
Relevance Pooling Guidance and Class-Balanced Feature Enhancement for Fine-Grained Oriented Object Detection in Remote Sensing Images

Abstract

1. Introduction
- We propose RGAM that replaces traditional pooling with relevance pooling. This approach mitigates the loss of details caused by down-sampling and enhances the feature representation.
- We propose a CBC strategy that directly operates within the feature space to highlight the boundaries of tail class features and utilizes a learnable reinforcement mechanism to dynamically amplify these features, alleviating the long-tail problem.
- We propose an ECL model that constrains inter-class distances while increasing intra-class compactness, thereby significantly enhancing the effectiveness of contrastive learning for imbalanced datasets.
2. Related Work
2.1. Fine-Grained Oriented Object Detection in RSI
2.2. Discriminant Feature
2.3. Class Imbalanced Learning
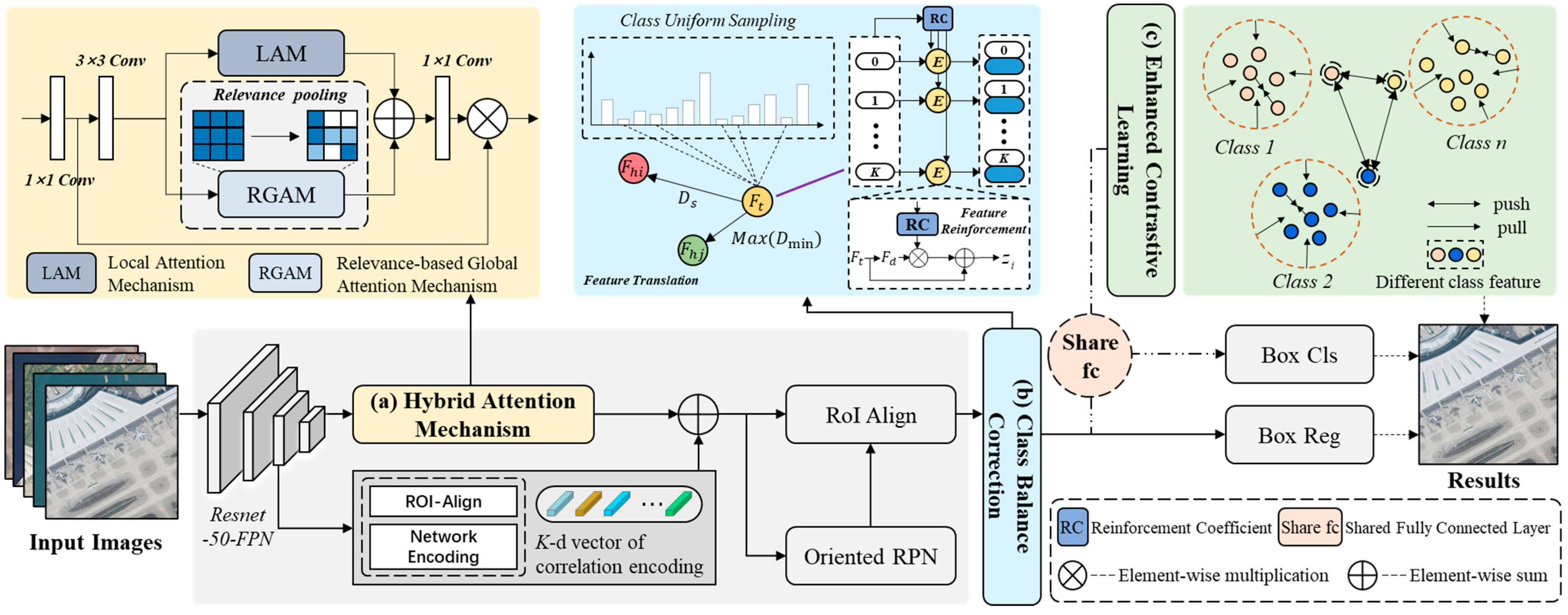
3. Methods
3.1. Relevance-Based Global Attention Mechanism
3.2. Class Balance Correction
3.3. Enhanced Contrast Learning
4. Results
4.1. Datasets
- (1)
- The FAIR1M dataset consists of 24,625 images, with 16,488 images allocated for training and 8137 images for testing. The spatial resolution of the image ranges from 0.3 m to 0.8 m, with each image ranging in size from 1000 × 1000 to 10,000 × 10,000 pixels. The dataset includes 5 coarse-grained classes and 37 fine-grained classes, encompassing objects of various scales, orientations, and shapes. All categories and the number of instances per category in the FAIR1M and MAR20 datasets are shown in Figure 4.
