4.1. Experiment Setting
Datasets. SYSU-MM01 [
31] is a popular cross-modality Person re-ID dataset with 303,420 images captured by 6 cameras. The training and test set include 34,167 and 4104 images, respectively. The dataset consists of two test modes: all search and indoor search. The all-search mode employs all available images, while the indoor-search mode exclusively utilizes images captured by the first, second, third, and sixth cameras.
RegDB [
46] contains 412 pedestrian identities, of which 254 are female and 158 are male. Of the 412 persons, 156 were taken from the front and 256 from the back. As the images were acquired during dynamic movements, the set of 10 images for each individual exhibits variations in body pose, capture distance, and lighting conditions. However, in 10 images of the same person, the camera’s weather conditions, viewing angles, and shooting perspectives (front and back view) are all the same. The image resolution of the visible image in the dataset is 800 × 600 pixels, and the image resolution of the infrared image is 640 × 480 pixels.
PRAI-1581 [
7] is captured using two DJI consumer drones positioned at an altitude ranging from 20 to 60 m above the ground. The drones collected approximately 120 videos by hovering, cruising, and rotating. A total of 39,461 images of 1581 individuals were collected by sampling the video at a rate of one frame per second. Image annotation is divided into three steps. First, pedestrian boxes are marked manually. Second, the same pedestrians in different videos are manually searched, grouped, and numbered. Finally, based on the generated annotation files containing pedestrian locations and numbers, person instances are cropped to form the final dataset. The dataset is partitioned into two distinct subsets: a training set and a test set. The training set comprises 19,523 images featuring 782 individuals, while the test set encompasses 19,938 images depicting 799 individuals. The size of each image in the dataset is 4000 × 2000 pixels, and the resolution of the person is 30–150 pixels.
The Matiwan Village dataset [
8] was collected by the full-spectrum multi-modal imaging spectrometer of the Gaofen Special Aviation System at a distance of 2000 m from the ground. Its spectral range is 400–1000 nm, the number of bands is 250, the image size is 3750 × 1580 pixels, and the spatial resolution is 0.5 m. It includes 19 categories of features, such as rice stubble, grassland, and elm trees. The preprocessing of the dataset is divided into four steps. First, the images are corrected for radiation through the ENVI platform. Second, the obtained positioning, orientation data, and collinear equations are used to calculate the coordinates of the corresponding ground points of the pixels to achieve geometric correction. Third, the image registration workflow tool is used to perform image registration. Finally, the processed images are stitched and cropped.
Evaluation Metrics. The Cumulative Matching Characteristic (CMC) and mean Average Precision (mAP) are chosen as the evaluation metrics. CMC is currently the most popular performance evaluation method in Person Re-ID. The rank-k accuracy of CMC represents the matching probability of the real identity label appearing in the first n bits of the result list. mAP is also currently the most commonly used indicator for evaluating the quality of the detection model, which measures the average of the retrieval performance of all classes.
Implementation Details. All experiments were performed using one NVIDIA 3090 GPU. For the SYSU-MM01 and RegDB datasets, the input sample was first adjusted to 288 × 144 pixels, and then data enhancement (such as random cropping and random horizontal flip) was performed on it. For the PRAI-1581 dataset, the input image was first resized to 384 × 192 pixels; data augmentation was performed by random horizontal flipping; and finally each channel of the processed image was normalized. For the Matiwan Village dataset, we cropped the original image based on the feature category annotation map provided by the dataset. The resolution of the cropped image block is 92 × 92 pixels.
