
Land Use Recognition by Applying Fuzzy Logic and Object-Based Classification to Very High Resolution Satellite Images


Abstract
1. Introduction
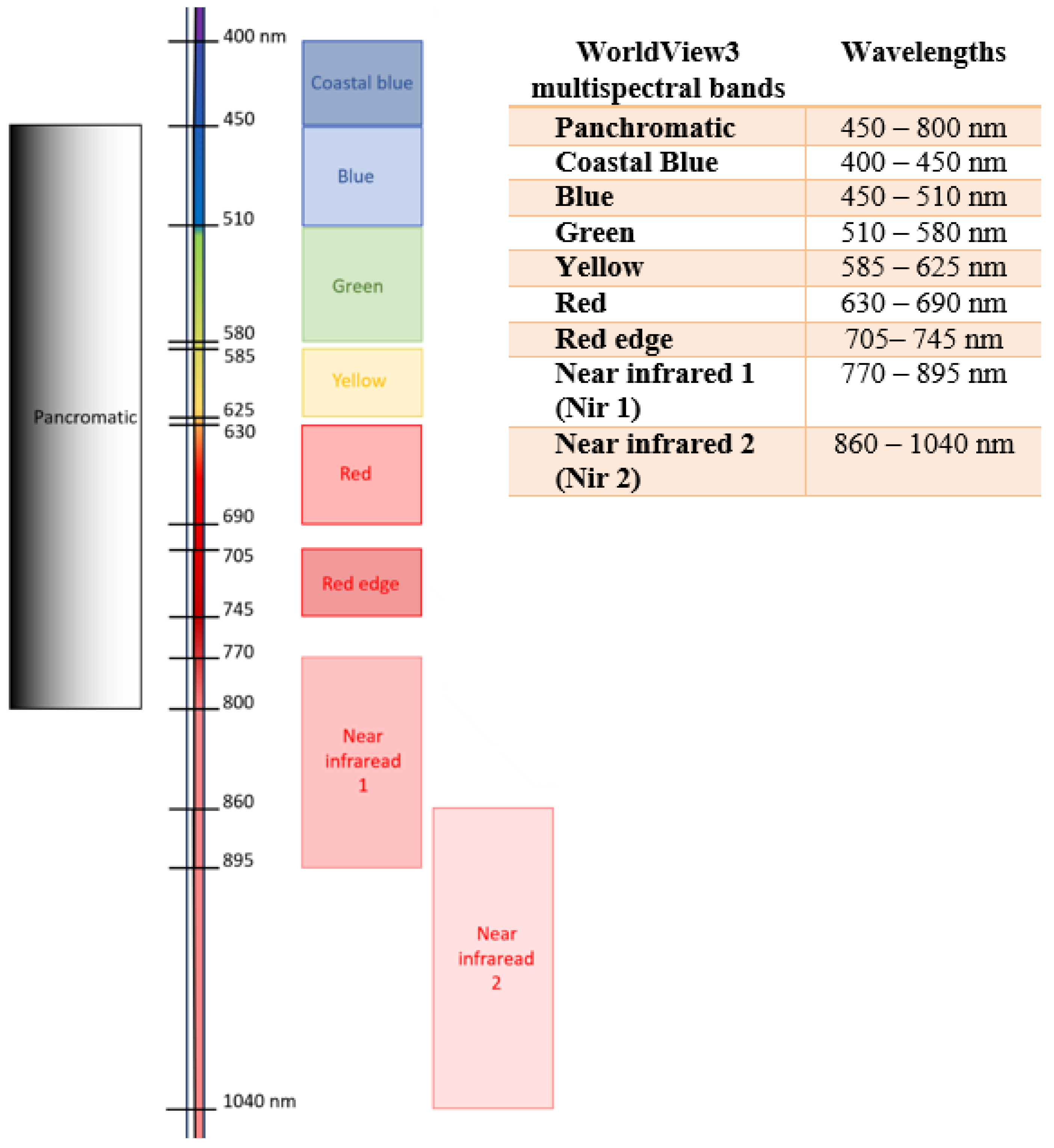
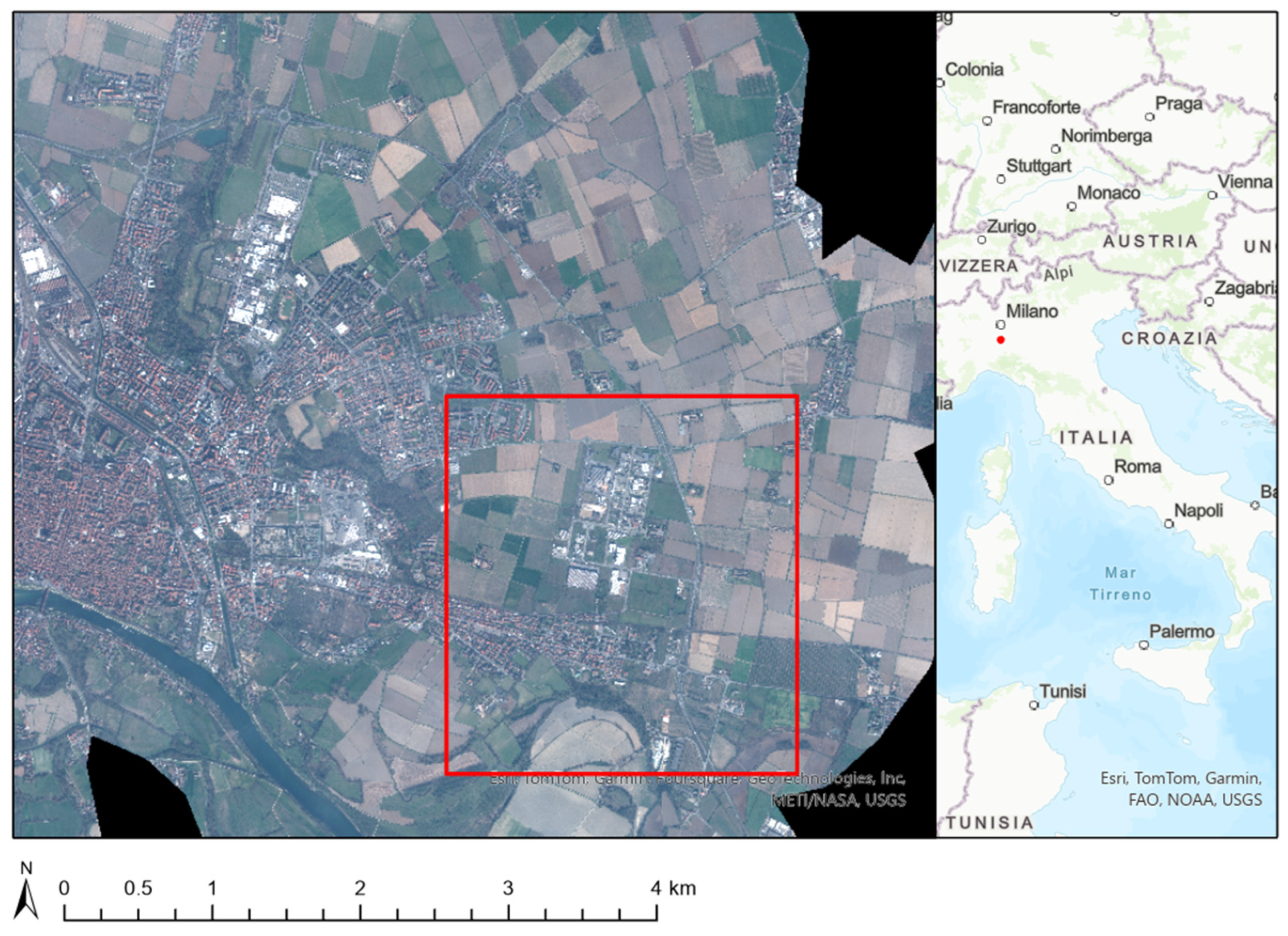
2. Materials and Methods
2.1. Index Calculations
2.2. Segmentation
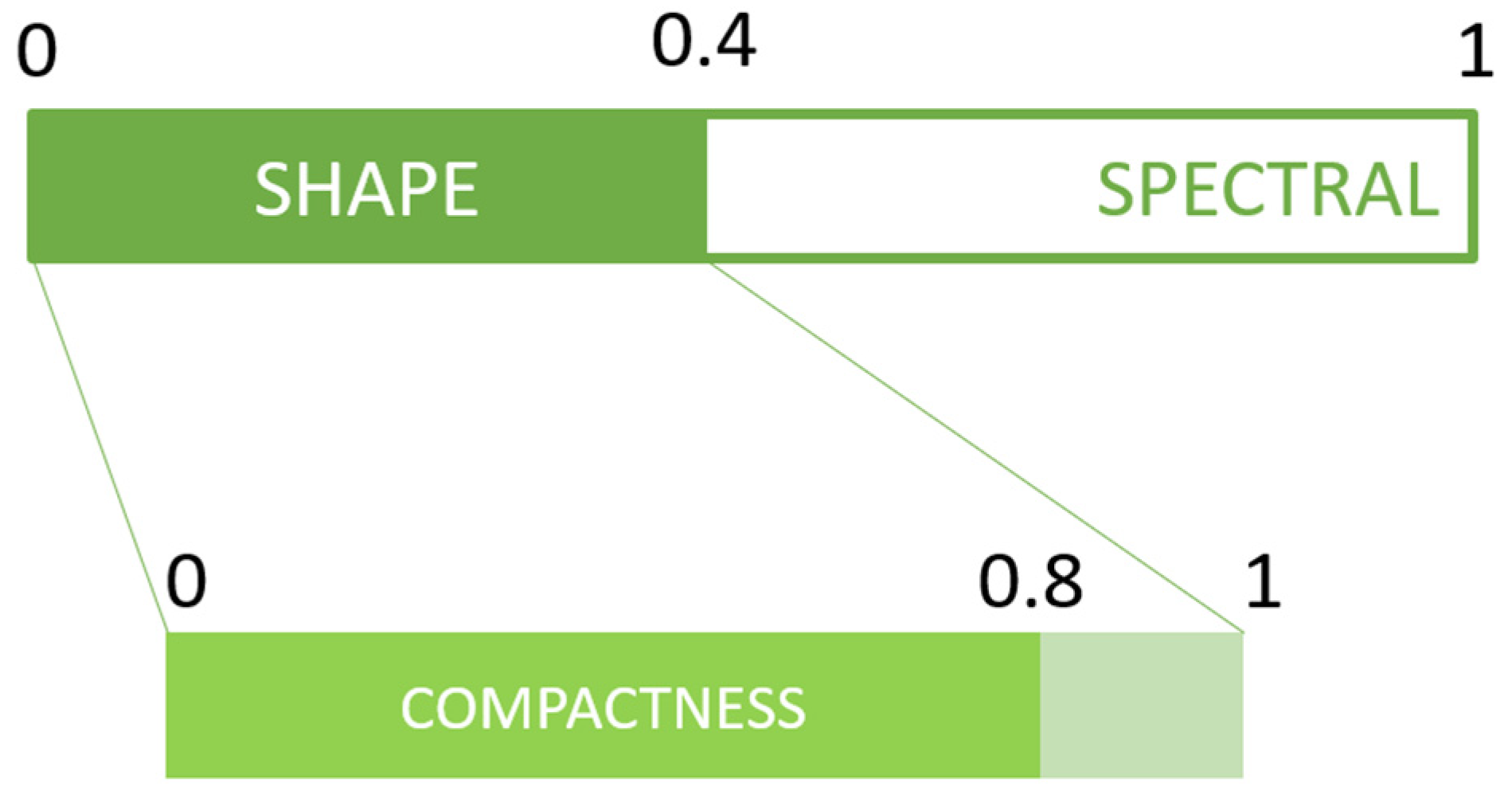
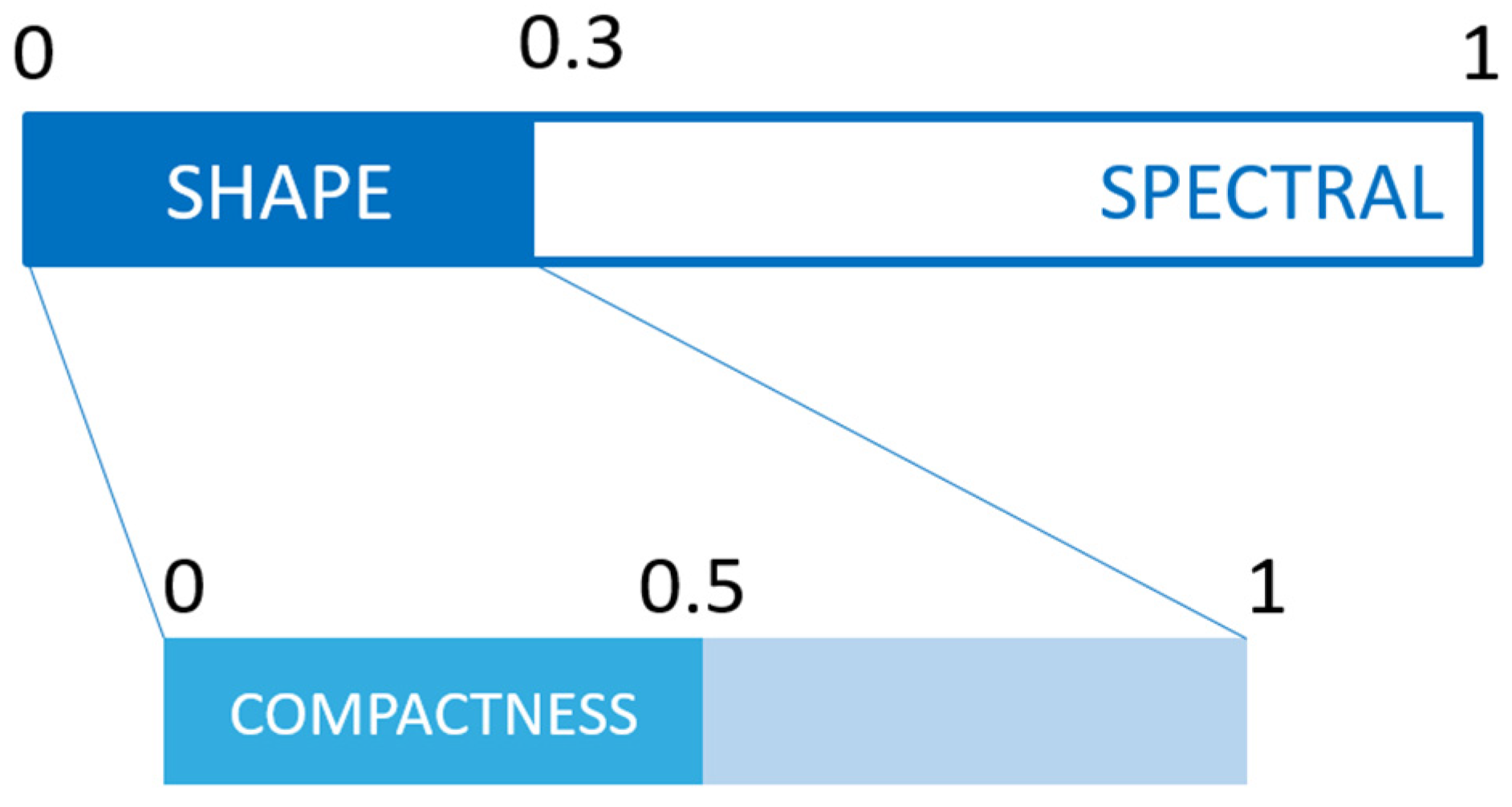
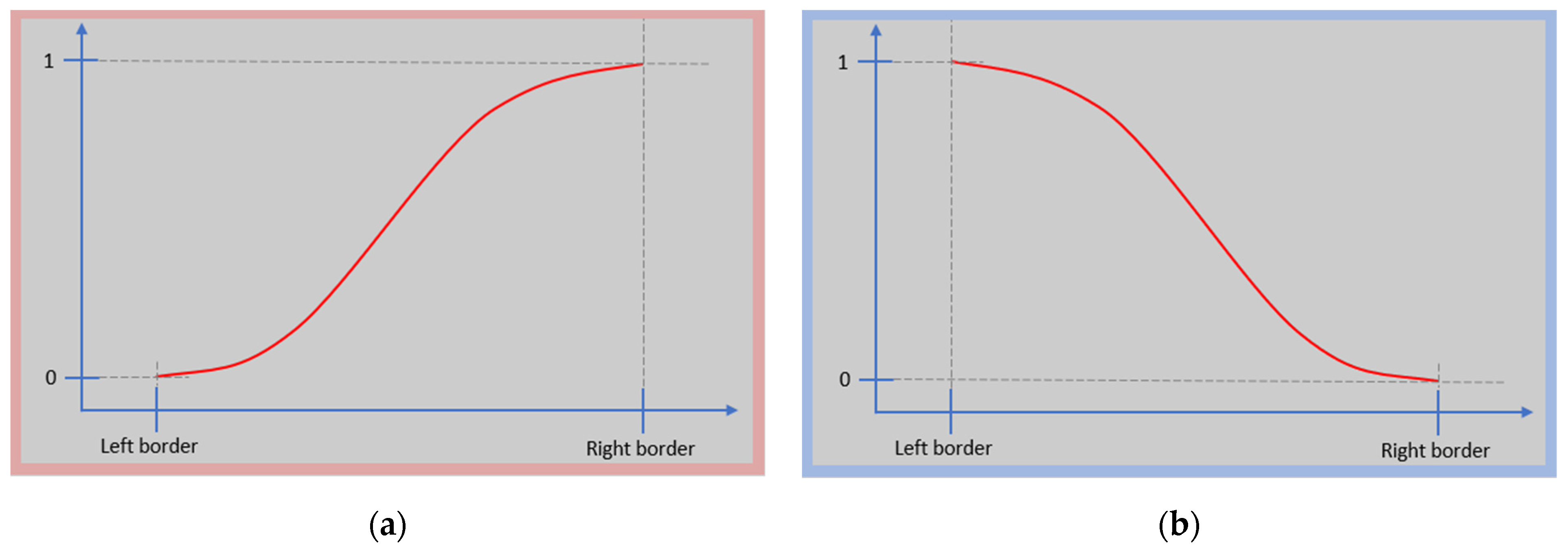
2.3. Classification
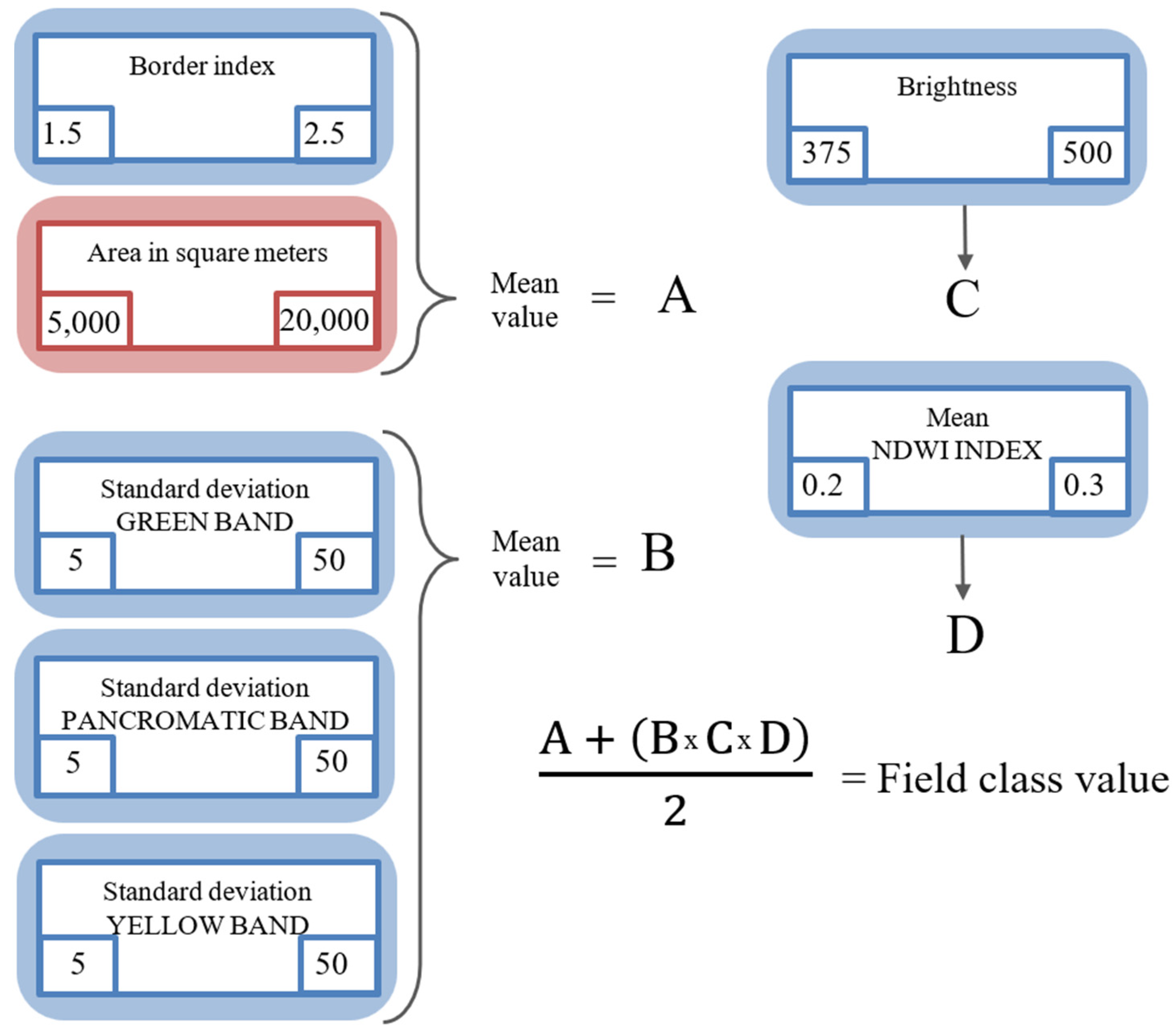
2.3.1. Field Class
2.3.2. Cultivated and Uncultivated Fields
2.3.3. Water Class
2.3.4. Vegetation Class
2.3.5. Impermeable Class
2.4. Refinement Process
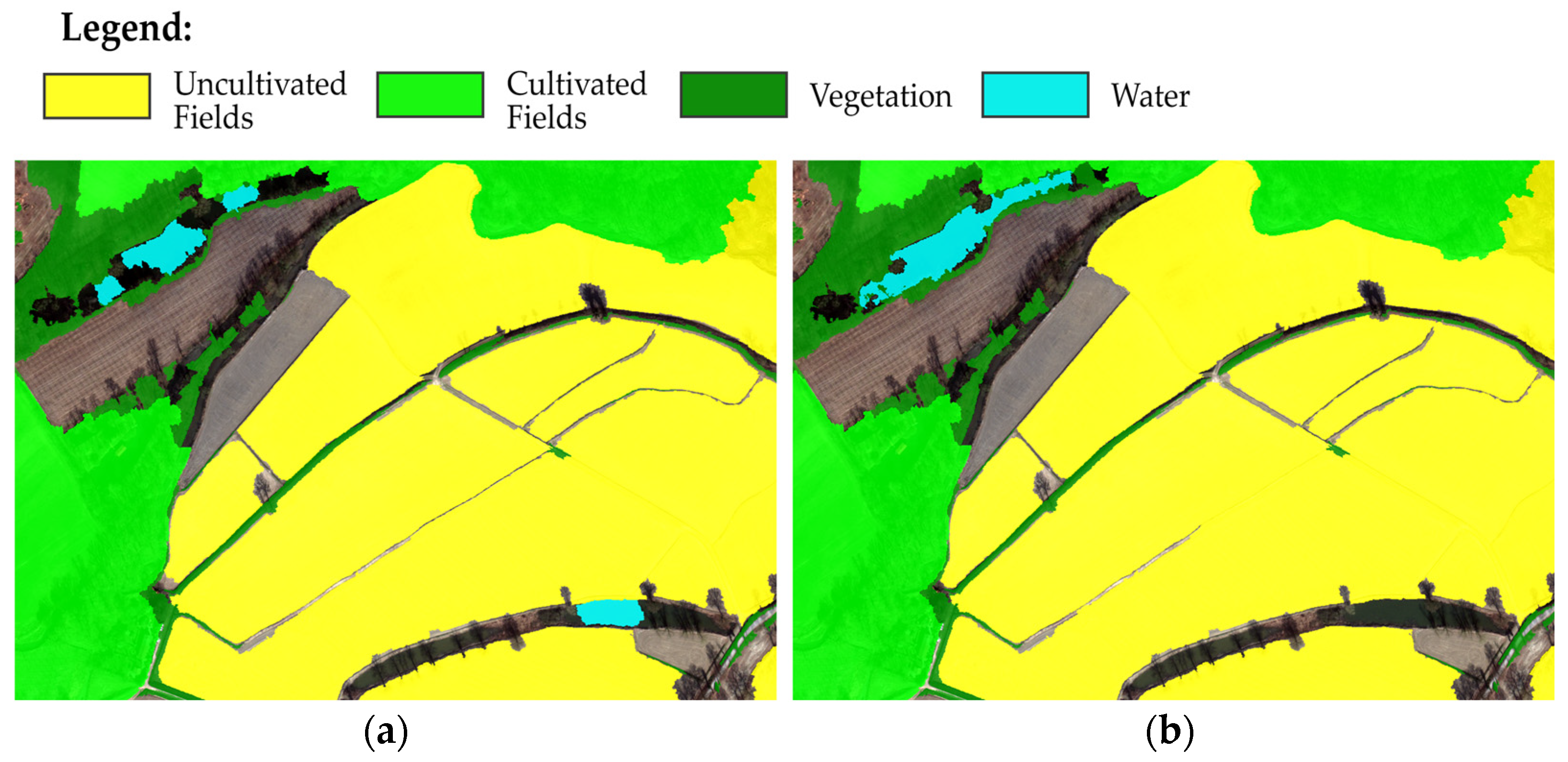
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A.; Zhang, L. Building Damage Assessment for Rapid Disaster Response with a Deep Object-Based Semantic Change Detection Framework: From Natural Disasters to Man-Made Disasters. Remote Sens. Environ. 