
Infrared Image Generation Based on Visual State Space and Contrastive Learning


Abstract
1. Introduction
- A visual state space attention module is introduced into V2IGAN to focus the generative network on key areas within visible-light images effectively.
- A multi-scale feature contrast learning function is considered in the present method to ensure semantic consistency between the generated and target images effectively.
- Experiments conducted on large benchmark datasets across various scenarios demonstrate that V2IGAN is capable of producing high-quality, reliable infrared images.
2. Related Work
2.1. Generative Adversarial Networks
2.2. Visible-to-Infrared Image Translation Based on CGAN
2.3. Contrastive Learning
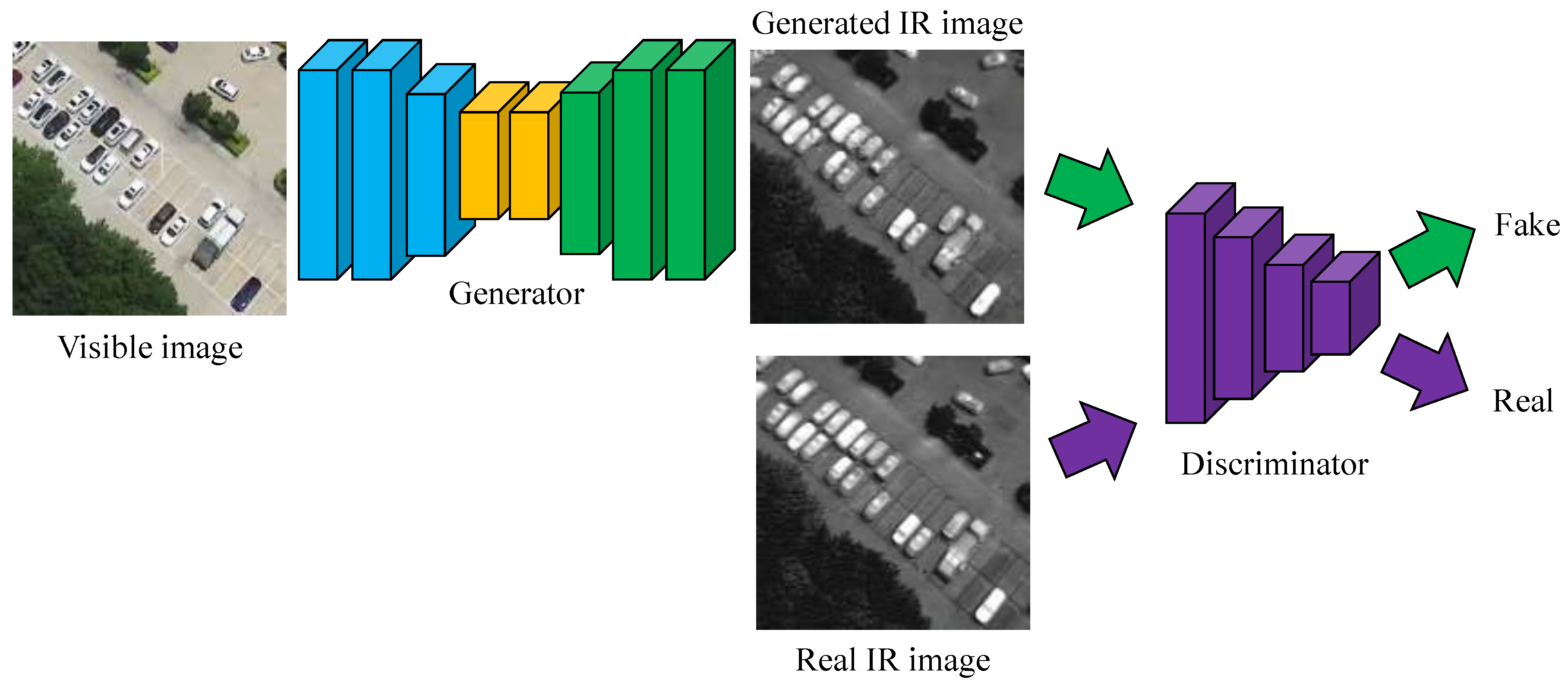
3. Proposed Method
