1. Introduction
Ships, as primary entities in safeguarding maritime interests, have garnered continuous attention [
1]. The detection and classification of such ships furnish strategic decision-makers with indispensable insights, effectively truncating decision cycles, and serve as a pivotal foundation for achieving real-time situational awareness in expansive operational environments [
2]. With the advancement of remote sensing imaging technologies, the surveillance of vast maritime domains has become feasible, consequently garnering widespread attention to maritime target detection and classification techniques [
3]. In civilian domains, this forms the bedrock for implementing marine resource regulation, illegal fishing monitoring, and aiding maritime rescue operations [
4], while in military domains, it finds utility in patrolling territorial waters, safeguarding maritime rights, and monitoring critical port facilities [
5]. In recent years, with the exponential augmentation of computational prowess, deep learning has witnessed accelerated development [
6,
7]. The application of deep learning-based target detection algorithms in maritime target detection not only economizes on human and material resources but also amplifies efficiency, thereby playing a pivotal role in ensuring maritime security [
8].
Infrared (IR) imaging technology has all-weather work, excellent concealment, wide detection range, and anti-electromagnetic interference ability; therefore, IR small target detection technology is one of the main means of marine monitoring. When the distance between IR detectors and targets exceeds 10 km, or even several tens of kilometers, the coverage area of the target typically diminishes [
9]. This phenomenon results in relatively diminutive ship dimensions in IR images, escalating the demands on detection algorithms and rendering the prevailing algorithms incapable of achieving satisfactory outcomes [
10]. Unlike conventional IR small target detection, maritime ship detection confronts multifarious challenges. As depicted in
Figure 1, atmospheric scattering and refraction, optical focusing, and various forms of noise precipitate a low signal-to-noise ratio (SNR) in IR imagery, with scant texture detail, resulting in weakened target signals and diminished contrast against backgrounds [
11,
12]. Additionally, maritime backgrounds are rife with myriad clutter interferences. Strong radiation clutter generated by phenomena such as waves and fish-scale ripples bears resemblance to ship shapes, thereby easily impeding ship detection [
13]. Simultaneously, radiation-intense phenomena such as cloud clusters and islands formed by seawater evaporation further impede ship detection. Moreover, maritime ships typically appear in fleets, engendering the presence of multiple ships in images, thus amplifying detection complexity. Consequently, maritime ship detection harbors distinctive characteristics and challenges in IR image processing.
To detect IR small targets, several conventional methods have been proposed, including filter-based, local information-based, and data structure-based algorithms. Filter-based methods encompass a wide array of techniques, including spatial domain filters and transform domain filters. The former predicts backgrounds in spatial domains to accentuate targets [
14], while the latter investigates target correlation properties in frequency domains [
15]. However, filter-based algorithms can only suppress uniform backgrounds and fail to mitigate complex background noise. Local information-based methods leverage the characteristics of the target and its local region’s grayscale and brightness variations [
16], but are susceptible to overlooking dim targets and prone to false alarms from high-contrast noise. Data structure-based methods evolve primarily from the differential data structures between targets and backgrounds [
17], accommodating low signal-to-clutter ratios (SCR) in IR imagery yet still manifesting high false alarm rates in images containing small targets and shape variations amidst complex backgrounds [
18]. These conventional IR small target detection algorithms hinge on robust prior knowledge, which poses challenges in handling complex backgrounds. In recent years, with the advent of deep learning-based algorithms, the field of IR small target detection has achieved leapfrog development, marked by a significant improvement in detection accuracy [
19].
Deep learning-based detection algorithms can be classified into those based on target detection strategies and those based on semantic segmentation. Algorithms based on target detection strategies further branch into two-stage, one-stage, and anchor-free algorithms. Two-stage algorithms encompass candidate generation, feature extraction, and classification regression as key steps [
20]. Although two-stage algorithms exhibit high precision, they tend to be slower. One-stage algorithms predict target categories and positions directly on the original image [
21], while anchor-free algorithms reduce model parameter volume [
22]. Algorithms based on semantic segmentation classify images by pixels to obtain position and contour information. Semantic segmentation-based algorithms include fully convolutional networks, encoder-decoder architectures, and attention mechanism algorithms. Fully convolutional networks extract features by replacing the final, fully connected layer with convolutional layers [
23]. Encoder-decoder architectures utilize downsampling to extract features and upsampling to restore resolution [
24]. Attention mechanism algorithms enhance detection accuracy and efficiency by directing network attention to critical areas in images through training [
25,
26]. This paper focuses on investigating maritime IR small ship target detection using an encoder-decoder structure semantic segmentation algorithm, with the following primary contributions:
Proposing FCNet, a network tailored for maritime IR small ship detection, exhibiting superior precision performance compared to other prominent algorithms.
Introducing an FEM to enhance input image features before encoding, thereby acquiring superior features.
Devising a CFM to fuse contextual information during encoding, balancing local and global information while mitigating target edge information loss.
Introducing an SFM in the decoding process to connect shallow features containing position and texture information with deep semantic information through skip connections, facilitating multiscale feature fusion, thereby retaining critical image information and enhancing detection accuracy.
Proposing the Maritime-SIRST dataset, derived from remote sensing satellite IR band images of complex maritime scenes, to meet the requirements of this research and foster development in related fields.
The structure of this paper is as follows:
Section 2 provides a brief overview of related works. In
Section 3, the network structure of FCNet is detailed, along with the introduction of the Maritime-SIRST maritime IR ship detection dataset we constructed.
Section 4 presents comparative experiments, ablation experimental results, and discussions. Finally,
Section 5 offers conclusions.
