1. Introduction
Climate change is one of the most significant challenges for the planet’s future [
1,
2,
3]. It has enormous ecological, social, and economic impacts across the globe, including an increase in extreme weather events, rising sea levels, melting glaciers, reduced biodiversity, and food security. Carbon dioxide (CO
2) is one of the greenhouse gases with the most significant impact on human life [
4,
5,
6]. Continuing increases in CO
2 concentrations will significantly accelerate temperature rise [
7,
8,
9]. The Earth’s annual carbon emissions have exceeded its natural absorptive capacity, resulting in rising atmospheric CO
2 concentrations [
10,
11]. Over the past few decades, as the global economy and population have grown, human activities have led to a steady rise in CO
2 emissions, which are still increasing at a rate of more than 2 ppm/yr (ppm: parts per million, yr: year) [
12]. If uncontrolled, the global average CO
2 concentrations are projected to exceed 415 ppmv (parts per million by volume, meaning 415 volume units of CO
2 per one million volume units of air) by 2030, contributing to more extreme weather events.
In response to climate change, governments have set policies and targets for greenhouse gas emissions reductions to keep CO
2 levels at specific levels [
13]. On 12 December 2015, 197 countries joined the Paris Agreement, which aimed to keep global temperatures below 2 °C [
14,
15]. In September 2018, the United Nations Framework Convention on Climate Change convened in Katowice, Poland. The conference aimed to develop rules and guidelines for implementing the Paris Agreement and accelerate global action to reduce emissions to meet the challenge of climate change [
16]. To effectively control and reduce CO
2 emissions and achieve the double carbon target, carbon monitoring is first needed to understand the characteristics and trends of the spatial and temporal distributions of atmospheric CO
2. However, the spatial distribution of CO
2 is not uniform and is closely related to human activities. Therefore, obtaining accurate CO
2 monitoring data is essential for understanding the spatial and temporal distribution characteristics of CO
2.
Satellite carbon dioxide data reconstruction uses satellite observation data and ancillary data to infer and estimate the spatial distribution and spatial–temporal variations in CO2 in the Earth’s atmosphere through data processing and analysis methods. The method makes up for the shortcomings of satellite observation, improves the precision and coverage of observation, and supports CO2 concentration data on a global scale.
Currently, there are three main ways to monitor CO2: ground based, airborne, and satellite based.
Ground-based monitoring is one of the critical methods for obtaining the spatial and temporal distributions of CO
2 and is one of the older means of CO
2 monitoring. In this method, the carbon dioxide concentration is monitored in real-time by ground stations or towers, such as the National Oceanic and Atmospheric Administration—Earth System Research Laboratory (NOAA-ESRL) [
17] and the Total Column Carbon Observing Network (TCCON) [
18]. This method has the advantage of high accuracy and high temporal resolution and therefore is often analyzed in comparison with results from satellite data inversion. However, the global ground-based monitoring network consists of sparsely distributed stations with limited coverage, low spatial resolution, and no real-time capability, so it cannot fully reflect the spatial and temporal distributions of CO
2 [
19]. Therefore, in the late 1970s, airborne monitoring methods were introduced.
Airborne monitoring is a method of monitoring the CO
2 concentration in the Earth’s atmosphere in real-time [
20,
21,
22]. Airborne refers to meteorological observations conducted from platforms that are flying or floating in the air. This method has the advantages of global coverage, high spatial and temporal resolution, long-term observation, and uncrewed operation. It helps to understand climate and environmental change trends. However, technical challenges, atmospheric disturbances, and calibration verification are disadvantages that must be overcome to ensure data accuracy and validity.
Satellite-based monitoring is a real-time or continuous monitoring of the CO
2 concentration in the Earth’s atmosphere by launching a dedicated satellite in space and utilizing high-resolution remote sensing technology [
23,
24,
25]. Satellite monitoring has the advantages of being free from time and space constraints, comprehensive coverage, stable observation, long-term time series, and three-dimensional observation, and its observation accuracy is gradually improving [
26]. However, it costs the most and is limited by shortcomings such as technical complexity, data processing challenges, and weather impacts, which need to be addressed to maximize its monitoring potential.
With the launching of more and more carbon satellites, the work of validating a large amount of CO
2 data has gradually begun. At present, scholars mainly validate the accuracy of CO
2 products inverted by different satellites by combining real-time ground station data, aircraft route measurement data, and model simulation data [
27,
28]. However, due to the limitations of the validation methods, the calibration of satellite CO
2 data usually focuses only on evaluating the data accuracy and the study of the temporal variation characteristics of the errors, neglecting the characterization of the spatial distribution of the errors. In addition, due to the existence of aerosols and the limitation of satellite orbit, there are a lot of data missing in the process of satellite inversion, so the reconstruction of satellite CO
2 data becomes particularly important [
29].
To deeply discuss strategies for addressing uncertainties and errors in carbon satellite data reconstruction, a comprehensive approach encompassing data processing, model validation, and error correction is essential. Firstly, optimizing data calibration and noise reduction techniques can enhance the quality of the raw observational data. Secondly, improving retrieval algorithms, such as through multi-model validation and error propagation analysis, can increase the processing accuracy. Additionally, integrating multi-source data and analyzing temporal sequences can enhance the spatial and temporal coverage of observations, mitigating the impact of data gaps. Concurrently, combining ground validation and simulation experiments for model calibration ensures result reliability. Finally, quantifying uncertainties through sensitivity analysis and statistical methods provides confidence intervals for the data results. These measures collectively reduce uncertainties and errors in the reconstruction process, thereby improving the accuracy and utility of CO2 data.
In the field of carbon remote sensing, many researchers and scholars have summarized the work of the time and published excellent review papers.
In 2015, Schimel et al. [
30] assessed the current development of terrestrial ecosystems and the carbon cycle through satellite observations. They presented the available satellite remote sensing data products such as vegetation index, surface temperature, chlorophyll fluorescence, land surface elevation, and their limitations. In addition, the article discusses the applications of satellite remote sensing technology in monitoring the carbon cycle and climate change and predicts future trends in satellite remote sensing technology and data products. Those trends include improving data resolution and accuracy, enhancing the real-time and spatial and temporal coverage of data, developing technologies such as multi-source data fusion and machine learning, and strengthening the integration of satellite observations with ground-based observations and model simulations to better understand the dynamics of terrestrial ecosystems.
In 2016, Yue et al. [
31] synthesized the latest research results and development trends of space and ground-based CO
2 concentration measurement technologies, outlining the research progress of CO
2 inversion algorithms, spatial interpolation methods, and ground-based observation data. In addition, they elaborated on the latest research results of CO
2 concentration measurement techniques and the application of these techniques in global climate change and carbon cycle research and looked forward to future research directions.
In 2019, Xiao et al. [
32] provided an overview of the terrestrial carbon cycle and carbon fluxes. They outlined critical milestones in the remote sensing of the terrestrial carbon cycle and synthesized the platforms/sensors, methods, research results, and challenges faced in the remote sensing of carbon fluxes. In addition, they explored the uncertainty and validity of carbon flux and stock estimates and provided an outlook on future research directions for the remote sensing of the terrestrial carbon cycle.
In 2021, Pan et al. [
33] assessed the ability of CO
2 satellites to serve as an objective, independent, and potentially low-cost and external data source while comparing the significance of nighttime optical satellite data for proxy CO
2 monitoring to distinguish the importance of direct CO
2 satellite monitoring.
In 2022, Kerimov et al. [
34] reviewed the application of machine learning models to greenhouse gas emissions estimation and modeling. They provided an overview of the methodology for applying machine learning in greenhouse gas emissions estimation and the main challenges faced.
As mentioned above, several past reviews have focused on CO2 monitoring, the carbon cycle, and carbon emissions. Although these reviews have covered the outlook of mapping the spatial and temporal distributions of CO2, they still lack content on CO2 data reconstruction methods. Therefore, a study focusing on satellite CO2 data reconstruction methods is urgently needed to help researchers interested in this field understand the latest developments in satellite CO2 data reconstruction.
This paper takes interpolation, data fusion, and super-resolution reconstruction as the main topics, systematically combs the satellite CO2 data reconstruction methods, and constructs high-resolution and high-precision CO2 data so that the readers can quickly understand the research hotspots of CO2 spatial and temporal distributions.
The contributions of this paper include the following:
(1) This paper provides a comprehensive review of CO2 monitoring methods and data sources.
(2) This paper describes in detail the comparative analysis of satellite CO2 data reconstruction methods on the basis of limited CO2 measurement data, with interpolation, data fusion, and super-resolution reconstruction as horizontal tasks, and traditional methods and machine/deep learning methods as vertical tasks. Combining these two types of analyses allows for a comprehensive evaluation and comparison of different CO2 data reconstruction methods. To the knowledge of the authors of this paper, this is the first review of CO2 reconstruction methods.
(3) This paper proposes the future development direction of satellite CO2 data reconstruction, namely, CO2 data with a longer period, a larger spatial range, a higher spatial resolution, and higher data accuracy can be obtained by super-resolution reconstruction and other methods.
This paper is divided into four main parts. As shown in
Figure 1, the first part primarily introduces the research background and the necessity of reconstructing CO
2 data. Through a summary of previous reviews, it also summarizes the innovative aspects and major contributions of this review. The second part discusses the monitoring methods for CO
2 and the sources of data. In this part, Citespace, a tool for visualization and analysis of scientific literature, is used to visualize the development trend and research focus in this field. The third part delves into the specific applications of interpolation and data fusion methods in the reconstruction of CO
2 data to achieve high-precision CO
2 data reconstruction. The fourth part provides an in-depth exploration of super-resolution reconstruction methods and offers suggestions for the future development of carbon dioxide data reconstruction. The authors of this paper believe that this review will serve as an important reference for the reconstruction of satellite-based CO
2 data.
3. Satellite CO2 Reconstruction Methods
Scholars have conducted CO2 data reconstruction studies across multiple satellites and developed a series of high-precision CO2 datasets over extended periods, considering the spatial and temporal coverage as well as the data accuracy of various CO2 satellites.
Interpolation is a method used to estimate information about a function’s value or its derivative at discrete points. It involves estimating approximate values at other points based on a finite number of known points. Interpolation techniques can be used to fill in unobserved spatial data within a single image or unobserved temporal data across multiple images over a fixed observation area. Kriging is a specific interpolation method that not only utilizes known data points but also models the spatial correlation structure between these points to make more accurate predictions. It achieves this by fitting a semivariogram to quantify the spatial correlation and then using this model to appropriately weight the known data points when estimating values at unknown locations. In CO2 data reconstruction, Kriging can estimate CO2 concentrations at locations without measurements by leveraging the spatial patterns observed in known data. However, not all CO2 data reconstruction methods use Kriging. Some methods may employ other statistical or machine learning techniques that do not involve the spatial correlation modeling characteristic of Kriging.
