


Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM



Abstract
1. Introduction
2. Materials and Methods
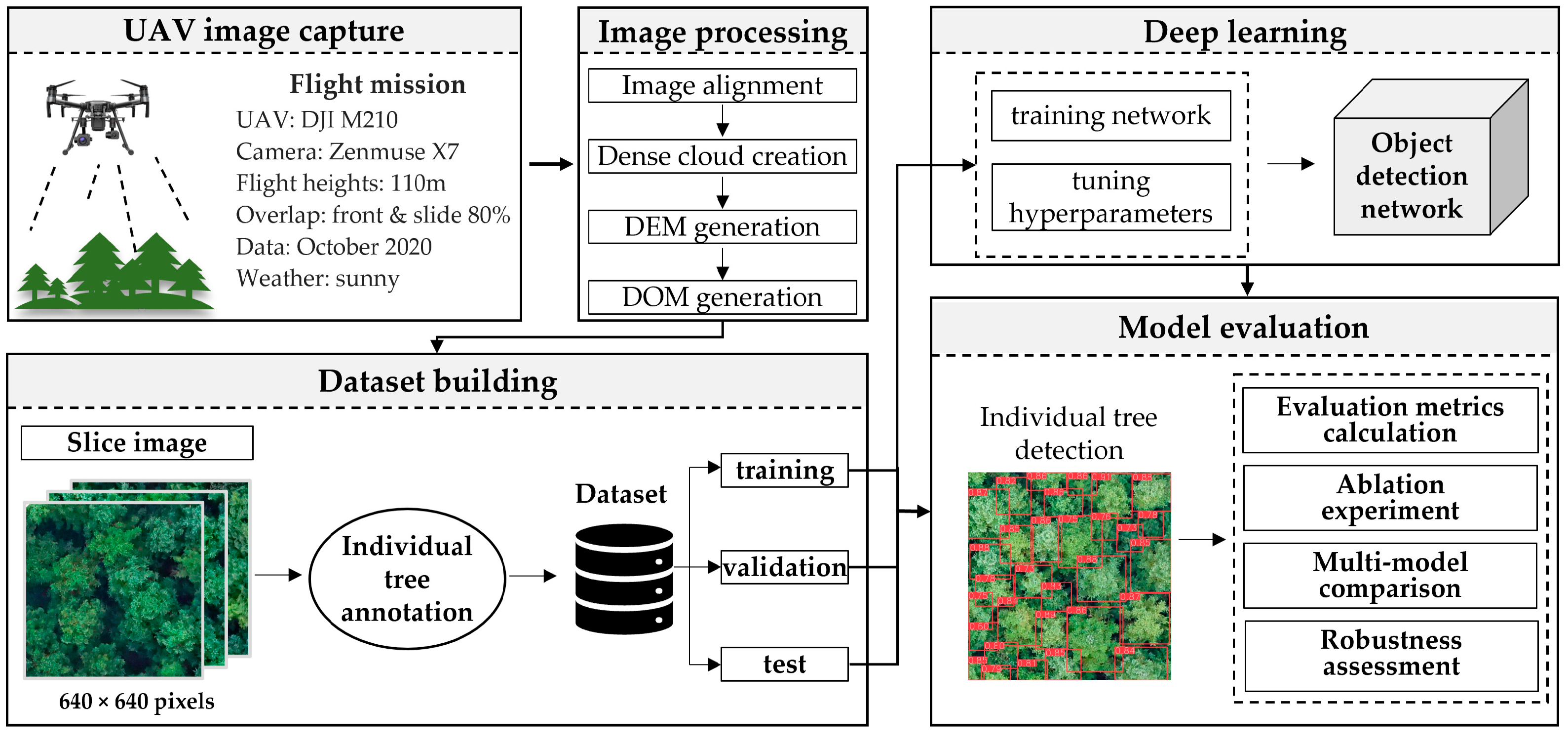
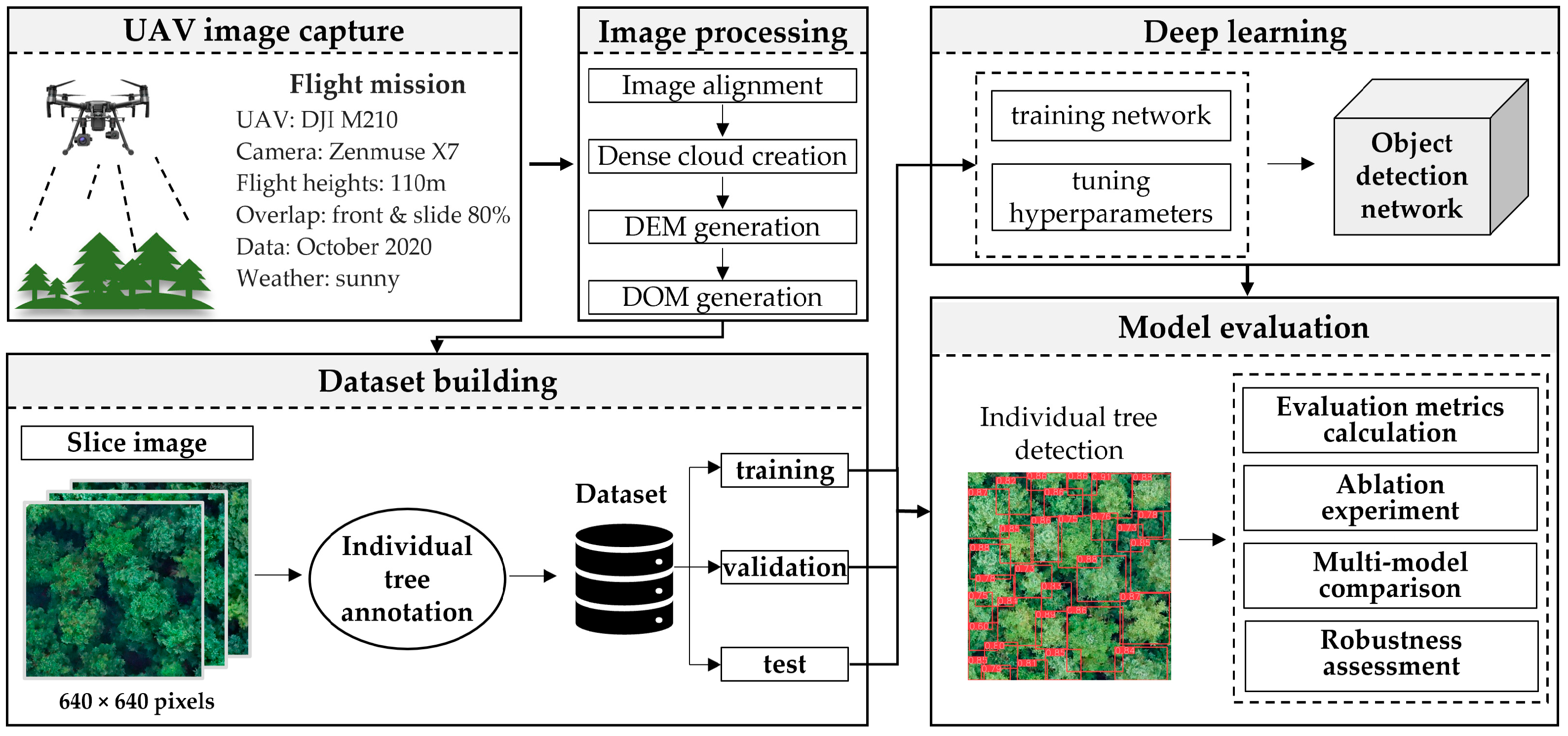
2.1. Framework of Study
2.2. Study Area
2.3. UAV Data Acquisition
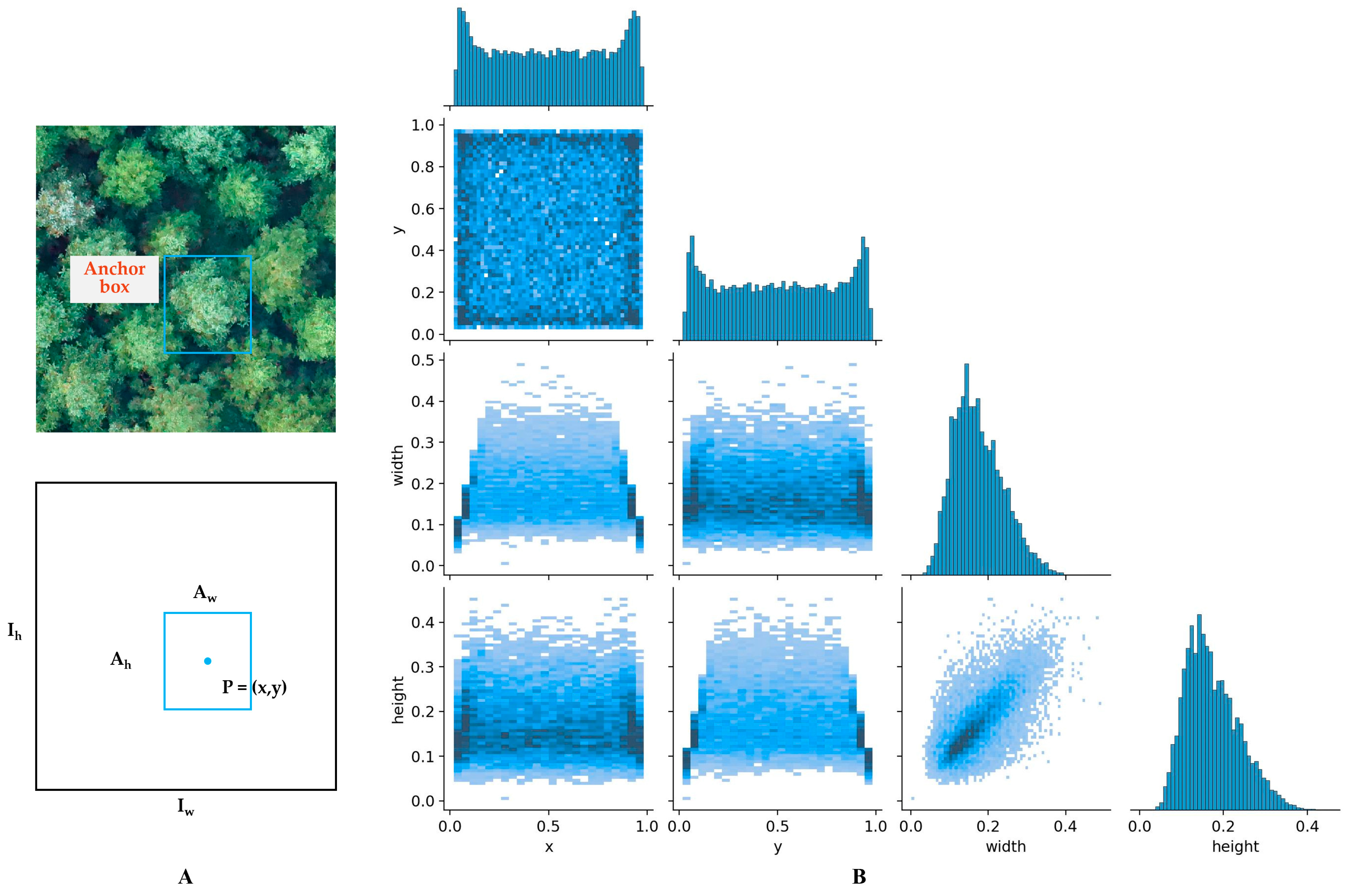
2.4. Dataset Preparation
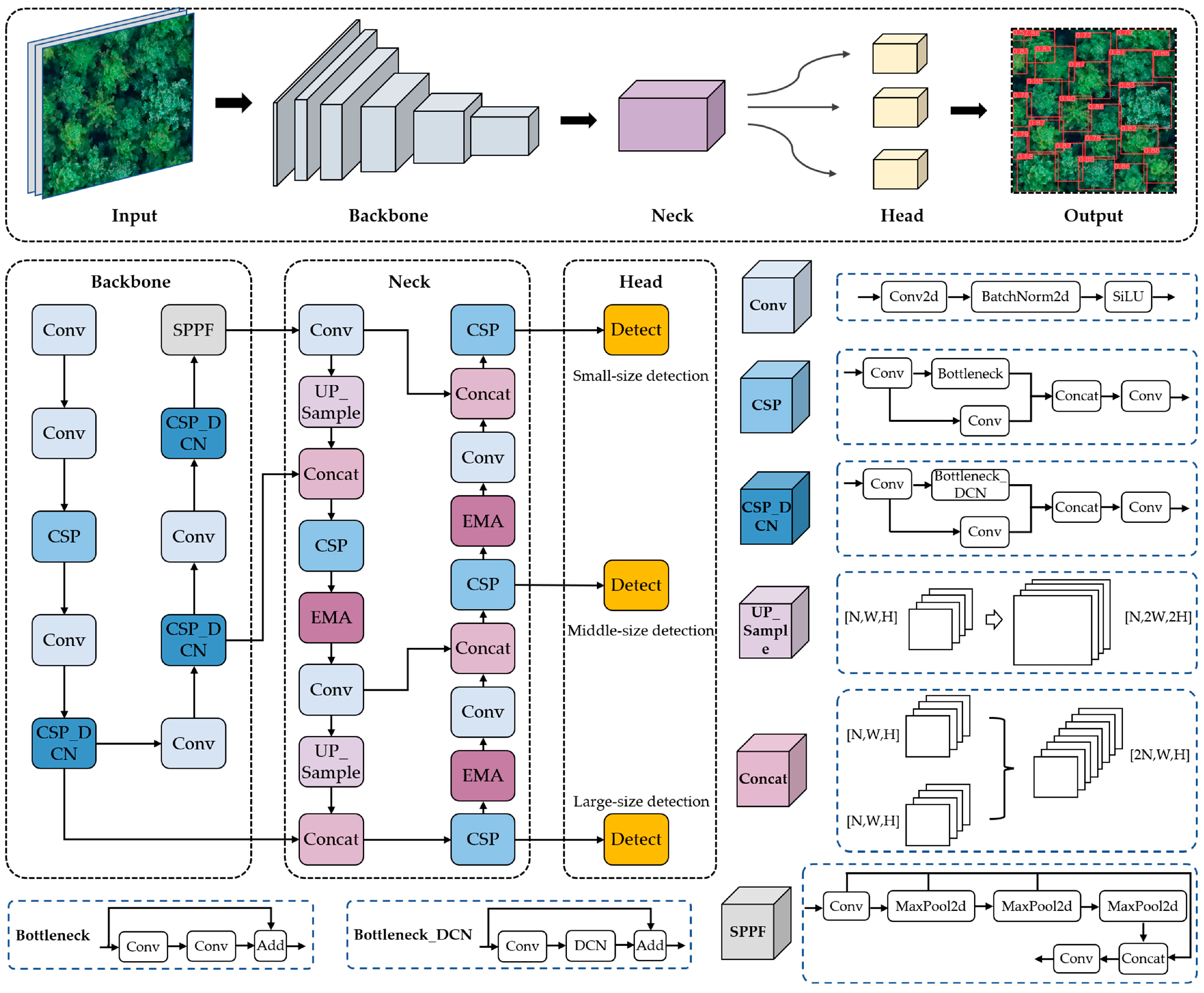
2.5. The YOLO-DCAM Network
2.5.1. YOLOv5 Network Baseline
2.5.2. Overview of YOLO-DCAM Network Architecture
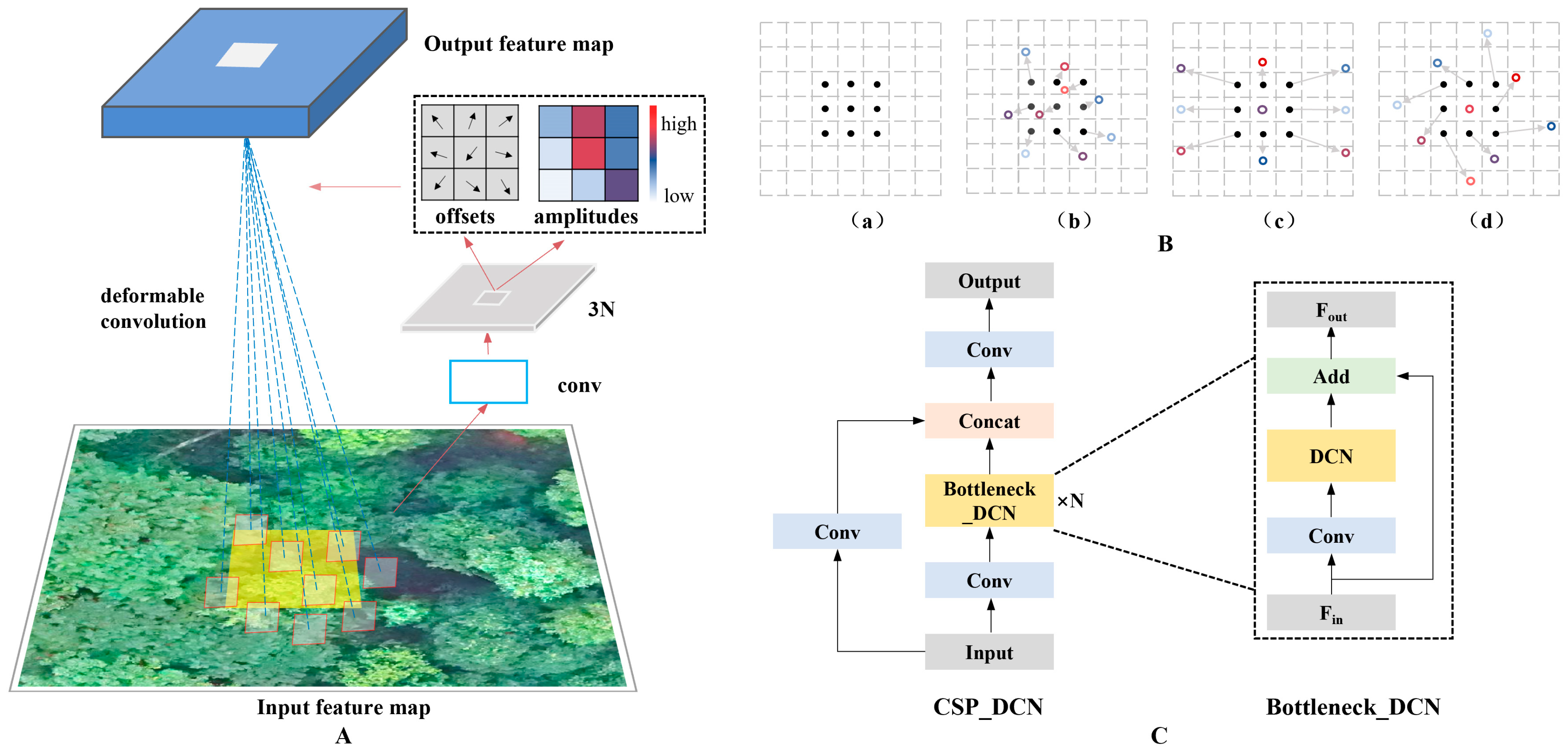
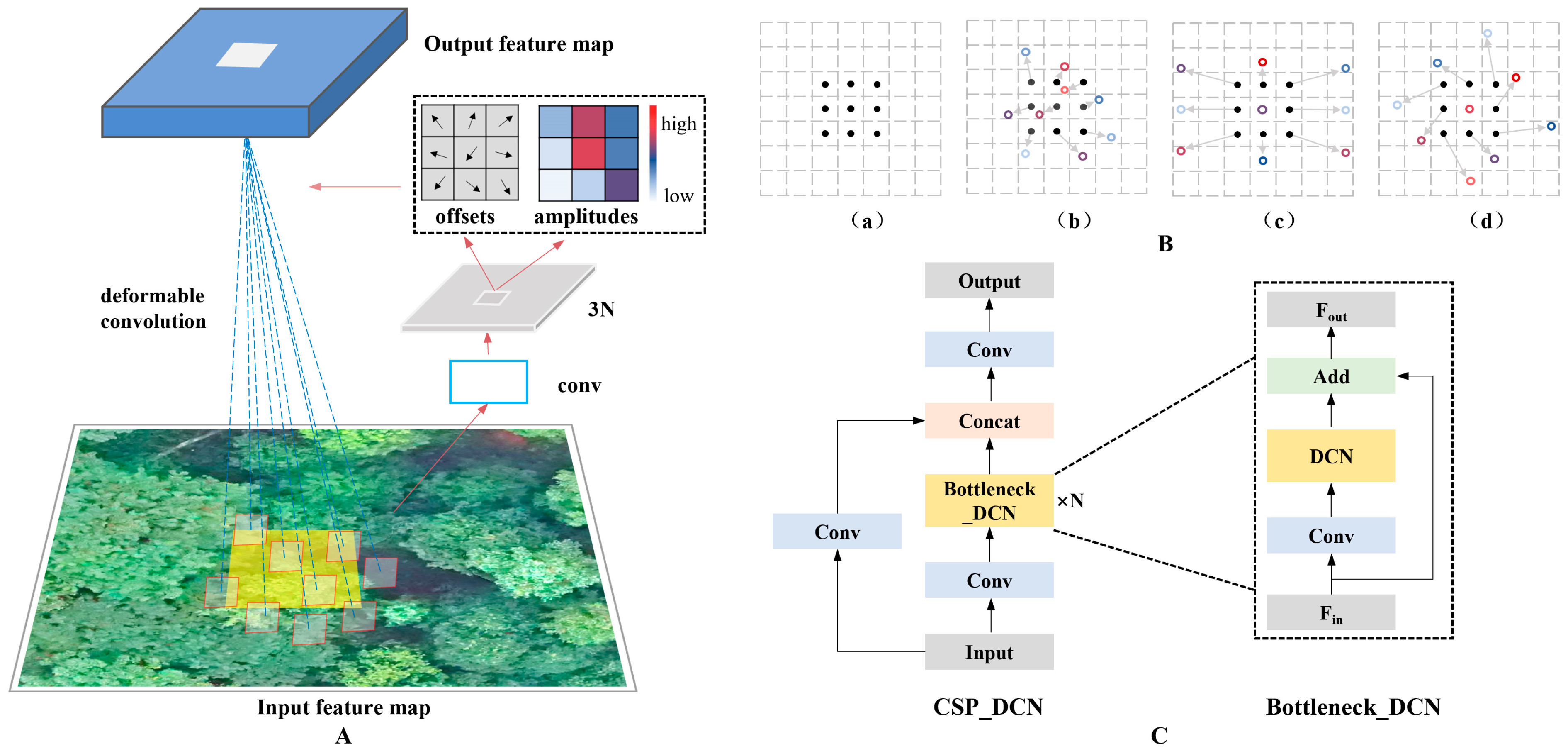
2.5.3. Improved Backbone with Deformable Convolution Network
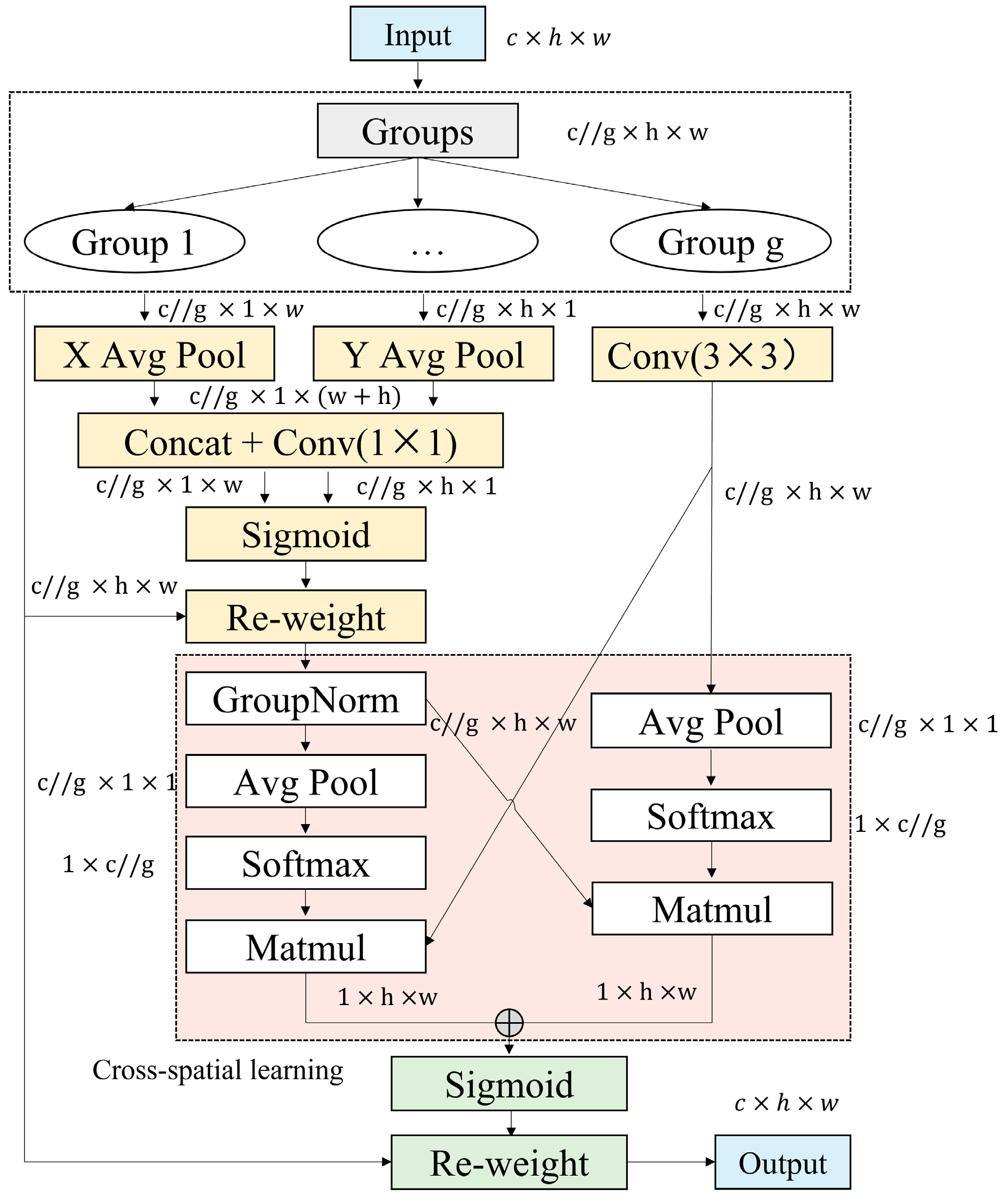
2.5.4. Improved Neck with the Attention Module
2.5.5. Loss Function
2.6. Model Evaluation
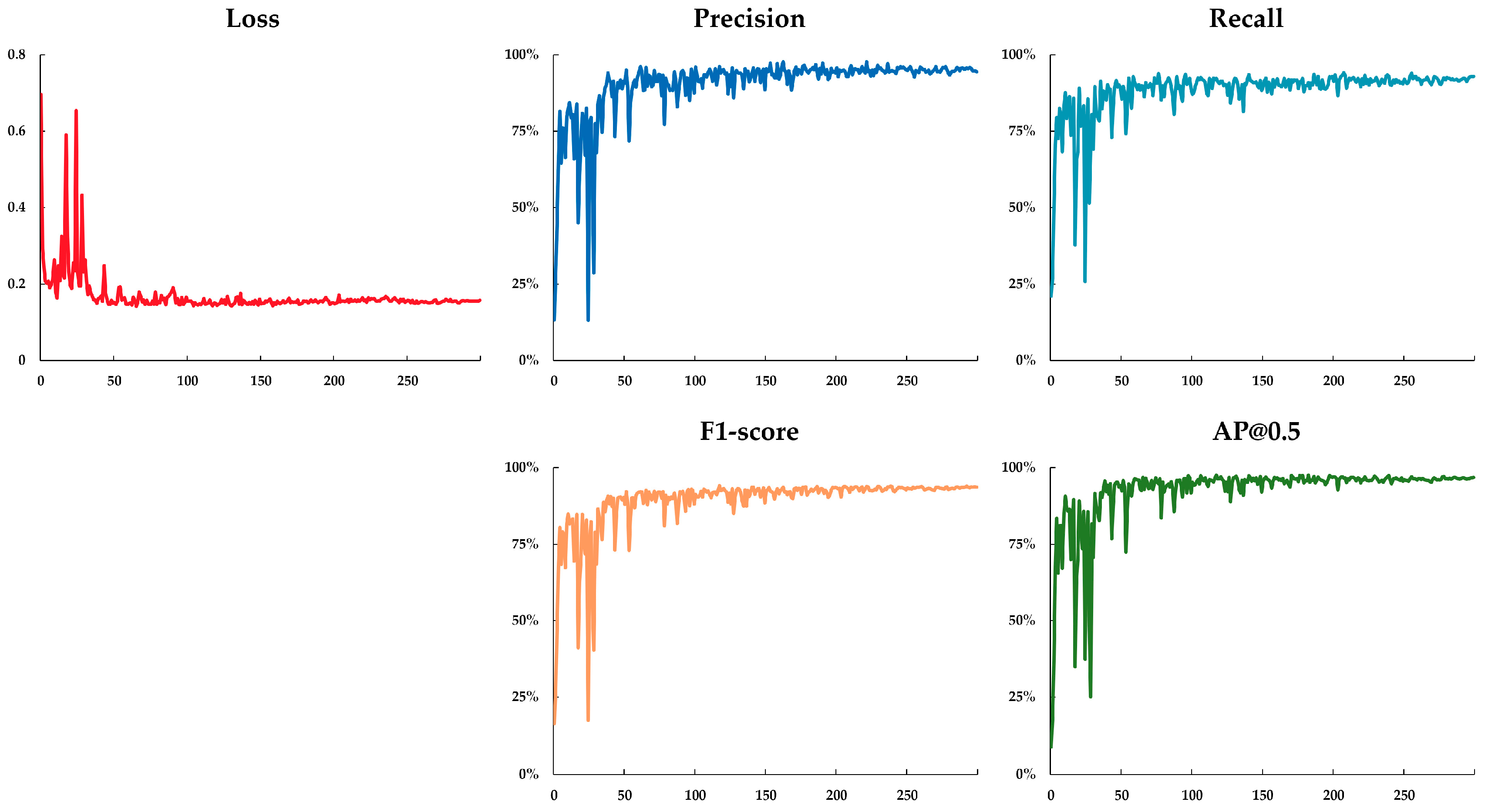
2.7. Experimental Settings
3. Result and Analysis
3.1. Ablation Experiment
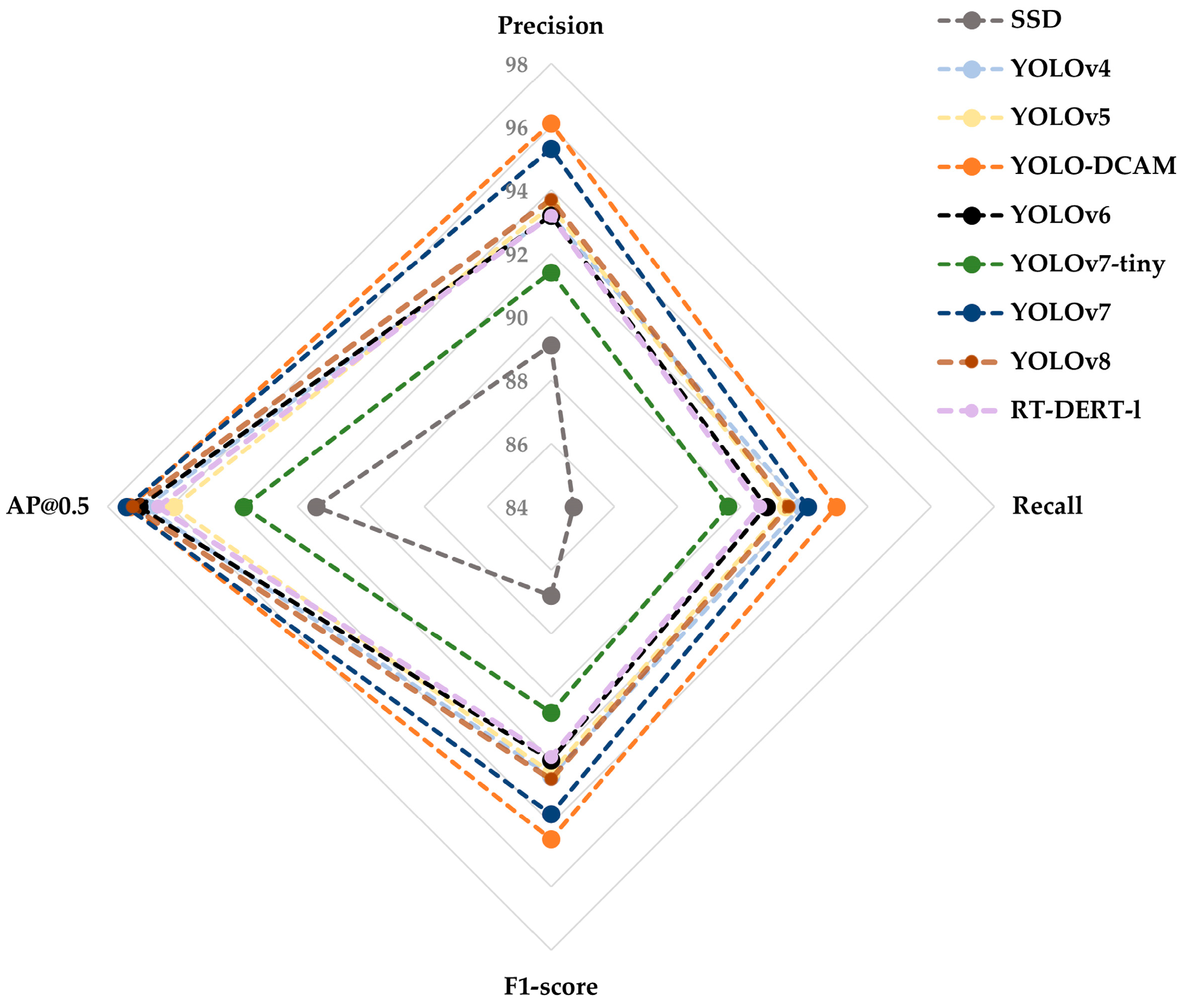
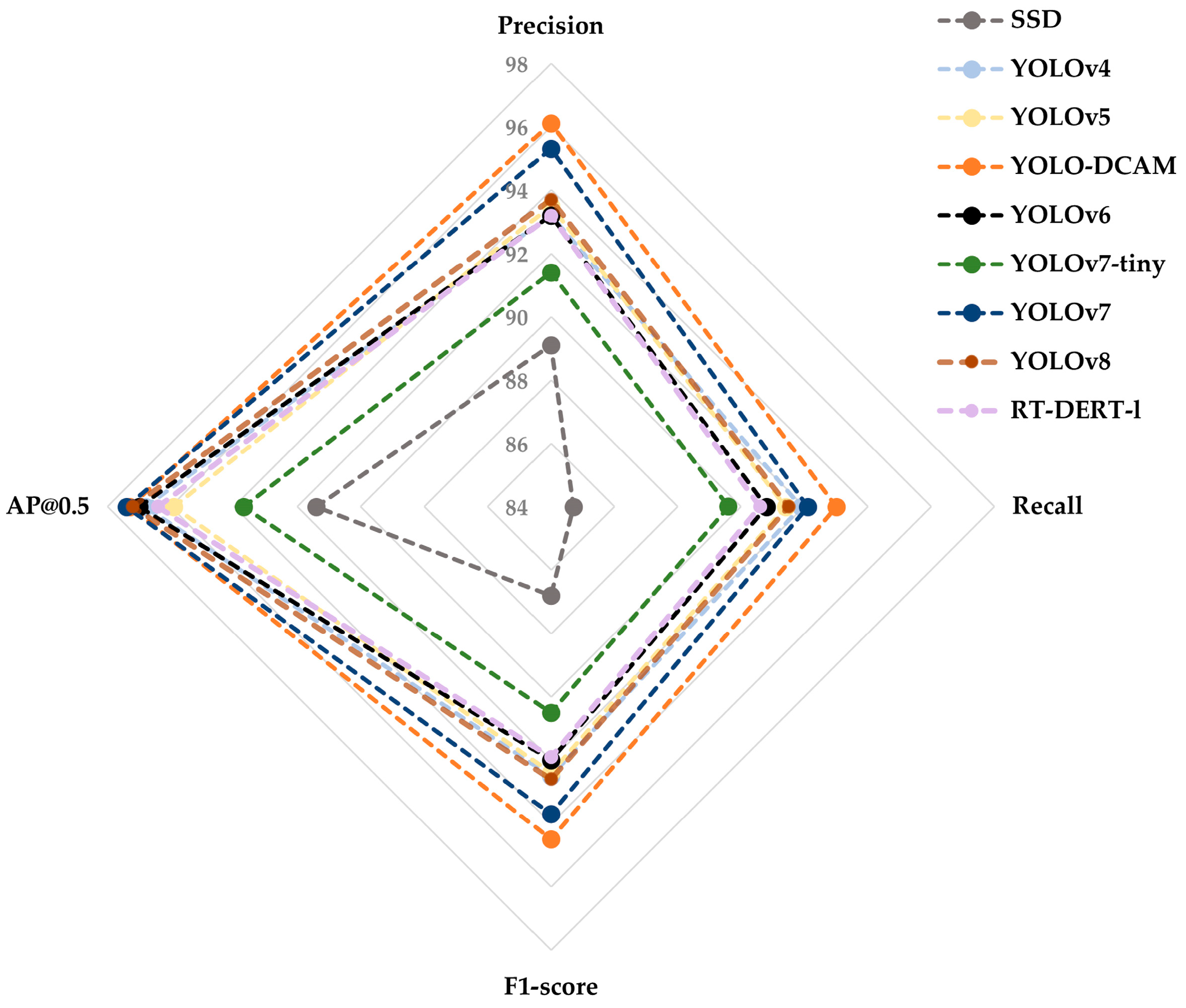
3.2. Comparison Experiments of Different Models
3.3. The Detection Result of YOLO-DCAM
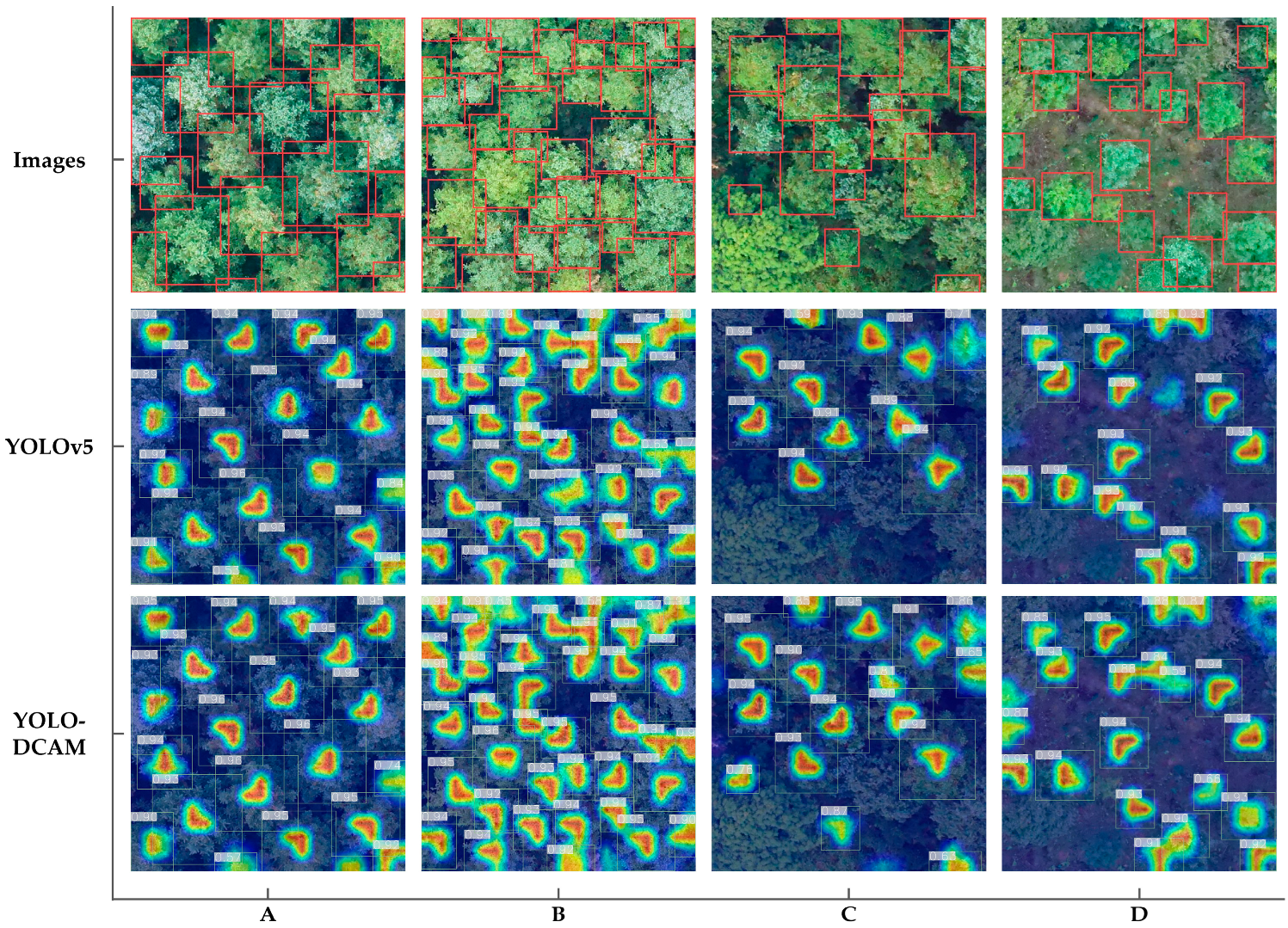
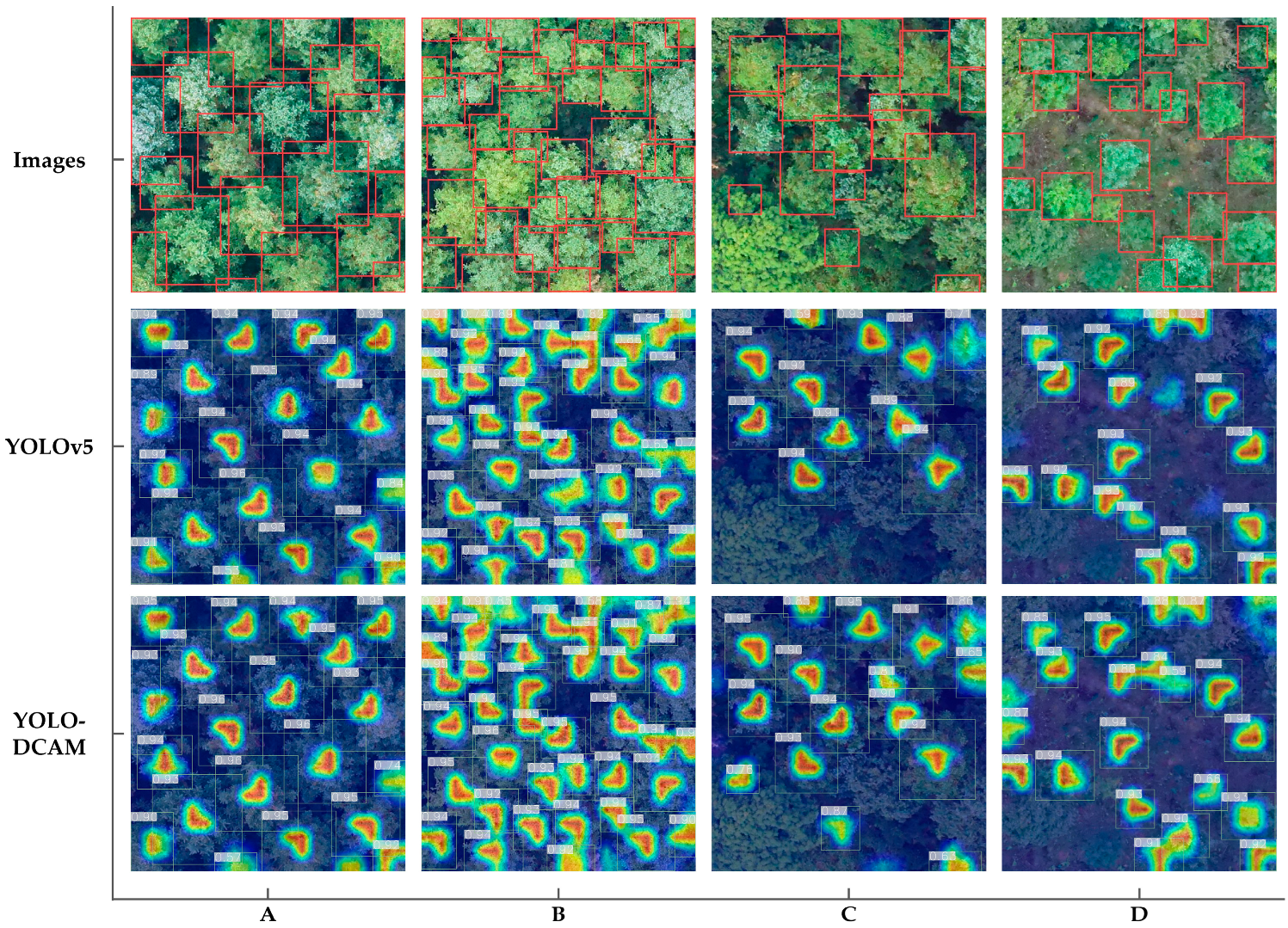
3.3.1. Visualized Detection Result of YOLO-DCAM
3.3.2. Quantitative Detection Result of YOLO-DCAM
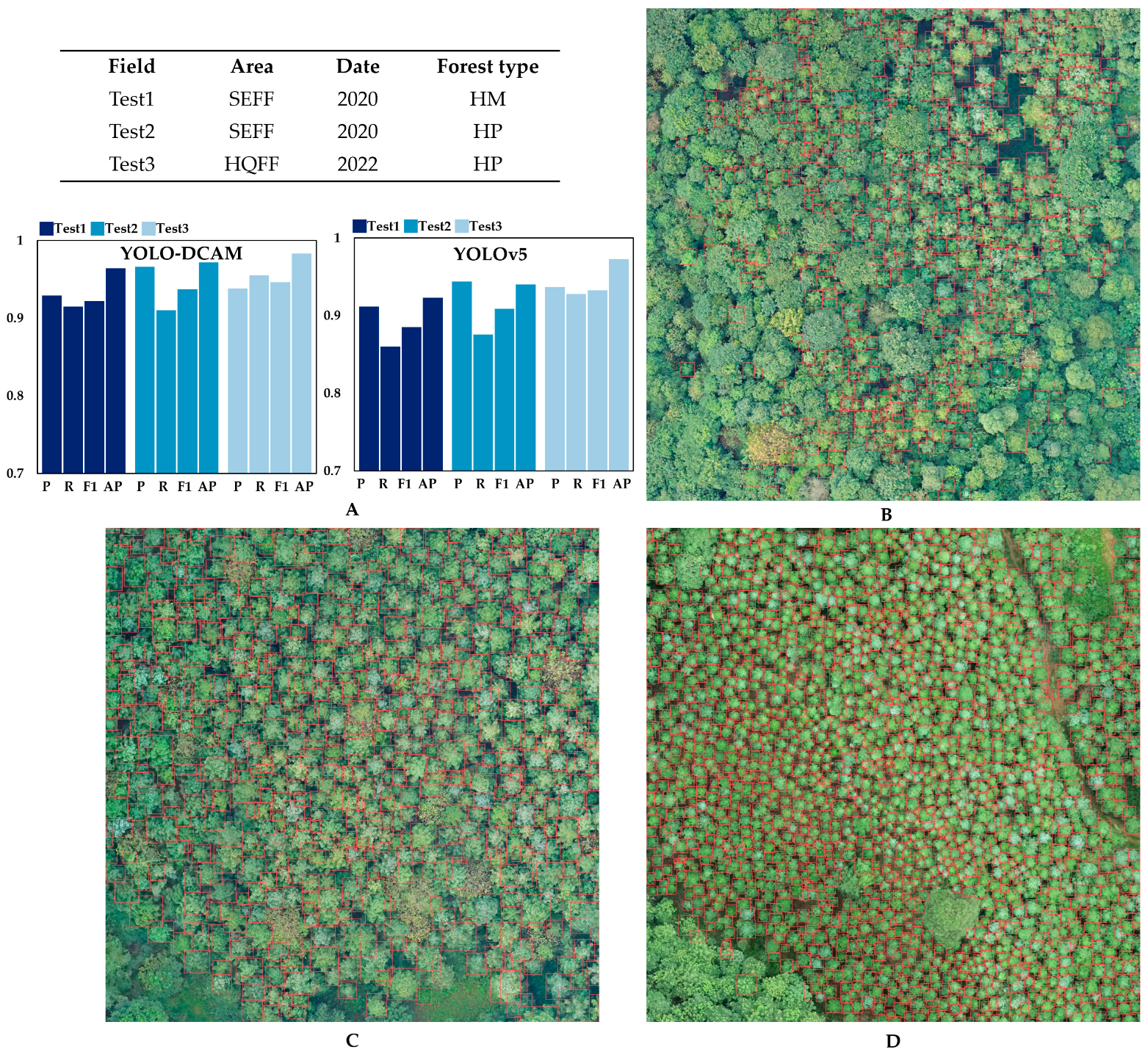
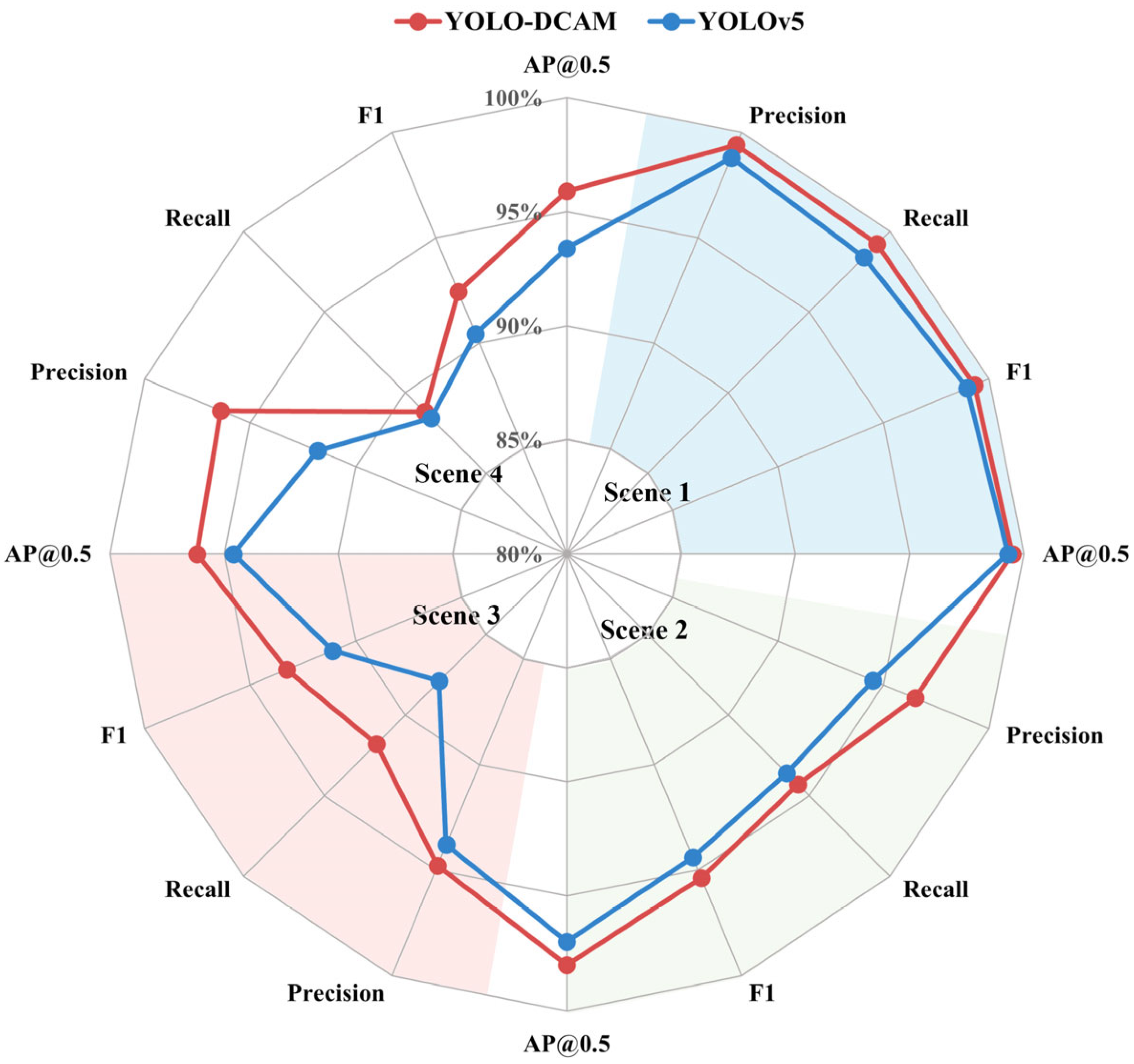
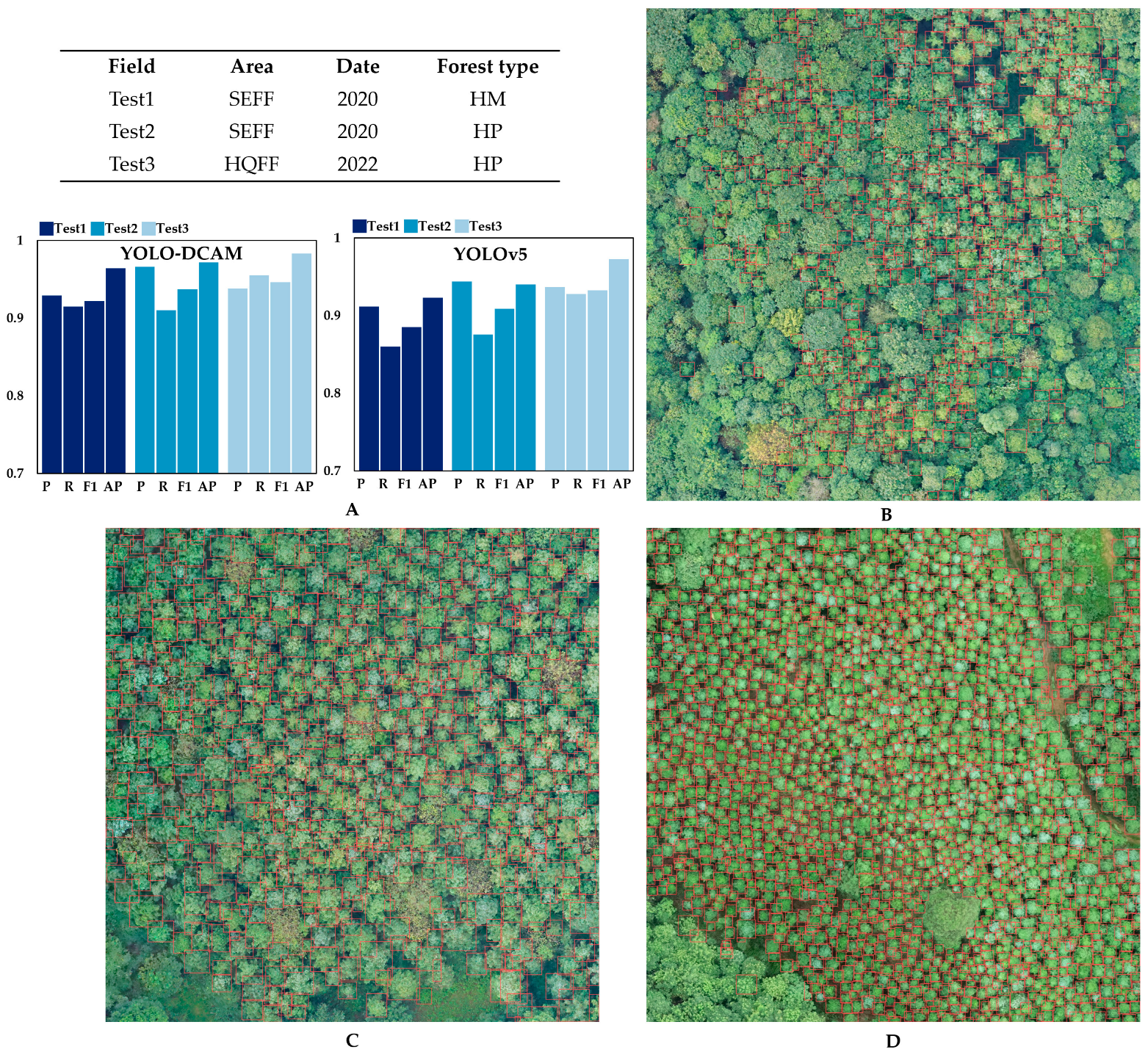
3.3.3. Robustness Testing
4. Discussion
4.1. YOLO-DCAM Network for Individual Chinese Fir Tree Detection
4.2. False and Missed Examination Analysis of Individual Tree Detection
- (1)
- Tree crown overlap. Within the high-density forest scene, continuous tree crown coverage leads to significant overlap and occlusion among individual trees. Although this model can identify most individual trees in the high-density environment, it still tends to interpret partially and heavily overlapping multiple tree crowns as a single tree crown entity, leading to missed detection, as illustrated in Figure 13A.
