



Direction of Arrival Joint Prediction of Underwater Acoustic Communication Signals Using Faster R-CNN and Frequency–Azimuth Spectrum


Abstract
1. Introduction
- (1)
- Joint Prediction Capability: The proposed framework for UWAC signals simultaneously determines the number of sources, recognizes modulation types, estimates frequency bands, and computes DOAs. This integrated approach enhances the efficiency and accuracy of signal processing in complex acoustic environments.
- (2)
- Application of FRAZ Spectrum and Faster R-CNN: This approach has strong generalization ability and can predict an arbitrary number of sources. It also extends the detection frequency range of the hydrophone array without interference from grating lobes.
- (3)
- Empirical Evaluation: Numerical studies were conducted to evaluate the effectiveness of our method in both simulated and experimental scenarios. The model trained solely on the simulated data performed competitively when applied to actual experimental data.
2. Signal Model
2.1. UWAC Signal
2.2. UWAC Signal
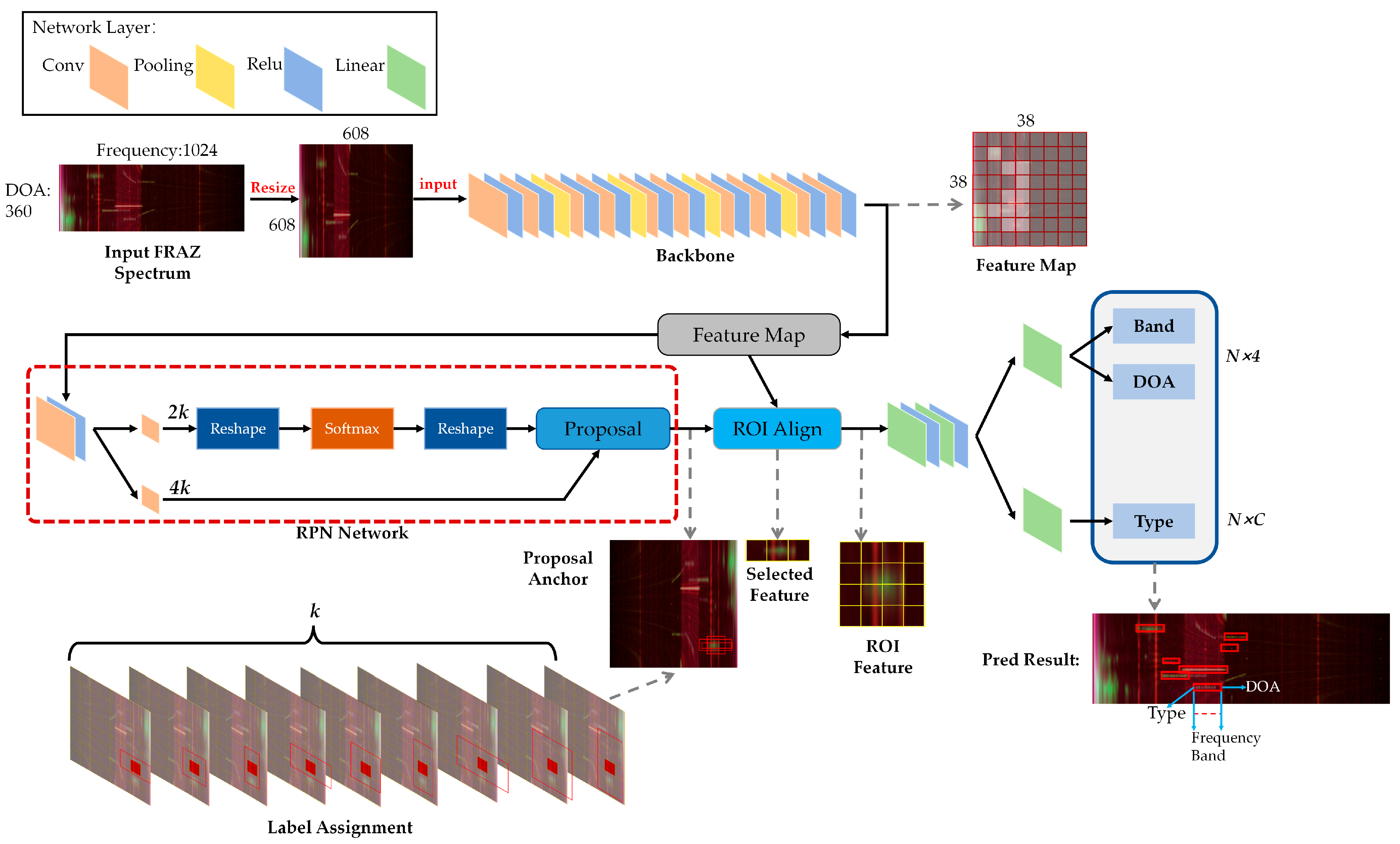
3. Faster R-CNN for Joint Prediction
3.1. Input FRAZ Spectrum and Feature Extraction
3.2. Signal RPNs
3.3. Signal RoI Alignment
3.4. Signal Joint Prediction Network
3.5. Loss Function of Joint Prediction
4. Simulation Studies
4.1. Data Generation, Baseline, Training Details, and Metrics
4.1.1. Data Generation
4.1.2. Baseline Methods
4.1.3. Training Details
4.1.4. Metrics
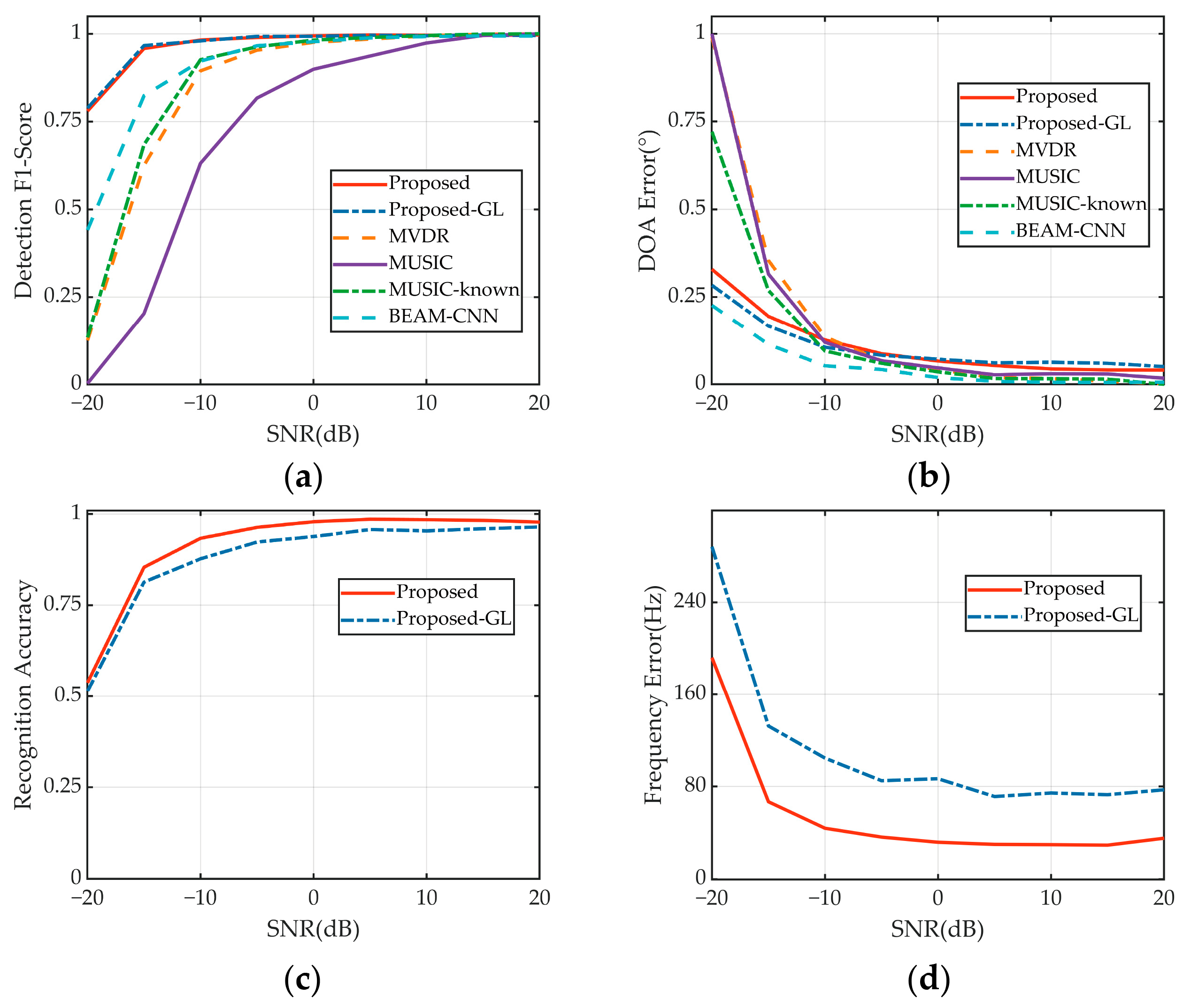
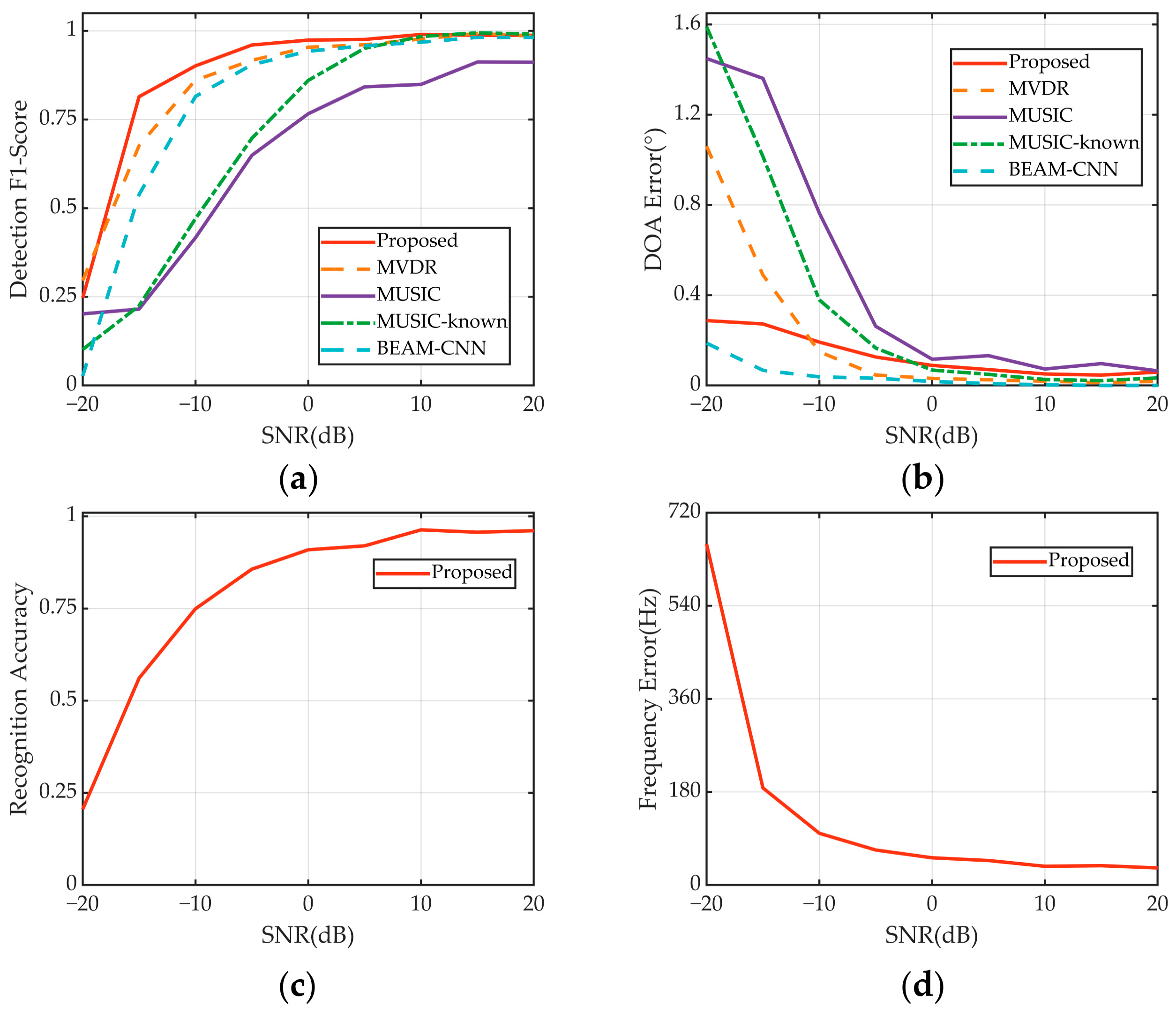
4.2. Performance at Different SNRs
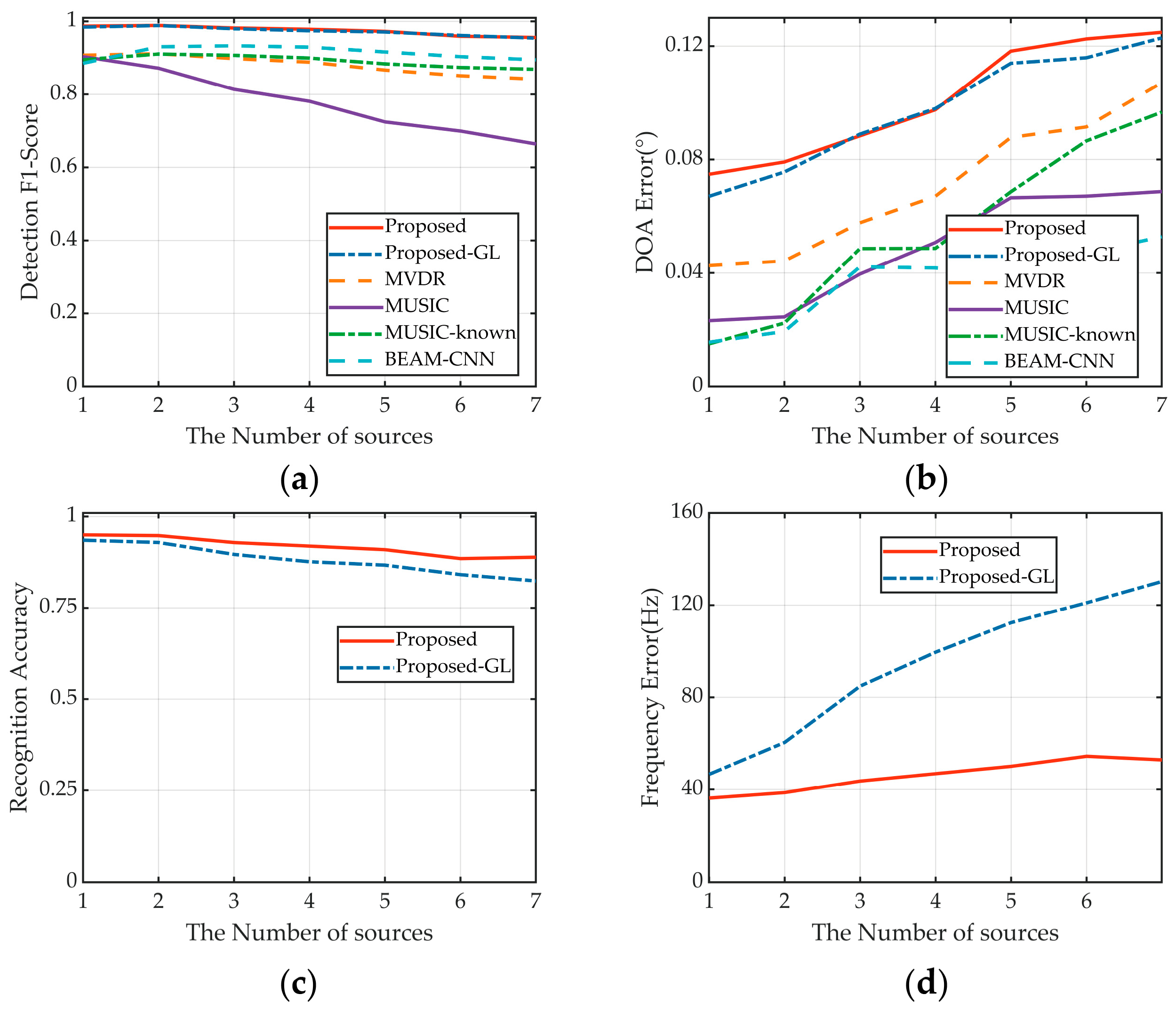
4.3. Performance Based on the Number of Sources
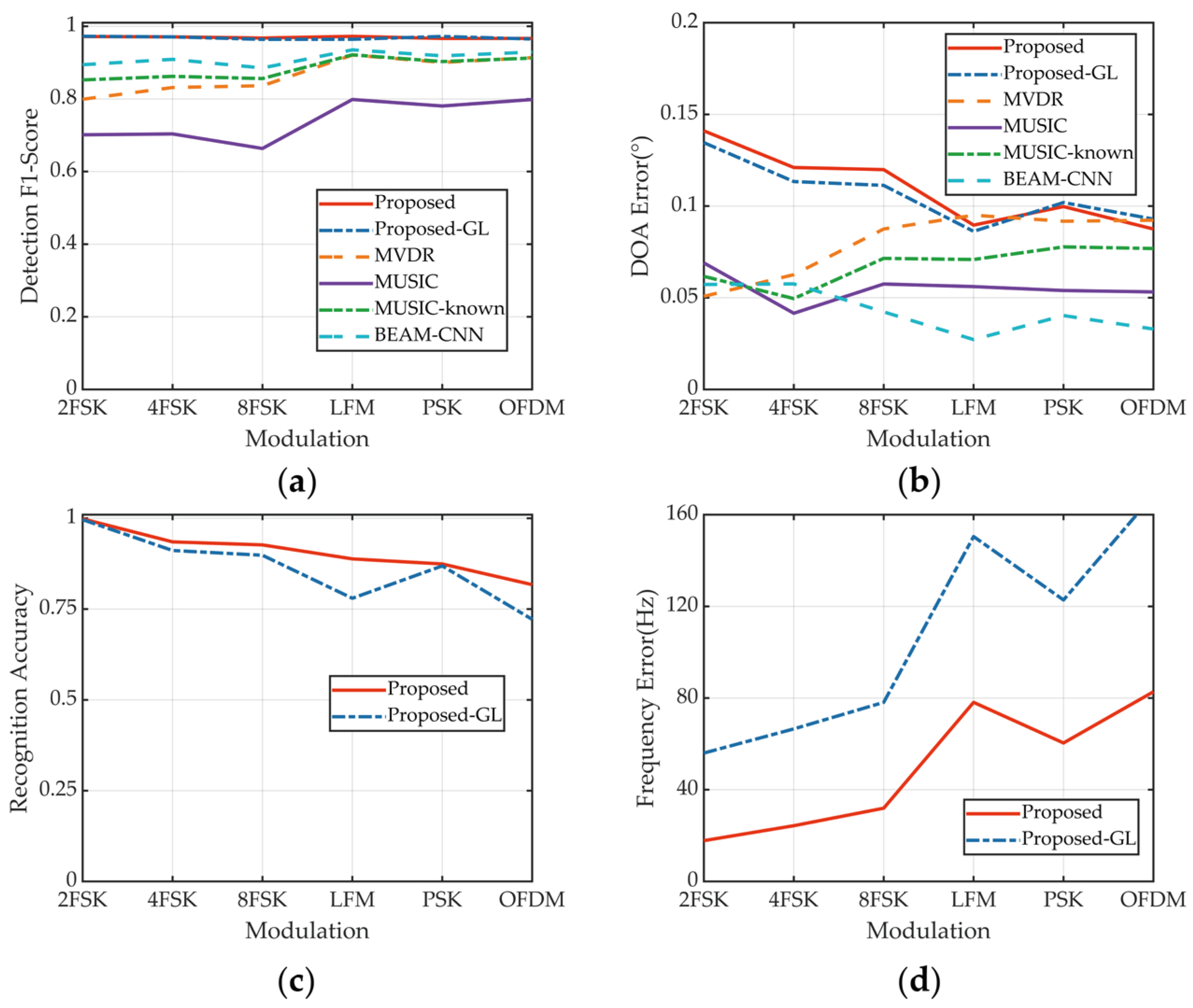
