
Frequency Diversity Array Radar and Jammer Intelligent Frequency Domain Power Countermeasures Based on Multi-Agent Reinforcement Learning

Abstract

1. Introduction
- (1)
- The FDA radar signal model with target response varying with frequency is established based on continuously adjustable jamming and radar power. Targets respond differently to different frequencies, and FDA radars and jammers can use target response characteristics to allocate power in different frequency bands.
- (2)
- The adversarial relationship between the FDA radar and the jammer is mapped to a MARL model. Power allocation in the frequency domain realizes the confrontation between the FDA radar and the jammer. In designing a reward function based on SJNR, the radar optimization strategy maximizes SJNR, while the jammer adjustment strategy minimizes SJNR.
- (3)
- In the DRL framework, the power allocation strategies of the FDA radar and jammer were fixed, respectively, and the performance of the frequency domain power countermeasures using the deep deterministic policy gradient (DDPG) algorithm was analyzed. When one side of the FDA radar or jammer had a fixed transmission strategy, the other side adopted the DRL framework to optimize the transmission strategy, which could significantly improve the performance.
- (4)
- The intelligent frequency domain power countermeasure of the FDA radar and jammer is analyzed using the MADDPG algorithm and the method of centralized training with decentralized execution (CTDE) based on MARL.
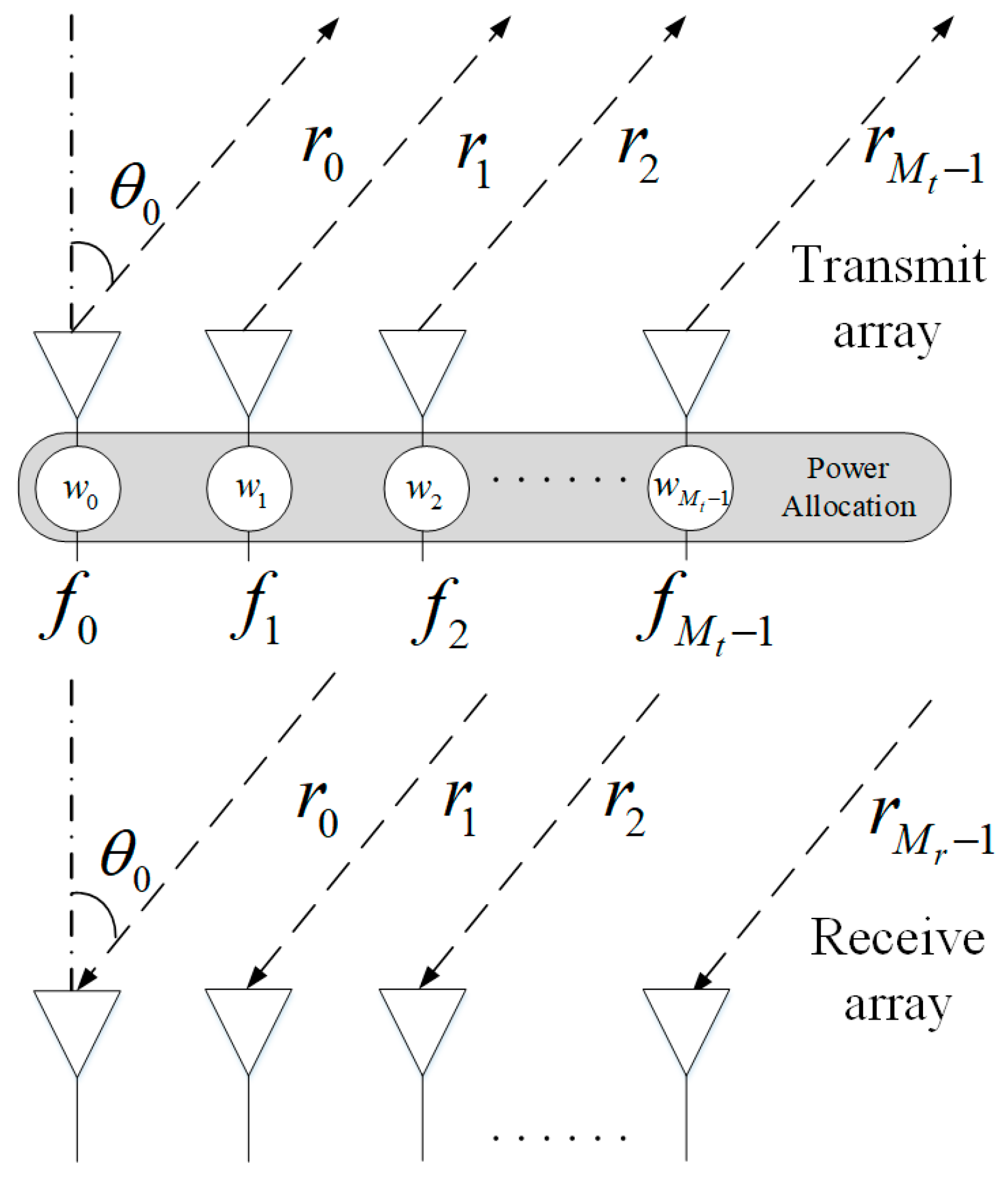
2. Signal Model
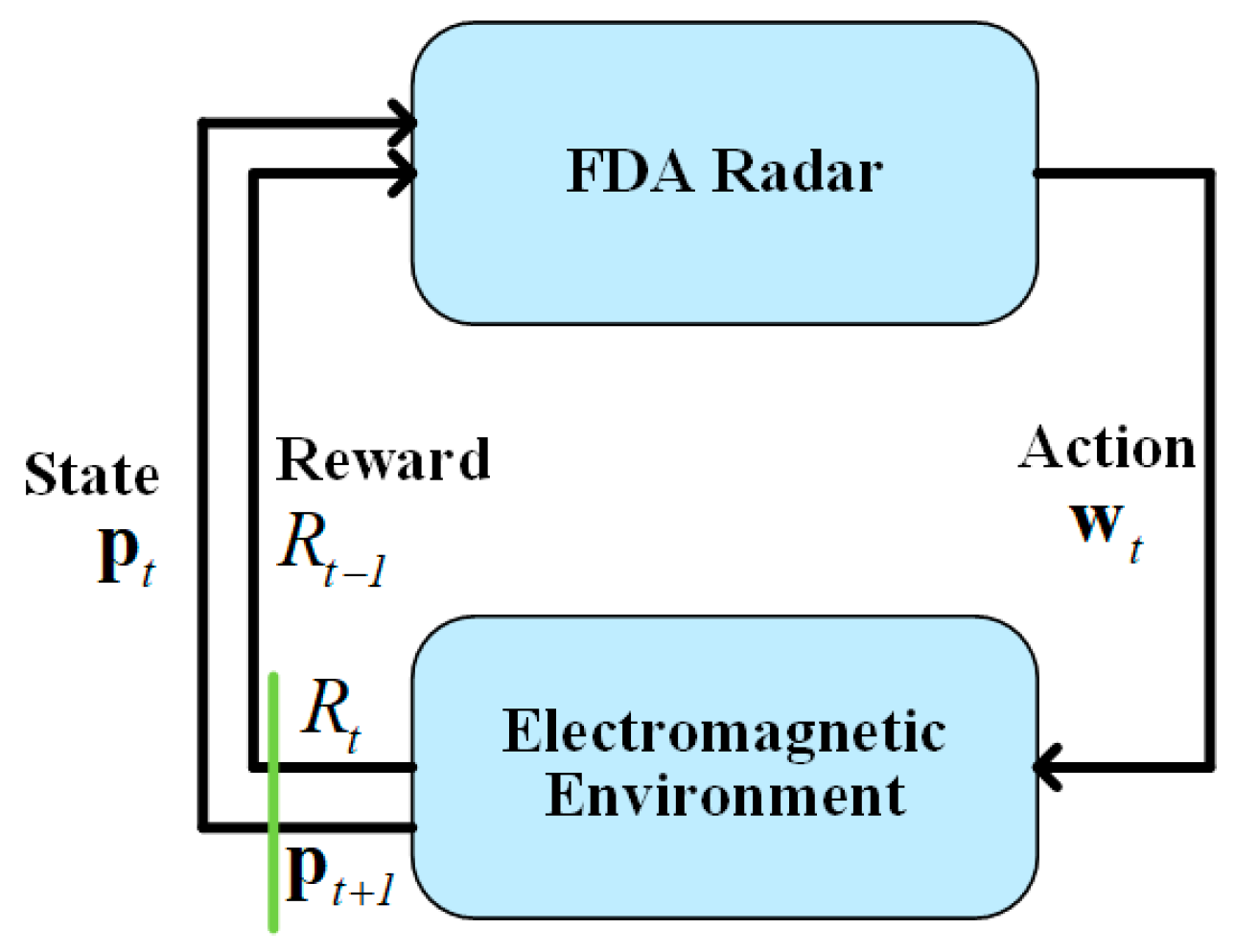
3. Single-Agent Reinforcement Learning
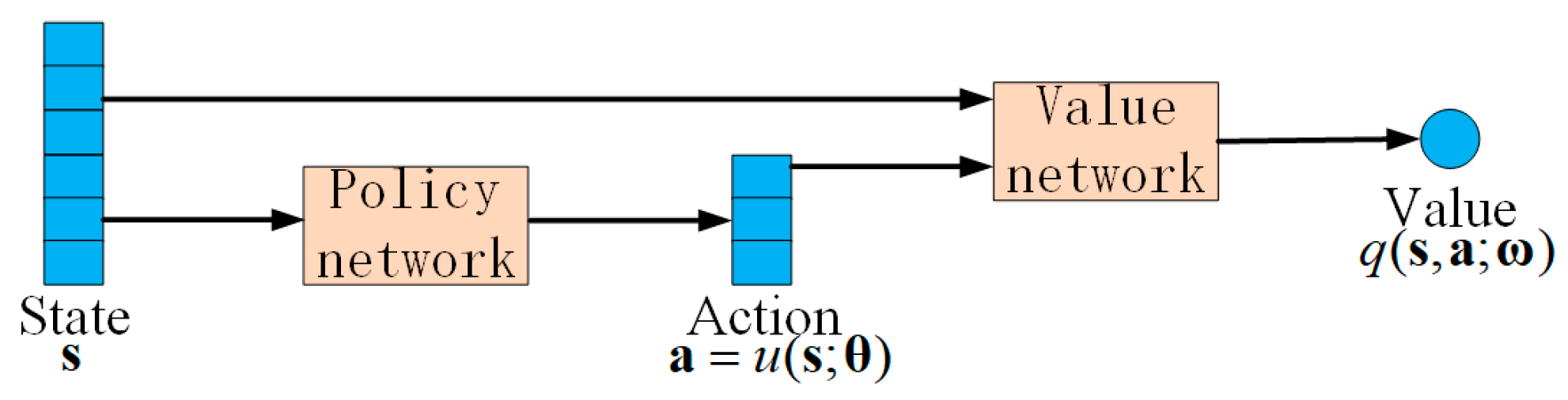
3.1. DDPG Algorithm
| Algorithm 1 DDPG algorithm applied to power allocation |
| Initialize policy network and value network with random network parameters and . Initialize the target network by copying the same parameters, and . |
| Initialize the experience playback pool |
