


Radiation-Variation Insensitive Coarse-to-Fine Image Registration for Infrared and Visible Remote Sensing Based on Zero-Shot Learning

Abstract
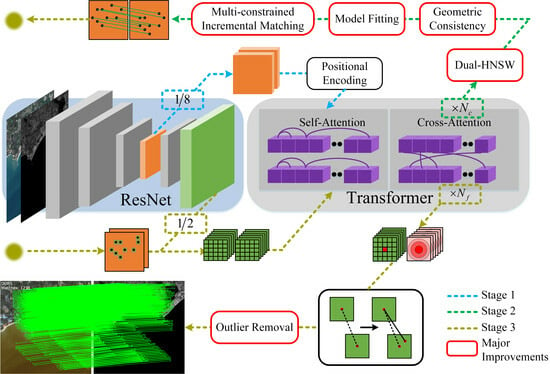
1. Introduction
- The small number of features in the sparse texture region of multi-source remote sensing images leads to the problem of difficult matching. Visible images can better reflect the texture information in the scene with a clear hierarchy, while infrared images have less texture, similar structure repetitions, and fuzzy edges, which makes it difficult to distinguish the details in these images.
- Heterogenous remote sensing images are difficult to acquire and screen, and the training of network models requires a large number of samples. Although there is a large amount of remote sensing image data available, datasets comprising real camera parameters, control points, or homography matrices as labels are scarce.
- There are image grayscale distortions and image aberrations of different degrees, natures, and irregularity due to nonlinear spectral radiation variations during the acquisition of remote sensing images by different sensors. This radiation variation is a bottleneck problem limiting the development of multi-source remote sensing image matching techniques, and the seasonal and temporal phase differences also lead to large feature variations. As a result, the similarity between the corresponding locations of remote sensing images from different sources is weak, and it is difficult to effectively establish a large number of correct matches with the existing similarity metrics.