- (2)
- Background information interference. For the mixed forest scene, these non-object tree species share similar visual characteristics with object trees, creating challenges in distinguishing the semantic characteristics between them. This similarity often leads to false detection, as depicted in Figure 13B.

4.3. Potential Uncertainty
4.4. Further Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. The State of the World’s Forests 2022: Forest Pathways for Green Recovery and Building Inclusive, Resilient and Sustainable Economies; FAO: Rome, Italy, 2022. [Google Scholar] [CrossRef]
- Bukoski, J.J.; Cook-Patton, S.C.; Melikov, C.; Ban, H.; Chen, J.L.; Goldman, E.D.; Harris, N.L.; Potts, M.D. Rates and drivers of aboveground carbon accumulation in global monoculture plantation forests. Nat. Commun. 2022, 13, 4206. [Google Scholar] [CrossRef] [PubMed]
- Smyth, M.-A. Plantation forestry: Carbon and climate impacts. Land Use Policy 2023, 130, 106677. [Google Scholar] [CrossRef]
- Payn, T.; Carnus, J.-M.; Freer-Smith, P.; Kimberley, M.; Kollert, W.; Liu, S.; Orazio, C.; Rodriguez, L.; Silva, L.N.; Wingfield, M.J. Changes in planted forests and future global implications. For. Ecol. Manag. 2015, 352, 57–67. [Google Scholar] [CrossRef]
- Zhou, P.; Sun, Z.; Zhang, X.; Wang, Y. A framework for precisely thinning planning in a managed pure Chinese fir forest based on UAV remote sensing. Sci. Total Environ. 2023, 860, 160482. [Google Scholar] [CrossRef]
- Pearse, G.D.; Tan, A.Y.S.; Watt, M.S.; Franz, M.O.; Dash, J.P. Detecting and mapping tree seedlings in UAV imagery using convolutional neural networks and field-verified data. ISPRS J. Photogramm. Remote Sens. 2020, 168, 156–169. [Google Scholar] [CrossRef]
