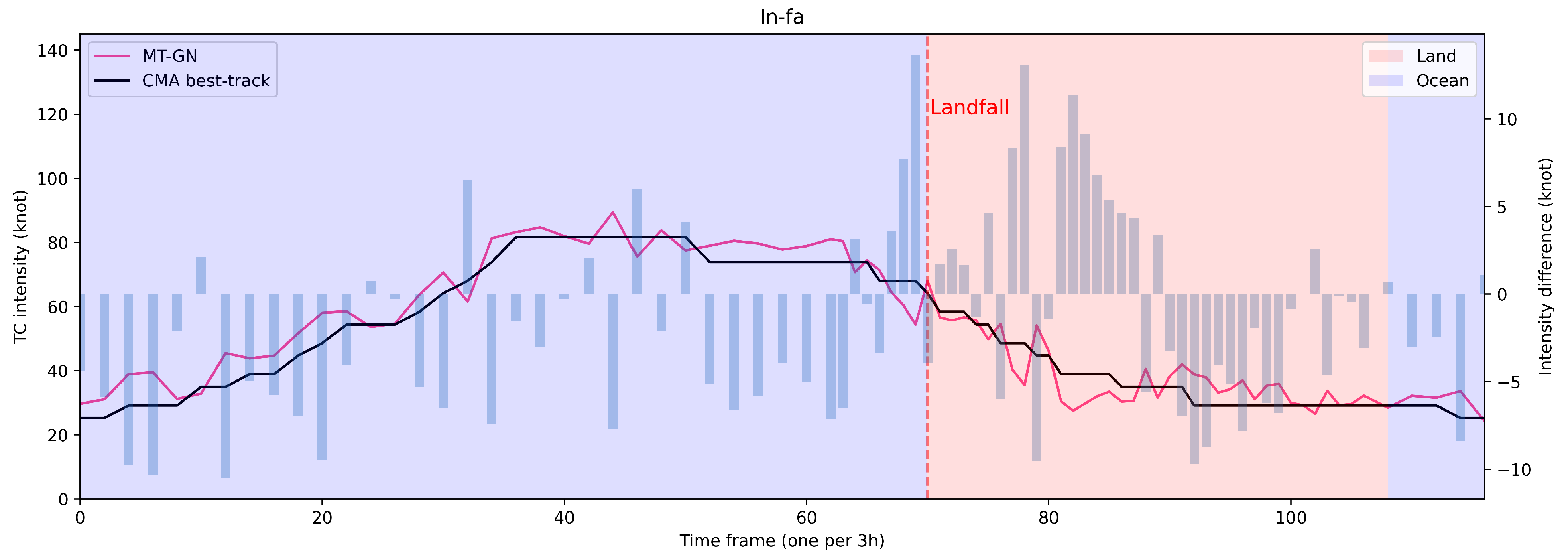
1. Introduction
Today, tropical cyclones (TCs) are becoming more and more frequent around the world due to global warming [
1]. With strong winds and rainstorms, TCs have disastrous impacts on human activity. Due to their complex physical processes, TCs are difficult to predict efficiently. There are already many studies regarding the axisymmetric structures and dynamic mechanisms of TCs [
2,
3]. In recent years, with the help of machine learning and deep learning, the development of TC study is rapidly increasing, including TC forecasting, tracking, intensity estimation, classification, and disaster impact forecasting. Today, those fields are separately investigated, which prevents further use of data analysis tools to understand TCs. In future research, introducing more prior knowledge and collecting a large amount of multi-source data can effectively improve the accuracy of TC modeling.
In the field of TC modeling, the research of TC classification starts before TC intensity estimation. A large amount of TC classification research based on machine learning and deep learning provide a rich experience for TC intensity prediction. Kar and Banerjee [
4] applied feature extraction techniques on input infrared images to gain simple geometric properties of the cyclone structure then fed the feature vectors to five machine learning classifiers, providing results with a classification accuracy of around 86.66%. Kurniawan et al. [
5] used a Gray-Level Co-Occurrence Matrix (GLCM) algorithm to extract features in the color space of images and carried out classification with a multi-class Support Vector Machines (SVM) using a one-against-all (OAA) coding design and a Gaussian kernel. In comparison, some researchers have recently divided the TC intensity grades into many categories using Convolution Network Networks (CNNs). Zhang et al. [
6] proposed a tropical cyclone intensity grade classification (TCIC) module that adopts Inception-ResNet-v2 [
7] as the basic network to extract richer features. With an attention mechanism, their TCIC achieved good accuracy for the classification task.