- RIZER, as a whole, employs a detector-free, end-to-end, coarse-to-fine registration framework, making the matching no longer dependent on texture and corner points. The innovative Transformer [11] architecture based on zero-shot learning in the field of infrared and visible remote sensing image registration improves the effectiveness of the pre-trained model, which makes the data-driven methods no longer limited by domain-specific datasets.
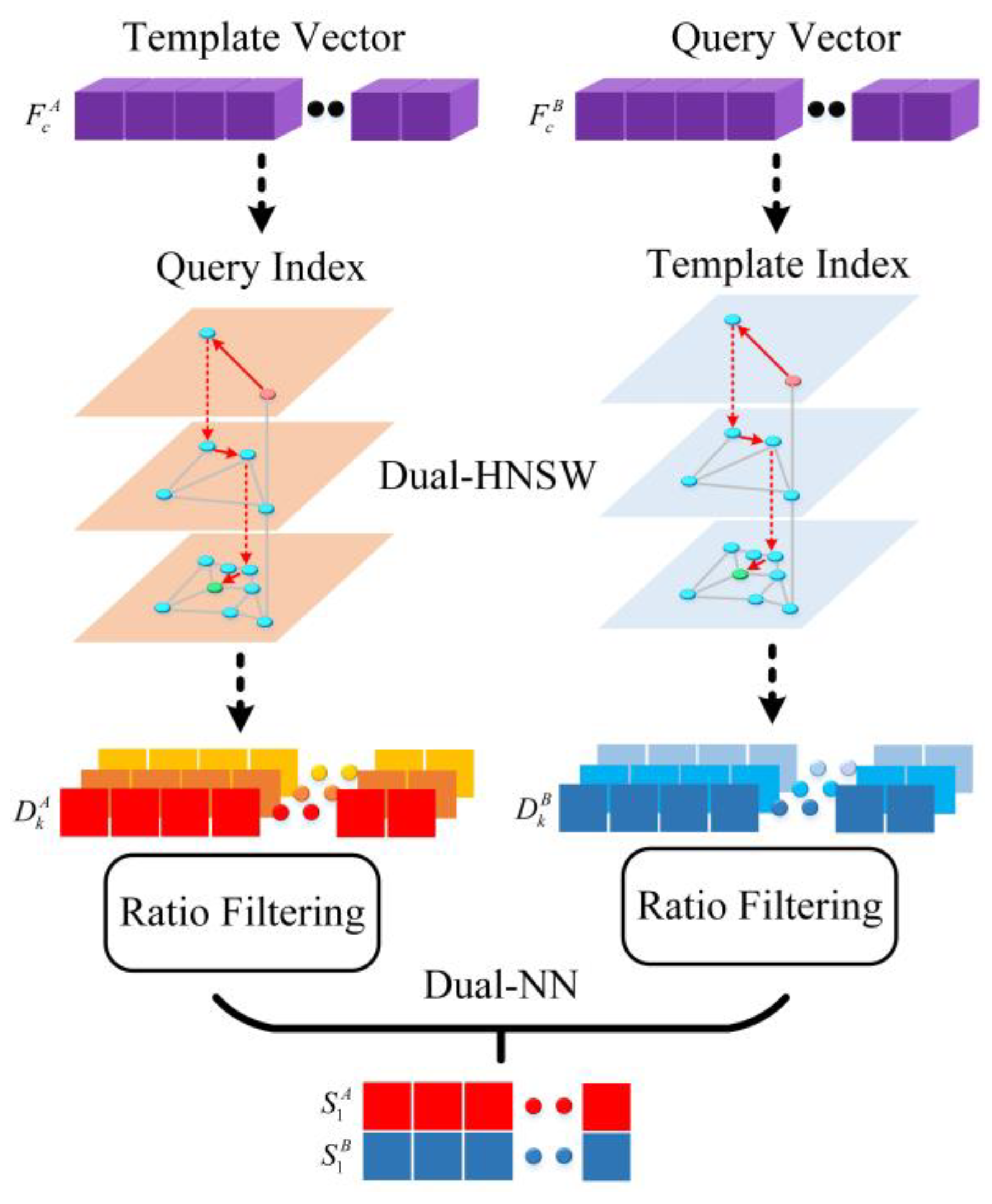
- Knowledge-driven methods were adopted for the coarse-level matches, and the graph model-based K-nearest neighbor algorithm—Hierarchical Navigable Small World (HNSW) [12,13]—is introduced in the field of image registration for deep learning to efficiently and accurately obtain a wide range of correspondences. We also introduce the a priori knowledge between the matchpoints for local geometric soft constraints to build control point sets, which improves the interpretability and reliability of feature vector utilization and is not affected by radiation variation.
- Simulating the strategy of first focusing on highly similar features before predicting the overall variation when the human eye is registered, the registration problem is transformed into a problem of fitting a transformation model through high-confidence control points, and multi-constrained incremental matching is used to filter between predicted matchpoints and establish a one-to-one matching relationship to achieve the overall insensitivity to radiation variations.
