
Fast Hyperspectral Image Classification with Strong Noise Robustness Based on Minimum Noise Fraction


Abstract

1. Introduction
2. Principle of Fast-3DCNN Algorithm
2.1. Basic Principles of Three-Dimensional Convolutional Neural Network (3DCNN)
- (1)
- The input data for a 3D Convolutional Neural Network is three-dimensional and suitable for the rectangular data mode of hyperspectral images.
- (2)
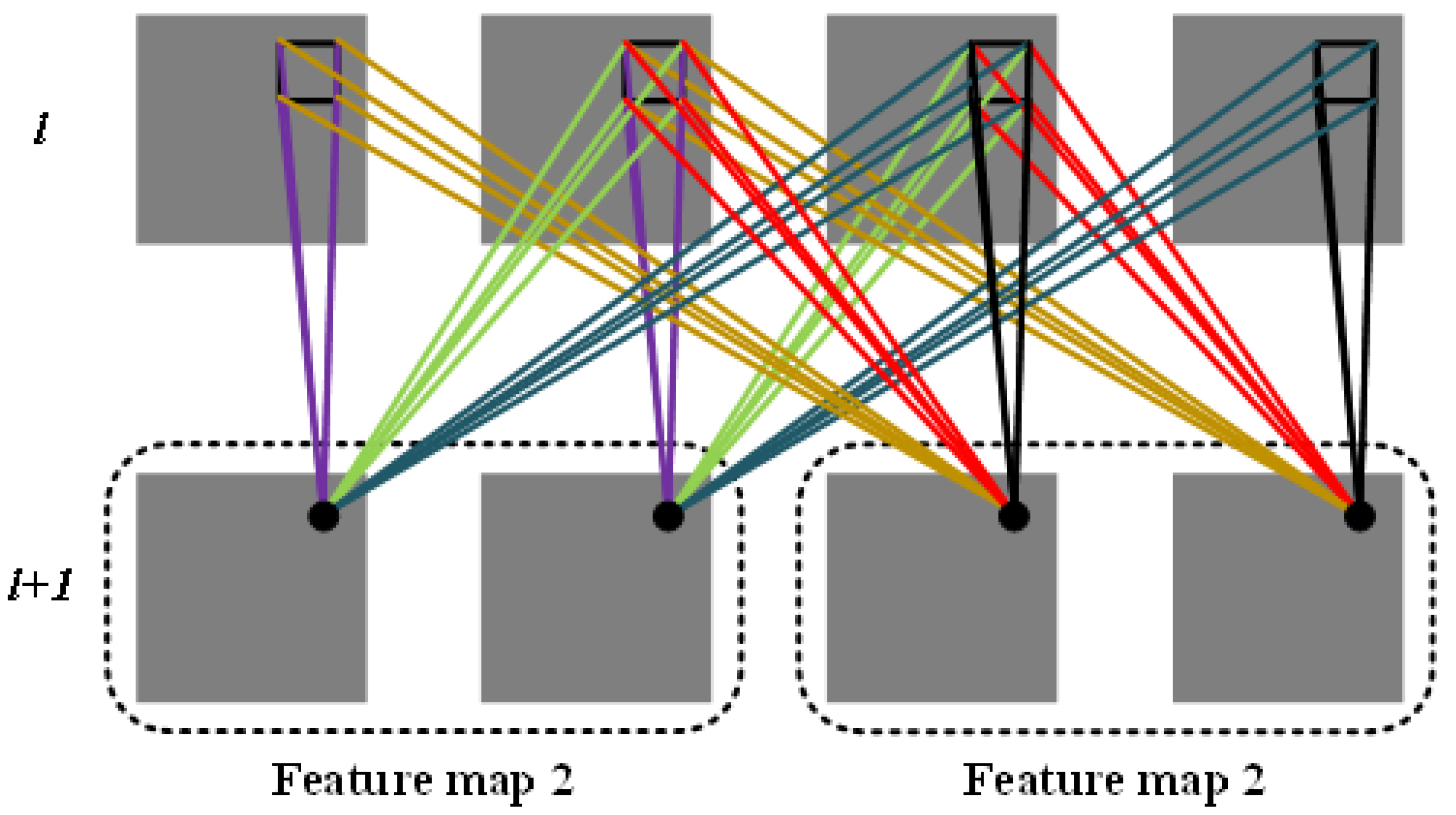
- In 3DCNN, the convolutional kernels are three-dimensional, so the convolution operations are also three-dimensional. As shown in Figure 2, the third dimension of the data in the layer l is four, and there are in total two convolutional kernels, and the third dimension of each convolutional kernel is three. Furthermore, the layer obtains two feature maps with a third dimension of two, and the lines of different colors in the diagram represent different values.
