The purpose of this section is to offer an overview of the research on hyperspectral data, encompassing both conventional and novel approaches. Given that our case study is focused on grape classification, the primary techniques for this task are outlined below.
2.1. Processing of Hyperspectral Signature
Remotely sensed data are subject to various factors, such as sensor-related random errors, atmospheric and surface effects and acquisition conditions. Therefore, radiometric correction is performed to obtain accurate data from the Earth’s surface. Although the literature in this field covers numerous topics, it primarily focuses on satellite imaging. While some of the techniques studied can be applied to UAV imaging, other topics are irrelevant to our case study. For instance, atmospheric effects like absorption are not significant in close-range work. However, due to low flight altitudes, UAV instability and varying viewing angles, preprocessing operations can be challenging [
12].
Most studies that classify satellite images use standard datasets with radiometric corrections, provided by the Grupo de Inteligencia Computacional [
13]. In the case of UAV hyperspectral imaging, various corrections are necessary to obtain precise data, including geometric and radiometric corrections and spectral calibrations [
14]. Geometric distortions are primarily caused by UAV instability and the acquisition technique, with push-broom sensors showing higher geometric distortions that can be reduced using stabilizers. Geometric correction can be achieved through an inertial navigation system (INS), Global Positioning System (GPS) and digital elevation model (DEM). Although commercial software is available for this approach, it requires a high-precision system for accurate correction. Alternatively, ground control points have been extensively utilized to ensure correct positioning [
15]. In addition, dual acquisition of visible and hyperspectral imagery enables matching both data sources [
15,
16,
17], with visible data being more geometrically accurate. Another technique for geometric correction is feature matching among overlapping images [
18].
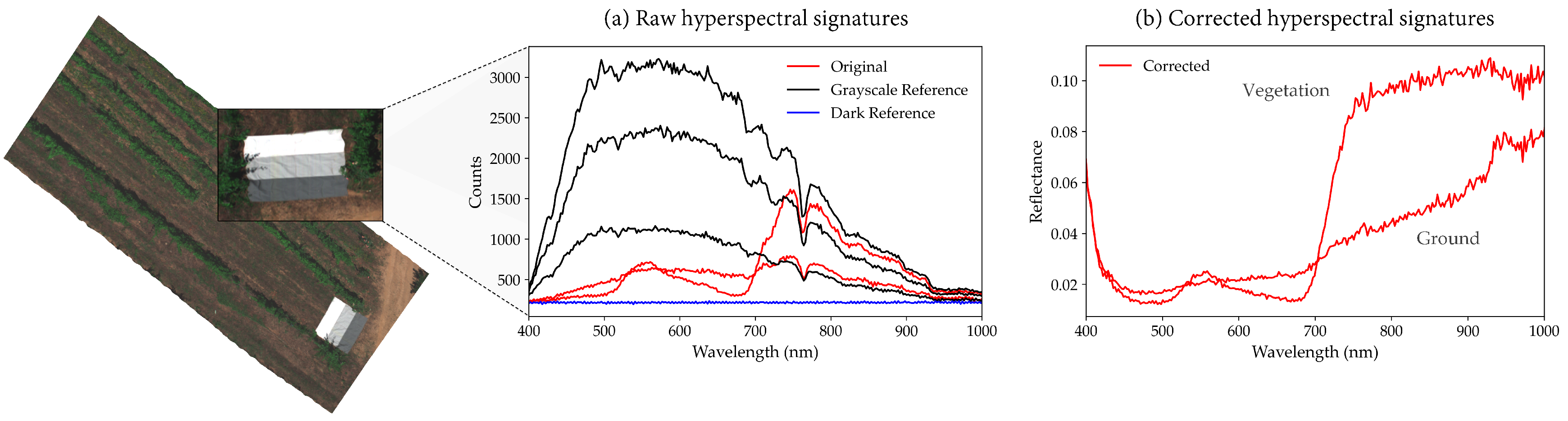
In a similar way to geometric distortions, radiometric anomalies can also be fixed with software tools provided by the hyperspectral manufacturer. The aim is to convert the digital numbers (DNs) of the sensor to radiance and reflectance of Earth’s surfaces, regardless of acquisition conditions. Therefore, the latter result must be applied to deep learning techniques for their implementation over any hyperspectral dataset. The coefficients required for this correction are generally calibrated in the laboratory, but they may vary over time [
14], which may affect the radiometric correction. Grayscale tarps, whose reflectance is known, can be used to support this process and perform linear interpolations to calibrate the acquired DNs [
19] using the empirical line method [
9,
20]. To perform the linear interpolation for the radiometric correction, it is necessary to have dark and gray/white references, which are usually obtained from isotropic materials that have a grayscale palette and exhibit near-Lambertian behaviour [
12,
21,
22]. An alternative approach is to acquire radiance samples, which can be used with fitting methods such as the least-square method to transform DNs.
2.2. Hyperspectral Transformation and Feature Extraction
In this section, we discuss the transformations that facilitate classification using traditional methods. Due to the extensive coverage of land by satellite imagery, it is uncommon for hyperspectral pixels to depict the spectral signature of a single material. Consequently, analyzing the surfaces visible in collected hyperspectral signatures is a prevalent topic in hyperspectral research. The problem is illustrated with , where M is the spectral signature of different materials, F is the weight, is an additive noise vector and is an matrix where L is the number of bands. Hence, the difficulty of finding a solution to M and F is lowered if M is fixed, i.e., the end-member signatures are known. Multiple end-member spectral mixture analysis (MESMA) was the initial approach taken, followed by the mixture-tuned matching filtering technique, which eliminates the need to know end-members in advance. This approach was further refined with the constrained energy minimization method, which effectively suppresses undesired background signatures.
The current state-of-the-art techniques for linear mixture models can be categorized based on their dependency on spectral libraries. Additionally, the level of supervision and computational cost also determine the taxonomy of methods [
23]. For instance, Bayesian methods and local unmixing do not necessitate end-member signatures, although Bayesian-inspired approaches are less supervised and more time-intensive. Besides MESMA, other proposed methods that require spectral signatures are based on artificial intelligence (AI) techniques such as machine learning (ML) and fuzzy unmixing. The latter is less supervised but more time-consuming. In recent years, interest in deep learning (DL) has grown, with techniques such as autoencoders, convolutional neural networks (CNNs) and generative adversarial networks being utilized for training with synthetic data [
24]. Non-negative matrix factorization (NMF) has also attracted attention as it can extract sparse and interpretable features [
25]. Recently, state-of-the-art methods such as NMF have been combined with spectral information [
26].