- After fine-level coordinate fine-tuning, a simple but effective outlier rejection method that only requires extremely few iterations further improves the final matching results. A manually labeled test dataset of infrared and visible remote sensing images containing city, coast, mountain, desert, and aerial remote sensing images is proposed. Compared with classical and state-of-the-art registration algorithms, RIZER achieved competitive results. At the same time, it has an excellent generalization ability for other multimodal remote-sensing images. Four ablation experiments were designed to demonstrate the effectiveness of the improved module.
2. Related Work
3. Methodology
3.1. Workflow of the Proposed Method
3.2. Dual HNSW
3.3. Local Geometric Soft Constraint
3.4. Least Squares Fitting Transform Model
3.5. Multi-Constraint Incremental Matching
3.6. Fine-Level Matching
4. Experiments
4.1. Datasets
4.2. Baseline and Metrics
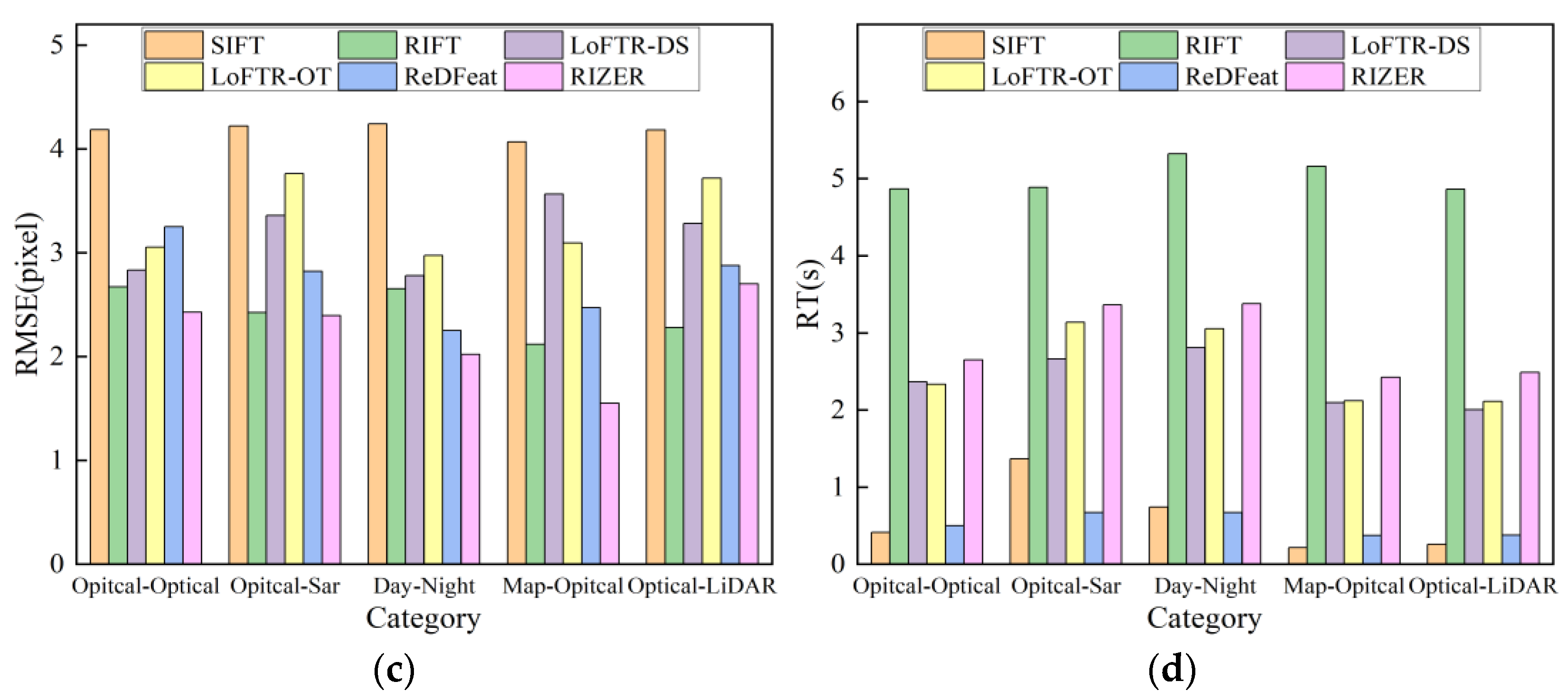
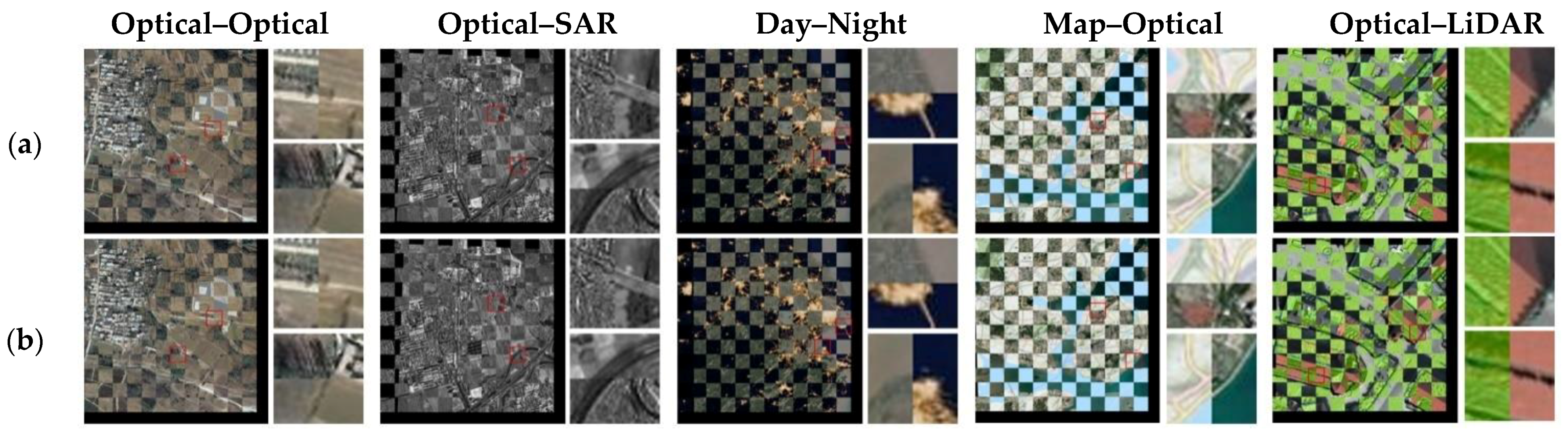
4.3. Registration Experiment for Infrared and Visible Remote Sensing Images
4.4. Registration Experiment for Multimodal Remote Sensing Images
4.5. Ablation Study
- In order to verify the validity of our proposed local geometric soft constraints module and the theory that a priori information about geometric structures has radiation variation invariance and is applicable to heterologous remote sensing image registration, we replaced it with the GMS algorithm [52] and likewise optimized the GMS algorithm by applying it to both the outlier removal of initial matches and incremental matching under multiple constraints.
