

Deep Ensemble Remote Sensing Scene Classification via Category Distribution Association


Abstract

1. Introduction
- •
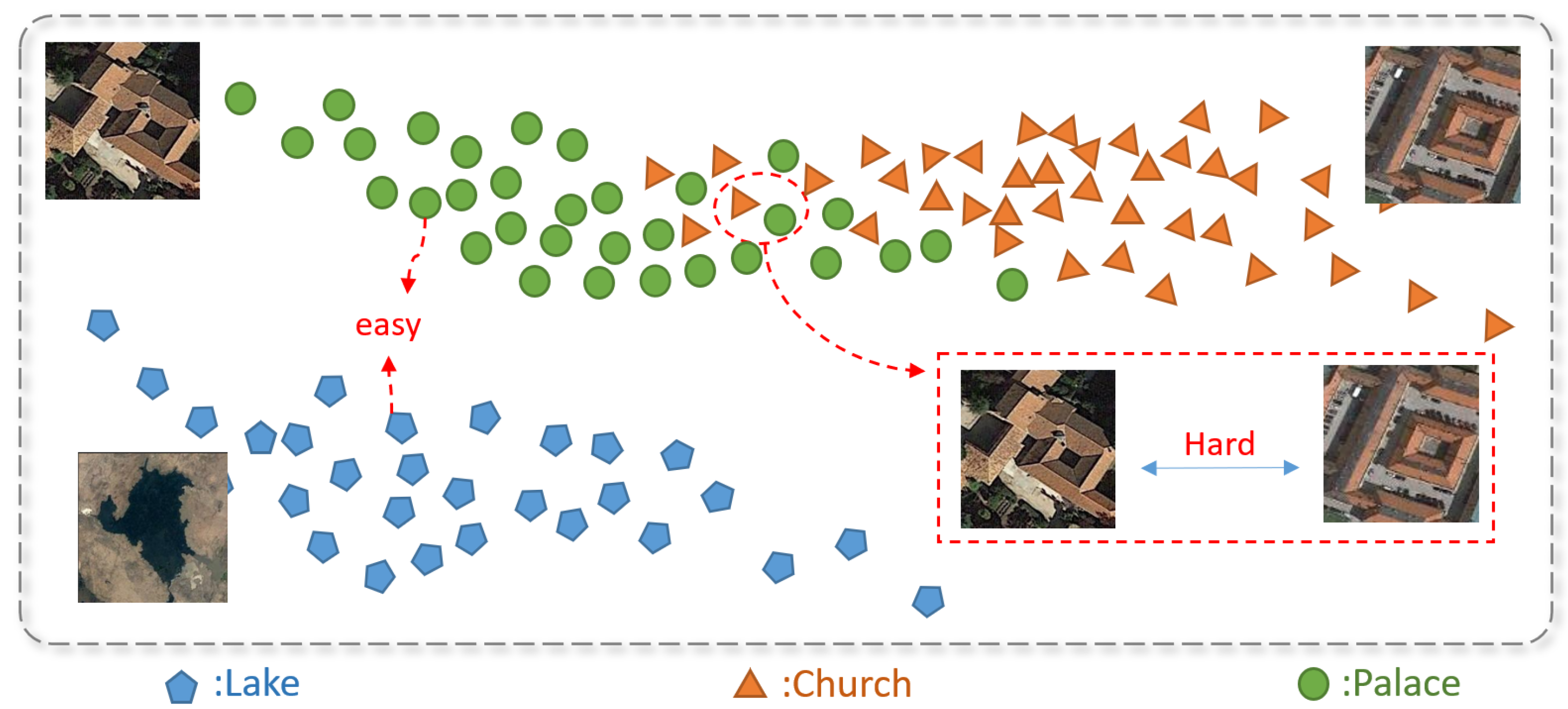
- In the category distribution information extraction module, we assume that the instance distributions between the scene categories follow Gaussian distributions. By leveraging the KL divergence, we ensure that the severity of misclassification from one category to another is different from the severity in the reverse direction. This ensures that the algorithm can capture the asymmetric fitting between different category distributions, thereby enabling more accurate classification decisions.
- •
- In the scene classification module, in the base layer of stacking, we aggregate the soft label outputs from multiple CNN models, allowing the model to effectively capture a broader range of information. In the meta layer of stacking, we propose a novel boosting approach. By introducing similarity among different scene distributions to adjust the instance weights, our algorithm pays more attention to difficult-to-separate category pairs.
- •
- Through exhaustive experimentation on remote sensing scene benchmarks, our proposed model demonstrates an enhancement in classification performance compared with previous methods. The effectiveness of the model components and theories was demonstrated through ablation experiments and parameter sensitivity experiments.
