This section first analyzes the data structure of noisy HSIs, forming the basis for designing an MTL-based anomaly detection method. This approach allows the sharing of noise components from the denoising task with the anomaly detection task, providing richer and more comprehensive training data for both subtasks. Next, the JointNet model used in the proposed method is introduced, which fully exploits the deep information in the original image by integrating the denoising algorithm MNF with an AE. Following that, the concept of a noise score is introduced to evaluate the degree of abnormality for the pixel under test by using the shared noise information as a weighting factor, instead of relying on manually setting the thresholds, to improve the detection accuracy. Finally, appropriate local loss functions are designed for each subtask, which are combined into a total loss function to train the entire JointNet model, ensuring shared information flows throughout the network, thereby improving information utilization and completeness.
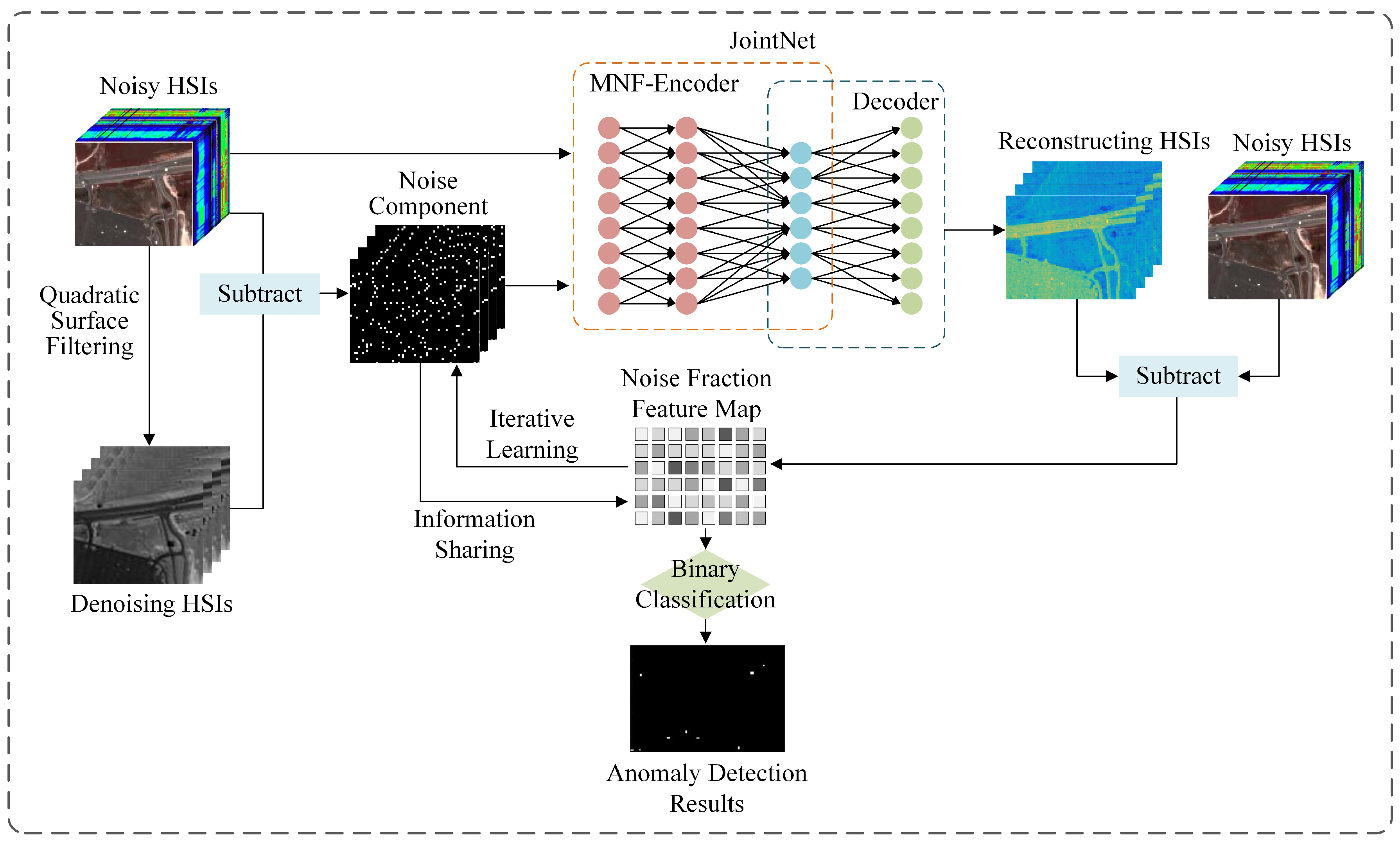
Figure 2 shows the workflow of the methodology in this study.