Data fusion is an information processing technique where computers analyze and synthesize observational data from multiple sensors collected over time under specific guidelines to perform decision-making or assessment tasks. It typically targets a specific observation area and integrates information from sources such as satellite carbon remote sensing, meteorological data, and Digital Elevation Models (DEMs) to address missing spatiotemporal data.
In this section, interpolation and data fusion methods will be explored in depth to enhance the spatial resolution of CO2 data, fill observational gaps, and improve data accuracy. This approach will provide more comprehensive information and support for CO2 concentration research and applications.
3.1. Data Reconstruction Based on Interpolation
Interpolation involves estimating values between several discrete data points using specific methods. These data points are often collected over a defined time or spatial range, though data may not be available at every point within that range. The goal of interpolation is to fill in these gaps to create a more continuous and complete dataset. It is important to note that interpolation methods generate estimates for unknown data points rather than actual measurements. Consequently, the interpolation error should be evaluated for each case, and the uncertainty of the data must be considered.
Table 5 compares different interpolation techniques to provide a comprehensive understanding. In different interpolation methods, the local trend, the information of coordinates, and the stratification have specific meanings. The local trend refers to systematic changes or trends within a local area of data, which can be linear or nonlinear and are usually caused by local factors rather than the overall trend of the data. The information of coordinates refers to the specific spatial locations of data points, which are used to determine the spatial relationships and distances between data points, and are fundamental for calculating spatial correlation and performing interpolation. Stratification involves dividing data into multiple subsets or layers based on certain criteria, such as geographic, geological, or statistical characteristics. This method is particularly useful for areas with significantly different characteristics, as the data within each layer may have distinct statistical properties and spatial variability structures. During interpolation, stratification can enhance the model’s accuracy and reliability by ensuring the data within each layer are more homogeneous and consistent.
Kriging interpolation methods include several variants for estimating attribute values at unknown locations. For example, Simple Kriging (SK) assumes that the attribute values follow a normal distribution with a constant mean; Ordinary Kriging (OK) takes into account local trends and semivariance functions; Universal Kriging (UK) is suitable for cases with external trends. In Kriging interpolation methods, external trends refer to systematic changes or trends present in the data, which are typically caused by known external factors rather than random spatial variation. These external trends can be explained and described by one or more known external variables. Simple Co-Kriging (SCK) and Ordinary Co-Kriging (OCK) are suitable for multi-attribute interpolation, considering covariance and local spatial trends, respectively. Probability Kriging (PCK) considers the probability distribution of the attribute values. At the same time, Simple Collocated Co-Kriging (SCCK) and Ordinary Collocated Co-Kriging (OCCK) are used in multi-attribute contexts and consider correlations and local trends between attributes. The selection of the appropriate Kriging method depends on the data characteristics and requirements and can provide accurate and reliable spatial interpolation results.
In satellite CO
2 reconstruction, Kriging interpolation is used in the field of carbon satellite data reconstruction [
96]. Interpolation methods based on discrete data points can be used to fill in missing or blank parts of satellite observations to obtain a complete picture of the CO
2 distribution [
97]. These methods utilize statistical properties and spatial correlations between known observations to infer CO
2 concentrations at unobserved locations.
In order to accurately reflect the spatial and temporal distributions of CO2, both temporal and spatial interpolation are essential. However, capturing spatial and temporal variability in satellite data reconstruction is challenging using only spatial interpolation methods. In contrast, spatiotemporal interpolation methods can capture spatiotemporal variability more accurately, and the model’s accuracy can be assessed by cross-validation in space and time. Next, spatial interpolation and combined spatiotemporal interpolation methods will be introduced.
3.1.1. Spatially Interpolated Data Reconstruction
Traditional statistical methods have widely utilized spatial Kriging interpolation to generate
data products. However, interpolation methods that utilize only spatial correlation do not consider the time-dependent structure of CO
2 data. As a result, temporal variations in dynamic CO
2, including annual growth and seasonal cycles, need to be adequately considered [
98]. The following
Table 6 lists the results obtained by researchers in recent years in satellite data reconstruction using spatial interpolation methods.
In 2008, Tomosada et al. [
99] used a spatial statistical approach to obtain CO
2 column concentrations from GOSAT data. In 2012, Hammerling et al. [
100] used a spatial interpolation approach to generate maps at high spatial and temporal resolutions without the need to use atmospheric transport models and estimates of CO
2 uptake and emissions. In 2014, Jing et al. [
101] combined the GOSAT and SCIAMACHY satellite measurements to propose a filling method to model the spatial correlation structure of the CO
2 concentration to solve the problem of limited CO
2 data provided by a single satellite due to cloud effects, in order to more accurately characterize the spatial and temporal distributions of atmospheric CO
2 concentration. In 2020, Shrutilipi Bhattacharjee et al. [
102] proposed a method to fill in the spatial correlation structure of the modeled CO
2 concentration based on the Kriging grid interpolation method of the spatial interpolation technique, which interpolates the CO
2 source points in the emission inventory and the types in the land use/cover information with the CO
2 column concentration separately, and then combines the interpolation results of the two to obtain a more accurate prediction of the CO
2 column concentration. Meanwhile, the researchers also demonstrated that the method can be applied to predict the CO
2 column concentration in other regions.
Although spatial interpolation can be used to reconstruct satellite CO2 data to address the problem of insufficient CO2 data, it has some limitations. First, interpolation methods rely on estimating values between known measurement points, but they may introduce errors, especially when data are sparse or when extrapolation beyond the range of measurements is required. Second, interpolation methods do not accurately capture the true spatial and temporal variability because they do not account for spatial and temporal autocorrelations in the data. This can lead to the generation of biased or noisy maps, particularly in situations where measurement points are sparse, resulting in a loss of information rather than overly smooth fields. In contrast, spatiotemporal interpolation methods can better address these issues.
3.1.2. Spatiotemporal Interpolation Data Reconstruction
Spatiotemporal interpolation methods can capture spatiotemporal variability more accurately and can also be used to assess the accuracy of models by cross-validating them in space and time. Additionally, spatiotemporal interpolation methods can utilize multiple data sources, including satellite observations, ground-based observations, and model simulations, to enhance spatiotemporal resolution and accuracy. However, these methods primarily focus on estimating values between existing data points, whereas data fusion methods aim to integrate data from different sources to create a more comprehensive and consistent representation. Data fusion typically involves calibrating and merging data sources to reduce systematic errors and improve the overall reliability of the results, potentially providing higher precision and consistency when handling different types of data. The following
Table 7 lists some excellent articles on satellite CO
2 data reconstruction using spatiotemporal interpolation methods in recent years for the readers’ convenience.
In 2015, Tadić et al. [
103] proposed a flexible moving-window Kriging method, which can serve as an effective technique for imputing missing data and reconstructing datasets. This method was demonstrated to generate high spatial and temporal resolution maps using satellite data, and its feasibility was validated using CO
2 data from the GOSAT satellite and the GOME-2 instrument. In 2017, Zeng et al. [
104] employed spatiotemporal geostatistical methods, effectively utilizing the spatial and temporal correlations between observational data, to establish a global land-based mapping dataset of total CO
2 amounts from satellite measurements. They conducted cross-validation and verification at the TCCON sites. The results revealed a correlation coefficient of 0.94 between the dataset and observational values, with an overall bias of 0.01 ppmv.
Due to the limited spatial and temporal resolution of
concentrations, more data sources must be available. If spatial and temporal interpolation is performed using fewer observational data sources, the uncertainty of the interpolated data will increase significantly. In the future, finding suitable data sources with high-quality, long-time series of CO
2 concentrations is another critical task. To create the longest possible
time series and to improve the accuracy by utilizing multiple measurements when possible, Zhonghua He’s team [
105] developed an accuracy-weighted spatiotemporal Kriging method for integrating and mapping
observed by multiple satellites, which fills in the data gaps from multiple satellites and generates continuous global 1° × 1° spatiotemporally resolved data every eight days from 2003 to 2016.
To better reconstruct the satellite CO
2 data and to observe the spatiotemporal variations of CO
2, an extended Gstat package was proposed. It reuses the spacetime class to estimate the spatiotemporal covariance/half-variance model and performs spatiotemporal interpolation. However, it is challenging to select reliable and reasonable semivariance models and their parameters in spatiotemporal Kriging interpolation. Inappropriate choices of models and parameters may lead to significantly inaccurate and inefficient interpolation results. To better understand the multi-fractal scale behavior, Ma et al. [
106] investigated the characteristics of the multi-fractal scale behavior of the time series of atmospheric
concentration in China from 2010 to 2018 in terms of spatial distribution. They gained insights into the dynamical mechanisms of the CO
2 concentration changes and proposed an improved spatiotemporal interpolation method (spatiotemporal thin-plate spline interpolation) to realize the spatiotemporal interpolation of the atmospheric
concentration. In 2023, Sheng et al. [
107] generated a global terrestrial
dataset with a grid resolution of 1° and a temporal resolution of 3 days, covering the period from 2009 to 2020 based on the spatiotemporal geostatistical method.
In summary, although interpolation methods can, to a certain extent, solve some of the missing data problems and maintain the spatial continuity of the data, some interpolation methods rely heavily on the number and quality of samples, meaning that they primarily depend on the distribution and accuracy of existing data points to estimate values at unmeasured locations. This can lead to several issues: firstly, if the number of samples is insufficient, the interpolation results may not adequately reflect the true spatial variability of the data, thereby reducing estimation accuracy. Secondly, if the sample quality is poor, these errors may be propagated into the interpolation results, further affecting their reliability. Additionally, these methods sometimes neglect the spatial characteristics of the geographic data, such as topographic variations or environmental conditions, which can lead to results that do not accurately represent the real situation, causing discrepancies from the actual data. In addition, due to the limitations of the data itself, interpolation reconstruction often fails to improve the data accuracy significantly. Therefore, when applying interpolation methods, it is necessary to carefully choose appropriate variants and parameters and make adjustments and corrections according to the actual situation.
3.2. Data Reconstruction Based on Data Fusion
Data fusion combines data from different data sources, sensors, or observation methods to obtain more comprehensive, accurate, and reliable information [
108].