For TC intensity estimation, the traditional methods require plenty of human intervention and handcrafted feature engineering. The widely used Dvorak [
8] and deviation-angle-variance (DAT) techniques estimate the TC intensity based on knowledge of cyclone eyes and the structure of TCs. Those traditional techniques require systematic meteorological knowledge and cannot easily adapt to diversified data. In recent years, deep-learning-based intensity estimation models have been prospering and yielding promising results [
9,
10,
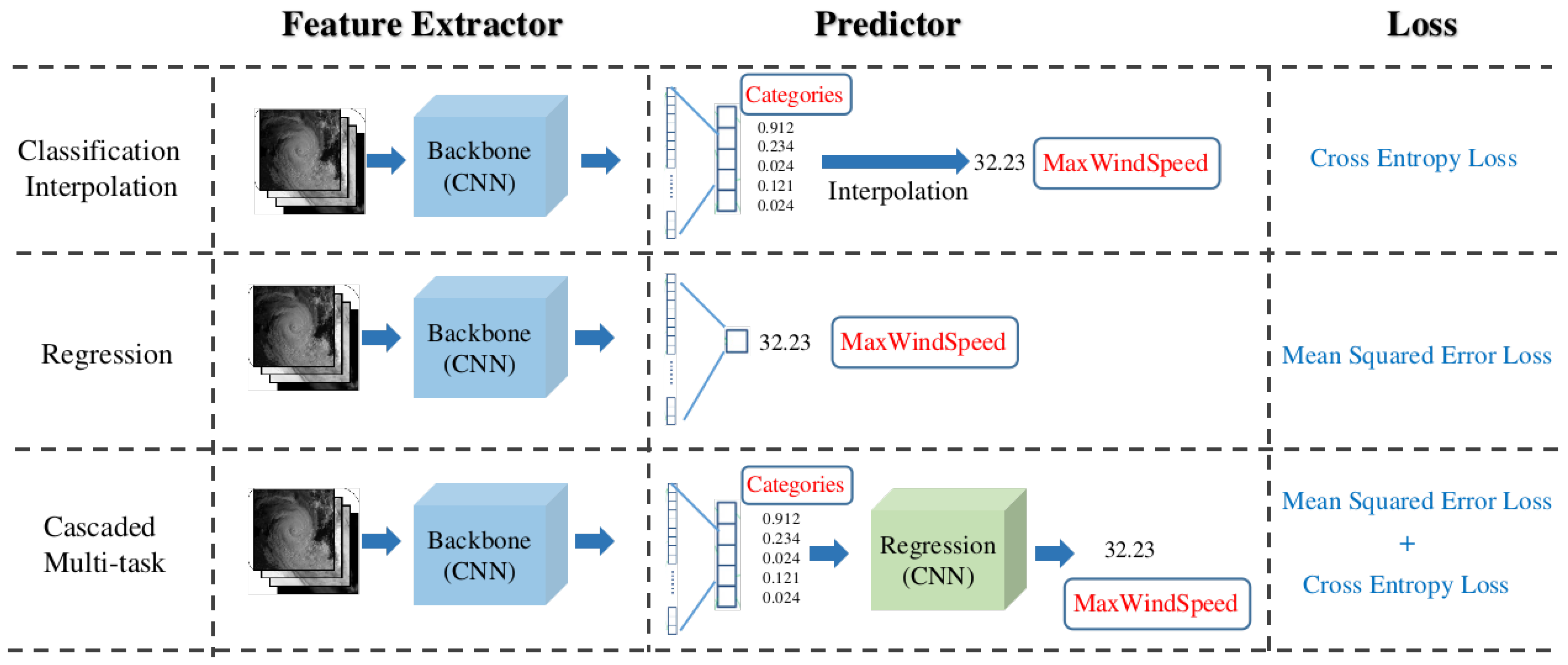
11]. DL-based methods can be categorized into three types, as shown in
Figure 1: (1) Classification-and-interpolation: Pradhan et al. [
12] first proposed a deep CNN for categorizing TCs by estimating the wind speed through weighting the average of two highest categories with respect to their probabilities. Wang et al. [
13] further improved the effect of intensity estimation by using a CNN with better feature extraction performance according to the idea proposed by Pradhan. (2) Regression: Recent studies [
14,
15,
16] estimate TC intensity as a straightforward regression task and outperform the classification-and-interpolation method. (3) Multi-tasking: This school of methods usually cascades a classification model and a regression model. Considering that the intensity range of TCs is wide and a single regression model is insufficient for all kinds of TCs, Zhang et al. [
17] proposed to use one classification model to divide the input image into three sub-classes and to then build three similar regression models to predict the max wind speed for each sub-class. Chen and Yu [
18] proposed a practical multi-tasking architecture called Tensor CNN (TCNN) to perform intensity categorization and wind speed regression successively, which uses the trained classification model to ensure the afterward regression work’s accuracy. Both of the two multi-tasking methods’ idea is fundamentally to employ regression to estimate TC wind speed after intensity categorization, which does not take the relation of the TC categories and intensity into consideration naturally. These two methods mentioned above [