| Input the maximum number of rounds , time step , discount factor , policy network learning rate , value network learning rate , soft update parameter , storage capacity , minimum amount of data required for sampling , and batch size , Gaussian noise variance . |
| For do |
| Initialize Gaussian noise |
| Get initial state |
| For do |
| Select action according to the current policy. |
| Act , get the reward , and the environment state changes to . |
| Store in the experience playback pool |
| Sample tuples from |
| Calculate the TD target for each tuple . |
| Minimize loss function and update value network |
| Calculate the policy gradient and update the policy network |
| Soft update target strategy network |
| Soft update target value network |
| End for |
| End for |
3.2. FDA Radar Agent
3.3. Jammer Agent
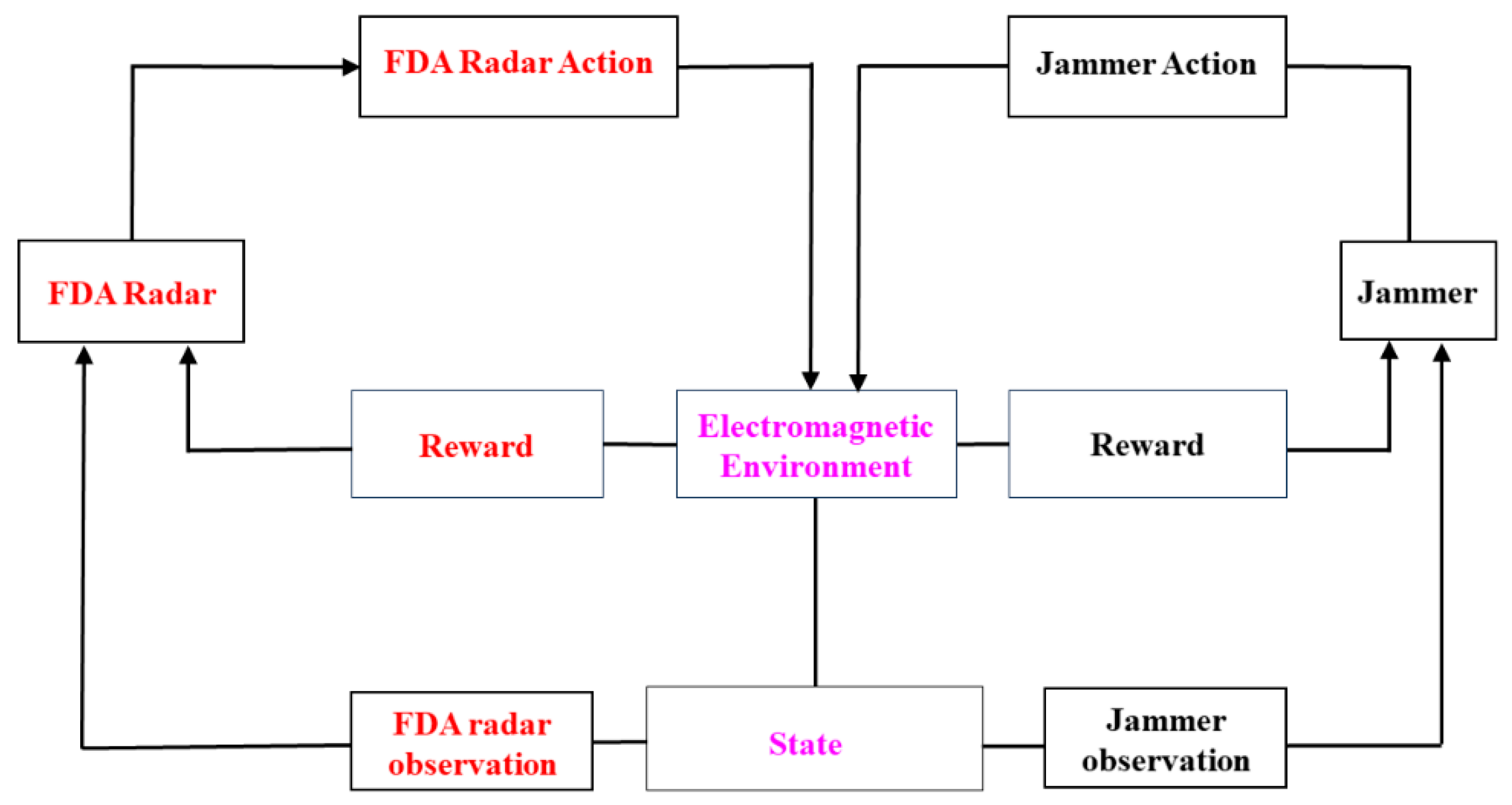
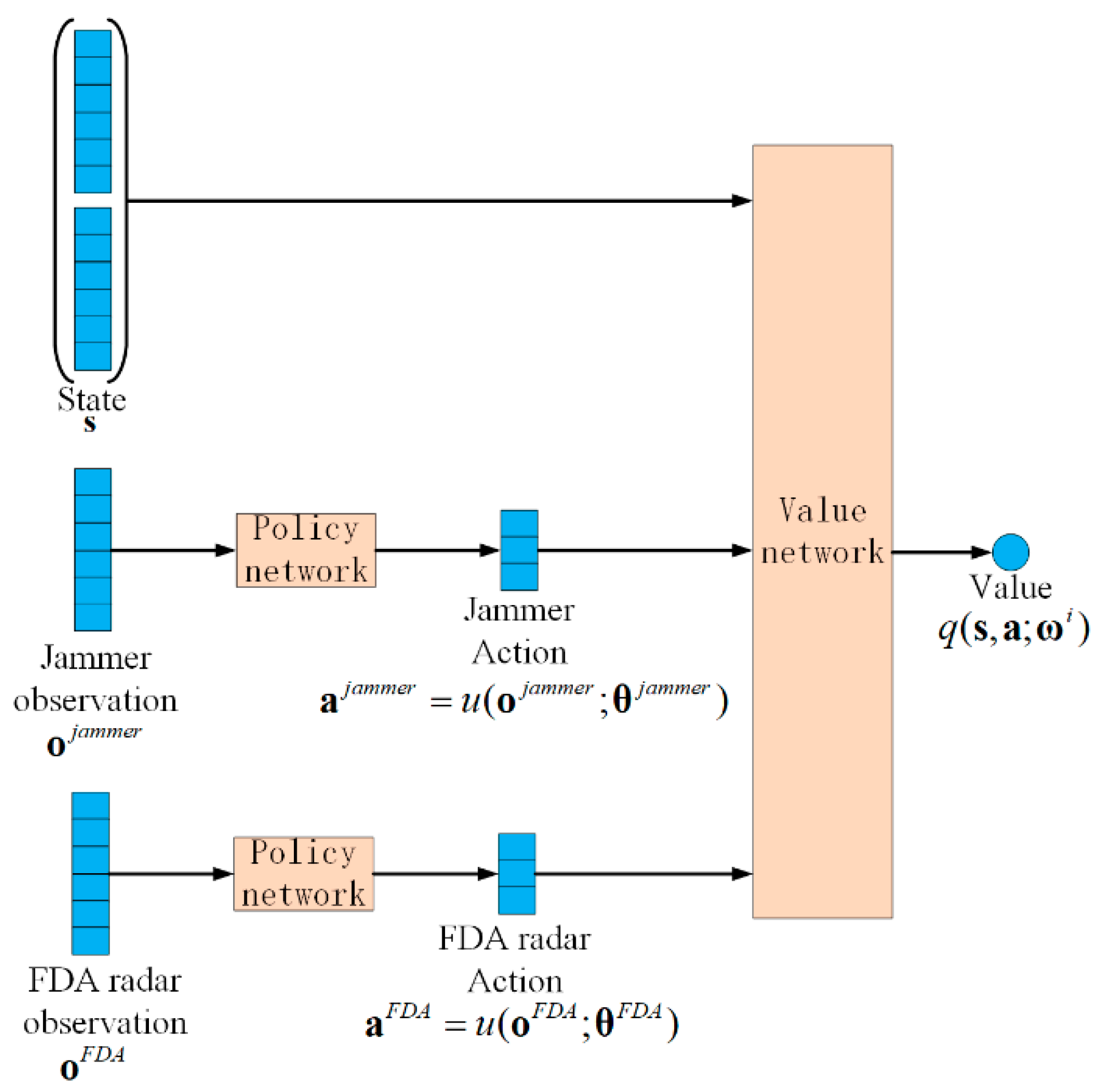
4. Multi-Agent Reinforcement Learning
| Algorithm 2 MADDPG algorithm applied to power allocation |
| Initialize the FDA radar and jammer strategy network and value network , with random network parameters and . Initialize the target network by copying the same parameters, and . |
| Initialize the experience playback pool |
| Input the maximum number of rounds , time step , discount factor , policy network learning rate , value network learning rate , soft update parameter , storage capacity , minimum amount of data required for sampling , and batch size , Gaussian noise variance . |
| For do |
| Initialize Gaussian noise |
| Initial observations of FDA radars and jammers obtained constitute the initial state |
| For do |
| For the -th agent, select an action based on the current policy . |
| Act , obtain the reward , and the environment state changes to . |
| Store in the experience playback pool |
| Sample tuples from |
| Let the FDA radar and jammer target strategy network make predictions , . Obtain predictive actions acting on the electromagnetic environment . |
