

Evaluating Machine-Learning Algorithms for Mapping LULC of the uMngeni Catchment Area, KwaZulu-Natal

Abstract

1. Introduction
2. Materials and Methods
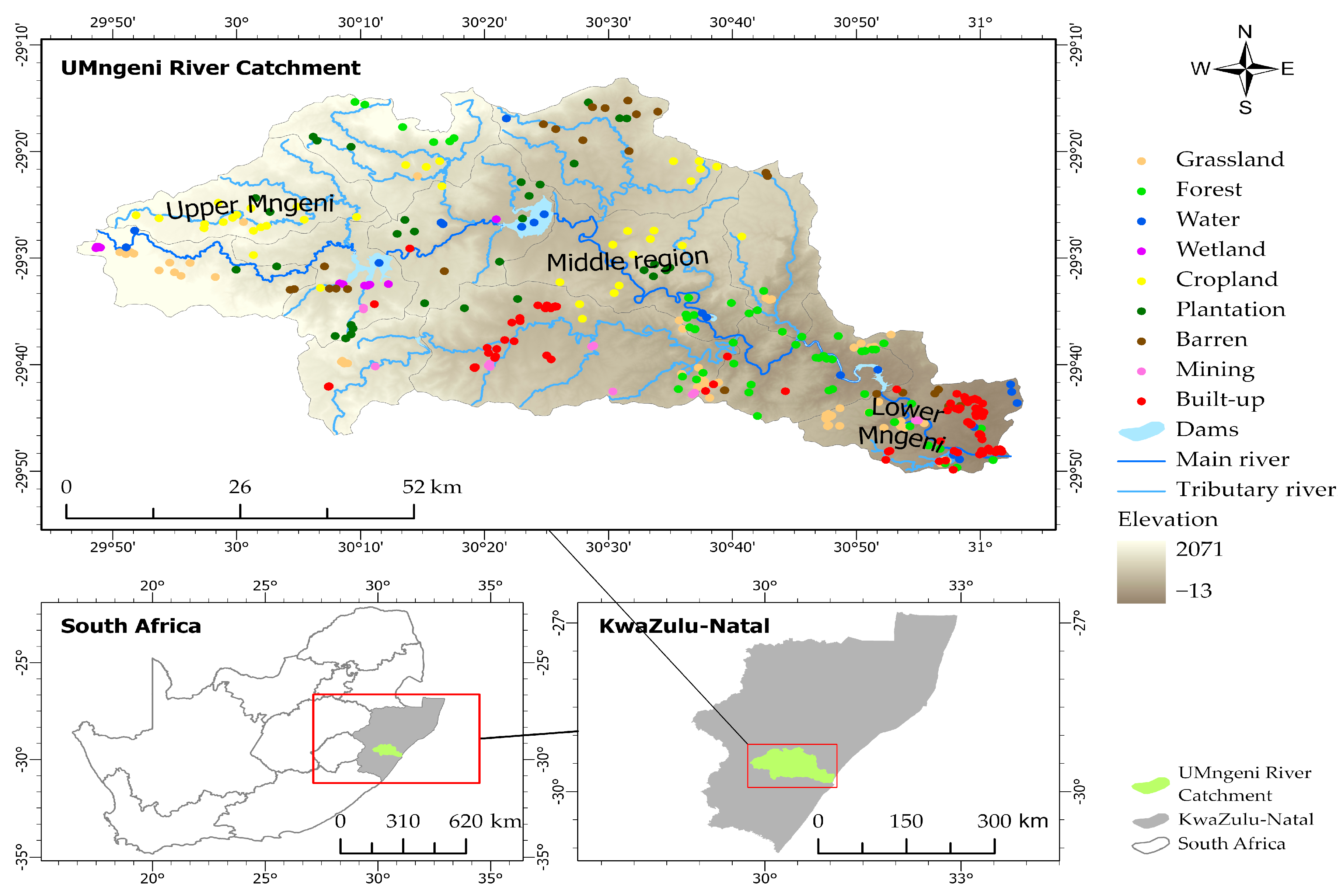
2.1. Study Area
2.2. Definition of LULC Classes in the Umngeni River Catchment
2.3. Remote Sensing Data Acquisition and Preprocessing
Calculated Spectral Indices
2.4. Reference Data Collection
2.5. Image Classification
2.5.1. Selected Classifiers and Parameter Tuning
Random Forests
Support Vector Machine
Artificial Neural Network
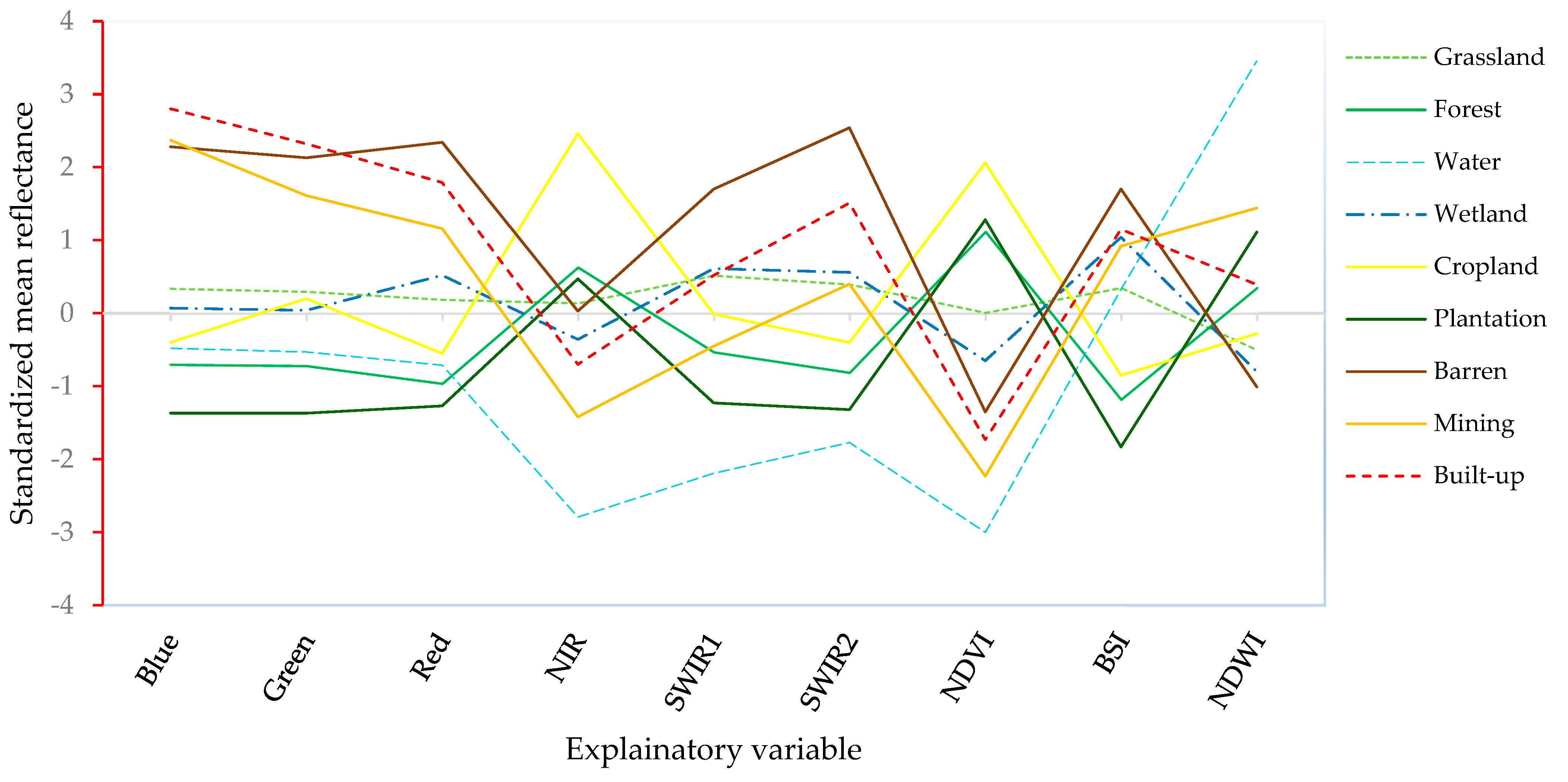
2.6. Variable Importance
2.7. Accuracy Assessment
3. Results
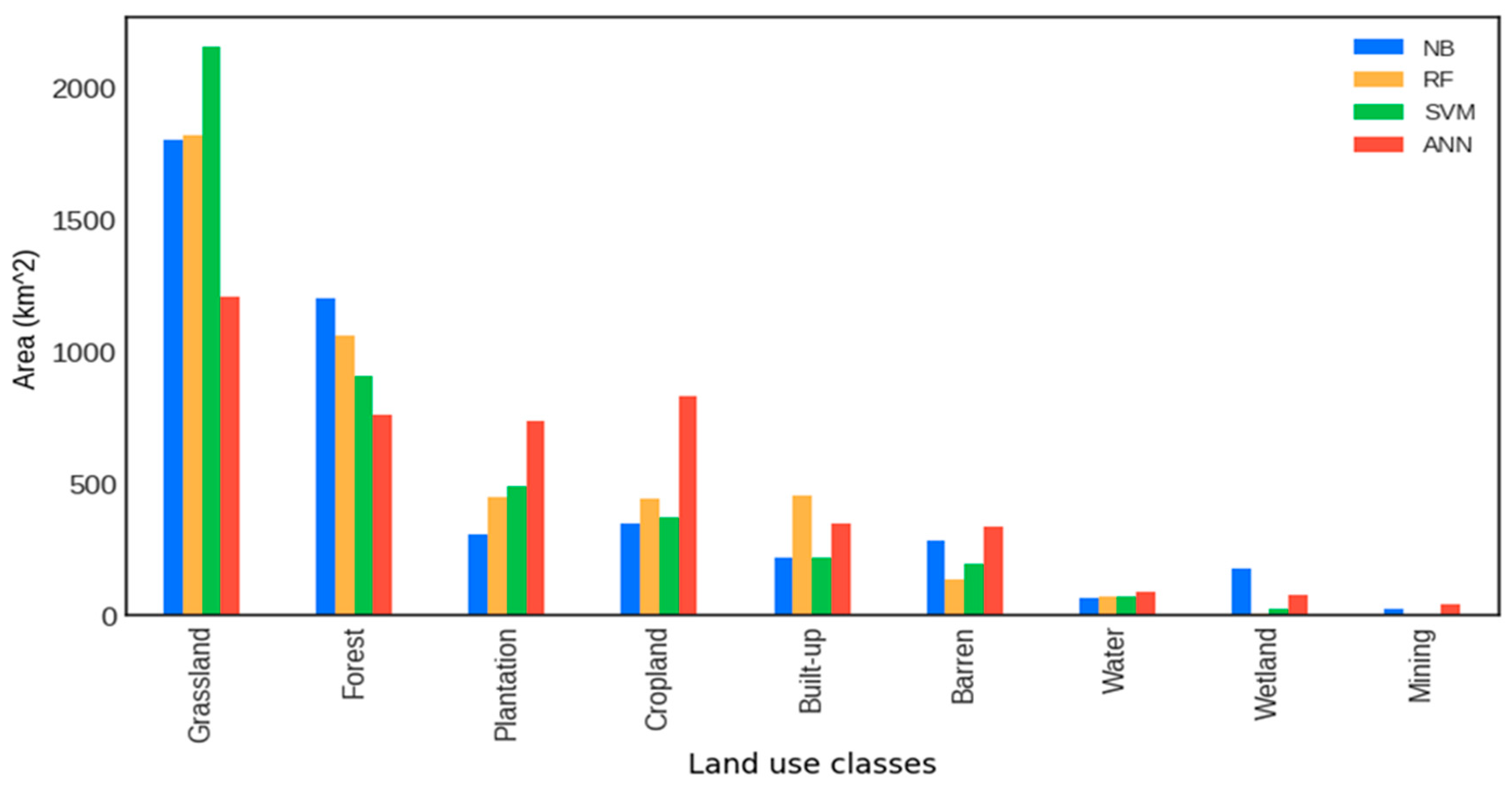
3.1. Mapping and Spatial Extent of LULC Classes
3.2. Comparison of the Mapping Accuracy of Machine Learning Algorithms
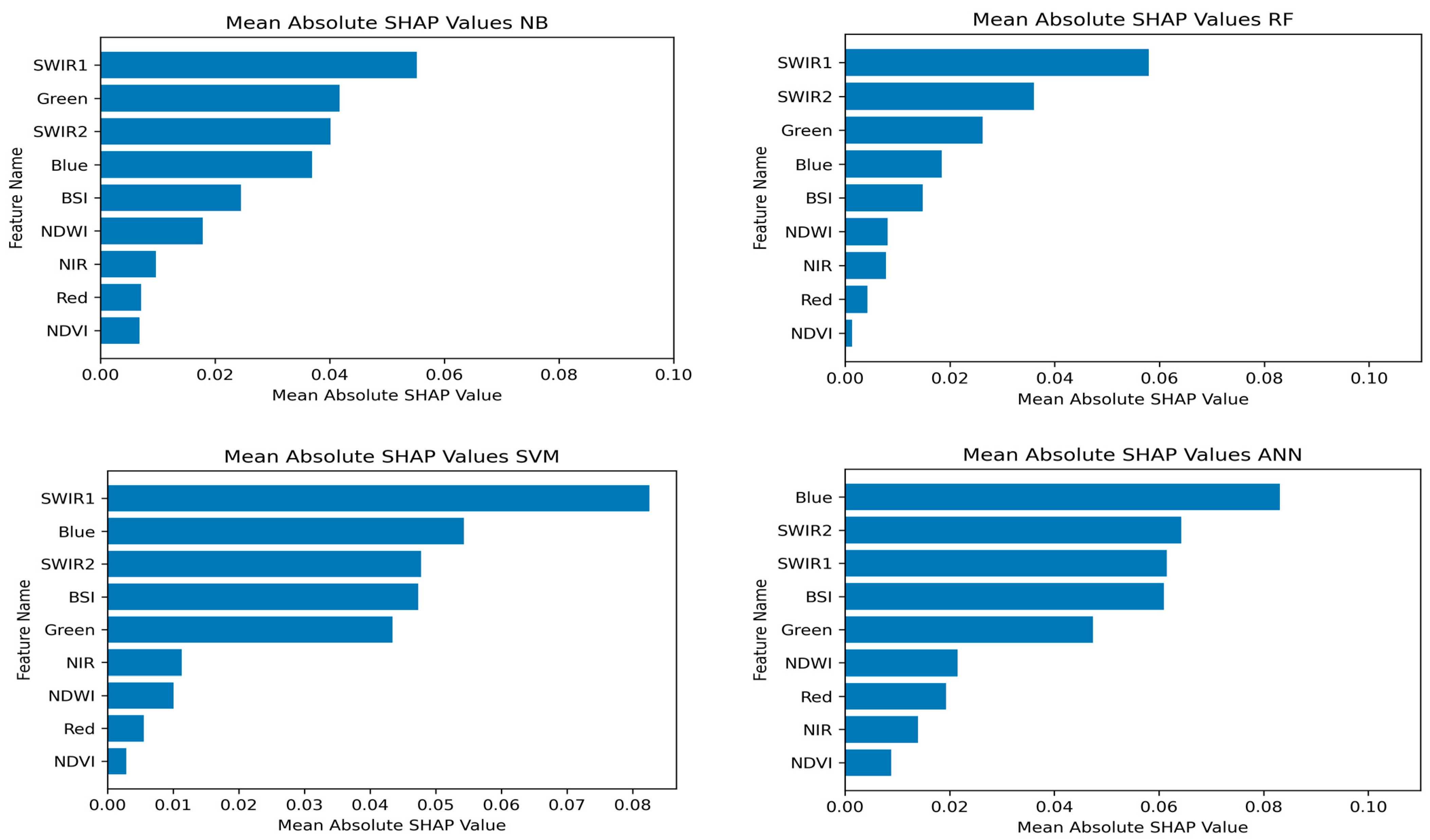
3.3. Model Feature Importance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mekuria, W.; Gedle, A.; Tesfaye, Y.; Phimister, E. Implications of Changes in Land Use for Ecosystem Service Values of Two Highly Eroded Watersheds in Lake Abaya Chamo Sub-Basin, Ethiopia. Ecosyst. Serv. 2023, 64, 101564. [Google Scholar] [CrossRef]
- Aneseyee, A.B.; Soromessa, T.; Elias, E. The Effect of Land Use/Land Cover Changes on Ecosystem Services Valuation of Winike Watershed, Omo Gibe Basin, Ethiopia. Hum. Ecol. Risk Assess. 2020, 26, 2608–2627. [Google Scholar] [CrossRef]
- Pullanikkatil, D.; Palamuleni, L.G.; Ruhiiga, T.M. Land Use/Land Cover Change and Implications for Ecosystems Services in the Likangala River Catchment, Malawi. Phys. Chem. Earth 2016, 93, 96–103. [Google Scholar] [CrossRef]
- Lynch, A.J.; Cooke, S.J.; Arthington, A.H.; Baigun, C.; Bossenbroek, L.; Dickens, C.; Harrison, I.; Kimirei, I.; Langhans, S.D.; Murchie, K.J.; et al. People Need Freshwater Biodiversity. Wiley Interdiscip. Rev. Water 2023, 10, e1633. [Google Scholar] [CrossRef]
- Nyathi, N.A.; Zhao, W.; Musakwa, W. Land Use Land Cover Changes and Their Impacts on Ecosystem Services in the Nzhelele River Catchment, South Africa. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 809–816. [Google Scholar] [CrossRef]
- Gyamfi-Ampadu, E.; Gebreslasie, M.; Mendoza-Ponce, A. Mapping Natural Forest Cover Using Satellite Imagery of Nkandla Forest Reserve, KwaZulu-Natal, South Africa. Remote Sens. Appl. 2020, 18, 100302. [Google Scholar] [CrossRef]
