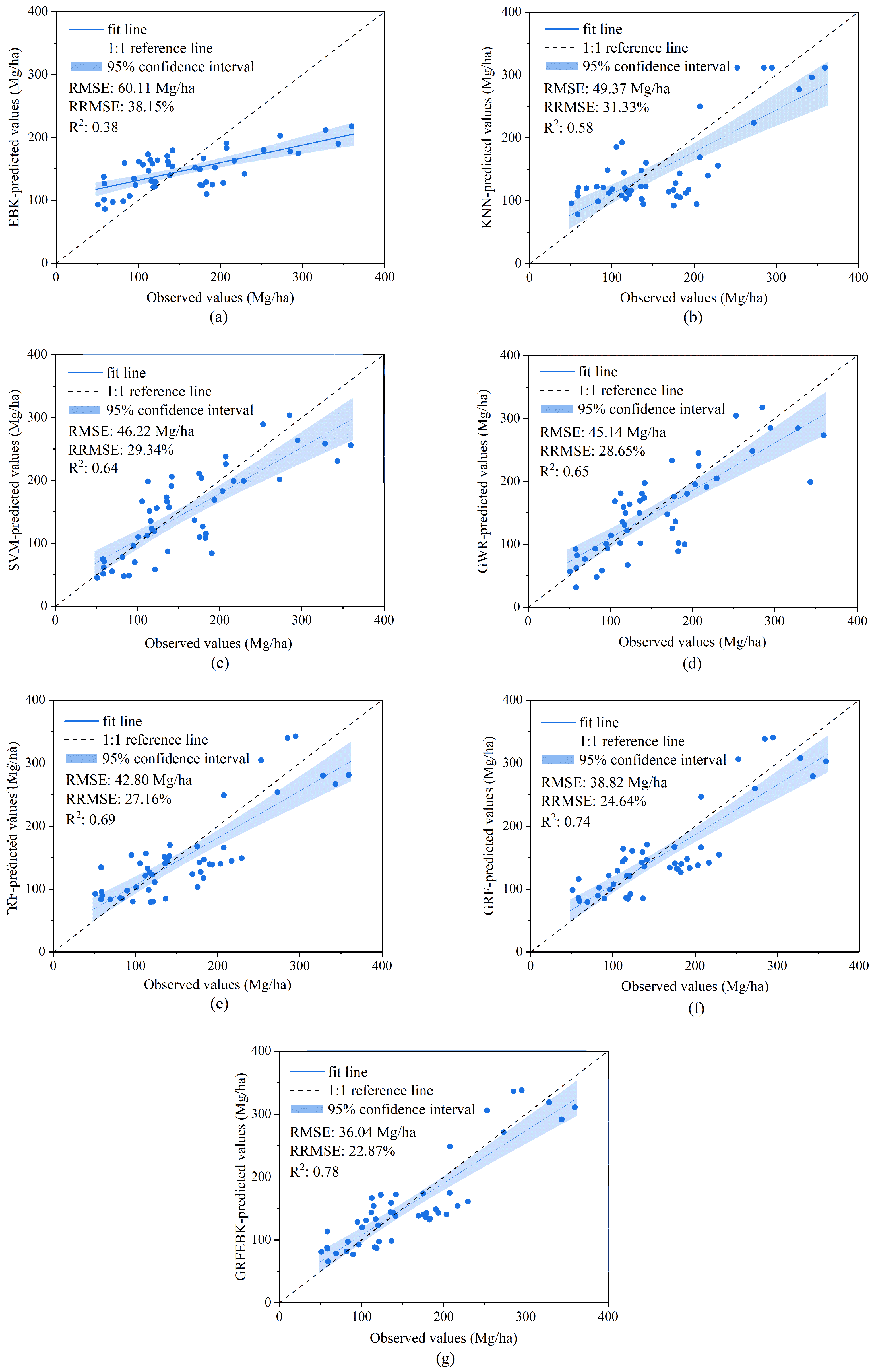
4.3. Comparison of Forest AGB Estimation Accuracy Among Models
4.4. Mapping of Forest AGB Estimated with GRFEBK
5. Discussion
5.1. Evaluating Current and Potential Explanatory Variables for AGB Modeling
5.2. Performance of GRFEBK in Estimating Forest AGB
5.3. Uncertainties in This Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Narine, L.L.; Popescu, S.; Neuenschwander, A.; Zhou, T.; Srinivasan, S.; Harbeck, K. Estimating aboveground biomass and forest canopy cover with simulated ICESat-2 data. Remote Sens. Environ. 2019, 224, 1–11. [Google Scholar] [CrossRef]
- Wu, C.; Shen, H.; Shen, A.; Deng, J.; Gan, M.; Zhu, J.; Xu, H.; Wang, K. Comparison of machine-learning methods for above-ground biomass estimation based on Landsat imagery. J. Appl. Remote Sens. 2016, 10, 035010. [Google Scholar] [CrossRef]
- Li, X.; Du, H.; Mao, F.; Zhou, G.; Chen, L.; Xing, L.; Fan, W.; Xu, X.; Liu, Y.; Cui, L.; et al. Estimating bamboo forest aboveground biomass using EnKF-assimilated MODIS LAI spatiotemporal data and machine learning algorithms. Agric. For. Meteorol. 2018, 256, 445–457. [Google Scholar] [CrossRef]
- Mitchard, E.T. The tropical forest carbon cycle and climate change. Nature 2018, 559, 527–534. [Google Scholar] [CrossRef]
- Li, L.; Zhou, B.; Liu, Y.; Wu, Y.; Tang, J.; Xu, W.; Wang, L.; Ou, G. Reduction in Uncertainty in Forest Aboveground Biomass Estimation Using Sentinel-2 Images: A Case Study of Pinus densata Forests in Shangri-La City, China. Remote Sens. 2023, 15, 559. [Google Scholar] [CrossRef]
- Shen, W.; Li, M.; Huang, C.; Tao, X.; Wei, A. Annual forest aboveground biomass changes mapped using ICESat/GLAS measurements, historical inventory data, and time-series optical and radar imagery for Guangdong province, China. Agric. For. Meteorol. 2018, 259, 23–38. [Google Scholar] [CrossRef]
- Chen, L.; Wang, Y.; Ren, C.; Zhang, B.; Wang, Z. Assessment of multi-wavelength SAR and multispectral instrument data for forest aboveground biomass mapping using random forest kriging. For. Ecol. Manag. 2019, 447, 12–25. [Google Scholar] [CrossRef]
- Zhang, R.; Zhou, X.; Ouyang, Z.; Avitabile, V.; Qi, J.; Chen, J.; Giannico, V. Estimating aboveground biomass in subtropical forests of China by integrating multisource remote sensing and ground data. Remote Sens. Environ. 2019, 232, 111341. [Google Scholar] [CrossRef]
- Liu, Y. Estimation of Forest Above-Ground Biomass and Net Primary Productivity Using Multi-Source Remote Sensing Data. Ph.D. Thesis, Wuhan University, Wuhan, China, 2019. [Google Scholar]
- Yang, M.; Zhou, X.; Peng, C.; Li, T.; Chen, K.; Liu, Z.; Li, P.; Zhang, C.; Tang, J.; Zou, Z. Developing allometric equations to estimate forest biomass for tree species categories based on phylogenetic relationships. For. Ecosyst. 2023, 10, 100130. [Google Scholar] [CrossRef]
- Mohd Zaki, N.A.; Abd Latif, Z. Carbon sinks and tropical forest biomass estimation: A review on role of remote sensing in aboveground-biomass modelling. Geocarto Int. 2017, 32, 701–716. [Google Scholar] [CrossRef]