- In order to verify the validity of the least-squares fitting transform model that we used, and the proposed theory that coarse-level maps lead to an inaccurate estimation of the homography matrix and strong linear laws between matchpoints, we replaced the least squares fitting transformation model with the homography fitting transformation model, with its context remaining unchanged. We did not optimize the homography fitting algorithm and still adopted the RANSAC algorithm.
- In order to verify the effectiveness as well as the efficiency of our proposed targeted outlier removal algorithm, we substituted the proposed approach with GC-RANSAC [53]. In addition, no optimization was performed on GC-RANSAC; instead, outliers were eliminated from all the matching points. Additionally, we devised an ablation study on the number of iterations to confirm that RIZER is capable of attaining optimal performance with an extremely low iteration count.
5. Disscussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, X.Y.; Ma, J.Y.; Xiao, G.B.; Shao, Z.F.; Guo, X.J. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Paul, S.; Pati, U.C. A comprehensive review on remote sensing image registration. Int. J. Remote Sens. 2021, 42, 5400–5436. [Google Scholar] [CrossRef]
- Rogalski, A. Infrared detectors: An overview. Infrared Phys. Technol. 2002, 43, 187–210. [Google Scholar] [CrossRef]
- Maathuis, B.H.P.; van Genderen, J.L. A review of satellite and airborne sensors for remote sensing based detection of minefields and landmines. Int. J. Remote Sens. 2004, 25, 5201–5245. [Google Scholar] [CrossRef]
- Eismann, M.T.; Stocker, A.D.; Nasrabadi, N.M. Automated Hyperspectral Cueing for Civilian Search and Rescue. Proc. IEEE 2009, 97, 1031–1055. [Google Scholar] [CrossRef]
- Parr, A.C.; Datla, R.U. NIST role in radiometric calibrations for remote sensing programs at NASA, NOAA, DOE and DOD. In Calibration and Characterization of Satellite Sensors and Accuracy of Derived Physical Parameters; Tsuchiya, K., Ed.; Advances in Space Research-Series; Elsevier Science BV: Amsterdam, The Netherlands, 2001; Volume 28, pp. 59–68. [Google Scholar]
- Zhang, X.C.; Ye, P.; Leung, H.; Gong, K.; Xiao, G. Object fusion tracking based on visible and infrared images: A comprehensive review. Inf. Fusion 2020, 63, 166–187. [Google Scholar] [CrossRef]
- Ma, W.H.; Wang, K.; Li, J.W.; Yang, S.X.; Li, J.F.; Song, L.P.; Li, Q.F. Infrared and Visible Image Fusion Technology and Application: A Review. Sensors 2023, 23, 23. [Google Scholar] [CrossRef]
- Bhardwaja, A.; Joshi, P.K.; Sam, L.; Snehmani. Remote sensing of alpine glaciers in visible and infrared wavelengths: A survey of advances and prospects. Geocarto Int. 2016, 31, 557–574. [Google Scholar] [CrossRef]
- Yebra, M.; Dennison, P.E.; Chuvieco, E.; Riano, D.; Zylstra, P.; Hunt, E.R.; Danson, F.M.; Qi, Y.; Jurdao, S. A global review of remote sensing of live fuel moisture content for fire danger assessment: Moving towards operational products. Remote Sens. Environ. 2013, 136, 455–468. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Malkov, Y.A.; Yashunin, D.A. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 824–836. [Google Scholar] [CrossRef]
- Bellavia, F.; Colombo, C. Is There Anything New to Say About SIFT Matching? Int. J. Comput. Vis. 2020, 128, 1847–1866. [Google Scholar] [CrossRef]