2. Related Studies
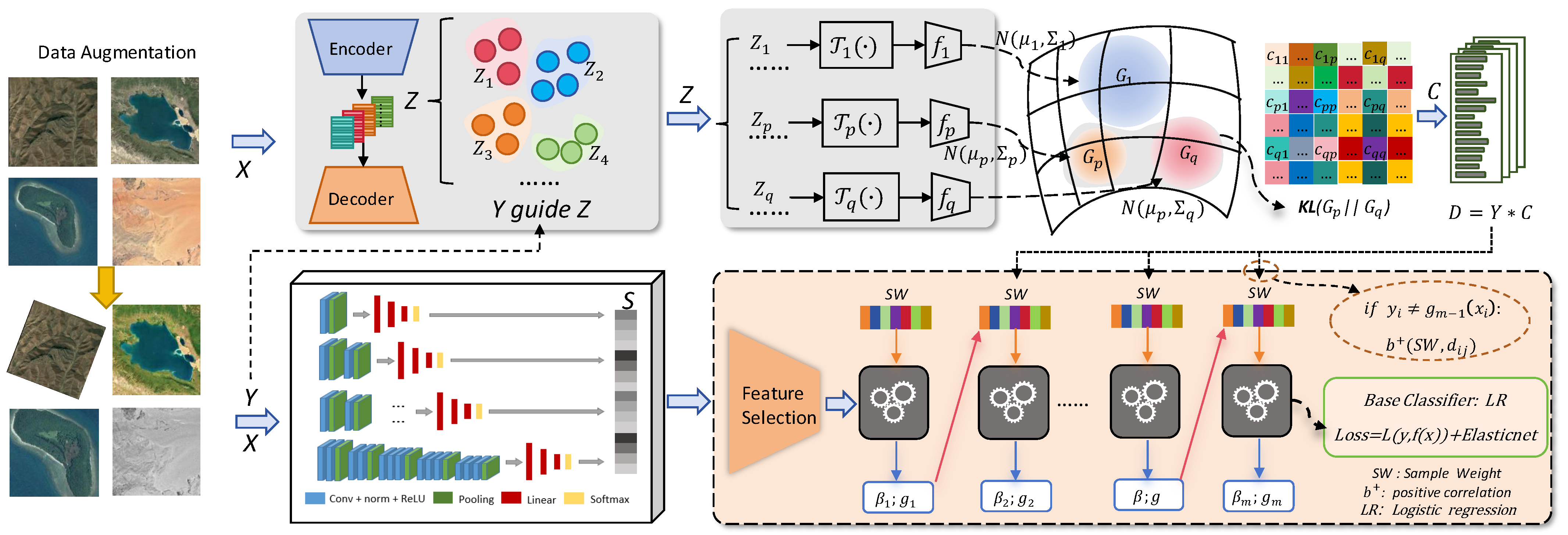
3. Proposed Method
3.1. Category Distribution Information Extraction Module
3.2. Scene Classification Module
3.2.1. The Base Layer
3.2.2. The Meta Layer
| Algorithm 1 LSAMME algorithm. |
Input: X: The generated meta-feature set; Y: sample label; C: result of extracting category distribution information; Output: ; 1. Initialize: ; 2. Optimization process: ; for to M do (a) Fit a classifier
to the training data using weights (b) The gradient descent method is used to calculate . . (c) Set , for . (d) Renormalize . end for 3. Output: |
4. Experiments
4.1. Dataset Description
4.2. Evaluation Metrics
4.2.1. Overall Accuracy
4.2.2. Average Accuracy
4.2.3. Kappa Coefficient
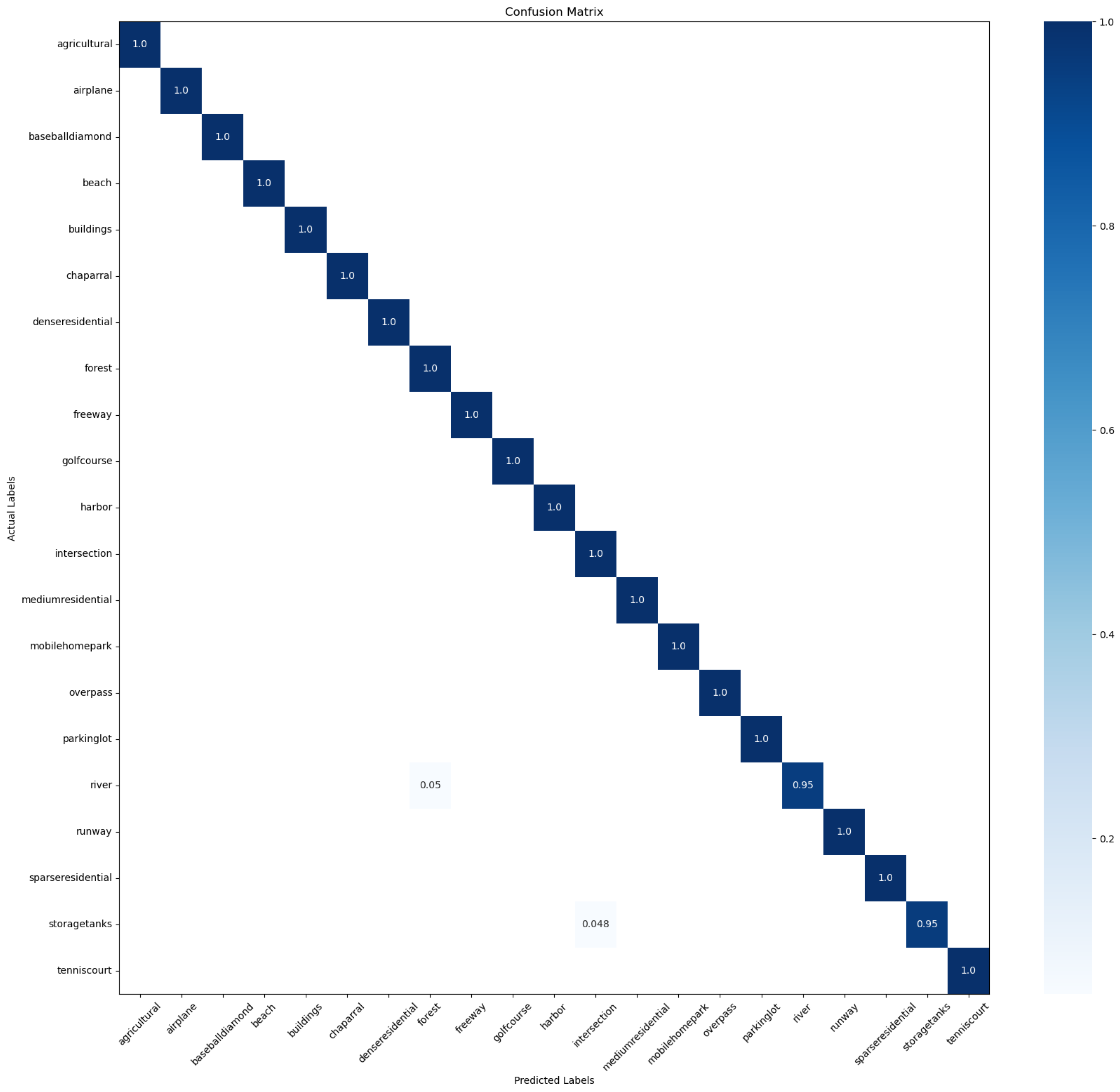
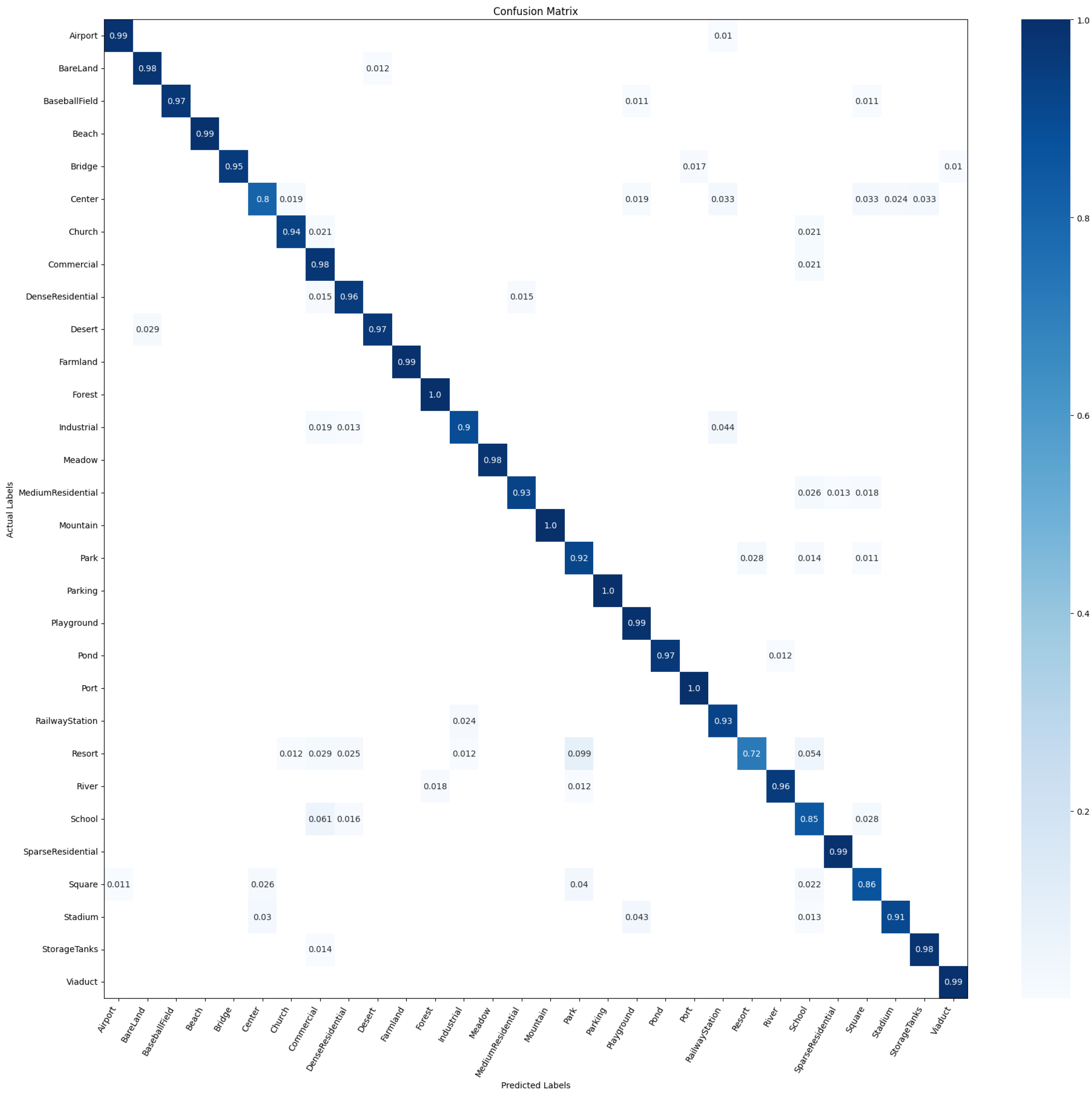
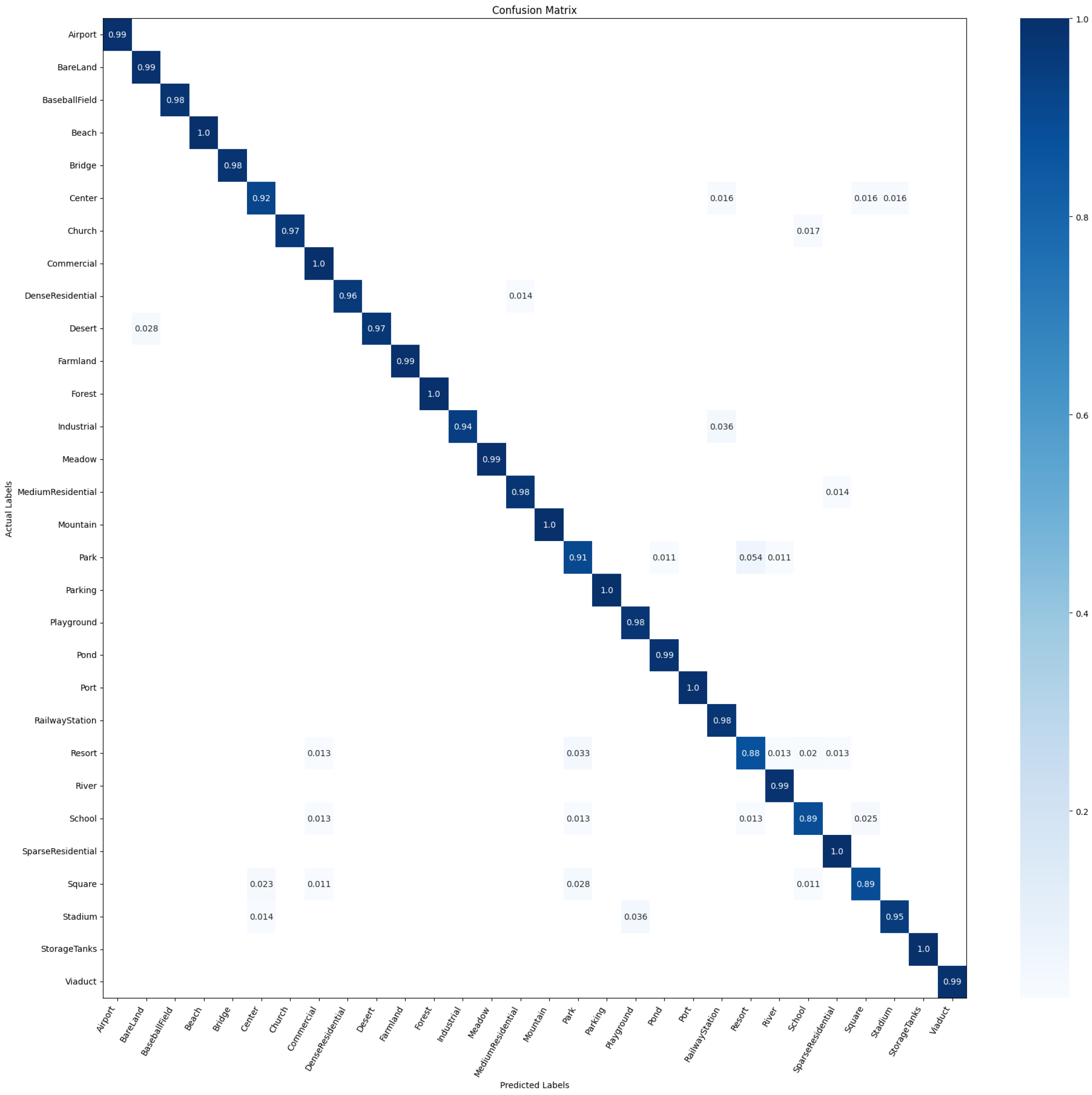
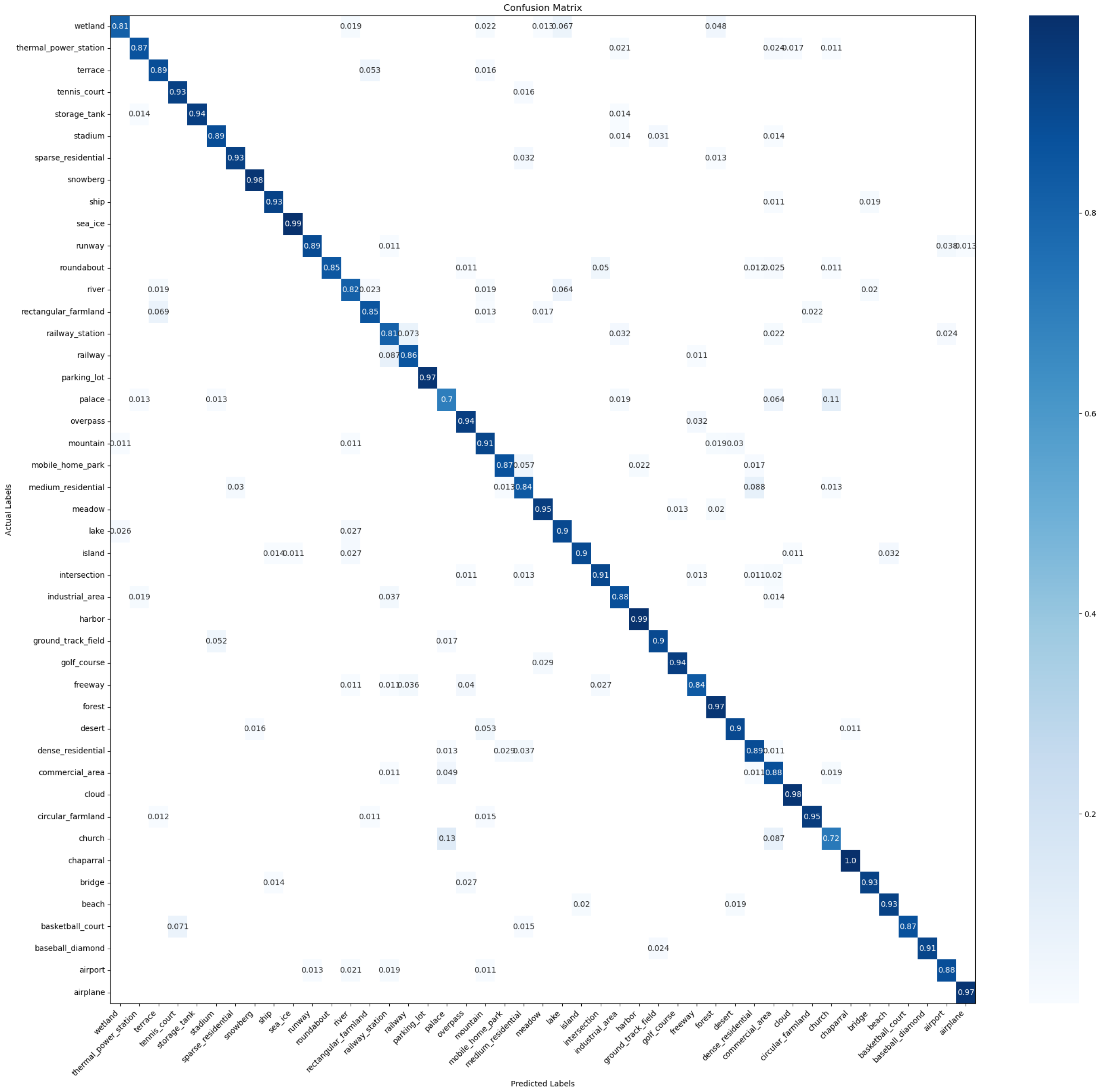
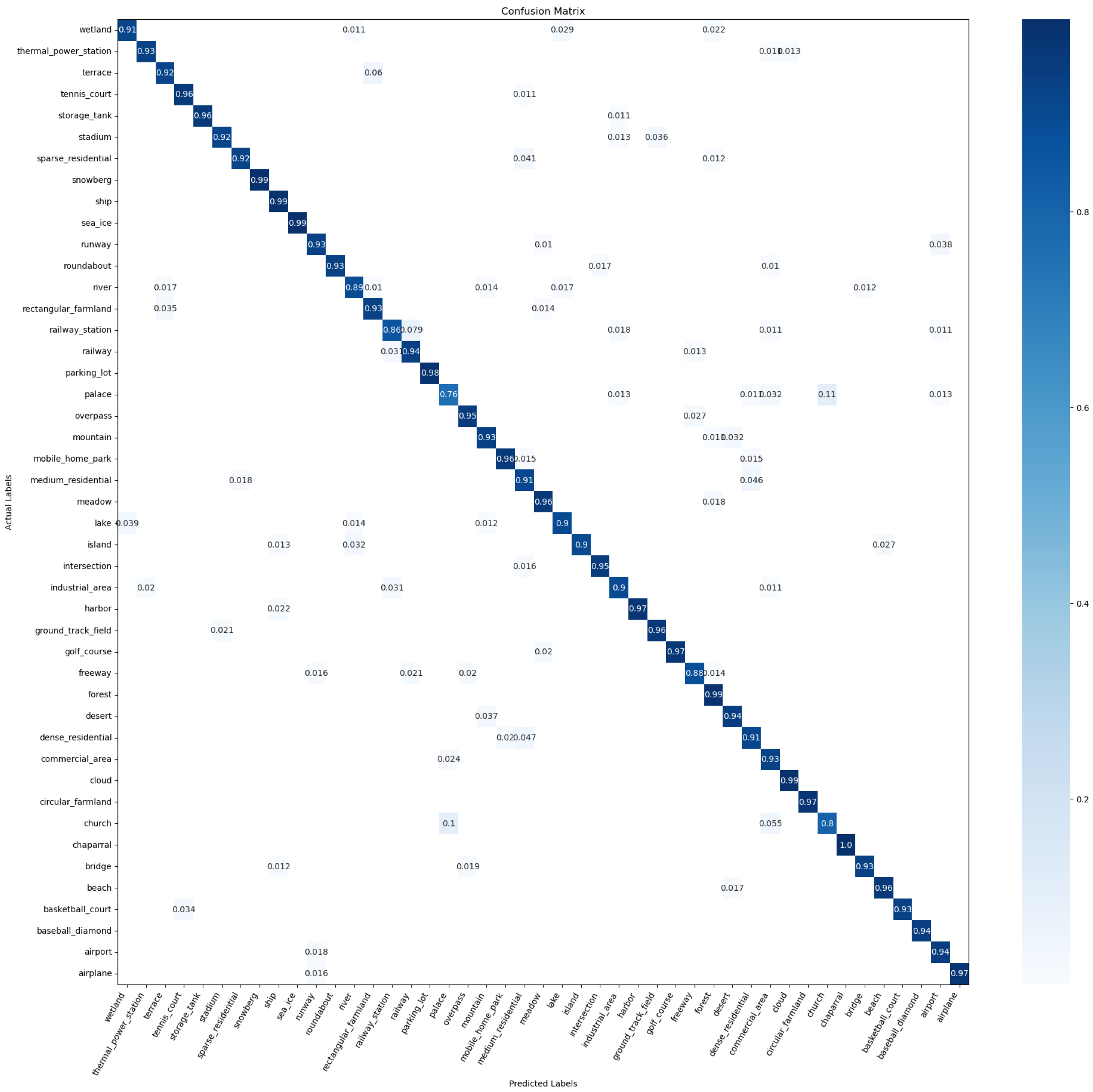
4.2.4. Confusion Matrix
4.3. Experiment Settings
4.3.1. Dataset Settings
4.3.2. Structural Parameter Settings
4.3.3. Training Settings
4.4. Results and Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Method | Publication Year | (OA) Training Ratio 80% (20% Testing) |
|---|---|---|---|
| † | BOVW(LBP) [12] | TGRS2017 | 77.12 ± 1.93 |
| BOVW(SIFT) [12] | TGRS2017 | 74.12 ± 3.30 | |
| LBP-CLM [47] | JSTARS2017 | 95.75 ± 0.80 | |
| salCLM(eSIFT) [47] | JSTARS2017 | 94.52 ± 0.79 | |
| ‡ | Two-Fusion [1] | CIN2018 | 98.02 ± 1.03 |
| CCPNet [2] | RS2018 | 97.52 ± 0.97 | |
| GCFs+LOFs [3] | RS2018 | 99.00 ± 0.35 | |
| CNN-CapsNet [4] | RS2019 | 99.05 ± 0.24 | |
| sCCov [5] | TNNLS2019 | 99.05 ± 0.25 | |
| ARCNet-VGG [6] | TGRS2019 | 99.12 ± 0.40 | |
| GBNet [48] | TGRS2020 | 98.57 ± 0.48 | |
| MGCAP [45] | TIP2020 | 99.00 ± 0.10 | |
| BiMobileNet [49] | Sensors2020 | 99.03 ± 0.28 | |
| SEMSDNet [46] | JSTARS2021 | 99.41 ± 0.41 | |
| T-CNN [10] | TGRS2022 | 99.33 ± 0.11 | |
| DFAGCN [9] | TNNLS2022 | 98.48 ± 0.42 | |
| OA: 99.47 ± 0.11 | |||