3.1. Multitask-Learning-Based Noise Information Sharing
Our proposed method focuses on discrete noise. Each pixel in the HSI uniquely belongs to either the background or anomaly target category, while some pixels may simultaneously be considered noise, since noisy HSIs can contain overlapping noise and anomaly target pixels. This study modeled hyperspectral pixels using Equations (
1) and (
2). According to this model, the key to denoising a noisy HSI is to separate the pure anomaly target
A from the HSI
Y.
Efforts to improve the accuracy of noisy HSI anomaly detection have yielded significant results; yet, the impact of the noise introduced during data acquisition and transmission has not been adequately addressed. The typical processing flow for noisy HSI anomaly detection involves single-task learning, where denoising is followed by anomaly detection as two separate tasks. This approach has limitations in scenarios where anomaly targets are small, sparsely distributed, and similar to noise pixels, leading to misidentification during denoising and resulting in the loss of valuable data for anomaly detection. Since denoising and anomaly detection both use the same data source to learn hyperspectral features, there is a natural correlation between these tasks, suggesting that sharing feature information could lead to better results [
37,
38].
The proposed MTL-based method combines denoising and anomaly detection, allowing the shared noise information to improve the model’s learning capacity and detection accuracy. In the first subtask, the JointNet model is used to encode and decode the noisy HSIs, allowing the model to learn the inherent features of the noise, anomaly targets, and the background, while simultaneously denoising the image. By computing the difference between the original and reconstructed image, reconstruction errors can be derived. Due to the relatively low frequency of noise and anomaly targets, they tend to be suppressed during model training, leading to incomplete representation in the reconstructed image, resulting in a high reconstruction error, referred to as the “noise–anomaly target mixing component”. The second subtask involves designing a binary classification algorithm to extract pure anomaly target pixels from this mixing component and integrate them into the final anomaly detection results.
Figure 2 shows the workflow of the MTL-based anomaly detection method for noisy HSIs. First, quadratic surface filtering is used to obtain a denoised HSI. The differential computation between the original noisy HSI and the denoised image provides the noise component, which serves as input to the JointNet model and as the weighting matrix for the noise score calculation. The original noisy HSI and noise component are then fed into the JointNet model, where the encoder comprising the noise-whitening and feature mapping modules produces the hidden layer coding. The decoder reconstructs the HSI from this coding. The difference between the reconstructed and the original noisy HSI yields the noise–anomaly target mixing component, using the noise scores’ calculation formula and a binary classification to obtain the final anomaly detection result.