Data fusion methods and techniques are diverse. Their advantage lies in their ability to fully utilize information from multiple data sources, thereby increasing the accuracy and confidence of the data while reducing uncertainty. Data fusion can also fill gaps and compensate for deficiencies while providing more comprehensive spatial and temporal coverage. The following
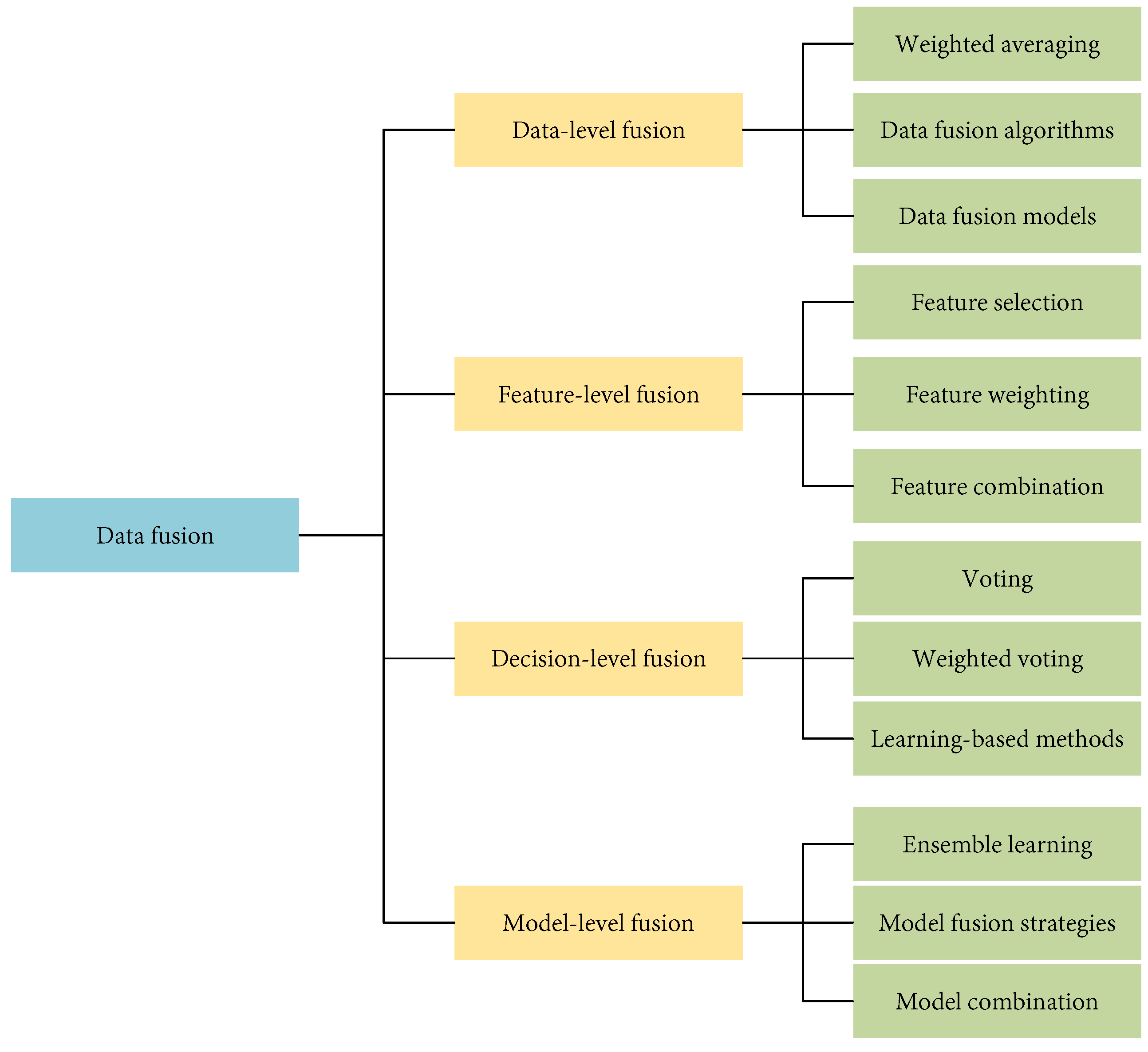
Figure 7 shows the categorization of data fusion methods to help readers understand better. In
Figure 7, Vvting aggregates predictions from multiple models by selecting the most frequent outcome, thereby enhancing accuracy through consensus. Weighted voting refines this approach by assigning different weights to each model’s predictions based on their accuracy, thus giving more influence to the more reliable models [
109].
Fusion methods are categorized into data-level fusion, feature-level fusion, decision-level fusion, and model-level fusion. Data-level fusion enhances the coverage and credibility of data by combining raw data from different sources. Feature-level fusion extracts features from different data sources and improves the expressiveness of the data. Extracting features means identifying and extracting variables or information that are useful for a specific task. For example, in image data, this might include extracting edge, texture, or shape features; in time series data, it could involve extracting trends, periodicities, or anomalies. The process of feature extraction typically includes steps such as data preprocessing, feature selection, and feature calculation. Enhancing the expressiveness of the data means integrating and optimizing features extracted from different data sources to make the data more accurate in representing and reflecting the actual situation. This can be achieved by increasing the detail and richness of the data, enabling subsequent analyses or models to better capture the underlying patterns and complexities of the data. Decision-level fusion integrates the decision results from different data sources to improve the credibility of classification and decision-making. Model-level fusion integrates outputs from different models to enhance overall model performance. First, different models may excel at handling specific types of data or tasks, and by combining their outputs, we can leverage each model’s strengths and address the weaknesses of individual models, improving overall prediction accuracy and robustness. Second, a single model might overfit the training data, leading to poor performance on new data. Model fusion helps mitigate this risk by incorporating diverse learning strategies and perspectives, thus enhancing generalization. Additionally, different models may react differently to noise and outliers in the data; combining multiple models can reduce the errors introduced by any single model and increase overall result stability. Finally, various models might use different feature sets, algorithms, or training methods, and model fusion can effectively utilize these diverse information sources to better handle complex data. In summary, model-level fusion combines the strengths of multiple models to improve prediction accuracy and overall model performance. Choosing the appropriate fusion method depends on the problem requirements and the nature of the data.
In satellite CO2 reconstruction, due to the presence of heavy clouds (or aerosols) and the limitation of satellite orbits, there is a large amount of missing data in satellite inversion, which limits the study of global CO2 sources and sinks. Therefore, satellite CO2 reconstruction using data fusion methods is a potential endeavor. Data fusion can improve the spatial resolution and temporal coverage, increase the data precision and accuracy, and enhance the spatial coverage. By integrating information from different data sources, data fusion can generate more detailed, continuous, and comprehensive maps of CO2 distribution, contributing to an in-depth understanding and study of the carbon cycle process.
Data fusion can be performed based on statistics, modeling, and learning algorithms. The choice of the specific method depends on the nature of the data, the purpose of the fusion, and the application requirements. These three approaches are described below to help understand satellite CO2 data reconstruction better.
3.2.1. Data Fusion Method Based on Statistics
The use of statistical-based data fusion methods is a commonly used data fusion technique that integrates information from multiple data sources by applying statistical principles and methods to obtain more accurate and reliable estimates.
Table 8 shows the results achieved by researchers in recent years in satellite CO
2 data reconstruction using statistics-based data fusion methods.
In 2013, Reuter et al. [
110] applied an ensemble median merging algorithm (EMMA) and used grid-weighted averaging to fuse CO
2 data, resulting in a new dataset. In 2014, Jing et al. [
111] fused measurements from GOSAT and SCIAMACHY and proposed a data imputation method based on spatial correlation structures of CO
2 concentrations. This method enabled the creation of high-spatiotemporal-resolution global land CO
2 distribution maps. Hai et al. [
112], in the same year, employed dimensionality reduction Kalman smoothing and a spatial random effects model to merge CO
2 observational data from GOSAT, AIRS, and OCO-2 satellites. In 2015, Zhou et al. [
113] introduced an improved fixed-rank Kriging method based on GOSAT and AIRS data. The results demonstrated a better correlation between the fused dataset and meteorological analysis data. In 2017, Zhao et al. [
114] introduced a method called High-Precision Surface Albedo Model Data Fusion (HSAM-DF). This approach utilized geological–chemical model CO
2 concentration outputs as a driving field and ground-based CO
2 concentration observations as accuracy control conditions to merge two types of CO
2 data. In 2023, Meng et al. [
107] used
inversion data from GOSAT and OCO-2 to create a global continuous spatiotemporal
dataset called “Mapping-
”. Mapping-
revealed the spatiotemporal characteristics of global
similar to those observed in the CarbonTracker model data.
Statistically based data fusion methods can derive spatial and temporal distributions of . These distributions are more accurate, have higher resolution, and span longer periods than the results generated based solely on a single satellite dataset.
3.2.2. Data Fusion Method Based on Model Simulation
Model-based simulation is a common approach to data fusion, mainly using chemical transport models (CTMs) to simulate atmospheric CO2. CTMs can infer the distribution of CO2 concentrations and fluxes in various regions of the globe and, at the same time, correct the simulation results using observational data to improve their accuracy. Commonly used CTMs include CarbonTracker and GEOS-Chem. They obtain optimized carbon flux and CO2 concentration distributions in various regions of the globe by assimilating data such as bottle-sampled CO2, continuous CO2 series from towers, and detected by satellites. These two commonly used chemical transport models are described in detail next.
- (1)
GEOS-Chem
GEOS-Chem is a global chemical transport model dedicated to simulating chemical reactions and transporting substances in the atmosphere [
115]. The model employs a high-resolution, three-dimensional grid to reflect atmospheric changes in space and time accurately. It fully accounts for many critical atmospheric processes, including radiation, convection, turbulence, wet and dry deposition, and chemical reactions. GEOS-Chem is particularly notable for its broad applications in atmospheric composition modeling, generating simulations of gases such as CO
2, CH
4, CO, and isoprene with spatial and temporal continuity. It has been extensively used to evaluate satellite-detected
data as well as ground-based observations.
GEOS-Chem is a 3D Eulerian transport model with a spatial resolution of 4° × 5°, containing 47 vertical levels, with coverage extending from the surface to a height of 0.01 hectopascal. During assimilation, the model uses a four-dimensional variational (4D-Var) approach by iterating the model’s equations to minimize the cost function J:
where
N is the number of time steps of the observation data,
c is the optimized model state,
is the observation data at the
ith time step,
is the observation operator, the model state
c is transferred to the observation space,
is the observation error covariance matrix at the
ith time step,
is the background estimation, and
is the background error covariance matrix.