- Guerra-Hernández, J.; Cosenza, D.N.; Rodriguez, L.C.E.; Silva, M.; Tomé, M.; Díaz-Varela, R.A.; González-Ferreiro, E. Comparison of ALS- and UAV(SfM)-derived high-density point clouds for individual tree detection in Eucalyptus plantations. Int. J. Remote Sens. 2018, 39, 5211–5235. [Google Scholar] [CrossRef]
- Fu, H.; Li, H.; Dong, Y.; Xu, F.; Chen, F. Segmenting individual tree from TLS point clouds using improved DBSCAN. Forests 2022, 13, 566. [Google Scholar] [CrossRef]
- Lindberg, E.; Holmgren, J. Individual tree crown methods for 3d data from remote sensing. Curr. For. Rep. 2017, 3, 19–31. [Google Scholar] [CrossRef]
- Puliti, S.; Astrup, R. Automatic detection of snow breakage at single tree level using YOLOv5 applied to UAV imagery. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102946. [Google Scholar] [CrossRef]
- Wagner, F.H.; Ferreira, M.P.; Sanchez, A.; Hirye, M.C.M.; Zortea, M.; Gloor, E.; Phillips, O.L.; de Souza Filho, C.R.; Shimabukuro, Y.E.; Aragão, L.E.O.C. Individual tree crown delineation in a highly diverse tropical forest using very high resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 362–377. [Google Scholar] [CrossRef]
- Xu, X.; Zhou, Z.; Tang, Y.; Qu, Y. Individual tree crown detection from high spatial resolution imagery using a revised local maximum filtering. Remote Sens. Environ. 2021, 258, 112397. [Google Scholar] [CrossRef]
- Qin, H.; Zhou, W.; Yao, Y.; Wang, W. Individual tree segmentation and tree species classification in subtropical broadleaf forests using UAV-based lidar, hyperspectral, and ultrahigh-resolution RGB data. Remote Sens. Environ. 2022, 280, 113143. [Google Scholar] [CrossRef]