3.2. JointNet Model
For noisy HSIs, some anomaly target pixels can morphologically resemble noise pixels [
39,
40], making them likely to be misinterpreted as noise and removed, leading to the failed detection of anomaly targets [
41]. Since discrete noise has highly similar morphological and distributional characteristics to the anomaly targets, the spectral characteristics of the pixel are destroyed, and the attributes of the pixel to be tested cannot be determined, resulting in the loss of a judgment basis for the detection of anomalies. If we map the image to a new feature space to analyze the real spectral information of the noisy HSI and reconstruct the original hyperspectral signal that is not contaminated by noise, we realize the separation of noise and anomalous targets. Therefore, a method was developed to map the latent information in the original HSI, which contains both background and anomaly targets, to a new feature space using an autoencoder. This approach aims to filter out noise while retaining complete anomaly targets, avoiding missed detections. The AE comprises two parts: The encoder extracts hidden layer codes preserve the intrinsic features of the HSI, which plays a specific role in denoising, allowing the pure background to be used to construct a background dictionary. The decoder reconstructs the HSI based on the background dictionary and calculates the loss function during backpropagation to guide the encoder to select the most informative features. A noisy HSI has high data dimensionality, and using zero or random initialization of convolutional kernels in traditional deep neural networks may increase the computational cost. Given that one of the AE’s functions is denoising, applying the transformation matrix to the original HSI is equivalent to a linear transformation of the data. This paper proposes the JointNet model, which combines neural networks with the traditional denoising algorithm MNF based on principal component analysis (PCA) to obtain a set of convolutional kernel initial values for targeted learning, achieving the compression, denoising, and anomaly detection of noisy HSIs while minimizing the model training computational costs. The network architecture is composed of an encoder and a decoder.
- (1)
Encoder: The encoder contains 12 convolution layers, and each layer consists of 3 × 3 convolutional operators, followed by batch normalization and a LeakyReLU activation function, and the outputs of the odd-numbered layers are simultaneously concatenated with the feature maps of the next odd-numbered layer through skip connections (except for layer #11). The first six layers implement the noise whitening, and the last six layers implement the feature mapping.