| ours | Stacking-LSAMME | AA: 99.47 ± 0.11 | |
| KC: 99.40 ± 0.12 |
| Type | Method | Publication Year | (OA) Training Ratio | |
|---|---|---|---|---|
| 20% (80% Testing) | 50% (50% Testing) | |||
| † | BOVW(LBP) [12] | TGRS2017 | 56.73 ± 0.54 | 64.25 ± 0.55 |
| BOVW(SIFT) [12] | TGRS2017 | 61.40 ± 0.41 | 67.65 ± 0.49 | |
| LBP-CLM [47] | JSTARS2017 | 86.92 ± 0.35 | 89.76 ± 0.45 | |
| salCLM(eSIFT) [47] | JSTARS2017 | 85.58 ± 0.83 | 88.41 ± 0.63 | |
| ‡ | VGG-VD-16 [12] | RPOC2017 | 86.59 ± 0.29 | 89.64 ± 0.36 |
| Two-Fusion [1] | CIN2018 | 92.32 ± 0.41 | 94.58 ± 0.25 | |
| GCFs+LoFs [3] | RS2018 | 92.48 ± 0.38 | 96.85 ± 0.23 | |
| CNN-CapsNet [4] | RS2019 | 93.79 ± 0.13 | 96.32 ± 0.12 | |
| SCCov [5] | TNNLS2019 | 93.12 ± 0.25 | 96.10 ± 0.16 | |
| ARCNet-VGG [6] | TGRS2019 | 88.75 ± 0.40 | 93.10 ± 0.55 | |
| GBNet [48] | TGRS2020 | 92.20 ± 0.23 | 95.48 ± 0.12 | |
| MG-CAP [45] | TIP2019 | 93.34 ± 0.18 | 96.12 ± 0.12 | |
| CSDS [44] | JSTARS2021 | 94.29 ± 0.35 | 96.70 ± 0.14 | |
| PSGAN [43] | TGRS2022 | 89.47± 0.34 | 92.67 ± 0.55 | |
| T-CNN [10] | TGRS2022 | 94.55 ± 0.27 | 96.27 ± 0.23 | |
| OA: 94.92 ± 0.27 | OA: 97.16 ± 0.17 | |||
| ours | Stacking-LSAMME | AA: 94.62 ± 0.31 | AA: 97.05 ± 0.20 | |
| KC: 94.74 ± 0.34 | KC: 97.06 ± 0.23 | |||
| Type | Method | Publication Year | (OA) Train Ratios | |
|---|---|---|---|---|
| 10% (90% Testing) | 20% (80% Testing) | |||
| † | BOVW [24] | RPOC2017 | 41.72 ± 0.21 | 44.79 ± 0.28 |
| BOVW+SPM [24] | RPOC2017 | 27.83 ± 0.61 | 32.96 ± 0.47 | |
| LLC [24] | RPOC2017 | 38.81 ± 0.23 | 40.03 ± 0.34 | |
| ‡ | Fine-tuned VGG-16 [24] | RPOC2017 | 87.15 ± 0.45 | 90.36 ± 0.18 |
| Two-Fusion [1] | CIN2018 | 80.22 ± 0.22 | 83.16 ± 0.18 | |
| D-CNN [50] | TGRS2018 | 89.22 ± 0.50 | 91.89 ± 0.22 | |
| Inception-v3-CapsNet [4] | RS2019 | 89.03 ± 0.21 | 92.60 ± 0.11 | |
| CNN-CapsNet [4] | RS2019 | 89.03 ± 0.21 | 92.60 ± 0.11 | |
| SCCov [5] | TNNLS2019 | 89.30 ± 0.35 | 92.10 ± 0.25 | |
| SF-CNN [51] | TGRS2019 | 89.89 ± 0.16 | 92.55 ± 0.14 | |