- Lu, J.; Wang, H.; Qin, S.; Cao, L.; Pu, R.; Li, G.; Sun, J. Estimation of aboveground biomass of Robinia pseudoacacia forest in the Yellow River Delta based on UAV and Backpack LiDAR point clouds. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102014. [Google Scholar] [CrossRef]
- Salazar Villegas, M.H.; Qasim, M.; Csaplovics, E.; González-Martinez, R.; Rodriguez-Buritica, S.; Ramos Abril, L.N.; Salazar Villegas, B. Examining the Potential of Sentinel Imagery and Ensemble Algorithms for Estimating Aboveground Biomass in a Tropical Dry Forest. Remote Sens. 2023, 15, 5086. [Google Scholar] [CrossRef]
- Forkuor, G.; Zoungrana, J.B.B.; Dimobe, K.; Ouattara, B.; Vadrevu, K.P.; Tondoh, J.E. Above-ground biomass mapping in West African dryland forest using Sentinel-1 and 2 datasets-A case study. Remote Sens. Environ. 2020, 236, 111496. [Google Scholar] [CrossRef]
- Izadi, S.; Sohrabi, H.; Khaledi, M.J. Estimation of coppice forest characteristics using spatial and non-spatial models and Landsat data. J. Spat. Sci. 2022, 67, 143–156. [Google Scholar] [CrossRef]
- Lu, D.; Chen, Q.; Wang, G.; Liu, L.; Li, G.; Moran, E. A survey of remote sensing-based aboveground biomass estimation methods in forest ecosystems. Int. J. Digit. Earth 2016, 9, 63–105. [Google Scholar] [CrossRef]
- Ghosh, S.M.; Behera, M.D. Aboveground biomass estimation using multi-sensor data synergy and machine learning algorithms in a dense tropical forest. Appl. Geogr. 2018, 96, 29–40. [Google Scholar] [CrossRef]
- Propastin, P. Modifying geographically weighted regression for estimating aboveground biomass in tropical rainforests by multispectral remote sensing data. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 82–90. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Niang Gadiaga, A.; Linard, C.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E.; Kalogirou, S. Geographical random forests: A spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 2021, 36, 121–136. [Google Scholar] [CrossRef]
- Wang, H.; Seaborn, T.; Wang, Z.; Caudill, C.C.; Link, T.E. Modeling tree canopy height using machine learning over mixed vegetation landscapes. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102353. [Google Scholar] [CrossRef]
- Grekousis, G.; Feng, Z.; Marakakis, I.; Lu, Y.; Wang, R. Ranking the importance of demographic, socioeconomic, and underlying health factors on US COVID-19 deaths: A geographical random forest approach. Health Place 2022, 74, 102744. [Google Scholar] [CrossRef]
- Ye, H.; Huang, W.; Huang, S.; Huang, Y.; Zhang, S.; Dong, Y.; Chen, P. Effects of different sampling densities on geographically weighted regression kriging for predicting soil organic carbon. Spat. Stat. 2017, 20, 76–91. [Google Scholar] [CrossRef]
- Imran, M.; Stein, A.; Zurita-Milla, R. Using geographically weighted regression kriging for crop yield mapping in West Africa. Int. J. Geogr. Inf. Sci. 2015, 29, 234–257. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, C.; Li, W. Comparison of geographically weighted regression and regression kriging for estimating the spatial distribution of soil organic matter. Giscience Remote Sens. 2012, 49, 915–932. [Google Scholar] [CrossRef]
