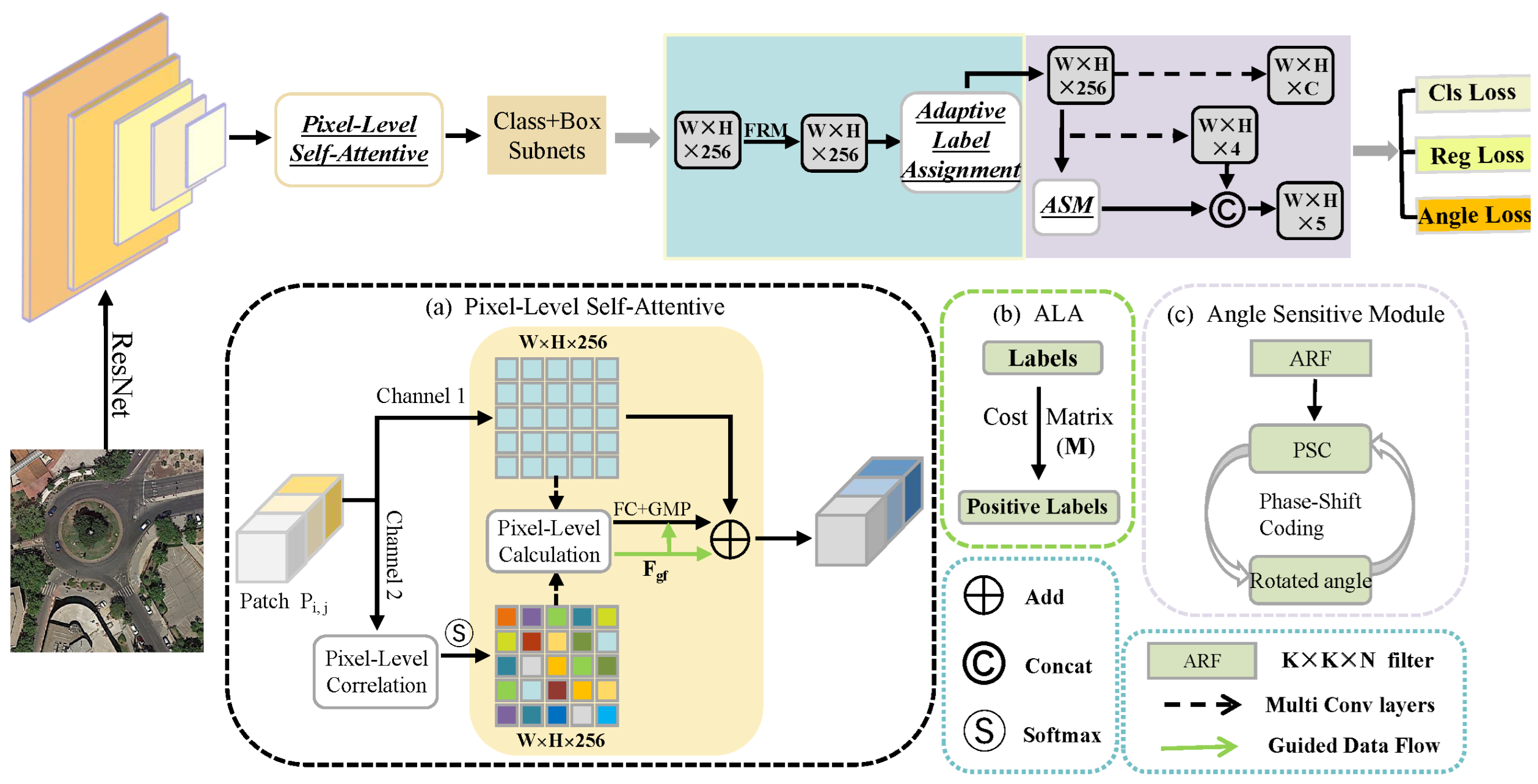
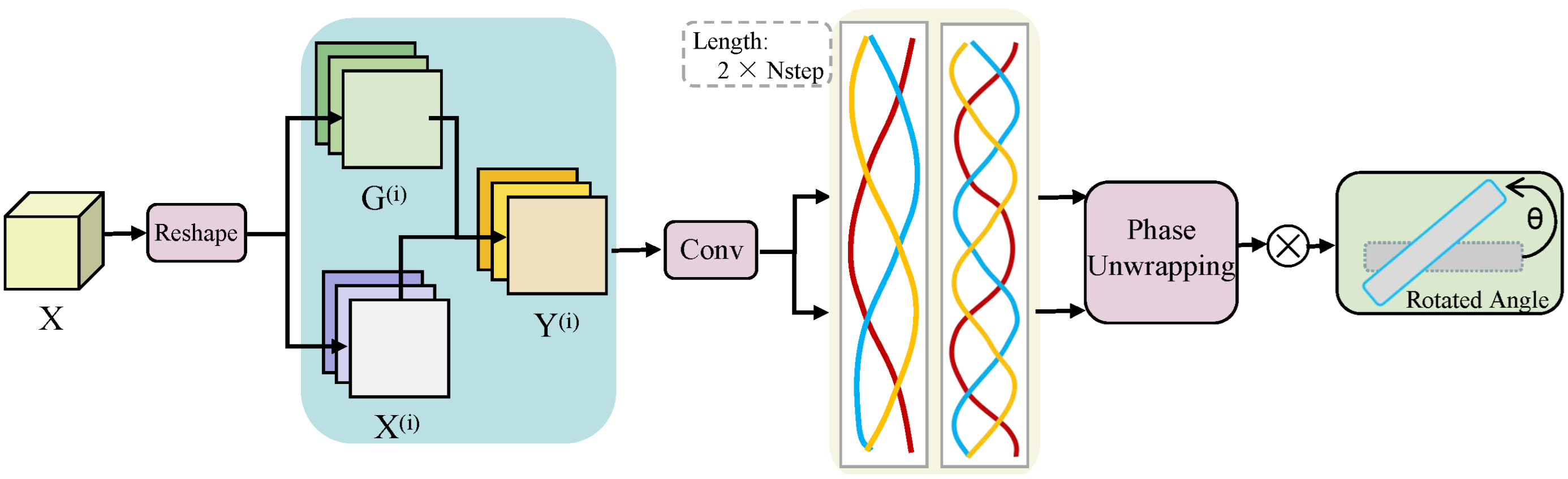
4.1. Experimental Setup
We conduct experiments on three rotated object detection datasets.
DOTA [
1] is one of the largest datasets used for object-oriented detection in aerial images, with two versions: DOTA-v1.0 and DOTA-v1.5. DOTA-v1.0 contains 2806 aerial images with a size range of 800 × 800 to 4000 × 4000, including 188,282 instances in 15 common categories: Plane (PL), Baseball diamond (BD), Bridge (BR), Ground track field (GTF), Small vehicle (SV), Large vehicle (LV), Ship (SH), Tennis court(TC), Basketball court (BC), Storage tank (ST), Soccer-ball field (SBF), Roundabout (RA), Harbor (HA), Swimming pool(SP), and Helicopter (HC).
DOTA-v1.5 is released with a new category, Container Crane (CC). DOTA-v1.5 contains 402,089 instances. Compared to DOTA-v1.0, DOTA-v1.5 is more challenging but remains stable in the training phase.
We use both training and validation sets for training, and the test set for testing. According to the settings in the previous method [
46], We cropped the original image to 1024 × 1024 blocks in step 824. Random horizontal flipping is adopted to avoid over-fitting during training, and no other tricks are utilized. For fair comparisons with other methods, we adopt data augmentation at three scales 0.5, 1.0, 1.5. The performance of the test set is evaluated on the official DOTA evaluation server.
HRSC2016 [
12] only contains one category “ship”. The image size ranges from 300 × 300 to 1500 × 900. The HRSC2016 dataset contains 1061 images in total (436 for training, 181 for validation, and 444 for testing). We use both training and validation sets for training and the test set for testing. All images are resized to (800, 512) without changing the aspect ratio. Random horizontal flipping is applied during training.
Implementation details. The experiments are based on the MMRotate [
46] toolbox, using libraries such as PyTorch 1.12.1, CUDA 10.2, and Python3.8. All experiments are carried out on NVIDIA RTX 2080Ti GPU cards (NVIDIA, Santa Clara, CA, USA).
In all experiments, We adopt ResNet50 and FPN (i.e., P3 to P7) as the backbone network for a fair comparison with other methods. We train all models in 12 epochs for DOTA and 36 epochs for HRSC2016. SGD optimizer is adopted with an initial learning rate of 0.01, and the learning rate is divided by 10 at each decay step. The momentum and weight decay are 0.9 and 0.0001, respectively. We use random flipping as the only data augmentation method which is also the original setting of the official MMDetection code when performing the comparison of the experiments.
