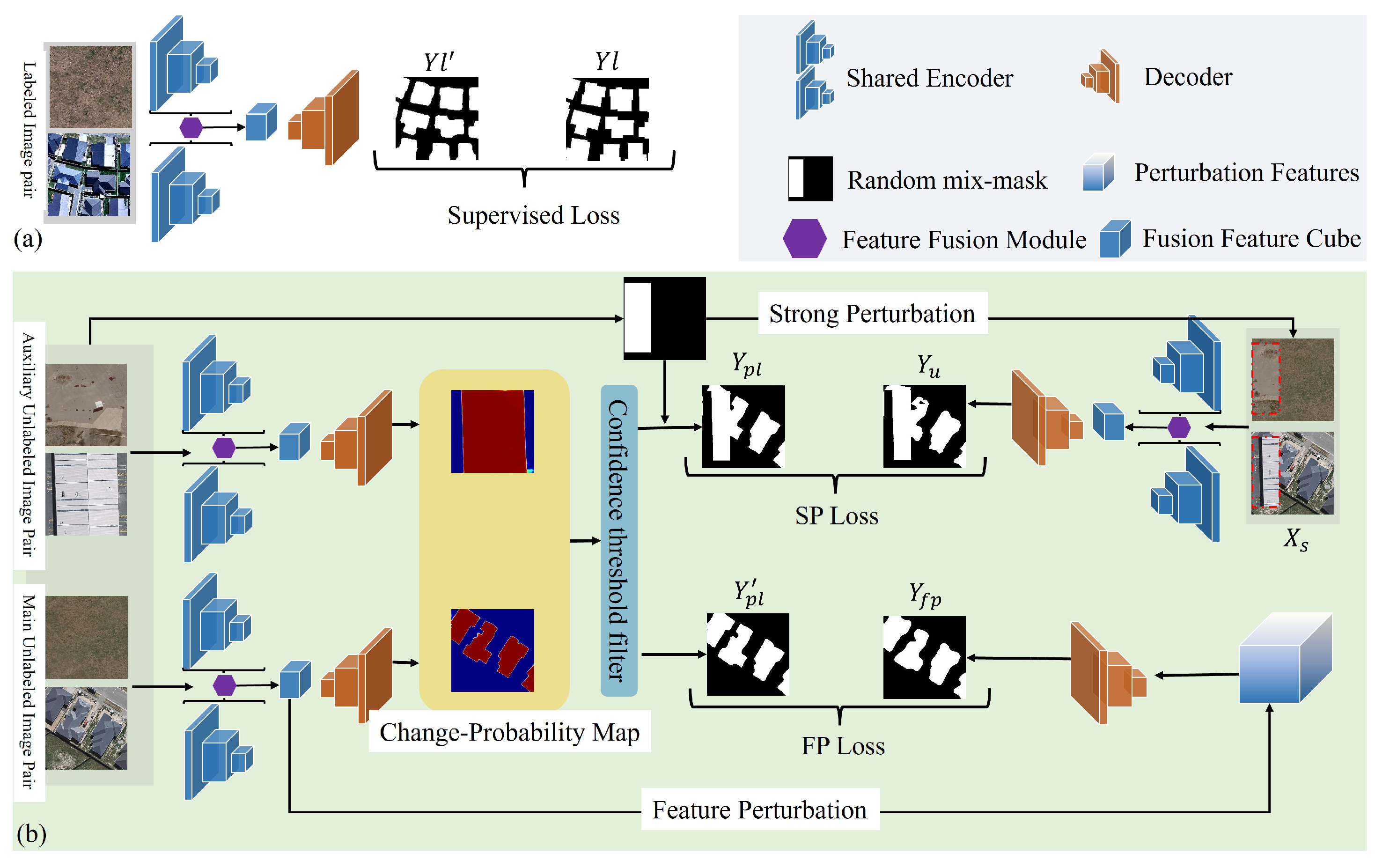
The network structure shown in
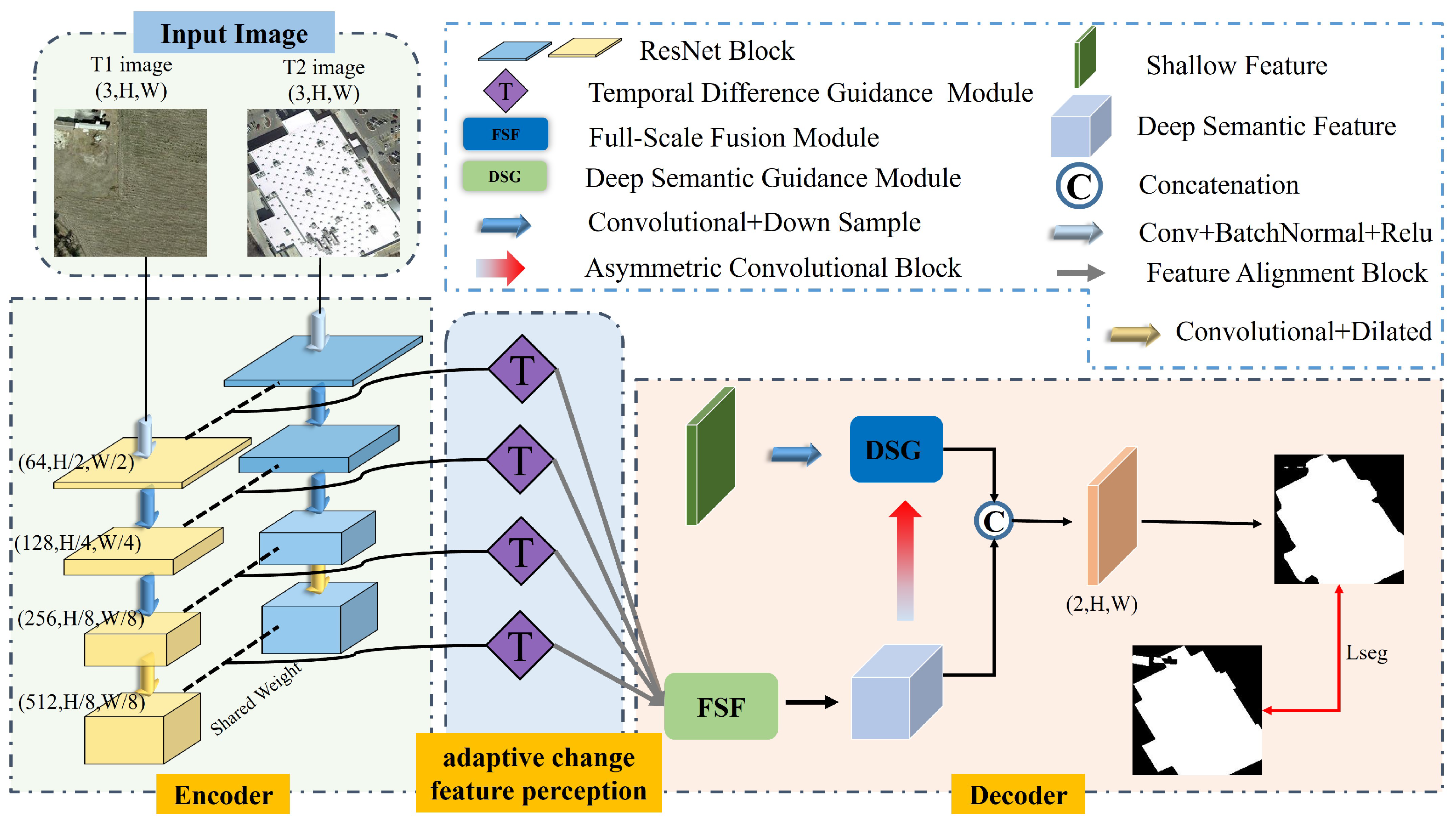
Figure 4 comprises three main components: an encoder, an adaptive change feature perception module, and a decoder. Initially, a pair of aligned bitemporal images, T1 and T2, are input into a weight-sharing Siamese network, which includes ResNet-18 [
46] for separate encoding. This process hierarchically transforms the bitemporal images from RGB color space to various high-level feature spaces. To preserve the spatial resolution of deep semantic features and gather more contextual information, dilated convolution is applied to the final layer of down-sampled features, resulting in a set of features with a larger receptive field and diverse representations but consistent spatial resolution. The extracted features can be expressed as
and
, where
, and the corresponding channel numbers are 64, 128, 256, and 512. The adaptive change feature perception incorporates four temporal difference guidance (TDG) modules to integrate and enhance coarse change features, extracting precise information on the differences between the bitemporal features. Different features at different scales are aligned using an adapter in the feature fusion guide module. Subsequently, a dilated convolution group refines the unified feature to create a semantically rich feature cube for multiscale variation target capture and refinement. Then, shallow change features are introduced to compensate for semantic features’ lack of detailed expression. To eliminate the effects of cross-scale feature fusion, deep semantic features guide learning shallow features to promote fusion and complementary information between the two. Finally, the fused features are passed through a simple decoder to generate the change map.