| Let the FDA radar and jammer target value network make predictions , . |
| Calculate the TD target for each tuple , . |
| Let the value network of FDA radars and jammers make predictions , . |
| Calculate TD error , . |
| Update value network , . |
| Let the FDA radar and jammer strategy network make predictions , . Obtain predictive actions acting on the electromagnetic environment . |
| Update policy network , . |
| Soft update target policy network , . |
| Soft update target value network , |
| End for |
| End for |
5. Simulation Results
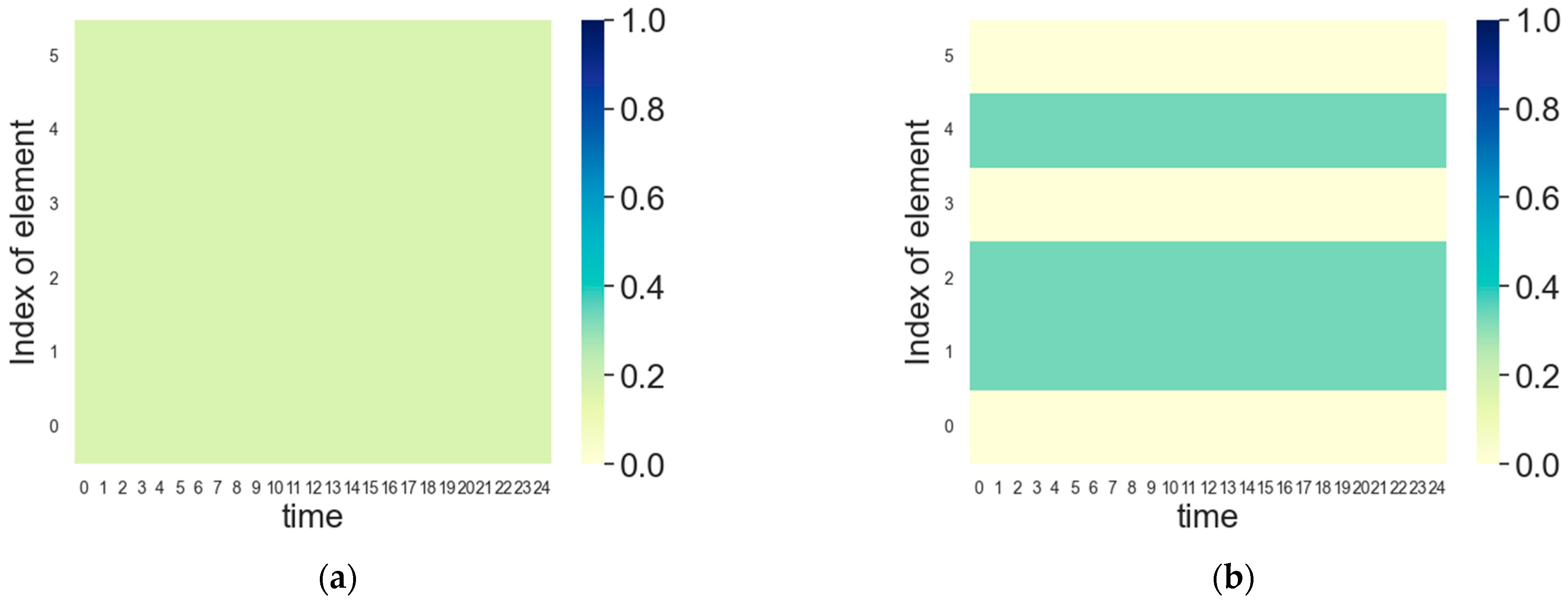
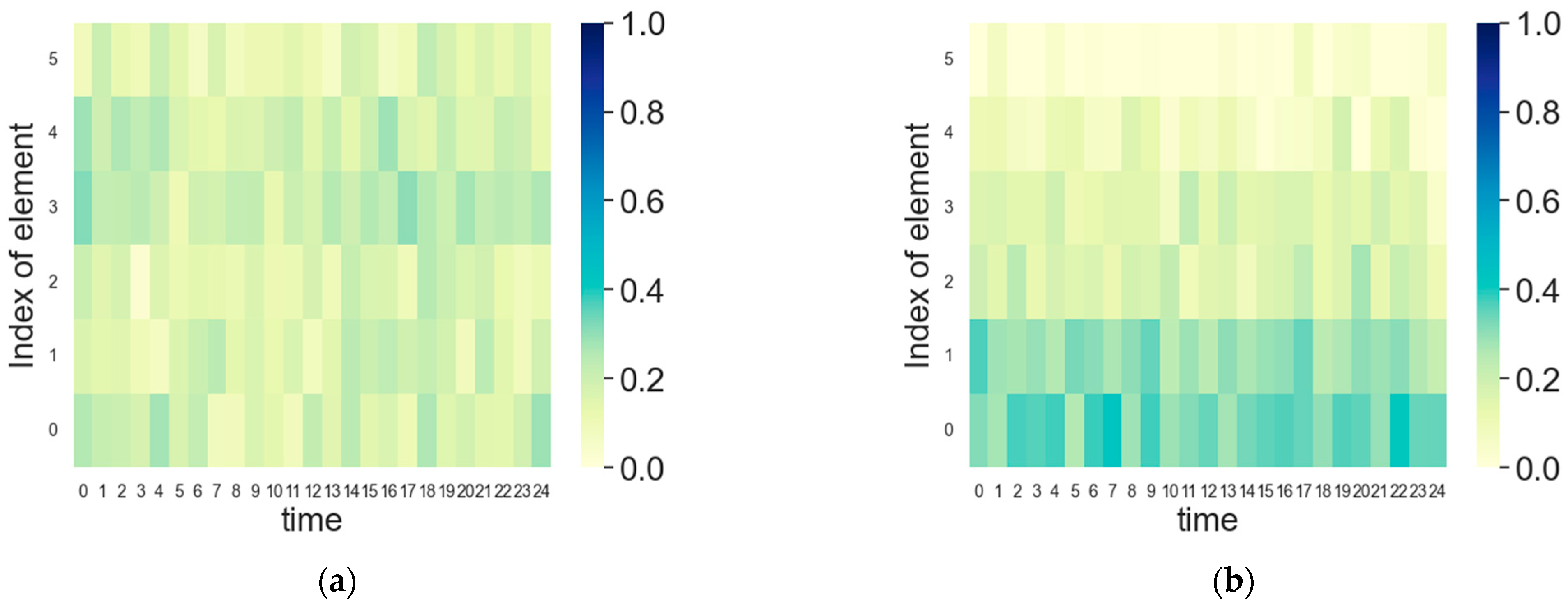
5.1. FDA Radar Intelligent Frequency Domain Power Allocation
5.2. Jammer Intelligent Frequency Domain Power Allocation
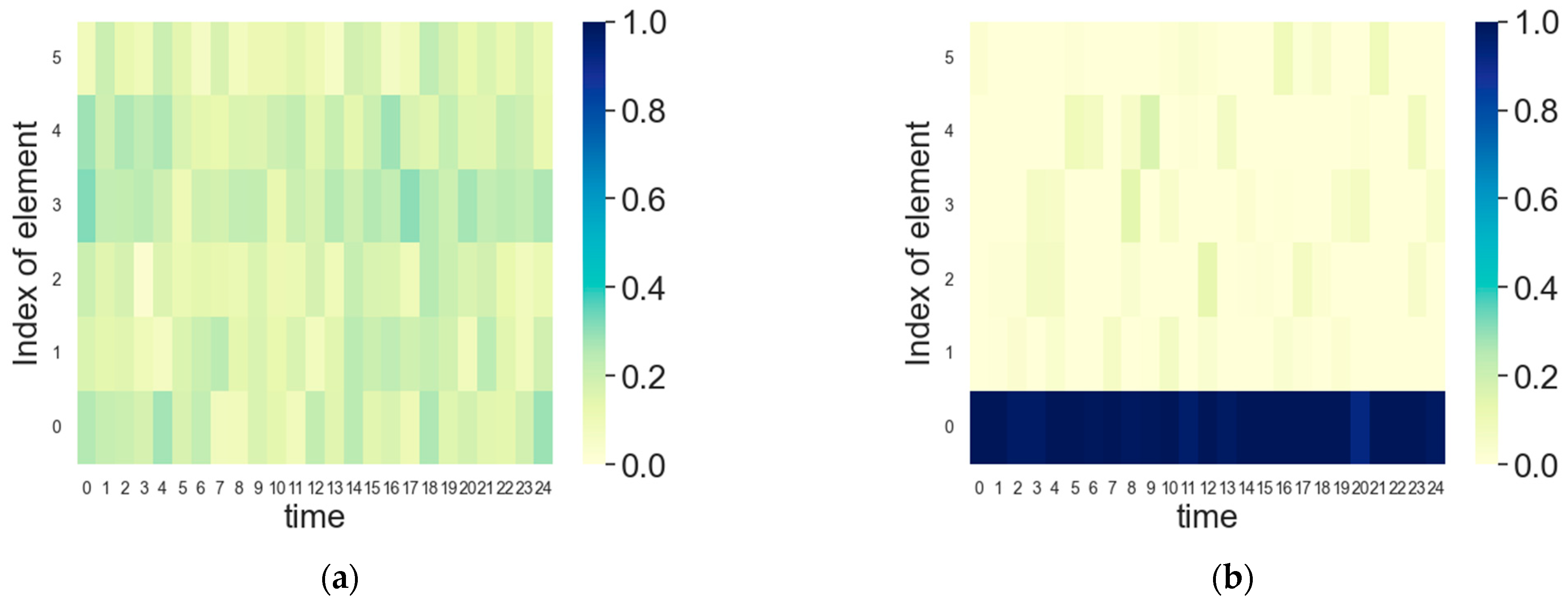
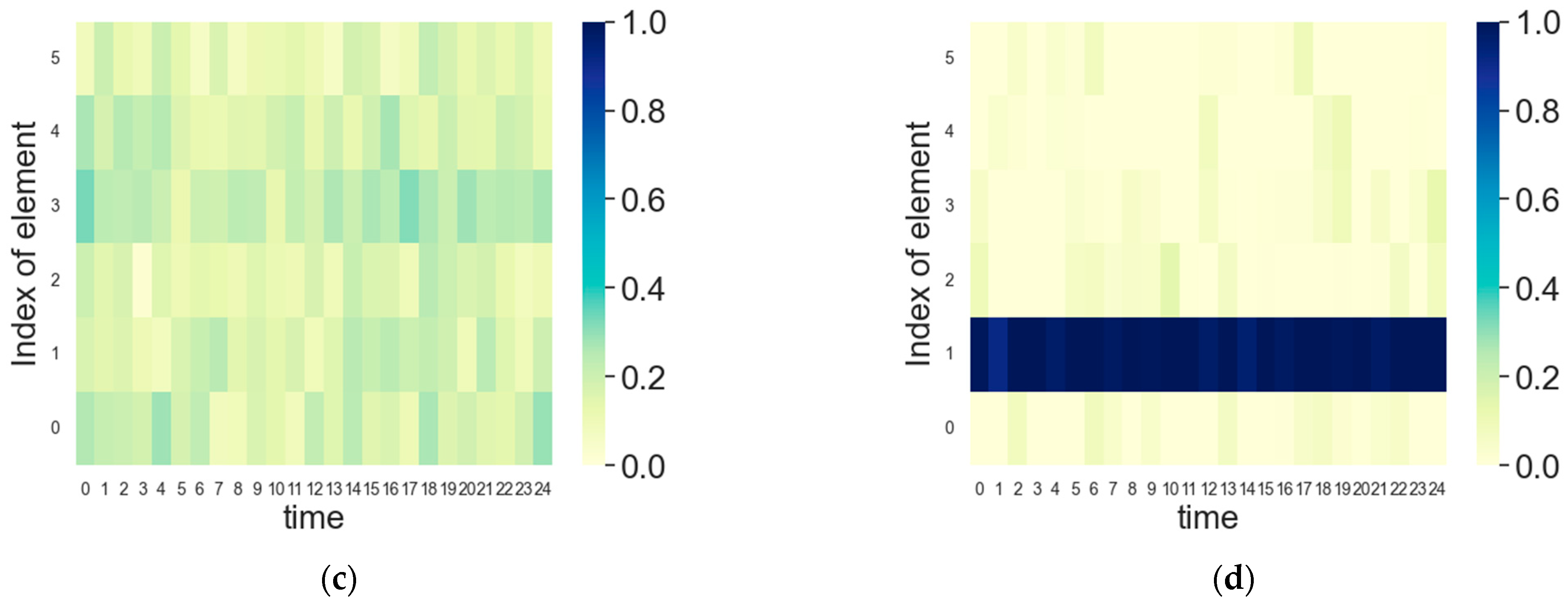
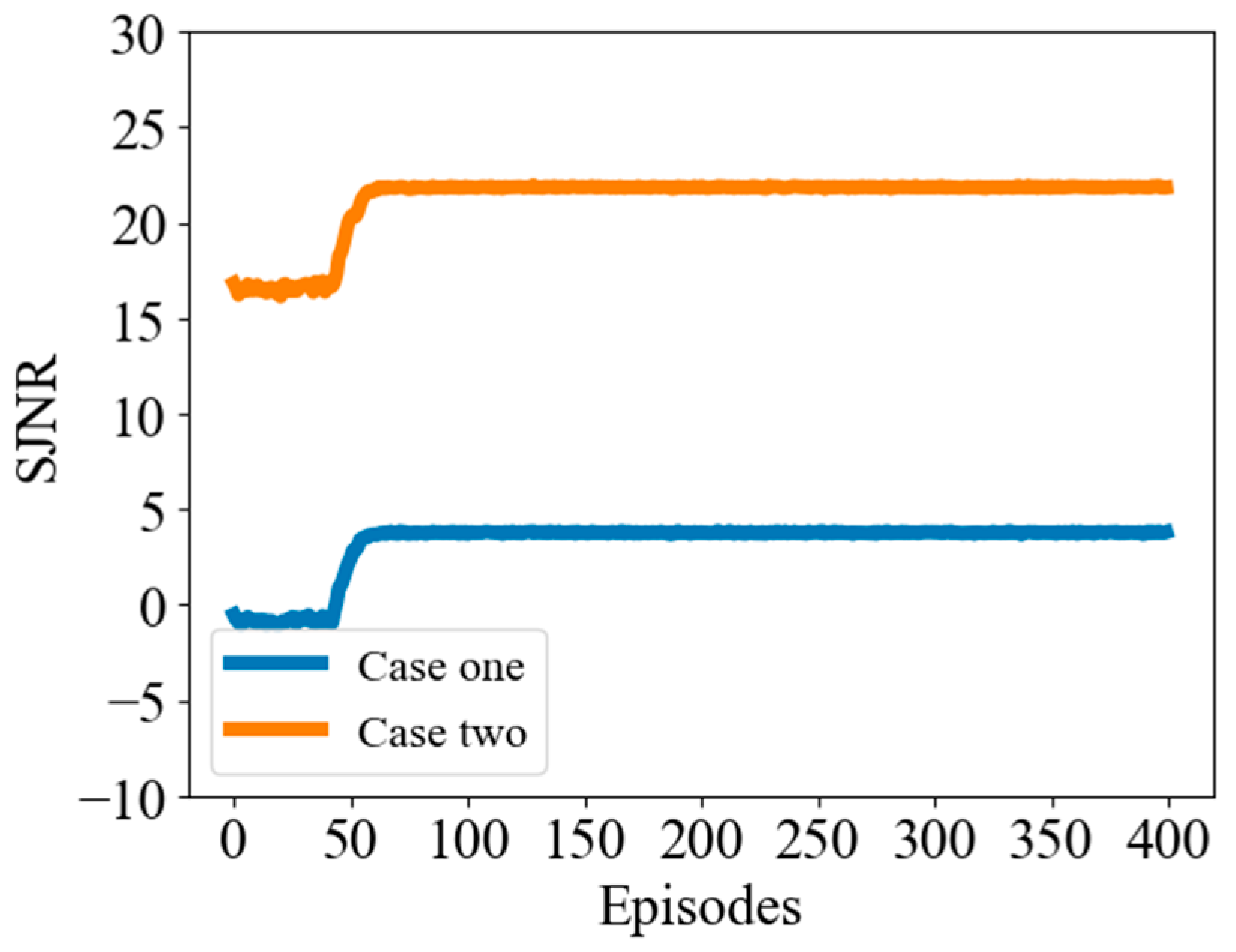
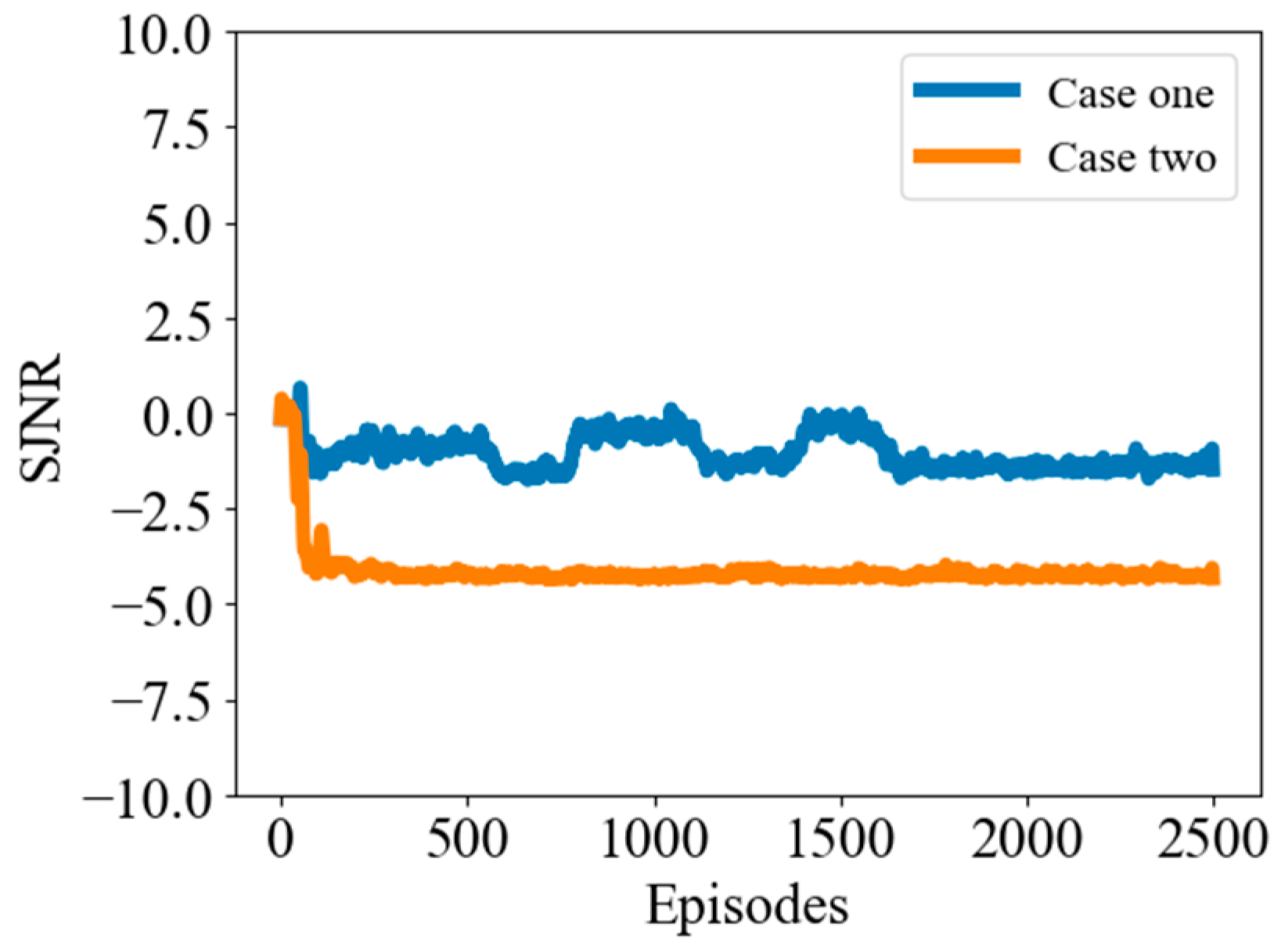
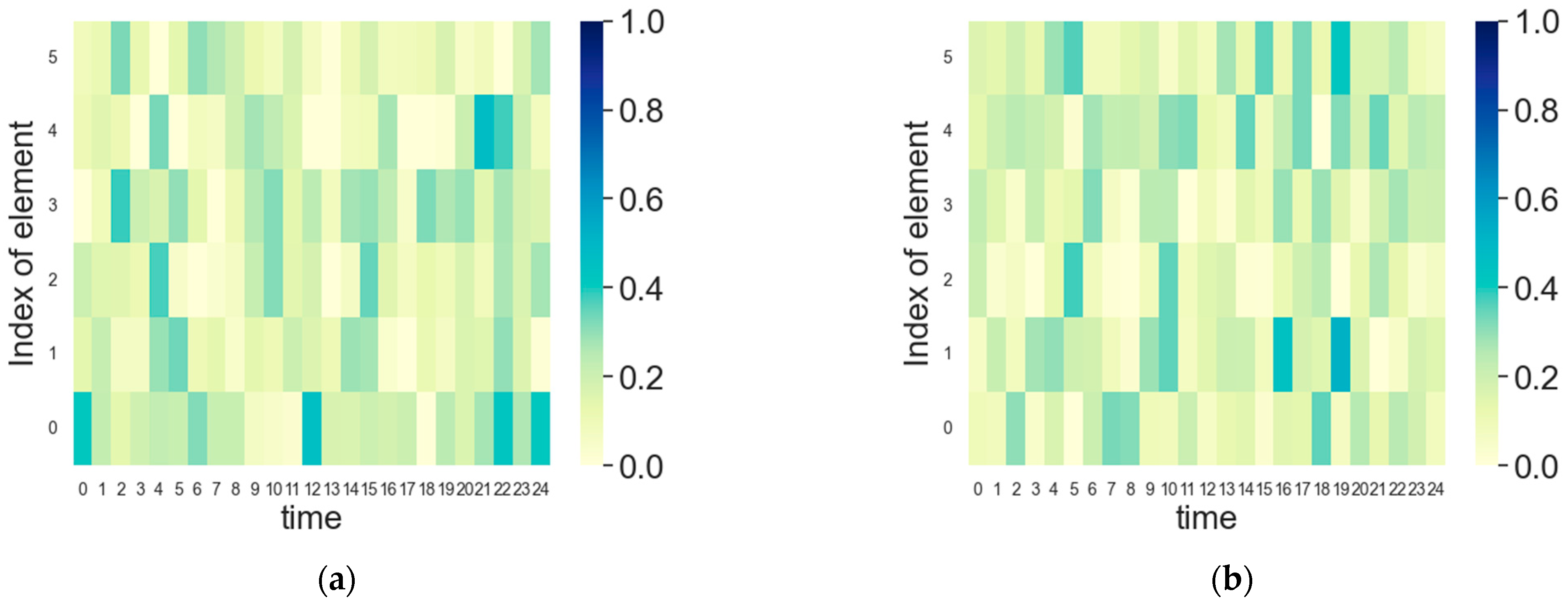
5.3. FDA Radar and Jammer Intelligent Frequency Domain Power Countermeasures
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ge, M.; Cui, G.; Yu, X.; Kong, L. Mainlobe jamming suppression with polarimetric multi-channel radar via independent component analysis. Digit. Signal Process. 2020, 106, 102806. [Google Scholar] [CrossRef]
- Shi, J.; Wen, F.; Liu, Y.; Liu, Z.; Hu, P. Enhanced and generalized coprime array for direction of arrival estimation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 1327–1339. [Google Scholar] [CrossRef]
- Li, K.; Jiu, B.; Liu, H.; Pu, W. Robust Antijamming Strategy Design for Frequency-Agile Radar against Main Lobe Jamming. Remote Sens. 2021, 13, 3043. [Google Scholar] [CrossRef]
- Shi, J.; Yang, Z.; Liu, Y. On Parameter Identifiability of Diversity-Smoothing-Based MIMO Radar. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 1660–1675. [Google Scholar] [CrossRef]