4.2. Ablation Experiment
In this subsection, we report on some experiments to evaluate our model.
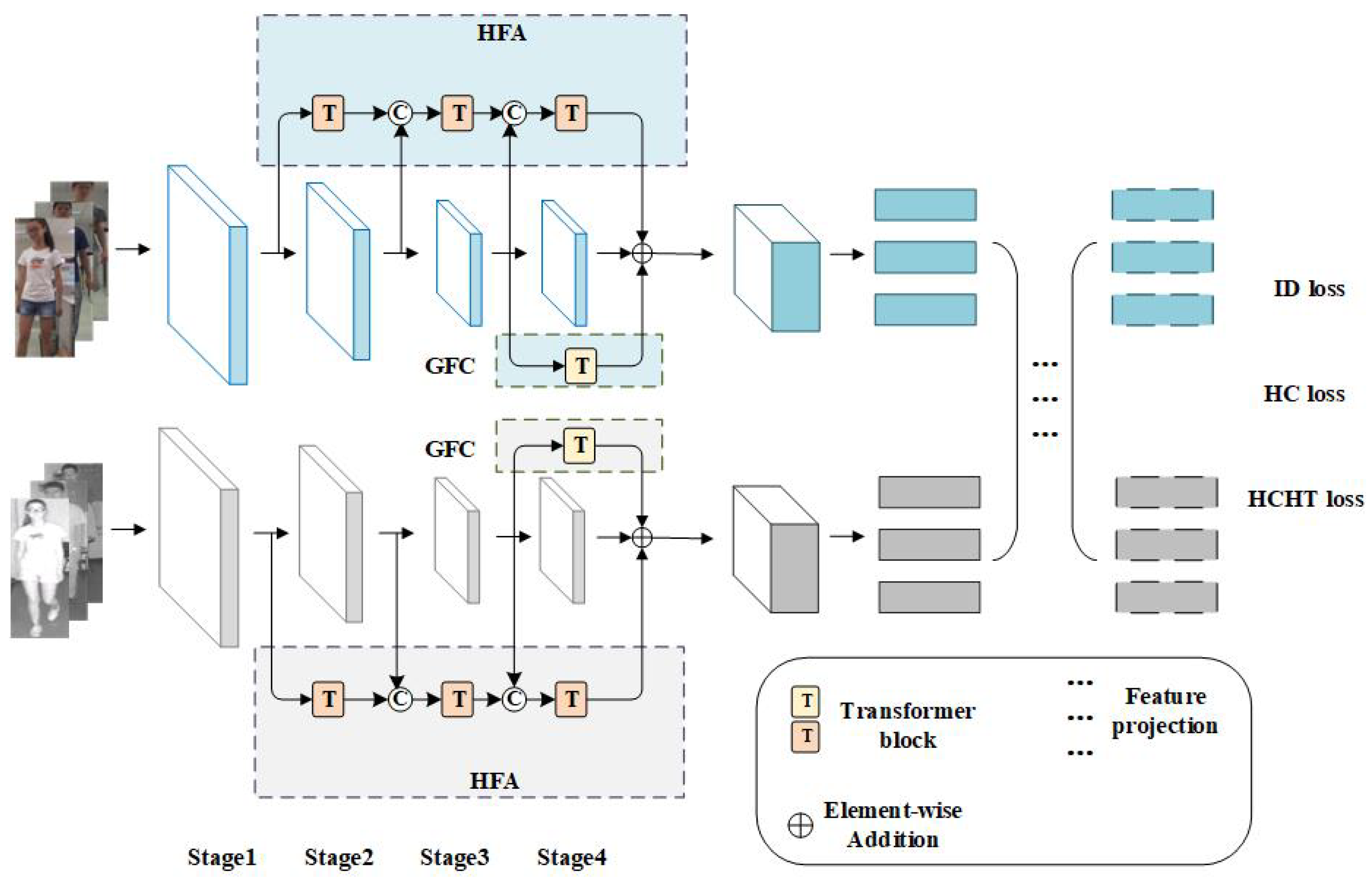
Analysis of each component: Our method consists of four components: a baseline network, HFA, GFC, and heterogeneous-center hard triplet loss. We chose TSLFN [
45] as the baseline, which is a two-stream network supervised jointly with cross-entropy loss and heterogeneous-center loss. The baseline is denoted as “B”, while HFA is denoted as “A”, GFC is indicated as “C”, and the heterogeneous-center hard triplet loss is denoted as “L”.
Table 1 shows the experimental results. The rank-1 and mAP of the baseline network are 54.85% and 55.88%, respectively. Adding the HFA module alone, rank-1 and mAP increased by 3.95% and 2.22%, respectively. Adding the GFC module alone, the rank-1 and mAP increased by 3.9% and 1.55%, respectively. This phenomenon proves the effectiveness of enriching deep features with detailed information and globally compensating for features. After combining the two modules, noteworthy enhancements in the network’s performance were observed, underscoring the mutually reinforcing nature of the HFA and GFC modules. Finally, we added the HCHT to the previous ones. The values of rank-1 and mAP reached 60.23% and 58.48%, respectively.
Parameter analysis of HFA: To analyze the validity of the HFA module, we performed comparative experiments on different combinations of aggregating hierarchical features. Meanwhile, we also analyzed the number of layers of each Transformer (the results are shown in
Table 2). In
,
represents the number of Transformer layers added after the
i-th stage.
means that the hierarchical features of the
i-th stage do not participate in the aggregation process. According to the setting in ViT [
42], we fixed the total layers of all Transformer blocks in HFA at 12 and the heads of each Transformer encoder at 16.
The experimental results of the first three groups show that it is not wise to let the hierarchical features of the four stages participate in the aggregation process. We infer that blindly integrating all the features will make the information too messy and overlapping, resulting in a burden to the network. Comparing the experimental results of the second and third group, we find that the effect of aggregating the hierarchical features from stage 2 to stage 4 is not ideal. The reason may be that, in the process of stage 1 to stage 4, the features extracted by the network contain less and less detailed information but more and more semantic information. This leads to shallow features with more details and less semantic information and to deep features with fewer details and more semantic information. If we choose to aggregate hierarchical features at a high level, the semantic information is enough, but the detailed information is mostly lost. Thus, we deduce that the low performance is caused by the loss of detailed information.
Comparing the experimental results of the third to seventh group, we find a very interesting phenomenon. When has fewer layers and has more layers, the performance is better. The optimal values of rank-1 and mAP reached 58.80% and 58.10%, respectively. The reason may be that semantic information is more advanced and complex than detailed information, so more layers are needed to process it. Comparing the experimental results of the last two groups, we find that blindly increasing the number of layers of will lead to performance degradation. We infer that the accuracy tends to converge as the depth of the Transformer increases. Finally, the performance is best when the depths of , , and are 3, 1, and 8, respectively.
