1. Introduction
Recently, infrared and visible image fusion (IVIF) has gained considerable attention, owing to its extensive applications in various fields [
1,
2,
3]. Single-modal images typically contain limited scene information and cannot fully reflect the true environment. Therefore, fusing information from different imaging sensors helps to enhance the informational richness of the images. Infrared and visible images have strong complementarity, i.e., infrared cameras capture thermal radiation but may not provide detailed information, while visible images are not sufficient in detecting hidden objects. Due to the complementarity and advantages of these two modalities, IVIF is widely applied in fields such as nighttime driving, military operations, and object detection.
In recent years, researchers have proposed various methods for IVIF, which can be categorized into traditional and deep learning-based methods. Traditional methods aim to design optimal representations across modalities and formulate fusion weights. These methods include multi-scale decomposition (MSD)-based methods [
3,
4,
5,
6], other transformation-based methods [
7,
8,
9], and saliency-based methods [
10,
11,
12]. The advancements of deep learning have significantly accelerated the evolution of IVIF. Researchers have proposed sophisticated modules or structures [
13,
14,
15,
16,
17,
18] for the integration of features from both infrared and visible images. Autoencoders [
19,
20,
21,
22,
23,
24] have also been introduced into the IVIF process due to their powerful feature extraction capabilities. Additionally, generative adversarial networks (GANs) [
25,
26,
27,
28] have been employed to enhance the fusion performance. However, existing research often neglects the differences between infrared and visible images, as well as the noise present in source images.
There are still some challenges that need to be tackled. Firstly, there is a significant difference between infrared and visible images. This difference leads to the inconsistent fusion of features when they come from these different sources. As a result, the quality of the fusion results is often affected. The differences between the infrared and visible modalities can be attributed to variations in wavelength, sources of radiation, and acquisition sensors. These modal differences lead to variations in images, such as texture, luminance, contrast, etc., subsequently affecting the fusion quality. Although decomposition representation-based methods can reduce the impact of modal differences, they often require complex decomposition and fusion rules. Secondly, low luminance may result in noisy source images. These images often impact the performance of image fusion, leading to suboptimal results. Thirdly, many methods neglect essential information from the middle layers, which are crucial in the fusion process. While dense connections [
22] have been introduced into the fusion network, these connections lead to higher computational costs.
To address these challenges, we propose a novel method (UNIFusion) for IVIF, which includes cosine similarity-based image decomposition, a unified feature space, and dense attention for feature extraction. To obtain high-quality fused images, our method reduces the differences between infrared and visible features through the unified feature space, while also preserving their unique information. We first decompose the infrared and visible images into common and unique regions, respectively. Then, the features extracted from common regions are fed into the unified feature space to obtain fused features without modal differences. Specifically, we first obtain unique and common regions based on the cosine similarity between the embedded features of infrared–visible images. The unique regions contain private information that should be preserved in the fusion process, while the common regions in both infrared and visible images contain similar content. Secondly, to obtain fusion results with more information, we design a unified feature space to eliminate the differences between common features. In the space, infrared features are transformed to the pseudo-visible domain, thereby eliminating the differences between modalities. Thirdly, we propose a dense attention to enhance the feature extraction capabilities of the encoder, particularly focusing on improving the model’s ability to capture important information from the input data. By applying an attention weight across all layers of the encoder, this method ensures that the model focuses on important features, which helps the model to perform fusion tasks better. Moreover, we propose the non-local Gaussian filter to enhance the fusion results. This filter can learn the shape and kernel parameters, enabling it to remove noise while retaining details.
As demonstrated in
Figure 1, our method outperforms current fusion algorithms like FusionGAN [
26], PMGI [
29], and U2Fusion [
15]. It is apparent that we can obtain better results through the unified feature space. Even the current state-of-the-art methods for IVIF cannot obtain satisfactory fused images. For example, FusionGAN generates blurred fused images, while PMGI and U2Fusion lead to fusion artifacts. Conversely, our method can improve the fusion performance by fusing multi-modal features in a consistent space.
The main contributions of this paper are summarized as follows.
To eliminate the modal difference, we propose a domain normalization method based on the unified feature space, which enables the transformation of infrared features to the pseudo-visible domain, ensuring that all features are fused within the same domain and minimizing the impact of modal differences during the fusion process.
We propose a feature-based image decomposition method that separates images into common and unique regions based on the cosine similarity. This approach eliminates the need to manually craft intricate decomposition algorithms, offering an adaptive solution that simplifies the process.
We design a dense attention to allow the encoder to focus on more relevant features while ignoring redundant or irrelevant ones. Moreover, the Non-local Gaussian filter is incorporated into the fusion network to reduce the impact of noisy images on the fusion results.
