



A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation

 ,
,  ,
,
Abstract
1. Introduction
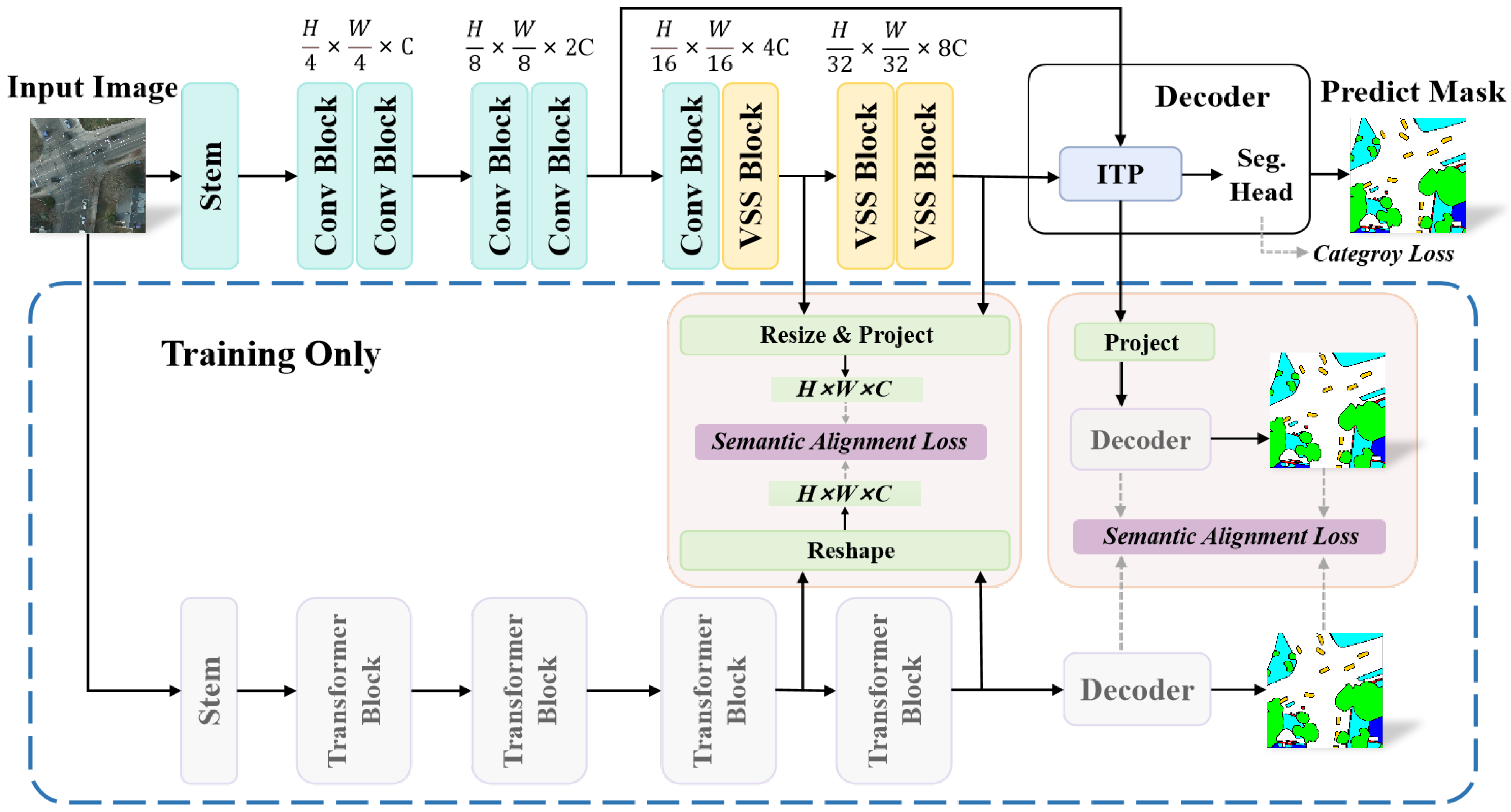
- In this paper, we propose a novel remote sensing Mamba architecture for real-time semantic segmentation tasks, named RTMamba. The backbone section leverages VSS blocks to exploit their potential in remote sensing semantic segmentation. During inference, only the backbone and decoder are retained, ensuring a lightweight design.
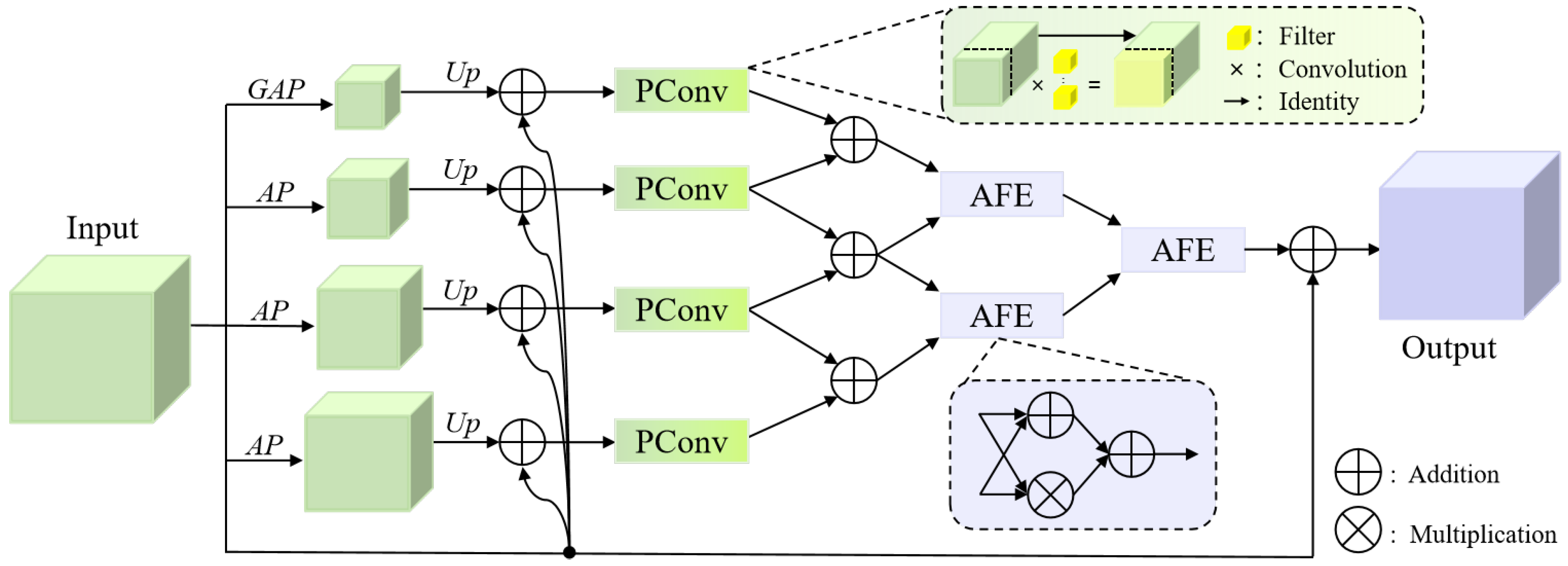
- To address the issue of redundant features from the backbone input to the decoder, we design a novel Inverted Triangle Pyramid Pooling (ITP) module. The ITP module effectively utilizes multiscale features, filtering redundant information and enhancing the perception capability of objects and their boundaries in remote sensing images.