Parameter analysis of GFC: To analyze the validity of the GFC module, we performed comparative experiments on the settings of
. Considering the burden of the entire network, we chose a Transformer with a relatively simple setting. Experimental results are detailed in
Table 3. When the number of heads is 4 and the depth is 1, rank-1 and mAP are optimal, 58.75% and 57.43%, respectively. Observing the overall results in
Table 3, there is a rule that, as the number of heads increases, the performance constantly improves. This phenomenon shows that the more heads the Transformer has, the stronger its ability to process features, and the more discriminative global features it can extract. We notice that when the number of heads is 4 and 8, their results are very close. In response to this phenomenon, we deduce that the accuracy tends to converge as the number of heads increases.
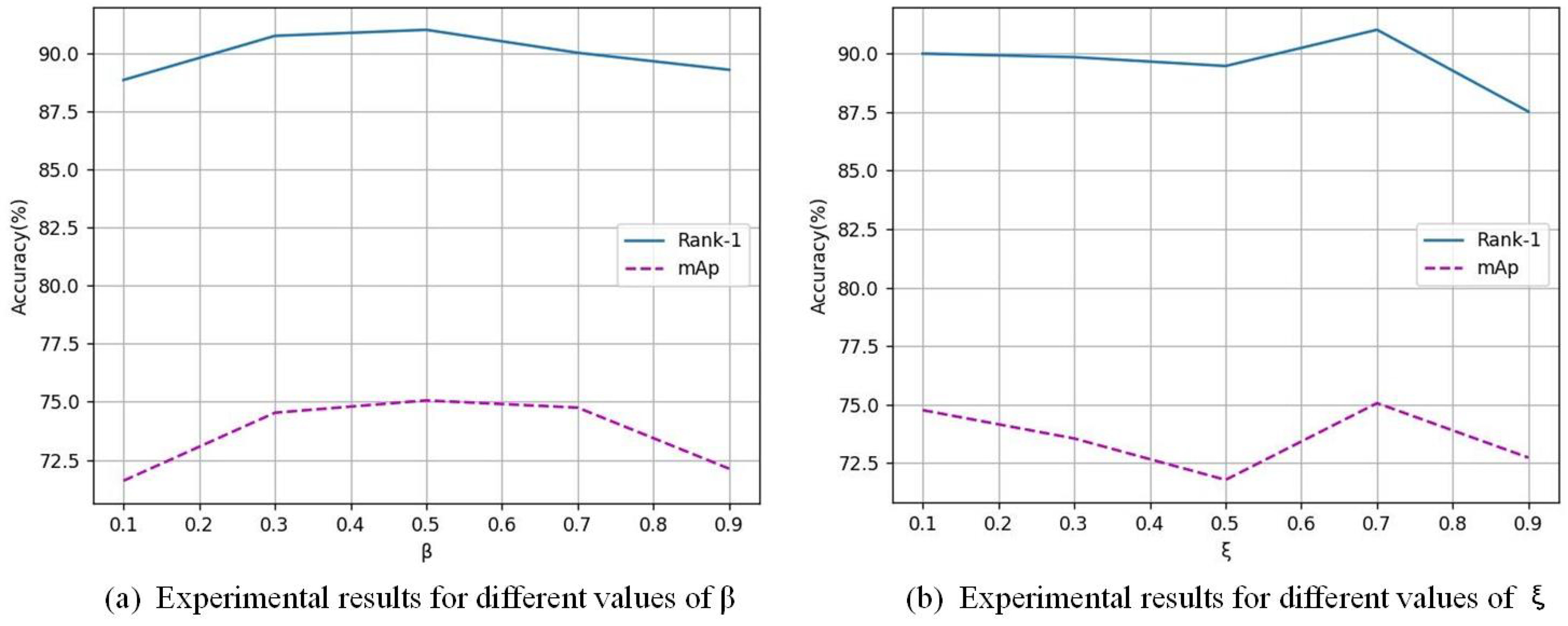
Analysis of parameters
and
: In this part, we explore the influence of
and
in the loss function. This experiment was performed on a network with HFA and GFC modules added. First, we kept the value of
at 0.7 and increased the value of
from 0.1 to 0.9.
Figure 3a shows that, when
= 0.5, the result reaches the best level. Secondly, we changed
regularly from 0.1 to 0.9.
Figure 3b shows that, when
= 0.7, the performance is optimal, and the rank-1 and mAP reach 91.02% and 75.06%, respectively. When the value of
is too large, the performance drops significantly. We infer that this is due to the network’s difficulty in balancing the distances between different identities.
Comparison of different backbones: The proposed TFCNet uses ResNet50 as the backbone and embeds multiple Transformer blocks in it. Considering that this structure may be costly, we adjusted it to use Transformer as the backbone. The results are shown in
Table 4 and
Table 5. We find that using Transformer as the backbone actually degrades the model’s performance. The reason may be that the four stages of ResNet50 are crucial for the extraction of semantic information, and it is not recommended to replace them with a series of simple convolution blocks. Specifically, our method uses the lost detail information to assist the semantic information in improving performance. In this process, semantic information dominates, and detailed information only plays a supporting role. However, in a network with Transformer as the backbone, the extraction of semantic information only relies on a series of simple convolution blocks, which may result in poor quality and small quantity of semantic information, thus reducing performance.