3. Methods
3.1. Overview
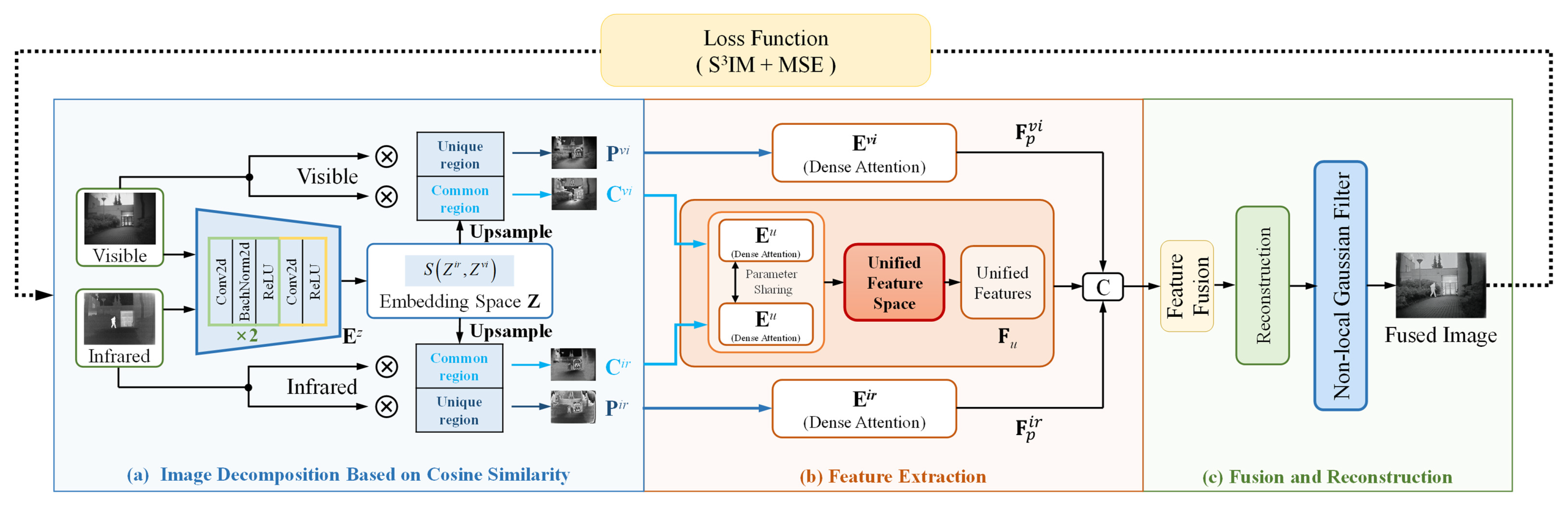
Our proposed UNIFusion is an autoencoder structure, which consists of image decomposition, feature extraction, fusion, and reconstruction modules. The feature extraction module is a three-branch network based on dense attention, consisting of encoders
,
, and
, which are used to extract unique and unified features. The fusion and reconstruction module is devised to fuse features and generate fusion results, while employing a non-local Gaussian filter to reduce the adverse impact of noise on the fusion quality. The complete architecture is depicted in
Figure 2, providing a detailed overview. Specifically, we decompose infrared–visible images into common regions (
and
) and unique regions (
and
). The dense attention is leveraged to effectively extract features from the common and unique regions. To eliminate modal differences, we propose the unified feature space to transform infrared features into the pseudo-visible domain. As noisy source images may degrade the fusion quality, we design a non-local Gaussian filter to minimize the impact of noise on the fusion results while maintaining the image details.
During the training phase, we use the S3SIM and MSE loss functions to evaluate the similarity between the fused image and the original inputs. This helps to refine the network parameters.
3.2. Image Decomposition Based on Cosine Similarity
To obtain the common regions (
and
) and unique regions (
and
) of the source images, we embed the infrared and visible images into a shared parameter space
Z to obtain consistent feature representations. By comparing the similarity of these features using cosine similarity, we can capture the directional similarity of the image features without being affected by the absolute luminance. The size of the feature map is
and the dimension is
d, which leads to the definitions (1) and (2) for feature representation. Elements within these feature maps are denoted by the lowercase
z, which are vectors in the
d-dimensional space. The superscript of
z indicates the modality (with
for visible light and
for infrared), and its subscript denotes the position of the element. The definitions are shown below:
where
is the element in the
i-th row and
j-th column of the visible feature matrix.
is the element in the
i-th row and
j-th column of the infrared feature matrix.
The cosine similarity (denoted as
in the Equation (
3)) is used to decompose infrared and visible images into common and unique regions. This is because the cosine similarity captures the structural similarity between infrared and visible images, which is more important for image fusion than absolute luminance. Two types of masks for source image decomposition are derived by computing the cosine similarity (denoted as
c), namely
(common mask) and
(unique mask), as detailed in Equations (4) and (5):
where
S is the similarity matrix of size
, representing the cosine similarity between visible and infrared features.
is the cosine similarity function.
represents the common mask, and
normalizes the similarity scores to a range [0, 1], where 1 indicates the maximum similarity.
is the unique mask, and the transformation
also normalizes the scores, with 1 indicating the maximum difference.
Next, we upsample the common mask and unique mask to align with the source image size. Element-wise multiplication is performed between the two masks (
and
) and infrared–visible images (
and
) to yield four decomposed outcomes (
,
,
, and
). The decomposed results are defined as followed, representing infrared–visible common regions and unique regions, respectively:
The employment of cosine similarity enables more precise decomposition, ensuring that the common regions and unique regions between the infrared and visible images are captured.
3.3. Dense Attention for Feature Extraction
Although the current fusion methods [
15,
22] try to utilize skip connection structures to obtain rich features, the differences between multi-scale features are not sufficiently taken into account. Specifically, low-level features capture basic input characteristics, while high-level features are more abstract, representing complex concepts and structures. Dense connections and residual connections concatenate multi-scale features directly, which can make it challenging for neural networks to differentiate important features, consequently limiting the fusion performance.
To address this limitation, we propose a dense attention-based feature extraction module to obtain multi-scale features, as shown in
Figure 3. By inserting attention into every dense connection, the model can learn the significant features and relationships between different layers. Furthermore, as the network depth increases, this attention mechanism helps the model to learn long-range dependencies, improving its generalization and robustness.
3.4. Unified Feature Space Based on Dynamic Instance Normalization
We construct the unified feature space to eliminate the difference between infrared and visible features at the multi-scale feature level. The core components of the space include a scale-aware module, shifted patch embedding, and dynamic instance normalization (DIN), as shown in
Figure 4. Specifically, the scale-aware module is trained to determine the size and shape of a patch. With the
n pairs of scale and size parameters output by this module, shifted patch embedding can divide the feature map into
n groups. For each group, it splits the feature map into patches according to the corresponding scale and size. DIN transforms infrared features into a pseudo-visible domain for each patch, which eliminates the differences between infrared and visible images. Subsequently, the learned confidence merges the features from the two modalities to produce the output result.
