Figure 1.
An example of fusion and object detection: (a) fusion results; (b) detection results. The source images are shown in the first two columns; the fusion and detection results of FGAN, SuperF, DSF, and our method are in the last four columns.
Figure 1.
An example of fusion and object detection: (a) fusion results; (b) detection results. The source images are shown in the first two columns; the fusion and detection results of FGAN, SuperF, DSF, and our method are in the last four columns.
Figure 2.
The overall network architecture of our method. , , and f refer to visible, infrared, and fusion images, respectively. stands for reconstructed visible and infrared images.
Figure 2.
The overall network architecture of our method. , , and f refer to visible, infrared, and fusion images, respectively. stands for reconstructed visible and infrared images.
Figure 3.
The hybrid pyramid dilated convolution block (HPDCB). d denotes dilation rate. R stands for ReLU activation function.
Figure 3.
The hybrid pyramid dilated convolution block (HPDCB). d denotes dilation rate. R stands for ReLU activation function.
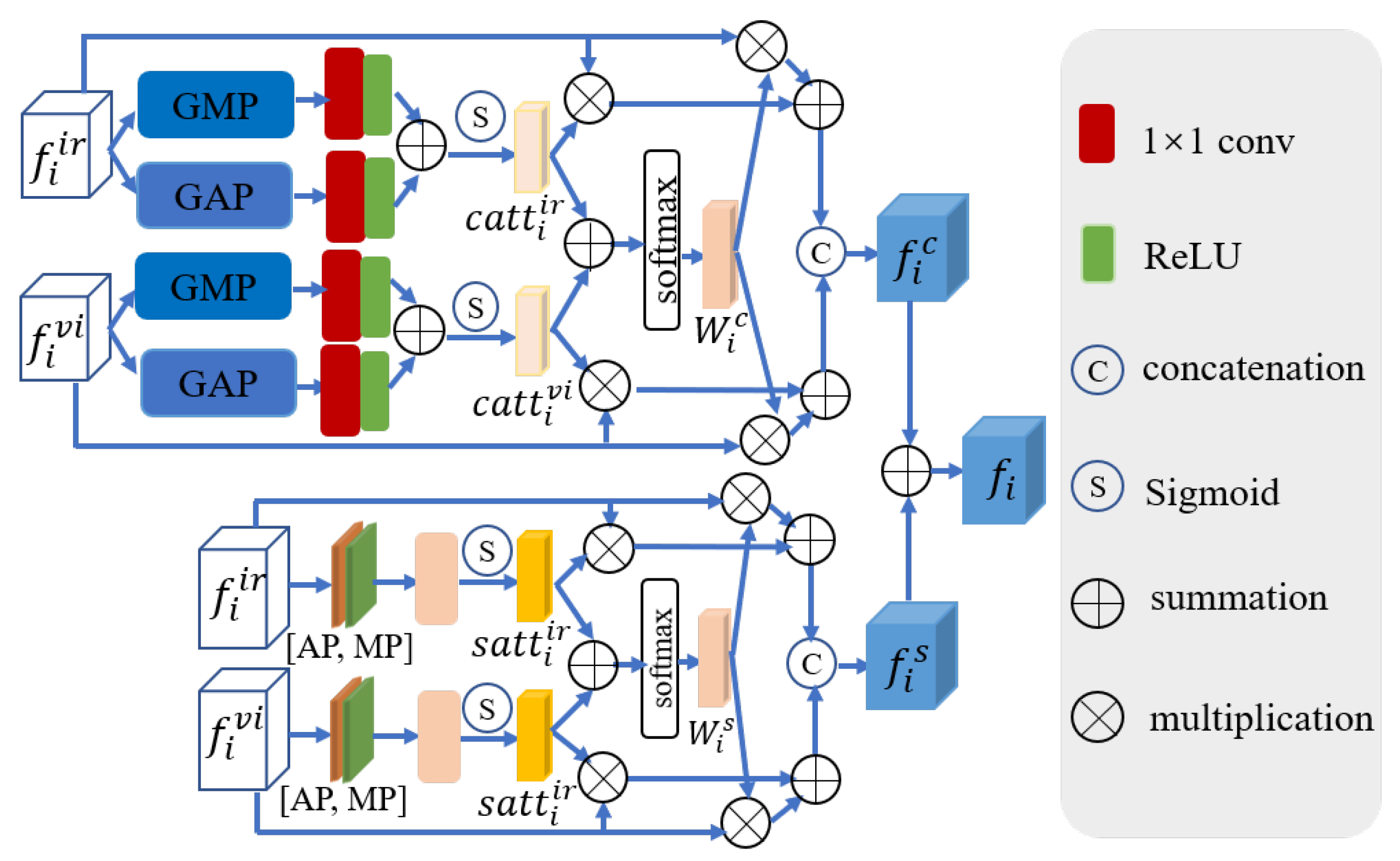
Figure 4.