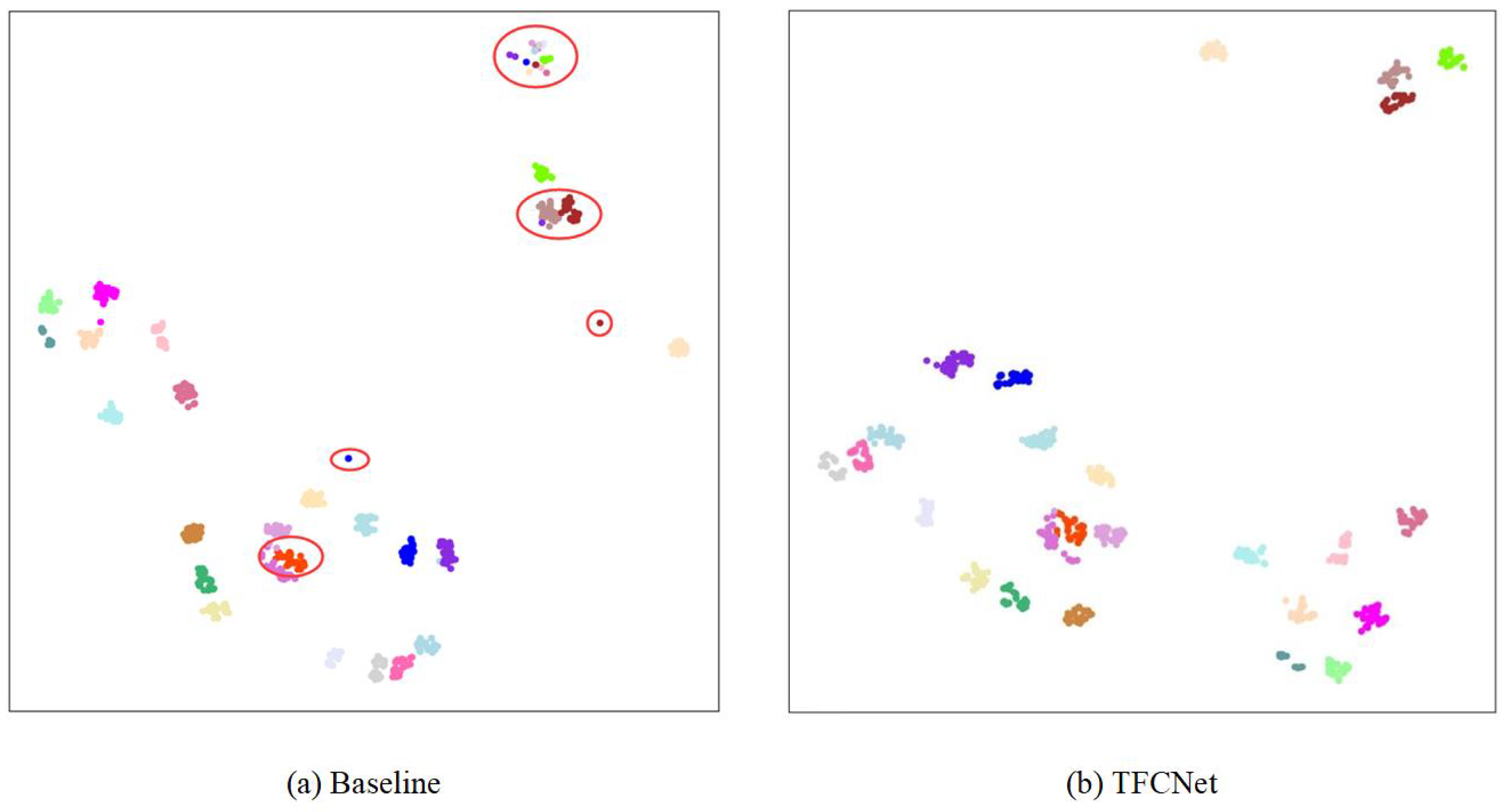
4.3. Analysis of the HFA Module
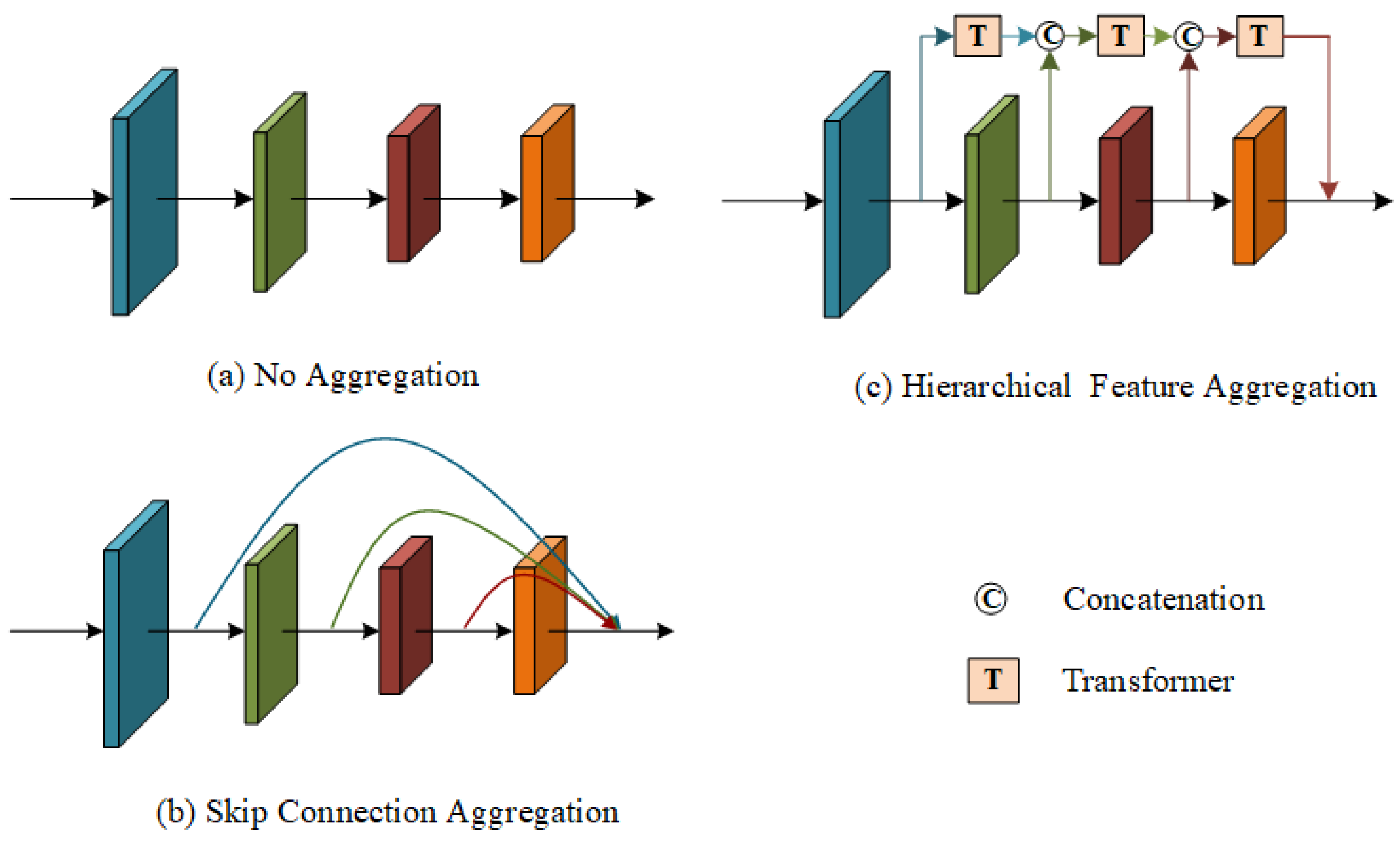
Comparison of feature aggregation methods: Skip connection is the most common method for aggregating multiple features at the same time. From
Figure 4b, we can see that this method is simple and crude, directly concatenating shallow-level, middle-level, and deep-level features. We replace hierarchical feature aggregation with skip connection aggregation in our model. By observing the results in
Table 6, we find that, whether we use skip connection aggregation or hierarchical feature aggregation, the model performance is significantly improved. However, the hierarchical feature aggregation is obviously better, being 2.48 points higher than the skip connection aggregation. This is due to the fact that simple aggregation operations of shallow and deep features will limit performance. To ensure the accuracy and fairness of the comparison, the three methods in
Table 6 all use the same losses, namely ID loss and HC loss.
Analysis of the effectiveness of each Transformer: We compare four sets of experiments to confirm its effectiveness: without adding a Transformer encoder, adding a Transformer encoder after stage 1, adding it after stage 1∼stage 2, and adding it after stage 1∼stage 3. The results are shown in
