1. Introduction
Urban water body extraction is a task aimed at identifying the parts containing water bodies from remote sensing images of urban and nearby areas. With the development of remote sensing sensors, water bodies extracted from high-resolution remote sensing imagery (HRSI) have been widely used in urban planning [
1] and flood detection [
2]. Acquiring urban water body areas is essential in today’s climate change and urbanization process [
3]. Meanwhile, accurate urban water body boundaries constitute a critical component of urban geographical information systems [
4].
In the 20th century, water bodies were traditionally annotated manually [
5], requiring substantial labor and material resources while being prone to errors and omissions. At the beginning of the 21st century, with the development of computer vision algorithms and deep learning, it became possible to successfully extract water bodies from HRSI. Researchers have proposed various water body extraction methods, mainly utilizing geometric, photometric, and textural features of water bodies [
6]. Since water body extraction focuses on land cover classification rather than land-use analysis, pixels obscured by non-water surface objects such as boats, bridges, and siltation are excluded from the water body definition, resulting in time-consuming labeling processes. Therefore, developing an urban water body extraction method capable of handling diverse surrounding environments with limited labeled samples is of significant importance.
As
Figure 1 illustrates, urban water bodies possess more complex shapes and distributions than natural water bodies. Consequently, their extraction poses numerous challenges.
Figure 1a shows that many small water bodies are on the construction site, which makes the encoding of these objects challenging. As shown in
Figure 1b, tiny ditches, a category of specially shaped water bodies that are hard to encode, pass through the vicinity of the built-up area. In
Figure 1c, seasonal siltation affects the surface of urban water bodies, further complicating boundary extraction. As depicted in
Figure 1d, roads shaded by buildings, which share spectral similarities with certain water bodies, are prone to being misidentified as water. In summary, several urban water body extraction issues need to be addressed. First, urban water bodies are prone to sharing similar spectral characteristics in some bands with other objects, requiring fuller exploitation of spectral information. Then, the diversity of the urban water bodies’ surroundings and the number of small urban water bodies is significantly higher than that of natural water bodies, thus requiring a stronger ability to integrate information of different levels.