3. Materials and Methods
3.1. Structure of FCNet
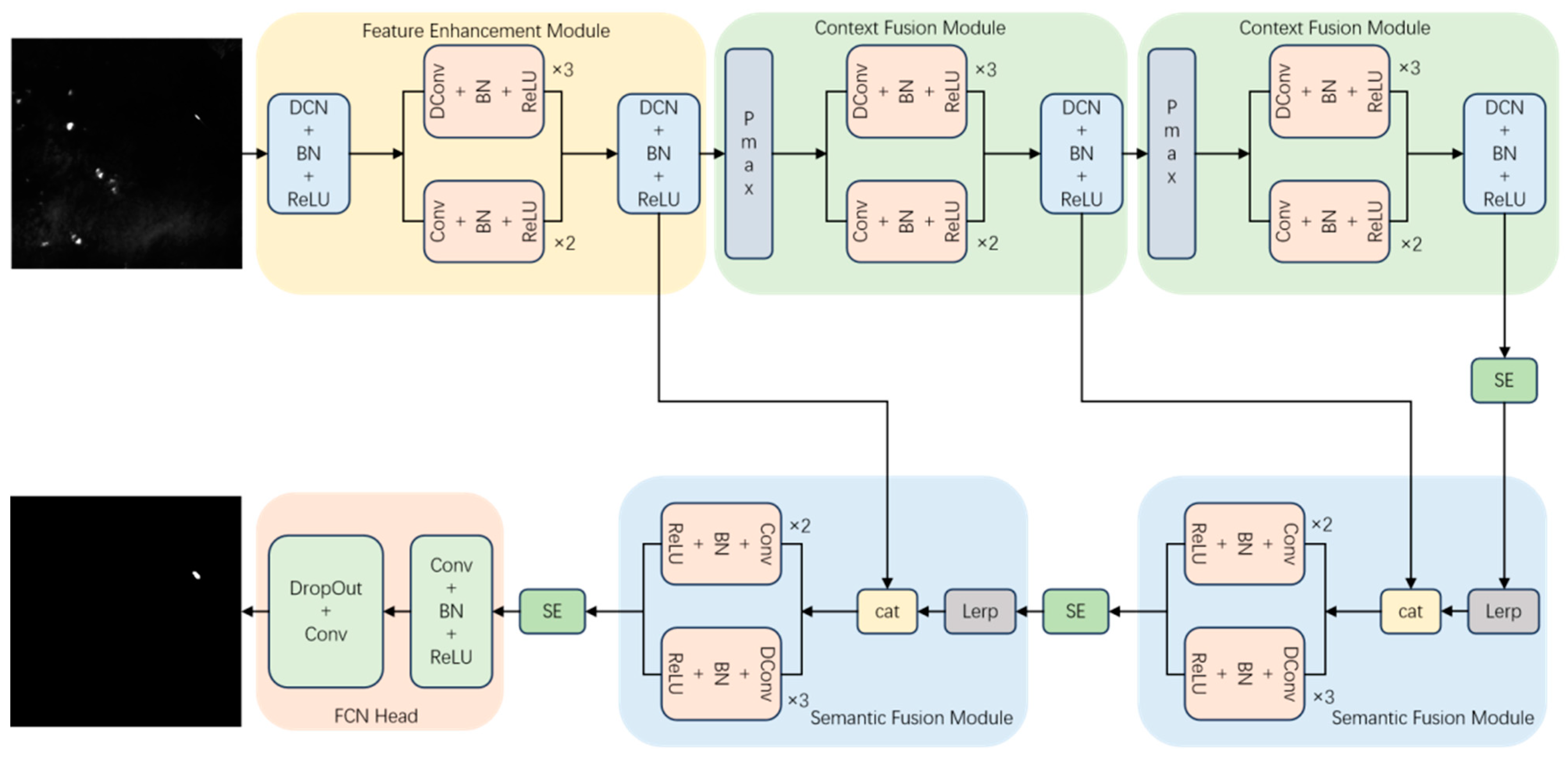
The model proposed in this paper is based on an encoder-decoder architecture. Given the limited pixel occupancy of small targets in images, traditional encoder layers with four levels of downsampling may lead to feature loss. Therefore, we opt for only two encoder and decoder layers.
Figure 4 illustrates the network structure of FCNet, comprising one feature enhancement module (FEM) and two context fusion modules (CFM) in the encoder, two semantic fusion modules (SFM), three squeeze-and-excitation (SE) blocks, and one FCN Head in the decoder. Initially, the original image is fed into the FEM. The FEM consists of two deformable convolutions and a joint module of standard convolution and dilated convolution (CDCFM), amalgamating multiple convolutions to yield enhanced feature maps. Subsequently, the enhanced feature maps are input into two CFMs. CFM comprises a max-pooling layer, a CDCFM, and a deformable convolution layer, extracting fused information from contextual and local aspects to mitigate information loss during encoding. During the upsampling process, we employ the SFM. Initially, this module linearly interpolates the feature maps conveyed from the encoder layers for upsampling. It then integrates shallow semantic information and amalgamates deep and shallow semantic information through a CDCFM. Additionally, during upsampling, we introduce three SE blocks [
38]. The SE block, a form of channel attention mechanism, aids in learning weights for different channels to attain superior feature representation. Ultimately, we utilize the FCN Head to output segmentation results.
3.2. Structure of FEM
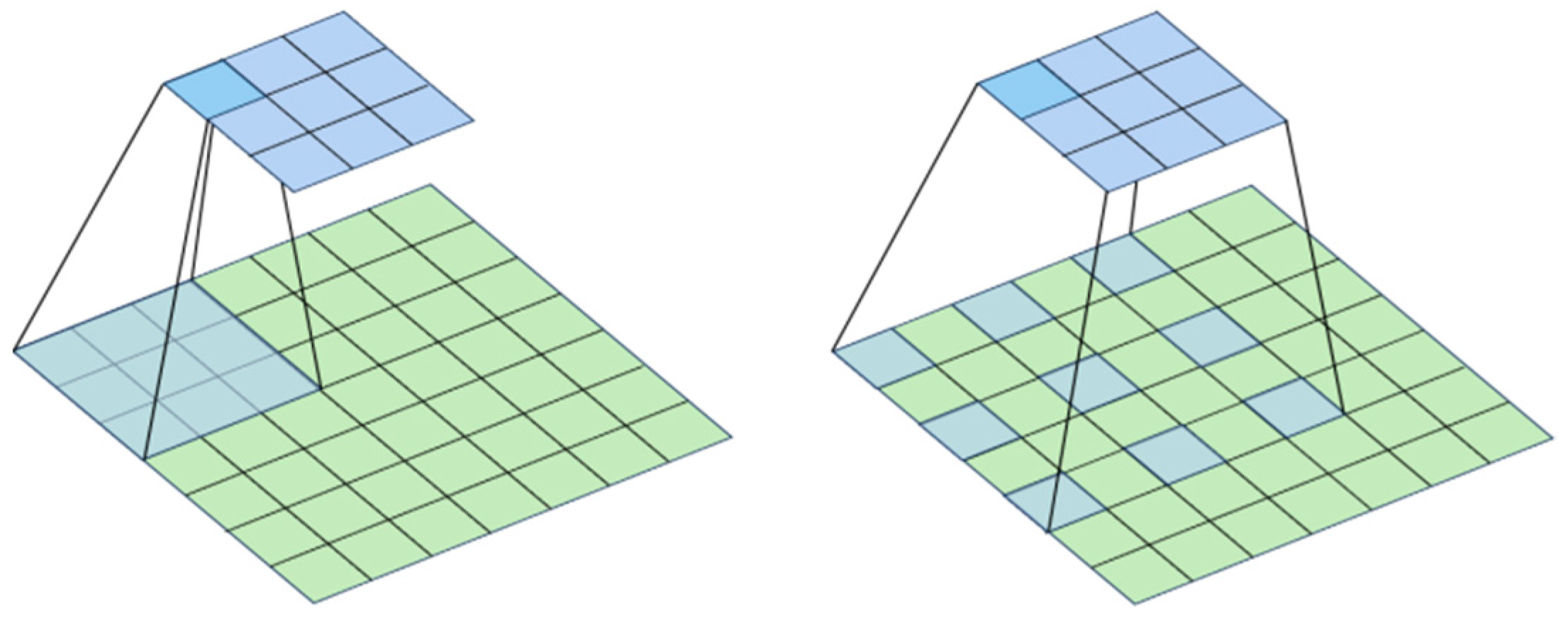
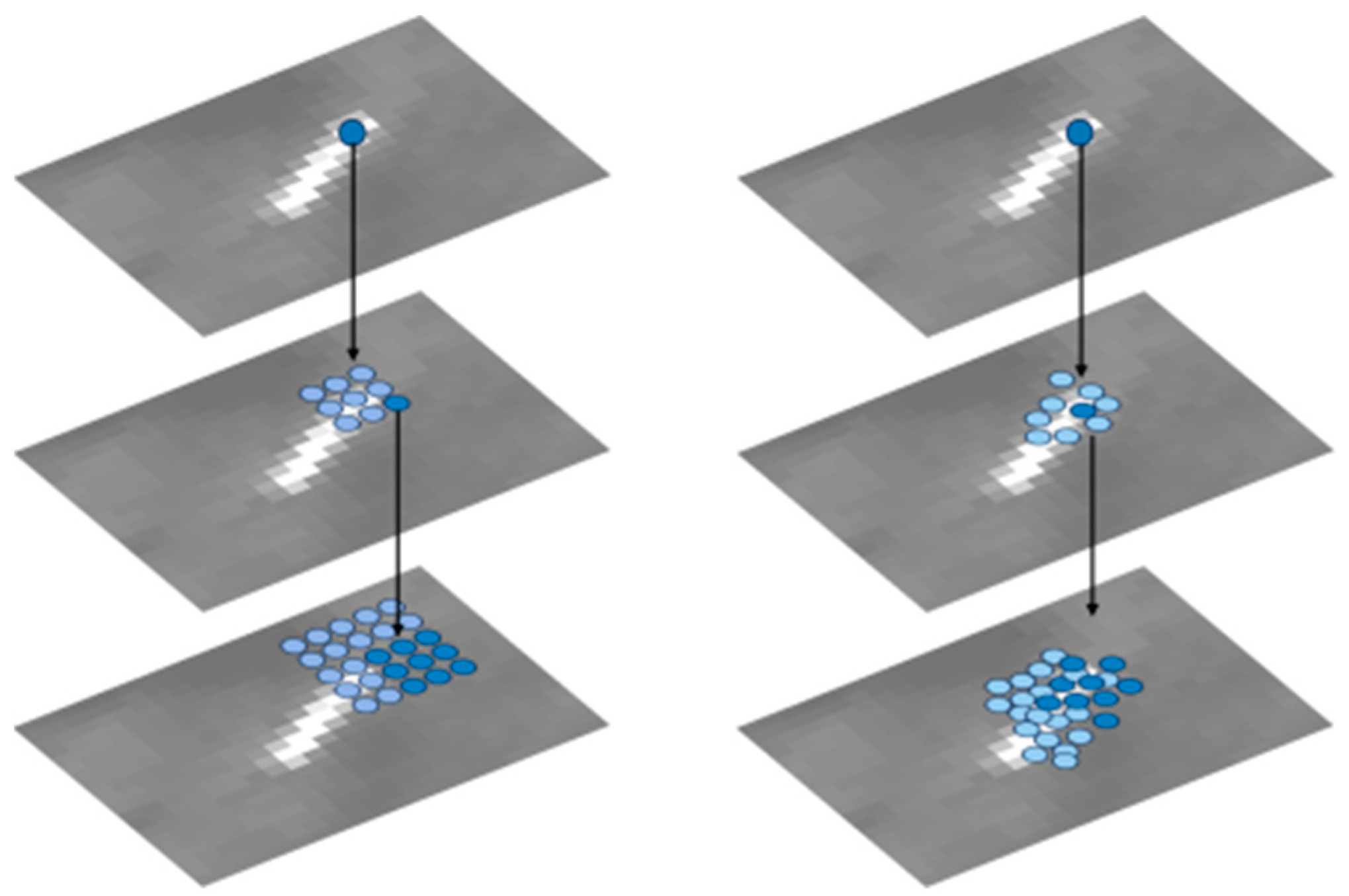
In the standard convolution process, the fixed-shape convolution kernel easily loses edge information of the target. For small targets, occupying merely a dozen pixels, the loss of even a few pixel edge details is considerably significant. Processing the input feature map through deformable convolutions allows the model to learn the shape information of the target, thereby reducing the loss of edge details.
