


CPROS: A Multimodal Decision-Level Fusion Detection Method Based on Category Probability Sets

Abstract
1. Introduction
2. Related Works
2.1. Multimodal Fusion
2.2. Decision-Level Fusion
- Multi-Bayesian estimation method [25,26]: Each sensor is regarded as a Bayesian estimator, and the associated probability distribution of each object is synthesized into a joint posterior probability distribution function. By minimizing the likelihood function of the joint distribution function, the final fusion value of the multisensor information is obtained, and a prior model of the fusion information and environment is developed to provide a feature description of the entire environment.
- D-S evidence reasoning method [27]: This method is an expansion of Bayesian reasoning; its reasoning structure is top-down and divided into three levels. The first level is the target synthesis, and its role is to synthesize the observation results from the independent sensor into a total output result. The second stage is inference, whose function is to obtain the observation results of the sensor, make inferences, and expand the observation results to the target report. The third level is updated, and the sensors are generally subject to random errors. Therefore, a set of successive reports from the same sensor that is sufficiently independent in time is more reliable than any single report. Therefore, before inference and multisensor synthesis, it is necessary to update the sensor observation data.
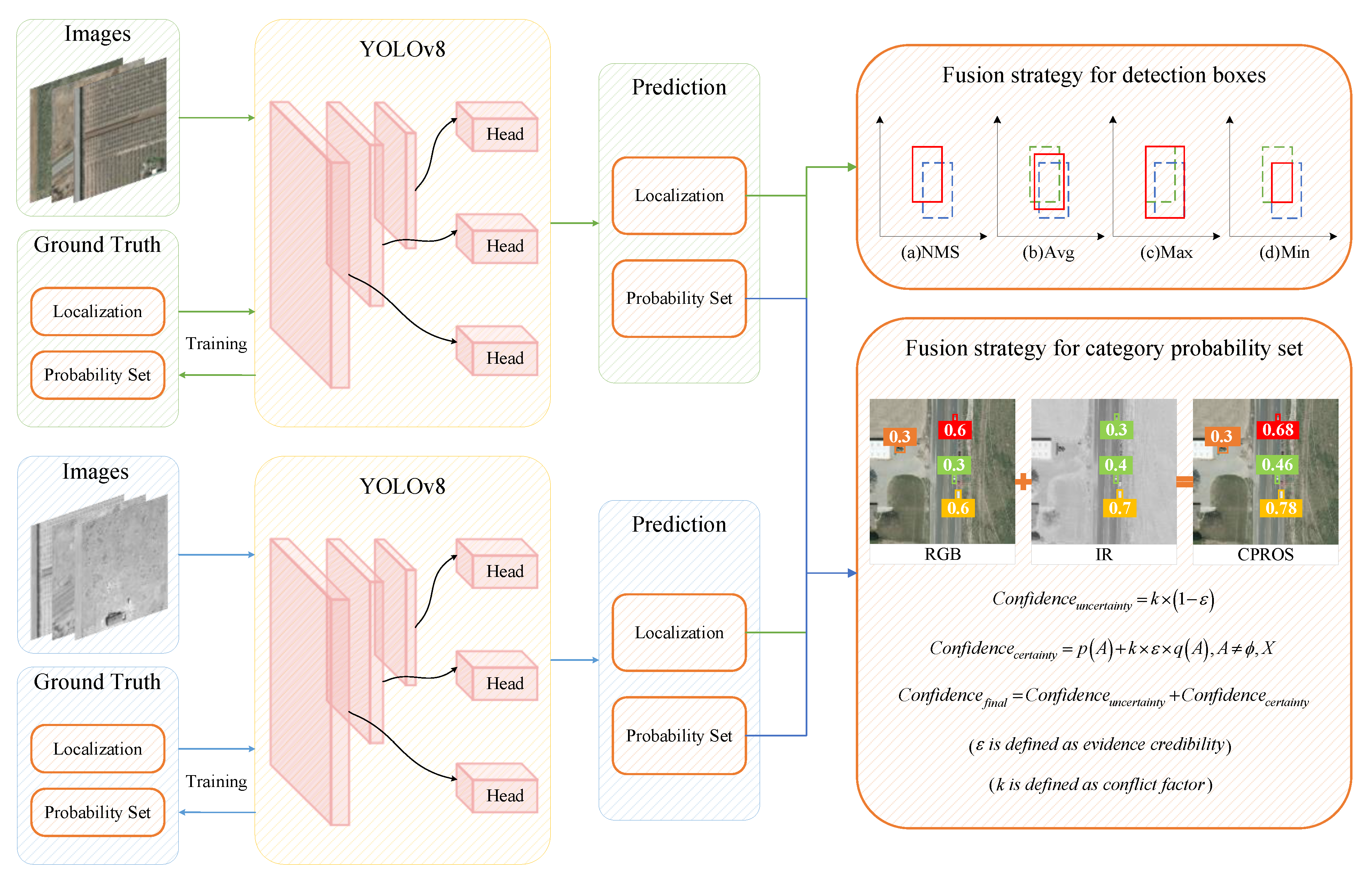
3. Fusion Strategies for Multimodal Detection
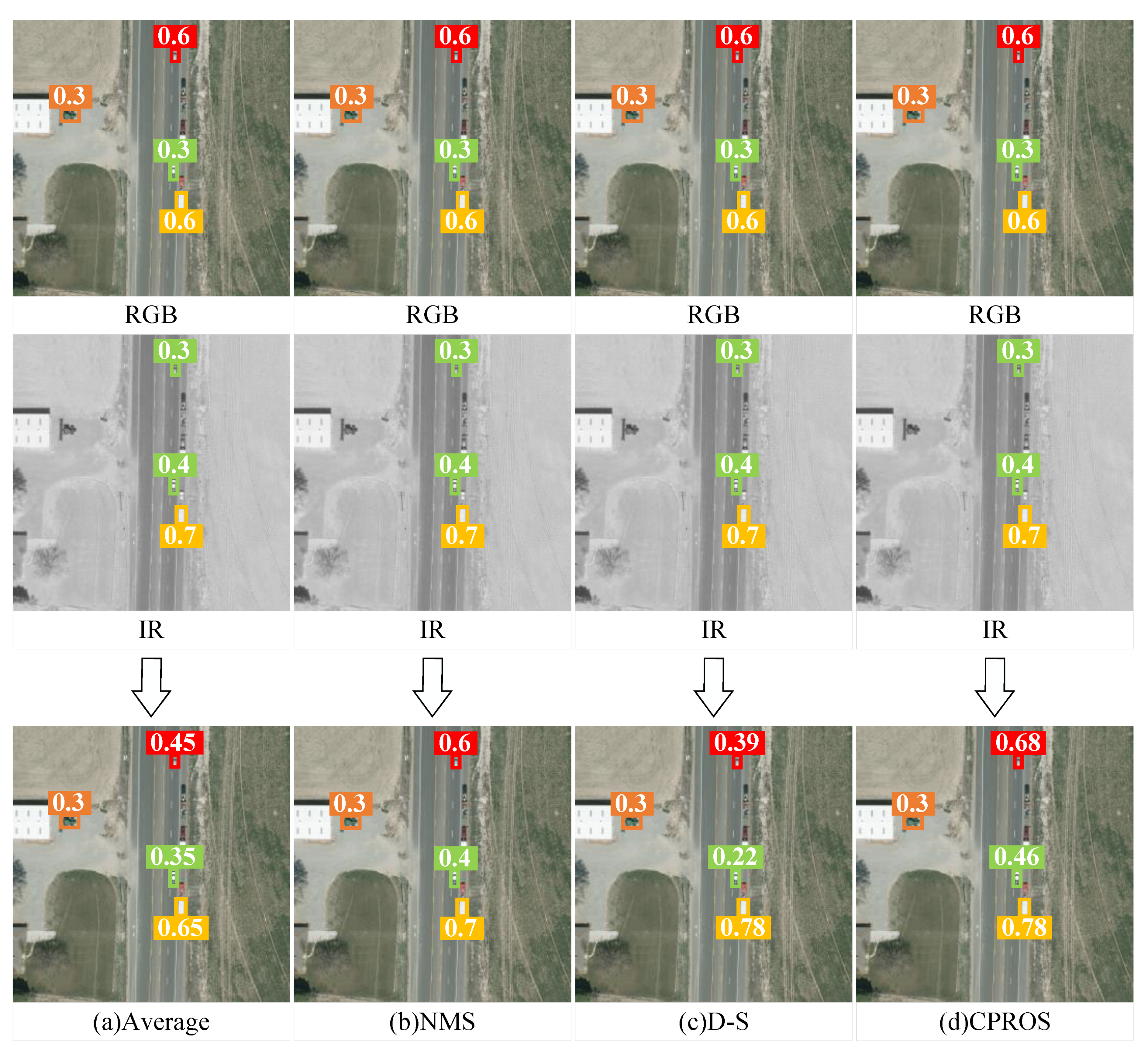
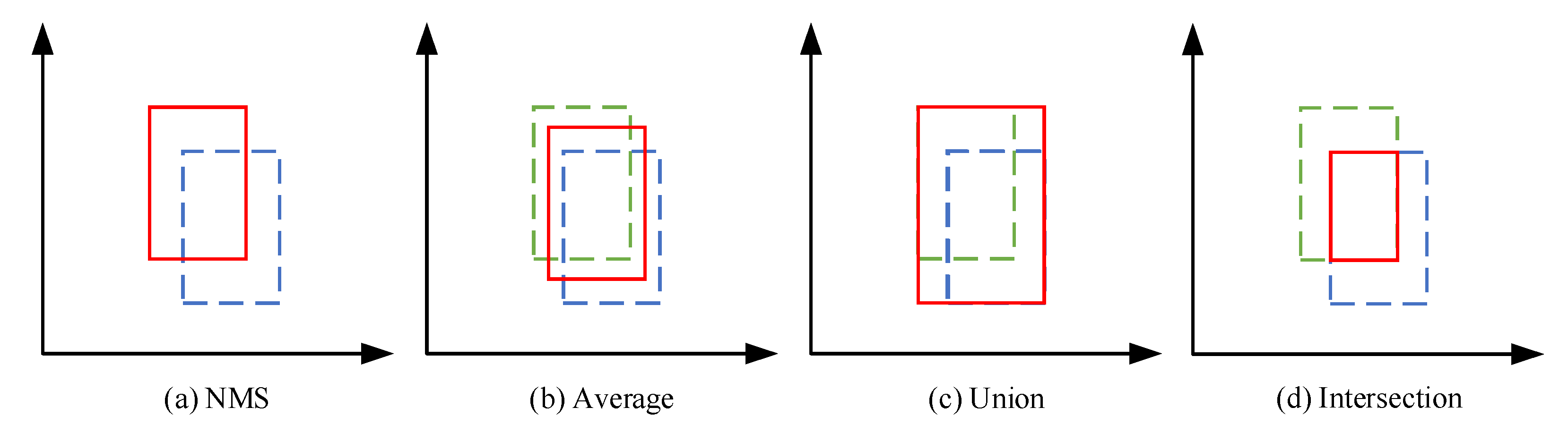
3.1. Fusion Strategy for Detection Boxes
3.2. Fusion Strategy for Category Probability Set (CPROS)
3.3. Fusion
| Algorithm 1. Fusion Strategies for Multimodal Detection | |
| 1 | Input: detections from multiple modes. Each detection d = (pro, box, cls, conf) contains category probability set pro = (p1, p2…pn), box coordinates box = (x, y, w, h), tag cls = (0/1/…/n) and confidence conf = (x). |
| 2 | Integrate the detection results of the same image corresponding to different modes. Set D = (d1, d2, … dn). |