- (3)
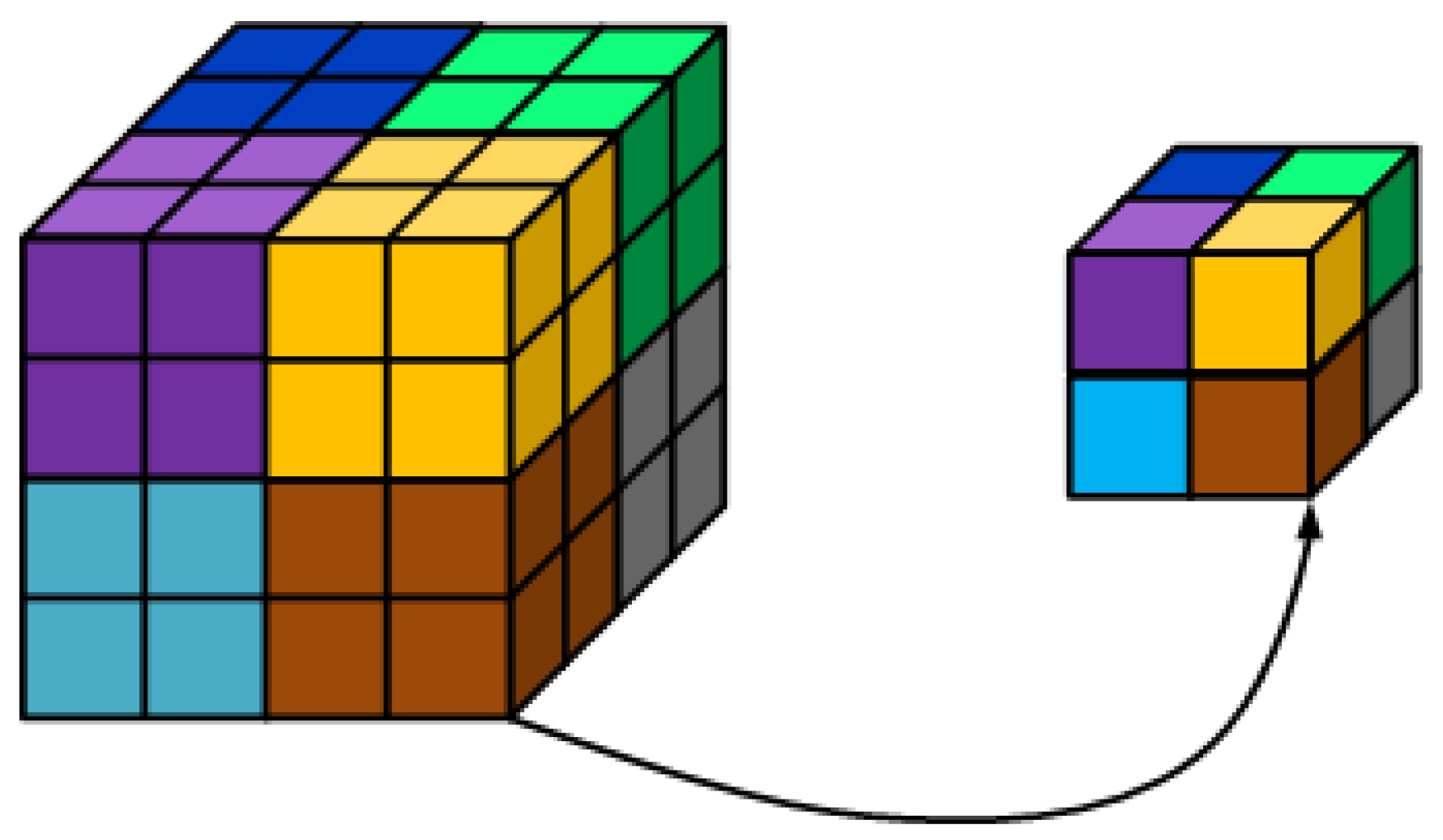
- As shown in Figure 3, the 3D downsampling operation downsamples a cube into a cube, with a sampling interval of .
2.2. Spectral–Space Joint Classification Algorithm Based on 3DCNN
- (1)
- The network structure is too complex and requires too many training parameters. For the Indian Pines dataset, a total of three convolutional layers and three downsampling layers were used in reference [15], and the feature maps of each layer were 128, 192, and 256, respectively. It can be seen that the network is too complex and requires too many training parameters.
- (2)
- Often, too many iterations are required during training, resulting in slow convergence speed of the network. The required iteration number in the network in reference [15] is 400, and the training phase takes approximately 30 min.
- (3)
- Some methods do not take the characteristics of each band in hyperspectral images into account and only use the raw data of hyperspectral images as input to train the network. In reference [15], the 3DCNN is trained using only the raw data directly as the input. However, in hyperspectral data, the similarity between different bands is relatively high, which is often the main reason for the low classification accuracy.