- Gu, J.; Congalton, R.G. Individual tree crown delineation from UAS imagery based on region growing by over-segments with a competitive mechanism. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, X.; Wu, B. Automatic detection of individual oil palm trees from UAV images using HOG features and an SVM classifier. Int. J. Remote Sens. 2018, 40, 7356–7370. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.; Hao, Z.; Post, C.J.; Mikhailova, E.A.; Lin, L.; Zhao, G.; Tian, S.; Liu, J. Comparison of classical methods and Mask R-CNN for automatic tree detection and mapping using UAV imagery. Remote Sens. 2022, 14, 295. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. arXiv 2016. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv 2015. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14, 2016. pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Santos, A.A.D.; Marcato Junior, J.; Araújo, M.S.; Di Martini, D.R.; Tetila, E.C.; Siqueira, H.L.; Aoki, C.; Eltner, A.; Matsubara, E.T.; Pistori, H.; et al. Assessment of CNN-based methods for individual tree detection on images captured by RGB cameras attached to UAVs. Sensors 2019, 19, 3595. [Google Scholar] [CrossRef]
- Sun, Y.; Li, Z.; He, H.; Guo, L.; Zhang, X.; Xin, Q. Counting trees in a subtropical mega city using the instance segmentation method. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102662. [Google Scholar] [CrossRef]
- Mo, J.; Lan, Y.; Yang, D.; Wen, F.; Qiu, H.; Chen, X.; Deng, X. Deep learning-based instance segmentation method of Litchi canopy from UAV-acquired images. Remote Sens. 2021, 13, 3919. [Google Scholar] [CrossRef]
- Jiang, P.Y.; Ergu, D.; Liu, F.Y.; Cai, Y.; Ma, B. A review of yolo algorithm developments. In Proceedings of the 8th International Conference on Information Technology and Quantitative Management (ITQM)—Developing Global Digital Economy after COVID-19, Chengdu, China, 9–11 July 2021; pp. 1066–1073. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 4 March 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors 2022. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Lou, X.W.; Huang, Y.X.; Fang, L.M.; Huang, S.Q.; Gao, H.L.; Yang, L.B.; Weng, Y.H.; Hung, I.K.U. Measuring loblolly pine crowns with drone imagery through deep learning. J. For. Res. 2022, 33, 227–238. [Google Scholar] [CrossRef]