- Antonik, P.; Wicks, M.C.; Griffiths, H.D.; Baker, C.J. Frequency diverse array radars. In Proceedings of the 2006 IEEE Conference on Radar, Verona, NY, USA, 24–27 April 2006; IEEE: Arlington, VA, USA, 2006; pp. 215–217. [Google Scholar]
- Lan, L.; Liao, G.; Xu, J.; Zhang, Y.; Liao, B. Transceive Beamforming with Accurate Nulling in FDA-MIMO Radar for Imaging. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4145–4159. [Google Scholar] [CrossRef]
- Lan, L.; Marino, A.; Aubry, A.; De Maio, A.; Liao, G.; Xu, J.; Zhang, Y. GLRT-Based Adaptive Target Detection in FDA-MIMO Radar. IEEE Trans. Aerosp. Electron. Syst. 2020, 57, 597–613. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, C.; Gong, J.; Tan, M.; Bao, L.; Liu, M. Ambiguity Function Evaluation and Optimization of the Transmitting Beamspace-Based FDA Radar. Signal Process. 2023, 203, 108810. [Google Scholar] [CrossRef]
- Lan, L.; Liao, G.; Xu, J.; Xu, Y.; So, H.C. Beampattern Synthesis Based on Novel Receive Delay Array for Mainlobe Interference Mitigation. IEEE Trans. Antennas Propag. 2023, 71, 4470–4485. [Google Scholar] [CrossRef]
- Ding, Z.; Xie, J.; Xu, J. A Joint Array Parameters Design Method Based on FDA-MIMO Radar. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 2909–2919. [Google Scholar] [CrossRef]
- Lan, L.; Rosamilia, M.; Aubry, A.; De Maio, A.; Liao, G. FDA-MIMO Transmitter and Receiver Optimization. IEEE Trans. Signal Process. 2024, 72, 1576–1589. [Google Scholar] [CrossRef]
- Huang, B.; Basit, A.; Gui, R.; Wang, W.-Q. Adaptive Moving Target Detection without Training Data for FDA-MIMO Radar. IEEE Trans. Veh. Technol. 2022, 71, 220–232. [Google Scholar] [CrossRef]
- Basit, A.; Wang, W.; Nusenu, S.Y. Adaptive transmit beamspace design for cognitive FDA radar tracking. IET Radar Sonar Navig. 2019, 13, 2083–2092. [Google Scholar] [CrossRef]