More specifically, the unified feature space enables the domain transformation from infrared to pseudo-visible, while also being adaptable to multi-scale targets. Dynamic instance normalization (DIN) is the core of the unified feature space, capable of transforming features from infrared features to pseudo-visible, thereby eliminating the difference between the two modalities. Moreover, we employ global pooling to concatenate features in order to enable a multilayer perceptron (MLP) to generate n pairs of size and shape parameters. The multi-patch embedding module divides the infrared and visible features into n groups along the channel dimension. Within each group, the features are segmented into patches of the same scale, determined by a set of size and shape parameters. Then, DIN transforms the infrared features to the pseudo-visible domain for each patch after shifted patch embedding. For the fusion of infrared and pseudo-visible features, we design a learnable confidence module to learn fusion weights; this method can adjust the fusion weight depending on the image content, compared with the fusion rules of addition, concatenation, and so on.
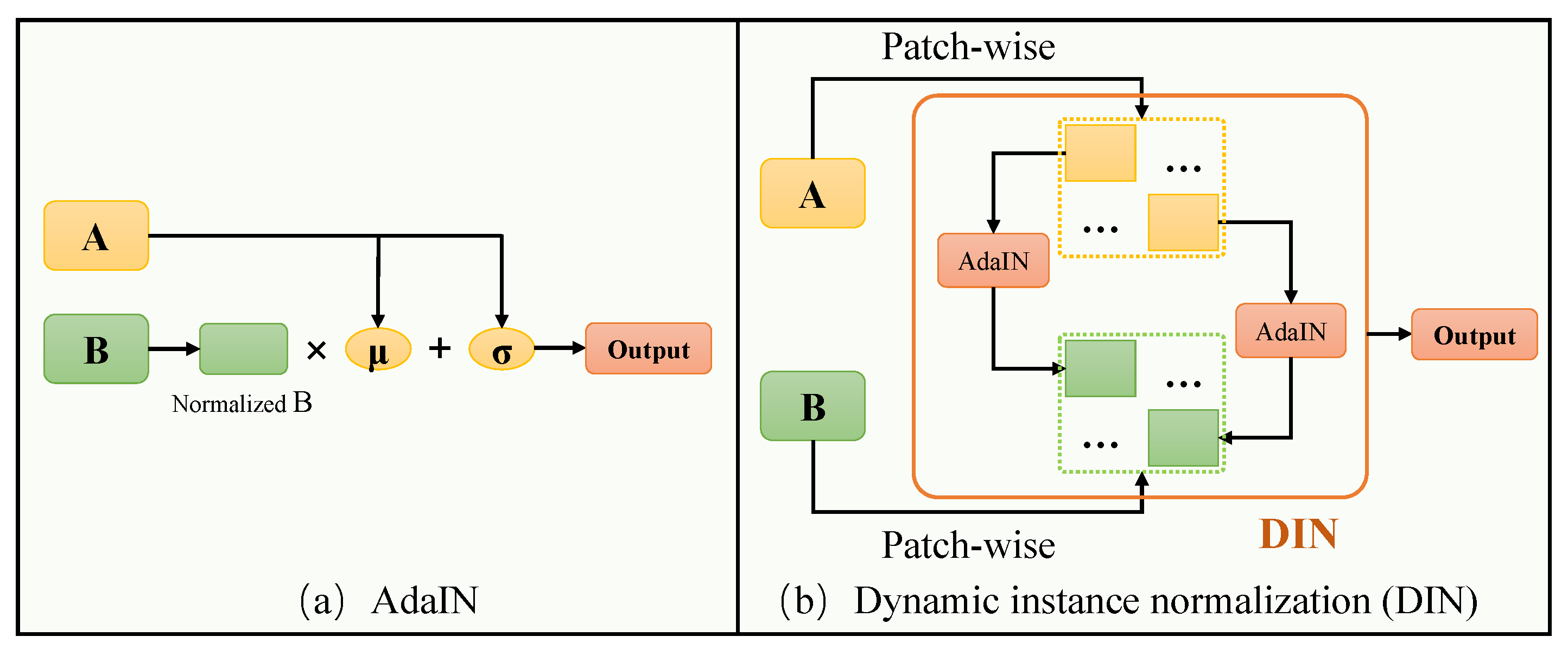
Although adaptive instance normalization (AdaIN) [
41,
42] plays a crucial role in image translation tasks, the core idea of AdaIN is to adjust the feature distribution of a content image to match the feature distribution of a target style image, thereby achieving style transfer. This process involves normalizing the features of the content image and then adjusting these normalized features with the statistical data (mean and variance) of the target style image. Through this method, the content image adopts the style characteristics of the style image while retaining its content structure. However, this method is not very precise due to the transformation of the domain at the level of global features. This limitation prevents independent domain transformations for each patch, restricting the effectiveness of domain transformation. To address this, we introduce dynamic instance normalization (DIN), which astutely segments the feature map into distinct subregions, as shown in
Figure 5. This segmentation allows for independent domain transformations on each patch, enhancing the adaptability of the process. The DIN function is mathematically represented as
where both X and Y denote global features, X represents the content input, and Y is the modal attribute input. Both X and Y are segmented into
n patches, resulting in patch-wise pairs denoted as
for
, where each pair corresponds to matching patches from X and Y. The terms
and
denote the means of
x and
y, respectively, while
and
denote their standard deviations.
In particular, we feed the concatenated infrared and visible features into a scale-aware module to obtain the scales and ratios. The shifted patch embedding module separately splits infrared and visible features into
n groups and partitions each group of features into patches based on the scale and ratio. Infrared and visible patches can be represented as
and
, respectively. Applying DIN to each infrared–visible patch pair, as shown in Equation (
10), we transform the infrared features into the pseudo-visible domain at the patch level. Then, we multiply them element-wise with a neural network-derived confidence metric to form the final fusion features. We obtain the final unified features by fusing pseudo-visible and visible features based on the learnable-confidence module.
3.5. Hierarchical Decoder for Fusion and Reconstruction
The hierarchical decoder does not only allow us to fuse infrared–visible features and generate fused images, but is also robust to the noise contained in source images and enhances the clarity of the fusion result. In this paper, we propose a multi-stage decoder to achieve more refined fusion, which can be divided into fusion, reconstruction, and enhancement stages.
