

A “Region-Specific Model Adaptation (RSMA)”-Based Training Data Method for Large-Scale Land Cover Mapping

Abstract
1. Introduction
- (1)
- Design a framework that integrates machine learning with multiple scientific datasets to minimize errors and uncertainties in the training samples, which are often sourced from a single dataset source.
- (2)
- Evaluate the efficacy of the training data method through experiments with two different sampling strategies and two different deep learning classifiers in the meta-learning framework.
- (3)
- Convert the online vegetation plot information into distinct land cover types (including wetland) for validating the developed training data method.
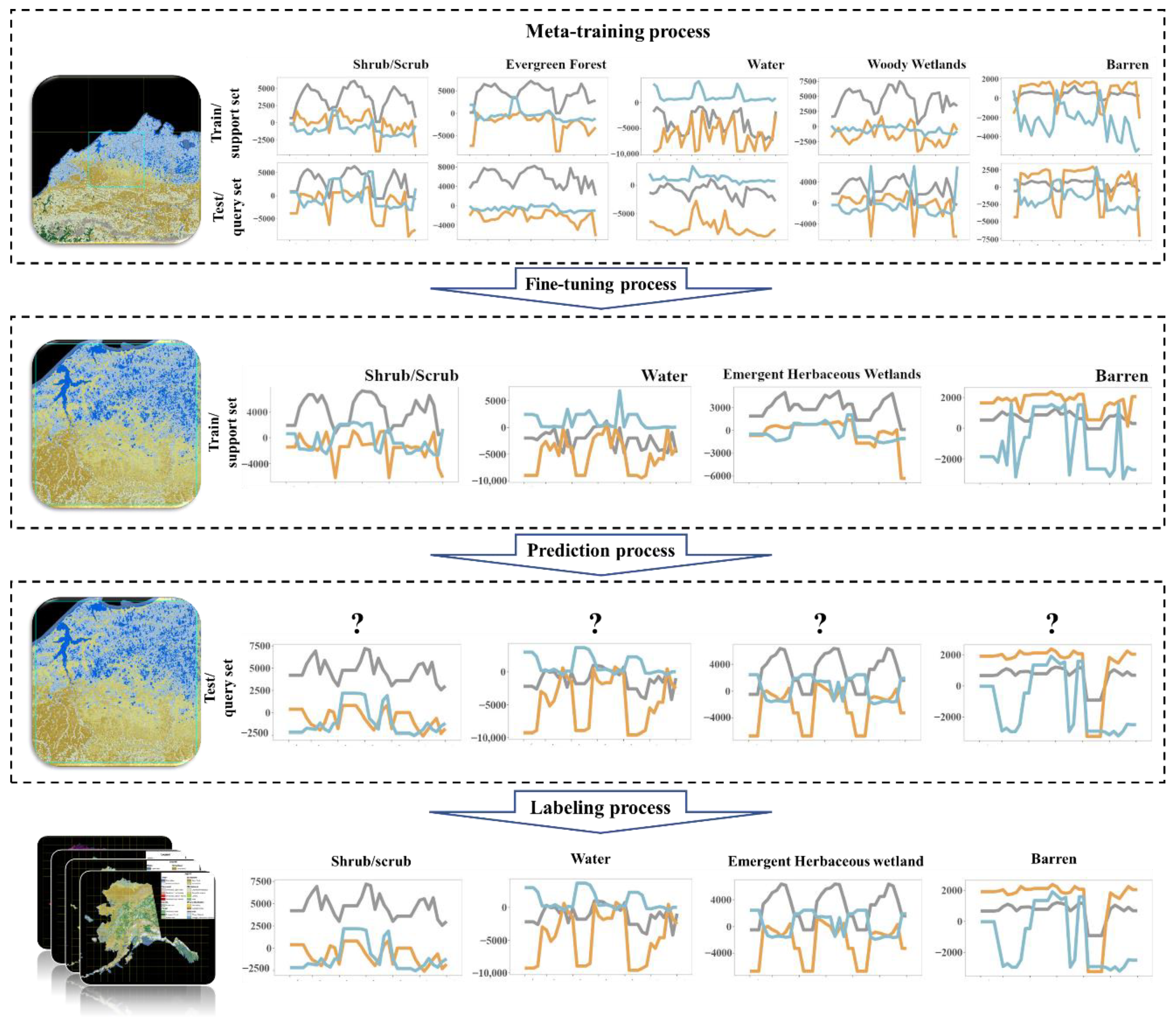
2. Method
2.1. Dataset
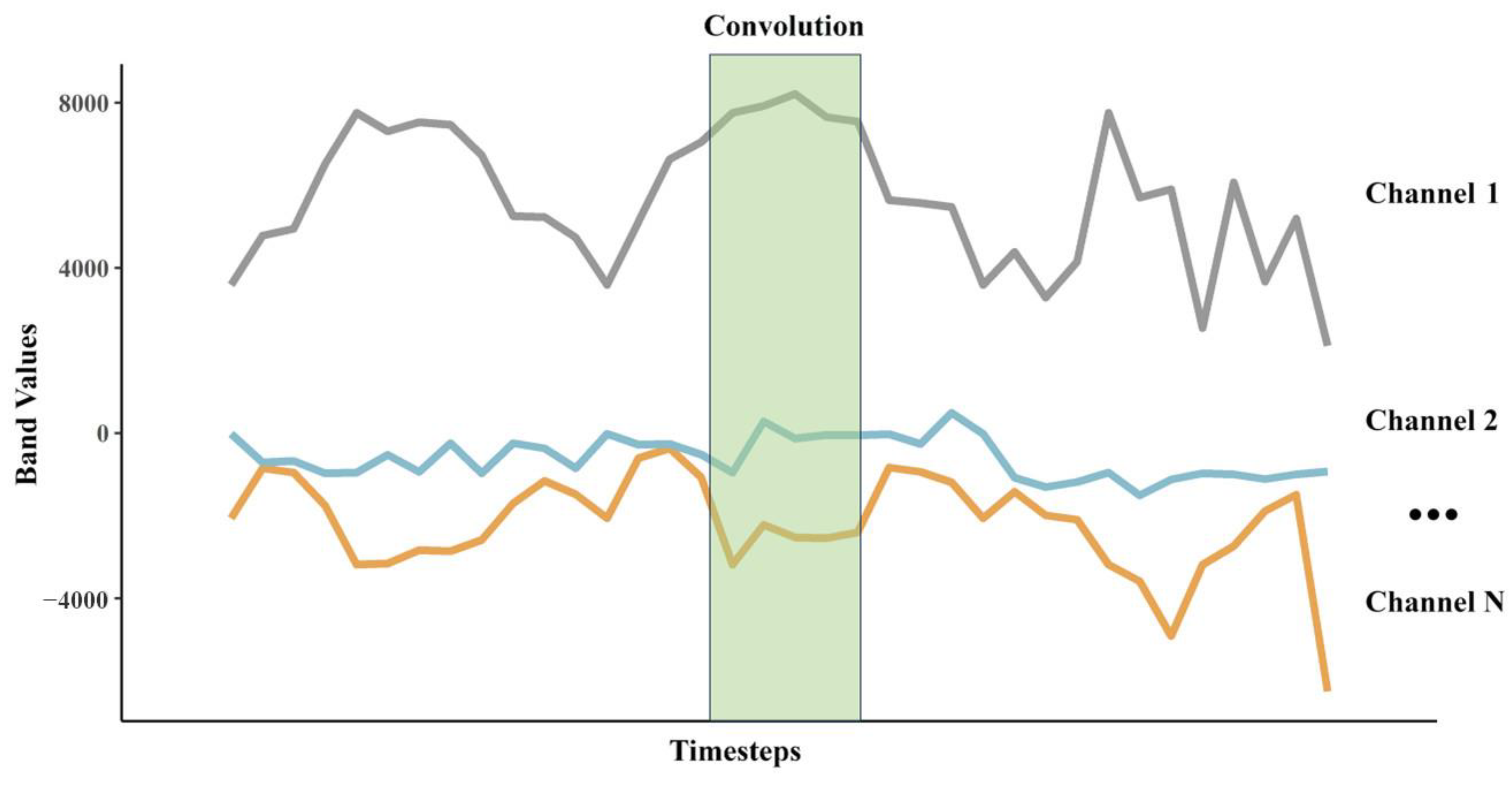
2.2. Basic Model of the RSMA-Based Training Data Method
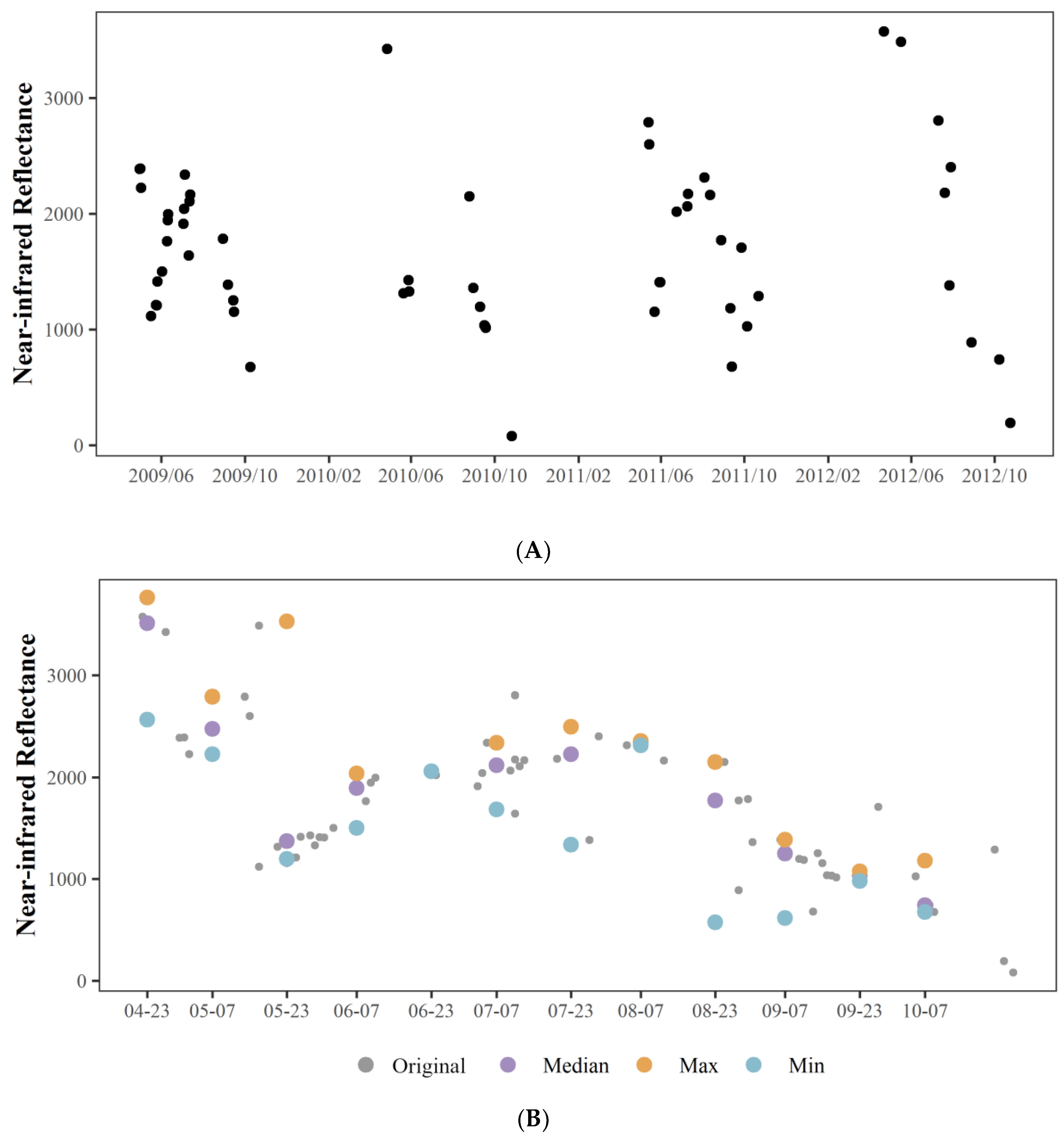
2.3. Implementation of the RSMA-Based Training Data Method
2.4. Method Assessment
3. Results
3.1. Validation Samples