The convolution kernel size in standard convolutions is typically set to 3 × 3. Small kernels have a limited receptive field, are capable of extracting only local information, and thus may lose contextual semantic information, while excessively large kernels require more computational resources. To compensate for the loss of contextual semantics by standard convolutions, we introduce dilated convolutions. Given their larger receptive field, dilated convolutions capture multiscale contextual information, whereas standard convolutions obtain more precise local information. Hence, we devise the CDCFM module to balance contextual and local semantic information by amalgamating the feature maps generated by both. The CDCFM module comprises two branches. The first branch includes three dilated convolutions, each with dilation rates of 1, 2, and 3, respectively, to capture multiscale contextual information. The second branch consists of two standard convolutions with 3 × 3 kernel sizes, extracting local information. Following each convolutional layer, we incorporate batch normalization layers to expedite training and enhance model generalization. Subsequent to the batch normalization layers, ReLU activation functions are introduced to introduce non-linearity and improve the model’s expressive capability.
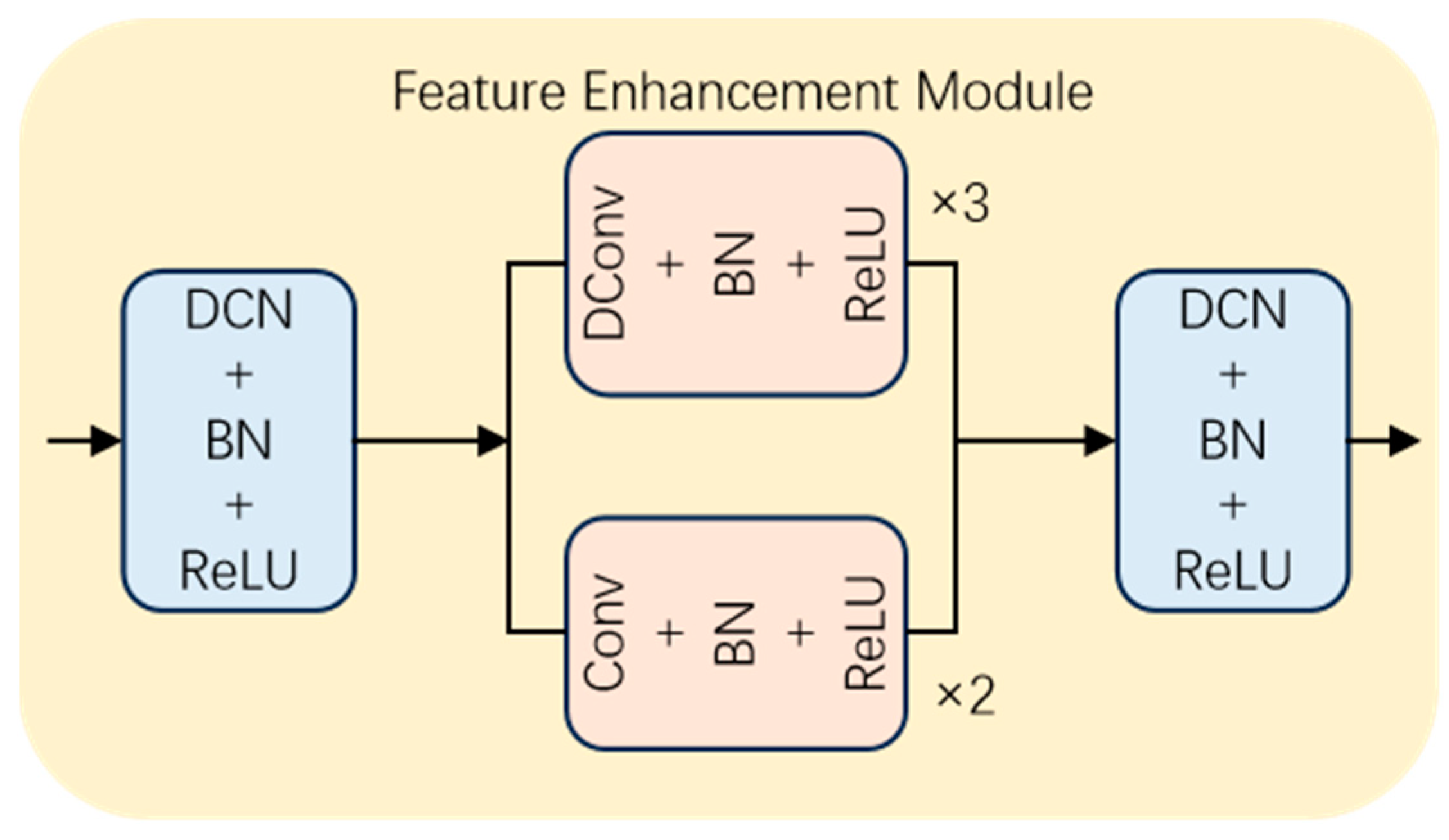
We have constructed an FEM based on the CDCFM and DCN modules, as illustrated in
Figure 5. Initially, the input feature map
undergoes processing via the DCN module to yield
, which adaptively learns receptive field information tailored to the contours of small targets. Subsequently, the output
is fed into the CDCFM, where it merges the localized details from standard convolutions with the multiscale contextual information from three layers of dilated convolutions, culminating in feature representation enhancement to yield
. Following this,
is obtained through another pass via the DCN module, effectively compensating for the loss of edge information pertaining to small targets. The precise computational procedures are detailed in Equations (1) and (2):
Here, DCN(·) denotes deformable convolution, DConv(·) denotes dilated convolution, with the superscript 3 indicating the operation of dilated convolution performed three times, Conv(·) denotes standard convolution, with the superscript 2 indicating the operation of standard convolution executed twice, and the symbol signifies direct addition of the corresponding values from the feature maps, followed by normalization through the ReLU function.