- Obaid, A.; Adam, E.; Ali, K.A. Land Use and Land Cover Change in the Vaal Dam Catchment, South Africa: A Study Based on Remote Sensing and Time Series Analysis. Geomatics 2023, 3, 205–220. [Google Scholar] [CrossRef]
- Namugize, J.N.; Jewitt, G.; Graham, M. Effects of Land Use and Land Cover Changes on Water Quality in the UMngeni River Catchment, South Africa. Phys. Chem. Earth 2018, 105, 247–264. [Google Scholar] [CrossRef]
- Ouchra, H.; Belangour, A.; Erraissi, A. Comparison of Machine Learning Methods for Satellite Image Classification: A Case Study of Casablanca Using Landsat Imagery and Google Earth Engine. J. Environ. Earth Sci. 2023, 5, 118–134. [Google Scholar] [CrossRef]
- Akar, O.; Tunc Gormus, E. Land Use/Land Cover Mapping from Airborne Hyperspectral Images with Machine Learning Algorithms and Contextual Information. Geocarto Int. 2022, 37, 3963–3990. [Google Scholar] [CrossRef]
- Lekka, C.; Petropoulos, G.P.; Detsikas, S.E. Appraisal of EnMAP Hyperspectral Imagery Use in LULC Mapping When Combined with Machine Learning Pixel-Based Classifiers. Environ. Model. Softw. 2024, 173, 105956. [Google Scholar] [CrossRef]
- Delogu, G.; Caputi, E.; Perretta, M.; Ripa, M.N.; Boccia, L. Using PRISMA Hyperspectral Data for Land Cover Classification with Artificial Intelligence Support. Sustainability 2023, 15, 13786. [Google Scholar] [CrossRef]
- James, D.; Collin, A.; Mury, A.; Costa, S. Very High Resolution Land Use and Land Cover Mapping Using Pleiades-1 Stereo Imagery and Machine Learning. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLIII-B2-2020, 675–682. [Google Scholar] [CrossRef]
- Mahmoud, R.; Hassanin, M.; Al Feel, H.; Badry, R.M. Machine Learning-Based Land Use and Land Cover Mapping Using Multi-Spectral Satellite Imagery: A Case Study in Egypt. Sustainability 2023, 15, 9467. [Google Scholar] [CrossRef]
- Bayas, S.; Sawant, S.; Dhondge, I.; Kankal, P.; Joshi, A. Land Use Land Cover Classification Using Different ML Algorithms on Sentinel-2 Imagery. In Advanced Machine Intelligence and Signal Processing; Springer: Singapore, 2022; pp. 761–777. [Google Scholar]
- Parashar, D.; Kumar, A.; Palni, S.; Pandey, A.; Singh, A.; Singh, A.P. Use of Machine Learning-Based Classification Algorithms in the Monitoring of Land Use and Land Cover Practices in a Hilly Terrain. Environ. Monit. Assess. 2024, 196, 8. [Google Scholar] [CrossRef]
- Loukika, K.N.; Keesara, V.R.; Sridhar, V. Analysis of Land Use and Land Cover Using Machine Learning Algorithms on Google Earth Engine for Munneru River Basin, India. Sustainability 2021, 13, 13758. [Google Scholar] [CrossRef]