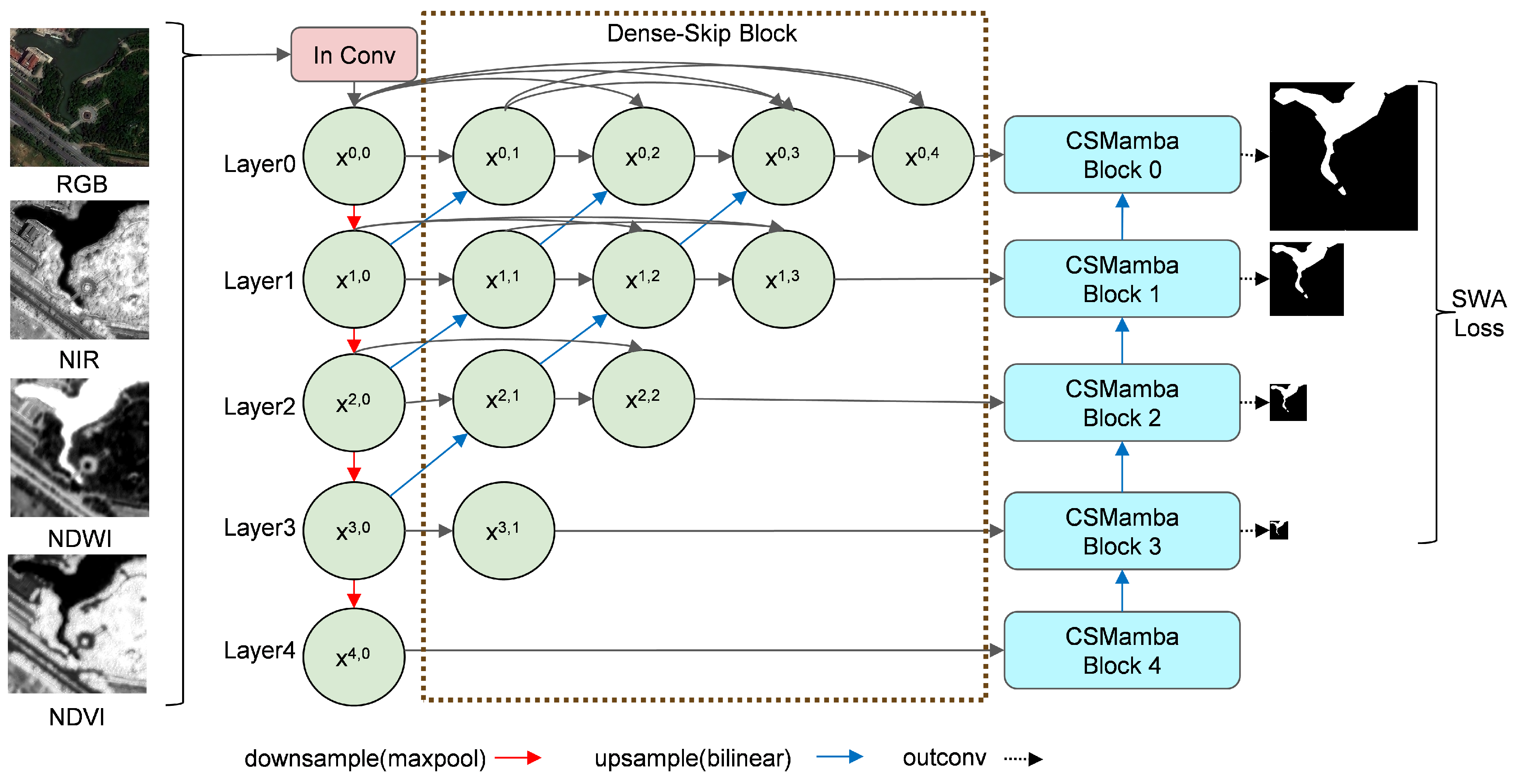
To address these challenges, we propose CM-UNet++, a neural network that contains CSMamba blocks and an encoder–decoder structure with a dense-skip module based on UNet++ for HRSI urban water body extraction. CM-UNet++ takes multiple features as input, using the dense-skip module to integrate low-level features into high-level feature maps. The CSMamba block subsequently extracts both global and local information from each layer’s features, while a size-weighted auxiliary (SWA) loss function balances the contributions of hierarchical features. The main contributions of this work are as follows:
(1) To enhance the ability to extract small and spectrally insignificant water bodies, we introduce a dense-skip module to make interactions between different levels’ feature maps, and we introduce the CSMamba module to enhance local–global information integration for each layer’s feature map.
(2) To balance the importance of high-level and low-level feature maps, the size-weighted auxiliary (SWA) loss function, a novel loss function modified by UNet-Former loss, is proposed. It considers the different sizes of each layer’s feature map and is proven to leverage the competence of our network.
(3) To verify the method’s validity, we created a labeled dataset of urban water bodies named the Anhui Urban Water Extraction Dataset (AUWED) encompassing parts of Hefei City, Lu’an City, and Yingshang County in Anhui, China, which represent large, medium, and small cities, respectively.
The remainder of this paper is organized as follows:
Section 2 reviews related works, including the progress of water extraction methods and semantic segmentation methods.
Section 3 presents the proposed method in this study, including the neural network structure, input features, and loss function.
Section 4 describes the datasets, experimental details, evaluation metrics, experimental results, ablation study, and comparative study. In the subsection on the ablation study, three aspects are included: input features, network structure, and loss functions. The comparative study comprises comparisons of results on two datasets and computational complexity.
Section 5 analyses results demonstrated in
Section 4 from the perspective of principle.
Section 6 summarizes the proposed method and analyses of experiments in this paper, then discusses the limitations of the study as well as prospects for future research.