Before the reconstruction of satellite CO
2 data, it is critical to assess the applicability of chemical transport models in CO
2 simulations through ground-based observations of atmospheric CO
2 and satellite-measured XCO
2 [
116]. Several studies have investigated the contribution of terrestrial ecosystems to atmospheric CO
2 concentrations through chemical model simulations. In 2011, Feng et al. [
117] evaluated the accuracy of a global chemical transport model for CO
2 simulations from 2003 to 2006 using ground-based observations, aircraft measurements, and AIRS satellite data. In 2013, Lei et al. [
118] compared and assessed the spatial and temporal variations in atmospheric CO
2 between June 2009 and May 2010 using XCO
2 from two datasets, GOSAT and GEOS-Chem, and analyzed the CO
2 differences between the Chinese land region and the U.S. land region to demonstrate the satellite observations and model simulations’ rationality and uncertainty. In 2017, Li et al. [
119] evaluated regional chemical modeling simulations of CO
2 concentrations in 2012 using GOSAT observations and ground-based measurements.
Due to limitations in data availability and precision, the spatiotemporal patterns of XCO
2 have not been well characterized at the regional scale. Researchers have utilized XCO
2 data from GOSAT to investigate the spatiotemporal patterns of XCO
2 in the Chinese region. They employed a high-resolution nested grid GEOS-Chem model to construct XCO
2 [
120]. In 2017, Zhang et al. [
121] compared the results of XCO
2 derived from the fusion of TCCON measurements with the GEOS-Chem model to the satellite observations. They found that the global OCO-2 XCO
2 estimates were closer to the HASM XCO
2. The primary methodological workflow can be seen in
Figure 8.
GEOS-Chem is essential in atmospheric chemistry, air quality research, climate change, and pollution management. However, CTM simulations require a higher level of certainty, primarily due to the limited knowledge of a priori fluxes, errors in the simulated atmospheric transport processes, and inaccuracies in the observational CO2 data being assimilated, particularly satellite-acquired data.
Errors in the representation of atmospheric transport in chemical transport models have long been recognized as a major source of uncertainty in atmospheric CO
2 inversion analyses. Improving transport models is critical for enhancing the accuracy of CO
2 inversions. Current efforts to improve model transport focus on two key areas: refining the parameterization of unresolved transport, particularly in coarse offline CTMs, and increasing the spatial and temporal resolutions of model simulations to better capture atmospheric transport processes. As transport models evolve, it will be crucial to regularly evaluate their ability to accurately represent large-scale atmospheric dynamics [
122].
- (2)
CarbonTracker
CarbonTracker is a CO
2 measurement and modeling system developed by NOAA to track CO
2 sources and sinks globally [
123]. The CarbonTracker model typically uses the Transport Model 5 chemical transport model to simulate the atmospheric transport of CO
2 and other trace gases. It integrates ground-based observatories, airborne observations, satellite observations, and model simulations to provide high-resolution estimates of CO
2 concentration and spatial distribution through data assimilation techniques. The current release is CarbonTracker 2022, which covers the period from January 2000 to December 2020 with global surface–atmosphere CO
2 flux estimates.
In CO
2 flux inversion, errors induced by atmospheric transport models can contribute to the uncertainty in inferring surface fluxes, in addition to biases in
retrieval. Furthermore, model grid cells are often relatively coarse and may have different representational capabilities compared to satellite observations. Therefore, analyzing the differences between the simulated CO
2 and satellite-derived results and assessing the uncertainty in model transport outcomes is crucial. To better understand CO
2 trends in the Asian region, Farhan Mustafa and colleagues conducted a comparison in 2020 between
obtained from CarbonTracker and
obtained from GOSAT and OCO-2 satellite observations [
124]. The results revealed good consistency between CarbonTracker and the other two satellite datasets, allowing the use of any of these datasets to understand CO
2 in the context of carbon budgets, climate change, and air quality.
CarbonTracker reconstructs atmospheric carbon emission and absorption processes by integrating multiple observations and simulation models. Satellite CO2 data are crucial in this process, as they provide high temporal and spatial resolution observations that can compensate for the lack of ground-based observations, monitor carbon emission sources and sinks, and validate and improve models. However, due to the coarse spatial resolution, data extracted by CarbonTracker may not capture the spatial heterogeneity of CO2.
In the field of carbon dioxide reconstruction, in addition to commonly used physical models like GEOS-Chem and CarbonTracker, many other models are widely applied. Numerical Weather Prediction (NWP) models, such as WRF, provide high-precision meteorological background data and can be coupled with Chemical Transport Models (CTMs) like CAMS (Copernicus Atmospheric Monitoring Service) to enhance the simulation of CO
2 transport [
125,
126]. Radiative Transfer Models (RTMs), such as MODTRAN and SCIATRAN, simulate the propagation of light through the atmosphere, providing a crucial foundation for satellite remote sensing inversion [
127]. Additionally, General Circulation Models (GCMs), like the GISS model, aim to simulate atmospheric circulation in the global climate system and are often combined with CTMs for long-term climate analysis [
128]. By integrating observational data across varying temporal and spatial scales, these models enable the accurate reconstruction of atmospheric CO
2 distribution and trends, providing essential scientific support for addressing climate change.
3.2.3. Data Fusion Method Based on Learning Algorithms
Data fusion methods based on learning algorithms belong to emerging technologies. They utilize neural networks, integrated learning, Convolutional Neural Networks, Generative Adversarial Networks, and transfer learning to learn and fuse information from multiple data sources automatically [
129]. Learning algorithms are widely used in action recognition [
130], image enhancement [
131,
132], and semantic segmentation [
133,
134]. These methods reveal complex relationships between data by training on a large amount of data, extracting feature representations, and merging information from different data sources to obtain more accurate and comprehensive data fusion results [
135].
Machine learning methods utilize existing observations and associated features as inputs, and models are trained to learn data relationships to predict and fill in missing data [
136,
137]. Deep learning methods, on the other hand, utilize deep neural network models for satellite data reconstruction. These deep learning models have multiple hidden layers to learn more advanced feature representations from the data [
138,
139,
140]. The success of machine learning and deep learning methods in satellite CO
2 data reconstruction depends on adequate training data and appropriate feature engineering.
With the assistance of multi-source data, even simple multiple linear regression models can obtain good fitting results. However, due to the complexity of CO
2 transport processes between terrestrial ecosystems, marine ecosystems, and the atmosphere, linear models face the challenge of having an inadequate fitting ability. To overcome this challenge, studies have been conducted in recent years to apply machine learning to derive continuous
distributions and to reconstruct satellite CO
2 data.
Table 9 summarizes the results of data fusion methods based on learning algorithms achieved by researchers in satellite CO
2 data reconstruction in recent years.
In 2019, Siabi et al. [
141] employed a Multi-layer Perceptron (MLP) model to establish a nonlinear relationship between OCO-2 satellite XCO
2 and various data sources, successfully filling the gaps in satellite observation data. In 2020, Phuong Nguyen et al. [
142] creatively combined compressed sensing and deep learning into a single framework to merge GOSAT and OCO-2 XCO
2 data. Compared to the original data, the fused dataset exhibited Root Mean Square Errors ranging from 1.31 ppm to 4.12 ppm, enhancing the spatiotemporal resolution of long-term analysis. He et al. [
143] developed a LightGBM (Light Gradient Boosting Machine)-based CO
2 reconstruction model that achieved strong objective fitting accuracy. This model filled gaps in OCO-2 inversion data for the Chinese region from 2015 to 2018, with a cross-validation R² of 0.95 and an RMSE (Root Mean Square Error) of 0.91 ppm.
In 2022, Li et al. [
144] proposed a high spatial and temporal resolution and spatial and temporal continuum method for reconstructing atmospheric CO
2 concentration. As shown in
Figure 9, they integrated data from OCO-2 satellite observations by selecting environmental factors that affect atmospheric CO
2 concentration and used an extreme random tree (ERT) model for training to determine the relationship between environmental factors and the atmospheric CO
2 concentration. With this method, they generated spatiotemporally continuous atmospheric CO
2 concentration data on a global continental scale. Validation results show that these reconstructed CO
2 data exhibit satisfactory performance.
In 2022, Wang et al. [
145] successfully reconstructed the daily variation in the CO
2 column concentration in the Beijing–Tianjin–Hebei region with full spatial coverage by analyzing the sources of atmospheric CO
2 and various factors affecting the spatial distribution of CO
2, using multi-source satellite data and a random forest model. Compared with direct CO
2 satellite observation data, these reconstructed CO
2 data can achieve daily global coverage and have richer application value. In addition, in 2022, Zhang et al. [
146] proposed an innovative geographically weighted neural network (GWNN) model by combining a neural network model with a geographically weighted regression (GWR) model, which can effectively capture the spatial heterogeneity of CO
2 and further improve the model’s accuracy.
There are a few longer time scales and more comprehensive studies of multiple satellites in China. In 2023, Zhang et al. [
147] planned to use machine learning techniques to create a long-term, monthly
dataset with missing data filled in and analyze its spatial and temporal variability in depth. As shown in
Figure 10, the spatial gradient of CO
2 is not very significant due to its long lifetime in the atmosphere and continuous accumulation. When dealing with
filled with missing data, it is more challenging to construct a machine learning model, which requires careful consideration of its spatial variation and influencing factors. To this end, Zhang et al. [
147] utilized near-infrared CO
2 observation satellites, including SCIAMACHY, GOSAT, and OCO-2, as well as a variety of auxiliary data such as emissions, vegetation, and meteorology. In a framework based on Convolutional Neural Networks, deep convolution and attention mechanisms are employed while focusing on the correlation between nearest neighbors. The specific methodology is described below.
- (1)
Data preprocessing
where
is the
data in a given monthly grid, and
is the inverse square of the precision, which is the uncertainty in the standard deviation for the SCIAMACHY dataset and the a posteriori error in
for GOSAT and OCO-2. Zhang et al. [
147] chose data with an ‘xco2_quality_flag’ value of 0 and excluded outliers of more than four times the standard deviation each month.
In the CarbonTracker model, Zhang et al. [
147] used auxiliary data to calculate
by employing 25 levels of CO
2 profile data as constraints and reference values for the machine learning model. In this process, they used a pressure weighting function, which is formulated as follows:
where
and
are the bottom and top pressures of the
i-th layer, respectively.
is the CO
2 mixing ratio in the dry air of layer
i.
is the column density of dry air per unit pressure.
,
g, and
are the specific humidity, gravitational acceleration, and molar mass of the dry air, respectively. To minimize discontinuities, monthly averaging was performed by Zhang et al. [
147]. Meanwhile, CT-
was used as a spatial constraint only. Then, all auxiliary variables were aggregated to a resolution of 0.25° × 0.25°. To increase the resolution, bilinear interpolation was used.