- Extensive experiments are conducted on three well-known remote sensing datasets: Vaihingen, Potsdam, and LoveDA. The results illustrate that RTMamba exhibits competitive performance advantages compared to existing state-of-the-art CNN and transformer methods. Additionally, testing on the Jetson AGX Orin edge device further underscores the potential application prospects of RTMamba in real-time remote sensing segmentation tasks for UAVs.
2. Related Works
2.1. Semantic Segmentation
2.2. Real-Time Semantic Segmentation of Remote Sensing Images
2.3. State-Space Models and Applications
3. Methods
3.1. Preliminary: State-Space Model
3.2. RTMamba Architecture
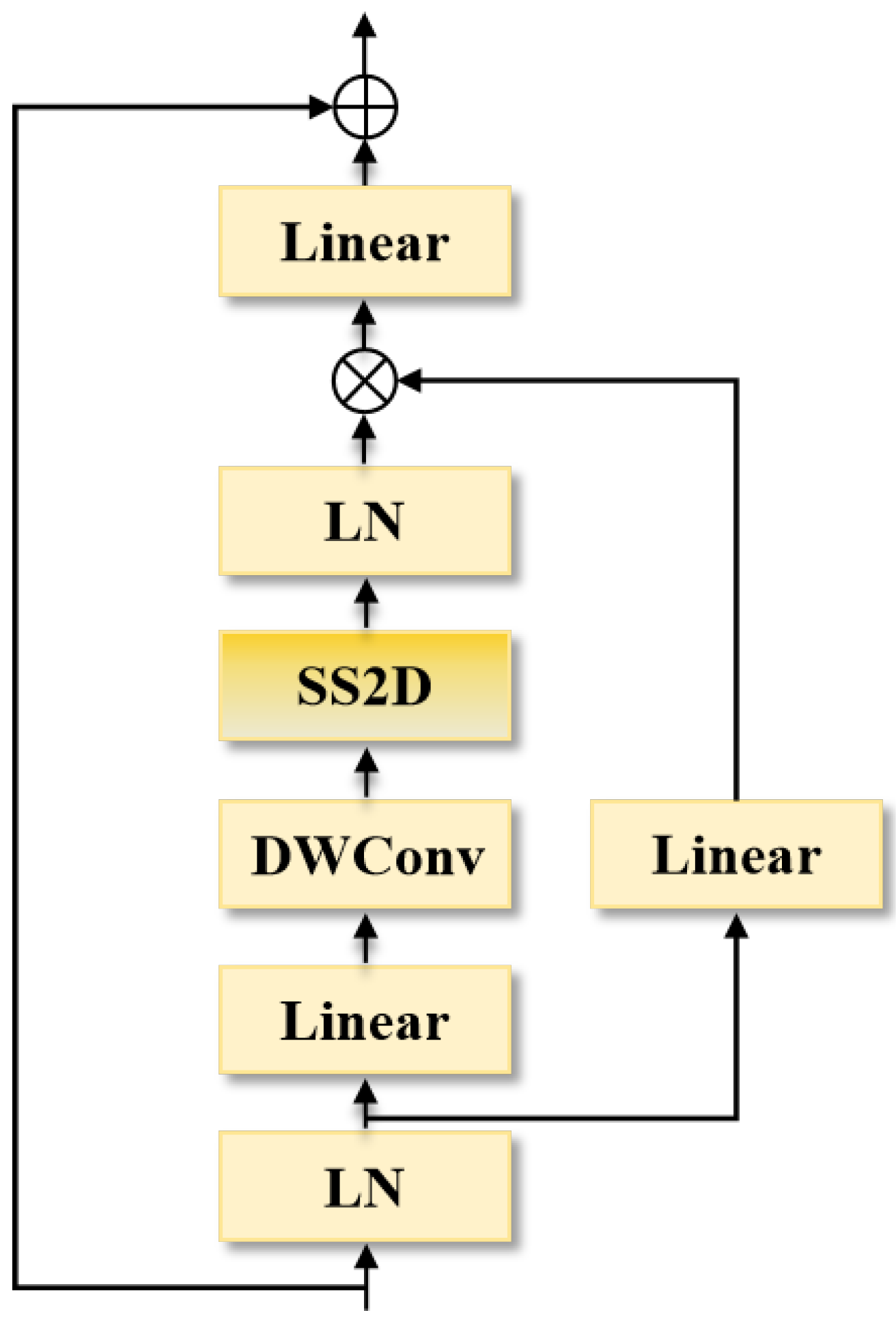
3.3. VSS Block
| Algorithm 1: S6 operation in SS2D: Pseudo-code |
|
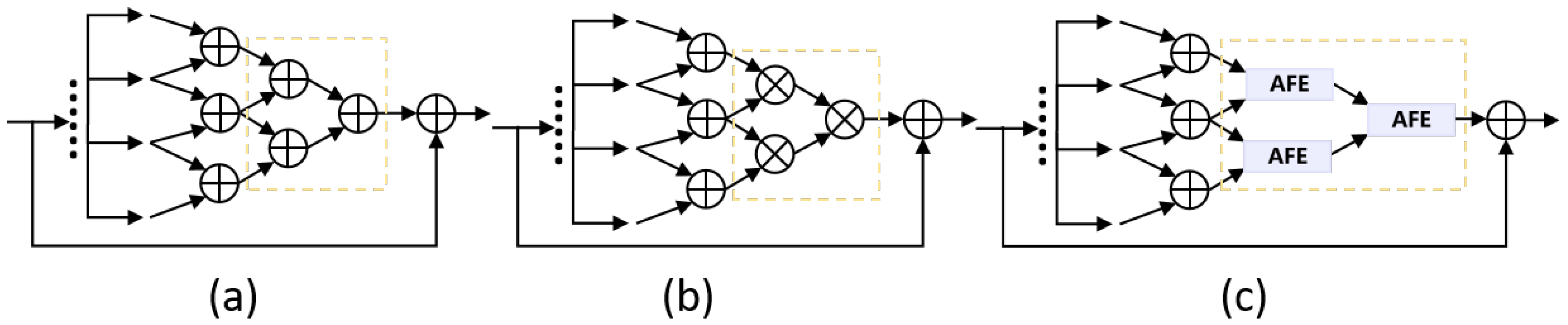
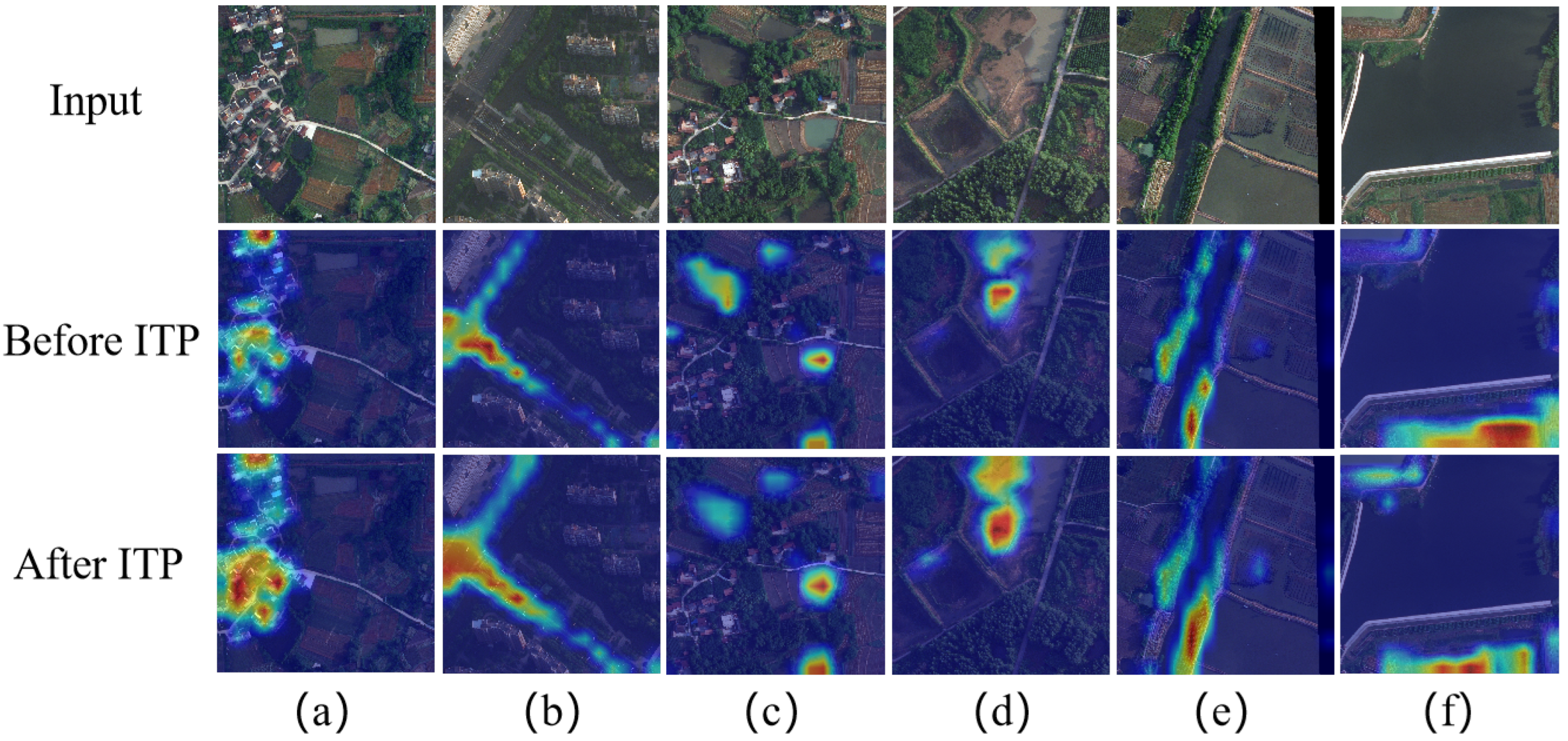
3.4. Inverted Triangle Pyramid Pooling (ITP) Module