3.2. Validation Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McGuire, A.D.; Anderson, L.G.; Christensen, T.R.; Dallimore, S.; Guo, L.; Hayes, D.; Heimann, M.; Lorenson, T.; Macdonald, R.; Roulet, N. Sensitivity of the carbon cycle in the Arctic to climate change. Ecol. Monogr. 2009, 79, 523–555. [Google Scholar] [CrossRef]
- McGuire, A.D.; Apps, M.; Chapin, F.S.; Dargaville, R.; Flannigan, M.D.; Kasischke, E.S.; Kicklighter, D.; Kimball, J.; Kurz, W.; McRae, D.J.; et al. Land Cover Disturbances and Feedbacks to the Climate System in Canada and Alaska. In Land Change Science: Observing, Monitoring and Understanding Trajectories of Change on the Earth’s Surface; Gutman, G., Janetos, A.C., Justice, C.O., Moran, E.F., Mustard, J.F., Rindfuss, R.R., Skole, D., Turner, B.L., Cochrane, M.A., Eds.; Springer: Dordrecht, The Netherlands, 2004; pp. 139–161. [Google Scholar]
- Jin, S.; Yang, L.; Zhu, Z.; Homer, C. A land cover change detection and classification protocol for updating Alaska NLCD 2001 to 2011. Remote Sens. Environ. 2017, 195, 44–55. [Google Scholar] [CrossRef]
- Vynne, C.; Dovichin, E.; Fresco, N.; Dawson, N.; Joshi, A.; Law, B.E.; Lertzman, K.; Rupp, S.; Schmiegelow, F.; Trammell, E.J. The Importance of Alaska for Climate Stabilization, Resilience, and Biodiversity Conservation. Front. For. Glob. Change 2021, 4, 701277. [Google Scholar] [CrossRef]