- Chen, Y.; Xu, H.; Zhang, X.; Gao, P.; Xu, Z.; Huang, X. An object detection method for bayberry trees based on an improved YOLO algorithm. Int. J. Digit. Earth 2023, 16, 781–805. [Google Scholar] [CrossRef]
- Dong, C.; Cai, C.; Chen, S.; Xu, H.; Yang, L.; Ji, J.; Huang, S.; Hung, I.-K.; Weng, Y.; Lou, X. Crown width extraction of Metasequoia Glyptostroboides using improved YOLOv7 based on UAV images. Drones 2023, 7, 336. [Google Scholar] [CrossRef]
- Wardana, D.P.T.; Sianturi, R.S.; Fatwa, R. Detection of oil palm trees using deep learning method with high-resolution aerial image data. In Proceedings of the 8th International Conference on Sustainable Information Engineering and Technology, Bali, Indonesia, 24–25 October 2023; ACM: Bali, Indonesia, 2023; pp. 90–98. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A small target forest fire detection model based on YOLOv5 improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Qin, B.; Sun, F.; Shen, W.; Dong, B.; Ma, S.; Huo, X.; Lan, P. Deep learning-based pine nematode trees’ identification using multispectral and visible UAV imagery. Drones 2023, 7, 183. [Google Scholar] [CrossRef]
- Moharram, D.; Yuan, X.; Li, D. Tree seedlings detection and counting using a deep learning algorithm. Appl. Sci. 2023, 13, 895. [Google Scholar] [CrossRef]
- Jintasuttisak, T.; Edirisinghe, E.; Elbattay, A. Deep neural network based date palm tree detection in drone imagery. Comput. Electron. Agric. 2022, 192, 106560. [Google Scholar] [CrossRef]
