
SA-Pmnet: Utilizing Close-Range Photogrammetry Combined with Image Enhancement and Self-Attention Mechanisms for 3D Reconstruction of Forests

 and
and
Abstract
1. Introduction
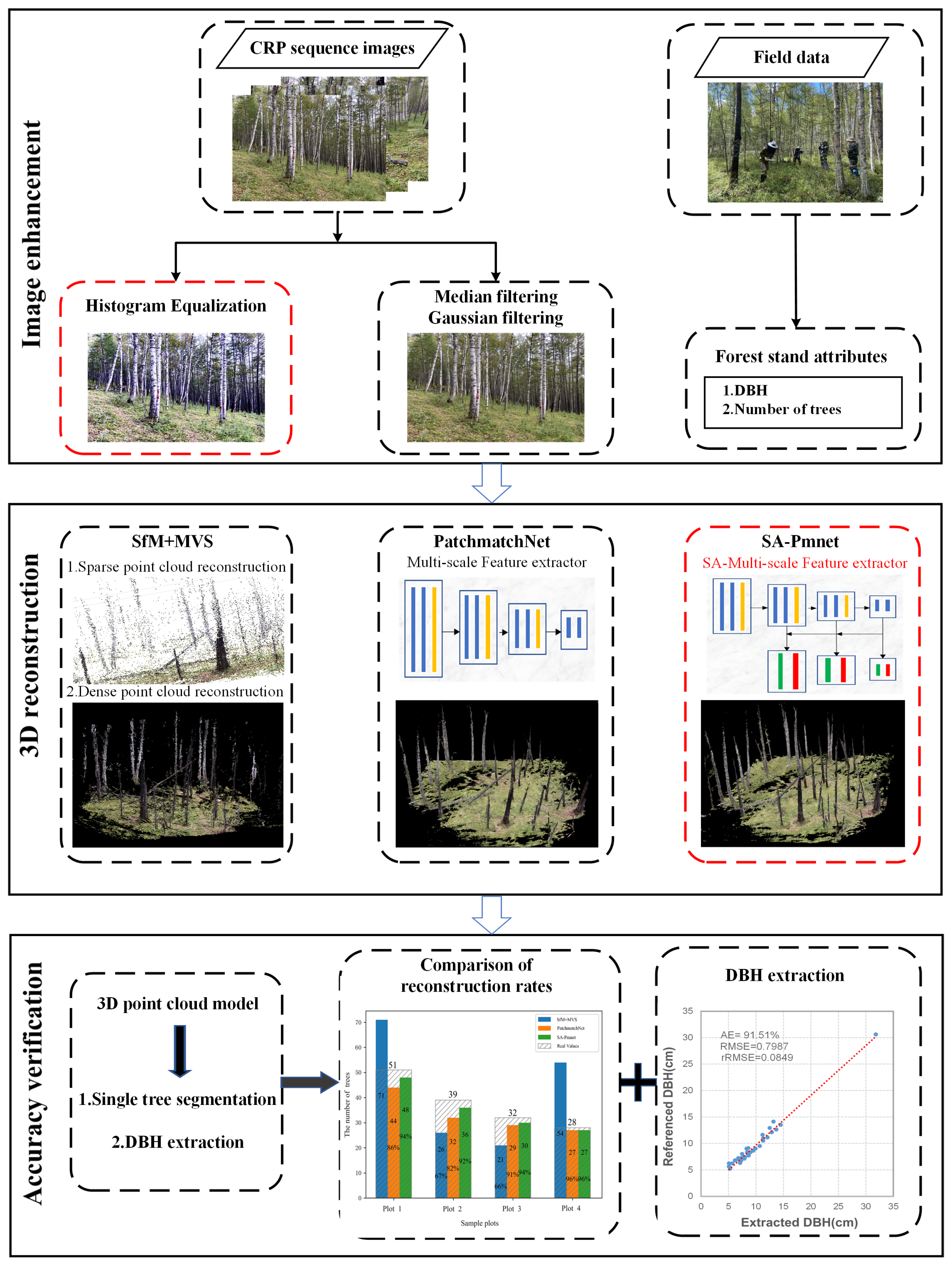
- Comparing two image enhancement algorithms, median–Gaussian filtering and histogram equalization, to solve the impact of lighting factors on image quality.