- (2)
Decoder: The decoder contains 10 convolution layers consisting of 3 × 3 convolutional operators, which perform upsampling using nearest-neighbor interpolation.
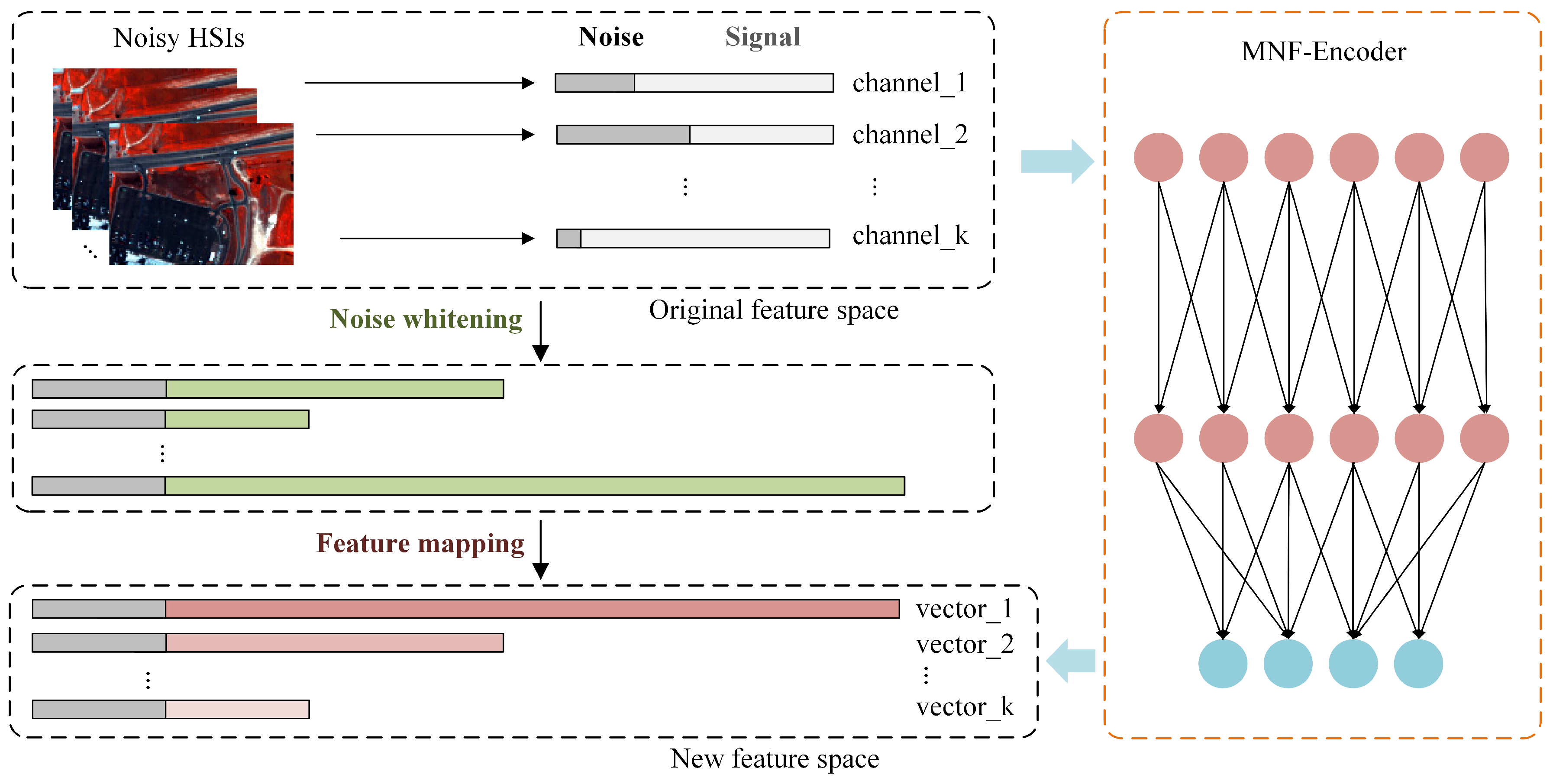
Figure 3 shows a schematic diagram of the MNF computation flow of the encoder. Through two steps, noise whitening and feature mapping, a total of three states exist in this computational flow for the noisy HSI. The first state occurs in the original feature space, where each rectangular bar represents the spectral vector of a pixel, consisting of a noise component and a signal component. In the second state, each rectangular bar represents a stretching of the spectral vector, where the corresponding signal-to-noise ratio of each vector is unchanged, but the noise component is a fixed value. The third state occurs in the new feature space, determining the direction of the basis vectors of the space, based on the magnitude of the signal component in the vectors, and the MNF rotation is accomplished. The JointNet model consists of two main modules: a noise-whitening module and a feature mapping module.
The key problem the MNF addresses is that calculating the signal-to-noise ratio for each spectral channel is challenging. The noise-whitening phase aims to convert the noise components in the HSI to a standard Gaussian distribution with a mean of 0 and a variance of 1, ensuring a fixed variance across all spectral channels. Assuming the HSI is a three-dimensional cube Y with dimensions , a quadratic surface filter is used to generate the noise components N of the same size during the initial stage. A sliding window of size samples the noise components, reshaping them into column vectors with a mean normalization, denoted as . The first eigenvectors of the matrix are selected and reshaped into a convolution kernel of size . This kernel is then used to convolve the HSI, producing the noise-whitened HSI.
The feature mapping phase is similar to the noise-whitening stage, with the difference being that the sampled data come from the noise-whitened HSI, where the noise component’s variance is fixed. Principal component analysis is applied to the covariance matrix of the noise-whitened HSI. The top eigenvectors are selected based on descending eigenvalues, forming a convolution kernel of size . This kernel is used to convolve the noise-whitened HSI, mapping it to a new feature space, thereby achieving both denoising and spectral dimensionality reduction. Since the JointNet model calculates the signal-to-noise ratio of each spectral channel, the sliding window during sampling should cover as many spectral channels as possible, with convolution calculated across the corresponding receptive field.