- Huang, L.; Zong, Z.; Zhang, S.; Wang, W.-Q. 2-D Moving Target Deception against Multichannel SAR-GMTI Using Frequency Diverse Array. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4006705. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, C.; Gong, J.; Tan, M.; Bao, L.; Liu, M. Joint optimisation of transmit beamspace and receive filter in frequency diversity array-multi-input multi-output radar. IET Radar Sonar Navig. 2022, 16, 2031–2039. [Google Scholar] [CrossRef]
- Xiong, J.; Cui, C.; Gao, K.; Wang, W.-Q. Cognitive FDA-MIMO radar for LPI transmit beamforming. IET Radar Sonar Navig. 2017, 11, 1574–1580. [Google Scholar] [CrossRef]
- Pengcheng, G.; Wu, Y. Improved transmit beamforming design based on ADMM for low probability of intercept of FDA-MIMO radar. J. Commun. 2022, 43, 133–142. [Google Scholar]
- Gong, P.; Zhang, Z.; Wu, Y.; Wang, W.-Q. Joint Design of Transmit Waveform and Receive Beamforming for LPI FDA-MIMO Radar. IEEE Signal Process. Lett. 2022, 29, 1938–1942. [Google Scholar] [CrossRef]
- Gong, P.; Xu, K.; Wu, Y.; Zhang, J.; So, H.C. Optimization of LPI-FDA-MIMO Radar and MIMO Communication for Spectrum Coexistence. IEEE Wirel. Commun. Lett. 2023, 12, 1076–1080. [Google Scholar] [CrossRef]
- Lan, L.; Xu, J.; Liao, G.; Zhang, Y.; Fioranelli, F.; So, H.C. Suppression of Mainbeam Deceptive Jammer with FDA-MIMO Radar. IEEE Trans. Veh. Technol. 2020, 69, 11584–11598. [Google Scholar] [CrossRef]
- Gui, R.; Wang, W.-Q.; Farina, A.; So, H.C. FDA Radar with Doppler-Spreading Consideration: Mainlobe Clutter Suppression for Blind-Doppler Target Detection. Signal Process. 2020, 179, 107773. [Google Scholar] [CrossRef]
- Tan, M.; Gong, J.; Wang, C. Range Dimensional Monopulse Approach with FDA-MIMO Radar for Mainlobe Deceptive Jamming Suppression. IEEE Antennas Wirel. Propag. Lett. 2023, 23, 643–647. [Google Scholar] [CrossRef]
- Gui, R.; Zheng, Z.; Wang, W. Cognitive FDA radar transmit power allocation for target tracking in spectrally dense scenario. Signal Process. 2021, 183, 108006. [Google Scholar] [CrossRef]
- Wang, L.; Wang, W.; Hing, C.S. Covariance Matrix Estimation for FDA-MIMO Adaptive Transmit Power Allocation. IEEE Trans. Signal Process. 2022, 70, 3386–3399. [Google Scholar] [CrossRef]