- Proposing a SA-Pmnet model by combining the self-attention mechanism with the multi-scale feature extraction module to enhance the ability of image details.
- Using the SfM+MVS algorithm to verify the superiority of the proposed deep learning network model for 3D reconstruction in complex forest environments.
2. Materials and Methods
2.1. Study Area
2.2. Data
2.3. Methods
2.3.1. Image Enhancement
- Median–Gaussian filtering
- 2.
- Histogram Equalization
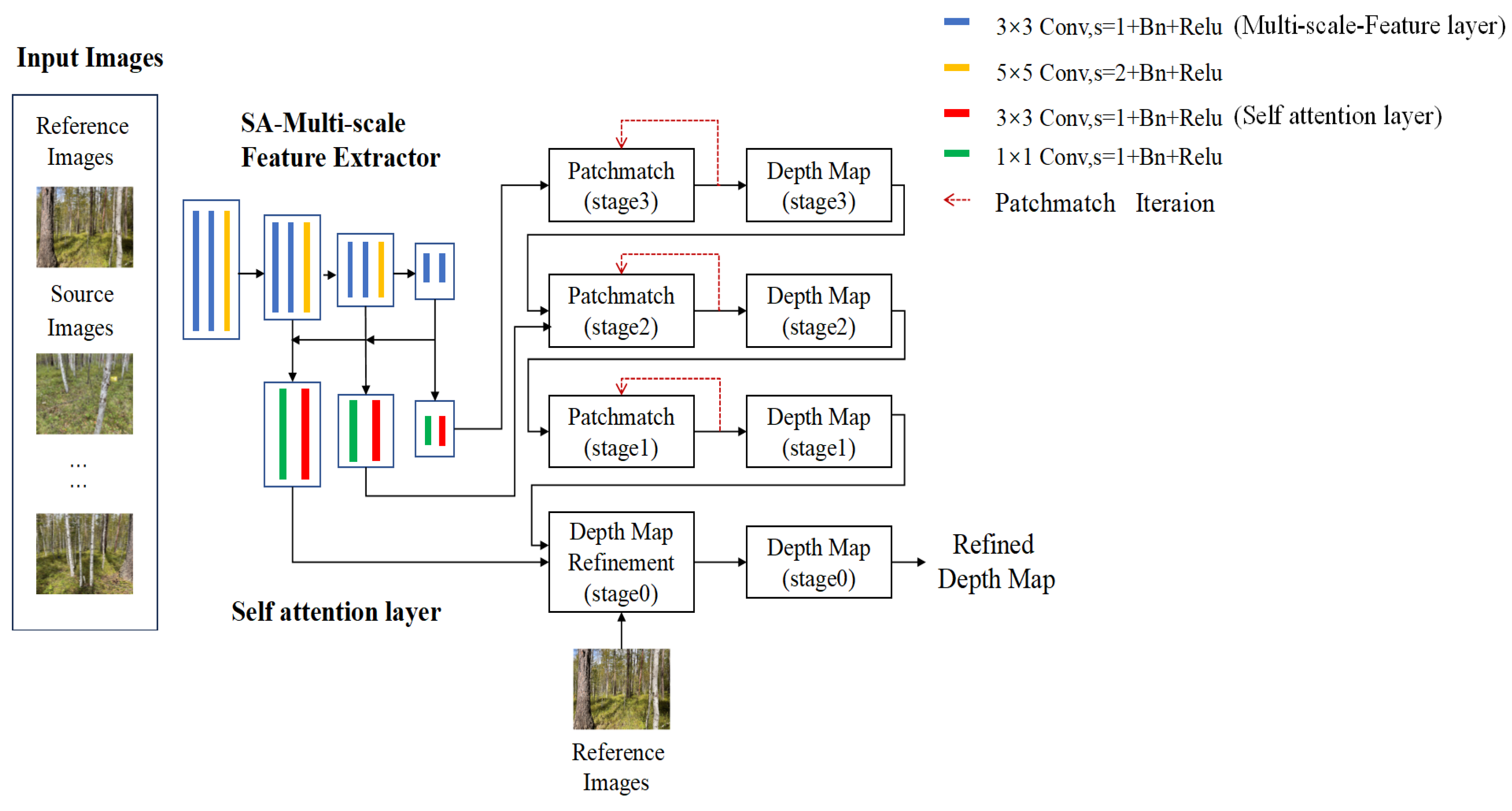
2.3.2. 3D Model Reconstruction
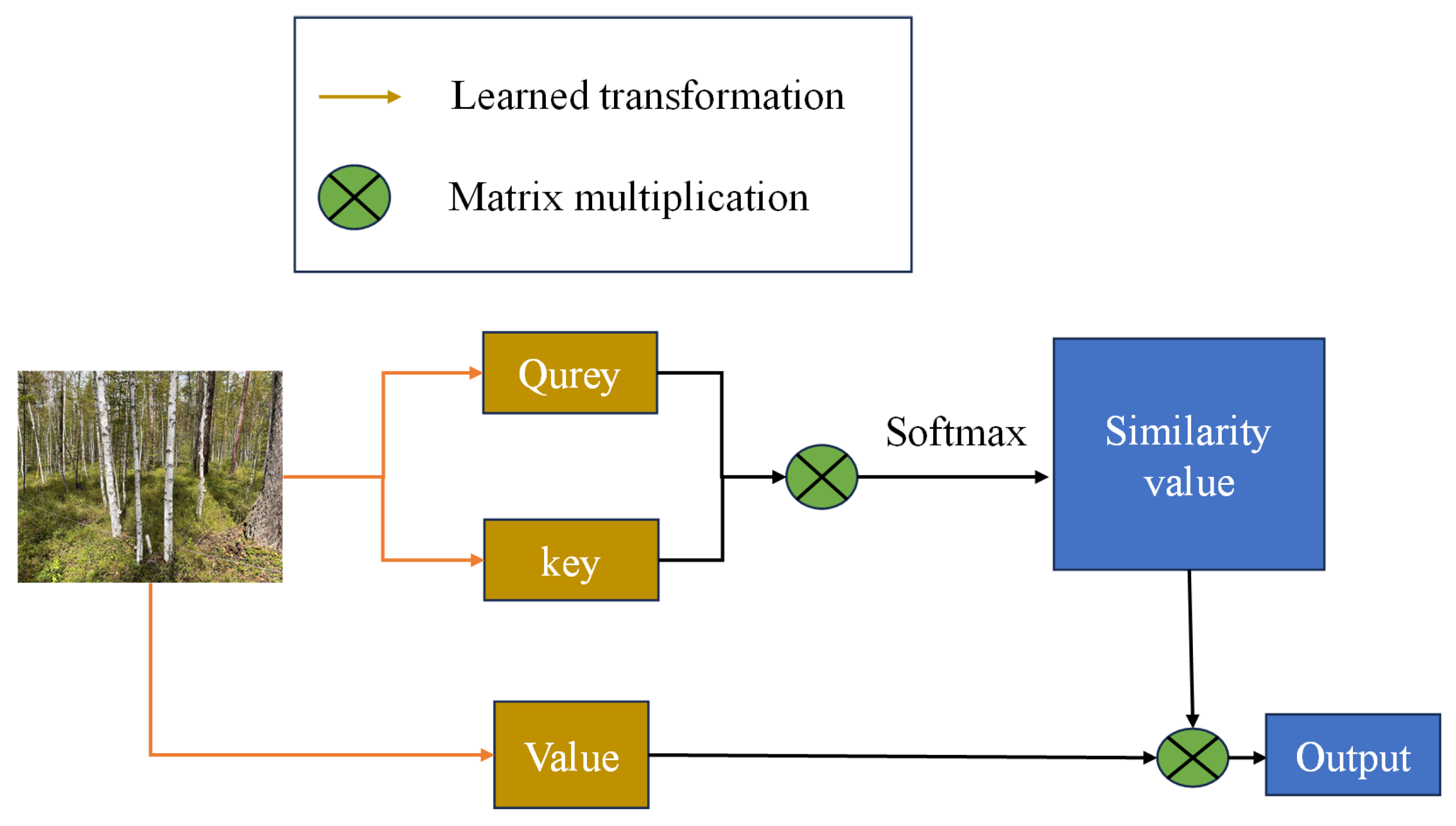
- Calculating the queries (), keys (), and values ();
- Assessing their similarity by computing the inner product of queries and keys (), followed by mapping the similarity into the range of (0,1) using the softmax operation;
- Assigning weights to the similarity values from step 2, repeating these steps for each pixel in B, and ultimately summing all the outputs.