3.5. Loss Function
3.6. Training and Inference Phases
| Algorithm 2: RTMamba training strategy |
 |
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Model Configuration
4.4. Evaluation Metrics
4.5. Ablation Study
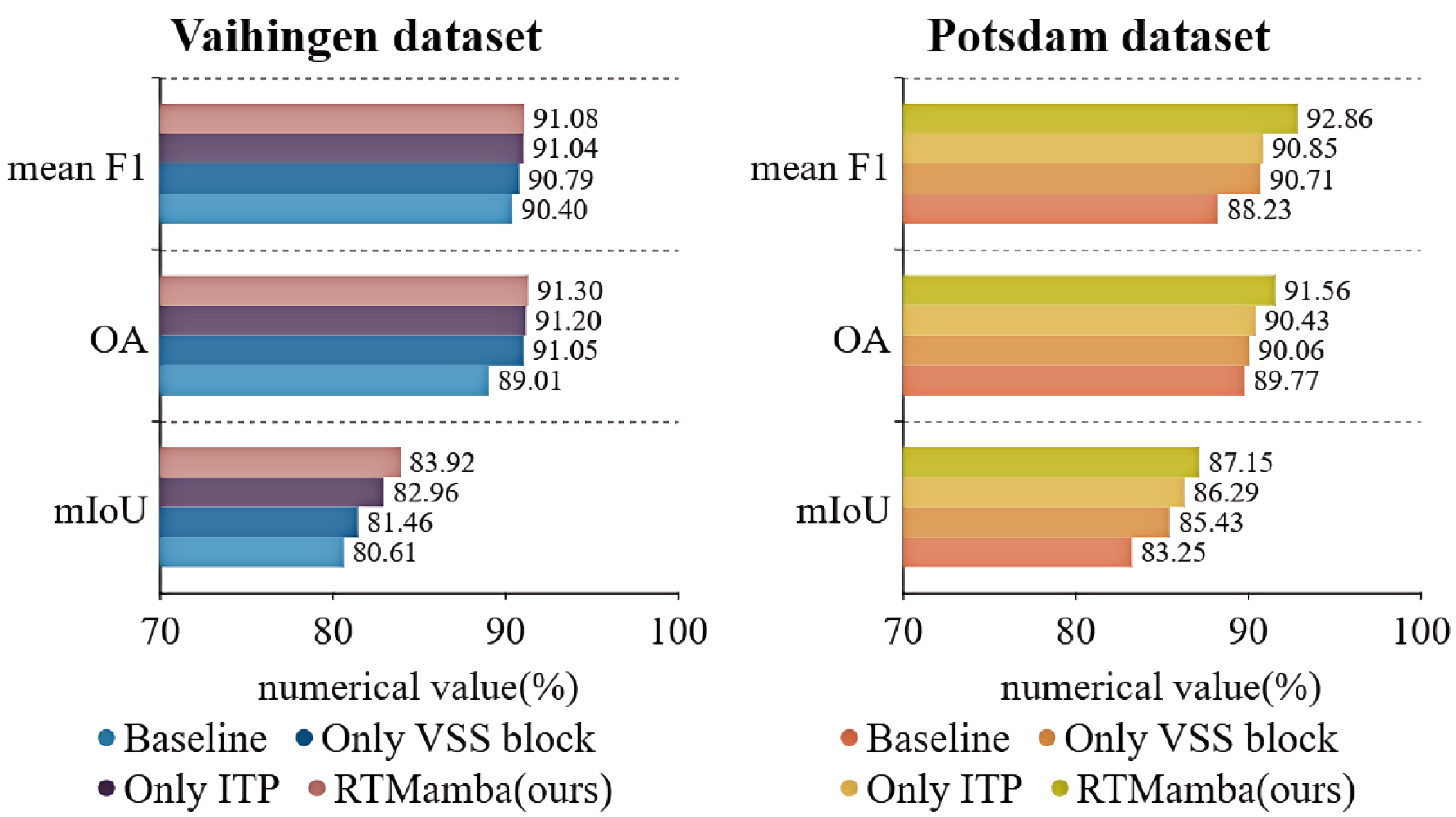
4.5.1. Ablation Experiments on Components
4.5.2. Design of ITP Module
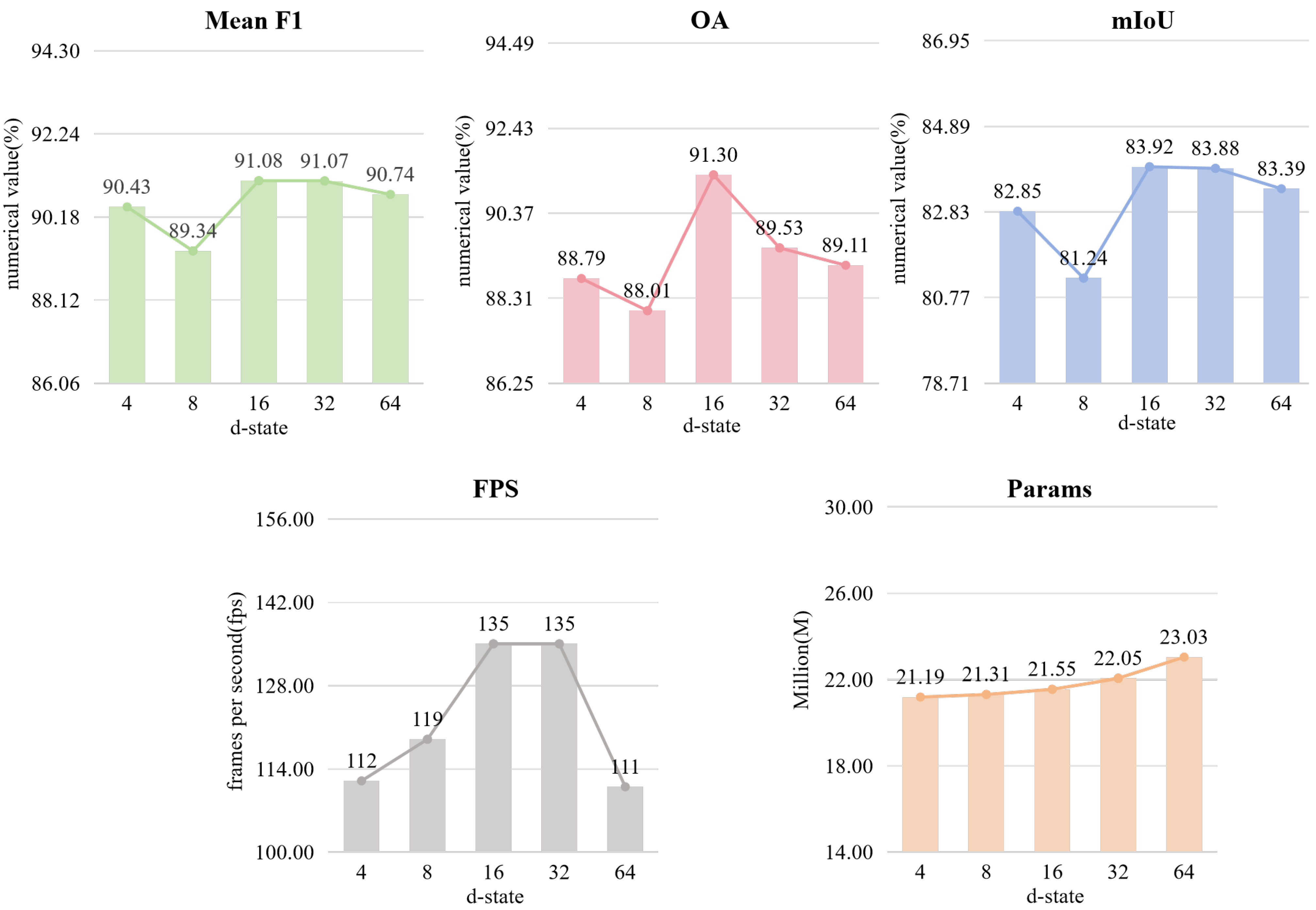
4.5.3. Setting the d-State in the VSS Block
4.6. Comparison with State-of-the-Art Methods
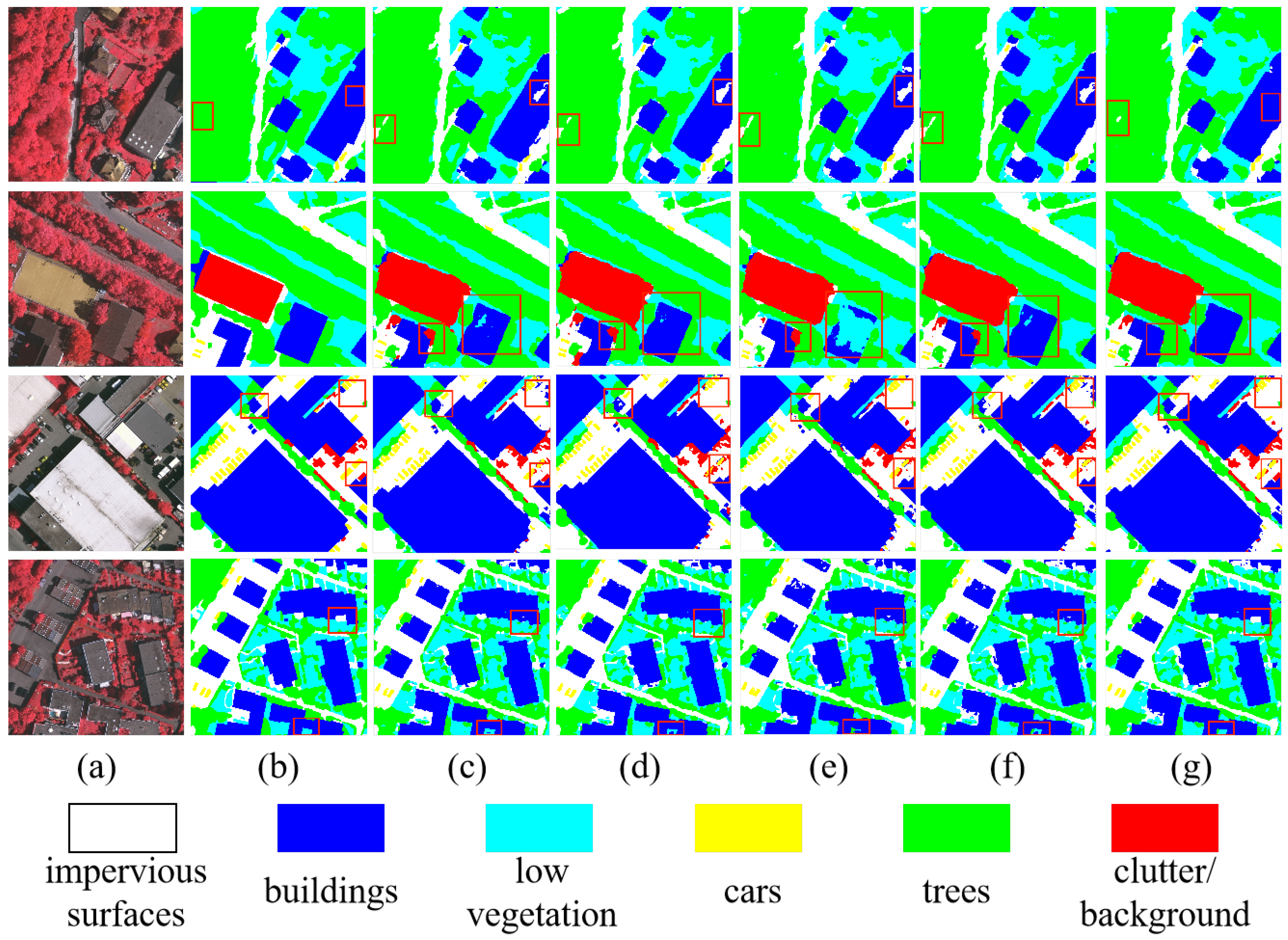
4.6.1. Results on Vaihingen
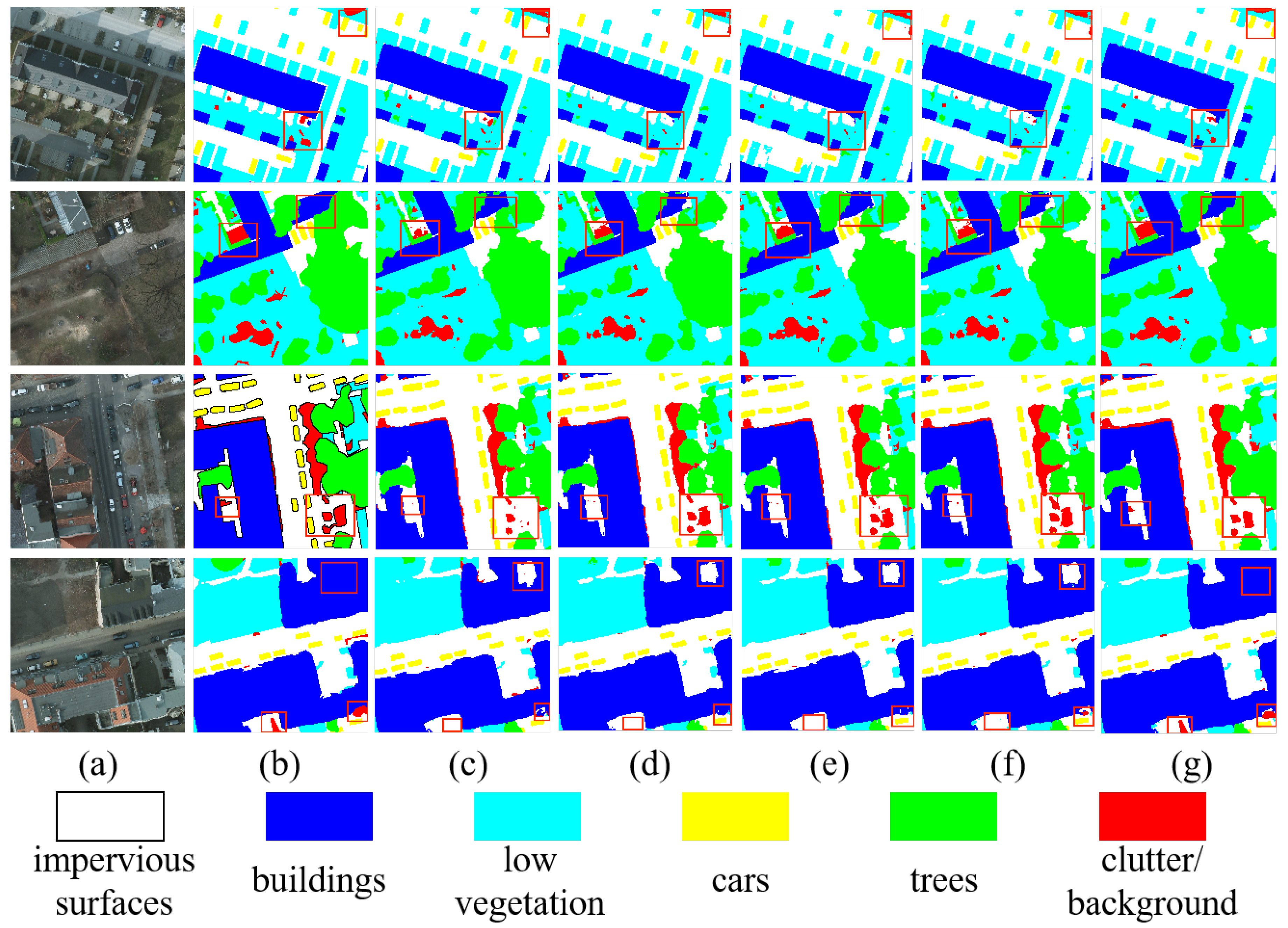
4.6.2. Results on Potsdam
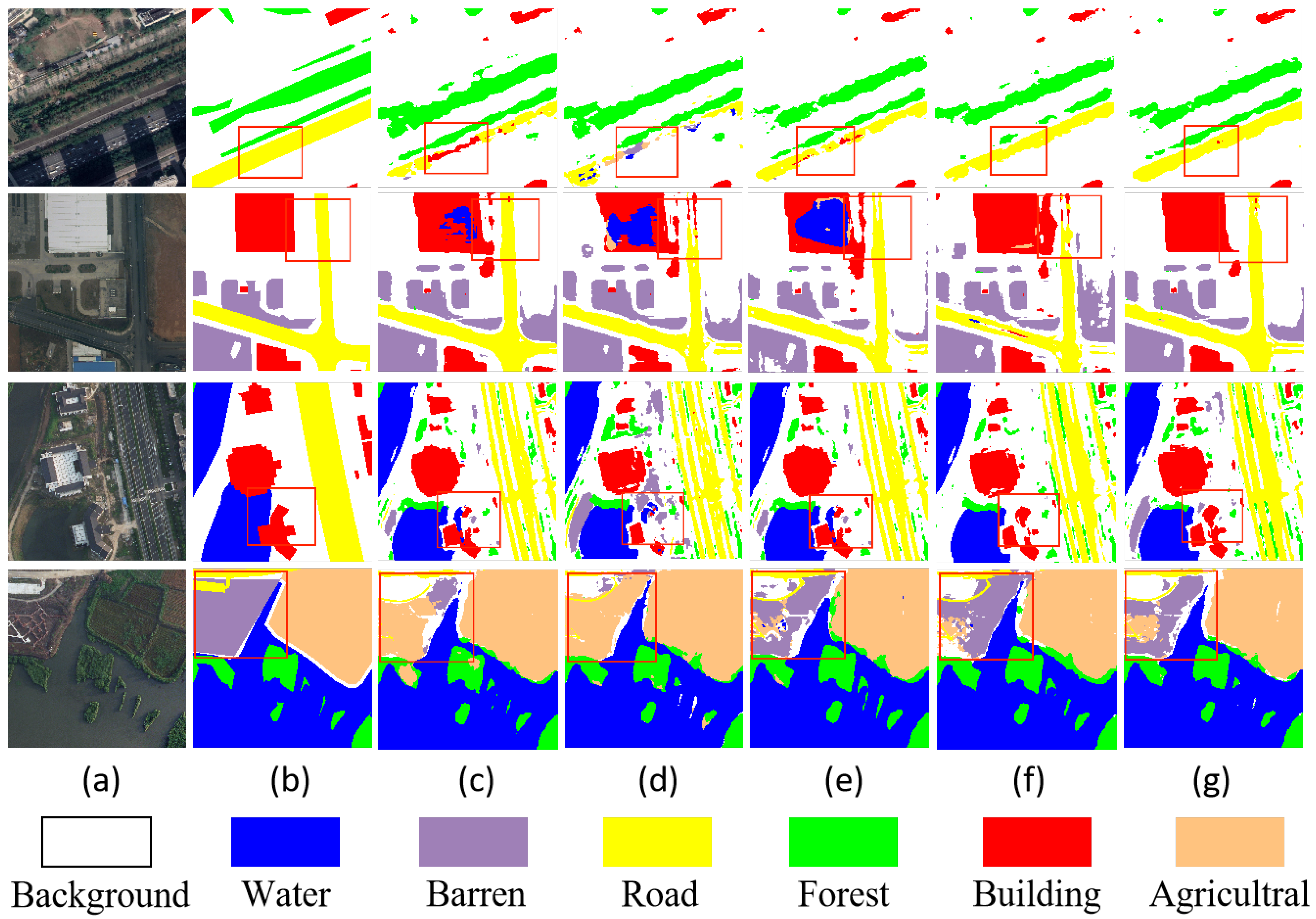
4.6.3. Results on LoveDA
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef]
- Phan, T.N.; Kuch, V.; Lehnert, L.W. Land cover classification using Google Earth Engine and random forest classifier—The role of image composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference (Part III 18), Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, C.; Wang, J.; Peg, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Zhou, W.; Fan, X.; Yan, W.; Shan, S.; Jiang, Q.; Hwang, J.N. Graph attention guidance network with knowledge distillation for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4506015. [Google Scholar] [CrossRef]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2022.3228042. [Google Scholar]
- Shi, W.; Meng, Q.; Zhang, L.; Zhao, M.; Su, C.; Jancsó, T. DSANet: A deep supervision-based simple attention network for efficient semantic segmentation in remote sensing imagery. Remote Sens. 2022, 14, 5399. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A real-time semantic segmentation network inspired by PID controllers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 19529–19539. [Google Scholar]
- Xu, Z.; Wu, D.; Yu, C.; Chu, X.; Sang, N.; Gao, C. SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation. Proc. Aaai Conf. Artif. Intell. 2024, 38, 6378–6386. [Google Scholar] [CrossRef]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. Rsmamba: Remote sensing image classification with state space model. arXiv 2024, arXiv:2403.19654. [Google Scholar] [CrossRef]
- Zhao, S.; Chen, H.; Zhang, X.; Xiao, P.; Bai, L.; Ouyang, W. Rs-mamba for large remote sensing image dense prediction. arXiv 2024, arXiv:2404.02668. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.O. RS3Mamba: Visual State Space Model for Remote Sensing Images Semantic Segmentation. arXiv 2024, arXiv:2404.02457. [Google Scholar] [CrossRef]
- Barnell, M.; Raymond, C.; Smiley, S.; Isereau, D.; Brown, D. Ultra low-power deep learning applications at the edge with Jetson Orin AGX hardware. In Proceedings of the 2022 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 19–23 September 2022; pp. 1–4. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- He, W.; Han, K.; Tang, Y.; Wang, C.; Yang, Y.; Guo, T.; Wang, Y. Densemamba: State space models with dense hidden connection for efficient large language models. arXiv 2024, arXiv:2403.00818. [Google Scholar]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Liu, Y. Vmamba: Visual state space model. arXiv 2024, arXiv:2401.10166. [Google Scholar]
- Zhang, Z.; Liu, A.; Reid, I.; Hartley, R.; Zhuang, B.; Tang, H. Motion mamba: Efficient and long sequence motion generation with hierarchical and bidirectional selective ssm. arXiv 2024, arXiv:2403.07487. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 5311–5320. [Google Scholar]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- 2D Semantic Labeling Contest—Vaihingen. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-semlabel-vaihingen.aspx (accessed on 8 February 2022).
