


Multi-Scale Image- and Feature-Level Alignment for Cross-Resolution Person Re-Identification


Abstract
1. Introduction
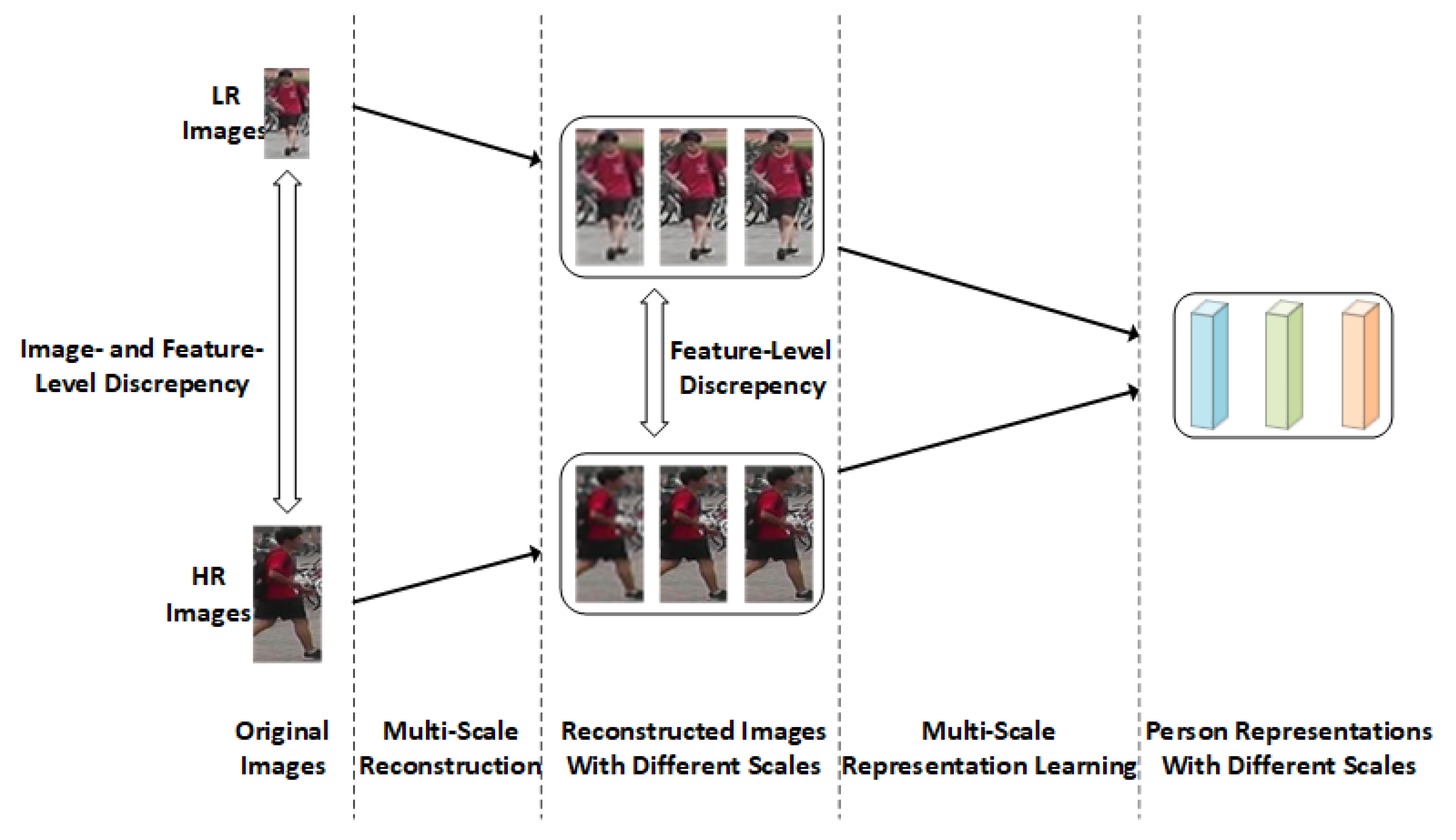
- We propose a Cascaded Multi-Scale Resolution Reconstruction module (CMSR) to align the images with different resolutions at the image level. Specifically, we first reconstruct all images into LR images, regardless of their resolution, so all images are aligned on the LR scale. Then, we reconstruct and align these images on higher resolution scales, so the model can also benefit from the discriminative clues that lie in HR images.