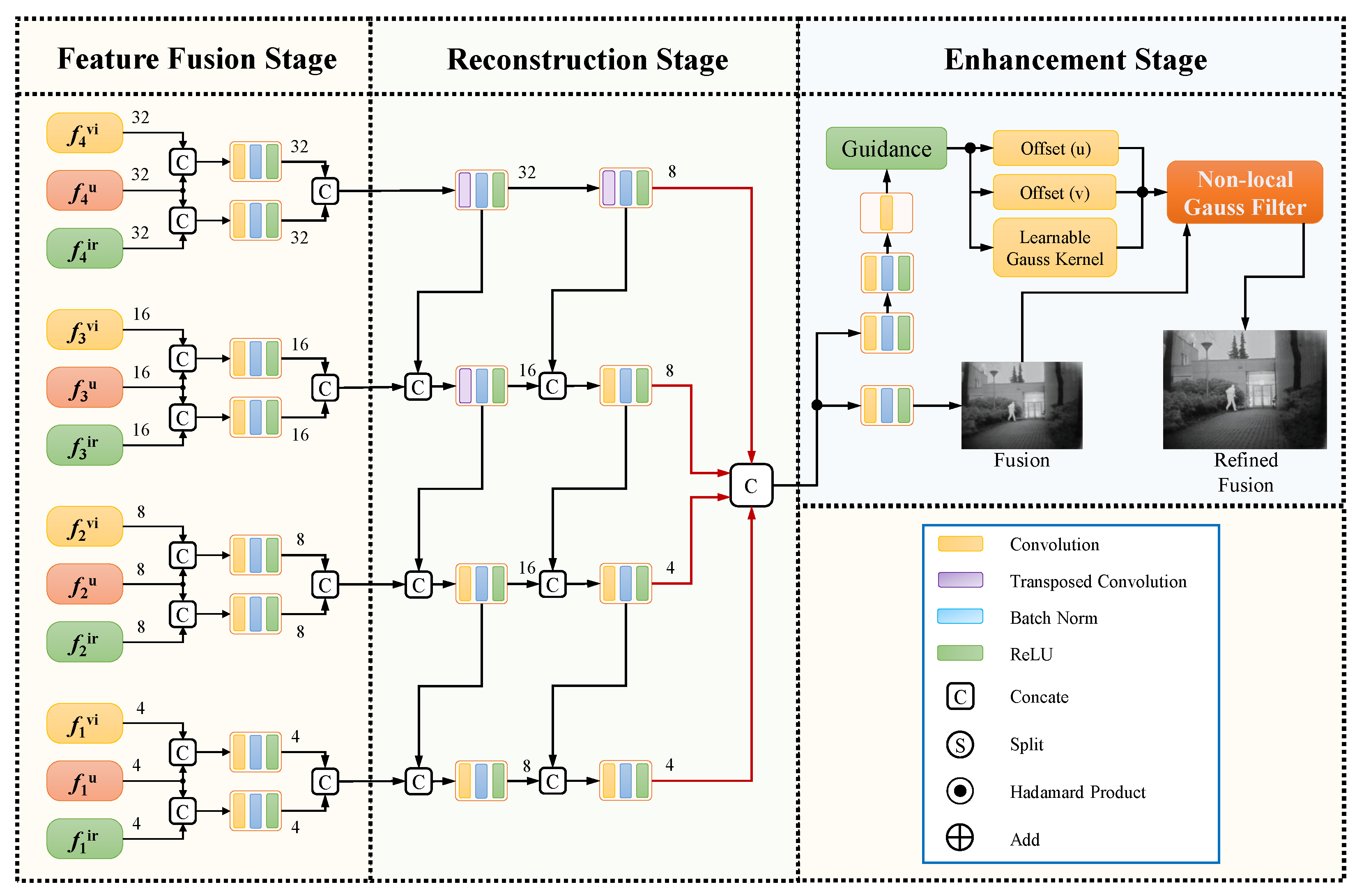
The specific design of the hierarchical decoder is shown in
Figure 6. We deploy two convolutional layers to fuse unified and unique features, receptively, in order to retain more infrared–infrared information. Then, in the reconstruction, we propose a novel module to learn the fusion strategy and obtain refined features. As every scale feature is vital to the fusion task, we not only insert a nest connection to learn the fusion strategy, but also propose a direct connection to output multi-scale features. Specifically, in the proposed architecture, features are reconstructed to match the size of the input image through a series of convolutional or transposed convolutional layers. These reconstructed features are then propagated to subsequent layers. In the final enhancement stage, we employ two distinct sets of convolutional layers to obtain a guidance feature used to obtain the filter parameters and preliminary fused images. Subsequently, we utilize a cascade of three convolutional layers to derive two-dimensional positional offsets and non-local Gaussian kernels.
Regarding the non-local Gaussian filter (shown in
Figure 7), used for image enhancement, the process involves refining a preliminary fusion result, denoted as
f. Here,
represents the value at position
after an initial fusion step. The refined fusion outcome,
, is achieved through an advanced filtering technique, mathematically formulated as
where
represents the value at position
, and
N is the total number of neighbors, with a default value of 9. The term
denotes learnable Gaussian kernels for the
n-th neighbor of the pixel at
.
is the sum of weights for all neighbors, used to normalize the weights such that the sum of weights within the neighborhood equals 1. The terms
and
represent the positional offset values for the
n-th neighbor, indicating the deviations in the row (vertical) and column (horizontal) directions, respectively, relative to the central pixel
.
The non-local Gaussian filter enables the adaptive refinement of the fusion process. By dynamically adjusting the offsets and weights based on the local structures of the initial fusion result, the network can achieve a more optimized and contextually aware fusion outcome.
3.6. Loss Function
In this paper, we introduce two types of loss functions to simultaneously preserve crucial information from the source images and enhance the saliency of the fused image. Our loss functions incorporate two key components: the mean squared error (MSE) loss
and the proposed saliency structural similarity index (S
3IM) loss
. The MSE loss is used to constrain the similarity between the fusion results and the infrared–visible images. This loss focuses on maintaining fidelity to the source images by minimizing pixel-wise differences. Our proposed S
3IM loss aims to emphasize the saliency in the fused image. The total loss is calculated as follows:
where
represents the parameters of the neural network,
D represents the training data, and
is the hyperparameter that balances the two losses.