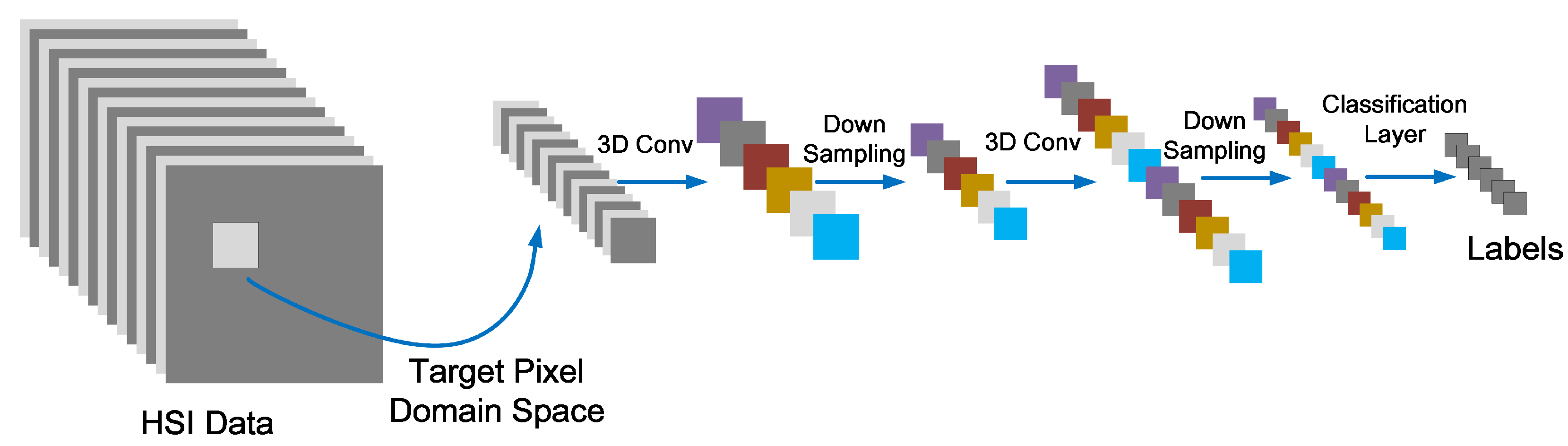
2.3. Principle of Fast-3DCNN
3. MNF-Fast-3DCNN
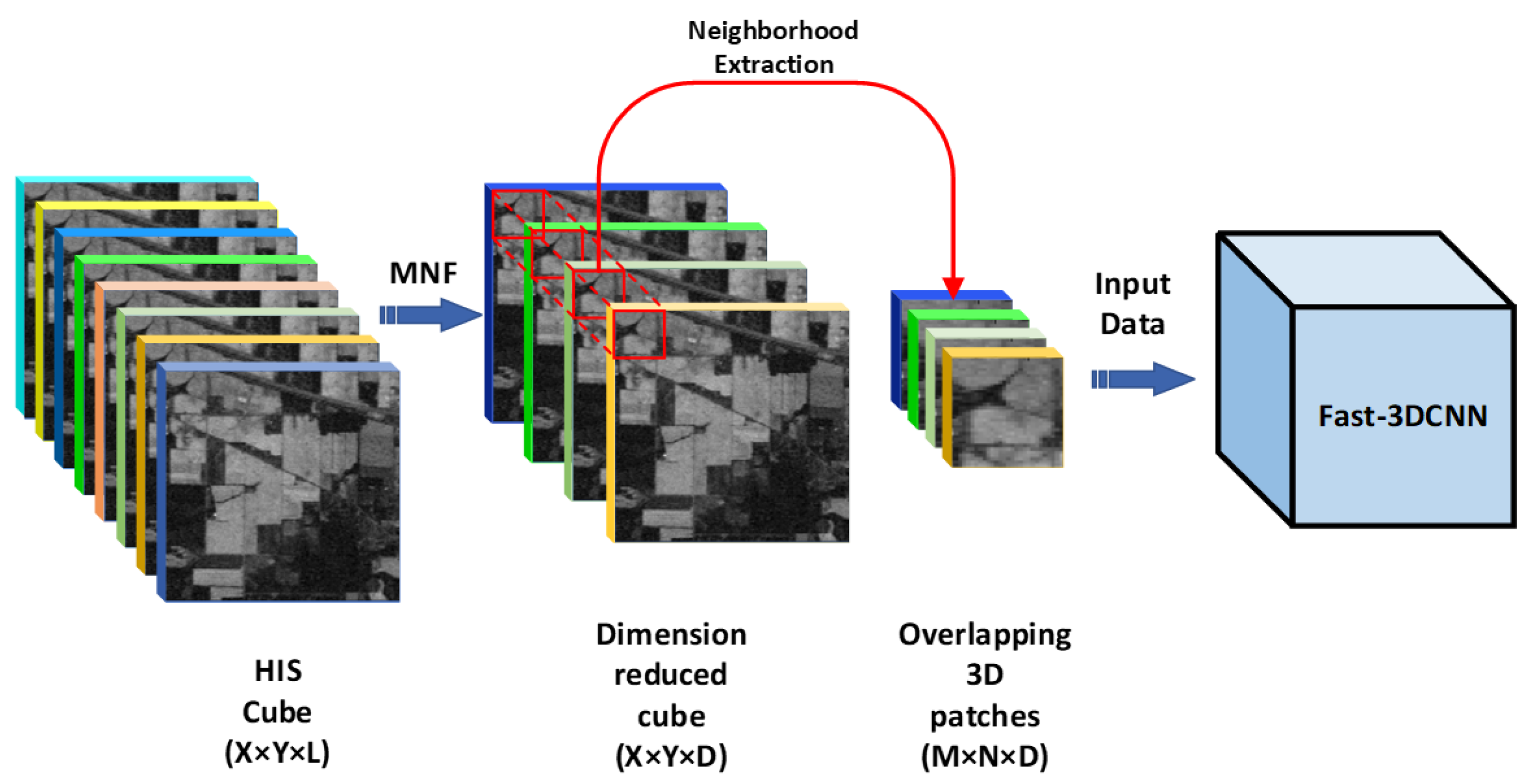
3.1. MNF Transform Processing of Hyperspectral Images with Noise