- We design a Multi-Resolution Representation Learning module (MRL) to align the images with different resolutions at the feature level. Specifically, we utilize the image-level aligned person images for supervised training to encourage the features of the reconstructed images to be aligned on each resolution scale.
- Experimental results on five cross-resolution person re-ID datasets demonstrate the superiority of the proposed method compared to other state-of-the-art methods. In addition, the generalization of the proposed method is verified on a UAV simulation cross-resolution vehicle dataset.
2. Related Work
2.1. Deep Learning Person Re-Identification
2.2. Cross-Resolution Person Re-Identification
3. The Proposed Method
3.1. Overview
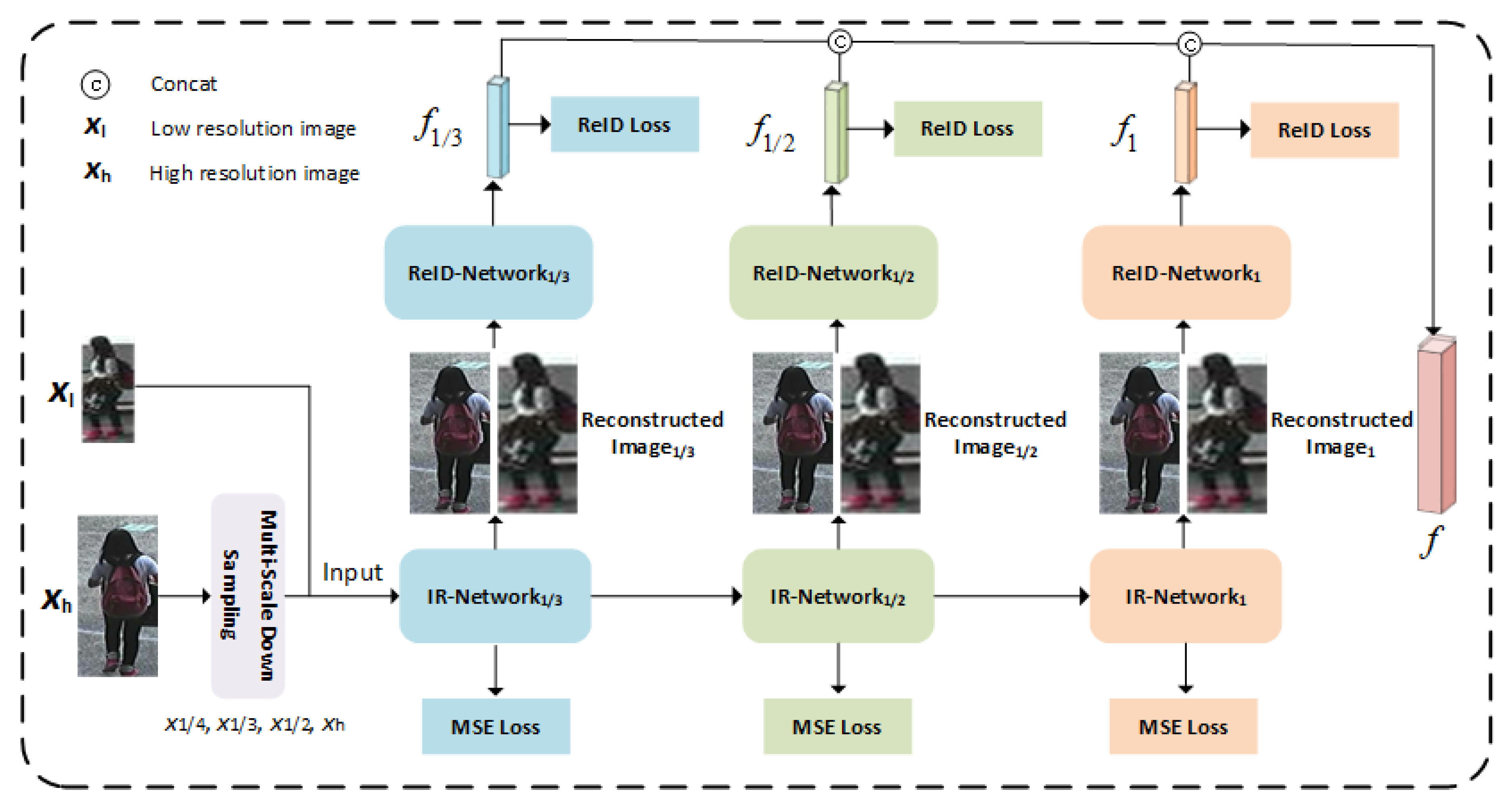
3.2. Cascaded Multi-Scale Resolution Reconstruction Module
3.3. Multi-Resolution Representation Learning Module
4. Experiments
4.1. Datasets
- (1)
- The CAVIAR dataset [40] consists of images captured by 2 cameras, which contains 1220 images with 72 identities. The person images captured by the two cameras are of different resolutions because the shooting distance of the two cameras is different. Following the experiment setting in [25], we exclude 22 identities that appear in only one camera. For the remaining 50 identities, we randomly select 10 HR and 10 LR images for each identity to construct the dataset.
- (2)