4.2. Comparison to State-of-the-Art
We compare SA3Det against some state-of-the-art methods (the selected comparison method comprehensively covers popular methods, including single-stage method, two-stage method, and anchor-free method) in oriented datasets. The results are shown in
Table 1,
Table 2 and
Table 3. The backbone used in the experiments is as follows: R-50, 101, 152 denotes ResNet-50, ResNet-101, ResNet-152, and H-104 refers to a 104-layer hourglass network.
Results on DOTA.
Table 1 shows a comparison of our SA3Det with the recently state-of-the-art detectors on the DOTA-v1.0 dataset with respect to oriented bounding-box detection. Among these methods, Redet and CSL are implemented by adding angle prediction channels in the bounding-box regression branch of the classical computer vision algorithms Faster-RCNN [
34] and RetinaNet [
55], respectively. Other methods are especially proposed to detect rotating objects in remote-sensing images. SCRDet++ [
21] introduces the idea of denoising to object detection. Instance-level denoising on the feature map is performed to enhance the detection of small and cluttered objects. DAL [
38] is a dynamic anchor learning method that uses a new matching mechanism to evaluate anchors and assign them more efficient labels.
A-Net [
13] uses a new alignment convolution, which can adaptively align convolution features according to anchors. CFA [
50] proposes a convex hull representation method that can more accurately locate the range of objects while reducing feature aliasing to some extent. LSKNet [
25] dynamically adjusts the receptive field of targets through a series of Depth wise convolution kernels and spatial selection mechanisms, allowing the model to adapt to target detection in different backgrounds. YOLOv5m [
19] is a model in the YOLOv5 series, and a rotation detection version of this model has already appeared in the field of remote sensing.
Unlike comparison methods, our method proposes a new pixel-level attention mechanism and independent angle regression branches to enhance the network’s regression and directional feature extraction, therefore improving the detection ability of rotating objects. For the accuracy measured by mAP, we achieved 76.31% mAP with single-scale data and 79.23% mAP with multi-scale data. Specifically, SA3Det outperforms RoI-Transformer 5.11% (74.67% vs. 69.56%), better than Det 2.9% (73.22% vs. 70.32%), SCRDet 2.06% (74.67% vs. 72.61%), -DNet 3.63% (74.67% vs. 71.04%), CFA 0.31% (73.22% vs. 72.91%), LSKNet 0.92% (73.22% vs. 72.30%), YOLOv5m 0.56% (73.22% vs. 72.66%), which is a great improvement. It is worth noting that our results have a good lead in the detection of GTF, RA, and SP. The directionality of these classes of objects is obvious, indicating that our detector has a strong ability in direction detection.
We further conduct the experiments by setting the backbone of all models to ResNet50 to investigate the effects of the backbone. From
Table 1, It can be observed that our SA3Det achieves the best result in comparison to all anchor-free methods. SA3Det achieves 73.22% mAP, about 2.52% mAP higher than the second-best method DRN*. Compared with the anchor-based methods, our method is better than most single-stage methods and two-stage methods, even though many of them use ResNet101, which contributes to a stronger backbone. The results show that our model performs slightly worse than
A-Net by 0.9%. Although our method does not achieve the best performance, the proposed method has some apparent advantages over the anchor-based methods. When detecting objects with dense distribution and large-scale differences, our SA3Det generates fewer error angles and a lower probability of missed detections. Partial visualization results are shown in
Figure 6.
Results on DOTA-v1.5. Compared to DOTA-v1.0, DOTA-v1.5 contains more tiny objects. We summarize the results for DOTA-vl.5 in
Table 2. Compared with state-of-the-art methods, SA3Det achieves 67.18% mAP with single-scale data and 76.02% mAP with multi-scale data, outperforming Mask RCNN [
56], AO2-DETR [
28], and HTC [
57]. The experiments verify that our proposed SA3Det can achieve superior performance in small-object detection.