Due to its efficiency and stability, the mean squared error loss
can provide high accuracy and reliability in many cases. Therefore, we use it to constrain the similarity between the source images
,
, and the fused image
. Its definition is as follows:
where
and
are hyperparameters that balance the weights of the two MSE terms in the loss function. This allows the model to adjust the reliance on the visible image and the infrared image according to the needs of the specific task.
The structural similarity index measure (SSIM) [
43] is a widely used image quality assessment metric that aims to quantify the perceptual similarity between two images. However, in infrared images, there are pixels with zero or very low intensity values, which means that the corresponding regions do not have objects with thermal radiation. In the fusion process, they should be assigned lower weights. To address this issue, we propose the saliency SSIM (S
3IM). Specifically, S
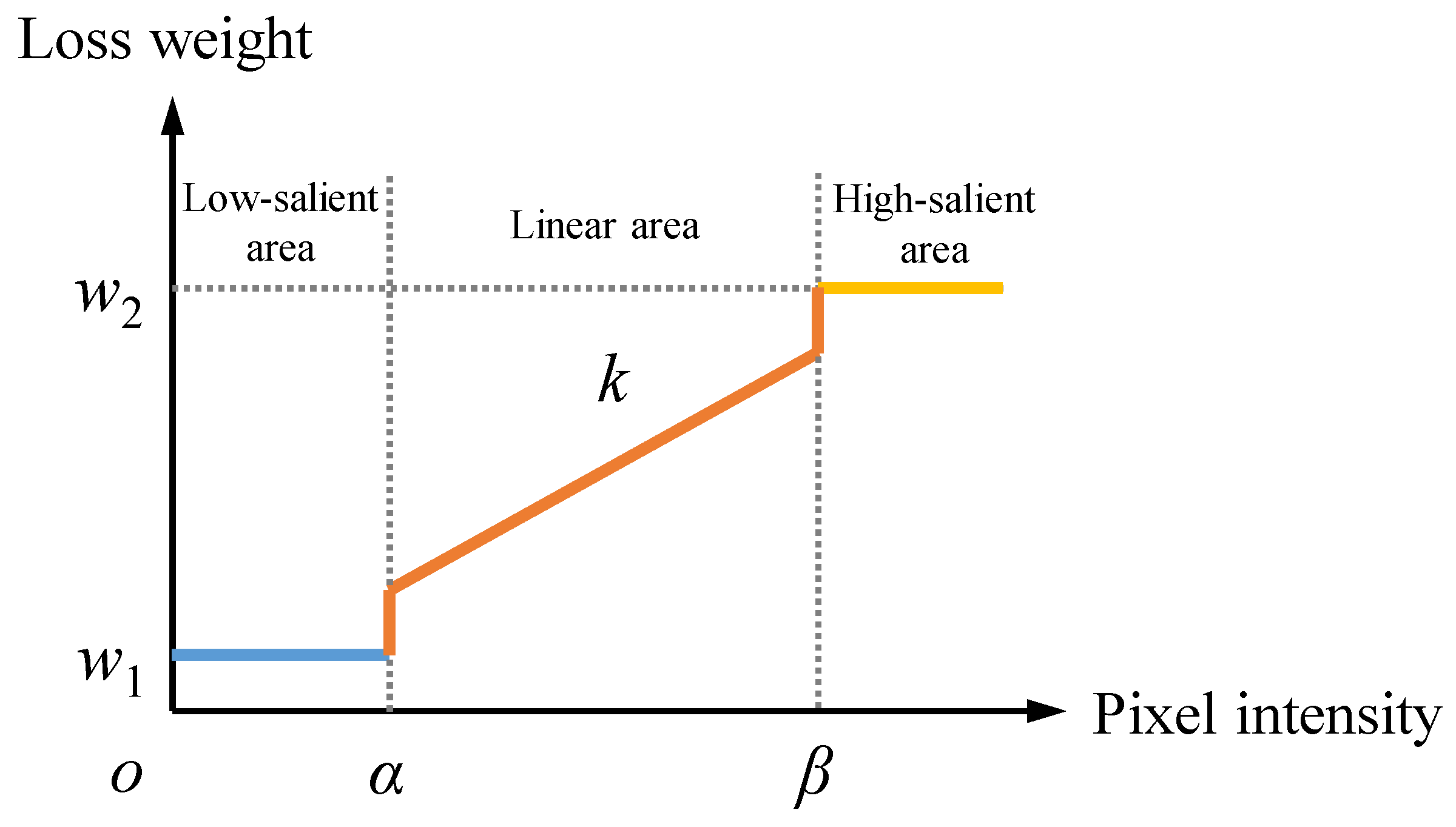
3IM can adaptively determine the loss weights based on the pixel intensity. We divide the normalized pixel values into three major regions: the low-saliency area, the linear area, and the high-saliency area, as shown in
Figure 8.
The low-saliency area contains pixels with lower intensity values, which typically do not contain target information. When calculating the loss, they should be assigned a very low weight. The high-saliency region contains pixels with high intensity values, indicating objects with high thermal radiation, and they should have higher saliency in the fused image. For the remaining pixels, we adopt a linear transformation strategy to determine their loss weights, corresponding to the linear region in
Figure 8. In summary, the calculation method is shown as follows:
where
is a hyperparameter used to adjust the weights of the infrared and visible images during the fusion process.
4. Experimental Results
In this section, we describe the experimental setup and the details of the network training. Following this, we perform a comparative analysis of the current fusion methods and carry out generalization experiments to highlight the benefits of our approach. Additionally, we conduct ablation studies to validate the effectiveness of our proposed methods.