| 3 | Traverse the set and place boxes with IOU greater than the threshold together to form a detection set at the same position. Set H = {D1, D2, …, Dn}. |
| 4 | if len(Di) > 1: |
| 5 | Take the two elements with the highest confidence in Di |
| 6 | Fusion strategy for detection boxes |
| 7 | Fusion strategy for category probability set(CPROS) |
| 8 | if len(Di) = 1: |
| 9 | No need for fusion |
| 10 | return set F of fused detections |
4. Experiments
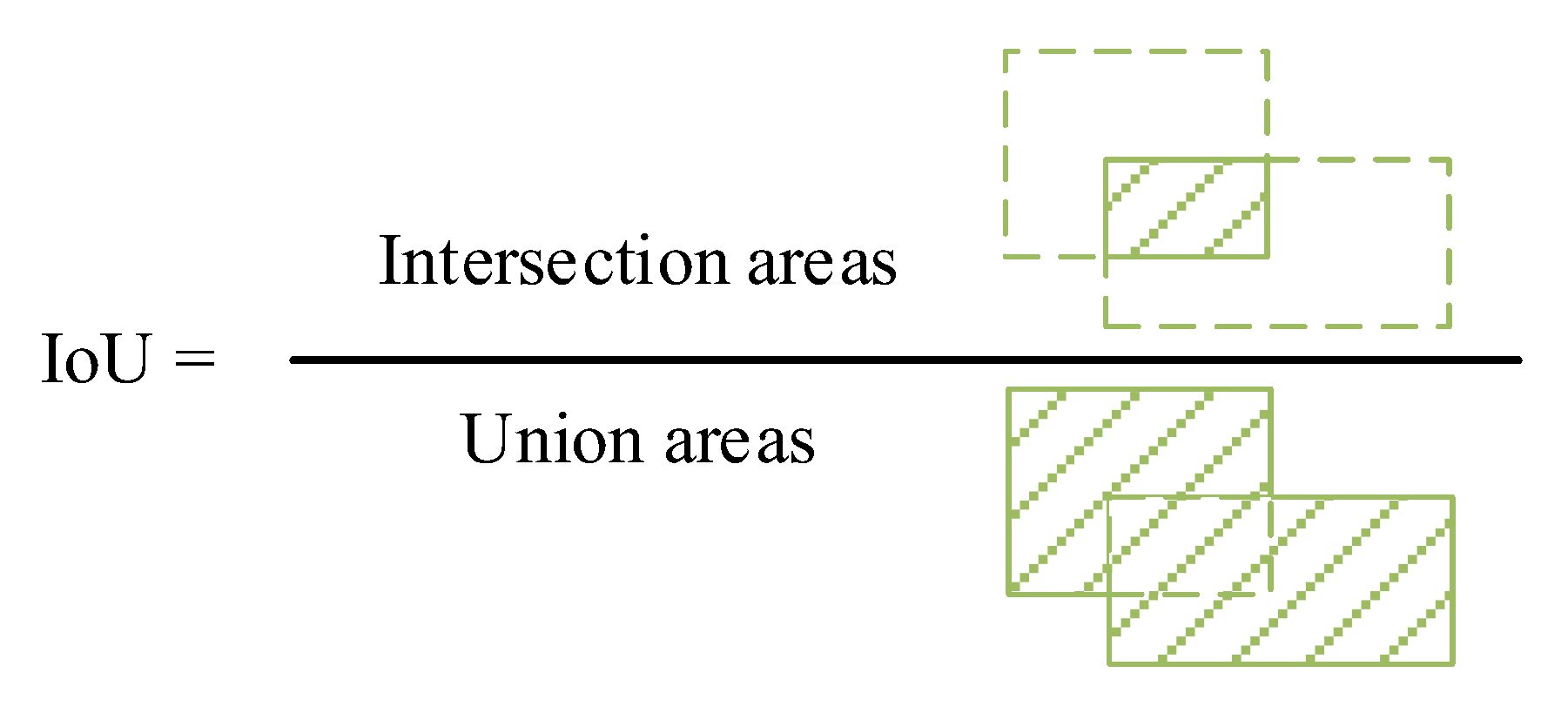
4.1. Evaluating Indicator
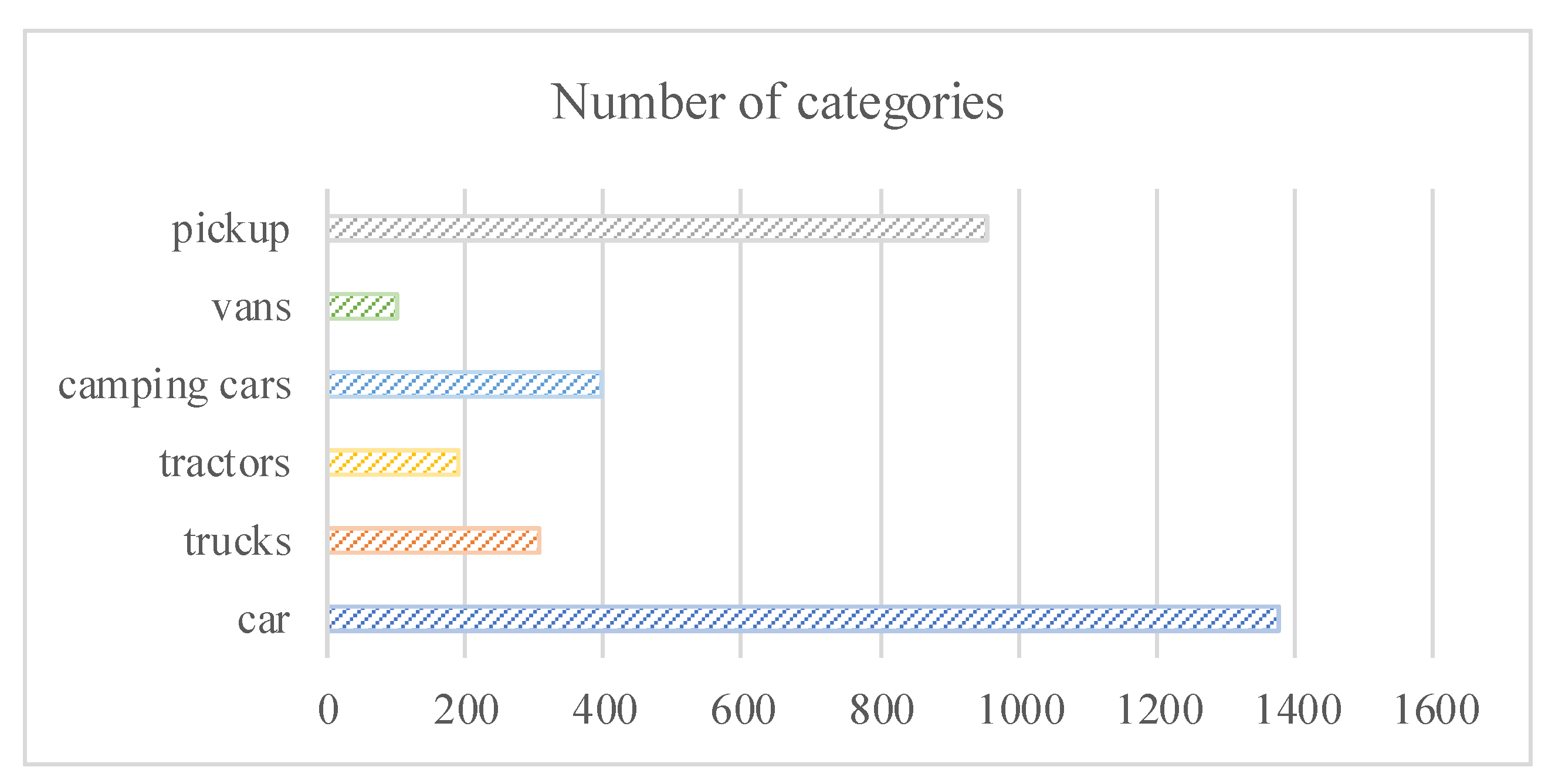
4.2. Experiment Settings and Datasets
4.3. Experimental Results
4.3.1. Comparative Experimental Results
4.3.2. Results of Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xie, Y.; Xu, C.; Rakotosaona, M.-J.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Khosravi, M.; Arora, R.; Enayati, S.; Pishro-Nik, H. A Search and Detection Autonomous Drone System: From Design to Implementation. arXiv 2020, arXiv:2211.15866. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 3354–3361. [Google Scholar]