- Le Moigne, J.; IEEE. INTRODUCTION TO REMOTE SENSING IMAGE REGISTRATION. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2565–2568. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In Computer Vision—Eccv 2006, Pt 1, Proceedings; Leonardis, A., Bischof, H., Pinz, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.; IEEE. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Morel, J.M.; Yu, G.S. ASIFT: A New Framework for Fully Affine Invariant Image Comparison. Siam J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yuanxin, Y.E.; Shen, L. HOPC: A NOVEL SIMILARITY METRIC BASED ON GEOMETRIC STRUCTURAL PROPERTIES FOR MULTI-MODAL REMOTE SENSING IMAGE MATCHING. In Proceedings of the 23rd ISPRS Congress, Prague, Czech Republic, 12–19 July 2016; pp. 9–16. [Google Scholar]
- Zhu, B.; Yang, C.; Dai, J.K.; Fan, J.W.; Qin, Y.; Ye, Y.X. R2FD2: Fast and Robust Matching of Multimodal Remote Sensing Images via Repeatable Feature Detector and Rotation-Invariant Feature Descriptor. IEEE Trans. Geosci. Remote Sens. 2023, 61, 15. [Google Scholar] [CrossRef]
- Ye, Y.X.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Ma, W.P.; Wen, Z.L.; Wu, Y.; Jiao, L.C.; Gong, M.G.; Zheng, Y.F.; Liu, L. Remote Sensing Image Registration with Modified SIFT and Enhanced Feature Matching. IEEE Geosci. Remote Sens. Lett. 2017, 14, 3–7. [Google Scholar] [CrossRef]
- Li, J.Y.; Hu, Q.W.; Ai, M.Y. RIFT: Multi-Modal Image Matching Based on Radiation-Variation Insensitive Feature Transform. IEEE Trans. Image Process. 2020, 29, 3296–3310. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A.; IEEE. SuperPoint: Self-Supervised Interest Point Detection and Description. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 337–349. [Google Scholar]
- Barroso-Laguna, A.; Riba, E.; Ponsa, D.; Mikolajczyk, K.; IEEE. Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5835–5843. [Google Scholar]
- Zhang, H.; Ni, W.P.; Yan, W.D.; Xiang, D.L.; Wu, J.Z.; Yang, X.L.; Bian, H. Registration of Multimodal Remote Sensing Image Based on Deep Fully Convolutional Neural Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3028–3042. [Google Scholar] [CrossRef]
- Dong, Y.Y.; Jiao, W.L.; Long, T.F.; Liu, L.F.; He, G.J.; Gong, C.J.; Guo, Y.T. Local Deep Descriptor for Remote Sensing Image Feature Matching. Remote Sens. 2019, 11, 21. [Google Scholar] [CrossRef]
- Deng, Y.X.; Ma, J.Y. ReDFeat: Recoupling Detection and Description for Multimodal Feature Learning. IEEE Trans. Image Process. 2023, 32, 591–602. [Google Scholar] [CrossRef]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A.; IEEE. SuperGlue: Learning Feature Matching with Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 4937–4946. [Google Scholar]
- Sun, J.M.; Shen, Z.H.; Wang, Y.A.; Bao, H.J.; Zhou, X.W.; IEEE Computer Society. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8918–8927. [Google Scholar]
- Chen, H.K.; Luo, Z.X.; Zhou, L.; Tian, Y.R.; Zhen, M.M.; Fang, T.; McKinnon, D.; Tsin, Y.G.; Quan, L. ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer. In Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 20–36. [Google Scholar]
- Wang, Q.; Zhang, J.M.; Yang, K.L.; Peng, K.Y.; Stiefelhagen, R. MatchFormer: Interleaving Attention in Transformers for Feature Matching. In Proceedings of the 16th Asian Conference on Computer Vision (ACCV), Macao, China, 4–8 December 2022; pp. 256–273. [Google Scholar]
- Fan, Y.B.; Wang, F.; Wang, H.P. A Transformer-Based Coarse-to-Fine Wide-Swath SAR Image Registration Method under Weak Texture Conditions. Remote Sens. 2022, 14, 25. [Google Scholar] [CrossRef]