- Woldemariam, G.W.; Tibebe, D.; Mengesha, T.E.; Gelete, T.B. Machine-Learning Algorithms for Land Use Dynamics in Lake Haramaya Watershed, Ethiopia. Model Earth Syst. Environ. 2022, 8, 3719–3736. [Google Scholar] [CrossRef]
- Dash, P.; Sanders, S.L.; Parajuli, P.; Ouyang, Y. Improving the Accuracy of Land Use and Land Cover Classification of Landsat Data in an Agricultural Watershed. Remote Sens. 2023, 15, 4020. [Google Scholar] [CrossRef]
- Hughes, C.J.; De Winnaar, G.; Schulze, R.E.; Mander, M.; Jewitt, G.P.W. Mapping of Water-Related Ecosystem Services in the UMngeni Catchment Using a Daily Time-Step Hydrological Model for Prioritisation of Ecological Infrastructure Investment—Part 2: Outputs. Water SA 2018, 44, 590–600. [Google Scholar] [CrossRef]
- Kusangaya, S.; Warburton, M.; Archer van Garderen, E. Use of ACRU, a Distributed Hydrological Model, to Evaluate How Errors from Downscaled Rainfall Are Propagated in Simulated Runoff in UMngeni Catchment, South Africa. Hydrol. Sci. J. 2017, 62, 1995–2011. [Google Scholar] [CrossRef]
- Kaur, H.; Tyagi, S.; Mehta, M.; Singh, D. Time Series (2001/2002–2021) Analysis of Earth Observation Data Using Google Earth Engine (GEE) for Detecting Changes in Land Use Land Cover (LULC) with Specific Reference to Forest Cover in East Godavari Region, Andhra Pradesh, India. J. Earth Syst. Sci. 2023, 132, 86. [Google Scholar] [CrossRef]
- Mandal, S.; Bandyopadhyay, A.; Bhadra, A. Dynamics and Future Prediction of LULC on Pare River Basin of Arunachal Pradesh Using Machine Learning Techniques. Environ. Monit Assess 2023, 195, 709. [Google Scholar] [CrossRef]
- Maviza, A.; Ahmed, F. Analysis of Past and Future Multi-Temporal Land Use and Land Cover Changes in the Semi-Arid Upper-Mzingwane Sub-Catchment in the Matabeleland South Province of Zimbabwe. Int. J. Remote Sens. 2020, 41, 5206–5227. [Google Scholar] [CrossRef]
- Foga, S.; Scaramuzza, P.L.; Guo, S.; Zhu, Z.; Dilley, R.D.; Beckmann, T.; Schmidt, G.L.; Dwyer, J.L.; Joseph Hughes, M.; Laue, B. Cloud Detection Algorithm Comparison and Validation for Operational Landsat Data Products. Remote Sens. Environ. 2017, 194, 379–390. [Google Scholar] [CrossRef]
- Mashala, M.J.; Dube, T.; Ayisi, K.K.; Ramudzuli, M.R. Using the Google Earth Engine Cloud-Computing Platform to Assess the Long-Term Spatial Temporal Dynamics of Land Use and Land Cover within the Letaba Watershed, South Africa. Geocarto Int. 2023, 38, 2252781. [Google Scholar] [CrossRef]