- Jakabosky, J.; Ravenscroft, B.; Blunt, S.D.; Martone, A. Gapped spectrum shaping for tandem-hopped radar/communications cognitive sensing. In Proceedings of the 2016 IEEE Radar Conference (RadarConf), Philadelphia, PA, USA, 2–6 May 2016; pp. 1–6. [Google Scholar]
- Ravenscroft, B.; Blunt, S.; Allen, C.; Martone, A.; Sherbondy, K. Analysis of spectral notching in fm noise radar using measured interference. In Proceedings of the International Conference on Radar Systems, Belfast, UK, 23–26 October 2017. [Google Scholar]
- Aubry, A.; Carotenuto, V.; De Maio, A.; Farina, A.; Pallotta, L. Optimization theory-based radar waveform design for spectrally dense environments. IEEE Aerosp. Electron. Syst. Mag. 2016, 31, 14–25. [Google Scholar] [CrossRef]
- Stinco, P.; Greco, M.; Gini, F.; Himed, B. Cognitive radars in spectrally dense environments. IEEE Aerosp. Electron. Syst. Mag. 2016, 31, 20–27. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, C.; Gong, J.; Tan, M.; Bao, L.; Liu, M. Phase Characteristics and Angle Deception of Frequency-Diversity-Array Transmitted Signals Based on Time Index within Pulse. Remote Sens. 2023, 15, 5171. [Google Scholar] [CrossRef]
- Selvi, E.; Buehrer, R.M.; Martone, A.; Sherbondy, K. Reinforcement Learning for Adaptable Bandwidth Tracking Radars. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3904–3921. [Google Scholar] [CrossRef]
- Thornton, C.E.; Kozy, M.A.; Buehrer, R.M. Deep Reinforcement Learning Control for Radar Detection and Tracking in Congested Spectral Environments. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 1335–1349. [Google Scholar] [CrossRef]
- Ding, Z.; Xie, J.; Qi, C. Transmit Power Allocation Method of Frequency Diverse Array-Multi Input and Multi Output Radar Based on Reinforcement Learning. J. Electron. Inf. Technol. 2023, 45, 550–557. [Google Scholar]