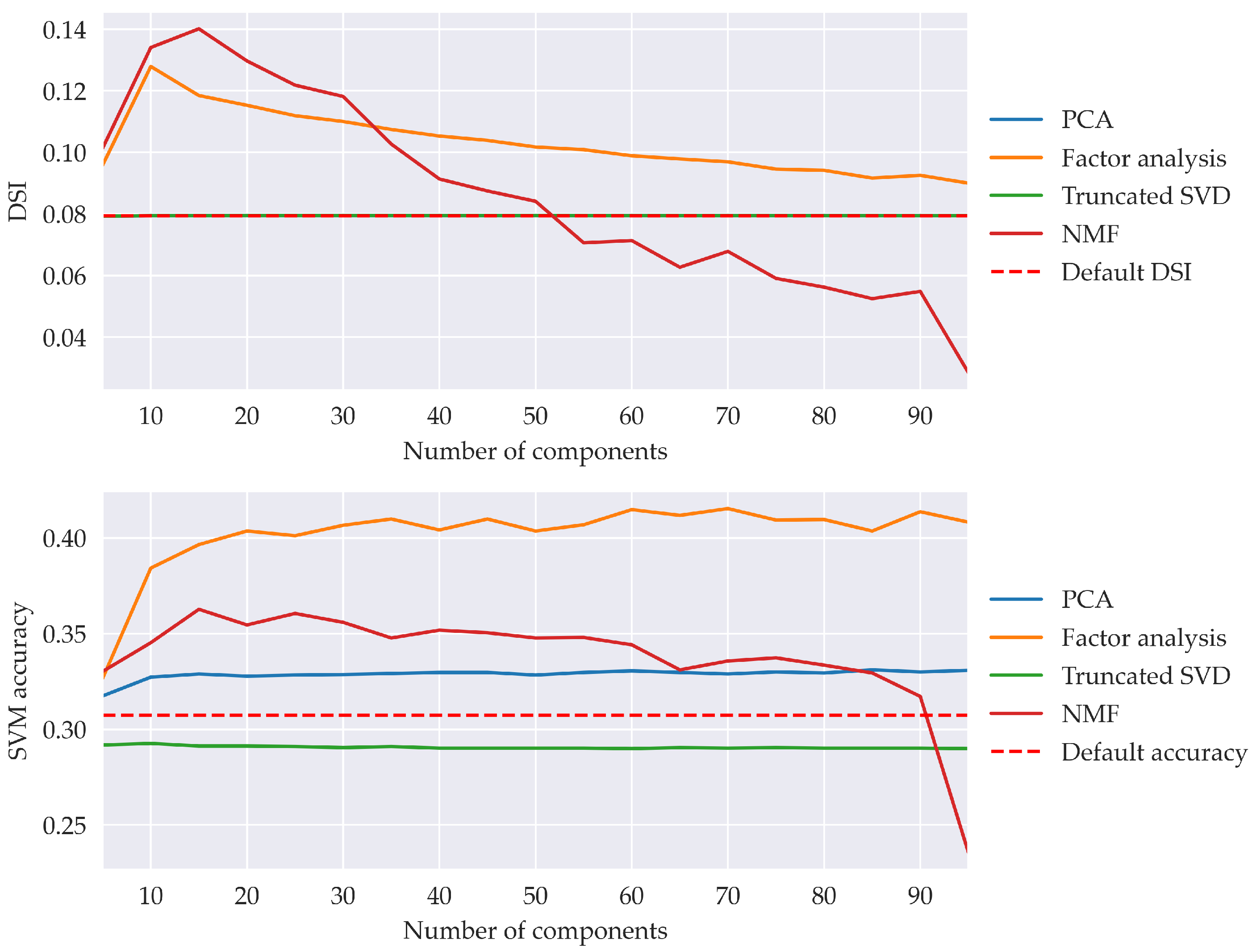
Besides discerning materials, the results of hyperspectral imaging (HSI) present a large number of layers that can be either narrowed or transformed, as many of them present a high correlation. Otherwise, the large dimensionality of HSI data leads neural networks and other classification algorithms to be hugely complex. Accordingly, the most frequent projection method is PCA (principal component analysis) [
27,
28,
29], which projects an HSI cube of size
into
, where
D has a size of
, and
B is a matrix such as
. In this formulation,
F is the number of target features. Independent component analysis is a variation of PCA that not only decorrelates data but also identifies normalized basis vectors that are statistically independent [
30]. Least discriminant analysis is another commonly used technique, but it is primarily applied after PCA to increase interclass and intraclass distance [
28]. In the literature, it is also referred to as partial least-square discriminant analysis, mainly as a classifier rather than a feature selection method.
Instead of projecting features into another space, these can be narrowed into the subset with maximum variance according to the classification labels of HSI samples. There are many techniques in this field, including the successive projection algorithm, which reduces colinearity in the feature vector. The competitive adaptive reweighted sampling method selects features with Monte Carlo sampling and iteratively removes those with small absolute regression coefficients. Two-dimensional correlation spectroscopy aims to characterize the similarity of variance in reflectance intensity. Liu et al. [
31] used the Ruck sensitivity analysis to discard bands with a value below a certain threshold. Agilandeeswari et al. [
32] calculated the band entropy, vegetation index and water index for wavelength subsets, generating a narrower cube only with bands above three different thresholds. Finally, the work of Santos et al. [
33] presents an in-depth evaluation of methods based on PLS regression. To this end, HSI data from olive orchards were first narrowed and then classified with LDA (least discriminant analysis) and K-nearest neighbors. In conclusion, the Lasso method [
34] as well as genetic algorithms [
35] showed the best performance with LDA.
2.4. Classification of Hyperspectral Imaging with ML and DL
This section reviews studies related to the classification of vineyard varieties using HSI. However, only a few studies address HSI classification over vineyard varieties; therefore, other state-of-the-art DL networks achieving high accuracy in HSI classification will also be reviewed. Note that our research investigates pixel-wise classification, and models aimed at semantic segmentation (e.g., encoder–decoder architectures) are omitted.
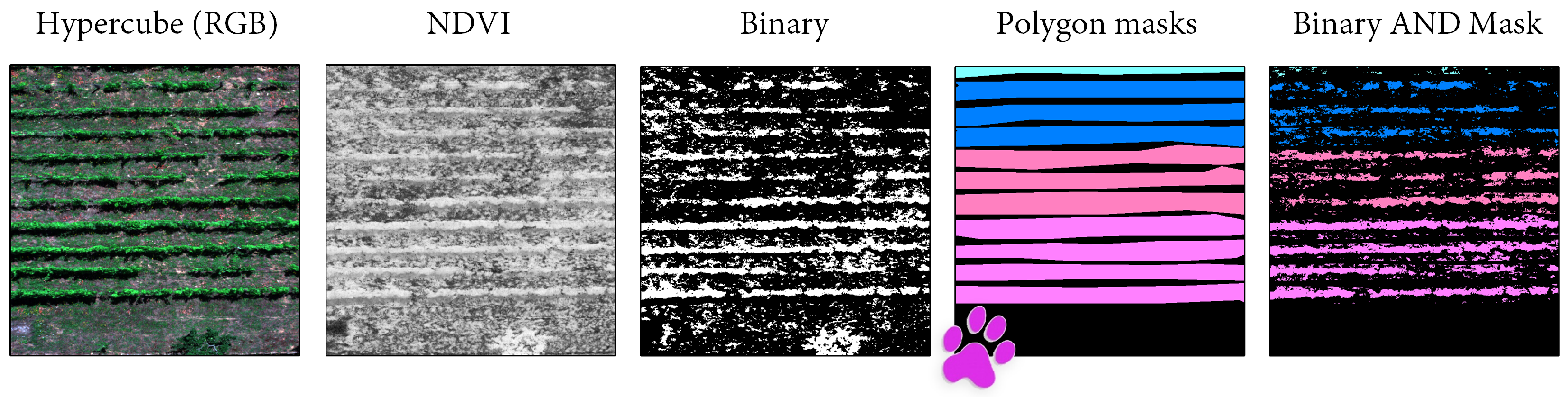
In previous grapevine classification studies, binary masks or grayscale maps were first extracted to distinguish soil, shadows and vineyards. Clustering, line detection and ML algorithms have been applied to segmenting vineyard rows [
11,
38,
39,
40,
41,
42], amongst which artificial neural networks (ANNs) stand out. Geometrical information from depth maps, DEMs, LiDAR data and photogrammetric reconstructions were also assessed [
11,
43,
44,
45], showing that this information improves the baseline performance. DL approaches for semantic segmentation and skeletonization algorithms have also been discussed [
46,
47]. Further insight into this field is provided by Li et al. [
48].