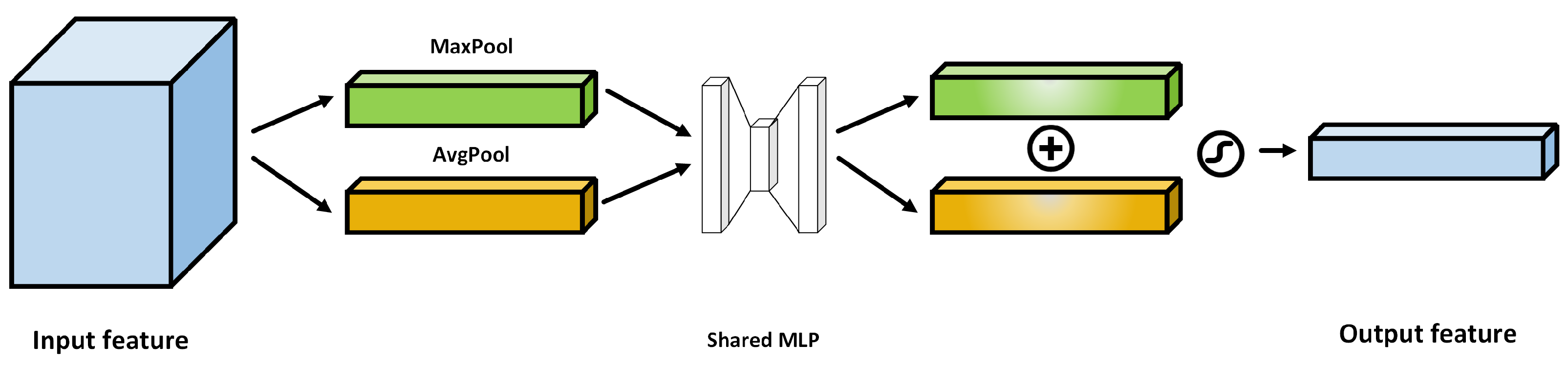
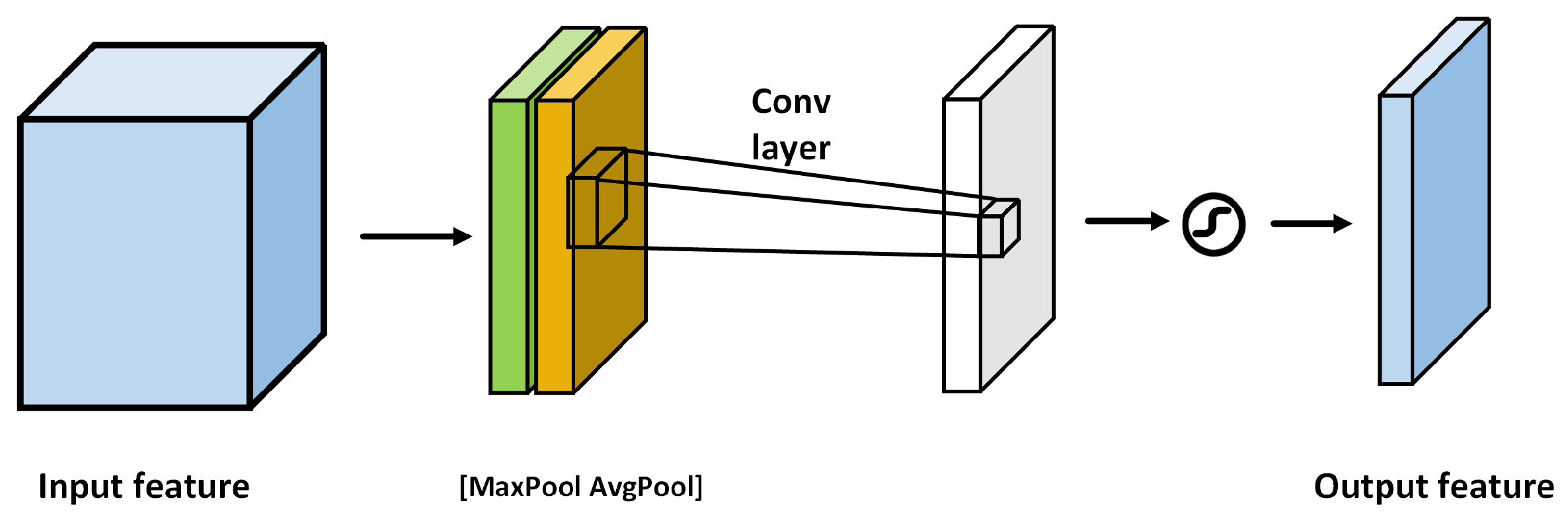
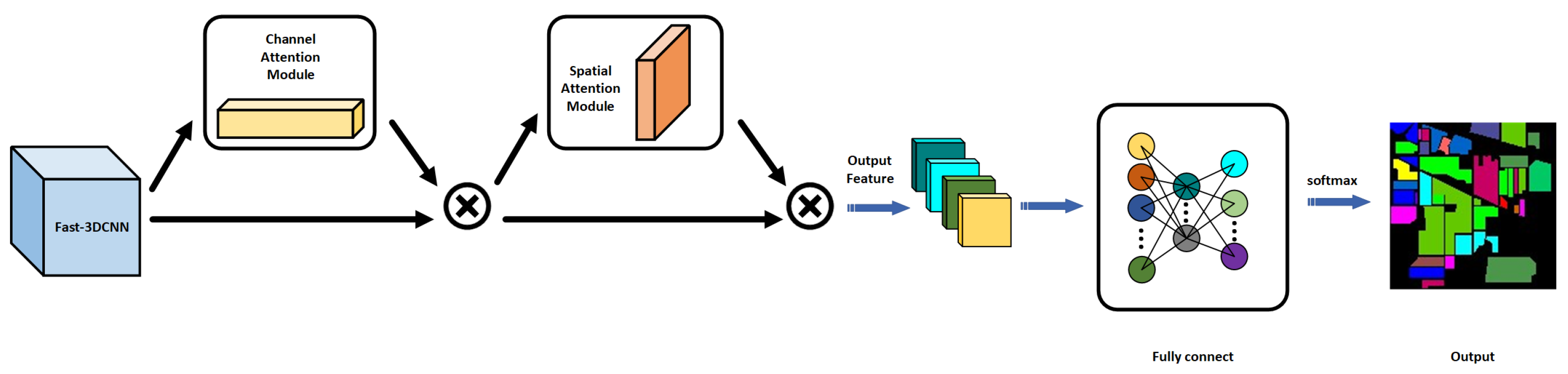
3.2. Fast-3DCNN with Channel–Space