- Depth initialization, which involves the generation of random depth hypotheses;
- Propagation, in which the depth hypotheses are propagated to neighboring pixels;
- Evaluation, focusing on the computation of matching costs for all depth hypotheses and the selection of the optimal solution.
2.4. Accuracy Verification
3. Results
3.1. Results of Different Image Enhancement Methods
3.1.1. Image Enhancement
3.1.2. Results of Feature Matching
3.2. 3D Forest Model Reconstruction Results
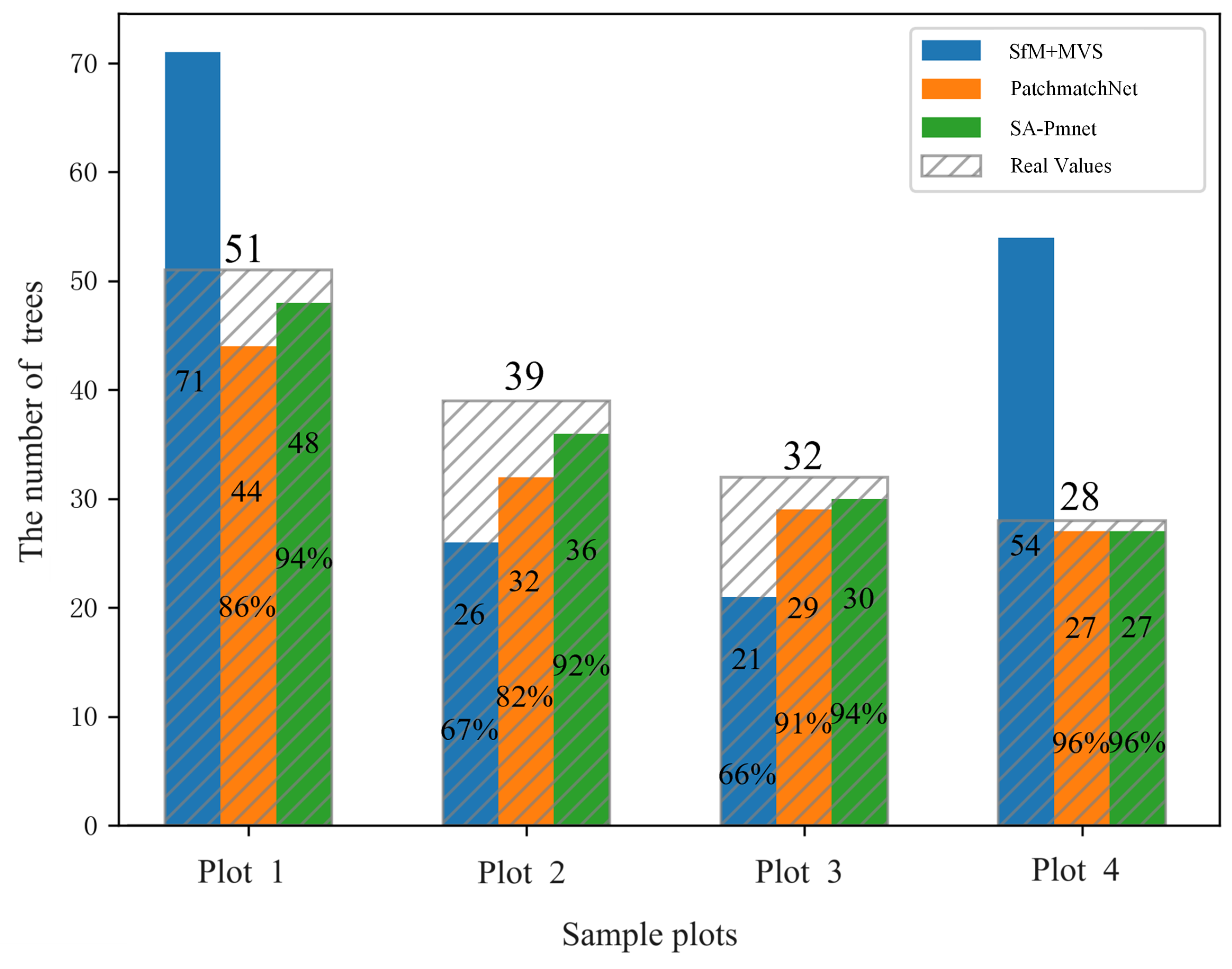
3.2.1. Reconstruction Rate Results
3.2.2. Individual Tree DBH Extraction
4. Discussion
4.1. The Effects of Different Image Enhancement Algorithms on Feature Matching
4.2. The Differences between the SfM+MVS Algorithm and Deep Learning Models for 3D Models
4.3. The Superiority of the SA-Pmnet Network Model
4.4. Research Limitations
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chirico, G.B.; Bonavolontà, F. Metrology for Agriculture and Forestry 2019. Sensors 2020, 20, 3498. [Google Scholar] [CrossRef] [PubMed]
- Holopainen, M.; Vastaranta, M.; Hyyppä, J. Outlook for the next Generation’s Precision Forestry in Finland. Forests 2014, 5, 1682–1694. [Google Scholar] [CrossRef]
- You, L.; Tang, S.; Song, X.; Lei, Y.; Zang, H.; Lou, M.; Zhuang, C. Precise Measurement of Stem Diameter by Simulating the Path of Diameter Tape from Terrestrial Laser Scanning Data. Remote Sens. 2016, 8, 717. [Google Scholar] [CrossRef]
- Yu, R.; Ren, L.; Luo, Y. Early Detection of Pine Wilt Disease in Pinus Tabuliformis in North China Using a Field Portable Spectrometer and UAV-Based Hyperspectral Imagery. For. Ecosyst. 2021, 8, 44. [Google Scholar] [CrossRef]
- Akay, A.E.; Oǧuz, H.; Karas, I.R.; Aruga, K. Using LiDAR Technology in Forestry Activities. Environ. Monit. Assess. 2009, 151, 117–125. [Google Scholar] [CrossRef]
- Faugeras, O.D.; Luong, Q.T.; Maybank, S.J. Camera Self-Calibration: Theory and Experiments. In Computer Vision—ECCV’92, Proceedings of the Second European Conference on Computer Vision, Santa Margherita, Italy, 19–22 May 1992; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Sandini, G., Ed.; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Andrew, A.M. Multiple View Geometry in Computer Vision. Kybernetes 2001, 30, 1333–1341. [Google Scholar] [CrossRef]