3. Methodology
The network uses an encoder–decoder structure to build the model. In the encoder, the input multi-features are first subjected to channel expansion, and then semantic information is obtained at five different scales by max-pooling. The channels of the feature map after channel expansion and max-pooling are 32, 64, 128, 256, and 256, respectively. Then, the interactions between each level of semantics are realized through the dense-skip part and then through the CSMamba module. Each layer feature map output from the CSMamba module enters into the decoder, which realizes up-sampling through bilinear interpolation, concatenates with the previous layer features, and finally realizes the task of extracting water bodies integrating semantic information at different levels. Additionally, we introduce a novel loss function designed to optimize the semantic segmentation performance of the proposed method, and we discuss its mechanism and impact in detail.
3.1. Multi-Feature Input
Figure 3 shows visualization examples of NIR, NDWI, and NDVI (normalized difference vegetation index) [
8] by linearly stretching their values to 0–255. As shown in
Figure 3a, the building shadows have a comparatively higher NIR value than water bodies. As shown in
Figure 3b, the siltation has a relatively lower NDWI value than the water body. As shown in
Figure 3c, The NDVI values are higher for water bodies than agricultural land.
To fully utilize the HRSI data that include both the RGB and near-infrared bands, inspired by feature engineering [
39], we utilize NDWI to enhance the network’s capability of distinguishing water from siltation, and we utilize NDVI [
40] to enhance the network’s ability to distinguish water from vegetation.
In the equations above, , , and represent the digital number (DN) of the red band, green band, and near-infrared band recorded by satellite sensor, respectively.
3.2. Dense-Skip Block
To realize the interaction between different layers of feature maps obtained by max-pooling, we remodel the skip pathways module in UNet++ [
41] to adjust it to our network’s structure. In U-Net [
29], each layer of feature maps after max-pooling is directly connected to the decoder by skip, which makes the features extracted from each layer of feature maps more limited. We introduce a feature map with a dense convolution operation to the feature maps obtained after max-pooling in order to overcome this weakness by integrating low-level information into high-level feature maps.
Specifically, the dense-skip block is designed as follows: As shown in
Figure 2, for the
l-th layer (l = 0, 1, 2, 3, 4), each layer has
feature-map nodes. Each layer’s first node is a feature map after the encoding convolution module operation, and the last node is followed by a CSMamba module. For the non-last node of each layer, each node will be connected to the next node of the previous layer through the convolution operation of up-sampling, and a copy of it is concatenated to all the nodes after this layer. In the following equation,
represents the input image of the network,
means the
l-th layer’s
m-th feature map node, and
denotes concatenate operation.
3.3. CSMamba Block
To extract complex and variable urban water bodies, both global and local information from each layer’s feature map should be integrated. With self-attention mechanisms, Transformer has demonstrated significant efficacy in various visual tasks [
20]. However, Transformer-based approaches encounter the limitation of squared time complexity, which reduces the efficiency of processing large-scale HRSI data. To address this issue, it is necessary to introduce an approach that preserves the strengths of the Transformer architecture while minimizing the model’s explicit requirement for GPU memory. We introduced the CSMamba block (
Figure 4) [
38], which combines the feature-enhance module and the Mamba module, into our methods, where one branch is responsible for the implementation of the channel attention and spatial attention mechanisms, and the other branch is responsible for the integration of the feature maps of that level inside the global and local information.
In the equations above, DWConv is depth-wise convolution; CS represents the channel and spatial attention module, 2D-SSM means the 2D selective scan module, and ⊙ denotes the Hadamard product.
3.4. Size-Weighted Auxiliary Loss
A novel loss function, the size-weighted auxiliary loss (SWA loss), is proposed to leverage the feature extraction component of non-final feature maps, which takes the size of each layer’s feature map into consideration.
For neural networks with encoder–decoder structures with different layers of feature maps, some semantic segmentation neural networks, such as UNet-Former [
42] and CM-UNet [
38], have introduced multi-output supervision modules and proved that their methods’ effectiveness can be improved.
Specifically, convolution and softmax operations are performed on each intermediate layer feature map that enters the decoder. Then, the combination
of the dice loss
and the standard cross-entropy loss
is taken as the loss of the feature maps of that layer.