17,
18] only used the classification knowledge to restrict the regression model. Thus, the potential of the multi-task learning way has not been completely exploited yet. Exploring a new way of multi-task learning to bridge the gap between classification and intensity estimation is needed.
Furthermore, there are more challenges facing TC modeling. In nature, the numbers of different types of TCs are seriously unbalanced. The TCs in most of the obtained satellite images are of medium and low intensity, while there are few high-intensity TCs. And the intensity range of TCs ranges widely from 30 knots to more than 150 knots. Traditionally, the remote sensing community treats TC intensity and classification separately and ignores the correspondence between TC categorization and intensity. And the cascaded way of multi-task learning only employs the classification model to guide the subsequent regression models.
Aiming at fully leveraging the advantages of the multi-tasking method, we propose a parallel way of multi-tasking for TC classification and intensity estimation: Multi-Task Graph Residual Network (MT-GN). Our proposed model consists of two parts: feature extraction and task-dependency embedding. Both parts are trained in a parallel multi-tasking way, which is more reliable because of the method of sharing information between the two different tasks. Using a two-stage training method, we first train a residual CNN feature extractor from scratch. Then, after obtaining a fine feature map for the classification and estimation from this simple CNN structure, we drop the last fully connected layers, fix the feature extraction part, and only train the task-dependency embedding module. Consisting of two GCN layers, our task-dependency embedding module further improves our precision with a reweighting process.