2021, 265, 112636. [Google Scholar] [CrossRef]
- Perregrini, D.; Casella, V. Classification of Water in an Urban Environment by Applying OBIA and Fuzzy Logic to Very High-Resolution Satellite Imagery. In Geomatics for Environmental Monitoring: From Data to Services; Borgogno Mondino, E., Zamperlin, P., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 285–301. [Google Scholar]
- Cantrell, S.J.; Christopherson, J.B.; Anderson, C.; Stensaas, G.L.; Ramaseri Chandra, S.N.; Kim, M.; Park, S. Open-File System Characterization Report on the WorldView-3 Imager System Characterization of Earth Observation Sensors; U.S. Geological Survey: Sioux Falls, SD, USA, 2021. [Google Scholar]
- Maurer, T. How to Pan-Sharpen Images Using the Gram-Schmidt Pan-Sharpen Method—A Recipe. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-1/W1, 239–244. [Google Scholar] [CrossRef]
- Björck, Å. Numerics of Gram-Schmidt Orthogonalization. Linear Algebra Appl. 1994, 197–198, 297–316. [Google Scholar] [CrossRef]
- Laben, C.A.; Brower, B.V. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pan-Sharpening. U.S. Patent 6,011,875, 4 January 2000. Volume 11. [Google Scholar]
- Yilmaz, V.; Serifoglu Yilmaz, C.; Güngör, O.; Shan, J. A Genetic Algorithm Solution to the Gram-Schmidt Image Fusion. Int. J. Remote Sens. 2020, 41, 1458–1485. [Google Scholar] [CrossRef]
- Baatz, M.; Schape, A. Multiresolution Segmentation—An Optimization Approach for High Quality Multi-Scale Image Segmentation Angewandte Geographische Informationsverarbeitung XII. Proc. Angew. Geogr. Inf. Verarb. XII 2000, 5, 12–23. [Google Scholar]