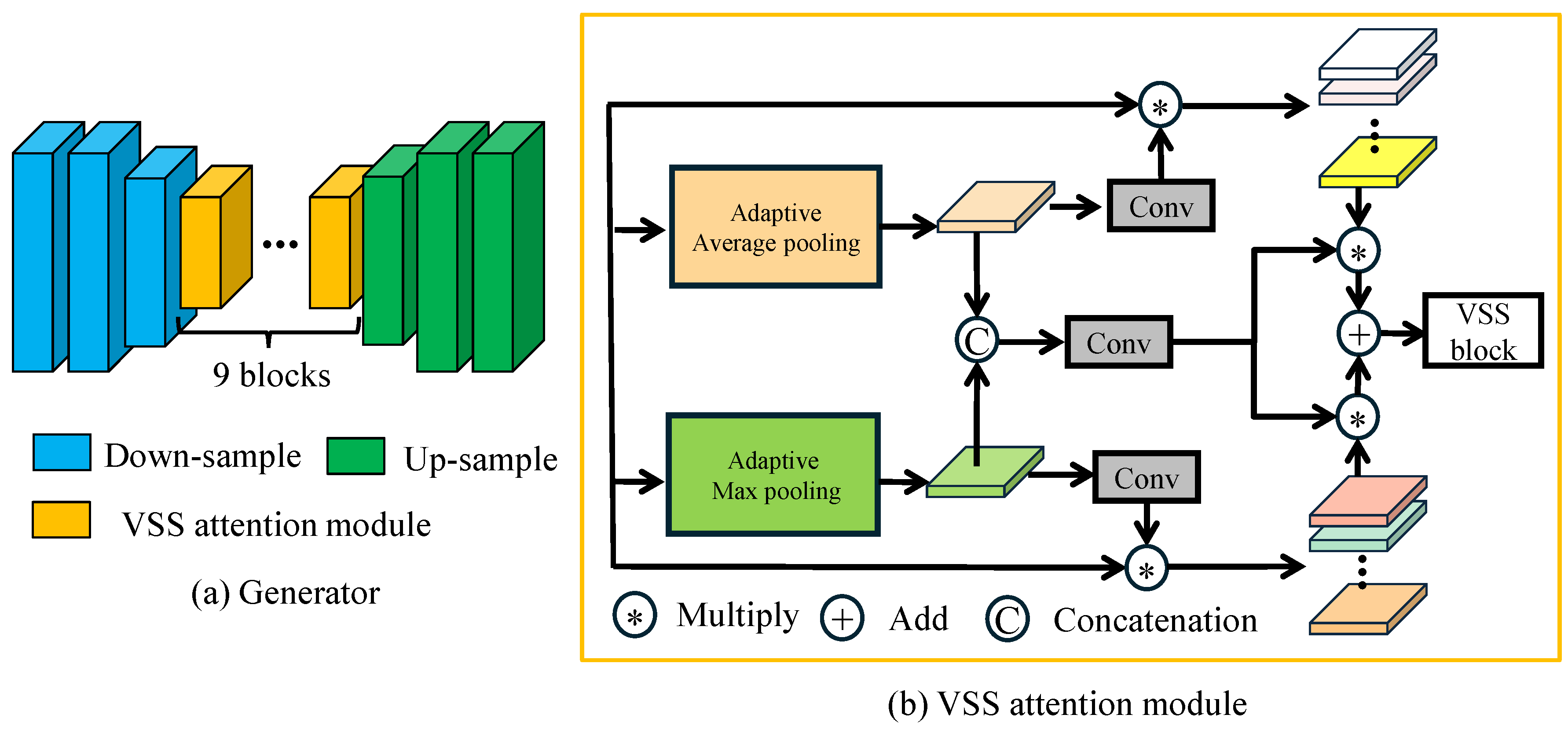
3.1. Proposed Network Architecture
3.2. VSS Attention Module
| Algorithm 1 Pseudo-code for S6 in SS2D. |
|
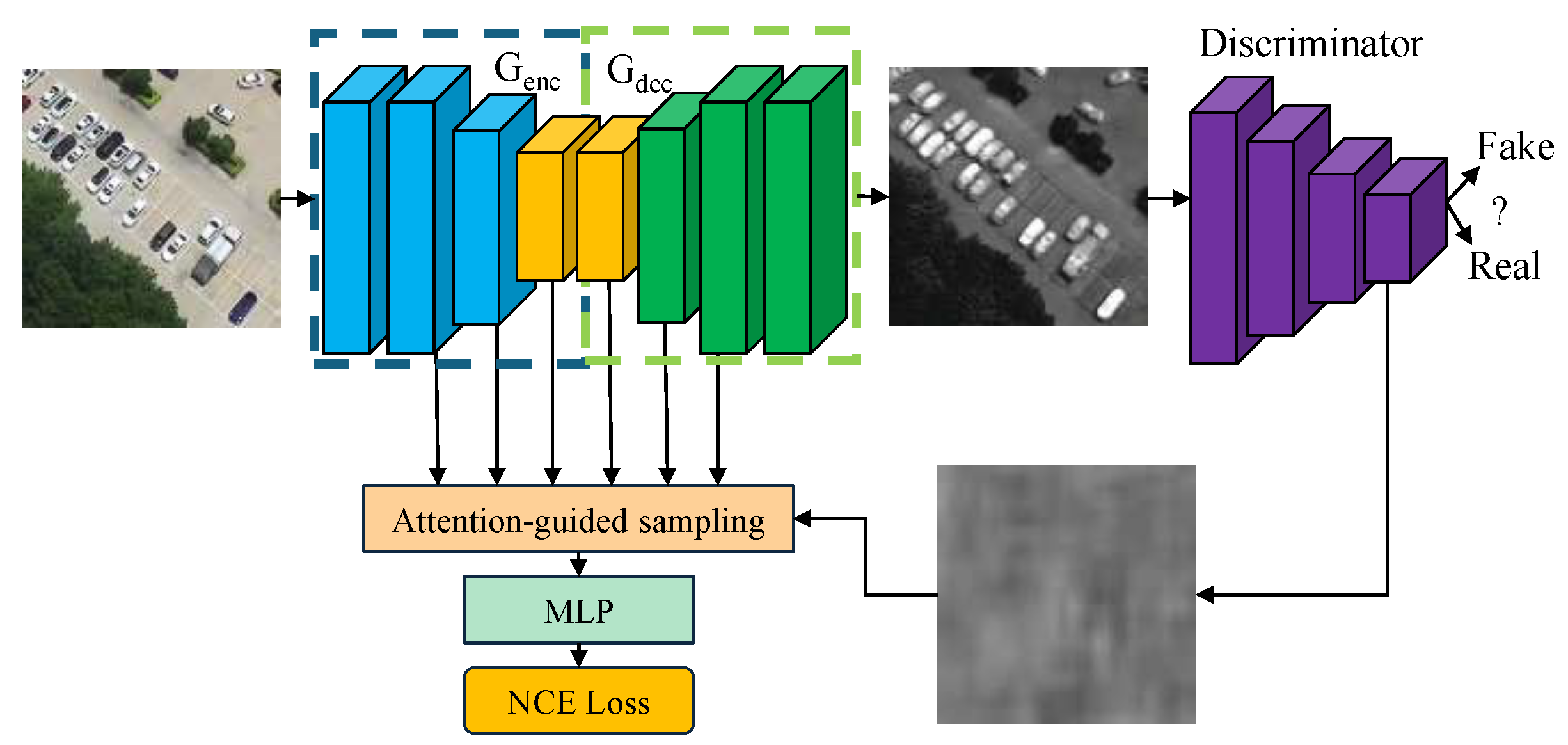
3.3. Multi-Scale Feature Contrastive Learning
3.4. Loss Function
| Algorithm 2 Pseudo code of V2IGAN-P algorithm. |
|
4. Experimental Results
4.1. Datasets
4.2. Implementation Details
4.3. Image Quality Evaluation Metrics
- (1) Peak signal-to-noise ratio (PSNR) [77]: This is a traditional measure that quantifies the maximum possible signal-to-noise ratio of an image, and it has often been used to assess the quality of reconstructed and compressed images.The PSNR is expressed as follows:wherewhere I is a real IR image, S is a simulated IR image, and M and N are the height and width of the images, respectively.