Hybrid Attention Module Introduced
3.3. MNF-Fast-3DCNN Network Structure
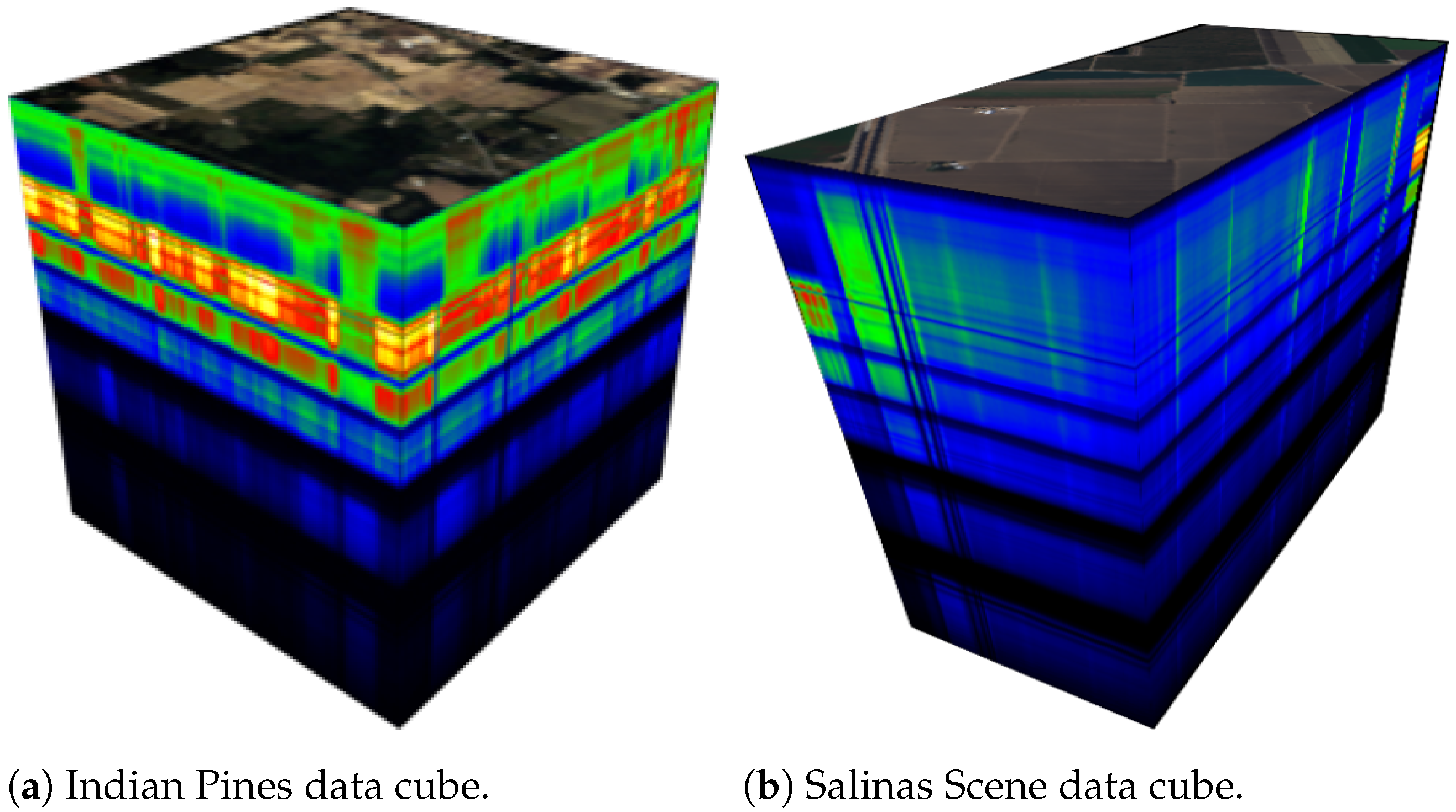
4. Experimental Verification and Results Analysis
- (1)
- GWN ().