Results on HRSC2016. For the HRSC2016 dataset, some of them have large aspect ratios and various orientations. In
Table 3, it can be seen that our SA3Det achieves good performance. Among these methods, R2CNN [
58] and RRPN [
23] are proposed in the field of computer vision to detect slanted text with angles. Other methods are proposed to detect rotated objects in RSIs. It is worth noting that we used the PASCAL VOC 2007 metric to calculate the mAP of the detection results (as we did not find the dataset for the 2012 metric), and the mAP of other methods compared was also calculated under this metric. Specifically, SA3Det achieved 88.5% and 89.4% mAP using R101 and R152, respectively, under VOC 2007. Partial visualization results are shown in
Figure 6. From it, it can be seen that although some ships have the characteristics of large-scale differences and dense arrangement, SA3Det can always provide appropriate OBB (Oriented Box Boundary) to tightly surround ships in any direction. Even in different environments such as ports, coasts, and seas, this method can still perform high-quality detection.
Table 2.
Comparison with state-of-the-art methods on DOTA-v1.5. R50-FPN stands for ResNet-50 with FPN, and H104 stands for Hourglass-104. * Indicates multi-scale training and testing.
Table 2.
Comparison with state-of-the-art methods on DOTA-v1.5. R50-FPN stands for ResNet-50 with FPN, and H104 stands for Hourglass-104. * Indicates multi-scale training and testing.
| Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | CC | mAP |
|---|
| Mask RCNN [56] | R50-FPN | 76.84 | 73.51 | 49.90 | 57.80 | 51.31 | 71.34 | 79.75 | 90.46 | 74.21 | 66.07 | 46.21 | 70.61 | 63.07 | 64.46 | 57.81 | 9.42 | 62.67 |
| HTC [57] | R50-FPN | 77.80 | 73.67 | 51.40 | 63.99 | 51.54 | 73.31 | 80.31 | 90.48 | 75.12 | 67.34 | 48.51 | 70.63 | 64.84 | 64.48 | 55.87 | 5.15 | 63.40 |
| AO2-DETR [28] | R50-FPN | 79.55 | 78.14 | 42.41 | 61.23 | 55.34 | 74.50 | 79.57 | 90.64 | 74.76 | 77.58 | 53.56 | 66.91 | 58.56 | 73.11 | 69.64 | 24.71 | 66.26 |
| AO2-DETR * [28] | R50-FPN | 87.13 | 85.43 | 65.87 | 74.69 | 77.46 | 84.13 | 86.19 | 90.23 | 81.14 | 86.56 | 56.04 | 70.48 | 75.47 | 78.30 | 72.66 | 42.62 | 75.89 |
| ReDet * [24] | ReR50-ReFPN | 88.51 | 86.45 | 61.23 | 81.20 | 67.60 | 83.65 | 90.00 | 90.86 | 84.30 | 75.33 | 71.49 | 72.06 | 78.32 | 74.73 | 76.10 | 46.98 | 76.80 |
| Point RCNN * [59] | ReR50-ReFPN | 83.40 | 86.59 | 60.76 | 80.25 | 79.92 | 83.37 | 90.04 | 90.86 | 87.45 | 84.50 | 72.79 | 77.32 | 78.29 | 77.48 | 78.92 | 47.97 | 78.74 |
| Our | | | | | | | | | | | | | | | | | | |
| SA3Det | R50-FPN | 78.07 | 84.33 | 48.04 | 70.30 | 55.80 | 75.52 | 80.54 | 90.86 | 78.04 | 74.67 | 50.63 | 69.96 | 68.12 | 65.63 | 60.02 | 15.59 | 67.18 |
| SA3Det * | R50-FPN | 85.48 | 86.39 | 59.82 | 76.30 | 69.13 | 81.49 | 89.15 | 90.86 | 83.05 | 84.28 | 65.21 | 74.43 | 78.92 | 75.33 | 69.90 | 40.57 | 76.02 |
Table 3.
Accuracy and speed on HRSC2016. And 07 (12) means using the 2007 (2012) evaluation metric.
Table 3.