The original image, when processed through the FEM, not only acquires a wealth of contextual information through flexible receptive fields of varying sizes and shapes but also amalgamates precise local semantic information. Consequently, the extracted feature maps from the original image become more efficacious, furnishing a more favorable foundation for subsequent encoding procedures.
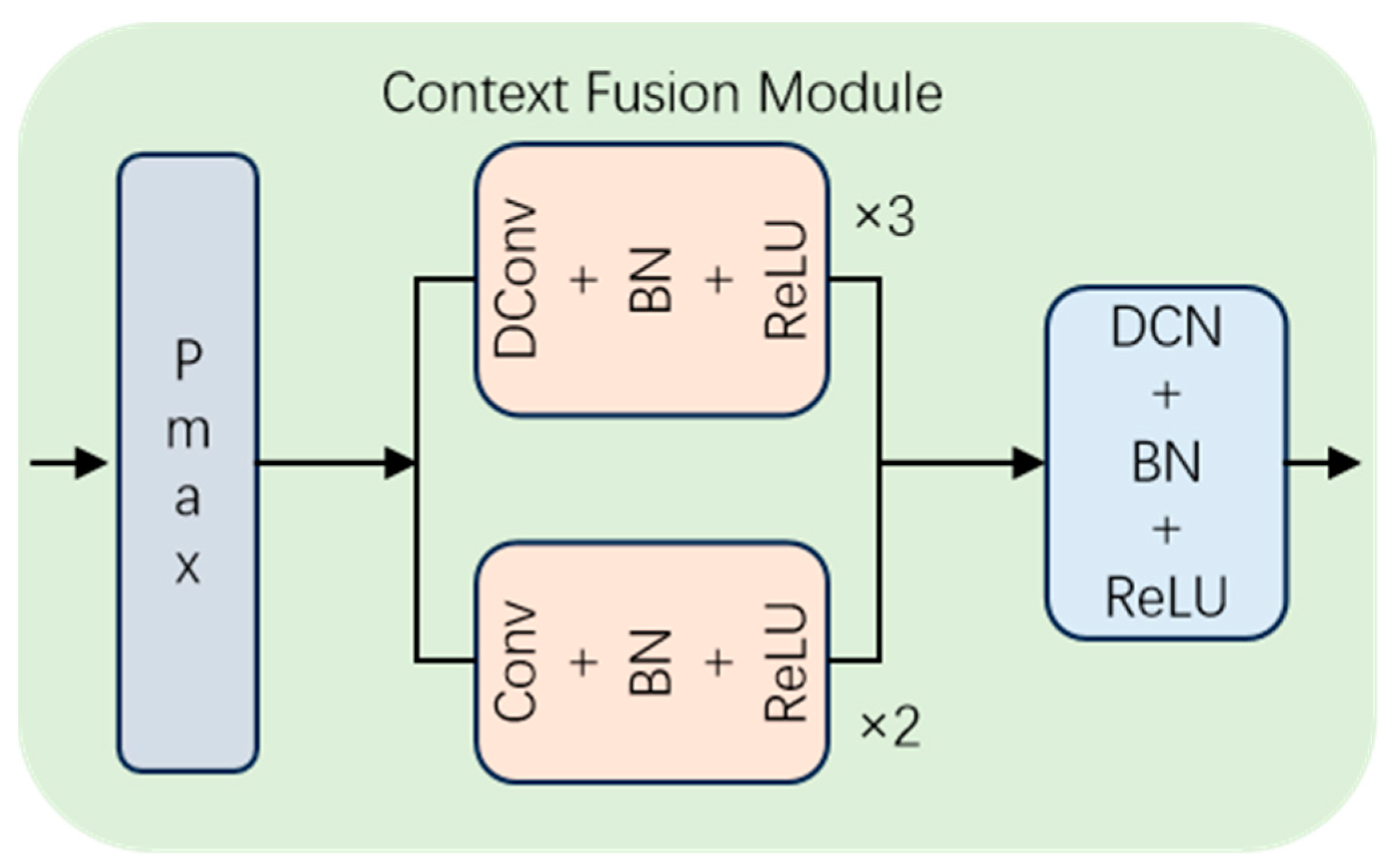
3.3. Structure of CFM
During the downsampling process, the resolution of the feature map gradually decreases, potentially leading to a significant loss of contextual information during pooling. Therefore, preserving the integrity of contextual semantic information becomes particularly crucial during downsampling.
Our proposed CFM aims to fuse contextual information after pooling, thereby reducing the loss of contextual information. As depicted in
Figure 6, the input feature map
undergoes maximum pooling to yield feature map
. Subsequently,
undergoes contextual information fusion via the CDCFM to obtain feature map
. Finally, after adjusting the shape of receptive fields through DCN to preserve edge information, the output feature map
is obtained. Through two successive CFM module treatments in the encoder, feature map
is ultimately obtained. The detailed computational procedures are elucidated in Equations (3) and (4):
Here, (·) denotes maximum pooling, DCN(·) represents deformable convolution, DConv(·) signifies dilated convolution, with the superscript 3 indicating the operation of dilated convolution performed three times, Conv(·) signifies standard convolution, with the superscript 2 indicating the operation of standard convolution executed twice, and the symbol denotes direct addition of the corresponding values from the feature maps.