- (2)
- GWN ().
- (3)
- GWN ().
- (4)
- GWN () and shot noise.
- (5)
- GWN (), shot noise and salt-and-pepper noise ( = 0.05).
4.1. Noise Robustness Experiments
4.2. Classification Accuracy Experiments
4.3. Algorithms’ Speed Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Available online: https://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 1 January 2024).
- Turner, D.J.; Rivard, B.; Groat, L.A. Visible and short-wave infrared reflectance spectroscopy of selected REE-bearing silicate minerals. Am. Mineral. 2018, 103, 927–943. [Google Scholar] [CrossRef]
- Lechevallier, P.; Villez, K.; Felsheim, C.; Rieckermann, J. Towards non-contact pollution monitoring in sewers with hyperspectral imaging. Environ. Sci. Water Res. Technol. 2024, 10, 1160–1170. [Google Scholar] [CrossRef]
- Awad, M.M. Forest mapping: A comparison between hyperspectral and multispectral images and technologies. J. For. Res. 2018, 29, 1395–1405. [Google Scholar] [CrossRef]
- Yamazaki, F.; Kubo, K.; Tanabe, R.; Liu, W. Damage Assessment And 3d Modeling by UAV Flights after the 2016 Kumamoto, Japan Earthquake. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3182–3185. [Google Scholar]
- Yadav, D.; Arora, M.K.; Tiwari, K.C.; Ghosh, J.K. Detection and Identification of Camouflaged Targets using Hyperspectral and LiDAR data. Def. Sci. J. 2018, 68, 540–546. [Google Scholar] [CrossRef]
- Zhang, Q.; Zheng, Y.; Yuan, Q.; Song, M.; Yu, H.; Xiao, Y. Hyperspectral Image Denoising: From Model-Driven, Data-Driven, to Model-Data-Driven. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 13143–13163. [Google Scholar] [CrossRef] [PubMed]
- Duan, P.; Kang, X.; Li, S.; Ghamisi, P. Noise-Robust Hyperspectral Image Classification via Multi-Scale Total Variation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1948–1962. [Google Scholar] [CrossRef]
- Sha, L.; Zhang, W.; Ma, J.; Li, Z.; Sun, R.; Qin, M. Full-spectrum Spectral Super-Resolution Method Based on LSMM. In Proceedings of the 2022 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2022), Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 2390–2393. [Google Scholar] [CrossRef]
- Chen, G.Y.; Krzyzak, A.; Qian, S.E. Hyperspectral Imagery Denoising Using Minimum Noise Fraction and Video Non-Local Bayes Algorithms. Can. J. Remote Sens. 2022, 48, 694–701. [Google Scholar] [CrossRef]
- Guilfoyle, K.; Althouse, M.; Chang, C.I. A quantitative and comparative analysis of linear and nonlinear spectral mixture models using radial basis function neural networks. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2314–2318. [Google Scholar] [CrossRef]
- Borsoi, R.; Imbiriba, T.; Bermudez, J.C.; Richard, C.; Chanussot, J.; Drumetz, L.; Tourneret, J.Y.; Zare, A.; Jutten, C. Spectral Variability in Hyperspectral Data Unmixing. IEEE Geosci. Remote Sens. Mag. 2021, 9, 223–270. [Google Scholar] [CrossRef]
- Meng, Z.; Li, L.; Jiao, L.; Feng, Z.; Tang, X.; Liang, M. Fully Dense Multiscale Fusion Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 2718. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Islam, M.R.; Islam, M.T.; Uddin, M.P.; Ulhaq, A. Improving Hyperspectral Image Classification with Compact Multi-Branch Deep Learning. Remote Sens. 2024, 16, 2069. [Google Scholar] [CrossRef]