The cross-modal feature correction block.
Figure 4.
The cross-modal feature correction block.
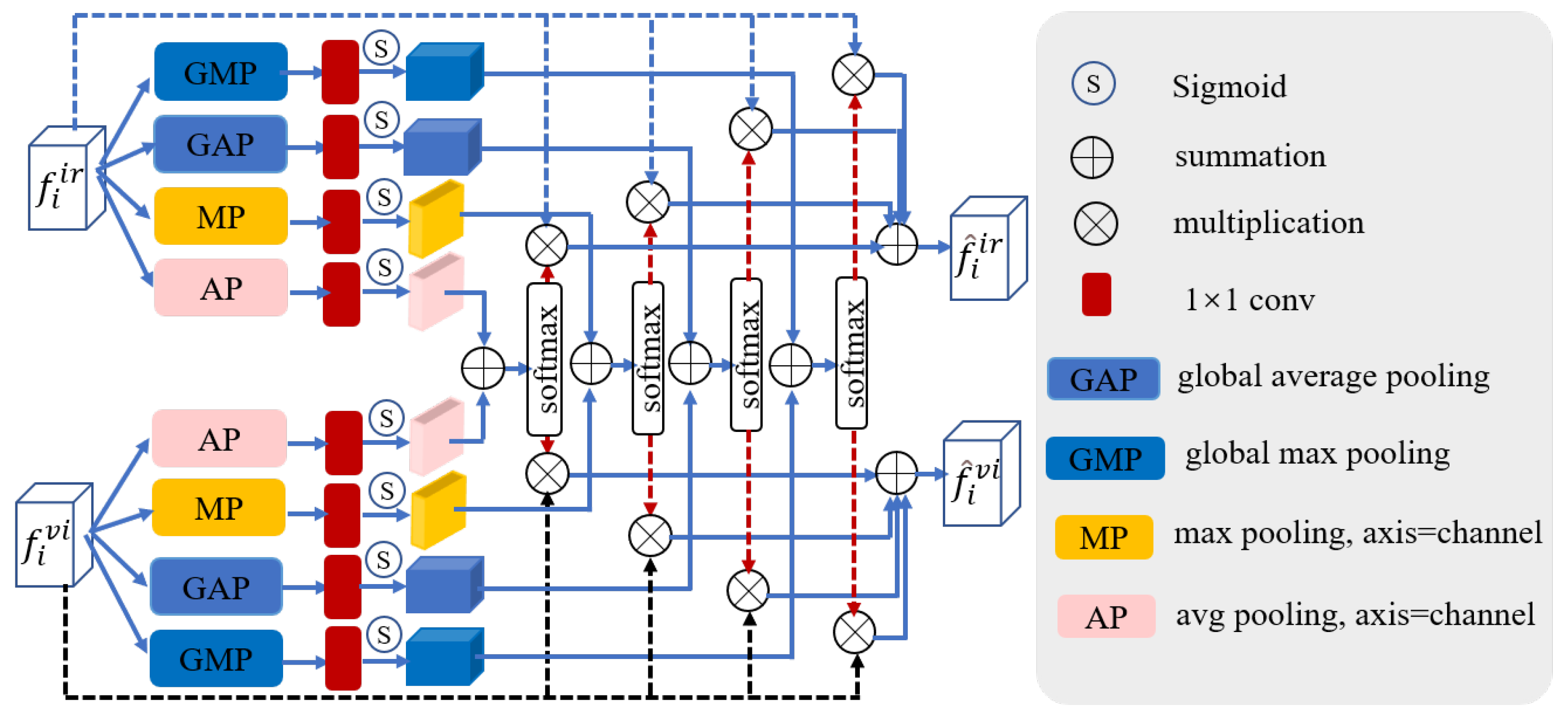
Figure 5.
The feature fusion block. and indicate global average pooling and global max pooling. and stand for average pooling and max pooling.
Figure 5.
The feature fusion block. and indicate global average pooling and global max pooling. and stand for average pooling and max pooling.