3.3.1. Adaptive Change Feature Perception
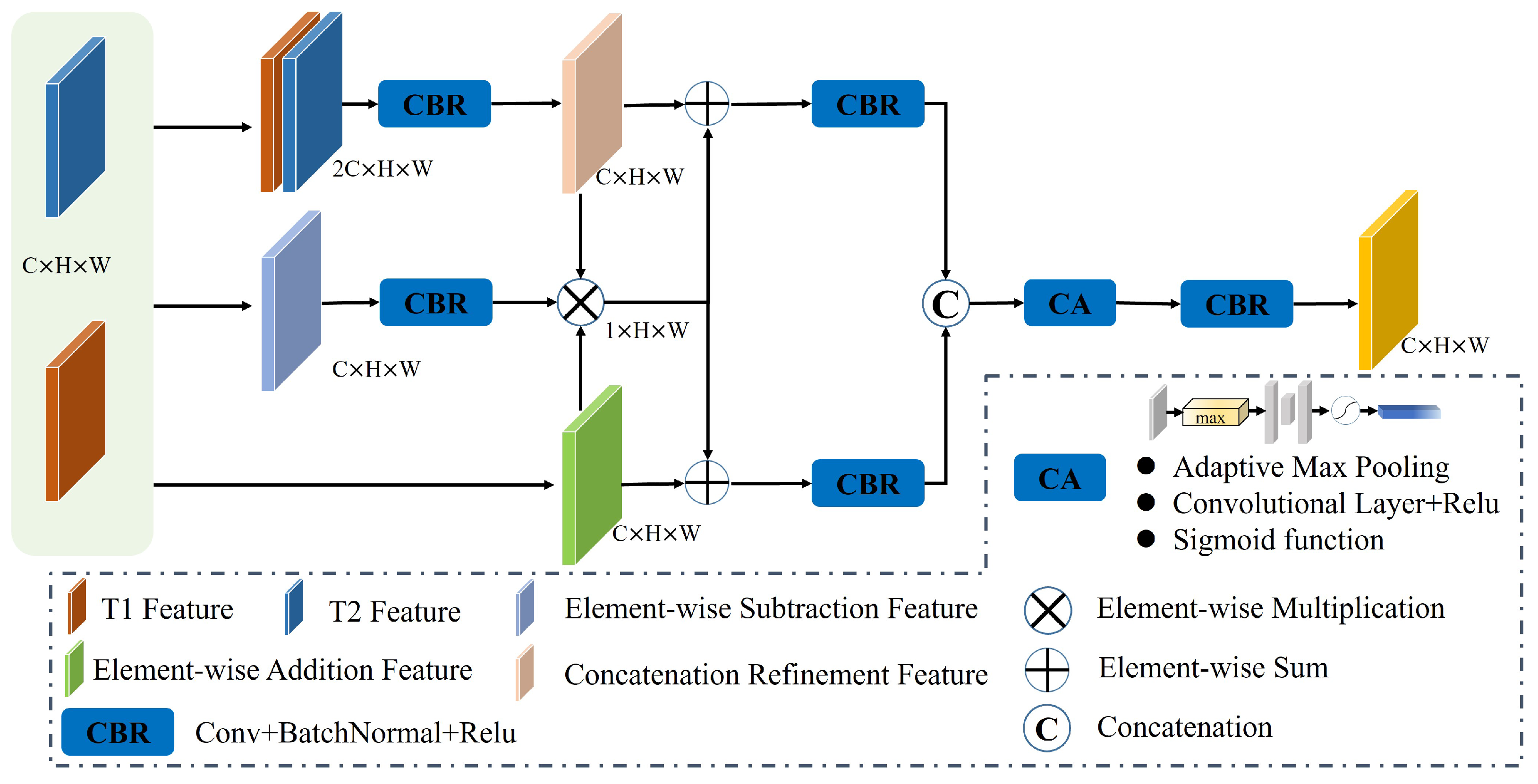
After encoding, the original image is transformed into multilevel features. Effective feature aggregation is crucial for improving change detection performance. Previous methods have utilized feature channel concatenation, element subtraction, and element addition. However, these methods have limitations in effectively aggregating bitemporal features to capture semantic differences, which is detrimental to change detection tasks. To address this issue, we propose that the TDG integrate diverse initial difference information and enhance the expression of semantic differences in bitemporal features. In
Figure 5, we illustrate this process using the bitemporal feature of layer i as an example. Initially, we obtain three coarse difference features (
,
, and
) through channel concatenation, element subtraction, and element addition.