- (2)
Machine learning model
In this study, to utilize the observed data, Zhang et al. [
147] selected the first N nearest-neighbor data points of each valid XCO
2 data point and used the corresponding XCO
2 values as inputs. Meanwhile, to combine the influencing factors, they selected a size of 7 × 7 in the region centered on each XCO
2 observation. To handle the C auxiliary variables, they designed a data block with dimensions (7, 7, 18), where 7 represents the spatial dimensions of the data block and 18 represents the number of channels. Through experiments, they found that Convolutional Neural Networks (CNNs) performed more effectively with these high-dimensional data. Considering the different characteristics of the channels, they concluded that a uniform convolutional kernel was not suitable and decided to use depthwise separable convolution and attention mechanisms to achieve better results.
As shown in
Figure 11, Zhang et al. [
147] proposed a machine learning network with the structure shown below. This architecture first took a data block consisting of each variable as input. A double convolution–activation operation was performed after channel and spatial attention processing, followed by spreading. Distance and
values of N points around each valid grid point were used as inputs. To integrate the time and latitude variations, the time, latitude, and global CO
2 background values were also introduced as auxiliary inputs.
- (3)
Model training
Zhang et al. [
147] used MAE (Mean Absolute Error) and RMSE as monitoring metrics in model training. To assess the accuracy of the model, they randomly divided all valid data and kept 30% of the whole dataset as the validation set, which was not involved in training but was used to validate the model’s performance. Meanwhile, predictive ability is also a critical assessment method. Zhang et al. [
147] generated a long-term
dataset using a model trained for prediction and evaluated it against satellite observations, model simulations, and ground-based observations.
Data fusion methods based on learning algorithms in satellite CO
2 data reconstruction can significantly improve data accuracy and processing efficiency. For the carbon satellite data reconstruction methods, this paper provides a comparative analysis of the reconstruction results (
Table 10), making them easier for readers to further understand and reference.
Based on the research conducted by the authors of this paper, it has been observed that the currently popular deep learning algorithms are scarcely applied in the field of CO
2 data fusion. As shown in
Table 11, we compiled a list of deep learning algorithms that can potentially be used in the field of data fusion, providing readers with a reference for further exploration.
In the field of CO2 data fusion, the vast majority of current research papers primarily focus on the fusion of multiple data sources, with very limited mention of methods for the fusion of multiple heterogeneous data sources. Multiple data source fusion predominantly concerns the integration of data from the same data types, whereas the fusion of multiple heterogeneous data sources comprehensively integrates data from different types and characteristics. Therefore, in the domain of satellite CO2 data reconstruction, the fusion of multiple heterogeneous data sources allows for a more comprehensive consideration of the strengths and limitations of various data sources, ultimately providing more accurate and reliable CO2 concentration information.
3.3. Summary of Satellite CO2 Reconstruction Methods
In the field of satellite CO2 data reconstruction, both interpolation methods and data fusion methods play crucial roles. Interpolation methods are employed to address missing data in the spatial and temporal dimensions, utilizing techniques such as Kriging interpolation and temporal interpolation to fill in the gaps. Data fusion methods, on the other hand, integrate CO2 concentration data from different sources, including satellite data, ground station data, and model-generated data, thereby enhancing the spatiotemporal coverage and accuracy of the data. This fusion can be achieved through combining satellite data with ground station data, and model data with satellite data, as well as integrating data from multiple sensors. Looking ahead, with the continuous advancement of technology, satellite CO2 data reconstruction is expected to become more precise, comprehensive, and effective in monitoring and understanding the spatiotemporal variations in CO2 concentration in the Earth’s atmosphere.
4. Super-Resolution Reconstruction Methods
Image super-resolution reconstruction aims to reconstruct a natural and clear high-resolution (HR) image from one or more low-resolution (LR) images. Image super-resolution algorithms can be broadly categorized into three groups based on their research methods: interpolation-based super-resolution algorithms, reconstruction-based super-resolution algorithms, and learning-based super-resolution algorithms [
153].
In remote sensing, super-resolution reconstruction methods are widely used to enhance the detail and clarity of satellite images. These methods benefit various fields such as geology, climatology, environmental science, agriculture, oceanography, and urban planning [
154,
155,
156,
157]. In the following sections, we will elaborate on the three classification methods of super-resolution reconstruction and discuss the application and potential of super-resolution reconstruction technology in satellite CO
2 data reconstruction.
4.1. Interpolation-Based Image Super-Resolution Algorithm
The interpolation method is a simple and fast image super-resolution algorithm that effectively improves image resolution. Its classification topological framework is shown in
Figure 12. The two super-resolution reconstruction methods, traditional interpolation and guided interpolation, are described below. Traditional interpolation methods (such as nearest-neighbor, bicubic, and bilinear interpolation) are based on geometric calculations of pixel values without involving image feature extraction and analysis. These methods are generally faster but may be less effective in handling complex image structures; their commonality is that they rely on straightforward mathematical operations based on pixel values for interpolation. In contrast, guided interpolation methods (such as edge-guided, gradient-guided, and wavelet transform interpolation) use specific image features (like edges, gradients, or frequency components) to guide the interpolation process, thereby enhancing the preservation of image details and edges. Their commonality lies in their reliance on image feature analysis to improve the interpolation results.
Table 12 compares each reconstruction algorithm based on the interpolation method.
- (1)
Traditional interpolation algorithm
Traditional interpolation methods do not consider the structural information of the image but are based on simple geometric operations of pixel values. For example, nearest-neighbor interpolation directly assigns the grey value of the nearest pixel as the interpolation result; bilinear interpolation calculates new pixel values through linear interpolation based on the nearest four pixels; and bicubic interpolation uses more complex cubic interpolation functions to achieve smoother results.
Nearest-neighbor interpolation [
158,
159] assigns the grey value of the pixel closest in Euclidean distance to the interpolating point as its interpolated grey value. The formula is as follows:
where
are floating point numbers in the
interval, and
is the pixel value of the low-resolution image at
.
Although nearest-neighbor interpolation is a simple interpolation algorithm with a low level of complexity and ease of implementation, it tends to produce aliasing artifacts and discontinuities in image intensity. This is because it does not take into account the influence of other neighboring pixels on the target interpolated point, especially when applied to higher-resolution images. To address the issue of aliasing artifacts caused by the neglect of interactions between adjacent pixels in nearest-neighbor interpolation, researchers introduced bilinear interpolation [
160,
161,
162].
The bilinear method primarily addresses the image interpolation problem by linearly interpolating four adjacent pixel points in both vertical and horizontal directions. The formula is as follows:
Although the bilinear interpolation method has improved the resolution of image greyscale discontinuity problems, the interpolated image may still exhibit noticeable detail degradation, especially when high-frequency information is severely affected.
Researchers extended bilinear interpolation to propose bicubic interpolation. Bicubic interpolation expands the neighborhood from four adjacent pixels to sixteen adjacent pixels and employs weighted averaging after applying cubic interpolation polynomials for image interpolation and reconstruction. This method uses cubic polynomials as the interpolation functions:
w is the weight or distance parameter used in the interpolation process.
is a piecewise cubic function that provides weights in different ranges depending on the value of
w. The interpolation formula is as follows:
wherein
A is a row vector containing the values of the function S at the points , u, , and ; B is a matrix containing the specific values of the function G around the points ; and C is a column vector containing the values of the function S at the points , v, , and .
The double-cubic interpolation method fully considers the influence of each pixel on the target interpolation point, which improves the reconstruction quality but increases the computational complexity and volume significantly.
Because these algorithms are designed based on the assumption of local smoothness in images, they may not perform well in regions with high-frequency information, such as edges or textured areas, where pixel intensity changes are abrupt. In these regions, traditional interpolation algorithms may fail to produce satisfactory results. Additionally, as the magnification factor increases, issues like ringing artifacts and aliasing effects can arise. Therefore, researchers have proposed guided interpolation methods to address these challenges.
- (2)
Guided interpolation algorithm
Guided interpolation methods utilize specific image information (such as edges or gradients) to enhance the interpolation effects. For example, edge-guided interpolation identifies edges in the image and aims to preserve their sharpness during interpolation; gradient-guided interpolation uses gradient information to guide the process, ensuring that areas with significant gradient changes (such as edges) are handled better; and wavelet transform interpolation employs wavelet transforms to decompose the image and guide interpolation using frequency domain information, thereby preserving more details.
Edge-guided interpolation methods [
163,
164,
165] are primarily used to enhance edge information in RGB (Red, Green, Blue) color images, addressing the perceptual impact of human vision characteristics on image edges. Li et al. [
163] introduced the edge-guided NEDI (New Edge-Directed Interpolation) algorithm, which utilizes the local covariance of edges in the LR image to reconstruct edge information similar to that in the HR image, thus improving edge sharpening. However, this algorithm is computationally intensive and has limited practical applications. Building on the NEDI algorithm, Zhang et al. [
165] proposed an adaptive interpolation method to optimize the structural information between LR and HR images, leading to more comprehensive image structural and edge information.
Gradient-guided interpolation [
166,
167] uses first- and second-order gradient information from the neighborhood to adjust gradient and pixel distributions. It combines edge-guided interpolation with bicubic interpolation for image reconstruction.
Wavelet transform interpolation [
168,
169,
170] leverages the wavelet transform’s ability to capture local details. It decomposes image features into different scales for analysis, then overlays and fuses these features, and uses wavelet inverse transform to enhance resolution. Ford et al. [
169] used one-dimensional wavelet signals for nonuniform image sampling reconstruction, while Nguyen et al. [
170] extended this approach to two-dimensional signals and reconstructed LR images within a multi-resolution framework.
Most interpolation-based image super-resolution algorithms are relatively simple and computationally efficient, but they cannot recover lost high-frequency details and have limited accuracy. Therefore, interpolation-based super-resolution algorithms are often used as preprocessing methods, where the interpolated image serves as the initial super-resolution result, which is then combined with other methods to further enhance the high-frequency information.
4.2. Reconstruction-Based Image Super-Resolution Algorithm
Reconstruction-based super-resolution methods are widely used in image processing and are primarily categorized into frequency domain and spatial domain approaches [
171]. These methods reconstruct the high-resolution image by extracting necessary feature information from multiple low-resolution images and estimating the HR image details.
4.2.1. Frequency Domain Method
Image super-resolution algorithms based on frequency domain reconstruction are used to improve the resolution of images by eliminating spectral aliasing in the frequency domain. Patti et al. [
172] first proposed to eliminate the spectral aliasing of LR images in the Fourier transform frequency domain and Fourier transform of multiple LR images to realize super-resolution image reconstruction. The frequency domain method improves the computing speed and image accuracy. However, the frequency domain-based method cannot utilize the a priori knowledge in the image null domain and is only suitable for the overall translation and spatially invariant model, which makes it difficult to solve the image noise problem. Thus, most of the research mainly focuses on studying image super-resolution algorithms based on null domain reconstruction.