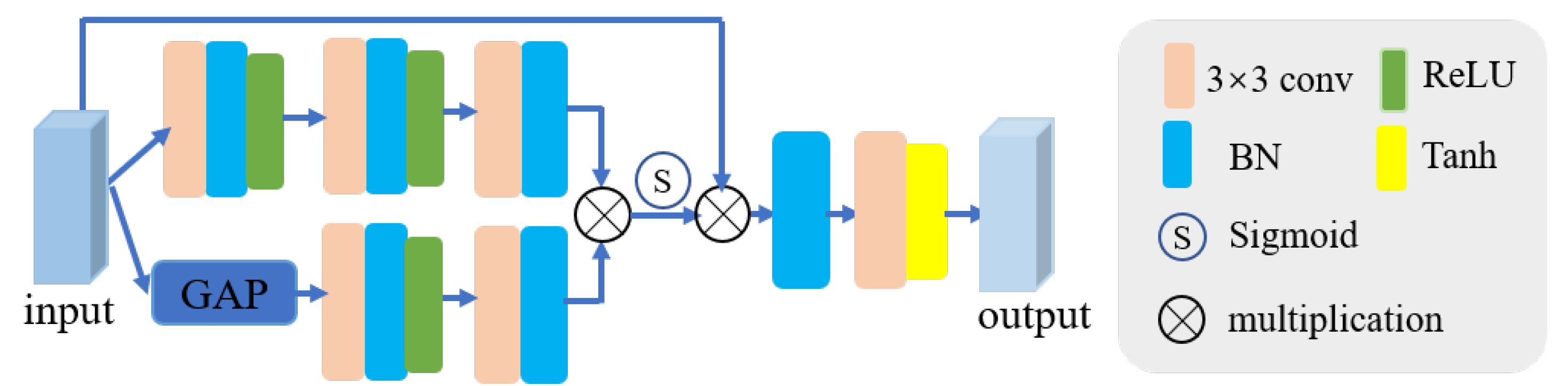
Figure 6.
The feature reconstruction module (FR). denotes Batch Normalization. represent global average pooling.
Figure 6.
The feature reconstruction module (FR). denotes Batch Normalization. represent global average pooling.
Figure 7.
Qualitative analysis of different methods on the dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left, upper-left, and upper-right corners.
Figure 7.
Qualitative analysis of different methods on the dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left, upper-left, and upper-right corners.
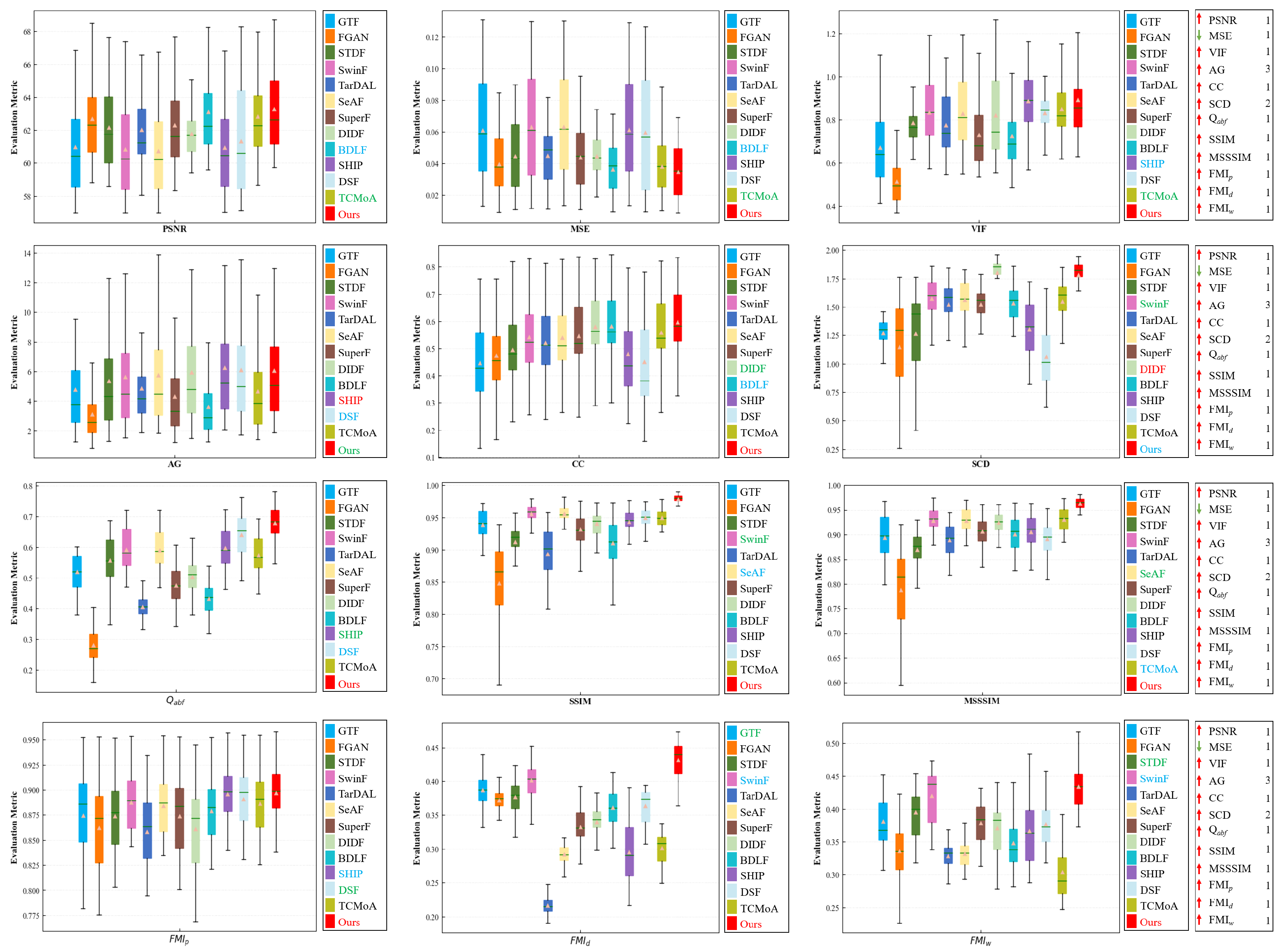
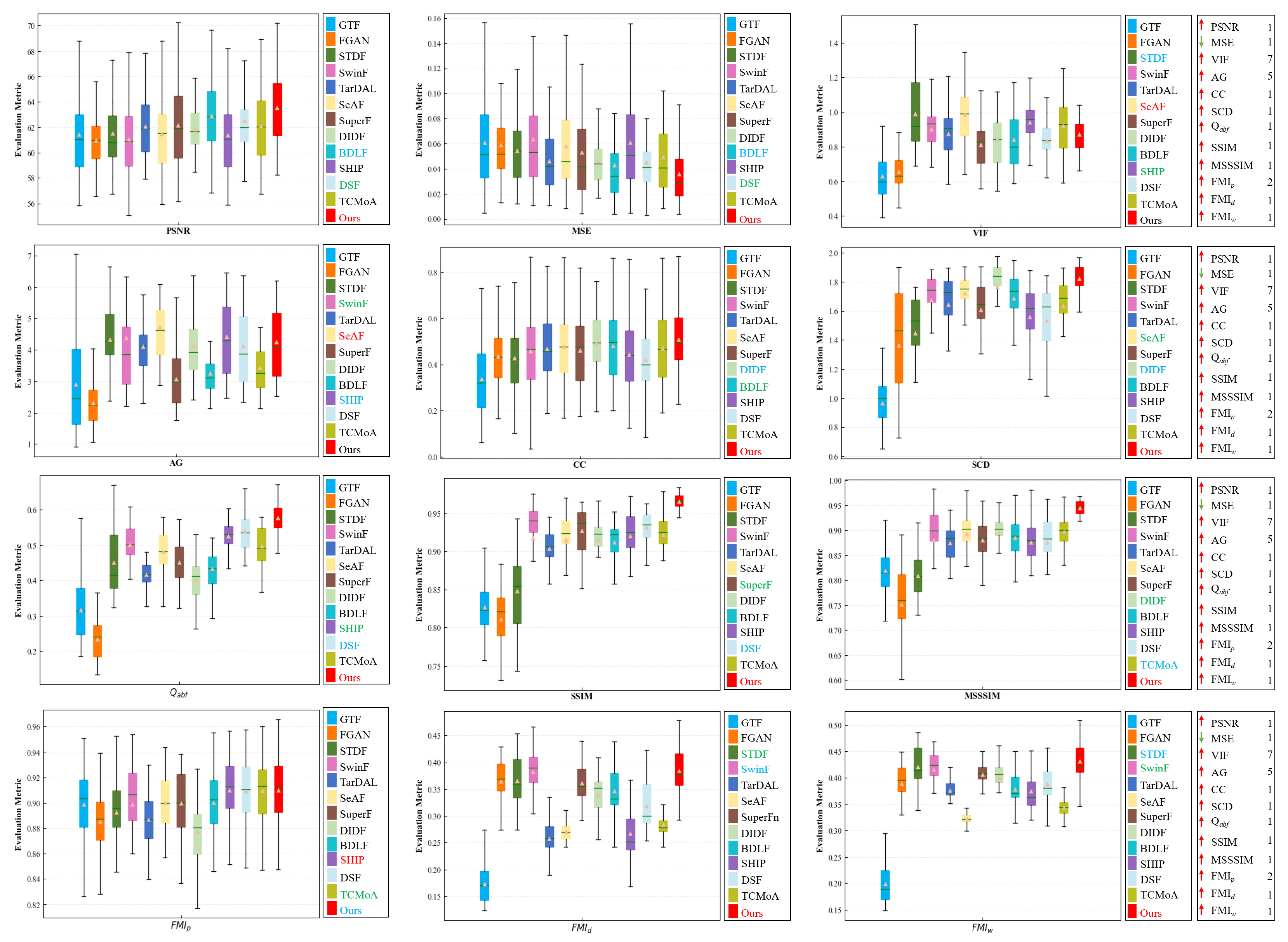
Figure 8.