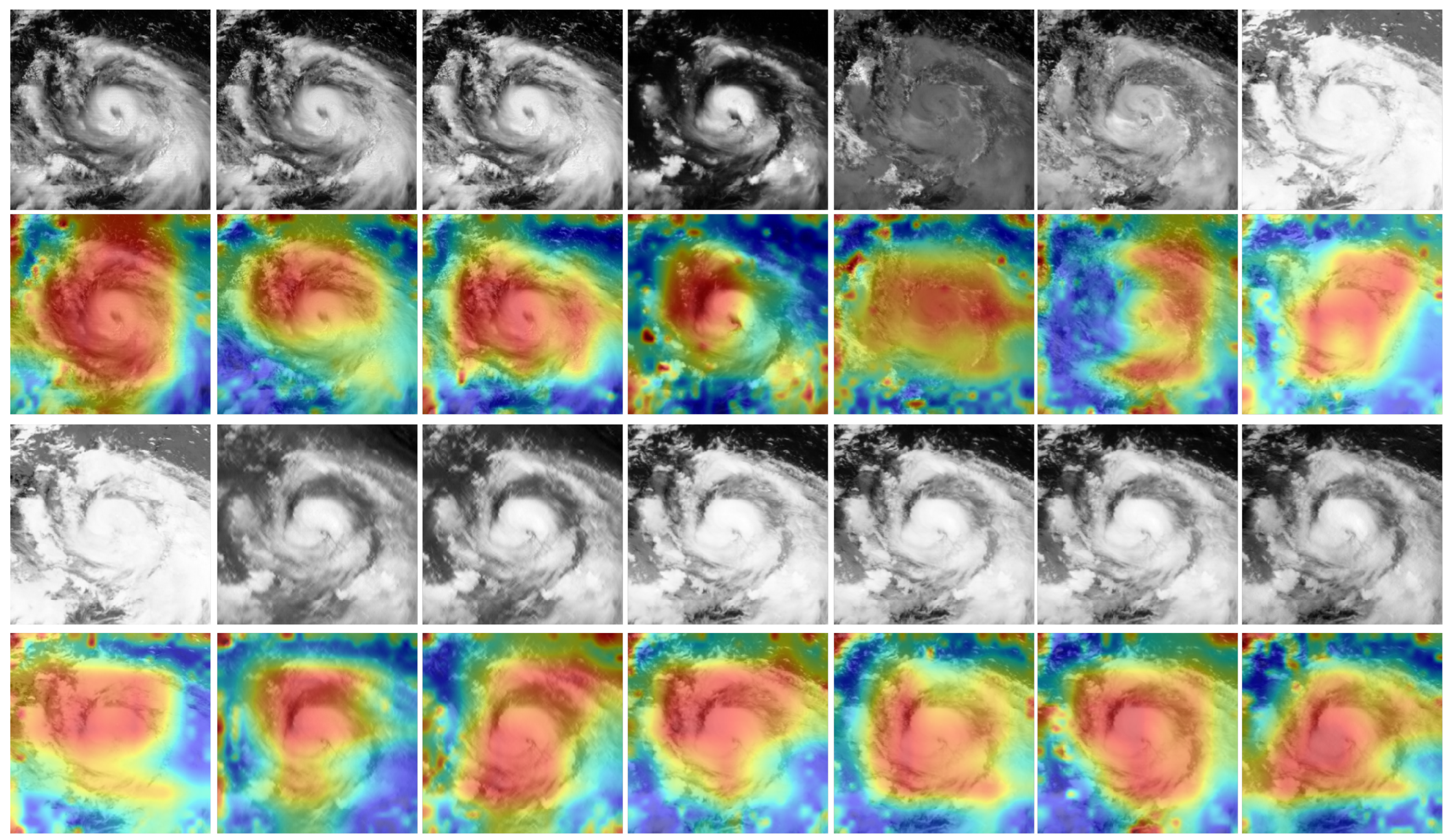
Further, we compared different feature extractors and input methods for multi-spectral images. Compared with infrared (IR) and water vapor (WV) images, using high-spectral-resolution multi-spectral data as input can provide more features and details of TCs. As high-dimensional data, multi-spectral images (MSIs) can cause the curse of dimensionality [
19], and with visible bands (VIS), the MSIs captured during daytime and nighttime actually have 14 bands and 8 bands, respectively. Thus, studying different input methods for MSI to the CNN model is necessary. Moreover, using MSI obtained by China’s FY-4A satellite, we studied the channel-wise heatmap of multi-spectral images, which shines a light of understanding on the role of different channels of multi-spectral images in the TC deep learning field.
The main contributions provided in this work are as follows:
We propose a parallel multi-tasking framework to classify TCs and estimate TC intensity simultaneously that has better performance than other methodologies under the comparison of the same dataset.
Improvement of classification and estimation performance is achieved by a task-dependency embedding model based on a GCN.
We improve the ability of the model using the residual modules and class balance loss to lay a solid foundation for prediction tasks.
We constructed a multi-spectral benchmark dataset for tropical cyclone intensity estimation task using FY-4A multi-spectral data, which facilitates the fair comparison between different methodologies.
The rest of this article is organized as follows.
Section 2 proposes the MT-GN for TC classification and intensity estimation, in which two modules, a feature extractor module and a task-dependency embedding module, are explained in full detail.