- Sui, H.G.; Li, J.J.; Lei, J.F.; Liu, C.; Gou, G.H. A Fast and Robust Heterologous Image Matching Method for Visual Geo-Localization of Low-Altitude UAVs. Remote Sens. 2022, 14, 22. [Google Scholar] [CrossRef]
- Liu, X.Z.; Xu, X.L.; Zhang, X.D.; Miao, Q.G.; Wang, L.; Chang, L.; Liu, R.Y. SRTPN: Scale and Rotation Transform Prediction Net for Multimodal Remote Sensing Image Registration. Remote Sens. 2023, 15, 21. [Google Scholar] [CrossRef]
- Di, Y.D.; Liao, Y.; Zhu, K.J.; Zhou, H.; Zhang, Y.J.; Duan, Q.; Liu, J.H.; Lu, M.Y. MIVI: Multi-stage feature matching for infrared and visible image. Vis. Comput. 2023, 13, 1–13. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V.; Soc, I.C. Do Better ImageNet Models Transfer Better? In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2656–2666. [Google Scholar]
- Zhang, Y.X.; Liu, Y.X.; Zhang, H.M.; Ma, G.R. Multimodal Remote Sensing Image Matching Combining Learning Features and Delaunay Triangulation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 17. [Google Scholar] [CrossRef]
- Efe, U.; Ince, K.G.; Alatan, A.A.; Soc, I.C. DFM: A Performance Baseline for Deep Feature Matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, 19–25 June 2021; pp. 4279–4288. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S.; IEEE. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, H.; Manjunath, B.S.; Mitra, S.K. A CONTOUR-BASED APPROACH TO MULTISENSOR IMAGE REGISTRATION. IEEE Trans. Image Process. 1995, 4, 320–334. [Google Scholar] [CrossRef]
- de Vos, B.D.; Berendsen, F.F.; Viergever, M.A.; Sokooti, H.; Staring, M.; Isgum, I. A deep learning framework for unsupervised affine and deformable image registration. Med. Image Anal. 2019, 52, 128–143. [Google Scholar] [CrossRef]
- Chui, H.L.; Rangarajan, A. A new point matching algorithm for non-rigid registration. Comput. Vis. Image Underst. 2003, 89, 114–141. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. RANDOM SAMPLE CONSENSUS—A PARADIGM FOR MODEL-FITTING WITH APPLICATIONS TO IMAGE-ANALYSIS AND AUTOMATED CARTOGRAPHY. Commun. Acm 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Holland, P.W.; Welsch, R.E. ROBUST REGRESSION USING ITERATIVELY RE-WEIGHTED LEAST-SQUARES. Commun. Stat. Part A-Theory Methods 1977, 6, 813–827. [Google Scholar] [CrossRef]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Deep Image Homography Estimation. arXiv 2016, arXiv:1606.03798. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]
- Hou, H.T.; Lan, C.Z.; Xu, Q.; Lv, L.; Xiong, X.; Yao, F.S.; Wang, L.H. Attention-Based Matching Approach for Heterogeneous Remote Sensing Images. Remote Sens. 2023, 15, 21. [Google Scholar] [CrossRef]
- Wang, C.W.; Xu, L.L.; Xu, R.T.; Xu, S.B.; Meng, W.L.; Wang, R.S.; Zhang, X.P. Triple Robustness Augmentation Local Features for multi-source image registration. Isprs J. Photogramm. Remote Sens. 2023, 199, 1–14. [Google Scholar] [CrossRef]
- Muja, M.; Lowe, D.G. Scalable Nearest Neighbor Algorithms for High Dimensional Data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2227–2240. [Google Scholar] [CrossRef]
- Bian, J.W.; Lin, W.Y.; Matsushita, Y.; Yeung, S.K.; Nguyen, T.D.; Cheng, M.M.; IEEE. GMS: Grid-based Motion Statistics for Fast, Ultra-robust Feature Correspondence. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2828–2837. [Google Scholar]
- Barath, D.; Matas, J.; IEEE. Graph-Cut RANSAC. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6733–6741. [Google Scholar]