- Wang, L.; Peng, J.; Xie, Z.; Zhang, Y. Optimal jamming frequency selection for cognitive jammer based on reinforcement learning. In Proceedings of the 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), Weihai, China, 28–30 September 2019; pp. 39–43. [Google Scholar]
- Liu, H.; Zhang, H.; He, Y.; Sun, Y. Jamming Strategy Optimization through Dual Q-Learning Model against Adaptive Radar. Sensors 2021, 22, 145. [Google Scholar] [CrossRef]
- Bachmann, D.J.; Evans, R.J.; Moran, B. Game Theoretic Analysis of Adaptive Radar Jamming. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 1081–1100. [Google Scholar] [CrossRef]
- Norouzi, T.; Norouzi, Y. Scheduling the usage of radar and jammer during peace and war time. IET Radar Sonar Navig. 2012, 6, 929–936. [Google Scholar] [CrossRef]
- Li, K.; Jiu, B.; Pu, W.; Liu, H.; Peng, X. Neural Fictitious Self-Play for Radar Antijamming Dynamic Game with Imperfect Information. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 5533–5547. [Google Scholar] [CrossRef]
- Geng, J.; Jiu, B.; Li, K.; Zhao, Y.; Liu, H.; Li, H. Radar and Jammer Intelligent Game under Jamming Power Dynamic Allocation. Remote Sens. 2023, 15, 581. [Google Scholar] [CrossRef]
- Huang, L.; Li, X.; Wan, W.; Ye, H.; Zhang, S.; Wang, W.Q. Adaptive FDA Radar Transmit Power Allocation for Target Detection Enhancement in Clutter Environment. IEEE Trans. Veh. Technol. 2023, 72, 11111–11121. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, C.; Gong, J.; Tan, M.; Bao, L.; Liu, M. Expert systems with applications reinforcement learning for FDA-MIMO radar power allocation in congested spectral environments. Expert Syst. Appl. 2024, 251, 123957. [Google Scholar] [CrossRef]
- Ding, Z.; Xie, J.; Yang, L. Cognitive Conformal Subaperturing FDA-MIMO Radar for Power Allocation Strategy. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 5027–5083. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6379–6390. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Input | Output | Activation Function |
|---|---|---|---|
| MLP1 | state dimension | hidden dimension | Relu |