- Fisher, J.; Sikka, M.; Oechel, W.; Huntzinger, D.N.; Melton, J.R.; Koven, C.D.; Ahlström, A.; Arain, M.A.; Baker, I.; Chen, J.M.; et al. Carbon cycle uncertainty in the Alaskan Arctic. Biogeosciences 2014, 11, 4271–4288. [Google Scholar] [CrossRef]
- Wang, J.A.; Sulla-Menashe, D.; Woodcock, C.E.; Sonnentag, O.; Keeling, R.F.; Friedl, M.A. Extensive land cover change across Arctic–Boreal Northwestern North America from disturbance and climate forcing. Glob. Change Biol. 2020, 26, 807–822. [Google Scholar] [CrossRef]
- Douglas, T.; Hiemstra, C.; Anderson, J.; Barbato, R.; Bjella, K.; Deeb, E.; Gelvin, A.; Nelsen, P.E.; Newman, S.D.; Saari, S.P.; et al. Recent degradation of interior Alaska permafrost mapped with ground surveys, geophysics, deep drilling, and repeat airborne lidar. Cryosphere 2021, 15, 3555–3575. [Google Scholar] [CrossRef]
- Crumley, R.; Hill, D.; Beamer, J.; Holzenthal, E. Hydrologic Diversity in Glacier Bay Alaska: Spatial Patterns and Temporal Change. In The Cryosphere Discussions; European Geosciences Union: Munich, Germany, 2019; pp. 1–31. [Google Scholar]