Quantitative analysis of multiple evaluation metrics on the dataset. Within each box, the green line indicates the median value, and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 8.
Quantitative analysis of multiple evaluation metrics on the dataset. Within each box, the green line indicates the median value, and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 9.
Qualitative analysis of different methods on the TNO dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-right or lower-left corners.
Figure 9.
Qualitative analysis of different methods on the TNO dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-right or lower-left corners.
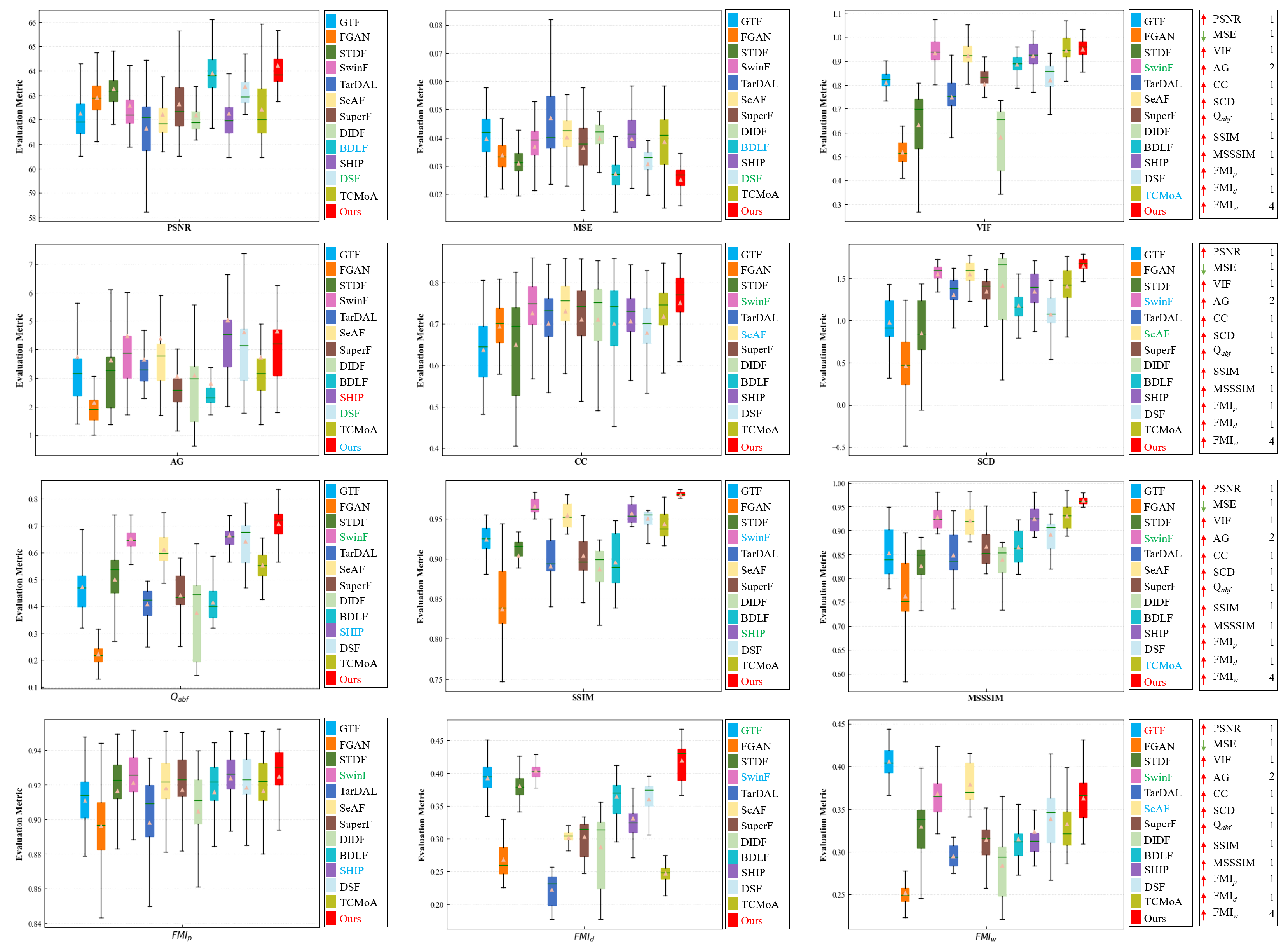
Figure 10.
Quantitative analysis of multiple evaluation metrics on the TNO dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 10.