4.2.2. Spatial Domain Method
Image super-resolution algorithms based on spatial domain reconstruction can conveniently and flexibly incorporate various prior knowledge and use this prior information as a constraint condition to ensure that the iterative solution process converges to an optimal or local optimal solution. Spatial domain-based image super-resolution algorithms mainly include nonuniform interpolation [
173], iterative back-projection [
174], convex set projection [
175], and maximum a posteriori probability methods [
176].
Table 13 comprehensively presents the characteristics and performance of reconstruction-based image reconstruction methods in terms of prior information dependence, the feasibility of unique solutions, computational complexity, processing speed, algorithm flexibility, and reconstructed image quality.
- (1)
Nonuniform interpolation
The nonuniform interpolation method [
173] works by fitting or interpolating the feature information from nonuniformly distributed LR images to generate uniformly distributed HR image features, thereby achieving super-resolution reconstruction. While this algorithm is effective for reconstruction, it depends heavily on having sufficient a priori information, which can limit its flexibility.
- (2)
Iterative inverse projection method
Irani et al. [
174] proposed the iterative back-projection approach. The iterative back-projection algorithm first estimates a high-resolution image
as the initial solution, then generates a low-resolution image
by simulating noise interference, and finally projects the difference between the real low-resolution image
y and
back onto
. The low-resolution image
and the iterative image
are shown in Equation:
where
represents the simulated low-resolution image,
H is the projection matrix,
is the initial estimation of the high-resolution image,
n represents noise,
is the final result image obtained after the first iteration,
represents the back-projection matrix, and
y represents the actual observed low-resolution image after back-projection. To compare the two images
y and
, if their values are equal, it indicates that the two images are the same, and the iteration stops. If the values of
y and
are not equal, the error between the two images needs to be back-projected onto
, and
is updated and corrected accordingly. This process continues until the error meets the desired criteria.
The iterative back-projection method addresses the issue of high dependence on a priori information in super-resolution image reconstruction algorithms and effectively improves the quality of the reconstructed images. However, it does not guarantee the uniqueness of the reconstructed image.
- (3)
Projections onto Convex Sets
Stark and Oskoui [
175] were the first to apply the Convex Projection Over the Union of Sets (POCS) algorithm to image super-resolution reconstruction. The POCS method maps the LR image into a set of HR images through interpolation, applies constraints based on prior knowledge to this set, and then iteratively projects the initial value to find a solution that satisfies the constraints. The iterative process of the convex set projection algorithm is shown in the following equation:
where
denotes the first
iteration of the high-resolution image, and
denotes the projection matrix of any pixel point of the high-resolution image projected onto the convex set.
The POCS algorithm can maintain the edge contour region relatively well. However, the algorithm has high computational complexity, slow convergence speed, and strong dependence on a priori information in each iteration.
- (4)
Maximum a posteriori probability method
Schultz and his team [
177] introduced an algorithm based on maximum a posteriori (MAP) estimation. The maximum a posteriori method treats the high-resolution image and the low-resolution image as two random variables, framing the image super-resolution reconstruction problem as a probability estimation problem to ultimately estimate the final high-resolution image. The maximum a posteriori estimation algorithm process is as follows. First, assume that the known image
A is the original low-resolution image, image
B is the reconstructed high-resolution image, and
is the objective function:
Equation (
15) can be converted to Equation (
16) below using the Bayesian formula:
Finally, by simplifying using logarithmic operations, Equation (
16) can be converted into Equation (
17) below:
where
denotes the conditional probability corresponding to the high-resolution image
B, and
denotes the a priori probability of the high-resolution image. MAP estimation can effectively utilize the internal information of known images and produce high-quality reconstructed images. However, its drawbacks include complexity, computational intensity, and the suboptimal handling of image details in the reconstructed result.
Reconstruction-based image super-resolution algorithms rely on solving the degradation model. Many of these algorithms incorporate a priori distribution information of the image as a constraint, which generally results in higher performance compared to interpolation-based methods. However, the reconstruction process primarily utilizes internal image information, which can lead to a lack of high-frequency details in the reconstructed image.
4.3. Learning-Based Image Super-Resolution Algorithm
Learning-based image super-resolution methods involve using machine learning techniques on a database of low-resolution and high-resolution image pairs to model the mapping relationship between these images. These methods can be categorized into four main approaches: example based, neighborhood embedding based, sparse representation based, and deep learning based. The first three categories are considered shallow learning algorithms, while deep learning-based approaches represent a more advanced, complex form of learning.
4.3.1. Shallow Learning-Based Image Super-Resolution Algorithm
Shallow learning-based image super-resolution algorithms utilize relatively simple neural network structures to achieve high-quality reconstruction of low-resolution images. These algorithms generally recover details by learning image features through convolution and pooling layers, and then map these features to a high-resolution image using upsampling or inverse convolution operations. The primary shallow learning-based image super-resolution methods include example-based learning, neighborhood embedding, and sparse representation-based techniques.
- (1)
Example-based learning method
The example-based learning method as developed by Freeman and others relies on a single-image reconstruction algorithm using Markov networks [
178,
179]. This approach involves applying degradation operations to original high-resolution images to create a training image feature library. It then learns prior information from these HR images to recover high-frequency details and features. The process is as follows.
For each input low-resolution block
y, the algorithm selects the 16 most similar high-resolution blocks as distinct states of the hidden node
x. The distribution is modeled as a conditional probability distribution, which is formulated as follows:
where the compatibility functions
and
represent the relationships between the adjacent nodes’ high-resolution blocks and between the same node’s high-resolution and low-resolution blocks, respectively, with
Z being a normalization constant. To define compatibility functions, nodes in the sampled image ensure that high-resolution blocks overlap with each other. Let
i and
j be two neighboring blocks,
be the 1st candidate block for block
i, and
be the
mth candidate block for block
j. If
(the 1st candidate block for node
i) and
have consistent pixels in their overlapping regions, they are considered mutually compatible. Let
be the corresponding low-resolution block for
. The compatibility matrix is defined as
where
and
represent noise parameters. The optimal high-resolution block is the block that maximizes the probability in the Markov network. Belief Propagation is introduced to iteratively calculate the probability distribution, and an approximate solution can be obtained in 3 to 4 iterations.
Algorithms based on example learning can effectively utilize sample libraries to increase the high-frequency information of an image. However, the amount of searching needed in sample libraries is huge and computationally expensive. If there is a mismatch, it can reconstruct details that do not match the overall characteristics of the image.
- (2)
Neighborhood-based embedding method
The neighborhood embedding method involves solving the k-nearest-neighbor representation coefficients of input low-resolution image blocks within the low-resolution image block sample set [
180]. Finally, these coefficients are used to linearly combine the neighbors in the high-resolution image block sample set to obtain the corresponding output high-resolution image block.
In 2004, Chang et al. [
181] utilized the same local structural linear properties of LR and HR images to obtain the weights of neighboring points for the final reconstructed image, substantially avoiding the overfitting problem in the modeling process. Chang et al. assumed that the low-resolution image chunks have similar local geometrical properties to the corresponding high-resolution image chunks for the near-neighbor embedding-based super-resolution reconstruction of the image. The low-resolution test image
y is divided into overlapping image blocks of size
, and features are extracted to form a feature vector
,
, where
Q is the total number of chunks of the LR test image. For each of them, the following operation is performed.
Step 1: In the low-resolution feature vector , of the training set, find the K low-resolution nearest neighbors of based on the Euclidean distance , where denotes the set of K nearest neighbors.
Step 2: According to the LLE (Locally Linear Embedding) algorithm [
182], a method used for dimensionality reduction, data are mapped to a lower-dimensional space while preserving the local relationships between the data points. It computes the reconstruction weights
such that the reconstruction error
is minimized and required to satisfy the constraints
, and for any
,
. In Formula (21), the double vertical bars denote the norm, used to measure the size or length of a vector or matrix:
Step 3: Keeping the weights
unchanged, reconstruct the high-resolution block
using the
K nearest-neighbor high-resolution training blocks
corresponding to
:
For the , superimposed low-frequency portion, which is then merged into the target high-resolution image x, local consistency and smoothing constraints are imposed on the neighboring blocks by taking the mean value at the overlapping pixels again.
Neighborhood embedding methods reduce the dependence of reconstructed images on the sample set. However, the number of nearest neighbors is fixed and lacks flexibility, which is prone to over-learning or under-learning phenomena, leading to blurred reconstruction results.
- (3)
Sparse representation-based methods
The sparse representation method focuses on dictionary learning and sparse coding as the core to realize a practical improvement in the image reconstruction efficiency and reconstruction quality [
183]. The sparse coding is used to represent the image blocks. Then, the HR image block and LR image block are captured from the sample image to form an ultra-complete dictionary. The sparse linear representation of the sample image is obtained according to the dictionary, and finally, the HR image is reconstructed according to the sparse coefficients.
Yang et al. [
184] proposed image super-resolution reconstruction based on sparse representations, where low-resolution image blocks are considered to have sparse representations for an overcomplete dictionary composed of prototype signal atoms. The authors used sparsity as a priori information to regularize the super-resolution reconstruction problem by randomly selecting 100,000 pairs of original image blocks from training images with similar statistical properties to be used as dictionaries
and
.
consists of high-resolution blocks, and
consists of low-resolution blocks. The problem is described as finding the sparsest representation of a low-resolution block
under dictionary
. The problem is summarized as follows:
where
represents the sparse representation of the low-resolution image block
,
represents the
norm, which is the number of nonzero elements in
, s.t. is the abbreviation for subject to, which means constrained by or satisfying the following conditions,
F is the feature extraction operator, and
is the allowable error. Donoho [
185] pointed out that when
is sparse enough, it can be equivalently minimized using the
norm:
Introducing the Lagrange factor, the problem is described as
The parameter balances the sparsity of the solution and the approximation to . This is a linear regression problem involving the norm. Once the optimal coefficients are determined, the HR block is computed.
Traditional sparse representation methods reconstruct image structures by independently considering the sparsity of image blocks. This approach can lead to a loss in fine texture details and spatial structural features. To address this issue, Timofte et al. [
186] combined neighborhood embedding with sparse coding, reducing computational complexity while constraining the relationship between image blocks and their neighborhood information. Li et al. [
187] introduced a self-learning super-resolution algorithm that merges nonlocal self-similarity with sparse coding, effectively reducing the model training time and enhancing robustness. Zeng et al. [
188] proposed using principal component analysis and hierarchical clustering to train a dictionary model, which differs from traditional sparse representation methods, aiming to improve the quality of reconstructed images.