- Marcot, B.G.; Jorgenson, M.T.; Lawler, J.P.; Handel, C.M.; DeGange, A.R. Projected changes in wildlife habitats in Arctic natural areas of northwest Alaska. Clim. Change 2015, 130, 145–154. [Google Scholar] [CrossRef]
- Pielke Sr, R.A.; Pitman, A.; Niyogi, D.; Mahmood, R.; McAlpine, C.; Hossain, F.; Goldewijk, K.K.; Nair, U.; Betts, R.; Fall, S.; et al. Land use/land cover changes and climate: Modeling analysis and observational evidence. WIREs Clim. Change 2011, 2, 828–850. [Google Scholar] [CrossRef]
- Nelson, K.J.; Long, D.G.; Connot, J.A. LANDFIRE 2010—Updates to the National Dataset to Support Improved Fire and Natural Resource Management; Report 2016-1010; USGS: Reston, VA, USA, 2016. [Google Scholar]
- Hall, J.V.; Frayer, W.E.; Wilen, B.O. Status of Alaska Wetlands; US Fish & Wildlife Service: Washington, DC, USA, 1994. [Google Scholar]
- U.S. Department of Interior (USDI); Fish and Wildlife Service (FWS). National Wetlands Inventory Website; U.S. Department of the Interior, Fish and Wildlife Service: Washington, DC, USA, 2018. Available online: http://www.fws.gov/wetlands/ (accessed on 2 November 2020).