Other vineyard classification studies operate with traditional methods and proximal hyperspectral sensing. In the work of Gutiérrez et al. [
49], samples were selected by manually averaging the variety signature and filtering those with high correlation to such a signature. A support vector machine (SVM) and multilayer perceptron (MLP) were then trained with k-fold to distinguish thirty varieties (80 samples for each one), with the latter obtaining a recall close to one. Murru et al. [
50] collected infrared spectroscopy data of five grape varieties and classified them using ANN with an overall accuracy (OA) of 85.3%. Similarly, Fuentes et al. [
51] employed identical data types across sixteen grapevine cultivars, contrasting with colorimetric and geometric leaf features. Their classification methodology leveraged ANNs, yielding an OA of 94.2% by integrating morpho-colorimetric attributes. Kicherer et al. [
52] presented a land phenotyping platform that segments grapes from the depth map and discerns between sprayed and nonsprayed leaves. To this end, several learning models were tested: LDA, partially least square (PLS), radial basis function (RBF), MLP and softmax output layer, with RBF and PLS showing the best results. Besides phenotyping, the following work is aimed at detecting diseases [
53,
54,
55] and plagues [
3]. Nguyen et al. [
53] attempted to differentiate healthy and infected leaves with data obtained from land. They flattened the data processed by 2D and 3D convolutional networks and used them as input for random forest (RF) and SVM algorithms. They found that combining PCA reduction (50 features) and RF resulted in the best performance (97%), and RF improved SVM classification regardless of data reduction. However, it notably varies according to the case study; for instance, Wang et al. [
56] reported that minimum noise fraction performed better in classifying crops over HSI. Another revised ML algorithm is gradient boosting for binary HSI classification over aircraft imagery [
57], with an OA over 98% when discriminating algae.
Nevertheless, some of these applications formulate a binary problem where signatures of distinct classes significantly differ in scale and shape. Others operate with small datasets obtained on land via close sensing [
58] or from imagery acquired at higher altitudes (hence showing more recognizable spatial features). For instance, a lightweight CNN composed of several inception blocks was also developed to classify up to 15 plant species [
58] using multispectral images with a size of at least
pixels. The authors found that the best results were achieved using a combination of six RGB and near-infrared features, with an accuracy of 94.7%. The use of PCA with only six features achieved an accuracy of 88%. Nezami et al. [