Although the resolution of the feature map decreases during downsampling, the comprehensive fusion of contextual and local information in the low-resolution feature map is achieved through two CFM modules. This minimizes the loss of contextual information as much as possible. This design aims to balance the relationship between downsampling and contextual information, ensuring better performance in small target detection tasks.
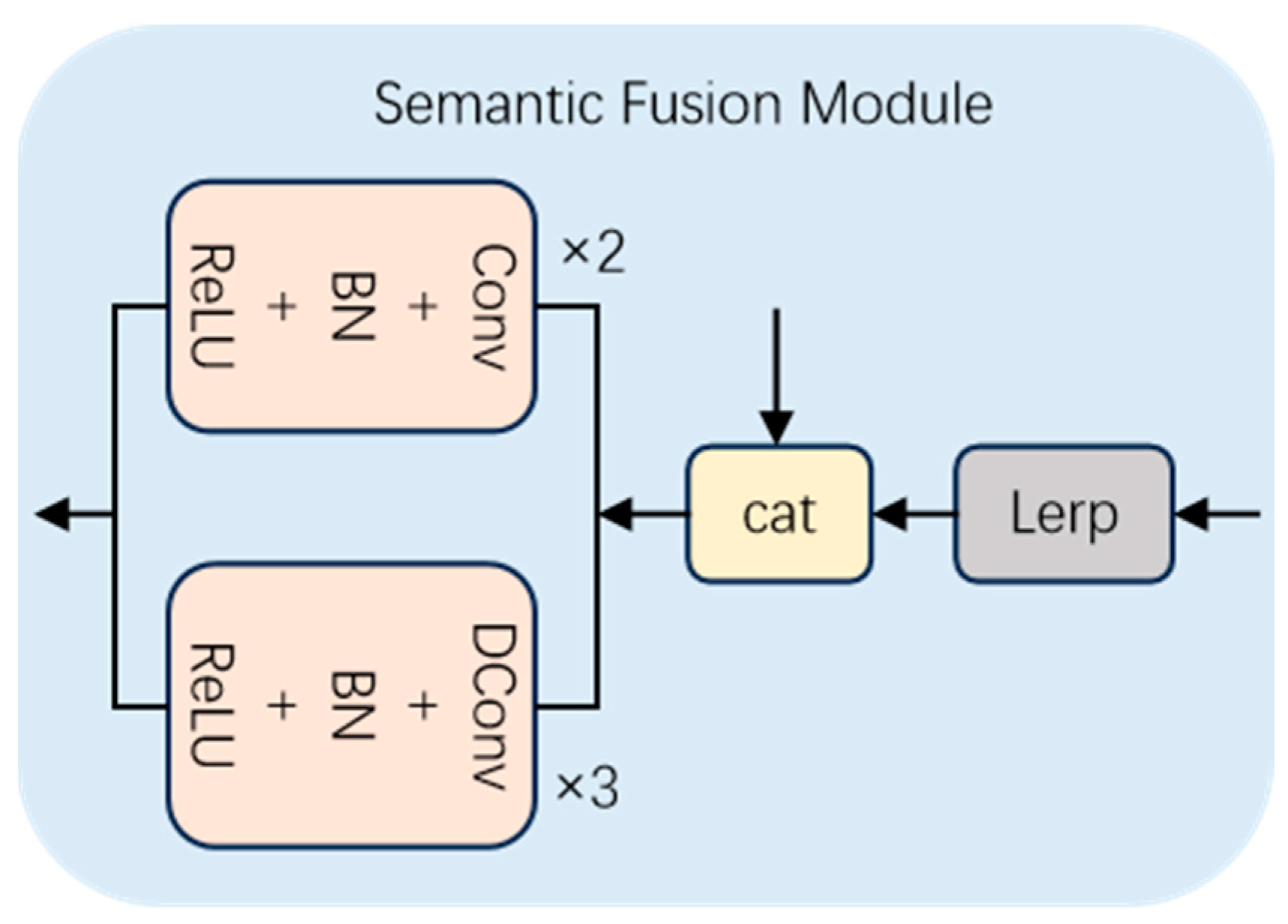
3.4. Structure of SFM
The SFM module, situated within the decoder segment, is tasked with amalgamating semantic information from both deep and shallow layers to offset any potential semantic loss incurred during the encoding process, thereby acquiring more enriched semantic information. As depicted in
Figure 7, initially, the feature map
outputted by the encoder undergoes upsampling via linear interpolation to yield
, which is then directly connected with the shallow feature map
to obtain
. Subsequently,
is fed into the CDCFM to integrate semantic information, ultimately yielding a feature map
that amalgamates shallow features and deep semantics. The detailed computational procedures are delineated in Equations (5) and (6):
Here, Concat(·) signifies the concatenation operation, Lerp(·) denotes linear interpolation, DConv(·) represents dilated convolution, with the superscript 3 indicating the operation of dilated convolution performed three times, Conv(·) denotes standard convolution, with the superscript 2 indicating the operation of standard convolution executed twice, and the symbol signifies direct addition of the corresponding values from the feature maps.
This design aims to enhance the performance of small target detection, particularly in addressing the issue of semantic loss, by fully integrating deep and shallow layer information through the SFM module during the decoding stage [
39].
3.5. Other Modules
The SE block stands as a highly effective channel attention mechanism, characterized by its minimal parameter and computational footprint. Through straightforward compression and excitation operations, it discerns weightings across different channels, thereby acquiring enhanced feature representation. As illustrated in
Figure 8, the SE block initiates by subjecting the input feature map
to spatial feature compression, effectuated through global average pooling across spatial dimensions, yielding the feature map
. Subsequently, via a fully connected (FC) layer, it derives a feature map
imbued with channel attention. The feature map
, augmented with channel attention, and the original input feature map
X undergo channel-wise multiplication by the weight coefficients, culminating in the output of a feature map
endowed with channel attention.
The FCN Head demonstrates commendable performance in small target detection tasks, prompting its integration into the network’s terminus to yield detection outcomes. As depicted in
Figure 9, the FCN Head comprises a 3 × 3 convolutional layer followed by batch normalization and activation layers, along with a dropout layer and a 1 × 1 convolutional layer, ultimately yielding segmented result maps.
3.6. Maritime-SIRST
The performance of deep learning algorithms is significantly influenced by the quality of the dataset [
40]. Presently, there exist several IR small target datasets, primarily based on land and sky backgrounds, which fail to accurately reflect real scenarios under maritime conditions, rendering them unsuitable for training and evaluating ship targets at sea. Despite recent efforts to construct IR maritime ship target detection datasets such as ISDD and NUDT-SIRST-SEA, analysis reveals that these two datasets exhibit relatively singular scenes and cannot adequately represent the complexity of maritime backgrounds. Thus, the construction of a representative IR maritime ship detection dataset is crucial for this study. Such a dataset must provide authentic maritime backgrounds, encompassing diverse maritime conditions such as waves, islands, and cloud formations, to closely align with real-world applications. This dataset not only holds paramount significance for this study but also contributes to propelling the advancement of IR maritime ship detection. By employing datasets with authentic scenes, algorithms’ performance in maritime ship detection tasks can be more accurately assessed, thereby enhancing algorithm robustness and reliability.