Considering that the subtraction can intuitively obtain the differences between features, we refine the difference feature
and use the Sigmoid function to convert the refined
into weight map
, which is used to guide the other two features for learning the bitemporal change. Which can be obtained as follows:
Since the concatenation is only a merge of the bitemporal feature channel, the direct use of this part of the feature can only be learned by the backpropagation algorithm to learn the embodiment of different features. For the RSCD task, the features after channel concatenation do not highlight the temporal difference information. For this reason, we utilize a convolution operation to learn the correlation between the concatenation of bitemporal features. Subsequently, the features are fine-tuned and aligned using
convolution. The formula is represented as follows:
represents the change features that are fine-tuned by channel concatenation. After that,
and
are multiplied with the weight
to highlight the change region to obtain the enhanced representation of the change features in different perspectives, respectively. Then, we combine the enhanced features with the original features to improve the representation of features. The details are as follows:
where
and
denote the change features of concatenation and addition reinforced by weights
, respectively. In order to learn the change semantic information from multiple perspectives, we introduce the channel attention mechanism (CA) to deal with the two difference features
,
, according to the perception of the change target to adaptively obtain the importance of the difference features, to realize the weight allocation of the difference features, and ultimately to enhance the network’s ability to perceive the change features. The formula is as follows:
3.3.2. Feature Fusion Guidance Module
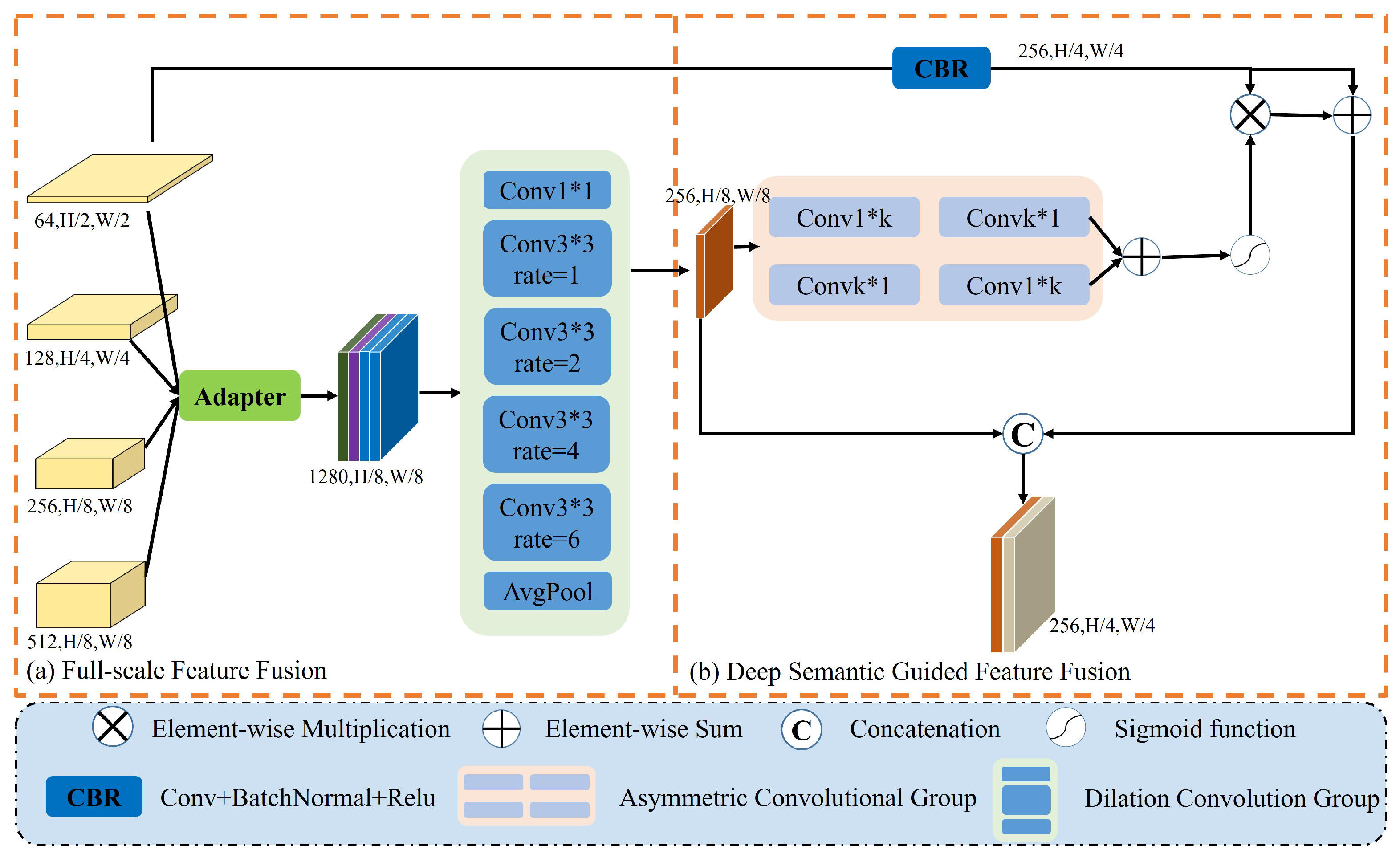
Unlike previous SSCD methods, where only the last layer of semantic features is used to obtain change features by element subtraction, we utilize the TDG module to obtain a multilevel representation of change features. For RSCD, the rich semantic information of deep features can localize the change target well, while the detailed information in shallow features aids in detecting the exact location of the change. Therefore, there is a need to address the fusion of multilevel change information. However, due to the differences between shallow and deep features, the direct fusion of change features at different scales may lead to interference information, resulting in the degradation of feature expression. As shown in
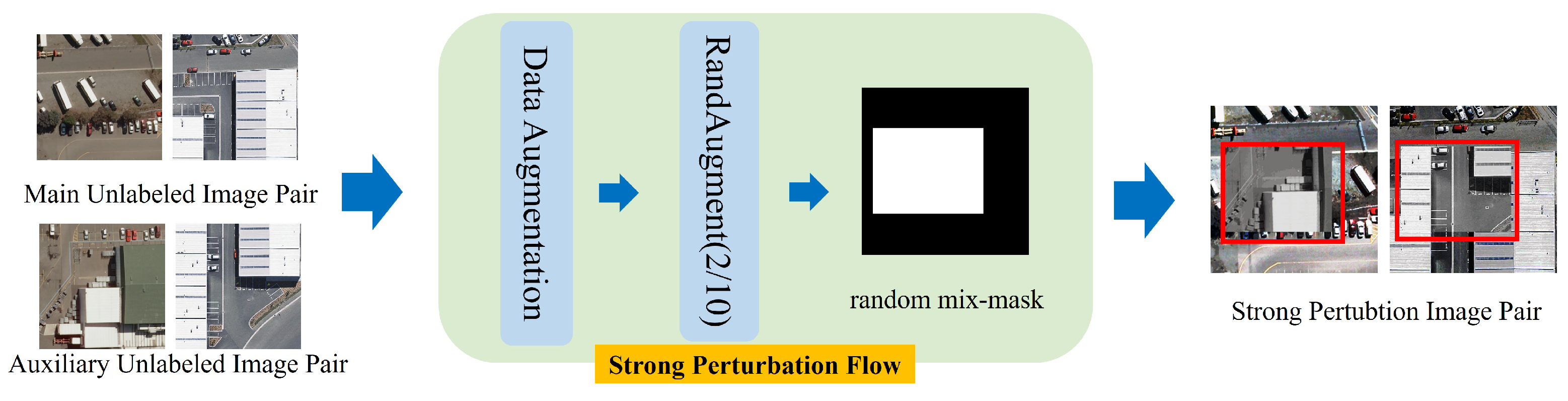
Figure 6, to ensure that different features can complement each other in information extraction and improve the expression ability when aggregated, the full-scale difference features are first aligned using an adapter. Subsequently, the uniformly represented features are filtered for background noise, fine-tuned for their semantic position using the dilated convolutional group, and mined for change information at multiple scales. In addition, to obtain more complete change detection results and alleviate the problem of learning bias in semi-supervision, we introduce shallow features to supplement the detailed information. However, a direct cross-scale fusion of deep semantic information with shallow features brings about performance loss; for this reason, we design a deep semantic guidance module to guide the learning of shallow features and facilitate the fusion of deep and shallow features.