| RAN [52] | TGRS2019 | 88.79 ± 0.53 | 91.40 ± 0.30 | |
| GLANet [37] | Access2019 | 89.50 ± 0.26 | 91.50 ± 0.17 | |
| PSGAN [43] | TGRS2022 | 84.72 ± 0.72 | 88.47 ± 0.56 | |
| T-CNN [10] | TGRS2022 | 90.25 ± 0.11 | 93.05 ± 0.12 | |
| OA: 90.45 ± 0.15 | OA: 93.47 ± 0.12 | |||
| ours | Stacking-LSAMME | AA: 90.45 ± 0.15 | AA: 93.47 ± 0.12 | |
| KC: 90.11 ± 0.16 | KC: 93.26 ± 0.14 | |||
4.5. Ablation Experiment
4.6. Confusion Matrix
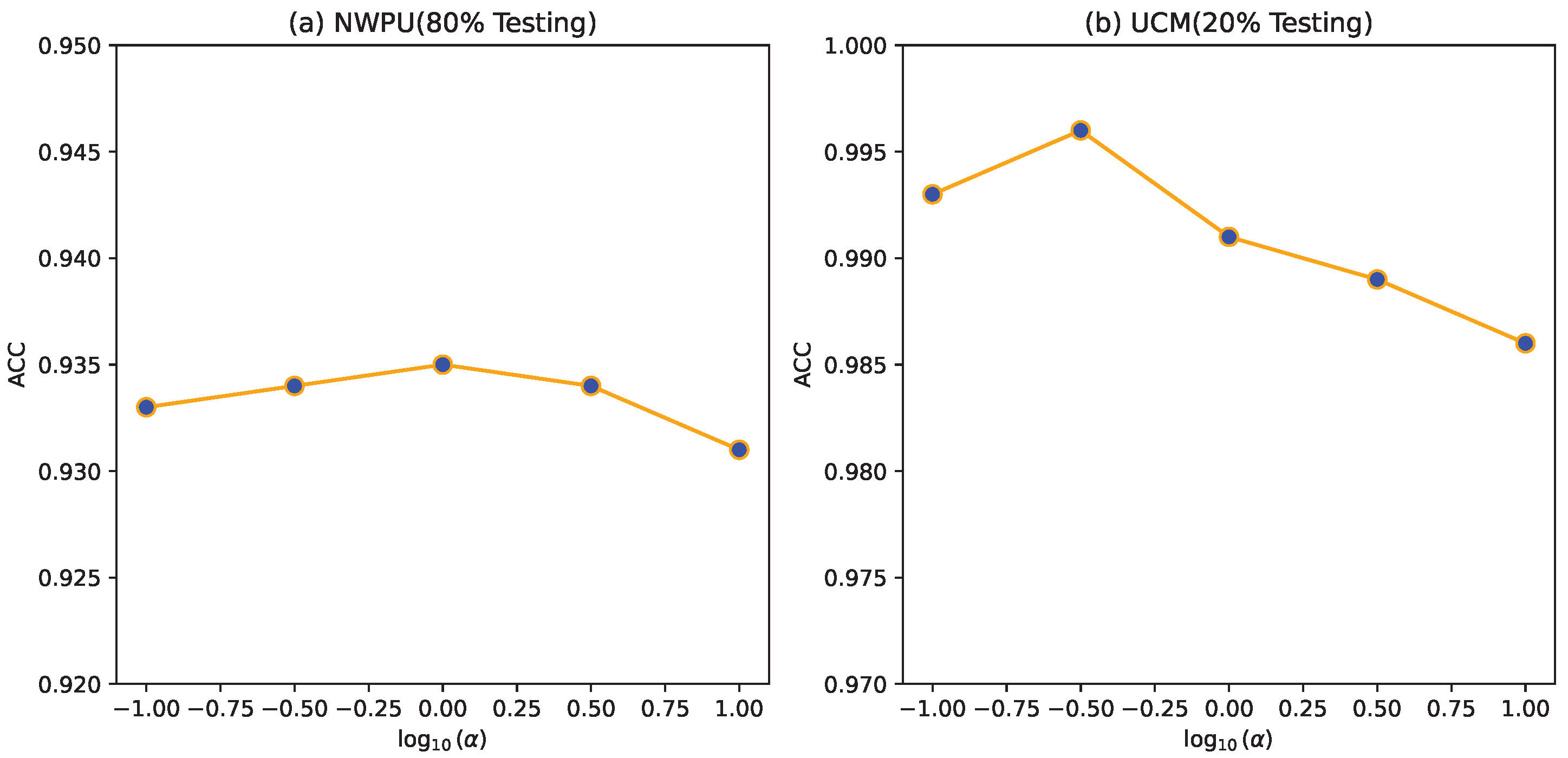
4.7. Parameter Sensitivity Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, Y.; Liu, F. A Two-Stream Deep Fusion Framework for High-Resolution Aerial Scene Classification. Comput. Intell. Neurosci. 2018, 18, 13. [Google Scholar] [CrossRef] [PubMed]
- Qi, K.; Guan, Q.; Yang, C.; Peng, F.; Shen, S.; Wu, H. Concentric Circle Pooling in Deep Convolutional Networks for Remote Sensing Scene Classification. Remote Sens. 2018, 10, 934. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-Connected Covariance Network for Remote Sensing Scene Classification. IEEE Trans. Neural Networks Learn. Syst. 2020, 31, 1461–1474. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene Classification With Recurrent Attention of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Hao, Z.; Lu, Z.; Li, G.; Nie, F.; Wang, R.; Li, X. Ensemble clustering with attentional representation. IEEE Trans. Knowl. Data Eng. 2024, 36, 581–593. [Google Scholar] [CrossRef]
- Hao, Z.; Lu, Z.; Nie, F.; Wang, R.; Li, X. Multi-view k-means with laplacian embedding. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Xu, K.; Huang, H.; Deng, P.; Li, Y. Deep Feature Aggregation Framework Driven by Graph Convolutional Network for Scene Classification in Remote Sensing. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 5751–5765. [Google Scholar] [CrossRef]