- Zhao, H.; Feng, K.; Wu, Y.; Gong, M. An Efficient Feature Extraction Network for Unsupervised Hyperspectral Change Detection. Remote Sens. 2022, 14, 4646. [Google Scholar] [CrossRef]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Pan, E.; Ma, Y.; Mei, X.; Huang, J.; Fan, F.; Ma, J. D2Net: Deep Denoising Network in Frequency Domain for Hyperspectral Image. IEEE/CAA J. Autom. Sin. 2023, 10, 813–815. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Ahmad, M. A Fast 3D CNN for Hyperspectral Image Classification. arXiv 2020, arXiv:2004.14152. [Google Scholar]
- Green, A.A.; Berman, M.; Switzer, P.; Craig, M. A transformation for ordering multispectral data in terms of image quality with implications for noise removal. IEEE Trans. Geosci. Remote Sens. 1988, 26, 65–74. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Chen, S.; Jin, M.; Ding, J. Hyperspectral remote sensing image classification based on dense residual three-dimensional convolutional neural network. Multimed. Tools Appl. 2021, 80, 1859–1882. [Google Scholar] [CrossRef]
- He, M.; Li, B.; Chen, H. Multi-scale 3D deep convolutional neural network for hyperspectral image classification. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3904–3908. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | No. of Parameters |
|---|---|---|
| Convolutional3D_1 (Conv3D) | (8,9,9,14) | 512 |
| Convolutional3D_2 (Conv3D) | (16,7,7,10) | 5776 |
| Convolutional3D_3 (Conv3D) | (32,5,5,8) | 13,856 |
| Convolutional3D_4 (Conv3D) | (64,3,3,6) | 55,360 |
| Channel attention module | (64,3,3,6) | 1024 |
| Spatial attention module | (64,3,3,6) | 686 |
| Flatten_1 (Flatten) | (3456) | 0 |
| Linear_1 (Linear) | (256) | 884,992 |
| Dropout_1 (Dropout) | (256) | 0 |
| Linear_2 (Linear) | (128) | 32,896 |
| Dropout_2 (Dropout) | (128) | 0 |
| Linear_3 (Linear) | (No. of Classes) | 2064 |
| In total 997,166 trainable parameters are required. | ||
| Different Noises | Index | DR3D-CNN | MS3D-CNN | Fast-3DCNN | MNF-Fast-3DCNN (without CBAM) | MNF-Fast-3DCNN |
|---|---|---|---|---|---|---|
| OA | 0.653 ± 0.035 | 0.765 ± 0.016 | 0.797 ± 0.015 | 0.890 ± 0.018 | 0.900 ± 0.009 | |
| GWN () | AA | 0.408 ± 0.045 | 0.619 ± 0.023 | 0.698 ± 0.021 | 0.818 ± 0.035 | 0.841 ± 0.009 |
| Kappa | 0.588 ± 0.044 | 0.729 ± 0.019 | 0.768 ± 0.017 | 0.874 ± 0.021 | 0.886 ± 0.010 | |
| OA | 0.622 ± 0.020 | 0.732 ± 0.016 | 0.777 ± 0.012 | 0.865 ± 0.009 | 0.876 ± 0.008 | |
| GWN () | AA | 0.384 ± 0.033 | 0.581 ± 0.025 | 0.678 ± 0.024 | 0.797 ± 0.031 | 0.806 ± 0.019 |
| Kappa | 0.549 ± 0.026 | 0.689 ± 0.019 | 0.745 ± 0.013 | 0.846 ± 0.011 | 0.858 ± 0.009 | |
| OA | 0.590 ± 0.019 | 0.682 ± 0.024 | 0.758 ± 0.022 | 0.848 ± 0.012 | 0.852 ± 0.014 | |
| GWN () | AA | 0.339 ± 0.027 | 0.531 ± 0.040 | 0.663 ± 0.029 | 0.780 ± 0.020 | 0.780 ± 0.038 |
| Kappa | 0.509 ± 0.024 | 0.631 ± 0.028 | 0.723 ± 0.026 | 0.826 ± 0.014 | 0.831 ± 0.016 | |
| GWN (), shot noise | OA | 0.678 ± 0.017 | 0.762 ± 0.014 | 0.797 ± 0.012 | 0.888 ± 0.017 | 0.897 ± 0.009 |
| AA | 0.433 ± 0.018 | 0.609 ± 0.019 | 0.690 ± 0.016 | 0.826 ± 0.029 | 0.821 ± 0.018 | |
| Kappa | 0.620 ± 0.022 | 0.725 ± 0.016 | 0.765 ± 0.014 | 0.872 ± 0.019 | 0.882 ± 0.011 | |
| GWN (), shot noise, salt and pepper () | OA | 0.594 ± 0.016 | 0.686 ± 0.009 | 0.782 ± 0.019 | 0.834 ± 0.014 | 0.850 ± 0.009 |
| AA | 0.333 ± 0.023 | 0.533 ± 0.023 | 0.679 ± 0.030 | 0.746 ± 0.023 | 0.751 ± 0.026 | |
| Kappa | 0.514 ± 0.021 | 0.636 ± 0.012 | 0.751 ± 0.021 | 0.810 ± 0.016 | 0.829 ± 0.010 |
| Different Noises | Index | DR3D-CNN | MS3D-CNN | Fast-3DCNN | MNF-Fast-3DCNN (without CBAM) | MNF-Fast-3DCNN |