Full-scale feature fusion: Multilevel difference features provide information about changes between bitemporal data at various scales. To better leverage the benefits of features at different scales and enhance the interaction of multiscale information, adapters are used to unify the representations of features at different levels and facilitate the fusion of features across scales. Initially, convolution operations are applied to different features for refinement and alignment. To prevent issues like gradient explosion or vanishing gradients and ensure the training process’s stability, batch normalization and nonlinear activation operations are incorporated. The details are described below:
where
i denotes the feature layer
.
k,
s, and
p represent the convolution kernel size, step size, and padding rate, respectively. BN denotes the batch normalization, and RELU is the nonlinear activation function. When
, we uniformly set
k = 3,
s = 2,
p = 1, mainly used to increase the diversity of feature expression and adjust the feature size. When
,
k = 3,
s =
p = 1, which is mainly used here to increase the diversity of feature expression. Then, we can obtain the feature map
,
. The
denotes the unified representation of features under different levels.
As shown in
Figure 6a, the features after unified representation are concatenated on the channel. Then, we utilize the dilated convolution group to fine-tune the features to obtain a finer semantic representation. The formula is expressed as follows.
where
k,
d, and
p represent the convolution kernel size, dilation rate, and padding rate, respectively. When
, we uniformly set
k = 1,
d = 0,
p = 0, which promotes the flow of information between channels. When
, we set
k = 3,
d =
,
p =
, respectively. When
, we use global average pooling to obtain the global semantic representation. With the above steps, we can obtain the feature maps
,
for different receptive fields, where r is mainly used to reduce the number of channels, and we set r to 4 in our experiments.
R is a further refined and integrated representation of the feature
.
Deep semantic guidance: To improve the completeness of change features and mitigate learning bias in semi-supervised learning. We introduce shallow features to complement the details in the deep features. However, considering the semantic gap between deep and shallow features, we utilize the localization ability of deep features to construct a learning weight to guide the learning of shallow features that promotes the fusion of deep and shallow features. As shown in
Figure 6b, for the strengthened feature R, we utilize a pair of vertical kernels and horizontal kernels of the convolution group instead of the large kernel
to reduce the computational load while further expanding the receptive field and obtaining more global attention. After that, we perform element addition and Sigmoid operations on two feature maps,
and
, to obtain the feature spatial location importance weight map
. The formula is depicted as follows:
Shallow features contain a mix of high-frequency information and noise, making it challenging to extract useful knowledge. In order to improve the effectiveness of learning from these shallow features, we fine-tune them. We then use a weight map to highlight the change regions and enhance the shallow features. By summing the shallow raw features with the enhanced ones, we aim to improve the overall feature representation. The detailed formulation is provided below:
where
denotes the first layer of change features,
denotes the fine-tuned shallow features, and
denotes the shallow enhanced features. Finally, the deep and shallow features are combined and fed into the decoder through the concatenation operation to promote the fusion between deep and shallow features, thus optimizing the final binary change map
.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}