- Pettorelli, N.; Ryan, S.; Mueller, T.; Bunnefeld, N.; Jedrzejewska, B.; Lima, M.; Kausrud, K. The Normalized Difference Vegetation Index (NDVI): Unforeseen Successes in Animal Ecology. Clim. Res. 2011, 46, 15–27. [Google Scholar] [CrossRef]
- McFEETERS, S.K. The Use of the Normalized Difference Water Index (NDWI) in the Delineation of Open Water Features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Wan, J.; Yong, B. Automatic Extraction of Surface Water Based on Lightweight Convolutional Neural Network. Ecotoxicol. Environ. Saf. 2023, 256, 114843. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Su, H.; Du, Q.; Wu, T. A Novel Surface Water Index Using Local Background Information for Long Term and Large-Scale Landsat Images. ISPRS J. Photogramm. Remote Sens. 2021, 172, 59–78. [Google Scholar] [CrossRef]
- Shao, Y.; Taff, G.N.; Walsh, S.J. Shadow Detection and Building-Height Estimation Using IKONOS Data. Int. J. Remote Sens. 2011, 32, 6929–6944. [Google Scholar] [CrossRef]
- Shi, L.; Zhao, Y. feng Urban Feature Shadow Extraction Based on High-Resolution Satellite Remote Sensing Images. Alex. Eng. J. 2023, 77, 443–460. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Huang, S.; Tang, L.; Hupy, J.P.; Wang, Y.; Shao, G. A Commentary Review on the Use of Normalized Difference Vegetation Index (NDVI) in the Era of Popular Remote Sensing. J. For. Res. 2021, 32, 1–6. [Google Scholar] [CrossRef]
- Roznik, M.; Boyd, M.; Porth, L. Improving Crop Yield Estimation by Applying Higher Resolution Satellite NDVI Imagery and High-Resolution Cropland Masks. Remote Sens. Appl. 2022, 25, 100693. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Q.; Jing, C. Multi-Resolution Segmentation Parameters Optimization and Evaluation for VHR Remote Sensing Image Based on Mean NSQI and Discrepancy Measure. J. Spat. Sci. 2021, 66, 253–278. [Google Scholar] [CrossRef]
- Zhao, M.; Meng, Q.; Zhang, L.; Hu, D.; Zhang, Y.; Allam, M. A Fast and Effective Method for Unsupervised Segmentation Evaluation of Remote Sensing Images. Remote Sens. 2020, 12, 3005. [Google Scholar] [CrossRef]
- Shetty, S.; Gupta, P.K.; Belgiu, M.; Srivastav, S.K. Assessing the Effect of Training Sampling Design on the Performance of Machine Learning Classifiers for Land Cover Mapping Using Multi-Temporal Remote Sensing Data and Google Earth Engine. Remote Sens. 2021, 13, 1433. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User Class\Sample | Water | Vegetation | Uncultivated Fields | Impermeable | Sum |
|---|---|---|---|---|---|
| Water | 60,357 | 0 | 0 | 0 | 60,357 |
| Vegetation | 59,486 | 2,573,163 | 7990 | 185,632 | 2,826,271 |
| Uncultivated Fields | 23,314 | 645 | 3,238,154 | 7695 | 3,269,808 |
| Impermeable | 108,647 | 70,175 | 11,748 | 3,799,636 | 3,990,206 |
| Sum | 251,804 | 2,643,983 | 3,257,892 | 3,992,963 |
| Accuracy | Water | Vegetation | Uncultivated Fields | Impermeable |
|---|---|---|---|---|
| Producer | 0.2397 | 0.9732 | 0.9939 | 0.9516 |
| User | 1 | 0.9104 | 0.9903 | 0.9522 |
| Hellden | 0.3867 | 0.9408 | 0.9921 | 0.9519 |
| Short | 0.2397 | 0.8882 | 0.9844 | 0.9082 |
| Kappa Per Class | 0.2351 | 0.9629 | 0.9911 | 0.9202 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perregrini, D.; Casella, V. Land Use Recognition by Applying Fuzzy Logic and Object-Based Classification to Very High Resolution Satellite Images. Remote Sens. 2024, 16, 2273. https://doi.org/10.3390/rs16132273
Perregrini D, Casella V. Land Use Recognition by Applying Fuzzy Logic and Object-Based Classification to Very High Resolution Satellite Images. Remote Sensing. 2024; 16(13):2273. https://doi.org/10.3390/rs16132273
Chicago/Turabian StylePerregrini, Dario, and Vittorio Casella. 2024. "Land Use Recognition by Applying Fuzzy Logic and Object-Based Classification to Very High Resolution Satellite Images" Remote Sensing 16, no. 13: 2273. https://doi.org/10.3390/rs16132273
APA StylePerregrini, D., & Casella, V. (2024). Land Use Recognition by Applying Fuzzy Logic and Object-Based Classification to Very High Resolution Satellite Images. Remote Sensing, 16(13), 2273. https://doi.org/10.3390/rs16132273