Finally, the layer loss function of the highest layer
and other layers
(i = 1, 2, 3) are linearly weighted according to a certain ratio as the final loss function.
In UNet-Former, the weight
for each layer is set to 0.4. However, only by linearly interpolating the non-final feature maps can we reach the same size as the data labels to calculate the loss function. A simple hypothesis is that the smaller the scale of the feature map, the greater the information loss in the linear interpolation process, so different weights
of each layer’s feature map should be given.
is set to the ratio of the layer’s feature map size
to the feature map size of the highest layer
.
4. Experiments
4.1. Datasets
4.1.1. Anhui Urban Water Extraction Dataset (AUWED)
In order to verify the validity of our method and analyze the effectiveness of its modules, we produced the Anhui Urban Water Extraction Dataset (AUWED) from Jilin-1 remote sensing satellite data, with a resolution of 0.75 m. It contains data in four bands: blue, green, red, and near-infrared. We calculated NDVI and NDWI, and we labeled water bodies using ArcGIS 10.8. As shown in
Figure 5, the AUWED dataset covers parts of Hefei City, Lu’an City, and Yingshang County in Anhui Province in China, which represent large, medium, and small cities, respectively.
To enhance the recognition ability of the band information, we linearly stretched each band’s data (including DN value of RGB, NIR along with NDWI and NDVI calculated by band-math) according to a threshold of 2%. Specifically, for each band, the highest 2% and the lowest 2% values of the pixels were assigned with the highest and lowest value, respectively. The pixels with the remaining 96% of the values were linearly stretched to generate the input features. Finally, we cut the above data according to a resolution of 512 × 512 and kept all the samples containing water body labels. For the three study regions, the dataset was randomly split into training and test sets at an 80:20 ratio, resulting in 1416 training samples and 351 test samples.
4.1.2. Kaggle Water Segmentation Dataset 2 (KWSD2)
To validate the robustness of our method for urban water body extraction, Kaggle Water Segmentation Dataset 2 (KWSD2), a water body dataset with labels available on Kaggle (
https://www.kaggle.com/datasets/kaoyuu/kaoyuuu/data, accessed on 3 January 2025) was selected. As shown in
Figure 6, this dataset contains some urban scenes.
This dataset contains a total of 1000 images of RGB channels and corresponding ground-truth labels. We divided this dataset into 800 training sets and 200 test sets. The original size of each image was 492 × 492, and we padded four edges with 10 pixels, making it 512 × 512 to input into the neural network. We binarized the labels as follows: Pixels with gray values above 127 were categorized as water, while other pixels were categorized as non-water.
4.2. Details and Evaluation Metrics
Experiments were conducted on a single NVIDIA 4090 GPU (Manufacturer: NVIDIA Corporation, Santa Clara, CA, USA) with the PyTorch 2.1 framework using the Windows 10 operating system. The AdamW optimizer was employed with an initial learning rate of 2 × , and exponential decay was adopted to reduce the learning rate at each step. Data augmentation methods, including random flip and random rotation, were used in training. The batch size was 4 in the training process, and the maximum epoch was 150.
In these experiments, we introduced
,
,
, and
(intersection over union) to evaluate the method’s effectiveness.
In the equations above, for pixels of the water body, , , and denote true positive, false positive, and false negative pixels, respectively. Among all the metrics mentioned above, is the most important evaluation metric in this study, as it incorporates both false positives () and false negatives (), which are the two categories that were not accurately classified.
4.3. Experimental Results
The performance of our proposed CM-UNet++ network on the AUWED dataset and the KWSD2 dataset is shown in
Table 1. The IOU on the AUWED dataset reached 0.8781, while on the KWSD2 dataset, it achieved 0.8956. Additionally, both precision and recall metrics are balanced on these two datasets, with differences less than 0.01.
As shown in
Figure 7, CM-UNet++ achieved satisfactory results on the AUWED dataset even when dealing with objects that were spectrally insignificant to their surroundings or those that were small in size or had unique shapes. In
Figure 7a, the water bodies and shadows of buildings were successfully distinguished. As shown in
Figure 7b, the boundaries between water bodies and siltation or bridges were extracted with relatively high accuracy.