Since the MNF’s core idea is principal component analysis, an important step is computing the transformation matrix, which defines the relationship between the original high-dimensional space and the new low-dimensional space. Applying the transformation matrix to the HSI is equivalent to taking the inner product of the matrix vectors with data vectors, a process similar to convolution. Since initializing convolution kernels for images can align with image features, it can accelerate network convergence. Thus, the MNF is used to derive initial convolution kernel parameters, replacing traditional zero or random initialization.
In summary, the primary process of denoising and reconstructing noisy HSIs using the JointNet model is as follows:
- (1)
Noisy HSI Data Sampling
An HSI can be considered a three-dimensional (3D) cube with two spatial dimensions and one spectral dimension. In a 3D coordinate system, the x and y axes represent the spatial dimensions, and the b axis represents the spectral dimension. Since the convolution kernels need to cover the entire spectral range during dimensionality reduction, they must learn weights for different band regions. Selecting different spatial locations within the data cube is equivalent to sampling along the spectral dimension. Consider a cube of size for data sampling, targeting a fixed spectral range from to with a length of . Sampling can be along the x axis or the y axis. This sampling process is repeated for various spectral ranges, and all the sampled data from the two moving directions are merged.
- (2)
Convolutional Kernel Initialization
For each group of sampled data from different spectral ranges, principal component analysis is utilized to compute the first eigenvectors of the covariance matrix and reshape them into convolutional kernels, forming the first set of kernels. Using these kernels, convolution is performed on the original noisy HSI to produce the noise-whitened image. The kernel initialization step is repeated, replacing the sampled data with the noise-whitened HSI, and the first eigenvectors are selected to create the second set of convolution kernels. The method of initialization allows the convolutional kernel parameters to be targeted based on different spectral ranges, unlike zero or random initialization, providing a more suitable approach for HSIs compared to typical RGB images.
- (3)
Convolution Calculation
Using the two sets of initialized convolution kernels, we apply them to different HSI data sources. The first set of kernels serves as a noise-whitening transformation matrix, altering the distribution of the noise component to conform to a standard Gaussian distribution with mean value of 0 and a variance of 1. Thus, these kernels should be applied to the original noisy HSI. The convolution result yields a noise-whitened HSI where the noise components between spectral channels have a consistent variance of 1. The second set of kernels acts as a feature-mapping transformation matrix, mapping the noise-whitened HSI to a low-dimensional feature space to explore new feature representations. This low-dimensional feature space is designed such that the noise components contribute minimally when mapped to the first basis vector and increase in significance with additional basis vectors. Given that each spectral channel’s noise component has a variance of 1, the noise level depends solely on the signal, i.e., the value of the noise-whitened image. Thus, the second set of convolution kernels should be applied to the noise-whitened HSI obtained from the first step of convolution calculation. At this stage, setting a stride greater than 1 allows for dimensionality resulting in a lower-dimensional HSI.
3.3. Noise Scores
In the current AE-based methods for HSI anomaly detection, the manual or automatic learning of thresholds is required to classify pixels as anomaly target or background pixels based on the reconstruction error. If the reconstruction error of the pixel to be tested is greater than the threshold, it is labeled as an anomaly target pixel. Otherwise, it is labeled as a background pixel. However, in noisy HSIs, anomaly target pixels may overlap with noise pixels, making it difficult to classify pixels accurately and reducing the detection precision and accuracy. Anomaly target pixels in noisy HSIs are usually clustered in small connected regions, whereas noise pixels are discretely and sparsely distributed. In addition, the noise component of noise pixels is always more significant than that of the anomaly target. Based on the above two data characteristics, for the MTL-based anomaly detection method, we proposesa noise score evaluation index using Equation (
3) to evaluate the degree to which the pixel belongs, reducing the possibility of the missed detection of anomaly targets.
Here, S denotes the noise score, the subscript c represents the center pixel of the sliding window, represents the reconstruction error at spatial location k, indicates the activation value of the noise component at the spatial location k, encompasses all pixels within the sliding window, and represents the eight pixels surrounding the center pixel in the sliding window.