4.1. Experimental Settings
We conduct experiments using four publicly available datasets. The M3FD dataset [
44] is used for model training, while the TNO [
45], RoadScene [
15], and VTUAV [
46] datasets are used to evaluate the performance of our method. The M3FD dataset contains 300 pairs of infrared and visible images for IVIF, including targets such as people, cars, buses, motorcycles, trucks, etc. These images were collected under various illuminance conditions and scenarios. The TNO dataset contains multispectral imagery from various military scenarios. The RoadScene dataset includes 221 image pairs featuring roads, vehicles, pedestrians, etc. The VTUAV dataset is used for remote sensing analysis and contains complex backgrounds and moving objects. We selected 20 pairs of infrared–visible images from both the TNO and RoadScene datasets, as well as 10 pairs from the VTUAV dataset, for the evaluation of our approach.
Our UNIFusion is compared with nine current state-of-the-art fusion methods, including a biological vision-based method, i.e., PFF [
47]; an autoencoder-based method, i.e., MFEIF [
48]; two generative adversarial network -based methods, i.e., FusionGAN [
26] and UMF [
49]; two convolutional neural network-based methods, i.e., U2Fusion [
15], PMGI [
29], and RFN [
50]; a transformer-based method, i.e., swinfusion [
17]; and a high-level task supervision-based method, i.e., PIAFusion [
18].
To quantitatively evaluate the fusion performance, we utilize five key metrics: the average gradient (AG) [
51], standard deviation (SD) [
26], correlation coefficient (CC) [
52], spatial frequency [
53], and multi-scale structural similarity index (MS-SSIM) [
54]. The AG measures the texture richness in the image, while the SD highlights the contrast within the fused image. The SF is indicative of the detail richness and image definition. The CC evaluates the linear relationship between the fusion results and infrared–visible images. MS-SSIM is employed to calculate the structural similarity between images. Generally, higher values in AG, SD, SF, MS-SSIM, and CC denote superior fusion performance.
4.2. Implementation Details
We trained our fusion model using the M3FD fusion dataset, which contains 300 infrared–visible pairs. During training, we randomly cropped the infrared–visible image pairs into multiple 256 × 256 patches, applied random affine transformations to enhance the model performance, and normalized all images to the [0, 1] range before inputting them into the fusion model. For training, we utilized the Adam optimizer with a batch size of 16. The initial learning rate was set to and was halved every two epochs starting from epoch 30, continuing this reduction until the final epoch at 60. Additionally, we set the parameters of Equations (13)–(16) as follows: = 1, = 1, = 1, = 0.2, = 0.7, k = 1, b = 0, = 0.2, = 2, = 1. The entire network was trained using the PyTorch 1.8.2 framework on an NVIDIA GeForce GTX 3080 GPU and a 3.69 GHz Intel Core i5-12600KF CPU.
4.3. Fusion Performance Analysis
In this section, we conduct a comprehensive qualitative and quantitative analysis to illustrate the advantages of our UNIFusion, comparing our method with nine state-of-the-art (SOTA) fusion approaches. In addition, we test the performance of our UNIFusion across various illumination scenarios within the VTUAV dataset.
4.3.1. Qualitative Results
The visualized comparisons of our UNIFusion with the nine SOTA methods are provided in
Figure 9,
Figure 10 and
Figure 11.
Figure 9 and
Figure 10 present the fusion results of the different methods on the TNO and RoadScene datasets, respectively, while
Figure 11 shows the color fusion results. Moreover, we evaluate our model’s performance with remote sensing data collected under normal and low-light conditions, as shown in
Figure 11. In our approach, we effectively transform infrared features into the pseudo-visible domain, resulting in fused images that maintain superior visual perception. This transformation process enhances the fusion of infrared and visible information, yielding more natural and clearer fusion results. Notably, our image decomposition method plays a crucial role in preserving unique information from multiple modalities, thereby highlighting salient objects in the fused images.
In
Figure 9, it can be seen that FusionGAN, PMGI, RFN, U2Fusion, and UMF generate fusion results with less information and lower brightness (see the red boxes), which contain more infrared information and do not fully fuse visible image. The objects in MFEIF and PIAFusion are not salient and therefore not easily observed (see the orange boxes in
Figure 9). SwinFusion suffers from overexposure and oversmoothing, resulting in some details not being clear enough (see the orange boxes in
Figure 9). Although PFF can fuse more details, the results of this method contain noise (see the yellow boxes in
Figure 9). On the contrary, our fused images can fuse more information through the unified feature space, which leads to rich details and structures (see the red boxes in
Figure 9). Our UNIFusion can also obtain better fusion performance on small objects (see the orange boxes in
Figure 9). Moreover, the results generated from our method are clear and contain less noise due to the non-local Gaussian filter (see the orange boxes in
Figure 9).
Figure 10 and
Figure 11 show more fused images on the RoadScene dataset. In the red boxes, it can be seen that the fused images obtained from PFF contain more visible information and lees infrared information. In the fusion results obtained by FusionGAN, PMGI, and RFN, the overall brightness of the image is relatively low, leading to objects in the fused image that are not salient (see the red boxes). FusionGAN, PMGI, and RFN generate fusion results with low overall brightness, resulting in less salient objects (see the red boxes). Although MFEIF, PIAFusion, SwinFusion, and UMF produce brighter fusion results, their results appear less contrasted in
Figure 10 and
Figure 11. In the orange boxes of
Figure 11, the fusion result from PIAFusion and SwinFusion exhibits blurry details for the cloud, and the results of UMF and U2Fusion are unable to successfully process object edges (see the edge of the tree in orange boxes). In comparison, our method can achieve superior fusion performance in both day and night conditions. The fusion results obtained by our UNIFusion can effectively integrate the source information from infrared and visible images, and it exhibits better performance on the edges of the target.
To assess the generalization of our method and its performance in low-light conditions, we conducted experiments on the VTUAV dataset.
Figure 12 displays our fusion results, with
Figure 12a showing the fusion results under normal-light conditions, and
Figure 12b showcasing the fusion results under low-light conditions. In the normal-light scene (see the red boxes in
Figure 12a), the infrared images display high thermal contrast, which our algorithm effectively integrates with the visible spectrum images, known for their rich contextual details. The resulting fusion images demonstrate the algorithm’s proficiency in synthesizing the distinct attributes of each spectrum to enhance the overall image quality. Under low-light conditions (see the red boxes in
Figure 12b), where visible images suffer from limited visibility, our algorithm leverages infrared imaging to accentuate thermal details otherwise obscured by darkness. The fusion process yields images that not only retain the luminance from visible light but also highlight thermal aspects, thus improving the interpretability of the scene in suboptimal lighting.