- Petschko, H.; Goetz, J.; Böttner, M.; Firla, M.; Schmidt, S. Erosion Processes and Mass Movements in Sinkholes Assessed by Terrestrial Structure from Motion Photogrammetry. In Advancing Culture of Living with Landslides; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Liang, X.; Wang, Y.; Jaakkola, A.; Kukko, A.; Kaartinen, H.; Hyyppä, J.; Honkavaara, E.; Liu, J. Forest Data Collection Using Terrestrial Image-Based Point Clouds from a Handheld Camera Compared to Terrestrial and Personal Laser Scanning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5117–5132. [Google Scholar] [CrossRef]
- Mokro, M.; Liang, X.; Surový, P.; Valent, P.; Čerňava, J.; Chudý, F.; Tunák, D.; Saloň, I.; Merganič, J. Evaluation of Close-Range Photogrammetry Image Collection Methods for Estimating Tree Diameters. ISPRS Int. J. Geo-Inf. 2018, 7, 93. [Google Scholar] [CrossRef]
- Forsman, M.; Holmgren, J.; Olofsson, K. Tree Stem Diameter Estimation from Mobile Laser Scanning Using Line-Wise Intensity-Based Clustering. Forests 2016, 7, 206. [Google Scholar] [CrossRef]
- Mikita, T.; Janata, P.; Surovỳ, P. Forest Stand Inventory Based on Combined Aerial and Terrestrial Close-Range Photogrammetry. Forests 2016, 7, 156. [Google Scholar] [CrossRef]
- Chai, G.; Zheng, Y.; Lei, L.; Yao, Z.; Chen, M.; Zhang, X. A Novel Solution for Extracting Individual Tree Crown Parameters in High-Density Plantation Considering Inter-Tree Growth Competition Using Terrestrial Close-Range Scanning and Photogrammetry Technology. Comput. Electron. Agric. 2023, 209, 107849. [Google Scholar] [CrossRef]
- Yang, H.; Meng, X.; Liu, Y.; Cheng, J. Measurement and Calculation Methods of a Stem Image Information. Front. For. China 2006, 1, 59–63. [Google Scholar] [CrossRef]
- Ullman, S. The Interpretation of Structure from Motion. Proc. R. Soc. Lond. B Biol. Sci. 1979, 203, 405–426. [Google Scholar] [CrossRef] [PubMed]
- Schonberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Luhmann, T. Close Range Photogrammetry for Industrial Applications. ISPRS J. Photogramm. Remote Sens. 2010, 65, 558–569. [Google Scholar] [CrossRef]
- Gao, L.; Zhao, Y.; Han, J.; Liu, H. Research on Multi-View 3D Reconstruction Technology Based on SFM. Sensors 2022, 22, 4366. [Google Scholar] [CrossRef] [PubMed]
- Slocum, R.K.; Parrish, C.E. Simulated Imagery Rendering Workflow for Uas-Based Photogrammetric 3d Reconstruction Accuracy Assessments. Remote Sens. 2017, 9, 396. [Google Scholar] [CrossRef]
- Puliti, S.; Ørka, H.O.; Gobakken, T.; Næsset, E. Inventory of Small Forest Areas Using an Unmanned Aerial System. Remote Sens. 2015, 7, 9632–9654. [Google Scholar] [CrossRef]
- Zarco-Tejada, P.J.; Diaz-Varela, R.; Angileri, V.; Loudjani, P. Tree Height Quantification Using Very High Resolution Imagery Acquired from an Unmanned Aerial Vehicle (UAV) and Automatic 3D Photo-Reconstruction Methods. Eur. J. Agron. 2014, 55, 89–99. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Yang, W. Forests Growth Monitoring Based on Tree Canopy 3D Reconstruction Using UAV Aerial Photogrammetry. Forests 2019, 10, 1052. [Google Scholar] [CrossRef]