To meet the aforementioned requirements, this study leverages publicly available images from the near-infrared band of the Landsat-8 remote sensing satellite to construct a high-quality IR ship detection dataset tailored for complex maritime scenes, named Maritime-SIRST. Within the Landsat-8 remote sensing images, we selected IR band images from various regions worldwide, including ports, canals, and open seas across Asia, Africa, and North America. The selected images span from 2013 to 2021, ensuring temporal diversity. To enhance representativeness, images with different months and varying cloud cover percentages were chosen. We utilized SenseTime’s open-source tool, LabelBee, to annotate the original images, generating label files in mask format. Compared to other datasets, Maritime-SIRST is specifically tailored for IR maritime ships, employing authentic remote sensing satellite IR images with more diverse and complex backgrounds. The proposed Maritime-SIRST dataset comprises 1131 images, totaling 2647 targets, with each image sized at 256 × 256 pixels. As illustrated in
Table 1, compared to the other two public datasets (ISDD, NUDT-SIRST-SEA), the Maritime-SIRST dataset exhibits the following characteristics:
More complex backgrounds: The proportion of images with complex backgrounds in the Maritime-SIRST dataset reaches 65.43%, surpassing that of NUDT-SIRST-SEA (approximately 54%) and ISDD (approximately 30%).
Diverse false alarm target types: Maritime-SIRST includes various false alarm targets such as wave clutter, complex cloud formations, islands, and ports, with a substantial proportion. In contrast, NUDT-SIRST-SEA lacks wave clutter background images, with over 80% featuring simple backgrounds or land near ports, while ISDD contains only about 10% of wave clutter and complex cloud formation backgrounds, with the rest featuring simple backgrounds and port island backgrounds.
Smaller targets: According to the definition by the Society of Photo-Optical Instrumentation Engineers (SPIE), small targets are those with an area of fewer than 80 pixels in a 256 × 256 image. In Maritime-SIRST, over 95% of images meet this definition, significantly higher than NUDT-SIRST-SEA (approximately 90%) and ISDD (approximately 1.5%).
Diverse target sizes: While meeting the criterion of small target size, targets in Maritime-SIRST vary in size from 0 to 80 pixels, demonstrating a more uniform distribution. In contrast, about 70% of targets in NUDT-SIRST-SEA are smaller than 20 pixels, while in ISDD, 98.5% of targets exceed 80 pixels, indicating a lack of representativeness.
More diverse target numbers: Images in Maritime-SIRST encompass scenarios with no targets, single targets, and multiple targets, whereas NUDT-SIRST-SEA consists solely of images with multiple targets, and ISDD lacks images with no targets. Thus, Maritime-SIRST more authentically reflects real maritime scenes.
4. Results
4.1. Experiment Settings
To validate the performance of our model, we selected three traditional algorithms, namely Top-hat [
41], MPCM [
42], and TTLDM [
43], along with six deep learning algorithms, including U-Net [
24], DNANet [
29], MTUNet [
37], ABCNet [
30], AGPCNet [
44], and LW-IRSTNet [
45], for comparative experiments. All models were run on a computer equipped with a 15vCPU AMD EPYC 7543 32-core processor and an NVIDIA GeForce RTX 3090 GPU using Python 3.8. Our model’s training parameters were configured with a batch size of 16, 1000 epochs, an SGD optimizer with an initial learning rate of 0.05, SoftIoULoss as the loss function, and other training parameters as specified in the original papers.
In order to verify the generalization performance of the model, we not only performed validation on our own constructed dataset, but we also used a public dataset for validation. The experiments utilized two datasets: One is our self-constructed Maritime-SIRST dataset, comprising 1131 images captured from authentic maritime scenes in the IR spectrum, each sized at 256 × 256 pixels. Among them, 800 images were allocated for training, while 331 were designated for validation. The second dataset is the publicly available NUDT-SIRST-SEA dataset, which includes 48 images sized at 10,000 × 10,000 pixels. Given the considerable computational resources and time required for training on these datasets and the presence of numerous low-quality images (e.g., predominantly landmasses, absence of targets), further processing was conducted. Initially, the original images were cropped into 256 × 256 images, followed by the removal of low-quality images, resulting in a selection of 2000 images. Among these, 1400 were assigned to the training set, while 600 were designated for validation. It is noteworthy that the ISDD dataset lacks semantic segmentation annotations and exhibits relatively simple backgrounds; hence, it was not utilized for comparative experiments.
4.2. Evaluation Metrics
In this article, Precision (
Prec) [
46], Recall (
Rec) [
46],
mIoU [
46],
F1 [
46], and AUC [
46] are selected as the evaluation indexes of algorithm accuracy, and Params [
45],
FlOPs [
45], and
FPS [
45] are selected as the evaluation metrics of computational complexity.
Prec,
Rec, and
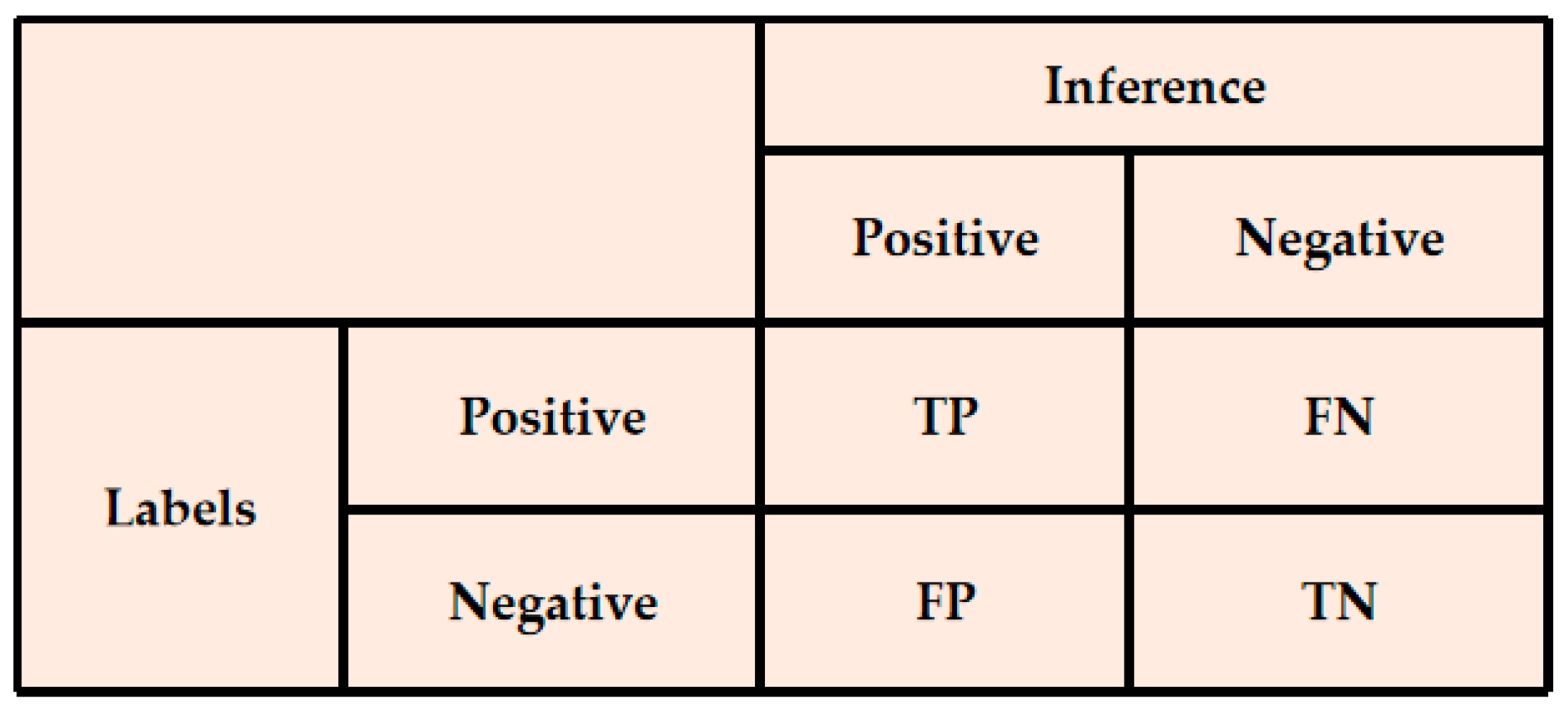
F1 are commonly used metrics for assessing the accuracy of models in binary classification tasks and can be defined using a confusion matrix, as illustrated in
Figure 10.