We evaluate the performance of our method using remote sensing data that include natural environments, urban landscapes, and beach scenes.
Figure 13 shows our fused images in these environments. Our fusion method effectively integrates valuable information from the source images, achieving satisfactory results in terms of illumination, detail, and structural integrity. The fused images across the first, second, and third columns exhibit our method’s capability to successfully fuse infrared and visible data, enhancing the clarity in details and structures, as highlighted in the red boxes. Moreover, our approach excels at retaining essential features while disregarding irrelevant information, as seen in the urban and beach scenes of the fourth and fifth columns, respectively. Despite the visible images in the fourth and fifth columns being somewhat dark and containing some details, our fusion outcome maintains these details without being affected by the abnormal illumination of the visible image. Our method is robust in preserving critical information across diverse scenes and lighting conditions.
4.3.2. Qualitative Results
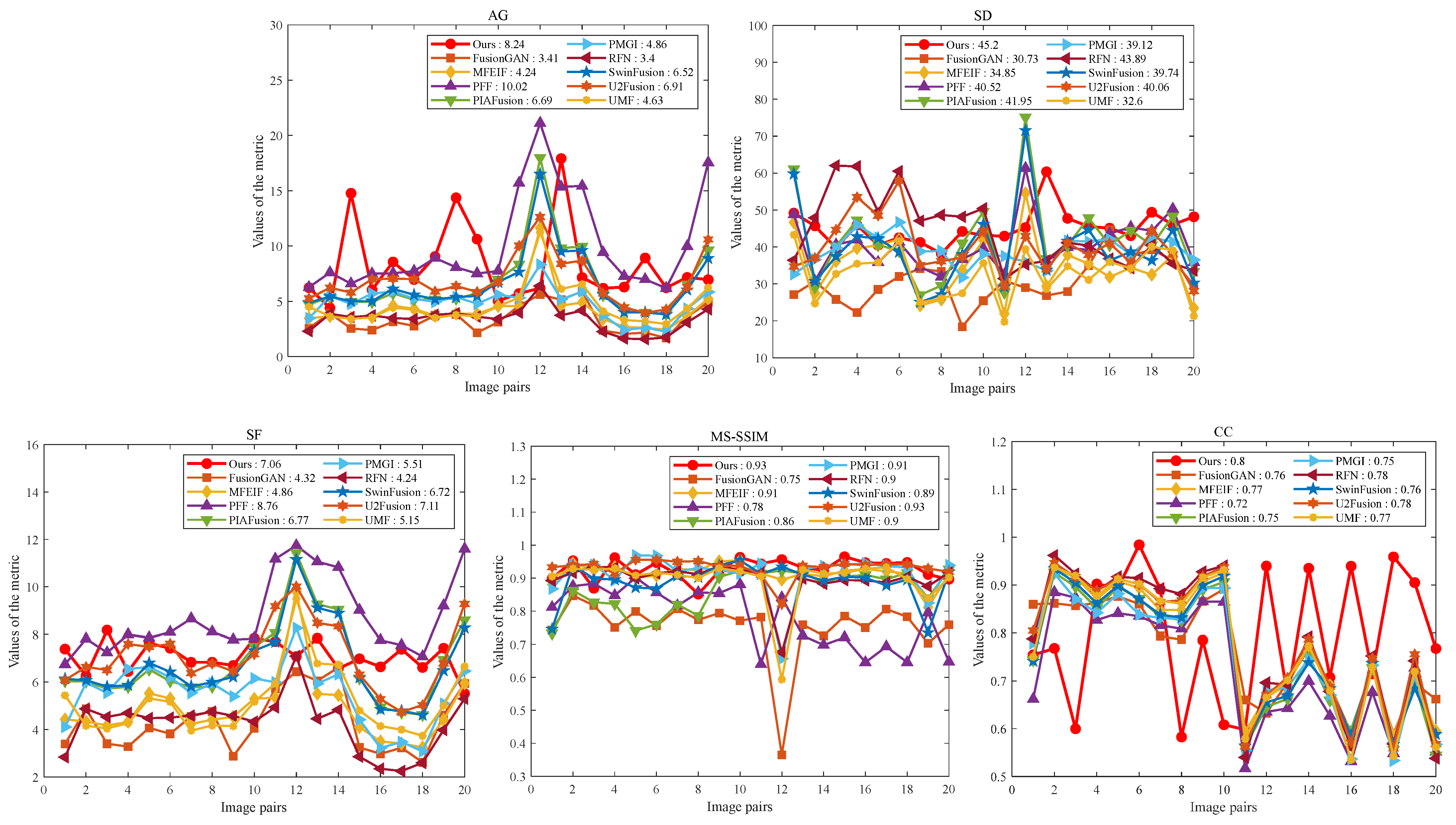
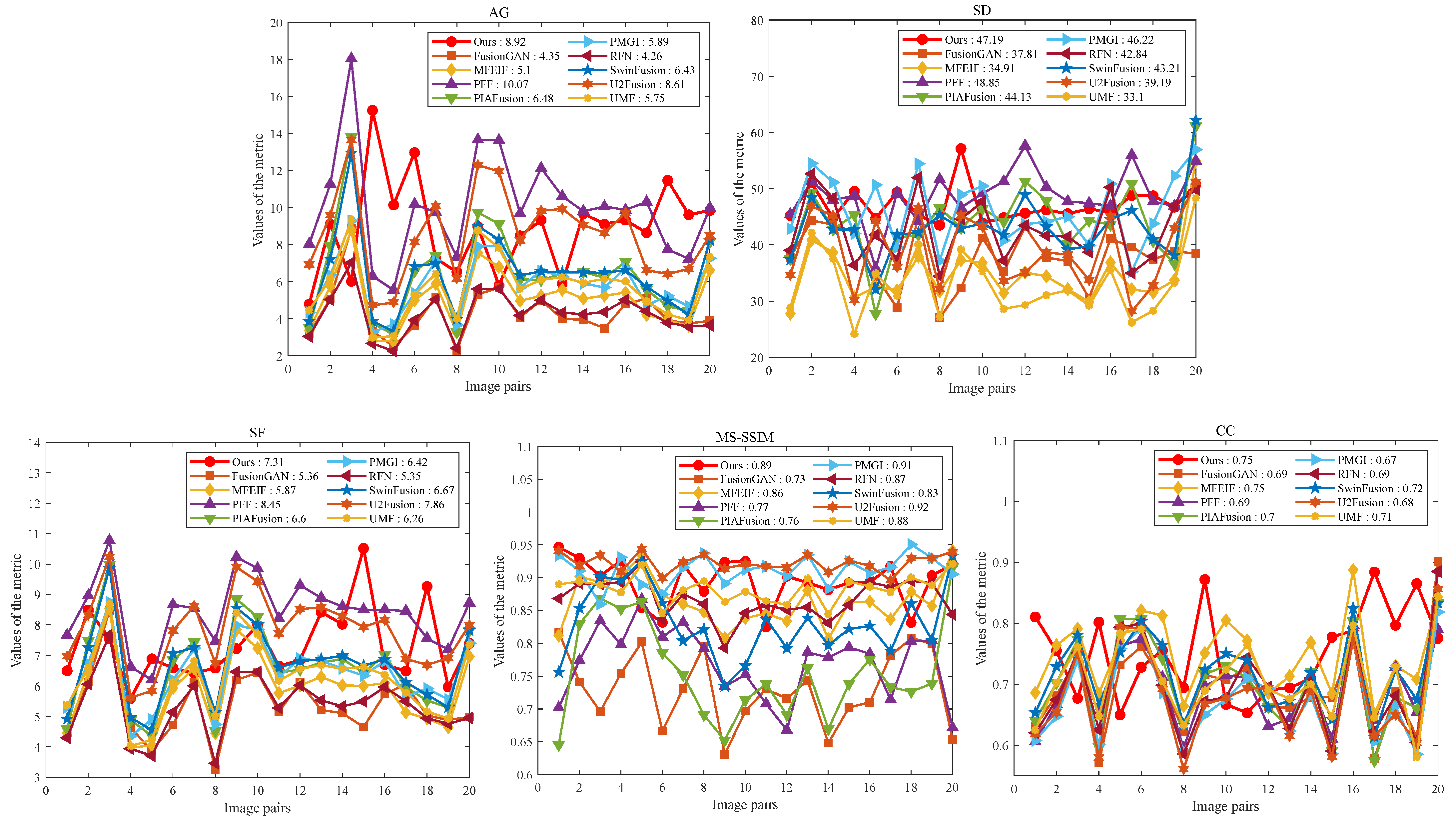
Figure 14 and
Figure 15 provide a quantitative comparison between our method and the state-of-the-art (SOTA) methods on the TNO and RoadScene datasets, respectively. The average metric values for these methods are summarized in
Table 1 and
Table 2, respectively. Our method stands out in terms of overall performance. On the TNO dataset, our UNIFusion obtains better performance with the highest average values of SD and CC, indicating the effective integration of information from the source images while preserving the rich details in the fused images. Additionally, our method achieves the second-best results in AG and MS-SSIM, coming close to the top performer. This demonstrates our method’s capability to integrate detailed information from source images effectively. In the RoadScene dataset’s results, our method obtains remarkably high scores in AG, SD, and CC, further confirming its outstanding overall performance. While PFF achieves the best metrics in AG and SF by incorporating the characteristics of the human visual system, it relies on complex decomposition algorithms and faces challenges in preserving the rich information from the source images.
4.4. Ablation Study
We conducted experiments to analyze the effectiveness of the proposed method for infrared and visible image fusion. The fusion results with and without the unified feature space (UFS), non-local Gaussian filter (NGF), and dense attention (DA) were compared in the experiments.