- The MLR-Market-1501 dataset is constructed based on Market-1501 [21] which contains images captured by 6 cameras. The dataset includes 3561 training images with 751 identities and 15,913 testing images with 750 identities. We adopt the same strategy as described in [25] to generate LR images with 3 resolution scales. Specifically, we randomly pick one camera and down-sample each image in the picked camera by randomly picking a down-sampling rate, and the images of other cameras remain unchanged.
- (3)
- The MLR-CUHK03 dataset is constructed based on CUHK03 [41] which contains 14,097 images with 1467 identities captured by 5 cameras. The training set includes images with 1367 identities, and the other 100 identities are used for testing. The down-sampling strategy is the same as for MLR-Market-1501.
- (4)
- The MLR-VIPeR dataset is constructed based on VIPeR [42] which contains 1264 images with 632 identities captured by 2 cameras. We randomly partition the dataset into two non-overlapping parts for training and testing according to the identity label. The down-sampling strategy is the same as for MLR-Market-1501.
- (5)
- The MLR-SYSU dataset is constructed based on SYSU [43] which contains 24,446 images with 502 identities captured by 2 cameras. For each identity, we randomly choose 3 images from each camera. We separate the dataset into two non-overlapping parts for training and testing according to the identity label. The down-sampling strategy is the same as for MLR-Market-1501.