Prec represents the proportion of true positives (
TP) among all samples predicted as positive by the model.
Rec indicates the proportion of true positives among all samples labeled as positive. The calculation formulas for
Prec and
Rec are as follows:
Here,
TP represents the number of detected target pixels matching real target pixels,
FP represents the number of background pixels mistakenly detected as real target pixels, and
FN represents the number of target pixels mistakenly detected as background pixels [
47,
48,
49].
Due to different threshold settings in classification models,
Prec may reach 100% at high thresholds, while
Rec may be 100% at low thresholds. Therefore, these two metrics may be biased. To balance
Prec and
Rec,
F1 is introduced, with the calculation formula as follows:
This formula indicates that
F1 will be high only when both
Prec and
Rec are high. Thus, the higher the
F1, the more effective the model’s performance [
50,
51].
mIoU, also known as the Jaccard similarity coefficient (JSC), refers to the mean intersection over union, which is the most commonly used semantic segmentation metric. In semantic segmentation,
IoU represents the overlap between predicted and labeled pixel masks. The mean
IoU (
mIoU) is the arithmetic mean of
IoU values for each class and is used to measure pixel overlap across the entire dataset, with the calculation formula as follows:
Here, n represents the total number of classes, represents true positives for the i-th class, represents false positives for the i-th class, and represents false negatives for the i-th class. For each class, its IoU is calculated, then the IoU values for all classes are summed and divided by the total number of classes to obtain the average IoU value.
ROC curve stands for receiver operating characteristic curve and is a commonly used tool for evaluating the performance of binary classification models. The ROC curve is plotted with a true positive rate on the vertical axis and a false positive rate on the horizontal axis. It illustrates the model’s classification performance for positive and negative instances at different thresholds. The area under the ROC curve (AUC) is widely used as a metric for evaluating model performance, with a value closer to 1 indicating better model performance.
Params usually refer to the number of learnable parameters in the model, including each value in the weight matrix in the convolution layer, fully connected layer, etc. It directly determines the size of the model and affects the amount of memory occupied during inference. Note that the number of parameters in the model is not the same as the size of the storage space.
FLOPs refers to the number of floating-point operations, understood as computational amount (computational time complexity), which can be used to measure the complexity of an algorithm, and is a common indirect standard to measure the speed of a neural network model. Although some recent studies have shown that relying on
FLOPs alone to evaluate model speed may not be reliable because the computing speed of the model is also affected by factors such as memory throughput,
FLOPs is still widely used as a reference standard for evaluating model speed. In computing, one multiplication or one addition is counted as one
FLOP. The calculation amount of the conventional convolution layer (multiply-plus operand) is
where
H,
W, and
C are respectively the height, width, and number of channels of the input,
N is the number of channels of the output (that is, the number of filters), and
k is the size of the convolution kernel.
FPS refers to the number of frames processed per second and is calculated by:
Here, t represents the time required for the network to predict the image, excluding the time required for post-processing, and FPS represents the number of frames per second that the network can process, which is the most direct indicator of the efficiency of the algorithm.
4.3. Quantitative Results
Table 2 presents a comparative analysis of experimental data between FCNet and other notable algorithms on the Maritime-SIRST dataset. From the data in the table, it is evident that on the Maritime-SIRST dataset, FCNet demonstrates a 3.59% improvement in
Prec compared to other algorithms, a 1.42% increase in
Rec, a 4.05% enhancement in
mIoU, and a 2.43% advancement in
F1. Notably, FCNet’s AUC is only slightly lower than that of the MTUNet algorithm. Overall, FCNet’s precision metrics surpass those of other algorithms, yielding promising outcomes.
As can be seen from
Table 2, although traditional algorithms such as Top-hat, MPCM, and TTLDM can detect the target, there are a large number of false alarms and missed detection. This is because these model-driven algorithms can only identify the target in a simple background based on the prior assumptions of the model and cannot do so well when there is a complex background, such as sea surface. It leads to a high false alarm rate and missed detection rate. As the most basic deep learning algorithm, UNet has a simple structure, so it has the problem of a high false alarm rate and missing detection rate. DNANet benefits from the dense nested attention mechanism and achieves good results, but some features will be lost in the process of multiple downsampling and feature fusion, so it is easy to miss some dim small targets. With the introduction of ViT, the MTUNet algorithm can obtain global semantic information, but when the target is too small, the global semantic does not gain much, so it will produce a lot of false alarms and missed detection in the face of a complex background. Both ABCNet and AGPCNet focus on the integration of global semantics and local semantics and achieve good results. However, due to the fixed receptive field, some details are still lost in the downsampling process, and it is easy to miss the detection of dim small targets. LW-IRSTNet focuses on the lightweight design of the model structure, so some details are lost, resulting in high false alarm rate and missed detection rate. FCNet can obtain a flexible receptive field by integrating multiple convolutions, greatly reducing feature loss in the process of encoding and decoding, so that the background and target can be accurately separated, and the false alarm rate and missed detection rate can be reduced.
FCNet’s Params, FLOPs, and FPS have some gaps compared to lightweight algorithms such as LW-IRSTNet, but are still on a similar level compared to other deep learning algorithms. However, the accuracy of FCNet has been greatly improved compared with other models, so the FCNet model is the best according to all indexes.
Table 3 illustrates a comparison of experimental results between FCNet and other algorithms on the NUDT-SIRST-SEA dataset. As depicted in the table, FCNet exhibits a 1.51% improvement in
Prec compared to other algorithms, a 0.65% increase in
Rec, a 1.27% enhancement in
mIoU, a 1.02% advancement in
F1, and also demonstrates commendable performance in terms of AUC.
By comparing the experimental data of these algorithms in the two datasets, we found that the experimental data of FCNet and other algorithms showed similar trends in the two datasets. Therefore, it can be seen that FCNet has similar excellent performance in different data sets, which proves that it has good generalization performance.