Table 7. We find that the rank-1/mAP of these four sets of experiments shows an upward trend, which affirms the idea of enriching features with detailed information to improve performance. Meanwhile, we calculate the rank-1/mAP increments between the four experiments, which are 3.04%/0.84%, 0.67%/0.72%, and 0.24%/0.66%, respectively. The results show that the increment between the second and first set of experiments is the largest. Because shallow features have more detailed information, Transformer extracts and transfers them to deep features, which can greatly improve model performance. Comparing the third and fourth group of experiments, although their results are improving, the increments are not obvious. This is because, as the number of convolutions increases, the features contain fewer and fewer details.
4.5. Comparison with State-of-the-Art Methods
Within this subsection, we conduct a comparative analysis of the proposed approach against state-of-the-art methods on the SYSU-MM01 and RegDB datasets. All methods use the ResNet-50 network as the backbone. The comparison methods are split into two categories, namely modality transformation-based methods and feature learning-based methods. D
RL [
35], AlignGAN [
34], Hi-CMD [
3], and XIV [
4] reduce cross-modality discrepancy through image generation techniques. For example, AlignGAN [
34] converts visible images into corresponding infrared images through CycleGAN to solve the issue of cross-modality discrepancies. DDAG [
1], AGW [
2], DLS [
6], NFS [
5], PIC [
47], and DFLN-ViT [
48] reduce cross-modality discrepancy by extracting discriminative modality-shared features. For example, DFLN-ViT [
48] considers potential correlations between different locations and channels.