59] also applied a 3D CNN to classify three tree species using both hyperspectral and visible imaging as well as canopy height models as input, with an OA below 95%. While it performs well over notably different materials, the network is not complex enough to discriminate similar hyperspectral signatures. On the other hand, transfer learning, attention-based and residual models are commonly observed in the literature [
60]. Zhou et al. [
61] delved into the realm of CNNs trained on distinct domains for satellite HSI classification, augmented with few-shot learning techniques. Although not yet attaining state-of-the-art performance, this approach showcased promise in expediting training procedures [
62].
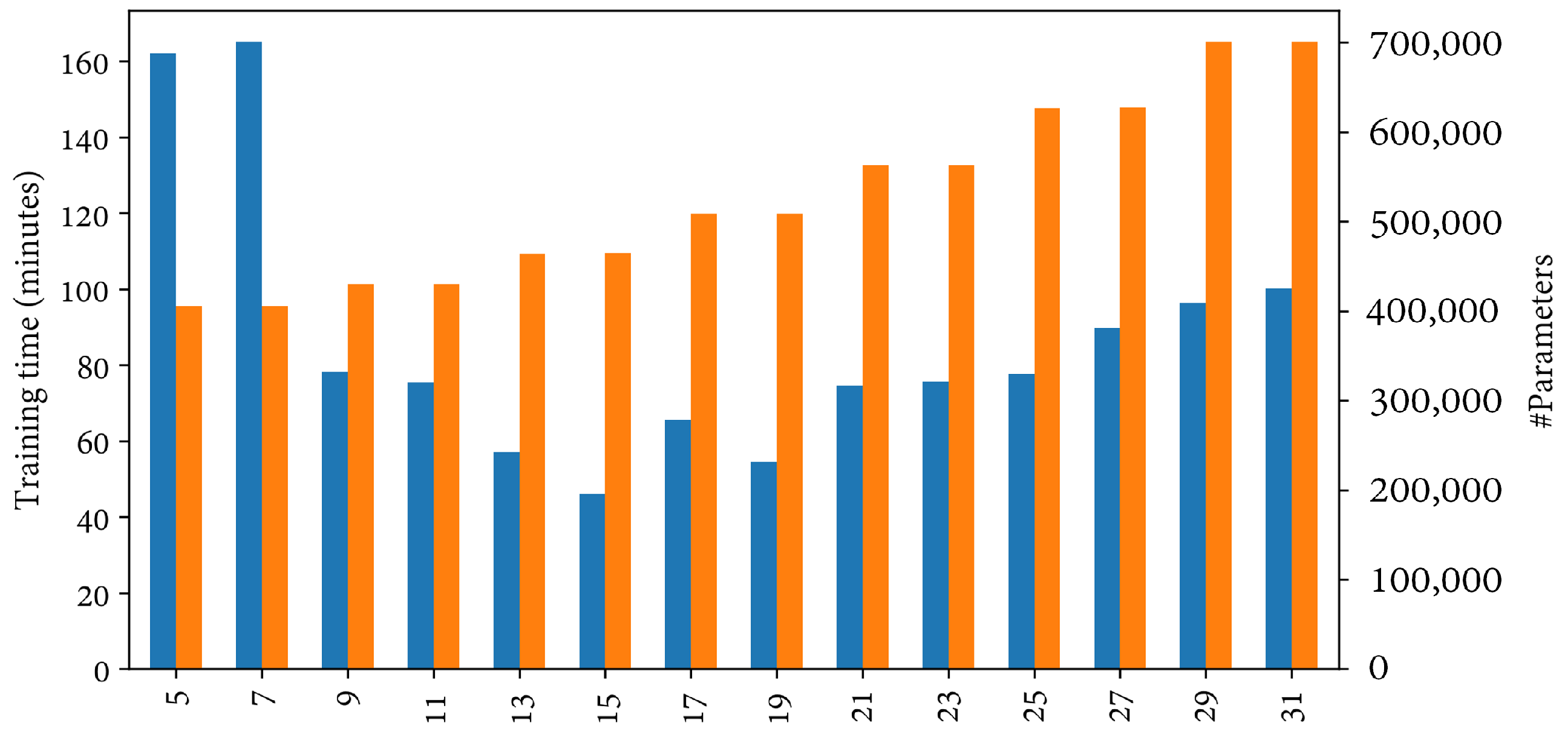
Regarding DL, the classification of satellite HSI is more frequent than using UAV imagery. Among previous works, the top-performing models based on their OA are discussed below. Zhong et al. [
63] published an HSI dataset and proposed a simple CNN with conditional random field (CRF) to extract spatial relations among data, even with the presence of gaps. They obtained an OA of 98% and 94% over their own HSI dataset. Moraga and Duzgun [
64] presented an inception-based model with parallel convolutional pipelines of increasing size, achieving near-perfect classification. Chakraborty and Trehan [
65] proposed the SpectralNet model, which combines wavelet decompositions with a traditional convolutional path (OA: 98.59–100%). HybridSN [
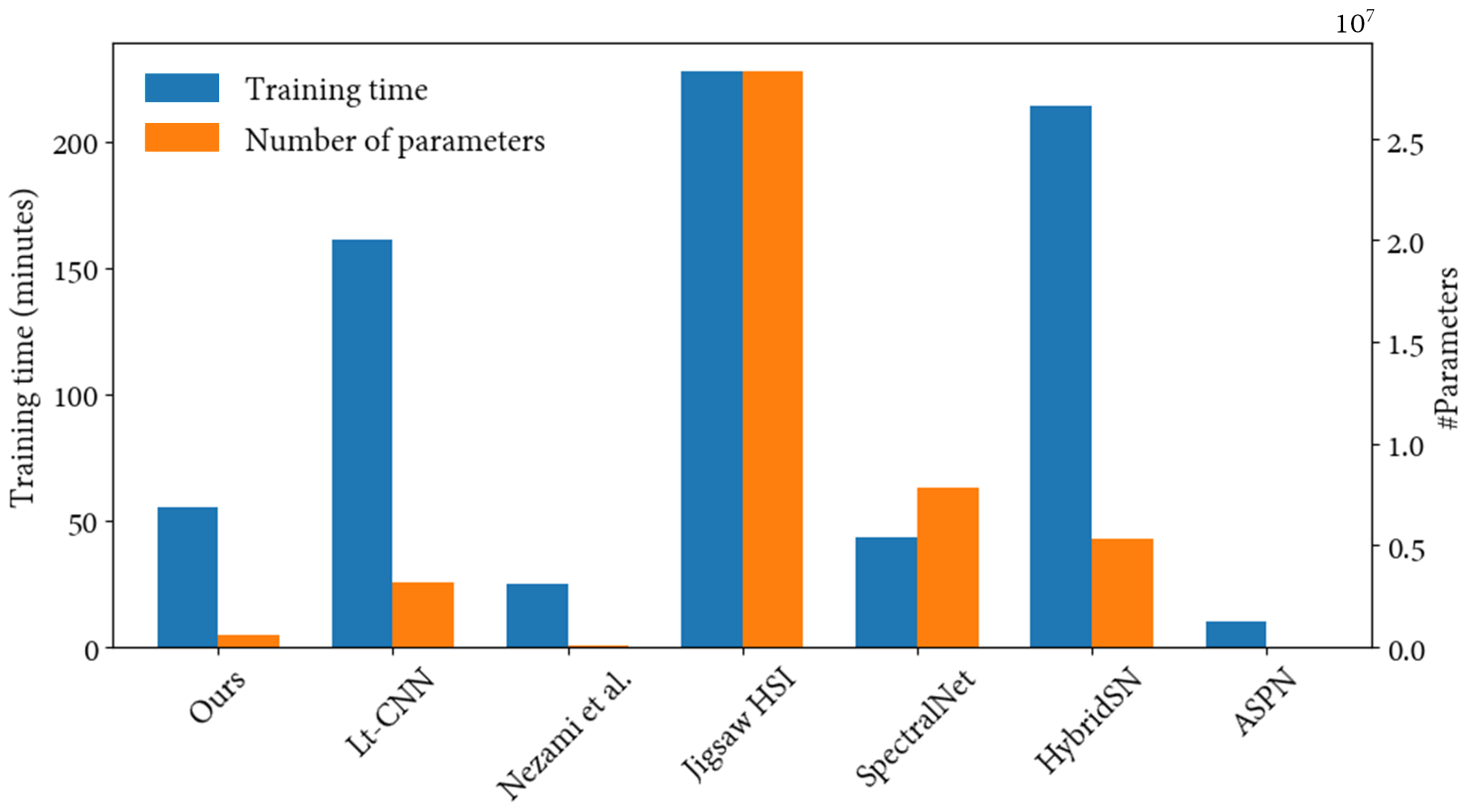
66] included both spectral–spatial and spatial feature learning using 3D and 2D convolutional layers (OA: 99.63–100%). Later, a network based on residual blocks and spectral–spatial attention modules with varying architecture (start, middle and ending ResBlock) (OA: 98.77–99.9%) was presented [
67]. Lastly, the A-SOP network [
68] proposed a module composed of matrix-wise operations that output a second-order pooling from the attention weights after extracting the first-order features (OA: 98.68–100%). Similar to Moraga and Duzgun’s work in 2022, the FSKNet model employs a combination of 2D and 3D convolutional layers with an intermediate separable convolution to reduce training latency while achieving comparable overall accuracy results. It achieves an OA above 99% with significantly fewer parameters and a shorter training time. Finally, other approaches have gained attention lately, such as contrastive learning, multi-instance segmentation and transformer networks [
69] (e.g., using the BERT architecture [
70] with an OA above 99%).