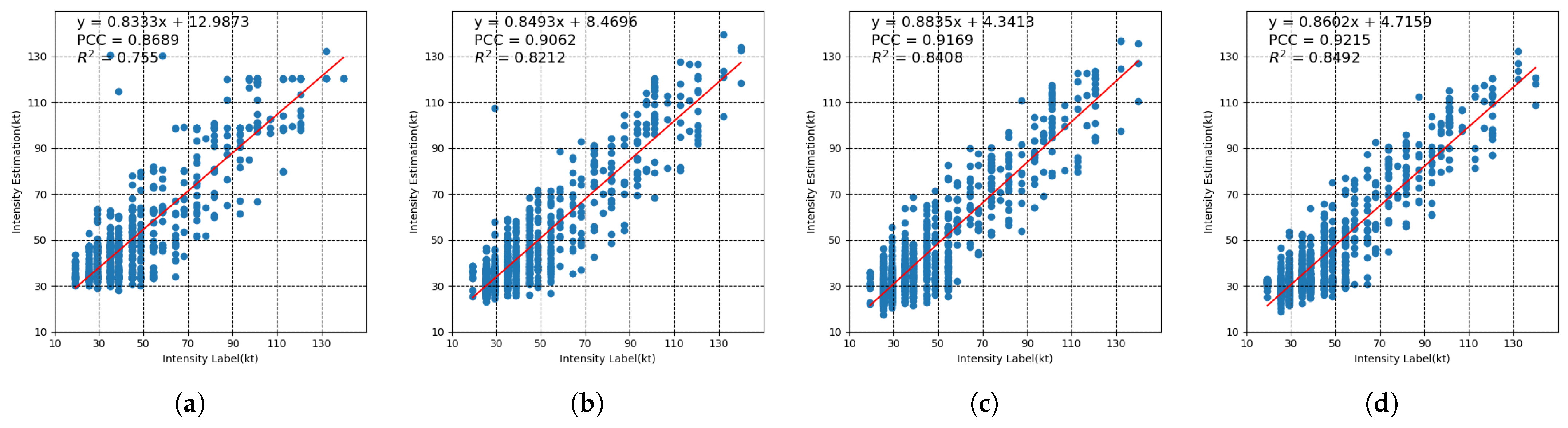
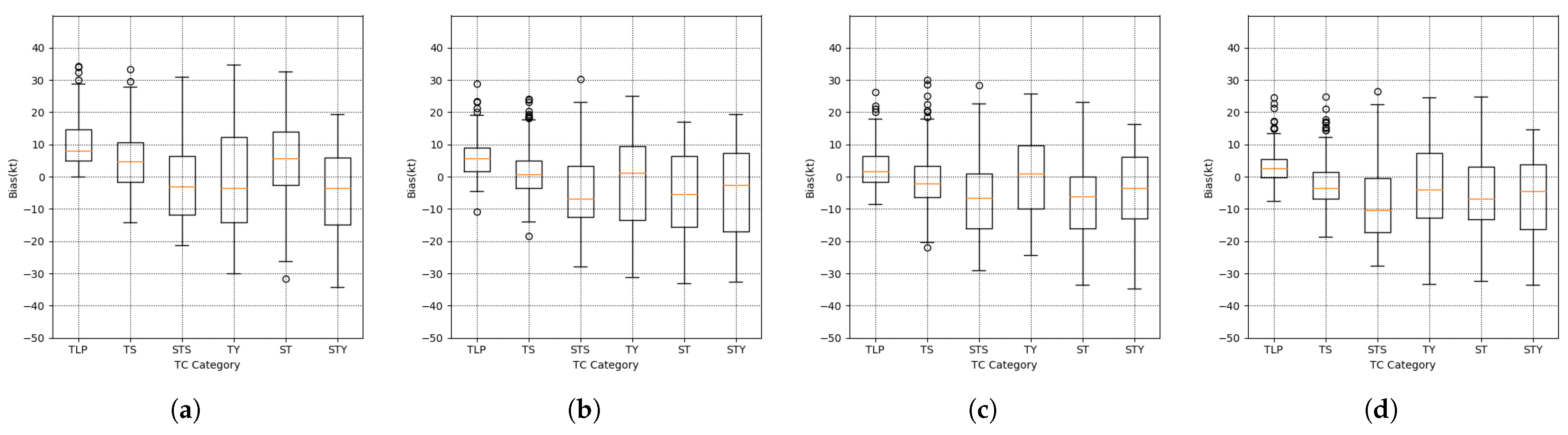
Section 3 presents the details of our dataset, experiment setting, and results. The detailed analysis and discussion are listed in
Section 4. Finally,
Section 5 provides the conclusion.