- (2) Structural Similarity Index Measure (SSIM): This is a perceptual image quality metric that compares local patterns of pixel intensities to evaluate the similarity between two images.The SSIM can be defined aswhere , , and are parameters used to ensure the stability of a partition; and are the respective means of I and S; and are their respective standard deviations; is the covariance of I and S; and L is the range of image pixels.
- (3) Multi-Scale Structural Similarity Index Measure (MS-SSIM) [78]: This metric represents an extension of the SSIM that operates on multiple scales, providing a more comprehensive assessment of image quality by capturing both local and global changes.The MS-SSIM is defined aswhere , , and are the brightness, contrast, and structural similarity, respectively; and , , and are weight coefficients for , , and , respectively. To simplify parameter selection, , , and .
- (4) Learned Perceptual Image Patch Similarity (LPIPS) [79]: This is a recently developed metric that leverages deep learning to measure the perceptual difference between image patches. It has been proposed to provide a closer correlation with human perception of image quality.The LPIPS is calculated asTo calculate this, comparative features were obtained from a convolutional neural network-based backbone and pretrained on ImageNet (the AlexNet network model was used in the experiment).
- (5) Fréchet Inception Distance (FID) [80]: This metric is derived from the field of machine learning, and it measures the distance between two statistical distributions of features extracted by the Inception-V3 Network, providing insight into the quality of generated images in a generative model.The FID is calculated aswhere and are the respective mean vectors of the real and generative data distributions, with covariance matrices of and , respective; is the trace of the matrix; and is the binary norm of the vector.
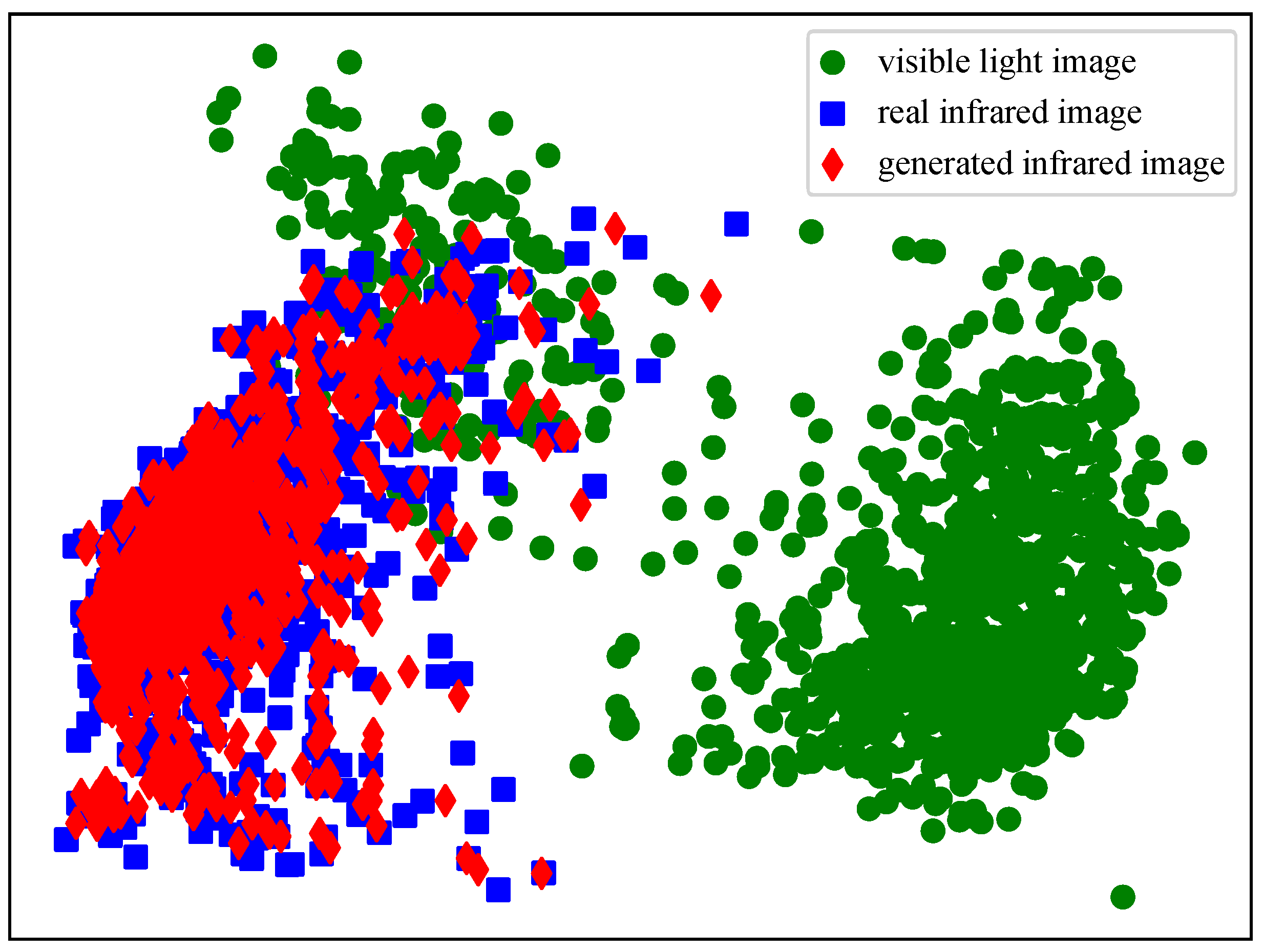
4.4. Simulation Evaluation of Infrared Image Generation Quality
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, D.; Wang, Y.; Wang, H.; Wang, F.; Gao, G. DCFNet: Infrared and Visible Image Fusion Network Based on Discrete Wavelet Transform and Convolutional Neural Network. Sensors 2024, 24, 4065. [Google Scholar] [CrossRef] [PubMed]
- Jia, R.; Chen, X.; Li, T.; Cui, J. V2T-GAN: Three-Level Refined Light-Weight GAN with Cascaded Guidance for Visible-to-Thermal Translation. Sensors 2022, 22, 2119. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Zhang, X.; Zhang, G.; Zhang, Y.; Li, X. Infrared Thermography and Its Applications in Aircraft Non-destructive Testing. In Proceedings of the 2016 International Conference on Identification, Information and Knowledge in the Internet of Things (IIKI), Beijing, China, 20–21 October 2016; pp. 374–379. [Google Scholar] [CrossRef]
- Patel, I.; Kulkarni, M.; Mehendale, N. Review of sensor-driven assistive device technologies for enhancing navigation for the visually impaired. Multimed. Tools Appl. 2023, 83, 52171–52195. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, Y.; Wang, S. Lightweight Small Ship Detection Algorithm Combined with Infrared Characteristic Analysis for Autonomous Navigation. J. Mar. Sci. Eng. 2023, 11, 1114. [Google Scholar] [CrossRef]