- 2D Semantic Labeling Contest—Potsdam. Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/2d-semlabel-potsdam.aspx (accessed on 8 February 2022).
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Zhang, R.; Zhang, Q.; Zhang, G. LSRFormer: Efficient Transformer Supply Convolutional Neural Networks with Global Information for Aerial Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5610713. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 8 February 2022).
- Xue, H.; Liu, C.; Wan, F.; Jiao, J.; Ji, X.; Ye, Q. Danet: Divergent activation for weakly supervised object localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6589–6598. [Google Scholar]
- Jeong, E.; Kim, J.; Tan, S.; Lee, J.; Ha, S. Deep learning inference parallelization on heterogeneous processors with tensorrt. IEEE Embed. Syst. Lett. 2021, 14, 15–18. [Google Scholar] [CrossRef]
- Jajal, P.; Jiang, W.; Tewari, A.; Woo, J.; Thiruvathukal, G.K.; Davis, J.C. Analysis of failures and risks in deep learning model converters: A case study in the onnx ecosystem. arXiv 2023, arXiv:2303.17708. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vaihingen | Potsdam | ||||||
|---|---|---|---|---|---|---|---|
| VSS Block | ITP | Mean F1 (%) | OA (%) | IoU (%) | Mean F1 (%) | OA (%) | mIoU (%) |
| - | - | 90.40 | 89.01 | 80.61 | 88.23 | 89.77 | 83.25 |
| ✓ | - | 90.79 | 91.05 | 81.46 | 90.71 | 90.06 | 85.43 |
| - | ✓ | 91.04 | 91.20 | 82.96 | 90.85 | 90.43 | 86.29 |
| ✓ | ✓ | 91.08 | 91.30 | 83.92 | 92.86 | 91.56 | 87.15 |
| Method | Mean F1 (%) ↑ | OA (%) ↑ | mIoU (%) ↑ | FPS ↑ | Params (M) ↓ |
|---|---|---|---|---|---|
| DAPPM [12] | 91.04 | 91.20 | 82.96 | 139 | 21.62 |
| ITP(MFF) | 89.39 | 90.98 | 81.37 | 140 | 21.55 |
| ITP(AFF) | 90.43 | 88.90 | 82.85 | 138 | 21.55 |
| ITP(AFE) | 91.08 | 91.30 | 83.92 | 135 | 21.55 |
| d-State | Mean F1 (%) ↑ | OA (%) ↑ | mIoU (%) ↑ | FPS ↑ | Params (M) ↓ |
|---|---|---|---|---|---|
| 4 | 90.43 | 88.79 | 82.85 | 112 | 21.19 |
| 8 | 89.34 | 88.01 | 81.24 | 119 | 21.31 |
| 16 | 91.08 | 91.30 | 83.92 | 135 | 21.55 |
| 32 | 91.07 | 89.53 | 83.88 | 135 | 22.05 |
| 64 | 90.74 | 89.11 | 83.39 | 111 | 23.03 |
| Method | Imp.surf | Building | Low.Veg | Tree | Car | Mean F1 (%) ↑ | OA (%) ↑ | mIoU (%) ↑ |
|---|---|---|---|---|---|---|---|---|
| BiSeNet [9] | 91.31 | 94.74 | 82.27 | 88.69 | 78.30 | 87.07 | 89.47 | 77.59 |
| BiSeNetv2 [10] | 91.59 | 94.16 | 82.16 | 89.01 | 78.98 | 87.18 | 89.42 | 77.72 |
| DANet [39] | 91.85 | 94.93 | 83.81 | 89.60 | 80.27 | 88.09 | 90.15 | 79.12 |
| SCTNet-s [17] | 91.31 | 94.02 | 80.45 | 88.56 | 78.14 | 88.25 | 86.50 | 79.46 |
| SCTNet-b [17] | 90.16 | 94.48 | 82.21 | 89.27 | 85.14 | 90.40 | 89.01 | 80.61 |
| TransUNet [14] | 92.80 | 95.40 | 84.40 | 89.90 | 85.30 | 89.50 | 90.70 | 81.30 |
| DeeplabV3+ [7] | 92.38 | 95.17 | 84.29 | 89.52 | 86.47 | 89.57 | 90.56 | 81.57 |
| PSPNet [8] | 92.79 | 95.46 | 84.51 | 89.94 | 88.61 | 90.26 | 90.85 | 82.58 |
| UNetFormer [15] | 92.70 | 95.30 | 84.90 | 90.60 | 88.50 | - | - | 82.70 |
| MANet [24] | 93.02 | 95.47 | 84.64 | 89.98 | 88.95 | 90.41 | 90.96 | 82.71 |
| RS3Mamba * [21] | 86.62 | 93.83 | 67.84 | 83.66 | 81.97 | 90.34 | - | 82.78 |
| PIDNet [16] | 92.30 | 95.50 | 85.40 | 89.90 | 89.40 | - | - | 83.00 |
| RTMamba-s | 92.48 | 94.46 | 85.62 | 90.32 | 85.64 | 89.11 | 90.39 | 81.01 |
| RTMamba-b | 93.75 | 95.30 | 85.97 | 90.93 | 88.70 | 91.08 | 91.30 | 83.92 |
| Method | Imp.surf | Building | Low.Veg | Tree | Car | Mean F1 (%) ↑ | OA (%) ↑ | mIoU (%) ↑ |
|---|---|---|---|---|---|---|---|---|
| SegNet [23] | 89.83 | 93.27 | 84.62 | 84.37 | 92.51 | 88.92 | 87.21 | 80.26 |
| SCTNet-s [17] | 88.41 | 94.31 | 81.47 | 78.25 | 90.06 | 89.54 | 88.52 | 81.87 |
| BiSeNet [9] | 91.07 | 95.12 | 85.81 | 86.63 | 91.37 | 90.00 | 89.06 | 81.99 |