- Floreano, I.X.; de Moraes, L.A.F. Land Use/Land Cover (LULC) Analysis (2009–2019) with Google Earth Engine and 2030 Prediction Using Markov-CA in the Rondônia State, Brazil. Environ. Monit. Assess. 2021, 193, 239. [Google Scholar] [CrossRef]
- Orieschnig, C.A.; Belaud, G.; Venot, J.-P.; Massuel, S.; Ogilvie, A. Input Imagery, Classifiers, and Cloud Computing: Insights from Multi-Temporal LULC Mapping in the Cambodian Mekong Delta. Eur. J. Remote Sens. 2021, 54, 398–416. [Google Scholar] [CrossRef]
- Palanisamy, P.A.; Jain, K.; Bonafoni, S. Machine Learning Classifier Evaluation for Different Input Combinations: A Case Study with Landsat 9 and Sentinel-2 Data. Remote Sens. 2023, 15, 3241. [Google Scholar] [CrossRef]
- Viana, C.M.; Girão, I.; Rocha, J. Long-Term Satellite Image Time-Series for Land Use/Land Cover Change Detection Using Refined Open Source Data in a Rural Region. Remote Sens. 2019, 11, 1104. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Nguyen, C.T.; Chidthaisong, A.; Kieu Diem, P.; Huo, L.-Z. A Modified Bare Soil Index to Identify Bare Land Features during Agricultural Fallow-Period in Southeast Asia Using Landsat 8. Land 2021, 10, 231. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the great plains with ERTS. In Proceedings of the Third NASA Earth Resources Technology Satellite Symposium, Washington, DC, USA, 10–14 December 1973; pp. 309–317. [Google Scholar]
- Rikimaru, A.; Roy, P.S.; Miyatake, S. Tropical Forest Cover Density Mapping. Trop. Ecol. 2002, 43, 39–47. [Google Scholar]
- Carlotto, M.J. Effect of Errors in Ground Truth on Classification Accuracy. Int. J. Remote Sens. 2009, 30, 4831–4849. [Google Scholar] [CrossRef]
- Foody, G.M. Assessing the Accuracy of Land Cover Change with Imperfect Ground Reference Data. Remote Sens. Environ. 2010, 114, 2271–2285. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good Practices for Estimating Area and Assessing Accuracy of Land Change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Gandhi, Ujaval, 2021. End-to-End Google Earth Engine Course. Spatial Thoughts. Available online: https://courses.spatialthoughts.com/end-to-end-gee.html (accessed on 2 February 2024).
- Gyamfi-Ampadu, E.; Gebreslasie, M.; Mendoza-Ponce, A. Evaluating Multi-sensors Spectral and Spatial Resolutions for Tree Species Diversity Prediction. Remote Sens. 2021, 13, 1033. [Google Scholar] [CrossRef]