Figure 16 shows the fused images with and without UFS. It can be seen that the method without UFS generates blurred text on the signboard (see the red boxes in the first row of
Figure 16) and does not sufficiently retain the information from the source images. In contrast, our method with UFS produces a detailed fusion result, particularly with much clearer text. From the second row of
Figure 16, it can be observed that our method can retain more details of the car compared with the method without UFS. Furthermore, the red boxes in the first row of
Figure 16 show that our method generates clearer edges on the signboard, indicating that the unified feature space (UFS) effectively fuses information from different modalities, thereby achieving high fusion performance. In the absence of NGF, there is an increase in noise within the fused image (see the red box in
Figure 17). Compared with the method without NGF, our method not only removes more noise but also preserves image details and structures. We propose the dense attention-based feature extraction module to obtain multi-scale features, which can learn the significant features and relationships between different layers. Without dense attention, the extraction of key features becomes challenging, resulting in fusion outcomes that are lacking in detail. In
Figure 18, without dense attention (DA), features such as the clouds in the sky and people on the grass appear less prominent and blurred. In contrast, our fusion results are richer in detail and clarity.
We selected three representative metrics to demonstrate the effectiveness of each module: AG, MS-SSIM, and CC. AG indicates that the image contains rich information, while MS-SSIM and CC suggest that the fusion results retain substantial content from the source images.
Table 3 presents the comparison results, which demonstrate that each component influences the overall performance. The removal of UFS lead to a marked decrease in AG, indicating its vital role in the fusion process and in maintaining rich information. The absence of NGF and DA leads to a decrease in MS-SSIM, as shown in
Table 3, which shows that our proposed NGF and DA are capable of retaining more information from the source image. The absence of DA leading to a significant decrease in MS-SSIM indicates that DA captures essential features, thereby enriching the fusion results with more details from the source images. Both the qualitative and quantitative results demonstrate that the UFS, NGF, and DA are effective in removing noise while maintaining the information from the source images.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}