- Devaguptapu, C.; Akolekar, N.; Sharma, M.M.; Balasubramanian, V.N. Borrow from Anywhere: Pseudo Multi-Modal Object Detection in Thermal Imagery. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1029–1038. [Google Scholar]
- Wu, W.; Chang, H.; Zheng, Y.; Li, Z.; Chen, Z.; Zhang, Z. Contrastive Learning-Based Robust Object Detection under Smoky Conditions. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; IEEE: New York, NY, USA, 2022; pp. 4294–4301. [Google Scholar]
- Mustafa, H.T.; Yang, J.; Mustafa, H.; Zareapoor, M. Infrared and Visible Image Fusion Based on Dilated Residual Attention Network. Optik 2020, 224, 165409. [Google Scholar] [CrossRef]
- Zhang, X.; Demiris, Y. Visible and Infrared Image Fusion Using Deep Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10535–10554. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection Using Deep Fusion Convolutional Neural Networks. In Proceedings of the ESANN 2016: 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Li, Q.; Zhang, C.; Hu, Q.; Fu, H.; Zhu, P. Confidence-Aware Fusion Using Dempster-Shafer Theory for Multispectral Pedestrian Detection. IEEE Trans. Multimed. 2023, 25, 3420–3431. [Google Scholar] [CrossRef]