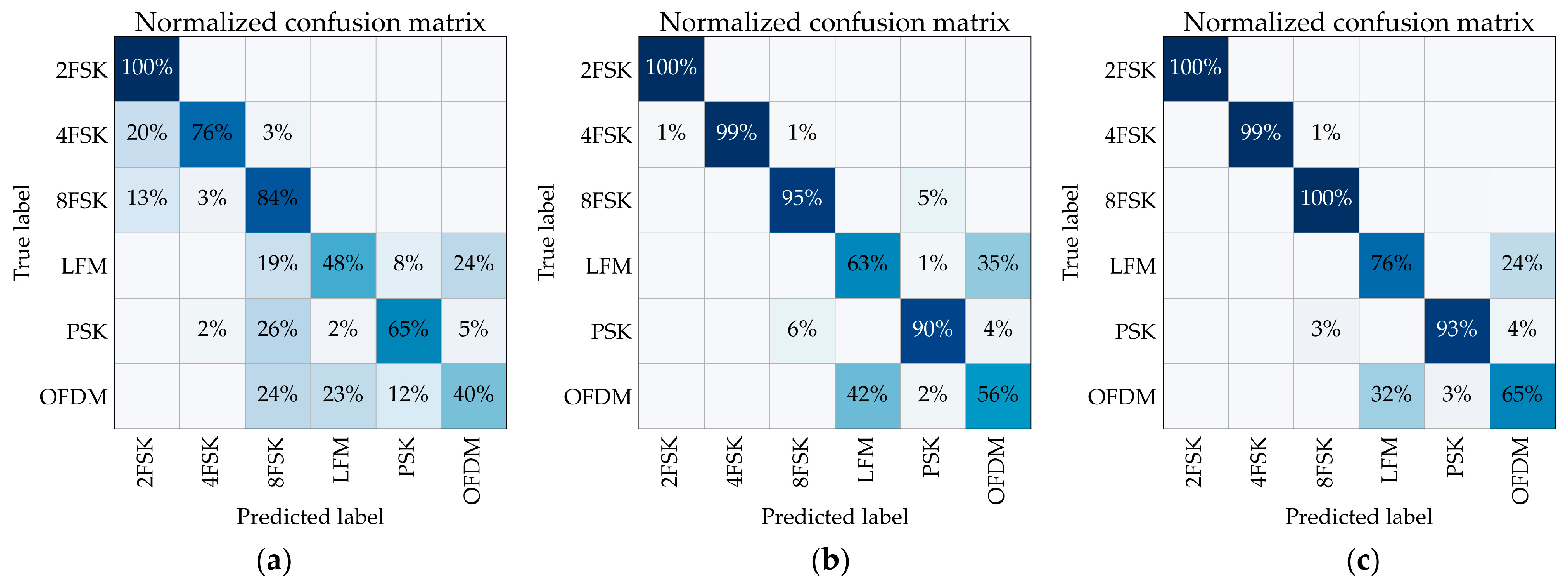
4.4. Performance for Different Modulations
4.5. Performance under Varying Signal Interference Levels
4.6. Performance across Various Array Structure Parameters
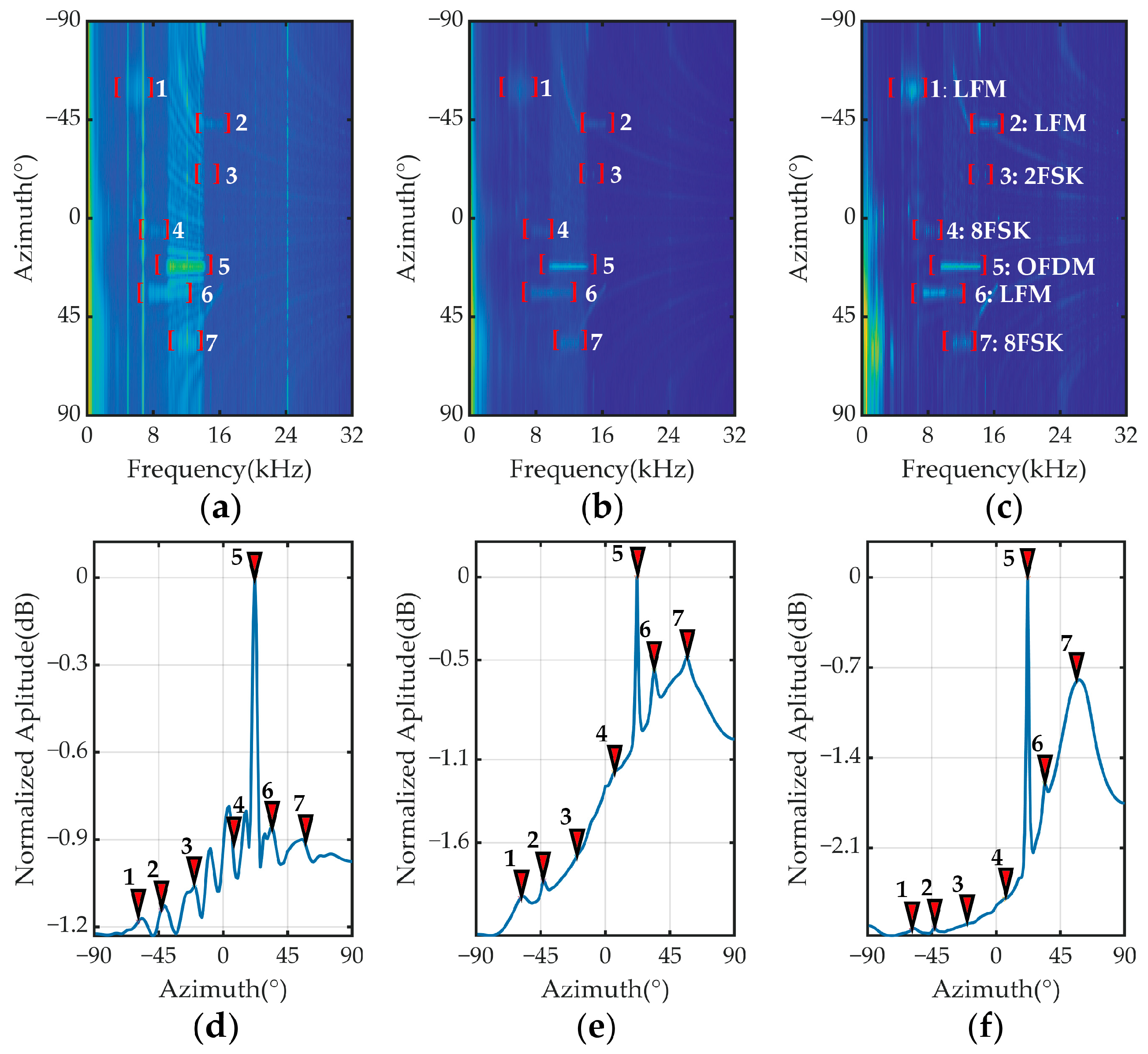
5. Experimental Studies
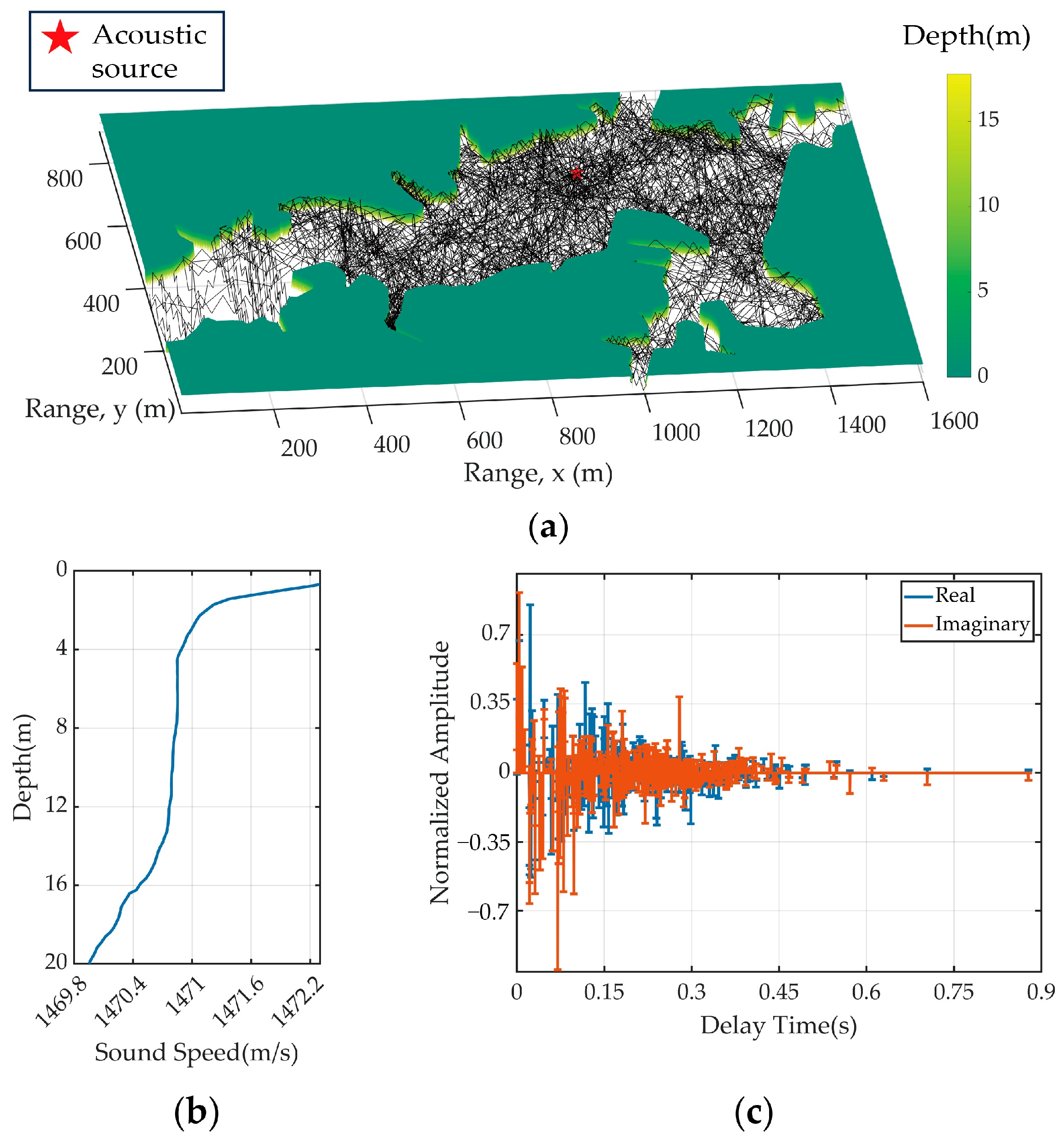
5.1. UWAC Signal Simulation and Experiment
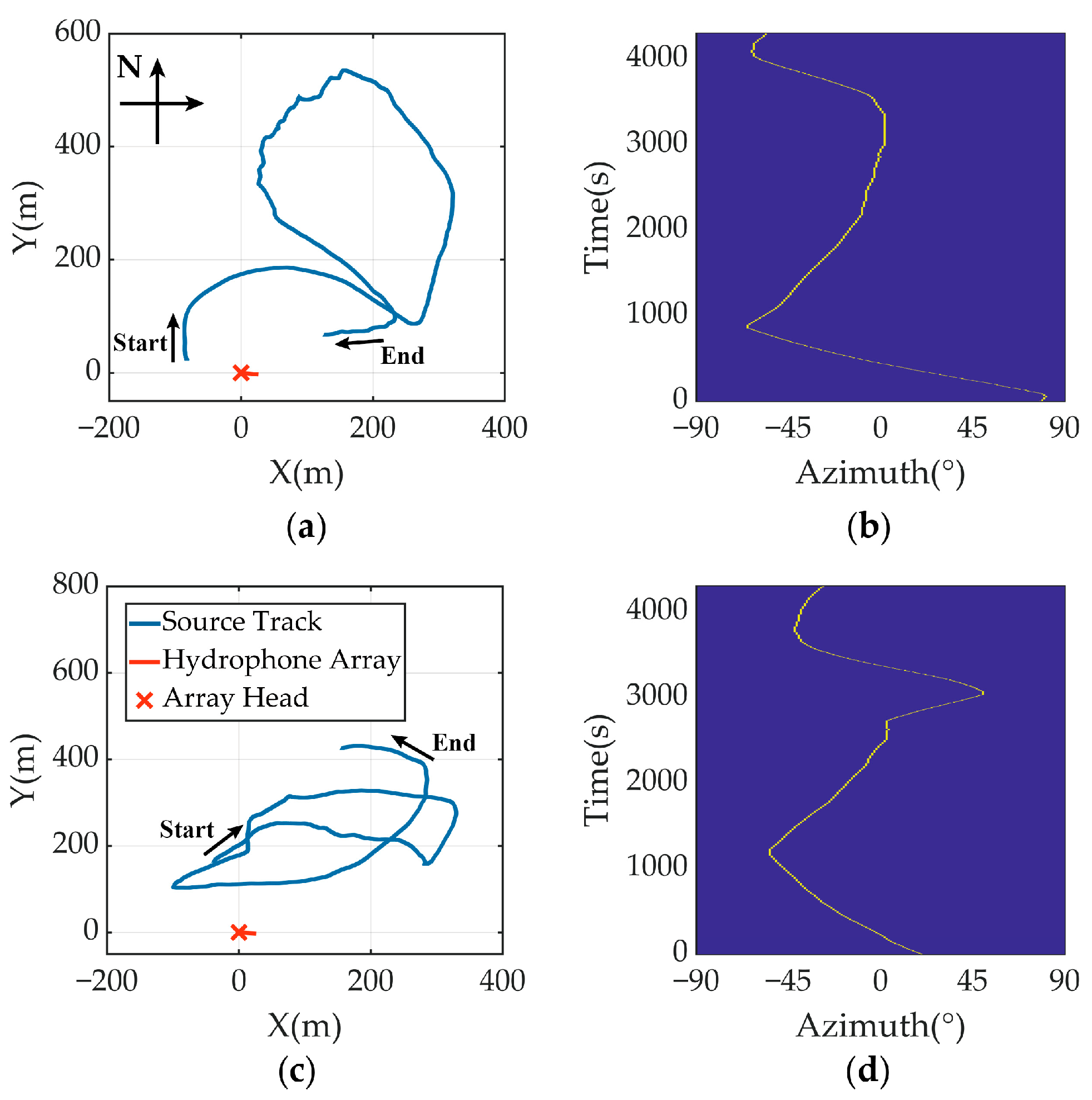
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Singer, A.C.; Nelson, J.K.; Kozat, S.S. Signal processing for underwater acoustic communications. IEEE Commun. Mag. 2009, 47, 90–96. [Google Scholar] [CrossRef]
- Lu, H.; Jiang, M.; Cheng, J. Deep learning aided robust joint channel classification, channel estimation, and signal detection for underwater optical communication. IEEE Trans. Commun. 2021, 69, 2290–2303. [Google Scholar] [CrossRef]
- Luo, X.; Shen, Z. A space-frequency joint detection and tracking method for line-spectrum components of underwater acoustic signals. Appl. Acoust. 2021, 172, 107609. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Volume 28, pp. 91–99. [Google Scholar]
- Han, K.; Nehorai, A. Improved source number detection and direction estimation with nested arrays and ULAs using jackknifing. IEEE Trans. Signal Process. 2013, 61, 6118–6128. [Google Scholar] [CrossRef]
- Johnson, D.H.; Dudgeon, D.E. Array Signal Processing: Concepts and Techniques; Prentice-Hall: Englewood Cliffs, NJ, USA, 1992. [Google Scholar]
- Schmidt, R.O. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef]
- Roy, R.; Kailath, T. ESPRIT-estimation of signal parameters via rotational invariance techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar] [CrossRef]