- Wang, W.; Chen, Y.; Ghamisi, P. Transferring CNN With Adaptive Learning for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Wang, J.; Li, W.; Zhang, M.; Tao, R.; Chanussot, J. Remote sensing scene classification via multi-stage self-guided separation network. IEEE Trans. Geosci. Remote. Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Hao, Z.; Xin, H.; Wei, L.; Tang, L.; Wang, R.; Nie, F. Towards Expansive and Adaptive Hard Negative Mining: Graph Contrastive Learning via Subspace Preserving. In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; pp. 322–333. [Google Scholar]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2018, 14, 241–258. [Google Scholar] [CrossRef]
- Sun, G.; Cholakkal, H.; Khan, S.; Khan, F.; Shao, L. Fine-grained recognition: Accounting for subtle differences between similar classes. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2020; Volume 34, pp. 12047–12054. [Google Scholar]
- Nie, F.; Hao, Z.; Wang, R. Multi-class support vector machine with maximizing minimum margin. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–28 February 2024; Volume 38, pp. 14466–14473. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, 12–49. [Google Scholar] [CrossRef]
- Ma, L.; Sheng, Z.; Li, X.; Gao, X.; Hao, Z.; Yang, L.; Zhang, W.; Cui, B. Acceleration algorithms in gnns: A survey. arXiv 2024, arXiv:2405.04114. [Google Scholar]
- Freund, Y.; Schapire, R.; Abe, N. A short introduction to boosting. J.-Jpn. Soc. Artif. Intell. 1999, 14, 1612. [Google Scholar]
- Cao, D.; Xing, H.; Wong, M.S.; Kwan, M.P.; Xing, H.; Meng, Y. A Stacking Ensemble Deep Learning Model for Building Extraction from Remote Sensing Images. Remote Sens. 2021, 13, 3898. [Google Scholar] [CrossRef]
- Xin, H.; Hao, Z.; Sun, Z.; Wang, R.; Miao, Z.; Nie, F. Multi-view and Multi-order Graph Clustering via Constrained l1, 2-norm. Inf. Fusion 2024, 111, 102483. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, H.; Wang, C.; Zhou, X. Wind power forecasting based on stacking ensemble model, decomposition and intelligent optimization algorithm. Neurocomputing 2021, 462, 169–184. [Google Scholar] [CrossRef]