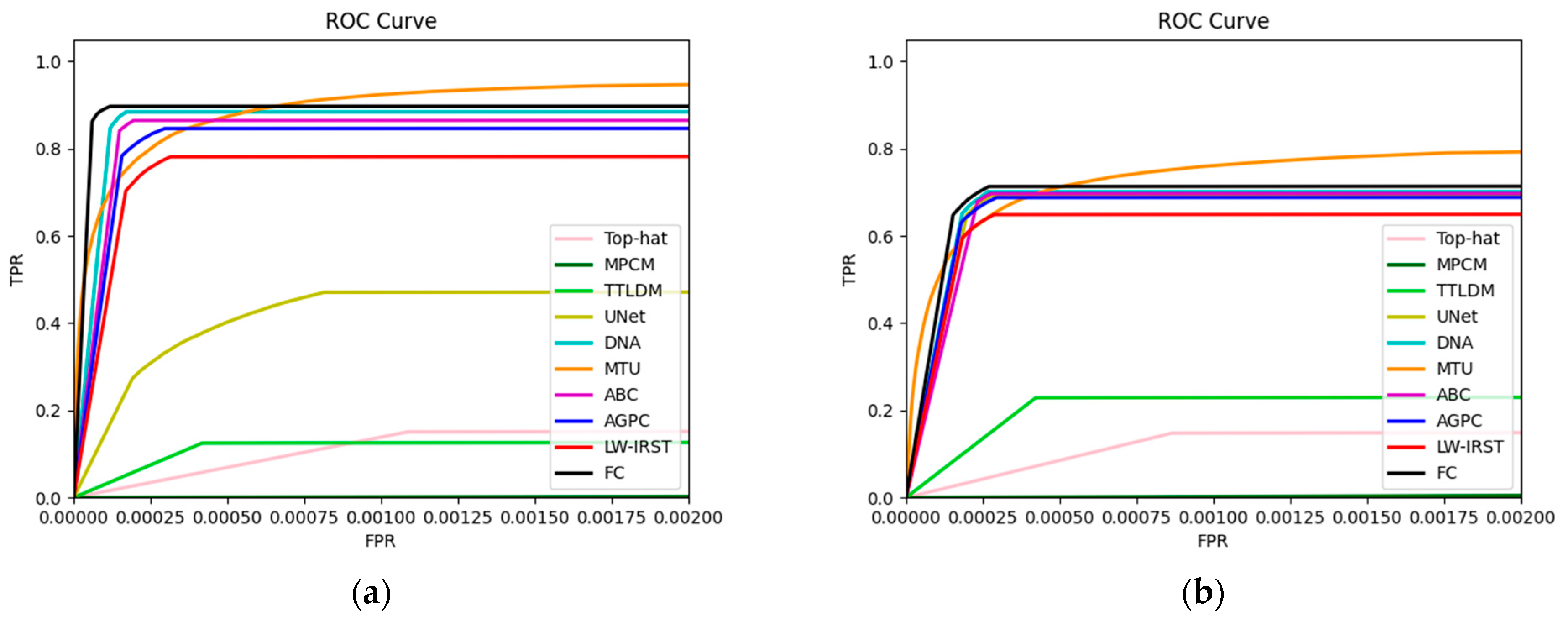
Furthermore, experimental data from the Maritime-SIRST and NUDT-SIRST-SEA datasets were utilized to construct ROC curves, as illustrated in
Figure 11. It can be observed from the ROC curves that the curve for FCNet closely approaches the top-left corner, trailing slightly behind MTUNet, indicating that the precision of our model, compared to other models and algorithms, operates at a relatively high level.
4.4. Visual Results
Figure 12 illustrates the comparative performance of FCNet and other algorithms on the Maritime-SIRST.
Figure 13 displays the detection performance comparison of FCNet and other algorithms on the NUDT-SIRST-SEA. The red boxes represent accurately detected targets, blue boxes denote false alarms, and green boxes signify missed targets. From the detection results, it is evident that traditional algorithms exhibit poor performance, characterized by high rates of missed and false detections. Moreover, some deep learning algorithms also suffer from high false alarm rates and missed detections, with significant disparities between segmented targets and reality. This is primarily attributed to the complexity of maritime scenes, where phenomena such as cloud clusters, waves, and islands are prone to misidentification as targets, while dim small ship targets are easily submerged in the background, leading to missed detections. Overall, our algorithm exhibits lower false alarm and missed detection rates, and from the segmentation results, FCNet’s performance is the most outstanding. Therefore, the proposed FCNet algorithm is better suited for IR small ship detection in maritime environments.
4.5. Ablation Study
To investigate the impact of the encoder-decoder layers on the performance of IR small target detection, this study conducted ablation experiments on different encoder-decoder layers of UNet using the Maritime-SIRST dataset. The results, as shown in
Table 4, show that in 2-layer UNet, the overall precision performance is the best, and compared with 4-layer UNet, the number of parameters and calculation amount are also greatly reduced. Although the number of parameters and calculation amount of 1-layer UNet are reduced a lot, the accuracy is reduced a lot. Therefore, the FCNet in this paper adopts the 2-layer encoder-decoder as its basic structure.
Subsequently, we performed ablation experiments on the introduced dilated convolutions (DC), deformable convolutions (DCN), and SE in the model. From the data in
Table 5, it is evident that the incorporation of DC, DCN, and SE, compared to the base network, significantly enhances the model’s performance. Compared to the base network, FCNet demonstrates a 4.75% increase in
Prec, a 2.82% increase in
Rec, a 6.11% increase in
mIoU, a 3.72% increase in
F1, and a 1.02% increase in AUC.
To obtain a more intuitive understanding of the roles played by DC, DCN, and SE in the network, we visualized the feature maps at each stage of the FCNet network model. As shown in
Figure 14, no-DCN represents the FCNet model without the DCN module, no-DC represents the FCNet model without the DC, and no-SE represents the FCNet model without the SE. From
Figure 14, it can be seen that the network without DCN loses a lot of edge information near the target; the network without DC lacks contextual semantic information in the encoding stage; and the network without SE has chaotic channel information in the feature map, with insufficient prominent features near the target.
5. Conclusions
This chapter focuses on the design of a high-precision model, FCNet, for IR small ship detection on the sea surface, considering the small size of such ships, the lack of color and texture information, and the complexity of the maritime background. Specifically, to address the challenge of small ship size, a two-layer encoder-decoder structure is employed to prevent the loss of small ships during downsampling. Subsequently, an FEM is proposed to enrich features by introducing dilated convolutions and deformable convolutions. Furthermore, a context fusion module is introduced to fuse multi-scale contextual information and local information to obtain richer semantic information. Then, a Semantic Fusion Module is proposed to integrate low-level features with deep semantic information. Finally, an attention module, SE, is incorporated into the decoding layer to adaptively learn the weights of channels and obtain more effective channel information. Experimental results on two datasets demonstrate that FCNet outperforms other algorithms in terms of accuracy metrics. Additionally, through ablation experiments, the effectiveness of adding modules is further verified. Moreover, a dataset focusing on IR small ships on the sea surface, named Maritime-SIRST, is proposed. This dataset encompasses various complex scenarios in maritime backgrounds, such as waves, complex cloud clusters, and port islands, closely resembling real-world applications. The dataset not only meets the research requirements of this study but also fosters further development in this field.
While this study concentrates on enhancing the precision of IR small ship detection at sea, the introduction of multiple modules to improve network accuracy also increases algorithm complexity. It is noteworthy that IR small ship detection algorithms are typically deployed on resource-constrained embedded devices, such as satellites and drones. Due to the limited memory and computing power of these devices, strict requirements are imposed on the parameter size and computational complexity of the algorithm model. To meet the needs of practical engineering applications, future directions should focus on the lightweight design of the model while maintaining accuracy, aiming to reduce the parameter size and computational load.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}