- Zhao, H.; Morgenroth, J.; Pearse, G.; Schindler, J. A systematic review of individual tree crown detection and delineation with convolutional neural networks (cnn). Curr. For. Rep. 2023, 9, 149–170. [Google Scholar] [CrossRef]
- Li, X.; Duan, A.; Zhang, J. Long-term effects of planting density and site quality on timber assortment structure based on a 41-year plantation trial of Chinese fir. Trees For. People 2023, 12, 100396. [Google Scholar] [CrossRef]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020), Washington, DC, USA, 14–19 June 2020; pp. 390–391. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 20–26 October 2019; pp. 9197–9206. [Google Scholar] [CrossRef]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–9 June 2023; IEEE: Rhodes Island, Greece, 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar] [CrossRef]
- Chen, X.; Yu, K.; Yu, S.; Hu, Z.; Tan, H.; Chen, Y.; Huang, X.; Liu, J. Study on single-tree segmentation of Chinese fir plantations using coupled local maximum and height-weighted improved k-means algorithm. Forests 2023, 14, 2130. [Google Scholar] [CrossRef]
- Gan, Y.; Wang, Q.; Iio, A. Tree crown detection and delineation in a temperate deciduous forest from UAV RGB imagery using deep learning approaches: Effects of spatial resolution and species characteristics. Remote Sens. 2023, 15, 778. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, S.; Lu, J.; Wang, H.; Feng, Y.; Shi, C.; Li, D.; Zhao, R. A lightweight dead fish detection method based on deformable convolution and YOLOV4. Comput. Electron. Agric. 2022, 198, 107098. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, W.; Li, C.; Zeng, C. SAR image near-shore ship target detection method in complex background. Int. J. Remote Sens. 2023, 44, 924–952. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Beloiu, M.; Heinzmann, L.; Rehush, N.; Gessler, A.; Griess, V.C. Individual tree-crown detection and species identification in heterogeneous forests using aerial rgb imagery and deep learning. Remote Sens. 2023, 15, 1463. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ene, L.; Gupta, S.; Heinzel, J.; Holmgren, J.; Pitkanen, J.; Solberg, S.; Wang, Y.; Weinacker, H.; Hauglin, K.M.; et al. Comparative testing of single-tree detection algorithms under different types of forest. Forestry 2012, 85, 27–40. [Google Scholar] [CrossRef]
- Rosnell, T.; Honkavaara, E. Point cloud generation from aerial image data acquired by a quadrocopter type micro unmanned aerial vehicle and a digital still camera. Sensors 2012, 12, 453–480. [Google Scholar] [CrossRef]
- Li, L.; Mu, X.; Chianucci, F.; Qi, J.; Jiang, J.; Zhou, J.; Chen, L.; Huang, H.; Yan, G.; Liu, S. Ultrahigh-resolution boreal forest canopy mapping: Combining UAV imagery and photogrammetric point clouds in a deep-learning-based approach. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102686. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Canopy Density | Tree Species | Ratio of Non-Target Tree Species | Image Number | Chinese Fir Instance | Description |
|---|---|---|---|---|---|---|
| Scene 1 | 0.55–0.70 | Single-class | <2% | 138 | 2501 | Pure Chinese fir forest with low density and uniform distribution. Corresponds to Figure 2a. |
| Scene 2 | 0.70–0.95 | Single-class | <5% | 310 | 8091 | Pure Chinese fir forest with high density, clustered, or random distribution. Corresponds to Figure 2b,c. |
| Scene 3 | 0.65–0.90 | Multi-class | 45% | 284 | 4288 | Mixed forest and non-target tree species can be viewed as background information. Corresponds to Figure 2d. |
| Scene 4 | 0.45–0.65 | Multi-class | 30% | 246 | 5559 | Low density and random distribution Chinese fir forest with multiple tree species and bare ground as background information. Corresponds to Figure 2e. |
| Basic Network | Precision | Recall | F1-Score | AP@0.5 |