4.2. Experiment Settings
4.3. Comparison with State-of-the-Art
4.4. Ablation Study
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hauptmann, A.; Yang, Y.; Zheng, L. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Fang, W.; Zheng, Y.; Wang, R. SDBAD-Net: A Spatial Dual-Branch Attention Dehazing Network based on Meta-Former Paradigm. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 60–70. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Zheng, Z.; Li, S.; Yang, Y. Camera style adaptation for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5157–5166. [Google Scholar]
- Zhang, G.; Zhang, H.; Lin, W.; Chandran, A.K.; Jing, X. Camera contrast learning for unsupervised person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4096–4107. [Google Scholar] [CrossRef]
- Chung, D.; Delp, E.J. Camera-aware image-to-image translation using similarity preserving StarGAN for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Miao, J.; Wu, Y.; Liu, P.; Ding, Y.; Yang, Y. Pose-guided feature alignment for occluded person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 542–551. [Google Scholar]
- Chen, P.; Liu, W.; Dai, P.; Liu, J.; Ye, Q.; Xu, M.; Chen, Q.; Ji, R. Occlude them all: Occlusion-aware attention network for occluded person re-id. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11833–11842. [Google Scholar]
- Zhu, Z.; Jiang, X.; Zheng, F. Viewpoint-aware loss with angular regularization for person re-identification [J/OL]. arXiv 2019. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, G.; Chen, Y.; Zheng, Y. Global relation-aware contrast learning for unsupervised person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8599–8610. [Google Scholar]
- Sun, X.; Zheng, L. Dissecting person re-identification from the viewpoint of viewpoint. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 608–617. [Google Scholar]
- Zhang, Z.; Da Xu, R.Y.; Jiang, S.; Li, Y.; Huang, C.; Deng, C. Illumination adaptive person reid based on teacher-student model and adversarial training. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Virtual, 25–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2321–2325. [Google Scholar]
- Zeng, Z.; Wang, Z.; Wang, Z.; Zheng, Y.; Chuang, Y.Y.; Satoh, S. Illumination-adaptive person re-identification. IEEE Trans. Multimed. 2020, 22, 3064–3074. [Google Scholar] [CrossRef]
- Zhang, G.; Luo, Z.; Chen, Y.; Zheng, Y.; Lin, W. Illumination unification for person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6766–6777. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. RGB-infrared cross-modality person re-identification via joint pixel and feature alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3623–3632. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Parameter sharing exploration and hetero-center triplet loss for visible-thermal person re-identification. IEEE Trans. Multimed. 2020, 23, 4414–4425. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, G.; Zhang, H.; Zheng, Y.; Lin, W. Multi-level Part-aware Feature Disentangling for Text-based Person Search. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2801–2806. [Google Scholar]
- Qian, X.; Wang, W.; Zhang, L.; Zhu, F.; Fu, Y.; Xiang, T.; Jiang, Y.G.; Xue, X. Long-term cloth-changing person re-identification. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Zhang, G.; Liu, J.; Chen, Y.; Zheng, Y.; Zhang, H. Multi-biometric unified network for cloth-changing person re-identification. IEEE Trans. Image Process. 2023, 32, 4555–4566. [Google Scholar] [CrossRef] [PubMed]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Chen, Y.C.; Li, Y.J.; Du, X.; Wang, Y.C.F. Learning resolution-invariant deep representations for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8215–8222. [Google Scholar]