- Malhotra, S.; Halabi, O.; Dakua, S.P.; Padhan, J.; Paul, S.; Palliyali, W. Augmented Reality in Surgical Navigation: A Review of Evaluation and Validation Metrics. Appl. Sci. 2023, 13, 1629. [Google Scholar] [CrossRef]
- Arafat, M.Y.; Alam, M.M.; Moh, S. Vision-Based Navigation Techniques for Unmanned Aerial Vehicles: Review and Challenges. Drones 2023, 7, 89. [Google Scholar] [CrossRef]
- Yang, S.; Sun, M.; Lou, X.; Yang, H.; Zhou, H. An Unpaired Thermal Infrared Image Translation Method Using GMA-CycleGAN. Remote Sens. 2023, 15, 663. [Google Scholar] [CrossRef]
- Zhang, Q.; Smith, W.; Shao, M. The Potential of Monitoring Carbon Dioxide Emission in a Geostationary View with the GIIRS Meteorological Hyperspectral Infrared Sounder. Remote Sens. 2023, 15, 886. [Google Scholar] [CrossRef]
- Fernández, J.I.P.; Georgiev, C.G. Evolution of Meteosat Solar and Infrared Spectra (2004–2022) and Related Atmospheric and Earth Surface Physical Properties. Atmosphere 2023, 14, 1354. [Google Scholar] [CrossRef]
- Xie, M.; Gu, M.; Hu, Y.; Huang, P.; Zhang, C.; Yang, T.; Yang, C. A Study on the Retrieval of Ozone Profiles Using FY-3D/HIRAS Infrared Hyperspectral Data. Remote Sens. 2023, 15, 1009. [Google Scholar] [CrossRef]
- Feng, C.; Yin, W.; He, S.; He, M.; Li, X. Evaluation of SST Data Products from Multi-Source Satellite Infrared Sensors in the Bohai-Yellow-East China Sea. Remote Sens. 2023, 15, 2493. [Google Scholar] [CrossRef]
- Torres Gil, L.K.; Valdelamar Martínez, D.; Saba, M. The Widespread Use of Remote Sensing in Asbestos, Vegetation, Oil and Gas, and Geology Applications. Atmosphere 2023, 14, 172. [Google Scholar] [CrossRef]
- Rotem, A.; Vidal, A.; Pfaff, K.; Tenorio, L.; Chung, M.; Tharalson, E.; Monecke, T. Interpretation of Hyperspectral Shortwave Infrared Core Scanning Data Using SEM-Based Automated Mineralogy: A Machine Learning Approach. Geosciences 2023, 13, 192. [Google Scholar] [CrossRef]
- Li, X.; Jiang, G.; Tang, X.; Zuo, Y.; Hu, S.; Zhang, C.; Wang, Y.; Wang, Y.; Zheng, L. Detecting Geothermal Anomalies Using Multi-Temporal Thermal Infrared Remote Sensing Data in the Damxung–Yangbajain Basin, Qinghai–Tibet Plateau. Remote Sens. 2023, 15, 4473. [Google Scholar] [CrossRef]
- Hamedianfar, A.; Laakso, K.; Middleton, M.; Törmänen, T.; Köykkä, J.; Torppa, J. Leveraging High-Resolution Long-Wave Infrared Hyperspectral Laboratory Imaging Data for Mineral Identification Using Machine Learning Methods. Remote Sens. 2023, 15, 4806. [Google Scholar] [CrossRef]
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and Visible Image Fusion Technology and Application: A Review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef]
- Cheng, C.; Fu, J.; Su, H.; Ren, L. Recent Advancements in Agriculture Robots: Benefits and Challenges. Machines 2023, 11, 48. [Google Scholar] [CrossRef]