- Costache, R.; Tin, T.T.; Arabameri, A.; Crăciun, A.; Costache, I.; Islam, A.R.M.T.; Sahana, M.; Pham, B.T. Stacking State-of-the-Art Ensemble for Flash-Flood Potential Assessment. Geocarto Int. 2022, 37, 13812–13838. [Google Scholar] [CrossRef]
- Breiman, L.E.O. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, M.; Zhang, Y.; Mao, D.; Li, F.; Wu, F.; Song, J.; Li, X.; Kou, C.; Li, C.; et al. Comparison of Machine Learning Methods for Predicting Soil Total Nitrogen Content Using Landsat-8, Sentinel-1, and Sentinel-2 Images. Remote Sens. 2023, 15, 2907. [Google Scholar] [CrossRef]
- Mather, P.M.; Koch, M. Computer Processing of Remotely-Sensed Images: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2011; ISBN 1119956404. [Google Scholar]
- Cuypers, S.; Nascetti, A.; Vergauwen, M. Land Use and Land Cover Mapping with VHR and Multi-Temporal Sentinel-2 Imagery. Remote Sens. 2023, 15, 2501. [Google Scholar] [CrossRef]
- Kim, Y.H.; Im, J.; Ha, H.K.; Choi, J.K.; Ha, S. Machine Learning Approaches to Coastal Water Quality Monitoring Using GOCI Satellite Data. GIsci Remote Sens. 2014, 51, 158–174. [Google Scholar] [CrossRef]
- Camargo, F.F.; Sano, E.E.; Almeida, C.M.; Mura, J.C.; Almeida, T. A Comparative Assessment of Machine-Learning Techniques for Land Use and Land Cover Classification of the Brazilian Tropical Savanna Using ALOS-2/PALSAR-2 Polarimetric Images. Remote Sens. 2019, 11, 1600. [Google Scholar] [CrossRef]
- Yulianto, F.; Raharjo, P.D.; Pramono, I.B.; Setiawan, M.A.; Chulafak, G.A.; Nugroho, G.; Sakti, A.D.; Nugroho, S.; Budhiman, S. Prediction and Mapping of Land Degradation in the Batanghari Watershed, Sumatra, Indonesia: Utilizing Multi-Source Geospatial Data and Machine Learning Modeling Techniques. Model Earth Syst. Environ. 2023, 9, 4383–4404. [Google Scholar] [CrossRef]
- Huang, C.; Davis, L.S.; Townshend, J.R.G. An Assessment of Support Vector Machines for Land Cover Classification. Int. J. Remote Sens. 2002, 23, 725–749. [Google Scholar] [CrossRef]
- Lantzanakis, G.; Mitraka, Z.; Chrysoulakis, N. X-SVM: An Extension of C-SVM Algorithm for Classification of High-Resolution Satellite Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 3805–3815. [Google Scholar] [CrossRef]
- Srivastava, P.K.; Han, D.; Rico-Ramirez, M.A.; Bray, M.; Islam, T. Selection of Classification Techniques for Land Use/Land Cover Change Investigation. Adv. Space Res. 2012, 50, 1250–1265. [Google Scholar] [CrossRef]