- Clewley, D.; Whitcomb, J.; Moghaddam, M.; McDonald, K.; Chapman, B.; Bunting, P. Evaluation of ALOS PALSAR Data for High-Resolution Mapping of Vegetated Wetlands in Alaska. Remote Sens. 2015, 7, 7272–7297. [Google Scholar] [CrossRef]
- Li, C.C.; Wang, J.; Wang, L.; Hu, L.Y.; Pong, P. Comparison of classification algorithms and training sample sizes in urban land classification with Landsat Thematic Mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Zhang, G.; Roslan, S.N.A.b.; Wang, C.; Quan, L. Research on land cover classification of multi-source remote sensing data based on improved U-net network. Sci. Rep. 2023, 13, 16275. [Google Scholar] [CrossRef] [PubMed]
- Shakya, A.K.; Ramola, A.; Vidyarthi, A. Landcover Pattern Recognization through Texture Classification Using LANDSAT Data of Dallas; Springer: Singapore, 2020; pp. 283–293. [Google Scholar]
- Zhao, W.; Peng, S.; Chen, J.; Peng, R. Contextual-Aware Land Cover Classification With U-Shaped Object Graph Neural Network. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510705. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Miller, J. Contextual land-cover classification: Incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens. Lett. 2010, 1, 45–54. [Google Scholar] [CrossRef]
- Zhu, Z.; Woodcock, C.E. Continuous change detection and classification of land cover using all available Landsat data. Remote Sens. Environ. 2014, 144, 152–171. [Google Scholar] [CrossRef]
- Li, C.; Xian, G.; Zhou, Q.; Pengra, B. A novel automatic phenology learning (APL) method of training sample selection using multiple datasets for time-series land cover mapping. Remote Sens. Environ. 2021, 266, 112670. [Google Scholar] [CrossRef]
- Li, C.; Gong, P.; Wang, J.; Yuan, C.; Hu, T.; Wang, Q.; Yu, L.; Clinton, N.; Li, M.; Guo, J.; et al. An all-season sample database for improving land-cover mapping of Africa with two classification schemes. Int. J. Remote Sens. 2016, 37, 4623–4647. [Google Scholar] [CrossRef]
- Li, C.; Gong, P.; Wang, J.; Zhu, Z.; Biging, G.S.; Yuan, C.; Hu, T.; Zhang, H.; Wang, Q.; Li, X.; et al. The first all-season sample set for mapping global land cover with Landsat-8 data. Sci. Bull. 2017, 62, 508–515. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Zhou, Q.; Tollerud, H.; Barber, C.; Smith, K.; Zelenak, D. Training data selection for annual land cover classification for the Land Change Monitoring, Assessment, and Projection (LCMAP) initiative. Remote Sens. 2020, 12, 699. [Google Scholar] [CrossRef]
- Brown, J.F.; Tollerud, H.J.; Barber, C.P.; Zhou, Q.; Dwyer, J.L.; Vogelmann, J.E.; Loveland, T.R.; Woodcock, C.E.; Stehman, S.V.; Zhu, Z.; et al. Lessons learned implementing an operational continuous United States national land change monitoring capability: The Land Change Monitoring, Assessment, and Projection (LCMAP) approach. Remote Sens. Environ. 2020, 238, 111356. [Google Scholar] [CrossRef]
- Li, C.; Xian, G.; Wellington, D.; Smith, K.; Horton, J.; Zhou, Q. Development of the LCMAP annual land cover product across Hawaiʻi. Int. J. Appl. Earth Obs. Geoinf. 2022, 113, 103015. [Google Scholar] [CrossRef]
- Maus, V.; Camara, G.; Cartaxo, R.; Sanchez, A.; Ramos, F.M.; Queiroz, G.R. A Time-Weighted Dynamic Time Warping method for land-use and land-cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3729–3739. [Google Scholar] [CrossRef]
- Pengra, B.; Stehman, S.V.; Horton, J.A.; Wellington, D.F. Land Change Monitoring, Assessment, and Projection (LCMAP) Version 1.0 Annual Land Cover and Land Cover Change Validation Tables; U.S. Geological Survey Data Release: Reston, VA, USA, 2020. [Google Scholar]