- Berveglieri, A.; Imai, N.N.; Tommaselli, A.M.G.; Casagrande, B.; Honkavaara, E. Successional Stages and Their Evolution in Tropical Forests Using Multi-Temporal Photogrammetric Surface Models and Superpixels. ISPRS J. Photogramm. Remote Sens. 2018, 146, 548–558. [Google Scholar] [CrossRef]
- Xu, C.; Wu, C.; Qu, D.; Xu, F.; Sun, H.; Song, J. Accurate and Efficient Stereo Matching by Log-Angle and Pyramid-Tree. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4007–4019. [Google Scholar] [CrossRef]
- Yang, B.; Ali, F.; Yin, P.; Yang, T.; Yu, Y.; Li, S.; Liu, X. Approaches for Exploration of Improving Multi-Slice Mapping via Forwarding Intersection Based on Images of UAV Oblique Photogrammetry. Comput. Electr. Eng. 2021, 92, 107135. [Google Scholar] [CrossRef]
- Jing, L.; Zhao, M.; Li, P.; Xu, X. A Convolutional Neural Network Based Feature Learning and Fault Diagnosis Method for the Condition Monitoring of Gearbox. Measurment 2017, 111, 1–10. [Google Scholar] [CrossRef]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. MVSNet: Depth Inference for Unstructured Multi-View Stereo. In Proceedings of the IEEE International Conference on Computer Vision, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Luo, K.; Guan, T.; Ju, L.; Huang, H.; Luo, Y. P-MVSNet: Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xue, Y.; Chen, J.; Wan, W.; Huang, Y.; Yu, C.; Li, T.; Bao, J. MVSCRF: Learning Multi-View Stereo with Conditional Random Fields. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, J.; Mao, W.; Alvarez, J.M.; Liu, M. Cost Volume Pyramid Based Depth Inference for Multi-View Stereo. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, Z.; Gao, S. Fast-MVSNet: Sparse-to-Dense Multi-View Stereo with Learned Propagation and Gauss-Newton Refinement. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yi, H.; Wei, Z.; Ding, M.; Zhang, R.; Chen, Y.; Wang, G.; Tai, Y.W. Pyramid Multi-View Stereo Net with Self-Adaptive View Aggregation. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Yu, A.; Guo, W.; Liu, B.; Chen, X.; Wang, X.; Cao, X.; Jiang, B. Attention Aware Cost Volume Pyramid Based Multi-View Stereo Network for 3D Reconstruction. ISPRS J. Photogramm. Remote Sens. 2021, 175, 448–460. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S.; Luo, Z.; Fang, T.; Yao, Y. Vis-MVSNet: Visibility-Aware Multi-View Stereo Network. Int. J. Comput. Vis. 2023, 131, 199–214. [Google Scholar] [CrossRef]