- Rao, B.; Hari, K. Performance analysis of root-Music. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1939–1949. [Google Scholar] [CrossRef]
- Capon, J. High-resolution frequency-wavenumber spectrum analysis. Proc. IEEE 1969, 57, 1408–1418. [Google Scholar] [CrossRef]
- Frost, O. An algorithm for linearly constrained adaptive array processing. Proc. IEEE 1972, 60, 926–935. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, W.; Langley, R.J. A class of constrained adaptive beamforming algorithms based on uniform linear arrays. IEEE Trans. Signal Process. 2010, 58, 3916–3922. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Wang, B. DOA estimation based on CNN for underwater acoustic array. Appl. Acoust. 2021, 172, 107594. [Google Scholar] [CrossRef]
- Ozanich, E.; Gerstoft, P.; Niu, H. A feedforward neural network for direction-of-arrival estimation. J. Acoust. Soc. Am. 2020, 147, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Feintuch, S.; Tabrikian, J.; Bilik, I.; Permuter, H. Neural-network-based DOA estimation in the presence of non-Gaussian interference. IEEE Trans. Aerosp. Electron. Syst. 2024, 60, 119–132. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, Y.; Tao, J.; Tang, S.; So, H.C.; Hong, W. A Two-stage multi-layer perceptron for high-resolution doa estimation. IEEE Trans. Veh. Technol. 2024, 1–16. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; Huang, Y. Dual class token vision transformer for direction of arrival estimation in low SNR. IEEE Signal Process. Lett. 2024, 31, 76–80. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Habets, E.A.P. Multi-speaker DOA estimation using deep convolutional networks trained with noise signals. IEEE J. Sel. Top. Signal Process. 2019, 13, 8–21. [Google Scholar] [CrossRef]