Figure 7c demonstrates the successful extraction of water bodies that have similar spectral features to their surroundings. As depicted in
Figure 7d, the narrow ditches and their boundaries were accurately extracted.
Figure 8 shows that CM-UNet++ achieved reasonable results on the KWSD2 dataset in the absence of NIR, NDVI, and NDWI. As shown in
Figure 8a, the boundaries of a river and several small ponds were accurately extracted.
Figure 8b,c demonstrate the successful extraction of slender water body branches. As depicted in
Figure 8d, slender water bodies with less-distinct color contrast to their surroundings have been relatively successfully extracted.
4.4. Ablation Study
In this subsection, we verified the performance of the proposed CM-UNet++ from three perspectives. First, we investigated the impact of adding three input features: NIR band, NDWI, and NDVI. Subsequently, we focused on network structure and illustrated the effectiveness of the dense-skip module and CSMamba module. Finally, we conducted ablation experiments on loss functions to demonstrate the effects of auxiliary loss and size-weighted strategy.
4.4.1. Ablation Study on Input Features
To verify the effectiveness of NIR, NDWI, and NDVI, the ablation experiments on these features were carried out. As shown in
Table 2, the inclusion of NIR, NDWI, and NDVI features improved the IOU metric by 0.83%, 0.47%, and 0.20%, respectively.
Figure 9 shows that the increasing number of input features improved the results of water body extraction. First, with the introduction of the NIR band, water bodies and building shadows in
Figure 9a were successfully distinguished, and building shadows were no longer misclassified as water bodies. Then, adding the NDWI index to the input features, the boundary between water bodies and siltation in
Figure 9b was extracted more accurately, with some pixels of siltation not being misclassified as water. Finally, with the NDVI index added as an input feature, in
Figure 9c, despite a pond with similar colors to the surrounding farmland, more pixels were classified correctly for water bodies.
4.4.2. Ablation Study on Network Structure
Ablation experiments on the dense-skip and CSMamba modules were carried out to verify their effectiveness. As shown in
Table 3 and
Table 4, the introduction of only the dense-skip module or CSMamba module slightly improved the IOU metric, while the combination of these modules improved it by 0.56% on the AUWED dataset and 0.81% on the KWSD2 dataset. Specifically, as illustrated in
Figure 10, the introduction of the dense-skip module and CSMamba module made the network perform better on small water bodies and boundaries. In
Figure 10a, U-Net fails to extract the pond located at the full image’s northern edge and the pond’s western half at the eastern edge of the image. The problem was not solved when only the dense-skip module (i.e., UNet++) was introduced. When the CSMamba module was introduced, parts of these two ponds were classified as water bodies. With the introduction of both modules (i.e., our proposed CM-UNet++), the boundaries of the ponds were closer to the ground-truth compared to the introduction of the CSMamba module only. As shown in
Figure 10b, the boundary of the water body close to the bridge and the bank was accurately extracted only when both modules were introduced simultaneously.
Figure 10c shows that the water bodies adjacent to brightly colored buildings and intersections were successfully extracted only when both modules were introduced simultaneously. As depicted in
Figure 10d, U-Net partially failed to extract successfully for both ditches and was not improved by introducing the CSMamba module. More portions of the ditches were extracted when only the dense-skip module was introduced. When we introduced both modules, most parts of the ditches were extracted. Overall, the simultaneous use of dense-skip and CSMamba was superior to the use of a single module, and the improvement in water body boundaries was significant. In terms of improving the extraction of small water bodies, CSMamba more greatly improved the parts located at the edges of the image, while dense-skip more greatly improved the parts located in the center of the image.