| MLP2 | hidden dimension | hidden dimension | Relu |
| MLP3 | hidden dimension | action dimension | softmax |
| Layer | Input | Output | Activation Function |
|---|---|---|---|
| MLP1 | state and action dimension | hidden dimension | Relu |
| MLP2 | hidden dimension | hidden dimension | Relu |
| MLP3 | hidden dimension | 1 | / |
| Layer | Input | Output | Activation Function |
|---|---|---|---|
| MLP1 | observation dimension | hidden dimension | Relu |
| MLP2 | hidden dimension | hidden dimension | Relu |
| MLP3 | hidden dimension | agent action dimension | softmax |
| Layer | Input | Output | Activation Function |
|---|---|---|---|
| MLP1 | state and environment action dimension | hidden dimension | Relu |
| MLP2 | hidden dimension | hidden dimension | Relu |
| MLP3 | hidden dimension | 1 | / |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, C.; Wang, C.; Bao, L.; Gao, X.; Gong, J.; Tan, M. Frequency Diversity Array Radar and Jammer Intelligent Frequency Domain Power Countermeasures Based on Multi-Agent Reinforcement Learning. Remote Sens. 2024, 16, 2127. https://doi.org/10.3390/rs16122127
Zhou C, Wang C, Bao L, Gao X, Gong J, Tan M. Frequency Diversity Array Radar and Jammer Intelligent Frequency Domain Power Countermeasures Based on Multi-Agent Reinforcement Learning. Remote Sensing. 2024; 16(12):2127. https://doi.org/10.3390/rs16122127
Chicago/Turabian StyleZhou, Changlin, Chunyang Wang, Lei Bao, Xianzhong Gao, Jian Gong, and Ming Tan. 2024. "Frequency Diversity Array Radar and Jammer Intelligent Frequency Domain Power Countermeasures Based on Multi-Agent Reinforcement Learning" Remote Sensing 16, no. 12: 2127. https://doi.org/10.3390/rs16122127
APA StyleZhou, C., Wang, C., Bao, L., Gao, X., Gong, J., & Tan, M. (2024). Frequency Diversity Array Radar and Jammer Intelligent Frequency Domain Power Countermeasures Based on Multi-Agent Reinforcement Learning. Remote Sensing, 16(12), 2127. https://doi.org/10.3390/rs16122127