Quantitative analysis of multiple evaluation metrics on the TNO dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 11.
Qualitative analysis of different methods on the RoadScene dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left or lower-right corners.
Figure 11.
Qualitative analysis of different methods on the RoadScene dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left or lower-right corners.
Figure 12.
Quantitative analysis of multiple evaluation metrics on the RoadScene dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 12.
Quantitative analysis of multiple evaluation metrics on the RoadScene dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 13.
Qualitative analysis of different methods on the LLVIP dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left or lower-right corners.
Figure 13.
Qualitative analysis of different methods on the LLVIP dataset. The regions to focus on are marked with red and green rectangles, with magnified views of these regions presented in the lower-left or lower-right corners.
Figure 14.
Quantitative analysis of multiple evaluation metrics on the LLVIP dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 14.
Quantitative analysis of multiple evaluation metrics on the LLVIP dataset. Within each box, the green line indicates the median value and the orange tangle stands for the mean value. Red serves to highlight the best mean value, blue for the second-best, and green for the third-best. The rankings of the proposed method for each metric are displayed on the right.
Figure 15.
The qualitative results of ablation experiments.
Figure 15.
The qualitative results of ablation experiments.
Figure 16.
Visualization of object detection results for different images on the dataset.
Figure 16.
Visualization of object detection results for different images on the dataset.
Table 1.
The ranking results of different metrics on the dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
Table 1.
The ranking results of different metrics on the dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
| | PSNR ↑ | MSE ↓ | VIF ↑ | AG ↑ | CC ↑ | SCD ↑ | ↑ | SSIM ↑ | MSSSIM ↑ | ↑ | ↑ | ↑ |
|---|
| GTF | 10 | 10 | 12 | 9 | 13 | 10 | 8 | 8 | 9 | 8 | 3 | 4 |
| FGAN | 4 | 4 | 13 | 13 | 11 | 12 | 13 | 13 | 13 | 11 | 5 | 10 |
| STDF | 6 | 6 | 8 | 7 | 9 | 11 | 7 | 10 | 12 | 9 | 4 | 3 |
| SwinF | 12 | 12 | 4 | 6 | 6 | 3 | 4 | 3 | 4 | 4 | 2 | 2 |
| TarDAL | 7 | 8 | 9 | 8 | 8 | 8 | 12 | 12 | 11 | 13 | 13 | 12 |
| SeAF | 13 | 13 | 6 | 5 | 7 | 4 | 5 | 2 | 3 | 6 | 12 | 11 |
| SuperF | 5 | 5 | 10 | 11 | 5 | 7 | 10 | 9 | 6 | 10 | 9 | 5 |
| DIDF | 8 | 7 | 7 | 4 | 3 | 1 | 9 | 7 | 5 | 12 | 8 | 7 |
| BDLF | 2 | 2 | 11 | 12 | 2 | 6 | 11 | 11 | 8 | 7 | 7 | 9 |
| SHIP | 11 | 11 | 2 | 1 | 10 | 9 | 3 | 6 | 7 | 2 | 11 | 8 |
| DSF | 9 | 9 | 5 | 2 | 12 | 13 | 2 | 4 | 10 | 3 | 6 | 6 |
| TCMoA | 3 | 3 | 3 | 10 | 4 | 5 | 6 | 5 | 2 | 5 | 10 | 13 |
| Ours | 1 | 1 | 1 | 3 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
Table 2.
The ranking results of different metrics on the TNO dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
Table 2.
The ranking results of different metrics on the TNO dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
| | PSNR ↑ | MSE ↓ | VIF ↑ | AG ↑ | CC ↑ | SCD ↑ | ↑ | SSIM ↑ | MSSSIM ↑ | ↑ | ↑ | ↑ |
|---|
| GTF | 10 | 11 | 13 | 12 | 13 | 13 | 12 | 12 | 11 | 9 | 13 | 13 |
| FGAN | 13 | 9 | 12 | 13 | 10 | 12 | 13 | 13 | 13 | 12 | 4 | 6 |
| STDF | 8 | 8 | 2 | 4 | 11 | 11 | 7 | 11 | 12 | 10 | 3 | 2 |
| SwinF | 12 | 13 | 5 | 3 | 8 | 5 | 4 | 6 | 7 | 8 | 2 | 3 |
| TarDAL | 6 | 5 | 6 | 7 | 6 | 6 | 10 | 10 | 8 | 11 | 12 | 10 |
| SeAF | 9 | 10 | 1 | 1 | 4 | 3 | 6 | 7 | 4 | 5 | 10 | 12 |
| SuperF | 4 | 7 | 11 | 11 | 7 | 8 | 8 | 3 | 6 | 7 | 5 | 4 |
| DIDF | 7 | 4 | 8 | 8 | 2 | 2 | 11 | 8 | 3 | 13 | 7 | 5 |
| BDLF | 2 | 2 | 9 | 10 | 3 | 4 | 9 | 9 | 5 | 6 | 6 | 8 |
| SHIP | 11 | 12 | 3 | 2 | 9 | 9 | 3 | 5 | 9 | 1 | 11 | 9 |
| DSF | 3 | 3 | 10 | 6 | 12 | 10 | 2 | 2 | 10 | 4 | 8 | 7 |
| TCMoA | 5 | 6 | 4 | 9 | 5 | 7 | 5 | 4 | 2 | 3 | 9 | 11 |
| Ours | 1 | 1 | 7 | 5 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 |
Table 3.