4.4.3. Ablation Study on Loss Functions
To validate the effectiveness of SWA loss proposed in this paper, we compared this loss function with non-auxiliary loss and UNet-former loss as the ablation study. As shown in
Table 5, compared to non-auxiliary loss and UNet-former loss, SWA loss improved the IOU metric by 0.22% and 0.33% on the AUWED dataset, respectively. Additionally, the SWA loss achieved a better balance between precision and recall, with a difference of only 0.12%, while the UNet-Former loss and non-auxiliary loss were 0.70% and 0.66%, respectively. As illustrated in
Table 6, similar results were also observed on the KWSD2 dataset. The recall–precision difference of SWA loss was 0.77%, while those of both the non-auxiliary loss and UNet-former loss were greater than 1%.
Figure 11 shows that the introduction of the SWA loss function successfully extracted some small or spectrally insignificant water bodies that non-auxiliary loss and UNet-former loss failed to. In
Figure 11a, it performed better in siltations and ditches. As shown in
Figure 11b, it did not misclassify the road as a water body, which was obscured by the shadow of the building. In
Figure 11c, it successfully extracted a small water body near the center of the figure. As depicted in
Figure 11d, a pond in the southwest corner that had a different color than other nearby water bodies was successfully extracted.
4.5. Comparative Study with Other Methods
In this subsection, we compared the performance of our proposed method with other semantic segmentation neural networks on the AUWED dataset and KWSD2 dataset in order to demonstrate the effectiveness of the proposed method.
4.5.1. Comparative Study with Other Methods on AUWED
To verify the effectiveness of our proposed method on this task, other methods that perform well in semantic segmentation tasks, including D-LinkNet [
30], DeeplabV3+ [
31], Trans-UNet [
35], RS-Mamba [
37], and CM-UNET [
38], were compared. As demonstrated in
Table 7, our proposed CM-UNet++ performed best in the recall, F1, and IOU metrics among these methods, with advantages of over 1% compared to other methods in IOU. CM-UNet++ ranked second in precision, lower than DeepLabv3+ by a margin of only 0.06%.
Figure 12 shows the advantages of our proposed CM-UNet++ network over other semantic segmentation methods on the AUWED dataset, including completeness, connectivity, and boundary accuracy. As shown in
Figure 12a,b, only CM-UNet++ extracted a water body whose narrow portion had no interruptions. DeeplabV3+, which contained atrous convolutions with multiple receptive field sizes, had the second best results, while the other models had more interruptions. As depicted in
Figure 12c, for the water body that had insignificant color contrast with the nearby farmland, only CM-UNet++ successfully extracted most of it. In
Figure 12d, CM-UNet++ successfully extracted the small water bodies, and their boundaries were closest to the ground-truth. In contrast, the CM-UNet, which also contained the CS-Mamba module, did not successfully extract some of the small water bodies. For the extraction of narrow parts of the water body, the second best performer after CM-UNet++ was DeeplabV3+.
4.5.2. Comparative Study with Other Methods on the KWSD2 Dataset
To validate the robustness of our method for urban water body extraction, experiments on the KWSD2 dataset that followed the same methods as
Section 4.5.1 were conducted. The hyperparameters other than the input features were set to the same as AUWED. For all methods mentioned in
Section 4.5.1,
Table 8 shows similar results to
Table 7. CM-UNet++ performed best in the recall, F1, and IOU metrics, and DeepLabv3+ ranked second in IOU. The KWSD2 dataset was also utilized in the study of Ad-SegFormer [
21] without an open-source code, and we present these results together in
Table 8. As illustrated in
Figure 13, the CM-UNet++ network achieved better results than other methods on the KWSD2 dataset. CM-UNet++ and DeeplabV3+ performed well in terms of completeness, and CM-UNet++ was better for boundaries and special scenarios. As shown in
Figure 13a, a small water body with insignificant contrast with its surroundings was successfully extracted only by CM-UNet++ with the closest boundary to the ground-truth. In
Figure 13b, only CM-UNet++ and DeeplabV3+ successfully extracted the ditch on the north side of the image, while TransUNet and CM-UNet failed to extract the boundary of the light-colored pond on the south side of the image. As depicted in
Figure 13c, for the end of the water body and the part blocked by artificial targets, CM-UNet++ performed significantly better than the other networks.