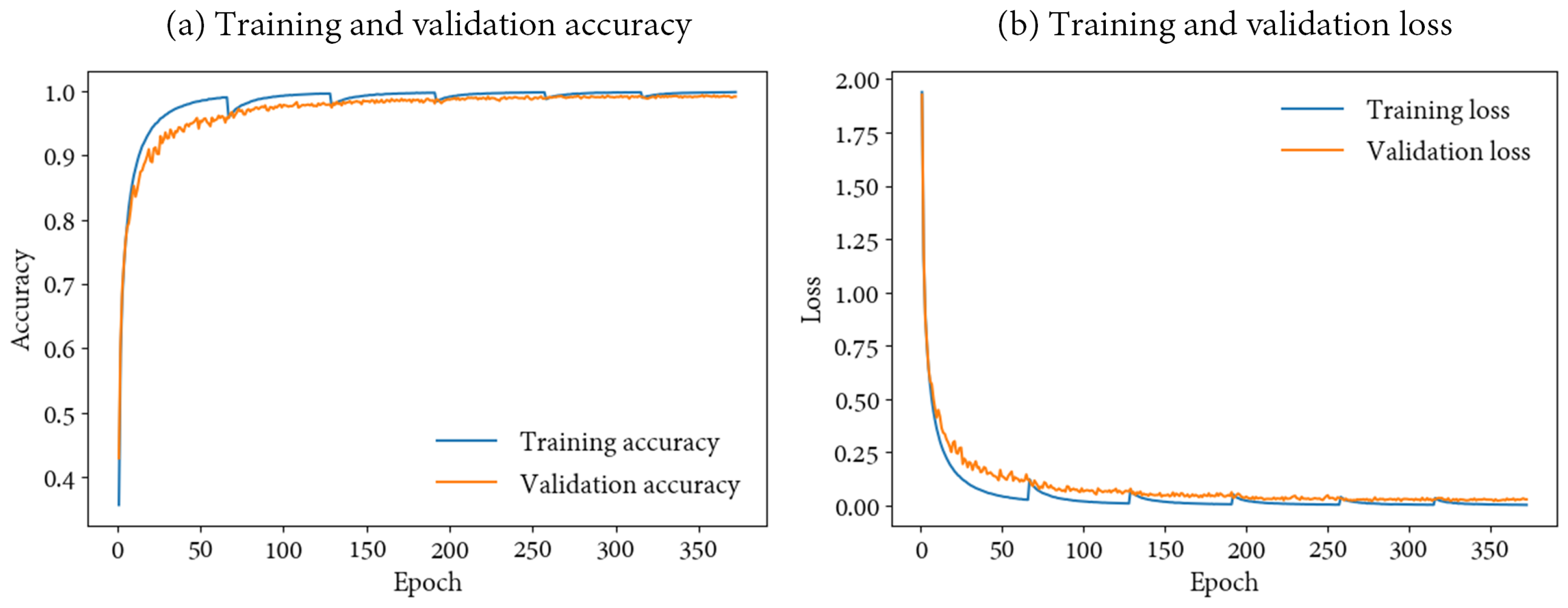
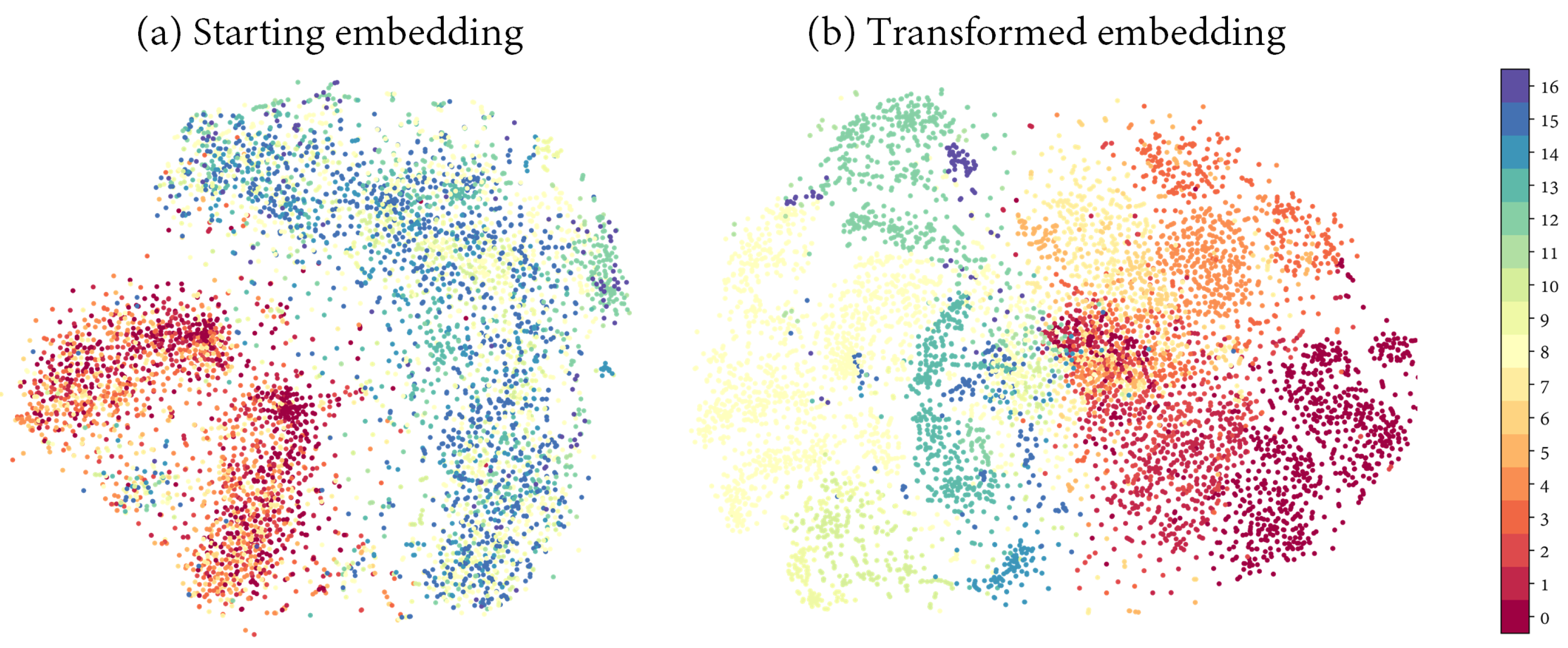
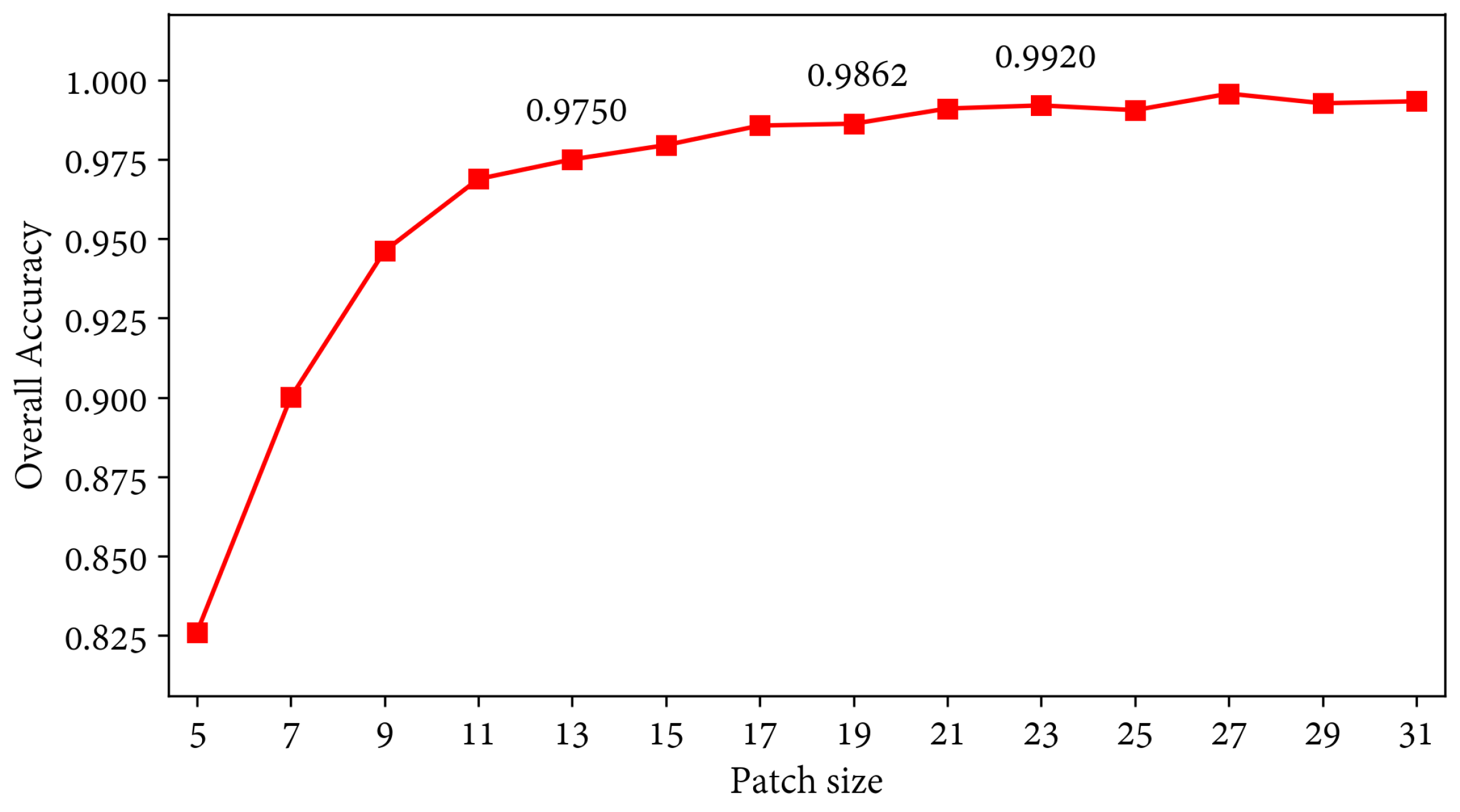
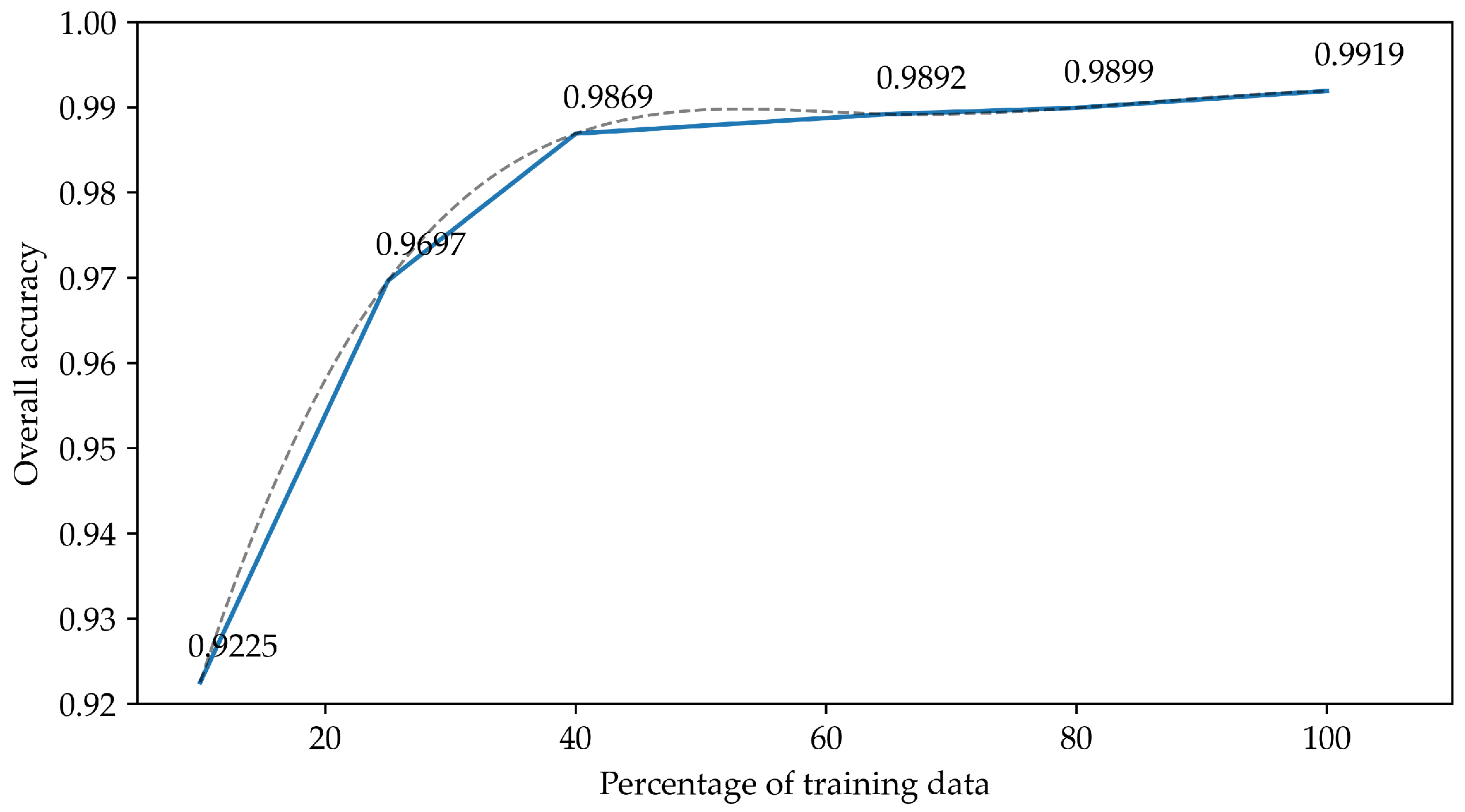
Although revised studies present outstanding results, most of them operate over satellite and aircraft imagery. These datasets are frequently less noisy and more curated than UAV images. Moreover, spatial features are not as relevant nor apparent in imagery obtained at a lower altitude, which is later subdivided into patches with low to no label heterogeneity. Indeed, we compare our method to numerous models to show that they underperform over UAV-based HSI.