The ranking results of different metrics on the RoadScene dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
Table 3.
The ranking results of different metrics on the RoadScene dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
| | PSNR ↑ | MSE ↓ | VIF ↑ | AG ↑ | CC ↑ | SCD ↑ | ↑ | SSIM ↑ | MSSSIM ↑ | ↑ | ↑ | ↑ |
|---|
| GTF | 9 | 10 | 11 | 11 | 13 | 13 | 12 | 11 | 11 | 6 | 4 | 10 |
| FGAN | 13 | 13 | 13 | 13 | 11 | 11 | 13 | 13 | 12 | 11 | 6 | 13 |
| STDF | 12 | 11 | 1 | 2 | 7 | 6 | 10 | 12 | 13 | 7 | 7 | 4 |
| SwinF | 11 | 12 | 5 | 10 | 5 | 4 | 8 | 9 | 7 | 9 | 8 | 5 |
| TarDAL | 4 | 5 | 9 | 8 | 9 | 9 | 9 | 10 | 9 | 12 | 13 | 9 |
| SeAF | 8 | 8 | 3 | 1 | 6 | 5 | 5 | 6 | 4 | 10 | 9 | 6 |
| SuperF | 6 | 6 | 7 | 9 | 8 | 8 | 6 | 4 | 5 | 5 | 1 | 3 |
| DIDF | 5 | 4 | 8 | 6 | 2 | 1 | 7 | 2 | 3 | 13 | 3 | 2 |
| BDLF | 1 | 2 | 10 | 12 | 3 | 7 | 11 | 8 | 6 | 8 | 5 | 8 |
| SHIP | 10 | 9 | 2 | 3 | 10 | 10 | 3 | 7 | 10 | 3 | 12 | 11 |
| DSF | 7 | 7 | 12 | 5 | 12 | 12 | 2 | 5 | 8 | 1 | 11 | 12 |
| TCMoA | 3 | 3 | 4 | 7 | 4 | 3 | 4 | 3 | 2 | 4 | 10 | 7 |
| Ours | 2 | 1 | 6 | 4 | 1 | 2 | 1 | 1 | 1 | 2 | 2 | 1 |
Table 4.
The ranking results of different metrics on the LLVIP dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
Table 4.
The ranking results of different metrics on the LLVIP dataset for different methods. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
| | PSNR ↑ | MSE ↓ | VIF ↑ | AG ↑ | CC ↑ | SCD ↑ | ↑ | SSIM ↑ | MSSSIM ↑ | ↑ | ↑ | ↑ |
|---|
| GTF | 10 | 10 | 8 | 6 | 13 | 11 | 8 | 7 | 9 | 10 | 3 | 1 |
| FGAN | 5 | 5 | 13 | 13 | 10 | 13 | 13 | 13 | 13 | 13 | 11 | 13 |
| STDF | 4 | 4 | 11 | 9 | 12 | 12 | 7 | 9 | 12 | 8 | 4 | 7 |
| SwinF | 7 | 7 | 3 | 4 | 3 | 2 | 3 | 2 | 3 | 3 | 2 | 3 |
| TarDAL | 13 | 13 | 10 | 8 | 9 | 8 | 11 | 11 | 10 | 12 | 13 | 11 |
| SeAF | 11 | 12 | 5 | 5 | 2 | 3 | 5 | 4 | 5 | 5 | 9 | 2 |
| SuperF | 6 | 6 | 9 | 11 | 5 | 7 | 9 | 8 | 7 | 6 | 8 | 10 |
| DIDF | 12 | 11 | 12 | 10 | 6 | 5 | 12 | 12 | 11 | 11 | 10 | 12 |
| BDLF | 2 | 2 | 6 | 12 | 8 | 9 | 10 | 10 | 8 | 9 | 5 | 9 |
| SHIP | 9 | 9 | 4 | 1 | 7 | 6 | 2 | 3 | 4 | 2 | 7 | 8 |
| DSF | 3 | 3 | 7 | 3 | 11 | 10 | 4 | 5 | 6 | 4 | 6 | 5 |
| TCMoA | 8 | 8 | 2 | 7 | 4 | 4 | 6 | 6 | 2 | 7 | 12 | 6 |
| Ours | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
Table 5.