Figure 13d shows that only CM-UNet++ and DeeplabV3+ successfully extracted the two narrow ditches on the west side of the image, and only CM-UNet++ successfully extracted the narrow water body at the southeast edge of the image. Ad-SegFormer achieved a slightly higher precision than CM-UNet++ on the KWSD2 dataset, indicating that fewer non-water pixels were misclassified as water. However, Ad-SegFormer underperformed compared to CM-UNet++ in other metrics, including IOU, notably with a significantly lower recall, meaning that a considerable number of water pixels failed to be correctly classified as water.
4.5.3. Computational Complexity Comparison
Table 9 and
Figure 14 demonstrates the comparison of model complexities using two metrics: floating-point operation per second (FLOPs) and model parameters. Among the six methods, the FLOPs of our proposed CM-UNet++ rank second highest, while it has the lowest number of parameters and highest IOU. By learning a limited number of parameters, CM-UNet++ manages to perform relatively complex computations and achieves the best results in the task of urban water body extraction.
5. Discussion
Section 4.4.1 shows that NIR, NDWI, and NDVI enhance the network’s performance in different aspects. The introduction of NIR can distinguish between water bodies and building shadows because water bodies are sensitive to the NIR band. The introduction of NDWI can improve the impact of the experimental results because the values of NDWI in the siltations are different from those of water and can thus be used as important additional information to optimize the boundary between water and siltation. The introduction of NDVI can lead to better recognition of water bodies with vegetation nearby because water bodies that are less spectrally distinguishable from vegetation also have a lower value, so different representations of water and vegetation can be learned through the neural network. With the absence of NDVI, water pixels with more spectral features close to vegetation fail to be successfully extracted. This results in a slightly higher precision but lower recall and IOU. When both NDVI and NDWI are absent, the network’s learning of water features from the original bands becomes relatively more unstable. It tends to misclassify more non-water pixels as water, leading to a slightly higher recall but significantly lower precision and IOU.
As shown in
Section 4.4.2, the introduction of the dense-skip module and CSMamba module resulted in a marginal increase in IOU but improved the networks’ performance on small water bodies and boundaries. Both the dense-skip module and the CSMamba module integrate features from different levels, but the former performs better in enhancing feature extraction near the center of the image, while the latter excels in improving feature extraction near the edges. This is because the dense-skip module enhances the interaction of different levels of feature maps. In contrast, the CSMamba module integrates global and local information for the interior of different levels of feature maps. The combined use of these two is equivalent to encoding more levels of feature maps with interaction capabilities and thus recovering a more complete set of features in the decoding process. The introduction of the dense-skip module is better for the extraction of small objects in the center of the image since the interaction of the different levels of the feature maps in the module contains a large number of convolutions, which can capture the association of each pixel with the different levels of features of its neighboring pixels, than without the module. CSMamba is better for the extraction of objects at the edges of the image because it is difficult for the pixels at the edges of the image to integrate their neighboring pixels through convolution directly and requires more global information as a reference, which is the strength of CSMamba. In addition, although U-Net and UNet++ achieved slightly higher values in precision or recall than CM-UNet++, they performed significantly worse in other metrics. This is because U-Net and UNet++, with only up-sampling, down-sampling, and connection operations, fail to obtain more robust feature maps compared to those obtained with CSMamba blocks. As a result, during network training, they are more prone to oscillation, and it is thus more difficult to achieve a balance between precision and recall.
As demonstrated in
Section 4.4.3 the network exhibits enhanced capability in extracting detailed features when utilizing the SWA loss as the loss function, outperforming the cases without size-weighting and without auxiliary loss. The successful extraction of small water bodies and water bodies with insignificant spectral features relies on the integration of different levels of feature maps. Our proposed CM-UNet++ focuses on the integration of features at different levels, but it requires appropriate weights for the parameters in the network to be optimized. When the auxiliary loss is not used, low-level feature maps cannot be directly involved in supervision during training. In that case, global information is not fully utilized, and water bodies with insignificant spectral features are difficult to extract. If auxiliary loss is used, but the same weight is given to the non-final feature maps as in UNet-Former loss, it is equivalent to lowering the weight of the high-level feature maps considering the loss of information of the low-level feature maps in the up-sampling, which causes the small bodies of water to be ignored. Therefore, it is necessary to give different weights to different levels of feature maps.