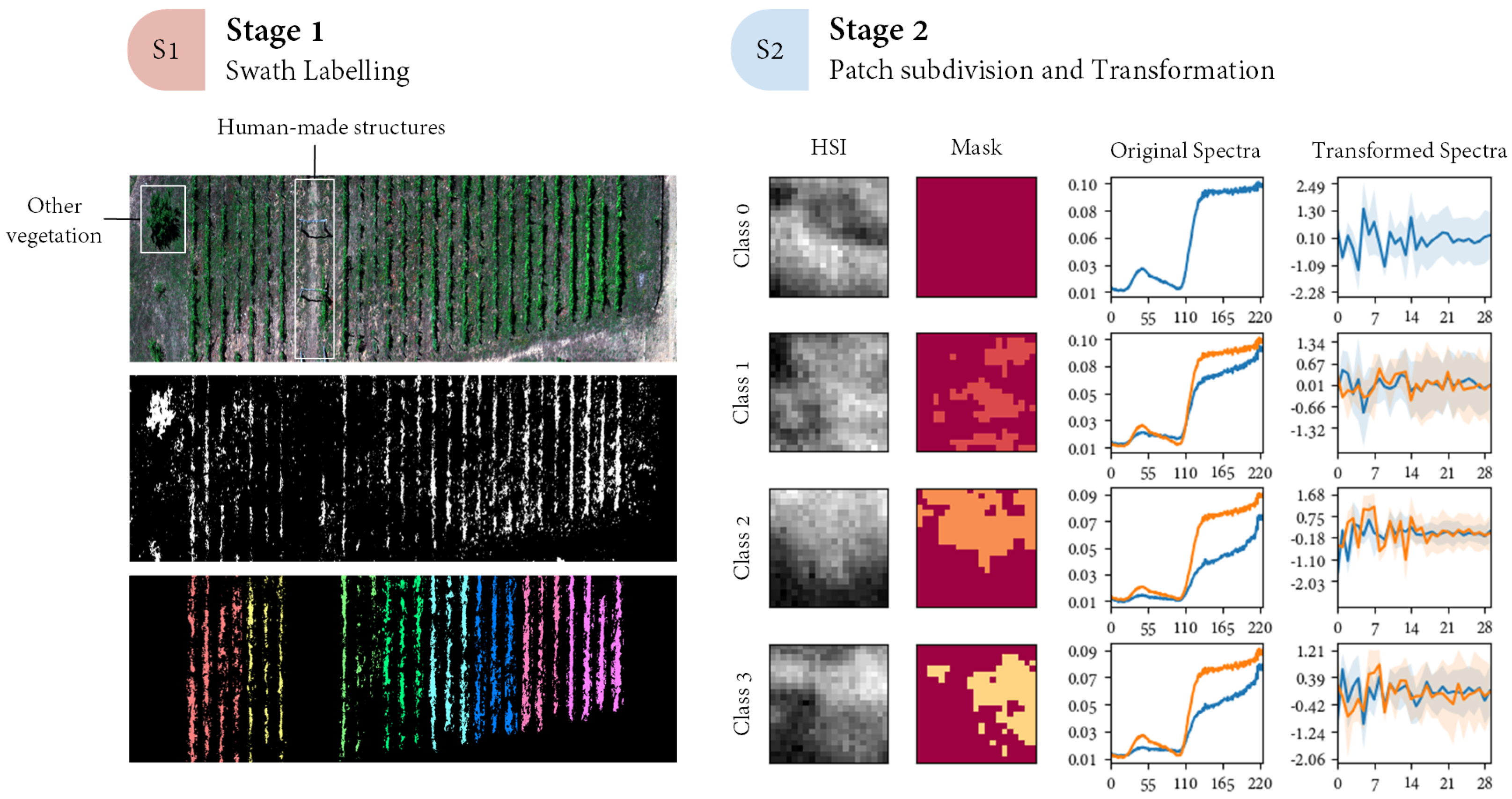
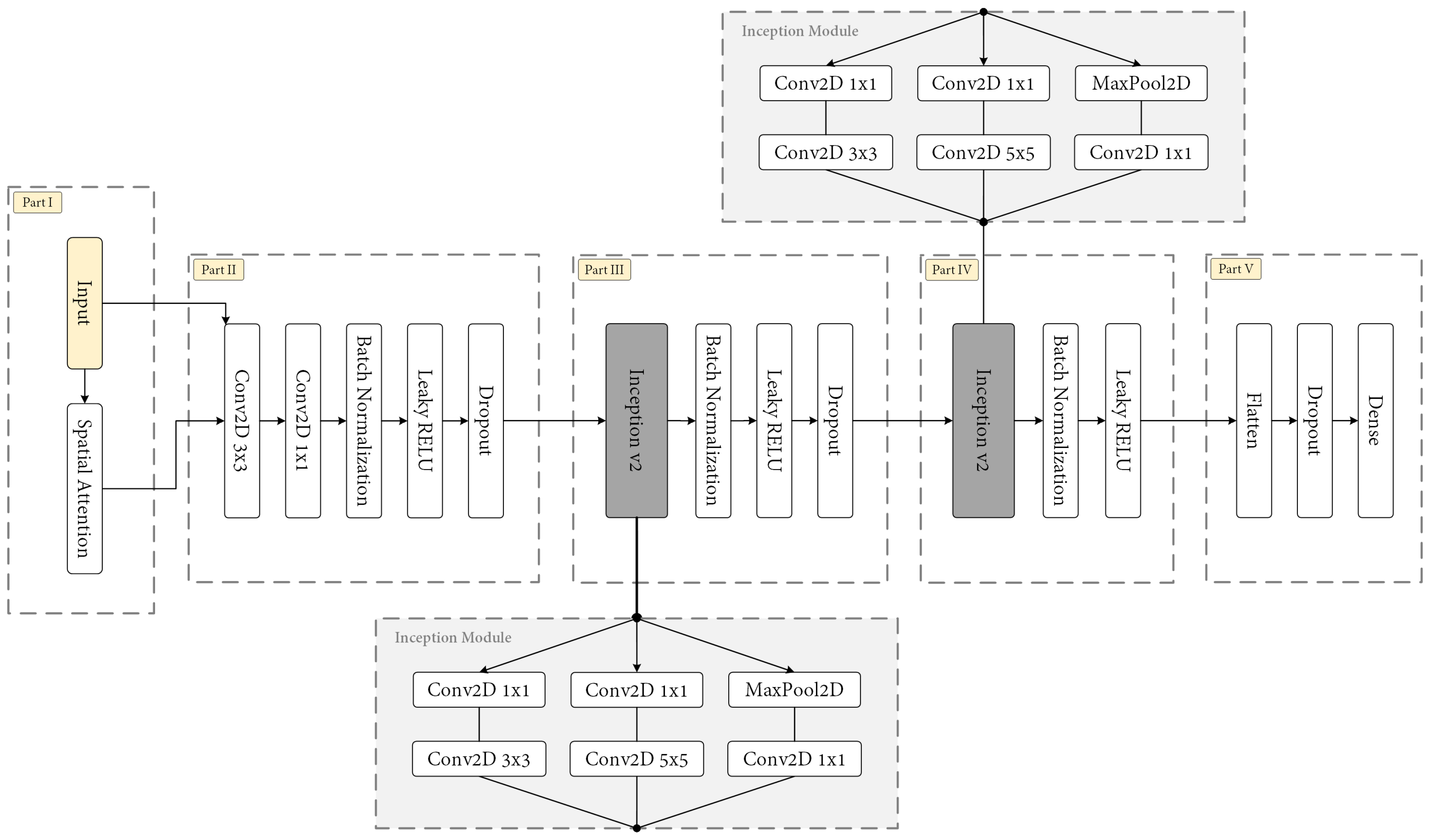
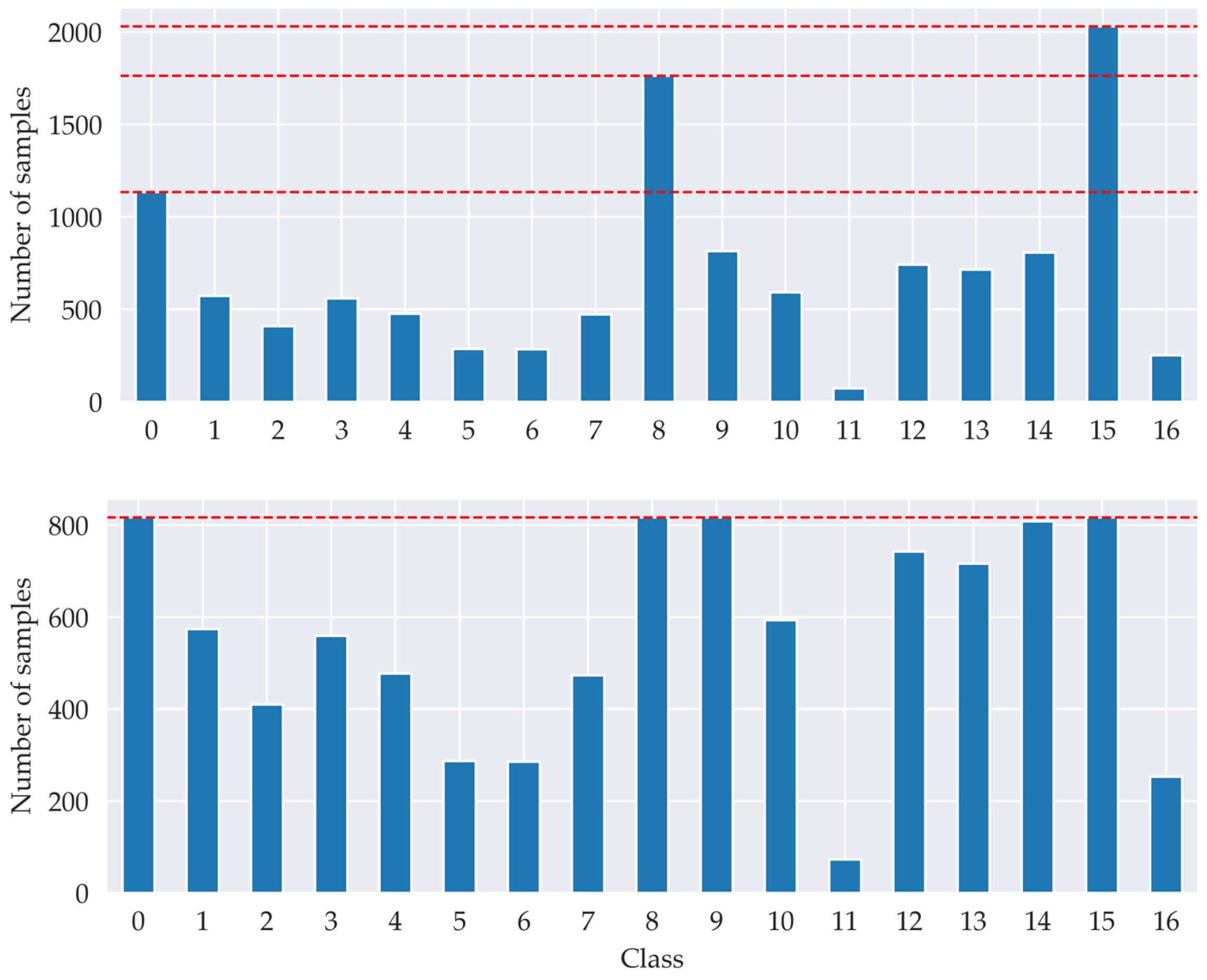