- Li, X.; Zheng, W.S.; Wang, X.; Xiang, T.; Gong, S. Multi-scale learning for low-resolution person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3765–3773. [Google Scholar]
- Jiao, J.; Zheng, W.S.; Wu, A.; Zhu, X.; Gong, S. Deep low-resolution person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, Z.; Ye, M.; Yang, F.; Bai, X.; Satoh, S. Cascaded SR-GAN for scale-adaptive low resolution person re-identification. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 1, p. 4. [Google Scholar]
- Zhang, G.; Ge, Y.; Dong, Z.; Wang, H.; Zheng, Y.; Chen, S. Deep high-resolution representation learning for cross-resolution person re-identification. IEEE Trans. Image Process. 2021, 30, 8913–8925. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G.; Chen, Y.; Lin, W.; Chandran, A.; Jing, X. Low resolution information also matters: Learning multi-resolution representations for person re-identification. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 1295–1301. [Google Scholar]
- Yan, C.; Fan, X.; Fan, J.; Wang, N. Improved U-Net remote sensing classification algorithm based on Multi-Feature Fusion Perception. Remote Sens. 2022, 14, 1118. [Google Scholar] [CrossRef]
- Chen, W.; Ouyang, S.; Tong, W.; Li, X.; Zheng, X.; Wang, L. GCSANet: A global context spatial attention deep learning network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1150–1162. [Google Scholar] [CrossRef]
- Wang, X.; Tan, L.; Fan, J. Performance Evaluation of Mangrove Species Classification Based on Multi-Source Remote Sensing Data Using Extremely Randomized Trees in Fucheng Town, Leizhou City, Guangdong Province. Remote Sens. 2023, 15, 1386. [Google Scholar] [CrossRef]
- Ma, M.; Ma, W.; Jiao, L.; Liu, X.; Li, L.; Feng, Z.; Yang, S. A multimodal hyper-fusion transformer for remote sensing image classification. Inf. Fusion 2023, 96, 66–79. [Google Scholar] [CrossRef]
- Tian, M.; Yi, S.; Li, H.; Li, S.; Zhang, X.; Shi, J.; Yan, J.; Wang, X. Eliminating background-bias for robust person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5794–5803. [Google Scholar]
- Miao, Z.; Liu, H.; Shi, W.; Xu, W.; Ye, H. Modality-aware Style Adaptation for RGB-Infrared Person Re-Identification. In Proceedings of the IJCAI, Montreal, QC, Canada, 19–27 August 2021; pp. 916–922. [Google Scholar]
- Han, K.; Huang, Y.; Chen, Z.; Wang, L.; Tan, T. Prediction and recovery for adaptive low-resolution person re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 193–209. [Google Scholar]
- Li, Y.J.; Chen, Y.C.; Lin, Y.Y.; Du, X.; Wang, Y.C.F. Recover and identify: A generative dual model for cross-resolution person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8090–8099. [Google Scholar]
- Cheng, Z.; Dong, Q.; Gong, S.; Zhu, X. Inter-task association critic for cross-resolution person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2605–2615. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Dong, S.C.; Cristani, M.; Stoppa, M.; Bazzani, L.; Murino, V. Custom pictorial structures for re-identification. In Proceedings of the British Machine Vision Conference, Dundee, UK, 29 August–2 September 2011; Volume 6. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. Deepreid: Deep filter pairing neural network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In Proceedings of the Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2008; pp. 262–275. [Google Scholar]
- Chen, Y.C.; Zheng, W.S.; Lai, J.H.; Yuen, P.C. An asymmetric distance model for cross-view feature mapping in person reidentification. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1661–1675. [Google Scholar] [CrossRef]