- Nawrocki, T.W. Alaska Vegetation Plots Database (AKVEG). Git Repository. 2021. Available online: https://github.com/accs-uaa/vegetation-plots-database (accessed on 20 April 2022).
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Alshalali, T.; Josyula, D. Fine-Tuning of Pre-Trained Deep Learning Models with Extreme Learning Machine. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 469–473. [Google Scholar]
- Anderson, J.R.; Hardy, E.E.; Roach, J.T.; Witmer, R.E. A Land Use and Land Cover Classification System for Use with Remote Sensor Data, Report 964; US Government Printing Office: Washington, DC, USA, 1976. [Google Scholar]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 1977. [Google Scholar]
- Crawford, C.J.; Roy, D.P.; Arab, S.; Barnes, C.; Vermote, E.; Hulley, G.; Gerace, A.; Choate, M.; Engebretson, C.; Micijevic, E.; et al. The 50-year Landsat collection 2 archive. Sci. Remote Sens. 2023, 8, 100103. [Google Scholar] [CrossRef]
- Tucker, C.J.; Sellers, P.J. Satellite remote sensing of primary production. Int. J. Remote Sens. 1986, 7, 1395–1416. [Google Scholar] [CrossRef]
- Zha, Y.; Gao, J.; Ni, S. Use of normalized difference built-up index in automatically mapping urban areas from TM imagery. Int. J. Remote Sens. 2003, 24, 583–594. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Feyisa, G.L.; Meilby, H.; Fensholt, R.; Proud, S. Automated Water Extraction Index: A new technique for surface water mapping using Landsat imagery. Remote Sens. Environ. 2014, 140, 23–35. [Google Scholar] [CrossRef]
- Crist, E.P. A TM Tasseled Cap equivalent transformation for reflectance factor data. Remote Sens. Environ. 1985, 17, 301–306. [Google Scholar] [CrossRef]
- Huang, C.; Wylie, B.; Yang, L.; Homer, C.; Zylstra, G. Derivation of a Tasseled Cap Transformation Based On Landsat 7 At-Satellite Reflectance. Int. J. Remote Sens. 2002, 23, 1741–1748. [Google Scholar] [CrossRef]
- Miller, J.D.; Yool, S.R. Mapping forest post-fire canopy consumption in several overstory types using multi-temporal Landsat TM and ETM data. Remote Sens. Environ. 2002, 82, 481–496. [Google Scholar] [CrossRef]
- Diek, S.; Fornallaz, F.; Schaepman, M.E.; Rogier, D.J. Barest Pixel Composite for Agricultural Areas Using Landsat Time Series. Remote Sens. 2017, 9, 1245. [Google Scholar] [CrossRef]
- Tegegne, A.M. Applications of Convolutional Neural Network for Classification of Land Cover and Groundwater Potentiality Zones. J. Eng. 2022, 2022, 6372089. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Into Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML 2017, 70, 1126–1135. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Macander, M.J.; Nelson, P.R.; Nawrocki, T.W.; Frost, G.V.; Orndahl, K.M.; Palm, E.C.; Wells, A.F.; Goetz, S.J. Time-series maps reveal widespread change in plant functional type cover across Arctic and boreal Alaska and Yukon. Environ. Res. Lett. 2022, 17, 054042. [Google Scholar] [CrossRef]
- Selkowitz, D.J.; Stehman, S.V. Thematic accuracy of the National Land Cover Database (NLCD) 2001 land cover for Alaska. Remote Sens. Environ. 2011, 115, 1401–1407. [Google Scholar] [CrossRef]
- Ducks Unlimited (DU). North Slope Science Initiative Landcover Mapping Summary Report; Ducks Unlimited: Rancho Cordova, CA, USA, 2013. [Google Scholar]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef]
- Zanaga, D.; Van De Kerchove, R.; Daems, D.; De Keersmaecker, W.; Brockmann, C.; Kirches, G.; Wevers, J.; Cartus, O.; Santoro, M.; Fritz, S.; et al. ESA WorldCover 10 m 2020 v100; Zenodo: Genève, Switzerland, 2021. [Google Scholar] [CrossRef]