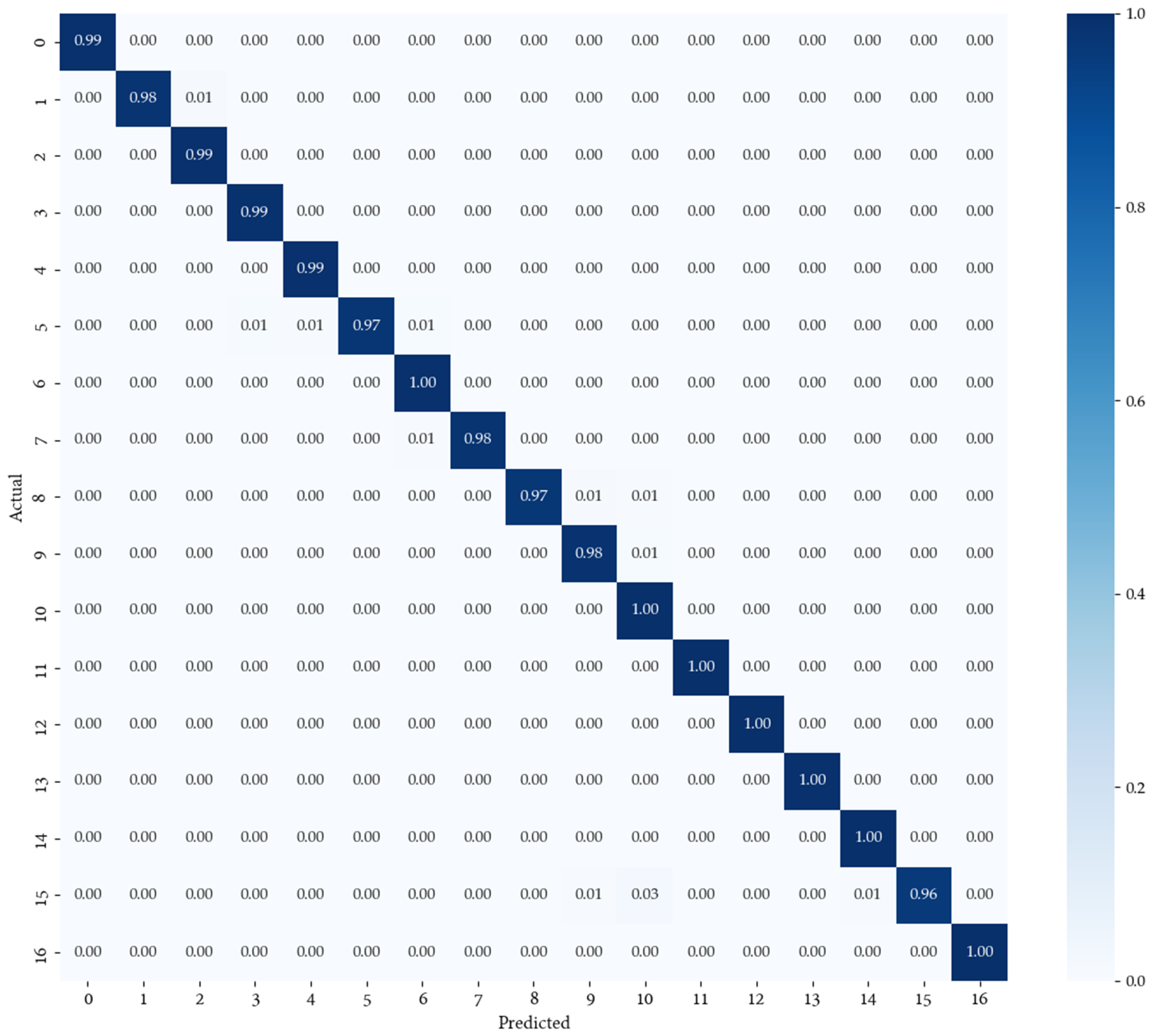

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}