- Sun, R.; Wang, Y.; Zhang, Z.; Hong, R.; Wang, M. Deep adversarial inconsistent cognitive sampling for multiview progressive subspace clustering. IEEE Trans. Neural Netw. Learn. Syst. 2021. Available online: https://api.semanticscholar.org/CorpusID:231572752 (accessed on 26 October 2024). [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Wu, J.; Cui, Z.; Sheng, V.S.; Zhao, P.; Su, D.; Gong, S. A Comparative Study of SIFT and its Variants. Meas. Sci. Rev. 2013, 13, 122–131. [Google Scholar] [CrossRef]
- Pang, Y.; Yuan, Y.; Li, X.; Pan, J. Efficient HOG human detection. Signal Process. 2011, 91, 773–781. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chatzimparmpas, A.; Martins, R.M.; Kucher, K.; Kerren, A. StackGenVis: Alignment of Data, Algorithms, and Models for Stacking Ensemble Learning Using Performance Metrics. IEEE Trans. Vis. Comput. Graph. 2021, 27, 1547–1557. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Zhu, J.; Zou, H.; Rosset, S.; Hastie, T. Mult-class Adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar]
- Dai, X.; Wu, X.; Wang, B.; Zhang, L. Semisupervised scene classification for remote sensing images: A method based on convolutional neural networks and ensemble learning. IEEE Geosci. Remote Sens. Lett. 2019, 16, 869–873. [Google Scholar] [CrossRef]
- Zhao, Q.; Lyu, S.; Li, Y.; Ma, Y.; Chen, L. MGML: Multigranularity multilevel feature ensemble network for remote sensing scene classification. IEEE Trans. Neural Networks Learn. Syst. 2021, 34, 2308–2322. [Google Scholar] [CrossRef]
- Li, J.; Gong, M.; Liu, H.; Zhang, Y.; Zhang, M.; Wu, Y. Multiform ensemble self-supervised learning for few-shot remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Hui, L.; Li, X.; Gong, C.; Fang, M.; Zhou, J.T.; Yang, J. Inter-class angular loss for convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3894–3901. [Google Scholar]