- Friedl, M.A.; Woodcock, C.E.; Olofsson, P.; Zhu, Z.; Loveland, T.; Stanimirova, R.; Arevalo, P.; Bullock, E.; Hu, K.T.; Zhang, Y.; et al. Medium Spatial Resolution Mapping of Global Land Cover and Land Cover Change Across Multiple Decades From Landsat. Front. Remote Sens. 2022, 3, 894571. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Pickens, A.H.; Hansen, M.C.; Hancher, M.; Stehman, S.V.; Tyukavina, A.; Potapov, P.; Marroquin, B.; Sherani, Z. Mapping and sampling to characterize global inland water dynamics from 1999 to 2018 with full Landsat time-series. Remote Sens. Environ. 2020, 243, 111792. [Google Scholar] [CrossRef]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Dewitz, J. National Land Cover Database (NLCD) 2016 Products (ver. 3.0, November 2023) [National Land Cover Database (NLCD) 2011 Land Cover—Alaska]; U.S. Geological Survey: Reston, VA, USA, 2019. [Google Scholar] [CrossRef]
- LANDFIRE. Existing Vegetation Type Layer, LANDFIRE 1.2.0, U.S. Department of the Interior, Geological Survey, and U.S. Department of Agriculture. 2010. Available online: http://www.landfire/viewer (accessed on 1 April 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Formula | Citation |
|---|---|---|
| Normalized Difference Vegetation Index (NDVI) | [37] | |
| Normalized Difference Built-Up Index (NDBI) | [38] | |
| Normalized Difference Water Index (NDWI) | [39] | |
| Modified Normalized Difference Water Index (MNDWI) | [40] | |
| Automated Water Extraction Index (AWEI) | [41] | |
| Wetness | For Landsat 5, For Landsat 7, | [42,43] |
| Brightness | For Landsat 5, For Landsat 7, | [42,43] |
| Normalized Burn Ratio (NBR) | [3,44] | |
| Bare Soil Index (BSI) | [45] |
| ID | Project | Site Code | Date | Accepted Name | Cover (%) | Plant Life-Form | Wetland Indicator Status |
|---|---|---|---|---|---|---|---|
| 34027 | USFWS Interior | KAN226 | 6/27/2013 | Betula neoalaskana | 36 | deciduous tree | FACU |
| 34024 | USFWS Interior | KAN226 | 6/27/2013 | Alnus viridis | 23 | shrub | FAC |
| 34029 | USFWS Interior | KAN226 | 6/27/2013 | Empetrum nigrum | 12 | dwarf shrub | FAC |
| 34031 | USFWS Interior | KAN226 | 6/27/2013 | Vaccinium uliginosum | 12 | dwarf shrub, shrub | FAC |
| 34026 | USFWS Interior | KAN226 | 6/27/2013 | Betula nana | 6 | shrub | FAC |
| 34030 | USFWS Interior | KAN226 | 6/27/2013 | Rhododendron tomentosum | 4 | dwarf shrub, shrub | FACW |
| 34032 | USFWS Interior | KAN226 | 6/27/2013 | Vaccinium vitis-idaea | 3 | dwarf shrub | FAC |
| 34025 | USFWS Interior | KAN226 | 6/27/2013 | Arctous alpina | 0.5 | dwarf shrub | FACU |
| 34028 | USFWS Interior | KAN226 | 6/27/2013 | Calamagrostis canadensis | 0.5 | graminoid | FAC |
| 34033 | USFWS Interior | KAN226 | 6/27/2013 | Carex bigelowii | 0.1 | graminoid | FAC |
| NLCD 2011 Land Cover | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 41 | 42 | 43 | 51 | 52 | 71 | 72 | 90 | 95 | Grand Total | PA (%) | ||
| Ground Truth | 31 | 3 | 1 | 1 | 5 | 60.0 | |||||||
| 41 | 2 | 4 | 2 | 1 | 9 | 22.2 | |||||||
| 42 | 2 | 2 | 1 | 5 | 40.0 | ||||||||
| 43 | 1 | 3 | 1 | 1 | 6 | 50.0 | |||||||
| 51 | 1 | 8 | 1 | 3 | 13 | 61.5 | |||||||
| 52 | 5 | 13 | 1 | 19 | 68.4 | ||||||||
| 71 | 0 | 0 | - | ||||||||||
| 72 | 1 | 2 | 1 | 4 | 25.0 | ||||||||
| 90 | 2 | 2 | 12 | 7 | 0 | 23 | 0.0 | ||||||
| 95 | 1 | 1 | 2 | 22 | 1 | 27 | 3.7 | ||||||
| Grand Total | 5 | 4 | 5 | 5 | 20 | 33 | 2 | 36 | - | 1 | 111 | 29.7% | |
| UA (%) | 60.0 | 50.0 | 40.0 | 60.0 | 40.0 | 39.4 | 0.0 | 2.8 | - | 100.0 | |||
| UNet-RSMA Based Training Data Method | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 41 | 42 | 43 | 51 | 52 | 72 | 90 | 95 | Grand Total | PA (%) | ||