- Kumar, S.; Lal, R.; Liu, D. A geographically weighted regression kriging approach for mapping soil organic carbon stock. Geoderma 2012, 189, 627–634. [Google Scholar] [CrossRef]
- Gribov, A.; Krivoruchko, K. Empirical Bayesian kriging implementation and usage. Sci. Total Environ. 2020, 722, 137290. [Google Scholar] [CrossRef] [PubMed]
- Krivoruchko, K.; Gribov, A. Evaluation of empirical Bayesian kriging. Spat. Stat. 2019, 32, 100368. [Google Scholar] [CrossRef]
- Krivoruchko, K. Empirical bayesian kriging. ArcUser Fall 2012, 6, 1145. [Google Scholar]
- Astola, H.; Seitsonen, L.; Halme, E.; Molinier, M.; Lönnqvist, A. Deep neural networks with transfer learning for forest variable estimation using sentinel-2 imagery in boreal forest. Remote Sens. 2021, 13, 2392. [Google Scholar] [CrossRef]
- Shaheen, F.; Verma, B.; Asafuddoula, M. Impact of automatic feature extraction in deep learning architecture. In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), IEEE, Gold Coast, QLD, Australia, 30 November–2 December 2016; pp. 1–8. [Google Scholar]
- Qin, Y.; Wu, B.; Lei, X.; Feng, L. Prediction of tree crown width in natural mixed forests using deep learning algorithm. For. Ecosyst. 2023, 10, 100109. [Google Scholar] [CrossRef]
- Diez, Y.; Kentsch, S.; Fukuda, M.; Caceres, M.L.L.; Moritake, K.; Cabezas, M. Deep learning in forestry using uav-acquired rgb data: A practical review. Remote Sens. 2021, 13, 2837. [Google Scholar] [CrossRef]
- Wu, S.; Xing, C.; Zhu, J. Analysis of climate characteristics in Hainan Island. J. Trop. Biol. 2022, 13, 315–323. [Google Scholar]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The shuttle radar topography mission. Rev. Geophys. 2007, 45, 21–24. [Google Scholar] [CrossRef]
- Hernández-Stefanoni, J.L.; Castillo-Santiago, M.Á.; Mas, J.F.; Wheeler, C.E.; Andres-Mauricio, J.; Tun-Dzul, F.; George-Chacón, S.P.; Reyes-Palomeque, G.; Castellanos-Basto, B.; Vaca, R.; et al. Improving aboveground biomass maps of tropical dry forests by integrating LiDAR, ALOS PALSAR, climate and field data. Carbon Balance Manag. 2020, 15, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Niu, C.; Liu, X.; Feng, Y.; Ma, Q.; Wang, X.; Tang, H.; Guo, Q. Mapping high-resolution forest aboveground biomass of China using multisource remote sensing data. GIScience Remote Sens. 2023, 60, 2203303. [Google Scholar] [CrossRef]
- Potapov, P.; Li, X.; Hernandez-Serna, A.; Tyukavina, A.; Hansen, M.C.; Kommareddy, A.; Pickens, A.; Turubanova, S.; Tang, H.; Silva, C.E.; et al. Mapping global forest canopy height through integration of GEDI and Landsat data. Remote Sens. Environ. 2021, 253, 112165. [Google Scholar] [CrossRef]
- Baig, M.H.A.; Zhang, L.; Shuai, T.; Tong, Q. Derivation of a tasselled cap transformation based on Landsat 8 at-satellite reflectance. Remote Sens. Lett. 2014, 5, 423–431. [Google Scholar] [CrossRef]