SYSU-MM01 dataset:
Table 8 shows the comparison results, and our proposed method reaches the optimum. Specifically, our rank-1/mAP achieves 60.87%/58.87% and 63.59%/70.28% for the two search modes, respectively. Comparing with the modality transformation-based method [
4], the rank-1/mAP of TFCNet is 10.95%/8.14% higher than it is in the all-search mode. This shows that our method can achieve good results without the additional cost of image generation. Comparing with the feature learning-based method [
48], the rank-1/mAP of TFCNet is 3.22%/2.91% and 3.01%/3% higher than it is in the two settings, respectively. This shows the effectiveness of enriching deep features with detailed information and global compensation for local features with Transformer.
RegDB dataset:
Table 9 shows the comparison results. The rank-1/mAP of our TFCNet reaches 91.02%/75.06% and 90.39%/74.68% under the two settings, respectively. Compared with the modality transformation-based method [
3], the rank-1/mAP of TFCNet is 20.09%/9.02% higher than it is in visible-to-infrared mode. Comparing with the feature learning-based method [
48], the rank-1 of TFCNet outperforms it by 1.99% and 1.56% in two settings, respectively. The rank-1 of our method is the highest. Although the value of mAP is not optimal, it is not much different from the value of the optimal method. The effectiveness of the designed network can also be demonstrated on this dataset.
It should be noted that the results of DFLN-ViT [
48] in
Table 8 and
Table 9 are inconsistent with the original paper. This is because we reproduced it on an NVIDIA 3090 GPU and filled the tables with the results of the reproduction.