- (2)
- The MAR20 dataset is a high-resolution, fine-grained military aircraft object detection dataset that includes 3842 images and 22,341 instance objects. We identify 20 classes of fine-grained military aircraft objects, including SU-35, C-130, C-17, C-5, F-16, TU-160, E-3, B-52, P-3C, B-1B, E-8, TU-22, F-15, KC-135, F-22, FA-18, TU-95, KC-10, SU-34, and SU-24. These models are abbreviated as A1 to A20 in sequential order. We adopt the official dataset partitioning scheme of MAR20, comprising 1331 images and 7870 objects for training and 2511 images and 14,471 objects for testing.
4.2. Implementation Details
4.3. Comparisons with Other Methods
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar]
- Yang, Z.; Luo, T.; Wang, D.; Hu, Z.; Gao, J.; Wang, L. Learning to navigate for fine-grained classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Lee, S.; Moon, W.; Heo, J.-P. Task Discrepancy Maximization for Fine-grained Few-Shot Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5321–5330. [Google Scholar]
- Ding, Y.; Zhou, Y.; Zhu, Y.; Ye, Q.; Jiao, J. Selective Sparse Sampling for Fine-Grained Image Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6598–6607. [Google Scholar]
- Han, Y.; Yang, X.; Pu, T.; Peng, Z. Fine-grained recognition for oriented ship against complex scenes in optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5612318. [Google Scholar] [CrossRef]
- Chen, J.; Chen, K.; Chen, H.; Li, W.; Zou, Z.; Shi, Z. Contrastive learning for fine-grained ship classification in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4707916. [Google Scholar] [CrossRef]
- Ouyang, L.; Fang, L.; Ji, X. Multigranularity Self-Attention Network for Fine-Grained Ship Detection in Remote Sensing Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2022, 15, 9722–9732. [Google Scholar] [CrossRef]
- Yu, S.; Guo, J.; Zhang, R.; Fan, Y.; Wang, Z.; Cheng, X. A Re-Balancing Strategy for Class-Imbalanced Classification Based on Instance Difficulty. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 70–79. [Google Scholar]
- Qin, Y.; Zheng, H.; Yao, J.; Zhou, M.; Zhang, Y. Class-Balancing Diffusion Models. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18434–18443. [Google Scholar]
- Alshammari, S.; Wang, Y.-X.; Ramanan, D.; Kong, S. Long-Tailed Recognition via Weight Balancing. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6887–6897. [Google Scholar]
- Luo, W.; Yang, X.; Mo, X.; Lu, Y.; Davis, L.; Li, J.; Yang, J.; Lim, S. Cross-X Learning for Fine-Grained Visual Categorization. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8241–8250. [Google Scholar]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 579–590. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Q.; Wang, G.; Xie, X.; Min, L.; Han, J. SFRNet: Fine-Grained Oriented Object Recognition via Separate Feature Refinement. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5610510. [Google Scholar] [CrossRef]
- Song, J.; Miao, L.; Ming, Q.; Zhou, Z.; Dong, Y. Fine-Grained Object Detection in Remote Sensing Images via Adaptive Label Assignment and Refined-Balanced Feature Pyramid Network. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2023, 16, 71–82. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, S.; Zhao, J.; Zhu, H.; Yao, R. Fine-Grained Feature Enhancement for Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6508305. [Google Scholar] [CrossRef]