- Albahar, M. A Survey on Deep Learning and Its Impact on Agriculture: Challenges and Opportunities. Agriculture 2023, 13, 540. [Google Scholar] [CrossRef]
- Xu, X.; Du, C.; Ma, F.; Qiu, Z.; Zhou, J. A Framework for High-Resolution Mapping of Soil Organic Matter (SOM) by the Integration of Fourier Mid-Infrared Attenuation Total Reflectance Spectroscopy (FTIR-ATR), Sentinel-2 Images, and DEM Derivatives. Remote Sens. 2023, 15, 1072. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-frame infrared small-target detection: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Bao, C.; Cao, J.; Hao, Q.; Cheng, Y.; Ning, Y.; Zhao, T. Dual-YOLO Architecture from Infrared and Visible Images for Object Detection. Sensors 2023, 23, 2934. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Xia, Y.; Zhang, W.; Zheng, C.; Zhang, Z. YOLO-ViT-Based Method for Unmanned Aerial Vehicle Infrared Vehicle Target Detection. Remote Sens. 2023, 15, 3778. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, B.; Huo, L.; Fan, Y. GT-YOLO: Nearshore Infrared Ship Detection Based on Infrared Images. J. Mar. Sci. Eng. 2024, 12, 213. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, H.; Pang, Y.; Han, J.; Mou, E.; Cao, E. RETRACTED: An Infrared Small Target Detection Method Based on a Weighted Human Visual Comparison Mechanism for Safety Monitoring. Remote Sens. 2023, 15, 2922. [Google Scholar] [CrossRef]
- Seo, H.; Raut, A.D.; Chen, C.; Zhang, C. Multi-Label Classification and Automatic Damage Detection of Masonry Heritage Building through CNN Analysis of Infrared Thermal Imaging. Remote Sens. 2023, 15, 2517. [Google Scholar] [CrossRef]
- Chehreh, B.; Moutinho, A.; Viegas, C. Latest Trends on Tree Classification and Segmentation Using UAV Data—A Review of Agroforestry Applications. Remote Sens. 2023, 15, 2263. [Google Scholar] [CrossRef]
- Bu, C.; Liu, T.; Wang, T.; Zhang, H.; Sfarra, S. A CNN-Architecture-Based Photovoltaic Cell Fault Classification Method Using Thermographic Images. Energies 2023, 16, 3749. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A. Deep Learning Approaches for Wildland Fires Remote Sensing: Classification, Detection, and Segmentation. Remote Sens. 2023, 15, 1821. [Google Scholar] [CrossRef]
- Huang, J.; Junginger, S.; Liu, H.; Thurow, K. Indoor Positioning Systems of Mobile Robots: A Review. Robotics 2023, 12, 47. [Google Scholar] [CrossRef]
- Yang, X.; Xie, J.; Liu, R.; Mo, F.; Zeng, J. Centroid Extraction of Laser Spots Captured by Infrared Detectors Combining Laser Footprint Images and Detector Observation Data. Remote Sens. 2023, 15, 2129. [Google Scholar] [CrossRef]
- Qi, L.; Liu, Y.; Yu, Y.; Chen, L.; Chen, R. Current Status and Future Trends of Meter-Level Indoor Positioning Technology: A Review. Remote Sens. 2024, 16, 398. [Google Scholar] [CrossRef]
- Guo, Y.; Zhou, Y.; Yang, F. AGCosPlace: A UAV Visual Positioning Algorithm Based on Transformer. Drones 2023, 7, 498. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, L.; Su, K.; Dai, D.; Li, N.; Wu, D. Infrared Moving Small Target Detection Based on Space–Time Combination in Complex Scenes. Remote Sens. 2023, 15, 5380. [Google Scholar] [CrossRef]