Accuracy and speed on HRSC2016. And 07 (12) means using the 2007 (2012) evaluation metric.
| Method | Backbone | Image Size | mAP (07) | mAP (12) | Speed |
|---|
| CNN [58] | R101-FPN | 800 × 800 | 73.07 | 79.73 | 5 fps |
| RoI-Transformer [4] | R101-FPN | 512 × 800 | 86.20 | - | 6 fps |
| Gliding Vertex [52] | R101-FPN | - | 88.20 | - | - |
| DRN [49] | H-104 | - | - | 92.70 | - |
| Det [39] | R101-FPN | 800 × 800 | 86.9 | - | - |
| CSL [51] | R152-FPN | - | 89.62 | - | - |
| RRPN [23] | R101-FPN | 800 × 800 | 79.08 | 85.64 | 1.5 fps |
| RRD [43] | VGG16 | 384 × 384 | 84.3 | - | - |
| CenterMap-Net [60] | R50-FPN | - | - | 92.8 | - |
| Our | | | | | |
| SA3Det | R50-FPN | 800 × 800 | 85.6 | - | - |
| SA3Det | R101-FPN | 800 × 800 | 88.5 | - | - |
| SA3Det | R152-FPN | 800 × 800 | 89.4 | - | - |
4.3. Ablation Studies
In this section, we conduct a series of experiments on the testing set to validate the effectiveness of our method. To further understand the effectiveness of our proposed method, we further explore and validate the contributions of different modules of the proposed SA3Det framework, i.e., the PSA module, the ALA module, and the ASM module. We conducted ablation experiments on the DOTA and HRSC2016 datasets, and the results are shown in
Table 4 and
Table 5, respectively.
As shown in
Table 4, in most categories, adding any module can improve the accuracy of detection, and the combination of the three modules is the best, with a mAP of 73.22%. This indicates that PSA retains more detailed features of small targets, the ALA module adaptively divides positive and negative sample labels, and ASM independently predicts angles. All three methods are effective. On the HRSC dataset, as shown in
Table 5, our module has also improved accuracy.
Figure 7 is a specific visualization of our three innovative methods, showing the problems we encountered in the baseline and the results we achieved after solving the corresponding problems.
In the ablation study of different losses, we classified the losses using Focal Loss and focused on the regression losses of the bounding box in the baseline. We compared several commonly used losses, as shown in
Table 6. Specifically, our loss achieves a 1.39% gain in mAP relative to the KFIoU, 2.05% gain relative to the KLD, 4.97% gain relative to the GWD, 2.9% gain relative to the Smooth-L1, and 3.67% gain relative to the L1 loss. Our loss achieves a significant improvement in performance, demonstrating the effectiveness of angle constraints.
4.4. Parameter Analysis
Method parameter. Det has high efficiency as an independent detector, but adding any module to it will introduce more computation, which may affect its efficiency. Therefore, We compared the models based on parameter counts (Params), inference speed (speed), floating-point operations per second (FLOPs), and mAP. The evaluated algorithms include RoI-Transformer, AO2-DETR, Yolov5m, S2ANet, Baseline (R3Det), and SA3Det, each evaluated using a standardized image size of 1024x1024 pixels and trained over a period of 12. All of these were evaluated under consistent conditions.
As shown in
Table 7. Although SA3Det has poorer speed and Flops compared to RoI-Transformer, AO2-DETR, and S2ANet, our parameter count is lower and detection accuracy is higher. The
Det achieved 70.32% mAP across 37.08 M parameters, indicating that the baseline is reliable. After adding three modules, SA3Det achieved a parameter count of 37.27 M, a speed of 65.7 ms, and 232.92 GFLOPs, achieving a mAP of 73.22, indicating a good trade-off between computational efficiency and detection accuracy. In addition, Yolov5m achieved similar performance to ours with fewer model parameters, but our model produces better results in small-object detection, as shown in
Section 4.5. These results indicate that our method can achieve competitive performance and a better balance of speed–accuracy, meeting the engineering needs of the real world.
The effect of ALA’s parameter
. Here, we delve into the influence of the hyperparameter
within the ALA, as delineated in
Table 8. When
is set to 0.5, SA3Det achieves a peak mean Average Precision (mAP) of 73.22%, indicating a notable performance enhancement. However, surpassing this threshold leads to a degradation in our method’s performance. Our rationale is rooted in the prevalence of diminutive targets in remote-sensing imagery, often characterized by low Intersection over Union (IoU) values, posing challenges for precise target localization by the model. Excessive emphasis on IoU, resulting from disproportionate weight allocation, exacerbates the detection constraints for small targets, therefore impinging on the efficacy of remote-sensing target detection. Thus, informed by this observation, we designate the default value of
as 0.5 to strike a harmonious balance between preserving detection rates for small targets and optimizing overall method performance.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}