- Papageorgiou, G.K.; Sellathurai, M.; Eldar, Y.C. Deep networks for direction-of-arrival estimation in low SNR. IEEE Trans. Signal Process. 2021, 69, 3714–3729. [Google Scholar] [CrossRef]
- Nie, W.; Zhang, X.; Xu, J.; Guo, L.; Yan, Y. Adaptive direction-of-arrival estimation using deep neural network in marine acoustic environment. IEEE Sens. J. 2023, 23, 15093–15105. [Google Scholar] [CrossRef]
- Zheng, S.; Yang, Z.; Shen, W.; Zhang, L.; Zhu, J.; Zhao, Z.; Yang, X. Deep learning-based DOA estimation. IEEE Trans. Cogn. Commun. Netw. 2024, 10, 819–835. [Google Scholar] [CrossRef]
- Cong, J.; Wang, X.; Huang, M.; Wan, L. Robust DOA estimation method for MIMO radar via deep neural networks. IEEE Sens. J. 2021, 21, 7498–7507. [Google Scholar] [CrossRef]
- Merkofer, J.P.; Revach, G.; Shlezinger, N.; Routtenberg, T.; van Sloun, R.J.G. DA-MUSIC: Data-driven DoA estimation via deep augmented MUSIC algorithm. IEEE Trans. Veh. Technol. 2024, 73, 2771–2785. [Google Scholar] [CrossRef]
- Wu, L.-L.; Liu, Z.-M.; Huang, Z.-T. Deep convolution network for direction of arrival estimation with sparse prior. IEEE Signal Process. Lett. 2019, 26, 1688–1692. [Google Scholar] [CrossRef]
- Bell, C.J.; Adhikari, K.; Freeman, L.A. Convolutional neural network-based regression for direction of arrival estimation. In Proceedings of the 2023 IEEE 14th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 12–14 October 2023; pp. 373–379. [Google Scholar]
- Cai, R.; Tian, Q. Two-stage deep convolutional neural networks for DOA estimation in impulsive noise. IEEE Trans. Antennas Propag. 2024, 72, 2047–2051. [Google Scholar] [CrossRef]