4.6. Migration Experiments on Remote Sensing Datasets
From
Figure 7, we can see that aerial pictures have a smaller field of view and less valuable information than those taken by traditional fixed cameras, which requires the network to have a higher degree of control over detailed information. Since our proposed HFA module involves detailed information, we only show the heatmap visualization of each Transformer encoder in the HFA model when conducting migration experiments on remote sensing datasets. Meanwhile, considering that the PRAI-1581 and Matiwan Village datasets are in the RGB modality, we only retain the visible branch of TFCNet.
PRAI-1581 dataset: The experimental results of our method on the PRAI-1581 dataset are shown in
Table 10, where rank-1/mAP reached 45.25%/56.40%. The results are 8.55%/10.3%, 6.8%/8.33%, and 3.15%/2% higher than SVDNet [
49], PCB+RPP [
50], and OSNET [
51] respectively, which proves that our method has good transferability and effectiveness.
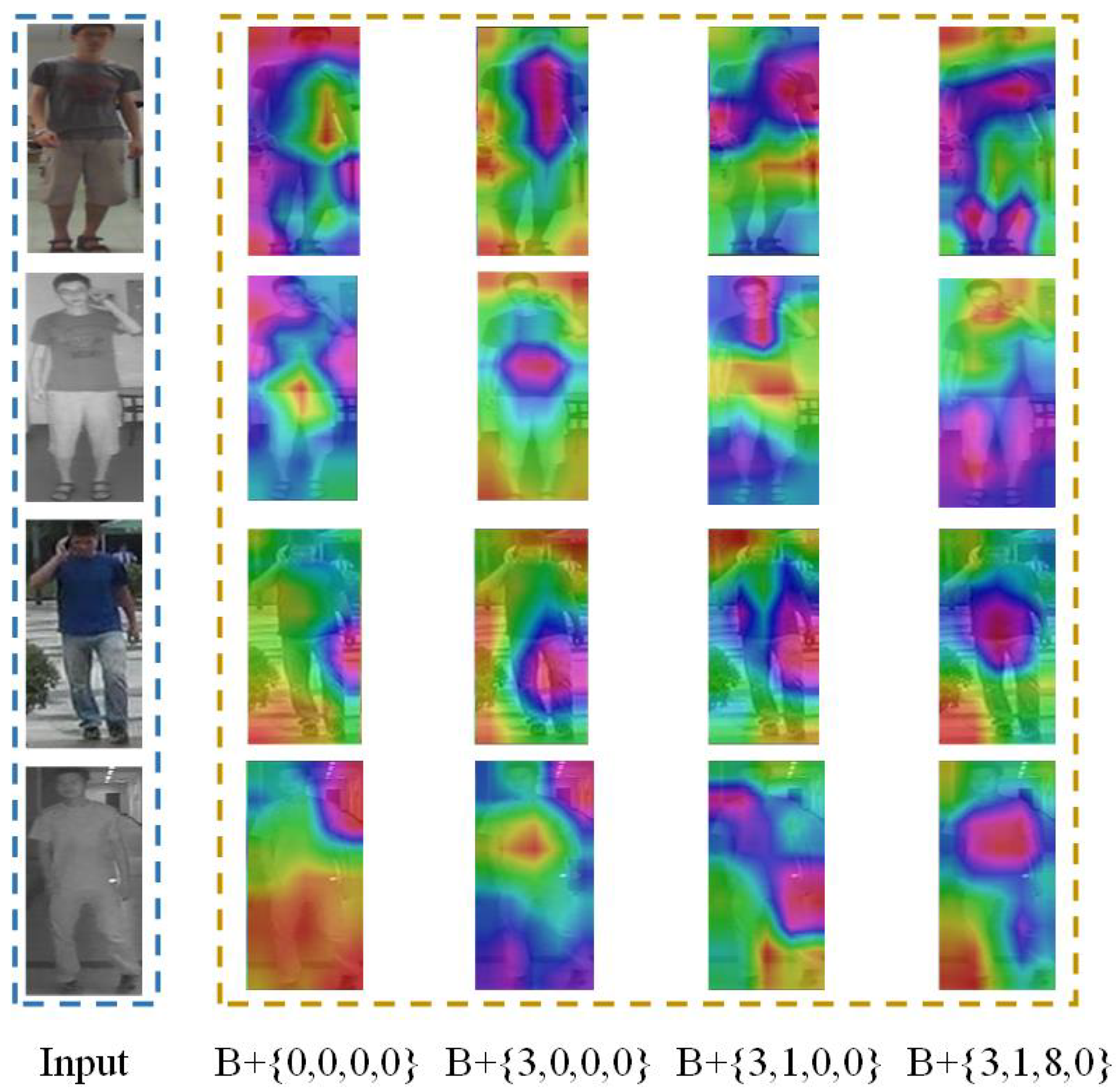
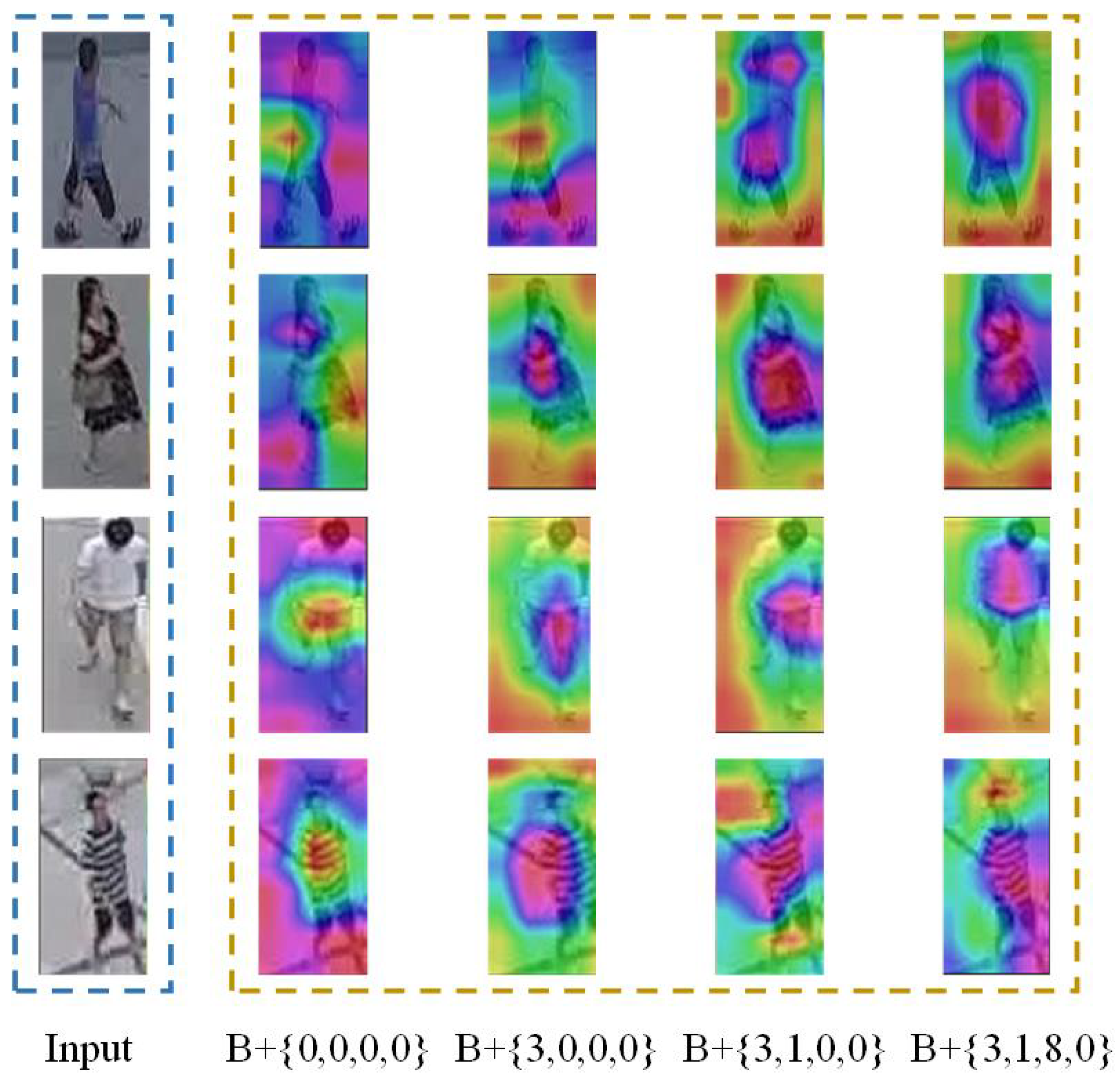
Due to the limitations of aerial images, more attention needs to be paid to detailed information. The HFA module of our method solves the problem of detailed information loss in the feature extraction process. Therefore, to prove the effectiveness of the HFA module on aerial images, we conducted heatmap visualization experiments for each Transformer encoder. The outcomes are depicted in
Figure 8. We find that, as the number of Transformer encoders increases, the high response becomes more and more concentrated in the body parts.