- Martins, S.; Bernardo, N.; Ogashawara, I.; Alcantara, E. Support Vector Machine Algorithm Optimal Parameterization for Change Detection Mapping in Funil Hydroelectric Reservoir (Rio de Janeiro State, Brazil). Model Earth Syst. Environ. 2016, 2, 138. [Google Scholar] [CrossRef]
- Roushangar, K.; Aalami, M.T.; Golmohammadi, H.; Shahnazi, S. Monitoring and Prediction of Land Use/Land Cover Changes and Water Requirements in the Basin of the Urmia Lake, Iran. Water Supply 2023, 23, 2299–2312. [Google Scholar] [CrossRef]
- Saraf, N.M.; Lokman, M.F.; Abdul Rasam, A.R.; Hashim, N. Assessment of Urban Growth Changes in Klang District Using Support Vector Machine by Different Kernel. IOP Conf Ser Earth Environ. Sci 2022, 1051, 012023. [Google Scholar] [CrossRef]
- Dahiya, N.; Gupta, S.; Singh, S. Qualitative and Quantitative Analysis of Artificial Neural Network-Based Post-Classification Comparison to Detect the Earth Surface Variations Using Hyperspectral and Multispectral Datasets. J. Appl. Remote Sens. 2023, 17, 032403. [Google Scholar] [CrossRef]
- Wu, J.L.; Ho, C.R.; Huang, C.C.; Srivastav, A.L.; Tzeng, J.H.; Lin, Y.T. Hyperspectral Sensing for Turbid Water Quality Monitoring in Freshwater Rivers: Empirical Relationship between Reflectance and Turbidity and Total Solids. Sensors 2014, 14, 22670–22688. [Google Scholar] [CrossRef]
- Chen, H.; Lin, X.; Sun, Y.; Wen, J.; Wu, X.; You, D.; Cheng, J.; Zhang, Z.; Zhang, Z.; Wu, C.; et al. Performance Assessment of Four Data-Driven Machine Learning Models: A Case to Generate Sentinel-2 Albedo at 10 Meters. Remote Sens. 2023, 15, 2684. [Google Scholar] [CrossRef]
- Deshpande, A.R.; Emmanuel, M. Context Based Recommendation Methods: A Brief Review. Presented at Conference on Cognitive Knowledge Engineering, Aurangabad, Maharashtra, India, 2016; pp. 14–19. Available online: https://www.researchgate.net/profile/Ratnadeep-Deshmukh-2/publication/329059854_2nd_International_Conference_on_Knowledge_Engineering/links/5bf3dcdba6fdcc3a8de38181/2nd-International-Conference-on-Knowledge-Engineering.pdf#page=58 (accessed on 30 March 2024).
- Hafeez, S.; Wong, M.S.; Ho, H.C.; Nazeer, M.; Nichol, J.; Abbas, S.; Tang, D.; Lee, K.H.; Pun, L. Comparison of Machine Learning Algorithms for Retrieval of Water Quality Indicators in Case-Ii Waters: A Case Study of Hong Kong. Remote Sens. 2019, 11, 617. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Allen, P.G.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://github.com/slundberg/shap (accessed on 23 May 2024).