| Ground Truth | 31 | 4 | 1 | 5 | 80.0 | |||||||
| 41 | 3 | 1 | 3 | 2 | 9 | 33.3 | ||||||
| 42 | 5 | 5 | 100.0 | |||||||||
| 43 | 3 | 3 | 6 | 50.0 | ||||||||
| 51 | 1 | 8 | 2 | 2 | 13 | 61.5 | ||||||
| 52 | 2 | 17 | 19 | 89.5 | ||||||||
| 72 | 1 | 2 | 1 | 4 | 25.0 | |||||||
| 90 | 1 | 1 | 1 | 1 | 6 | 2 | 8 | 3 | 23 | 34.8 | ||
| 95 | 3 | 2 | 1 | 2 | 1 | 18 | 27 | 66.7 | ||||
| Grand Total | 6 | 10 | 11 | 4 | 12 | 29 | 7 | 9 | 23 | 111 | 60.4% | |
| UA (%) | 66.7 | 30.0 | 45.5 | 75.0 | 66.7 | 58.6 | 14.3 | 88.9 | 78.3 | |||
| Pretrained Model by Meta-Training Process in UNet-RSMA | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 41 | 42 | 43 | 51 | 52 | 72 | 90 | 95 | Grand Total | PA (%) | ||
| Ground Truth | 31 | 4 | 1 | 5 | 80.0 | |||||||
| 41 | 3 | 1 | 2 | 1 | 2 | 9 | 33.3 | |||||
| 42 | 1 | 3 | 1 | 5 | 60.0 | |||||||
| 43 | 3 | 3 | 6 | 50.0 | ||||||||
| 51 | 1 | 5 | 1 | 3 | 1 | 2 | 13 | 38.5 | ||||
| 52 | 1 | 2 | 2 | 7 | 2 | 4 | 1 | 19 | 36.8 | |||
| 72 | 2 | 2 | 0 | 4 | 0.0 | |||||||
| 90 | 1 | 1 | 1 | 2 | 5 | 9 | 4 | 23 | 39.1 | |||
| 95 | 2 | 1 | 2 | 1 | 7 | 1 | 13 | 27 | 48.1 | |||
| Grand Total | 8 | 12 | 6 | 7 | 11 | 16 | 12 | 16 | 23 | 111 | 42.3 | |
| UA (%) | 50.0 | 25.0 | 50.0 | 42.9 | 45.5 | 43.8 | 0.0 | 56.3 | 56.5 | |||
| Transferring Model Using the Equal-Number Random Sampling Method for Each Category | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 41 | 42 | 43 | 51 | 52 | 71 | 72 | 90 | 95 | Grand Total | PA (%) | ||
| Ground Truth | 31 | 4 | 1 | 5 | 80.0 | ||||||||
| 41 | 3 | 1 | 2 | 1 | 2 | 9 | 33.3 | ||||||
| 42 | 1 | 3 | 1 | 5 | 60.0 | ||||||||
| 43 | 3 | 3 | 6 | 50.0 | |||||||||
| 51 | 1 | 6 | 1 | 2 | 1 | 2 | 13 | 46.2 | |||||
| 52 | 1 | 2 | 2 | 7 | 2 | 4 | 1 | 19 | 36.8 | ||||
| 71 | 0 | 0 | - | ||||||||||
| 72 | 2 | 1 | 1 | 4 | 25.0 | ||||||||
| 90 | 1 | 1 | 1 | 2 | 5 | 1 | 10 | 2 | 23 | 43.5 | |||
| 95 | 3 | 2 | 1 | 4 | 17 | 27 | 63.0 | ||||||
| Grand Total | 8 | 13 | 6 | 6 | 11 | 16 | 1 | 10 | 15 | 25 | 111 | ||
| UA (%) | 50.0 | 23.1 | 50.0 | 50.0 | 54.5 | 43.8 | 0.0 | 10.0 | 66.7 | 68.0 | 48.6% | ||
| 1D-CNN-RSMA | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 31 | 41 | 42 | 43 | 51 | 52 | 72 | 90 | 95 | Grand Total | PA (%) | ||
| Ground Truth | 31 | 3 | 1 | 1 | 5 | 60.0 | ||||||
| 41 | 4 | 5 | 9 | 44.4 | ||||||||
| 42 | 3 | 2 | 5 | 60.0 | ||||||||
| 43 | 1 | 4 | 1 | 6 | 66.7 | |||||||
| 51 | 9 | 2 | 2 | 13 | 69.2 | |||||||
| 52 | 3 | 4 | 12 | 19 | 63.2 | |||||||
| 72 | 1 | 2 | 1 | 0 | 4 | 0.0 | ||||||
| 90 | 1 | 3 | 1 | 4 | 6 | 8 | 23 | 26.1 | ||||
| 95 | 2 | 1 | 1 | 23 | 27 | 85.2 | ||||||
| Grand Total | 4 | 8 | 10 | 7 | 16 | 26 | 1 | 6 | 33 | 111 | ||
| UA (%) | 75.0 | 50.0 | 30.0 | 57.1 | 56.3 | 46.2 | 0.0 | 100.0 | 69.7 | 57.7% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Xian, G.; Jin, S. A “Region-Specific Model Adaptation (RSMA)”-Based Training Data Method for Large-Scale Land Cover Mapping. Remote Sens. 2024, 16, 3717. https://doi.org/10.3390/rs16193717
Li C, Xian G, Jin S. A “Region-Specific Model Adaptation (RSMA)”-Based Training Data Method for Large-Scale Land Cover Mapping. Remote Sensing. 2024; 16(19):3717. https://doi.org/10.3390/rs16193717
Chicago/Turabian StyleLi, Congcong, George Xian, and Suming Jin. 2024. "A “Region-Specific Model Adaptation (RSMA)”-Based Training Data Method for Large-Scale Land Cover Mapping" Remote Sensing 16, no. 19: 3717. https://doi.org/10.3390/rs16193717
APA StyleLi, C., Xian, G., & Jin, S. (2024). A “Region-Specific Model Adaptation (RSMA)”-Based Training Data Method for Large-Scale Land Cover Mapping. Remote Sensing, 16(19), 3717. https://doi.org/10.3390/rs16193717