2. Materials and Methods
2.1. Overall Framework
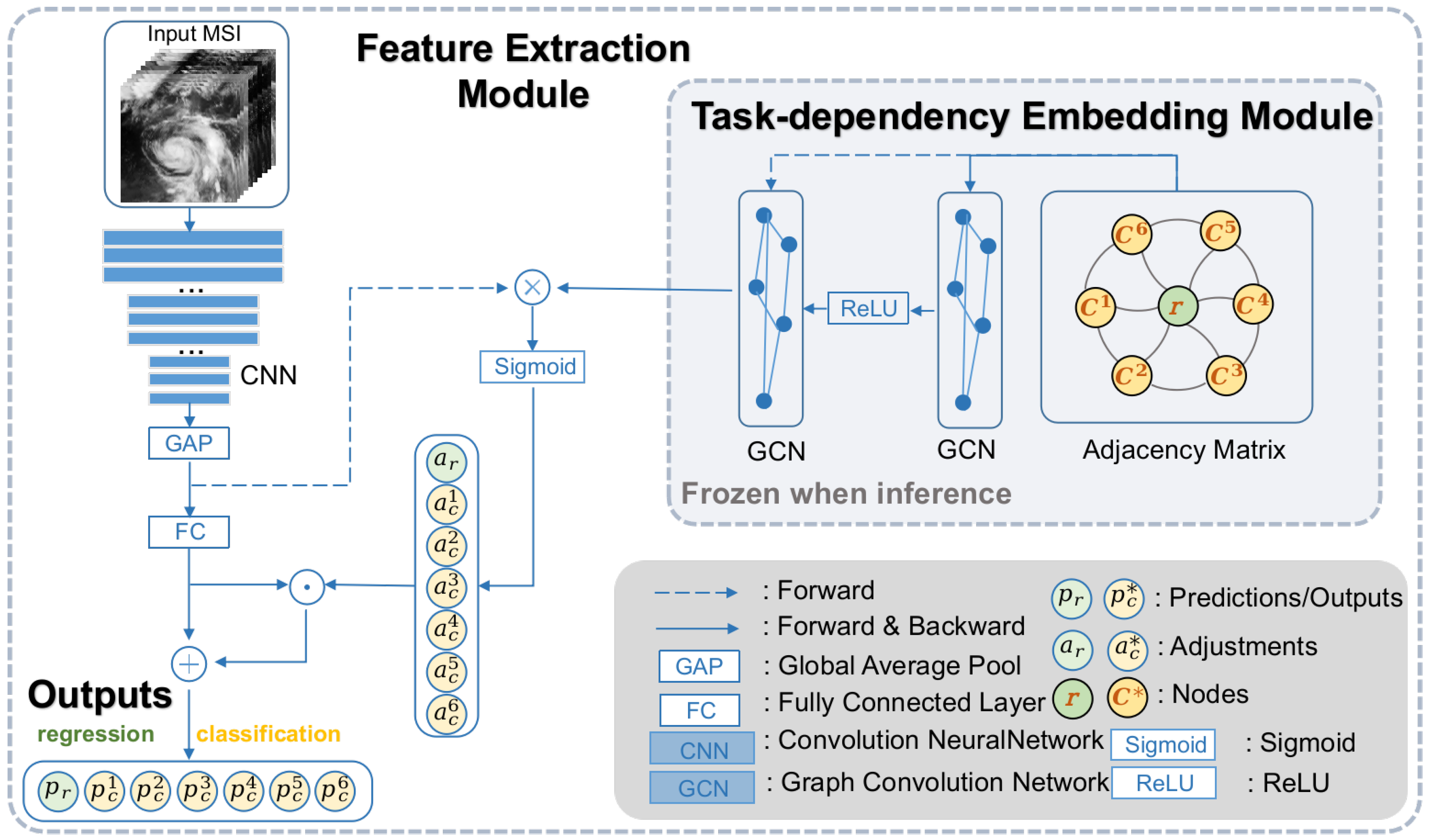
We illustrate the proposed parallel multi-task learning architecture MT-GN in
Figure 2 as an overview. The input of our model is MSI image data, and the output is the predicted max wind speed and classification scores corresponding to the input. As shown in
Figure 2, the left side is the CNN-based feature extraction module, and the right side is the GCN-based multi-task module. The
r and
nodes in the GCN module are embedded nodes corresponding to the GCN matrix, the green
r node corresponds to the regression task, and the yellow
nodes correspond to different categories in the classification task. Variables
and
are the adjustment vectors produced by the multi-task module, while
and
are the final outputs of the model.