- Wei, G.; Chen, H.; Lin, E.; Hu, X.; Xie, H.; Cui, Y.; Luo, Y. Identification of Water Layer Presence in Paddy Fields Using UAV-Based Visible and Thermal Infrared Imagery. Agronomy 2023, 13, 1932. [Google Scholar] [CrossRef]
- Ma, J.; Guo, H.; Rong, S.; Feng, J.; He, B. Infrared Dim and Small Target Detection Based on Background Prediction. Remote Sens. 2023, 15, 3749. [Google Scholar] [CrossRef]
- Niu, K.; Wang, C.; Xu, J.; Yang, C.; Zhou, X.; Yang, X. An Improved YOLOv5s-Seg Detection and Segmentation Model for the Accurate Identification of Forest Fires Based on UAV Infrared Image. Remote Sens. 2023, 15, 4694. [Google Scholar] [CrossRef]
- Xie, X.; Xi, J.; Yang, X.; Lu, R.; Xia, W. STFTrack: Spatio-Temporal-Focused Siamese Network for Infrared UAV Tracking. Drones 2023, 7, 296. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, J.; Lin, Z.; Li, C.; Huo, B.; Zhang, Y. SiamCAF: Complementary Attention Fusion-Based Siamese Network for RGBT Tracking. Remote Sens. 2023, 15, 3252. [Google Scholar] [CrossRef]
- Dang, C.; Li, Z.; Hao, C.; Xiao, Q. Infrared Small Marine Target Detection Based on Spatiotemporal Dynamics Analysis. Remote Sens. 2023, 15, 1258. [Google Scholar] [CrossRef]
- Yang, M.; Li, M.; Yi, Y.; Yang, Y.; Wang, Y.; Lu, Y. Infrared simulation of ship target on the sea based on OGRE. Laser Infrared 2017, 47, 53–57. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Hladůvka, J.; Kropatsch, W.G.; Mizginov, V. ThermalGAN: Multimodal Color-to-Thermal Image Translation for Person Re-identification in Multispectral Dataset. In Computer Vision—ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Springer: Cham, Switzerland, 2019; pp. 606–624. [Google Scholar]
- Mizginov, V.; Kniaz, V.; Fomin, N. A method for synthesizing thermal images using GAN multi-layered approach. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2021, 44, 155–162. [Google Scholar] [CrossRef]
- Özkanoğlu, M.A.; Ozer, S. InfraGAN: A GAN architecture to transfer visible images to infrared domain. Pattern Recognit. Lett. 2022, 155, 69–76. [Google Scholar] [CrossRef]
- Ma, D.; Xian, Y.; Li, B.; Li, S.; Zhang, D. Visible-to-infrared image translation based on an improved CGAN. Vis. Comput. 2023, 40, 1289–1298. [Google Scholar] [CrossRef]
- Ma, D.; Li, S.; Su, J.; Xian, Y.; Zhang, T. Visible-to-Infrared Image Translation for Matching Tasks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 18, 1–16. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Zhang, R.; Mu, C.; Xu, M.; Xu, L.; Shi, Q.; Wang, J. Synthetic IR image refinement using adversarial learning with bidirectional mappings. IEEE Access 2019, 7, 153734–153750. [Google Scholar] [CrossRef]
- Li, Y.; Ko, Y.; Lee, W. RGB image-based hybrid model for automatic prediction of flashover in compartment fires. Fire Saf. J. 2022, 132, 103629. [Google Scholar] [CrossRef]
- Liu, H.; Ma, L. Infrared Image Generation Algorithm Based on GAN and contrastive learning. In Proceedings of the 2022 International Conference on Artificial Intelligence and Computer Information Technology (AICIT), Yichang, China, 16–18 September 2022; pp. 1–4. [Google Scholar]