- Zhang, X.X.; Lu, X.Y.; Peng, L. A Complementary and Precise Vehicle Detection Approach in RGB-T Images via Semi-Supervised Transfer Learning and Decision-Level Fusion. Int. J. Remote Sens. 2022, 43, 196–214. [Google Scholar] [CrossRef]
- Tziafas, G.; Kasaei, H. Early or Late Fusion Matters: Efficient RGB-D Fusion in Vision Transformers for 3D Object Recognition. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023. [Google Scholar]
- Guan, D.; Cao, Y.; Liang, J.; Cao, Y.; Yang, M.Y. Fusion of Multispectral Data Through Illumination-Aware Deep Neural Networks for Pedestrian Detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, W.; Xiao, J.; Zhang, H.; Shao, J.; Zhuang, Y.; Chen, L. VL-NMS: Breaking Proposal Bottlenecks in Two-Stage Visual-Language Matching. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 166. [Google Scholar] [CrossRef]
- Xiao, F. A New Divergence Measure of Belief Function in D–S Evidence Theory. Inf. Sci. 2019, 514, 462–483. [Google Scholar] [CrossRef]
- Sentz, K.; Ferson, S. Combination of Evidence in Dempster-Shafer Theory; U.S. Department of Energy: Oak Ridge, TN, USA, 2002; SAND2002-0835; p. 800792.