The whole model follows a two-stage training strategy. First, we train the dual tasks of classification and regression on the CNN part, which includes a feature extraction backbone and a prediction layer (fully connected later). Then, a GCN-based task-dependency embedding module (TDEM) is introduced into our model. With the feature extraction backbone’s parameters frozen, the TDEM module takes the extracted feature map as input and learns the inter-task dependency knowledge to enhance the performance of multi-task prediction. Finally, in the evaluation stage, the MT-GN model formulates the inter-task dependency learned by the TDEM part as prior information to re-rank the original dual-task results predicted by the CNN part. The implementation details of our method are described in
Section 2.2,
Section 2.3 and
Section 2.4.
2.2. Feature Extraction Module
In order to obtain better features, the depth of the neural network grows fast, which makes training deep CNNs difficult and lengthy. To overcome this problem, He et al. [
20] introduces a residual module. Referring to it as the VGG19 network, He et al. [
20] modifies the configuration of every layer and adds residual units through a short-circuit mechanism. An important design principle of ResNet [
20] is that when the size of feature maps is reduced by half, the number of feature maps is doubled, which maintains the complexity of the network. To further reduce the number of parameters and matrix multiplications, He et al. [
20] proposed a variant of the residual block that utilizes 1 × 1 convolutions to create a bottleneck. As shown in
Figure 3, the bottleneck is composed of 1 × 1, 3 × 3, and 1 × 1 convolutions. The 1 × 1 convolution layer is used to reduce and restore dimensions. The 3 × 3 layer is used to integrate neighborhood information. With the shortcut connections in the convolution bottleneck in the CNN, the residual module can be used to reduce the number of parameters and increase the network depth efficiently.
Imitating the structure of ResNet and the bottleneck, we designed a feature extraction module as the basis of the network, which is composed of a convolution backbone and a fully connected prediction layer. After the extraction of CNN feature maps, we apply a global average pooling (GAP) layer before the fully connected layer [
21]. With the GAP, we do not need to resize the input images to a fixed shape, which is often a required preprocessing cutting step for satellite images. The detailed structure of our feature extraction module is shown in
Table 1.
During the first training stage, the whole feature extraction module along with its FC prediction layer is trained from scratch without the task-dependency embedding module. From the perspective of multi-task learning, the training of our feature extraction module is a hard parameter sharing technique in which the sharing layers are jointly optimized with multi-task supervisory signals. While in the second training stage, the proposed feature extraction module is kept fixed to maintain its strong feature extraction capability. With this multi-task feature extraction module, we can simultaneously tackle the TCs classification and intensity prediction tasks through a learned shared representation.
2.3. Task-Dependency Embedding Module
Although trained with two tasks’ labeled data, the CNN’s discriminative capability is still limited by the inconsistency between the two tasks. To mitigate this effect, we propose a task-dependency embedding module to adjust the network predictions through reweighting. The proposed task-dependency embedding module consists of two graph convolution layers with the ReLU activation function [
22], which is trained with the image feature extraction modules’ parameters fixed. The detailed structure of the TDEM is demonstrated in
Figure 2. With this GCN-based module, we can encode the graph structure of the feature maps directly and fit the prior relationship between the two tasks’ predictions.