- Lu, M.; Xu, Y.; Li, H. Vehicle Re-Identification Based on UAV Viewpoint: Dataset and Method. Remote Sens. 2022, 14, 4603. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Jing, X.Y.; Zhu, X.; Wu, F.; You, X.; Liu, Q.; Yue, D.; Hu, R.; Xu, B. Super-resolution person re-identification with semi-coupled low-rank discriminant dictionary learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 695–704. [Google Scholar]
- Wang, Z.; Hu, R.; Yu, Y.; Jiang, J.; Liang, C.; Wang, J. Scale-adaptive low-resolution person re-identification via learning a discriminating surface. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; Volume 2, p. 6. [Google Scholar]
- Han, K.; Huang, Y.; Song, C.; Wang, L.; Tan, T. Adaptive super-resolution for person re-identification with low-resolution images. Pattern Recognit. 2021, 114, 107682. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | CAVIAR | MLR-Market-1501 | MLR-CUHK03 | MLR-VIPeR | MLR-SYSU | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | |
| JUDEA [24] | 22.0 | 60.1 | - | - | 26.2 | 58.0 | 26.0 | 55.1 | 18.3 | 41.9 |
| SLDL [46] | 18.4 | 44.8 | - | - | - | - | 20.3 | 44.0 | 20.3 | 34.8 |
| SDF [47] | 14.3 | 37.5 | - | - | 22.2 | 48.0 | 9.3 | 38.1 | 13.3 | 26.7 |
| SING [25] | 33.5 | 72.7 | 74.4 | 87.8 | 67.7 | 90.7 | 33.5 | 57.0 | 50.7 | 75.4 |
| CSR-GAN [26] | 32.3 | 70.9 | 76.4 | 88.5 | 70.7 | 92.1 | 37.2 | 62.3 | - | - |
| CAD-Net [36] | 42.8 | 76.2 | 83.7 | 92.7 | 82.1 | 97.4 | 43.1 | 68.2 | - | - |
| INTACT [37] | 44.0 | 81.8 | 88.1 | 95.0 | 86.4 | 97.4 | 46.2 | 73.1 | - | - |
| PRI [35] | 43.2 | 78.5 | 84.9 | 93.5 | 85.2 | 97.5 | - | - | - | - |
| PCB + PRI [35] | 44.3 | 83.7 | 88.1 | 94.2 | 86.2 | 97.9 | - | - | - | - |
| APSR [48] | 44.0 | 77.6 | - | - | 84.1 | 97.5 | 48.8 | 73.2 | 63.7 | 83.5 |
| Ours | 62.4 | 81.2 | 89.6 | 95.6 | 92.4 | 96.2 | 60.3 | 85.7 | 75.4 | 88.1 |
| Methods | CAVIAR | MLR-Market-1501 | MLR-CUHK03 | MLR-VIPeR | MLR-SYSU | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | |
| Baseline | 50.4 | 76.0 | 87.7 | 94.3 | 88.8 | 94.7 | 55.2 | 83.2 | 68.7 | 86.1 |
| Baseline + CMSR | 51.6 | 71.2 | 88.0 | 94.9 | 90.5 | 94.8 | 55.9 | 81.3 | 70.0 | 85.3 |
| Baseline + CMSR + MRL | 62.4 | 81.2 | 89.6 | 95.6 | 92.4 | 96.2 | 60.3 | 85.7 | 75.4 | 88.1 |
| Methods | CAVIAR | MLR-Market-1501 | MLR-CUHK03 | MLR-VIPeR | MLR-SYSU | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | Rank-1 | Rank-5 | |
| 50.4 | 76.0 | 87.7 | 94.3 | 88.8 | 94.7 | 55.2 | 83.2 | 68.7 | 86.1 | |
| 52.0 | 74.4 | 88.9 | 95.4 | 89.0 | 94.4 | 57.5 | 84.0 | 72.0 | 86.3 | |
| 62.4 | 81.2 | 89.6 | 95.6 | 92.4 | 96.2 | 60.3 | 85.7 | 75.4 | 88.1 | |
| 61.6 | 77.6 | 89.1 | 95.5 | 90.5 | 95.2 | 61.3 | 88.0 | 74.2 | 87.1 | |
| Identities/Images | Rank-1 | Rank-5 | Rank-10 | mAP |
|---|---|---|---|---|
| 1415/14,611 | 65.7 | 88.4 | 92.9 | 75.7 |
| 2418/27,918 | 74.1 | 92.0 | 94.5 | 82.1 |
| 4413/52,172 | 79.6 | 97.7 | 99.5 | 87.4 |
| 7086/80,532 | 74.6 | 95.8 | 98.5 | 83.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Wang, Z.; Zhang, J.; Luo, Z.; Zhao, Z. Multi-Scale Image- and Feature-Level Alignment for Cross-Resolution Person Re-Identification. Remote Sens. 2024, 16, 278. https://doi.org/10.3390/rs16020278
Zhang G, Wang Z, Zhang J, Luo Z, Zhao Z. Multi-Scale Image- and Feature-Level Alignment for Cross-Resolution Person Re-Identification. Remote Sensing. 2024; 16(2):278. https://doi.org/10.3390/rs16020278
Chicago/Turabian StyleZhang, Guoqing, Zhun Wang, Jiangmei Zhang, Zhiyuan Luo, and Zhihao Zhao. 2024. "Multi-Scale Image- and Feature-Level Alignment for Cross-Resolution Person Re-Identification" Remote Sensing 16, no. 2: 278. https://doi.org/10.3390/rs16020278
APA StyleZhang, G., Wang, Z., Zhang, J., Luo, Z., & Zhao, Z. (2024). Multi-Scale Image- and Feature-Level Alignment for Cross-Resolution Person Re-Identification. Remote Sensing, 16(2), 278. https://doi.org/10.3390/rs16020278