The super-resolution reconstruction algorithm based on sparse representation avoids the artificial selection of the number of nearest neighbors, resulting in better reconstruction effects. However, challenges remain in terms of algorithm efficiency and the rapid acquisition of more compliant dictionaries from a large set of training images.
In conclusion, shallow learning-based image super-resolution algorithms offer advantages in computational efficiency and simplicity, making them suitable for specific scenarios. However, they may require improvements for tasks involving complex texture and detail reconstruction, for which deep learning methods are often more effective.
4.3.2. Deep Learning-Based Image Super-Resolution Algorithm
Deep learning-based image super-resolution algorithms employ deep neural network architectures to achieve high-quality image reconstruction. These algorithms excel in processing complex textures, preserving details, and generating high-resolution images by leveraging the representation learning capabilities of deep learning. They provide advanced solutions for image super-resolution reconstruction.
In 2014, Dong et al. [
189] made a groundbreaking contribution to the field by introducing deep learning techniques for image super-resolution. They developed the first Convolutional Neural Network-based super-resolution model, called SRCNN (Super-Resolution Convolutional Neural Network). While SRCNN improved the speed and reconstruction quality compared to traditional methods, it faced challenges such as computational complexity and slow training convergence due to its pre-upsampling model architecture. Additionally, the relatively simple SRCNN structure struggled to fully utilize contextual information in images.
- (1)
Inverse Convolution Layer
To address the high computational cost and complex real-time application issues of SRCNN, Dong et al. [
190] proposed an improved and accelerated model in 2016 called FSRCNN (Fast SRCNN). FSRCNN includes a feature extraction layer, a contraction layer, a nonlinear mapping layer, an expansion layer, and an inverse convolution layer. The main improvement in FSRCNN is the replacement of the SRCNN pre-upsampling model framework with a post-upsampling framework. Up-sampling is performed by the deconvolutional layer at the end of the network, which helps to reduce the computational complexity. Additionally, FSRCNN enhances the computational efficiency by modifying feature dimensions and sharing parameters in the mapping layer, which also contributes to the improved quality of the reconstructed image.
- (2)
Subpixel layer
To reduce computational complexity and enhance efficiency, Shi et al. [
191] introduced a fast and effective super-resolution network model called ESPCN (Efficient Sub-Pixel CNN) in 2016. Like FSRCNN, ESPCN employs a post-upsampling framework. However, it utilizes a sub-pixel convolutional layer for up-sampling the image. The ESPCN network consists of a hidden layer with two convolutional layers and a sub-pixel convolutional layer. Initially, it extracts features from the low-resolution input image using the hidden layers. Subsequently, it reconstructs the high-resolution image through the sub-pixel convolutional layer. This approach facilitates fast and efficient end-to-end learning, yielding better reconstruction results compared to the FSRCNN model.
- (3)
Residual network
In 2016, He et al. [
192] introduced the concept of a residual network (ResNet) to address the degradation problem in deep Convolutional Neural Networks caused by excessively deep architectures. They developed a ResNet structure by stacking multiple residual blocks as illustrated in
Figure 13. Residual networks utilize skip connections between residual blocks to enhance the transfer of image feature information across layers and alleviate the vanishing gradient issue in deep networks. However, since feature information extracted by each residual block must pass through these skip connections to reach the subsequent modules, it can become increasingly complex as it propagates deeper into the network. This complexity might result in the loss of simpler features from earlier layers.
To address the challenges associated with residual networks, researchers have proposed various novel architectures based on the original ResNet framework. In 2016, Kim et al. [
193] applied ResNet (
Figure 14a) to image super-resolution, introducing the Very Deep Super-Resolution (VDSR) network model. Recognizing the similarity in low-frequency information between low-resolution and high-resolution images, VDSR used residual learning to focus on high-frequency details. This approach significantly reduced training time and improved training speed.
In 2017, Lim et al. [
194] built upon the SRResNet structure [
195] (
Figure 14b) to develop the Enhanced Deep Super-Resolution (EDSR) network. They made a notable improvement by removing the batch normalization (BN) layers from the SRResNet architecture (
Figure 14c), which had previously compromised the image quality. The removal of BN layers not only enhanced image quality but also reduced memory usage by approximately 40%, allowing for deeper networks with similar computational resources. Lim et al. also addressed the training instability using residual scaling, leading to significant improvements in image quality.
In 2018, Li et al. [
196] introduced the Multi-Scale Residual Network (MSRN) to address limitations in utilizing low-resolution image features and handling multi-scale tasks with a single model. The MSRN incorporated Multi-Scale Residual Blocks (
Figure 14d), which combined ResNet with convolutional kernels of varying scales to capture diverse image features. This design allowed MSRN to fuse local multi-scale features with global features, enhancing the performance and quality of the reconstructed image.
In 2021, Lan et al. [
197] observed that many CNN-based models did not fully exploit low-level features, leading to suboptimal performance. To address this, they introduced two new models: the Cascading Residual Network (CRN) and the Enhanced Residual Network (ERN). The CRN featured a cascading mechanism with multiple locally shared groups to improve feature fusion and gradient propagation, enhancing feature extraction efficiency. The ERN employed a dual global pathway structure to capture long-distance spatial features from the input, resulting in a more robust feature representation. Both CRN and ERN achieved comparable or superior performance to EDSR while using fewer parameters.
ResNet excels in extracting feature information from low-resolution input images in super-resolution networks through both local and global residual learning. It effectively addresses various training and gradient issues associated with very deep networks. Consequently, many super-resolution network models have adopted the concept of residual learning to enhance network performance. Additionally, subsequent super-resolution models have integrated residual learning with other network design strategies to achieve improved super-resolution reconstruction results.
- (4)
Attention mechanisms
As network structures deepen, residual networks may struggle to capture correlations between the image space, structure, and texture. This often results in training focusing on low-value image regions, which can degrade the quality of reconstructed images.
To address these challenges, several advancements have been made. In 2018, Hu et al. [
198] introduced the Squeeze-and-Excitation Network, which incorporates “squeeze-and-excitation” blocks to model interdependencies between channels, enhancing feature learning capabilities. Zhang et al. [
199] integrated channel attention mechanisms (
Figure 15) with residual networks to create deeper networks that reduce interference from low-frequency information in LR images. They proposed the ResNet in ResNet residual structure to bypass low-frequency information, adaptively scaling features in each channel to improve the processing efficiency and model robustness. Woo et al. [
200] developed the Convolutional Block Attention Module by combining channel and spatial attention modules, which strengthened the network’s ability to focus on crucial image regions.
In 2019, Dai et al. [
201] introduced the Second-Order Attention Network, incorporating second-order channel attention mechanisms to capture feature correlations through covariance normalization. This approach improved feature-related learning and expression capabilities. Xu et al. [
202] proposed a binocular image reconstruction algorithm guided by a dual-layer attention mechanism and disparity attention mechanism, tailored to enhance image quality under varying conditions. This method preserved fine details in underwater images despite external factors. Lu et al. [
203] further advanced high-frequency image reconstruction by incorporating hybrid attention mechanisms and long–short skip connections, which improved the edge information and texture structure.
Compared to other CNN-based network models, those utilizing attention mechanisms differentiate between essential and less important regions in the image. By assigning higher weights to critical regions, these models enhance feature extraction and obtain more effective image information.
- (5)
Recurrent Neural Networks
Recurrent neural networks (RNNs) can achieve infinite memory depth through successive network updates [
204]. In super-resolution, RNNs apply the same module multiple times in a recursive manner, leveraging parameter sharing within the internal module. This allows the network to learn higher-level features without introducing excessive parameters, thereby enhancing network performance.
Kim et al. [
205] introduced the DRCN (Deeply Recursive Convolutional Network) algorithm, which utilizes RNNs for super-resolution image reconstruction. By repeatedly applying convolution and recursion, DRCN continuously learns the differences between low-resolution and high-resolution images. This approach enables image information to circulate and recurse within the network, aiming to recover high-frequency image details and address the challenge of increasing parameter counts. Han et al. [
206] proposed the DSRN (Dual-State Recurrent Network), viewing many deep super-resolution network structures as finite expansions of single-state RNNs with various recursive functions. The RNN structure in DSRN operates at different spatial resolutions, employing two recurrent states for LR and HR spaces. Through a delayed feedback mechanism, it exchanges cyclic signals between these spaces, effectively utilizing features from both domains to produce the final reconstructed image.
In 2019, Li et al. [
207] introduced the SRFBN (Super-Resolution Feedback Network), an image super-resolution feedback network. SRFBN refines high-level information into low-level representations and progressively generates the final HR image, achieving improved performance with fewer parameters. As depicted in
Figure 16, SRFBN employs a feedback mechanism with hidden states in a constrained RNN. It also incorporates a curriculum learning strategy, where target HR images of increasing reconstruction difficulty are sequentially fed into the network for continuous iteration. This strategy allows the network to gradually learn complex degradation models and adapt more effectively to challenging tasks.
The characteristic of parameter sharing in RNNs enables them to learn higher-level features without introducing excessive parameters. However, RNNs still face gradient and training issues common to deep networks. To address these challenges, RNNs are often integrated with advanced network designs and learning strategies, such as ResNet, multi-supervised learning, and curriculum learning. These combinations help alleviate gradient and training problems, leading to improved network performance.
- (6)
Generating Adversarial Networks
Super-resolution image reconstruction algorithms based on Generative Adversarial Networks (GANs) have demonstrated excellent performance in terms of image reconstruction quality, network complexity, and computational speed. Adversarial methods in AI have the advantage of generating high-quality and realistic images, making them particularly effective in super-resolution image reconstruction. In 2014, Goodfellow et al. [
208] introduced the concept of Generative Adversarial Networks (
Figure 17), depicted in the structure below.
Figure 17 depicts a Generative Adversarial Network with two main components: the generator and the discriminator. The generator converts low-resolution input into high-resolution output, while the discriminator evaluates whether these outputs are real or fake. If the discriminator deems the data real, the generator is successful; otherwise, the generator needs improvement. This adversarial process continuously loops, allowing the generator to progressively produce more realistic data. In 2017, Ledig et al. introduced the SRGAN (Super-Resolution Generative Adversarial Network) algorithm, which was pioneering in applying adversarial training to super-resolution image reconstruction. SRGAN employs a generator network to produce high-resolution images and a discriminator network to distinguish between these reconstructed HR images and the original HR images. The generator and discriminator are trained in an adversarial manner, which enhances the reconstruction of fine image details. Unlike traditional methods that use Mean Square Error loss, SRGAN utilizes a perceptual loss function. This approach improves the recovery of image details, resulting in high-fidelity and high-quality reconstructed images.