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-Level Image Fusion: A Survey of the State of the Art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Zhang, Z.; Jin, L.; Li, S.; Xia, J.; Wang, J.; Li, Z.; Zhu, Z.; Yang, W.; Zhang, P.; Zhao, J.; et al. Modality Meets Long-Term Tracker: A Siamese Dual Fusion Framework for Tracking UAV. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; IEEE: New York, NY, USA, 2023; pp. 1975–1979. [Google Scholar]
- Wu, Y.; Guan, X.; Zhao, B.; Ni, L.; Huang, M. Vehicle Detection Based on Adaptive Multimodal Feature Fusion and Cross-Modal Vehicle Index Using RGB-T Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 8166–8177. [Google Scholar] [CrossRef]
- Yang, K.; Xiang, W.; Chen, Z.; Zhang, J.; Liu, Y. A Review on Infrared and Visible Image Fusion Algorithms Based on Neural Networks. J. Vis. Commun. Image Represent. 2024, 101, 104179. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Jiang, J.; Liu, R.; Luo, Z. Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 105–119. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Glaser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Zhang, S.; Feng, J.; Xia, H.; Rao, P.; Ai, J. A Space Infrared Dim Target Recognition Algorithm Based on Improved DS Theory and Multi-Dimensional Feature Decision Level Fusion Ensemble Classifier. Remote Sens. 2024, 16, 510. [Google Scholar] [CrossRef]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted Boxes Fusion: Ensembling Boxes from Different Object Detection Models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Yang, F.-J. An Implementation of Naive Bayes Classifier. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; IEEE: New York, NY, USA, 2018; pp. 301–306. [Google Scholar]
- Zhou, H.; Dong, C.; Wu, R.; Xu, X.; Guo, Z. Feature Fusion Based on Bayesian Decision Theory for Radar Deception Jamming Recognition. IEEE Access 2021, 9, 16296–16304. [Google Scholar] [CrossRef]
- Ghosh, M.; Dey, A.; Kahali, S. Type-2 Fuzzy Blended Improved D-S Evidence Theory Based Decision Fusion for Face Recognition. Appl. Soft Comput. 2022, 125, 109179. [Google Scholar] [CrossRef]
- Song, Y.; Fu, Q.; Wang, Y.-F.; Wang, X. Divergence-Based Cross Entropy and Uncertainty Measures of Atanassov’s Intuitionistic Fuzzy Sets with Their Application in Decision Making. Appl. Soft Comput. 2019, 84, 105703. [Google Scholar] [CrossRef]
- Zhang, S.; Rao, P.; Hu, T.; Chen, X.; Xia, H. A Multi-Dimensional Feature Fusion Recognition Method for Space Infrared Dim Targets Based on Fuzzy Comprehensive with Spatio-Temporal Correlation. Remote Sens. 2024, 16, 343. [Google Scholar] [CrossRef]
- Zhang, P.; Li, T.; Wang, G.; Luo, C.; Chen, H.; Zhang, J.; Wang, D.; Yu, Z. Multi-Source Information Fusion Based on Rough Set Theory: A Review. Inf. Fusion 2021, 68, 85–117. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Hewage, K.; Sadiq, R. A Method of Measuring Uncertainty for Z-Number. IEEE Trans. Fuzzy Syst. 2019, 27, 731–738. [Google Scholar] [CrossRef]
- Lai, H.; Liao, H. A Multi-Criteria Decision Making Method Based on DNMA and CRITIC with Linguistic D Numbers for Blockchain Platform Evaluation. Eng. Appl. Artif. Intell. 2021, 101, 104200. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Shi, J.; Ye, Z.; Mertz, C.; Ramanan, D.; Kong, S. Multimodal Object Detection via Probabilistic Ensembling. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Yager, R.R. On the Dempster-Shafer Framework and New Combination Rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Sun, Q.; Ye, X.; Gu, W. A New Combination Rules of Evidence Theory. Acta Electron. Sin. 2000, 28, 117–119. [Google Scholar]