As illustrated in
Section 4.5, our proposed CM-UNet++ outperforms several other semantic segmentation methods commonly used in recent years on IOU. Nonetheless, a more detailed analysis of the results is still valuable. The results of DeeplabV3+ follow closely behind CM-UNet++. This is because DeeplabV3+ contains atrous convolutions with multi-scale receptive fields, and the essence of atrous convolution is to extend the receptive field in multiple directions, thus acquiring information from more distant pixels, which makes it suitable for the extraction of strip objects. It also achieves fusion of information at different scales to some extent. However, compared to DeeplabV3+, CM-UNet++ handles the edges of the image better because the higher layers of its encoder retain larger-sized feature maps and integrate the information of lower layers to them using the dense-skip module, finally optimizing the combination of global and local information within each layer of the feature maps through the CS-Mamba module. Thus, a more accurate representation of the image edge pixels can be learned. TransUNet and CM-UNet, which employ ResNet as their encoder, are incapable of generating feature maps of larger sizes, thereby hindering their ability to process more detailed information effectively and causing them to ignore some small water bodies. The cause for RS-Mamba’s failure to extract water bodies that are not distinctly different in spectral features from the surroundings is that, after the image is input into the model, it is directly subjected to patch-embedding and then fed into the Mamba module. Consequently, this neural network lacks the same degree of integration between high-level and low-level information as that in CM-UNet++. Ad-SegFormer, a water segmentation network based on Transformer, achieves a slightly higher precision but a markedly lower recall. The reason for the difference in results is that the Transformer module in Ad-SegFormer, with its self-attention mechanism, scans the entire encoded feature map, thereby more readily focusing on the more common features within each category. In contrast, the Mamba modules in CM-UNet++ employ a selective scanning mechanism to compress homogeneous features, reducing redundancy while paying more attention to detailed features. This enables the network to learn a more diverse set of water body features, leading to a larger number of water pixels being successfully classified. Similarly, in experiments on the KWSD2 dataset, the Trans-UNet, which also includes a Transformer module, exhibits a marked superiority in precision over recall.
6. Conclusions
In this study, we proposed CM-UNet++, a novel deep neural network that significantly improved urban water body extraction from high-resolution remote sensing images through the following innovations, especially in terms of the completeness, connectivity, and boundary accuracy of small and oddly shaped water bodies: First, a hierarchical fusion architecture was designed integrating dense-skip modules for multi-level feature interaction and CSMamba modules for global–local context encoding. Then, a size-weighted auxiliary (SWA) loss function was employed to balance feature maps’ importance of layers. Additionally, a multi-input strategy combining NIR, NDWI, and NDVI was adopted to enhance the network’s feature extraction abilities. Experiments on the newly labeled AUWED dataset demonstrated that CM-UNet++ outperforms existing methods. Validation on the KWSD2 dataset and computational complexity analysis further confirmed its robustness and practical efficiency.
Although we have improved the results of extracting urban water bodies using deep learning through the above aspects, some limitations remain. However, these limitations offer insights into potential avenues for future research. First of all, the distribution of urban water bodies is very fragmented and complicated in shape compared to natural water bodies, and it takes a long time for researchers to label water bodies. To address the data labeling bottleneck, developing semi-supervised and weakly supervised learning frameworks will become a trend. Subsequently, the significant variations in spatial resolution and spectral bands across different remote sensing platforms, as well as atmospheric conditions, affect the model’s generalizability. Therefore, multi-source datasets including LiDAR and crowdsourced data will be a point of future research on urban water extraction. Moreover, while the current framework demonstrates strong performance in static water body mapping, it lacks the capability to monitor dynamic seasonal variations for practical applications. This study has also only accomplished pixel-level water body extraction and has not advanced to the level of vector mapping. Future research will focus on water body vector mapping to better align with the practical requirements of urban mapping.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}