- Prasad, K.N.R.S.V.; D’Souza, K.B.; Bhargava, V.K. A Downscaled faster-RCNN framework for signal detection and time-frequency localization in wideband RF systems. IEEE Trans. Wirel. Commun. 2020, 19, 4847–4862. [Google Scholar] [CrossRef]
- O’Shea, T.; Roy, T.; Clancy, T.C. Learning robust general radio signal detection using computer vision methods. In Proceedings of the 2017 51st Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2017; pp. 829–832. [Google Scholar]
- Nguyen, H.N.; Vomvas, M.; Vo-Huu, T.D.; Noubir, G. WRIST: Wideband, real-time, spectro-temporal RF identification system using deep learning. IEEE Trans. Mob. Comput. 2023, 23, 1550–1567. [Google Scholar] [CrossRef]
- Cheng, L.; Zhu, H.; Hu, Z.; Luo, B. A Sequence-to-Sequence Model for Online Signal Detection and Format Recognition. IEEE Signal Process. Lett. 2024, 31, 994–998. [Google Scholar] [CrossRef]
- Adavanne, S.; Politis, A.; Nikunen, J.; Virtanen, T. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 34–48. [Google Scholar] [CrossRef]
- He, W.; Motlicek, P.; Odobez, J.-M. Adaptation of multiple sound source localization neural networks with weak supervision and domain-adversarial training. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, Great Britain, 12–17 May 2019; pp. 770–774. [Google Scholar]
- Le Moing, G.; Vinayavekhin, P.; Agravante, D.J.; Inoue, T.; Vongkulbhisal, J.; Munawar, A.; Tachibana, R. Data-efficient framework for real-world multiple sound source 2D localization. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3425–3429. [Google Scholar]
- Schymura, C.; Bönninghoff, B.; Ochiai, T.; Delcroix, M.; Kinoshita, K.; Nakatani, T.; Araki, S.; Kolossa, D. PILOT: Introducing transformers for probabilistic sound event localization. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Ranjan, R.; Jayabalan, S.; Nguyen, T.N.T.; Gan, W.S. Sound event detection and direction of arrival estimation using residual net and recurrent neural networks. In Proceedings of the 4th Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE 2019), New York, NY, USA, 25–26 October 2019. [Google Scholar]
- Yasuda, M.; Koizumi, Y.; Saito, S.; Uematsu, H.; Imoto, K. Sound event localization based on sound intensity vector refined by DNN-based denoising and source separation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 651–655. [Google Scholar]
- Chytas, S.; Potamianos, G. Hierarchical detection of sound events and their localization using convolutional neural networks with adaptive thresholds. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019; pp. 50–54. [Google Scholar]
- Sundar, H.; Wang, W.; Sun, M.; Wang, C. Raw waveform based end-to-end deep convolutional network for spatial localization of multiple acoustic sources. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4642–4646. [Google Scholar]
- He, Y.; Trigoni, N.; Markham, A. SoundDet: Polyphonic moving sound event detection and localization from raw waveform. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Chakrabarty, S.; Habets, E.A.P. Broadband DOA estimation using convolutional neural networks trained with noise signals. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 136–140. [Google Scholar]
- Diaz-Guerra, D.; Miguel, A.; Beltran, J.R. Robust sound source tracking using SRP-PHAT and 3D convolutional neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 300–311. [Google Scholar] [CrossRef]
- Lu, Z. Sound event detection and localization based on CNN and LSTM. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 25–26 October 2019. [Google Scholar]