- Razakarivony, S.; Jurie, F. Vehicle Detection in Aerial Imagery: A Small Target Detection Benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0 | 1 | … | n | Background | |
|---|---|---|---|---|---|
| RGB | a0 | a1 | … | an | an+1 |
| IR | b0 | b1 | … | bn | bn+1 |
| AP/mAP | IOU = 0.5 | ||||||
|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | |
| RGB | 62.3% | 37.5% | 35.6% | 51.4% | 58.0% | 64.8% | 51.6% |
| IR | 62.0% | 36.3% | 17.0% | 39.4% | 45.4% | 62.9% | 43.8% |
| SeAFusion | 57.0% | 44.1% | 38.7% | 55.3% | 44.2% | 57.2% | 49.4% |
| MMIF-CDDFuse | 69.9% | 38.1% | 30.8% | 51.2% | 55.8% | 63.3% | 51.5% |
| RFN-Nest | 56.9% | 33.3% | 19.4% | 45.4% | 57.1% | 53.2% | 44.2% |
| YDTR | 49.7% | 23.4% | 15.4% | 40.7% | 49.2% | 52.8% | 38.5% |
| CPROS (ours) | 71.8% | 47.1% | 52.1% | 50.4% | 70.0% | 69.7% | 60.2% |
| MR | IOU = 0.5 | ||||||
|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | |
| RGB | 20.2% | 43.0% | 39.4% | 25.0% | 36.7% | 21.3% | 24.8% |
| IR | 23.2% | 48.7% | 65.6% | 41.5% | 43.3% | 20.9% | 29.6% |
| SeAFusion | 27.6% | 36.7% | 35.3% | 28.6% | 40.0% | 25.9% | 29.0% |
| MMIF-CDDFuse | 18.0% | 44.2% | 50.0% | 28.9% | 26.7% | 18.8% | 23.7% |
| RFN-Nest | 27.9% | 45.9% | 67.7% | 25.3% | 26.7% | 24.9% | 30.2% |
| YDTR | 30.6% | 52.7% | 77.4% | 41.8% | 33.3% | 23.4% | 34.1% |
| CPROS (ours) | 17.7% | 34.9% | 29.8% | 19.1% | 28.1% | 19.7% | 21.2% |
| FPPI | IOU = 0.5 | ||||||
|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | |
| RGB | 0.186 | 0.087 | 0.055 | 0.096 | 0.006 | 0.167 | 0.598 |
| IR | 0.170 | 0.080 | 0.048 | 0.077 | 0.013 | 0.196 | 0.585 |
| SeAFusion | 0.273 | 0.087 | 0.051 | 0.074 | 0.023 | 0.170 | 0.678 |
| MMIF-CDDFuse | 0.177 | 0.077 | 0.048 | 0.096 | 0.029 | 0.196 | 0.624 |
| RFN-Nest | 0.238 | 0.103 | 0.029 | 0.141 | 0.032 | 0.222 | 0.765 |
| YDTR | 0.257 | 0.132 | 0.023 | 0.061 | 0.026 | 0.222 | 0.720 |
| CPROS (ours) | 0.164 | 0.087 | 0.045 | 0.129 | 0.006 | 0.135 | 0.566 |
| Score -Fusion | Box -Fusion | AP/mAP (IOU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | ||
| Avg | NMS | 73.3% | 45.7% | 43.7% | 49.4% | 66.9% | 70.7% | 58.3% |
| Avg | 71.5% | 46.2% | 51.7% | 49.4% | 66.9% | 69.2% | 59.2% | |
| Max | 61.5% | 46.2% | 51.7% | 49.4% | 66.9% | 61.2% | 56.2% | |
| Min | 73.6% | 45.7% | 43.7% | 49.4% | 66.9% | 70.1% | 58.2% | |
| Max | NMS | 73.4% | 46.0% | 43.9% | 50.2% | 66.9% | 70.9% | 58.6% |
| Avg | 71.5% | 46.8% | 51.8% | 50.2% | 66.9% | 69.4% | 59.4% | |
| Max | 61.5% | 46.8% | 51.8% | 50.2% | 66.9% | 61.3% | 56.4% | |
| Min | 73.6% | 46.0% | 43.9% | 50.2% | 66.9% | 70.4% | 58.5% | |
| D-S | NMS | 73.7% | 46.4% | 44.0% | 50.2% | 66.9% | 71.1% | 58.7% |
| Avg | 71.9% | 47.1% | 51.8% | 50.2% | 66.9% | 69.7% | 59.6% | |
| Max | 61.9% | 47.1% | 51.8% | 50.2% | 66.9% | 61.6% | 56.6% | |
| Min | 73.8% | 46.4% | 44.0% | 50.2% | 66.9% | 70.6% | 58.7% | |
| CPROS (ours) | NMS | 73.6% | 46.4% | 44.2% | 50.4% | 70.0% | 71.0% | 59.3% |
| Avg | 71.8% | 47.1% | 52.1% | 50.4% | 70.0% | 69.7% | 60.2% | |
| Max | 61.9% | 47.1% | 52.1% | 50.4% | 70.0% | 61.7% | 57.2% | |
| Min | 74.0% | 46.4% | 44.2% | 50.4% | 70.0% | 70.5% | 59.3% | |
| Score -Fusion | Box -Fusion | MR (IOU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | ||
| Avg | NMS | 15.7% | 36.1% | 31.9% | 20.2% | 28.1% | 18.5% | 20.4% |
| Avg | 17.7% | 34.9% | 29.8% | 19.1% | 28.1% | 19.7% | 21.2% | |
| Max | 20.3% | 34.9% | 29.8% | 20.2% | 28.1% | 20.2% | 22.5% | |