- Feng, L.; Wang, H.; Jin, B.; Li, H.; Xue, M.; Wang, L. Learning a distance metric by balancing kl-divergence for imbalanced datasets. IEEE Trans. Syst. Man, Cybern. Syst. 2018, 49, 2384–2395. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-Local Attention Network for Aerial Scene Classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- Yarotsky, D. Error bounds for approximations with deep ReLU networks. Neural Netw. 2017, 94, 103–114. [Google Scholar] [CrossRef] [PubMed]
- Xia, Y.; Chen, K.; Yang, Y. Multi-label classification with weighted classifier selection and stacked ensemble. Inf. Sci. 2021, 557, 421–442. [Google Scholar] [CrossRef]
- Riccardi, A.; Fernández-Navarro, F.; Carloni, S. Cost-sensitive AdaBoost algorithm for ordinal regression based on extreme learning machine. IEEE Trans. Cybern. 2014, 44, 1898–1909. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Cheng, G.; Sun, X.; Li, K.; Guo, L.; Han, J. Perturbation-Seeking Generative Adversarial Networks: A Defense Framework for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, R.; Qi, J.; Tao, C. Cross-Sensor remote sensing Images Scene Understanding Based on Transfer Learning Between Heterogeneous Networks. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, S.; Guan, Y.; Shao, L. Multi-Granularity Canonical Appearance Pooling for Remote Sensing Scene Classification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef]
- Tian, T.; Li, L.; Chen, W.; Zhou, H. SEMSDNet: A Multiscale Dense Network With Attention for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5501–5514. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing Local and Global Features for High-Resolution Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote Sensing Scene Classification by Gated Bidirectional Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Yu, D.; Xu, Q.; Guo, H.; Zhao, C.; Lin, Y.; Li, D. An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification. Sensors 2020, 20, 1999. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-Free Convolutional Neural Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Fan, R.; Wang, L.; Feng, R.; Zhu, Y. Attention based Residual Network for High-Resolution Remote Sensing Imagery Scene Classification. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1346–1349. [Google Scholar] [CrossRef]