- Comanducci, L.; Borra, F.; Bestagini, P.; Antonacci, F.; Tubaro, S.; Sarti, A. Source localization using distributed microphones in reverberant environments based on deep learning and ray space transform. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2238–2251. [Google Scholar] [CrossRef]
- Vera-Diaz, J.M.; Pizarro, D.; Macias-Guarasa, J. Towards domain independence in CNN-based acoustic localization using deep cross correlations. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; pp. 226–230. [Google Scholar]
- Gelderblom, F.B.; Liu, Y.; Kvam, J.; Myrvoll, T.A. Synthetic data for DNN-based DOA estimation of indoor speech. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 4390–4394. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceeding of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]
- Wax, M.; Kailath, T. Detection of signals by information theoretic criteria. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 387–392. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Porter, M.B. The BELLHOP Manual and User’s Guide: Preliminary Draft; Heat Light Sound Research Inc.: La Jolla, CA, USA, 2011; Available online: http://oalib.hlsresearch.com/Rays/HLS-2010-1.pdf (accessed on 16 January 2024).
- Qarabaqi, P.; Stojanovic, M. Statistical characterization and computationally efficient modeling of a class of underwater acoustic communication channels. IEEE J. Ocean. Eng. 2013, 38, 701–717. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, L.; Zou, Y.; Hu, Z. Thin Fiber-Optic Hydrophone Towed Array for Autonomous Underwater Vehicle. IEEE Sens. J. 2024, 24, 15125–15132. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Training Set | Test Set I | Test Set II | Test Set III | Test Set IV |