We randomly seleced four images from the dataset, and the Top-10 retrieval results are shown in
Figure 9. As can be seen, only a few images match correctly. These erroneous images are very similar to the query image and can be mainly attributed to the similar appearance of different pedestrians caused by the aerial photography angle and altitude.
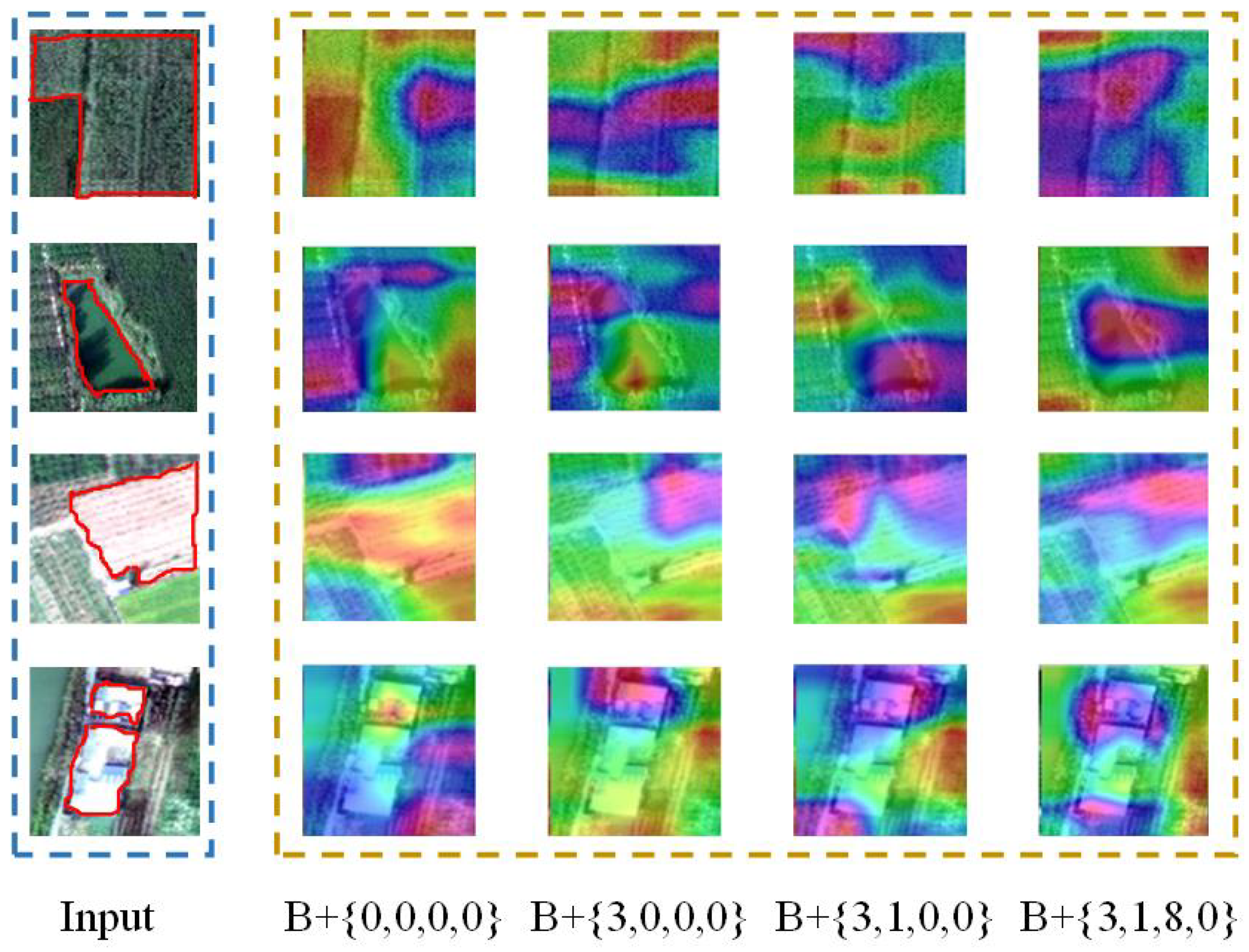
Matiwan Village dataset:
Figure 7c is the overall aerial picture of Matiwan Village, which contains 19 categories of features. We selected four of them (willow trees, water bodies, grasslands, and houses) for study. To showcase the efficacy of the HFA module across these categories, we conducted heatmap visualization experiments for each Transformer encoder. The specific results are shown in
Figure 10. We found that, as the number of Transformer encoders increases, high responses are increasingly concentrated in areas that need to be recognized. This proves that our method is good at identifying pedestrians and can be transferred to other targets.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}