- Scholkopf, B. Making large scale SVM learning practical. In Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999; pp. 41–56. [Google Scholar]



| Dataset | Instances | Features | Classes | Resolution |
|---|---|---|---|---|
| UCM dataset | 2100 | 256 × 256 | 21 | 0.3 m |
| AID dataset | 10,000 | 600 × 600 | 30 | 0.5–8 m |
| NWPU-RESISC452 | 31,500 | 256 × 256 | 45 | 0.2–30 m |
| Stacking CNN | Feature Selection | SVM | GBDT | SAMME | LSAMME | NWPU (10%) | NWPU (20%) | UCM (80%) |
|---|---|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | 88.34± 0.26 | 92.98± 0.19 | 97.76 ± 0.23 | |||
| ✓ | ✓ | ✓ | 89.07± 0.21 | 92.95± 0.21 | 97.98 ± 0.18 | |||
| ✓ | ✓ | 88.67± 0.21 | 92.65± 0.16 | 98.21 ± 0.12 | ||||
| ✓ | ✓ | 89.26± 0.17 | 93.07± 0.11 | 98.88 ± 0.14 | ||||
| ✓ | ✓ | ✓ | 89.67± 0.14 | 93.30± 0.12 | 99.21 ± 0.12 | |||
| ✓ | ✓ | ✓ | 90.45 ± 0.15 | 93.47± 0.12 | 99.47 ± 0.11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Li, G.; Wang, Z.; He, G.; Yan, H.; Wang, R. Deep Ensemble Remote Sensing Scene Classification via Category Distribution Association. Remote Sens. 2024, 16, 4084. https://doi.org/10.3390/rs16214084
He Z, Li G, Wang Z, He G, Yan H, Wang R. Deep Ensemble Remote Sensing Scene Classification via Category Distribution Association. Remote Sensing. 2024; 16(21):4084. https://doi.org/10.3390/rs16214084
Chicago/Turabian StyleHe, Zhenxin, Guoxu Li, Zheng Wang, Guanxiong He, Hao Yan, and Rong Wang. 2024. "Deep Ensemble Remote Sensing Scene Classification via Category Distribution Association" Remote Sensing 16, no. 21: 4084. https://doi.org/10.3390/rs16214084
APA StyleHe, Z., Li, G., Wang, Z., He, G., Yan, H., & Wang, R. (2024). Deep Ensemble Remote Sensing Scene Classification via Category Distribution Association. Remote Sensing, 16(21), 4084. https://doi.org/10.3390/rs16214084