- Zeng, L.; Guo, H.; Yang, W.; Yu, H.; Yu, L.; Zhang, P.; Zou, T. Instance Switching-Based Contrastive Learning for Fine-Grained Airplane Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5633416. [Google Scholar] [CrossRef]
- Zhuang, P.; Wang, Y.; Qiao, Y. Learning attentive pairwise interaction for fine-grained classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 30 July–3 August 2020; Volume 34, pp. 13130–13137. [Google Scholar]
- Zheng, H.; Fu, J.; Zha, Z.-J.; Luo, J. Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5007–5016. [Google Scholar]
- Shi, W.; Gong, Y.; Tao, X.; Cheng, D.; Zheng, N. Fine-Grained Image Classification Using Modified DCNNs Trained by Cascaded Softmax and Generalized Large-Margin Losses. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 683–694. [Google Scholar] [CrossRef]
- Bao, W.; Hu, J.; Huang, M.; Xu, Y.; Ji, N.; Xiang, X. Detecting Fine-Grained Airplanes in SAR Images With Sparse Attention-Guided Pyramid and Class-Balanced Data Augmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8586–8599. [Google Scholar] [CrossRef]
- Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4682–4692. [Google Scholar]
- Wang, Y.; Peng, J.; Wang, H.; Wang, M. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification. Sci. China Inf. Sci. 2022, 65, 160103. [Google Scholar] [CrossRef]
- Li, X.; Wu, J.; Sun, Z.; Ma, Z.; Cao, J.; Xue, J.-H. BSNet: Bi-Similarity Network for Few-shot Fine-grained Image Classification. IEEE Trans. Image Process. 2021, 30, 1318–1331. [Google Scholar] [CrossRef] [PubMed]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. FSCE: Few-shot object detection via contrastive proposal encoding. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7348–7358. [Google Scholar]
- Byrd, J.; Lipton, Z. What is the effect of importance weighting in deep learning? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 872–881. [Google Scholar]
- Li, J.; Lin, X.; Zhang, W.; Tan, X.; Li, Y.; Han, J.; Ding, E.; Wang, J.; Li, G. Gradient-based Sampling for Class Imbalanced Semi-supervised Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 16344–16354. [Google Scholar]
- Zhang, Z.; Pfister, T. Learning Fast Sample Re-weighting Without Reward Data. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 705–714. [Google Scholar]
- Tan, J.; Wang, C.; Li, B.; Li, Q.; Ouyang, W.; Yin, C.; Yan, J. Equalization loss for long-tailed object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11662–11671. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.V.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; van der Maaten, L. Exploring the limits of weakly supervised pretraining. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 181–196. [Google Scholar]
- Khan, S.H.; Hayat, M.; Bennamoun, M.; Sohel, F.A.; Togneri, R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3573–3587. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. Combination of clustering and ranking techniques for unsupervised band selection of hyperspectral images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2015, 8, 2814–2823. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging- boosting- and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Zhou, B.; Cui, Q.; Wei, X.-S.; Chen, Z.-M. BBN: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9719–9728. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Feature transfer learning for face recognition with under-represented data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, T.; Wang, L.; Wu, G. Self supervision to distillation for long-tailed visual recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Cui, J.; Zhong, Z.; Liu, S.; Yu, B.; Jia, J. Parametric contrastive learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, H.; Yao, M.; Chen, Y.; Xu, Y.; Liu, H.; Jia, W.; Fu, X.; Wang, Y. Manifold-based Incomplete Multi-view Clustering via Bi-Consistency Guidance. IEEE Trans. Multimed. 2024. early access. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Yu, W.Q.; Cheng, G.; Wang, M.J.; Yao, Y.Q.; Xie, X.X.; Yao, X.X.; Han, J.W. MAR20: A benchmark for military aircraft recognition in remote sensing images. National Remote Sensing Bulletin 2023, 27, 2688–2696. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 9626–9635. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Han, J.; Ding, J.; Li, J.; Xia, G.-S. Align Deep Features for Oriented Object Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Ding, J.; Xue, N.; Xia, G.-S. ReDet: A rotation-equivariant detector for aerial object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2785–2794. [Google Scholar]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented R-CNN for object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3520–3529. [Google Scholar]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning RoI transformer for oriented object detection in aerial images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Xu, Y.; Fu, M.; Wang, Q.; Wang, Y.; Chen, K.; Xia, G.-S.; Bai, X. Gliding Vertex on the Horizontal Bounding Box for Multi-Oriented Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1452–1459. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, L.; Guo, G.; Fang, L.; Ghamisi, P.; Yue, J. PCLDet: Prototypical Contrastive Learning for Fine-Grained Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5613911. [Google Scholar] [CrossRef]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10183–10192. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FCOS-O [42] | RetinaNet-O [43] | S2A-Net [44] | Faster R-CNN-O [45] | Redet [46] | Oriented R-CNN [47] | RoI-Transformer [48] | Gliding Vertex [49] | SFRNet [13] | RB-FPN [14] | PCLDet [50] | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Airplane | B737 | 32.43 | 35.24 | 36.06 | 37.11 | 36.51 | 35.17 | 40.14 | 36.50 | 40.63 | 39.16 | 43.51 | 46.21 |
| B747 | 79.97 | 74.90 | 84.33 | 84.23 | 87.03 | 85.17 | 84.92 | 81.88 | 84.32 | 86.70 | 87.37 | 88.51 | |
| B777 | 13.76 | 10.54 | 15.62 | 15.64 | 22.45 | 14.57 | 15.39 | 14.06 | 17.64 | 16.17 | 28.73 | 31.55 | |
| B787 | 46.85 | 38.49 | 42.34 | 46.95 | 50.68 | 47.68 | 49.17 | 44.60 | 48.88 | 49.16 | 55.37 | 58.32 | |
| C919 | 1.18 | 0.96 | 1.95 | 9.88 | 10.82 | 11.68 | 19.73 | 10.16 | 21.25 | 13.60 | 20.04 | 26.25 | |
| A220 | 45.87 | 41.39 | 44.09 | 48.15 | 47.92 | 46.55 | 50.46 | 46.43 | 48.59 | 49.18 | 51.65 | 53.15 | |
| A321 | 65.38 | 63.51 | 68.00 | 66.46 | 71.70 | 68.18 | 70.31 | 65.47 | 71.18 | 66.91 | 73.06 | 72.18 | |
| A330 | 61.39 | 46.28 | 63.84 | 68.86 | 72.45 | 68.60 | 71.42 | 67.73 | 72.97 | 71.43 | 74.52 | 73.52 | |
| A350 | 67.25 | 63.42 | 70.00 | 69.33 | 77.57 | 70.21 | 72.62 | 68.31 | 74.05 | 74.34 | 79.86 | 79.44 | |
| ARJ21 | 10.40 | 2.29 | 12.10 | 25.23 | 38.80 | 25.32 | 33.65 | 25.97 | 32.41 | 29.00 | 31.08 | 42.50 | |