Although the SRGAN algorithm preserves more image detail features, the use of BN layers in the network introduces a large number of parameters, consuming a significant amount of runtime memory and potentially degrading network performance. In response to this issue, Lim et al. [
194] proposed the EDSR algorithm by removing the BN layers. They found that this modification did not negatively impact network training, reduced the number of network parameters, and improved the preservation of image texture information. Wang et al. [
209] introduced the Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) algorithm to enhance network generalization. They employed residual scaling to accelerate deep network training and reduce computational parameters. This resulted in reconstructed HR images with richer texture features and colors that closely resembled the original HR images. Shang et al. [
210] improved the ESRGAN algorithm by using small kernel convolutions instead of large filters for detail feature extraction. This change maintained network performance while reducing computational complexity and handling noisy input more effectively.
Overall, researchers have tried to apply super-resolution techniques in scenarios with limited computational and storage resources by designing lightweight network models and applying search methods. Although some methods have achieved performance improvements, there is still a need to balance model performance and computational complexity.
4.4. Potential of Super-Resolution Reconstruction in Satellite CO2
After discussing various super-resolution reconstruction methods, we will specifically explore their potential applications to carbon dioxide datasets, highlighting the unique challenges and opportunities these methods present in the field of climate monitoring. Super-resolution reconstruction not only improves the spatial resolution of satellite meteorological images but also enables meteorologists and climate scientists to observe and predict weather patterns, climate change, and precipitation distribution. It provides more reliable data for meteorological disaster monitoring and climate modeling. Therefore, it is possible to improve the spatial resolution of the data using image super-resolution reconstruction.
However, the application of super-resolution reconstruction methods to satellite CO2 reconstruction is limited primarily due to the complexity and sparsity of the data, challenges of applying these algorithms to atmospheric science data, high-precision requirements, computational costs, and the difficulty of cross-disciplinary applications. Super-resolution techniques are mainly used in image processing, while satellite CO2 reconstruction involves complex physical and chemical processes. Applying the super-resolution reconstruction method to satellite CO2 data is a work with great potential, and the super-resolution reconstruction method can construct a long series satellite CO2 dataset with high precision and high resolution, which can provide vital data support for the better application of satellite CO2 data to the study of the small-scale carbon source-sink pattern. At the same time, we can combine super-resolution reconstruction techniques with multi-source heterogeneous data fusion techniques to provide more comprehensive, accurate, and reliable CO2 concentration information.
In 2022, Ru Xiang and colleagues [
211] proposed a method using bicubic interpolation to perform the super-resolution reconstruction of CO
2 data from the GOSAT satellite to enhance the spatial resolution and accuracy of the data. As shown in
Figure 18, to objectively and quantitatively evaluate the quality of the reconstructed results, high-precision in situ measurement data are required. However, due to the limited and sparse distribution of TCCON stations, it is not possible to provide CO
2 measurements globally, especially in regions such as oceans, deserts, polar areas, and other sparsely populated areas. Therefore, additional high-precision OCO-2 satellite observation data are needed to assess the quality of the reconstructed GOSAT data. Recognizing the spatial continuity of CO
2 data, Ru Xiang and colleagues performed preprocessing on the GOSAT data by filling the missing pixel values with the average values of their surrounding 8 pixels. They then used bicubic interpolation to reconstruct the GOSAT data. To better evaluate the reconstructed data at a global scale, OCO-2 data were processed into data of different resolutions using Kriging interpolation. The specific workflow was as follows.
- (1)
Data preprocessing
Ru Xiang et al. employed a neighborhood mean method to fill in the missing data in the GOSAT L3
product. As shown in
Figure 19, they used a combination of gridded statistics and Kriging to generate OCO-2
monthly-scale data at various spatial resolutions. Addressing the temporal scale issue of TCCON data, they obtained TCCON monthly-scale data for different sites by averaging the daily data.
- (2)
Super-resolution reconstruction with double cubic interpolation
Bicubic interpolation is a commonly used super-resolution method, producing better interpolation results compared to bilinear interpolation or nearest-neighbor interpolation. The value of a pixel point
can be obtained by taking the weighted average of the sixteen nearest sampled pixels within a rectangular grid. This method requires the use of two cubic polynomial interpolation functions, one for each direction. The
value of the pixel after super-resolution reconstruction is calculated using the following formula:
where
is the XCO
2 value of pixel
P after reconstruction,
are the coordinates of pixel
P, and
is the value of the nearest pixel of pixel
P at the corresponding position in the original data. There are 16 pixels in total, and
i and
j are the indexes of these 16 pixels,
representing the weight of the 16 pixels, respectively, which can be computed by the following formula:
where
denotes the weight of each pixel, and
x denotes the distance of each pixel to the corresponding position of pixel
P in the original data. The double triple convolutional interpolation kernel is typically configured with the parameter
a set to −0.5, as this value provides the best fit for the intended applications.
- (3)
Verification of the accuracy of GOSAT reconstruction results based on TCCON, OCO-2.
In the evaluation, the MAE, MSE, and Average Relative Error (AVER) are used to describe the accuracy of data. The following formulas define them:
where
denotes the TCCON-measured XCO
2 value, and
is the satellite-observed XCO
2 value at the corresponding TCCON site location.
The OCO-2 observations were preprocessed and then processed into XCO
2 data at different resolutions. The original and reconstructed GOSATs were evaluated using this method. ME, MAE and RMSE were used to characterize the differences between the original reconstructed GOSAT and OCO-2 with the following equations:
where
denotes the XCO
2 value of the preprocessed OCO-2 data, and
is either the original GOSAT data or the reconstructed GOSAT data.
The reconstructed GOSAT data improved the resolution from 2.5° to 0.5°. The mean error in the reconstructed data for January 2016 was 1.335 ppmv, with no loss in precision compared to the original data. The errors in the original data caused errors in the reconstructed data, and the average error had significant temporal variation.
The reconstruction of the GOSAT XCO2 data by the double cubic interpolation method can improve the data resolution, but more is needed to improve the data accuracy effectively. Due to the problem of the method itself, the accuracy of the reconstructed data largely depends on the accuracy of the original data. The information contained in the reconstructed results is also affected by the original data, which cannot produce additional CO2 source or sink information, and there are some edge areas with missing data after reconstruction. Ru Xiang et al. used the SRCNN network model to reconstruct the GOSAT XCO2 data to improve the resolution and accuracy of the data.
The network structure of the model has three main layers, including three main processes of resolution reconstruction: data feature extraction, nonlinear mapping, and the final data reconstruction process. Unlike the SRCNN structure in the image domain, Ru Xiang et al. used the low-resolution and low-precision GOSAT XCO2 data as the input to the model. After undergoing the main processes of the model, the output is CO2 data with the resolution and precision of OCO-2, involving both resolution and precision reconstruction. The rest of the model structure is consistent with the standard SRCNN network model.
Therefore, the process of reconstructing GOSAT XCO2 data based on the SRCNN model mainly includes feature extraction of the original GOSAT XCO2 data, mapping the low-resolution and low-precision GOSAT features into high-resolution and high-precision OCO-2 features, and reconstructing the data based on these features.
The model’s network structure does not involve an up-scaling or down-scaling process for the data. The input to the model is the low-resolution GOSAT XCO2 data, which are upsampled using bicubic interpolation to match the output resolution. Thus, the SRCNN model focuses solely on improving the accuracy of the satellite CO2 data, requiring GOSAT and OCO-2 XCO2 data with the same resolution. To address the size of training samples, Ru Xiang and his team used bicubic-interpolated GOSAT XCO2 data (0.5°) and preprocessed OCO-2 XCO2 data (0.5°) to obtain a larger training dataset. Through experimental comparisons, they selected the ReLU activation function for the first two layers of the SRCNN model due to its good convergence speed and fitting performance, and the Adam optimization algorithm as the model’s optimization method.
The results indicate that, compared to the original data, the data reconstructed by the SRCNN model better preserve the distribution characteristics of the original data, although the overall spatial continuity is not very high. When compared to OCO-2 data, the results reconstructed by the SRCNN model exhibit higher data accuracy, with an improvement of approximately 0.5 ppmv over the original data. The data with improved accuracy are primarily distributed in the Southern Hemisphere.
With the continuous advancement of deep learning technology [
212,
213,
214], the importance of satellite carbon dioxide reconstruction is becoming increasingly evident. In the future, it will be possible to obtain high-resolution, gap-free, long-term XCO
2 data, which holds profound significance for the study and resolution of global environmental issues.
5. Summary and Outlook
Satellite CO2 data reconstruction work has a wide range of applications in today’s society and has received significant attention from researchers in related fields. In order to help beginners understand the satellite CO2 reconstruction methods and follow up on the research hotspots, this paper summarizes the related research on satellite CO2 data reconstruction, which aims to provide global CO2 concentration data by filling the gaps in the satellite observations or increasing the accuracy and coverage of the observations. In this article, the authors first introduce the necessity of satellite CO2 data reconstruction, as well as the monitoring methods and data sources for carbon dioxide. Secondly, the article discusses the specific applications of interpolation and data fusion methods in the reconstruction of CO2 data. Finally, the authors delve into the topic of super-resolution reconstruction technology and its specific applications in the field of satellite CO2 data reconstruction.
In recent years, researchers have made significant achievements in CO2 data reconstruction. Interpolation and data fusion methods have become the mainstream methods of carbon satellite data reconstruction, and super-resolution reconstruction technology has gradually developed in the field of data reconstruction. However, there are still many challenges and directions to pursue in further research.
(1) Although interpolation can, to some extent, solve the problem of partially missing data and ensure the spatial continuity of the data, part of the interpolation method overly relies on the number and quality of sample points and ignores the geographic characteristics of the data. Therefore, combining the interpolation and deep learning methods is a future research hotspot. The fusion of multi-modal data, modeling uncertainty, and adaptive interpolation methods will receive more attention to enhance the accuracy of interpolation results.
(2) The reconstructed results of the data fusion method have an extended time coverage. However, the method needs to focus more on improving the data resolution, and the reconstructed data often loses accuracy. Based on this, researchers can consider using migration learning to optimize and enhance the model in the sparse data region. Furthermore, multi-source heterogeneous data fusion can comprehensively integrate different types and characteristics of data sources, providing more comprehensive, accurate, and reliable CO2 concentration information, which is also a future trend in this field.
(3) The low resolution of satellite CO2 data makes them difficult to be directly applied to the study of small-scale carbon sources and sinks. Therefore, the idea of image super-resolution reconstruction is also one of the future trends.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}