|---|---|---|---|---|---|
| Number of Signals | 4000 | 6000 | 6000 | 6000 | 8000 |
| DOA Range | −85° to 85° | −85° to 85° | −85° to 85° | −85° to 85° | −85° to 85° |
| Carrier Frequency (Hz) | 5000–8000 | 5000–8000 | 5000–15,000 | 5000–8000 | 5000–8000 |
| Bandwidth (Hz) | 1000–5000 | 1000–5000 | 1000–5000 | 1000–5000 | 1000–5000 |
| SNR (dB) | −20 to 20 | −20 to 20 | −20 to 20 | 30; −20 to 20 | −20 to 20 |
| Maximum SNR Difference 1 (dB) | 20 | 20 | 20 | 40 | 40 |
| Number of Sources | 1–7 | 1–7 | 1–7 | 2–7 | 1–7 |
| Number of Array Elements | 32 | 32 | 32 | 32 | 8–64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, L.; Liu, Y.; Zhang, B.; Hu, Z.; Zhu, H.; Luo, B. Direction of Arrival Joint Prediction of Underwater Acoustic Communication Signals Using Faster R-CNN and Frequency–Azimuth Spectrum. Remote Sens. 2024, 16, 2563. https://doi.org/10.3390/rs16142563
Cheng L, Liu Y, Zhang B, Hu Z, Zhu H, Luo B. Direction of Arrival Joint Prediction of Underwater Acoustic Communication Signals Using Faster R-CNN and Frequency–Azimuth Spectrum. Remote Sensing. 2024; 16(14):2563. https://doi.org/10.3390/rs16142563
Chicago/Turabian StyleCheng, Le, Yue Liu, Bingbing Zhang, Zhengliang Hu, Hongna Zhu, and Bin Luo. 2024. "Direction of Arrival Joint Prediction of Underwater Acoustic Communication Signals Using Faster R-CNN and Frequency–Azimuth Spectrum" Remote Sensing 16, no. 14: 2563. https://doi.org/10.3390/rs16142563
APA StyleCheng, L., Liu, Y., Zhang, B., Hu, Z., Zhu, H., & Luo, B. (2024). Direction of Arrival Joint Prediction of Underwater Acoustic Communication Signals Using Faster R-CNN and Frequency–Azimuth Spectrum. Remote Sensing, 16(14), 2563. https://doi.org/10.3390/rs16142563