|---|---|---|---|---|---|---|
| OA | 0.810 ± 0.018 | 0.888 ± 0.015 | 0.861 ± 0.018 | 0.938 ± 0.010 | 0.947 ± 0.009 | |
| GWN () | AA | 0.669 ± 0.034 | 0.875 ± 0.015 | 0.856 ± 0.012 | 0.936 ± 0.016 | 0.940 ± 0.014 |
| Kappa | 0.786 ± 0.021 | 0.875 ± 0.024 | 0.846 ± 0.019 | 0.932 ± 0.011 | 0.941 ± 0.010 | |
| OA | 0.776 ± 0.015 | 0.874 ± 0.013 | 0.855 ± 0.019 | 0.911 ± 0.020 | 0.927 ± 0.012 | |
| GWN () | AA | 0.620 ± 0.022 | 0.864 ± 0.020 | 0.835 ± 0.024 | 0.908 ± 0.022 | 0.919 ± 0.014 |
| Kappa | 0.748 ± 0.017 | 0.859 ± 0.014 | 0.838 ± 0.021 | 0.901 ± 0.022 | 0.919 ± 0.013 | |
| OA | 0.756 ± 0.009 | 0.875 ± 0.004 | 0.843 ± 0.018 | 0.898 ± 0.011 | 0.898 ± 0.010 | |
| GWN () | AA | 0.598 ± 0.018 | 0.863 ± 0.012 | 0.820 ± 0.018 | 0.894 ± 0.014 | 0.901 ± 0.015 |
| Kappa | 0.724 ± 0.011 | 0.861 ± 0.005 | 0.825 ± 0.020 | 0.887 ± 0.012 | 0.886 ± 0.012 | |
| GWN (), shot noise | OA | 0.806 ± 0.014 | 0.890 ± 0.011 | 0.870 ± 0.016 | 0.941 ± 0.006 | 0.950 ± 0.007 |
| AA | 0.662 ± 0.024 | 0.877 ± 0.016 | 0.853 ± 0.027 | 0.933 ± 0.013 | 0.945 ± 0.008 | |
| Kappa | 0.782 ± 0.017 | 0.877 ± 0.012 | 0.855 ± 0.018 | 0.935 ± 0.007 | 0.944 ± 0.008 | |
| GWN (), shot noise, salt and pepper () | OA | 0.701 ± 0.016 | 0.851 ± 0.011 | 0.828 ± 0.023 | 0.860 ± 0.021 | 0.873 ± 0.017 |
| AA | 0.545 ± 0.020 | 0.839 ± 0.023 | 0.812 ± 0.019 | 0.842 ± 0.036 | 0.854 ± 0.029 | |
| Kappa | 0.661 ± 0.019 | 0.833 ± 0.012 | 0.808 ± 0.025 | 0.844 ± 0.024 | 0.858 ± 0.019 |
| Index | Classification Accuracy of Each Algorithm (%) | |||
|---|---|---|---|---|
| DR3D-CNN | MS3D-CNN | Fast-3DCNN | MNF-Fast-3DCNN | |
| OA (5%) | 67.32 | 82.01 | 88.39 | 94.09 |
| AA (5%) | 45.66 | 89.78 | 79.91 | 85.15 |
| Kappa (5%) | 61.52 | 79.30 | 86.75 | 93.27 |
| OA (10%) | 71.27 | 85.53 | 93.30 | 96.77 |
| AA (10%) | 55.04 | 91.02 | 90.93 | 94.75 |
| Kappa (10%) | 66.97 | 83.70 | 92.36 | 96.32 |
| OA (15%) | 79.74 | 89.71 | 96.59 | 98.17 |
| AA (15%) | 61.99 | 91.44 | 93.15 | 95.86 |
| Kappa (15%) | 76.24 | 88.30 | 96.11 | 97.91 |
| Experimental Environment | Hardware Parameters and Software Version |
|---|---|
| OS | Ubuntu-20.04 |
| GPU | NVIDIA GeForce GTX3090 |
| Memory | 128 G |
| Programming language | Python 3.8.19 |
| Deep learning framework | Pytorch 2.3.0 |
| \ | DR3D-CNN | MS3D-CNN | Fast-3DCNN | MNF-Fast-3DCNN |
|---|---|---|---|---|
| IP | 474.14 | 104.65 | 72.07 | 102.33 |
| SA | 407.83 | 89.95 | 63.18 | 87.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Yu, G.; Cheng, J.; Zhang, Z.; Wang, X.; Xu, Y. Fast Hyperspectral Image Classification with Strong Noise Robustness Based on Minimum Noise Fraction. Remote Sens. 2024, 16, 3782. https://doi.org/10.3390/rs16203782
Wang H, Yu G, Cheng J, Zhang Z, Wang X, Xu Y. Fast Hyperspectral Image Classification with Strong Noise Robustness Based on Minimum Noise Fraction. Remote Sensing. 2024; 16(20):3782. https://doi.org/10.3390/rs16203782
Chicago/Turabian StyleWang, Hongqiao, Guoqing Yu, Jinyu Cheng, Zhaoxiang Zhang, Xuan Wang, and Yuelei Xu. 2024. "Fast Hyperspectral Image Classification with Strong Noise Robustness Based on Minimum Noise Fraction" Remote Sensing 16, no. 20: 3782. https://doi.org/10.3390/rs16203782
APA StyleWang, H., Yu, G., Cheng, J., Zhang, Z., Wang, X., & Xu, Y. (2024). Fast Hyperspectral Image Classification with Strong Noise Robustness Based on Minimum Noise Fraction. Remote Sensing, 16(20), 3782. https://doi.org/10.3390/rs16203782