| Min | 15.1% | 36.1% | 31.9% | 20.2% | 28.1% | 18.9% | 20.3% | |
| Max | NMS | 15.7% | 36.1% | 31.9% | 20.2% | 28.1% | 18.5% | 20.4% |
| Avg | 17.7% | 34.9% | 29.8% | 19.1% | 28.1% | 19.7% | 21.2% | |
| Max | 20.3% | 34.9% | 29.8% | 20.2% | 28.1% | 20.2% | 22.5% | |
| Min | 15.1% | 36.1% | 31.9% | 20.2% | 28.1% | 18.9% | 20.3% | |
| D-S | NMS | 15.7% | 36.1% | 31.9% | 20.2% | 28.1% | 18.5% | 20.4% |
| Avg | 17.7% | 34.9% | 29.8% | 19.1% | 28.1% | 19.7% | 21.2% | |
| Max | 20.3% | 34.9% | 29.8% | 20.2% | 28.1% | 20.2% | 22.5% | |
| Min | 15.1% | 36.1% | 31.9% | 20.2% | 28.1% | 18.9% | 20.3% | |
| CPROS (ours) | NMS | 15.7% | 36.1% | 31.9% | 20.2% | 28.1% | 18.5% | 20.4% |
| Avg | 17.7% | 34.9% | 29.8% | 19.1% | 28.1% | 19.7% | 21.2% | |
| Max | 20.3% | 34.9% | 29.8% | 20.2% | 28.1% | 20.2% | 22.5% | |
| Min | 15.1% | 36.1% | 31.9% | 20.2% | 28.1% | 18.9% | 20.3% | |
| Score -Fusion | Box -Fusion | FPPI (IOU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|
| Car | Trucks | Tractors | Camping Cars | Vans | Pickup | All | ||
| Avg | NMS | 0.135 | 0.090 | 0.048 | 0.129 | 0.006 | 0.122 | 0.531 |
| Avg | 0.164 | 0.087 | 0.045 | 0.129 | 0.006 | 0.135 | 0.566 | |
| Max | 0.196 | 0.087 | 0.045 | 0.129 | 0.006 | 0.141 | 0.605 | |
| Min | 0.125 | 0.090 | 0.048 | 0.129 | 0.006 | 0.125 | 0.524 | |
| Max | NMS | 0.135 | 0.090 | 0.048 | 0.129 | 0.006 | 0.122 | 0.531 |
| Avg | 0.164 | 0.087 | 0.045 | 0.129 | 0.006 | 0.135 | 0.566 | |
| Max | 0.196 | 0.087 | 0.045 | 0.129 | 0.006 | 0.141 | 0.605 | |
| Min | 0.125 | 0.090 | 0.048 | 0.129 | 0.006 | 0.125 | 0.524 | |
| D-S | NMS | 0.135 | 0.090 | 0.048 | 0.129 | 0.006 | 0.122 | 0.531 |
| Avg | 0.164 | 0.087 | 0.045 | 0.129 | 0.006 | 0.135 | 0.566 | |
| Max | 0.196 | 0.087 | 0.045 | 0.129 | 0.006 | 0.141 | 0.605 | |
| Min | 0.125 | 0.090 | 0.048 | 0.129 | 0.006 | 0.125 | 0.524 | |
| CPROS (ours) | NMS | 0.135 | 0.090 | 0.048 | 0.129 | 0.006 | 0.122 | 0.531 |
| Avg | 0.164 | 0.087 | 0.045 | 0.129 | 0.006 | 0.135 | 0.566 | |
| Max | 0.196 | 0.087 | 0.045 | 0.129 | 0.006 | 0.141 | 0.605 | |
| Min | 0.125 | 0.090 | 0.048 | 0.129 | 0.006 | 0.125 | 0.524 | |
| Detector | IOU = 0.5 | |||
|---|---|---|---|---|
| mAP | MR | FPPI | ||
| YOLOv8(RGB) | 51.6% | 24.8% | 0.598 | |
| YOLOv8(IR) | 43.8% | 29.6% | 0.585 | |
| YOLOv8(RGB) | YOLOv8(IR) | 60.2% | 21.2% | 0.566 |
| YOLOv5(RGB) | 51.3% | 24.0% | 0.656 | |
| YOLOv5(IR) | 46.1% | 29.6% | 0.662 | |
| YOLOv5(RGB) | YOLOv5(IR) | 58.1% | 21.9% | 0.611 |
| YOLOv8(RGB) | 51.6% | 24.8% | 0.598 | |
| YOLOv5(IR) | 46.1% | 29.6% | 0.662 | |
| YOLOv8(RGB) | YOLOv5(IR) | 58.4% | 20.7% | 0.595 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Zuo, Z.; Tong, X.; Huang, H.; Yuan, S.; Dang, Z. CPROS: A Multimodal Decision-Level Fusion Detection Method Based on Category Probability Sets. Remote Sens. 2024, 16, 2745. https://doi.org/10.3390/rs16152745
Li C, Zuo Z, Tong X, Huang H, Yuan S, Dang Z. CPROS: A Multimodal Decision-Level Fusion Detection Method Based on Category Probability Sets. Remote Sensing. 2024; 16(15):2745. https://doi.org/10.3390/rs16152745
Chicago/Turabian StyleLi, Can, Zhen Zuo, Xiaozhong Tong, Honghe Huang, Shudong Yuan, and Zhaoyang Dang. 2024. "CPROS: A Multimodal Decision-Level Fusion Detection Method Based on Category Probability Sets" Remote Sensing 16, no. 15: 2745. https://doi.org/10.3390/rs16152745
APA StyleLi, C., Zuo, Z., Tong, X., Huang, H., Yuan, S., & Dang, Z. (2024). CPROS: A Multimodal Decision-Level Fusion Detection Method Based on Category Probability Sets. Remote Sensing, 16(15), 2745. https://doi.org/10.3390/rs16152745