- Carreiras, J.M.; Pereira, J.M.; Pereira, J.S. Estimation of tree canopy cover in evergreen oak woodlands using remote sensing. For. Ecol. Manag. 2006, 223, 45–53. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, X.; Lu, F. Comprehensive Database of Biomass Regressions for China’s Tree Species; China Forestry Publishing House: Beijing, China, 2015. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Roy, D.P.; Wulder, M.A.; Loveland, T.R.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Helder, D.; Irons, J.R.; Johnson, D.M.; Kennedy, R.; et al. Landsat-8: Science and product vision for terrestrial global change research. Remote Sens. Environ. 2014, 145, 154–172. [Google Scholar] [CrossRef]
- Ahamed, T.; Tian, L.; Zhang, Y.; Ting, K. A review of remote sensing methods for biomass feedstock production. Biomass Bioenergy 2011, 35, 2455–2469. [Google Scholar] [CrossRef]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A. A review of vegetation indices. Remote Sens. Rev. 1995, 13, 95–120. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Viña, A.; Arkebauer, T.J.; Rundquist, D.C.; Keydan, G.; Leavitt, B. Remote estimation of leaf area index and green leaf biomass in maize canopies. Geophys. Res. Lett. 2003, 30, 1248. [Google Scholar] [CrossRef]
- Hunt, E.R., Jr.; Daughtry, C.; Eitel, J.U.; Long, D.S. Remote sensing leaf chlorophyll content using a visible band index. Agron. J. 2011, 103, 1090–1099. [Google Scholar] [CrossRef]
- Schlerf, M.; Atzberger, C.; Hill, J. Remote sensing of forest biophysical variables using HyMap imaging spectrometer data. Remote Sens. Environ. 2005, 95, 177–194. [Google Scholar] [CrossRef]
- Pu, R.; Gong, P.; Yu, Q. Comparative analysis of EO-1 ALI and Hyperion, and Landsat ETM+ data for mapping forest crown closure and leaf area index. Sensors 2008, 8, 3744–3766. [Google Scholar] [CrossRef] [PubMed]
- Lymburner, L.; Beggs, P.J.; Jacobson, C.R. Estimation of canopy-average surface-specific leaf area using Landsat TM data. Photogramm. Eng. Remote Sens. 2000, 66, 183–192. [Google Scholar]
- Rosenqvist, A.; Shimada, M.; Suzuki, S.; Ohgushi, F.; Tadono, T.; Watanabe, M.; Tsuzuku, K.; Watanabe, T.; Kamijo, S.; Aoki, E. Operational performance of the ALOS global systematic acquisition strategy and observation plans for ALOS-2 PALSAR-2. Remote Sens. Environ. 2014, 155, 3–12. [Google Scholar] [CrossRef]
- Aguirre-Gutiérrez, J.; Rifai, S.; Shenkin, A.; Oliveras, I.; Bentley, L.P.; Svátek, M.; Girardin, C.A.; Both, S.; Riutta, T.; Berenguer, E.; et al. Pantropical modelling of canopy functional traits using Sentinel-2 remote sensing data. Remote Sens. Environ. 2021, 252, 112122. [Google Scholar] [CrossRef]
- Zhao, P.; Lu, D.; Wang, G.; Liu, L.; Li, D.; Zhu, J.; Yu, S. Forest aboveground biomass estimation in Zhejiang Province using the integration of Landsat TM and ALOS PALSAR data. Int. J. Appl. Earth Obs. Geoinf. 2016, 53, 1–15. [Google Scholar] [CrossRef]