- Lee, D.G.; Jeon, M.H.; Cho, Y.; Kim, A. Edge-guided multi-domain rgb-to-tir image translation for training vision tasks with challenging labels. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 8291–8298. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Sommervold, O.; Gazzea, M.; Arghandeh, R. A Survey on SAR and Optical Satellite Image Registration. Remote Sens. 2023, 15, 850. [Google Scholar] [CrossRef]
- Wang, Z.; Nie, F.; Zhang, C.; Wang, R.; Li, X. Worst-Case Discriminative Feature Learning via Max-Min Ratio Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 641–658. [Google Scholar] [CrossRef]
- Wang, Z.; Yuan, Y.; Wang, R.; Nie, F.; Huang, Q.; Li, X. Pseudo-Label Guided Structural Discriminative Subspace Learning for Unsupervised Feature Selection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 18, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Hua, Y.; Zuo, Z. Infrared Image Generation By Pix2pix Based on Multi-receptive Field Feature Fusion. In Proceedings of the 2021 International Conference on Control, Automation and Information Sciences (ICCAIS), Xi’an, China, 14–17 October 2021; pp. 1029–1036. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wand, M. Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 702–716. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Schönfeld, E.; Schiele, B.; Khoreva, A. A U-Net Based Discriminator for Generative Adversarial Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8204–8213. [Google Scholar] [CrossRef]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Xu, R.; Samat, A.; Zhu, E.; Li, E.; Li, W. Unsupervised Domain Adaptation with Contrastive Learning-Based Discriminative Feature Augmentation for RS Image Classification. Remote Sens. 2024, 16, 1974. [Google Scholar] [CrossRef]
- Xiao, H.; Yao, W.; Chen, H.; Cheng, L.; Li, B.; Ren, L. SCDA: A Style and Content Domain Adaptive Semantic Segmentation Method for Remote Sensing Images. Remote Sens. 2023, 15, 4668. [Google Scholar] [CrossRef]
- Mahara, A.; Rishe, N. Multispectral Band-Aware Generation of Satellite Images across Domains Using Generative Adversarial Networks and Contrastive Learning. Remote Sens. 2024, 16, 1154. [Google Scholar] [CrossRef]
- Baek, K.; Choi, Y.; Uh, Y.; Yoo, J.; Shim, H. Rethinking the truly unsupervised image-to-image translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14154–14163. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 319–345. [Google Scholar]
- Han, J.; Shoeiby, M.; Petersson, L.; Armin, M.A. Dual contrastive learning for unsupervised image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 746–755. [Google Scholar]
- Cai, X.; Zhu, Y.; Miao, D.; Fu, L.; Yao, Y. Constraining multi-scale pairwise features between encoder and decoder using contrastive learning for unpaired image-to-image translation. arXiv 2022, arXiv:2211.10867. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 276–280. [Google Scholar]