- Wei, P.; Lu, Z.; Song, J. Variable importance analysis: A comprehensive review. Reliab. Eng. Syst. Saf. 2015, 142, 399–432. [Google Scholar] [CrossRef]
- Hosseiny, B.; Abdi, A.M.; Jamali, S. Urban land use and land cover classification with interpretable machine learning—A case study using Sentinel-2 and auxiliary data. Remote Sens. Appl. Soc. Environ. 2022, 28, 100843. [Google Scholar] [CrossRef]
- Yilmaz, E.O.; Kavzoglu, T. Classification of jilin-1 gp01 hyperspectral image using machine learning techniques with explainable artificial intelligence. Intercont. Geoinf. Days 2022, 5, 145–148. [Google Scholar]
- Hua, A.K. Land Use Land Cover Changes in Detection of Water Quality: A Study Based on Remote Sensing and Multivariate Statistics. J. Environ. Public Health 2017, 2017, 5–7. [Google Scholar] [CrossRef]
- Congalton, R.G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Kang, C.S.; Kanniah, K.D.; Mohd Najib, N.E. Google Earth Engine for Landsat Image Processing and Monitoring Land Use/Land Cover Changes in the Johor River Basin, Malaysia. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 4236–4239. [Google Scholar]
- Story, M.; Congalton, R.G. Accuracy Assessment: A User’s Perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- Lukeš, P.; Stenberg, P.; Rautiainen, M.; Mõttus, M.; Vanhatalo, K.M. Optical Properties of Leaves and Needles for Boreal Tree Species in Europe. Remote Sens. Lett. 2013, 4, 667–676. [Google Scholar] [CrossRef]
- Schultz, B.; Immitzer, M.; Formaggio, A.; Sanches, I.; Luiz, A.; Atzberger, C. Self-Guided Segmentation and Classification of Multi-Temporal Landsat 8 Images for Crop Type Mapping in Southeastern Brazil. Remote Sens. 2015, 7, 14482–14508. [Google Scholar] [CrossRef]
- Sothe, C.; Almeida, C.; Liesenberg, V.; Schimalski, M. Evaluating Sentinel-2 and Landsat-8 Data to Map Sucessional Forest Stages in a Subtropical Forest in Southern Brazil. Remote Sens. 2017, 9, 838. [Google Scholar] [CrossRef]
- Chen, H.; Yang, L.; Wu, Q. Enhancing Land Cover Mapping and Monitoring: An Interactive and Explainable Machine Learning Approach Using Google Earth Engine. Remote Sens. 2023, 15, 4585. [Google Scholar] [CrossRef]
- McCarty, D.A.; Kim, H.W.; Lee, H.K. Evaluation of Light Gradient Boosted Machine Learning Technique in Large Scale Land Use and Land Cover Classification. Environments 2020, 7, 84. [Google Scholar] [CrossRef]
- Abdi, A.M. Land Cover and Land Use Classification Performance of Machine Learning Algorithms in a Boreal Landscape Using Sentinel-2 Data. GIsci Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef]
- Ashiagbor, G.; Asare-Ansah, A.O.; Amoah, E.B.; Asante, W.A.; Mensah, Y.A. Assessment of Machine Learning Classifiers in Mapping the Cocoa-Forest Mosaic Landscape of Ghana. Sci. Afr. 2023, 20, e01718. [Google Scholar] [CrossRef]
- Foody, G.M. Valuing Map Validation: The Need for Rigorous Land Cover Map Accuracy Assessment in Economic Valuations of Ecosystem Services. Ecol. Econ. 2015, 111, 23–28. [Google Scholar] [CrossRef]
- Machado, R.A.S.; Oliveira, A.G.; Lois-González, R.C. Urban Ecological Infrastructure: The Importance of Vegetation Cover in the Control of Floods and Landslides in Salvador/Bahia, Brazil. Land Use Policy 2019, 89, 104180. [Google Scholar] [CrossRef]
- Abbas, H.; Tao, W.; Khan, G.; Alrefaei, A.F.; Iqbal, J.; Albeshr, M.F.; Kulsoom, I. Multilayer Perceptron and Markov Chain Analysis Based Hybrid-Approach for Predicting Land Use Land Cover Change Dynamics with Sentinel-2 Imagery. Geocarto Int. 2023, 38, 2256297. [Google Scholar] [CrossRef]
- Gyamfi-Ampadu, E.; Gebreslasie, M.; Mendoza-Ponce, A. Multi-Decadal Spatial and Temporal Forest Cover Change Analysis of Nkandla Natural Reserve, South Africa. J. Sustain. For. 2022, 41, 959–982. [Google Scholar] [CrossRef]
- du Plessis, A.; Harmse, T.; Ahmed, F. Quantifying and Predicting the Water Quality Associated with Land Cover Change: A Case Study of the Blesbok Spruit Catchment, South Africa. Electron. J. Theor. Phys. 2014, 11, 2946–2968. [Google Scholar] [CrossRef]
- Mararakanye, N.; Le Roux, J.J.; Franke, A.C. Long-Term Water Quality Assessments under Changing Land Use in a Large Semi-Arid Catchment in South Africa. Sci. Total Environ. 2022, 818, 151670. [Google Scholar] [CrossRef]
- Schütte, S.; Schulze, R.E. Projected Impacts of Urbanisation on Hydrological Resource Flows: A Case Study within the UMngeni Catchment, South Africa. J. Environ. Manag. 2017, 196, 527–543. [Google Scholar] [CrossRef]
- Kibena, J.; Nhapi, I.; Gumindoga, W. Assessing the Relationship between Water Quality Parameters and Changes in Landuse Patterns in the Upper Manyame River, Zimbabwe. Phys. Chem. Earth 2014, 67–69, 153–163. [Google Scholar] [CrossRef]
- Tena, T.M.; Mwaanga, P.; Nguvulu, A. Impact of Land Use/Land Cover Change on Hydrological Components in Chongwe River Catchment. Sustainability 2019, 11, 6415. [Google Scholar] [CrossRef]
- Jewitt, D.; Goodman, P.S.; Erasmus, B.F.N.; O’Connor, T.G.; Witkowski, E.T.F. Systematic Land-Cover Change in KwaZulu-Natal, South Africa: Implications for Biodiversity. S. Afr. J. Sci. 2015, 111, 9. [Google Scholar] [CrossRef]
- Twesigye, C.K. The Impact of Land Use Activities on Vegetation Cover and Water Quality in the Lake Victoria Watershed. Open Environ. Eng. J. 2011, 4, 66–77. [Google Scholar] [CrossRef]