| BiSeNetv2 [10] | 90.92 | 94.92 | 85.99 | 86.17 | 91.93 | 89.99 | 89.98 | 81.97 |
| SCTNet-b [17] | 88.95 | 94.68 | 80.71 | 80.01 | 92.33 | 88.23 | 89.77 | 83.25 |
| DeepLabV3+ [7] | 92.95 | 95.88 | 87.62 | 88.15 | 96.02 | 92.12 | 90.88 | 84.32 |
| DANet [39] | 92.31 | 96.21 | 86.82 | 88.14 | 94.85 | 91.67 | 90.23 | 84.83 |
| PSPNet [8] | 93.36 | 96.97 | 87.75 | 88.50 | 95.42 | 92.40 | 91.08 | 84.88 |
| TransUNet [14] | 92.60 | 96.00 | 86.80 | 87.90 | 95.30 | 91.70 | 90.10 | 84.90 |
| UNetFormer [15] | 93.60 | 97.20 | 87.70 | 88.90 | 96.50 | - | - | 86.80 |
| PIDNet [16] | 92.60 | 96.90 | 89.00 | 89.20 | 96.30 | - | - | 86.90 |
| MANet [24] | 93.40 | 96.96 | 88.32 | 89.36 | 96.48 | 92.90 | 91.32 | 86.95 |
| RTMamba-s | 92.11 | 96.26 | 86.92 | 88.94 | 95.67 | 91.35 | 90.45 | 84.58 |
| RTMamba-b | 93.91 | 96.52 | 88.98 | 89.98 | 96.64 | 92.86 | 91.56 | 87.15 |
| Method | Background | Building | Road | Water | Barren | Forest | Agriculture | mIoU (%) ↑ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|
| SCTNet-s [17] | 38.17 | 49.06 | 51.06 | 75.70 | 18.50 | 42.19 | 54.44 | 47.02 | - |
| BiSeNet [9] | 41.78 | 50.23 | 52.54 | 74.93 | 14.05 | 41.99 | 56.12 | 47.37 | 121.9 |
| DeeplabV3+ [7] | 42.97 | 50.88 | 52.02 | 74.36 | 10.40 | 44.21 | 58.53 | 47.62 | 53.7 |
| SCTNet-b [17] | 43.37 | 52.17 | 50.51 | 75.71 | 18.15 | 43.21 | 52.97 | 47.73 | - |
| PSPNet [8] | 44.40 | 52.13 | 53.52 | 76.50 | 9.73 | 44.07 | 57.85 | 48.31 | - |
| BiSeNetv2 [10] | 43.04 | 51.19 | 52.77 | 75.93 | 14.99 | 43.66 | 60.65 | 48.89 | 40.3 |
| TransUNet [14] | 43.00 | 56.10 | 53.70 | 78.00 | 9.30 | 44.90 | 56.90 | 48.90 | 13.4 |
| MANet [24] | 43.29 | 55.35 | 56.20 | 74.18 | 14.28 | 42.85 | 58.62 | 49.26 | - |
| PIDNet [16] | 44.15 | 54.72 | 56.54 | 76.81 | 17.49 | 47.13 | 57.54 | 50.63 | 52.2 |
| RS3Mamba * [21] | 39.72 | 58.75 | 57.92 | 61.00 | 37.24 | 39.67 | 33.98 | 50.93 | - |
| UNetFormer [15] | 44.70 | 58.80 | 54.90 | 79.60 | 20.10 | 46.00 | 62.40 | 52.40 | 115.3 |
| RTMamba-s | 42.40 | 51.06 | 50.45 | 76.09 | 18.25 | 43.81 | 58.51 | 48.65 | 139 |
| RTMamba-b | 44.72 | 56.43 | 52.49 | 79.90 | 20.96 | 44.46 | 55.06 | 50.57 | 95.63 |
| Method | Inference | Acceleration | Data Type | Latency ↓ | FPS ↑ |
|---|---|---|---|---|---|
| RTMamba-s | ONNX | fp32 | 16.736 | 59.751 | |
| RTMamba-s | TensorRT | fp16 | 16.334 | 61.222 | |
| RTMamba-s | ONNX | fp32 | 19.482 | 51.329 | |
| RTMamba-s | TensorRT | fp16 | 17.881 | 55.927 | |
| RTMamba-s | ONNX | fp32 | 22.846 | 43.771 | |
| RTMamba-s | TensorRT | fp16 | 20.825 | 48.018 | |
| RTMamba-b | ONNX | fp32 | 17.400 | 57.472 | |
| RTMamba-b | TensorRT | fp16 | 16.224 | 61.638 | |
| RTMamba-b | ONNX | fp32 | 19.055 | 52.479 | |
| RTMamba-b | TensorRT | fp16 | 18.753 | 53.324 | |
| RTMamba-b | ONNX | fp32 | 22.446 | 44.551 | |
| RTMamba-b | TensorRT | fp16 | 21.570 | 46.360 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, H.; Xia, B.; Liu, W.; Zhang, Z.; Zhang, J.; Wang, X.; Xu, S. A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation. Remote Sens. 2024, 16, 2620. https://doi.org/10.3390/rs16142620
Ding H, Xia B, Liu W, Zhang Z, Zhang J, Wang X, Xu S. A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation. Remote Sensing. 2024; 16(14):2620. https://doi.org/10.3390/rs16142620
Chicago/Turabian StyleDing, Hao, Bo Xia, Weilin Liu, Zekai Zhang, Jinglin Zhang, Xing Wang, and Sen Xu. 2024. "A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation" Remote Sensing 16, no. 14: 2620. https://doi.org/10.3390/rs16142620
APA StyleDing, H., Xia, B., Liu, W., Zhang, Z., Zhang, J., Wang, X., & Xu, S. (2024). A Novel Mamba Architecture with a Semantic Transformer for Efficient Real-Time Remote Sensing Semantic Segmentation. Remote Sensing, 16(14), 2620. https://doi.org/10.3390/rs16142620