- Zhang, J.; Ji, M.; Wang, G.; Xue, Z.; Wang, S.; Fang, L. SurRF: Unsupervised Multi-View Stereopsis by Learning Surface Radiance Field. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7912–7927. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; Pollefeys, M. PatchMatchNet: Learned Multi-View Patchmatch Stereo. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashcille, TN, USA, 20–25 June 2021. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch. ACM Trans. Graph. 2009, 28, 1–11. [Google Scholar] [CrossRef]
- Chen, H.; Li, A.; Kaufman, L.; Hale, J. A Fast Filtering Algorithm for Image Enhancement. IEEE Trans. Med. Imaging 1994, 13, 557–564. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shi, X.J. A Simple and Effective Histogram Equalization Approach to Image Enhancement. Digit. Signal Process. A Rev. J. 2004, 14, 158–170. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle Adjustment—A Modern Synthesis. In Vision Algorithms: Theory and Practice, Proceedings of the International Workshop on Vision Algorithms, Corfu, Greece, 21–22 September 1999; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Merrell, P.; Akbarzadeh, A.; Wang, L.; Mordohai, P.; Frahm, J.M.; Yang, R.; Nistér, D.; Pollefeys, M. Real-Time Visibility-Based Fusion of Depth Maps. In Proceedings of the IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–24 October 2007. [Google Scholar]
- Karunasingha, D.S.K. Root Mean Square Error or Mean Absolute Error? Use Their Ratio as Well. Inf. Sci. 2022, 585, 609–629. [Google Scholar] [CrossRef]
- Zhu, R.; Guo, Z.; Zhang, X. Forest 3d Reconstruction and Individual Tree Parameter Extraction Combining Close-Range Photo Enhancement and Feature Matching. Remote Sens. 2021, 13, 1633. [Google Scholar] [CrossRef]
- Zhu, H.; Chan, F.H.Y.; Lam, F.K. Image Contrast Enhancement by Constrained Local Histogram Equalization. Comput. Vis. Image Underst. 1999, 73, 281–290. [Google Scholar] [CrossRef]
- Nurminen, K.; Karjalainen, M.; Yu, X.; Hyyppä, J.; Honkavaara, E. Performance of Dense Digital Surface Models Based on Image Matching in the Estimation of Plot-Level Forest Variables. ISPRS J. Photogramm. Remote Sens. 2013, 83, 104–115. [Google Scholar] [CrossRef]
- Capolupo, A. Accuracy Assessment of Cultural Heritage Models Extracting 3D Point Cloud Geometric Features with RPAS SfM-MVS and TLS Techniques. Drones 2021, 5, 145. [Google Scholar] [CrossRef]
- Eulitz, M.; Reiss, G. 3D Reconstruction of SEM Images by Use of Optical Photogrammetry Software. J. Struct. Biol. 2015, 191, 190–196. [Google Scholar] [CrossRef]