- Chum, O.; Matas, J. Matching with PROSAC—Progressive Sample Consensus. In Proceedings of the Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 220–226. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | VIS Date | NIR Date | Position |
|---|---|---|---|
| Desert | 28 November 2015 | 28 December 2015 | Bayingolin, Xinjiang, China |
| Coast | 8 January 2016 | 7 February 2016 | Shantou, Guangzhou, China |
| City | 25 December 2015 | 7 August 2015 | Beijing, China |
| Mountain | 19 January 2016 | 18 April 2016 | Garz, Sichuan, China |
| Category | Template Image Sensor | Query Image Sensor | Size | Image Characteristic |
|---|---|---|---|---|
| Visible–Visible | Google Earth | Google Earth | 600 × 600 | Different times |
| Visible–SAR | ZY-3 PAN optical | CF-3 SL SAR | 1000 × 1000 | Different bands |
| Day–Night | Optical | SNPP/VIIS | 1000 × 1000 | Day–night |
| Map–Visible | Open Street Map | Google Earth | 512 × 512 | Different models |
| Visible–LiDAR | WorldView-2 optical | LiDAR depth | 512 × 512 | Different models |
| Algorithm | NCM (Pair) | SR (%) | RMSE (Pixel) | RT (s) |
|---|---|---|---|---|
| SIFT | 29.61 | 39.34 | 3.32 | 0.23 |
| RIFT | 341.83 | 88.25 | 2.17 | 4.67 |
| LoFTR-DS | 1103.71 | 89.00 | 1.97 | 2.13 |
| LoFTR-OT | 1148.92 | 82.29 | 2.17 | 2.16 |
| ReDFeat | 585.06 | 95.49 | 1.92 | 0.40 |
| RIZER | 1389.44 | 99.55 | 1.36 | 2.48 |
| Algorithm | NCM (Pair) | SR (%) | RMSE (Pixel) | RT (s) |
|---|---|---|---|---|
| SIFT | 1.60 | 4.04 | 4.18 | 0.60 |
| RIFT | 372.00 | 94.24 | 2.43 | 8.19 |
| LoFTR-DS | 577.20 | 61.86 | 3.16 | 2.39 |
| LoFTR-OT | 696.60 | 52.10 | 3.32 | 2.55 |
| ReDFeat | 253.60 | 83.44 | 2.73 | 0.52 |
| RIZER | 1213.20 | 93.92 | 2.22 | 2.86 |
| Metric | EXP 1 | EXP 2 | EXP 3 | EXP 4 | RIZER |
|---|---|---|---|---|---|
| 242.84 | 367.36 | 424.36 | 422.02 | 422.06 | |
| 447.52 | 995.2 | 647.98 | 1068.74 | 1069.22 | |
| 939.73 | 714.36 | 605.58 | 434.42 | 455.38 | |
| 1630.09 | 2076.92 | 1677.92 | 1925.18 | 1946.66 | |
| 1290.75 | 1373.96 | 891.32 | 1346.98 | 1500.58 | |
| 1287.32 | 1363.68 | 889.66 | 1333.46 | 1496.72 | |
| 99.14% | 98.31% | 99.56% | 98.56% | 99.78% | |
| 1.22 | 1.33 | 1.21 | 1.09 | 1.17 | |
| 2.63 | 2.41 | 2.50 | 2.48 | 2.46 |
| Max Iteration Count | 1 | 3 | 5 | 10 | None |
|---|---|---|---|---|---|
| NCM (pair) ↑ | 1149.70 | 1367.96 | 1418.52 | 1482.18 | 1496.72 |
| SR (%) ↑ | 98.95 | 99.26 | 99.74 | 99.77 | 99.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Bi, G.; Wang, X.; Nie, T.; Huang, L. Radiation-Variation Insensitive Coarse-to-Fine Image Registration for Infrared and Visible Remote Sensing Based on Zero-Shot Learning. Remote Sens. 2024, 16, 214. https://doi.org/10.3390/rs16020214
Li J, Bi G, Wang X, Nie T, Huang L. Radiation-Variation Insensitive Coarse-to-Fine Image Registration for Infrared and Visible Remote Sensing Based on Zero-Shot Learning. Remote Sensing. 2024; 16(2):214. https://doi.org/10.3390/rs16020214
Chicago/Turabian StyleLi, Jiaqi, Guoling Bi, Xiaozhen Wang, Ting Nie, and Liang Huang. 2024. "Radiation-Variation Insensitive Coarse-to-Fine Image Registration for Infrared and Visible Remote Sensing Based on Zero-Shot Learning" Remote Sensing 16, no. 2: 214. https://doi.org/10.3390/rs16020214
APA StyleLi, J., Bi, G., Wang, X., Nie, T., & Huang, L. (2024). Radiation-Variation Insensitive Coarse-to-Fine Image Registration for Infrared and Visible Remote Sensing Based on Zero-Shot Learning. Remote Sensing, 16(2), 214. https://doi.org/10.3390/rs16020214