- Han, Z.; Zhang, Z.; Zhang, S.; Zhang, G.; Mei, S. Aerial visible-to-infrared image translation: Dataset, evaluation, and baseline. J. Remote Sens. 2023, 3, 0096. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Simoncelli, E.; Bovik, A. Multiscale structural similarity for image quality assessment. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








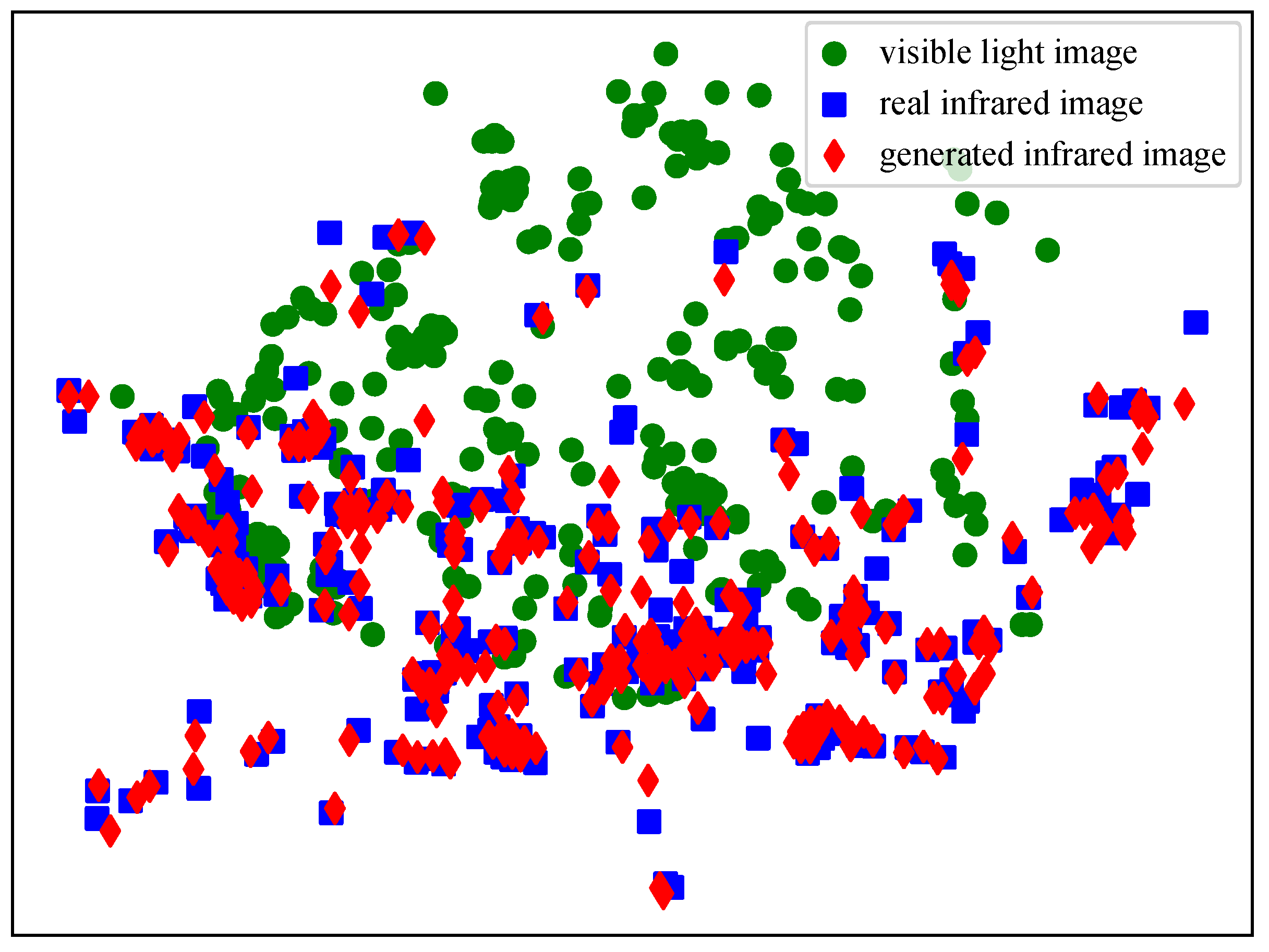
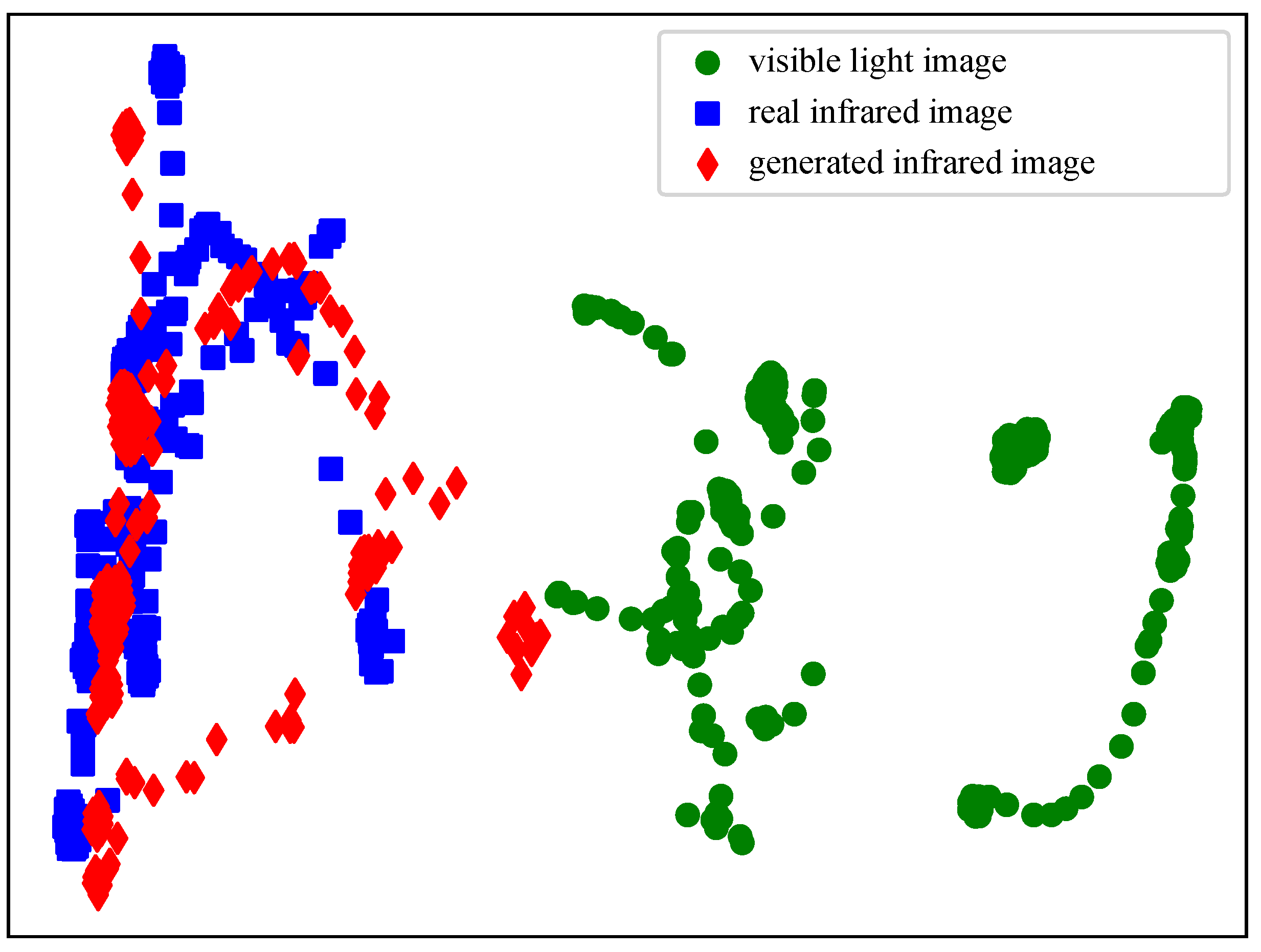

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FLIR | PSNR ↑ | SSIM ↑ | MS-SSIM ↑ | LPIPS ↓ | FID ↓ | Training Time (h) | Inference Time (s) |
|---|---|---|---|---|---|---|---|
| Pix2Pix | 22.1529 | 0.6163 | 0.5140 | 0.3312 | 138.8828 | 8.94 | 0.16 |
| ThermalGAN | 22.4735 | 0.6287 | 0.5475 | 0.2746 | 139.2642 | 6.98 | 0.17 |
| Pix2Pix-MRFFF | 21.8622 | 0.6158 | 0.5281 | 0.3216 | 126.7535 | 7.92 | 0.15 |
| InfraGAN | 22.1961 | 0.6304 | 0.5411 | 0.3043 | 136.1309 | 25.72 | 0.17 |
| V2IGAN-P | 23.0628 | 0.6417 | 0.5726 | 0.2636 | 122.9724 | 66.33 | 0.19 |
| AVIID | PSNR ↑ | SSIM ↑ | MS-SSIM ↑ | LPIPS ↓ | FID ↓ | Training Time (h) | Inference Time (s) |
| Pix2Pix | 26.6464 | 0.7923 | 0.8143 | 0.1844 | 110.9060 | 2.05 | 0.16 |
| ThermalGAN | 25.1461 | 0.7520 | 0.7775 | 0.1822 | 99.3957 | 1.61 | 0.17 |
| Pix2Pix-MRFFF | 23.0939 | 0.6972 | 0.6817 | 0.4106 | 172.5763 | 3.27 | 0.15 |
| InfraGAN | 24.9415 | 0.7603 | 0.5411 | 0.1815 | 96.5861 | 5.71 | 0.17 |
| V2IGAN-P | 28.0679 | 0.8376 | 0.8677 | 0.1211 | 71.0606 | 16.56 | 0.19 |
| IRVI | PSNR ↑ | SSIM ↑ | MS-SSIM ↑ | LPIPS ↓ | FID ↓ | Training Time (h) | Inference Time (s) |
| CycleGAN | 12.9192 | 0.2634 | 0.1368 | 0.4268 | 185.8868 | 7.76 | 0.16 |
| CUT | 10.6941 | 0.2603 | 0.1098 | 0.5013 | 175.6123 | 7.16 | 0.16 |
| DCLGAN | 11.3122 | 0.2668 | 0.0297 | 0.5051 | 208.3874 | 11.03 | 0.16 |
| EMRT | 11.0906 | 0.2635 | 0.0411 | 0.5006 | 188.9970 | 16.53 | 0.24 |
| V2IGAN-U | 14.9734 | 0.3876 | 0.2372 | 0.3031 | 136.4583 | 16.15 | 0.19 |
| AVIID | PSNR ↑ | SSIM ↑ | MS-SSIM ↑ | LPIPS ↓ | FID ↓ |
|---|---|---|---|---|---|
| baseline | 26.6464 | 0.7923 | 0.8143 | 0.1844 | 110.9060 |
| +VSS | 27.0306 | 0.8173 | 0.8489 | 0.1435 | 81.7944 |
| + | 27.0197 | 0.7964 | 0.8356 | 0.1339 | 80.3518 |
| V2IGAN | 28.0679 | 0.8376 | 0.8677 | 0.1211 | 71.0606 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Ma, D.; He, F.; Zhang, Z.; Zhang, D.; Li, S. Infrared Image Generation Based on Visual State Space and Contrastive Learning. Remote Sens. 2024, 16, 3817. https://doi.org/10.3390/rs16203817
Li B, Ma D, He F, Zhang Z, Zhang D, Li S. Infrared Image Generation Based on Visual State Space and Contrastive Learning. Remote Sensing. 2024; 16(20):3817. https://doi.org/10.3390/rs16203817
Chicago/Turabian StyleLi, Bing, Decao Ma, Fang He, Zhili Zhang, Daqiao Zhang, and Shaopeng Li. 2024. "Infrared Image Generation Based on Visual State Space and Contrastive Learning" Remote Sensing 16, no. 20: 3817. https://doi.org/10.3390/rs16203817
APA StyleLi, B., Ma, D., He, F., Zhang, Z., Zhang, D., & Li, S. (2024). Infrared Image Generation Based on Visual State Space and Contrastive Learning. Remote Sensing, 16(20), 3817. https://doi.org/10.3390/rs16203817