|---|---|---|---|---|
| YOLOv5 | 93.5 | 91.4 | 92.4 | 95.9 |
| YOLOv5 + DCN | 94.0 | 92.0 | 93.0 | 96.5 |
| YOLOv5 + EMA | 94.6 | 91.2 | 92.9 | 96.3 |
| YOLOv5 + DCN + EMA | 96.1 | 93.0 | 94.5 | 97.3 |
| Network | Precision | Recall | F1-Score | AP@0.5 | Model Size (MB) | FPS |
|---|---|---|---|---|---|---|
| SSD | 89.1 | 84.7 | 86.8 | 91.4 | 90.5 | 28 |
| YOLOv4 | 93.2 | 91.9 | 92.5 | 96.8 | 100.6 | 44 |
| YOLOv5 | 93.5 | 91.4 | 92.4 | 95.9 | 14.4 | 62 |
| YOLO-DCAM | 96.1 | 93.0 | 94.5 | 97.3 | 14.8 | 53 |
| YOLOv6 | 93.2 | 90.8 | 92.0 | 97.0 | 32.8 | 85 |
| YOLOv7-tiny | 91.4 | 89.6 | 90.5 | 93.7 | 12.3 | 68 |
| YOLOv7 | 95.3 | 92.1 | 93.7 | 97.4 | 74.8 | 47 |
| YOLOv8 | 93.7 | 91.5 | 92.6 | 97.2 | 22.5 | 74 |
| RT-DERT-l | 93.2 | 90.6 | 91.9 | 96.4 | 66.1 | 80 |
| Classes | Precision | Recall | F1-Score | AP@0.5 |
|---|---|---|---|---|
| All | 96.1 | 93.0 | 94.5 | 97.3 |
| Scene 1 | 99.4 | 99.2 | 99.3 | 99.5 |
| Scene 2 | 96.5 | 94.3 | 95.4 | 98.0 |
| Scene 3 | 94.8 | 91.8 | 93.3 | 96.2 |
| Scene 4 | 96.4 | 88.8 | 92.4 | 95.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, H.; Liu, Y.; Zhang, H.; Zheng, D. Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM. Remote Sens. 2024, 16, 335. https://doi.org/10.3390/rs16020335
Wang J, Zhang H, Liu Y, Zhang H, Zheng D. Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM. Remote Sensing. 2024; 16(2):335. https://doi.org/10.3390/rs16020335
Chicago/Turabian StyleWang, Jiansen, Huaiqing Zhang, Yang Liu, Huacong Zhang, and Dongping Zheng. 2024. "Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM" Remote Sensing 16, no. 2: 335. https://doi.org/10.3390/rs16020335
APA StyleWang, J., Zhang, H., Liu, Y., Zhang, H., & Zheng, D. (2024). Tree-Level Chinese Fir Detection Using UAV RGB Imagery and YOLO-DCAM. Remote Sensing, 16(2), 335. https://doi.org/10.3390/rs16020335