- Ali, A.; Lin, S.L.; He, J.K.; Kong, F.M.; Yu, J.H.; Jiang, H.S. Climate and soils determine aboveground biomass indirectly via species diversity and stand structural complexity in tropical forests. For. Ecol. Manag. 2019, 432, 823–831. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Pham, T.D.; Le, N.N.; Ha, N.T.; Nguyen, L.V.; Xia, J.; Yokoya, N.; To, T.T.; Trinh, H.X.; Kieu, L.Q.; Takeuchi, W. Estimating mangrove above-ground biomass using extreme gradient boosting decision trees algorithm with fused sentinel-2 and ALOS-2 PALSAR-2 data in can Gio biosphere reserve, Vietnam. Remote Sens. 2020, 12, 777. [Google Scholar] [CrossRef]
- Du, Z.; Wang, Z.; Wu, S.; Zhang, F.; Liu, R. Geographically neural network weighted regression for the accurate estimation of spatial non-stationarity. Int. J. Geogr. Inf. Sci. 2020, 34, 1353–1377. [Google Scholar] [CrossRef]
- Lu, X. Estimation of Mountain Forest Aboveground Biomass by Inteerating ICEsat and Landsat Data. Ph.D. Thesis, Chinese Academy of Sciences, Beijing, China, 2017. [Google Scholar]
- Wu, D. Forest Canopy Height and Aboveground Biomass Estimation Based on GLAS and MISR Data. Ph.D. Thesis, Northeast Forestry University, Harbin, China, 2015. [Google Scholar]

| Tree Species | Allometric Equations (M Represents the Biomass of Individual Tree) |
|---|---|
| Dacrycarpus imbricatus var. patulus de Laub | |
| Eucalyptus urophylla S.T. Blake | |
| Manglietia fordiana var. hainanensis (Dandy) N. H. | |
| Gmelina hainanensis Oliv. | |
| Homalium hainanense Gagnep. | |
| Sonneratia caseolaris (Linn.) Engl. | |
| Bruguiera gymnorhiza (L.) Lam. | |
| Chinese coniferous tree | |
| Chinese broadleaf tree |
| Model | Hyperparapmeter | Meaning | Tuning Result |
|---|---|---|---|
| RF | n_estimators | Number of decision trees | 52 |
| max_depth | Maximum depth of trees | 8 | |
| GRF | n_estimators | Number of decision trees | 59 |
| max_depth | Maximum depth of trees | 7 | |
| neighbors | Number of neighbors | 68 | |
| KNN | n_neighbors | Number of neighbors | 6 |
| weights | Neighbor weighting | uniform | |
| p | Distance metric parameter | 1 | |
| SVM | gamma | Kernel coefficient | 0.04 |
| kernel | Kernel function | linear | |
| C | Regularization parameter | 3 | |
| GWR | kernel | Weighting kernel type | gaussian |
| bandwidth | Kernel bandwidth | 81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Yao, F.; Zhang, J.; Liu, H. Estimating Forest Aboveground Biomass Using a Combination of Geographical Random Forest and Empirical Bayesian Kriging Models. Remote Sens. 2024, 16, 1859. https://doi.org/10.3390/rs16111859
Wu Z, Yao F, Zhang J, Liu H. Estimating Forest Aboveground Biomass Using a Combination of Geographical Random Forest and Empirical Bayesian Kriging Models. Remote Sensing. 2024; 16(11):1859. https://doi.org/10.3390/rs16111859
Chicago/Turabian StyleWu, Zhenjiang, Fengmei Yao, Jiahua Zhang, and Haoyu Liu. 2024. "Estimating Forest Aboveground Biomass Using a Combination of Geographical Random Forest and Empirical Bayesian Kriging Models" Remote Sensing 16, no. 11: 1859. https://doi.org/10.3390/rs16111859
APA StyleWu, Z., Yao, F., Zhang, J., & Liu, H. (2024). Estimating Forest Aboveground Biomass Using a Combination of Geographical Random Forest and Empirical Bayesian Kriging Models. Remote Sensing, 16(11), 1859. https://doi.org/10.3390/rs16111859