According to this method of calculating the noise score, if the center pixel of the sliding window is a noise pixel, its reconstruction error and noise component activation value differ significantly from the mean values of the neighboring pixels, making it impossible to represent them jointly and linearly. Consequently, the corresponding noise score is higher. Conversely, if the center pixel is an anomaly target pixel, its reconstruction error has only a minor difference from the mean value of the neighboring pixels, making it easier to represent them jointly and linearly. As a result, the corresponding noise score is lower. Following this principle, the spectral difference between the pixel under test and its neighboring pixels is computed using a representation learning approach, which serves as the basis for evaluating the extent to which the pixel belongs to the anomaly target. The noise score is computed pixel by pixel and then binary-classified to obtain the initial set of anomaly target pixels. This set is then refined by merging neighboring pixels and removing discrete ones to yield the final abnormal target detection result.
3.4. Loss Function
Reasonable local loss functions were designed for Subtask I and Subtask II and combined to form the total loss function, enabling MTL to denoise HSIS and detect the anomalies in HSIs.
For Subtask I, the computational principle of the MNF algorithm is integrated with a deep neural network AE. This combination compresses the spectral channel information from the noisy HSI, which has a low signal-to-noise ratio and poor image quality, into a new low-dimensional feature space layer by layer. This process retains valuable signals representing both anomaly targets and the background portions of the original image. Firstly, the AE aims to analyze the properties of the pixels to be tested using the reconstruction error between the original and reconstructed images. Therefore, a regularization term Equation (
4) was designed to quantify the reconstruction error, serving as the first part of the local loss function for Subtask I.
Here, represents the differential computation loss function, X represents the noisy HSI, and is the reconstructed image output by the JointNet model. The difference between these images reflects the magnitude of the reconstruction error.
Next, considering the sparse and discrete distribution of noise in noisy HSIs, the
norm is utilized as the second part of the local loss function for Subtask I. The computation is shown in Equation (
5).
Here, represents the activation matrix of the noise component, N represents the noise component, m indicates the number of feature groups, and n represents the number of features within each group. The paradigm is also known as group sparse regularization, where computes the paradigm of all the features in the ith group, and denotes the paradigm regularization of the paradigm of all the groups, which combines the characteristics of the paradigm and the paradigm. For handling multistructured features, it achieves intergroup sparsity while maintaining intragroup feature density, aligning with the property of using noise components to restrict the distribution of anomaly targets.
In summary, the local loss function for Subtask I is given by Equation (
6).
For Subtask II, the reconstruction error is obtained by subtracting the reconstructed image output by the JointNet from the noisy HSI. Pixels with significant reconstruction errors form the noise–anomaly target mixing component. Filtering anomaly targets from this mixing component is treated as a binary classification problem. Hence, the cross-entropy loss function Equation (
7) is adopted as the optimization objective for Subtask II.
Here, represents the loss function of Subtask II, ∑ represents the summation function, represents the label of the pixel to be tested, which is numerically equivalent to the activation value of the noise component in Subtask I, and is the predicted probability that the pixel belongs to the noise, which is equivalent to the noise scores. This local loss function realizes the application of MTL ideas by sharing the noise component between the denoising and anomaly detection.
In summary, the total loss function of the proposed method consists of the local loss functions for Subtasks I and II, as shown in Equation (
8).
Here, L represents the total loss function, serving as the final optimization objective of noisy HSI anomaly detection based on MTL, and and are regularization parameters. This loss function enables the achievement of three objectives: (1) analyzing noise distribution characteristics and morphological features, denoising the noisy HSI, and utilizing the noise component as prior information for anomaly detection, enriching the information available for both subtasks; (2) generating a denoised HSI without noise and accurately representing the background portion; and (3) considering the influence of noise and intrinsic data characteristics to calculate the anomaly degree of the pixel, thereby avoiding misclassifying anomaly target pixels as noise pixels.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}