- Zeng, W.; Zhong, S.; Yao, Y.; Shao, Z. 3D Model Reconstruction Based on Close-Range Photogrammetry. Appl. Mech. Mater. 2013, 263–266, 2393–2398. [Google Scholar] [CrossRef]
- Zhao, H.; Jia, J.; Koltun, V. Exploring Self-Attention for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions, and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions, or products referred to in the content. |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Plot | Slope (°) | Major Tree Species | Number of Trees | Stand Complexity |
|---|---|---|---|---|
| 1 | 36 | Larch, Birch | 51 | Complex |
| 2 | 9 | Larch, Birch | 39 | Complex |
| 3 | 13 | Red oatchestnut | 32 | Simple |
| 4 | 27 | Chinese fir | 28 | Medium |
| Sample Plots | Original Images | HE | MG |
|---|---|---|---|
| 1 | 29 | 72 | 41 |
| 2 | 38 | 103 | 62 |
| 3 | 57 | 116 | 45 |
| 4 | 31 | 97 | 39 |
| Sample Plots | SfM+MVS (106) | PatchmatchNet (106) | SA-Pmnet (106) |
|---|---|---|---|
| 1 | 3.32 | 10.96 | 11.78 |
| 2 | 4.75 | 19.87 | 20.64 |
| 3 | 2.58 | 22.61 | 24.05 |
| 4 | 34.58 | 79.46 | 84.17 |
| Sample Plots | SfM+MVS (h) | PatchmatchNet (h) | SA-Pmnet (h) |
|---|---|---|---|
| 1 | 7 | 10 | 10 |
| 2 | 8 | 12 | 12 |
| 3 | 6.5 | 10 | 10 |
| 4 | 10 | 15 | 15 |
| Sample Plots | SA-Pmnet (%) | PatchmatchNet (%) | Accuracy Improvement Ratio (%) |
|---|---|---|---|
| 1 | 91.83 | 89.94 | 1.89 |
| 2 | 91.51 | 90.66 | 0.85 |
| 3 | 93.55 | 92.84 | 0.71 |
| 4 | 92.35 | 91.32 | 1.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Chai, G.; Han, X.; Lei, L.; Wang, G.; Jia, X.; Zhang, X. SA-Pmnet: Utilizing Close-Range Photogrammetry Combined with Image Enhancement and Self-Attention Mechanisms for 3D Reconstruction of Forests. Remote Sens. 2024, 16, 416. https://doi.org/10.3390/rs16020416
Yan X, Chai G, Han X, Lei L, Wang G, Jia X, Zhang X. SA-Pmnet: Utilizing Close-Range Photogrammetry Combined with Image Enhancement and Self-Attention Mechanisms for 3D Reconstruction of Forests. Remote Sensing. 2024; 16(2):416. https://doi.org/10.3390/rs16020416
Chicago/Turabian StyleYan, Xuanhao, Guoqi Chai, Xinyi Han, Lingting Lei, Geng Wang, Xiang Jia, and Xiaoli Zhang. 2024. "SA-Pmnet: Utilizing Close-Range Photogrammetry Combined with Image Enhancement and Self-Attention Mechanisms for 3D Reconstruction of Forests" Remote Sensing 16, no. 2: 416. https://doi.org/10.3390/rs16020416
APA StyleYan, X., Chai, G., Han, X., Lei, L., Wang, G., Jia, X., & Zhang, X. (2024). SA-Pmnet: Utilizing Close-Range Photogrammetry Combined with Image Enhancement and Self-Attention Mechanisms for 3D Reconstruction of Forests. Remote Sensing, 16(2), 416. https://doi.org/10.3390/rs16020416