The quantitative analysis of various modules on the dataset. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
Table 5.
The quantitative analysis of various modules on the dataset. Red serves to highlight the best result, blue for the second-best, and green for the third-best.
| Model | M1 | M2 | M3 | M4 | M5 | M6 | M7 (Ours) |
|---|
| CMFC | × | × | ✓ | ✓ | ✓ | ✓ | ✓ |
| FFB | × | ✓ | × | ✓ | ✓ | ✓ | ✓ |
| HPDCB | × | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| FR | × | ✓ | ✓ | ✓ | × | ✓ | ✓ |
| × | ✓ | ✓ | ✓ | ✓ | × | ✓ |
| PSNR ↑ | 63.6507 | 63.4210 | 63.5573 | 63.4941 | 63.3877 | 63.4001 | 63.3531 |
| MSE ↓ | 0.0329 | 0.0341 | 0.0334 | 0.0336 | 0.0342 | 0.0342 | 0.0346 |
| VIF ↑ | 0.7298 | 0.8480 | 0.7603 | 0.7797 | 0.8410 | 0.8491 | 0.8977 |
| AG ↑ | 5.9649 | 6.0204 | 5.9805 | 5.9546 | 5.9800 | 5.9264 | 6.0230 |
| CC ↑ | 0.5946 | 0.5807 | 0.5930 | 0.5984 | 0.5883 | 0.5880 | 0.5995 |
| SCD ↑ | 1.6584 | 1.6623 | 1.6962 | 1.7565 | 1.7076 | 1.7179 | 1.7835 |
| ↑ | 0.6147 | 0.6857 | 0.6160 | 0.6248 | 0.6766 | 0.6697 | 0.6803 |
| SSIM ↑ | 0.9804 | 0.9812 | 0.9800 | 0.9800 | 0.9809 | 0.9801 | 0.9797 |
| MSSSIM ↑ | 0.9643 | 0.9642 | 0.9674 | 0.9678 | 0.9640 | 0.9638 | 0.9638 |
| ↑ | 0.8886 | 0.8988 | 0.8877 | 0.8883 | 0.8973 | 0.8970 | 0.8977 |
| ↑ | 0.3684 | 0.4158 | 0.3871 | 0.3804 | 0.4236 | 0.4337 | 0.4317 |
| ↑ | 0.3832 | 0.4246 | 0.3920 | 0.3991 | 0.4264 | 0.4301 | 0.4341 |
Table 6.
The average runtime of various fusion methods on the TNO dataset.
Table 6.
The average runtime of various fusion methods on the TNO dataset.
| Methods | GTF | FGAN | STDF | SwinF | TarDAL | SeAF | SuperF |
|---|
| time (s) | 2.8868 | 0.4853 | 0.3270 | 2.4847 | 0.7605 | 0.0989 | 0.2218 |
| Methods | DIDF | BDLF | SHIP | DSF | TCMoA | Ours | - |
| time (s) | 1.4027 | 0.2110 | 0.4293 | 0.1614 | 1.0688 | 0.2025 | - |
Table 7.
The detection precision of different images. Red serves to highlight the best result, blue for the second-best, and green for the third-best. VI and IR represent the visible and infrared images.
Table 7.
The detection precision of different images. Red serves to highlight the best result, blue for the second-best, and green for the third-best. VI and IR represent the visible and infrared images.
| | Precision | AP@0.5 | mAP@[0.5:0.95] |
|---|
| VI | 0.6737 | 0.5979 | 0.3916 |
| IR | 0.6027 | 0.5305 | 0.3003 |
| GTF | 0.5351 | 0.5492 | 0.3411 |
| FGAN | 0.5338 | 0.5117 | 0.3148 |
| STDF | 0.5760 | 0.5632 | 0.3512 |
| SwinF | 0.5984 | 0.5783 | 0.3716 |
| TarDAL | 0.6236 | 0.5997 | 0.3820 |
| SeAF | 0.5835 | 0.5772 | 0.3659 |
| SuperF | 0.5699 | 0.5365 | 0.3367 |
| DIDF | 0.6256 | 0.5941 | 0.3774 |
| BDLF | 0.6124 | 0.5751 | 0.3597 |
| SHIP | 0.5619 | 0.5316 | 0.3347 |
| DSF | 0.6596 | 0.6421 | 0.4279 |
| TCMoA | 0.6220 | 0.5890 | 0.3752 |
| Ours | 0.6995 | 0.6533 | 0.4341 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}