| Ship | PS | 10.02 | 5.78 | 8.82 | 9.08 | 18.38 | 13.77 | 13.21 | 10.01 | 17.39 | 18.38 | 18.21 | 20.92 |
| MB | 51.99 | 23.00 | 48.03 | 49.44 | 61.71 | 60.42 | 56.54 | 51.63 | 60.55 | 68.41 | 62.88 | 68.02 | |
| FB | 8.19 | 2.52 | 6.79 | 4.55 | 11.77 | 9.10 | 6.82 | 5.26 | 8.46 | 10.55 | 12.05 | 11.61 | |
| TB | 31.67 | 24.87 | 34.01 | 31.85 | 35.87 | 36.83 | 35.71 | 34.00 | 34.92 | 38.27 | 35.17 | 41.78 | |
| ES | 11.31 | 6.98 | 7.49 | 9.31 | 13.35 | 11.32 | 9.96 | 10.34 | 12.60 | 11.83 | 13.52 | 15.93 | |
| LCS | 18.35 | 7.39 | 18.3 | 9.79 | 23.83 | 21.86 | 16.91 | 14.53 | 19.68 | 25.12 | 23.79 | 24.89 | |
| DCS | 38.26 | 21.75 | 37.62 | 25.93 | 41.56 | 38.22 | 36.01 | 33.10 | 38.22 | 38.41 | 42.26 | 46.76 | |
| WS | 20.90 | 2.75 | 22.96 | 10.42 | 34.36 | 22.67 | 17.30 | 12.45 | 21.44 | 34.72 | 37.45 | 40.02 | |
| Vehicle | SC | 48.09 | 37.22 | 61.57 | 54.38 | 61.82 | 57.62 | 58.29 | 54.39 | 58.75 | 70.75 | 61.26 | 66.79 |
| BUS | 11.54 | 4.25 | 11.76 | 18.76 | 19.96 | 24.40 | 28.02 | 28.63 | 32.77 | 36.14 | 29.13 | 37.02 | |
| CT | 29.66 | 18.38 | 34.28 | 35.85 | 41.74 | 40.84 | 40.55 | 36.90 | 41.05 | 44.94 | 42.81 | 43.18 | |
| DT | 20.70 | 12.59 | 36.03 | 41.29 | 47.33 | 45.20 | 45.97 | 42.16 | 46.63 | 50.20 | 47.99 | 47.27 | |
| VAN | 40.77 | 26.44 | 54.62 | 48.91 | 56.30 | 54.01 | 54.10 | 48.52 | 54.12 | 70.77 | 56.93 | 69.55 | |
| TRI | 7.50 | 0.01 | 3.47 | 8.25 | 13.60 | 15.46 | 11.82 | 13.38 | 15.70 | 16.75 | 14.57 | 19.56 | |
| TRC | 3.73 | 0.02 | 0.96 | 1.88 | 1.98 | 2.37 | 2.61 | 1.39 | 7.12 | 1.68 | 5.19 | 7.79 | |
| EX | 7.60 | 0.13 | 7.24 | 7.17 | 12.20 | 13.55 | 11.74 | 12.19 | 16.02 | 17.24 | 13.08 | 16.97 | |
| TT | 0.30 | 0.03 | 0.04 | 0.40 | 0.79 | 0.24 | 0.72 | 0.19 | 0.39 | 0.49 | 1.36 | 1.48 | |
| Court | BC | 41.27 | 27.51 | 38.44 | 48.93 | 54.67 | 48.18 | 47.50 | 45.83 | 49.78 | 54.59 | 55.01 | 58.18 |
| TC | 79.34 | 79.20 | 80.44 | 78.58 | 79.35 | 78.45 | 80.12 | 77.99 | 79.25 | 80.49 | 78.69 | 79.37 | |
| FF | 60.04 | 55.44 | 56.34 | 53.55 | 70.09 | 60.79 | 58.03 | 59.27 | 59.87 | 65.69 | 69.55 | 69.63 | |
| BF | 87.03 | 87.89 | 87.47 | 87.80 | 90.57 | 88.43 | 87.37 | 86.08 | 88.73 | 88.92 | 90.69 | 92.94 | |
| Road | IS | 58.95 | 54.38 | 50.76 | 59.15 | 61.70 | 57.90 | 58.58 | 58.19 | 59.52 | 56.64 | 62.35 | 66.44 |
| RA | 23.46 | 23.91 | 16.67 | 22.44 | 20.47 | 17.57 | 21.85 | 19.45 | 22.08 | 20.37 | 20.55 | 23.56 | |
| BR | 24.22 | 4.38 | 17.24 | 13.48 | 38.82 | 28.63 | 23.52 | 22.82 | 32.79 | 32.19 | 39.30 | 37.64 | |
| mAP | 34.10 | 26.58 | 34.71 | 35.38 | 42.00 | 38.85 | 39.15 | 36.47 | 40.87 | 42.62 | 43.50 | 46.44 | |
| Category | One-Stage | Two-Stage | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| FCOS-O [42] | RetinaNet-O [43] | S2A-Net [44] | Faster R-CNN-O [45] | Double-Head-O [51] | Oriented R-CNN [47] | Gliding Vertex [49] | RoI-Transformer [48] | SFRNet [13] | Ours | |
| A1 | 68.50 | 79.04 | 82.62 | 85.01 | 86.35 | 86.05 | 85.85 | 85.40 | 85.22 | 88.27 |
| A2 | 79.70 | 84.31 | 81.59 | 81.63 | 80.85 | 81.73 | 81.53 | 81.53 | 82.04 | 84.29 |
| A3 | 61.00 | 71.05 | 86.21 | 87.47 | 88.90 | 88.08 | 86.80 | 87.61 | 88.71 | 87.96 |
| A4 | 52.34 | 54.72 | 80.75 | 70.68 | 82.54 | 69.57 | 76.35 | 78.33 | 79.73 | 86.19 |
| A5 | 64.00 | 73.18 | 76.86 | 79.63 | 76.04 | 75.61 | 72.22 | 80.45 | 79.84 | 82.58 |
| A6 | 83.30 | 86.59 | 90.00 | 90.58 | 90.06 | 89.92 | 89.90 | 90.49 | 90.68 | 90.14 |