- Moodley, K.; Toucher, M.L.; Lottering, R.T. Simulating Future Land-Use within the UThukela and UMngeni Catchments in KwaZulu-Natal. Sci. Afr. 2023, 20, e01666. [Google Scholar] [CrossRef]
- Balha, A.; Mallick, J.; Pandey, S.; Gupta, S.; Singh, C.K. A Comparative Analysis of Different Pixel and Object-Based Classification Algorithms Using Multi-Source High Spatial Resolution Satellite Data for LULC Mapping. Earth Sci. Inform. 2021, 14, 2231–2247. [Google Scholar] [CrossRef]
- Nayak, A.; Bhushan, B. Wetland Ecosystems and Their Relevance to the Environment. In Handbook of Research on Monitoring and Evaluating the Ecological Health of Wetlands; IGI Global: Hershey, PA, USA, 2022; pp. 1–16. [Google Scholar]
- Campbell, J.B.; Wynne, R.H. Introduction to Remote Sensing; Guilford Press: New York, NY, USA, 2011; ISBN 1609181778. [Google Scholar]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015; ISBN 111834328X. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class ID | LULC Classes | Description |
|---|---|---|
| 1 | Grassland | Includes grass and shrubs open areas, as well as golf courses, and sport fields grounds |
| 2 | Forest | Natural forests or transition foarest areas rangeing from low to highly dense canopy cover, dominated with trees of appraximately 5 m high. |
| 3 | Water | This class considers natural or artificial surface fresh waterbodies within the study area, which includes main rivers and tributries, dams, lakes, and ponds |
| 4 | Wetland | This class is mainly made up of hydrphytes and herbaceous species which are solely based on the moisture of the soil to survive. The wetlands can be permanent or temporary depending on the local climate or its size and water holding capacity. |
| 5 | Cropland | Composed of both subsistance and ecommercial farming, which might be annual crops, or seasonal. During the post harvest, cultivated lands are charecterised as bare land in the case of seasonal crops. |
| 6 | Plantation | Range of tree species cultivated for commercial purposes, this class includes greener patches of the mature trees, sub adult, young, jiviniles, and tree stumps. |
| 7 | Barren | Partial vegetated areas, bare land due to either erosion, natural degradation or human factors, post harvest crop fields, dry river banks, and stripped rock areas. |
| 8 | Mining | Small patches of mining scars, which comprise of open cast pits, sand mining, and the open raw material processing sites. |
| 9 | Built-up | Built-up structures, which includes all forms residential areas, economic corridors, industrial, commercial, educational, religious and health infrastructures. |
| Bands | Wavelength (λ) | Resolution (m) |
|---|---|---|
| Blue | 0.45–0.51 µm | 30 m |
| Green | 0.53–0.59 µm | 30 m |
| Red | 0.64–0.67 µm | 30 m |
| Near Infrared (NIR) | 0.85–0.87 µm | 30 m |
| Shortwave Infrared 1 (SWIR 1) | 1.56–1.65 µm | 30 m |
| Shortwave Infrared 2 (SWIR 2) | 2.10–2.29 µm | 30 m |
| Index | Equation | References |
|---|---|---|
| NDVI | NDVI | [30] |
| NDWI | NDWI | [32] |
| BSI | BSI = | [33] |
| LULC Class | No. of Polygons | Training Pixel Count | Test Pixel Count |
|---|---|---|---|
| Grassland | 63 | 6944 | 1685 |
| Forest | 51 | 5823 | 1483 |
| Water | 38 | 1865 | 435 |
| Wetland | 11 | 357 | 86 |
| Cropland | 38 | 8965 | 2163 |
| Plantation | 32 | 7820 | 1957 |
| Barren | 30 | 4492 | 1075 |
| Built-up | 86 | 2504 | 598 |
| Mining | 13 | 667 | 159 |
| Total | 362 | 39437 | 9641 |
| Classifier | Classifiers | Parameters | Parameter Adjustments |
|---|---|---|---|
| NB | ee.Classifier.smileNaiveBayes() | λ | 0.000001 |
| RF | ee.Classifier.smileRandomForest() | Ntree | 25.00 |
| Mtry | null | ||
| MinLeafPopulation | 2.00 | ||
| MaxNodes | 1000.00 | ||
| BagFraction | 0.50% | ||
| SVM | ee.Classifier.libsvm() | kernelType | POLY |
| svmType | C_SVC | ||
| coef0 | 0.3 | ||
| degree | 1.00 | ||
| cost | 10 | ||
| ANN | MLPClassifier (ANN) | activation | RELU |
| hidden_layer | 1.00 | ||
| nuerons | 10 |
| LULC Class | Area in km2 | Area in % |
|---|---|---|
| Grassland | 1819.31 | 40.94 |
| Forest | 1058.55 | 23.82 |
| Built-up | 455.69 | 10.25 |
| Cropland | 446.49 | 10.05 |
| Plantation | 440.29 | 9.91 |
| Barren | 134.68 | 3.03 |
| Water | 74.81 | 1.68 |
| Wetland | 5.29 | 0.12 |
| Mining | 3.35 | 0.08 |
| Total | 4444.00 | 100.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhungeni, O.; Ramjatan, A.; Gebreslasie, M. Evaluating Machine-Learning Algorithms for Mapping LULC of the uMngeni Catchment Area, KwaZulu-Natal. Remote Sens. 2024, 16, 2219. https://doi.org/10.3390/rs16122219
Bhungeni O, Ramjatan A, Gebreslasie M. Evaluating Machine-Learning Algorithms for Mapping LULC of the uMngeni Catchment Area, KwaZulu-Natal. Remote Sensing. 2024; 16(12):2219. https://doi.org/10.3390/rs16122219
Chicago/Turabian StyleBhungeni, Orlando, Ashadevi Ramjatan, and Michael Gebreslasie. 2024. "Evaluating Machine-Learning Algorithms for Mapping LULC of the uMngeni Catchment Area, KwaZulu-Natal" Remote Sensing 16, no. 12: 2219. https://doi.org/10.3390/rs16122219
APA StyleBhungeni, O., Ramjatan, A., & Gebreslasie, M. (2024). Evaluating Machine-Learning Algorithms for Mapping LULC of the uMngeni Catchment Area, KwaZulu-Natal. Remote Sensing, 16(12), 2219. https://doi.org/10.3390/rs16122219