As a branch of graph neural networks, a GCN performs similar operations as a CNN, which learns features from neighborhoods [
23,
24,
25,
26]. The key difference between a GCN and CNN is that the GCN is more general than the CNN and can handle unordered non-Euclidean data.
As introduced by [
27], to perform semi-supervised classification, the output of a GCN is the probability of each prediction. Following Kipf and Welling [
27], we denote the symmetric weighted adjacency matrix as
A and the parameters of the two GCN layers as
and
. And
represents for classification score adjustment for the
i-th category, and
represents the regression adjustment. In our TDEM module, the graph structure embedded by the GCN formulates the regression adjustment
and the classification scores adjustment
as independent nodes, which models the relationship between different nodes via a relationship matrix
, where
N represents the number of output nodes. Taking both the CNN features
X and the adjacency matrix
A as inputs, the TDEM produces the learned relationship matrix
and adjustment output
. The initial input feature
X is the output of the CNN’s GAP layer, while the input feature of the second GCN layer is the output feature of the first GCN. Through backpropagation, the learned adjacency matrix
in a GCN can represent the dependencies of two tasks in the feature space. The values in the adjacency matrix measure the corresponding correlation between prediction nodes.
To sum up, the whole process of the TDEM module is as follows: first, obtain the feature vector
X obtained by the GAP layer and calculate the relationship matrix
of the graph structure by the adjacency matrix
A; then, input them into a two-layer GCN network to obtain the prediction nodes
J. Our forward calculation takes the form:
Here, is an input-to-hidden weight matrix for a hidden layer with H feature maps. is a hidden-to-output weight matrix. And the relationship matrix is defined as , with and .
Finally, we apply the output
of the TDEM to the original output
of the FC layer of the feature extraction module in an element-wise manner as a weighted adjustment. The reweighting process can be written as follows:
Here, denotes the final prediction result of our MT-GN network. In this way, we integrate the task-dependency prior to the following prediction part of the model.
2.4. Loss Function
Traditionally, classification and regression tasks are tackled in isolation, i.e., a separate neural network is trained for each task. Unlike the traditional learning way, multiple tasks are solved jointly in multi-task learning (MTL), and inductive bias is shared between the tasks [
28,
29,
30,
31]. MTL can be formulated as a weighted minimization problem as:
where
demonstrates the predefined or dynamic weights for the
t-th task, and
represents the empirical loss of the
t-th task, which is defined by Equation (
4):
In the above equation, N represents the number of sample for the t-th task, represents the network model for the t-th task, represents the model parameters shared among multiple tasks, represents the exclusive model parameter of the t-th task, and represents the label for the i-th sample of the t-th task.
For our multi-task learning model, we design a mixed loss function. For the regression part, we use the mean squared loss. For the classification part, we choose a class-balanced loss. Because the distribution of TC categories is very uneven, previous studies usually apply manual oversampling or downsampling to the datasets. However, upsampling simply expands the dataset by rotation and additional noise in order to replicate small class samples [
6]. The characteristics of the new data are highly similar to the original data, and there is no essential performance improvement. Downsampling reduces the performance of the model for major categories. Neither of them introduce the prior knowledge of the relative quantity of different categories. Therefore, we use the class-balanced loss function based on the relative number of classes [
32]. Finally, we use the weighted sum method to balance the two sub-parts of the mixed loss function. Our mixed loss function
formula is as follows:
Here,
and
represent the loss function for regression and classification, respectively, and
denotes the weight of the classification part. The following equations formulate the details of the two loss functions:
where
represents the label for regression or classification,
represents the original output of the CNN part of the final output adjusted by the GCN part,
represents the number of samples of category
i,
C represents the number of categories, and
and
are hyperparameters in the loss function.
It is worth noting that the GCN network weights and are trained with the same loss function and learning rate as the CNN part. Thus, we obtain a simple yet consistent training scheme for the two parts of the model.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}