| A7 | 72.90 | 75.57 | 84.73 | 89.71 | 89.76 | 90.49 | 89.84 | 90.24 | 90.21 | 89.87 |
| A8 | 82.28 | 85.51 | 85.70 | 89.82 | 87.28 | 89.54 | 89.38 | 87.58 | 89.62 | 91.58 |
| A9 | 81.11 | 88.65 | 88.70 | 90.40 | 89.20 | 89.78 | 89.14 | 87.93 | 89.93 | 91.82 |
| A10 | 84.55 | 85.84 | 90.84 | 90.89 | 90.78 | 90.91 | 90.77 | 90.89 | 90.77 | 90.75 |
| A11 | 67.70 | 68.20 | 81.67 | 85.54 | 84.35 | 87.62 | 86.20 | 85.88 | 86.55 | 90.56 |
| A12 | 78.77 | 73.22 | 86.09 | 88.08 | 86.18 | 88.39 | 87.45 | 89.29 | 88.39 | 88.72 |
| A13 | 60.86 | 63.51 | 69.59 | 68.39 | 65.76 | 67.52 | 64.94 | 67.24 | 67.12 | 70.34 |
| A14 | 81.26 | 79.72 | 85.25 | 88.27 | 87.42 | 88.50 | 88.28 | 88.20 | 88.08 | 87.14 |
| A15 | 32.82 | 24.10 | 47.69 | 42.44 | 44.13 | 46.33 | 47.01 | 47.85 | 53.45 | 53.73 |
| A16 | 81.84 | 84.85 | 88.10 | 88.86 | 87.49 | 88.27 | 87.84 | 89.11 | 88.56 | 91.74 |
| A17 | 90.60 | 90.32 | 90.20 | 90.45 | 90.25 | 90.59 | 90.40 | 90.46 | 90.34 | 92.47 |
| A18 | 51.06 | 49.19 | 61.98 | 62.23 | 56.40 | 70.50 | 64.94 | 74.59 | 76.14 | 77.47 |
| A19 | 68.12 | 74.96 | 83.59 | 78.25 | 82.82 | 78.72 | 83.90 | 81.30 | 84.29 | 86.53 |
| A20 | 71.10 | 76.07 | 79.84 | 77.71 | 76.69 | 80.25 | 76.83 | 80.00 | 72.67 | 78.94 |
| mAP | 70.69 | 73.43 | 81.10 | 81.35 | 81.16 | 81.92 | 81.48 | 82.72 | 84.41 | 85.05 |
| Baseline | Modules | mAP (%) | FLOPs (G) | Param (M) | Training Time (ms) | |||
|---|---|---|---|---|---|---|---|---|
| RGAM | CBC | ECL | FAIR1M | MAR20 | ||||
| √ | 38.85 | 81.92 | 134.52 | 41.14 | 558 | |||
| √ | √ | 39.87 | 82.34 | 134.57 | 41.14 | 587 | ||
| √ | √ | 44.08 | 84.37 | 134.74 | 41.46 | 654 | ||
| √ | √ | 41.83 | 83.02 | 134.66 | 41.34 | 628 | ||
| √ | √ | √ | √ | 46.44 | 85.05 | 134.93 | 41.63 | 672 |
| Baseline | Submodules | Similar Modules | mAP (%) | |||
|---|---|---|---|---|---|---|
| FAIR1M | Gain | MAR20 | Gain | |||
| √ | 38.85 | 0 | 81.92 | 0 | ||
| √ | RGAM | 39.87 | 1.02 ↑ | 82.34 | 0.42 ↑ | |
| √ | Global average pooling | 39.01 | 0.16 ↑ | 82.11 | 0.19 ↑ | |
| √ | CBC | 44.08 | 5.23 ↑ | 84.37 | 2.45 ↑ | |
| √ | Reweighting | 41.31 | 2.46 ↑ | 82.72 | 0.80 ↑ | |
| √ | ECL | 41.83 | 2.98 ↑ | 83.02 | 1.20 ↑ | |
| √ | - | Contrast learning | 39.84 | 0.99 ↑ | 82.33 | 0.41 ↑ |
| Hyper-Parameter λ | λ = 0.1 | λ = 0.25 | λ = 0.5 | λ = 1 | |
| mAP (%) | FAIR1M | 45.82 | 46.44 | 45.97 | 44.89 |
| MAR20 | 84.67 | 85.05 | 84.55 | 83.25 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Chen, H.; Zhang, Y.; Li, G. Relevance Pooling Guidance and Class-Balanced Feature Enhancement for Fine-Grained Oriented Object Detection in Remote Sensing Images. Remote Sens. 2024, 16, 3494. https://doi.org/10.3390/rs16183494
Wang Y, Chen H, Zhang Y, Li G. Relevance Pooling Guidance and Class-Balanced Feature Enhancement for Fine-Grained Oriented Object Detection in Remote Sensing Images. Remote Sensing. 2024; 16(18):3494. https://doi.org/10.3390/rs16183494
Chicago/Turabian StyleWang, Yu, Hao Chen, Ye Zhang, and Guozheng Li. 2024. "Relevance Pooling Guidance and Class-Balanced Feature Enhancement for Fine-Grained Oriented Object Detection in Remote Sensing Images" Remote Sensing 16, no. 18: 3494. https://doi.org/10.3390/rs16183494
APA StyleWang, Y., Chen, H., Zhang, Y., & Li, G. (2024). Relevance Pooling Guidance and Class-Balanced Feature Enhancement for Fine-Grained Oriented Object Detection in Remote Sensing Images. Remote Sensing, 16(18), 3494. https://doi.org/10.3390/rs16183494